
Ключевые слова:GENMO, Seed-Coder, DeepSeek, LlamaParse, Агентный ИИ, Пограничные вычисления, Квантовые вычисления, Модель движения человека NVIDIA GENMO, Кодовая модель Seed-Coder от ByteDance, Влияние стратегии открытого исходного кода DeepSeek, Оценка достоверности анализа документов LlamaParse, Обработка данных в реальном времени с помощью пограничных вычислений
🔥 Фокус
NVIDIA представляет универсальную модель движений человека GENMO: NVIDIA выпустила модель ИИ под названием GENMO (GENeralist Model for Human MOtion), способную преобразовывать различные входные данные, такие как текст, видео, музыка и даже силуэты ключевых кадров, в реалистичные 3D-движения человека. Модель может понимать и объединять различные типы входных данных, например, изучать движения из видео и изменять их на основе текстовых подсказок или генерировать танцы в соответствии с музыкальным ритмом. GENMO демонстрирует огромный потенциал в таких областях, как игровая анимация и создание персонажей для виртуальных миров, способна генерировать сложные и естественные последовательные движения, а также поддерживает интуитивное редактирование временной шкалы анимации. Хотя в настоящее время она не может обрабатывать выражения лица и детали рук и зависит от внешних методов SLAM, ее мультимодальный ввод и высококачественный вывод представляют собой важный прогресс в области генерации движений с помощью ИИ (Источник: YouTube — Two Minute Papers
)
ByteDance выпускает серию больших моделей с открытым исходным кодом Seed-Coder: ByteDance выпустила серию больших языковых моделей с открытым исходным кодом Seed-Coder, включающую базовую модель, модель инструкций и модель вывода с масштабом 8B параметров. Ключевой особенностью этой серии моделей является их способность «самостоятельно курировать данные для кодовых моделей», что направлено на минимизацию участия человека в построении данных. Seed-Coder достиг текущего наилучшего уровня (SOTA) во многих аспектах, таких как генерация и редактирование кода, демонстрируя потенциал оптимизации и построения обучающих данных с помощью собственных возможностей ИИ, что открывает новые перспективы для разработки больших кодовых моделей (Источник: _akhaliq)
Модели DeepSeek вызывают широкий интерес в сообществе ИИ: Модели серии DeepSeek, особенно их кодовые модели, вызвали широкое обсуждение в сообществе ИИ благодаря своей высокой производительности и стратегии открытого исходного кода. Многие разработчики и исследователи впечатлены их результатами, считая, что они изменили глобальное восприятие моделей с открытым исходным кодом. В ходе обсуждений отмечалось, что успех DeepSeek может побудить такие компании, как OpenAI, пересмотреть свои стратегии открытого исходного кода и ускорить темпы открытия исходного кода местными производителями больших моделей. Несмотря на проблемы, связанные с коммерциализацией, аппаратной адаптацией и т.д., появление DeepSeek рассматривается как важная сила, способствующая демократизации технологий ИИ и развитию отрасли (Источники: Ronald_vanLoon, 36氪)

Обновление LlamaParse: интеграция GPT-4.1 и Gemini 2.5 Pro для улучшения анализа документов: LlamaParse выпустил важное обновление, интегрировав последние модели GPT-4.1 и Gemini 2.5 Pro, что значительно повысило точность анализа документов. Новые функции включают автоматическое определение ориентации и перекоса, обеспечивая выравнивание и точность анализируемого содержимого. Кроме того, введена функция оценки достоверности, позволяющая пользователям оценивать качество анализа каждой страницы и настраивать процесс ручной проверки на основе пороговых значений достоверности. Это обновление направлено на решение проблем с ошибками, которые могут возникать у LLM/LVM при обработке сложных документов, обеспечивая надежность автоматизированных процессов за счет предоставления пользовательского опыта ручной проверки и коррекции (Источник: jerryjliu0)
🎯 Тенденции
Прогноз тенденций технологической отрасли на 2025 год: В отчете прогнозируются основные тенденции технологической отрасли на 2025 год, включая дальнейшее развитие и глубокую интеграцию таких новых технологий, как искусственный интеллект, машинное обучение, 5G, носимые устройства, блокчейн и кибербезопасность. Ожидается, что эти технологии сыграют важную роль в улучшении жизни, стимулировании инноваций и решении социальных проблем, предвещая светлое будущее, основанное на технологиях (Источники: Ronald_vanLoon, Ronald_vanLoon)

Прогноз тенденций развития ИИ на 2025 год: IBM прогнозирует, что в 2025 году область искусственного интеллекта продолжит быстро развиваться, технологии машинного обучения (ML) и искусственного интеллекта (MI) станут еще более зрелыми и будут широко применяться в различных отраслях. Ожидается, что ИИ будет играть более значительную роль в автоматизации, анализе данных, поддержке принятия решений и других областях, способствуя технологическим инновациям и модернизации промышленности (Источник: Ronald_vanLoon)

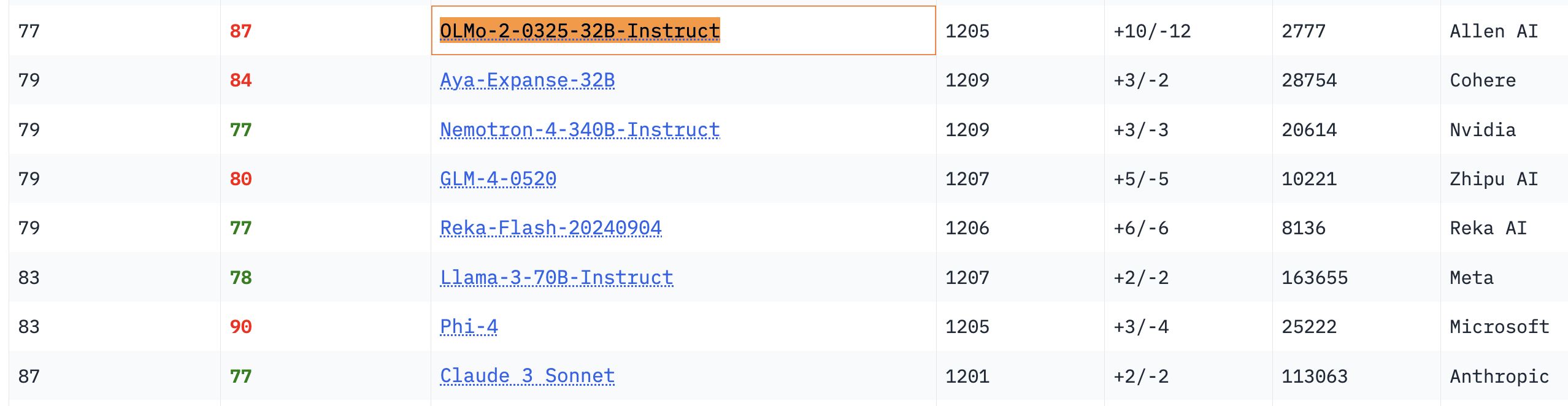
Выдающаяся производительность модели OLMo 32B: В соответствующих бенчмарках полностью открытая модель OLMo 32B показала лучшие результаты, чем модели Nemotron 340B и Llama 3 70B с большим количеством параметров. Этот результат показывает, что в некоторых аспектах полностью открытые модели с меньшим количеством параметров могут достигать и даже превосходить более крупные коммерческие модели, демонстрируя огромный потенциал и скорость развития исследований открытых моделей (Источники: natolambert, teortaxesTex, lmarena_ai)
Количество загрузок модели Gemma превысило 150 миллионов, количество вариантов — более 70 тысяч: Количество загрузок модели Gemma от Google на платформе Hugging Face превысило 150 миллионов, и существует более 70 тысяч ее вариантов. Эти данные отражают популярность и широкое применение модели Gemma в сообществе разработчиков. Пользователи сообщества также с нетерпением ожидают итераций ее будущих версий (Источники: osanseviero, _akhaliq)
Unsloth обновляет модели Qwen3 GGUF, улучшает набор данных для калибровки: Unsloth обновил все свои модели Qwen3 GGUF и использовал новый, улучшенный набор данных для калибровки. Кроме того, для Qwen3-30B-A3B было добавлено больше вариантов GGUF. Пользователи сообщают, что в версии 30B-A3B-UD-Q5_K_XL качество перевода улучшилось по сравнению с другими GGUF Q5 и Q4 (Источник: Reddit r/LocalLLaMA)

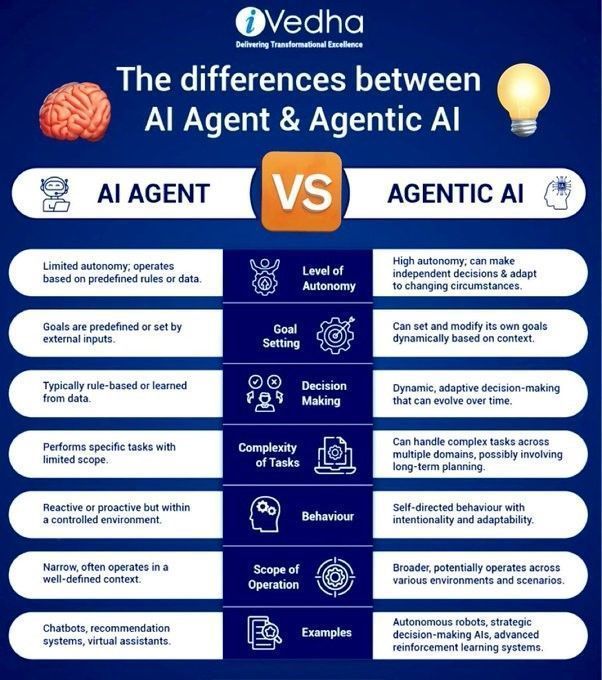
Разница между Agentic AI и GenAI: Agentic AI и генеративный ИИ (GenAI) являются актуальными темами в современной области ИИ. GenAI в основном относится к ИИ, способному создавать новый контент (текст, изображения и т.д.), в то время как Agentic AI больше ориентирован на интеллектуальных агентов, способных автономно выполнять задачи, взаимодействовать с окружающей средой и принимать решения. Agentic AI обычно сочетает в себе возможности GenAI, но делает больший акцент на своей автономии и целеустремленности (Источник: Ronald_vanLoon)

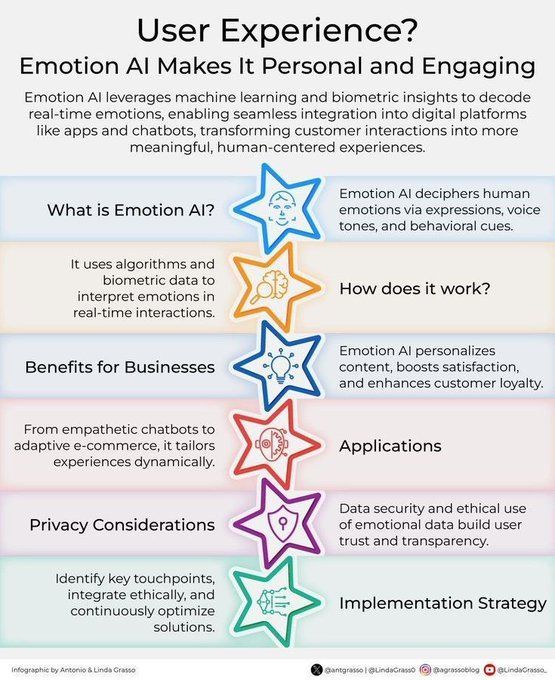
Эмоциональный ИИ улучшает клиентский опыт: Технология эмоционального ИИ, анализируя и понимая человеческие эмоции, применяется для улучшения клиентского опыта (CX). Она может помочь компаниям лучше понимать потребности и эмоции клиентов, тем самым предоставляя более персонализированные и эмпатичные услуги, способствуя инновациям в управлении взаимоотношениями с клиентами в условиях цифровой трансформации (Источник: Ronald_vanLoon)
Концепция персонализированных инструментов на базе ИИ “Jigging”: Karina Nguyen предложила концепцию “Jigging”, метафорически описывающую модели ИИ как индивидуализированных, самосовершенствующихся мастеров инструментов. При каждом взаимодействии с пользователем ИИ будет создавать новые специализированные инструменты на основе характеристик пользователя и задачи, тем самым расширяя свои возможности. Например, ИИ может создавать персонализированные диагностические фреймворки для врачей или уникальные нарративные структуры для писателей. Такое рекурсивное улучшение сделает ИИ продолжением когнитивной архитектуры пользователя, способствуя фундаментальному сдвигу в сотрудничестве человека и машины (Источник: karinanguyen_)
Разница между AI Agents и Agentic AI: Khulood Almani далее разъяснила разницу между агентами ИИ (AI Agents) и Agentic AI. Агенты ИИ обычно относятся к программным приложениям, выполняющим определенные задачи, в то время как Agentic AI делает больший акцент на автономии, способности к обучению и адаптивности системы, способной более активно взаимодействовать с окружающей средой и достигать сложных целей. Понимание этой разницы помогает уловить направление и потенциал развития ИИ (Источник: Ronald_vanLoon)
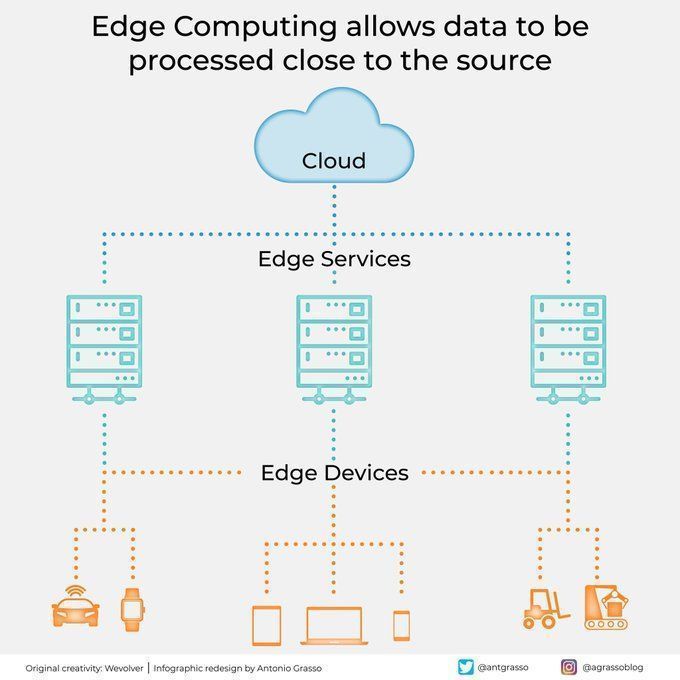
Граничные вычисления обрабатывают данные вблизи источника: Технология граничных вычислений (edge computing) обрабатывает данные вблизи их источника, что позволяет сократить задержки, снизить требования к пропускной способности и усилить защиту конфиденциальности. Это крайне важно для приложений ИИ, требующих реакции в реальном времени и обработки больших объемов данных (например, автономное вождение, промышленный Интернет вещей), и является важной частью облачных вычислений и цифровой трансформации (Источник: Ronald_vanLoon)
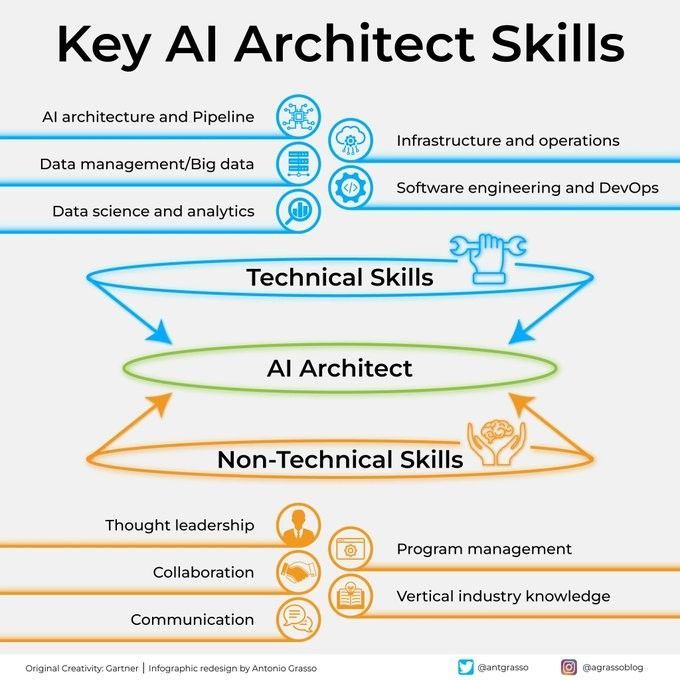
Ключевые навыки архитектора ИИ: Чтобы стать успешным архитектором ИИ, необходимо обладать многогранными навыками, включая глубокие технические знания (алгоритмы машинного обучения, глубокого обучения), способность к проектированию систем, знания в области управления данными, а также понимание бизнес-потребностей. Кроме того, крайне важны навыки коммуникации и сотрудничества, а также энтузиазм в постоянном изучении новых технологий (Источник: Ronald_vanLoon)
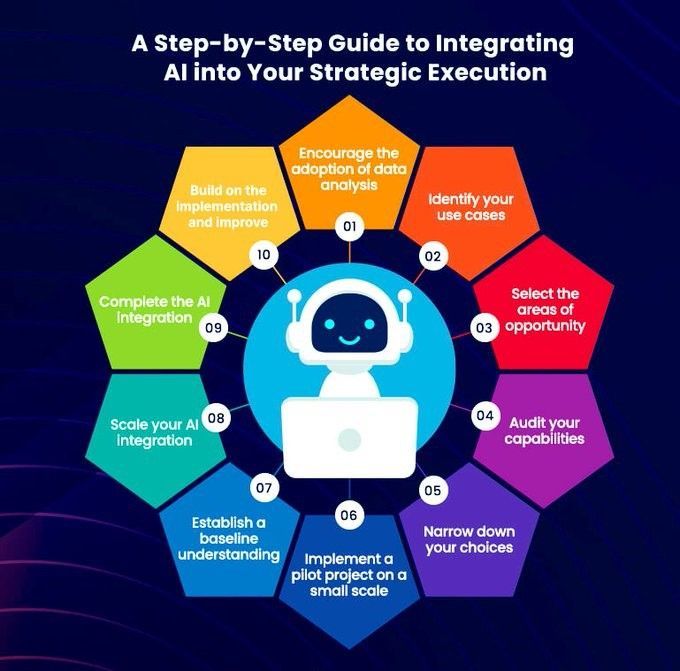
Пошаговое руководство по интеграции ИИ в стратегическое исполнение: Khulood Almani предоставила пошаговое руководство, призванное помочь предприятиям интегрировать искусственный интеллект в свои процессы стратегического выполнения. Это включает определение целей ИИ, оценку существующих возможностей, выбор подходящих технологий ИИ, разработку дорожной карты внедрения, а также создание механизмов мониторинга и оценки для обеспечения соответствия проектов ИИ общей бизнес-стратегии и достижения ожидаемой ценности (Источник: Ronald_vanLoon)
Как квантовые вычисления изменят кибербезопасность: Появление квантовых вычислений оказывает двойственное влияние на кибербезопасность. С одной стороны, их мощные вычислительные возможности могут взломать существующие алгоритмы шифрования, создавая угрозы безопасности; с другой стороны, квантовые технологии также породили новые средства защиты, такие как квантовая криптография. Khulood Almani обсуждает преобразующую роль квантовых вычислений в области кибербезопасности, подчеркивая важность подготовки к постквантовой эре (Источник: Ronald_vanLoon)
Инструменты, которые будут доминировать в области ИИ в 2025 году: Perplexity прогнозирует ключевые инструменты, которые будут доминировать в области искусственного интеллекта в 2025 году. Вероятно, это будут более продвинутые большие языковые модели (LLM), платформы генеративного ИИ, инструменты для науки о данных, а также специализированные ИИ-решения для конкретных отраслей. Эти инструменты будут способствовать дальнейшему распространению и углублению применения ИИ в различных сферах деятельности (Источник: Ronald_vanLoon)

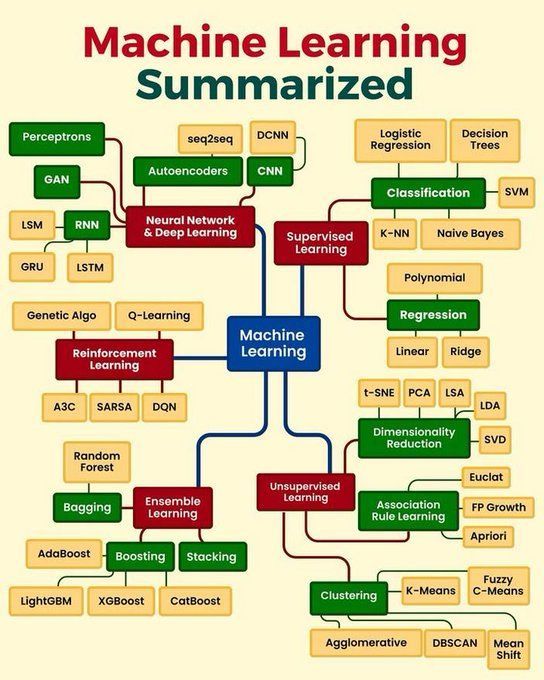
Обзор основных концепций машинного обучения: Python_Dv обобщил основные концепции машинного обучения, которые могут охватывать такие фундаментальные принципы, как обучение с учителем, обучение без учителя, обучение с подкреплением, глубокое обучение, а также часто используемые алгоритмы и сценарии их применения. Это предоставляет краткий обзор для начинающих и тех, кто хочет укрепить свои базовые знания (Источник: Ronald_vanLoon)
🧰 Инструменты
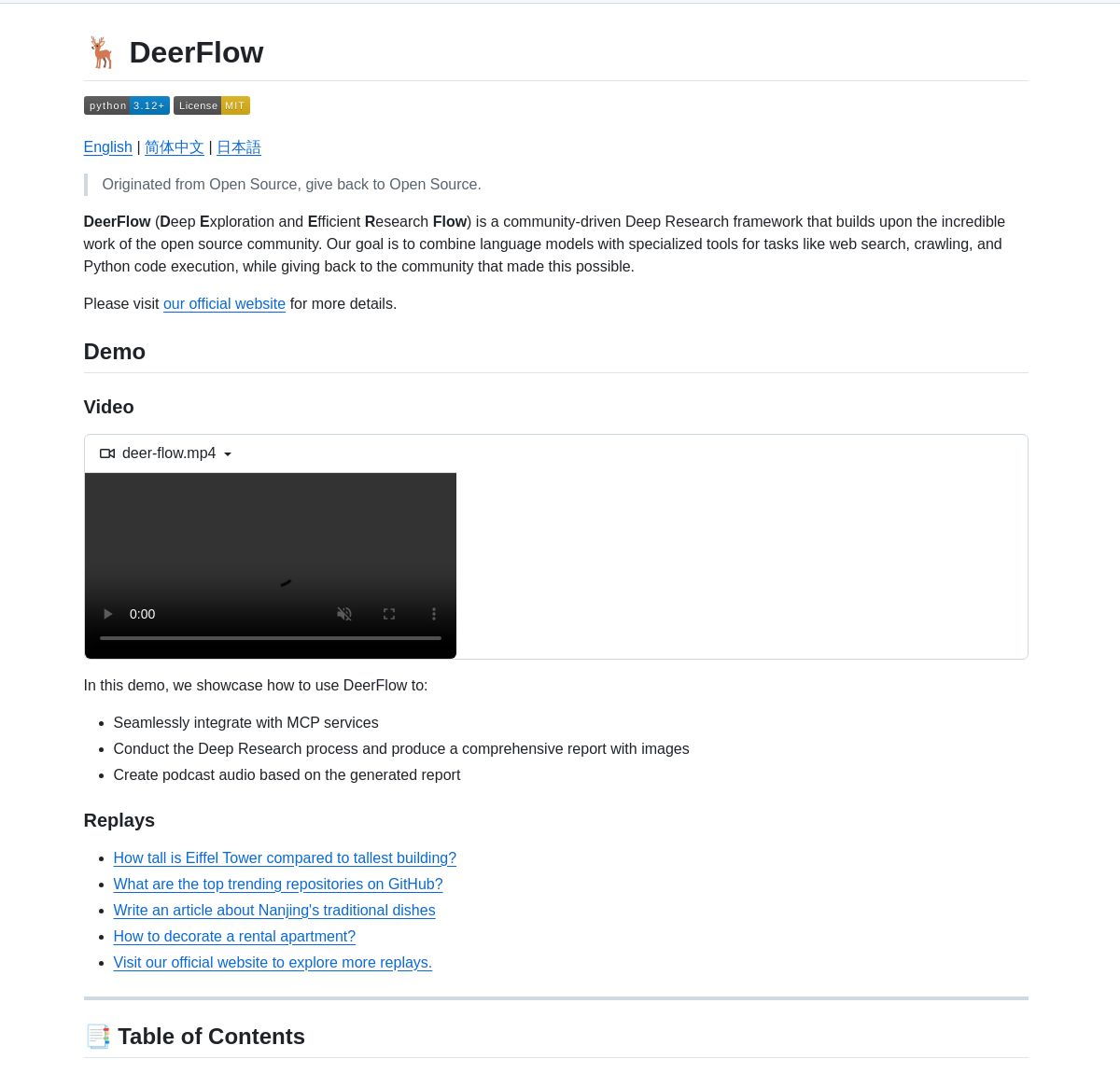
ByteDance представляет фреймворк для глубоких исследований DeerFlow: ByteDance представила DeerFlow с открытым исходным кодом — фреймворк для систематических глубоких исследований путем координации агентов LangGraph. Он поддерживает всесторонний анализ литературы, синтез данных и структурированное извлечение знаний, нацеленный на повышение эффективности и глубины применения ИИ в научно-исследовательской сфере (Источники: LangChainAI, Hacubu)
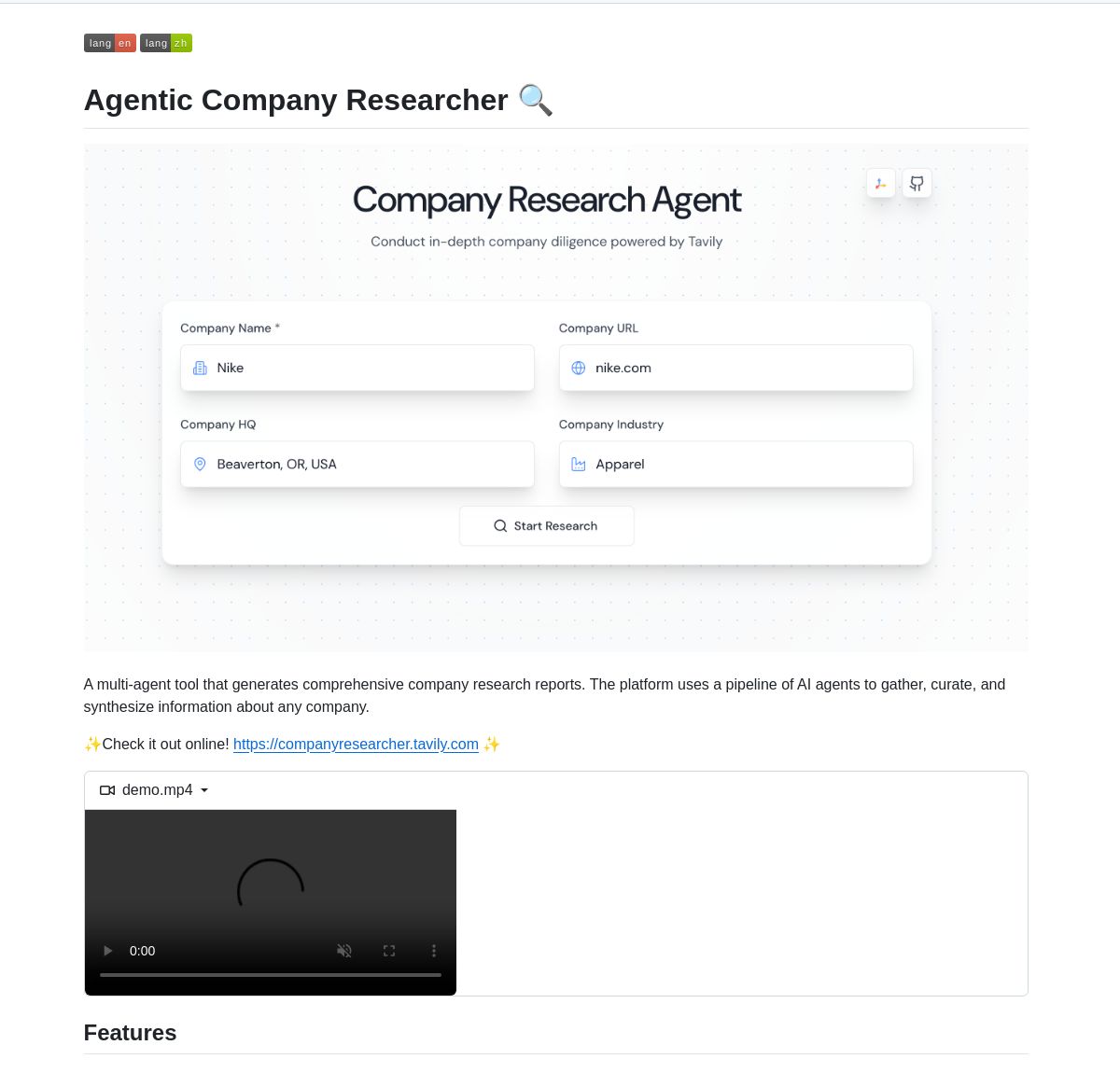
Многоагентная система для исследования компаний на базе LangGraph: Разработана многоагентная система на базе LangGraph для генерации отчетов об исследованиях компаний в реальном времени. Система использует интеллектуальные процессы и специализированные узлы для анализа коммерческих, финансовых и рыночных данных, предоставляя пользователям глубокие сведения о компаниях. Демонстрация и код доступны на GitHub (Источники: LangChainAI, Hacubu)
RunwayML Gen-4 References обеспечивает точное позиционирование персонажей/объектов: Обнаружено, что функция Gen-4 References в RunwayML может использоваться для точного контроля положения персонажей или объектов в генерируемом контенте. Пользователи могут, предоставляя сцену и референсное изображение с метками (например, простые цветные фигуры, указывающие положение), направлять ИИ для размещения определенных элементов в желаемых точных позициях, что открывает новые возможности для творческих рабочих процессов. Эта модель, будучи универсальной, может адаптироваться к различным рабочим процессам без необходимости тонкой настройки (Источники: c_valenzuelab, c_valenzuelab)

Code Chrono: инструмент для оценки времени программирования проектов с помощью локальной LLM: Rafael Viana разработал терминальный инструмент под названием Code Chrono для отслеживания продолжительности сеансов кодирования и использования локальной LLM для оценки времени разработки будущих функций. Инструмент призван помочь разработчикам более реалистично оценивать затраты времени на проекты и избегать недооценки объема работ. Код проекта открыт (Источник: Reddit r/LocalLLaMA)

Прогресс в интеграции PyTorch и языка Mojo: Mark Saroufim на хакатоне Mojo рассказал, как PyTorch упрощает поддержку новых языков и аппаратных бэкендов, и продемонстрировал WIP-бэкенд, разработанный в сотрудничестве с командой Mojo. Chris Lattner высоко оценил это сотрудничество, считая, что сочетание Mojo и PyTorch придаст новую энергию экосистеме PyTorch и будет способствовать инновациям в инструментах разработки ИИ (Источники: clattner_llvm, marksaroufim)
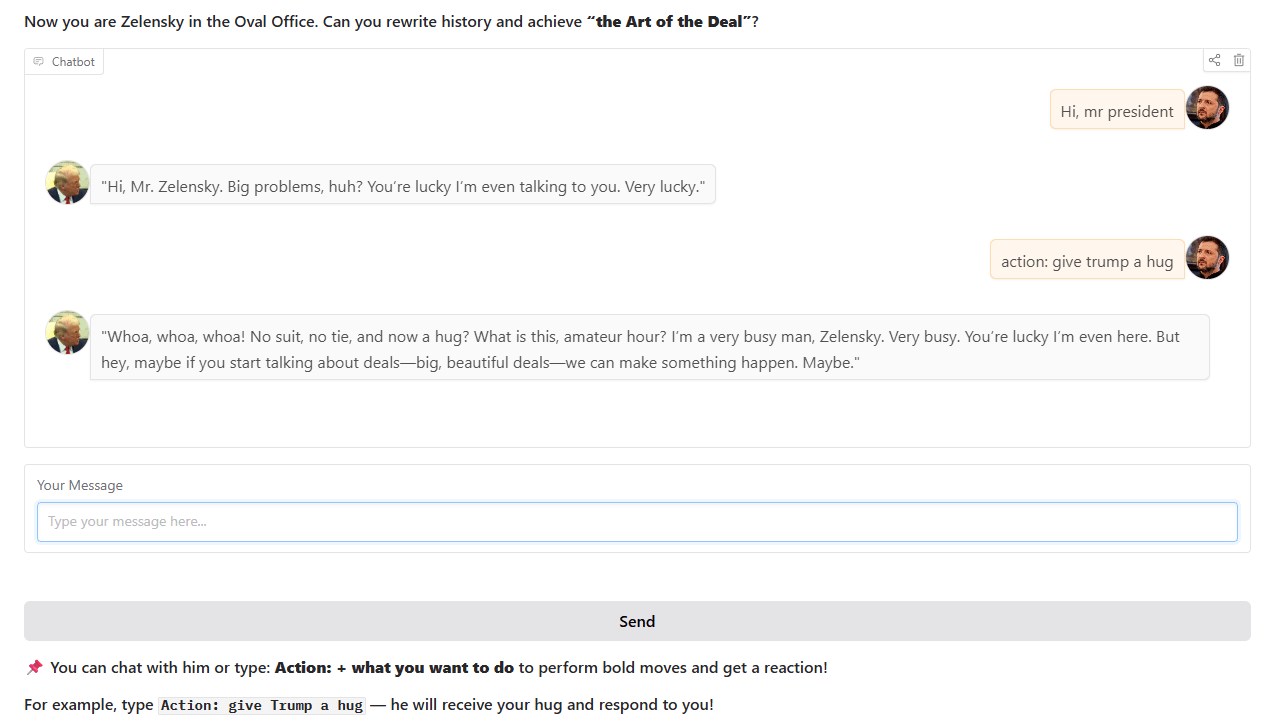
Чат-бот в стиле Трампа: Один разработчик, основываясь на реальных исторических событиях в Овальном кабинете, обучил и запустил чат-бота, имитирующего стиль Трампа. С этим ботом можно взаимодействовать на Hugging Face Spaces, и разработчик надеется получить отзывы и предложения от пользователей (Источник: Reddit r/artificial)
Инструмент с открытым исходным кодом для создания Agentic Network: Инструмент с открытым исходным кодом под названием python-a2a упрощает процесс создания Agentic Network, поддерживая операции перетаскивания. Пользователи могут попробовать использовать этот инструмент для создания и управления сетями агентов ИИ (Источник: Reddit r/ClaudeAI)
carcodes.xyz: социальная платформа для автолюбителей: Один пользователь, после измены подруги, использовал Claude 3.7 в качестве помощника по программированию и разработал carcodes.xyz. Эта платформа, похожая на Linktree, позволяет автолюбителям демонстрировать свои тюнингованные автомобили, следить за другими автолюбителями, делиться информацией о ближайших авто-встречах и находить их, а также предоставляет QR-коды, которые можно наклеить на автомобиль, чтобы другие могли легко сканировать и переходить на личную страницу. Весь проект создан с использованием Next.js, TailwindCSS, MongoDB и Stripe (Источник: Reddit r/ClaudeAI)

Локальный запуск модели Gemma 3 27B на AMD RX 7800 XT 16GB: Пользователь поделился опытом успешного локального запуска модели Gemma 3 27B на видеокарте AMD RX 7800 XT 16GB. Используя версию gemma-3-27B-it-qat-GGUF, предоставленную lmstudio-community, и сервер llama.cpp, удалось полностью загрузить модель в VRAM и запустить ее с длиной контекста 16K. В публикации подробно описаны конфигурация оборудования, команды запуска, настройки параметров (на основе рекомендаций команды Unsloth), а также результаты тестов производительности в средах ROCm и Vulkan, которые показали, что ROCm демонстрирует лучшую производительность в данной конфигурации (Источник: Reddit r/LocalLLaMA)

📚 Обучение
Разбор основных идей и преимуществ фреймворка DSPy: Omar Khattab подробно изложил основные концепции дизайна фреймворка DSPy. DSPy нацелен на предоставление набора стабильных абстракций (таких как Signatures, Modules, Optimizers), позволяющих разработке программного обеспечения ИИ адаптироваться к постоянному прогрессу LLM и их методов. Его ключевые идеи включают: поток информации является ключевым, взаимодействие с LLM должно быть функционализировано и структурировано, стратегии рассуждений должны быть полиморфными модулями, спецификация поведения ИИ должна быть отделена от парадигм обучения, оптимизация на естественном языке является мощной парадигмой обучения. Эти принципы направлены на создание программного обеспечения ИИ, «ориентированного на будущее», снижая затраты на переписывание, вызванные изменениями в базовых моделях или парадигмах. Эта серия твитов вызвала широкое обсуждение и признание, и считается важным источником для понимания DSPy и современной разработки программного обеспечения ИИ (Источники: menhguin, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction)
Воркшоп по математике ИИ для начинающих: ProfTomYeh объявил о проведении воркшопа по математике ИИ для начинающих, цель которого — помочь участникам понять математические принципы, лежащие в основе глубокого обучения, такие как скалярное произведение, умножение матриц, линейные слои, функции активации и искусственные нейроны. Воркшоп будет включать серию интерактивных упражнений, позволяющих участникам самостоятельно выполнять математические вычисления, тем самым устраняя мистику вокруг математики ИИ (Источник: ProfTomYeh)
Публикация обновленных слайдов к учебнику «Обработка речи и языка»: Опубликованы обновленные слайды к классическому учебнику Дэна Джурафски и Джеймса Х. Мартина из Стэнфордского университета «Обработка речи и языка» (Speech and Language Processing). Этот учебник является авторитетным трудом в области NLP, и данное обновление предоставляет учащимся и преподавателям ценный ресурс с открытым доступом, способствующий пониманию передовых технологий, таких как LLM и Transformer (Источник: stanfordnlp)
Учебное пособие по созданию исследовательского агента ИИ: использование LangGraph и Ollama: LangChainAI опубликовал учебное пособие, в котором рассказывается, как создать исследовательского агента ИИ. Этот агент способен выполнять поиск в Интернете и генерировать аннотации со ссылками с использованием LangGraph и Ollama, предоставляя пользователям комплексное автоматизированное решение для исследований. Видеоурок опубликован на YouTube (Источники: LangChainAI, Hacubu)

DAIR.AI публикует популярные научные статьи по ИИ за неделю: DAIR.AI собрал популярные научные статьи по ИИ за период с 5 по 11 мая 2025 года, включая такие исследования, как ZeroSearch, Discuss-RAG, Absolute Zero, Llama-Nemotron, The Leaderboard Illusion и Reward Modeling as Reasoning, предоставляя исследователям информацию о последних разработках (Источник: omarsar0)
Статья об агентных паттернах (Agentic Patterns): Phil Schmid поделился статьей, в которой подробно рассматриваются распространенные агентные паттерны, проводится различие между структурированными рабочими процессами и более динамичными агентными моделями. Эта статья помогает понять и спроектировать более эффективные системы агентов ИИ (Источник: dl_weekly)
Обсуждение феномена «подхалимства» GPT-4o и его последствий для обучения моделей: В статье рассматривается феномен «подхалимства» (sycophancy) у модели GPT-4o, анализируется его связь с RLHF (обучение с подкреплением на основе обратной связи от человека) и проблемами настройки предпочтений, а также обсуждаются более широкие последствия этого для обучения моделей, их оценки и прозрачности в отрасли (Источник: dl_weekly)
Утечка системного промпта Claude и анализ его дизайна: Bindu Reddy проанализировала утекший системный промпт Claude. Этот промпт, длиной 24k токенов, что значительно превышает ожидания, был разработан для расширения пределов логического мышления LLM, уменьшения галлюцинаций и обеспечения понимания LLM путем многократного повторения инструкций различными способами. Это показывает, что современные LLM все еще сталкиваются с проблемами в области надежности и следования инструкциям, и для коррекции их поведения требуются сложные системные промпты (Источник: jonst0kes)

Моделирование предвзятости в машинном обучении: метод байесовских сетей: Аспирант Кембриджского университета и курируемые им студенты бакалавриата провели исследовательский проект по изучению предвзятости в машинном обучении. Они использовали байесовские сети для моделирования процесса генерации данных «реального мира», а затем запускали на этих данных модели машинного обучения, чтобы измерить предвзятость, создаваемую самой моделью (а не предвзятость, распространяемую обучающими данными). На веб-сайте проекта представлена подробная методология, результаты и инструменты визуализации, а также запрашивается обратная связь от специалистов с опытом в ML (Источник: Reddit r/MachineLearning)
💼 Бизнес
Слухи: OpenAI и Microsoft обсуждают новый раунд финансирования и будущее IPO: По сообщению Financial Times, OpenAI ведет переговоры с Microsoft с целью получения новой финансовой поддержки и обсуждает возможность проведения первичного публичного размещения акций (IPO) в будущем. Это указывает на то, что OpenAI продолжает искать финансирование для поддержки своих дорогостоящих исследований и разработок больших моделей и потребностей в вычислительных мощностях, а также, возможно, планирует более четкий путь привлечения капитала для своего долгосрочного развития (Источник: Reddit r/artificial)

CoreWeave завершает приобретение Weights & Biases: Поставщик облачных вычислений CoreWeave объявил о завершении приобретения платформы инструментов машинного обучения Weights & Biases. Это приобретение объединит GPU-инфраструктуру CoreWeave с возможностями MLOps от Weights & Biases с целью предоставления разработчикам ИИ более мощной и интегрированной среды для разработки и развертывания (Источник: charles_irl)
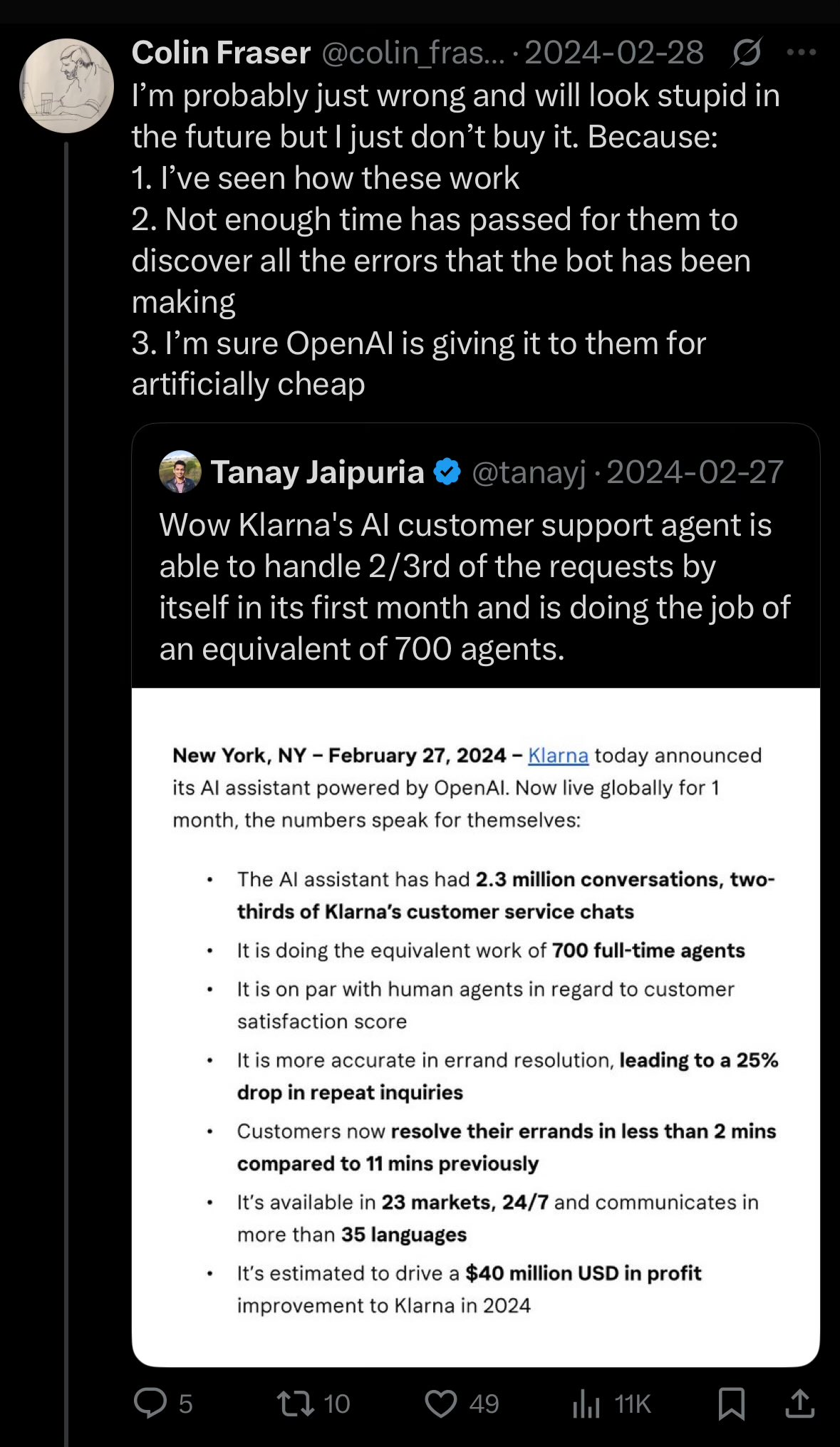
CEO Klarna размышляет о снижении качества обслуживания клиентов из-за чрезмерного сокращения расходов с помощью ИИ: CEO платежного гиганта Klarna заявил, что компания «зашла слишком далеко» в стремлении сократить расходы с помощью искусственного интеллекта, что привело к снижению качества обслуживания клиентов, и в настоящее время компания переходит к увеличению числа сотрудников службы поддержки. Этот инцидент вызвал дискуссию о том, как найти баланс между снижением затрат и повышением эффективности с помощью ИИ и обеспечением качества обслуживания в компаниях (Источник: colin_fraser)
🌟 Сообщество
Горячие споры о том, являются ли LLM путем к AGI: В сообществе развернулась бурная дискуссия о том, являются ли большие языковые модели (LLM) правильным путем к достижению общего искусственного интеллекта (AGI). Одна сторона считает, что LLM — это самая успешная технология в области машинного обучения на сегодняшний день, и утверждение, что они «ни в коем случае не являются» путем к AGI, слишком радикально. Другая сторона полагает, что, несмотря на значительный прогресс LLM, для достижения AGI могут потребоваться принципиально иные подходы, чем существующие LLM, например, решение проблем с масштабированием, когерентностью длинных контекстов, взаимодействием с реальным миром и т.д. Участники дискуссии подчеркивают, что научные исследования должны сохранять открытость, а не делать преждевременных выводов (Источники: cloneofsimo, teortaxesTex, Dorialexander)
Разница во взглядах разработчиков ПО и общественности на перспективы замены ИИ: Обсуждения на нескольких форумах Reddit, посвященных разработке программного обеспечения, показывают, что многие разработчики считают маловероятным, что ИИ массово заменит их в ближайшие 5-10 лет, и даже называют текущий ИИ «мусором». Анализ комментариев указывает на то, что эта точка зрения может быть связана с глубоким пониманием разработчиками реальных возможностей ИИ и сложности программирования. Они считают, что ИИ в настоящее время хорошо справляется с генерацией шаблонного кода или простых инструментов, но далек от уровня самостоятельного выполнения сложных задач программной инженерии. В то же время инвесторы или общественность могут быть введены в заблуждение поверхностными возможностями ИИ из-за незнания технических деталей. Также существует мнение, что ИИ действительно является мощным инструментом повышения производительности, но его роль скорее вспомогательная, чем полная замена, и ИИ все еще сталкивается с такими проблемами, как «потеря контекста» и «непоследовательность логики» при работе с крупномасштабными и сложными проектами (Источник: Reddit r/ArtificialInteligence)
Политика приема статей на конференциях по ML вызывает споры: требование обязательного присутствия называют дискриминационным: Neel Nanda и другие раскритиковали политику конференций по машинному обучению, таких как ICML, требующую, чтобы по крайней мере один автор статьи присутствовал на конференции лично, в противном случае принятая статья будет отклонена. Они считают это лицемерием, поскольку, несмотря на заявления конференций о важности DEI (разнообразие, равенство и инклюзивность), эта политика фактически дискриминирует начинающих исследователей или исследователей, испытывающих финансовые трудности, которым часто трудно позволить себе высокие расходы на участие в конференции, в то время как публикации на ведущих конференциях имеют решающее значение для их карьерного роста. Gabriele Berton уточнил, что ICML не будет отклонять статьи по этой причине, а лишь требует приобретения очной регистрации, но это не сняло споров, и в качестве сравнения были упомянуты такие журналы, как TMLR, которые публикуют статьи бесплатно и имеют высокое качество рецензирования (Источники: menhguin, jeremyphoward)

Восприятие «оглупления» новых моделей и обсуждение переобучения: Некоторые пользователи на Reddit сообщают, что недавно выпущенные большие модели, такие как Qwen3, Llama 3.3/4, в практическом использовании кажутся «глупее» старых версий, что проявляется в более частой потере контекста, повторении контента и жестком языковом стиле. Некоторые комментаторы считают, что это может быть связано с переобучением моделей в погоне за высокими баллами в бенчмарках (например, по программированию, математике, уменьшению галлюцинаций), что приводит к снижению их производительности в творческом письме, естественном диалоге и т.д., и они становятся больше похожими на тех, кто «жертвует связностью, чтобы казаться умным». Некоторые исследования указывают на то, что базовые модели могут лучше подходить для задач, требующих креативности (Источник: Reddit r/LocalLLaMA)
Обсуждение сложности распознавания контента, сгенерированного ИИ: ошибка парика: В ответ на утверждение о том, что «легко распознать контент, сгенерированный ИИ», в обсуждении сообщества для опровержения приводится «ошибка парика» (toupee fallacy). Эта ошибка заключается в том, что люди считают, будто все парики выглядят фальшиво, потому что качественные парики просто не замечаются. Аналогично, те, кто утверждает, что всегда легко распознает контент ИИ, возможно, обращают внимание только на низкокачественный или неотредактированный текст ИИ, игнорируя высококачественный контент, сгенерированный ИИ, который трудно отличить (Источник: Reddit r/ChatGPT)
YC подает экспертное заключение по антимонопольному делу о монополии Google на поиск: Y Combinator представил в Министерство юстиции США экспертное заключение (amicus brief) по антимонопольному делу против Google. YC считает, что монопольное положение Google в области поиска и поисковой рекламы подавляет инновации, делая практически невозможным прорыв для стартапов (особенно в настоящее время, когда ИИ находится на переломном этапе). Некоторые комментаторы расценили этот шаг как поддержку YC новых поисковых компаний на базе ИИ, таких как Exa, с целью разрушить монополию Google (Источник: menhguin)

Проблемы с производительностью модели Claude продолжаются, пользователи повсеместно недовольны: Мега-тред на Reddit в разделе ClaudeAI (4-11 мая) показывает, что пользователи продолжают сообщать о проблемах с доступностью Claude, включая крайне низкие лимиты контекста/сообщений, частые зависания и обрывы вывода. Страница состояния Anthropic подтвердила повышение частоты ошибок 6-8 мая. Около 75% отзывов пользователей были негативными, особенно от пользователей Pro, которые считают, что происходит «скрытое ухудшение» с целью вынудить пользователей перейти на более дорогой тариф Max. Внешняя информация подтверждает ужесточение политики использования тарифа Max и высокую стоимость веб-поиска. Несмотря на наличие некоторых временных решений, многие ключевые проблемы остаются нерешенными, и пользователи возмущены отсутствием прозрачности и необъявленными изменениями (Источник: Reddit r/ClaudeAI)
Рекомендации по выбору моделей OpenAI и анализ соотношения цена/качество: В ответ на распространяемые в сети руководства по выбору моделей OpenAI, Karminski3 предложил более экономически выгодные рекомендации: GPT-4o подходит для повседневных задач и генерации изображений (не для кода), цена 2,5 доллара США/миллион токенов; GPT-image-1 хоть и дорог (10 долларов США/миллион токенов), но хорошо генерирует/редактирует изображения; O3-mini-high (1,1 доллара США/миллион токенов) можно использовать для кода/математики, если не подходит, рекомендуется перейти на Claude-3.7-Sonnet-Thinking или Gemini-2.5-Pro, а не на более дорогие модели OpenAI. Автор считает, что в настоящее время написание кода с помощью моделей OpenAI обходится дорого, и эффект не всегда оптимален, а API-вызовы чисто текстовых моделей стоимостью более 2 долларов США/миллион токенов следует рассматривать с осторожностью (Источник: karminski3)

💡 Прочее
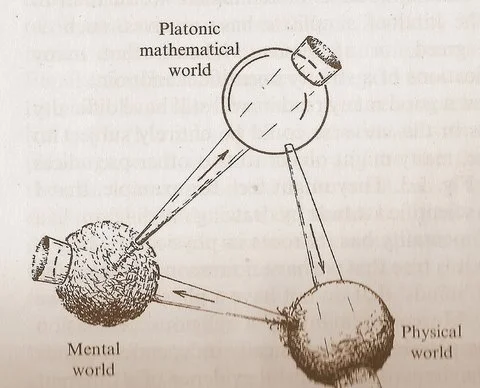
Диаграмма «трех миров» Пенроуза вызывает размышления о связи математики, физики и интеллекта: Циклическая диаграмма Роджера Пенроуза из его книги «Путь к реальности», включающая «платоновский мир математики», «физический мир» и «ментальный мир», вызвала новые обсуждения. Комментаторы считают, что прорывы в машинном обучении, по-видимому, подтверждают существование «платоновского мира математики», то есть эффективность математики проистекает из математической структуры, лежащей в основе физической вселенной. Появление ИИ («мозга из песка») ускоряет этот цикл с беспрецедентными масштабами и частотой, что может раскрыть более глубокие истины о вселенной (Источник: riemannzeta)
Страховые компании предлагают страхование от убытков из-за ошибок чат-ботов ИИ: Страховые компании начали предлагать страховые продукты от убытков, вызванных ошибками чат-ботов ИИ. Этот шаг, с одной стороны, признает, что неправильное использование ИИ может нанести серьезный ущерб, а с другой — вызывает опасения, не будет ли такое страхование стимулировать компании к более небрежному применению ИИ, полагаясь на страховку для покрытия убытков, вместо того чтобы стремиться к повышению надежности и безопасности систем ИИ (Источник: Reddit r/artificial)
Потенциал ИИ в создании музыки недооценен: В сообществе существует мнение, что многие недооценивают возможности ИИ в создании музыки, часто утверждая, что музыка ИИ не может «тронуть душу» так, как человеческое творчество. Однако уже существуют музыкальные произведения, созданные ИИ, которые по звучанию приближаются к уровню человеческого исполнения. Учитывая, что музыка ИИ все еще находится на начальном этапе развития, ее будущий потенциал огромен, и не следует преждевременно его отрицать (Источник: Reddit r/artificial)
