
Ключевые слова:Применение ИИ, FDA, OpenAI, GPT-4.1, WebThinker, Runway Gen-4, Периферийный интеллект, Точная настройка с подкреплением (RFT), Мультиагентная платформа DeerFlow, WebThinker-32B-RL, Обновление Gen-4 References, Плотность знаний
🔥 В фокусе
FDA США объявляет об ускорении внутреннего применения AI: Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) объявило об историческом шаге: к 30 июня 2025 года планируется внедрить использование искусственного интеллекта (AI) во всех центрах FDA. Ранее FDA успешно завершило пилотный проект по генеративному AI для научных рецензентов. Этот шаг направлен на повышение регуляторных возможностей с помощью AI, увеличение скорости и эффективности клинических испытаний, снижение затрат. Это важный прорыв для AI в области государственного регулирования и одобрения лекарств, который может задать тенденцию применения AI в мировых регуляторных органах по лекарственным средствам (Источник: ajeya_cotra)

OpenAI раскрывает детали технологии Reinforcement Learning Fine-tuning (RFT) и концепцию разработки GPT-4.1: Руководитель проекта GPT-4.1 в OpenAI, Mich Pokrass, в подкасте Unsupervised Learning поделился подробностями RFT и процессом разработки GPT-4.1. При создании GPT-4.1 OpenAI уделяла больше внимания отзывам разработчиков, а не традиционным бенчмаркам. RFT использует логические цепочки рассуждений (chain-of-thought reasoning) и оценку по конкретным задачам для повышения производительности модели, особенно в сложных областях, и уже доступна на OpenAI o4-mini. В интервью также обсуждались текущее состояние применения AI-агентов, повышение их надежности, как стартапы могут успешно использовать оценку и перспективные продуктовые стратегии (Источник: OpenAIDevs, aidan_mclau, michpokrass)

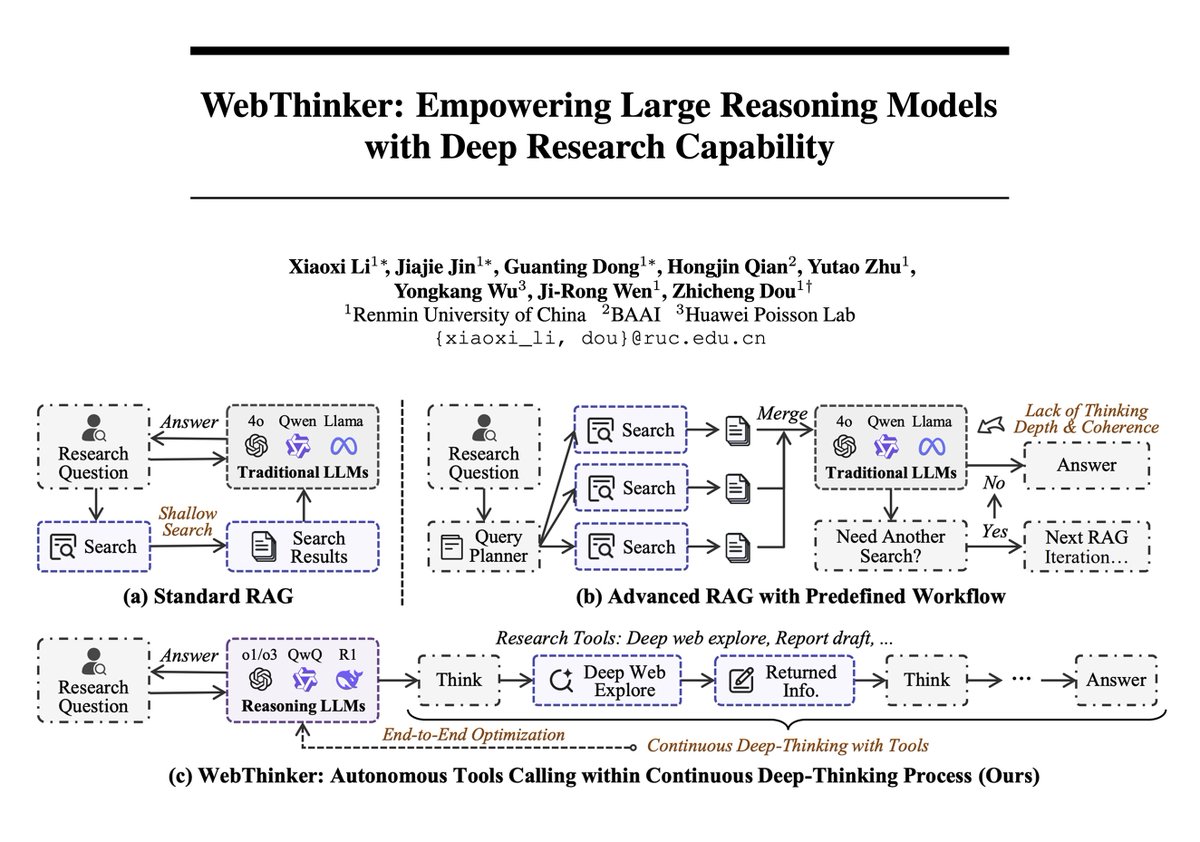
Фреймворк WebThinker объединяет возможности больших моделей и глубокого веб-поиска, достигая новых высот в сложных рассуждениях: В новой статье представлен WebThinker, фреймворк для агентов-рассуждателей, который наделяет большие модели рассуждений (LRMs) возможностями автономного веб-поиска и составления отчетов, чтобы преодолеть ограничения статических внутренних знаний. WebThinker интегрирует модуль глубокого веб-браузера и автономную стратегию «думай-ищи-составляй», позволяя модели одновременно искать в сети, рассуждать над задачами и генерировать комплексные выходные данные. На сложных бенчмарках рассуждений, таких как GPQA и GAIA, WebThinker-32B-RL достиг SOTA-результатов среди 32B моделей, превзойдя GPT-4o и другие. Его RL-обученная версия превзошла базовую версию на всех бенчмарках, демонстрируя важность итеративного обучения на основе предпочтений для улучшения координации рассуждений и инструментов (Источник: omarsar0, dair_ai)
Runway выпускает обновление Gen-4 References, улучшая эстетику, композицию и сохранение идентичности в генерации видео: Runway Gen-4 References получило обновление, значительно улучшающее эстетическое качество генерируемых видео, композицию сцен и согласованность идентичности персонажей. Интересной новой функцией является способность модели точно размещать объекты в сцене в соответствии с предоставленным пользователем макетом, и даже изменять такие детали, как направление взгляда персонажей, сохраняя при этом согласованность других элементов. Это знаменует собой еще один шаг вперед в управляемости и детализации генерации AI-видео, предоставляя создателям более мощные инструменты (Источник: c_valenzuelab, c_valenzuelab)

CEO Mianbi Intelligence Ли Дахай: AGI в физическом мире будет реализован через периферийный интеллект, ключевым фактором является плотность знаний: CEO Mianbi Intelligence Ли Дахай считает, что для реализации общего искусственного интеллекта (AGI) в физическом мире в будущем периферийный интеллект является неизбежным путем. Он подчеркивает, что «плотность знаний» больших моделей является ключевым показателем интеллекта, сравнивая ее с техпроцессом производства чипов: чем выше плотность знаний, тем сильнее интеллект. Модели с высокой плотностью знаний имеют естественное преимущество на периферийных устройствах с ограниченной вычислительной мощностью, памятью и энергопотреблением. Mianbi Intelligence уже выпустила несколько моделей для периферийных устройств и внедряет их в автомобилях, роботах, мобильных телефонах и других областях, например, Mianbi Xiaogangpao Super Assistant, с целью наделить каждое устройство интеллектом, обеспечивая чувствительное восприятие, своевременное принятие решений и идеальное реагирование (Источник: 量子位)

🎯 Динамика
Новая функция Google Maps использует возможности Gemini для распознавания названий мест на скриншотах: Google Maps представила новую функцию, которая использует AI-возможности Gemini для распознавания названий мест, содержащихся на скриншотах пользователя, и сохранения их в список на карте, что облегчает пользователям доступ к ним в любое время и планирование поездок. Эта функция призвана упростить процесс исследования путешествий и улучшить пользовательский опыт (Источник: Google)
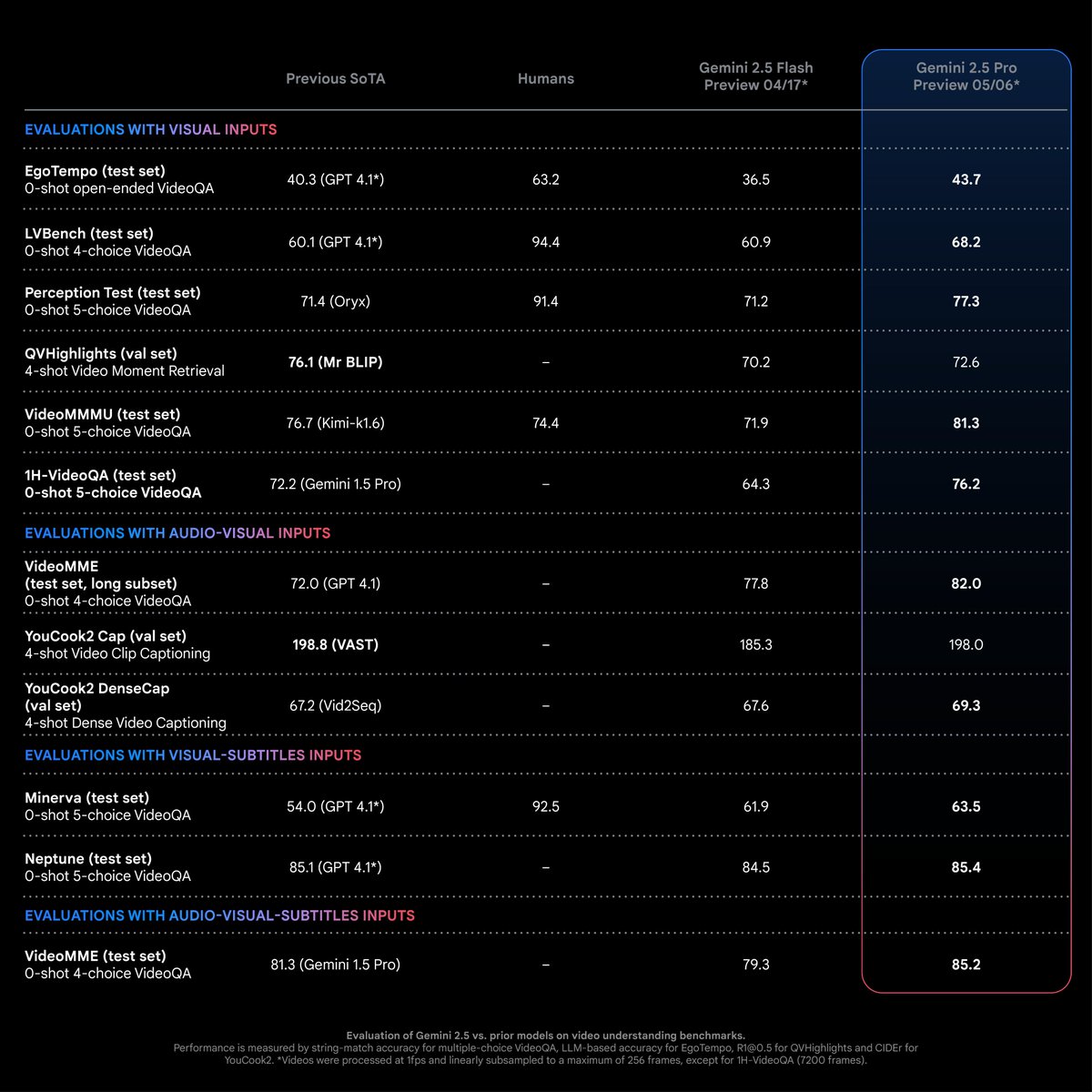
Gemini 2.5 Pro демонстрирует SOTA-производительность в задачах понимания видео: По словам Logan Kilpatrick, Gemini 2.5 Pro (версия 05-06) достигла лидирующего в отрасли уровня (SOTA) в большинстве задач понимания видео, причем с заметным преимуществом. Это результат усилий команды Gemini по мультимодальности, и ожидается, что это подтолкнет разработчиков к исследованию новых возможностей применения в этой области (Источник: matvelloso)
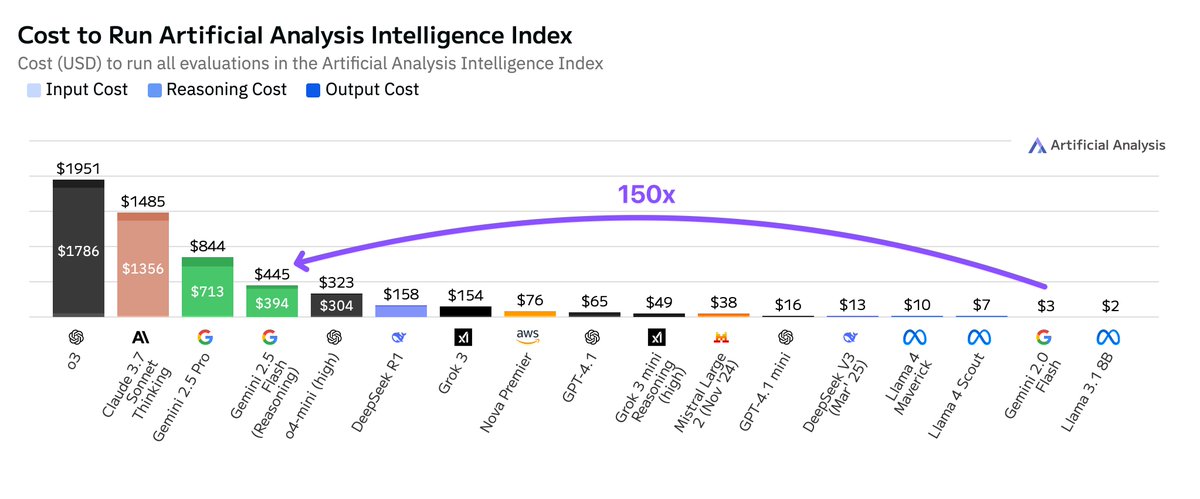
Стоимость эксплуатации Google Gemini 2.5 Flash значительно выше, чем у версии 2.0: Artificial Analysis отмечает, что при запуске их индекса интеллекта стоимость Google Gemini 2.5 Flash в 150 раз выше, чем у Gemini 2.0 Flash. Резкий рост стоимости в основном связан с 9-кратным увеличением цены выходных токенов (3,5 доллара США за миллион токенов с включенной функцией вывода, 0,6 доллара США с выключенной, по сравнению с 0,4 доллара США для 2.0 Flash) и 17-кратным увеличением использования токенов. Это вызвало дискуссии о балансе между низкой задержкой и экономической эффективностью моделей серии Flash (Источник: arohan)
Google интегрирует Gemini Nano AI в браузер Chrome для предотвращения интернет-мошенничества: Google объявила об интеграции AI-модели Gemini Nano в браузер Chrome с целью повышения способности браузера распознавать и блокировать онлайн-мошенничество, а также для повышения безопасности пользователей в сети. Этот шаг является дальнейшим применением AI-технологий в функциях безопасности основных браузеров (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)
Lightricks выпускает LTXVideo 13B 0.9.7, улучшая качество и скорость видео, а также представляет квантованную версию и модели для апскейлинга в латентном пространстве: Lightricks обновила свою видеомодель LTXVideo до версии 13B 0.9.7, обеспечивая кинематографическое качество видео и более высокую скорость генерации. Одновременно была выпущена квантованная версия LTXV 13B, снижающая требования к памяти и подходящая для потребительских GPU, а также модели для пространственного и временного апскейлинга в латентном пространстве, поддерживающие многомасштабный вывод и повышающие эффективность генерации HD-видео при меньшем количестве операций декодирования/кодирования. Соответствующие узлы и рабочие процессы ComfyUI также были обновлены (Источник: GitHub Trending)

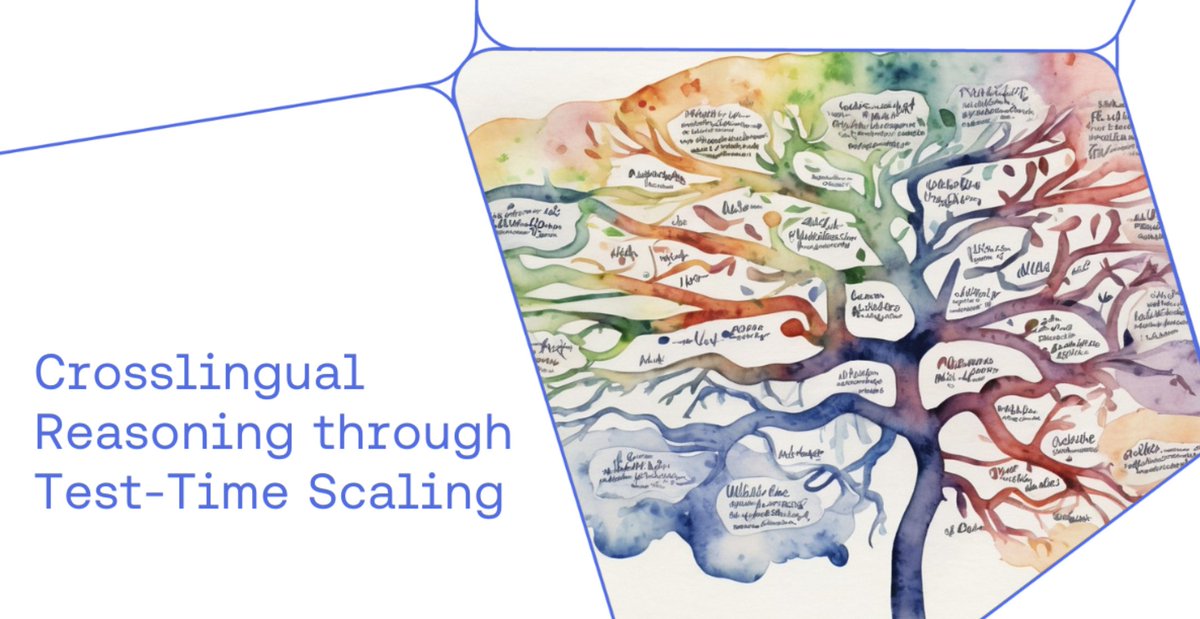
Исследование Cohere Labs показывает, что масштабирование во время тестирования улучшает производительность межъязыкового вывода больших моделей: Исследование Cohere Labs указывает на то, что, хотя модели логического вывода в основном обучаются на англоязычных данных, масштабирование во время тестирования (test-time scaling) может улучшить их производительность в задачах межъязыкового вывода без предварительного обучения (zero-shot) в многоязычных средах и различных областях. Это исследование предлагает новые подходы к повышению эффективности существующих больших моделей в неанглоязычных сценариях (Источник: sarahookr)
AI использует фотографии лиц для оценки физиологического возраста и прогнозирования исходов рака: Новый AI-инструмент может оценивать физиологический возраст человека путем анализа фотографий лица и на основе этого прогнозировать исходы лечения таких заболеваний, как рак, и шансы на выживание. Эта технология предлагает новый неинвазивный метод для оценки прогноза заболеваний (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)
AI-модели демонстрируют тенденцию к чрезмерно сложному мышлению при обработке простых задач: Некоторые разработчики заметили, что более новые модели логического вывода при столкновении с простыми задачами склонны запускать чрезмерно сложные процессы мышления, проявляя «сверхосторожность». Более идеальным подходом, возможно, было бы наличие мощной базовой модели, способной динамически определять, когда следует вызывать инструмент «мышления», чтобы избежать ненужных вычислений и задержек (Источник: skirano)
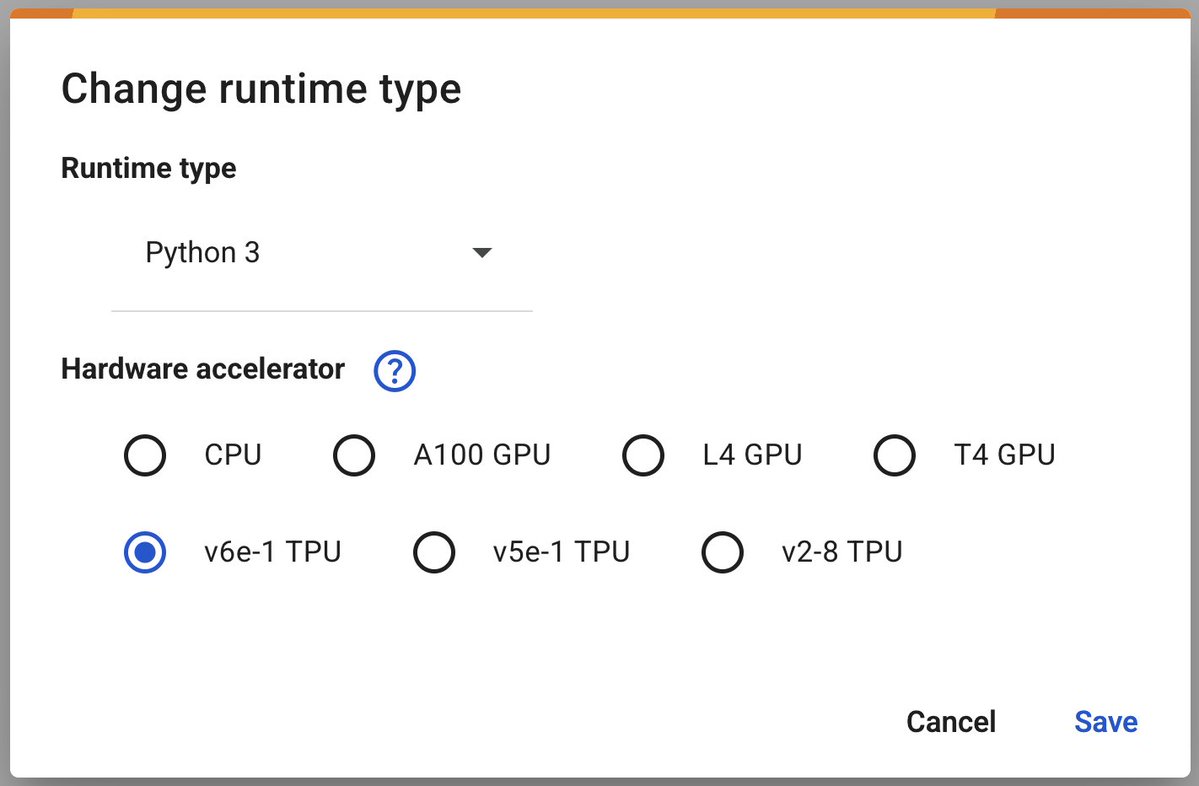
Google Colab запускает TPU v6e-1 (Trillium) для ускорения глубокого обучения: Google Colaboratory объявил о запуске своего самого быстрого ускорителя глубокого обучения — TPU v6e-1 (Trillium). Этот TPU обладает 32 ГБ высокоскоростной памяти (вдвое больше, чем у v5e-1) и пиковой производительностью до 918 BF16 TFLOPS (почти в три раза больше, чем у A100), предоставляя исследователям и разработчикам более мощные вычислительные ресурсы (Источник: algo_diver)
Google AMIE: демонстрация мультимодального диалогового AI-агента для диагностики: Google поделился первой демонстрацией своего мультимодального диалогового AI-агента для диагностики AMIE. AMIE способен вести мультимодальные (например, сочетая текстовую и графическую информацию) диагностические диалоги, что знаменует собой дальнейшее исследование AI в области вспомогательной медицинской диагностики (Источник: dl_weekly)
Anthropic обвиняют в жестком кодировании информации о «победе Трампа» в модели Claude: Пользователи обнаружили, что модель Claude от Anthropic при ответе на вопросы о выборах 2024 года, похоже, содержит жестко закодированную информацию о победе Трампа, несмотря на то, что ее база знаний обрывается в октябре 2024 года. Это вызвало дискуссии о механизмах обновления информации в AI-моделях, потенциальных предубеждениях и влиянии жестко закодированного контента на доверие пользователей (Источник: Reddit r/ClaudeAI)
🧰 Инструменты
ByteDance выпускает фреймворк для мультиагентных систем DeerFlow с открытым исходным кодом: ByteDance представила DeerFlow, фреймворк для мультиагентных систем (Multi-Agent) на базе LangChain с открытым исходным кодом. Этот фреймворк предназначен для упрощения и ускорения разработки мультиагентных приложений, предоставляя инструменты для создания сложных совместных AI-систем. Разработчики могут получить доступ к его репозиторию на GitHub и официальному веб-сайту для получения дополнительной информации и примеров (Источник: hwchase17)
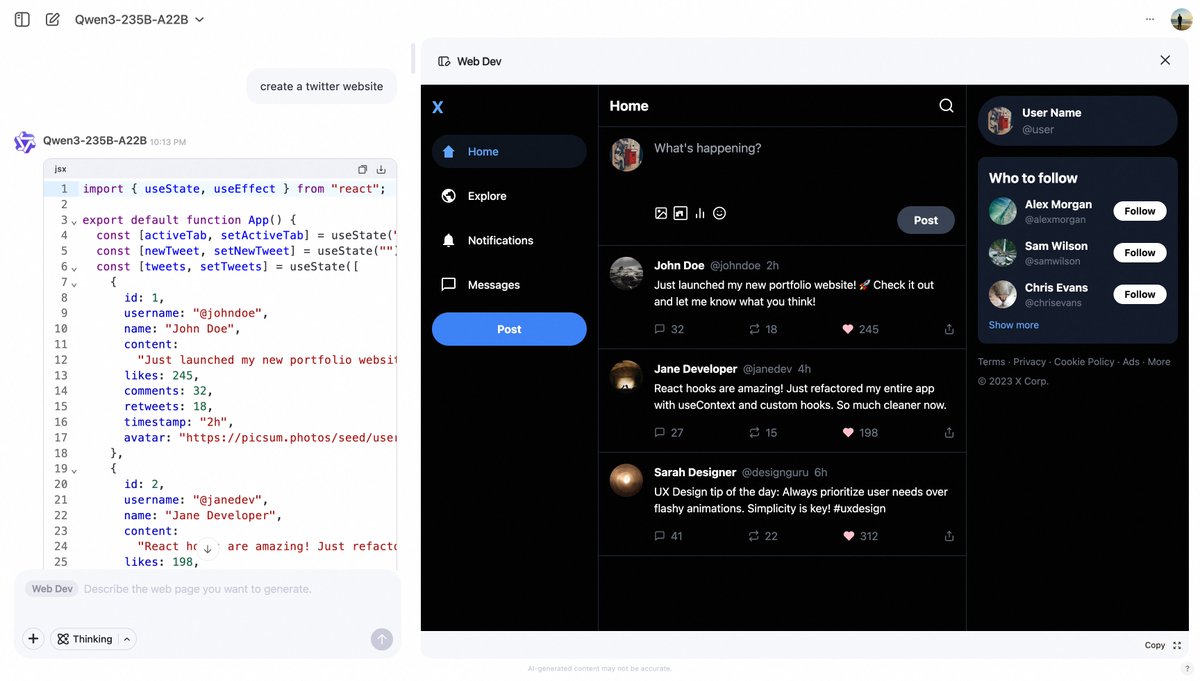
Alibaba Qwen Chat представляет функцию Web Dev для генерации веб-страниц по текстовым подсказкам: Alibaba Qwen Chat добавил функцию «Web Dev», позволяющую пользователям быстро генерировать код для фронтенд-веб-страниц и приложений с помощью простых текстовых подсказок (например, «создать сайт типа твиттера»). Эта функция призвана снизить порог входа в веб-разработку, позволяя пользователям без знаний программирования создавать веб-сайты с помощью естественного языка (Источник: Alibaba_Qwen, huybery)
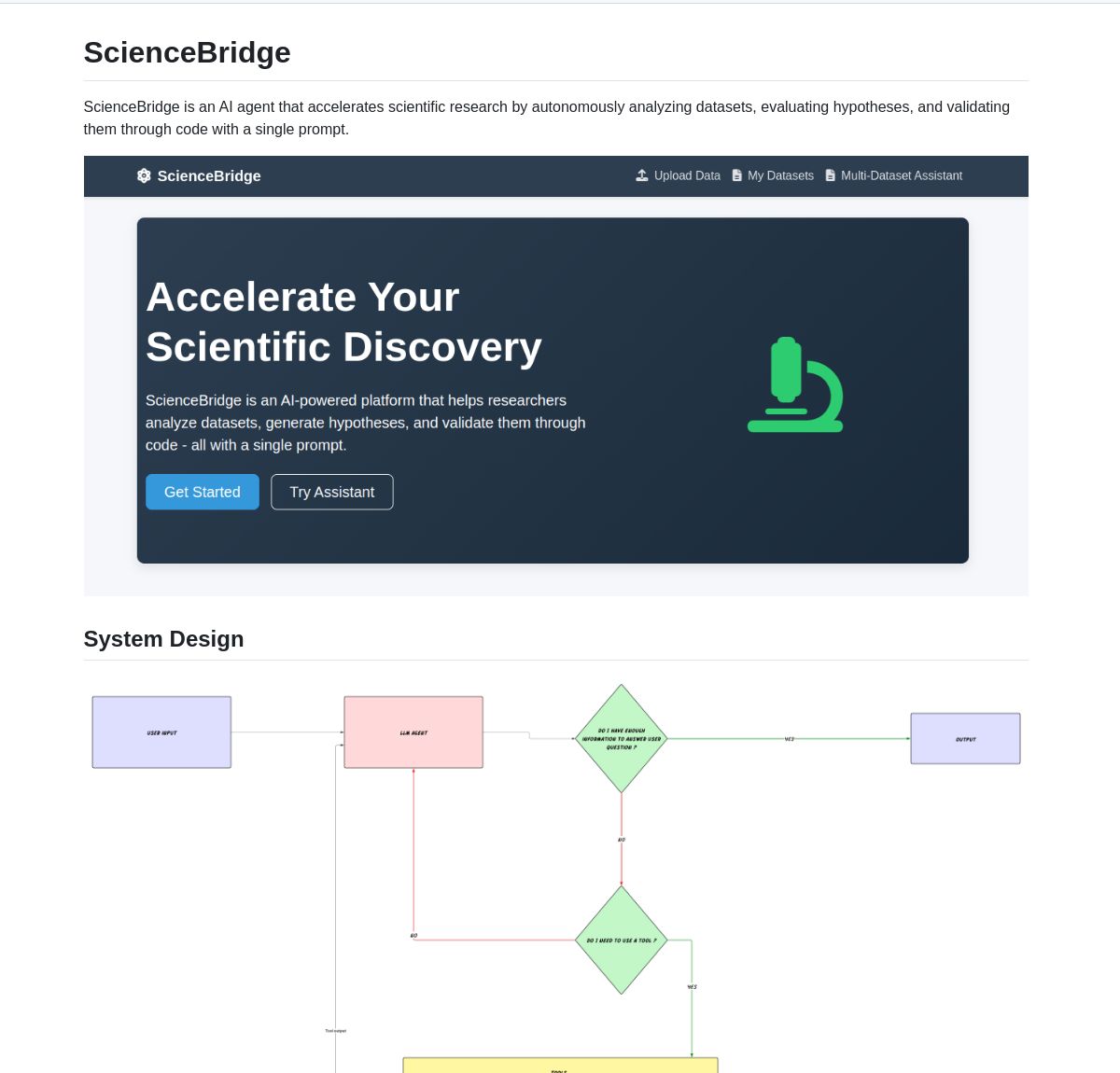
ScienceBridge AI: агент для автоматизации научных исследований на базе LangGraph: Агент под названием ScienceBridge AI использует фреймворк LangGraph для автоматизации рабочих процессов научных исследований, включая анализ данных, проверку гипотез, и способен генерировать визуализации уровня публикаций, с целью ускорения научных открытий. Проект опубликован с открытым исходным кодом на GitHub (Источник: LangChainAI, hwchase17)
El Agente Q: мультиагентная система на базе LangGraph расширяет возможности квантовой химии: Новое исследование демонстрирует El Agente Q, мультиагентную систему на базе LangGraph, которая демократизирует вычисления в квантовой химии посредством взаимодействия на естественном языке и достигает 87% успеха в автоматизации сложных рабочих процессов. Соответствующая статья опубликована на arXiv, демонстрируя потенциал AI в ускорении исследований в области квантовой химии (Источник: LangChainAI, hwchase17)
LocalSite: локальная альтернатива DeepSite, использующая локальные LLM для создания веб-страниц: Вдохновленный проектом DeepSite на HuggingFace, инструмент LocalSite позволяет пользователям создавать веб-страницы и UI-компоненты с помощью текстовых подсказок, используя локально запущенные LLM (например, модели GLM-4, Qwen3, развернутые через Ollama и LM Studio), а также облачные LLM с OpenAI-совместимым API. Проект опубликован с открытым исходным кодом на GitHub и нацелен на предоставление локализованного, настраиваемого решения для генерации веб-страниц с помощью AI (Источник: Reddit r/LocalLLaMA)

Альтернатива NotebookLM с открытым исходным кодом демонстрирует мощь открытых технологий: Разработчик m_ric создал бесплатную версию Google NotebookLM с открытым исходным кодом. Это приложение может извлекать контент из PDF или URL, использовать Llama 3.3-70B от Meta (работающую со скоростью 1000 токенов/сек через Cerebras Systems) для написания сценариев подкастов и использовать Kokoro-82M для преобразования текста в речь. Генерация аудио бесплатно выполняется на Zero GPU на HuggingFace H200s, демонстрируя, что решения с открытым исходным кодом уже могут конкурировать с закрытыми аналогами по функциональности и экономической эффективности (Источник: huggingface, mervenoyann)
DeepFaceLab: ведущее программное обеспечение с открытым исходным кодом для создания Deepfake: DeepFaceLab — это известное программное обеспечение с открытым исходным кодом, предназначенное для создания Deepfake-контента. Оно предоставляет функции замены лиц, омоложения, замены головы и т.д., и широко используется для создания контента на платформах YouTube, TikTok и других. Проект постоянно обновляется, предоставляет версии для Windows и Linux и имеет активную поддержку сообщества (Источник: GitHub Trending)
GPUI Component: библиотека UI-компонентов для десктопных приложений на Rust на базе GPUI: Команда longbridge представила GPUI Component, библиотеку из более чем 40 кроссплатформенных UI-компонентов для десктопных приложений, дизайн которой вдохновлен элементами управления macOS, Windows и shadcn/ui. Она поддерживает несколько тем, адаптивные размеры, гибкую компоновку (Dock и Tiles) и эффективно обрабатывает рендеринг больших объемов данных (виртуализированные Table/List) и контента (Markdown/HTML). Первым примером ее применения стало десктопное приложение Longbridge Pro (Источник: GitHub Trending)

Ultralytics YOLO11: ведущий фреймворк для моделей обнаружения объектов и компьютерного зрения: Ultralytics продолжает обновлять свою серию моделей YOLO, последняя версия YOLO11 обеспечивает SOTA-производительность в задачах обнаружения объектов, отслеживания, сегментации, классификации и оценки позы. Фреймворк прост в использовании, поддерживает интерфейсы CLI и Python и интегрирован с платформами Weights & Biases, Comet ML, Roboflow, OpenVINO и другими. Ultralytics HUB предлагает решения для визуализации данных, обучения и развертывания без написания кода. Модели распространяются под лицензией AGPL-3.0 с открытым исходным кодом, также доступна коммерческая лицензия (Источник: GitHub Trending)

Tensorlink: фреймворк для распределенного обучения моделей PyTorch и совместного использования P2P-ресурсов: SmartNodes Lab представила Tensorlink, фреймворк с открытым исходным кодом, предназначенный для упрощения распределенного обучения и вывода больших моделей PyTorch. Он инкапсулирует основные объекты PyTorch, абстрагируя сложность распределенных систем и позволяя пользователям использовать GPU-ресурсы нескольких компьютеров без специальных знаний или оборудования. Tensorlink поддерживает API для вывода по требованию и фреймворк узлов, облегчая пользователям совместное использование или предоставление вычислительных мощностей, и в настоящее время находится на ранней стадии разработки (Источник: Reddit r/MachineLearning)
Оптимизация промптов для генерации фотографий аниме-фигурок: Пользователь поделился примерами генерации фотографий фигурок в стиле японского аниме из загруженных фотографий персонажей с помощью AI (например, GPT-4o) путем оптимизации промптов. Ключевым моментом является точное описание позы, выражения лица, одежды, материала (например, полуматового), цветовых градиентов фигурки, а также ракурса съемки (настольная, ощущение случайного снимка на телефон). Дальнейшая оптимизация включает генерацию видов с нескольких ракурсов (спереди, сбоку, сзади), расположенных в виде сетки из четырех ячеек, для обеспечения полноты деталей фигурки и подставки, что облегчает последующее 3D-моделирование (Источник: dotey, dotey)

NVIDIA Agent Intelligence Toolkit выпущен с открытым исходным кодом: NVIDIA выпустила Agent Intelligence Toolkit с открытым исходным кодом, представляющий собой репозиторий ресурсов для создания интеллектуальных агентских приложений. Этот инструментарий призван помочь разработчикам более удобно создавать и развертывать AI-агентов на базе технологий NVIDIA (Источник: nerdai)
SkyPilot и SGLang упрощают самостоятельное развертывание Llama 4 на нескольких узлах: Nebius AI продемонстрировала, как с помощью SkyPilot и SGLang (от LMSYS.org) можно одной командой самостоятельно развернуть модель Llama 4 от Meta на нескольких узлах (например, 8x H100). Это решение обеспечивает высокую пропускную способность, эффективное использование памяти и интегрировано с функциями производственного уровня, такими как аутентификация и HTTPS, а также легко интегрируется с инструментом llm от Simon Willison (Источник: skypilot_org)

📚 Обучение
Vector Institute запускает AI Pocket References: Команда AI-инженеров Vector Institute выпустила проект AI Pocket References — серию кратких информационных карточек по AI, охватывающих такие области, как NLP (особенно LLM), федеративное обучение, ответственный AI и высокопроизводительные вычисления. Эти справочные материалы предназначены для предоставления начальных указаний новичкам и быстрого повторения для опытных практиков, причем каждая карточка рассчитана на чтение в течение 7 минут. Проект опубликован с открытым исходным кодом и приветствует вклад сообщества (Источник: nerdai)

HuggingFace выпускает 9 бесплатных курсов по AI: HuggingFace представила серию из 9 бесплатных курсов по AI, охватывающих различные направления, включая большие языковые модели (LLM), компьютерное зрение, AI-агентов и другие. Эти курсы предоставляют ценные ресурсы для тех, кто хочет систематически изучать знания в области AI (Источник: ClementDelangue)
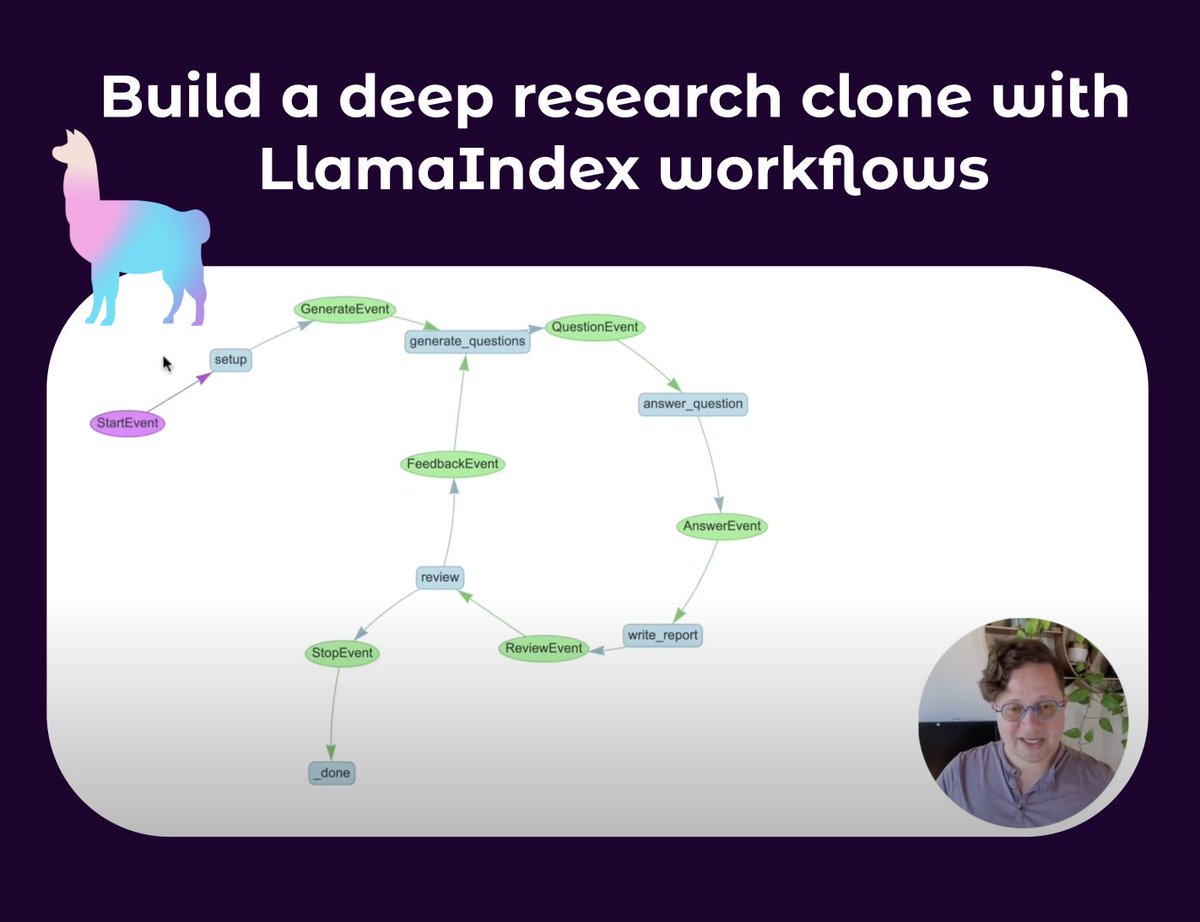
LlamaIndex публикует учебное пособие по созданию агента для глубоких исследований: Seldo из LlamaIndex опубликовал видеоурок, в котором рассказывается, как создать клона агента, подобного Deep Research. Учебное пособие начинается с основ работы с одним агентом и постепенно переходит к продвинутым многоагентным рабочим процессам, включая использование нескольких баз знаний и сети для исследований, поддержание контекста, а также реализацию полного процесса исследования, написания и рецензирования. В учебном пособии подчеркивается создание сложных агентских рабочих процессов, способных к циклам, ветвлению, параллельному выполнению и саморефлексии (Источник: jerryjliu0, jerryjliu0)
Ретроспектива развития технологии RAG: статья Lewis и др. и ранние работы: Aran Komatsuzaki отмечает, что, хотя статья Lewis и др. 2020 года широко цитируется за введение термина RAG (Retrieval-Augmented Generation), сама по себе генерация с дополненным поиском была активным направлением исследований и до этого, например, работы DrQA (2017), ORQA (2019), REALM (2020). Основной вклад Lewis и др. заключался в предложении нового метода совместного предварительного обучения RAG, но это не самый распространенный способ реализации RAG на сегодняшний день. Это напоминает нам о важности непрерывности технологического развития и ранних основополагающих работ (Источник: arankomatsuzaki)
Реализация формата вывода цепочки мыслей, подобного Gemini 2.5 Pro, с помощью Qwen3: Вдохновленный README Apriel-Nemotron-15b-Thinker о принуждении модели начинать вывод в определенном формате (например, «Here are my reasoning steps:\n»), разработчик с помощью функции OpenWebUI заставил модель Qwen3 всегда начинать вывод с <think>\nMy step by step thinking process went something like this:\n1.. Эксперименты показали, что это побуждает Qwen3 рассуждать и выводить информацию пошагово, подобно Gemini 2.5 Pro, хотя само по себе это не повышает интеллект модели, но изменяет формат ее мышления и изложения (Источник: Reddit r/LocalLLaMA)
Подкаст о философии дизайна и разработке Claude Code: В подкасте Latent Space создатели Claude Code, Catherine Wu и Boris Cherny, поделились философией дизайна и историей разработки этого AI-инструмента для программирования. Ключевые моменты: CC уже может писать около 80% собственного кода (с ручной проверкой), вдохновлен Aider, ориентирован на простоту реализации (например, использование Markdown-файлов для памяти вместо векторных баз данных), использует небольшую команду и внутренние итерации для развития продукта, предоставляет продвинутым пользователям доступ к необработанной модели и поддерживает параллельные рабочие процессы. В подкасте также обсуждались сравнения с такими инструментами, как Cursor и Windsurf, а также вопросы стоимости, дизайна UI/UX, возможности открытия исходного кода и другие темы (Источник: Reddit r/ClaudeAI)

💼 Бизнес
Salesforce запускает саудовскую AI-инициативу на 500 миллионов долларов и формирует команду: Salesforce начала формировать команду в Саудовской Аравии в рамках своего пятилетнего плана инвестиций в размере 500 миллионов долларов, направленного на содействие внедрению и развитию искусственного интеллекта в стране. Это знаменует собой еще один важный шаг крупных технологических компаний в освоении AI-сферы на Ближнем Востоке (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)
Новый CEO прикладного подразделения OpenAI Фиджи Симо покинет совет директоров Shopify: Фиджи Симо, нынешний CEO Instacart, после назначения на должность CEO нового прикладного подразделения OpenAI, покинет свой пост в совете директоров Shopify. Этот шаг, вероятно, направлен на то, чтобы она могла больше сосредоточиться на своей руководящей роли в OpenAI, управляя ее быстрорастущим бизнесом и продуктовыми линейками. Ранее сообщалось, что OpenAI может заключить потенциальную сделку с Arm на 1 миллиард долларов (Источник: steph_palazzolo, steph_palazzolo)
Lux Capital учреждает фонд в 100 миллионов долларов для поддержки американских ученых, столкнувшихся с сокращением финансирования: В ответ на значительное сокращение бюджета Национального научного фонда США (NSF) (по сообщениям, на 50%, что привело к отмене текущих проектов и сокращению персонала), Lux Capital объявила о запуске «Горячей линии научной помощи Lux» с бюджетом в 100 миллионов долларов для поддержки пострадавших американских ученых. Цель — обеспечить продолжение ключевых научных исследований и поддержать инновационную конкурентоспособность США (Источник: ylecun, riemannzeta)

🌟 Сообщество
Продолжаются дискуссии о том, заменит ли AI людей на рабочих местах: В сообществе широко распространены дискуссии о том, приведет ли AI к массовой безработице. Одна точка зрения заключается в том, что под давлением капитализма компании будут стремиться к эффективности, заменяя дорогостоящую рабочую силу на AI, что приведет к сокращению таких должностей, как программисты. Другая точка зрения ссылается на историю, утверждая, что технический прогресс (например, электрическая лампа, заменившая фонарщиков) устраняет старые рабочие места, но одновременно создает новые (например, заводы по производству лампочек, отрасли, связанные с электроэнергией), ключевым моментом является повышение квалификации и инновации. В настоящее время AI все еще нуждается в человеческом вмешательстве для выполнения сложных задач и отладки кода, но его быстрое развитие и высокая эффективность в некоторых областях заставляют многих беспокоиться о будущих перспективах трудоустройства, в то время как другие считают это паникерством или краткосрочной переоценкой возможностей AI (Источник: Reddit r/ArtificialInteligence)
Опасения по поводу пределов возможностей LLM и «зимы AI»: Некоторые члены сообщества и эксперты (такие как Yann LeCun, François Chollet) начинают обсуждать, не достигли ли большие языковые модели (LLM) своего потолка. Хотя LLM отлично справляются с имитацией паттернов, они все еще имеют ограничения в истинном понимании, рассуждениях и решении проблемы галлюцинаций, а чрезмерная зависимость от синтетических данных также может создавать проблемы. Если не появятся новые направления исследований (такие как мировые модели, нейросимволические системы), нынешний ажиотаж вокруг AI может пойти на спад, что приведет к сокращению инвестиций и даже спровоцирует новую «зиму AI». Однако существует и мнение, что, хотя универсальные LLM могут столкнуться с потолком, специализированные модели и AI-агенты все еще быстро развиваются (Источник: Reddit r/ArtificialInteligence)
Планы OpenAI по выпуску модели с открытым исходным кодом летом вызывают обсуждение в сообществе: Sam Altman во время выступления в Сенате заявил, что OpenAI планирует выпустить модель с открытым исходным кодом этим летом. Реакция сообщества на это неоднозначна: одни с нетерпением ждут ее производительности, другие сомневаются, не будет ли она, как FSD Маска, «вечно в разработке» или «урезанной», чтобы не конкурировать с платными моделями. Некоторые анализируют, что компании, такие как Meta и Alibaba, выпуская высококачественные бесплатные предварительно обученные модели, стремятся ослабить рыночные позиции таких компаний, как OpenAI, и этот шаг OpenAI может быть ответной стратегией. Однако, учитывая бизнес-модель OpenAI и высокие операционные расходы, позиционирование и конкурентоспособность ее модели с открытым исходным кодом еще предстоит оценить (Источник: Reddit r/LocalLLaMA)

Влияние AI на надежность информации в интернете вызывает беспокойство: Пользователи на Reddit выражают обеспокоенность по поводу влияния AI на надежность интернета. В частности, такие функции, как Google AI Overviews, иногда предоставляют неточные или «совершенно бредовые» ответы (например, объясняя вымышленные пользователем фразы), что может ввести в заблуждение следующее поколение пользователей и даже заставить их сомневаться во всей информации. Мнения в комментариях разделились: одни считают, что интернет никогда не был полностью надежным, и критическое мышление всегда важно; другие шутят, что автор поста выдал свой возраст (Источник: Reddit r/ArtificialInteligence)
Пользователь делится опытом облегчения депрессивного состояния через общение с ChatGPT: Один пользователь поделился опытом, как после долгого разговора с ChatGPT его депрессия и суицидальные мысли ослабли. Он заявил, что даже излияние души AI помогло ему снять огромное психологическое напряжение и обрести смелость двигаться дальше и обратиться за помощью к родным и друзьям. Многие в комментариях сообщили о подобном опыте, считая, что AI в плане психологической поддержки может обеспечить беспристрастное, терпеливое общение, а некоторые пользователи даже поделились промптами, заставляющими ChatGPT играть роль «высшего Я» для глубоких диалогов. Это вызвало дискуссию о потенциале AI в области вспомогательной психологической помощи (Источник: Reddit r/ChatGPT)
Размышления о высказывании «LLM просто предсказывают следующее слово»: В сообществе обсуждается, что высказывание «LLM просто предсказывают следующее слово» является чрезмерным упрощением, которое может привести к недооценке реальных возможностей и потенциального влияния LLM. Ключевым является сложность и практическая польза контента, производимого LLM (например, код, анализ), а не механизм его генерации. Эксперты выражают обеспокоенность быстрым развитием AI и его неизвестными возможностями, в то время как широкая общественность из-за подобных упрощенных высказываний может не в полной мере осознавать грядущие глубокие изменения, которые принесет технология AI. Обсуждение также затрагивает вопросы «интеллекта» и «сознания» AI, утверждая, что даже если AI не обладает сознанием в человеческом понимании, его возможностей достаточно, чтобы оказать огромное влияние на мир (Источник: Reddit r/ArtificialInteligence)
Обсуждение ценности платной версии Claude: управление проектами, длина контекста и режим мышления являются ключевыми факторами: Платные пользователи Claude поделились тем, в чем заключается ценность подписки. Основные преимущества включают функцию «Проекты (Projects)», позволяющую пользователям загружать большие объемы справочных материалов (базу знаний) для конкретных задач (например, подготовка к курсам, SEO веб-сайта, анализ рекламы, составление сводок новостей, поиск рецептов), что позволяет Claude постоянно оказывать помощь в определенном контексте. Кроме того, привлекательность платной версии заключается в большем окне контекста, более сильном «режиме мышления (Thinking Mode)» и большем количестве запросов. Пользователи отмечают, что при решении сложных задач, рецензировании кода, анализе документов и составлении электронных писем Claude Pro в сочетании с инструментами MCP (такими как Desktop Commander) превосходит некоторые интегрированные решения для IDE, которые могут ограничивать возможности глубокого анализа модели из-за оптимизации затрат или встроенных системных подсказок (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Изменение лицензии OpenWebUI вызывает беспокойство у сообщества и корпоративных пользователей: Проект OpenWebUI недавно изменил лицензию на свое программное обеспечение, что вызвало беспокойство у некоторых членов сообщества и корпоративных пользователей. Некоторые компании заявили, что обсуждают прекращение использования и внесения вклада в проект и временно создадут форк на основе последней версии с лицензией BSD. Этот инцидент подчеркивает возможное влияние изменений лицензий проектов с открытым исходным кодом на экосистему пользователей и контрибьюторов, особенно в сценариях коммерческого применения (Источник: Reddit r/OpenWebUI)
💡 Прочее
Ватикан планирует инвестировать в новые источники данных для решения проблемы «стены данных»: С 2023 года обучение больших языковых моделей сталкивается с проблемой «стены данных», то есть большая часть известных текстовых данных человечества уже проиндексирована и использована для обучения. Для решения этой проблемы Ватикан планирует инвестировать в новые источники данных, например, путем транскрипции средневековых церковных документов с помощью технологии OCR и генерации синтетических данных, чтобы постоянно повышать возможности AI-моделей (Источник: jxmnop, Dorialexander)

Стремительное развитие технологий в Китае, инновации во многих областях привлекают внимание: В одном посте подробно перечислены многочисленные поразительные технологические применения, которые автор наблюдал во время своей 15-дневной поездки в Китай, включая секс-кукол DeepSeek, электрические дирижабли, беспилотники для оформления ДТП и т.д. Это вызвало дискуссии о скорости технологического развития и широте применения в Китае в таких областях, как искусственный интеллект, робототехника, транспорт на новых источниках энергии, а также сравнения с такими высокотехнологичными странами, как Сингапур (Источник: GavinSBaker)

Ожидания от развития AI в области медицины: Члены сообщества выражают надежду на достижение большего прогресса AI в области медицины. Представления включают AI-роботов, способных мгновенно сканировать тело и обнаруживать симптомы заболеваний на ранних стадиях, а также системы, способные помогать в точном лечении, хирургии и ускорении реабилитации. Хотя существующие технологии уже достигли прогресса в некоторых аспектах, люди в целом считают, что AI все еще обладает огромным нераскрытым потенциалом в повышении доступности и точности медицинской помощи, а также в спасении жизней (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial)