Ключевые слова:Абсолютный ноль, Qwen3, Mistral Medium 3, Фонд PyTorch, Самоэволюция ИИ, Мультимодальная модель, Открытый ИИ, Парадигма RLVR, Система AZR, Qwen3-235B-A22B, Оптимизационная библиотека DeepSpeed, Мультимодальная поддержка LangSmith
🔥 В фокусе
Университет Цинхуа опубликовал статью Absolute Zero: ИИ может самосовершенствоваться без внешних данных: Команда LeapLabTHU из Университета Цинхуа представила новую парадигму RLVR (Reinforcement Learning with Verifiable Rewards) под названием “Absolute Zero”. В рамках этой парадигмы одна модель может сама ставить задачи, максимизирующие процесс обучения, и повышать свои способности к рассуждению, решая эти задачи, совершенно не полагаясь на какие-либо внешние данные. Ее система AZR (Absolute Zero Reasoner) использует исполнитель кода для проверки задач и ответов, реализуя открытое, но обоснованное обучение. Эксперименты показывают, что AZR достигает уровня SOTA в задачах кодирования и математических рассуждений, превосходя существующие модели zero-shot, которые полагаются на десятки тысяч образцов, аннотированных человеком (источник: Reddit r/LocalLLaMA)
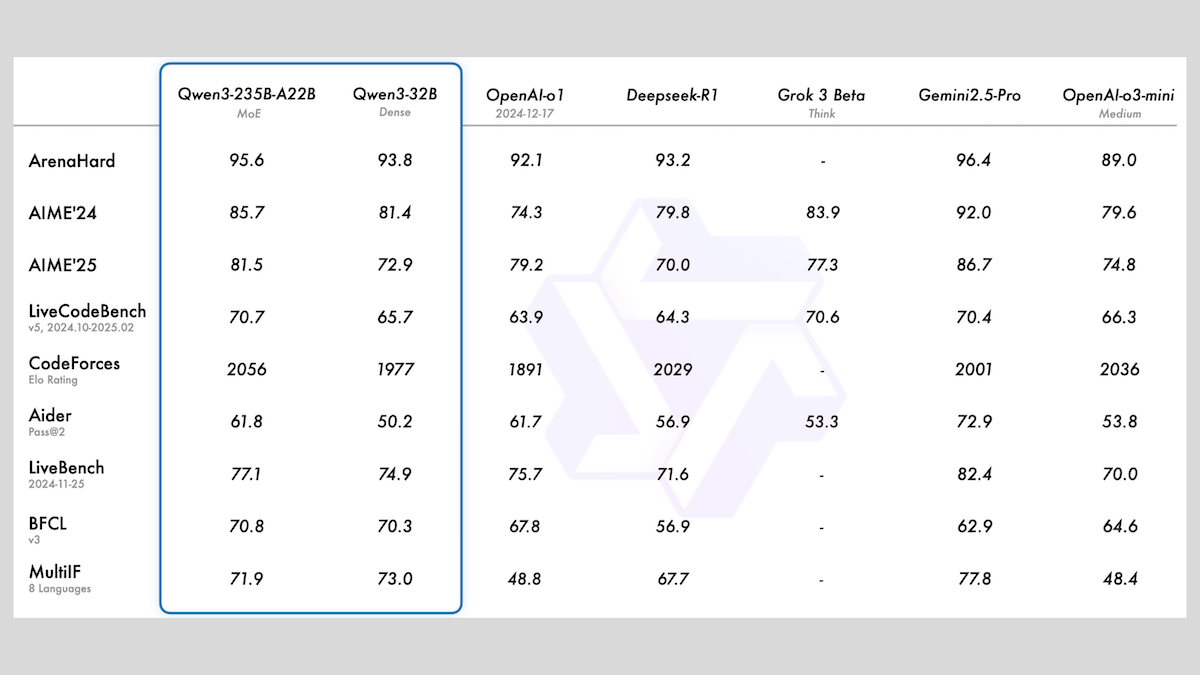
Alibaba выпустила серию моделей Qwen3, включающую MoE и различные размеры: Alibaba выпустила серию больших языковых моделей Qwen3, включающую 8 моделей с количеством параметров от 0.6B до 235B. Из них Qwen3-235B-A22B и Qwen3-30B-A3B используют архитектуру MoE, остальные являются плотными моделями. Модели этой серии предварительно обучены на 36T токенов, охватывают 119 языков и имеют переключаемый режим вывода, подходящий для таких областей, как код, математика, наука и др. Оценка показывает, что модели MoE демонстрируют превосходную производительность: версия 235B превосходит DeepSeek-R1 и Gemini 2.5 Pro по многим бенчмаркам, версия 30B также показывает высокие результаты, а модель 4B даже превосходит модели со значительно большим количеством параметров по некоторым бенчмаркам. Модели опубликованы в открытом доступе на HuggingFace и ModelScope под лицензией Apache 2.0 (источник: DeepLearning.AI Blog)
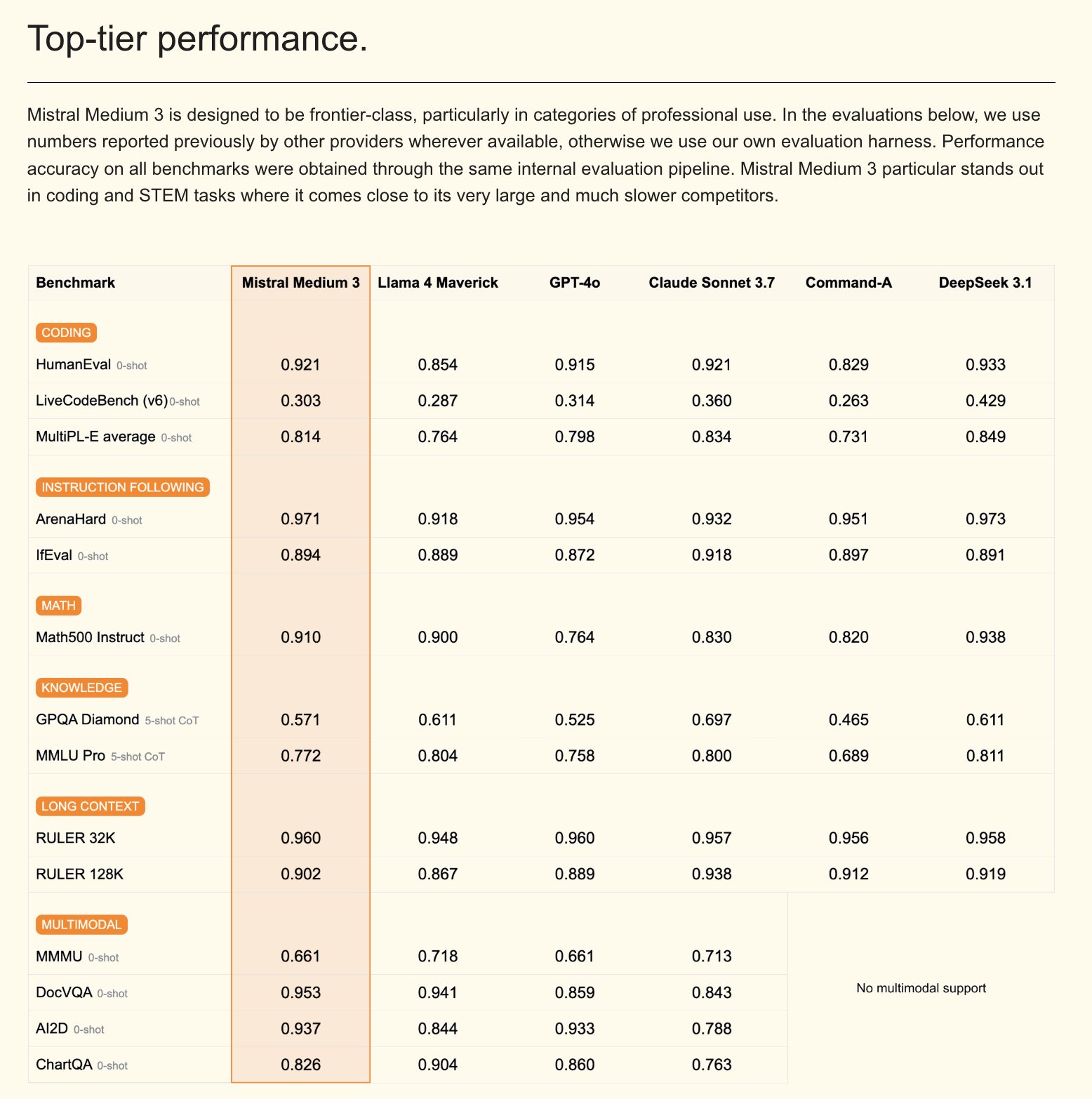
Mistral выпустила мультимодальную модель Mistral Medium 3 и корпоративного AI-ассистента: Mistral AI представила Mistral Medium 3, новую мультимодальную модель, которая, по утверждениям, по производительности приближается к Claude Sonnet 3.7, но при этом значительно дешевле (вход $0.4/M токенов, выход $2/M токенов), что в 8 раз ниже. Модель отлично справляется с кодированием и вызовом функций, а также предлагает корпоративные функции, такие как гибридное или локальное развертывание и кастомизированное пост-обучение. Одновременно Mistral выпустила Le Chat Enterprise, настраиваемого и безопасного корпоративного AI-ассистента, поддерживающего интеграцию с базами знаний компании (например, Gmail, Google Drive, Sharepoint), обладающего функциями Agent, помощника по кодированию, веб-поиска и нацеленного на повышение конкурентоспособности предприятий. Mistral анонсировала выпуск новой Large модели в ближайшие недели (источник: Mistral AI, GuillaumeLample, scaling01, karminski3)
PyTorch Foundation расширяется до зонтичного фонда, включая vLLM и DeepSpeed: PyTorch Foundation объявила о расширении до структуры зонтичного фонда с целью объединения большего количества высококачественных проектов AI с открытым исходным кодом. Первыми присоединившимися проектами стали vLLM и DeepSpeed. vLLM — это высокопроизводительный и память-эффективный движок для инференса и обслуживания LLM; DeepSpeed — это библиотека оптимизации глубокого обучения, делающая обучение крупномасштабных моделей более эффективным. Этот шаг направлен на содействие развитию AI, управляемого сообществом, охватывая весь жизненный цикл от исследований до производства, и получил поддержку от многих членов, включая AMD, Arm, AWS, Google, Huawei и других (источник: PyTorch, soumithchintala, vllm_project, code_star)

🎯 Тенденции
Лаборатория Tencent ARC выпустила FlexiAct: инструмент для переноса движений в видео: Лаборатория Tencent ARC опубликовала на Hugging Face новый инструмент под названием FlexiAct. Этот инструмент способен переносить движения из эталонного видео на любое целевое изображение, даже если расположение, ракурс или структура скелета целевого изображения отличаются от эталонного видео. Это открывает новые возможности в области генерации и редактирования видео, позволяя пользователям более гибко контролировать движения и позы в генерируемом контенте (источник: _akhaliq)
White Circle выпустила CircleGuardBench: новый бенчмарк для моделей модерации контента AI: White Circle представила CircleGuardBench, новый бенчмарк для оценки моделей модерации контента AI. Бенчмарк предназначен для оценки на производственном уровне и тестирует обнаружение вредоносного контента, устойчивость к “джейлбрейку”, частоту ложных срабатываний и задержку, охватывая 17 категорий реальных угроз. Соответствующий пост в блоге и рейтинговая таблица опубликованы на Hugging Face, предоставляя новые стандарты оценки для области безопасности AI и модерации контента (источник: TheTuringPost, _akhaliq)

Hugging Face выпустила SIFT-50M: крупный многоязычный набор данных для тонкой настройки речевых инструкций: На Hugging Face опубликован набор данных SIFT-50M, представляющий собой крупномасштабный многоязычный набор данных, специально разработанный для тонкой настройки речевых инструкций. Набор данных содержит более 50 миллионов пар инструктивных вопросов и ответов на 5 языках. Модель SIFT-LLM, обученная на этом наборе данных, превосходит SALMONN и Qwen2-Audio в бенчмарках следования речевым инструкциям. Набор данных также включает бенчмарк EvalSIFT для акустической и генеративной оценки и поддерживает управляемую генерацию речи (например, высота тона, темп, акцент), построенный на базе Whisper, HuBERT, X-Codec2 & Qwen2.5 (источник: ClementDelangue, huggingface)
Meta выпустила Perception Language Model (PLM): воспроизводимую визуально-языковую модель с открытым исходным кодом: Meta AI представила Meta Perception Language Model (PLM), открытую и воспроизводимую визуально-языковую модель, предназначенную для решения сложных визуальных задач. Meta надеется, что PLM поможет сообществу разработчиков открытого ПО создавать более мощные системы компьютерного зрения. Соответствующая исследовательская статья, код и наборы данных были опубликованы для использования исследователями и разработчиками (источник: AIatMeta)
Google обновила модель генерации изображений Gemini 2.0: улучшено качество и скорость: Google объявила об обновлении своей модели генерации изображений Gemini 2.0 (предварительная версия). Новая версия обеспечивает лучшее визуальное качество, более точное отображение текста, более низкие показатели блокировки (block rates) и более высокие лимиты скорости (rate limits). Стоимость генерации каждого изображения составляет $0.039. Это обновление направлено на улучшение опыта и результатов разработчиков при использовании Gemini для генерации изображений (источник: m__dehghani, scaling01, andrew_n_carr, demishassabis)
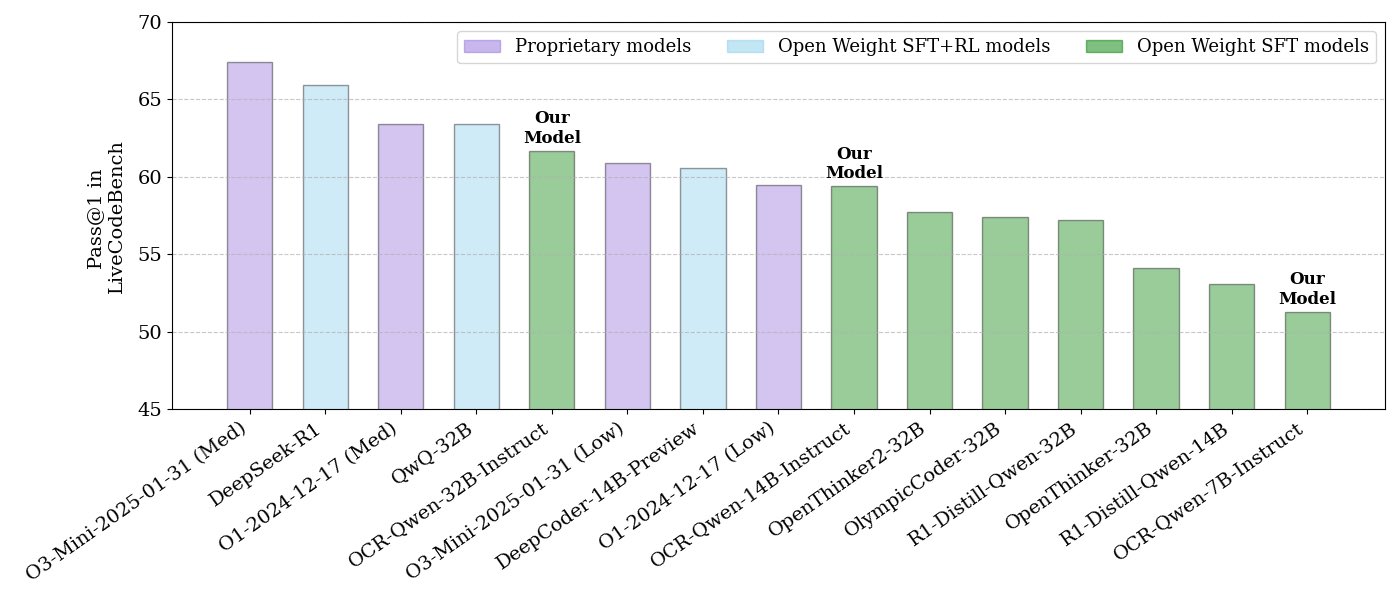
NVIDIA выпустила серию моделей для логического вывода кода с открытым исходным кодом: NVIDIA выпустила серию моделей для логического вывода кода с открытым исходным кодом, включающую три размера: 32B, 14B и 7B, все под лицензией APACHE 2.0. Эти модели обучены на наборах данных OCR и, по утверждениям, превосходят O3 mini и O1 (low) на бенчмарке LiveCodeBench, а также на 30% эффективнее по токенам, чем аналогичные модели для логического вывода. Модели совместимы с различными фреймворками, такими как llama.cpp, vLLM, transformers, TGI и др. (источник: huggingface, ClementDelangue)
ServiceNow и NVIDIA в сотрудничестве выпустили модель Apriel-Nemotron-15b-Thinker: ServiceNow и NVIDIA совместно выпустили модель с 15B параметрами под названием Apriel-Nemotron-15b-Thinker, распространяемую под лицензией MIT. Утверждается, что эта модель обладает производительностью, сравнимой с моделями 32B, но при этом значительно сокращает потребление токенов (примерно на 40% меньше, чем Qwen-QwQ-32b). Она демонстрирует отличные результаты в нескольких бенчмарках, включая MBPP, BFCL, корпоративный RAG, IFEval, и особенно конкурентоспособна в задачах корпоративного RAG и кодирования (источник: Reddit r/LocalLLaMA)

Модель s1: тонкая настройка на небольшом количестве примеров для достижения способности к рассуждению, техника “Wait” повышает производительность: Исследователи из Стэнфордского университета и других учреждений разработали модель s1, продемонстрировав, что всего около 1000 примеров цепочек рассуждений (CoT) для контролируемой тонкой настройки достаточно, чтобы наделить предварительно обученную LLM (например, Qwen 2.5-32B) способностью к рассуждению. Исследование также показало, что принуждение модели генерировать токен “Wait” в процессе рассуждения для удлинения цепочки рассуждений может значительно повысить точность модели в таких задачах, как математика, приближая ее производительность к OpenAI o1-preview. Это открытие предлагает новый подход к недорогому повышению способности моделей к рассуждению (источник: DeepLearning.AI Blog)
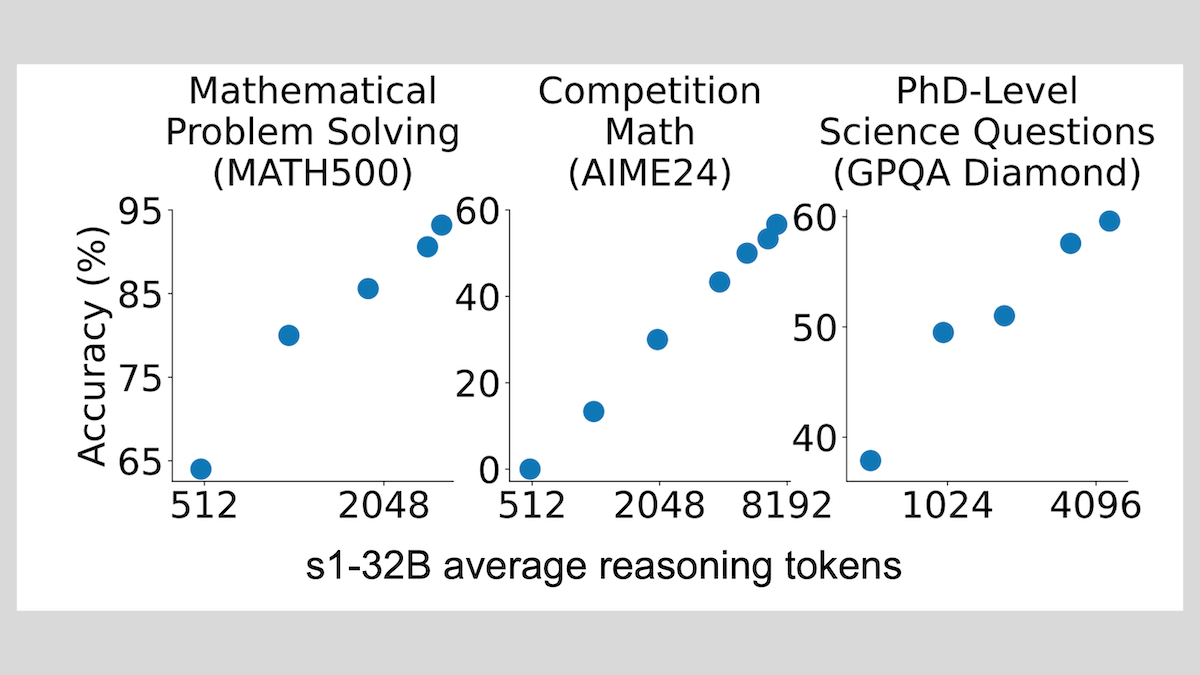
ThinkPRM: генеративная модель вознаграждения за процесс, обучаемая всего на 8K метках: Исследователи предложили ThinkPRM, генеративную модель вознаграждения за процесс (PRM), для тонкой настройки которой требуется всего 8K меток процесса. Эта модель способна проверять процесс рассуждения путем генерации длинных цепочек мыслей (long chains-of-thought), решая проблему дорогостоящего сбора большого количества пошаговых данных для обучения PRM. Соответствующий код, модель и данные опубликованы на GitHub и Hugging Face (источник: Reddit r/MachineLearning)
🧰 Инструменты
Zed выпустила, по утверждению, самый быстрый в мире AI-редактор кода: Zed представила AI-редактор кода, который, по ее словам, является самым быстрым в мире. Редактор создан с нуля на Rust и нацелен на оптимизацию сотрудничества между человеком и AI, обеспечивая молниеносный опыт редактирования с помощью агента (agentic editing experience). Он поддерживает популярные модели, такие как Claude 3.7 Sonnet, и позволяет пользователям использовать собственные API-ключи или локальные модели через Ollama (источник: andersonbcdefg, ollama)
Hugging Face выпустила nanoVLM: минималистичную библиотеку визуально-языковых моделей: Hugging Face опубликовала в открытом доступе nanoVLM, библиотеку на чистом PyTorch, предназначенную для обучения визуально-языковых моделей (VLM) с нуля примерно в 750 строках кода. Эта модель достигает точности 35.3% на бенчмарке MMStar, что сопоставимо с SmolVLM-256M, но требует в 100 раз меньше часов GPU для обучения. nanoVLM использует SigLiP-ViT в качестве визуального кодировщика, декодер в стиле LLaMA и соединяет их через модальный проектор, что подходит для обучения, прототипирования или создания пользовательских VLM (источник: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS выпустила DBOS Python 1.0: легковесный инструмент для персистентных рабочих процессов: DBOS выпустила версию DBOS Python 1.0. Этот инструмент предназначен для обеспечения легковесных и простых в использовании возможностей персистентных рабочих процессов для Python-приложений (включая бизнес-процессы, автоматизацию AI, конвейеры данных и т.д.). Новая версия включает персистентные очереди (с поддержкой ограничения параллелизма, ограничения скорости, тайм-аутов, приоритетов, дедупликации и т.д.), программное управление рабочими процессами (через таблицы Postgres для запросов, приостановки, возобновления, перезапуска и т.д.), поддержку синхронного/асинхронного кода и улучшенные инструменты (панель управления, визуализация и т.д.) (источник: lateinteraction)
Qdrant представила TySVA: голосового ассистента, специально разработанного для TypeScript-разработчиков: Qdrant представила TySVA (TypeScript Voice Assistant), голосового ассистента, предназначенного для предоставления точных, контекстно-зависимых ответов TypeScript-разработчикам. TySVA использует локальное хранилище Qdrant для документации TypeScript, интегрирует платформу Linkup для извлечения релевантных веб-данных и использует LlamaIndex для выбора наилучшего источника данных. Он поддерживает голосовой и текстовый ввод, помогая разработчикам получать надежную помощь без помощи рук во время кодирования (источник: qdrant_engine, qdrant_engine)
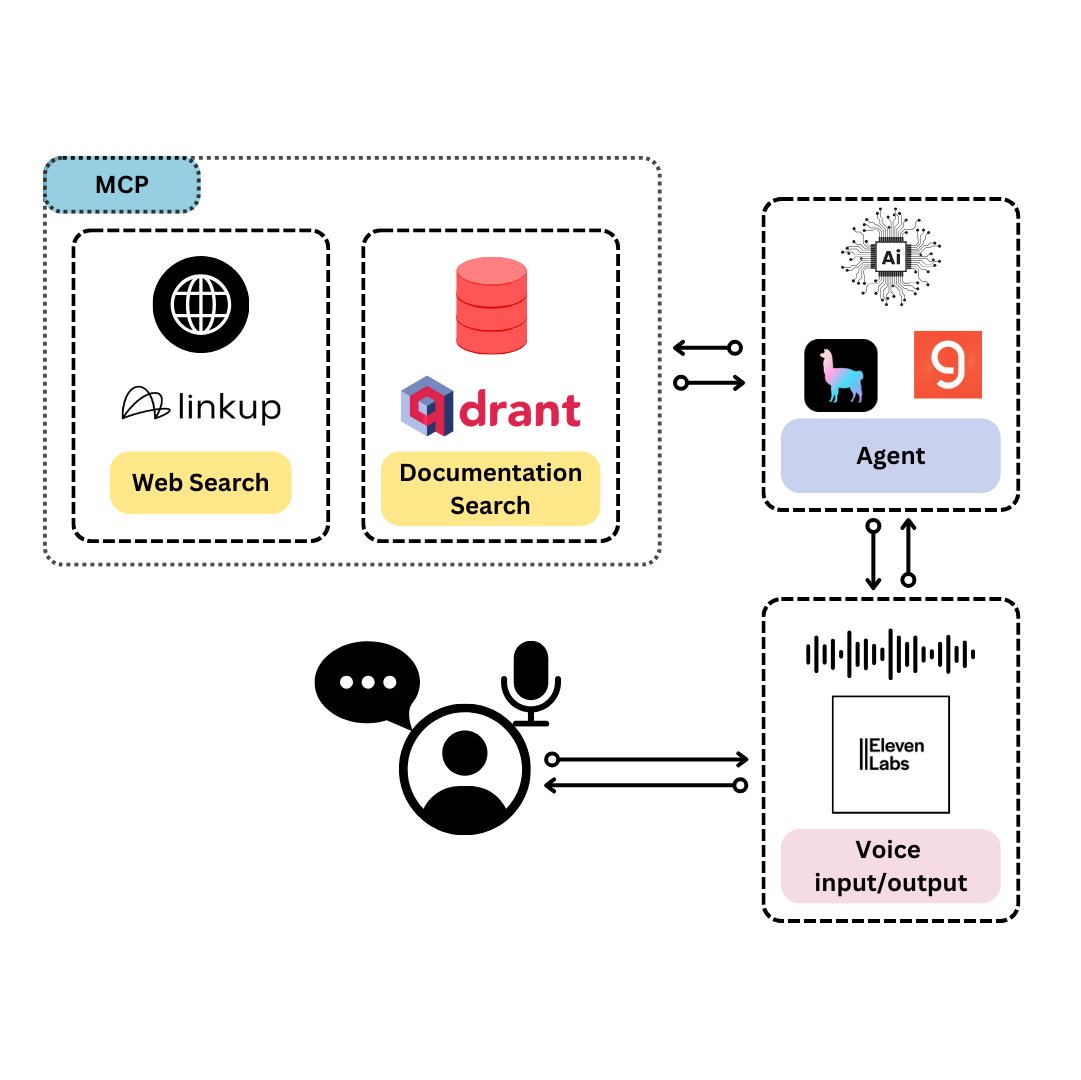
LlamaIndex представила новые функции LlamaExtract: поддержка ссылок и логических выводов: Инструмент LlamaExtract от LlamaIndex получил новые функции, направленные на повышение достоверности и прозрачности AI-приложений. Новые функции позволяют при извлечении информации из сложных источников данных (например, документов SEC) предоставлять точные ссылки на источники (citations) и процесс логического вывода при извлечении (reasoning). Это помогает разработчикам создавать более ответственные и интерпретируемые AI-системы (источник: jerryjliu0, jerryjliu0, jerryjliu0)

Разработчик Hugging Face создает прототип сервера MCP для соединения Agent с Hub: Разработчик из Hugging Face, Wauplin, работает над прототипом сервера Hugging Face MCP (Machine Communication Protocol), предназначенного для соединения AI Agent с Hugging Face Hub. Этот прототип можно рассматривать как “HfApi встречает MCP”, позволяя Agent взаимодействовать с Hub через протокол, например, для обмена и редактирования моделей, наборов данных, Spaces и т.д. Разработчик запрашивает отзывы сообщества о практичности этого инструмента и потенциальных вариантах использования (источник: ClementDelangue, ClementDelangue, huggingface)

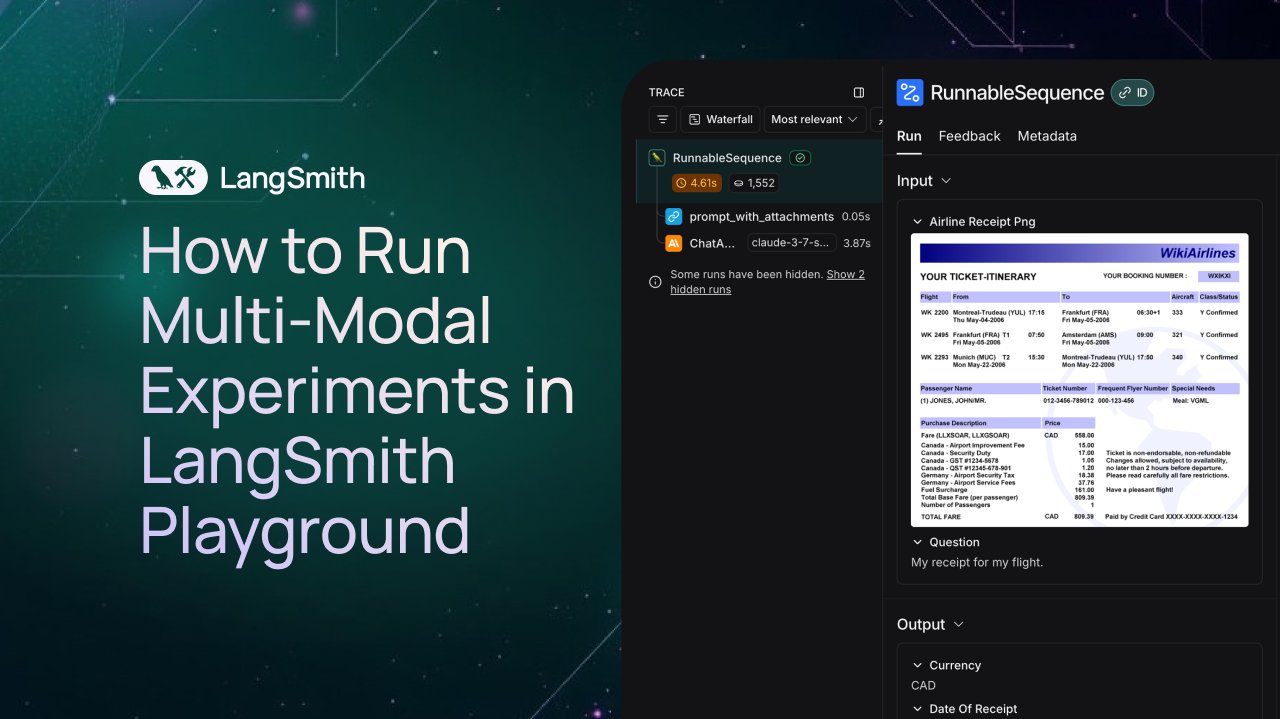
LangSmith добавила поддержку наблюдения и оценки мультимодальных Agent: Платформа LangSmith теперь поддерживает обработку изображений, PDF и аудиофайлов в Playground, очередях аннотирования и наборах данных. Это обновление упрощает создание и оценку мультимодальных приложений (например, Agent для извлечения данных из счетов). Официально выпущены демонстрационное видео и документация, чтобы помочь пользователям начать работу с новыми функциями (источник: LangChainAI, Hacubu, hwchase17)
DFloat11 выпустила версии моделей FLUX.1 без потерь сжатия, работающие на 20GB VRAM: Проект DFloat11 выпустил версии моделей FLUX.1-dev и FLUX.1-schnell (12B параметров) без потерь сжатия. С помощью метода сжатия DFloat11 (применение энтропийного кодирования к весам BFloat16) размер модели уменьшен с 24GB примерно до 16.3GB (около 30%), при этом выходные данные остаются неизменными. Это позволяет запускать эти модели на одном GPU с 20GB VRAM или более, с дополнительными затратами всего в несколько секунд на изображение. Соответствующие модели и код опубликованы на Hugging Face и GitHub (источник: Reddit r/LocalLLaMA)

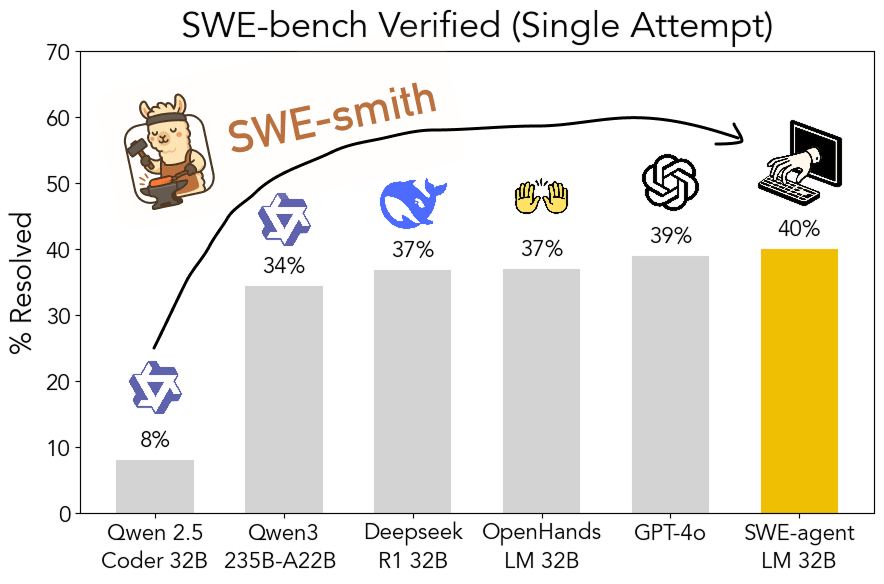
Инструментарий SWE-smith с открытым исходным кодом: масштабируемая генерация обучающих данных для программной инженерии: Исследователи из Стэнфордского университета опубликовали в открытом доступе SWE-smith, масштабируемый конвейер для генерации обучающих данных для программной инженерии из любого Python-репозитория. С помощью этого инструментария было сгенерировано более 50 тысяч экземпляров, на основе которых была обучена модель SWE-agent-LM-32B. Эта модель достигла 40.2% Pass@1 на бенчмарке SWE-bench Verified, став лучшей моделью с открытым исходным кодом на этом бенчмарке. Код, данные и модель находятся в открытом доступе (источник: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 Обучение
Weaviate выпустила бесплатный курс: Оценка и выбор моделей встраивания: Weaviate Academy запустила бесплатный курс “Оценка и выбор моделей встраивания”. Курс подчеркивает важность выхода за рамки общих бенчмарков (таких как MTEB) и учит слушателей, как курировать “золотой набор для оценки” (golden evaluation set) для конкретных случаев использования, а также настраивать пользовательские бенчмарки для выбора наиболее подходящей модели встраивания и оценки применимости недавно выпущенных моделей. Это крайне важно для создания эффективных систем поиска и RAG (источник: bobvanluijt)
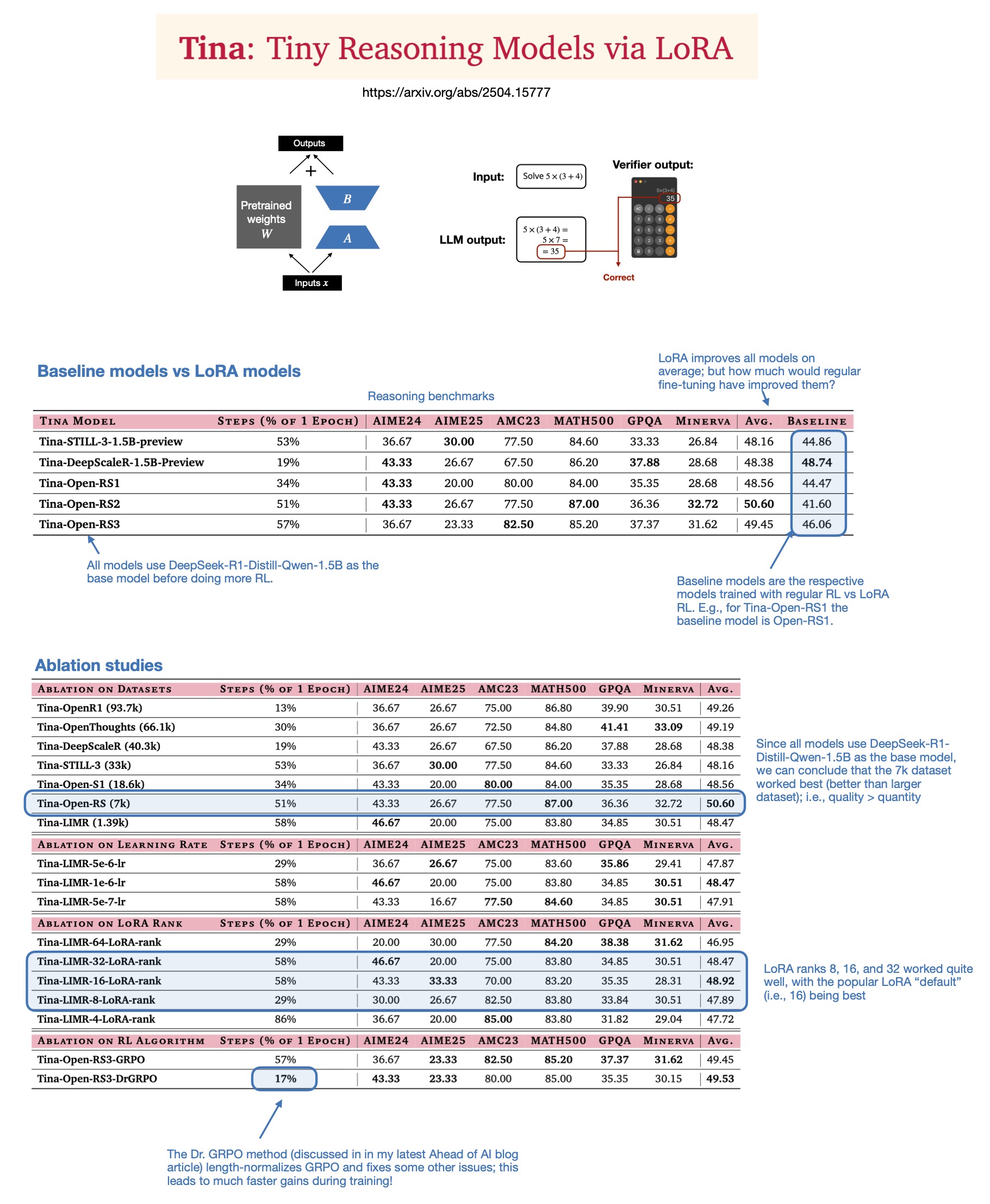
Sebastian Rasbt обсуждает ценность LoRA в моделях логического вывода 2025 года: Sebastian Rasbt, после прочтения статьи “Tina: Tiny Reasoning Models via LoRA”, пересмотрел значение LoRA (Low-Rank Adaptation) в современную эпоху больших моделей. Несмотря на популярность полнопараметрической тонкой настройки и техник дистилляции, Rasbt считает, что LoRA по-прежнему имеет ценность в определенных сценариях (например, задачи логического вывода, сценарии с несколькими клиентами/несколькими вариантами использования). Статья демонстрирует возможность использования LoRA в сочетании с обучением с подкреплением (RL) для недорогого (стоимость обучения всего $9) повышения способности к логическому выводу у небольших моделей (1.5B), причем LoRA превосходит стандартную тонкую настройку RL на нескольких бенчмарках. Свойство LoRA не изменять базовую модель делает ее экономически выгодной, когда требуется хранить большое количество кастомизированных весов моделей (источник: rasbt)
DeepLearning.AI запускает новый курс: Создание AI-голосовых агентов производственного уровня: DeepLearning.AI в сотрудничестве с LiveKit и RealAvatar запустила новый краткосрочный курс под названием “Создание AI-голосовых агентов производственного уровня”. Курс направлен на обучение созданию AI-голосовых агентов, способных вести диалог в реальном времени, отвечать с низкой задержкой и звучать естественно. Слушатели будут реализовывать технологии обнаружения голосовой активности, поочередного говорения и узнают, как оптимизировать архитектуру для снижения задержки, в конечном итоге создавая и развертывая масштабируемых голосовых агентов. Курс ведут CEO LiveKit, евангелист-разработчик и руководитель AI в RealAvatar (источник: DeepLearningAI, AndrewYNg)
LangChain и LangGraph совместно проведут техническую лекцию ACM: Ранний разработчик-контрибьютор LangChain Mayowa Oshin и создатель LangGraph Nuno Campos поделятся на технической лекции ACM тем, как использовать LangChain и LangGraph для создания надежных AI Agent и LLM-приложений. Лекция бесплатная и будет транслироваться в прямом эфире, зарегистрировавшиеся участники позже получат ссылку для просмотра (источник: hwchase17, hwchase17)

Cohere Labs проведет лекцию о глубинах оптимизации первого порядка: Cohere Labs приглашает Jeremy Bernstein 8 мая выступить с докладом на тему “Глубины оптимизации первого порядка” (Depths of First-Order Optimization). Лекция направлена на углубленное изучение применения и теории алгоритмов оптимизации в машинном обучении (источник: eliebakouch)

AI2 проведет AMA-сессию по моделям OLMo: Allen Institute for AI (AI2) проведет сессию “Спроси меня о чем угодно” (AMA) по своему семейству открытых языковых моделей OLMo 8 мая с 8 до 10 утра по тихоокеанскому времени на сабреддите r/huggingface. Исследователи ответят на вопросы сообщества (источник: natolambert)

💼 Бизнес
OpenAI планирует сократить долю выручки, выплачиваемую Microsoft: По сообщению The Information, OpenAI уведомила инвесторов о планах сократить долю выручки, выплачиваемую ее крупнейшему спонсору, Microsoft, в процессе реструктуризации компании. Конкретные детали и потенциальные последствия пока не раскрыты полностью, но это может означать изменение коммерческих отношений между двумя компаниями (источник: steph_palazzolo)
Венчурные капиталисты предоставляют основателям AI больше полномочий, вызывая опасения по поводу пузыря: The Information сообщает, что венчурные капиталисты (VCs), чтобы привлечь ведущих основателей AI (особенно с опытом работы в известных AI-лабораториях), предлагают беспрецедентно выгодные условия, включая право вето в совете директоров, отсутствие мест для VCs в совете директоров и разрешение основателям продавать часть своих акций. Это явление некоторые расценивают как признак возможного пузыря в сфере AI (источник: steph_palazzolo)
Toloka привлекает стратегические инвестиции во главе с Bezos Expeditions, Mikhail Parakhin присоединяется в качестве председателя совета директоров: Компания по разметке данных и обучению AI Toloka объявила о привлечении стратегических инвестиций во главе с Bezos Expeditions Джеффа Безоса. Бывший топ-менеджер Microsoft Mikhail Parakhin также участвовал в инвестициях и присоединился к компании в качестве председателя совета директоров. Этот раунд инвестиций поддержит расширение решений Toloka в области сотрудничества человека и AI (human+AI), а также дальнейшее развитие бизнеса по сбору и разметке данных (источник: menhguin, teortaxesTex, TheTuringPost)

🌟 Сообщество
Обсуждение добросовестного использования (Fair Use) обучающих данных для LLM: Dorialexander упоминает, что аргумент о добросовестном использовании обучающих данных для LLM в значительной степени опирается на предположение, что LLM не вступают в прямую коммерческую конкуренцию с источниками обучения. По мере расширения возможностей LLM (например, Perplexity и другие начинают предлагать опыт, подобный чтению нехудожественной литературы), это предположение может быть оспорено, вызывая новые вопросы о авторском праве и коммерческой конкуренции (источник: Dorialexander)
Обеспокоенность и обсуждение засилья AI-генерируемого контента: В социальных сетях и на Reddit пользователи выражают обеспокоенность засильем низкокачественного, повторяющегося AI-генерируемого контента (например, AI-сгенерированные видео с историями с Reddit). Пользователи считают, что это вытесняет человеческих создателей, распространяет ложную или однородную информацию, и выражают недовольство тем, что технология AI используется для легкого получения прибыли при отсутствии оригинальности (источник: Reddit r/ArtificialInteligence)
Философская дискуссия о том, обладает ли AI уже сознанием: В сообществе Reddit вновь возникла дискуссия о том, возможно ли, что AI уже обладает сознанием. Сторонники считают, что наше определение сознания может быть слишком узким или антропоцентричным, в то время как противники подчеркивают, что текущие основные механизмы LLM (например, предсказание следующего токена) недостаточны для возникновения истинного сознания. Дискуссия отражает постоянное любопытство и разногласия общественности относительно сущности и будущего потенциала AI (источник: Reddit r/ArtificialInteligence)
Обсуждение снижения производительности и изменения поведения ChatGPT(4o): Пользователи Reddit сообщают о недавнем снижении производительности модели ChatGPT 4o в обработке длинных документов и удержании контекста, появлении большего количества галлюцинаций и даже неспособности читать форматы документов, которые ранее обрабатывались. В то же время OpenAI также признала, что в недавних обновлениях версии GPT-4o возникла проблема чрезмерной угодливости (sycophancy), и уже откатила изменения. Это вызвало обеспокоенность сообщества по поводу стабильности модели и контроля качества итераций (источник: Reddit r/ChatGPT, DeepLearning.AI Blog)
Влияние AI на образовательные модели и размышления: Обсуждения в сообществе указывают на то, что американская образовательная модель, основанная на домашних заданиях и индивидуальных эссе, чрезвычайно уязвима для способности AI (например, LLM) автоматически выполнять задания. В отличие от этого, некоторые европейские страны (например, Дания) уделяют больше внимания совместной работе в классе, обсуждениям и проектному обучению, и меньше подвержены влиянию AI. Это вызывает размышления о будущих образовательных моделях, которые должны больше фокусироваться на развитии критического мышления, сотрудничества и других межличностных навыков, используя AI для выполнения механических задач и продвигая образование в более синхронном и социальном направлении (источник: alexalbert__, riemannzeta, aidan_mclau)
💡 Прочее
Прогресс в применении AI в робототехнике: Несколько источников демонстрируют примеры применения AI в робототехнике: включая робота-повара, способного приготовить жареный рис за 90 секунд, демонстрацию применения роботов Figure AI в реальном мире, робота Pickle, демонстрирующего разгрузку товаров из загроможденного грузового прицепа, робота Unitree G1, сохраняющего равновесие на неровной поверхности, а также демонстрацию его внутренней структуры, и деформируемого робота Mori3, разработанного швейцарским EPFL. Эти примеры показывают потенциал AI в повышении автономности, адаптивности и практичности роботов (источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

Исследование применения технологий AI в конкретных отраслях (медицина, текстиль, мобильные телефоны): Компания Johnson & Johnson поделилась своей AI-стратегией, сфокусированной на применении в поддержке продаж, ускорении разработки лекарств (отбор соединений, оптимизация клинических испытаний), прогнозировании рисков в цепочках поставок и внутренней коммуникации (HR-чат-боты). В то же время технологии AI также расширяют возможности традиционной текстильной промышленности, от AI-ассистированного дизайна и точного контроля окрашивания до автоматизированного контроля качества, повышая эффективность и устойчивость. Мобильная индустрия рассматривает AI как новый двигатель роста, производители конкурируют вокруг локальных больших моделей, нативных AI-операционных систем и сценарий-ориентированных интеллектуальных сервисов, формируя три основных лагеря: Apple, Huawei и открытый лагерь (источник: DeepLearning.AI Blog, 36氪, 36氪)
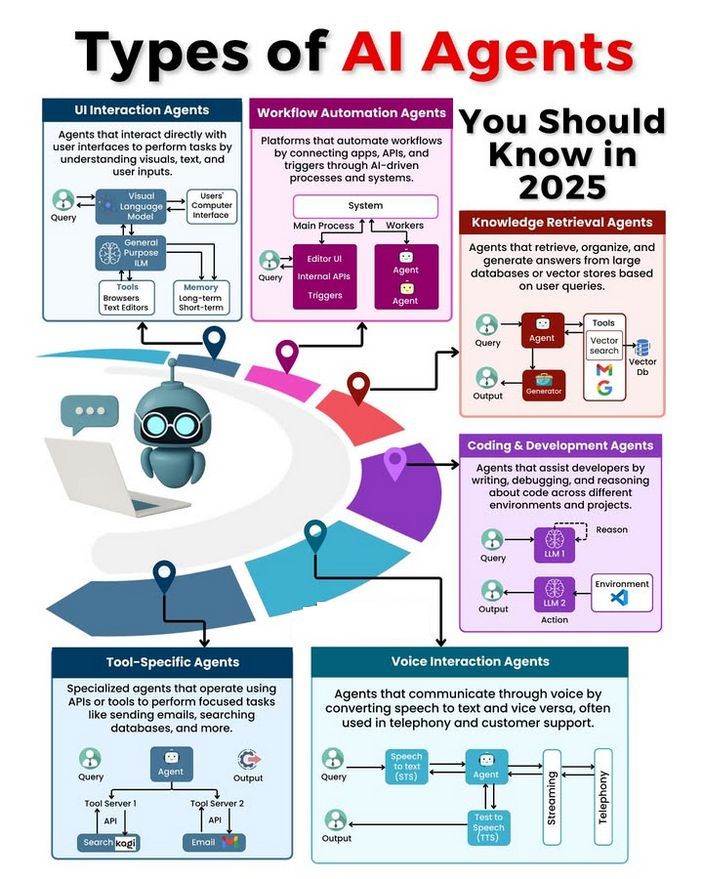
Обсуждение типов и развития AI Agent: В сообществе обсуждаются различные типы AI Agent (например, простые рефлексивные, рефлексивные на основе модели, целеориентированные, основанные на полезности, обучающиеся Agent) и методологии создания надежных Agent (например, с использованием LangChain/LangGraph). В то же время существует мнение, что будущий AGI, возможно, не будет единой моделью, а будет состоять из нескольких специализированных моделей, работающих совместно (источник: Ronald_vanLoon, hwchase17, nrehiew_)