
Ключевые слова:ИИ-модель, Глубокое обучение, Искусственный интеллект, Большая языковая модель, Машинное обучение, ИИ-агент, Ограничение вычислительной мощности, Применение ИИ, Системная подсказка Grok, Математический рекорд AlphaEvolve, ИИ-агент Gemini, Метод обучения FP4, Анализ таблиц Sonnet 4.0
🔥 В фокусе
xAI раскрывает системные подсказки Grok и усиливает механизмы проверки: Компания xAI недавно объявила, что из-за несанкционированного изменения подсказок ее робота-ответчика Grok на платформе X и публикации им политических заявлений, нарушающих политику и ценности компании, компания решила опубликовать системные подсказки Grok на GitHub. Этот шаг направлен на повышение прозрачности и надежности Grok как ИИ, стремящегося к истине. xAI также заявила, что усилит внутренние процессы проверки кода и создаст круглосуточную команду мониторинга для предотвращения подобных инцидентов в будущем и более быстрого реагирования на проблемы, не обнаруженные автоматическими системами. (Источник: xai, xai)
DeepMind AlphaEvolve снова бьет математический рекорд, сотрудничество ИИ и человека демонстрирует новую парадигму научных исследований: DeepMind AlphaEvolve дважды за неделю побил математический рекорд, державшийся 18 лет, что привлекло внимание математика Теренса Тао и других. Тао считает, что различные исследовательские подходы могут взаимодополнять друг друга, способствуя прогрессу в математике, а не просто следовать принципу «победитель получает все». Этот случай подчеркивает потенциал сотрудничества ИИ и человека в создании новых моделей прогресса в технологической и научной сферах. ИИ больше не является просто инструментом замены, а партнером человека в исследовании неизвестного и ускорении инноваций. (Источник: Yuchenj_UW)

Google сотрудничает с сообществом открытого исходного кода для упрощения создания ИИ-агентов на базе Gemini: Google объявила о сотрудничестве с фреймворками с открытым исходным кодом, такими как LangChain LangGraph, crewAI, LlamaIndex и ComposIO, с целью упростить разработчикам создание ИИ-агентов на базе моделей Google Gemini. Этот шаг отражает решимость Google способствовать развитию экосистемы ИИ-агентов, предоставляя более простые в использовании инструменты и фреймворки, снижая порог входа для разработки и поощряя появление большего количества инновационных приложений. (Источник: osanseviero, Hacubu)

Возможности логического вывода ИИ-моделей могут столкнуться с узким местом в вычислительных мощностях в течение года: Хотя модели логического вывода, такие как o3 от OpenAI, в краткосрочной перспективе демонстрируют значительное повышение производительности за счет вычислительных мощностей (например, вычислительная мощность для обучения o3 в 10 раз больше, чем у o1), исследовательские институты, такие как Epoch AI, прогнозируют, что при текущем темпе удвоения вычислительных мощностей каждые несколько месяцев, масштабирование вычислительных мощностей для моделей логического вывода может достичь «потолка» максимум в течение года. К тому времени темпы роста вычислительных мощностей могут снизиться до 4 раз в год, и скорость обновления моделей соответственно замедлится. Данные обучения моделей, таких как DeepSeek-R1, также косвенно подтверждают текущие масштабы потребления вычислительных мощностей для обучения логическому выводу. Хотя инновации в данных и алгоритмах все еще могут способствовать прогрессу, замедление роста вычислительных мощностей станет важной проблемой для индустрии ИИ. (Источник: WeChat)

🎯 Новости и тенденции
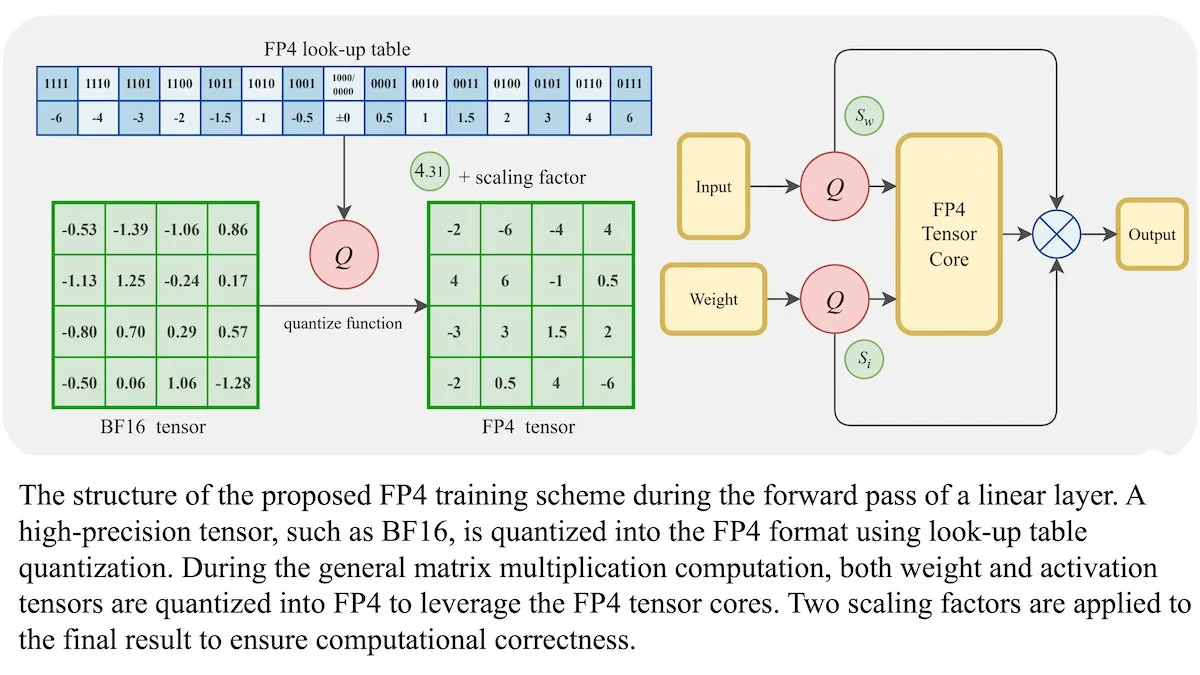
Новый метод обучения LLM: точность с плавающей запятой 4 бита (FP4) может достигать уровня BF16: Исследователи показали, что большие языковые модели (LLM) могут обучаться с использованием 4-битной точности с плавающей запятой (FP4) без ущерба для точности. Используя FP4 для матричных умножений, которые составляют 95% вычислений при обучении, была достигнута производительность, сравнимая с широко используемым форматом BF16. Команда ввела дифференцируемую аппроксимацию для преодоления недифференцируемости квантования, повысив эффективность обучения. Симуляции на GPU Nvidia H100 показали, что FP4 демонстрирует сравнимую или лучшую производительность по сравнению с BF16 в различных языковых бенчмарках. (Источник: DeepLearningAI)
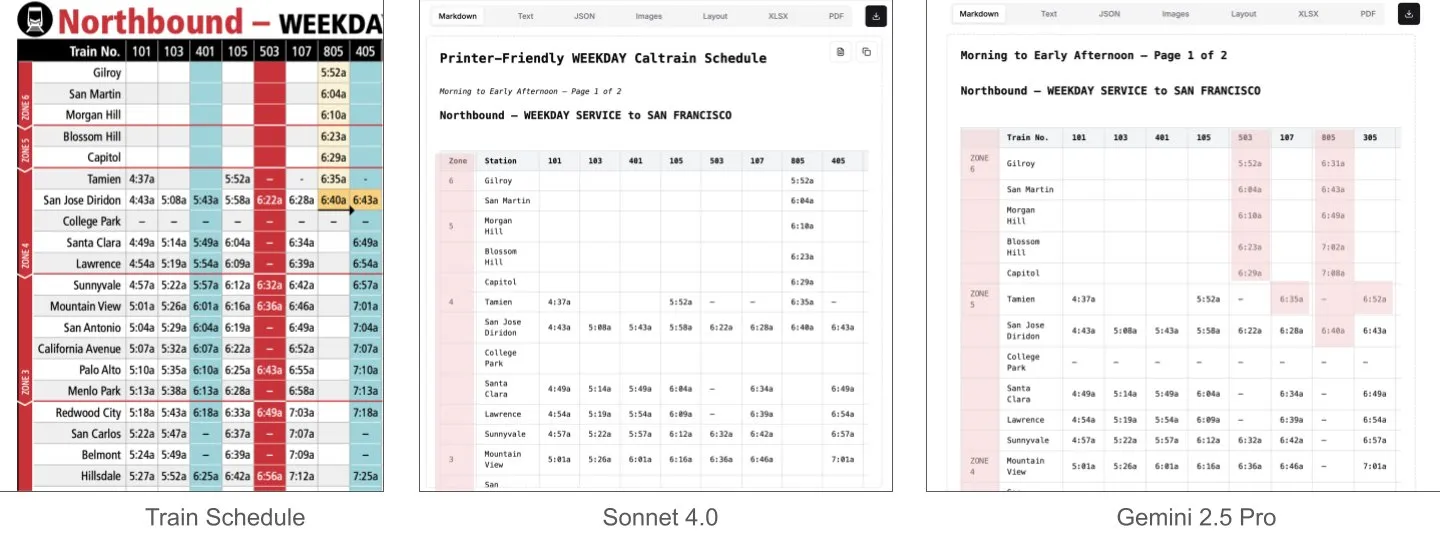
Sonnet 4.0 превосходит Gemini 2.5 Pro в понимании документов, особенно в анализе таблиц: Jerry Liu из LlamaIndex в ходе сравнительного тестирования обнаружил, что Sonnet 4.0 от Anthropic значительно превосходит Gemini 2.5 Pro от Google в способности анализировать таблицы при обработке скриншота расписания Caltrain, содержащего плотные табличные данные. Gemini 2.5 Pro допустил смещение столбцов, в то время как Sonnet 4.0 смог достаточно хорошо восстановить большинство числовых значений, допустив ошибки только в заголовках таблиц и небольшом количестве других значений. Хотя Sonnet 4.0 в настоящее время дороже и медленнее, его производительность в визуальном выводе и анализе таблиц выделяется. (Источник: jerryjliu0)
xAI, TWG Global и Palantir сотрудничают для преобразования применения ИИ в сфере финансовых услуг: xAI объявила о партнерстве с TWG Global и Palantir Technologies для совместной разработки и внедрения корпоративных решений на базе ИИ, направленных на преобразование способов внедрения ИИ и масштабирования технологий поставщиками финансовых услуг. Генеральный директор Palantir Alex Karp и сопредседатель TWG Global Thomas Tull обсудили на конференции Института Милкена, как это сотрудничество будет способствовать инновациям в области ИИ в финансовой отрасли. (Источник: xai, xai)
Усиление цензуры в DeepSeek-R1-0528 после обновления вызвало обсуждение в сообществе: Пользователи сообщают, что DeepSeek-R1-0528 (полная модель 671B, FP8) по сравнению со старой версией R1 заметно ужесточил цензуру контента. Например, на вопросы о чувствительных исторических событиях новая модель дает более уклончивые и официальные ответы, в то время как старая версия R1 могла предоставить более прямую информацию. Это изменение вызвало в сообществе дискуссии об открытости модели, масштабах цензуры и ее потенциальном влиянии на исследования и приложения, особенно в сценариях, где модель используется для получения нецензурированной информации. (Источник: Reddit r/LocalLLaMA)
Huawei выпускает модель Pangu Embedded, объединяющую когнитивную архитектуру двойной системы «быстрого» и «медленного» мышления: Команда Huawei Pangu на базе NPU Ascend предложила модель Pangu Embedded, инновационно интегрирующую двойной режим вывода «быстрого мышления» и «медленного мышления». Эта модель посредством двухэтапного обучения (итеративная дистилляция и слияние моделей, многоисточниковая динамическая система вознаграждений RL) и когнитивной архитектуры, автоматически переключающейся в зависимости от управления пользователем или сложности задачи, нацелена на достижение динамического баланса между эффективностью вывода и глубиной, решая противоречие традиционных больших моделей, заключающееся в чрезмерном обдумывании простых задач и недостаточном обдумывании сложных. (Источник: WeChat)

Новая модель видеомира сочетает SSM и диффузионные модели, обеспечивая длинный контекст и интерактивную симуляцию: Исследователи из Стэнфордского университета, Принстонского университета и Adobe Research предложили новую модель видеомира, которая, сочетая модели пространства состояний (SSM, в частности, схему поблочного сканирования Mamba) и видеодиффузионные модели, решает проблему ограниченной длины контекста существующих видеомоделей и сложности моделирования долгосрочной согласованности. Эта модель может эффективно обрабатывать причинно-следственную временную динамику, отслеживать состояние мира и обеспечивать точность генерации за счет механизма локального внимания к кадрам, открывая новые пути для генерации видео неограниченной длины, в реальном времени и согласованного в интерактивных приложениях (например, играх). (Источник: WeChat)

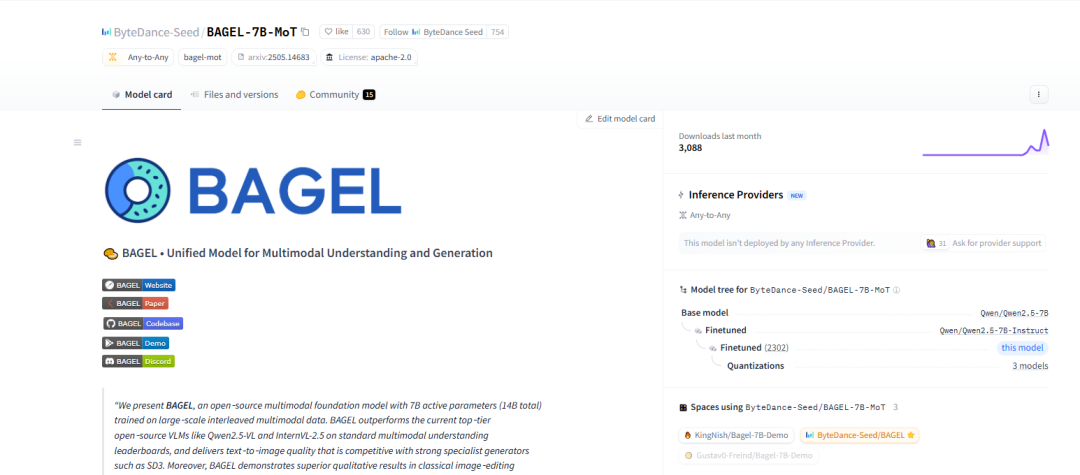
ByteDance выпускает мультимодальную базовую модель BAGEL с открытым исходным кодом, поддерживающую понимание и генерацию текста, изображений и видео: ByteDance выпустила модель BAGEL (ByteDance Agnostic Generation and Empathetic Language model) с открытым исходным кодом. Это унифицированная мультимодальная базовая модель, способная одновременно обрабатывать задачи понимания и генерации текста, изображений и видео. Версия BAGEL-7B-MoT имеет 14 миллиардов общих параметров (7 миллиардов активных параметров) и требует около 30 ГБ видеопамяти при полной загрузке. Пользователи могут опробовать и развернуть модель с помощью предоставленных Hugging Face Demo и адреса модели, реализуя такие функции, как редактирование изображений и преобразование стилей. (Источник: WeChat)
Выпущен FLUX.1 Kontext: объединение редактирования и генерации текста и изображений, скорость увеличена в 8 раз: Black Forest Labs (BFL) выпустила новое поколение моделей изображений FLUX.1 Kontext. Эта серия моделей поддерживает генерацию изображений в контексте, может одновременно обрабатывать текстовые и графические подсказки, реализуя мгновенное редактирование текста и изображений, а также генерацию текста в изображение. FLUX.1 Kontext демонстрирует превосходные результаты в согласованности персонажей, понимании контекста и локальном редактировании. Генерация изображений разрешением 1024×1024 занимает всего 3-5 секунд, что в 8 раз быстрее GPT-Image-1, и поддерживает многоэтапное итеративное редактирование. Модель основана на технологии rectified flow transformer и adversarial diffusion distillation sampling. (Источник: WeChat, WeChat)

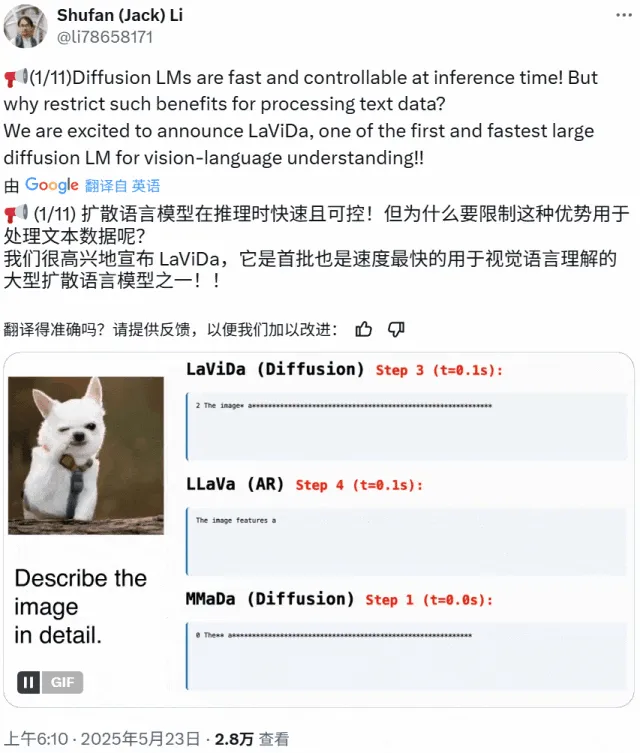
LaViDa: новая мультимодальная VLM для понимания на основе диффузионных моделей: Исследователи из Калифорнийского университета в Лос-Анджелесе, Panasonic, Adobe и Salesforce представили LaViDa (Large Vision-Language Diffusion Model with Masking), визуально-языковую модель (VLM) на основе диффузионных моделей. В отличие от традиционных VLM на основе авторегрессионных LLM, LaViDa использует дискретный диффузионный процесс для генерации текста, теоретически обладая лучшей параллельностью, компромиссом между скоростью и качеством, а также способностью обрабатывать двунаправленный контекст. Модель интегрирует визуальные признаки через визуальный кодировщик и использует двухэтапный процесс обучения (предварительное обучение для выравнивания визуального и скрытого пространства DLM, тонкая настройка для следования инструкциям). Эксперименты показывают, что LaViDa демонстрирует конкурентоспособность в различных задачах, таких как визуальное понимание, логический вывод, OCR и научные вопросы-ответы. (Источник: WeChat)
ИИ-модели сталкиваются с риском «деградации модели» из-за поглощения слишком большого количества данных, сгенерированных ИИ: Исследования показывают, что если ИИ-модели в процессе обучения поглощают слишком много данных, сгенерированных другими ИИ, может произойти явление «деградации модели» (model collapse), в результате чего модели становятся более хаотичными и ненадежными. Даже если разрешить моделям искать информацию в Интернете, проблема может усугубиться из-за того, что Интернет наводнен низкокачественным контентом, сгенерированным ИИ. Это явление впервые было предложено в 2023 году и сейчас становится все более очевидным, создавая проблемы для долгосрочного развития ИИ-моделей и контроля качества данных. (Источник: Reddit r/ArtificialInteligence)

Восьмиядерный процессор AMD Ryzen AI Max Pro 385 замечен в Geekbench, предвещая выход на рынок доступных чипов Strix Halo: Новый восьмиядерный процессор AMD Ryzen AI Max Pro 385 был обнаружен в Geekbench, что может означать скорое появление на рынке более доступных ИИ-чипов под кодовым названием Strix Halo. Пользователи ожидают, что такие чипы предложат больше линий PCIe для поддержки гибридных конфигураций, удовлетворяя потребности в добавлении карт расширения и устройств USB4. Хотя встроенная память приемлема из-за ее скоростных преимуществ, расширяемость остается в центре внимания. (Источник: Reddit r/LocalLLaMA)

Компания 1X представляет новейший прототип гуманоидного робота Neo Gamma: Норвежская робототехническая компания 1X выпустила свой новейший прототип гуманоидного робота Neo Gamma. Выпуск этого робота представляет собой еще один шаг вперед в технологии гуманоидных роботов в области автоматизации и искусственного интеллекта, демонстрируя его потенциал применения в будущем в различных сценариях, таких как промышленность, сфера услуг и т. д. (Источник: Ronald_vanLoon)
Ожидается, что потребление электроэнергии ИИ скоро превысит майнинг биткойнов: Ожидается, что потребление электроэнергии ИИ-моделями будет быстро расти и вскоре может составить почти половину электроэнергии дата-центров, а их энергопотребление будет сопоставимо с энергопотреблением некоторых стран. Рост спроса на ИИ-чипы оказывает давление на электросети США, стимулируя строительство новых проектов на ископаемом топливе и атомной энергии. Из-за отсутствия прозрачности и сложности региональных источников электроэнергии точное отслеживание углеродного следа ИИ становится затруднительным. (Источник: Reddit r/ArtificialInteligence)

🧰 Инструменты
e-library-agent: персональный агент для управления книгами, созданный LlamaIndex: Clelia Bertelli, используя рабочий процесс LlamaIndex, создала инструмент под названием e-library-agent, предназначенный для помощи пользователям в организации, поиске и исследовании личных коллекций для чтения. Инструмент интегрирует технологии ingest-anything, Qdrant, Linkup_platform, FastAPI и Gradio, решая проблему «прочитал, но не могу найти» и повышая эффективность управления личными знаниями. (Источник: jerryjliu0, jerryjliu0)
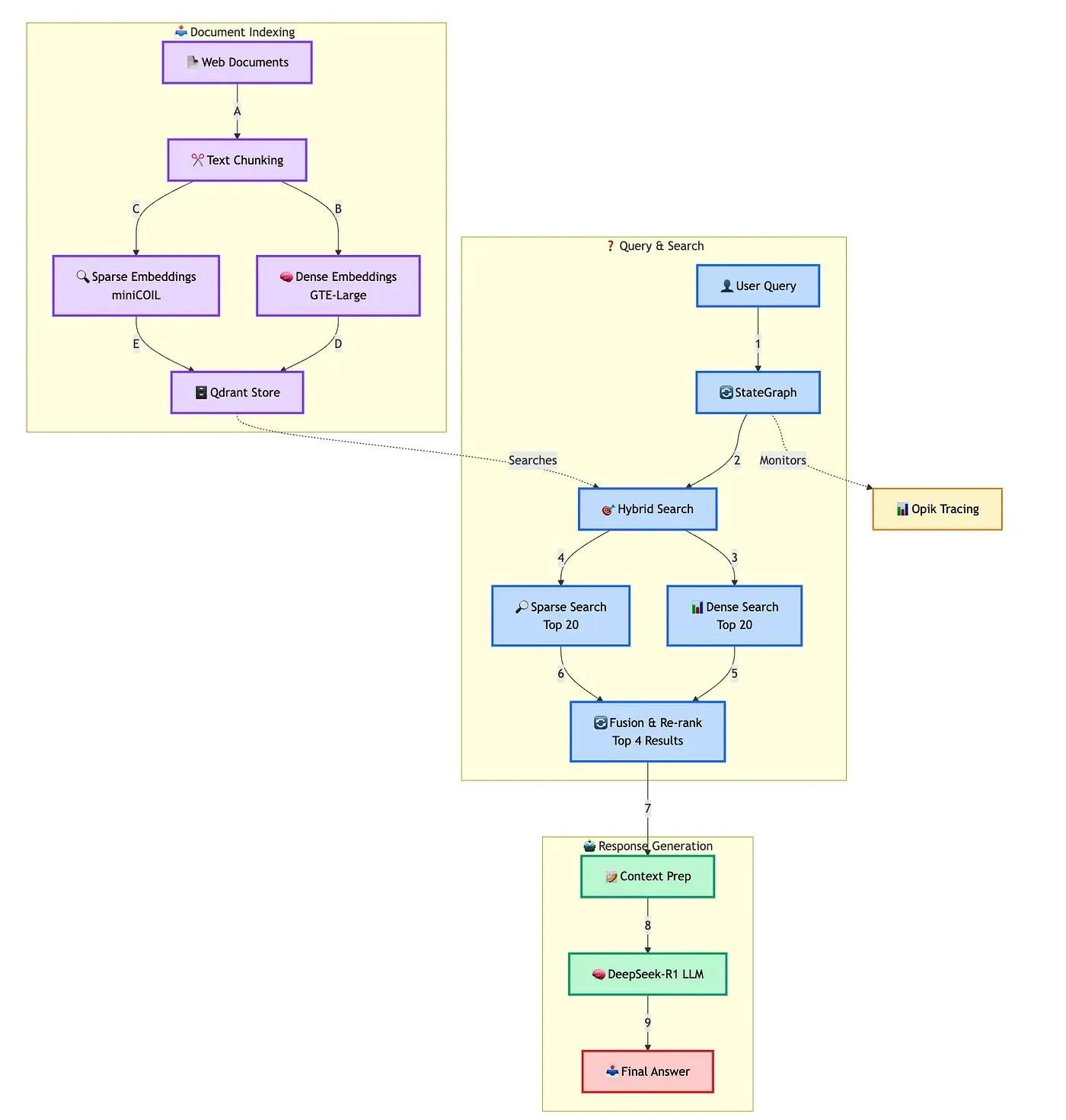
Qdrant демонстрирует решение для создания продвинутого гибридного RAG-чат-бота: Qdrant совместно с TRJ_0751 продемонстрировали, как создать продвинутого гибридного чат-бота для поддержки клиентов на основе RAG (Retrieval Augmented Generation), используя miniCOIL, LangGraph и DeepSeek-R1. Это решение использует miniCOIL для улучшения семантической осведомленности при разреженном поиске, LangGraph (от LangChainAI) для оркестровки гибридного процесса (включая MMR и переранжирование), Opik для отслеживания и оценки каждого шага процесса, а DeepSeek-R1 (от SambaNovaAI) для предоставления ответов с низкой задержкой и целенаправленных ответов. (Источник: qdrant_engine, hwchase17)
Google выпускает приложение AI Edge Gallery, поддерживающее локальный запуск ИИ-моделей: Google выпустила приложение под названием AI Edge Gallery, которое позволяет пользователям загружать и запускать ИИ-модели локально на своих устройствах. Это означает, что пользователи могут использовать ИИ-инструменты для генерации изображений, ответов на вопросы или написания кода без подключения к Интернету, обеспечивая при этом конфиденциальность данных. Приложение в настоящее время доступно в виде предварительной версии и поддерживает такие модели, как Gemma 3n. (Источник: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs поддерживает поиск по документам SEC EDGAR, усиливая возможности финансовых исследований: Perplexity Labs добавила новую функцию, позволяющую пользователям осуществлять поиск по документам компаний в базе данных EDGAR Комиссии по ценным бумагам и биржам США (SEC). Это обновление направлено на дальнейшее усиление ее применения в области финансовых исследований, предоставляя пользователям более удобный доступ к поиску и анализу информации о публичных компаниях. (Источник: AravSrinivas)
Meituan открывает доступ к ИИ-инструменту без кода NoCode, позволяющему создавать приложения на естественном языке: Meituan выпустила ИИ-инструмент без кода NoCode, с помощью которого пользователи без опыта программирования могут создавать персональные инструменты для повышения эффективности, прототипы продуктов, интерактивные страницы и даже простые игры посредством диалога на естественном языке. NoCode поддерживает предварительный просмотр в реальном времени, локальные изменения и развертывание одним щелчком мыши, стремясь снизить порог входа в разработку и позволить большему количеству людей раскрыть свой творческий потенциал. За этим инструментом стоит совместная работа нескольких ИИ-моделей, включая собственную 7B-параметрическую модель apply от Meituan, оптимизированную на реальных данных кода внутри Meituan. (Источник: WeChat)
VAST обновляет Tripo Studio, добавляя функции ИИ-моделирования, такие как интеллектуальное разделение частей, волшебная кисть для текстур и др.: Стартап в области 3D-моделей VAST произвел важное обновление своего инструмента ИИ-моделирования Tripo Studio, представив четыре основные функции: интеллектуальное разделение частей, волшебную кисть для наложения текстур, интеллектуальную генерацию низкополигональных моделей и автоматическую привязку скелета ко всему. Эти функции направлены на решение проблем традиционного процесса 3D-моделирования, таких как сложность редактирования частей, трудоемкое исправление дефектов текстур, громоздкая оптимизация высокополигональных моделей и сложная привязка скелета, что значительно повышает эффективность и простоту создания 3D-контента и снижает порог входа для непрофессиональных пользователей. (Источник: 量子位)
Hugging Face выпускает двух доступных по цене гуманоидных роботов с открытым исходным кодом HopeJR и Reachy Mini: Hugging Face в сотрудничестве с The Robot Studio и Pollen Robotics представила двух гуманоидных роботов с открытым исходным кодом: полноразмерного HopeJR (около 3000 долларов) и настольного Reachy Mini (около 250-300 долларов). Этот шаг направлен на популяризацию робототехники и открытых исследований, позволяя любому собирать, модифицировать и изучать принципы робототехники. HopeJR способен ходить и двигать руками, им можно управлять дистанционно с помощью перчатки; Reachy Mini может двигать головой, говорить и слушать, и используется для тестирования ИИ-приложений. (Источник: WeChat)

Выпущен EvoAgentX, первый в мире фреймворк с открытым исходным кодом для самоэволюции ИИ-агентов: Исследовательская группа из Университета Глазго выпустила EvoAgentX, первый в мире фреймворк с открытым исходным кодом для самоэволюции ИИ-агентов. Этот фреймворк направлен на решение проблемы сложности построения и оптимизации систем с несколькими ИИ-агентами. Внедряя механизм самоэволюции, он поддерживает создание рабочих процессов одним щелчком мыши и позволяет системе непрерывно оптимизировать свою структуру и производительность в процессе работы в соответствии с изменениями среды и целей. EvoAgentX надеется способствовать переходу многоагентных систем от ручной отладки к автономной эволюции, предоставляя исследователям и инженерам единую платформу для экспериментов и развертывания. (Источник: WeChat)

Perplexity Labs представляет новую функцию: бесплатный экспорт финансовых данных компаний в CSV: Perplexity Labs объявила, что пользователи теперь могут бесплатно экспортировать данные из любого раздела финансовых отчетов компаний на ее финансовых страницах в формат CSV. Ранее аналогичные функции на платформах, таких как Yahoo Finance, обычно требовали платной подписки. Perplexity заявляет, что в будущем добавит больше исторических данных. (Источник: AravSrinivas)
📚 Обучение
Советы по вызову функций LLM: четкий контекст, последовательность и границы, избегайте CoT и галлюцинаций: _philschmid делится рекомендациями по вызову функций для моделей логического вывода, таких как Gemini 2.5 или OpenAI o3. Ключевые моменты включают: установку общего контекста (например, подсказка роли), определение четкой последовательности вызовов функций для сложных задач и установление четких границ для использования инструментов (когда использовать/не использовать). Необходимо подробно описать условия вызова функций и способы построения параметров. Избегайте явных подсказок CoT, так как модель будет выполнять внутренний вывод; можно использовать функции API для сохранения мыслей между вызовами инструментов или использовать “thinking_tools”. Одновременно внедряйте четкие отрицательные инструкции (например, “не обещайте будущие вызовы”) для предотвращения галлюцинаций при вызове функций. (Источник: _philschmid)
12 профессиональных советов по программированию с ИИ: Cline поделился 12 советами по программированию с ИИ с недавней конференции по лучшим инженерным практикам, подчеркивая планирование, использование продвинутых моделей для сложных задач, внимание к контекстному окну, создание файлов правил, четкое определение намерений, рассмотрение ИИ как соавтора, использование банков памяти, изучение стратегий управления контекстом и создание обмена знаниями в команде. Основная цель — быстрее и лучше создавать программное обеспечение, используя ИИ как усилитель способностей, а не как замену. (Источник: cline, cline)

Рекомендации по оптимизации творческих инструкций после обновления DeepSeek-R1-0528: В связи с обновлением модели DeepSeek-R1-0528 (68,5 млрд параметров, контекст 128K, возможности кодирования близки к o3), создатель контента поделился 10 оптимизированными творческими инструкциями. Рекомендации включают использование ее сверхдлинной способности к выводу (30-60 минут) для глубокого осмысления, обработку длинных текстов до 128K, оптимизацию генерации кода, настройку системных подсказок, повышение качества задач по написанию текстов, проверку на анти-галлюцинации, преодоление творческих тупиков в письме, проведение диагностики и анализа проблем, интеграцию знаний для обучения и оптимизацию коммерческих текстов. Подчеркивается конкретизация инструкций, полное использование длинного контекста, эффективное применение глубокого вывода, создание памяти диалога и проверка важной информации. (Источник: WeChat)
Фреймворк RM-R1: преобразование моделей вознаграждения в задачи логического вывода для повышения интерпретируемости и производительности: Исследовательская группа из Иллинойсского университета в Урбане-Шампейне предложила фреймворк RM-R1, который переопределяет построение моделей вознаграждения (Reward Models) как задачу логического вывода. Этот фреймворк, внедряя механизм «цепочки оценочных критериев» (Chain-of-Rubrics, CoR), позволяет модели генерировать структурированные оценочные критерии и процесс вывода перед вынесением суждения о предпочтениях, тем самым повышая интерпретируемость модели вознаграждения и точность оценки в сложных задачах (таких как математика, программирование). RM-R1, обучаемый в два этапа (дистилляция вывода и обучение с подкреплением), демонстрирует превосходство над существующими открытыми и закрытыми моделями в нескольких бенчмарках моделей вознаграждения. (Источник: WeChat)

Глубокий анализ протокола контекста модели (MCP): упрощение интеграции ИИ с внешними сервисами: Протокол контекста модели (MCP), являясь открытым стандартом, направлен на решение проблемы фрагментации при интеграции ИИ-моделей с внешними источниками данных и инструментами (такими как Slack, Gmail). Через единый системный интерфейс (поддерживающий протоколы STDIO и SSE) MCP позволяет разработчикам создавать MCP-клиенты (например, Claude для настольных ПК, Cursor IDE) и MCP-серверы (для работы с базами данных, файловыми системами, вызова API), упрощая сложную сеть адаптации «M×N» до модели «M+N», обеспечивая «подключи и работай» для ИИ и внешних сервисов. Тан Ю, партнер Fabarta (枫清科技), считает, что ценность MCP заключается в предоставлении базовых возможностей подключения, а его коммерциализация зависит от конкретной ценности, предоставляемой базовой системой, например, упрощение пользовательских процессов через интеграцию MCP Server с интеллектуальным агентом для супер-офиса Fabarta. (Источник: WeChat)

Agentic ROI: ключевой показатель для оценки применимости агентов больших моделей: Шанхайский университет Цзяотун совместно с Китайским научно-техническим университетом предложил Agentic ROI (рентабельность инвестиций в агентов) в качестве основного показателя для оценки практической полезности агентов больших моделей в реальных сценариях. Этот показатель комплексно учитывает качество информации, временные затраты пользователя и агента, а также экономические издержки. Исследование указывает, что в настоящее время агенты чаще применяются в областях с высокими затратами на человеческий труд, таких как научные исследования и программирование, но в повседневных сценариях, таких как электронная коммерция и поиск, Agentic ROI низок из-за незначительной предельной ценности и высоких затрат на взаимодействие. Оптимизация Agentic ROI требует следования «зигзагообразному» пути развития: «сначала масштабное повышение качества информации, затем облегчение для снижения затрат». (Источник: WeChat)
💼 Бизнес
Годовой доход Anthropic взлетел до 3 миллиардов долларов благодаря спросу на корпоративный ИИ: По словам двух источников, годовой доход Anthropic вырос с 1 миллиарда до 3 миллиардов долларов всего за пять месяцев. Этот значительный рост в основном обусловлен высоким спросом на ИИ со стороны предприятий, особенно в области генерации кода. Это свидетельствует о быстром росте применения и готовности платить за продвинутые ИИ-модели (такие как серия Claude от Anthropic) на корпоративном рынке. (Источник: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Финансовый отчет Nvidia за Q1 2026 финансового года: общий доход 44,1 млрд долларов, бизнес дата-центров принес почти 90%: Nvidia опубликовала финансовый отчет за первый квартал 2026 финансового года, закончившийся 27 апреля 2025 года. Общий доход составил 44,1 млрд долларов, что на 12% больше по сравнению с предыдущим кварталом и на 69% больше по сравнению с аналогичным периодом прошлого года. Доход от бизнеса дата-центров составил 39,1 млрд долларов, что составляет 88,91% от общего дохода и на 73% больше по сравнению с аналогичным периодом прошлого года. Доход от игрового бизнеса составил 3,8 млрд долларов, установив исторический рекорд. Несмотря на то, что чип H20 пострадал от экспортных ограничений, что привело к списанию запасов на 4,5 млрд долларов и расходам по обязательствам на закупку, и ожидается, что во втором квартале из-за этого будет потеряно 8 млрд долларов дохода, общие показатели остаются сильными. Новые продукты, такие как Blackwell Ultra, должны способствовать дальнейшему росту. (Источник: 量子位, WeChat)

Meta реорганизует команду ИИ, большинство основных авторов Llama ушли, статус FAIR вызывает беспокойство: Meta объявила о реорганизации своей команды ИИ, разделив ее на команду продуктов ИИ под руководством Connor Hayes и отдел фундаментальных исследований AGI под совместным руководством Ahmad Al-Dahle и Amir Frenkel. Отдел фундаментальных исследований ИИ FAIR остается относительно независимым, но некоторые мультимедийные команды были интегрированы. Эта реструктуризация направлена на повышение автономии и скорости разработки. Однако из 14 первоначальных основных авторов модели Llama остались только 3, большинство из них ушли или присоединились к конкурентам (например, Mistral AI). Вдобавок к этому, сдержанная реакция на выпуск Llama 4, а также внутренние корректировки в распределении вычислительных мощностей и направлениях исследований вызывают опасения относительно способности Meta сохранить лидерство в области ИИ с открытым исходным кодом и будущего развития FAIR. (Источник: WeChat)

🌟 Сообщество
Обсуждение выравнивания ИИ: смогут ли «мягкие нормы» сохранить власть человека в эпоху AGI?: Ryan Greenblatt обсуждает точку зрения Dwarkesh Patel, который скептически относится к выравниванию ИИ и вместо этого надеется, что «мягкие нормы» позволят сохранить некоторую власть и пространство для выживания человечества после того, как AGI (искусственный общий интеллект) получит «жесткую власть». Greenblatt считает, что если ИИ обладает чувствительностью к масштабу (scope sensitive) и способен захватить власть, то попытки выявить его рассогласование или заставить его работать на человечество посредством сделок или контрактов вряд ли увенчаются успехом. Кроме того, дешевая тонкая настройка, улучшение выравнивания человеком и свободное копирование делают контроль человека над собственностью очень нестабильным до решения проблемы выравнивания. Как только появится выровненный ИИ или более дешевая рабочая сила ИИ, люди будут отдавать им предпочтение, что сильно стимулирует невыровненный ИИ к захвату власти. (Источник: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Создатель Redis считает, что ИИ в программировании значительно уступает программистам-людям, что вызывает резонанс и обсуждение среди разработчиков: Salvatore Sanfilippo (Antirez), создатель Redis, поделился своим опытом разработки, отметив, что хотя ИИ в настоящее время полезен в программировании, он значительно уступает программистам-людям, особенно в нестандартном мышлении и разработке необычных, но эффективных решений. Он сравнивает ИИ с «достаточно умным помощником», который помогает проверять идеи. Эта точка зрения вызвала бурное обсуждение среди разработчиков. Многие согласны, что ИИ может служить «резиновой уточкой» для помощи в размышлениях, но отмечают, что ИИ слишком самоуверен и легко вводит в заблуждение начинающих разработчиков. Некоторые разработчики заявили, что ошибочные ответы, сгенерированные ИИ, наоборот, мотивируют их писать код вручную. В обсуждении подчеркивается важность опыта для эффективного использования ИИ, а также возможное негативное влияние ИИ на начинающих программистов. (Источник: WeChat)

Отношения DeepMind и Google Research снова вызывают споры: дебаты о бренде и реальном вкладе в инновации: Faruk Guney опубликовал длинный твит, комментируя отношения DeepMind и Google Research. Он считает, что ключевые прорывы текущей революции ИИ (например, архитектура Transformer) в основном исходят от Google Research, а не от DeepMind после ее приобретения Google. Он отмечает, что хотя AlphaFold является достижением DeepMind, оно также стало возможным благодаря вычислительным ресурсам и исследовательской инфраструктуре Google, а ключевыми авторами являются ученые-инженеры, такие как John Jumper и Pushmeet Kohli. Guney считает, что последующее включение Google Research в DeepMind было скорее корректировкой бренда и организационной структуры, за которой стояла сложная корпоративная политика, возможно, скрывавшая истинные источники инноваций. Он подчеркивает, что многие прорывы в ИИ являются результатом многолетних исследований команд, а не заслугой лишь нескольких известных личностей или брендов. (Источник: farguney, farguney)
Изменение рабочих мест и навыков в эпоху ИИ вызывает беспокойство и обсуждение: В социальных сетях продолжаются дискуссии о влиянии ИИ на рынок труда. С одной стороны, существует мнение, что ИИ приведет к массовой безработице, как, например, выражал опасения генеральный директор Anthropic, что заставляет людей задуматься о том, как с этим справиться. С другой стороны, есть голоса, утверждающие, что ИИ в основном повышает производительность и вряд ли вызовет массовую безработицу, если только не произойдет серьезный экономический спад, поскольку потребительский спрос зависит от занятости и доходов. В то же время пользователи делятся личным опытом потери работы из-за ИИ (например, начальник заменил сотрудника на ChatGPT). В отношении будущего дискуссии указывают на необходимость сбережений, изучения практических навыков, адаптации к возможному снижению доходов, а также на то, как система образования должна измениться, чтобы развивать навыки, необходимые в эпоху ИИ, такие как критическое мышление и способность эффективно использовать инструменты ИИ. (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial)

Чрезмерная зависимость от ChatGPT вызывает опасения по поводу снижения способности к мышлению: Пользователь Reddit выразил обеспокоенность тем, что его девушка чрезмерно полагается на ChatGPT для принятия решений, получения мнений и творческих идей, полагая, что это может привести к потере ею способности к независимому мышлению и оригинальности. Пост вызвал широкое обсуждение. Некоторые комментаторы согласились с этими опасениями, считая, что чрезмерная зависимость от инструментов ИИ действительно может ослабить личное мышление; другие комментаторы утверждали, что ИИ — это всего лишь инструмент, подобный энциклопедиям или поисковым системам прошлого, и ключевым моментом является то, как пользователь его использует — как отправную точку для мышления или как полную замену. Некоторые комментарии также предлагали решать проблему путем общения, наставничества и демонстрации ограничений ИИ. (Источник: Reddit r/ChatGPT)
Проблемы ИИ в образовании: профессор обеспокоен злоупотреблением ChatGPT студентами, призывает развивать подлинные мыслительные способности: Профессор древней истории написал на Reddit, что злоупотребление ChatGPT серьезно повлияло на его преподавание: студенческие работы полны «пустого мусора», сгенерированного ИИ и даже содержащего фактические ошибки, что заставляет его сомневаться в том, действительно ли студенты учатся. Он подчеркнул, что ядром гуманитарного образования является развитие новых знаний, творческих идей и независимого мышления, а не простое повторение уже существующей информации. Пост вызвал бурное обсуждение, комментаторы предложили различные стратегии противодействия, такие как переход на устные доклады, написание эссе от руки на занятиях, требование от студентов представлять метаанализ процесса использования ИИ или интеграция ИИ в учебный процесс, чтобы студенты критически оценивали результаты работы ИИ. (Источник: Reddit r/ChatGPT)
Ядро, сгенерированное ИИ, неожиданно превзошло экспертное ядро PyTorch, китайская команда из Стэнфорда раскрывает новые возможности: Команда из Стэнфордского университета в составе Anne Ouyang, Azalia Mirhoseini и Percy Liang, пытаясь сгенерировать синтетические данные для обучения модели генерации ядер, неожиданно обнаружила, что их ядро, сгенерированное ИИ и написанное на чистом CUDA-C, по производительности приблизилось или даже превзошло встроенное в PyTorch, оптимизированное экспертами ядро FP32. Например, в матричном умножении оно достигло 101,3% производительности PyTorch, а в двумерной свертке — 179,9%. Команда использовала многоэтапную итеративную оптимизацию, сочетая идеи оптимизации логического вывода на естественном языке и стратегию поиска с расширением ветвей, используя модели OpenAI o3 и Gemini 2.5 Pro. Этот результат показывает, что благодаря продуманному поиску и параллельному исследованию ИИ имеет потенциал для достижения прорывов в генерации высокопроизводительных вычислительных ядер. (Источник: WeChat)

💡 Прочее
Мощное лоббирование ИИ-индустрии привлекает внимание Max Tegmark: Профессор MIT Max Tegmark отметил, что число лоббистов ИИ-индустрии в Вашингтоне и Брюсселе уже превысило общее число лоббистов от нефтегазовой и табачной промышленности. Это явление раскрывает растущее влияние ИИ-индустрии на формирование политики, а также ее активное участие в формировании регуляторной среды, что может оказать глубокое влияние на направление развития технологий ИИ, этические нормы и конкурентную среду на рынке. (Источник: Reddit r/artificial)

ИИ может имитировать биотеррористические атаки с помощью дипфейков, создавая новую угрозу общественному здравоохранению: Статья в STAT News указывает, что помимо риска создания биоинженерного оружия с помощью ИИ, использование технологии дипфейков для имитации биотеррористических атак также может представлять серьезную угрозу. Особенно в странах, находящихся в состоянии военного конфликта, такая сфабрикованная информация может вызвать панику, ошибочные суждения и ненужную военную эскалацию. Поскольку расследованием, скорее всего, будут заниматься правоохранительные или военные органы, а не группы общественного здравоохранения или технические специалисты, они могут быть более склонны верить в реальность атаки, что затруднит эффективное опровержение. (Источник: Reddit r/ArtificialInteligence)
Стоит ли получать инженерное образование в эпоху ИИ, вызывает бурные дебаты: В сообществе обсуждается ценность получения инженерного образования в эпоху ИИ. Одна сторона считает, что ИИ может заменить многие традиционные инженерные задачи, снижая ценность диплома. Другая сторона утверждает, что системное мышление, навыки решения проблем и фундаментальные знания математики и физики, которые дает инженерное образование, по-прежнему важны, особенно для понимания и применения инструментов ИИ. Некоторые отмечают, что если ИИ сможет заменить инженеров, то и другие профессии вряд ли уцелеют, и ключевым моментом является непрерывное обучение и адаптация. Области, требующие практических навыков и трудно поддающиеся автоматизации, такие как ветеринария, считаются относительно безопасным выбором. (Источник: Reddit r/ArtificialInteligence)