
Ключевые слова:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, регулирование ИИ, Seed1.5-VL, кодирующий агент на базе Gemini, оптимизация алгоритмов матричного умножения, оптимизация эффективности дата-центров, многоязычные мультимодальные модели, децентрализованная сеть для обучения ИИ
🔥 В фокусе
Google DeepMind выпустила AlphaEvolve: ИИ-агент для кодирования на базе Gemini, революционизирующий поиск алгоритмов: Google DeepMind представила AlphaEvolve, ИИ-агента для кодирования на базе Gemini, предназначенного для открытия и оптимизации сложных алгоритмов путем сочетания творческого потенциала больших языковых моделей с автоматизированными оценщиками. AlphaEvolve успешно разработал более быстрые алгоритмы умножения матриц, решил открытые математические проблемы, такие как проблема минимального перекрытия Эрдёша и проблема контактного числа, а также используется внутри Google для оптимизации эффективности центров обработки данных (в среднем восстанавливая 0.7% вычислительных ресурсов), проектирования чипов и ускорения обучения самого Gemini, демонстрируя огромный потенциал ИИ в научных открытиях и инженерной оптимизации. (Источник: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic скоро выпустит новые модели Claude Sonnet и Opus с улучшенными возможностями логического вывода и вызова инструментов: По сообщению The Information, Anthropic планирует в ближайшие недели выпустить новые версии Claude Sonnet и Claude Opus. Ключевой особенностью новых моделей является возможность гибкого переключения между «режимом мышления» и «режимом использования инструментов». Когда модель сталкивается с трудностями при решении проблем с использованием внешних инструментов (таких как приложения, базы данных), она может активно возвращаться в «режим рассуждения» для рефлексии и самокоррекции. В области генерации кода новые модели смогут автоматически тестировать сгенерированный код, и в случае обнаружения ошибок приостанавливаться, обдумывать и исправлять их. Этот замкнутый цикл «мышление — действие — рефлексия», как ожидается, значительно повысит способность и надежность моделей в решении сложных проблем. (Источник: steph_palazzolo, dotey)

Республиканские законодатели США предлагают 10-летний запрет на федеральное и штатное регулирование ИИ, вызывая бурные дебаты: Республиканские законодатели США внесли в законопроект о бюджетном согласовании положение, предлагающее запретить федеральным и штатным органам власти регулировать модели, системы или автоматизированные системы принятия решений на основе ИИ в течение следующих десяти лет, а также планируют выделить 500 миллионов долларов на поддержку коммерциализации ИИ и его применения в ИТ-системах федерального правительства. Этот шаг рассматривается некоторыми представителями технологического сообщества как позитивный сигнал для защиты инноваций в области ИИ и предотвращения удушения их законодательством, но также вызывает опасения по поводу потенциальных рисков, таких как распространение DeepFake, потеря контроля над конфиденциальностью данных, этические проблемы ИИ и его воздействие на окружающую среду. В случае принятия это предложение окажет значительное влияние на существующее и будущее законодательство в области ИИ. (Источник: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI выпускает модель GPT-4.1 и запускает Центр оценки безопасности, подчеркивая возможности кодирования и следования инструкциям: OpenAI объявила, что по просьбе пользователей модель GPT-4.1 с сегодняшнего дня доступна в ChatGPT (для пользователей Plus, Pro, Team; корпоративная и образовательная версии появятся позже). GPT-4.1 специально оптимизирована для задач кодирования и следования инструкциям, работает быстрее и может служить повседневной заменой o3 и o4-mini для кодирования. Одновременно GPT-4.1 mini заменит текущую GPT-4o mini для всех пользователей. Кроме того, OpenAI запустила Центр оценки безопасности (Safety Evaluations Hub) для публикации результатов тестов безопасности своих моделей и соответствующих метрик, который будет регулярно обновляться для повышения прозрачности коммуникации в области безопасности. (Источник: openai, michpokrass)
Meta FAIR анонсировала ряд научных достижений в области ИИ, фокусируясь на открытии молекул и атомарном моделировании: Meta AI (FAIR) объявила о последних релизах с открытым исходным кодом в областях прогнозирования свойств молекул, обработки языка и нейронаук. Среди них Open Molecules 2025 (OMol25), набор данных для открытия молекул для моделирования крупных атомарных систем; Universal Model for Atoms (UMA), модель машинного обучения межатомных потенциалов, широко применимая для моделирования атомарных взаимодействий в материалах и молекулах; а также Adjoint Sampling, масштабируемый алгоритм для обучения генеративных моделей на основе скалярного вознаграждения. Кроме того, FAIR в сотрудничестве с больницей Фонда Ротшильда провела исследование, выявившее значительное сходство в развитии языка у людей и LLM. (Источник: AIatMeta)
🎯 Тренды
ByteDance выпустила большую визуально-языковую модель Seed1.5-VL с 20 млрд активных параметров и выдающейся производительностью: ByteDance представила свою мультимодальную большую визуально-языковую модель Seed1.5-VL, которая при всего 20 млрд активных параметров демонстрирует производительность, сопоставимую с Gemini 2.5 Pro, и достигла SOTA (state-of-the-art) в 38 из 60 общедоступных бенчмарков. Seed1.5-VL обладает улучшенными возможностями общего мультимодального понимания и логического вывода, особенно выделяясь в задачах визуального позиционирования, логического вывода, понимания видео и мультимодальных интеллектуальных агентов. Модель доступна через API на платформе Volcano Engine, стоимость инференса составляет 0.003 юаня за тысячу токенов на входе и 0.009 юаня за тысячу токенов на выходе. (Источник: 机器之心)

Технический отчет Qwen3 раскрывает секреты: слияние режимов мышления и не-мышления, дистилляция больших моделей в малые: Alibaba опубликовала технический отчет по серии моделей Qwen3, включающей 8 моделей с параметрами от 0.6B до 235B. Ключевая инновация заключается в двойном режиме работы: модель может автоматически переключаться между «режимом мышления» (сложный логический вывод) и «режимом не-мышления» (быстрые ответы) в зависимости от сложности задачи, динамически распределяя вычислительные ресурсы с помощью параметра «бюджет мышления». Обучение проходит в три этапа предварительного обучения (общие знания, усиление логического вывода, длинные тексты) и четыре этапа последующего обучения (холодный старт длинных цепочек рассуждений, обучение с подкреплением для логического вывода, слияние режимов мышления, общее обучение с подкреплением). Также используется стратегия дистилляции данных «большой обучает малого», где модель-учитель (например, 235B) используется для обучения модели-ученика (например, 30B), обеспечивая перенос знаний. (Источник: 36氪)

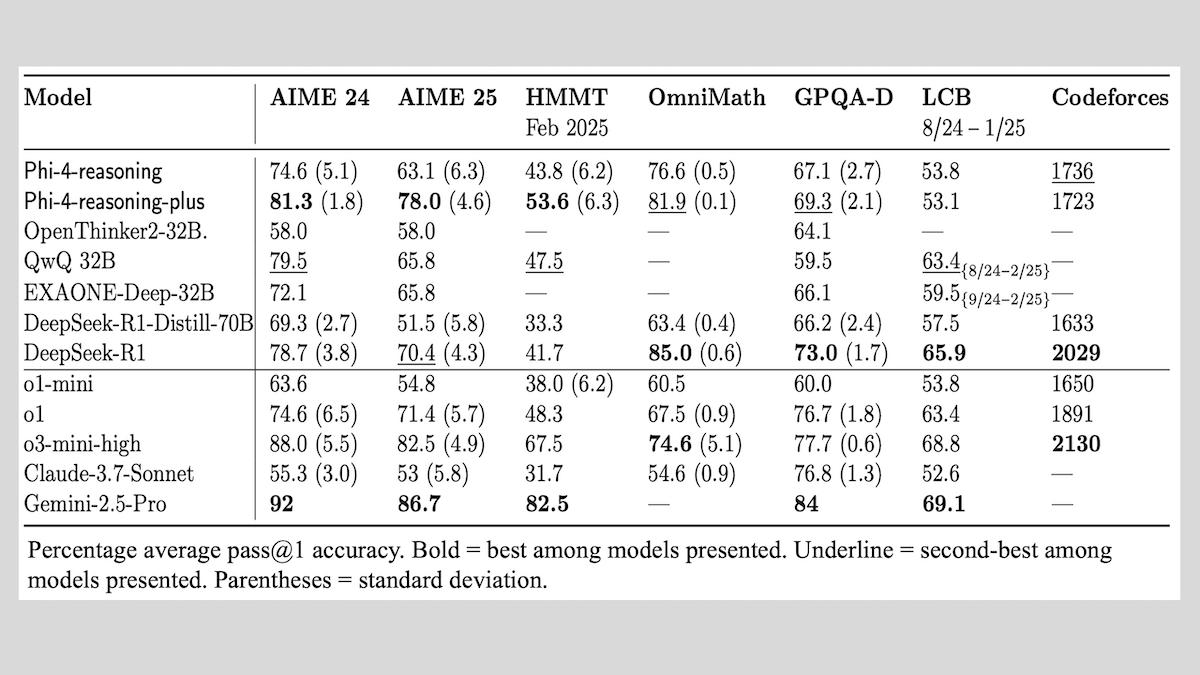
Microsoft выпустила серию моделей Phi-4-reasoning и поделилась опытом обучения моделей логического вывода: Microsoft представила три модели: Phi-4-reasoning, Phi-4-reasoning-plus (обе с 14B параметров) и Phi-4-mini-reasoning (3.8B параметров), а также обнародовала методы и опыт их обучения. Эти модели, дообученные на основе предварительно обученных моделей, сфокусированы на улучшении способностей к математическому логическому выводу. Например, Phi-4-reasoning-plus демонстрирует превосходные результаты в математических задачах благодаря обучению с подкреплением, а Phi-4-mini-reasoning проходит поэтапное дообучение SFT и RL. В отчете рассматриваются возможные проблемы нестабильности при обучении малых моделей и стратегии их решения, а также соображения по выбору данных и разработке функций вознаграждения при RL-обучении больших моделей. Веса моделей доступны на Hugging Face под лицензией MIT. (Источник: DeepLearning.AI Blog)
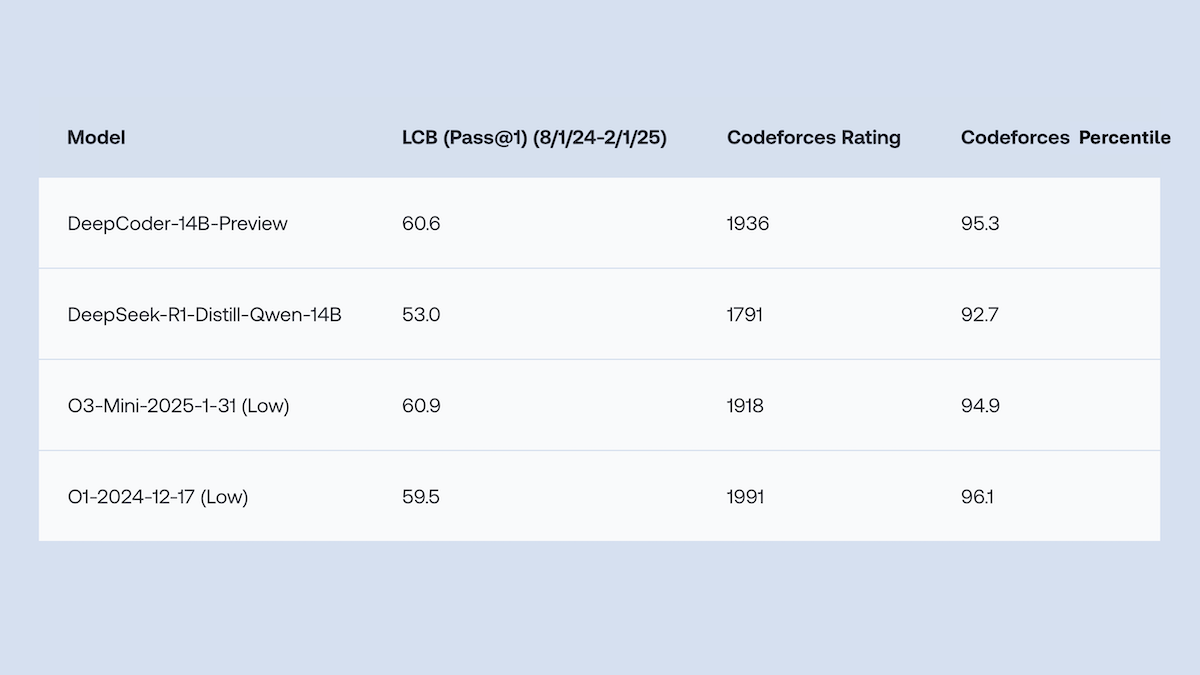
Together.AI и Agentica открыли исходный код DeepCoder-14B-Preview, производительность генерации кода сравнима с o1: Команды Together.AI и Agentica выпустили DeepCoder-14B-Preview, модель для генерации кода с 14B параметров, производительность которой на нескольких бенчмарках кодирования сравнима с более крупными моделями, такими как DeepSeek-R1 и OpenAI o1. Модель была дообучена на основе DeepSeek-R1-Distilled-Qwen-14B с использованием упрощенного метода обучения с подкреплением (сочетание оптимизаций GRPO и DAPO) и улучшенной способности параллельной обработки в библиотеке RL Verl, что значительно сократило время обучения. Веса модели, код, наборы данных и журналы обучения опубликованы под лицензией MIT. (Источник: DeepLearning.AI Blog)
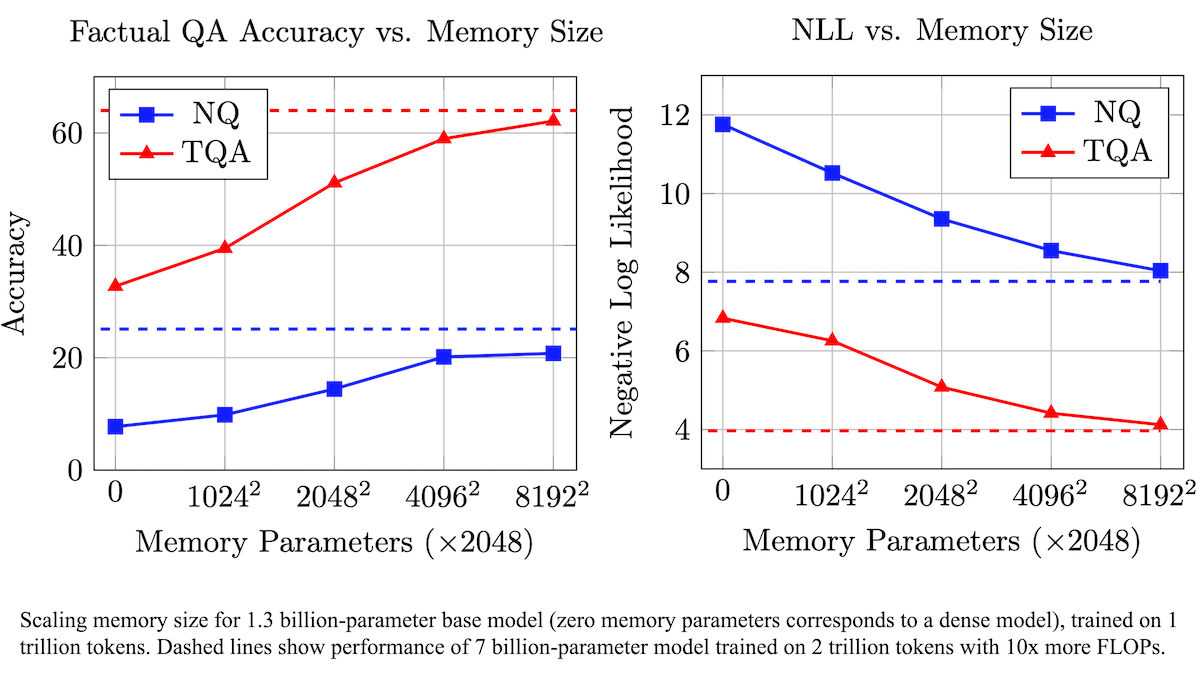
Meta предложила обучаемый слой памяти для повышения фактической точности LLM и снижения вычислительных требований: Исследователи из Meta улучшили точность воспроизведения фактов большими языковыми моделями, добавив обучаемый слой памяти в архитектуру Transformer, не требуя при этом значительного увеличения вычислительных ресурсов. Этот метод сохраняет информацию путем изучения ключей и соответствующих значений и использует стратегию разделения ключей на два полуключа, эффективно решая проблему вычислительной сложности при поиске по большим наборам ключей. Эксперименты показали, что модель с 8B параметров, оснащенная слоем памяти, превосходит аналогичные модели без слоя памяти на нескольких наборах данных для ответов на вопросы, демонстрируя преимущества в отношении требований к данным предварительного обучения и вычислительным ресурсам. (Источник: DeepLearning.AI Blog)
Alibaba открыла исходный код серии базовых видеомоделей Wan2.1, поддерживающих генерацию и редактирование видео из текста/изображений: Alibaba выпустила Wan2.1, комплексный набор базовых видеомоделей с открытым исходным кодом, включающий версии с 1.3B и 14B параметров, под лицензией Apache 2.0. Wan2.1 демонстрирует отличные результаты в различных задачах, таких как преобразование текста в видео, изображения в видео, редактирование видео, преобразование текста в изображение и видео в аудио, а также особенно поддерживает визуальную генерацию на китайском и английском языках. Ее модель T2V-1.3B требует всего 8.19 ГБ видеопамяти, может работать на потребительских GPU и генерировать 5-секундное видео 480P за 4 минуты. Сопутствующий Wan-VAE эффективно кодирует и декодирует видео 1080P, сохраняя временную информацию. (Источник: _akhaliq, Reddit r/LocalLLaMA)

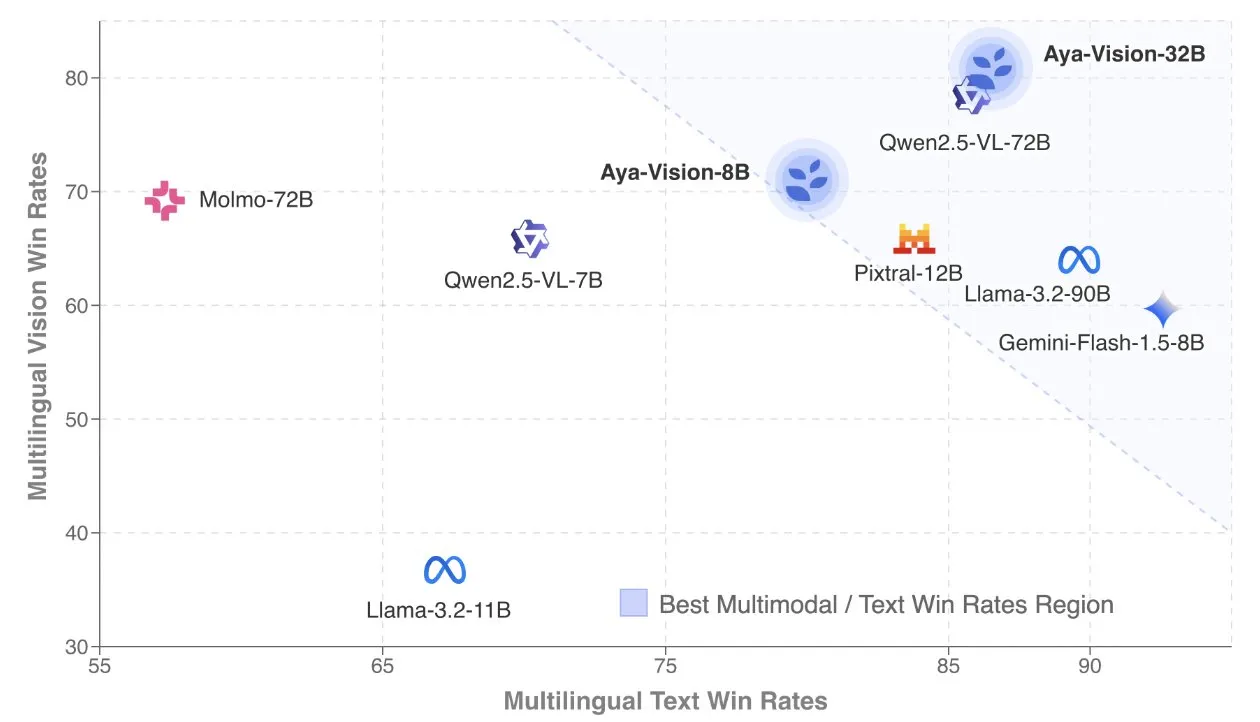
Cohere опубликовала технический отчет Aya Vision, посвященный многоязычным мультимодальным моделям: Cohere Labs обнародовала технический отчет Aya Vision, подробно описывающий их рецепт создания SOTA многоязычных мультимодальных моделей. Модели Aya Vision нацелены на унификацию возможностей 23 языков в мультимодальных и текстовых задачах. В отчете рассматриваются фреймворк синтетических многоязычных данных, архитектурный дизайн, методы обучения, слияние кросс-модальных моделей и всесторонняя оценка в открытых многоязычных генеративных задачах. Их модель 8B превосходит по производительности более крупные модели, такие как Pixtral-12B, в то время как модель 32B более эффективна, превосходя модели более чем в два раза большего размера, такие как Llama3.2-90B. (Источник: sarahookr, Cohere Labs)
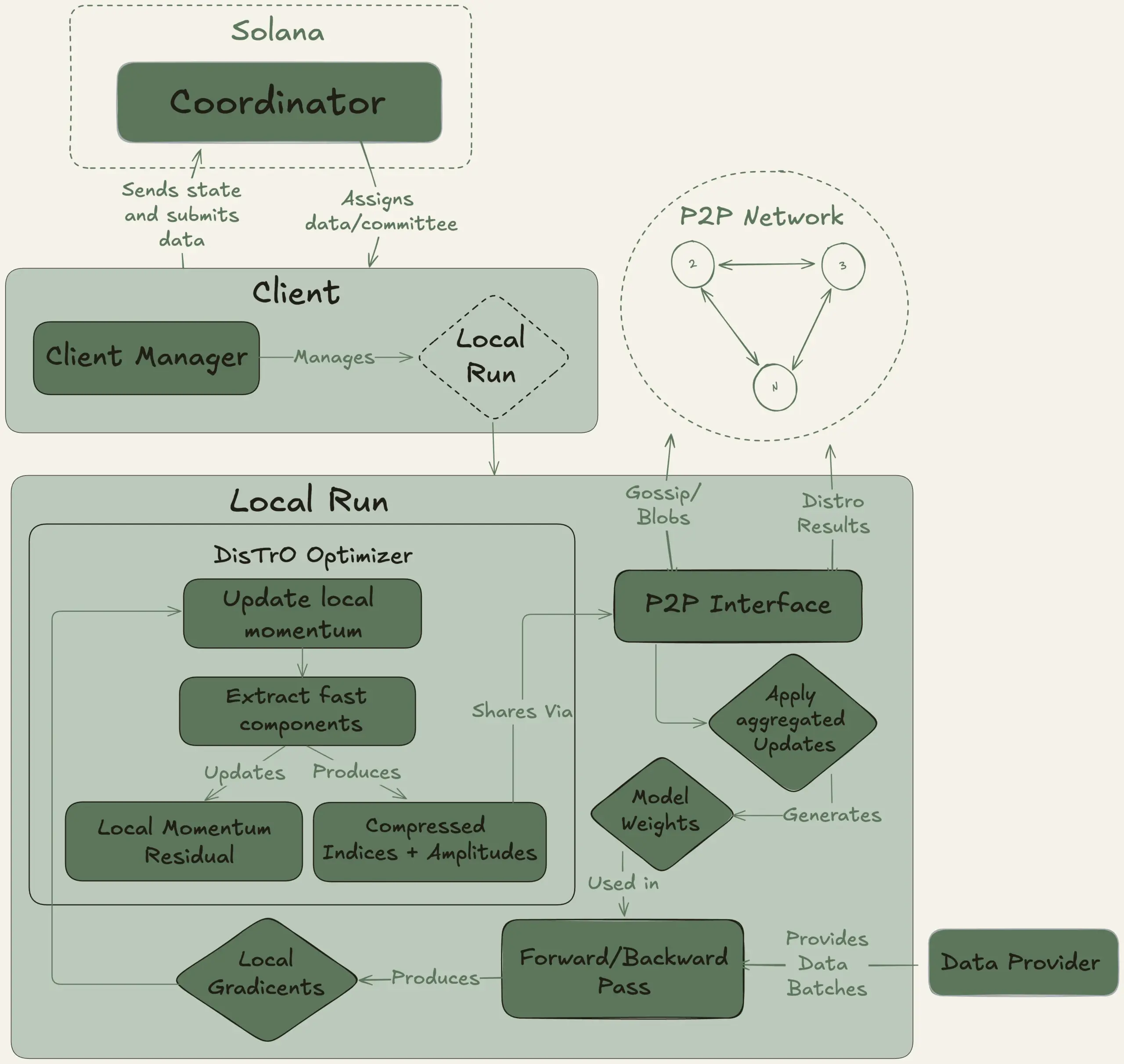
Nous Research запускает проект Psyche, нацеленный на децентрализованное обучение большой модели с 40B параметров: Nous Research объявила о запуске сети Psyche, децентрализованной сети для обучения ИИ, целью которой является объединение глобальных вычислительных мощностей для совместного обучения мощных ИИ-моделей, позволяя отдельным лицам и небольшим сообществам участвовать в разработке крупномасштабных моделей. Ее тестовая сеть уже начала предварительное обучение LLM с 40B параметров, использующей архитектуру MLA, с набором данных, включающим FineWeb (14T), часть FineWeb-2 (4T) и The Stack v2 (1T), общим объемом около 20T токенов. После завершения обучения этой модели все контрольные точки (включая неоткаленные и откаленные версии) и наборы данных будут опубликованы с открытым исходным кодом. (Источник: eliebakouch, Teknium1)
Stability AI выпустила модель Stable Audio Open Small с открытым исходным кодом, ориентированную на быструю генерацию аудио из текста: Stability AI опубликовала на Hugging Face модель Stable Audio Open Small, разработанную специально для быстрой генерации аудио из текста и использующую технологию состязательного пост-обучения. Модель призвана предоставить эффективное решение для генерации аудио с открытым исходным кодом. (Источник: _akhaliq)
Google Gemini Advanced интегрирован с GitHub для усиления возможностей помощи в кодировании: Google объявила, что Gemini Advanced теперь подключен к GitHub, что еще больше расширяет его возможности в качестве помощника по кодированию. Пользователи могут напрямую подключать публичные или частные репозитории GitHub, используя Gemini для генерации или изменения функций, объяснения сложного кода, задания вопросов по кодовой базе, отладки и других операций. Чтобы начать использовать, нужно нажать кнопку «+» в строке подсказок и выбрать «Импортировать код», вставив URL-адрес GitHub. (Источник: algo_diver)
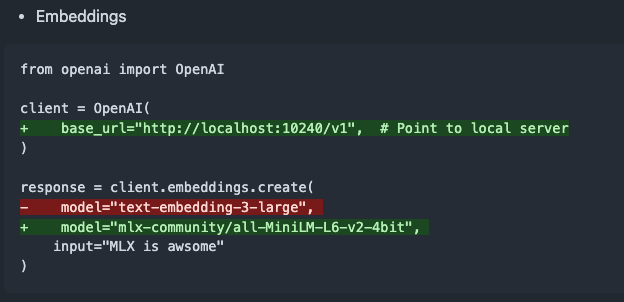
Выпущена mlx-omni-server v0.4.0, добавлены сервис embeddings и больше моделей TTS: mlx-omni-server обновлен до версии v0.4.0, в которой представлен новый сервис /v1/embeddings, упрощающий генерацию эмбеддингов через mlx-embeddings. Одновременно интегрировано больше моделей TTS (таких как kokoro, bark) и обновлен mlx-lm для поддержки новых моделей, таких как qwen3. (Источник: awnihannun)
Together Chat добавил функцию обработки PDF-файлов: Together Chat объявил о поддержке загрузки и обработки PDF-файлов. Текущая версия в основном анализирует текстовое содержимое PDF и передает его модели для обработки, в будущем планируется выпустить версию v2 с функцией OCR для чтения изображений в PDF. (Источник: togethercompute)
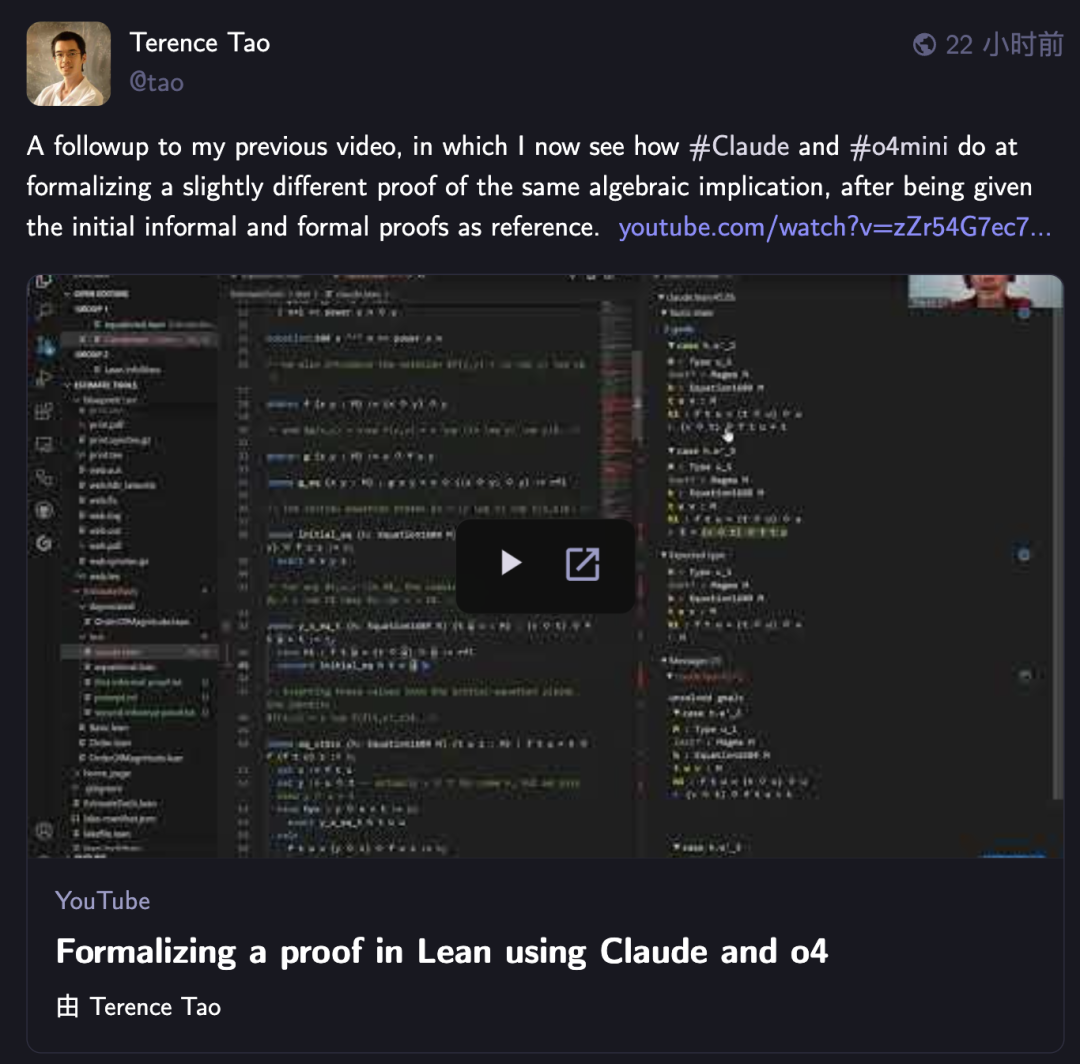
Теренс Тао снова использует ИИ для формализации математических доказательств, Claude превосходит o4-mini: Математик Теренс Тао в своей серии видео на YouTube протестировал способность ИИ к формализации доказательства алгебраической импликации в системе Lean. В эксперименте Claude смог выполнить задачу примерно за 20 минут, хотя в процессе компиляции выявились ошибки в понимании правила начала натуральных чисел с 0 в Lean и проблемы с обработкой симметрии, которые были исправлены вручную. В сравнении, o4-mini действовал более осторожно, смог распознать проблему с определением степенной функции, но на ключевом этапе доказательства отказался от выполнения задачи. Тао заключил, что чрезмерная зависимость от автоматизации может ослабить понимание общей структуры доказательства, и оптимальный уровень автоматизации должен находиться между 0% и 100%, сохраняя возможность человеческого вмешательства для углубления понимания. (Источник: 36氪)
Интервью с Альтманом: конечная цель OpenAI — создание основной ИИ-подписки: CEO OpenAI Сэм Альтман на мероприятии Sequoia Capital AI Ascent 2025 заявил, что «платоническим идеалом» OpenAI является разработка операционной системы ИИ, которая станет основной ИИ-подпиской для пользователей. Он представляет, что будущие модели ИИ смогут обрабатывать данные всей жизни пользователя (триллионы контекстных токенов), обеспечивая глубокую персонализированную логику. Альтман признал, что это пока на «стадии PPT», но подчеркнул, что компания гордится своей гибкостью и адаптивностью. Он также говорил о потенциале голосового взаимодействия с ИИ, о том, что 2025 год станет годом расцвета ИИ-агентов, и считает, что кодирование будет ядром, управляющим работой моделей и вызовами API. (Источник: 36氪, 量子位)

Karminski3 поделился модифицированной сообществом версией Qwen3-30B с удвоенным числом активных экспертов: Сообщество разработчиков модифицировало модель Qwen3, выпустив версию Qwen3-30B-A6B-16-Extreme. Путем изменения параметров модели количество активных экспертов было увеличено с A3B до A6B, что, по утверждениям, приводит к небольшому улучшению качества, но соответственно замедляет скорость генерации. Пользователи также могут добиться аналогичного эффекта, изменив параметры запуска llama.cpp --override-kv http://qwen3moe.expert_used_count=int:24, или наоборот, уменьшить количество активных экспертов в Qwen3-235B-A22B для ускорения. (Источник: karminski3)

🧰 Инструменты
Выпущен OpenMemory MCP: локально работающая система общей памяти, объединяющая множество ИИ-инструментов: Команда mem0ai представила OpenMemory MCP, частный сервер памяти, построенный на основе протокола контекста открытых моделей (MCP). Он поддерживает 100% локальную работу и нацелен на решение проблемы отсутствия обмена контекстной информацией между текущими ИИ-инструментами (такими как Cursor, Claude Desktop, Windsurf, Cline) и потери памяти по завершении сеанса. Данные пользователя хранятся локально, обеспечивая конфиденциальность. OpenMemory MCP предоставляет стандартизированный API для операций с памятью (CRUD) и централизованную панель управления для управления памятью и правами доступа клиентов, упрощая развертывание с помощью Docker. (Источник: 36氪, AI进修生)

LangChain представила официальную версию платформы LangGraph и ряд обновлений, усиливающих разработку и наблюдаемость ИИ-агентов: LangChain на конференции Interrupt объявила об официальной общедоступности (GA) своей платформы LangGraph, специально разработанной для создания и управления долго работающими, сохраняющими состояние рабочими процессами ИИ-агентов. Платформа поддерживает развертывание в один клик, горизонтальное масштабирование и API для памяти, взаимодействия человека с машиной (HIL), истории диалогов и т.д. Одновременно выпущена LangGraph Studio V2, IDE для агентов, поддерживающая локальный запуск, прямое редактирование конфигураций, интеграцию с Playground и возможность извлечения данных трассировки из производственной среды для локальной отладки. Кроме того, LangChain представила платформу для создания агентов без кода с открытым исходным кодом Open Agent Platform (OAP) и улучшила наблюдаемость агентов в LangSmith в части вызова инструментов и траекторий. (Источник: LangChainAI, hwchase17)
PatronusAI представила Percival: ИИ-агент, способный оценивать и исправлять другие ИИ-агенты: PatronusAI выпустила Percival, который, по их утверждению, является первым ИИ-агентом, способным оценивать и автоматически исправлять ошибки других ИИ-агентов. Percival не только обнаруживает сбои в записях отслеживания агентов, но и предлагает рекомендации по их исправлению. Утверждается, что на наборе данных TRAIL, содержащем ошибки, аннотированные человеком из GAIA и SWE-Bench, производительность Percival в 2.9 раза выше, чем у SOTA LLM. Его функции включают автоматическое предложение исправлений для подсказок агентов, обнаружение более 20 типов сбоев агентов (охватывающих использование инструментов, координацию планирования, ошибки, специфичные для предметной области, и т.д.) и сокращение времени ручной отладки с нескольких часов до менее чем 1 минуты. (Источник: rebeccatqian, basetenco)
PyWxDump: инструмент для получения и экспорта информации из WeChat, поддержка обучения ИИ: PyWxDump — это Python-инструмент для получения информации об аккаунте WeChat (никнейм, аккаунт, телефон, email, ключ базы данных), расшифровки базы данных, локального просмотра истории чатов, а также экспорта истории чатов в форматы CSV, HTML и др., которые могут использоваться для обучения ИИ, автоматических ответов и т.д. Инструмент поддерживает получение информации о нескольких аккаунтах и все версии WeChat, а также предоставляет веб-интерфейс для просмотра истории чатов. (Источник: GitHub Trending)

Airweave: инструмент, позволяющий ИИ-агентам искать в любом приложении, совместим с протоколом MCP: Airweave — это инструмент, предназначенный для того, чтобы ИИ-агенты могли семантически искать контент в любом приложении. Он совместим с протоколом контекста моделей (MCP) и может бесшовно подключаться к различным приложениям, базам данных или API, преобразуя их контент в знания, доступные агентам. Его основные функции включают синхронизацию данных, извлечение и преобразование сущностей, многопользовательскую архитектуру, инкрементные обновления, семантический поиск и контроль версий. (Источник: GitHub Trending)

iFlytek выпустила новое поколение ИИ-наушников iFLYBUDS Pro3 и Air2 с ИИ-мозгом viaim: Future Intelligence (дочерняя компания iFlytek) выпустила ИИ-наушники для конференций iFLYBUDS Pro3 и iFLYBUDS Air2, обе модели оснащены новым ИИ-мозгом viaim. viaim — это ИИ-агент для персонального делового офиса, объединяющий четыре основных модуля: сквозную интеллектуальную обработку восприятия, совместный логический вывод интеллектуальных агентов, мультимодальные возможности в реальном времени и защиту данных и конфиденциальности. Наушники поддерживают удобную запись (звонков, на месте, аудио- и видеозаписей), ИИ-ассистента (автоматическое создание заголовков и резюме, целевые вопросы), многоязычный перевод (32 языка, синхронный перевод, перевод при личной встрече, перевод звонков) и другие функции, а также улучшенное качество звука и комфорт ношения. (Источник: WeChat)

Выпущен KoboldCpp Smart Launcher: инструмент автоматической настройки Tensor Offload для оптимизации производительности LLM: Выпущен GUI и CLI инструмент под названием KoboldCpp Smart Launcher, предназначенный для помощи пользователям в автоматическом поиске оптимальной стратегии Tensor Offload в KoboldCpp при локальном запуске LLM. Благодаря более гранулированному распределению тензоров между CPU и GPU (а не целых слоев), инструмент, по утверждениям, может более чем удвоить скорость генерации без увеличения требований к VRAM. Например, скорость QwQ Merge на GPU с 12 ГБ VRAM увеличилась с 3.95 т/с до 10.61 т/с. (Источник: Reddit r/LocalLLaMA)
OpenBMB открыла исходный код AgentCPM-GUI: первого GUI-агента для устройств, оптимизированного для китайского языка: Команда OpenBMB открыла исходный код AgentCPM-GUI, первого GUI (графического пользовательского интерфейса) агента для устройств, специально оптимизированного для китайских приложений. Этот агент улучшил свои возможности логического вывода благодаря усиленному дообучению (RFT), использует компактный дизайн пространства действий и обладает высококачественными возможностями GUI-локализации (grounding), нацеленными на улучшение пользовательского опыта при работе с различными приложениями в китайскоязычной среде. (Источник: Reddit r/LocalLLaMA)
MAESTRO: локально-ориентированное приложение для ИИ-исследований, поддерживающее совместную работу нескольких агентов и настраиваемые LLM: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) — это недавно выпущенное приложение для исследований на базе ИИ, подчеркивающее локальный контроль и возможности. Оно предоставляет модульный фреймворк, включающий извлечение документов, мощные процессы RAG и систему из нескольких агентов (планирование, исследование, рефлексия, написание), способную решать сложные исследовательские задачи. Пользователи могут взаимодействовать через веб-интерфейс Streamlit или CLI, используя собственные наборы документов и выбранные локальные или API LLM. (Источник: Reddit r/LocalLLaMA)
Contextual AI выпустила парсер документов, оптимизированный для RAG: Contextual AI представила новый парсер документов, специально разработанный для систем Retrieval Augmented Generation (RAG). Инструмент нацелен на обеспечение высокоточного анализа сложных неструктурированных документов путем сочетания визуальных данных, OCR и визуально-языковых моделей. Он способен сохранять иерархическую структуру документов, обрабатывать сложные модальности, такие как таблицы, диаграммы и графики, а также предоставлять ограничивающие рамки и уровни уверенности для аудита пользователем, тем самым уменьшая пропуски контекста и галлюцинации в системах RAG, вызванные ошибками парсинга. (Источник: douwekiela)
Gradio добавил функцию отмены/повтора в ImageEditor: Компонент ImageEditor в Gradio теперь дополнен кнопками отмены (undo) и повтора (redo), предоставляя пользователям функции редактирования изображений на Python, аналогичные профессиональным платным приложениям, что повышает интерактивность и удобство использования. (Источник: _akhaliq)
RunwayML представила новую функцию References, поддерживающую zero-shot тестирование материалов, одежды, локаций и поз: Функция References в RunwayML была обновлена. Пользователи могут использовать традиционные изображения предпросмотра 3D-материалов в качестве входных данных, чтобы применять их материалы к любым объектам, реализуя zero-shot перенос и визуализацию материалов. Кроме того, новая функция поддерживает zero-shot тестирование одежды, локаций и поз персонажей, расширяя возможности творческой генерации и быстрого прототипирования. (Источник: c_valenzuelab, c_valenzuelab)

Mita AI запустила функцию «Чему бы сегодня научиться?», ИИ помогает в структурированном обучении: Mita AI представила новую функцию «Чему бы сегодня научиться?», цель которой — превратить ИИ из помощника по поиску информации и обработке документов в «ИИ-учителя», способного активно направлять и обучать. После загрузки или поиска материалов пользователем, эта функция может автоматически генерировать систематизированные, структурированные видеокурсы и PPT-презентации, помогая пользователям разобраться в ключевых моментах, а также поддерживает выбор различной глубины изложения (для начинающих/экспертов) и стиля (рассказчик/грубый собеседник и т.д.). Кроме того, поддерживаются вопросы в процессе обучения и тесты по окончании. (Источник: WeChat)

📚 Обучение
Эндрю Ын и Anthropic запускают новый курс: создание ИИ-приложений с богатым контекстом с помощью MCP: DeepLearning.AI Эндрю Ына в сотрудничестве с Anthropic запускает новый курс «MCP: Build Rich-Context AI Apps with Anthropic», который ведет Эли Шоппик, руководитель технического образования в Anthropic. Курс посвящен протоколу контекста моделей (MCP), открытому протоколу, предназначенному для стандартизации доступа LLM к внешним инструментам, данным и подсказкам. Слушатели изучат основную архитектуру MCP, создадут чат-бота, совместимого с MCP, разработают и развернут сервер MCP, а также подключат его к приложениям на базе Claude и другим сторонним серверам для упрощения разработки ИИ-приложений с богатым контекстом. (Источник: AndrewYNg, DeepLearningAI)
FlashInfer: лучшая статья MLSys 2025, эффективный и настраиваемый движок внимания для инференса LLM: Проект FlashInfer, разработанный Цзыхао Е (Zihao Ye) из Вашингтонского университета, NVIDIA, Тяньци Чэнем из OctoAI и другими, получил награду за лучшую статью на MLSys 2025. FlashInfer — это высокоэффективный и настраиваемый движок внимания, оптимизированный для инференса LLM. Благодаря оптимизации доступа к памяти (использование формата блочной разреженности и композитных форматов для обработки KV-кэша), предоставлению гибких шаблонов вычисления внимания на основе JIT-компиляции и внедрению механизма планирования задач с балансировкой нагрузки, FlashInfer значительно повышает производительность инференса LLM и уже интегрирован в такие проекты, как vLLM и SGLang. (Источник: 机器之心)
Статья ICML 2025: теоретический анализ Graph Prompting с точки зрения операций с данными: Цюньчжун Ван, доктор Сянго Сунь и профессор Хун Чэн из Китайского университета Гонконга опубликовали на ICML 2025 статью, впервые представляющую систематическую теоретическую основу для эффективности Graph Prompting с точки зрения «операций с данными». Исследование вводит понятие «мостового графа» и доказывает, что механизм Graph Prompting теоретически эквивалентен выполнению определенных операций над входными данными графа, что позволяет предварительно обученной модели правильно обрабатывать их для адаптации к новым задачам. В статье выведены верхние границы ошибки, проанализированы источники ошибки и их контролируемость, а также смоделировано распределение ошибок, что обеспечивает теоретическую основу для проектирования и применения Graph Prompting. (Источник: WeChat)
Статья ICML 2025: синтез текстовых данных путем редактирования на уровне токенов для предотвращения коллапса моделей: Исследовательская группа из Шанхайского университета Цзяотун и других учреждений опубликовала на ICML 2025 статью, посвященную проблеме «коллапса моделей», вызванного синтетическими данными, и предложила стратегию генерации данных под названием «Token-Level Editing». Этот метод заключается в микроредактировании и замене «слишком уверенных» токенов модели в реальных данных, а не в полной генерации нового текста, с целью создания полусинтетических данных с более стабильной структурой и лучшей обобщающей способностью. Теоретический анализ показывает, что этот метод может эффективно ограничивать ошибку на тестовых данных и предотвращать коллапс производительности модели с ростом итерационных циклов. Эффективность метода подтверждена экспериментами на этапах предварительного обучения, непрерывного предварительного обучения и контролируемого дообучения. (Источник: WeChat)

Статья ICML 2025: OmniAudio, генерация 3D-пространственного аудио из панорамных видео 360°: Команда OmniAudio на ICML 2025 продемонстрировала технологию генерации пространственного аудио первого порядка объемного звучания (FOA) непосредственно из панорамных видео 360°. Для решения проблемы нехватки данных команда создала крупномасштабный набор данных 360V2SA Sphere360 (более 100 тысяч фрагментов, 288 часов). OmniAudio использует двухэтапное обучение: самоконтролируемое предварительное обучение с согласованием потоков от грубого к точному, сначала с использованием обычного стереозвука, преобразованного в псевдо-FOA, затем дообучение на реальном FOA; затем контролируемое дообучение с использованием двухпоточного видеокодера для извлечения глобальных и локальных признаков перспективы и генерации высококачественного пространственного аудио с точным направлением. (Источник: 量子位)

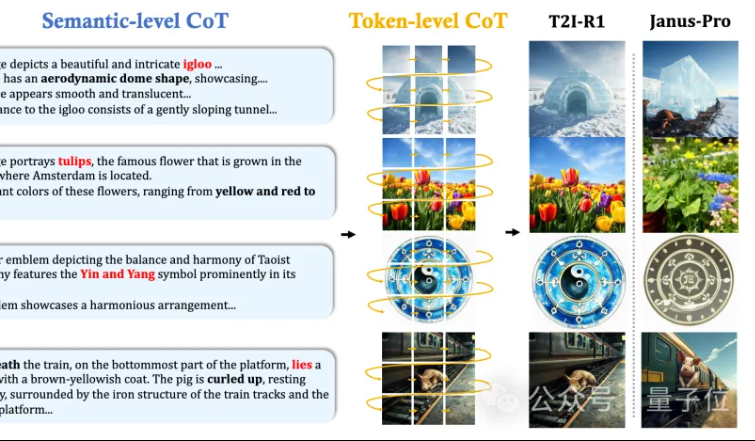
MMLab из Китайского университета Гонконга представила T2I-R1: двухуровневый CoT-вывод и обучение с подкреплением для генерации изображений из текста: Команда MMLab из Китайского университета Гонконга выпустила T2I-R1, первую модель генерации изображений из текста с усиленным логическим выводом на основе обучения с подкреплением. Модель инновационно предлагает двухуровневую структуру логического вывода «цепочка мыслей» (CoT): Semantic-CoT (текстовый вывод, планирование глобальной структуры изображения) и Token-CoT (поблочная генерация токенов изображения, фокусировка на деталях нижнего уровня). С помощью метода обучения с подкреплением BiCoT-GRPO эти два уровня CoT совместно оптимизируются в единой LMM (Janus-Pro) без необходимости в дополнительных моделях. Модель вознаграждения использует интеграцию нескольких экспертных визуальных моделей, обеспечивая надежность оценки и предотвращая переобучение. Эксперименты показывают, что T2I-R1 лучше понимает намерения пользователя, генерирует изображения, более соответствующие ожиданиям, и значительно превосходит базовые модели на бенчмарках T2I-CompBench и WISE. (Источник: 量子位, WeChat)
OpenAI выпустила легковесную библиотеку для оценки языковых моделей simple-evals: OpenAI открыла исходный код simple-evals, легковесной библиотеки для оценки языковых моделей, с целью сделать прозрачными данные о точности своих последних моделей. Библиотека подчеркивает настройки оценки zero-shot и chain-of-thought и предоставляет подробное сравнение производительности моделей на нескольких бенчмарках, таких как MMLU, MATH, GPQA, включая собственные модели OpenAI (например, o3, o4-mini, GPT-4.1, GPT-4o) и другие основные модели (например, Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Источник: GitHub Trending)
Выпущена корейская версия «LLM Engineer’s Handbook»: «LLM Engineer’s Handbook» Максима Лабонна теперь доступна на корейском языке в переводе У Чхоль Чо. В ближайшее время также выйдут версии этого руководства на русском, китайском, польском и других языках, предоставляя учебные ресурсы разработчикам LLM по всему миру. (Источник: maximelabonne)

Объявлен семинар по машинному обучению для аудио ML4Audio на ICML 2025: Популярный семинар по машинному обучению для аудио (ML for Audio) вернется во время ICML 2025 в Ванкувере, конкретная дата — 19 июля (суббота). На семинаре выступят известные ученые, такие как Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti и Pratyusha Rakshit. Крайний срок подачи статей — 23 мая. (Источник: sedielem)
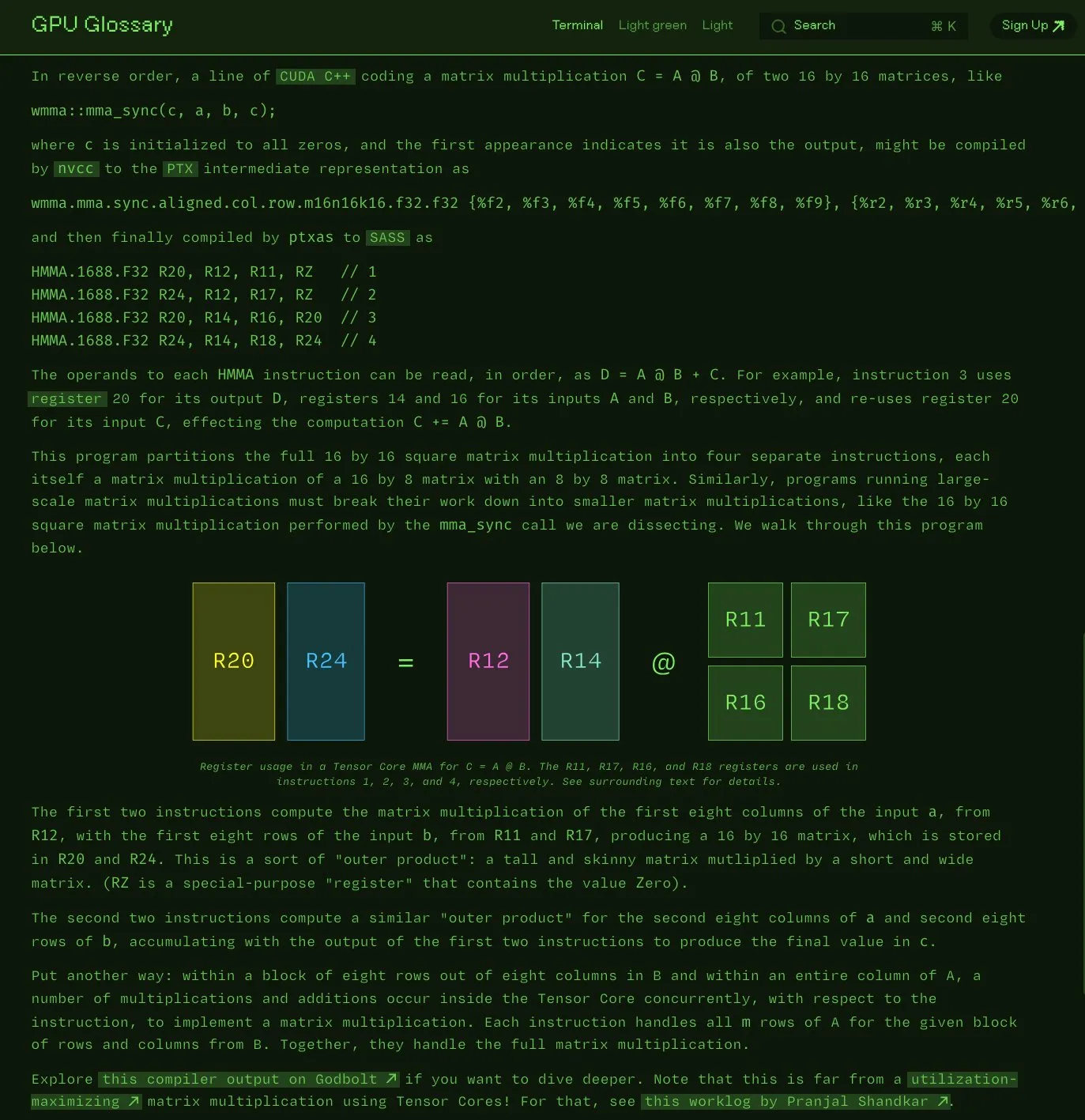
Чарльз Фрай открыл исходный код глоссария терминов GPU: Чарльз Фрай объявил, что его глоссарий терминов GPU (GPU Glossary) теперь доступен с открытым исходным кодом. Глоссарий предназначен для помощи в понимании концепций, связанных с аппаратным обеспечением GPU и программированием, и недавно был обновлен информацией о декомпозиции инструкций SASS для выполнения простых операций умножения-сложения матриц (mma) на Tensor Core. Проект размещен на GitHub и содержит список задач, которые предстоит выполнить. (Источник: charles_irl)
OpenAI опубликовала руководство по промпт-инжинирингу для GPT-4.1, подчеркивая структурированность и четкие инструкции: OpenAI выпустила руководство по промпт-инжинирингу для GPT-4.1, призванное помочь пользователям более эффективно создавать промпты, особенно для приложений, требующих структурированного вывода, логического вывода, использования инструментов и работы на основе агентов. Руководство подчеркивает важность четкого определения роли и цели, предоставления ясных инструкций (включая тон, формат, границы), необязательных под-инструкций, пошагового логического вывода/планирования, точного определения формата вывода и использования примеров, а также предлагает некоторые практические советы, такие как выделение ключевых инструкций, использование Markdown или XML для структурирования ввода и т.д. (Источник: Reddit r/MachineLearning)

Kaggle и Hugging Face углубляют сотрудничество, упрощая вызов и обнаружение моделей: Kaggle объявила об усилении сотрудничества с Hugging Face. Теперь пользователи могут напрямую запускать модели Hugging Face в Kaggle Notebooks, находить связанные общедоступные примеры кода и беспрепятственно исследовать модели на обеих платформах. Эта интеграция направлена на расширение доступности моделей и предоставление пользователям Kaggle более удобного доступа к ресурсам моделей в экосистеме Hugging Face. (Источник: huggingface)
FedRAG: фреймворк с открытым исходным кодом для дообучения систем RAG, поддерживающий федеративное обучение: Исследователь из Vector Institute представил FedRAG, фреймворк с открытым исходным кодом, предназначенный для упрощения дообучения систем Retrieval Augmented Generation (RAG). Этот фреймворк не только поддерживает типичное централизованное обучение, но и специально вводит архитектуру федеративного обучения для удовлетворения потребностей в обучении на распределенных наборах данных. FedRAG совместим с экосистемами PyTorch и Hugging Face, поддерживает использование Qdrant в качестве хранилища базы знаний и может быть подключен к LlamaIndex. (Источник: nerdai)

💼 Бизнес
Материнская компания Cursor, Anysphere, за два года достигла ARR в 200 миллионов долларов, оценка взлетела до 9 миллиардов долларов: Компания Anysphere, возглавляемая 25-летним Майклом Труэллом, бросившим учебу в MIT, благодаря своему ИИ-редактору кода Cursor, без проведения маркетинговых кампаний за два года достигла годового регулярного дохода (ARR) в 200 миллионов долларов, а оценка компании быстро выросла до 9 миллиардов долларов. Cursor, глубоко интегрировав ИИ в процесс разработки, изменил парадигму разработки программного обеспечения, сосредоточившись на обслуживании индивидуальных разработчиков и получив широкое признание и сарафанное радио от разработчиков по всему миру. Thrive Capital возглавил ее последний раунд финансирования. (Источник: 36氪)

Databricks объявляет о приобретении компании Neon, разработчика Serverless Postgres: Databricks согласилась приобрести компанию Neon, ориентированную на разработчиков и предоставляющую Serverless Postgres. Neon известна своей новой архитектурой баз данных, обеспечивающей скорость, эластичное масштабирование, а также функции ветвления и форкинга, которые привлекательны как для разработчиков, так и для ИИ-агентов. Это приобретение направлено на совместное создание открытой, бессерверной базы данных для разработчиков и ИИ-агентов. (Источник: jefrankle, matei_zaharia)
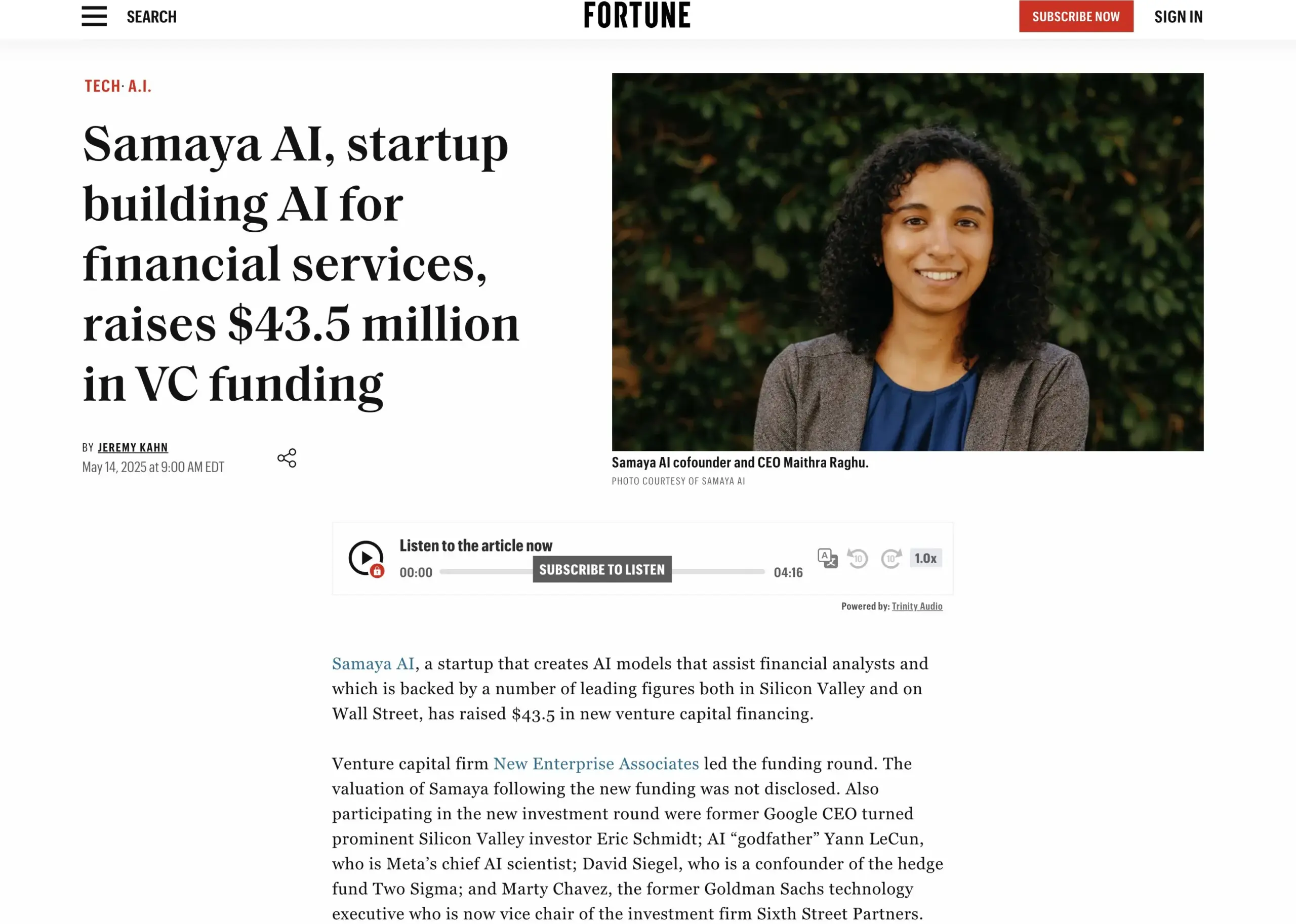
Стартап в области финансовых ИИ-услуг Samaya AI привлек 43,5 миллиона долларов финансирования: Samaya AI объявила о привлечении 43,5 миллиона долларов финансирования под руководством NEA для создания экспертных ИИ-агентов для финансовых услуг, нацеленных на масштабное преобразование интеллектуальной работы. Компания, основанная в 2022 году, специализируется на создании специализированных ИИ-решений для сложных финансовых рабочих процессов. Ее экспертные ИИ-агенты на базе собственных LLM уже используются тысячами пользователей в ведущих учреждениях, таких как Morgan Stanley, для проведения комплексной проверки, экономического моделирования и поддержки принятия решений, с акцентом на точность, прозрачность и отсутствие галлюцинаций. (Источник: maithra_raghu)
🌟 Сообщество
Заменит ли ИИ программистов? В сообществе активно обсуждается необходимость повышения квалификации: В социальных сетях вновь разгорелась дискуссия о том, заменит ли ИИ программистов. Общее мнение сводится к тому, что ИИ не заменит программистов полностью, поскольку разработка программного обеспечения — это гораздо больше, чем просто написание кода. Однако те, кто в основном занимается рутинной работой по написанию кода, так называемые «кодовые обезьяны» (code monkeys), не имеющие глубокого понимания системы в целом, рискуют быть замененными ИИ-инструментами, если не повысят свою квалификацию, не углубятся в архитектуру систем и решение сложных проблем. (Источник: cto_junior, cto_junior)
Будущее ИИ-агентов: возможности и вызовы сосуществуют, лидеры отрасли оптимистично оценивают их потенциал: CEO OpenAI Сэм Альтман прогнозирует, что 2025 год станет годом прорыва для ИИ-агентов, которые будут активнее участвовать в реальной работе. Лю Чжии в своем интервью также подчеркнул, что агенты трансформируются из пассивных инструментов в активные исполнительные системы, их развитие зависит от прогресса базовых моделей и способности взаимодействовать с физическим миром. Несмотря на то, что в настоящее время агенты все еще имеют недостатки в скорости отклика, контроле галлюцинаций и т.д., их способность автономно выполнять задачи и помогать в обучении большим моделям высоко ценится и уже находит применение в таких областях, как интеллектуальные службы поддержки клиентов и финансовое консультирование. (Источник: 36氪, 量子位)

Perplexity AI сотрудничает с PayPal и Venmo для интеграции платежей в электронной коммерции и путешествиях: Perplexity AI объявила о сотрудничестве с PayPal и Venmo для интеграции платежных функций в свою платформу для покупок в электронной коммерции, бронирования путешествий, а также в голосового помощника и готовящийся к выпуску браузер Comet. Этот шаг направлен на упрощение всего коммерческого процесса от просмотра, поиска, выбора до безопасной оплаты, улучшая пользовательский опыт. (Источник: AravSrinivas, perplexity_ai)
Обсуждение оценки ИИ-моделей: IFEval и ChartQA в центре внимания, необходимо остерегаться загрязнения обучающих данных: В обсуждениях сообщества IFEval считается одним из лучших бенчмарков для оценки следования инструкциям благодаря своему простому и остроумному дизайну. В то же время некоторые пользователи отмечают, что тестовые данные ChartQA содержат шум, нечеткие ответы и несоответствия, что может потребовать их исключения. Vikhyatk напоминает, что многие модели, заявляющие о высокой точности на бенчмарках, могут иметь проблему загрязнения обучающих данных, которая остается незамеченной. (Источник: clefourrier, vikhyatk)

Авторские права и этика ИИ-контента вызывают озабоченность: Audible планирует использовать ИИ-озвучку, ИИ-сгенерированные персонажи для онлайн-знакомств вызывают опасения: Audible объявила о планах использовать ИИ-сгенерированную озвучку для создания аудиокниг, стремясь «привнести больше историй в жизнь», что вызвало дискуссии о применении ИИ в творческих индустриях. С другой стороны, на Reddit пользователь сообщил, что его мать взаимодействовала на сайте знакомств с предположительно ИИ-сгенерированным образом «реального мужчины», опасаясь обмана. Это подчеркивает потенциальные риски ИИ-сгенерированного контента в плане достоверности, эмоциональной манипуляции и мошенничества. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Прочее
Китайская компания «Star Computing» успешно запустила первые 12 спутников для космических вычислений, открывая новую эру вычислений на базе космоса: Проект «Star Computing», возглавляемый Guoxing Aerospace, успешно вывел на орбиту первые 12 вычислительных спутников, сформировав первую в мире космическую вычислительную группировку. Каждый спутник обладает возможностями космических вычислений и межсоединений, вычислительная мощность одного спутника увеличена с терафлопс до петафлопс, орбитальная вычислительная мощность первой группировки достигает 5 POPS, а скорость лазерной связи между спутниками составляет до 100 Гбит/с. Цель этого шага — создание космической интеллектуальной вычислительной инфраструктуры, решение проблем большого энергопотребления и сложного охлаждения наземных вычислительных мощностей, а также поддержка обработки данных глубокого космоса в реальном времени на орбите, реализуя концепцию «космические данные — космические вычисления». В будущем планируется запустить 2800 спутников для создания крупной космической вычислительной сети. (Источник: 量子位)

NVIDIA опубликовала годовой отчет, подчеркнув, что ИИ является ядром новой промышленной революции, а интеллект — продуктом: В своем годовом отчете NVIDIA отметила, что мир вступает в новую промышленную революцию, основным продуктом которой является «интеллект». NVIDIA стремится создавать интеллектуальную инфраструктуру, превращая вычисления в генеративную силу, способствующую развитию всех отраслей. (Источник: nvidia)

NBA и Kling AI от Kuaishou совместно выпустили ИИ-короткометражку «Детский данк Карри»: NBA в сотрудничестве с Kling AI, большой моделью генерации видео из текста от Kuaishou (аналог Sora), и при участии AI TALK создала ИИ-короткометражку под названием «Childhood Curry’s Dunk». В фильме предпринята попытка с помощью Kling AI воссоздать сцену данка Карри, «путешествующего во времени», для поддержки плей-офф NBA. В фильме также есть специальные камео Баркли, О’Нила и Йокича. (Источник: TomLikesRobots)