
Ключевые слова:AlphaEvolve, Дизайн алгоритмов ИИ, Мультимодальный ИИ, Инструменты программирования ИИ, Алгоритмы автономной эволюции, Крупные языковые модели, Агенты ИИ, Открытая реализация AlphaEvolve, Автономное проектирование алгоритмов умножения матриц ИИ, Унифицированный интерфейс для мультимодального ИИ, Влияние инструментов программирования ИИ на разработчиков, Производительность локальной большой модели Qwen 3
🔥 В центре внимания
Google DeepMind выпустил AlphaEvolve, ИИ для автономной разработки и эволюции алгоритмов: Google DeepMind представил проект AlphaEvolve и связанную с ним научную работу, демонстрируя интеллектуального агента AI, способного автономно разрабатывать, тестировать, обучаться и развивать более эффективные алгоритмы. Система использует промпт-инжиниринг для управления большими языковыми моделями (такими как Gemini) с целью генерации первоначальных вариантов алгоритмов, а затем оптимизирует их в эволюционном цикле посредством оценки приспособленности и отбора выживших. Сообщество быстро отреагировало: появилась реализация с открытым исходным кодом OpenAlpha_Evolve, а исследователи, используя такие инструменты, как Claude, подтвердили прорывы AlphaEvolve в таких областях, как умножение матриц, что демонстрирует огромный потенциал AI в области инноваций алгоритмов. (Источник: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

Проявляется мультимодальная стратегия OpenAI: интеграция интерфейсов и централизация инфраструктуры привлекают внимание: Недавние релизы продуктов OpenAI, таких как GPT-4o, Sora и Whisper, не только демонстрируют прогресс компании в мультимодальных возможностях (текст, изображение, аудио и видео), но и раскрывают ее стратегическое намерение интегрировать различные модальности в единый интерфейс и API. Хотя такая стратегия обеспечивает удобство для пользователей, она также вызывает дискуссии о том, что централизация инфраструктуры может ограничить инновационное пространство для внешних разработчиков и исследователей. В частности, модели генерации видео, такие как Sora, из-за их высоких требований к вычислительным ресурсам, еще больше включают дорогостоящие приложения в экосистему OpenAI, что может усилить «вычислительную гравитацию» ведущих платформ и повлиять на открытость и модульность развития в области AI. (Источник: Reddit r/deeplearning)
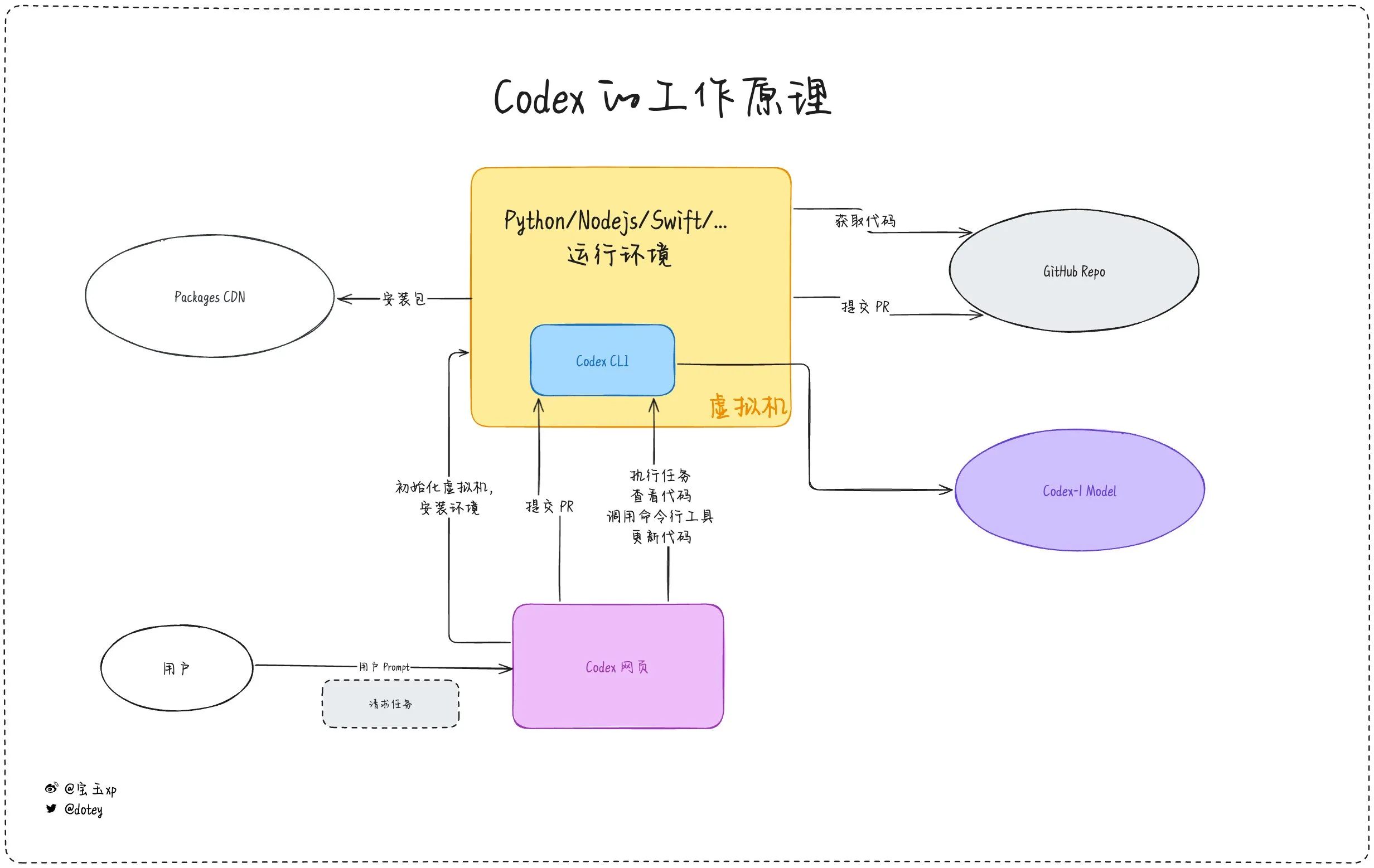
Усиливается проникновение инструментов AI-программирования, разработчики делятся опытом и размышлениями: Инструменты AI-программирования, такие как Codex, Devin и различные AI Agent, все активнее внедряются в процессы разработки программного обеспечения. Отзывы разработчиков показывают, что Codex демонстрирует высокую эффективность в интернационализации кода, обновлении проектов и других задачах, значительно сокращая циклы разработки. Однако, как отмечает dotey в своем обзоре Codex, текущие инструменты AI больше похожи на «аутсорс-сотрудников»: они могут выполнять задачи, но все еще имеют ограничения в подключении к сети, продолжительности выполнения задач и накоплении опыта. В сообществе также обсуждается, что некоторые разработчики после длительного использования AI-ассистентов в программировании начинают задумываться об их влиянии на собственное мышление и креативность, и даже предпочитают возвращаться к моделям разработки, в большей степени полагающимся на «человеческий мозг». Это показывает, что баланс между повышением эффективности с помощью инструментов AI и сохранением основных способностей разработчиков остается важным вопросом. (Источник: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 Тренды
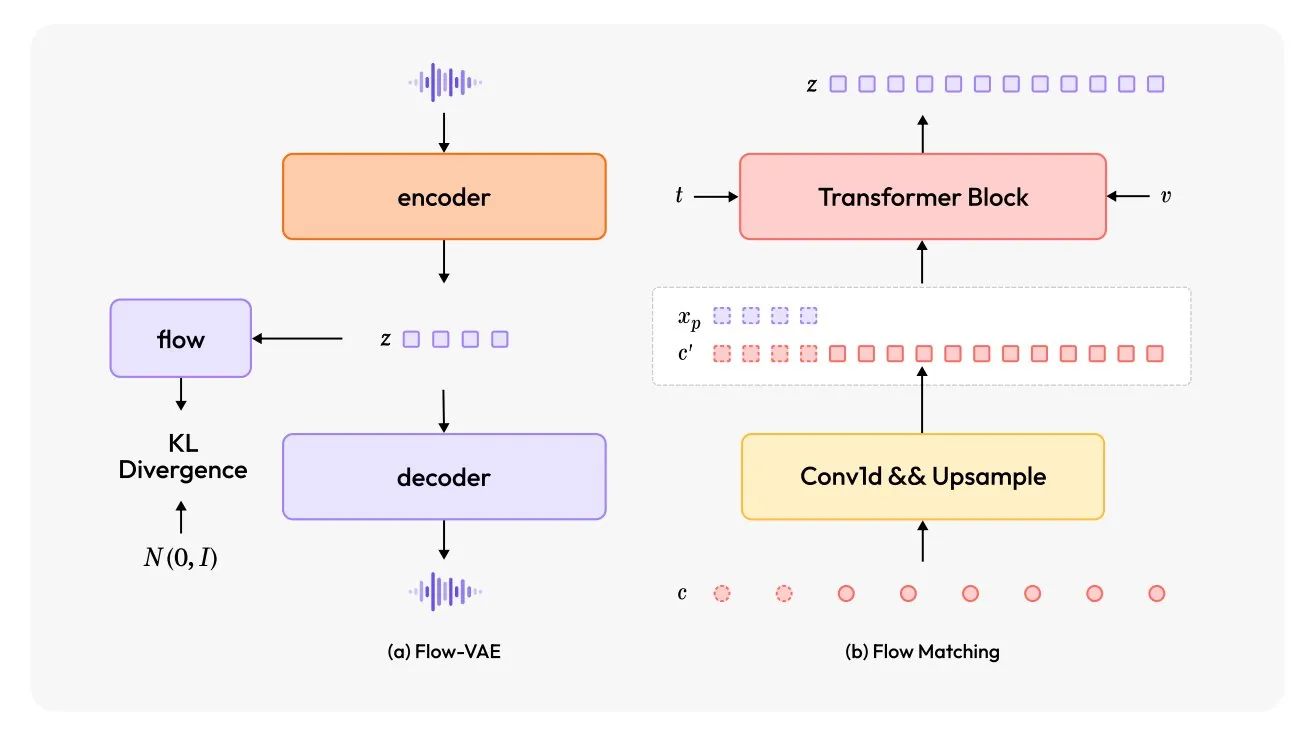
MiniMax-Speech: Выпущена новая многоязычная модель TTS: TheTuringPost представил MiniMax-Speech, новую модель преобразования текста в речь (TTS). Модель использует два основных нововведения: обучаемый кодировщик голоса говорящего, способный улавливать тембр из коротких аудиозаписей, и модуль Flow-VAE для повышения качества звука. MiniMax-Speech поддерживает 32 языка и может использоваться для добавления эмоций в речь, генерации речи из текстовых описаний или клонирования голоса без предварительного обучения (zero-shot), демонстрируя свой потенциал в персонализированном и высококачественном синтезе речи. (Источник: TheTuringPost, TheTuringPost)
Qwen выпустила серию моделей предпочтений WorldPM: Команда Qwen представила четыре новые модели для моделирования предпочтений: WorldPM-72B, WorldPM-72B-HelpSteer2, WorldPM-72B-RLHFLow и WorldPM-72B-UltraFeedback. Эти модели в основном используются для оценки качества ответов других моделей и для помощи в процессе обучения с учителем. По заявлению разработчиков, обучение с использованием этих моделей предпочтений позволяет достичь лучших результатов, чем обучение с нуля. Соответствующая научная работа также была опубликована. (Источник: karminski3)
Grok добавил функцию генерации диаграмм: Модель Grok от XAI теперь поддерживает функцию генерации диаграмм. Пользователи могут создавать диаграммы с помощью Grok в браузере, и ожидается, что эта функция будет доступна на большем количестве платформ в ближайшие дни. Это обновление расширяет возможности Grok в области визуализации данных и представления информации. (Источник: grok, Yuhu_ai_, TheGregYang)
DeepRobotics представила среднеразмерного четвероногого робота Lynx: Компания DEEP Robotics выпустила своего нового среднеразмерного четвероногого робота Lynx. Этот робот продемонстрировал способность стабильно передвигаться по сложной местности, что отражает прогресс компании в технологиях управления движением роботов и восприятия. Робот может применяться в различных сценариях, таких как инспекции и логистика. (Источник: Ronald_vanLoon)
Sanctuary AI интегрировала новые тактильные датчики в универсального робота: Sanctuary AI объявила об интеграции новой технологии тактильных датчиков в своего универсального робота. Это усовершенствование направлено на улучшение способностей робота к восприятию и манипулированию объектами, позволяя ему более точно взаимодействовать с окружающей средой, что является важным шагом на пути к созданию более мощных роботов с общим искусственным интеллектом. (Источник: Ronald_vanLoon)
Робот Unitree продемонстрировал продвинутые способности походки: Робот Go2 от Unitree Robotics продемонстрировал несколько продвинутых видов походки, включая ходьбу на передних конечностях (вверх ногами), адаптивное кувыркание и преодоление препятствий. Реализация этих способностей знаменует значительный прогресс в алгоритмах управления движением и адаптивности к окружающей среде у их роботов-собак. (Источник: Ronald_vanLoon)
Китайская исследовательская группа разрабатывает робота, управляемого культивированными клетками человеческого мозга: По сообщению InterestingSTEM, китайская исследовательская группа разрабатывает робота, управляемого выращенными в лаборатории клетками человеческого мозга. Это исследование изучает слияние биокомпьютинга и робототехники с целью использования способностей биологических нейронов к обучению и адаптации для предоставления новых идей в управлении роботами. Хотя исследование все еще находится на ранней стадии, оно вызвало широкие дискуссии о будущих формах роботизированного интеллекта. (Источник: Ronald_vanLoon)
Новый наноразмерный мозговой датчик достиг точности распознавания нейронных сигналов 96,4%: Новый наноразмерный мозговой датчик продемонстрировал точность распознавания нейронных сигналов до 96,4%. Ожидается, что эта технология найдет применение в интерфейсах мозг-компьютер, нейробиологических исследованиях и медицинской диагностике, предоставляя новые инструменты для более точной интерпретации мозговой активности. (Источник: Ronald_vanLoon)

Слухи об использовании MistralAI тестовых наборов для обучения вызвали обеспокоенность: В сообществе возникли дискуссии, ставящие под сомнение возможное использование MistralAI данных из тестовых наборов в бенчмарках, таких как NIAH, для обучения своих моделей. Kalomaze, сравнивая производительность на тесте NIAH из GitHub с кастомным NIAH (программно сгенерированные факты и вопросы), указал, что MistralAI показывает значительно лучшие результаты на первом, что намекает на возможное загрязнение данных. Dorialexander предположил, что «синтетическое приближение» оценочного набора могло быть использовано при разработке смесей данных, что вызвало опасения относительно справедливости и прозрачности оценки моделей. (Источник: Dorialexander)
Исследование утверждает, что Claude 3.5 превосходит людей в убедительности: Научная статья на arXiv указывает, что модель Claude 3.5 от Anthropic превосходит людей в способности убеждать. Исследование сравнивало производительность модели и людей в конкретных задачах убеждения, и результаты показали, что AI может обладать значительным преимуществом в построении убедительных аргументов и коммуникации, что имеет потенциальное влияние на такие области, как маркетинг, связи с общественностью и взаимодействие человека с компьютером. (Источник: Reddit r/ClaudeAI)

Локальные большие модели значительно улучшили свои возможности на потребительском оборудовании: Пользователь Reddit сообщил, что 14-миллиардная модель Qwen 3 (с патчем yarn для поддержки контекста 128k) на потребительском ПК с всего лишь 10 ГБ видеопамяти и 24 ГБ ОЗУ, с квантованием IQ4_NL и конфигурацией контекста 80k, уже способна достаточно хорошо запускать AI-помощников для программирования, таких как Roo Code и Aider. Хотя при обработке длинных контекстов (например, 20k+) скорость низкая (около 2 т/с), качество редактирования кода и способность к распознаванию кодовой базы хорошие. Это первый случай, когда локальная модель смогла стабильно обрабатывать сложные задачи кодирования в длительном диалоге и выводить осмысленные различия в коде. Этот прогресс стал возможен благодаря улучшениям самой модели, оптимизации фреймворков вывода, таких как llama.cpp, и адаптации фронтенд-инструментов, таких как Roo. (Источник: Reddit r/LocalLLaMA)
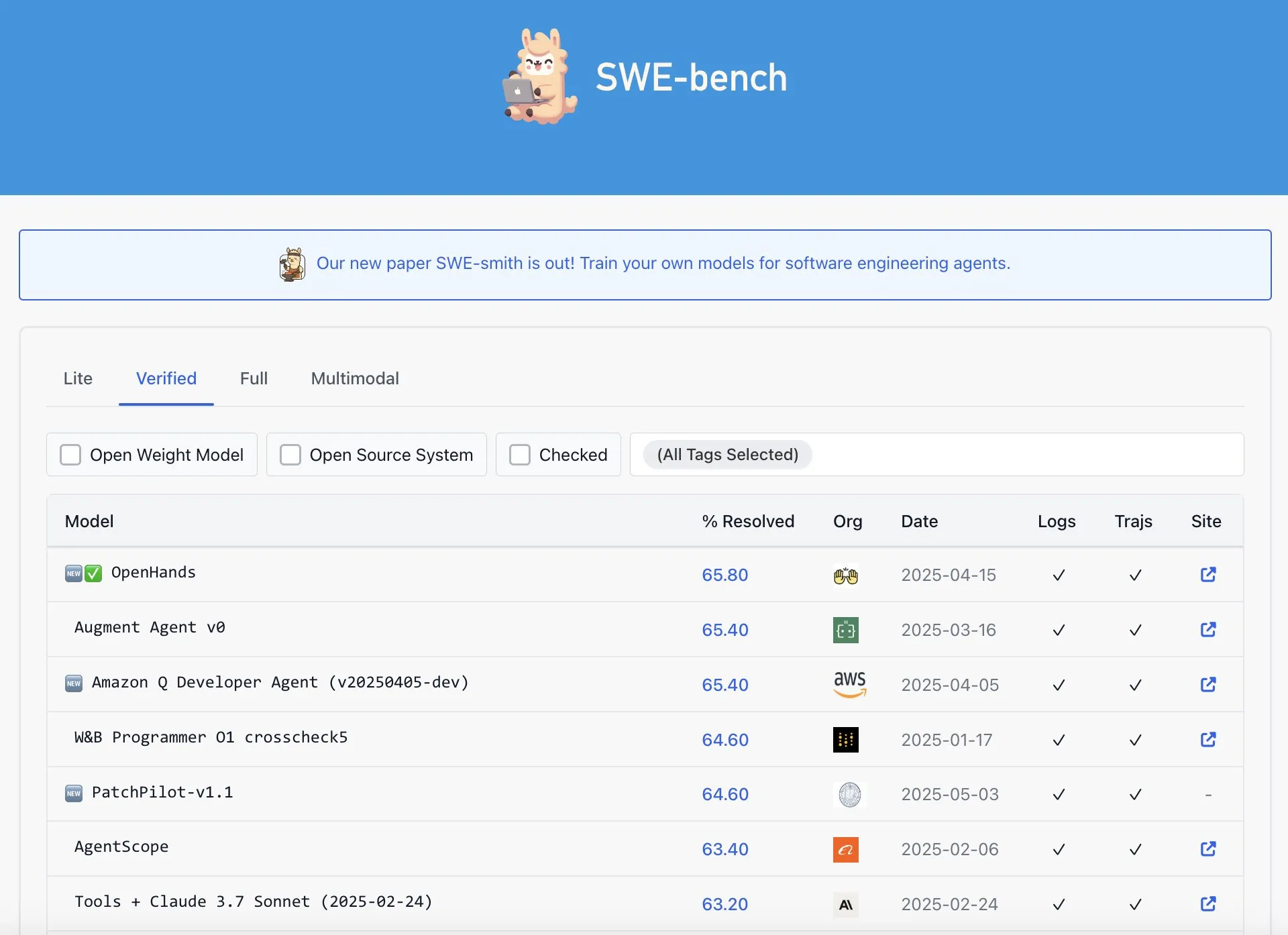
Утверждается, что OpenAI Codex не является лучшим в рейтинге SWE-Bench Verified: Graham Neubig отметил, что утверждения о том, что модель Codex от OpenAI достигла результатов SOTA (state-of-the-art) в рейтинге SWE-Bench Verified, не совсем точны. Анализируя данные и различные критерии оценки, он пришел к выводу, что с любой точки зрения производительность Codex в этом конкретном бенчмарке является спорной и не является бесспорно лучшей. (Источник: JayAlammar)
🧰 Инструменты
OpenAlpha_Evolve с открытым исходным кодом: воспроизведение интеллектуального агента Google для проектирования AI-алгоритмов: После публикации научной работы Google DeepMind об AlphaEvolve, разработчик shyamsaktawat быстро выпустил реализацию с открытым исходным кодом OpenAlpha_Evolve. Этот Python-фреймворк позволяет пользователям экспериментировать с идеями проектирования алгоритмов с помощью AI, включая определение задач, промпт-инжиниринг, генерацию кода (с помощью LLM, таких как Gemini), выполнение тестов, оценку приспособленности и эволюционный отбор. Цель состоит в том, чтобы более широкое сообщество могло участвовать в исследовании передовых методов проектирования новых алгоритмов с помощью AI. (Источник: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Редактор Cursor добавил функцию быстрого редактирования целых файлов: Редактор кода Cursor, ориентированный на AI, объявил, что теперь пользователи могут быстро редактировать целые файлы. Эта новая функция призвана повысить эффективность работы разработчиков, делая масштабные изменения и рефакторинг кода в Cursor более удобными. (Источник: cursor_ai)
Codex эффективно выполняет задачи интернационализации и локализации приложений: Разработчик Katsuya поделился опытом использования OpenAI Codex для интернационализации приложений. Он поручил Codex локализовать приложение на японский язык, и эта задача, обычно занимающая несколько дней, была выполнена за одну ночь, что в полной мере демонстрирует мощные возможности Codex в автоматической генерации кода и обработке сложных языковых задач. (Источник: gdb, ShunyuYao12)
llmbasedos: безопасная MCP-песочница, разработанная специально для LLM: Проект llmbasedos представляет собой операционную среду на базе урезанной версии Arch Linux, предназначенную для обеспечения безопасной песочницы с модульным вычислительным протоколом (MCP) для больших языковых моделей (LLM). Он инкапсулирует файловую систему, почту, синхронизацию, прокси и другие функции в виде MCP-сервисов. Пользователи могут вызывать эти сервисы после загрузки с ISO на виртуальной или физической машине, что облегчает безопасное взаимодействие и разработку с LLM. (Источник: karminski3)

cachelm: инструмент семантического кэширования LLM с открытым исходным кодом для повышения эффективности и снижения затрат: Разработчик devanmolsharma выпустил инструмент с открытым исходным кодом cachelm, семантический кэширующий слой, разработанный для приложений LLM. Он использует векторный поиск для реализации кэширования на основе семантической схожести, что позволяет эффективно сократить количество повторных вызовов API LLM (даже если пользователь формулирует вопросы по-разному), тем самым снижая потребление токенов и ускоряя ответы. Инструмент поддерживает OpenAI, ChromaDB, Redis, ClickHouse и другие, а также позволяет пользователям настраивать собственные векторизаторы, базы данных или LLM. (Источник: Reddit r/MachineLearning)
Выпущен ArchGW 0.2.8, AI-нативный прокси для унификации низкоуровневых функций: Вышла версия 0.2.8 ArchGW, AI-нативного прокси на базе Envoy, предназначенного для унификации повторяющихся «низкоуровневых» функций в приложениях. Новая версия добавляет поддержку двунаправленного трафика (в рамках подготовки к Google A2A), улучшенную модель Arch-Function-Chat 3B для быстрой маршрутизации и вызова инструментов, а также поддержку LLM, размещенных на Groq. ArchGW упрощает разработку AI-приложений за счет локального прокси, повышая безопасность, согласованность и наблюдаемость. (Источник: Reddit r/artificial)
SparseDepthTransformer: старшеклассник разработал решение для повышения эффективности Transformer с динамическим пропуском слоев: Старшеклассник разработал проект под названием SparseDepthTransformer, который с помощью легковесного механизма оценки оценивает семантическую важность каждого токена и позволяет неважным токенам пропускать глубокие вычисления в Transformer. Эксперименты показали, что этот метод, сохраняя качество вывода, сокращает использование памяти примерно на 15% и снижает среднее количество обрабатываемых слоев на токен примерно на 40%, предлагая новый подход к повышению эффективности Transformer. (Источник: Reddit r/MachineLearning)

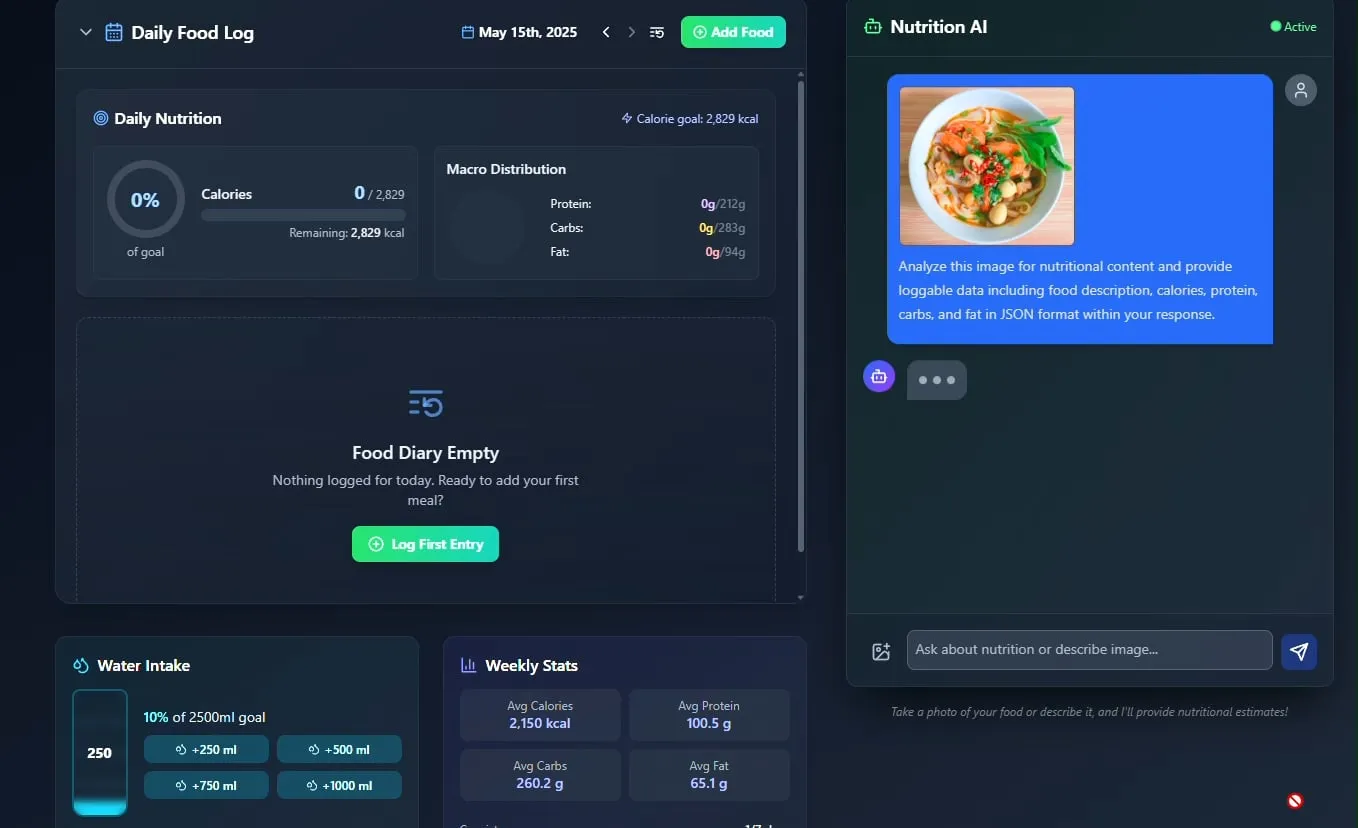
Представлен AI-трекер еды и питательных веществ, планируется открыть исходный код: Разработчик Pavankunchala продемонстрировал приложение для отслеживания диеты и питательных веществ на базе AI. Основная функция приложения — анализ загруженных пользователем фотографий еды для идентификации продуктов и оценки питательной информации (калории, белки и т.д.), а также поддержка ручного ввода, ежедневного обзора питательных веществ и отслеживания потребления воды. Разработчик планирует в будущем открыть исходный код этого проекта. (Источник: Reddit r/LocalLLaMA)
Итальянский AI-агент автоматизировал поиск работы, подав тысячу заявок за минуту, что вызвало бурное обсуждение: AI Agent, предположительно из Италии, продемонстрировал свои мощные возможности по автоматизации поиска работы, сумев за 1 минуту подать 1000 заявок на вакансии. Эта демонстрация вызвала широкое обсуждение в сообществе применения AI в сфере рекрутинга: с одной стороны, восхищение его эффективностью, а с другой — опасения по поводу его результативности, влияния на рынок труда и того, как бороться с «обнаружением роботов». (Источник: Reddit r/ChatGPT)

📚 Обучение
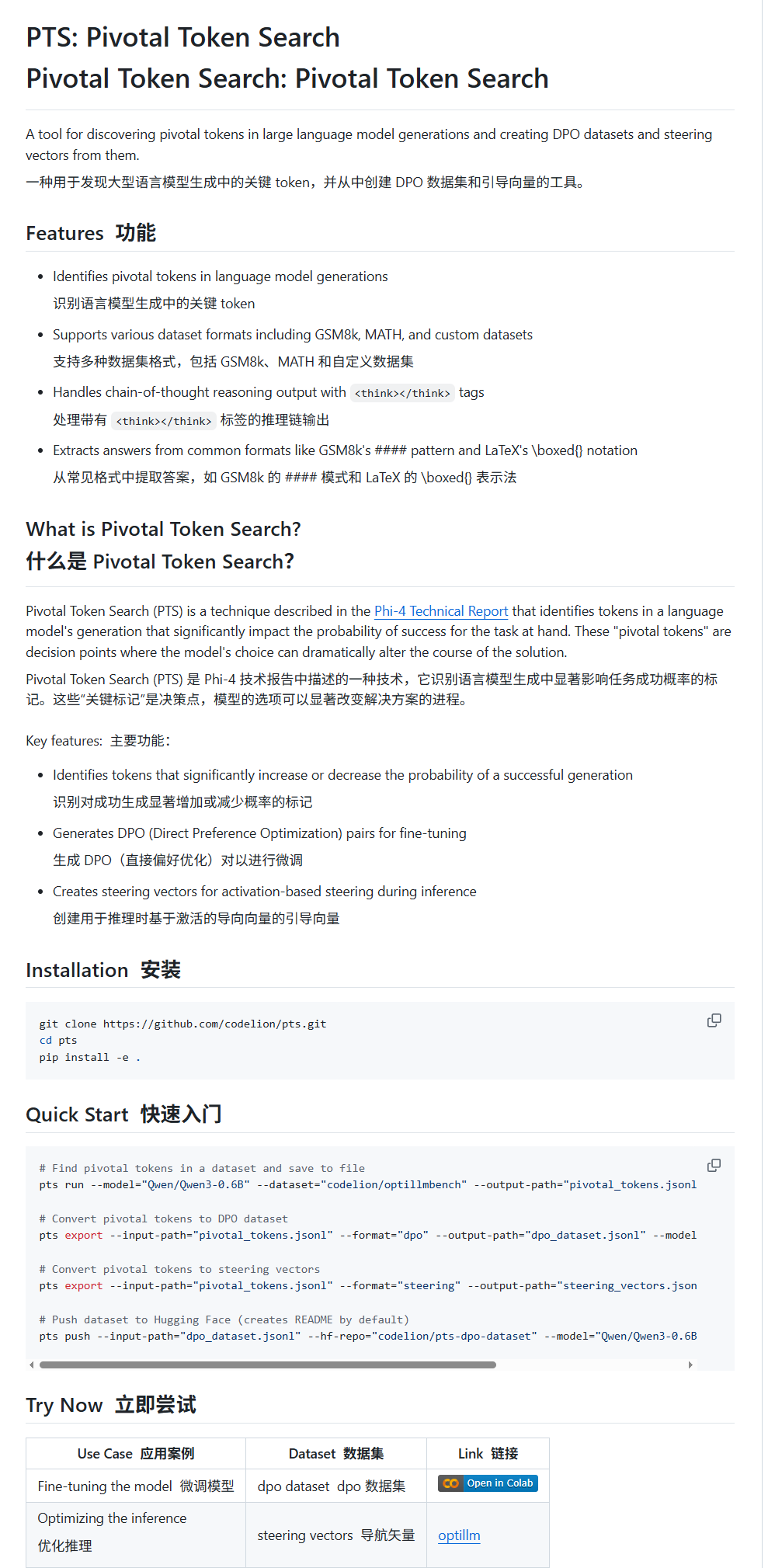
Pivotal Token Search (PTS): новая технология тонкой настройки и управления LLM: Karminski3 представил новую технологию под названием PTS (Pivotal Token Search). Эта технология основана на идее, что ключевые точки принятия решений в выводе больших моделей зависят от небольшого числа ключевых токенов. Путем извлечения этих токенов, которые могут значительно повлиять на правильность вывода (разделенных на «выбранные токены» и «отклоненные токены»), создается набор данных DPO для тонкой настройки. Кроме того, PTS может извлекать паттерны активации ключевых токенов для генерации управляющих векторов (steering vectors), которые направляют поведение модели во время вывода без необходимости тонкой настройки. Утверждается, что этот метод вдохновлен Phi4, и его эффективность вызвала обсуждение в сообществе. (Источник: karminski3)
OpenAI Codex CLI предоставляет бесплатные квоты API, поощряя обмен данными: Аккаунт разработчиков OpenAI объявил, что пользователи Plus или Pro могут получить бесплатные квоты API, выполнив команды npm i -g @openai/codex@latest и codex --free. Кроме того, пользователи могут получать бесплатные ежедневные токены, выбрав в настройках платформы опцию обмена данными для улучшения и обучения моделей OpenAI. Эта мера направлена на поощрение разработчиков к использованию инструментов Codex и участию в улучшении моделей. (Источник: OpenAIDevs, fouad)
Подборка бесплатных учебных ресурсов по мультиагентным системам (MAS): TheTuringPost собрал и поделился 7 бесплатными ресурсами для изучения мультиагентных систем (MAS). Среди них CrewAI, мультиагентный фреймворк CAMEL и учебник по мультиагентным системам LangChain; книга под названием «Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations»; а также три онлайн-курса, охватывающих темы от промптов до мультиагентных систем, освоение разработки мультиагентных систем с помощью AutoGen и практическое применение мульти-AI-агентов с продвинутыми сценариями использования crewAI. (Источник: TheTuringPost)

Учебник по быстрой классификации изображений с помощью MobileNetV2: Пользователь Reddit Eran Feit поделился Python-учебником по классификации изображений с использованием MobileNetV2. Учебник пошагово показывает, как загрузить предварительно обученную модель MobileNetV2, предварительно обработать изображение с помощью OpenCV (преобразование BGR в RGB, масштабирование до 224×224, пакетная обработка), выполнить вывод и декодировать результаты прогнозирования для получения удобочитаемых меток и вероятностей. Этот учебник подходит для начинающих, чтобы быстро освоить задачи легковесной классификации изображений. (Источник: Reddit r/deeplearning)
Опубликовано руководство по реализации многоисточникового RAG и гибридного поиска в OpenWebUI: Сайт productiv-ai.guide опубликовал подробное пошаговое руководство по реализации многоисточниковой генерации с расширенным поиском (RAG) и гибридного поиска (Hybrid Search) с переранжированием (Re-ranking) в OpenWebUI. Руководство призвано помочь пользователям настроить и использовать функции RAG в OpenWebUI, включая недавно добавленную функцию внешнего переранжирования, для повышения точности и релевантности поиска информации. (Источник: Reddit r/OpenWebUI)
💼 Бизнес
Острая конкуренция на рынке AI Agent: глубокое сравнение Manus и Lovart: AI Agent “Lovart”, ориентированный на вертикальный рынок дизайна, привлек внимание своим уникальным рабочим процессом «приема заказов». Он пытается имитировать полный процесс проектирования, от обсуждения требований до предоставления послойных материалов, что контрастирует с «диспетчерской» логикой универсального агента “Manus”. Хотя Lovart демонстрирует неплохие результаты в понимании эстетики дизайна, выражении концепций и организации информации, а также превосходит Manus по скорости, оба сталкиваются с проблемами стабильности, обработки китайского языка и согласованности изменений. Появление Lovart рассматривается как правильное направление для вертикальных агентов в углубленном освоении сценариев и усвоении отраслевого опыта, предвещая, что AI Agent смогут по-настоящему закрепиться в контент-индустрии. (Источник: 36氪)

Рынок детских умных часов на подъеме, тренд AIoT способствует росту выручки китайских производителей SoC-чипов: Благодаря стимулирующей потребительской политике и тенденциям развития AIoT, продажи на китайском рынке умных носимых устройств (особенно детских умных часов) резко возросли. Появление моделей с открытым исходным кодом, таких как DeepSeek, снизило барьер для развертывания AI на конечных устройствах, ускорив проникновение AI в бытовую технику, AI-наушники и другие терминалы. Китайские производители SoC-чипов, такие как Rockchip и Bestechnic, благодаря своим разработкам в области низкого энергопотребления и вычислительных мощностей AI, а также флагманским чипам, таким как Rockchip RK3588, охватывающим множество сценариев (ПК, умное оборудование, автомобильная электроника), демонстрируют значительный рост выручки и, соответственно, оценки. (Источник: 36氪)
Сообщается, что OpenAI скорректировала план реструктуризации компании и ответила на критику по поводу своего некоммерческого статуса: По данным Garrison Lovely, было обнародовано ранее не публиковавшееся письмо OpenAI генеральному прокурору Калифорнии. Содержание письма не только раскрывает неожиданные детали плана реструктуризации компании OpenAI, но и показывает, что OpenAI активно предпринимает шаги, чтобы ответить на критику и сомнения относительно попыток ослабить некоммерческую структуру управления компанией. (Источник: NeelNanda5)

🌟 Сообщество
Сущность N-Gram в LLM и границы «интеллекта» вызывают бурные дебаты: Сообщество продолжает обсуждать, в какой степени большие языковые модели (LLM) все еще полагаются на статистические свойства N-Gram, и представляют ли текущие LLM «настоящий AI». Существует мнение (например, комментарий pmddomingos к статье jxmnop на NeurIPS), что LLM в более чем 2/3 случаев ведут себя подобно N-Gram моделям. Ученый по данным с Reddit отметил, что текущим LLM не хватает настоящего понимания, рассуждений и здравого смысла, они далеки от AGI (общего искусственного интеллекта) и по сути являются сложными «системами предсказания следующего слова», а не интеллектуальными агентами, обладающими самосознанием и адаптивностью. (Источник: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

Стиль «прозрачной пленки» в AI-генерируемых изображениях и сомнительные изображения от «Doubao» привлекают внимание: В последнее время в социальных сетях появилось большое количество изображений, сгенерированных инструментами AI-рисования, такими как Doubao, в определенном стиле, особенно изображения с эффектом обертывания «прозрачной пленкой». Эти изображения из-за своего необычного визуального эффекта и возможного «сомнительного» содержания вызвали широкое обсуждение, подражание и вторичное творчество среди пользователей, став популярным трендом в области AI-генерируемого контента. (Источник: op7418, dotey)

Этика AI и будущее: создание «Бога» или самоуничтожение?: Сообщество ведет ожесточенные дебаты о конечных целях развития AI и потенциальных рисках. Emad Mostaque прямо заявил, что кто-то пытается создать AGI, подобный «Богу», что может привести к утопии или разрушению. Генеральный директор NVIDIA Дженсен Хуанг предвидит будущее, в котором инженеры-люди будут сотрудничать с 1000 AI для проектирования чипов. В то же время, дискуссия, вызванная комиксом SMBC, переводит вопрос сознания AI на более практический уровень этического обращения — сможем ли мы спокойно относиться к этим «вещам»? Эти точки зрения вместе формируют сложное представление о будущем AI. (Источник: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
Подорвет ли AI бизнес-модель SaaS? Горячие дебаты в сообществе разработчиков: С распространением мощных инструментов AI-программирования, таких как Claude Code, сообщество разработчиков начало обсуждать их потенциальное влияние на бизнес-модель SaaS (программное обеспечение как услуга). Считается, что барьер для индивидуальных разработчиков в копировании основных функций существующих SaaS-продуктов с помощью AI снижается. Это может привести к тому, что предприятия и частные пользователи сократят свою зависимость от традиционных SaaS-сервисов, обратившись к более экономичным самописным или AI-ассистированным решениям. В будущем разработка программного обеспечения может в большей степени зависеть от микроменеджмента AI. (Источник: Reddit r/ClaudeAI)
Различия в многоязычной обработке AI привлекают внимание, претокенизатор Llama может быть одной из причин: В обсуждениях сообщества отмечается, что большие языковые модели (LLM) обычно показывают лучшие результаты на английском языке, чем на других языках. Одной из возможных причин указывается способ обработки неанглийских текстов (особенно с нелатинскими символами) претокенизаторами моделей, таких как Llama. Например, претокенизатор может чрезмерно разделять китайские иероглифы на более мелкие единицы, что влияет на понимание моделью языковой структуры и семантики и, следовательно, приводит к снижению производительности на этих языках. (Источник: giffmana)

💡 Прочее
Фреймворк DSPy подчеркивает важность низкоуровневых примитивов для разработки AI-агентов: С момента открытия исходного кода своих основных абстракций в январе 2023 года, AI-фреймворк DSPy, за исключением небольших упрощений, практически не претерпел изменений, оставаясь стабильным на протяжении нескольких итераций API LLM. В обсуждениях сообщества отмечается, что это связано с тем, что DSPy фокусируется на создании правильных низкоуровневых примитивов, а не просто на поверхностном удобстве для разработчиков или быстром создании «агентов». Считается, что многие современные фреймворки для разработки агентов слишком сосредоточены на простоте использования, пренебрегая прочностью базовых строительных блоков, в то время как философия DSPy заключается в том, что сначала должна быть прочная основа «реакций», чтобы затем можно было построить сложное «агентное» поведение. (Источник: lateinteraction, lateinteraction)
Эстетическая усталость от AI-генерируемого контента порождает спрос на кастомизированные модели: В обсуждениях сообщества высказывается мнение, что результаты многих моделей генерации изображений, оптимизированных с помощью обучения с подкреплением (RL), часто выглядят «посредственно» или «пошло», и хотя технически они могут быть хороши, им не хватает захватывающей креативности и индивидуальности. Это отражает то, что цели оптимизации моделей могут быть смещены в сторону усредненных эстетических предпочтений масс, а не уникальных художественных поисков. Поэтому кастомизированные модели и методы, способные производить выборку в соответствии с индивидуальными эстетическими целями, считаются ключом к преодолению этой проблемы и созданию более привлекательного AI-контента в будущем. (Источник: torchcompiled)

Ollama выпустила мультимодальный движок, пользователи OpenWebUI интересуются совместимостью: Ollama объявила об официальном выпуске своего мультимодального движка, что привлекло внимание пользователей сообщества OpenWebUI. Пользователи в основном интересуются, сможет ли OpenWebUI поддерживать новый мультимодальный движок Ollama «из коробки», то есть без необходимости сложных изменений конфигурации для использования его возможностей по обработке различных типов данных, таких как изображения, текст и т.д. (Источник: Reddit r/OpenWebUI)
