
Ключевые слова:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, Искусственный интеллект (ИИ), Большая языковая модель (LLM), Смесь экспертов (MoE), dspy.GRPO, DeepSeek MoE, Parakeet TDT, Агентные системы, EQ-Bench 3
🔥 В центре внимания
OpenAI подтверждает сохранение некоммерческой структуры: OpenAI объявила, что ее существующая коммерческая структура будет преобразована в Public Benefit Corporation (PBC), но контроль останется у текущей некоммерческой организации. Этот шаг подтверждает, что OpenAI продолжит контролироваться некоммерческой организацией, и подтверждает ее миссию по обеспечению того, чтобы AGI (Общий искусственный интеллект) приносил пользу всему человечеству. Это решение было принято после внутренних потрясений и внешних вопросов о структуре компании (включая иск Маска). Реакция сообщества неоднозначна: одни считают это приверженностью миссии, другие ставят под сомнение истинные намерения реструктуризации капитала (источник: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
Фреймворк DSPy выпускает экспериментальный онлайн-оптимизатор RL dspy.GRPO: Команда Stanford NLP выпустила экспериментальную новую функцию для фреймворка DSPy — dspy.GRPO, онлайн-оптимизатор на основе обучения с подкреплением (RL). Этот инструмент предназначен для оптимизации программ DSPy, даже сложных многомодульных, многоэтапных программ, и может применяться напрямую без изменения существующего кода. Этот шаг рассматривается как важный шаг к внедрению оптимизации RL (например, GRPO, используемой DeepSeek) на более высоком уровне абстракции (рабочие процессы LLM) с целью повышения производительности и эффективности AI-агентов и сложных пайплайнов. Сообщество восприняло новость с энтузиазмом, считая, что это станет важной частью DSPy 3.0 (источник: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
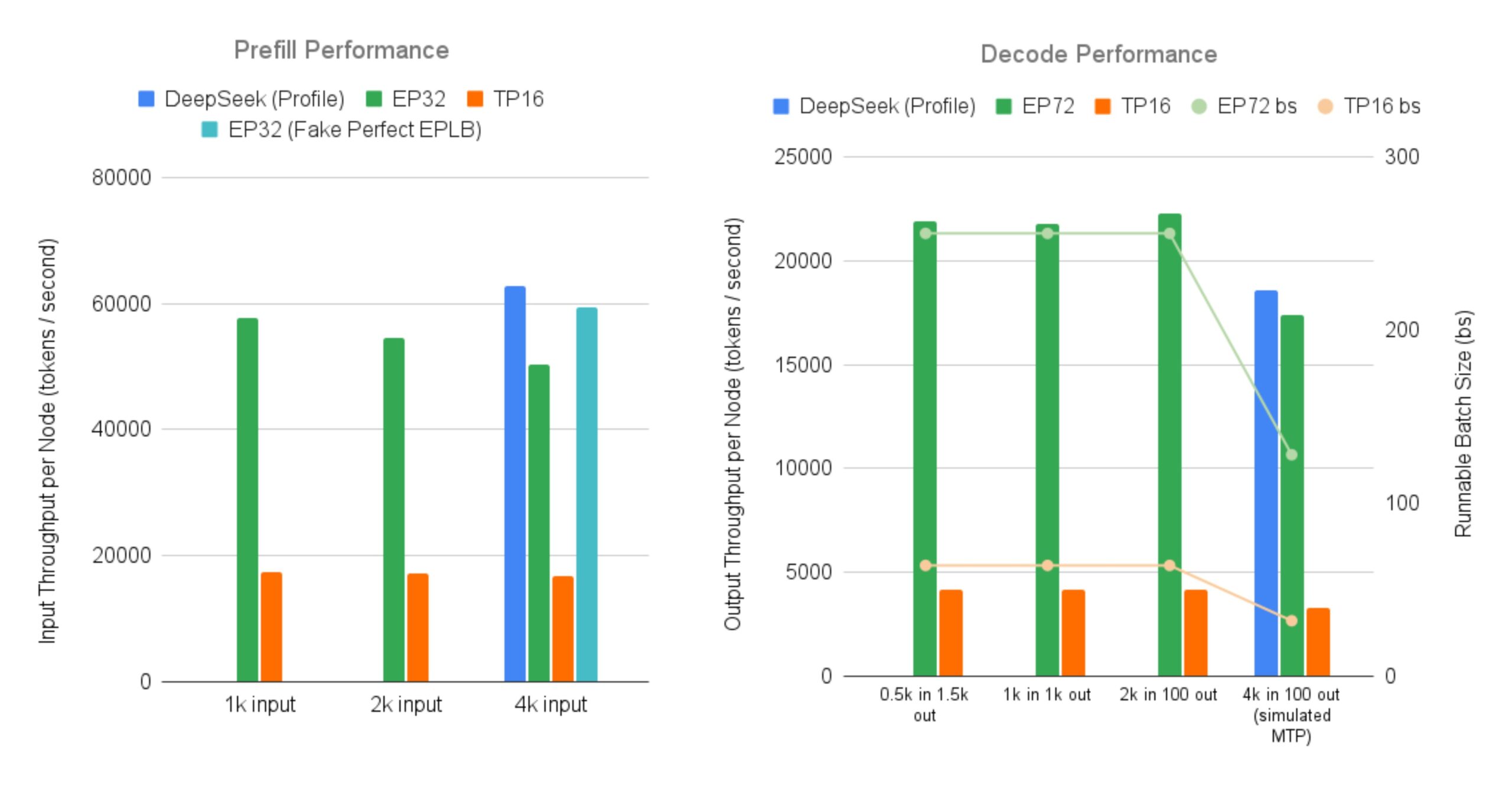
SGLang с открытым исходным кодом реализует эффективное обслуживание больших моделей DeepSeek MoE: LMSYS Org объявила, что SGLang предоставляет первую реализацию с открытым исходным кодом для обслуживания моделей MoE (Mixture-of-Experts), таких как DeepSeek V3/R1, на 96 GPU с функциями масштабного параллелизма экспертов (Expert Parallelism) и разделения фаз prefill и decode (Prefill-Decode Disaggregation). Эта реализация почти достигает пропускной способности, заявленной DeepSeek официально (52.3k токенов/сек на вход и 22.3k токенов/сек на выход на узел), что до 5 раз выше пропускной способности на выходе по сравнению с традиционным тензорным параллелизмом. Это предоставляет сообществу открытое решение для эффективного запуска и развертывания больших моделей MoE (источник: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
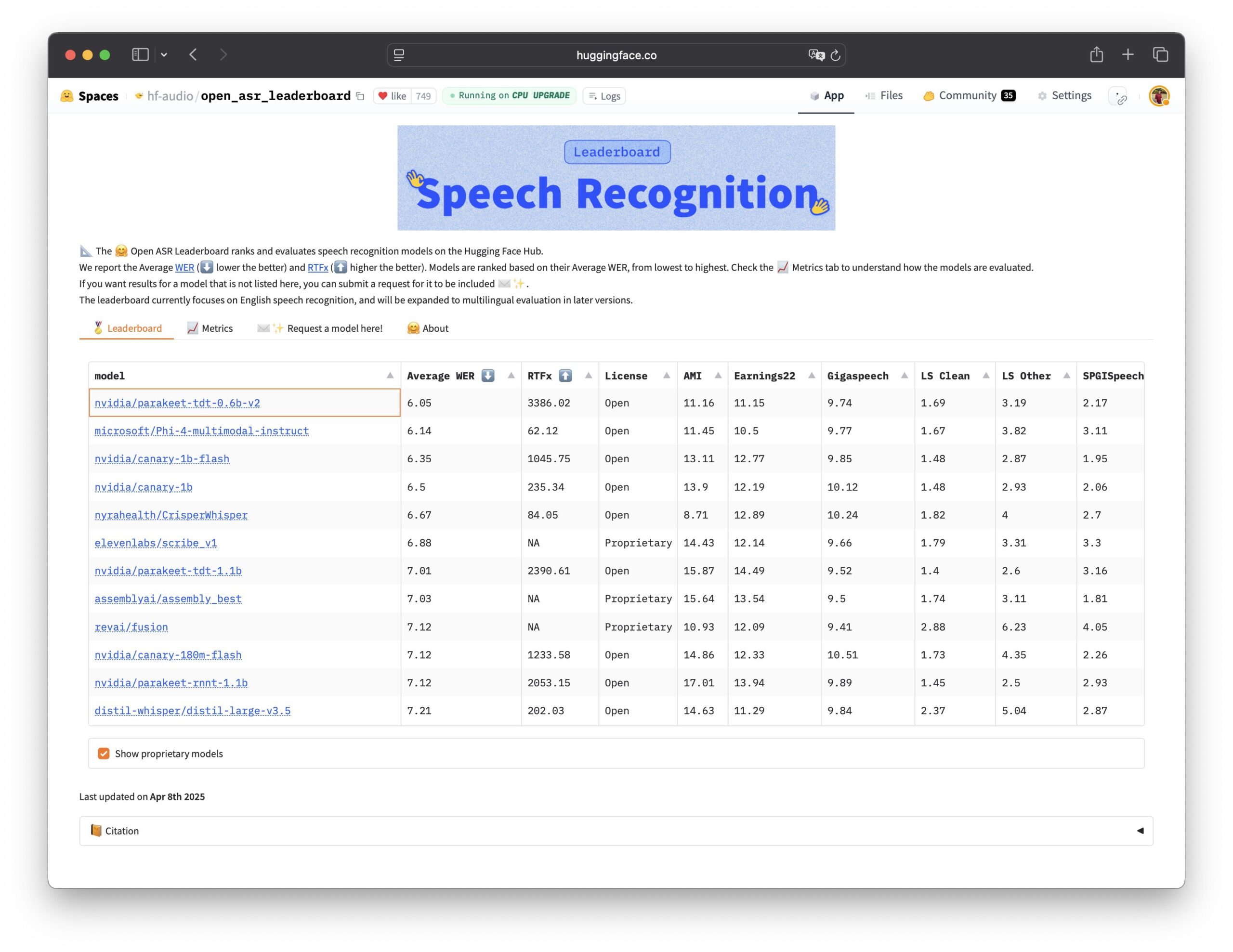
Nvidia открывает исходный код модели распознавания речи Parakeet TDT: Nvidia открыла исходный код модели Parakeet TDT 0.6B, которая показала лучшие результаты в рейтинге Open ASR Leaderboard, став текущей лидирующей опенсорсной моделью автоматического распознавания речи (ASR). Модель имеет 600 миллионов параметров и способна транскрибировать 60 минут аудио за 1 секунду, превосходя по производительности многие основные закрытые модели. Модель распространяется под лицензией CC-BY-4.0, разрешающей коммерческое использование, и предоставляет мощный опенсорсный вариант для области распознавания речи (источник: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 Тенденции
Посещаемость ChatGPT продолжает расти, опережая X: Данные Similarweb показывают, что посещаемость ChatGPT продолжает расти, и в апреле общий объем посещений (4,786 млрд) превысил платформу X (4,028 млрд). С начала 2025 года посещаемость ChatGPT неуклонно росла: от случайного отставания в январе до почти полного превосходства над X в апреле, что демонстрирует сильную динамику активности пользователей AI-чатботов (источник: dotey)
Доверие к данным и лидерство становятся ключом к трансформации AI: Множество отчетов и обсуждений подчеркивают, что доверие к данным является невидимой силой, ускоряющей трансформацию AI. В то же время успешные лидеры GenAI демонстрируют различные качества в стратегии, организации и применении технологий. Это указывает на то, что ключ к успеху AI заключается не только в самой технологии, но и в высококачественной, надежной базе данных, а также в эффективном лидерстве и стратегическом развертывании (источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT показывает SOTA результаты в задачах эмбеддинга длинных текстов: Выпущенная LightOn модель многовекторных эмбеддингов GTE-ModernColBERT достигла SOTA (State-of-the-Art) результатов в бенчмарке поиска по длинным документам LongEmbed, опередив конкурентов почти на 10 пунктов. Примечательно, что модель обучалась только на коротких документах MS MARCO (длиной 300), но продемонстрировала превосходную способность к zero-shot обобщению на задачах с длинными текстами. Это еще раз подтверждает потенциал моделей с поздним взаимодействием (Late Interaction), таких как ColBERT, в обработке поиска по длинному контексту, превосходя традиционные модели BM25 и плотного поиска (источник: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

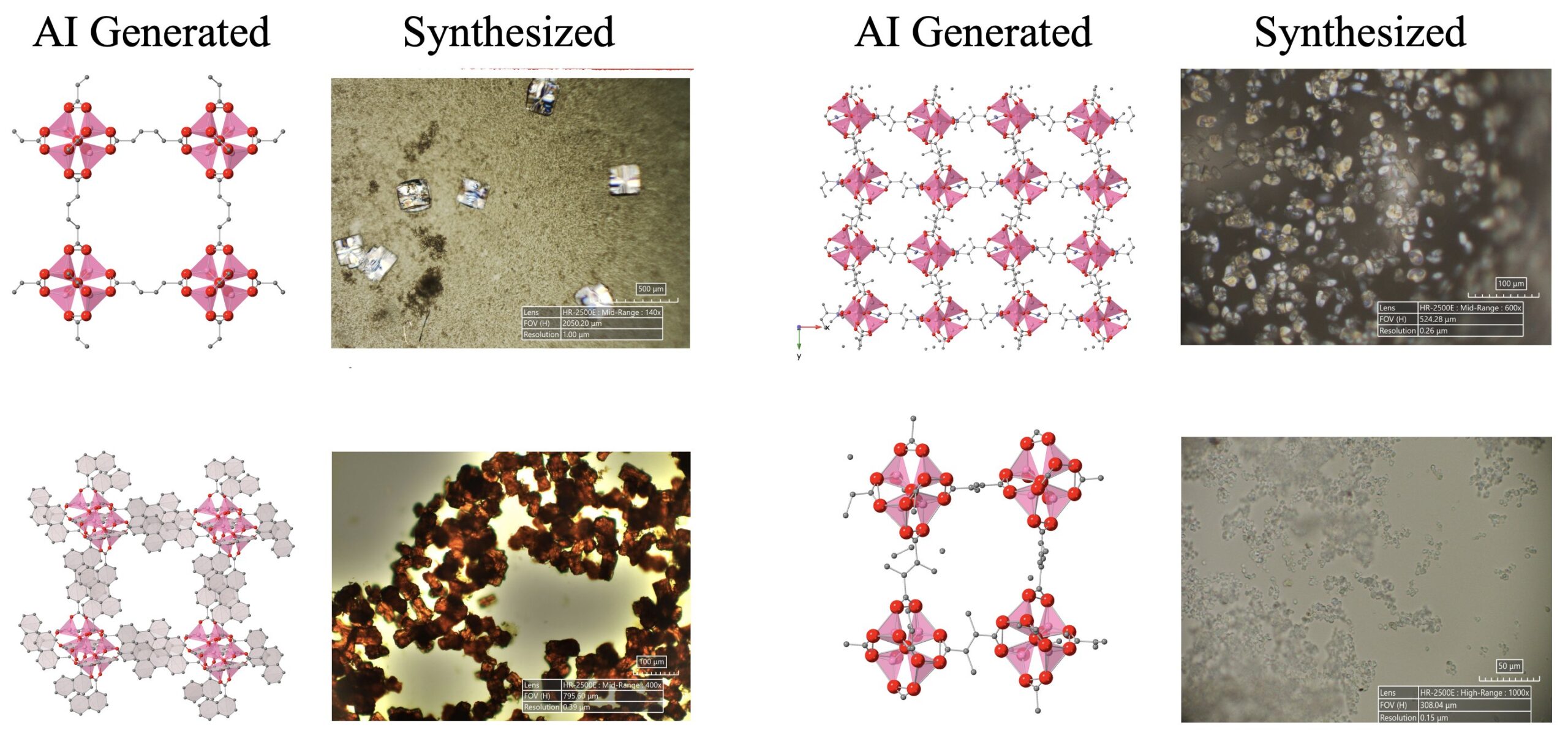
AI-управляемые научные открытия достигают прогресса: Система AI-агентов, состоящая из LLM, диффузионных моделей и аппаратных устройств, успешно и автономно открыла и синтезировала 5 новых металлоорганических каркасных структур (MOFs), которые выходят за рамки существующих человеческих знаний. Исследование демонстрирует потенциал AI-агентов в автоматизации научных исследований, способных выполнять весь процесс от выдвижения исследовательских идей до проверки в «мокрой» лаборатории (источник: Sherry Yang)
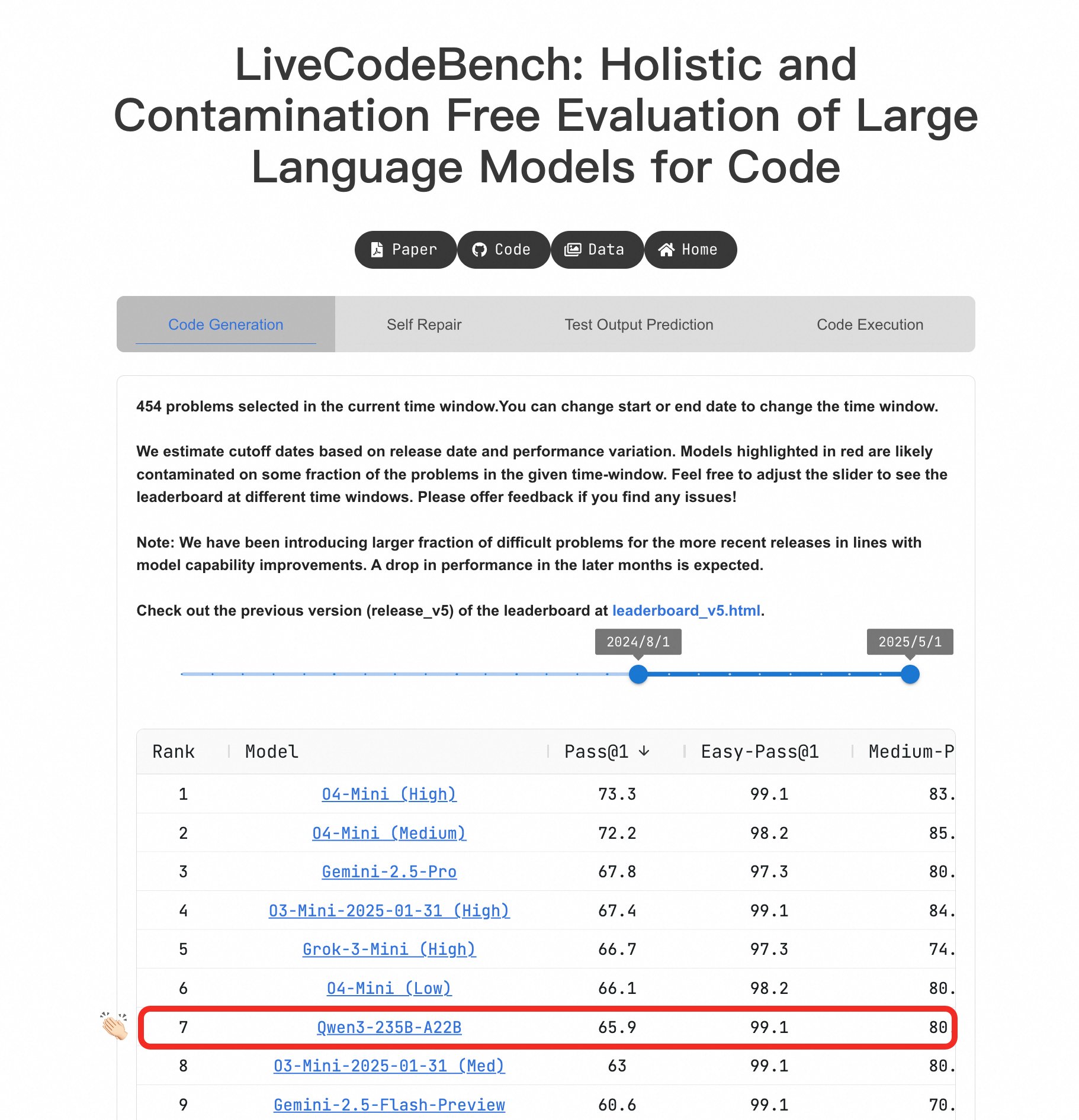
Большая модель Qwen3 демонстрирует выдающиеся способности к программированию: В бенчмарке LiveCodeBench модель Qwen3-235B-A22B показала отличную производительность и считается одной из лучших опенсорсных моделей для генерации кода соревновательного уровня, ее производительность сравнима с o4-mini (с низкой уверенностью). Даже на сложных задачах Qwen3 может поддерживать уровень, эквивалентный O4-Mini (Low), превосходя o3-mini (источник: Binyuan Hui, teortaxesTex)
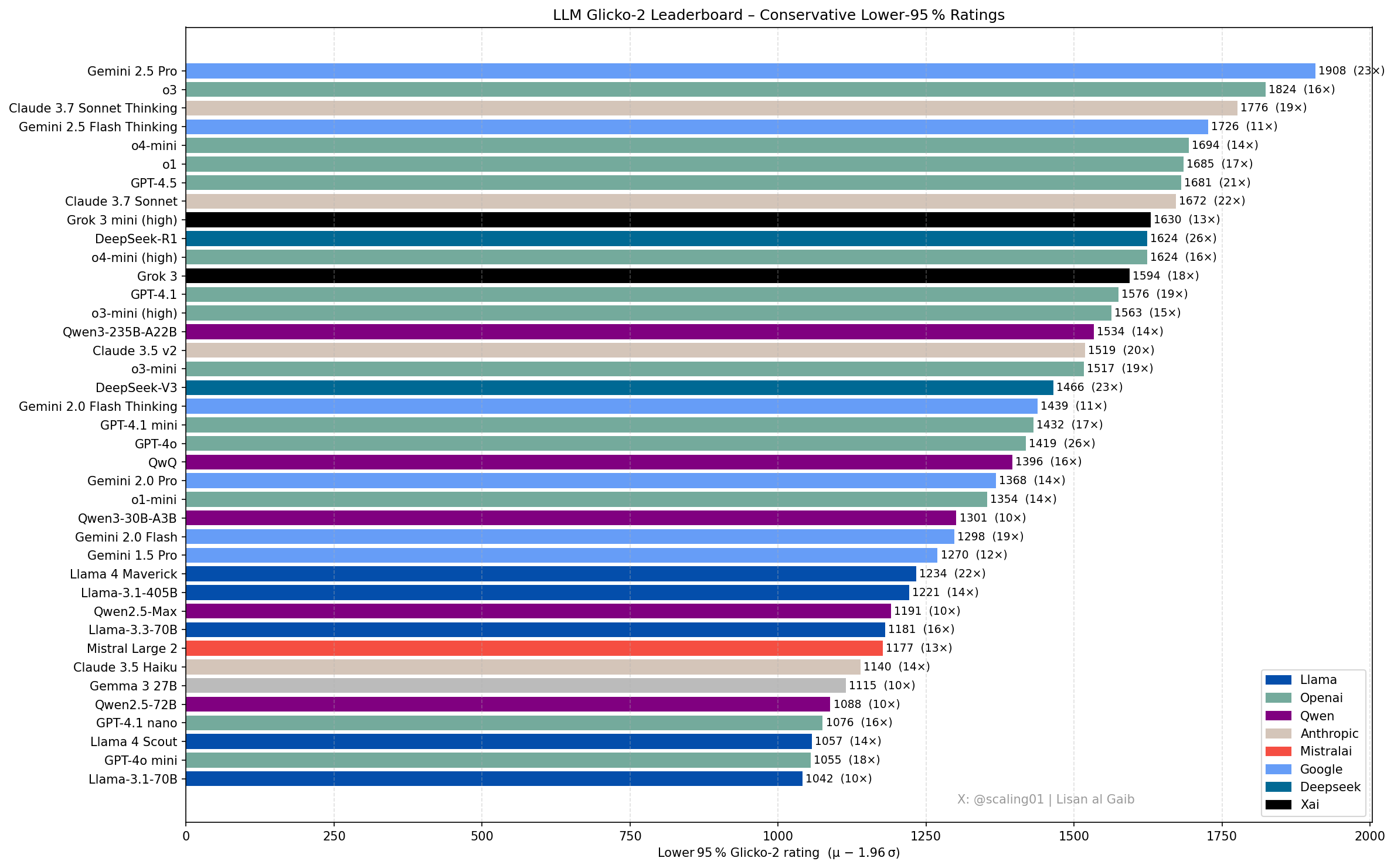
Новые достижения и обсуждения в рейтинге LLM: Член сообщества Lisan al Gaib обновил рейтинг LLM с использованием системы рейтинга Glicko-2, что вызвало обсуждение. Scaling01 считает, что этот рейтинг на 95% соответствует его субъективным ощущениям, Gemini 2.5 Pro по-прежнему лидирует, но Gemini 2.5 Flash, Grok 3 mini и GPT-4.1 могут быть переоценены. Рейтинг показывает разумную последовательность прогресса моделей серий OpenAI, Llama и Gemini, o3 (high) находится на одном уровне с Gemini 2.5 Pro (источник: Lisan al Gaib)
Экосистема опенсорсной робототехники быстро развивается: Clem Delangue из Hugging Face выразил восторг по поводу прогресса в области AI-робототехники после общения с NPeW и Matth Lapeyre. Peter Welinder (OpenAI) также похвалил работу Hugging Face по продвижению экосистемы опенсорсной робототехники, отметив, что эта область быстро растет (источник: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
Направление исследований интерпретируемости AI привлекает внимание: Исследователи призывают к большей работе в области интерпретируемости AI (Interpretability), особенно для объяснения странного поведения моделей. Понимание этого поведения может, в свою очередь, привести к более глубоким выводам о внутренних механизмах LLM и потенциально породить новые инструменты интерпретируемости. Это считается перспективным и влиятельным направлением исследований (источник: Josh Engels)
FutureHouseSF стремится создать «AI-ученого»: CEO компании FutureHouseSF Сэм Родригес (Sam Rodriques) дал интервью, в котором изложил цель компании по созданию «AI-ученого». Обсуждались конкретное значение «AI-ученого», роль робототехники в этом, и почему научная область нуждается в движущей силе, подобной проекту «Звездные врата», с целью использования AI для ускорения научных открытий (источник: steph_palazzolo)
Преимущество Google TPU может быть недооценено: Комментатор Джастин Хэлфорд (Justin Halford) считает, что инвесторы могут недооценивать преимущество Google в области TPU (Tensor Processing Unit). Он отмечает, что при отсутствии значительных алгоритмических «рвов», вычислительная мощность будет ключом к гонке AI, а собственные TPU Google позволяют избежать промежуточных затрат, что критически важно в условиях, когда сотни миллиардов долларов вливаются в инфраструктуру (источник: Justin_Halford_)
Выпущена опенсорсная VLA модель Nora: Declare Lab открыла исходный код новой модели типа Vision-Language-Action (VLA) под названием Nora, основанной на Qwen2.5VL и токенизаторе FAST+. Модель была обучена на наборе данных Open X-Embodiment и показала лучшие результаты, чем Spatial VLA и OpenVLA, в реальных задачах WidowX (источник: Reddit r/MachineLearning)

Новый метод оптимизации инференса LLM: Снимок и Восстановление: Столкнувшись с проблемами холодного старта и развертывания нескольких моделей при инференсе LLM, команда разработала новую систему времени выполнения. Эта система делает снимок полного состояния выполнения модели (включая раскладку памяти, кэш внимания, контекст выполнения) и восстанавливает его непосредственно на GPU, достигая холодного старта менее чем за 2 секунды. Это позволяет размещать более 50 моделей на 2 GPU A4000 с использованием GPU более 90% и без постоянного раздувания памяти. Этот подход подобен созданию «операционной системы» для инференса (источник: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Опенсорсный детектор объектов в реальном времени D-FINE: Библиотека Hugging Face Transformers добавила детектор объектов в реальном времени D-FINE. Утверждается, что эта модель быстрее и точнее, чем YOLO, распространяется под лицензией Apache 2.0 и может работать на GPU T4 (в бесплатной среде Colab), предоставляя новый опенсорсный вариант SOTA для обнаружения объектов в реальном времени (источник: merve, algo_diver)
Ценообразование LLM становится более динамичным: Наблюдается, что ценообразование на большие языковые модели становится более динамичным. Это может помочь рынку со временем найти более оптимальные ценовые точки, отражая тенденцию поставщиков моделей корректировать ценовые стратегии под влиянием затрат, спроса и конкурентного давления (источник: xanderatallah)
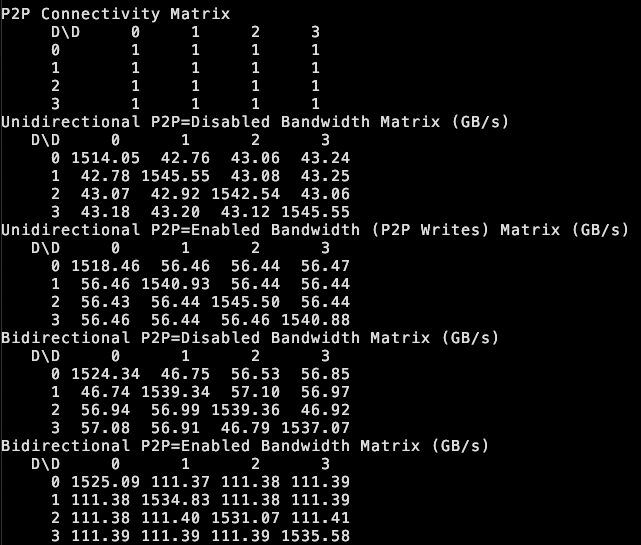
tinybox green v2 поддерживает P2P между GPU: Компания the tiny corp объявила, что ее продукт tinybox green v2, благодаря модифицированным драйверам, поддерживает связь точка-точка (P2P) между GPU RTX 5090. Это означает, что данные могут передаваться напрямую между GPU, минуя оперативную память CPU, что повышает эффективность совместной работы нескольких GPU. Функция совместима с tinygrad и PyTorch (любой библиотекой, использующей NCCL) (источник: the tiny corp)
Исследователи выпустили EQ-Bench 3 для оценки эмоционального интеллекта LLM: Сэм Печ (Sam Paech) выпустил EQ-Bench 3, инструмент для измерения эмоционального интеллекта (EQ) больших языковых моделей (LLM). Команда разработчиков выпустила эту версию после нескольких неудачных прототипов, стремясь более точно и надежно оценивать способность моделей понимать и реагировать на эмоции (источник: Sam Paech, fabianstelzer)

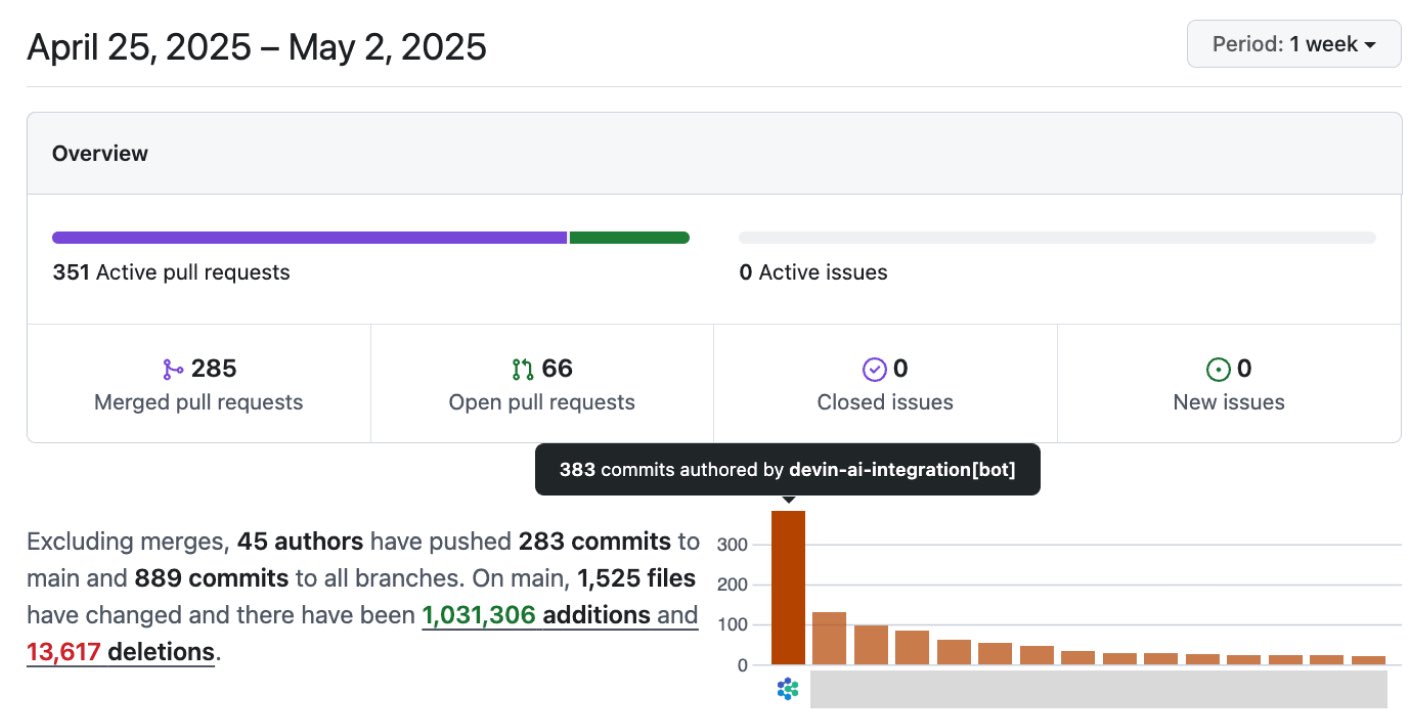
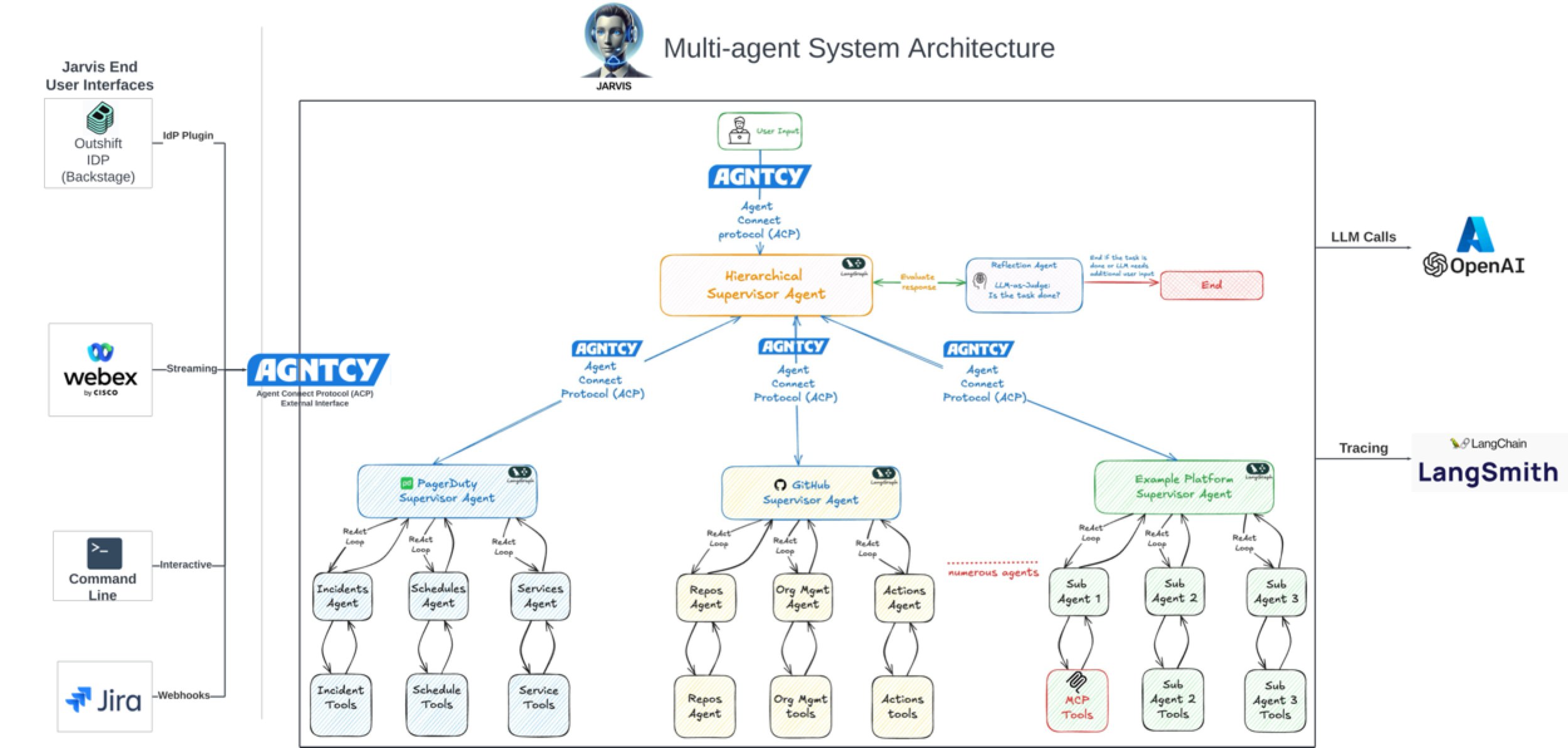
AI значительно повышает эффективность разработки ПО: Обсуждения в сообществе и кейсы показывают, что AI значительно повышает эффективность разработки программного обеспечения. Например, в кодовой базе компании Vesta коммиты от AI уже занимают первое место. Cisco Outshift, используя платформу AI-инженера JARVIS, построенную на LangGraph и LangSmith, сократила время настройки CI/CD с недели до менее часа, а время выделения ресурсов с полдня до нескольких секунд, достигнув 10-кратного повышения производительности (источник: mike, LangChainAI, hwchase17)
AI проникает в киноиндустрию и творческие отрасли: Disney/Lucasfilm через Industrial Light & Magic (ILM) выпустили свою первую публичную работу с использованием генеративного AI, что знаменует принятие технологии AI ведущими студиями VFX. Это предвещает, что AI будет играть более важную роль в киноспецэффектах, креативном дизайне и других областях, изменяя процессы создания контента (источник: Bilawal Sidhu)
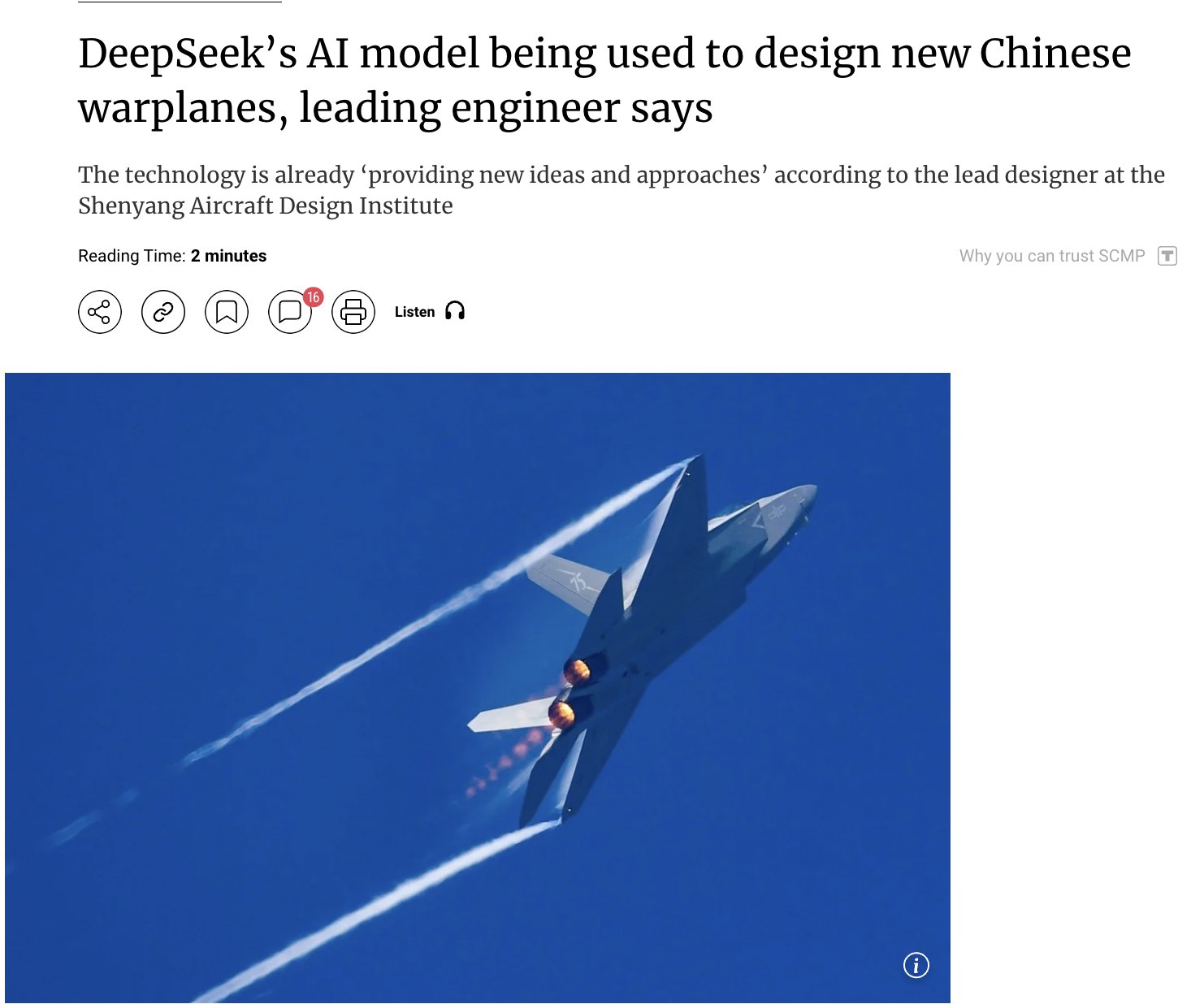
Применение AI в военной сфере вызывает обеспокоенность: Появились сообщения о том, что Китай использует свою собственную модель AI DeepSeek для проектирования передовых истребителей (таких как J-15, J-35) и формирования облика самолетов следующего поколения (J-36, J-50). Утверждается, что AI ускоряет разработку за счет оптимизации стелс-характеристик, материалов и производительности. Хотя к источнику информации следует относиться с осторожностью, это отражает потенциал применения AI в оборонной и аэрокосмической отраслях и вызываемую этим обеспокоенность (источник: Clash Report)
Кадровые изменения: Рохан Пандей (Rohan Pandey) покидает OpenAI: Исследователь из команды OpenAI Training Рохан Пандей объявил об уходе. Он заявил, что возьмет перерыв, чтобы посвятить себя решению проблемы OCR для санскрита, чтобы «навечно сохранить» классику индийской литературы «в весах сверхинтеллекта», после чего объявит о своих дальнейших планах. Члены сообщества высоко оценивают его, считая чрезвычайно талантливым исследователем (источник: Rohan Pandey, JvNixon, teortaxesTex)

Регистрация авторских прав на контент, созданный AI, превысила 1000 случаев: Бюро авторского права США зарегистрировало более 1000 произведений, содержащих контент, сгенерированный AI. Это отражает все более широкое применение AI в творческой сфере, а также подчеркивает, что вопросы принадлежности и защиты авторских прав на контент, созданный AI, становятся все более актуальными (источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo сокращает контрактников, применение AI вызывает опасения: Duolingo сократила часть контрактных работников, поскольку AI может генерировать контент для курсов в 12 раз быстрее. Этот шаг вызвал опасения по поводу влияния автоматизации на изучение языков и занятость в смежных отраслях, демонстрируя потенциал AI в замене ручного труда при создании контента и сопутствующие социально-экономические последствия (источник: Reddit r/ArtificialInteligence)

Microsoft опережает Amazon в гонке облаков и AI?: В отчетах анализируется, что Microsoft, благодаря своим активным шагам в области AI (например, инвестициям в OpenAI) и интеграции облачных сервисов (Azure), опережает Amazon (AWS) в гонке облаков и AI. В статье утверждается, что Amazon может отставать от Microsoft в стратегическом фокусе (источник: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

Обсуждение использования экспертов в моделях MoE: Сообщество обсуждает, следует ли использование экспертов в моделях MoE принципу Парето (меньшинство экспертов обрабатывает большую часть трафика). Большинство мнений сходится к тому, что цель обучения обычно заключается в равномерной загрузке экспертов, и в модели Mixtral отклонение невелико. Однако в Qwen3 может наблюдаться некоторое отклонение, но оно далеко от распределения 80/20. Пример DeepSeek-R1 (256 экспертов, активируется 8) также показывает, что даже если определенные задачи (например, кодирование) склоняются к определенным экспертам, это не является фиксированным, и общие эксперты активируются всегда (источник: Reddit r/LocalLLaMA)

Файн-тюнинговая модель Josiefied-Qwen3-8B получает положительные отзывы: Пользователь поделился положительными отзывами о модели Qwen3 8B, дообученной Goekdeniz-Guelmez (Josiefied-Qwen3-8B-abliterated-v1). Считается, что эта модель превосходит оригинальную Qwen3 8B в следовании инструкциям и генерации живых ответов, при этом не подвержена цензуре. Пользователь запускал ее с квантованием Q8 и считает, что ее производительность превосходит ожидания от модели 8B, особенно для онлайн-систем RAG (источник: Reddit r/LocalLLaMA)

RTX 5060 Ti 16GB может стать выгодным выбором для AI: Пользователь поделился опытом, считая, что версия RTX 5060 Ti 16GB (около 499 долларов), хотя и имеет плохие отзывы по игровой производительности, весьма выгодна для AI-приложений благодаря 16 ГБ VRAM. По сравнению с GPU 12 ГБ при запуске LightRAG для обработки PDF, версия 16 ГБ работает более чем в 2 раза быстрее, так как может вместить больше слоев модели, избегая частых переключений моделей и повышая утилизацию GPU. Ее более короткий корпус также подходит для сборок SFF (источник: Reddit r/LocalLLaMA)
Обсуждение возможности использования RGB-изображений для детальной классификации объектов: Сообщество задает вопрос, достаточно ли использовать только RGB-изображения для классификации или обнаружения аномалий одного класса детальных объектов (например, кофейных зерен) в реальном времени, если нет возможности использовать гиперспектральную съемку (HSI). Хотя литература часто рекомендует HSI для обработки тонких различий, пользователь хочет узнать об успешных случаях или осуществимости таких задач только с помощью RGB (источник: Reddit r/deeplearning)
Предполагаемая утечка System Prompt модели Claude: На GitHub появился текст, предположительно являющийся System Prompt модели Claude, длиной 25 тыс. токенов. Он содержит подробные инструкции, например, требование к модели ни при каких обстоятельствах (включая результаты поиска и сгенерированный контент) не копировать и не цитировать тексты песен, даже в приблизительной или закодированной форме, что, предположительно, связано с ограничениями авторских прав. Эта утечка (если она подлинная) дает представление о внутренних механизмах работы и ограничениях безопасности Claude (источник: karminski3)
Выпущена новая модель восстановления изображений AI PixelHacker: Выпущена модель PixelHacker, специализирующаяся на восстановлении изображений (inpainting), с акцентом на сохранение структурной и семантической согласованности в процессе восстановления. Утверждается, что эта модель превосходит текущие SOTA модели на наборах данных, таких как Places2, CelebA-HQ и FFHQ (источник: Reddit r/deeplearning)

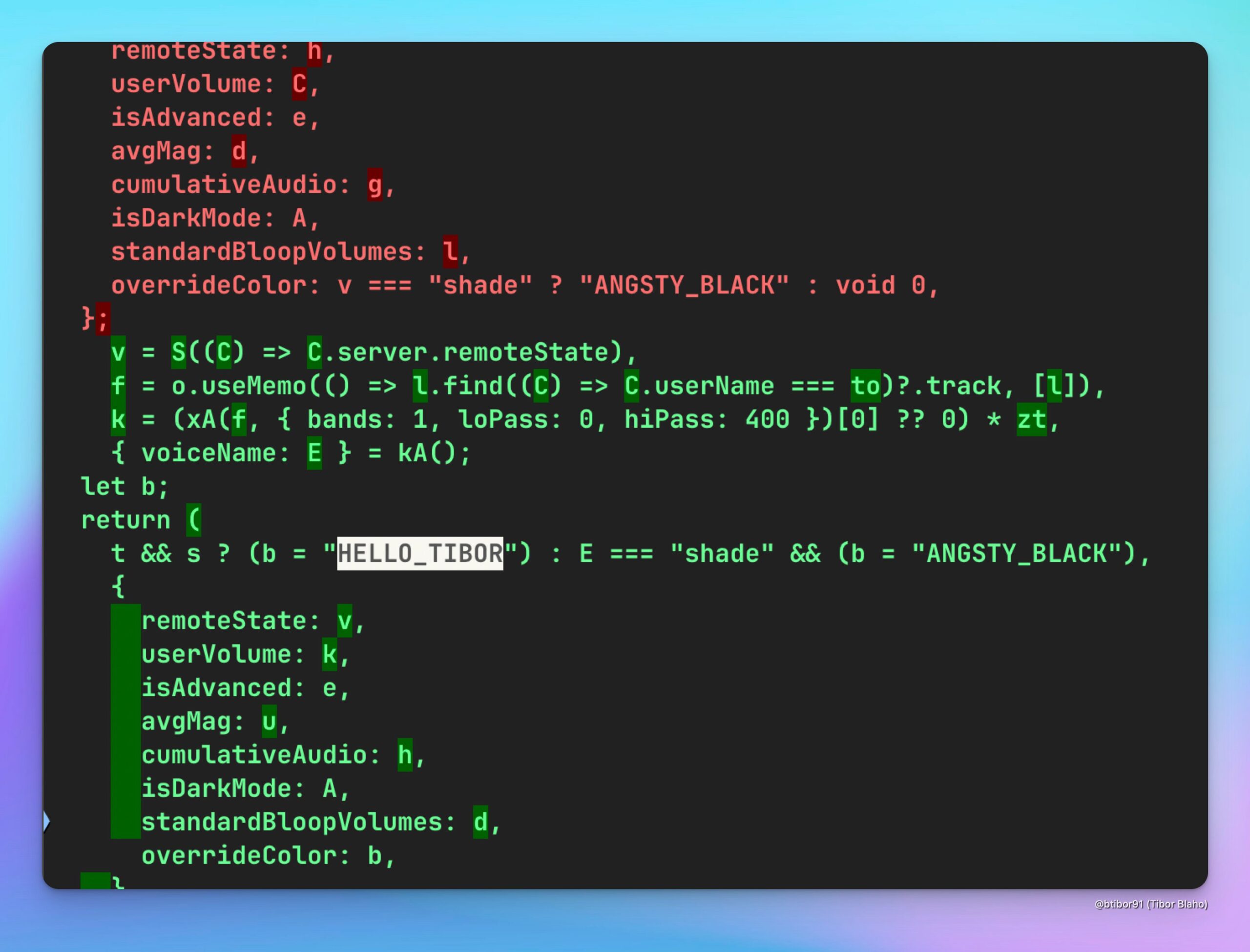
В ChatGPT добавлен новый голос HELLO_TIBOR: Пользователи обнаружили в последней версии веб-приложения ChatGPT новую опцию голоса под названием “HELLO_TIBOR”. Это указывает на то, что OpenAI, возможно, продолжает расширять свои функции голосового взаимодействия, предлагая более разнообразный выбор голосов (источник: Tibor Blaho)
🧰 Инструменты
Runway реализует преобразование изображений в скриншоты игр и трибьюты к фильмам: Пользователь экспериментировал с функцией Gen-4 References в Runway, используя подробные многошаговые промпты (анализ сцены, понимание намерения, установка игрового движка и требований к рендерингу), и успешно преобразовал обычное изображение в скриншот 2.5D изометрической игры в стиле Unreal Engine. Другой пользователь использовал Runway References и Gen-4 для создания видеофрагмента в честь фильма «Славные парни» (Goodfellas). Эти примеры демонстрируют мощные возможности Runway в управляемой генерации изображений/видео, особенно в сочетании с референсными изображениями и переносом стиля (источник: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway поддерживает импорт 3D-ассетов для повышения управляемости генерации видео: Функция Gen-4 References в Runway теперь поддерживает использование 3D-ассетов в качестве референсов для достижения более точного контроля над формой и деталями объектов в генерируемом видео. Пользователю достаточно предоставить фоновое изображение сцены, простое композитное изображение 3D-модели в этой сцене и референсное изображение стиля, чтобы внедрить в рабочий процесс генерации высокодетализированные и специфические модели, повышая согласованность и управляемость генерируемого контента (источник: Runway, c_valenzuelab, op7418)
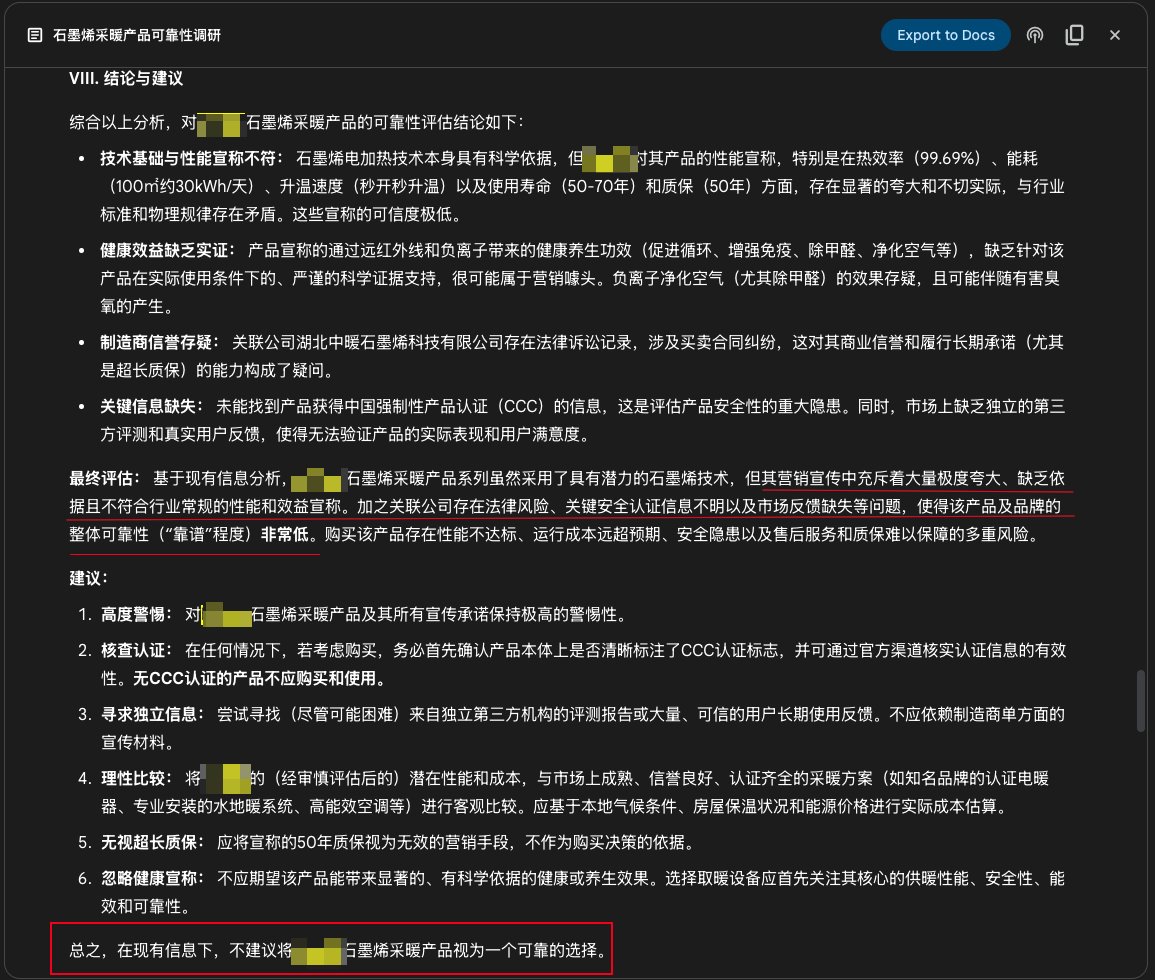
Функция Google Gemini Deep Research для исследования продуктов: Пользователь поделился опытом использования функции Deep Research в Google Gemini для исследования надежности продукта. Введя рекламное описание продукта, Gemini проанализировал сотни веб-страниц и четко указал, что реклама графенового отопительного продукта преувеличена, не имеет оснований, связана с рисками и не рекомендуется к покупке. Это демонстрирует практическую ценность инструментов глубокого исследования AI для проверки информации и помощи в принятии потребительских решений (источник: dotey)
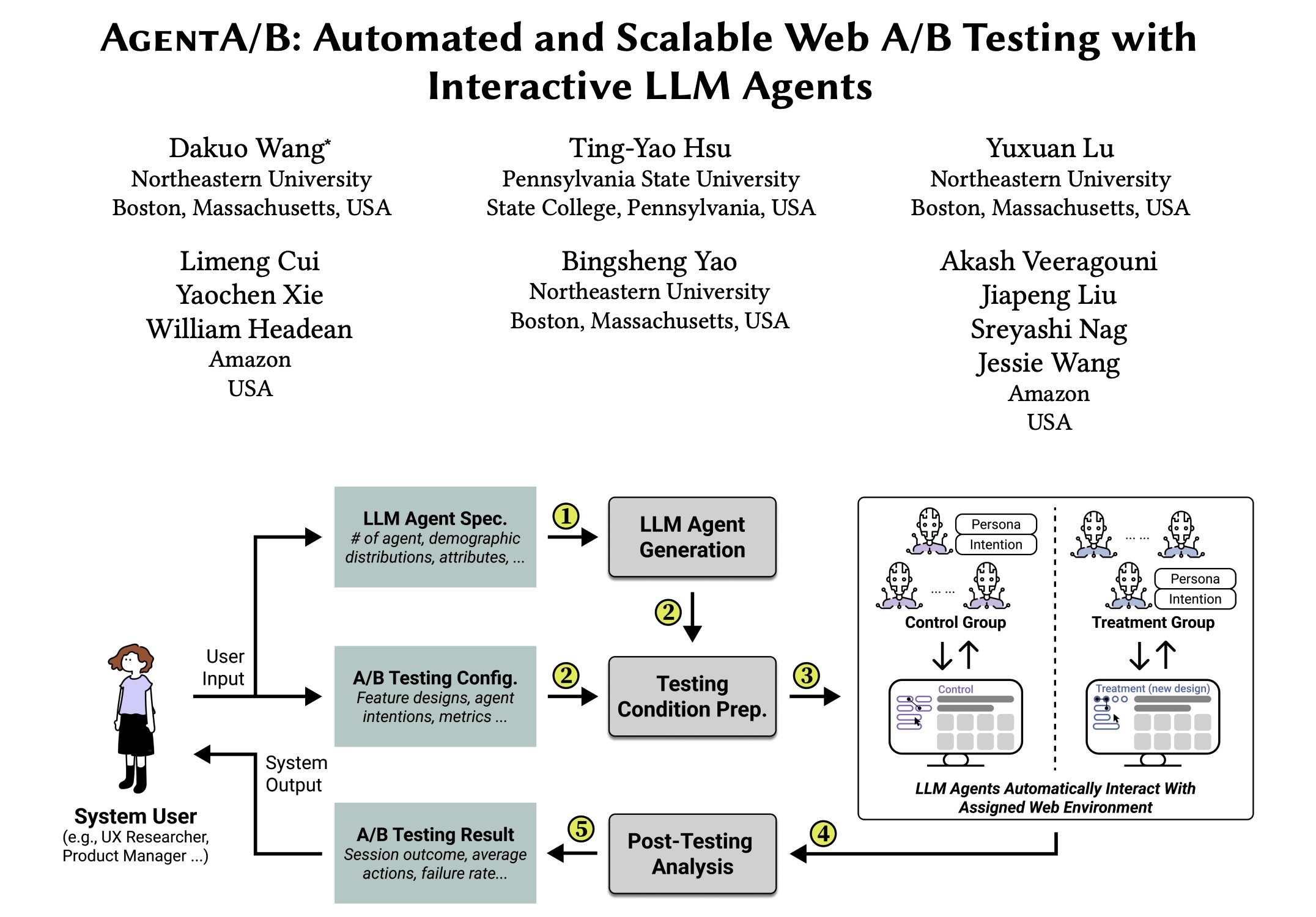
AgentA/B: Фреймворк автоматического A/B-тестирования на основе LLM-агентов: AgentA/B — это полностью автоматический фреймворк для A/B-тестирования, который использует крупномасштабных агентов на базе LLM для замены реального пользовательского трафика. Эти агенты могут имитировать реалистичное, целенаправленное поведение пользователей в реальной веб-среде, обеспечивая более быструю, дешевую и безрисковую оценку пользовательского опыта (UX), даже без реального трафика (источник: elvis)
Qdrant помогает Pariti повысить эффективность найма: Рекрутинговая платформа Pariti использует векторную базу данных Qdrant для поддержки своей системы подбора кандидатов на базе AI. Благодаря возможностям векторного поиска Qdrant в реальном времени, Pariti может ранжировать и динамически оценивать соответствие 70 000 профилей кандидатов за 40 миллисекунд, сократив время проверки кандидатов на 70%, удвоив успешность найма, при этом 94% лучших кандидатов появляются в топ-10 результатах поиска (источник: qdrant_engine)

Qwen 3 и LangGraph для создания опенсорсного агента глубокого исследования: Soham разработал и открыл исходный код агента глубокого исследования. Этот агент использует модель Qwen 3 в сочетании с Composio, LangGraph от LangChain, Together AI и Perplexity/Tavily для поиска. Утверждается, что его производительность превосходит многие другие опробованные опенсорсные модели. Код открыт и предоставляет воспроизводимое решение для автоматизации исследований (источник: Soham, hwchase17)
Perplexity в WhatsApp улучшает опыт использования AI на мобильных устройствах: CEO Perplexity Арав Шринивас (Arav Srinivas) упомянул, что использовать Perplexity AI в WhatsApp очень удобно, особенно на борту самолета с плохим интернет-соединением. Поскольку WhatsApp сам по себе оптимизирован для работы в условиях слабого сигнала, доступ к AI через мессенджер становится стабильным и надежным способом, повышая доступность AI на мобильных устройствах и в особых сценариях (источник: AravSrinivas)
Обновление iOS-приложения Suno: поддержка генерации музыкальных фрагментов для шаринга: iOS-версия приложения для генерации музыки Suno AI обновилась, добавив функцию преобразования сгенерированных песен в фрагменты для шаринга. Пользователи могут выбрать длину фрагмента 10, 20 или 30 секунд, который будет сопровождаться текстом песни и обложкой или официальной визуализацией (в будущем добавятся новые стили), что облегчает пользователям обмен и демонстрацию музыки, созданной AI, в социальных сетях (источник: SunoMusic, SunoMusic)
Обсуждение AI-помощника для программирования Cursor: Пользователь Andrew Carr выразил симпатию к AI-помощнику для программирования Cursor. В то же время Justin Halford считает, что Cursor — это всего лишь функция, а не полноценный продукт, и его легко могут заменить релизы от крупных модельных компаний. Инструмент Cline объявил о поддержке формата конфигурационных файлов Cursor .cursorrules, что свидетельствует о внимании сообщества и попытках интеграции (источник: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools: гибкий фреймворк для вызова инструментов LLM получил награду за лучшую статью на NALCL: Фреймворк OctoTools получил награду за лучшую статью на KnowledgeNLP@NAACL. Это гибкий и простой в использовании фреймворк, который с помощью модульных «карт инструментов» (подобно кубикам Lego) оснащает LLM разнообразными инструментами (такими как визуальное понимание, поиск знаний в предметной области, числовые рассуждения и т. д.) для выполнения сложных задач рассуждения. В настоящее время поддерживаются модели OpenAI, Anthropic, DeepSeek, Gemini, Grok и Together AI, а также выпущен пакет PyPI (источник: lupantech)

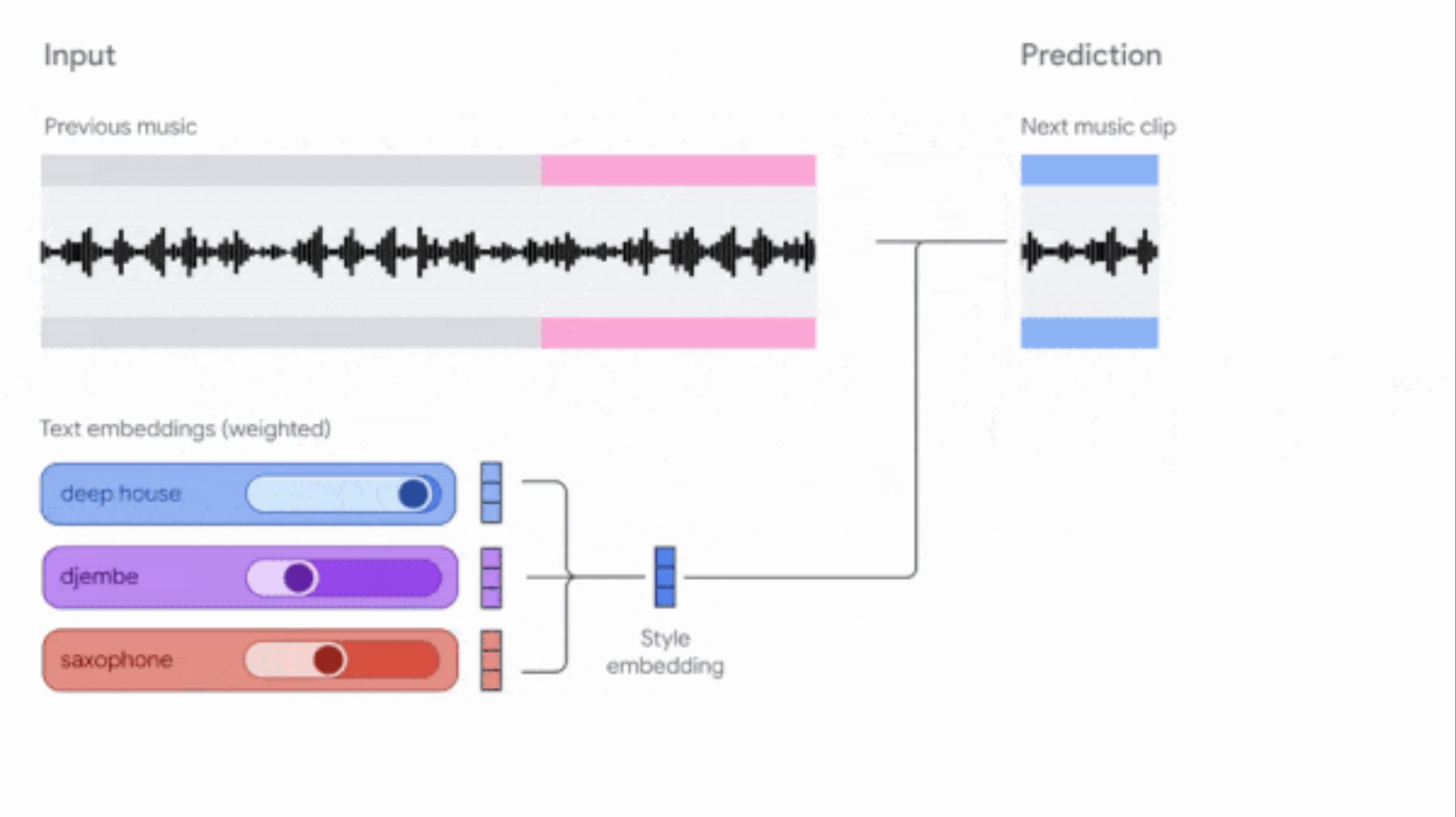
Google обновляет инструменты Music AI Sandbox и MusicFX DJ: Google обновил свои инструменты для генерации музыки, предназначенные для композиторов и продюсеров. Music AI Sandbox теперь позволяет пользователям вводить текст песни для генерации полной композиции; MusicFX DJ позволяет пользователям управлять потоковой музыкой в реальном времени. Оба инструмента основаны на обновленной модели Lyria (Lyria 2 и Lyria RealTime соответственно), могут генерировать высококачественное аудио 48 кГц и предоставляют широкий контроль над тональностью, темпом, инструментами и т. д. Доступ к Music AI Sandbox в настоящее время предоставляется по списку ожидания (источник: DeepLearningAI)
AI-агент для ревью кода: Инструменты, такие как Composiohq, LlamaIndex, в сочетании с Grok 3 и Replit Agent, позволили создать AI-агента, способного проводить ревью Pull Requests на GitHub. Процесс включает: Grok 3 генерирует код агента ревью, Replit Agent автоматически создает фронтенд-интерфейс, пользователь через интерфейс отправляет ссылку на PR, агент проводит ревью и предоставляет обратную связь. Это демонстрирует потенциал AI-агентов в автоматизации процессов разработки ПО (например, ревью кода) (источник: LlamaIndex 🦙)
AI генерирует раскраски (с референсным изображением): Пользователь поделился опытом и промптом для генерации черно-белых раскрасок с небольшим цветным референсным изображением с помощью AI. Цель — решить проблему ребенка, который не знает, как раскрашивать. Промпт требует генерации четкого черно-белого контурного рисунка, подходящего для печати, с небольшим цветным изображением в углу в качестве референса, а также указывает стиль, размер, подходящий возраст и содержание изображения (источник: dotey)

Пример кода агента для генерации изображений с использованием модели gpt-image-1: Пользователь поделился фрагментом кода, демонстрирующим, как создать агента, использующего модель gpt-image-1 для генерации изображений. Это предоставляет разработчикам быстрый пример кода для реализации функции генерации изображений (источник: skirano)
VectorVFS: Использование файловой системы в качестве векторной базы данных: VectorVFS — это легковесный пакет Python и инструмент CLI, который использует расширенные атрибуты (xattr) файловой системы Linux для хранения векторных эмбеддингов непосредственно в inode файловой системы. Это позволяет превратить существующую структуру каталогов в эффективное и семантически поисковое хранилище эмбеддингов без необходимости поддерживать отдельный индекс или внешнюю базу данных (источник: Reddit r/MachineLearning)
AI-помощник для Kubernetes kubectl-ai: Google Cloud Platform выпустила kubectl-ai, AI-помощника для командной строки Kubernetes. Он может понимать инструкции на естественном языке, выполнять соответствующие команды kubectl и интерпретировать результаты. Поддерживаются модели Gemini, Vertex AI, Azure OpenAI, OpenAI, а также локально запущенные Ollama и Llama.cpp. Проект также включает бенчмарк k8s-bench для оценки производительности различных LLM в задачах K8s (источник: GitHub Trending)

Higgsfield Effects: Пакет визуальных эффектов кинематографического уровня на базе AI: Higgsfield AI представила Higgsfield Effects, набор из 10 визуальных эффектов (VFX) кинематографического уровня, таких как молнии Тора, невидимость, металлизация, возгорание и т. д. Пользователи могут вызывать эти эффекты с помощью одного промпта. Цель — упростить сложные процессы производства VFX, чтобы обычные пользователи могли легко создавать впечатляющие визуальные эффекты (источник: Higgsfield AI 🧩)
Agent-S: Открытый фреймворк агента, имитирующего использование компьютера человеком: Agent-S — это опенсорсный фреймворк агента, цель которого — позволить AI использовать компьютер так же, как человек. Он может включать в себя способности понимать намерения пользователя, управлять графическим интерфейсом, использовать различные приложения и т. д., стремясь к созданию более универсального и автономного поведения AI-агентов (источник: dl_weekly)
AI генерирует расширение Chrome для автоматического прохождения онлайн-тестов: Пользователь использовал Gemini AI для создания расширения Chrome, которое может автоматически проходить тесты на определенной онлайн-платформе обучения. Это демонстрирует потенциал применения AI в автоматизации рутинных задач, но также может вызвать дискуссии об академической честности (источник: Reddit r/ArtificialInteligence)
Генерация изображений GPT-4o: Портреты знаменитостей в стиле Рембрандта: Пользователь использовал GPT-4o для преобразования портретов нескольких известных главных героев телесериалов (таких как Walter White, Don Draper, Tony Soprano, SpongeBob и др.) в стиль живописи Рембрандта. Эти изображения демонстрируют способность AI понимать черты персонажей и имитировать определенный художественный стиль (источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta выпускает набор инструментов Llama Prompt Ops: Meta AI выпустила Llama Prompt Ops, набор инструментов Python для оптимизации промптов для моделей Llama. Инструмент предназначен для помощи разработчикам в более эффективном проектировании и настройке промптов для моделей Llama с целью повышения производительности модели и качества вывода (источник: Reddit r/artificial, Reddit r/ArtificialInteligence)
Пользователь ищет бесплатный/недорогой AI для генерации Excel/таблиц: Пользователь Reddit ищет бесплатный или недорогой AI-инструмент, способный генерировать документы электронных таблиц Excel или OpenOffice, надеясь избежать дневных ограничений бесплатной версии ChatGPT. Сообщество рекомендовало Claude, Google Gemini (в связке с Sheets), а также локальное развертывание опенсорсных моделей (через LM Studio или LocalAI) и другие варианты (источник: Reddit r/artificial)
Пользователь консультируется о методах обработки длинного контекста в Claude: Пользователь Reddit спрашивает, как обойти ограничение длины контекста и проблему потери памяти в новом чате при работе со сложными проектами в Claude. Сообщество предлагает методы, такие как: сохранение ключевой информации в файле проекта или просьба к Claude резюмировать основные моменты диалога и переносить их в новый чат (источник: Reddit r/ClaudeAI)
Пользователь консультируется об использовании новых функций OpenWebUI: Пользователь Reddit спрашивает, как конкретно использовать новые функции в версии OpenWebUI v0.6.6, такие как «Запись и импорт совещаний», а также импорт заметок (Markdown), интеграцию с OneDrive и т. д. (источник: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Пользователь консультируется о методе обработки большого количества JSON-файлов для RAG в OpenWebUI: Пользователь Reddit ищет лучшие практики для эффективной обработки тысяч JSON-файлов для RAG в OpenWebUI. Учитывая, что прямая загрузка в «Базу знаний» может быть неэффективной, пользователь спрашивает о рекомендуемых настройках внешней векторной базы данных или методах интеграции пользовательских конвейеров данных (источник: Reddit r/OpenWebUI)
Пользователь сообщает о проблеме тайм-аута при интеграции OpenWebUI с n8n: Пользователь столкнулся с проблемой при использовании OpenWebUI в качестве фронтенда для AI-агента n8n: когда выполнение рабочего процесса n8n превышает примерно 60 секунд, OpenWebUI отображает ошибку, даже если пользователь подтверждает, что бэкенд n8n успешно завершил работу. Пользователь ищет способы увеличить время ожидания или поддерживать соединение (источник: Reddit r/OpenWebUI)
📚 Обучение
LangGraph для создания сложных агентных систем: LangGraph, как часть экосистемы LangChain, фокусируется на создании многоакторных приложений с состоянием. В докладе Джейкоба Шоттенштейна (Jacob Schottenstein) рассматривается использование LangGraph для преобразования направленных ациклических графов (DAG) в направленные циклические графы (DCG) для построения более мощных агентных систем. В реальном кейсе Cisco Outshift использовала LangGraph и LangSmith для создания AI-инженера платформы JARVIS, значительно повысив эффективность разработки и эксплуатации (источник: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
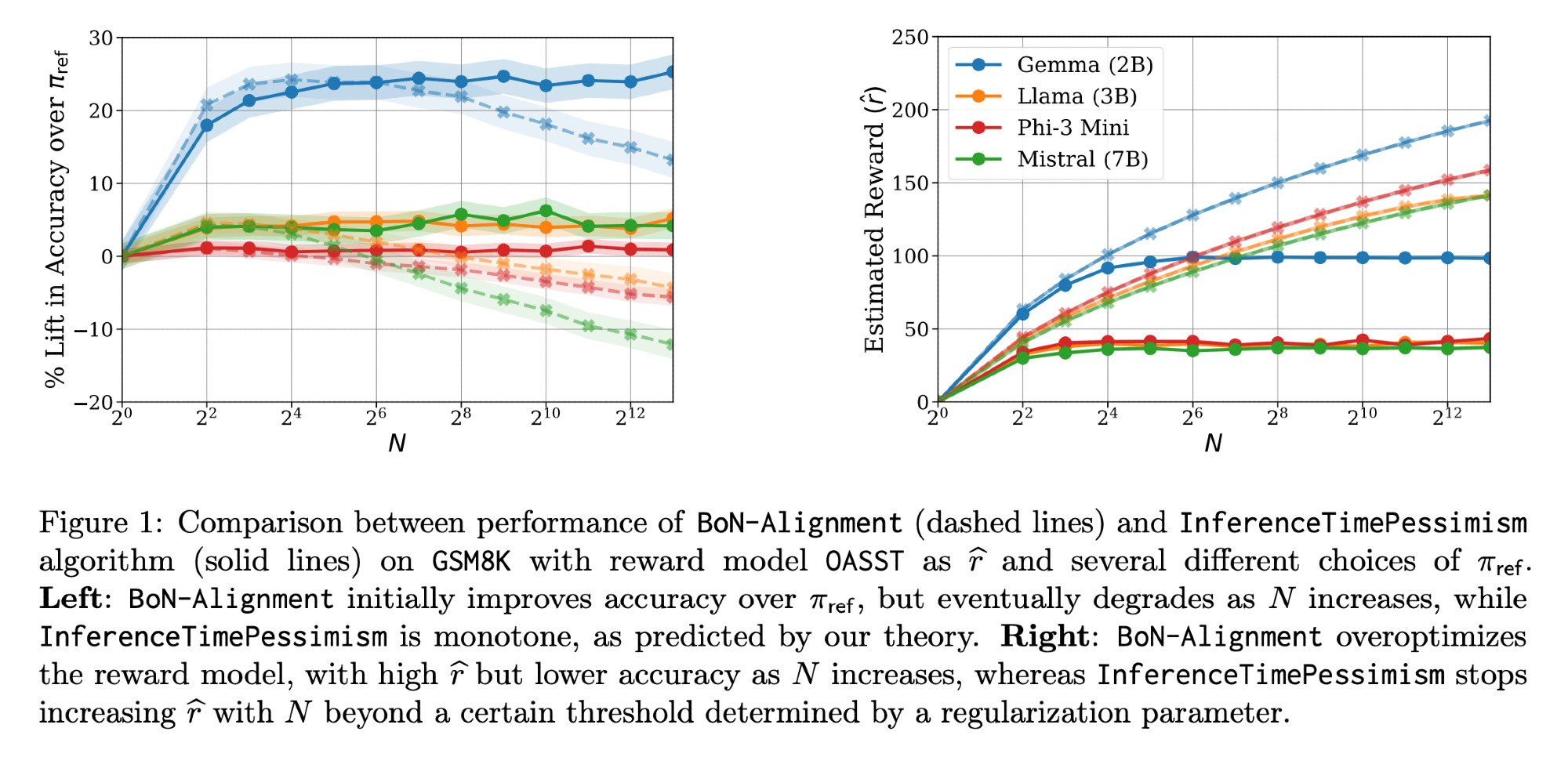
Оптимизация инференса LLM: Статья Llama-Nemotron и InferenceTimePessimism: Статья Llama-Nemotron (arXiv:2505.00949v1), опубликованная Meta AI & Nvidia Research, демонстрирует ряд методов прямой оптимизации для снижения затрат при сохранении качества в рабочих нагрузках инференса. В то же время, статья ICML ‘25 представляет алгоритм InferenceTimePessimism как потенциальное улучшение метода инференса Best-of-N, направленное на использование дополнительной информации для оптимизации процесса инференса (источник: finbarrtimbers, Dylan Foster 🐢)
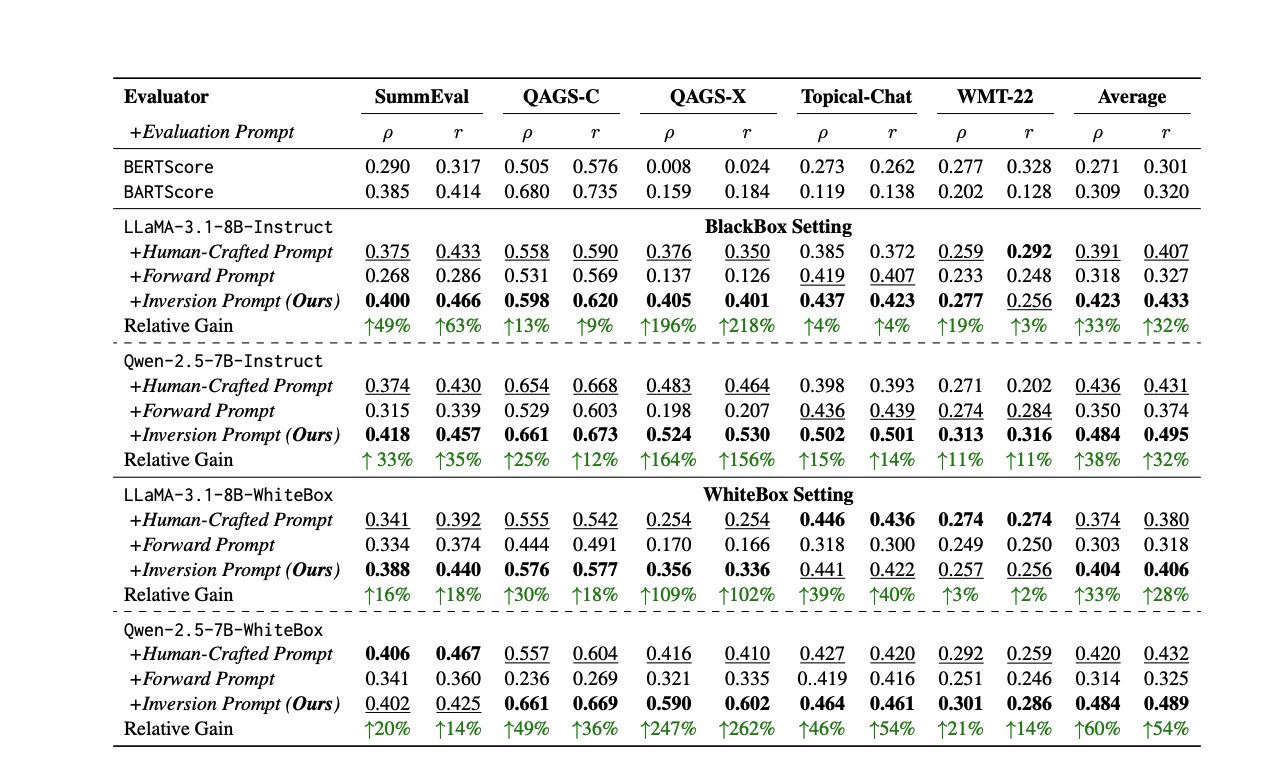
Новые методы и ресурсы для оценки LLM: Оценка производительности LLM является постоянной проблемой. В одной статье предлагается метод автоматической генерации высококачественных оценочных промптов путем инвертирования ответов, чтобы решить проблему несогласованности между человеческими или LLM-оценщиками. В то же время эксперт по оценке LLM Шрея Шанкар (Shreya Shankar) открыла курс по оценке LLM для инженеров и менеджеров по продуктам. Кроме того, бенчмарк SciCode был опубликован как соревнование Kaggle, бросая вызов AI в написании кода для сложных физических и математических явлений (источник: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
Ресурсы, связанные с контролем и выравниванием AI: Контроль AI (исследование того, как безопасно контролировать и использовать AI, который еще не достиг сверхинтеллекта, но может быть не выровнен) становится все более важной областью. FAR.AI опубликовала видеозаписи докладов с конференции ControlConf, включая мнения Нила Нанды (Neel Nanda) и других экспертов. В то же время статья, обсуждающая ценности (различая конечные и инструментальные ценности), считается релевантной для обсуждения выравнивания AI (источник: FAR.AI, Séb Krier)

Common Crawl выпускает новые наборы данных: Common Crawl выпустил архив веб-сканирования за апрель 2025 года. В то же время Брэм Ванрой (Bram Vanroy) представил C5 (Common Crawl Creative Commons Corpus), тщательно отфильтрованный поднабор Common Crawl, содержащий только документы с лицензией CC. На данный момент собрано 150 миллиардов токенов, охватывающих 8 европейских языков, что предоставляет новый источник совместимых данных для обучения языковых моделей (источник: CommonCrawl, Bram)
Учебные мероприятия и руководства по AI: Опубликовано несколько ресурсов по мероприятиям и руководствам, связанным с AI: Qdrant провел онлайн-сессию кодирования по оркестровке AI-агентов с использованием MCP; Corbtt планирует провести вебинар по использованию RL для оптимизации реальных агентов; Comet ML организовал мероприятие для обмена мнениями о создании и внедрении систем GenAI в продакшн; Офир Пресс (Ofir Press) поделится опытом создания SWE-bench и SWE-agent на вебинаре PyTorch; Nous Research совместно с несколькими организациями проводит хакатон по средам RL; LlamaIndex спонсирует хакатон MCP в Тель-Авиве; Hugging Face предлагает 1-минутное руководство по созданию сервера MCP; Together AI выпустила серию видеороликов Matryoshka по машинному обучению; снова рекомендуется лекция Эндрю Прайса (Andrew Price) об изменении 3D-индустрии под влиянием AI; giffmana поделился видеозаписью лекции о Transformer (источник: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

Обсуждение теории и методов AI: Сообщество обсудило некоторые фундаментальные теории и методы в области AI: 1. Обсуждение концепции «мировых моделей» (World Models), решаемых ими проблем, технической архитектуры и вызовов. 2. Обсуждение причин, по которым методы на основе преобразования Фурье/спектральные методы не получили широкого применения в глубоком обучении. 3. Предложение концептуальной основы «Serenity Framework», интегрирующей пять основных теорий сознания для исследования рекурсивного самосознания AI. 4. Обсуждение того, не слишком ли сильно AI полагается на предварительно обученные модели. 5. Обсуждение важности уменьшения масштаба (Downscaling) LLM (источник: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

Ресурсы по инжинирингу промптов и оптимизации моделей: LiorOnAI поделился фреймворком президента OpenAI Грега Брокмана (Greg Brockman) для создания идеальных промптов. Modal предоставил руководство по обслуживанию LLaMA 3 8B с задержкой менее 250 мс с использованием таких технологий, как TensorRT-LLM, квантование FP8 и спекулятивное декодирование. N8 Programs поделился опытом обучения в условиях нехватки видеопамяти (64 ГБ ОЗУ) с использованием 6-битной квантованной модели в качестве учителя и 4-битной модели в качестве ученика. Kling_ai ретвитнул пост с ресурсами, содержащими промпты для инструментов, таких как Midjourney v7, Kling 2.0 и др. (источник: LiorOnAI, Modal, N8 Programs, TechHalla)

Применение и исследования AI в образовании: Докторская диссертация Роуз (Rose), доктора компьютерных наук Стэнфордского университета, посвящена использованию методов AI, оценки и вмешательства для улучшения образования. Это представляет собой направление углубленных исследований применения AI в образовательной сфере (источник: Rose)

Vibe-coding: новый способ программирования с помощью AI: В заметках из подкаста YC с интервью CEO Windsurf упоминается концепция «Vibe-coding». Возможно, это парадигма программирования, более ориентированная на интуицию, атмосферу и быструю итерацию, с глубокой интеграцией помощи AI, что намекает на потенциальные изменения в процессах и философии разработки ПО под влиянием AI (источник: Reddit r/ArtificialInteligence)
Информация о путях обновления Nvidia CUDA: Статья на Phoronix обсуждает пути обновления Nvidia CUDA после архитектуры Volta, что может быть полезно для пользователей со старыми GPU Nvidia (например, серии 10xx), желающих продолжать использовать их для разработки AI (источник: NerdyRodent)
💼 Бизнес
CoreWeave завершила приобретение Weights & Biases: AI-облачная платформа CoreWeave официально завершила приобретение MLOps-платформы Weights & Biases (W&B). Цель этого приобретения — объединить высокопроизводительную облачную инфраструктуру AI от CoreWeave с инструментами разработчика W&B для создания AI-облачной платформы следующего поколения, помогая командам быстрее создавать, развертывать и итерировать AI-приложения (источник: weights_biases, Chen Goldberg)

Роботы Figure AI проходят тестирование и оптимизацию на заводе BMW: Команда компании по производству гуманоидных роботов Figure AI провела двухнедельный визит на завод BMW Group в Спартанбурге, где оптимизировала процессы своих роботов в кузовном цехе X3 и исследовала новые сценарии применения. Это знаменует переход к практическому этапу сотрудничества сторон в 2025 году, демонстрируя потенциал применения гуманоидных роботов в автомобилестроении (источник: adcock_brett)

Reborn и Unitree Robotics заключили стратегическое партнерство: AI-компания Reborn объявила о стратегическом партнерстве с робототехнической компанией Unitree Robotics. Стороны будут сотрудничать в области данных, моделей и гуманоидных роботов с общей целью ускорения развития соответствующих технологий (источник: Reborn)

🌟 Сообщество
Осторожная позиция Баффетта по AI вызывает дискуссии: На собрании акционеров 2025 года Уоррен Баффетт выразил «спокойное наблюдение» и «ограниченное применение» в отношении AI. Он подчеркнул, что AI не может заменить человеческое суждение в сложных решениях (приведя в пример руководителя страхового бизнеса Аджита Джайна (Ajit Jain)), и Berkshire рассматривает AI как инструмент для повышения эффективности существующих бизнесов, а не для инвестиций в чисто алгоритмические компании. Он считает, что в области AI существует пузырь, и нужно дождаться, пока технология докажет долгосрочную прибыльность. Это вызвало дискуссии о ценности моделей «AI + отрасль» и «отрасль + AI» (источник: 36氪)
CEO Anthropic признает нехватку понимания принципов работы AI: CEO Anthropic Дарио Амодей (Dario Amodei) признал, что в настоящее время отсутствует глубокое понимание внутренних механизмов работы больших AI-моделей (таких как LLM), назвав эту ситуацию «беспрецедентной» в истории технологий. Это откровенное заявление вновь подчеркнуло проблему «черного ящика» AI, вызвав широкие дискуссии и опасения в сообществе относительно интерпретируемости, контролируемости и безопасности AI (источник: Reddit r/ArtificialInteligence)

Планы OpenAI по выпуску непередовых опенсорсных моделей и споры вокруг них: CPO OpenAI Кевин Вейл (Kevin Weil) заявил, что компания готовится выпустить модель с открытыми весами, построенную на демократических ценностях, но эта модель будет намеренно отставать от передовых моделей на одно поколение, чтобы избежать ускорения развития конкурентов (например, Китая). Эта стратегия вызвала бурное обсуждение в сообществе. Критики считают такое позиционирование противоречивым: модель не сможет стать «лучшей в мире» опенсорсной моделью (необходимо конкурировать с передовыми моделями, такими как DeepSeek-R2), но может стать бесполезной из-за отставания в производительности, одновременно подрывая собственные доходы OpenAI от API среднего и низкого уровня, что является «проигрышной» ситуацией (источник: Haider., scaling01)
Обсуждение автоматизации на базе AI и будущих форм работы: CEO Fiverr считает, что AI устранит «простые задачи», сделает «сложные задачи» простыми, а «невозможные задачи» — сложными, подчеркивая, что специалисты должны стать мастерами в своей области, чтобы избежать вытеснения. Сообщество обсуждает, заменит ли AI все рабочие места, и возможные социальные изменения (экономический коллапс или утопия UBI). В то же время применение AI в разработке ПО становится все более распространенным, и AI даже становится основным контрибьютором кода, что заставляет задуматься о будущих моделях разработки (источник: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
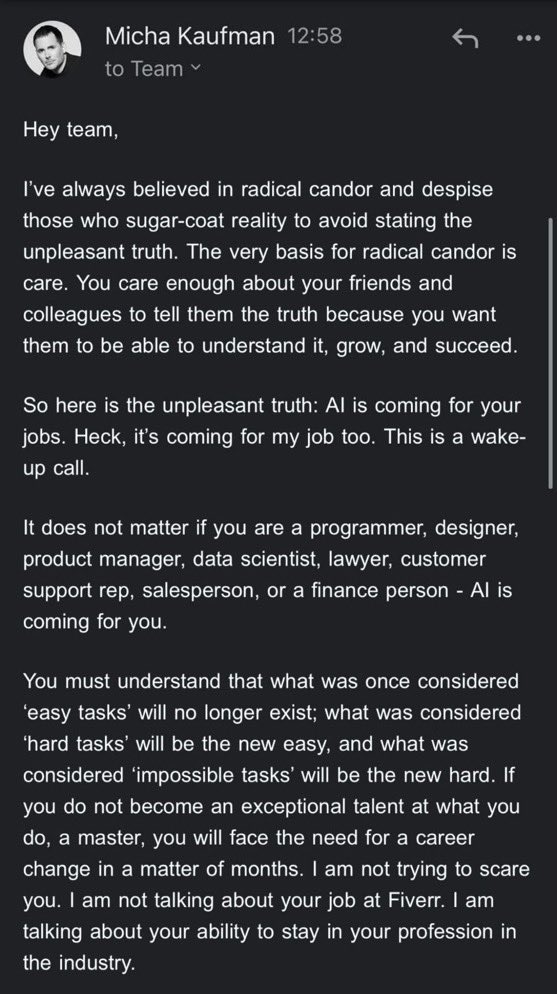
Обсуждение безопасности и рисков AI продолжает накаляться: CEO Google DeepMind Демис Хассабис (Demis Hassabis) предупреждает, что AGI может появиться через 5-10 лет, но общество еще не готово справиться с его преобразующим влиянием, призывая к активному глобальному сотрудничеству. В то же время состоялся содержательный диалог о рисках катастрофы от AI между обеспокоенной Аджеей Котрой (Ajeya Cotra) и скептиком random_walker, где стороны стремились понять точки зрения друг друга и выявить ключевые точки разногласий. Сообщество также начинает обсуждать проблемы контроля AI, фокусируясь на том, как безопасно контролировать и использовать сильные AI-системы (источник: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
Применение и влияние AI в повседневной жизни и межличностных отношениях: Пользователь поделился опытом использования AI (Anthropic Sonnet) для помощи в ответах в приложениях для знакомств и повышения успешности, а также размышляет о возможности «Cursor для отношений». В то же время есть статьи, указывающие на то, что AI подпитывает у некоторых людей ментальные фантазии, приводя к их отчуждению от реальных друзей и родственников. Это отражает проникновение AI в эмоциональную и социальную сферы, а также связанные с этим возможности и потенциальные риски (источник: arankomatsuzaki, Reddit r/artificial)

Обсуждение опыта использования LLM и сравнение моделей: Пользователь сообщает, что Gemini 2.5 Pro испытывает затруднения с собственной функцией загрузки файлов и даже не может загрузить файлы, подозревая ограничение платной функции. В то же время член семьи другого пользователя предпочитает использовать Gemini, а не ChatGPT. Еще один пользователь хвалит Claude за генерацию письменного контента, превосходящую другие LLM, считая его ответы более естественными и похожими на настоящие статьи, а не простое выполнение задачи. Эти обсуждения отражают проблемы, с которыми сталкиваются пользователи на практике, различия в предпочтениях и интуитивное восприятие возможностей разных моделей (источник: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

Обсуждение этики AI и социальных норм: Обсуждаются применение AI в разработке лекарств и связанные с этим этические соображения, а также отношение к этому противников AI. В то же время есть мнение, что распространение AI-перевода в реальном времени может заставить людей ностальгировать по «чувству борьбы» при межъязыковом общении в прошлом, которое создавало связь. Также обсуждается AI для перевода речи домашних животных, предполагая, что люди любят питомцев отчасти потому, что могут проецировать на них эмоции, в то время как реальный AI-переводчик может просто сообщать «голоден» и «хочу спариваться» (источник: Reddit r/ArtificialInteligence, jxmnop, menhguin)
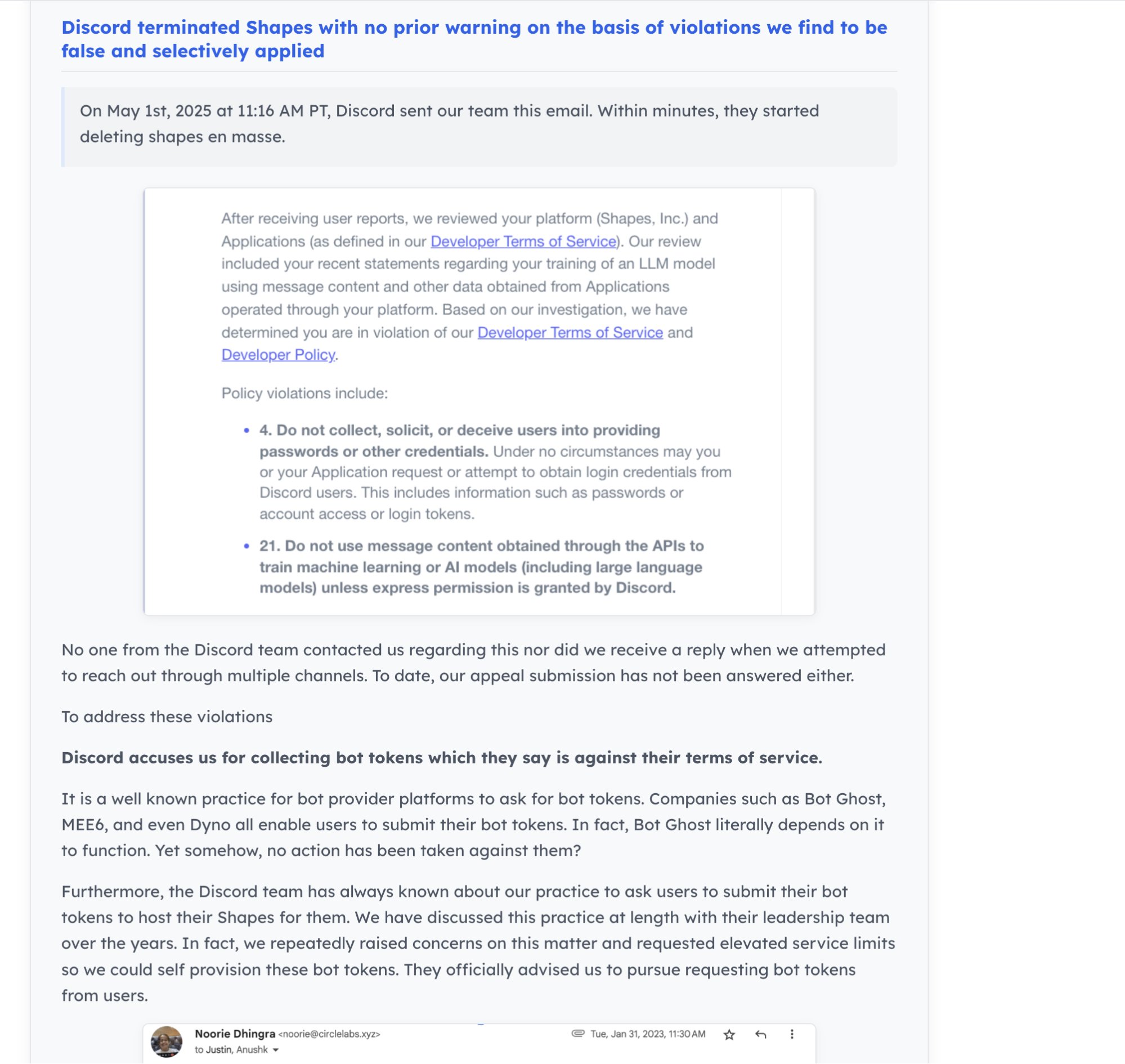
Динамика сообщества AI и экосистема разработчиков: Discord закрыл AI-бота “Shapes” с 30 миллионами пользователей, вызвав у разработчиков опасения по поводу рисков платформы. В то же время существует мнение, что для AI-стартапов вклад в опенсорсные проекты лучше доказывает компетентность, чем решение задач на LeetCode, и облегчает получение работы. Nous Research совместно с XAI, Nvidia и другими организует хакатон по средам RL с целью стимулирования разработки сред RL (источник: shapes inc, pash, Nous Research)
Аномальное поведение ChatGPT: зацикливание на «Боэции»: Пользователь сообщает, что при вопросе «Кто был первым композитором?» ChatGPT-4o ведет себя аномально, постоянно упоминая Боэция (музыкального теоретика, а не композитора), и даже в последующем диалоге «извиняется» и шутит, что Боэций преследует ответы, как «призрак». Этот забавный «сбой» демонстрирует неожиданные паттерны поведения, которые могут возникать у LLM, и потенциальную путаницу во внутреннем состоянии (источник: Reddit r/ChatGPT)

Размышления о будущих этапах развития AI: Сообщество задает вопрос: если текущее развитие AI находится на стадии «мейнфреймов» (mainframe), то как будет выглядеть будущая стадия «микропроцессоров» (microprocessor)? Этот вопрос вызывает размышления о путях эволюции технологии AI, формах ее распространения и возможных будущих более миниатюрных, персонализированных и встроенных формах AI (источник: keysmashbandit)
Стиль и распознавание контента, сгенерированного AI: Пользователи отмечают, что текст, сгенерированный AI (особенно моделями типа GPT), часто использует некоторые фиксированные фразы и конструкции (например, «significant implications for…» и т. д.), что делает его легко узнаваемым. В то же время, хотя качество сгенерированной AI речи улучшилось, она все еще звучит неестественно по структуре, ритму и паузам. Это вызывает дискуссии о «шаблонности» и естественности вывода LLM (источник: Reddit r/ArtificialInteligence)
Признание дизайна Perplexity AI: Пользователь jxmnop считает, что Perplexity AI, похоже, вкладывает больше ресурсов в дизайн, чем в разработку собственных моделей, но опыт использования продукта (vibes) ощущается как хороший. Это отражает, что в конкуренции AI-продуктов, помимо возможностей основной модели, пользовательский интерфейс и дизайн взаимодействия также являются важными факторами дифференциации (источник: jxmnop)

Забавные применения AI вне работы: Пользователь Reddit собирает интересные или странные способы использования AI вне работы. Примеры включают: анализ снов с точки зрения Юнга и Фрейда, гадание на кофейной гуще, составление рецептов из случайных продуктов в холодильнике, прослушивание сказок на ночь, прочитанных AI, резюмирование юридических документов и т. д. Это демонстрирует креативность пользователей в исследовании границ применения AI (источник: Reddit r/ArtificialInteligence)
Пользователь ищет лучшую LLM для 48 ГБ VRAM: Пользователь Reddit ищет лучшую LLM для условий 48 ГБ VRAM, сочетающую объем знаний и приемлемую скорость (>10 т/с). В обсуждении упоминаются Deepcogito 70B (файн-тюнинг Llama 3.3), Qwen3 32B, а также предлагается попробовать Nemotron, YiXin-Distill-Qwen-72B, GLM-4, квантованную Mistral Large, Command R+, Gemma 3 27B или частично выгруженную Qwen3-235B. Это отражает реальные потребности пользователей в выборе и оптимизации моделей при определенных аппаратных ограничениях (источник: Reddit r/LocalLLaMA)
💡 Прочее
Прогресс в робототехнике: В этой области постоянно появляются новости: 1. PIPE-i: Beca Group представила роботизированную тележку для инспекции трубопроводов и другой инфраструктуры. 2. Опенсорсный гуманоидный робот: Калифорнийский университет в Беркли запустил проект опенсорсного гуманоидного робота. 3. Роботизированная рука Hugging Face: Hugging Face выпустила проект 3D-печатной роботизированной руки. 4. Съедобный робот-торт: Исследователи создали съедобный робот-торт. 5. Канализационные дроны: Появились дроны для инспекции канализации, заменяющие людей в грязной работе (источник: Ronald_vanLoon, TheRundownAI)

Обсуждение регулирования AI: Выпущен документальный фильм о законопроекте SB-1047: Микаэль Трацци (Michaël Trazzi) выпустил документальный фильм о закулисной истории дебатов по калифорнийскому законопроекту о безопасности AI SB-1047. Законопроект был направлен на введение минимального регулирования разработки передовых AI, но в итоге не был принят. Фильм исследует причины провала законопроекта, несмотря на значительную поддержку со стороны жителей Калифорнии, что побуждает к дальнейшим размышлениям о путях и проблемах регулирования AI (источник: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
Сочетание квантовых вычислений и AI: Nvidia прокладывает путь к практическим квантовым вычислениям, интегрируя квантовое оборудование с суперкомпьютерами AI, с акцентом на коррекцию ошибок и ускорение перехода от экспериментов к практическому применению. В то же время существует мнение, что квантовые вычисления могут принести скорее научный прорыв, чем просто переворот в области кибербезопасности (источник: Ronald_vanLoon, NVIDIA HPC Developer)
