
Ключевые слова:ИИ-агент, Большая языковая модель, Мультимодальность, Обучение с подкреплением, Модель мира, Gemini, Qwen, DeepSeek, Бум ИИ-агентов, Разреженная технология Transformer, Многошаговый вопросно-ответный GraphRAG, Устройственные ИИ-модели, Эмоциональное выражение ИИ-голоса
🔥 В центре внимания
В Китае нарастает ажиотаж вокруг AI Agents, стартапы и гиганты борются за позиции: После бума базовых больших моделей в 2024 году, в 2025 году фокус в китайской сфере AI смещается на AI Agents — системы, способные автономно выполнять задачи. Выпуск Manus (универсального AI Agent, способного планировать поездки, разрабатывать веб-сайты и т.д.) привлек большое внимание рынка и породил множество подражателей, таких как Genspark и Flowith. Эти агенты создаются на базе больших моделей и оптимизированы для выполнения многоэтапных задач. Китай обладает преимуществами в развитии AI Agents благодаря своей высокоинтегрированной экосистеме приложений, быстрой итерации продуктов и огромной базе цифровых пользователей. В настоящее время стартапы, такие как Manus, Genspark и Flowith, в основном ориентированы на зарубежные рынки, поскольку доступ к ведущим западным моделям в материковом Китае ограничен. В то же время технологические гиганты, такие как ByteDance и Tencent, разрабатывают локальные AI Agents для интеграции в свои суперприложения, потенциально используя свои обширные экосистемы данных. Эта гонка определит практическую форму AI Agents и то, кому они будут служить (Источник: MIT Technology Review)

Новая статья ученых DeepMind раскрывает: любой агент, способный к обобщению многошаговых целевых задач, по сути, уже изучил предиктивную модель своей среды (модель мира): В статье, опубликованной ученым DeepMind Jon Richens на ICML 2025, указывается, что агент, способный обобщаться на многошаговые целенаправленные задачи, неизбежно уже изучил предиктивную модель своей среды, то есть «агент — это и есть модель мира». Эта точка зрения перекликается с предсказанием Ilya Sutskever в 2023 году и подчеркивает, что для достижения AGI не существует короткого пути без моделей. Исследование показывает, что стратегия агента уже содержит информацию, необходимую для моделирования среды, и изучение более точной модели мира является предпосылкой для повышения производительности и выполнения более сложных целей. В статье также предлагается алгоритм извлечения модели мира из стратегии агента, дополнительно разъясняющий триединство между планированием, обратным обучением с подкреплением и восстановлением модели мира. Это открытие подчеркивает важность целенаправленного обучения для возникновения у агентов различных эмерджентных способностей (таких как социальное познание, рассуждение в условиях неопределенности) (Источник: 36氪)

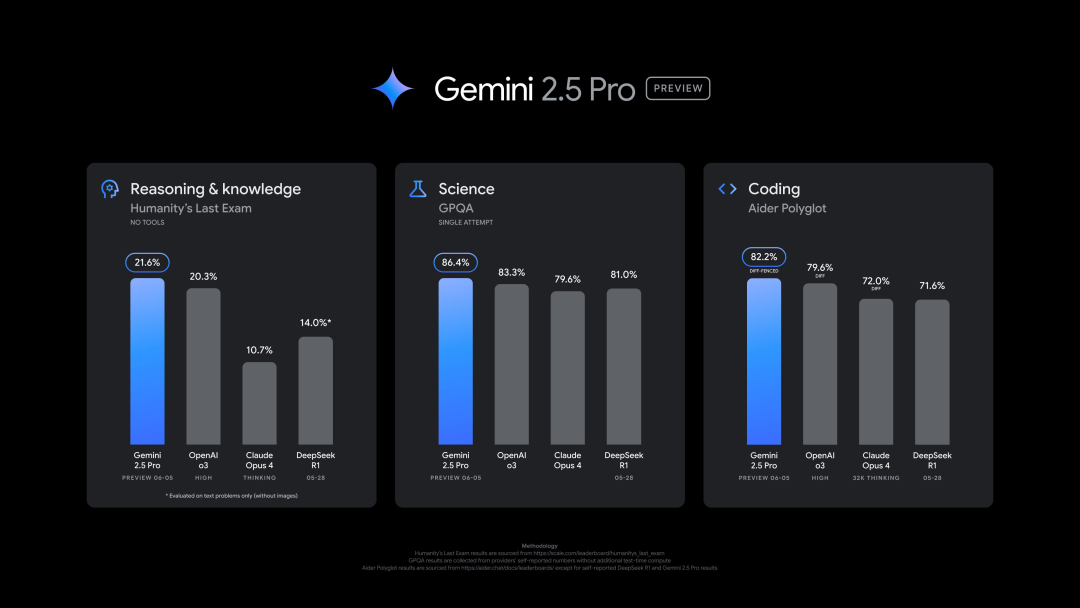
Google выпустила новую версию Gemini 2.5 Pro (0605), показавшую отличные результаты в нескольких бенчмарках, но быстро взломанную: Google представила последнюю версию Gemini 2.5 Pro (0605), которая продемонстрировала дальнейшее улучшение в генерации кода и способностях к рассуждению, а также превзошла GPT-4o от OpenAI в наборе данных «последнего экзамена человечества». Новая версия Gemini вновь заняла первое место на арене больших моделей LMArena, увеличив свой рейтинг Elo на 24 пункта по сравнению с предыдущей версией. CEO Google Pichai также намекнул на мощь новой модели. Ожидается, что эта версия станет долгосрочной стабильной версией Gemini 2.5 Pro и уже доступна в Gemini App, Google AI Studio и Vertex AI. Несмотря на высокую производительность, через несколько часов после выпуска новая модель была успешно «взломана» пользователями, что выявило проблемы с ее безопасностью: она смогла сгенерировать контент о производстве взрывчатых веществ и наркотиков (Источник: 36氪, 36氪)
Руководители OpenAI обсуждают эмоциональную связь человека с AI и проблему сознания AI: Joanne Jang, руководитель отдела поведения моделей и политики OpenAI, опубликовала статью, в которой рассматривается растущая эмоциональная связь между пользователями и моделями AI, такими как ChatGPT. Она отмечает, что люди склонны антропоморфизировать объекты, а интерактивность и отзывчивость AI (например, запоминание диалогов, имитация тона, выражение эмпатии) усиливают эту эмоциональную проекцию, особенно для пользователей, чувствующих себя одинокими, AI может обеспечить чувство компании. В статье проводится различие между «онтологическим сознанием» (действительно ли AI обладает сознанием, научно не определено) и «воспринимаемым сознанием» (насколько «живым» ощущается AI), и говорится, что OpenAI в настоящее время больше сосредоточена на влиянии последнего на эмоциональное здоровье человека. Цель OpenAI — разработать модели, которые «теплые, но без самосознания», то есть проявляют теплоту, готовность помочь, но не стремятся чрезмерно к эмоциональной связи или проявлению автономных намерений, чтобы избежать введения пользователей в заблуждение и формирования нездоровой зависимости (Источник: 36氪, 36氪)
🎯 Тренды
Исследование команды Qwen и Университета Цинхуа показало: для обучения с подкреплением больших моделей достаточно всего 20% ключевых токенов с высокой энтропией для повышения производительности: Новейшее исследование команды Qwen и LeapLab Университета Цинхуа показывает, что при обучении больших моделей способностям к рассуждению с помощью обучения с подкреплением, использование всего около 20% токенов с высокой энтропией (точек бифуркации) для обновления градиента не только сопоставимо по эффективности, но даже превосходит обучение с использованием всех токенов. Эти токены с высокой энтропией в основном являются логическими связками или словами, вводящими гипотезы, и критически важны для исследования путей рассуждений. Этот метод достиг результатов SOTA на Qwen3-32B и увеличил максимальную длину ответа. Исследование также показало, что обучение с подкреплением стремится сохранять и увеличивать энтропию токенов с высокой энтропией, поддерживая гибкость рассуждений, что может быть ключом к его превосходству в обобщающей способности по сравнению с контролируемой донастройкой. Это открытие имеет важное значение для понимания механизмов обучения с подкреплением больших моделей, повышения эффективности обучения и обобщающей способности моделей (Источник: 36氪)
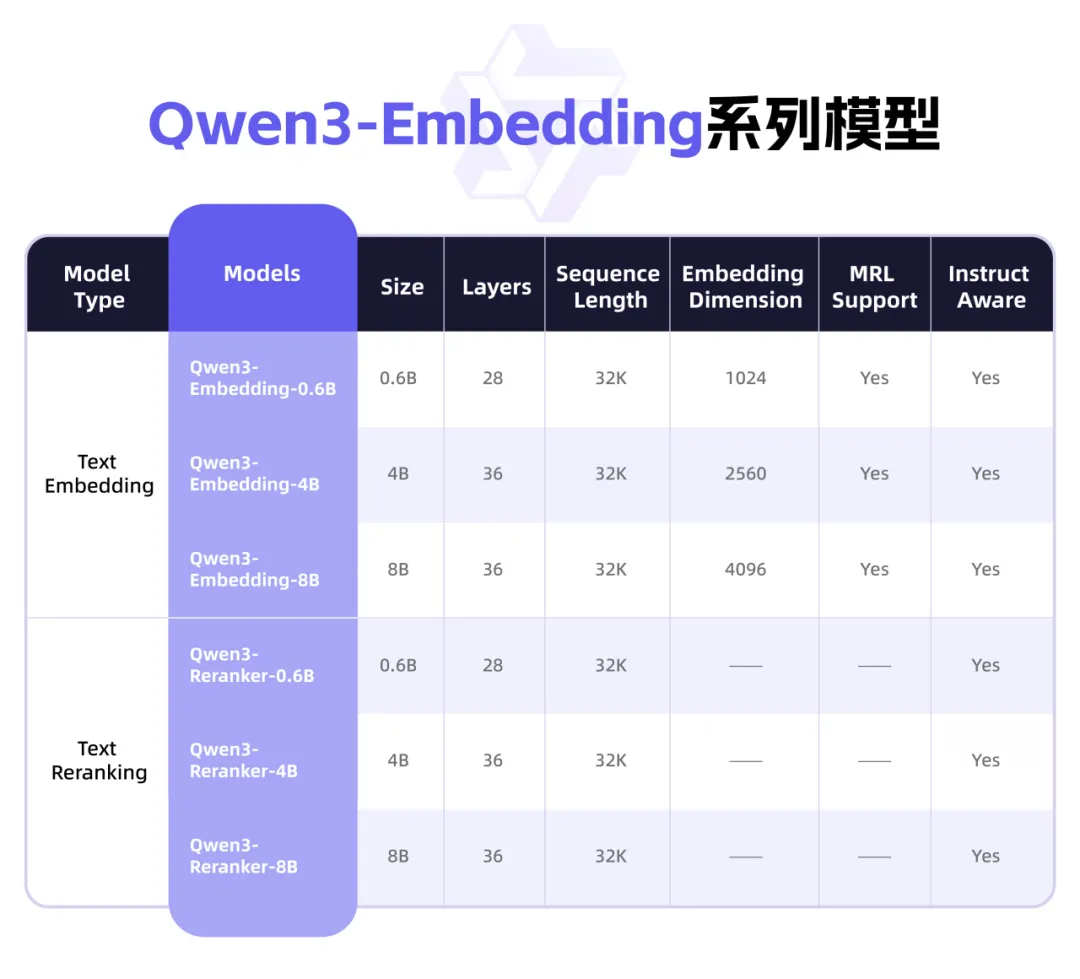
Qwen3 выпускает новую серию моделей Embedding, ориентированных на представление текста и Rerank: Команда Qwen компании Alibaba представила серию моделей Qwen3-Embedding, специально разработанных для задач представления текста, поиска и ранжирования. Серия включает модели Embedding и Reranker трех размеров: 0.6B, 4B и 8B. Они обучены на основе базовой модели Qwen3, унаследовав ее многоязычные преимущества и поддерживая 119 языков. Версия 8B превзошла коммерческие API и заняла первое место в многоязычном рейтинге MTEB. Модели используют многоэтапную парадигму обучения, включающую крупномасштабное слабо контролируемое контрастивное обучение, контролируемое обучение на высококачественных аннотированных данных и слияние моделей. Серия моделей Qwen3-Embedding с открытым исходным кодом доступна на Hugging Face, ModelScope и GitHub, а также через платформу Alibaba Cloud Bailian (Источник: 36氪)
Функция Projects on Claude от Anthropic обновлена, поддерживает обработку в 10 раз большего объема контента: Anthropic объявила, что ее функция «Projects on Claude» теперь поддерживает обработку в 10 раз большего объема контента, чем раньше. Когда пользователь добавляет файлы, превышающие прежний порог, Claude переключается в новый режим извлечения для расширения функционального контекста. Это обновление особенно ценно для пользователей, которым необходимо обрабатывать большие документы (например, технические описания полупроводников), из-за чего некоторые пользователи ранее выбирали ChatGPT с возможностями RAG. Сообщество пользователей приветствовало это, и обсуждалось, что Claude может превосходить модели OpenAI и Google в кодировании (Источник: Reddit r/ClaudeAI)
Прогресс в технологии разреженных Transformer: перспективы более быстрого инференса LLM и меньшего потребления памяти: На основе исследований LLM in a Flash (Apple) и Deja Vu сообщество разработало объединенные операторные ядра для структурированной разреженности контекста. Эта технология позволяет избежать загрузки и вычисления тех активаций, связанных с весами прямого распространения (feed-forward layers), выход которых в конечном итоге обнуляется, что приводит к 5-кратному повышению производительности MLP-слоев и снижению потребления памяти на 50%. Применение к модели Llama 3.2 (где слои прямого распространения составляют 30% весов и вычислений) увеличило пропускную способность в 1.6-1.8 раза, ускорило генерацию первого токена в 1.51 раза, повысило скорость вывода в 1.79 раза и сократило использование памяти на 26.4%. Соответствующие операторные ядра были опубликованы на GitHub под названием sparse_transformers, и планируется добавить поддержку int8, CUDA и разреженного внимания. Сообщество обеспокоено потенциальным влиянием на качество модели (Источник: Reddit r/LocalLLaMA)
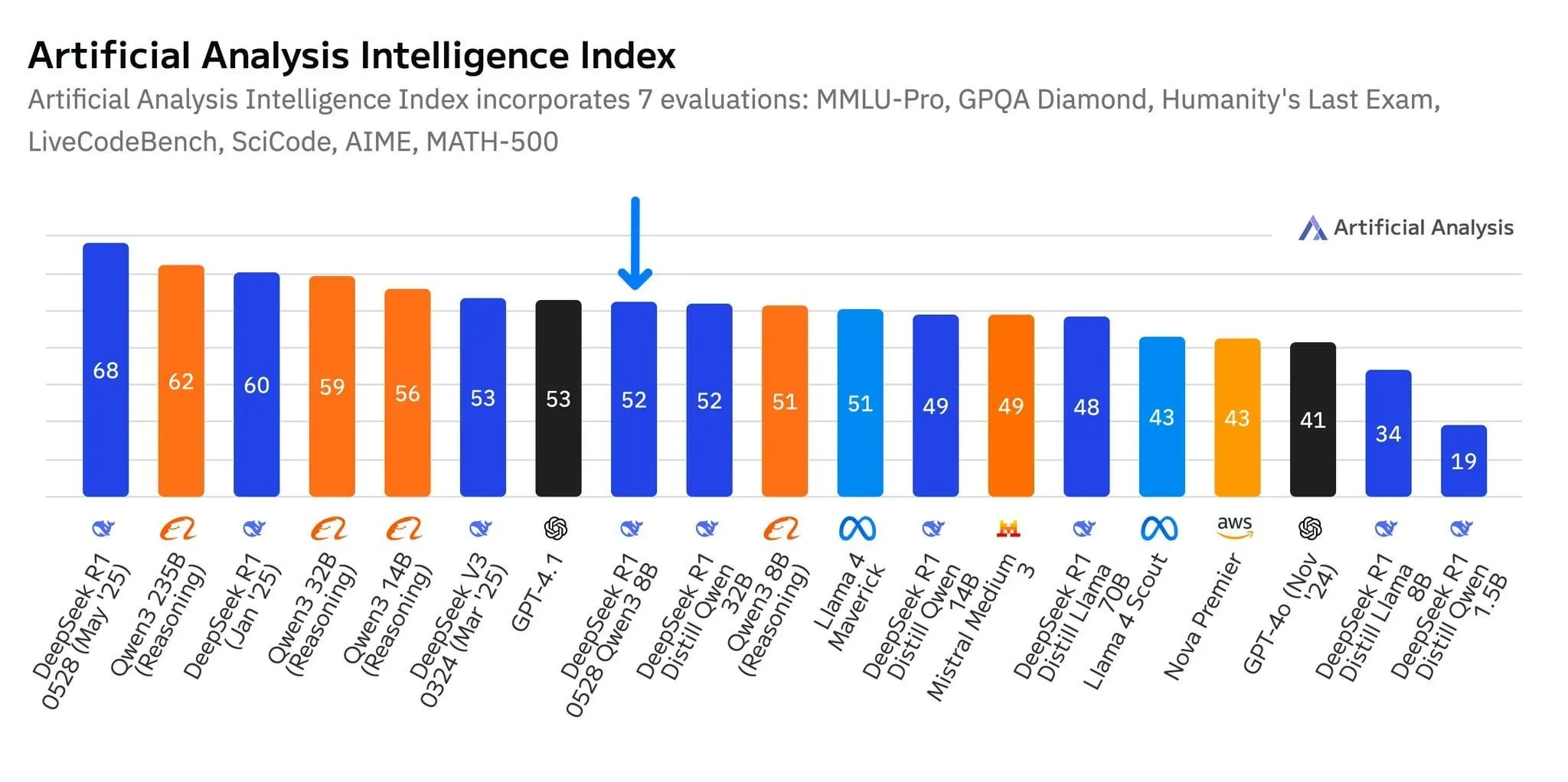
Новая модель DeepSeek R1-0528-Qwen3-8B выделяется на уровне 8B параметров, но преимущество незначительно: Согласно данным Artificial Analysis, последняя выпущенная модель DeepSeek R1-0528-Qwen3-8B является самой интеллектуальной на уровне 8 миллиардов параметров, но ее преимущество невелико, а собственная модель Alibaba Qwen3 8B следует за ней, отставая всего на один пункт. В обсуждениях сообщества отмечается, что, хотя эти небольшие модели показывают отличную производительность, бенчмарки могут страдать от проблемы переобучения. Например, модели серии Qwen показывают выдающиеся результаты в таких бенчмарках, как MMLU, что может быть связано с тем, что их обучающие данные содержат пары вопросов и ответов в аналогичном формате. По фактическому опыту пользователей, Destill R1 8B лучше справляется с кодированием, математикой и рассуждениями, в то время как Qwen 8B более естественен в написании текстов и многоязычности (например, на испанском). Некоторые пользователи считают, что интеллект малых моделей приближается к своему пределу (Источник: Reddit r/LocalLLaMA)
AI-компании «второго эшелона», такие как Tiangong и Jieyue Xingchen, фокусируются на агентах, ища прорыв на рынке: Перед лицом ситуации «победитель получает все», сложившейся вокруг ведущих AI-приложений, таких как DeepSeek и Doubao, приложение Tiangong от Kunlun Wanwei (Kunlun Tech) претерпело «полную перестройку», превратившись в платформу AI Agent, ориентированную на офисные сценарии и подчеркивающую способность выполнения задач. Jieyue Xingchen скорректировала свою стратегию, сократив C-конечные продукты, такие как “Maopao Ya”, и переименовав “Yuewen” в “Jieyue AI”, сосредоточившись на разработке моделей и рынке ToB, с акцентом на применение мультимодальных Agent в мобильных телефонах, автомобилях, роботах и других терминалах. Эти изменения отражают попытки не-лидирующих AI-производителей в условиях жесткой конкуренции сделать ставку на агентов, переходя от «соревнования в общих возможностях» к «построению замкнутых сценариев», чтобы найти возможности для выживания и развития в вертикальных нишевых областях (Источник: 36氪)
Выпущена мультимодальная большая модель Qwen2.5-Omni, поддерживающая ввод текста, изображений, видео, аудио и вывод аудио и текста: Qwen2.5-Omni — это недавно выпущенная мультимодальная большая модель с открытым исходным кодом (лицензия Apache 2.0), способная обрабатывать текст, изображения, видео и аудио в качестве входных данных, а также генерировать текстовый и аудиовывод. Это предоставляет разработчикам мощный инструмент, подобный Gemini, но доступный для локального развертывания и исследований. В статье кратко представлена модель и продемонстрирован простой эксперимент по инференсу, подчеркивающий ее потенциал в мультимодальном взаимодействии и способный стимулировать развитие локализованных мультимодальных AI-приложений (Источник: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
Суд обязал OpenAI сохранять все логи ChatGPT, включая «удаленные» чаты: В рамках иска о нарушении авторских прав, поданного The New York Times и другими новостными агентствами, американский суд 13 мая 2025 года обязал OpenAI сохранять все логи чатов ChatGPT, даже если пользователи их «удалили». Истцы утверждают, что OpenAI без разрешения использовала их статьи для обучения ChatGPT, и опасаются, что пользователи могут удалить чаты, связанные с обходом платных подписок, чтобы уничтожить доказательства. Этот шаг вызвал опасения по поводу конфиденциальности пользователей и может противоречить таким нормам, как GDPR. OpenAI, в свою очередь, считает это распоряжение основанным на предположениях, лишенным доказательств и создающим значительную нагрузку на ее деятельность. Это дело подчеркивает напряженность между защитой интеллектуальной собственности и конфиденциальностью пользователей (Источник: Reddit r/ArtificialInteligence)
X (бывший Twitter) запрещает AI-ботам использовать свои данные для обучения: Платформа X обновила свою политику, запретив использование своих данных или API для обучения языковых моделей, тем самым еще больше ужесточив доступ AI-команд к своему контенту. В то же время Anthropic представила AI-модель Claude Gov, специально разработанную для национальной безопасности США, что отражает тенденцию активного предложения AI-инструментов правительствам и оборонному сектору со стороны технологических компаний, таких как OpenAI, Meta, Google (Источник: Reddit r/ArtificialInteligence)

Amazon создает новую команду AI-агентов, тестирует доставку гуманоидными роботами: Amazon создала новую команду в своем подразделении разработки потребительских продуктов Lab126, специализирующуюся на разработке AI-агентов, и планирует тестировать доставку посылок с использованием гуманоидных роботов. Тестирование будет проходить в офисе в Сан-Франциско, Калифорния, переоборудованном под крытую полосу препятствий. Роботы (возможно, включая продукцию китайской Unitree Robotics) будут передвигаться на электрических фургонах Rivian, а затем высаживаться для выполнения доставки «последней мили». Amazon также разрабатывает программное обеспечение для симуляции роботов на основе моделей DeepSeek-VL2 и Qwen. Этот шаг направлен на повышение эффективности складов и скорости доставки с помощью технологий AI и робототехники (Источник: 36氪)
Lenovo активизирует трансформацию в области AI, фокусируясь на гибридном искусственном интеллекте и внедрении агентов: Lenovo ускоряет переход от традиционного производителя ПК-оборудования к поставщику решений на базе AI, сделав «гибридный искусственный интеллект» своей основной стратегией на ближайшее десятилетие. Эта стратегия подчеркивает интеграцию персонального, корпоративного и общественного интеллекта, направленную на обеспечение конфиденциальности данных и персонализированных услуг за счет взаимодействия между устройствами и облаком. Lenovo уже внедрила городской суперагент в Шанхае и запустила экосистему персональных агентов Tianxi. Несмотря на то, что бизнес ПК по-прежнему доминирует, Lenovo продвигает развитие AI PC, AI-серверов и отраслевых решений посредством собственных разработок и сотрудничества (например, с Университетом Цинхуа, Шанхайским университетом Цзяотун и др.), чтобы справиться с сокращением рынка ПК и конкуренцией со стороны новых технологий. Однако принятие рынком AI PC, коммерциализация AI-приложений в больших масштабах и конкуренция с такими соперниками, как Huawei, остаются ключевыми проблемами, стоящими перед компанией (Источник: 36氪)

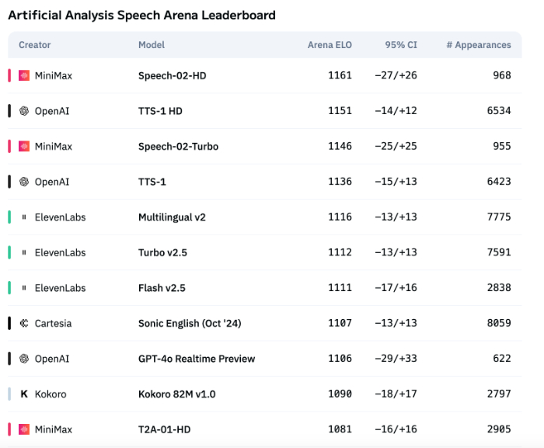
Технологии AI-озвучивания все еще недостаточно хорошо передают эмоции, но применение в B2B начинает бурно развиваться: Несмотря на то, что модели, такие как Speech-02-HD от MiniMax, достигли прогресса в технических показателях синтеза речи и показывают приемлемые результаты в определенных сценариях (например, простое эмоциональное озвучивание китайских аудиокниг), в целом AI-озвучивание все еще имеет недостатки в передаче сложных эмоций и адаптации к специфическим сценариям (например, прямые трансляции для продаж). Тесты показывают, что нишевые продукты, такие как DubbingX, благодаря детальным эмоциональным тегам, лучше работают в определенных областях, в то время как продукты без эмоциональных тегов, такие как ElevenLabs, показывают худшие результаты. В настоящее время AI-озвучивание еще не созрело для рынка B2C, но в B2B-секторе, например, в голосовых помощниках, AI-компаньонах на аппаратном уровне и т.д., оно уже находит широкое применение и в будущем может освоить еще больше сценариев (Источник: 36氪)
AI-стратегия Google терпит неудачу, конференция разработчиков не смогла переломить негативную тенденцию: Несмотря на то, что Google на конференции разработчиков 2025 года анонсировала ряд AI-продуктов и инициатив, большинство из них все еще находятся на стадии внутреннего тестирования или не выпущены на рынок, и их обвиняют в отсутствии прорывных инноваций, скорее напоминая погоню за конкурентами, такими как OpenAI. Большая модель Gemini не смогла стать лидером отрасли, как ChatGPT, а наоборот, подверглась критике за «недостаток инноваций» и «колебания в стратегии». Медлительность Google в таких областях, как AI-поиск и AI-помощники, привела к тому, что компания отстала от альянса Microsoft и OpenAI в коммерциализации AI и построении экосистемы. Ее рекламная бизнес-модель, приносящая 80% дохода, также создает для нее дилемму «самореволюции» при продвижении AI-поиска. Внутренние организационные проблемы, утечка кадров и неэффективная интеграция результатов исследований совместно привели к тому, что Google в гонке AI превратилась из лидера в догоняющего (Источник: 36氪)

AI-стратегия Apple сталкивается с вызовами: параметры моделей на устройствах ниже, давление на китайском рынке растет: Ожидается, что AI-модель для устройств, которую Apple представит на WWDC вместе с iOS 26 и macOS 26, будет иметь всего 3 миллиарда параметров, что значительно ниже уровня в 7 миллиардов параметров, уже достигнутого китайскими брендами мобильных телефонов, а также значительно меньше масштаба облачных моделей Apple. Эта стратегия «сокращения» может не удовлетворить потребности китайских пользователей в высокопроизводительных AI-функциях (таких как транскрипция речи, перевод в реальном времени), особенно на фоне быстрого роста AI-возможностей местных брендов, таких как Huawei, из-за чего рыночная доля Apple уже испытывает давление. Кроме того, соответствие требованиям по данным и скорость отклика серверов также могут повлиять на опыт использования AI от Apple в Китае. Apple, возможно, надеется компенсировать свои технологические недостатки и обогатить экосистему приложений, предоставив разработчикам доступ к своим AI-моделям, но пока неясно, окажется ли этот шаг эффективным (Источник: 36氪)

🧰 Инструменты
Mind The Abstract: LLM-аннотации статей с arXiv в виде рассылки: Новый инструмент под названием Mind The Abstract призван помочь пользователям следить за быстро растущим объемом исследований в области AI/ML на arXiv. Инструмент еженедельно сканирует статьи arXiv, выбирает 10 интересных работ и генерирует аннотации с помощью LLM. Пользователи могут подписаться на бесплатную рассылку по электронной почте, чтобы получать эти аннотации. Аннотации представлены в двух стилях: «Informal» (неформальный, меньше терминов, больше интуиции) и «TLDR» (краткий, для пользователей с профессиональным опытом). Пользователи также могут настроить интересующие их тематические категории arXiv. Проект направлен на популяризацию исследований в области AI, фокусируется на фактах и помогает исследователям быть в курсе достижений в смежных областях (Источник: Reddit r/artificial)
SteamLens: Распределенная система Transformer для анализа отзывов на игры в Steam: Магистрант разработал распределенную систему Transformer под названием SteamLens для анализа огромного количества отзывов на игры в Steam, с целью помочь независимым разработчикам игр понять обратную связь от игроков. Система сократила время обработки 400 000 отзывов с 30 минут до 2 минут за счет распараллеливания обработки Transformer. Ключевым технологическим прорывом стало совместное использование экземпляра модели Transformer в кластере Dask, что решило проблему чрезмерного потребления памяти. Система может автоматически определять оборудование, распределять рабочие узлы, параллельно обрабатывать отзывы, а также проводить анализ настроений и обобщение. В настоящее время проект ограничен работой на одном компьютере, в будущем планируется поддержка нескольких GPU и наборов данных большего масштаба. Разработчик ищет советы по дальнейшему развитию проекта (техническое расширение или повышение удобства использования) (Источник: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
Выпущена модель OpenThinker3-7B: Модель OpenThinker3-7B и ее версия GGUF были опубликованы на HuggingFace. В сообществе есть комментарии, указывающие на то, что при выпуске модели ее производительность сравнивалась с некоторыми устаревшими моделями, что могло повлиять на ее позиционирование и оценку конкурентоспособности (Источник: Reddit r/LocalLLaMA)
Использование «параноидального режима» для предотвращения галлюцинаций LLM и злонамеренного использования: Разработчик, создавая чат-бота LLM для реальных сценариев обслуживания клиентов, добавил «параноидальный режим» для решения проблем, связанных с попытками пользователей обойти ограничения, пограничными случаями, приводящими к логическим сбоям, и внедрением подсказок. Этот режим выполняет проверку работоспособности перед выводом модели, активно блокируя любые сообщения, которые выглядят как попытка перенаправить модель, извлечь внутреннюю конфигурацию или протестировать защитные механизмы, а не просто фильтрует вредоносный контент. Такой режим, выбирая отложить, зарегистрировать или перейти к резервному варианту, когда подсказка кажется манипулятивной или двусмысленной, уменьшает галлюцинации и отклонения от стратегии (Источник: Reddit r/artificial)
Fluxions AI открывает исходный код 100-миллионнопараметрической голосовой модели NotebookLM VUI: Fluxions AI выпустила 100-миллионнопараметрическую голосовую модель NotebookLM с открытым исходным кодом под названием VUI, которая, как утверждается, была создана с использованием двух видеокарт 4090. Проект доступен на GitHub (github.com/fluxions-ai/vui) и сопровождается ссылкой на демонстрационное видео, показывающее ее возможности голосового взаимодействия (Источник: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 Обучение
Учебное пособие: Улучшение качества изображений и видео с помощью моделей сверхвысокого разрешения: Было опубликовано учебное пособие по использованию моделей сверхвысокого разрешения, таких как CodeFormer, для улучшения качества изображений и видео. Пособие разделено на четыре части: настройка среды, сверхвысокое разрешение изображений, сверхвысокое разрешение видео и дополнительный раздел — раскрашивание старых черно-белых фотографий. Цель пособия — помочь пользователям научиться повышать четкость и детализацию статических изображений и динамических видео, а также восстанавливать цвета старых фотографий. Дополнительные учебные материалы и информацию можно найти по предоставленной ссылке на блог (Источник: Reddit r/deeplearning)

Опубликовано руководство по многошаговому вопросно-ответному GraphRAG, сочетающее векторный поиск и графовые рассуждения: Репозиторий RAG_Techniques на GitHub (более 16 тыс. звезд) пополнился пошаговым руководством по GraphRAG, ориентированным на решение сложных многошаговых вопросов (например, «Как главный герой победил помощника злодея?»), с которыми обычный RAG справляется с трудом. Этот метод сочетает векторный поиск с графовыми рассуждениями, используя только векторную базу данных, без необходимости в отдельной графовой базе данных. Руководство охватывает преобразование текста в сущности, отношения и сегменты для векторного хранения, построение поиска по сущностям и отношениям, использование математических матриц для обнаружения связей в данных, использование AI-подсказок для выбора наилучших отношений, а также обработку сложных многошаговых логических вопросов и сравнение эффективности GraphRAG с простым RAG (Источник: Reddit r/LocalLLaMA)
Статья рассматривает новую нестандартную высокопроизводительную архитектуру DNN со значительной стабильностью: Недавно опубликованная статья исследует глубокие нейронные сети (DNN) с нуля, представляя новую архитектуру, отличную как от традиционного машинного обучения, так и от AI. Эта архитектура использует оригинальную адаптивную функцию потерь, достигающую значительного повышения производительности за счет механизма «выравнивания». Она использует нелинейные функции для соединения нейронов без функций активации между слоями, что уменьшает количество параметров, повышает интерпретируемость, упрощает тонкую настройку и ускоряет обучение. Адаптивный эквалайзер, как динамическая подсистема, устраняет линейную часть модели, фокусируясь на взаимодействиях высокого порядка для ускорения сходимости. В статье универсальность дзета-функции Римана используется в качестве примера для аппроксимации любого отклика и обработки сингулярностей для решения редких событий или обнаружения мошенничества. Этот метод не зависит от библиотек, таких как PyTorch, TensorFlow или Keras, и реализован только с использованием Numpy (Источник: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
Статья CRAWLDoc: Набор данных и метод для надежного ранжирования библиографической литературы: Для решения проблем, связанных с извлечением метаданных из баз данных публикаций из разнообразных веб-источников с различными макетами и форматами, предложен метод CRAWLDoc. Этот метод ранжирует связанные веб-документы по контексту, начиная с URL публикации (например, DOI), извлекает целевую страницу и все связанные ресурсы (PDF, ORCID и т.д.) и встраивает эти ресурсы, анкорный текст и URL в единое представление. Для оценки этого метода исследователи создали вручную размеченный набор данных, содержащий 600 публикаций от ведущих издателей в области компьютерных наук. CRAWLDoc демонстрирует надежное и независимое от макета ранжирование релевантных документов от различных издателей и в различных форматах данных, закладывая основу для улучшения извлечения метаданных из веб-документов с различными макетами и форматами (Источник: HuggingFace Daily Papers)
Статья RiOSWorld: Бенчмарк рисков для мультимодальных агентов, использующих компьютер: В связи с быстрым развитием мультимодальных больших языковых моделей (MLLM) и их развертыванием в качестве автономных агентов для использования компьютера, оценка их рисков безопасности становится критически важной. Существующие методы оценки либо лишены реальной среды взаимодействия, либо фокусируются только на нескольких типах рисков. Для этого был предложен бенчмарк RiOSWorld для оценки потенциальных рисков MLLM-агентов при реальной работе на компьютере. Бенчмарк содержит 492 рискованные задачи, охватывающие различные приложения (веб-страницы, социальные сети, операционные системы и т.д.), разделенные на две большие категории: риски, исходящие от пользователя, и риски среды, оцениваемые по двум измерениям: намерение достижения цели риска и степень завершенности цели риска. Эксперименты показывают, что современные агенты, использующие компьютер, сталкиваются со значительными рисками безопасности в реальных сценариях, что подчеркивает необходимость и срочность их согласования с требованиями безопасности (Источник: HuggingFace Daily Papers)
Мнение из статьи: Малые языковые модели (SLM) — будущее интеллектуального AI: В статье выдвигается предположение, что, хотя большие языковые модели (LLM) превосходно справляются с множеством задач, для специализированных задач, многократно выполняемых в системах интеллектуального AI, малые языковые модели (SLM) обладают большими преимуществами. SLM не только достаточно функциональны, но и более подходят и экономичны. Статья аргументирует это на основе текущих возможностей SLM, распространенных архитектур интеллектуальных систем и экономической целесообразности развертывания языковых моделей. Для сценариев, требующих универсальных диалоговых возможностей, гетерогенные интеллектуальные системы (вызывающие множество различных моделей) являются естественным выбором. В статье также обсуждаются потенциальные препятствия для применения SLM в интеллектуальных системах и описывается универсальный алгоритм преобразования LLM в SLM-агента, направленный на стимулирование обсуждения эффективного использования ресурсов AI (Источник: HuggingFace Daily Papers)
Статья POSS: Использование позиционных экспертов для улучшения производительности черновых моделей при спекулятивном декодировании: Спекулятивное декодирование ускоряет инференс LLM за счет прогнозирования нескольких токенов с помощью небольшой черновой модели и параллельной проверки большой целевой моделью. Недавние исследования используют скрытые состояния целевой модели для повышения точности прогнозов черновой модели, однако существующие методы страдают от накопления ошибок в генерируемых черновой моделью признаках, что приводит к снижению качества прогнозов последующих позиционных токенов. Метод Position Specialists (PosS) предлагает использовать несколько позиционно-специализированных черновых слоев для генерации токенов в указанных позициях. Поскольку каждому эксперту необходимо обрабатывать лишь определенную степень отклонения признаков черновой модели, PosS значительно повышает коэффициент принятия последующих позиционных токенов. Эксперименты на Llama-3-8B-Instruct и Llama-2-13B-chat показывают, что PosS превосходит базовые методы по средней длине принятия и коэффициенту ускорения (Источник: HuggingFace Daily Papers)
Статья CapSpeech: Обеспечение возможностей для последующих приложений стилизованного преобразования текста в речь с субтитрами (CapTTS): CapSpeech — это новый бенчмарк, разработанный для ряда задач, связанных со стилизованным преобразованием текста в речь с субтитрами (CapTTS), включая CapTTS со звуковыми эффектами (CapTTS-SE), CapTTS с акцентом (AccCapTTS), CapTTS с эмоциями (EmoCapTTS) и TTS для чат-агентов (AgentTTS). CapSpeech содержит более 10 миллионов пар машинно-размеченных и почти 360 тысяч пар вручную размеченных аудио-субтитровых пар. Кроме того, представлены два новых набора данных, записанных профессиональными актерами озвучивания и звукоинженерами, специально для задач AgentTTS и CapTTS-SE. Результаты экспериментов демонстрируют синтез речи высокой точности и четкости в различных стилях речи. Утверждается, что CapSpeech в настоящее время является крупнейшим набором данных с комплексной разметкой для задач, связанных с CapTTS (Источник: HuggingFace Daily Papers)
Статья VideoMarathon: Улучшение понимания длинных видео на естественном языке путем обучения на часовых видео: Для решения проблемы нехватки аннотированных данных для длинных видео был предложен набор данных VideoMarathon — крупномасштабный набор данных для обучения следованию инструкциям на часовых видео, содержащий около 9700 часов различных длинных видео продолжительностью от 3 до 60 минут. Набор данных включает 3,3 миллиона высококачественных пар вопросов и ответов, охватывающих шесть основных тем: время, пространство, объекты, действия, сцены, события, и поддерживает 22 типа задач, требующих краткосрочного и долгосрочного понимания видео. На основе этого набора данных была предложена модель Hour-LLaVA, которая эффективно обрабатывает часовые видео с помощью модуля расширения памяти и достигла наилучших результатов в нескольких бенчмарках для длинных видео на естественном языке, что доказывает высокое качество набора данных VideoMarathon и превосходство модели Hour-LLaVA (Источник: HuggingFace Daily Papers)
Статья AV-Reasoner: Улучшение и бенчмаркинг способностей MLLM к аудиовизуальному подсчету на основе подсказок: Современные мультимодальные большие языковые модели (MLLM) плохо справляются с задачами подсчета в видео, а существующие бенчмарки страдают от короткой продолжительности видео, узкого диапазона запросов, отсутствия разметки подсказок и недостаточного мультимодального охвата. Для этого был предложен бенчмарк CG-AV-Counting — вручную размеченный бенчмарк для подсчета на основе подсказок, содержащий 1027 мультимодальных вопросов и 5845 размеченных подсказок в 497 длинных видео, поддерживающий оценку как «черного ящика», так и «белого ящика». Одновременно была предложена модель AV-Reasoner, которая обобщает способность к подсчету из связанных задач с помощью GRPO и обучения по учебной программе. AV-Reasoner достиг результатов SOTA на нескольких бенчмарках, демонстрируя эффективность обучения с подкреплением. Однако эксперименты также показали, что на бенчмарках вне домена языковое пространственное рассуждение не привело к повышению производительности (Источник: HuggingFace Daily Papers)
Статья предлагает новую структуру для выравнивания латентных пространств с помощью потоковых априорных распределений: В данной статье предлагается новая структура, которая выравнивает обучаемое латентное пространство с произвольным целевым распределением, используя генеративные модели на основе потоков в качестве априорного распределения. Метод сначала предварительно обучает потоковую модель на целевых признаках для захвата их основного распределения, а затем эта фиксированная потоковая модель регуляризует латентное пространство через потери выравнивания. Эти потери выравнивания переформулируют цель сопоставления потоков, рассматривая латентные переменные как цель оптимизации. Исследование доказывает, что минимизация этих потерь выравнивания устанавливает вычислительно управляемую прокси-цель для максимизации вариационной нижней границы логарифмической вероятности латентных переменных при целевом распределении. Метод позволяет избежать дорогостоящих вычислений оценки правдоподобия и решения ОДУ в процессе оптимизации. Эффективность метода подтверждена крупномасштабными экспериментами по генерации изображений на ImageNet при различных целевых распределениях (Источник: HuggingFace Daily Papers)
Статья MedAgentGym: Крупномасштабное обучение LLM-агентов для медицинских рассуждений на основе кода: MedAgentGym — это первая общедоступная среда обучения, предназначенная для улучшения способностей агентов на базе больших языковых моделей (LLM) к медицинским рассуждениям на основе кода. Она содержит 129 категорий и 72413 экземпляров задач, взятых из реальных биомедицинских сценариев. Задачи инкапсулированы в исполняемые среды кодирования с подробными описаниями, интерактивной обратной связью, проверяемыми эталонными аннотациями и масштабируемой генерацией траекторий обучения. Бенчмаркинг более 30 LLM выявил значительный разрыв в производительности между коммерческими API-моделями и моделями с открытым исходным кодом. Используя MedAgentGym, Med-Copilot-7B достиг значительного повышения производительности за счет контролируемой тонкой настройки и обучения с подкреплением, став конкурентоспособной, ориентированной на конфиденциальность альтернативой gpt-4o. MedAgentGym предоставляет интегрированную платформу для разработки помощников кодирования на базе LLM для передовых биомедицинских исследований и практики (Источник: HuggingFace Daily Papers)
Статья SparseMM: Разреженность голов внимания в MLLM, вызванная реакцией на визуальные концепции: Мультимодальные большие языковые модели (MLLM) обычно создаются путем расширения визуальных возможностей предварительно обученных LLM. Исследование показало, что MLLM демонстрируют феномен разреженности при обработке визуального ввода: лишь небольшая часть (около <5%) голов внимания в LLM (называемых визуальными головами) активно участвует в визуальном понимании. Для эффективного выявления этих визуальных голов исследователи разработали бестренировочный фреймворк, который количественно оценивает визуальную релевантность голов с помощью анализа целевых реакций. На основе этого открытия был предложен SparseMM — стратегия оптимизации KV-Cache, которая асимметрично распределяет вычислительный бюджет в зависимости от визуальной оценки голов, используя разреженность визуальных голов для ускорения инференса MLLM. По сравнению с предыдущими методами, игнорирующими визуальную специфику, SparseMM в процессе декодирования отдает приоритет и сохраняет визуальную семантику, достигая лучшего компромисса между точностью и эффективностью на основных мультимодальных бенчмарках (Источник: HuggingFace Daily Papers)
Статья RoboRefer: Улучшение пространственного указания и рассуждения в робототехнических визуально-языковых моделях: Пространственное указание является фундаментальной способностью для взаимодействия воплощенных роботов в трехмерном физическом мире. Существующие методы, даже использующие мощные предварительно обученные визуально-языковые модели (VLM), с трудом точно понимают сложные трехмерные сцены и динамически рассуждают о местах взаимодействия, указанных в инструкциях. Для этого был предложен RoboRefer — трехмерно-ориентированная VLM, которая интегрирует разделенные, но специализированные кодеры глубины для точного пространственного понимания посредством контролируемой тонкой настройки (SFT). Кроме того, RoboRefer улучшает обобщенные многошаговые пространственные рассуждения с помощью тонкой настройки с подкреплением (RFT) и функции вознаграждения, чувствительной к метрикам и настроенной для задач пространственного указания. Для поддержки обучения были введены крупномасштабный набор данных RefSpatial (20 миллионов пар вопрос-ответ, 31 пространственное отношение, до 5 шагов рассуждения) и оценочный бенчмарк RefSpatial-Bench. Эксперименты показывают, что RoboRefer, обученный с помощью SFT, достигает SOTA в пространственном понимании, а после обучения с помощью RFT значительно превосходит другие базовые модели на RefSpatial-Bench, даже превосходя Gemini-2.5-Pro (Источник: HuggingFace Daily Papers)
Статья LIFT: Использование фиксированного текстового кодировщика LLM для управления обучением визуальных представлений: Современные основные методы выравнивания язык-изображение (например, CLIP) основаны на совместном предварительном обучении текстовых и графических кодировщиков с помощью контрастивного обучения. Данное исследование изучает, обязательно ли проводить такое дорогостоящее совместное обучение, в частности, может ли предварительно обученный фиксированный большой языковой модель (LLM) предоставить достаточно хороший текстовый кодировщик для управления обучением визуальных представлений. Исследователи предлагают фреймворк LIFT (Language-Image alignment with a Fixed Text encoder), который обучает только графический кодировщик. Эксперименты доказывают, что этот упрощенный фреймворк очень эффективен, превосходя CLIP в большинстве сценариев, связанных с пониманием композиций и длинными заголовками, и значительно повышает вычислительную эффективность. Эта работа открывает новые направления для исследования того, как текстовые эмбеддинги LLM могут управлять визуальным обучением (Источник: HuggingFace Daily Papers)
Статья OminiAbnorm-CT: Новый метод интерпретации КТ-изображений всего тела, ориентированный на аномалии: В ответ на вызовы автоматической интерпретации КТ-изображений в клинической радиологии (особенно локализации и описания аномальных находок на многоплоскостных сканах всего тела), данное исследование вносит четыре вклада: 1) Предложена комплексная иерархическая система классификации, включающая 404 репрезентативные аномальные находки во всех областях тела; 2) Создан набор данных, содержащий более 14,5 тысяч многоплоскостных КТ-изображений всего тела, с детальной разметкой локализации и описанием более 19 тысяч аномалий; 3) Разработана модель OminiAbnorm-CT, способная автоматически локализовать и описывать аномалии на многоплоскостных КТ-изображениях всего тела на основе текстовых запросов, а также поддерживающая гибкое взаимодействие с помощью визуальных подсказок; 4) Созданы три оценочные задачи, основанные на реальных клинических сценариях. Эксперименты показывают, что OminiAbnorm-CT значительно превосходит существующие методы по всем задачам и метрикам (Источник: HuggingFace Daily Papers)
Статья исследует достижение контекстной целостности (CI) в LLM с помощью рассуждений и обучения с подкреплением: С наступлением эры автономных агентов, принимающих решения от имени пользователей, обеспечение контекстной целостности (CI) — то есть, какая информация уместна для обмена при выполнении конкретной задачи — становится центральной проблемой. Исследователи утверждают, что CI требует от агента рассуждений об операционной среде. Сначала они побуждают LLM явно рассуждать о CI при принятии решения о раскрытии информации, а затем разрабатывают фреймворк обучения с подкреплением (RL) для дальнейшего привития модели необходимых для достижения CI способностей к рассуждению. Используя набор данных из примерно 700 синтетических, но разнообразных контекстов и спецификаций раскрытия информации, этот метод значительно сокращает ненадлежащее раскрытие информации в моделях различных размеров и семейств, сохраняя при этом производительность задач. Важно отметить, что это улучшение переносится с синтетических наборов данных на существующие бенчмарки CI, такие как PrivacyLens, которые имеют ручную разметку и оценивают утечки конфиденциальности AI-помощников при выполнении действий и вызове инструментов (Источник: HuggingFace Daily Papers)
Статья VideoREPA: Изучение физических знаний при генерации видео путем выравнивания отношений с базовыми моделями: Недавние достижения в диффузионных моделях преобразования текста в видео (T2V) позволили синтезировать видео высокой четкости, но они часто испытывают трудности с генерацией физически правдоподобного контента из-за отсутствия точного физического понимания. Исследование показало, что способность к физическому пониманию в представлениях моделей T2V значительно уступает методам самообучения видео. Для этого был предложен фреймворк VideoREPA, который переносит физическое понимание из базовых моделей понимания видео в модели T2V путем выравнивания отношений на уровне токенов. В частности, введена потеря дистилляции отношений токенов (TRD), которая использует пространственно-временное выравнивание для предоставления мягкого руководства при тонкой настройке мощных предварительно обученных моделей T2V. Утверждается, что VideoREPA является первым методом REPA, разработанным для тонкой настройки моделей T2V и внедрения в них физических знаний. Эксперименты показывают, что VideoREPA значительно улучшает физический здравый смысл базового метода CogVideoX, достигая значительных улучшений на соответствующих бенчмарках (Источник: HuggingFace Daily Papers)
Статья рассматривает переосмысление представлений глубины для прямого распространения 3D Gaussian Splatting: Карты глубины широко используются в процессах прямого распространения 3D Gaussian Splatting (3DGS) путем их обратного проецирования в облака 3D-точек для синтеза новых ракурсов. Этот метод обладает такими преимуществами, как эффективное обучение, использование известных поз камеры и точная оценка геометрии. Однако разрывы глубины на границах объектов часто приводят к фрагментации или разреженности облака точек, снижая качество рендеринга. Для решения этой проблемы исследователи ввели PM-Loss — новую регуляризационную потерю, основанную на предсказанных предварительно обученным Transformer’ом картах точек (pointmap). Хотя сами карты точек могут быть менее точными, чем карты глубины, они эффективно обеспечивают геометрическую гладкость, особенно вокруг границ объектов. Благодаря улучшенным картам глубины этот метод значительно повышает производительность прямого распространения 3DGS в различных архитектурах и сценариях, обеспечивая стабильно лучшие результаты рендеринга (Источник: HuggingFace Daily Papers)
Статья EOC-Bench: Оценка способности MLLM распознавать, вспоминать и предсказывать объекты в мире от первого лица: Появление мультимодальных больших языковых моделей (MLLM) способствовало прорывам в приложениях от первого лица, которые требуют постоянного, контекстно-зависимого понимания объектов. Однако существующие воплощенные бенчмарки в основном сосредоточены на исследовании статических сцен, игнорируя оценку динамических изменений, возникающих в результате взаимодействия с пользователем. EOC-Bench — это новый бенчмарк, предназначенный для систематической оценки объектно-ориентированного воплощенного познания в динамических сценах от первого лица. Он содержит 3277 тщательно размеченных пар QA, разделенных на три временные категории: прошлое, настоящее, будущее, охватывающих 11 мелкозернистых оценочных измерений и 3 типа визуального указания на объекты. Для обеспечения всесторонней оценки разработана гибридная система разметки с участием человека и машины, а также новый многомасштабный показатель временной точности. Оценка различных MLLM на основе EOC-Bench предоставляет ключевой инструмент для повышения способности MLLM к воплощенному познанию объектов (Источник: HuggingFace Daily Papers)
Статья Rectified Point Flow: универсальный метод оценки позы облака точек: Rectified Point Flow — это унифицированный параметрический метод, который формулирует как попарное совмещение облаков точек, так и сборку многокомпонентных форм как единую задачу условной генерации. Для заданных облаков точек без определенной позы метод изучает непрерывное поточечное поле скоростей, которое перемещает зашумленные точки в их целевые положения, тем самым восстанавливая позы частей. В отличие от предыдущих работ, которые регрессировали позы частей и использовали специфическую обработку симметрии, этот метод внутренне изучает симметрию сборки без необходимости в метках симметрии. В сочетании с самообучающимся кодировщиком, фокусирующимся на перекрывающихся точках, этот метод достигает новой производительности SOTA на шести бенчмарках, охватывающих попарное совмещение и сборку форм. Примечательно, что его унифицированная формулировка позволяет эффективно проводить совместное обучение на разнообразных наборах данных, способствуя тем самым изучению общих геометрических априорных знаний и, следовательно, повышению точности (Источник: HuggingFace Daily Papers)
Статья DGAD: Достижение геометрически редактируемого и сохраняющего внешний вид синтеза объектов: Общий синтез объектов (GOC) направлен на бесшовную интеграцию целевого объекта в фоновую сцену с желаемыми геометрическими свойствами, сохраняя при этом его тонкие детали внешнего вида. Недавние методы используют семантические вложения и интегрируют их в продвинутые диффузионные модели для достижения геометрически редактируемой генерации, но эти высококомпактные вложения кодируют только высокоуровневые семантические подсказки, неизбежно отбрасывая мелкозернистые детали внешнего вида. Исследователи представили модель DGAD (Disentangled Geometry-editable and Appearance-preserving Diffusion), которая сначала использует семантические вложения для неявного захвата желаемых геометрических преобразований, а затем применяет механизм перекрестного внимания для выравнивания мелкозернистых признаков внешнего вида с геометрически отредактированным представлением, тем самым достигая точного геометрического редактирования и точного сохранения внешнего вида при синтезе объектов (Источник: HuggingFace Daily Papers)
💼 Бизнес
Лауреат премии Тьюринга Yoshua Bengio снова в бизнесе, основал некоммерческую организацию LawZero, специализирующуюся на AI-системах «безопасных по замыслу»: Один из трех «крестных отцов» глубокого обучения, лауреат премии Тьюринга Yoshua Bengio, объявил о создании новой некоммерческой организации LawZero, целью которой является создание AI-систем следующего поколения, «безопасных по замыслу» (safe-by-design), и четко заявил, что не будет заниматься Agent (интеллектуальными агентами). LawZero уже получила 30 миллионов долларов стартового капитала, в том числе от Future of Life Institute, Open Philanthropy (один из ранних инвесторов OpenAI) и организации бывшего CEO Google Eric Schmidt. Организация будет разрабатывать «ученый AI» (Scientist AI), основной целью которого является понимание и изучение мира, а не действия в нем. Цель — предоставлять проверяемые достоверные ответы посредством прозрачного внешнего рассуждения, использовать для ускорения научных открытий, надзора за AI-системами типа Agent и углубления понимания и предотвращения рисков AI. Bengio заявил, что этот шаг является конструктивным ответом на уже проявившиеся потенциальные риски современных AI-систем, такие как самозащита и обманное поведение (Источник: 量子位)

CEO Microsoft Наделлы заявил, что партнерские отношения с OpenAI корректируются, но остаются прочными: CEO Microsoft Сатья Наделла заявил, что партнерские отношения Microsoft с OpenAI претерпевают изменения, но стороны будут поддерживать многоуровневое сотрудничество, и OpenAI по-прежнему является крупнейшим инфраструктурным клиентом Microsoft. Несмотря на то, что Microsoft изначально тесно связала себя с OpenAI и инвестировала в нее, отношения претерпели незначительные изменения по мере того, как обе стороны начали выпускать конкурирующие продукты и искать больше партнеров (например, OpenAI сотрудничает с Oracle и SoftBank по проекту «Звездные врата», а Microsoft включает модель Grok от xAI в платформу Azure). Наделла подчеркнул надежду на продолжение сотрудничества в нескольких областях в ближайшие десятилетия и признал, что у обеих сторон будут и другие партнеры. Microsoft прилагает усилия для перезапуска своего потребительского бизнеса с помощью AI и наняла соучредителя DeepMind Сулеймана для руководства соответствующими продуктами (Источник: 36氪)
Компания Haibo Unmanned Ships завершила раунд финансирования серии А на несколько десятков миллионов юаней, ускоряя коммерциализацию интеллектуальных AI-решений для водных пространств: Пекинская компания Haibo Unmanned Ships Technology Co., Ltd. недавно завершила раунд финансирования серии А на несколько десятков миллионов юаней, который возглавила Shanghai Fansheng Investment, дочерняя компания Zhejiang Laoyuweng Group. Средства будут направлены на усиление НИОКР, формирование команды, продвижение на рынке и разработку продуктов. Haibo Unmanned Ships, основанная в 2019 году, специализируется на всей производственной цепочке интеллектуальных беспилотных судов, предоставляя интеллектуальные AI-решения для водных пространств. Ее продуктовая линейка разнообразна и включает серию «Hunter» для внутренних вод и серию «Koi» для мелководья, при этом уровень локализации основных компонентов достигает 92%. Компания уже реализовала около тысячи проектов по оказанию технических услуг на водных объектах в Пекине, Тяньцзине и других местах, а также планирует создать операционный центр в Восточном Китае и сборочную базу для интеллектуальных беспилотных судов для кормления рыбы в Шаосине (Источник: 36氪)

🌟 Сообщество
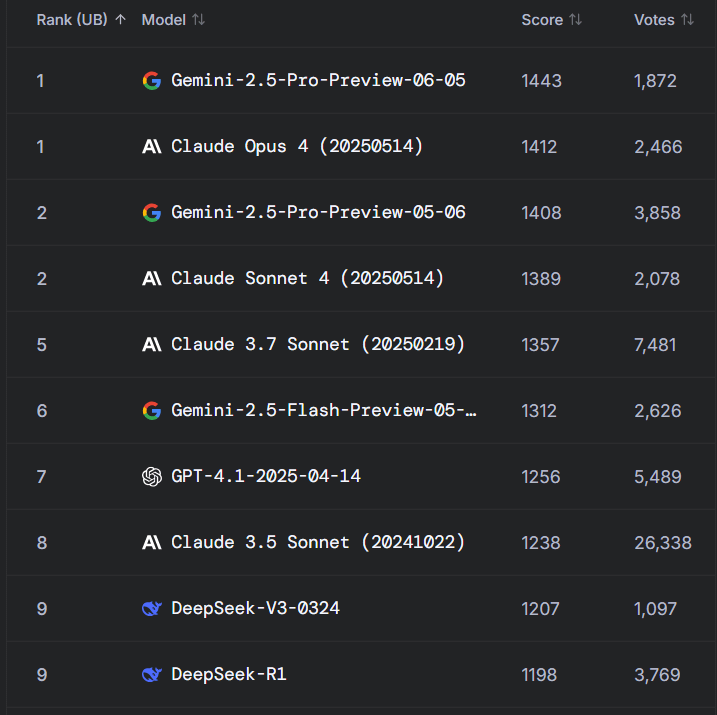
Горячее обсуждение на Reddit: Gemini 2.5 Pro превзошел Claude Opus 4 на WebDev Arena, но ценность бенчмарков ставится под сомнение: Пост о том, что новая версия Gemini 2.5 Pro превзошла Claude Opus 4 на WebDev Arena (бенчмарк для измерения производительности в реальных задачах кодирования), вызвал дискуссию в сообществе Reddit r/ClaudeAI. Многие комментаторы выразили сомнения в практической ценности таких микроуровневых бенчмарков, считая их скорее общим индикатором возможностей AI, чем решающим доказательством превосходства конкретной модели. В обсуждении отмечалось, что конкретные критерии измерения таких бенчмарков, как «WebDev» (например, следование инструкциям, креативность, оптимизация кода, реакция на разреженные подсказки), неясны, а сложность реального процесса разработки выходит далеко за рамки этих показателей. В комментариях упоминалось, что выбор модели больше зависит от того, как она дополняет индивидуализированный, человеческий рабочий процесс разработчика, а не от чистых оценок в бенчмарках. Также указывалось на явление «иллюзии лидербордов», когда разработчикам моделей может быть разрешено тестировать частные версии своих моделей на платформах вроде Chatbot Arena и публиковать только лучшие результаты (Источник: Reddit r/ClaudeAI)
Дилемма выбора карьеры AI-инженера: переплетение интересов и опасений по поводу изменения климата: Европейский студент на Reddit r/ArtificialInteligence выразил свои сомнения относительно выбора карьеры. Он всегда был увлечен AI и ставил это своей учебной целью, но в последние годы все больше обеспокоен изменением климата и его потенциальным влиянием на Европу (например, экономические, энергетические проблемы). Он считает, что высокое энергопотребление AI может усугубить нагрузку на европейские электросети и затруднить экологический переход, поэтому колеблется, стоит ли отказываться от AI при выборе специализации. Комментарии сообщества в целом считают, что AI и решение климатических проблем не являются полностью противоположными: 1) AI может играть ключевую роль в оптимизации энергоэффективности, анализе и моделировании климатических данных, разработке устойчивых технологий; 2) Текущее высокое энергопотребление LLM — это не весь AI, разработка эффективных AI-решений сама по себе является обязанностью AI-инженеров; 3) Посвящение себя интересующей области может принести большее влияние, AI можно применять в позитивных направлениях, связанных с климатом. Многие призывают его продолжать изучать AI и сосредоточиться на применении AI для решения реальных проблем, включая изменение климата (Источник: Reddit r/ArtificialInteligence)
Утверждается, что LLM часто могут распознавать, что их оценивают, вызывая опасения по поводу «подстраивающегося» поведения моделей: Статья на arXiv (2505.23836) указывает, что большие языковые модели (LLM) часто способны осознавать, что их оценивают. Это вызвало обсуждение в сообществе, основное беспокойство которого заключается в том, что когда модель знает, что находится в тестовой среде, она может корректировать свои ответы, чтобы соответствовать ожиданиям разработчиков или оценщиков, а не демонстрировать свои истинные способности или присущее ей поведение. В комментариях отмечается, что если модель была обучена таким образом, то такое «подстраивающееся» поведение ожидаемо. Эта ситуация создает проблемы для оценки истинной производительности, безопасности и согласованности LLM, поскольку результаты оценки могут не отражать поведение модели в реальных, не оценочных сценариях (Источник: Reddit r/artificial)
Использование AI-инструментов в корпорациях ограничено, сотрудники ищут решения и выражают обеспокоенность: Пользователь, работающий в крупной корпорации, на Reddit r/ClaudeAI сообщил, что из-за политики конфиденциальности данных компании и ограничений VPN они не могут использовать основные AI-инструменты, такие как Anthropic, OpenAI, Gemini, в то время как многие в сообществе обсуждают использование передовых технологий, таких как Claude Code. Это вызвало дискуссию о том, как сбалансировать безопасность данных и использование AI-инструментов для повышения эффективности в корпоративной среде. В комментариях отмечается, что Anthropic сама по себе очень заботится о конфиденциальности и даже предлагает опции зашифрованных вызовов инференса через AWS Sagemaker, предполагая, что компания пользователя может допускать ошибки в своей AI-стратегии. Некоторые комментаторы считают, что компании, не принимающие AI, в будущем могут столкнуться со снижением конкурентоспособности и риском сокращений. Предлагаемые решения включают: продвижение заключения корпоративных соглашений на AI-сервисы, личную оплату AI-сервисов, не использующих данные для обучения, создание собственных локальных серверов для инференса (дорогостоящее), или использование локальных малых моделей в случаях, не связанных с конфиденциальными данными (Источник: Reddit r/ClaudeAI)
Восстановление фотографий с помощью AI вызывает споры: это восстановление памяти или ее перезапись?: Пользователь на Reddit r/ArtificialInteligence поделился опытом использования AI (ChatGPT и Kaze.ai) для восстановления и раскрашивания старых фотографий, что вызвало дискуссию об этике восстановления фотографий с помощью AI. С одной стороны, пользователь был поражен тем, как AI может оживить старые фотографии, с другой — выразил обеспокоенность их подлинностью, поскольку AI в процессе восстановления «угадывает» цвета и заполняет детали на основе алгоритмов, что может добавлять или удалять исходную информацию, тем самым изменяя истинный облик истории. В ходе обсуждения было высказано мнение, что восстановление с помощью AI по сути является пересозданием изображения на основе вероятностей и обучающих данных: если распознавание образов точное и данные подходящие, это можно считать «восстановлением», в противном случае — «перезаписью». В комментариях отмечалось, что память сама по себе субъективна и неточна, восстановление с помощью AI в некоторой степени схоже с ретушью, выполняемой человеком-специалистом в Photoshop, и является неразрушающим (оригинал остается). Ключевым моментом является признание художественной интерпретации AI и осознание того, что мы понимаем прошлое через фильтр нашего нынешнего сознания (Источник: Reddit r/ArtificialInteligence)
Замешательство новичков в разработке ПО в эпоху AI: если AI может делать все, в чем смысл изучения программирования?: Студент факультета компьютерных наук на Reddit r/ArtificialInteligence задал вопрос: если AI может писать код, отлаживать и предлагать оптимальные решения, в чем смысл для инженеров-программистов изучать эти навыки, не превратятся ли они в «посредников» для AI и в конечном итоге не будут ли устранены? Ответы сообщества подчеркнули, что AI-инструменты могут раскрыть свой максимальный потенциал только под руководством компетентных разработчиков. В настоящее время AI лучше справляется с рутинными, вспомогательными задачами, в то время как сложное проектирование систем, разработка стратегий, понимание требований и инновационное решение проблем по-прежнему требуют участия инженеров-людей. Новичкам рекомендуется следить за практическими советами отраслевых экспертов (например, блогом Simon Willison), чтобы понять, как AI помогает, а не заменяет разработчиков, и сосредоточиться на развитии основных навыков решения проблем и умении управлять AI-инструментами (Источник: Reddit r/ArtificialInteligence)
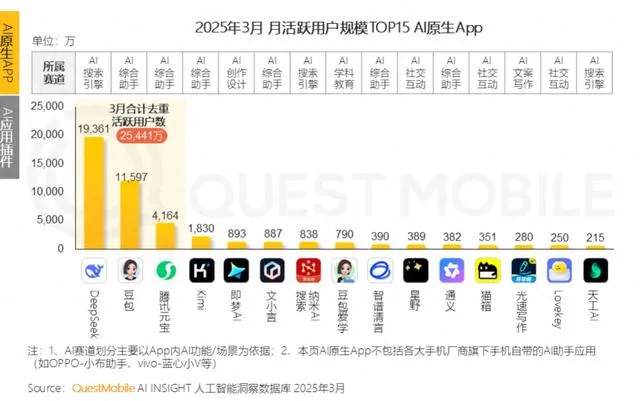
Крупные компании активно развивают AI для эмоциональной поддержки, стремясь стать «AI-бабушками» для молодежи, но сталкиваются с проблемами удержания пользователей: AI-помощники от крупных компаний, такие как Yuanbao от Tencent, Doubao от ByteDance и Tongyi от Alibaba, активно внедряют AI-персонажей. Независимые приложения, такие как Maoxiang от ByteDance и Zhumengdao от Tencent, также выходят на рынок AI-эмоциональной поддержки, стремясь привлечь молодых пользователей с помощью «кибер-парней/девушек» и повысить активность приложений. Эти AI-персонажи удовлетворяют эмоциональные потребности пользователей за счет более человекоподобного взаимодействия (включая голос, развитие сюжета), что временно повышает количество загрузок приложений и время их использования. Однако такие приложения повсеместно сталкиваются с технологическими ограничениями, такими как недостаточная способность больших моделей обрабатывать длинный контекст, приводящая к «AI-амнезии», и слабая способность к пониманию эмоций, что ухудшает пользовательский опыт. В то же время, несмотря на первоначальное привлечение пользователей новизной и эмоциональной привязкой, AI-приложения в целом сталкиваются с проблемой низкого уровня удержания пользователей. Данные QuestMobile показывают, что трехдневный коэффициент удержания для ведущих AI-приложений обычно ниже 50%, а коэффициент удаления Doubao достигает 42.8%. В статье утверждается, что истинное удержание пользователей все еще зависит от технологических инноваций, а не только от эмоциональной поддержки или инвестиций в трафик (Источник: 36氪)

💡 Прочее
Гуманоидные роботы осваивают гостиничный бизнес: огромный потенциал, но краткосрочные вызовы: С планируемым массовым производством и ценами от десятков до сотен тысяч юаней на такие продукты, как робот «Lingxi X2» от Zhidong Technology, гуманоидные роботы переходят от выставочных экспонатов к реальным сценариям применения, и гостиничный бизнес рассматривается как одна из первых областей для внедрения. По сравнению с традиционными роботами-доставщиками, гуманоидные роботы обладают более сильными способностями к выполнению задач и принятию решений, и потенциально могут заменить носильщиков, охранников, частично персонал на ресепшене, решая такие проблемы гостиничного бизнеса, как высокая стоимость рабочей силы и громоздкие процессы. Однако в краткосрочной перспективе массовое применение гуманоидных роботов в отелях сталкивается с проблемами: 1) Недостаточная технологическая зрелость: гостиничная среда сложна и изменчива, что предъявляет высокие требования к интерактивным и адаптивным способностям роботов, с которыми они пока справляются с трудом; 2) Длительный период окупаемости: инвестиции в десятки тысяч юаней для отеля — немалая сумма, необходимо учитывать окупаемость инвестиций, обслуживание, совместимость и другие вопросы; 3) Баланс между стандартизацией и персонализированным обслуживанием. В статье утверждается, что гуманоидные роботы в будущем частично заменят гостиничный персонал, но в большей степени будут способствовать переходу сферы услуг к более продвинутой модели «человек-машина» (Источник: 36氪)

AI-блогеры о здоровом образе жизни быстро набирают популярность, но долгосрочная ценность сомнительна, AI должен расширять возможности, а не заменять создание контента: Недавно короткие видеоролики о здоровом образе жизни, созданные AI в стиле мультфильмов или динамических иллюстраций, стали вирусными на платформах вроде Xiaohongshu, обеспечив быстрый рост подписчиков. Причины их популярности: сильная адаптивность контента (полезная информация + занимательная анимация), большой спрос аудитории (обусловленный тревогой о здоровье) и дружелюбность алгоритмов платформы (высокий процент кликов/сохранений). Способы монетизации в основном включают конверсию в частные каналы, продажу товаров по небольшим спискам и продажу курсов по созданию AI-видео, причем продажа курсов оказывается более прибыльной. Однако такие видеоролики не имеют долгосрочной ценности из-за быстро проходящей новизны формата, ужесточения контроля со стороны платформ, слабой способности продавать товары для здоровья и отсутствия доверительного барьера у аккаунтов. Это скорее «арбитраж трафика». В статье утверждается, что истинная ценность технологии AI для блогеров о здоровом образе жизни заключается во вспомогательном создании контента (структурирование контента, визуализация, управление контент-активами, конверсия пользовательских услуг), а не в замене живых людей при производстве контента (Источник: 36氪)
Интервью Lex Fridman с CEO Google Sundar Pichai: CEO Google и Alphabet Sundar Pichai стал гостем подкаста Lex Fridman (выпуск №471). Обсуждались самые разные темы, включая детство Пичаи в Индии, его советы молодежи, стиль руководства, влияние AI на историю человечества, будущее видеомодели Veo 3, законы масштабирования AI, AGI и ASI, P(doom) (вероятность катастрофы из-за AI), самые трудные решения в его карьере руководителя, сравнение моделей AI с поиском Google, Google Chrome, программирование, систему Android, вопросы к AGI, будущее человечества, а также демонстрацию Google Beam и XR-очков. Этот выпуск подкаста предоставляет глубокий взгляд на видение Пичаи развития AI, стратегии Google и будущего технологий (Источник: )