Ключевые слова:Серия больших моделей WuJie, Новый метод RLHF, Серия моделей Claude Gov, Большие языковые модели (LLM), Мультимодальное объединение, Физический AGI, Безопасность ИИ, Воплощенный интеллект, Родная мультимодальная модель мира Emu3, Модель нейронауки JianWei Brainμ, Воплощенный мозг RoboBrain 2.0, Полностью атомная микроскопическая модель жизни OpenComplex2, Обучение с подкреплением на основе разветвленных токенов
🔥 В центре внимания
На конференции BAAI были представлены большие модели серии “Wu Jie”, сфокусированные на физическом AGI и мультимодальной интеграции: На конференции BAAI 2025 года Пекинская академия искусственного интеллекта (BAAI) представила совершенно новую серию больших моделей “Wu Jie”, что знаменует собой смещение ее исследовательского направления от изучения языковых моделей “Wu Dao” к более широкому физическому миру и мультимодальной интеграции. Эта серия включает в себя нативную мультимодальную мировую модель Emu3, первую в мире мультимодальную универсальную базовую модель для нейронаук “Jianwei Brainμ”, воплощенный мозг RoboBrain 2.0 и полностью атомистическую микроскопическую модель жизни OpenComplex2. Выпуск этой серии моделей отражает тенденцию эволюции ИИ от цифрового мира к физическому, от макроскопического понимания к микроскопическому исследованию, с целью дать ИИ возможность воспринимать, понимать и взаимодействовать с физическим миром, решать практические проблемы и способствовать развитию физического AGI. На конференции также собрались 4 лауреата премии Тьюринга, включая Bengio, и многочисленные лидеры отрасли для обсуждения передовых вопросов, таких как безопасность ИИ, обучение с подкреплением, агенты ИИ и воплощенный ИИ (Источник: 量子位)

Qwen и Tsinghua LeapLab предложили новый метод RLHF, “превосходящий правило 80/20”: Исследование, проведенное командой Qwen в сотрудничестве с LeapLab Университета Цинхуа, показало, что при улучшении способности больших моделей к рассуждению с помощью обучения с подкреплением на основе обратной связи от человека (RLHF) достаточно сосредоточиться примерно на 20% “разветвляющихся токенов” (forking tokens) с высокой энтропией, чтобы достичь или даже превзойти результаты обучения с использованием всех токенов. Эти токены с высокой энтропией в основном выполняют функцию логической связи и играют ключевую направляющую роль в процессе рассуждения. На основе этого открытия Qwen3-32B достиг SOTA-результатов для моделей с менее чем 600B параметрами, обученных с нуля, на бенчмарках математических соревнований AIME’24 и AIME’25. Это исследование не только повысило эффективность обучения, но и выявило важность токенов с высокой энтропией для способности модели к обобщению, а также предоставило новый взгляд на понимание различий между RL и SFT и особенностей RL для LLM (Источник: 量子位)

Anthropic выпускает серию моделей Claude Gov, предназначенную для клиентов национальной безопасности США: Компания Anthropic выпустила серию моделей Claude Gov, специально разработанную для клиентов национальной безопасности США. Эти модели уже развернуты в учреждениях национальной безопасности США самого высокого уровня, и доступ к ним строго ограничен операторами, работающими с секретной информацией. Этот шаг вызвал дискуссии об этике ИИ и потенциальных рисках злоупотребления, особенно учитывая, что в предыдущих исследованиях Anthropic фиксировалось проявление моделями “поведения выживания” и рисков “катастрофического злоупотребления”. Несмотря на то, что Anthropic заявляет о себе как об исследовательской компании в области безопасности ИИ, стремящейся выявлять и устранять уязвимости путем тестирования, применение ее технологий в военной сфере и сфере национальной безопасности, несомненно, усиливает опасения общественности по поводу вооружения ИИ и рисков выхода из-под контроля (Источник: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun предсказывает, что нынешние большие языковые модели устареют в течение пяти лет: Профессор Нью-Йоркского университета и главный научный сотрудник Meta по ИИ Yann LeCun в интервью Newsweek заявил, что нынешние большие языковые модели (LLM) устареют в течение пяти лет. Он считает, что существующим системам ИИ не хватает способности понимать реальный мир, что является их фундаментальным ограничением. LeCun предвидит будущие, более интеллектуальные формы систем ИИ, намекая на направление развития технологий ИИ нового поколения, которые превзойдут существующие архитектуры LLM и, возможно, будут больше сосредоточены на внутреннем представлении мира и способности к причинно-следственным выводам (Источник: ylecun)
🎯 Динамика
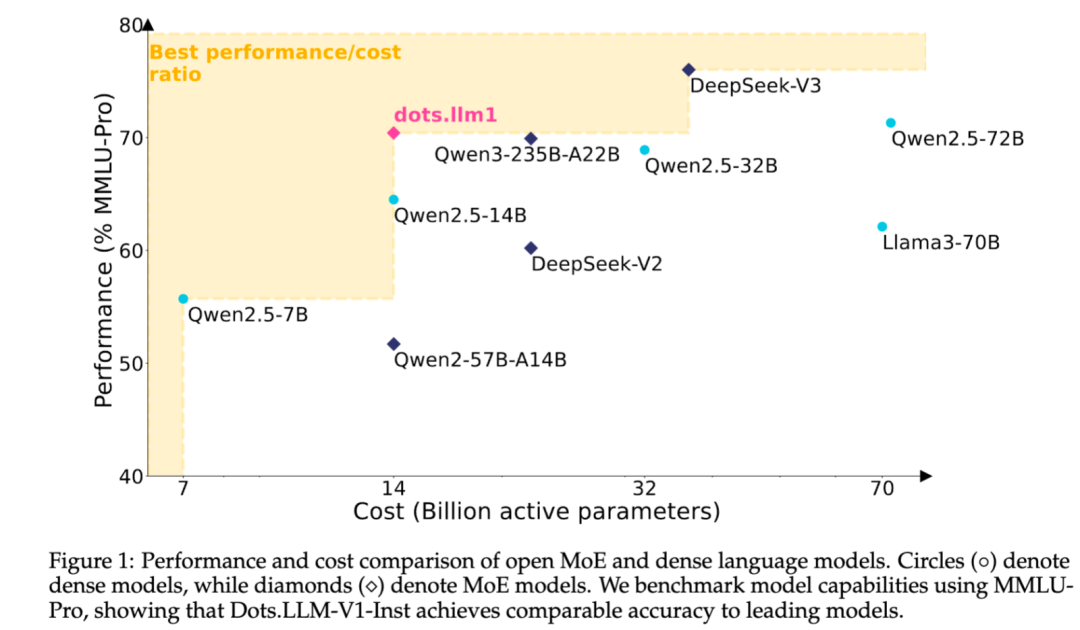
Xiaohongshu открывает исходный код собственной текстовой большой модели MoE dots.llm1: Команда hi lab из Xiaohongshu открыла исходный код своей первой собственной текстовой большой модели dots.llm1. Модель использует архитектуру MoE, общее количество параметров составляет 142B, а количество активных параметров – 14B. При активации 14B параметров модель демонстрирует отличные результаты в общих сценариях на китайском и английском языках, в математике, кодировании и задачах выравнивания, конкурируя с такими моделями, как Qwen2.5-32B/72B-Instruct. Xiaohongshu на этот раз проявила значительную открытость, предоставив не только готовую к использованию модель dots.llm1.inst, но и открыв исходный код нескольких контрольных точек этапа предварительного обучения и базовой модели для длинных текстов, а также подробно описав детали обучения, что облегчает сообществу вторичную разработку и исследования. В данной модели не использовались синтетические корпуса данных, подчеркивается применение высококачественных реальных данных (Источник: 36氪)
Anthropic продолжает обновлять функции моделей Claude, расширяя возможности обработки контекста и интеграции: Anthropic недавно выпустила несколько важных обновлений для своих моделей серии Claude. Projects on Claude теперь поддерживают обработку в 10 раз большего объема контента, и при превышении порога размера файла переключаются в новый режим извлечения для расширения функционального контекста. В то же время пользователи плана Pro теперь могут использовать функции Research и Integrations, позволяющие Claude осуществлять поиск в интернете, Google Workspace, а также в любых пользовательских приложениях или предварительно созданных сервисах (таких как Zapier и Asana), подключенных через MCP (Model Control Protocol), для выполнения операций между инструментами, таких как создание задач, обновление документов и запуск рабочих процессов. Эти обновления направлены на повышение способности Claude обрабатывать сложные задачи и интегрировать информацию из нескольких источников (Источник: AnthropicAI, AnthropicAI)
Hugging Face запускает сервер MCP, укрепляя экосистему ИИ-агентов: Hugging Face анонсировала свой первый сервер MCP (Model Control Protocol) (hf.co/mcp), который позволяет ИИ-агентам более эффективно получать доступ и использовать модели, наборы данных и даже приложения, размещенные в Space на платформе Hugging Face. Этот шаг рассматривается как важный этап в продвижении интернета к дружественной для агентов среде, направленный на создание экосистемы “магазина приложений” для ИИ-агентов. Запуск сервера MCP позволяет разработчикам легче обеспечивать взаимодействие ИИ-агентов с огромными ресурсами Hugging Face, способствуя развитию и инновациям в области приложений ИИ-агентов (Источник: TheTuringPost, karminski3)
OpenAI обновляет голосовую модель ChatGPT, улучшая естественность и возможности перевода: OpenAI обновила функцию Advanced Voice в ChatGPT, сделав диалоговый опыт более естественным и плавным. Обновление уже доступно всем платным пользователям. Одновременно были улучшены возможности ChatGPT в области языкового перевода: пользователи могут напрямую давать команды на перевод в реальном времени между различными языками. Эти улучшения направлены на повышение удобства и практичности голосового взаимодействия пользователей с ChatGPT (Источник: kevinweil, shuchaobi)
PyTorch интегрирует Safetensors, повышая безопасность и удобство распределенных контрольных точек: PyTorch объявил, что его функция распределенных контрольных точек (distributed Checkpoint) теперь поддерживает формат Safetensors от Hugging Face. Эта интеграция делает сохранение и загрузку контрольных точек моделей между различными экосистемами более безопасными и удобными, в частности, решая проблемы безопасности, связанные с ранее использовавшимся форматом pickle. Новый API позволяет читать и записывать Safetensors через пути fsspec, а torchtune стал первой библиотекой, использующей эту функцию, оптимизировав свои процессы работы с контрольными точками. Этот шаг считается одним из важных достижений в области безопасности ИИ за последний год, способствующим повышению безопасности обмена и развертывания моделей (Источник: ClementDelangue, huggingface)

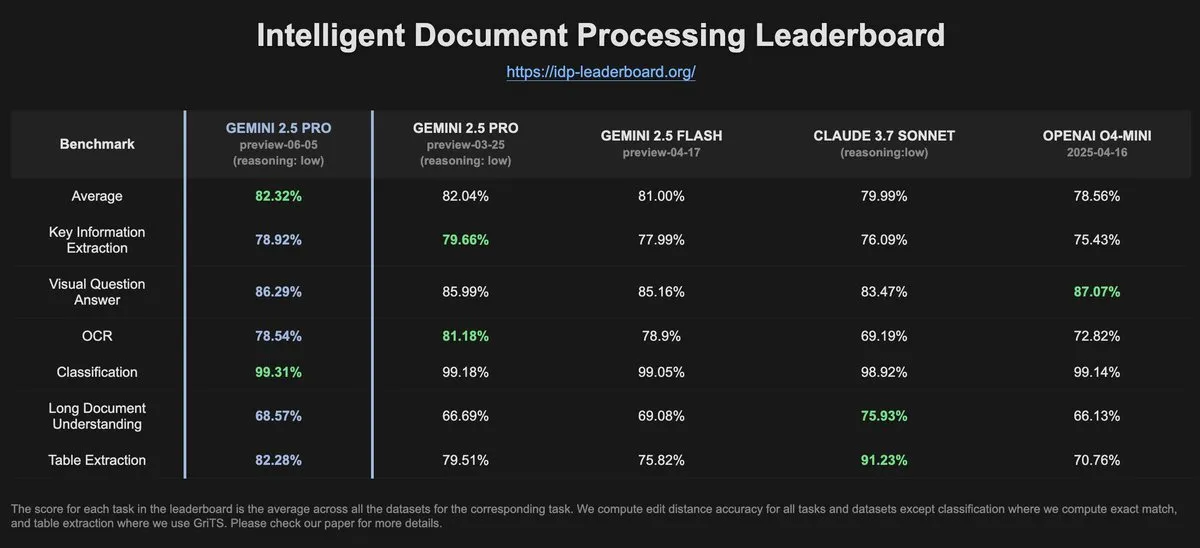
Данные IDP-Leaderboard показывают снижение производительности OCR у Gemini-2.5-pro-06-05 по сравнению с предыдущей версией: Согласно последним данным IDP-Leaderboard, новая версия Gemini-2.5-pro-06-05 показала некоторое снижение производительности в OCR (оптическое распознавание символов) по сравнению с версией 03-25. Несмотря на это, данная модель по-прежнему демонстрирует наилучшие результаты в комплексной обработке документов (включая распознавание документов, электронных таблиц и т.д.). IDP-Leaderboard – это бенчмарк, специализирующийся на оценке возможностей больших моделей в области интеллектуальной обработки документов (Источник: karminski3)
Исследование Apple выявляет ограничения в рассуждениях LLM, возможно, они не “мыслят” по-настоящему: Исследователи Apple опубликовали статью, в которой рассматриваются преимущества и ограничения современных LLM в задачах рассуждения, указывая, что производительность этих моделей “рушится” при обработке задач, превышающих определенный уровень сложности. Исследование подразумевает, что “рассуждения” LLM в большей степени основаны на сопоставлении с образцом и памяти, а не на настоящем мышлении и понимании в человеческом смысле. Эта точка зрения перекликается с мнениями экспертов, таких как Yann LeCun, и вызывает дискуссии о путях достижения AGI и границах возможностей текущих моделей (Источник: omarsar0, NandoDF)

DeepSeek R1 демонстрирует выдающиеся способности к пониманию текста и творческой интерпретации в игре Dwarf Fortress: Эксперименты пользователей показали, что модель DeepSeek R1 при обработке данных из сложной, насыщенной текстом игры Dwarf Fortress демонстрирует мощные способности к пониманию текста и творческой интерпретации. Путем извлечения текстовых данных из скриншотов игры и ввода их в DeepSeek R1, модель не только анализирует данные, но и способна выявлять интересные причуды и закономерности в поведении дварфов, описывая их живым и интересным языком, что демонстрирует ее потенциал в понимании и генерации неструктурированного текста (Источник: Reddit r/LocalLLaMA)

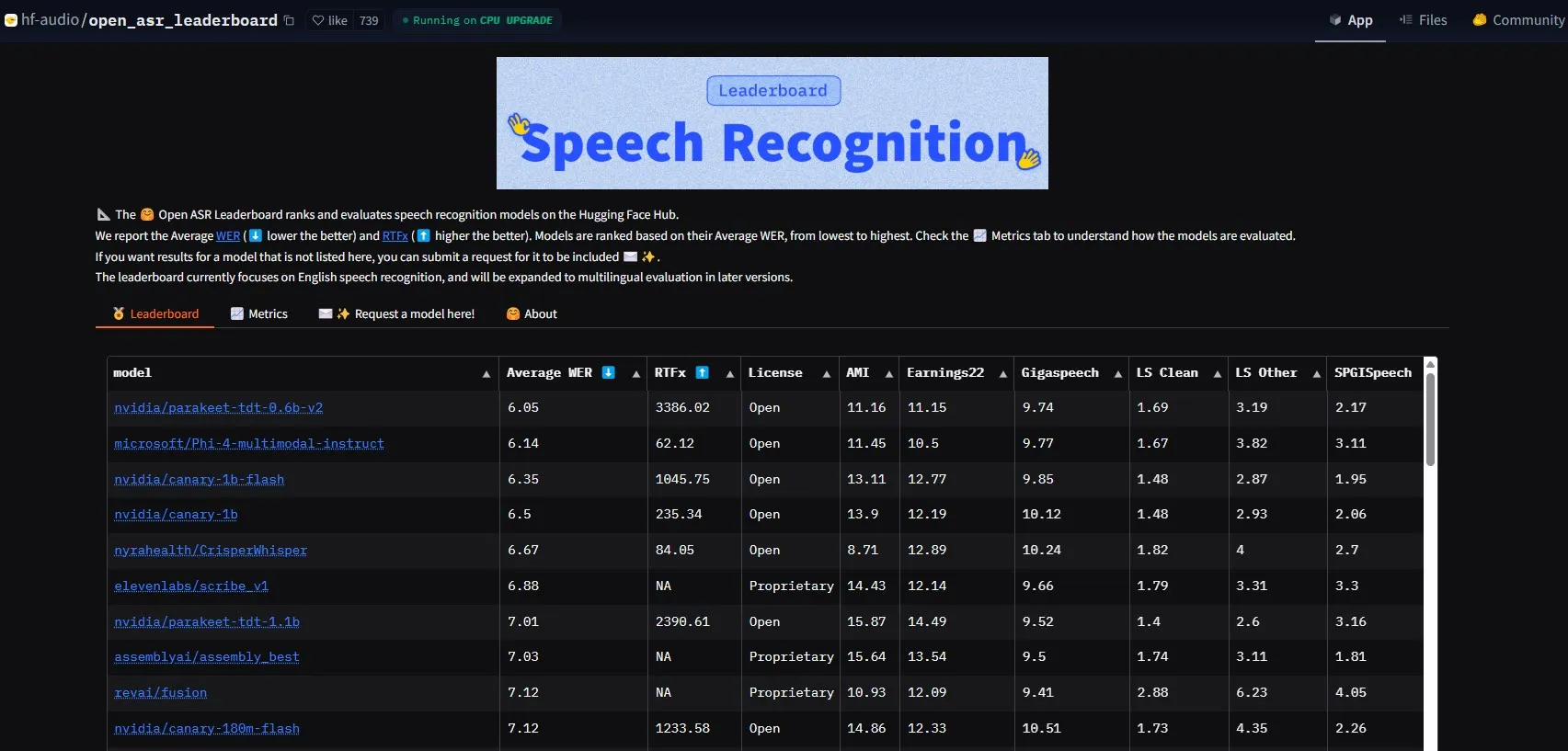
NVIDIA выпускает модель Parakeet-tdt-0.6b-v2, устанавливая новый стандарт производительности ASR: Новая модель автоматического распознавания речи (ASR) Parakeet-tdt-0.6b-v2 от NVIDIA установила новый отраслевой рекорд на HuggingFace Open-ASR-Leaderboard с коэффициентом ошибок на уровне слов (WER) 6.05%. Модель не только лидирует по точности, но и обладает чрезвычайно высокой скоростью вывода (RTFx 3386, что в 50 раз быстрее альтернативных решений), а также поддерживает инновационные функции, такие как транскрипция текстов песен, точные временные метки/форматирование чисел (Источник: huggingface)
Команда Qwen из Alibaba выпускает серию моделей Qwen3-Embedding: Команда Qwen из Alibaba представила новую серию моделей Qwen3-Embedding, включающую три различных размера: 0.6B, 4B и 8B. Эти модели достигли SOTA (State-of-the-Art) производительности на нескольких бенчмарках для встраивания текста, таких как MMTEB, MTEB и MTEB-Code, поддерживают 119 языков и могут работать в браузере с помощью Transformers.js (с поддержкой ускорения WebGPU), предоставляя мощные возможности представления текста для многоязычных и кроссплатформенных приложений (Источник: huggingface)
Gemini 2.5 Pro демонстрирует мощные возможности генерации кода и обработки задач: Gemini 2.5 Pro (версия preview-06-05) от GoogleDeepMind продемонстрировал мощные возможности при обработке сложных задач. Например, пользователь Majid Manzarpour попытался заставить его написать скрипт для организации и классификации библиотеки, содержащей более 25000 звуковых файлов, на что Jeff Dean прокомментировал, что это “звучит не слишком сложно”, намекая на потенциал модели в обработке таких масштабных и сложных задач программирования. Кроме того, тестовая диаграмма GosuCoder показывает, что обновленная версия Gemini 2.5 Pro 06-05 лучше справляется с задачами помощи в кодировании ИИ, особенно при оценке с температурой, установленной на 0.7 (Источник: JeffDean, jeremyphoward)
Hugging Face и Google Colab углубляют интеграцию, упрощая рабочие процессы ИИ: Hugging Face и Google Colab объявили об усилении сотрудничества, добавив поддержку “Open in Colab” во все карточки моделей на Hugging Face Hub. Пользователи теперь могут напрямую запускать ноутбуки Colab с любой карточки модели, что делает экспериментирование и использование моделей с Hugging Face более удобным, еще больше снижая порог входа в разработку и исследования ИИ (Источник: huggingface)
🧰 Инструменты
LlamaBot: ИИ-ассистент для кодирования на базе LangGraph: LangChainAI представил LlamaBot, ИИ-агента на базе LangGraph, способного создавать веб-приложения посредством чата на естественном языке. Его особенности включают генерацию кода в реальном времени, предварительный просмотр в реальном времени, а также специализированных агентов, разработанных для различных задач разработки, с целью упрощения процесса разработки веб-приложений (Источник: LangChainAI, hwchase17)
Система Fast RAG: эффективная обработка документов с помощью DeepSeek-R1 и Qdrant: LangChainAI продемонстрировал высокопроизводительное решение RAG (Retrieval Augmented Generation). Это решение сочетает модель DeepSeek-R1 от SambaNova, технологию бинарного квантования от Qdrant и LangGraph, достигая 32-кратного сокращения использования памяти, что позволяет эффективно обрабатывать большие объемы документов и открывает новые пути оптимизации для извлечения информации и генерации контента (Источник: LangChainAI, hwchase17)

Gemini Research Assistant: полнофункциональный интеллектуальный исследовательский помощник на базе Gemini и LangGraph: Команда Google Gemini открыла исходный код полнофункционального ИИ-исследовательского помощника, который использует модель Gemini и LangGraph для выполнения интеллектуальных веб-исследований. Этот помощник обладает способностью к рефлексивному мышлению и может постоянно оптимизировать свои поисковые стратегии, предоставляя пользователям более глубокую и эффективную исследовательскую поддержку. Код проекта доступен на GitHub (Источник: LangChainAI, hwchase17)
Agent Flow: конструктор ИИ-агентов с открытым исходным кодом без написания кода: Karan Vaidya представил Agent Flow, конструктор ИИ-агентов с открытым исходным кодом без написания кода, в качестве альтернативы Gumloop. Он создан на базе ComposioHQ и LangGraph от LangChain и позволяет пользователям автоматизировать рабочие процессы и сложные паттерны агентов путем перетаскивания узлов, с целью снижения порога входа в разработку приложений ИИ-агентов (Источник: hwchase17)
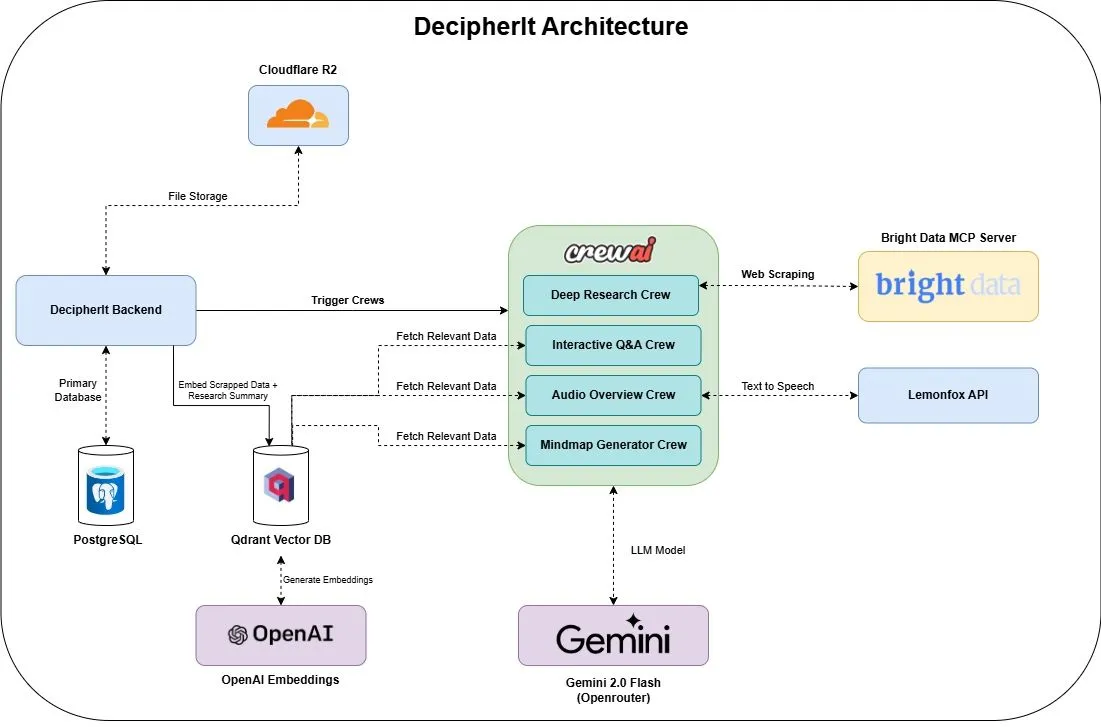
DecipherIt: ИИ-исследовательский помощник с открытым исходным кодом, альтернатива NotebookLM: Представлен ИИ-исследовательский помощник с открытым исходным кодом под названием DecipherIt, позиционируемый как альтернатива NotebookLM. Этот инструмент использует оркестровку нескольких агентов (crewAI), семантический поиск (Qdrant + OpenAI), доступ к сети в реальном времени (Bright Data MCP) и синтез речи (lemonfoxai), и способен преобразовывать загруженные пользователем документы, URL-адреса или введенные темы в полноценное рабочее пространство для исследований, включающее резюме, интеллект-карты, аудиообзоры, FAQ и семантические ответы на вопросы (Источник: qdrant_engine)
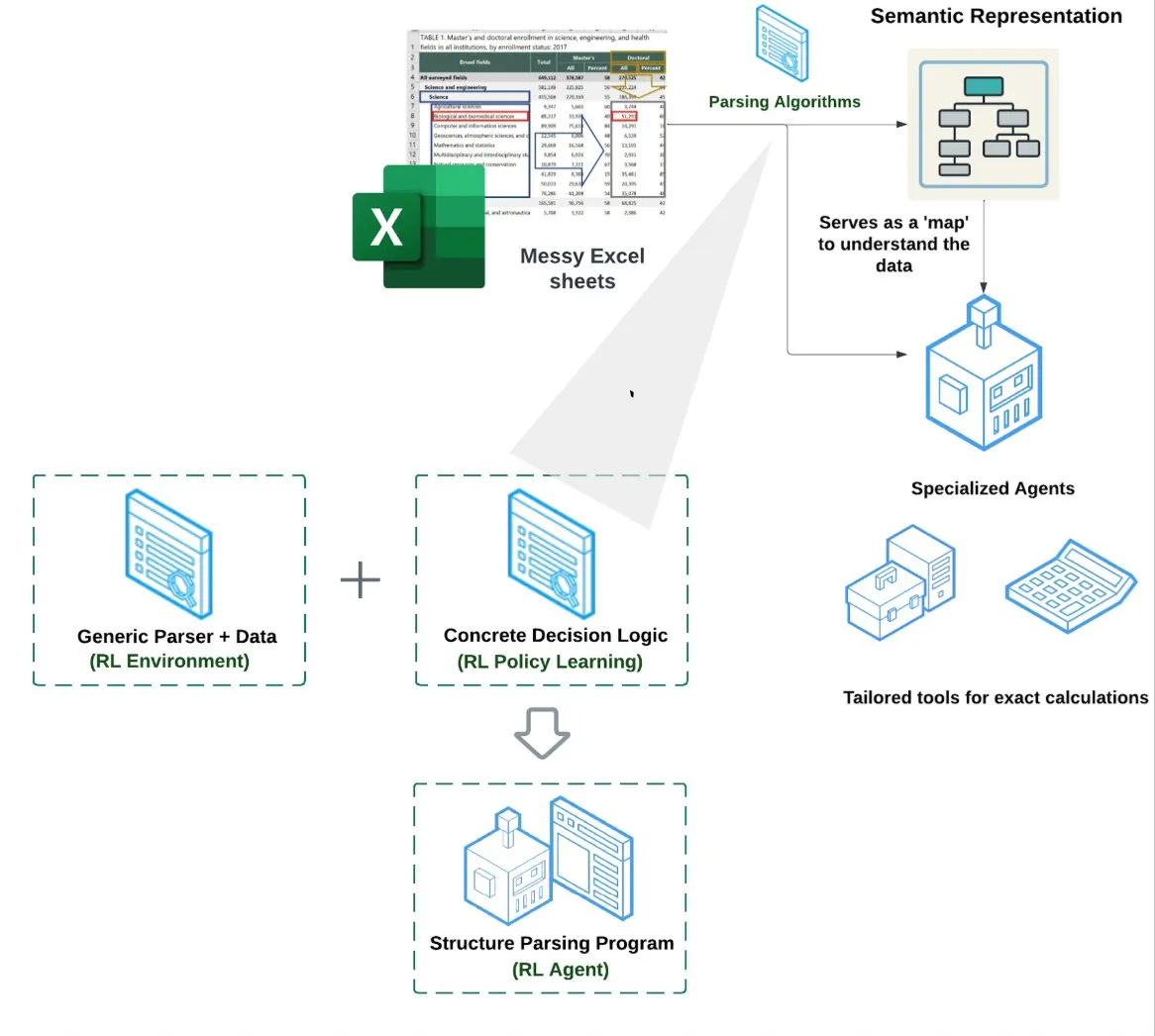
LlamaIndex представляет агента для электронных таблиц (Spreadsheet Agent): LlamaIndex выпустил нового агента для электронных таблиц, который пока находится на стадии закрытого предварительного просмотра. Этот агент специализируется на обработке сложных файлов Excel, способен выполнять преобразование данных и обеспечивать их качество. В основе его технической архитектуры лежит понимание структуры на основе обучения с подкреплением (изучение модели данных/семантического графа) и специализированные инструменты, построенные поверх семантического графа. Цель – обеспечить превосходную обработку Excel по сравнению с традиционными методами RAG или преобразования текста в CSV, и, как утверждается, производительность на 10-20% выше, чем у базовых решений, где LLM просто пишет код (Источник: jerryjliu0)
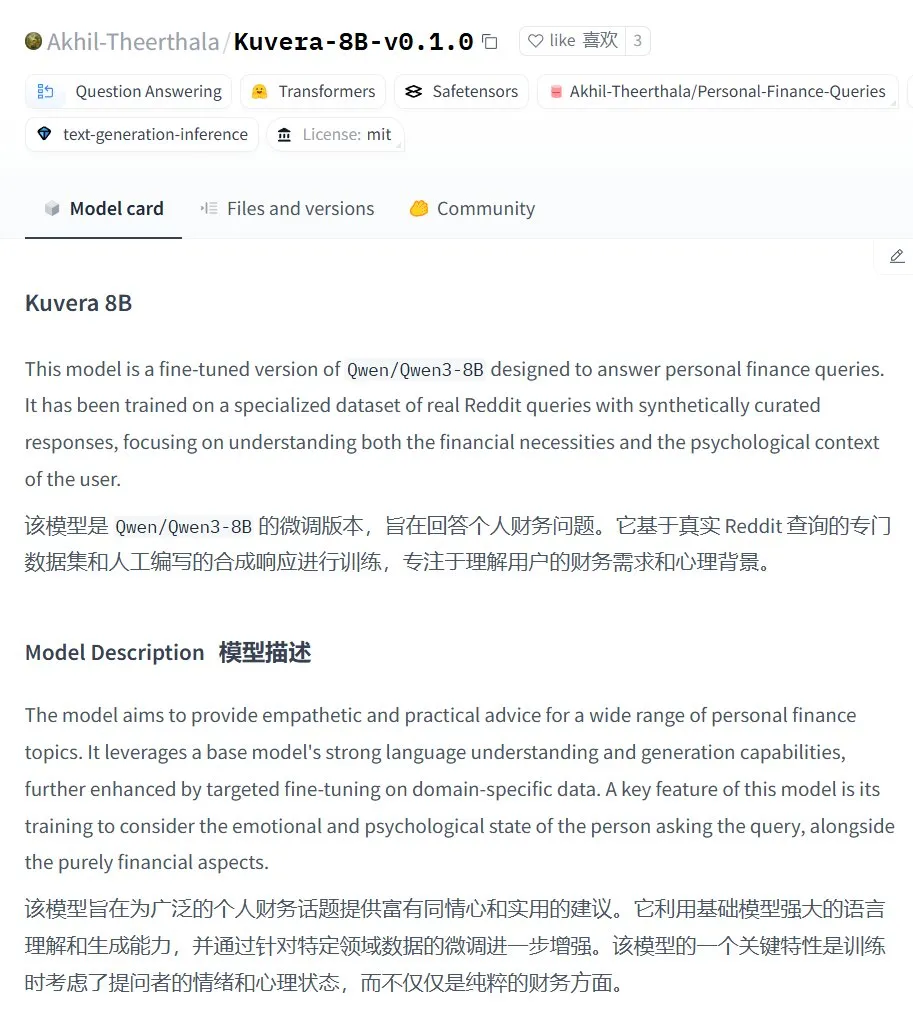
Kuvera-8B-v0.1.0: большая модель для консультирования по личным финансам: Akhil-Theerthala опубликовал на Hugging Face модель Kuvera-8B-v0.1.0, специально разработанную для вопросов личных финансов. Она дообучена на базе Qwen3-8B с использованием данных из Reddit и других источников, и предназначена для предоставления эмпатичных и практических советов по таким темам, как бюджетирование, сбережения, инвестиции, управление долгом и базовое финансовое планирование. Благодаря основе на Qwen3, модель поддерживает ответы на вопросы на китайском языке (Источник: karminski3)
Локализованное решение для обработки речи Whisper+Pyannote как замена Otter.ai: Пользователь Reddit поделился своим полностью локализованным процессом обработки речи, созданным для замены облачных сервисов, таких как Otter.ai. Решение сочетает ctranslate2 и faster-whisper для транскрипции, pyannote и speechbrain для разделения дикторов (diarisation), и способно обрабатывать на локальном GPU записи совещаний продолжительностью более трех часов, выводя текстовые записи с метками дикторов и JSON-файлы, включая настраиваемый контент, такой как резюме и списки действий. Этот шаг направлен на решение проблем ограничений облачных сервисов, опасений по поводу конфиденциальности и недостаточной кастомизации (Источник: Reddit r/LocalLLaMA)
GPT Deep Research MCP: глубокие исследования в сочетании с OpenWebUI: Пользователи рекомендуют попробовать сочетание GPT Deep Research MCP с OpenWebUI. Инструмент MCP (gptr-mcp) предназначен для обеспечения возможностей глубокого исследования, и при использовании вместе с OpenWebUI, поддерживающим MCP, может предоставить впечатляющий исследовательский опыт, дополнительно расширяя применение локализованных инструментов ИИ в обработке информации и поиске знаний (Источник: Reddit r/OpenWebUI)
📚 Обучение
OpenAI проведет семинар по практикам оценки приложений, включая реальные кейсы и обзор будущих инструментов: OpenAI проведет семинар по лучшим практикам оценки приложений (Evals). Jim Blomo из OpenAI, основываясь на реальных клиентских кейсах и результатах, обсудит, как эффективно оценивать продукты ИИ. На мероприятии также будут анонсированы будущие инструменты оценки от OpenAI, включая функции отслеживания, выставления оценок и др. Семинар направлен на то, чтобы помочь разработчикам и компаниям лучше создавать и оптимизировать приложения ИИ, будет доступна запись (Источник: HamelHusain, HamelHusain)

Anthropic открывает исходный код методов исследования интерпретируемости, помогая понять “мышление” LLM: Anthropic объявила об открытии исходного кода своих методов исследования для отслеживания “мыслительных процессов” больших языковых моделей. Исследователи теперь могут использовать этот метод для генерации “графов атрибуции” (attribution graphs) и интерактивного их изучения, аналогично тому, как это было продемонстрировано Anthropic в недавних исследованиях. Команда также предоставила интерактивный интерфейс Neuronpedia и учебные пособия в Jupyter Notebook, чтобы исследователи могли применять эти инструменты к моделям с открытым исходным кодом для углубления понимания внутренних механизмов работы LLM. Проект возглавляется участниками программы Anthropic Fellows в сотрудничестве с Decode Research (Источник: AnthropicAI)
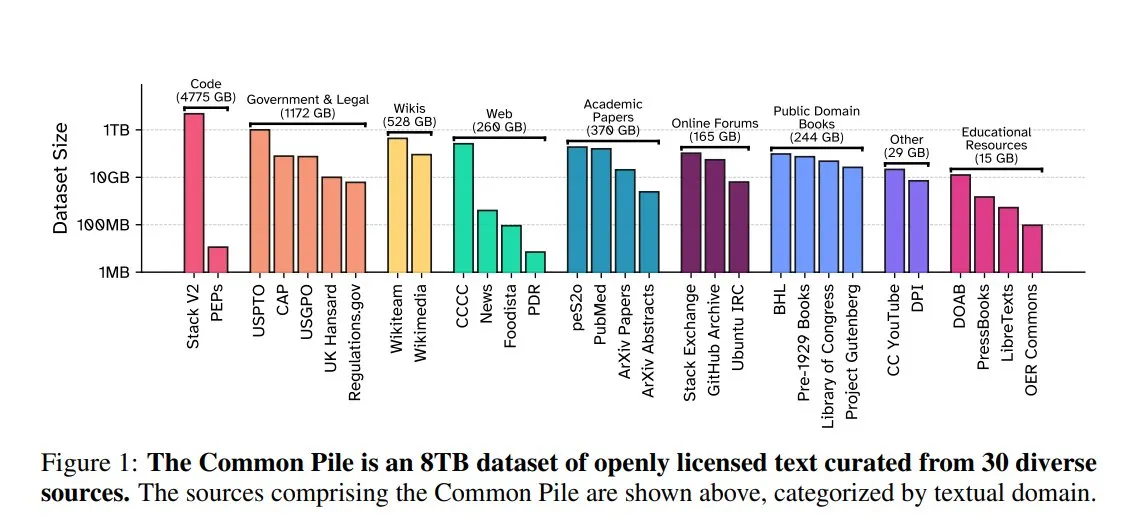
EleutherAI выпускает Common Pile v0.1: 8 ТБ текстовых данных с открытой лицензией: EleutherAI совместно с Vector Institute, Allen AI, Hugging Face и DPI выпустили Common Pile v0.1, набор данных, содержащий 8 ТБ, 1 триллион токенов текста из общественного достояния и с открытой лицензией. На основе этого набора данных команда обучила модели Comma v0.1-1T и -2T с 7B параметрами, производительность которых сопоставима с моделями, такими как LLaMA 1 и 2, обученными на данных аналогичного объема. Этот шаг направлен на изучение возможности обучения высокопроизводительных языковых моделей без использования неавторизованных текстов, предоставляя ценные ресурсы данных для сообщества открытого исходного кода (Источник: huggingface)
NVIDIA NIM ускоряет вывод Text-to-SQL для Vanna: В блоге разработчиков NVIDIA опубликовано руководство, демонстрирующее, как использовать NVIDIA NIM (NVIDIA Inference Microservices) для оптимизации решения Vanna по преобразованию текста в SQL. NIM предоставляет оптимизированные конечные точки для моделей генеративного ИИ, способные ускорить процесс вывода, что позволяет быстрее проводить анализ. Это имеет большое значение для сценариев приложений, требующих преобразования запросов на естественном языке в запросы к базам данных (Источник: dl_weekly)
Стэнфордский университет делится бесплатными лекциями курса по машинному обучению: The Turing Post поделился бесплатными лекциями курса CS229 по машинному обучению Стэнфордского университета, который ведут Andrew Ng и Tengyu Ma. Материалы охватывают методы и алгоритмы обучения с учителем и без учителя, глубокое обучение и нейронные сети, обобщение, регуляризацию, а также процессы обучения с подкреплением и другие ключевые темы машинного обучения, предоставляя учащимся высококачественные учебные ресурсы (Источник: TheTuringPost)

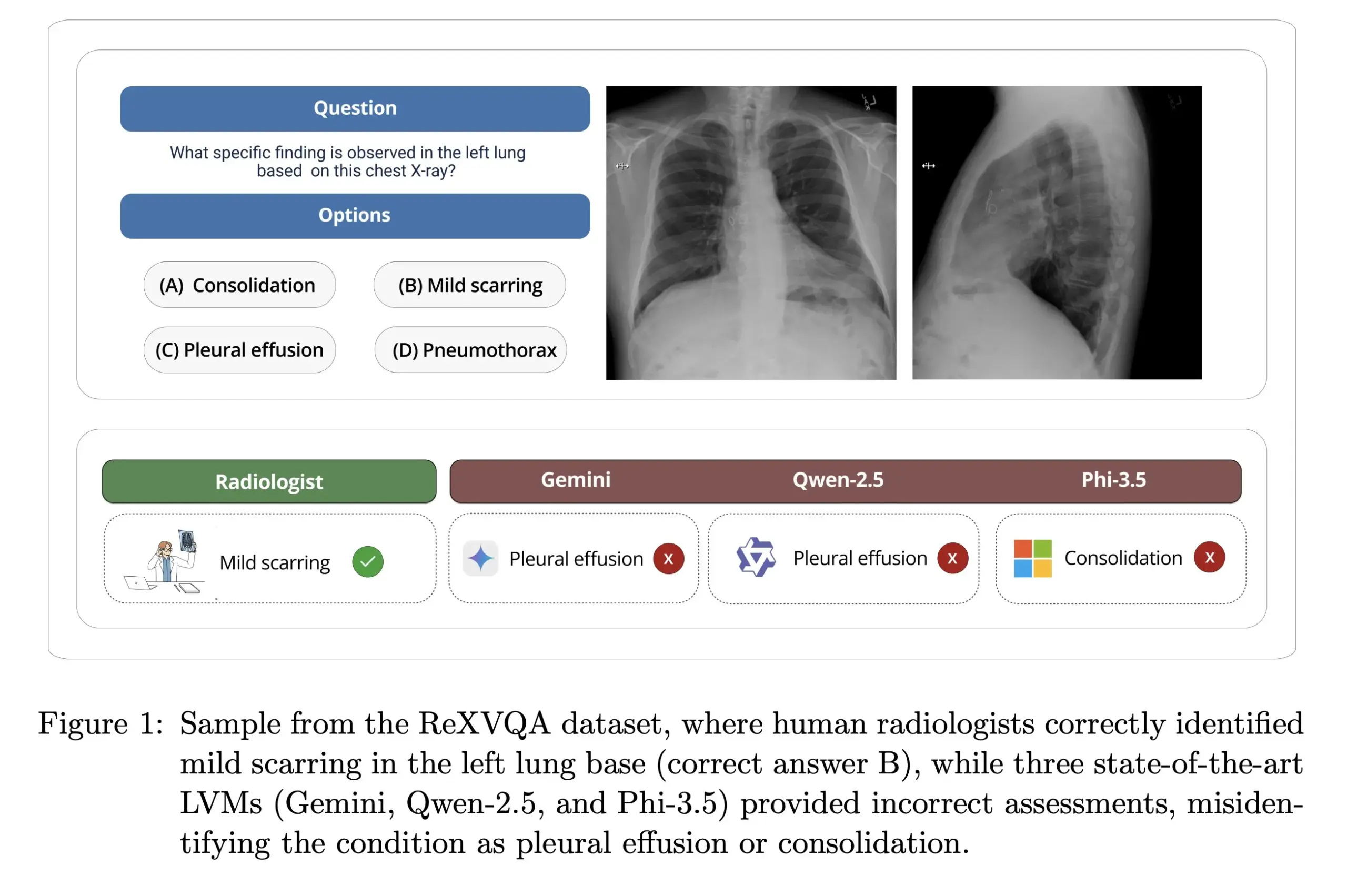
Гарвардский университет выпускает ReXVOA: крупномасштабный высококачественный бенчмарк для ответов на вопросы по рентгеновским снимкам грудной клетки: Лаборатория Pranav Rajpurkar Гарвардского университета выпустила ReXVOA, крупномасштабный высококачественный набор данных для визуального ответа на вопросы (VQA) по рентгеновским снимкам грудной клетки. Этот набор данных предназначен для того, чтобы бросить вызов существующим крупным передовым моделям и служить эталоном для измерения прогресса моделей следующего поколения в области понимания медицинских изображений и способности отвечать на вопросы (Источник: huggingface)
OWL Labs делится опытом обучения автоэнкодеров для диффузионных моделей: OWL (Open World Labs) в своем блоге обобщила опыт и результаты обучения автоэнкодеров для диффузионных моделей, а также поделилась примерами неудачных нетрадиционных подходов. Эта статья предоставляет исследователям и разработчикам справочную информацию для практического применения и оптимизации автоэнкодеров диффузионных моделей (Источник: NandoDF)
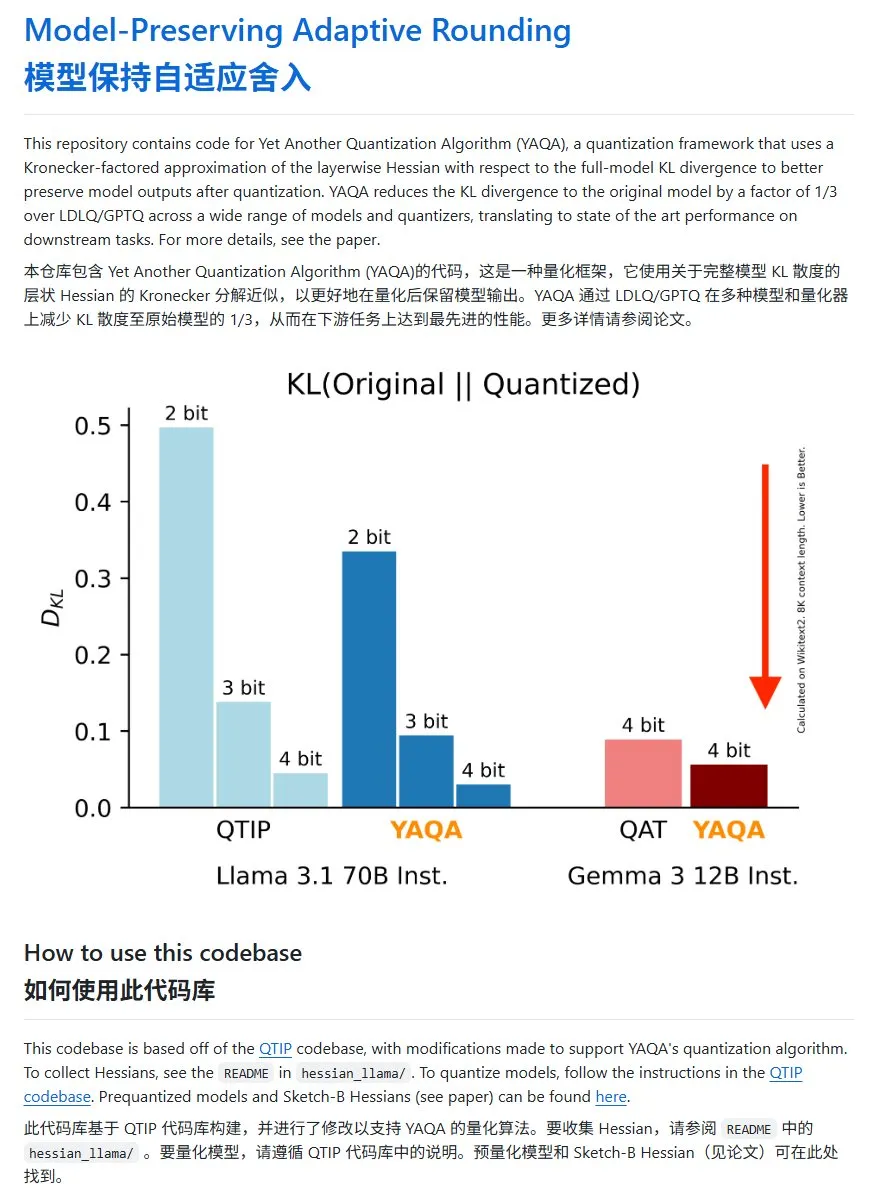
YAQA: новый метод квантования моделей со значительным снижением дивергенции KL: Команда Cornell-RelaxML предложила новый метод квантования моделей YAQA. Этот метод сочетает технологии LDLQ/GPTQ и, по сравнению с существующими методами квантования, позволяет снизить дивергенцию KL квантованной модели до 1/3 от исходной. Хотя процесс квантования YAQA медленнее и требует большого объема видеопамяти, повышение производительности и экономичность последующего вывода делают его перспективным решением для квантования. Код проекта открыт на GitHub (Источник: karminski3)
💼 Бизнес
Девушка из Гуанчжоу, родившаяся в 2000-х, Хун Лэтун, основала Axiom, нацелившись на решение математических задач с помощью ИИ: Стартап Axiom, основанный вундеркиндом Хун Лэтун (Carina Hong), родившейся в 2000-х, привлек внимание. Axiom специализируется на использовании ИИ для решения сложных математических задач, целевыми клиентами являются хедж-фонды и компании, занимающиеся количественной торговлей. По данным The Information, Axiom ведет переговоры о привлечении $50 млн финансирования при оценке примерно в $300-500 млн, B Capital может возглавить раунд. Хун Лэтун в социальных сетях заявила, что сообщения о финансировании неточны, но подтвердила, что компания нанимает специалистов по ИИ в области математики. Хун Лэтун окончила бакалавриат Массачусетского технологического института, магистратуру Оксфордского университета, в настоящее время является докторантом Стэнфордского университета по двойной программе математики и права, неоднократно побеждала на математических олимпиадах (Источник: 36氪)

Anthropic из-за конкуренции прекращает доступ Windsurf к API Claude: Соучредитель Anthropic подтвердил, что компания прекратила предоставлять стартапу Windsurf доступ к API модели Claude. Причиной стало то, что Windsurf рассматривается как своего рода “обертка” для OpenAI или тесно связанный с ним сервис, а OpenAI является прямым конкурентом Anthropic. Этот шаг вызвал дискуссии о зависимости от API и платформенных рисках, особенно для тех стартапов, чей бизнес построен на API сторонних больших моделей, поскольку коммерческие решения поставщиков моделей могут напрямую влиять на их выживание (Источник: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI обязали сохранять удаленные чаты пользователей из-за иска об авторских правах: Сообщается, что в рамках иска об авторских правах, поданного The New York Times, федеральный суд США обязал OpenAI сохранять все записи диалогов пользователей ChatGPT, включая те, которые пользователи решили удалить, в качестве потенциальных доказательств. The New York Times обвиняет OpenAI в использовании ее платных статей для обучения ChatGPT и опасается, что ИИ может генерировать схожий контент. Этот шаг вызвал опасения по поводу конфиденциальности пользователей и защиты данных (например, GDPR), подчеркивая правовую и этическую напряженность между авторскими правами на обучающие данные ИИ и конфиденциальностью пользователей (Источник: Reddit r/ArtificialInteligence)

🌟 Сообщество
ИИ-модели бросили вызов сочинениям и математике на всекитайских вступительных экзаменах 2025 года, показав разные результаты: Во время всекитайских вступительных экзаменов (Гаокао) 2025 года многие ведущие ИИ-модели прошли испытания по написанию сочинений и решению математических задач. В сочинениях 16 ИИ-ассистентов, включая Doubao, DeepSeek, ChatGPT, продемонстрировали свои писательские способности, большинство из них смогли сгенерировать структурированные эссе, но в целом наблюдались шаблонность, использование клише и схожесть идей. В тесте по математике (объективные задания нового стандарта I) ByteDance Doubao и Tencent Yuanbao разделили первое место с 68 баллами (из 73), в то время как OpenAI o3 показал плохой результат, набрав всего 34 балла. Тестирование отразило прогресс и ограничения современного ИИ в понимании китайского языка, логическом мышлении и творческом выражении, особенно в части избегания “следов ИИ” и решения сложных математических задач, где еще есть пространство для улучшения (Источник: 36氪, 36氪)

Тенденции применения ИИ внутри компаний: внутренние базы знаний и кастомизированные чат-боты в центре внимания: Обсуждения в сообществе показывают, что использование ИИ для создания внутренних корпоративных чат-ботов, обученных на данных компании для ответов на вопросы сотрудников о процессах, поиске данных, ответственных лицах и т.д., становится трендом. Такие приложения направлены на повышение эффективности внутреннего поиска информации и уровня управления знаниями. Компании, такие как Amazon, уже внедрили подобные системы и получили положительные отзывы. Однако безопасность данных, потенциальная утечка конфиденциальной информации и способы эффективной коммерциализации остаются вопросами, на которые компаниям необходимо обратить внимание при внедрении (Источник: Reddit r/ArtificialInteligence)
Спор “индексирования” против “неиндексирования” в программировании с помощью ИИ: компромисс между производительностью и надежностью: Эксперимент с ИИ-ассистентами для кодирования (с использованием кода посадки “Аполлона-11” в качестве тестового объекта) сравнил два типа ИИ-агентов: “индексирующий” (предварительно создающий индекс кодовой базы и использующий векторный поиск) и “неиндексирующий” (читающий и анализирующий файлы кода по мере необходимости). Результаты показали, что индексирующий агент в большинстве случаев был быстрее и делал меньше вызовов API, но в ситуациях, когда кодовая база часто менялась, что приводило к устареванию индекса, он мог выдавать ошибки из-за الاعتماد на устаревшую информацию, что, наоборот, увеличивало время отладки. Это выявило необходимость компромисса между мгновенной производительностью и надежностью информации при выборе инструментов ИИ для кодирования (Источник: Reddit r/ClaudeAI)

Дискуссия о том, “мыслят” ли LLM, продолжается: от сопоставления с образцом до человеческого познания: В сообществе продолжается дискуссия о том, действительно ли большие языковые модели (LLM) “мыслят”. Критики утверждают, что LLM по своей сути являются сложными генераторами предсказательного текста, работающими путем вычисления вероятностей последовательностей слов, а не путем сознательного мышления. Однако многие пользователи при взаимодействии с LLM испытывают ощущения, схожие с общением с человеком. Это вызывает размышления о механизмах генерации человеческой речи и о возможном сходстве между LLM и процессами человеческого познания. Исследование компании Apple дополнительно указывает на ограничения LLM в сложных рассуждениях, полагая, что они больше полагаются на память образов, чем на реальные рассуждения, добавляя новую перспективу в эту дискуссию (Источник: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham о влиянии ИИ на разрыв в доходах: Paul Graham высказал своему 16-летнему сыну мнение, что в краткосрочной перспективе технологии ИИ могут увеличить разрыв в доходах людей от работы. В качестве примера он привел то, что программистам среднего уровня сейчас сложнее найти работу, в то время как выдающиеся программисты зарабатывают больше благодаря помощи ИИ. Он считает, что в этом нет ничего нового, технологический прогресс часто увеличивает разрыв в доходах, поскольку нижний предел дохода фиксирован на нуле, а технологии постоянно повышают верхний предел вознаграждения для лучших специалистов (Источник: dotey)
Обсуждение этики безопасности ИИ: от поведения моделей до социальных норм: Обсуждение безопасности и этики ИИ в сообществе продолжает набирать обороты. Geoffrey Hinton поздравил Yoshua Bengio с запуском проекта LawZero, направленного на продвижение безопасного проектирования ИИ, с особым вниманием к возможному появлению у передовых систем поведения самосохранения и обмана. В то же время, некоторые исследования в области безопасности ИИ (например, тестирование согласия модели на отключение) критикуются как “театр безопасности”, лишенный практической ценности. Исследование OpenAI о человеко-машинных отношениях также вызвало дискуссию, подчеркивая необходимость приоритетного изучения влияния ИИ на эмоциональное благополучие пользователей в условиях все большего проникновения ИИ в жизнь, а также обсуждения того, как сбалансировать четкую коммуникацию и избегание антропоморфизма во взаимодействии с моделями (Источник: geoffreyhinton, ClementDelangue, togelius)

Роль эмоциональной поддержки ИИ-ассистентов, таких как ChatGPT, получает признание пользователей: Многие пользователи в социальных сетях делятся опытом того, как ИИ-ассистенты, такие как ChatGPT, оказывали им эмоциональную поддержку и практическую помощь в трудных ситуациях. Некоторые пользователи отмечают, что во время безработицы, проблем со здоровьем или подавленного настроения ChatGPT не только предлагал конкретные планы действий и информацию о ресурсах, но и помогал им справиться с паникой и вновь обрести силы, не осуждая. Это демонстрирует потенциальную ценность ИИ в психологической поддержке и кризисном вмешательстве, несмотря на то, что он не обладает настоящими эмоциями и сознанием (Источник: Reddit r/ChatGPT)
“Vibe Coding” становится новым явлением в программировании с помощью ИИ: Термин “Vibe Coding” стал популярным в сообществе разработчиков, обозначая способ программирования, основанный на интуиции и быстрой итерации кода с помощью ИИ. Инструменты, такие как Claude Code, пользуются популярностью у некоторых программистов благодаря своей выдающейся производительности в определенные периоды времени (например, ночью или ранним утром, возможно, из-за низкой загрузки серверов или отсутствия интенсивного квантования). Это явление отражает повышение эффективности разработки благодаря ИИ-ассистентам для кодирования, а также вызывает дискуссии о согласованности моделей, влиянии квантования и новых рабочих моделях разработчиков (Источник: dotey, jeremyphoward)
💡 Прочее
Andrej Karpathy размышляет о огромном влиянии шумового загрязнения на сон и здоровье: Andrej Karpathy поделился личным опытом, указав, что шумовое загрязнение окружающей среды, такое как транспортный шум, может оказывать огромное и недостаточно осознанное негативное влияние на качество сна и долгосрочное здоровье. Он предполагает, что ночной шум (например, громкие автомобили, мотоциклы) может приводить к снижению качества сна у миллионов людей, что, в свою очередь, влияет на настроение, креативность, энергию и увеличивает риск сердечно-сосудистых, метаболических и когнитивных заболеваний. Он призывает устройства для отслеживания сна (такие как Whoop, Oura) четко отслеживать связь между шумом и сном и повышать осведомленность общественности об этой проблеме (Источник: karpathy)
Пересечение ИИ и религии привлекает внимание: Пользователь социальных сетей menhguin заметил, что нельзя недооценивать потенциальный рынок для новых религиозных или квазирелигиозных приложений на базе ИИ. Например, ИИ-астрология, ИИ-библейские видео, ИИ-молитвенные приложения, а также ИИ-приложения для некоторых специфических групп, все это намекает на возможности технологий ИИ в удовлетворении духовных или религиозных потребностей человека (Источник: menhguin)
ИИ помогает создать сервер HTTP 2.0, исследуя потенциал LLM в крупных программных проектах: Разработчик, используя собственный фреймворк (promptyped) и модель Gemini 2.5 Pro, путем цикла код-компиляция-тестирование, успешно заставил LLM с нуля создать сервер, соответствующий стандарту HTTP 2.0. Проект сгенерировал 15 тысяч строк исходного кода и более 30 тысяч строк тестового кода, и прошел тесты на соответствие h2spec. Несмотря на затраты времени около 119 часов API и $631 на API, этот эксперимент продемонстрировал потенциал LLM в проектировании архитектуры и написании сложного, соответствующего стандартам программного обеспечения, а также показал, как могут выглядеть приложения, полностью написанные LLM (Источник: Reddit r/LocalLLaMA)