
Ключевые слова:Крупная языковая модель, Способность к рассуждению, Универсальный искусственный интеллект, Сопоставление шаблонов, Когнитивные иллюзии, Исследования Apple, Детекторы ИИ, Регулирование ИИ, Механизм Log-Linear Attention, Модель Huawei Pangu MoE, Расширенный голосовой режим ChatGPT, Фреймворк TensorZero, Взгляды CEO Anthropic на регулирование
🔥 В центре внимания
Исследование Apple выявило “иллюзию мышления”: текущие модели “логического вывода” не мыслят по-настоящему, а больше полагаются на сопоставление с образцом: В последней исследовательской работе Apple под названием «Иллюзия мышления: понимание сильных и слабых сторон моделей логического вывода через призму сложности задач» отмечается, что текущие большие языковые модели, заявляющие о наличии способности к «логическому выводу» (такие как Claude, DeepSeek-R1, GPT-4o-mini и др.), скорее ведут себя как эффективные системы сопоставления с образцом, а не как системы, способные к настоящему логическому мышлению. Исследование показало, что производительность этих моделей значительно снижается при обработке задач, выходящих за рамки их обучающего распределения или имеющих высокую сложность, и они могут даже ошибаться в простых задачах из-за «чрезмерного обдумывания», при этом им трудно исправлять ранние ошибки. В исследовании подчеркивается, что так называемый «мыслительный» процесс моделей (например, цепочка мыслей) часто дает сбой при столкновении с новыми или сложными задачами, что указывает на то, что мы можем быть дальше от общего искусственного интеллекта (AGI), чем ожидалось. (Источник: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

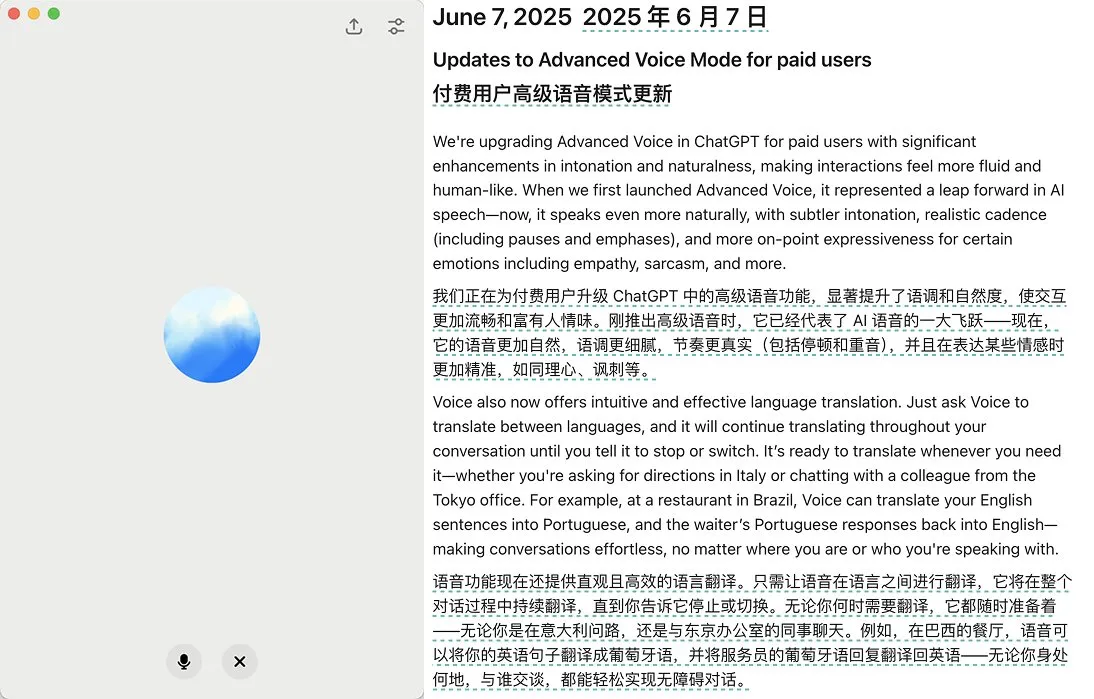
OpenAI выпускает обновление расширенного голосового режима ChatGPT, улучшая естественность речи и функции перевода: OpenAI выпустила крупное обновление расширенного голосового режима (Advanced Voice Mode) для платных пользователей ChatGPT. Новая версия значительно улучшила естественность и плавность речи, благодаря чему она звучит скорее как человеческая, а не как голос ИИ-ассистента. Кроме того, обновление улучшило производительность языкового перевода и способность следовать инструкциям, а также добавило режим перевода, в котором пользователи могут заставить ChatGPT непрерывно переводить диалог обеих сторон на протяжении всего разговора, пока его не попросят остановиться. Это обновление направлено на то, чтобы сделать голосовое взаимодействие более легким и естественным, улучшая пользовательский опыт. (Источник: juberti, Plinz, op7418, BorisMPower)
Детекторы ИИ обвиняются в неэффективности и возможном содействии “скрытности” ИИ-контента: В социальных сетях и на технологических форумах развернулась широкая дискуссия о том, что существующие инструменты для обнаружения ИИ-контента не только малоэффективны, но даже могут непреднамеренно способствовать тому, чтобы контент, сгенерированный ИИ, становился труднее обнаруживаемым. Многие пользователи и эксперты считают, что эти детекторы в основном выносят суждения на основе языковых моделей и специфической лексики (например, академического термина «delve»), а не на реальном понимании источника контента. Из-за риска ложных срабатываний (что может привести к несправедливости по отношению к таким группам, как студенты) и того факта, что сами ИИ-модели развиваются, чтобы обходить обнаружение, надежность этих инструментов подвергается серьезному сомнению. Существует мнение, что наличие детекторов ИИ, наоборот, побуждает ИИ при генерации контента избегать определенных легко маркируемых признаков, тем самым делая его более похожим на человеческое письмо. (Источник: Reddit r/ArtificialInteligence, sytelus)

Генеральный директор Anthropic призывает к усилению прозрачности и ответственности в регулировании ИИ-компаний: Генеральный директор компании Anthropic опубликовал в «New York Times» статью, в которой подчеркнул, что нельзя ослаблять регулирование ИИ-компаний, особенно в части повышения их прозрачности и привлечения к ответственности. Эта точка зрения особенно важна на фоне быстрого развития ИИ-индустрии и постоянно растущих возможностей технологий, и она созвучна общественной обеспокоенности потенциальными рисками и этическими вопросами, связанными с ИИ. В статье утверждается, что по мере роста влияния ИИ-технологий крайне важно обеспечить их развитие в общественных интересах и избежать злоупотреблений, что требует совместных усилий как со стороны саморегулирования отрасли, так и внешнего надзора. (Источник: Reddit r/artificial)

🎯 Тренды
Jeff Dean о будущем ИИ: специализированное оборудование, эволюция моделей и научные применения: Руководитель Google AI Jeff Dean на мероприятии Sequoia Capital AI Ascent поделился своим видением будущего развития ИИ. Он подчеркнул важность специализированного оборудования (такого как TPU) для прогресса в области ИИ и обсудил тенденции эволюции архитектур моделей. Dean также представил свое видение будущей формы вычислительной инфраструктуры и огромный потенциал применения ИИ в таких областях, как научные исследования, считая ИИ ключевым инструментом для продвижения научных открытий. (Источник: TheTuringPost)

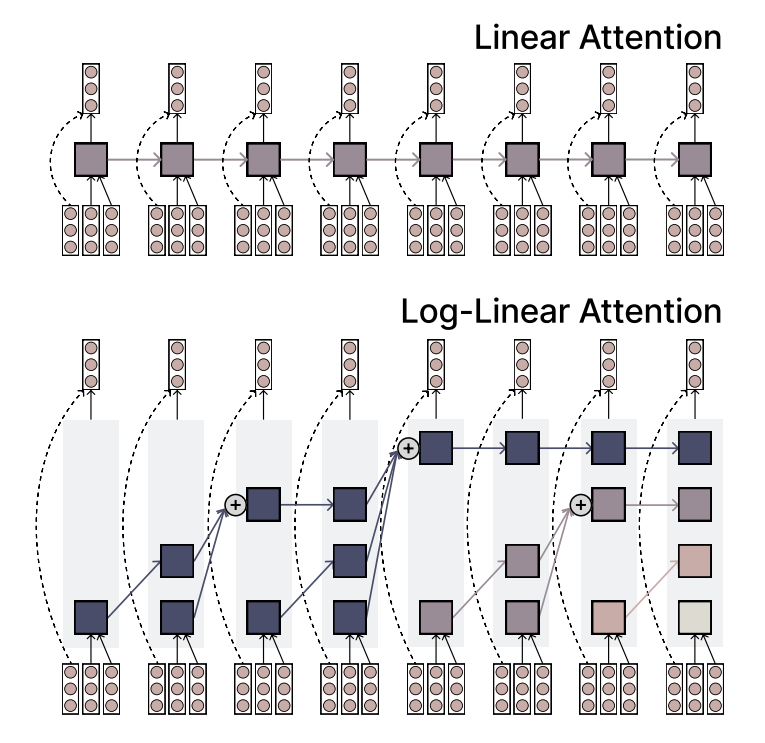
MIT предлагает механизм Log-Linear Attention, сочетающий эффективность и выразительность: Исследователи из MIT предложили новый механизм внимания под названием Log-Linear Attention. Этот механизм призван объединить высокую эффективность линейного внимания (Linear Attention) с мощной выразительной способностью Softmax-внимания. Его ключевой особенностью является использование небольшого количества слотов памяти (memory slots), количество которых растет логарифмически с длиной последовательности, что позволяет поддерживать низкую вычислительную сложность при обработке длинных последовательностей, одновременно захватывая ключевую информацию. (Источник: TheTuringPost)
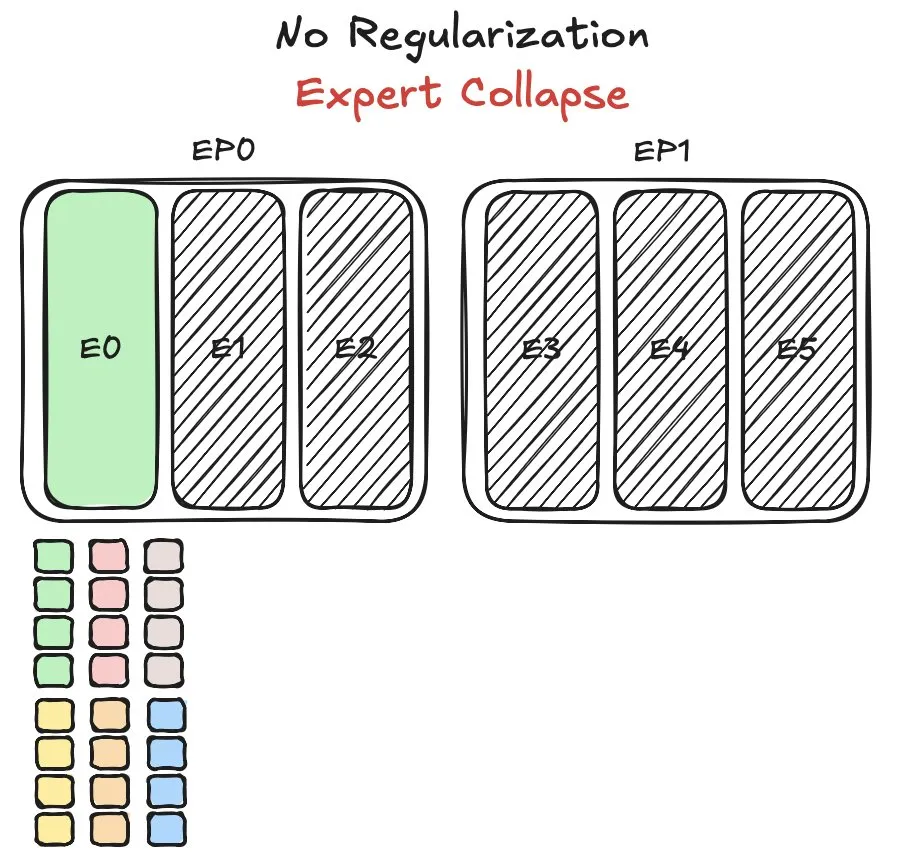
Модель MoE от Huawei Pangu сталкивается с проблемой балансировки нагрузки экспертов, предложен новый метод: При обучении своей модели смеси экспертов (MoE) Pangu Ultra MoE, компания Huawei столкнулась с ключевой проблемой балансировки нагрузки экспертов. Балансировка нагрузки экспертов требует компромисса между динамикой обучения и эффективностью системы. Huawei предложила новое решение этой проблемы, направленное на оптимизацию распределения задач и вычислительной нагрузки между различными экспертными модулями в модели MoE для повышения эффективности обучения и производительности модели. Соответствующее исследование опубликовано в виде научной статьи. (Источник: finbarrtimbers)
NVIDIA выпускает модель Cascade Mask R-CNN Mamba Vision, ориентированную на обнаружение объектов: NVIDIA опубликовала на Hugging Face новую модель под названием cascade_mask_rcnn_mamba_vision_tiny_3x_coco. Судя по названию, эта модель специально разработана для задач обнаружения объектов и, возможно, сочетает в себе архитектуру Cascade R-CNN с визуальной технологией Mamba (модель пространства состояний), с целью повышения точности и эффективности обнаружения объектов. (Источник: _akhaliq)
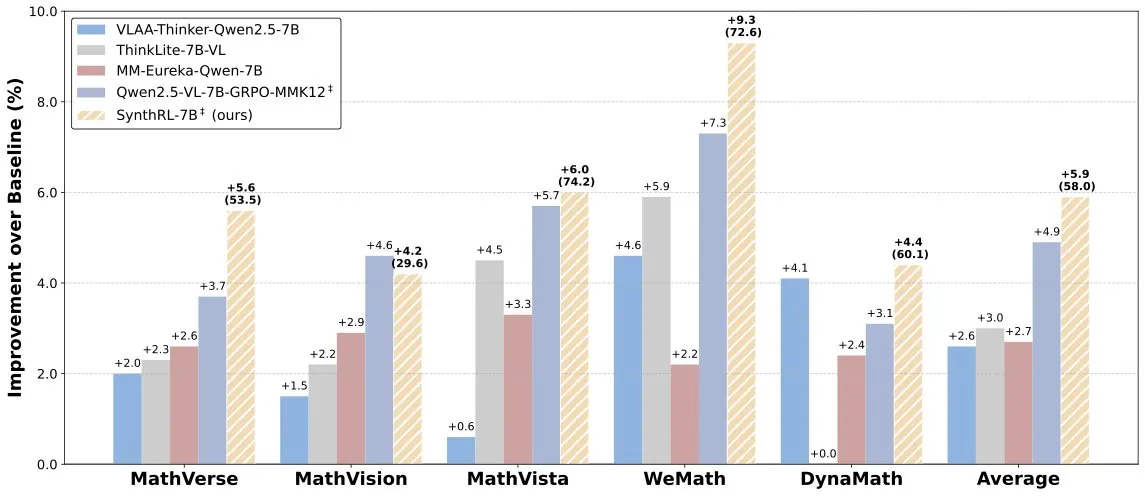
Выпущена модель SynthRL: масштабируемый визуальный логический вывод посредством синтеза проверяемых данных: На Hugging Face выпущена модель SynthRL, которая фокусируется на масштабируемых возможностях визуального логического вывода. Ее основная технология заключается в синтезе более сложных вариантов задач визуального логического вывода с помощью проверяемых методов синтеза данных, при этом сохраняя правильность исходных ответов. Это помогает повысить уровень понимания и логического вывода модели в сложных визуальных сценариях. (Источник: _akhaliq)
Несмотря на хорошие показатели DeepSeek-R1, продуктовые преимущества ChatGPT остаются непоколебимыми: VentureBeat отмечает, что, хотя новые модели, такие как DeepSeek-R1, демонстрируют выдающиеся результаты в некоторых аспектах, ChatGPT, благодаря своему преимуществу первопроходца, широкой пользовательской базе, зрелой продуктовой экосистеме и постоянным итерациям, сохраняет лидирующие позиции на продуктовом уровне, которые вряд ли будут превзойдены в краткосрочной перспективе. Конкуренция в области ИИ — это не только соревнование технических параметров, но и комплексная борьба за пользовательский опыт, построение экосистемы и бизнес-модели. (Источник: Ronald_vanLoon)

Команда Qwen подтвердила, что Qwen3-coder находится в разработке: Junyang Lin из команды Qwen подтвердил, что они разрабатывают Qwen3-coder, версию модели серии Qwen3 с улучшенными возможностями кодирования. Хотя конкретные сроки не объявлены, исходя из цикла выпуска Qwen2.5, ожидается, что модель может появиться в течение нескольких недель. Сообщество ожидает, что эта модель принесет прорывы в генерации кода, интеграции с автономными/агентными рабочими процессами и сохранит хорошую поддержку нескольких языков программирования. (Источник: Reddit r/LocalLLaMA)

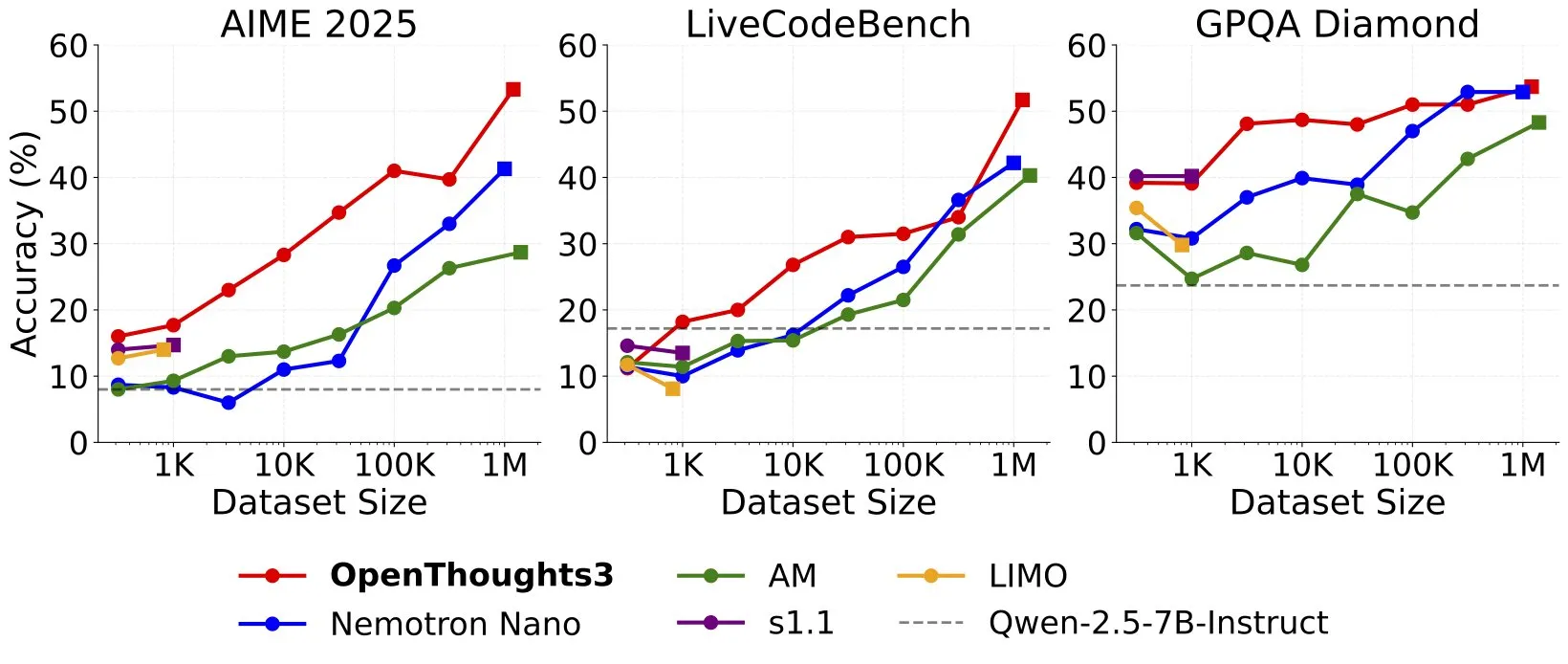
Выпущен OpenThinker3-7B, заявленный как SOTA модель для логического вывода с 7B параметрами на открытых данных: Ryan Marten объявил о выпуске модели OpenThinker3-7B, назвав ее самой передовой на данный момент моделью для логического вывода с 7 миллиардами параметров, обученной на открытых данных. Утверждается, что эта модель в среднем на 33% превосходит DeepSeek-R1-Distill-Qwen-7B в оценках по коду, науке и математике. Одновременно был выпущен и обучающий набор данных OpenThoughts3-1.2M. (Источник: menhguin)
🧰 Инструменты
TensorZero: открытый фреймворк LLMOps для оптимизации разработки и развертывания LLM-приложений: TensorZero — это открытый фреймворк для оптимизации LLM-приложений, разработанный для преобразования производственных данных в более умные, быстрые и экономичные модели с помощью циклов обратной связи. Он объединяет шлюз LLM (поддерживающий нескольких поставщиков моделей), наблюдаемость, оптимизацию (промпты, тонкая настройка, RL), оценку и эксперименты (A/B-тестирование), а также поддерживает низкую задержку, высокую пропускную способность и GitOps. Инструмент написан на Rust и ориентирован на производительность и требования промышленного уровня. (Источник: GitHub Trending)

LangChain представляет высокопроизводительную RAG-систему, сочетающую SambaNova, Qdrant и LangGraph: LangChain представил решение для высокопроизводительной генерации с расширенным поиском (RAG). Это решение сочетает модель DeepSeek-R1 от SambaNova, технологию бинарного квантования от Qdrant и LangGraph, что позволяет достичь 32-кратного сокращения использования памяти и, таким образом, эффективно обрабатывать большие объемы документов. Это открывает новые возможности для создания более экономичных и быстрых RAG-приложений. (Источник: hwchase17, qdrant_engine)
Приложение Sparkify от Google для создания научно-популярных видео одним кликом демонстрирует высококачественные примеры: Приложение Sparkify, представленное Google, способно создавать научно-популярные видео одним кликом, и продемонстрированные им примеры отличаются высоким качеством. Видеоконтент обладает хорошей общей согласованностью, естественной озвучкой и даже способен реализовывать сложные эффекты, такие как разделение экрана, что демонстрирует потенциал ИИ в автоматизации создания видеоконтента. (Источник: op7418)
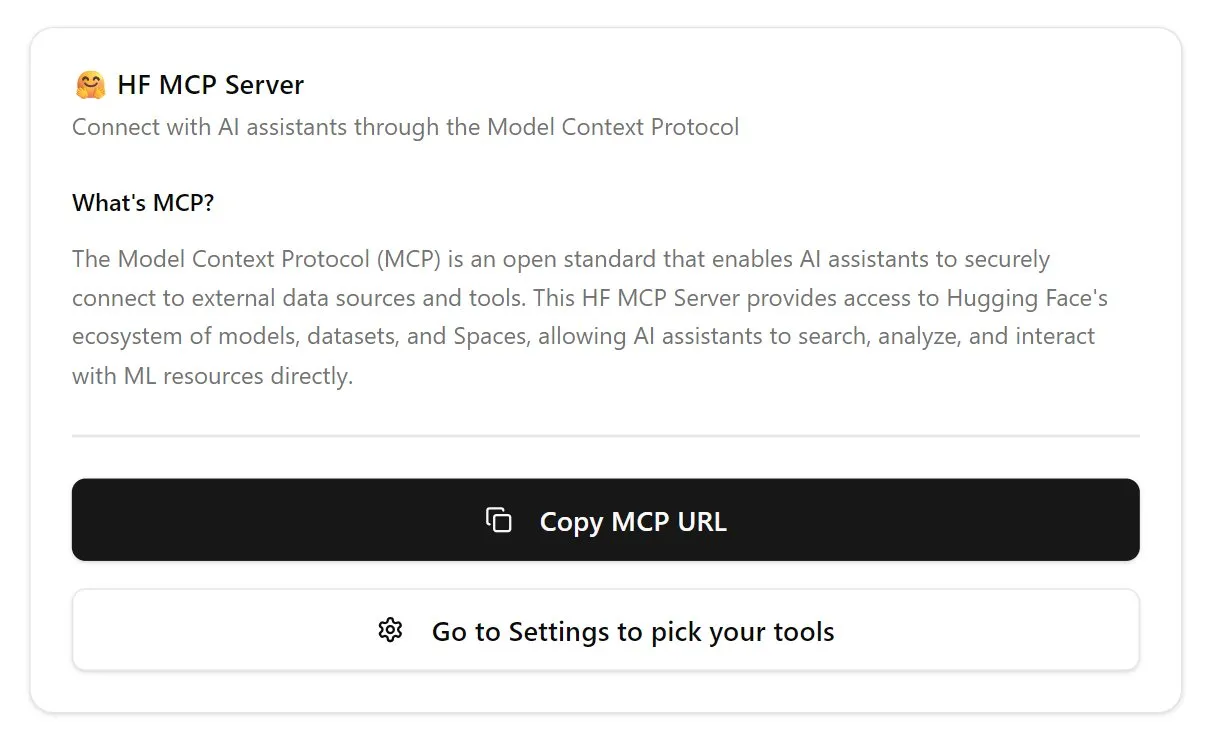
Hugging Face запускает первый MCP-сервер, расширяя функциональность чат-ботов: Hugging Face выпустила свой первый MCP (Modular Chat Processor) сервер (hf.co/mcp), который пользователи могут вставить в окно чата для использования. MCP-сервер предназначен для расширения функциональности чат-ботов, предоставляя более богатый интерактивный опыт с помощью модульных блоков обработки. Сообщество также составило список других полезных MCP-серверов, таких как Agentset MCP, GitHub MCP и др. (Источник: TheTuringPost)
Эффективность Chatterbox TTS сравнима с ElevenLabs, уже интегрирован в gptme: Инструмент TTS (преобразование текста в речь) Chatterbox привлек внимание благодаря превосходному качеству синтеза речи. Пользователи отмечают, что его эффективность сравнима с известным ElevenLabs и превосходит Kokoro. Chatterbox поддерживает настройку голоса с помощью эталонных образцов и теперь добавлен в качестве бэкенда TTS для gptme, предоставляя пользователям высококачественные опции голосового вывода. (Источник: teortaxesTex, _akhaliq)
E-Library-Agent: интеллектуальная система поиска и ответов на вопросы для локальных книг/документов: E-Library-Agent — это самоуправляемый ИИ-агент, способный извлекать, индексировать и запрашивать личные коллекции книг или научных работ. Проект основан на ingest-anything и поддерживается платформами LlamaIndex, Qdrant и Linkup, реализуя локальное извлечение материалов, контекстно-зависимые ответы на вопросы и сетевое обнаружение через единый интерфейс, что облегчает пользователям управление и использование личных баз знаний. (Источник: qdrant_engine)
Claude Code высоко ценится разработчиками за мощные возможности помощи в кодировании: Пользователи сообщества Reddit поделились положительным опытом использования Claude Code от Anthropic для разработки программного обеспечения, особенно в таких областях, как разработка игр (например, проекты на Godot C#). Пользователи хвалят его способность решать сложные проблемы, значительно превосходящую другие ИИ-помощники для кодирования (такие как GitHub Copilot), его умение понимать контекст и генерировать эффективный код, даже ежемесячная плата в 100 долларов считается оправданной. Разработчики считают, что опытные программисты в сочетании с Claude Code будут чрезвычайно продуктивны. (Источник: Reddit r/ClaudeAI)
ChatterUI реализует поддержку локальных визуальных моделей, но обработка на Android медленная: Предварительная версия LLM-клиента для чата ChatterUI добавила поддержку вложений и локальных визуальных моделей (через llama.rn). Пользователи могут загружать файлы mmproj для локально совместимых моделей или подключаться к API с поддержкой визуальных функций (например, Google AI Studio, OpenAI). Однако из-за отсутствия стабильного GPU-бэкенда для llama.cpp на Android скорость обработки изображений крайне низкая (например, изображение 512×512 обрабатывается 5 минут), производительность на iOS относительно лучше. (Источник: Reddit r/LocalLLaMA)
FLUX kontext демонстрирует отличные результаты в замене фона на рекламных изображениях автомобилей: Пользовательское тестирование показало, что инструмент для редактирования изображений с ИИ FLUX kontext эффективно справляется с изменением фона на рекламных изображениях автомобилей. Например, при замене фона на официальных изображениях Xiaomi SU7 (например, на пляж на закате, гоночную трассу) инструмент не только естественно интегрирует фон, но и интеллектуально добавляет эффект размытия движения для движущихся автомобилей, повышая реалистичность и визуальное воздействие изображения. (Источник: op7418)

📚 Материалы для изучения
Новая функция flexicache в fastcore: гибкий декоратор кэширования: Jeremy Howard представил полезную новую функцию flexicache в библиотеке fastcore. Это очень гибкий декоратор кэширования со встроенными стратегиями ‘mtime’ (на основе времени модификации файла) и ‘time’ (на основе временной метки), который также позволяет пользователям определять новые стратегии кэширования с помощью небольшого количества кода. Эта функция подробно описана в статье Daniel Roy Greenfeld и помогает повысить эффективность выполнения кода. (Источник: jeremyphoward)
Обсуждение потенциала сочетания MuP и Muon для обучения Transformer-моделей: Jingyuan Liu углубленно изучил работу Jeremy Bernstein по выводу Muon и спектральных условий и выразил восхищение элегантностью вывода, особенно тем, как MuP (Maximal Update Parametrization) и Muon (оптимизатор) работают вместе. Он считает, что, судя по выводу, использование Muon в качестве оптимизатора для обучения моделей на основе MuP является естественным выбором, и отмечает, что это может быть более захватывающим, чем перенос гиперпараметров из AdamW в Muon путем сопоставления среднеквадратичного значения обновлений, как в работе Moonshot Moonlight. В сообществе обсуждается, что комбинация MuP + Muon может быть масштабно применена крупными технологическими компаниями к концу года. (Источник: jeremyphoward)

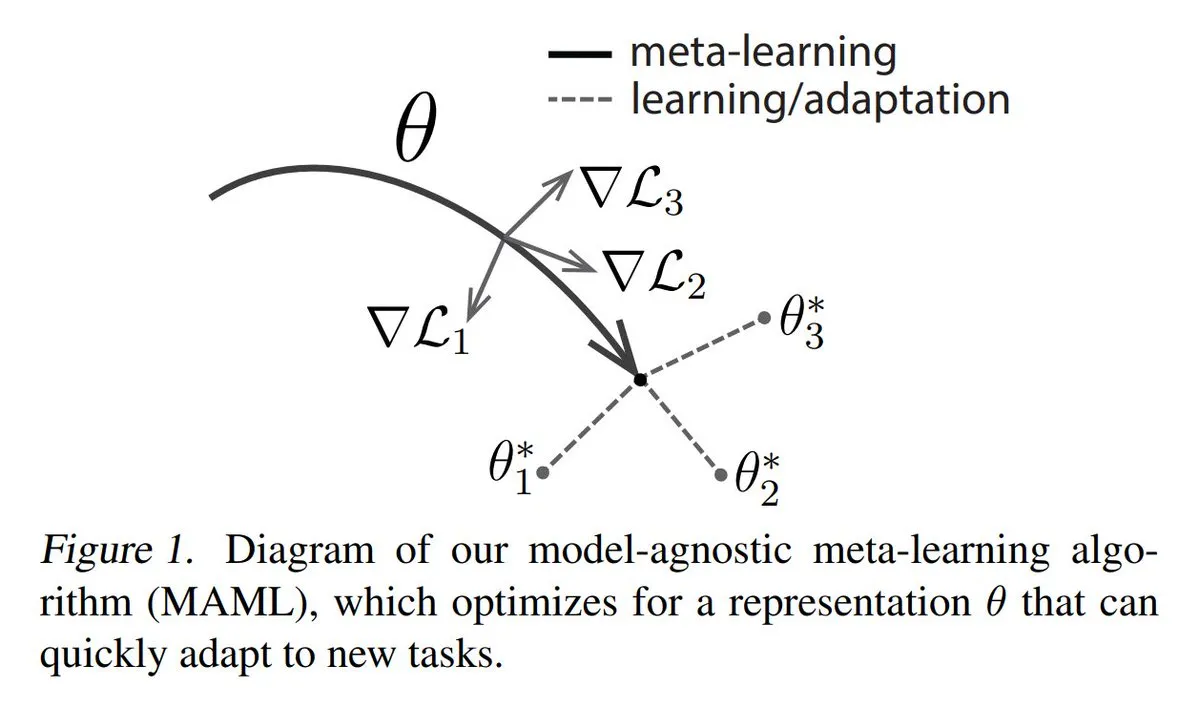
Анализ трех основных подходов к мета-обучению (Meta-learning): Мета-обучение направлено на обучение моделей быстрому освоению новых задач, даже при наличии небольшого количества примеров. Распространенные методы включают: 1. На основе оптимизации/градиентов: поиск параметров модели, которые можно эффективно дообучить на задаче за небольшое количество шагов градиентного спуска. 2. На основе метрик: помощь модели в поиске лучших способов измерения сходства между новыми и старыми примерами для эффективной группировки связанных примеров. 3. На основе моделей: вся модель спроектирована так, чтобы использовать встроенную память или динамические механизмы для быстрой адаптации. TuringPost предоставляет подробный разбор методов мета-обучения от основ до современных подходов. (Источник: TheTuringPost)
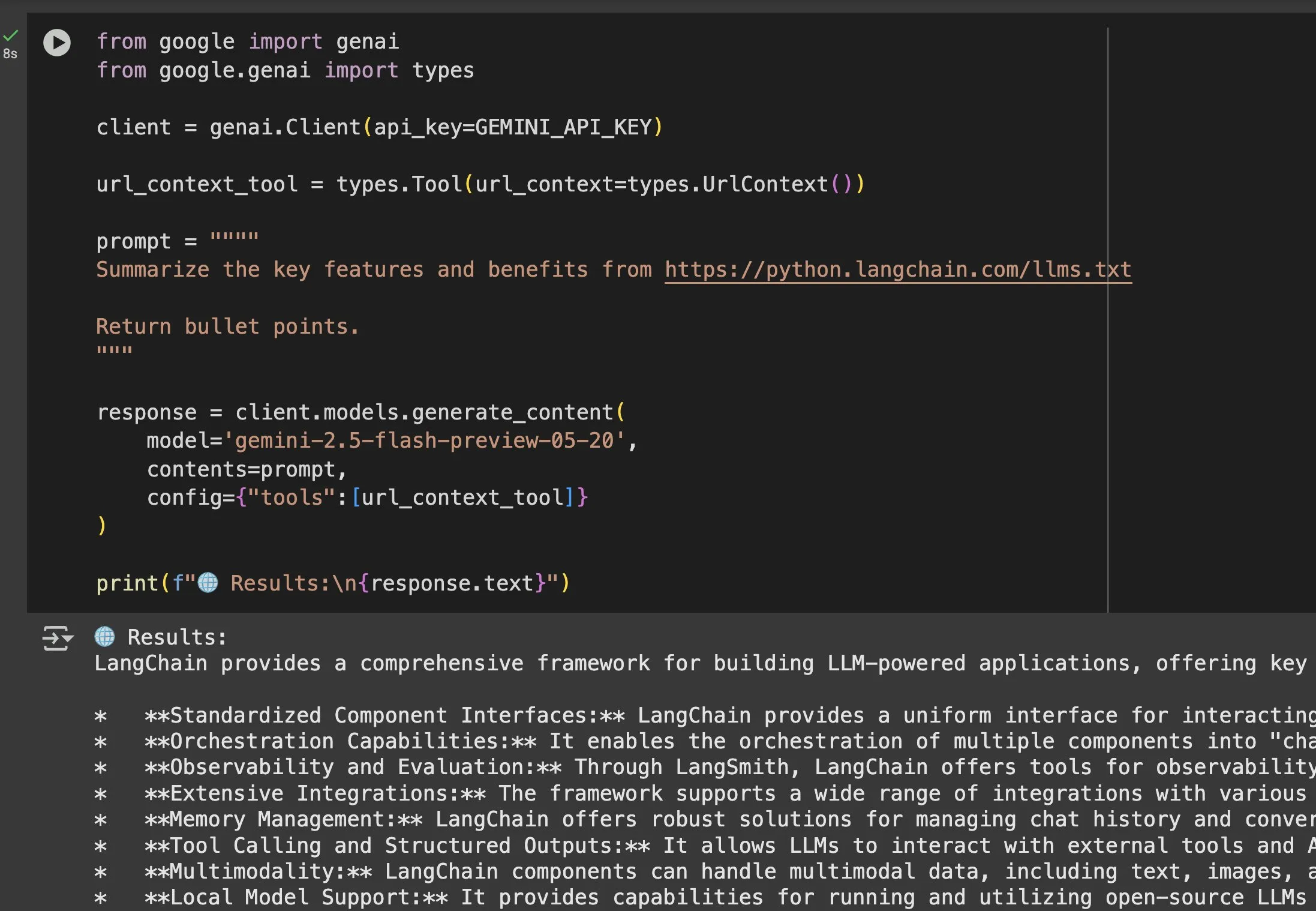
Ценность файла llms.txt в применении моделей, таких как Gemini, становится очевидной: Jeremy Phoward подчеркнул практичность файла llms.txt. Например, Gemini теперь может понимать содержимое URL-адресов; достаточно добавить URL-адрес в промпт и настроить инструмент контекста URL. Это означает, что клиент (например, Gemini), читая конечную точку llms.txt, может точно знать, где хранится необходимая информация, что значительно упрощает программное получение и использование информации. (Источник: jeremyphoward)
EleutherAI выпускает 8 ТБ текстового набора данных Common Pile v0.1 с открытой лицензией: EleutherAI объявила о выпуске Common Pile v0.1, крупного набора данных, содержащего 8 ТБ текста с открытой лицензией и из общественного достояния. На основе этого набора данных они обучили языковые модели с 7 миллиардами параметров (используя 1Т и 2Т токенов для обучения соответственно), производительность которых сопоставима с аналогичными моделями, такими как LLaMA 1 и LLaMA 2. Это предоставляет ценный ресурс и практическое подтверждение для исследования обучения высокопроизводительных языковых моделей с использованием полностью соответствующих требованиям данных. (Источник: clefourrier)

SelfCheckGPT: метод обнаружения галлюцинаций LLM без использования эталона: В одной из статей блога рассматривается SelfCheckGPT как альтернатива LLM-as-a-judge (использование LLM в качестве оценщика) для обнаружения галлюцинаций в языковых моделях. Это метод обнаружения, не требующий эталонного текста и нулевых ресурсов, что открывает новые перспективы для оценки и повышения достоверности вывода LLM. (Источник: dl_weekly)
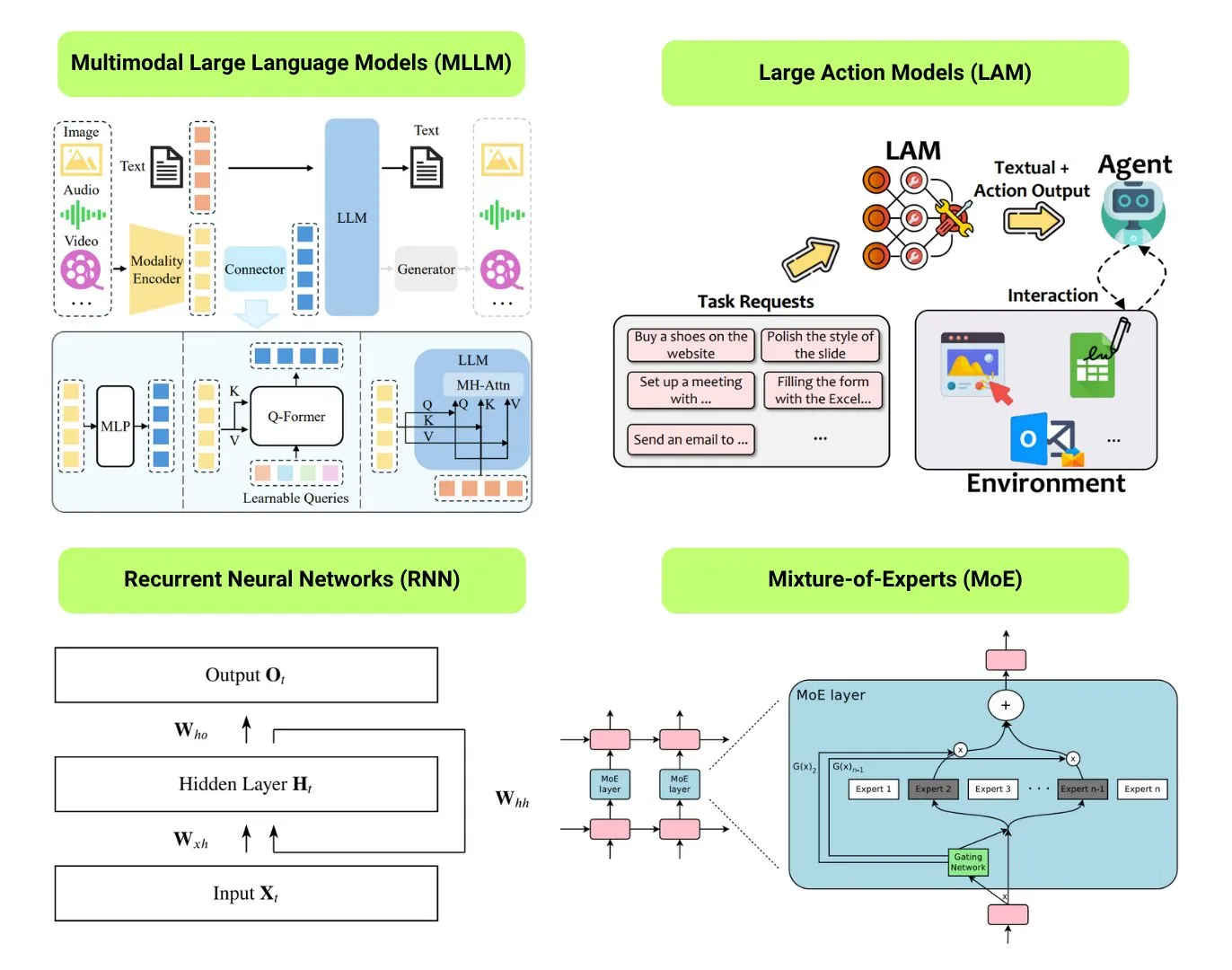
Обзор 12 базовых типов ИИ-моделей: The Turing Post составил обзор 12 базовых типов ИИ-моделей, включая LLM (большие языковые модели), SLM (малые языковые модели), VLM (визуально-языковые модели), MLLM (мультимодальные большие языковые модели), LAM (большие поведенческие модели), LRM (большие модели логического вывода), MoE (модели смеси экспертов), SSM (модели пространства состояний), RNN (рекуррентные нейронные сети), CNN (сверточные нейронные сети), SAM (модели сегментации всего) и LNN (логические нейронные сети). Связанные ресурсы предоставляют объяснения этих типов моделей и полезные ссылки. (Источник: TheTuringPost)
Популярное на GitHub: Руководство Kubernetes The Hard Way: Руководство Kelsey Hightower «Kubernetes The Hard Way» продолжает пользоваться популярностью на GitHub. Это руководство предназначено для того, чтобы помочь пользователям постепенно создать кластер Kubernetes вручную, глубоко понять его основные компоненты и принципы работы, а не полагаться на автоматизированные скрипты. Руководство ориентировано на тех, кто хочет освоить основы Kubernetes, и охватывает весь процесс от подготовки среды до очистки кластера. (Источник: GitHub Trending)
Популярное на GitHub: Список бесплатных GPT и промптов: Репозиторий friuns2/BlackFriday-GPTs-Prompts стал популярным на GitHub. Он собирает и систематизирует серию бесплатных моделей GPT и высококачественных промптов, которыми пользователи могут пользоваться без подписки Plus. Эти ресурсы охватывают множество областей, таких как программирование, маркетинг, академические исследования, поиск работы, игры, творчество, и содержат некоторые приемы «Jailbreaks», предоставляя пользователям GPT богатый набор готовых инструментов и идей. (Источник: GitHub Trending)

Использование CSV для планирования и отслеживания проектов кодирования с ИИ, повышение качества и эффективности кода: Один разработчик поделился опытом использования Claude Code при разработке ERP-системы, где создание подробных CSV-файлов для планирования и отслеживания прогресса кодирования каждого файла значительно повысило эффективность разработки сложных функций и качество кода. CSV-файл содержал статус, имя файла, приоритет, количество строк кода, сложность, зависимости, описание функциональности, используемые хуки, импортируемые/экспортируемые модули и ключевые «заметки о прогрессе». Такой подход позволил ИИ более целенаправленно создавать код, а разработчику — четко понимать фактический прогресс проекта и его отличия от первоначального плана. (Источник: Reddit r/ClaudeAI)
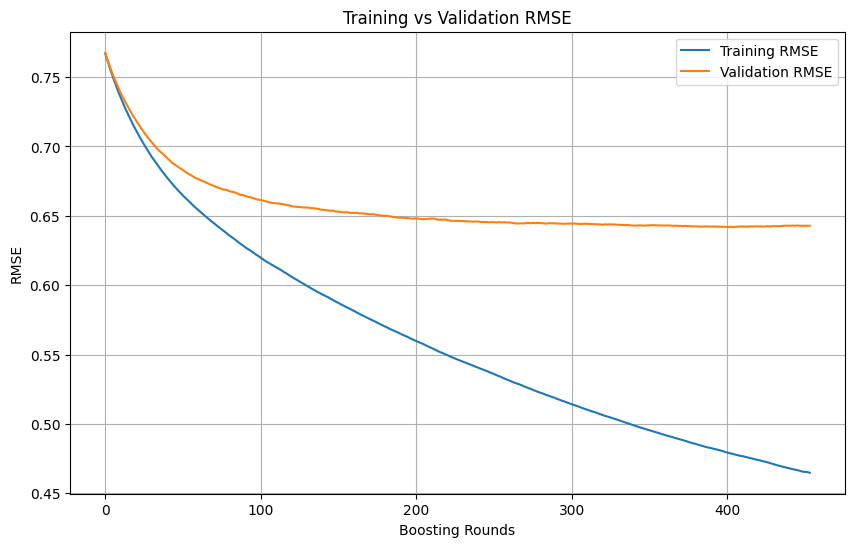
Определение переобучения и момента остановки при обучении моделей машинного обучения: В процессе обучения моделей машинного обучения, когда потери на обучающей выборке продолжают быстро снижаться, а потери на валидационной выборке снижаются медленно, останавливаются или даже начинают расти, это обычно указывает на возможное переобучение модели. В принципе, пока потери на валидационной выборке все еще снижаются, обучение можно продолжать. Ключевым моментом является обеспечение того, чтобы валидационный набор был независим от обучающего и представлял реальное распределение данных задачи. Если потери на валидационной выборке перестают снижаться или начинают расти, следует рассмотреть возможность досрочной остановки обучения или применить методы регуляризации для улучшения обобщающей способности модели. (Источник: Reddit r/MachineLearning)
🌟 Сообщество
AI Engineer World’s Fair 2025 фокусируется на темах RL+Reasoning, Eval и др.: Темы конференции AI Engineer World’s Fair 2025 охватывают такие передовые направления, как обучение с подкреплением + логический вывод (RL+Reasoning), оценка (Eval), программно-инженерные агенты (SWE-Agent), архитекторы ИИ и инфраструктура для агентов. Участники отметили, что конференция была полна энергии и инновационных идей, многие смело пробуют новое, постоянно переосмысливают себя и посвящают себя области ИИ. Конференция также предоставила платформу для общения и обучения инженеров ИИ. (Источник: swyx, hwchase17, charles_irl, swyx)

Идеальный ИИ по мнению Sam Altman: маленькая модель + сверхмощный логический вывод + огромный контекст + универсальные инструменты: Sam Altman описал свое видение идеальной формы ИИ: модель со сверхчеловеческими способностями к логическому выводу, чрезвычайно малого размера, способная получать доступ к триллионам единиц контекстной информации и вызывать любые вообразимые инструменты. Эта точка зрения вызвала дискуссию; некоторые считают, что это отличается от текущего положения дел, когда большие модели полагаются на хранение знаний, и сомневаются в возможности маленьких моделей анализировать знания в огромном контексте и выполнять сложные логические выводы, полагая, что знания и мыслительные способности трудно эффективно разделить. (Источник: teortaxesTex)
Кодирующие агенты вызывают желание рефакторинга кода, вызовы и возможности ИИ-ассистированного программирования: Разработчики отмечают, что появление кодирующих агентов значительно усилило их «искушение» рефакторить чужой код, а также принесло новые опасности. Один разработчик поделился опытом выполнения задачи программирования, которая вручную заняла бы около 10 минут, с помощью ИИ. Хотя ИИ смог быстро сгенерировать рабочий код, для достижения уровня организации и стиля опытного программиста все еще требовалось значительное ручное руководство и рефакторинг. Это подчеркивает проблемы ИИ-ассистированного программирования в повышении качества кода от начального/среднего до продвинутого уровня. (Источник: finbarrtimbers, mitchellh)
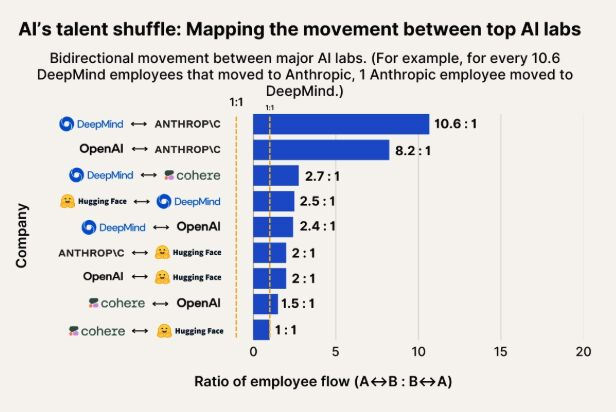
Наблюдение за миграцией талантов в сфере ИИ: Anthropic становится важным направлением для специалистов из Google DeepMind и OpenAI: Диаграмма, иллюстрирующая миграцию талантов в сфере ИИ, показывает, что Anthropic становится важной компанией, привлекающей исследователей из Google DeepMind и OpenAI. Сообщество считает это соответствующим действительности, а некоторые пользователи предполагают, что Anthropic может обладать неким «секретным оружием» или уникальными направлениями исследований, привлекающими ведущих специалистов. (Источник: bookwormengr, TheZachMueller)
Распространение человекоподобных роботов сталкивается с проблемами доверия и социального принятия: Технологический обозреватель Faruk Guney прогнозирует, что первая волна человекоподобных роботов может потерпеть неудачу из-за огромного дефицита доверия. Он считает, что, несмотря на постоянный технологический прогресс, общество еще не готово принять этих «интеллектуальных черных ящиков» в свои дома для выполнения таких задач, как компаньонство, домашние дела и даже уход за детьми. Непрозрачность принятия решений роботами, потенциальные риски наблюдения и совершенно отличный от человеческого «милый» внешний вид (не такой, как у Wall-E) могут стать препятствиями для их широкого применения. Только после всестороннего общественного обсуждения, регулирования, аудита и восстановления доверия можно будет говорить о настоящем распространении человекоподобных роботов. (Источник: farguney, farguney)
Персонализированный дизайн ИИ: «несовершенство» лучше «совершенства»: Один разработчик поделился опытом создания 50 персонализированных ИИ-образов на аудиоплатформе ИИ. Вывод: чрезмерно проработанные предыстории, абсолютная логическая последовательность и крайняя однобокость характера делают ИИ механистичным и нереалистичным. Успешное формирование личности ИИ заключается в «3-уровневом стеке личности» (основные черты + модифицирующие черты + причуды), умеренных «паттернах несовершенства» (например, случайные оговорки, самокоррекция) и точном объеме фоновой информации (300-500 слов, включая положительный и сложный опыт, конкретные увлечения и уязвимые места, связанные с профессией). Эти «несовершенные» детали, наоборот, делают ИИ более человечным и способным к установлению связи. (Источник: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Дискуссия о том, обладают ли LLM «восприятием» и являются ли они «AGI»: волнение и скептицизм сосуществуют: Сообщество в целом воодушевлено огромным потенциалом LLM, считая их сравнимыми с исторически значимыми изобретениями, которые изменят все. Однако многие по-прежнему скептически относятся к утверждениям о том, что LLM уже обладают «способностью к восприятию», нуждаются в «правах», «уничтожат человечество» или приведут к «AGI». Подчеркивается необходимость сохранять внимательность и осмотрительность при интерпретации возможностей LLM и результатов исследований. (Источник: fabianstelzer)
💡 Прочее
Обсуждение совместной автономной ходьбы нескольких роботов: В социальных сетях появились исследования по совместной работе нескольких роботов в области автономной ходьбы. Это включает в себя сложные технологии, такие как планирование пути роботов, распределение задач, обмен информацией и предотвращение столкновений, и является постоянно актуальным направлением исследований в робототехнике, RPA (роботизированная автоматизация процессов) и машинном обучении. (Источник: Ronald_vanLoon)
Прием оптимизации гиперпараметров ULMFiT с использованием случайных лесов: Jeremy Howard поделился приемом, который он использовал при оптимизации ULMFiT (метод трансферного обучения): путем проведения большого количества экспериментов по исключению компонентов (ablation studies) и передачи всех гиперпараметров и данных о результатах модели случайного леса, чтобы выявить гиперпараметры, оказывающие наибольшее влияние на производительность модели. Этот метод был интегрирован Weights & Biases в их продукт, предоставляя новый подход к настройке гиперпараметров. (Источник: jeremyphoward)

Человекоподобный робот компании Figure демонстрирует 60-минутную обработку логистических задач: Компания Figure опубликовала 60-минутное видео, демонстрирующее, как ее человекоподобный робот под управлением нейронной сети Helix автономно выполняет различные задачи в логистическом сценарии. Эта демонстрация призвана доказать способность их робота к длительной стабильной работе и автономному принятию решений в сложных реальных условиях. (Источник: adcock_brett)