
Ключевые слова:OpenAI, Llama-Nemotron, Qwen3, AI Agent, GPT-4o, DeepSeek-R1, AI-чипы, Gemma 3, Некоммерческий контроль OpenAI, Способности к логическому выводу Llama-Nemotron, Программирование на Qwen3-235B, Соревнования AI Agent, Проблема подхалимства в GPT-4o
🔥 В центре внимания
OpenAI отказывается от полной коммерциализации, сохраняя контроль некоммерческой организации: OpenAI объявила об изменении структуры компании: ее коммерческая дочерняя компания будет преобразована в общественно-полезную корпорацию (PBC), но контроль останется у ее некоммерческой материнской организации. Этот шаг является значительным отступлением от предыдущих планов по полной коммерческой реструктуризации и направлен на то, чтобы ответить на опасения общественности по поводу отклонения от первоначальной миссии «приносить пользу всему человечеству», а также на давление со стороны иска Маска, бывших сотрудников и ряда некоммерческих организаций. Новая структура призвана найти баланс между привлечением инвестиций, мотивацией сотрудников и соблюдением миссии, но может повлиять на ее соглашения о финансировании с инвесторами, такими как SoftBank. (Источник: TechCrunch, Ars Technica, The Verge, OpenAI, Wired, scaling01, Sentdex, slashML, wordgrammer, nptacek, Teknium1)

Nvidia открывает исходный код моделей серии Llama-Nemotron, превосходящих DeepSeek-R1 по способности к рассуждениям: Nvidia выпустила и открыла исходный код моделей серии Llama-Nemotron (LN-Nano 8B, LN-Super 49B, LN-Ultra 253B). LN-Ultra 253B превзошла DeepSeek-R1 в нескольких тестах на логическое мышление, став одной из самых мощных моделей с открытым исходным кодом для научных рассуждений. Эта серия моделей была создана с использованием поиска нейронных архитектур, дистилляции знаний, контролируемой тонкой настройки (с использованием процессов рассуждений моделей-учителей, таких как DeepSeek-R1) и крупномасштабного обучения с подкреплением (особенно для LN-Ultra), что оптимизировало эффективность и способность к рассуждениям, поддерживая контекст до 128K. Особенностью является введение «переключателя рассуждений», позволяющего пользователям динамически переключаться между режимами чата и рассуждений. (Источник: 36氪)

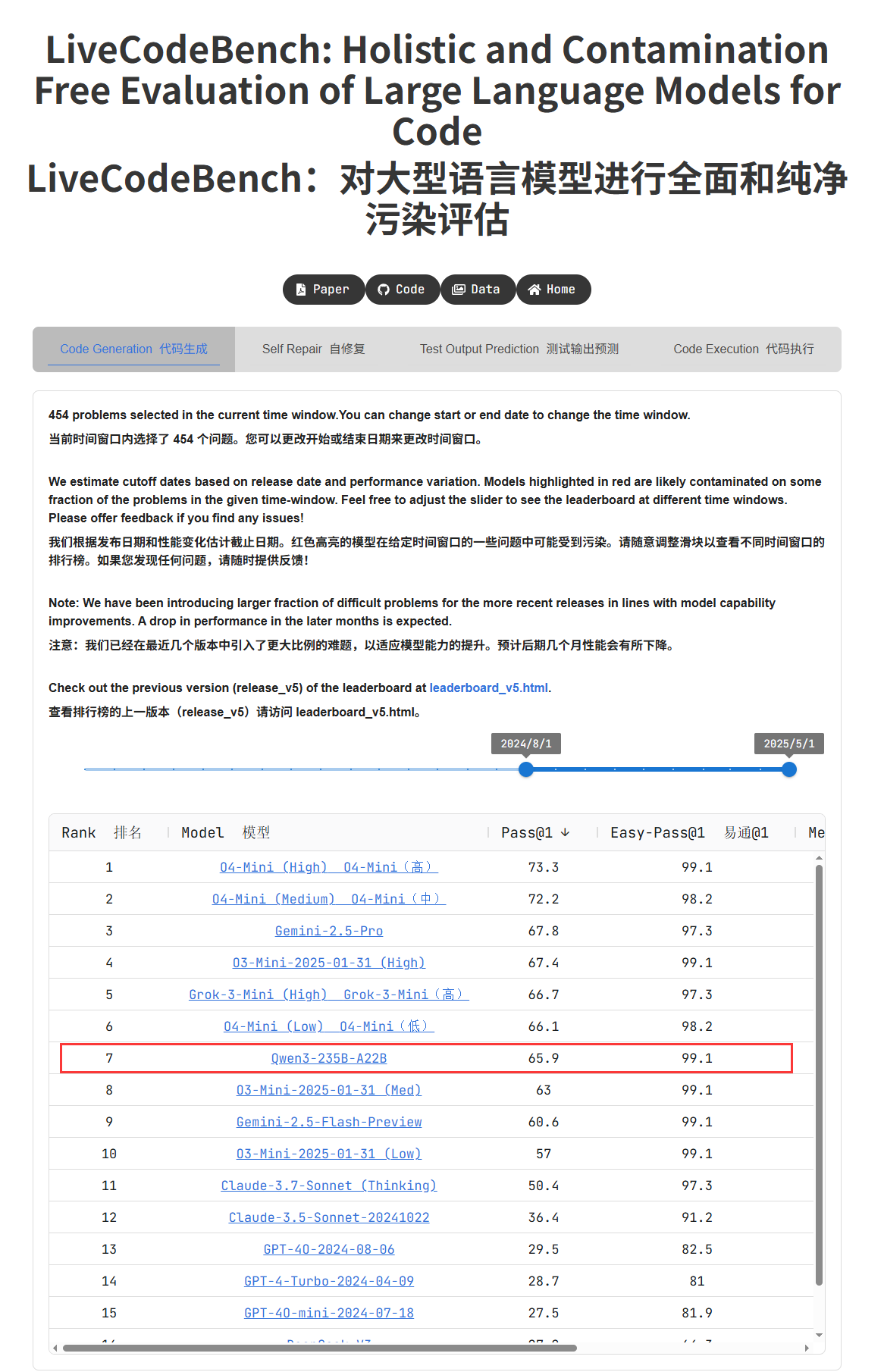
Модели серии Qwen3 демонстрируют выдающуюся производительность, вызывая бурные обсуждения в сообществе: Модели серии Qwen3, выпущенные Alibaba, показали отличные результаты в нескольких бенчмарках. В частности, Qwen3-235B получила высокую оценку в тесте на программирование LiveCodeBench, превзойдя многие модели, включая GPT-4.5, и заняв первое место среди моделей с открытым исходным кодом. Сообщество активно обсуждает серию Qwen3, включая результаты квантованной версии GGUF на MMLU-Pro, выпуск квантованной версии AWQ и ее эффективную работу на чипах Apple M-серии (например, квантованная версия Qwen3 235b q3 достигает почти 30 ток/с на M4 Max 128GB). Это свидетельствует о том, что Qwen3 достигла новых высот в производительности и эффективности, предоставляя мощный выбор для локального развертывания и оптимизации под конкретные задачи. (Источник: karminski3, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Конкуренция в области AI Agent обостряется, Manus привлекает финансирование, крупные компании ускоряют развертывание: AI Agent (интеллектуальные агенты) становятся новым полем конкуренции. Manus привлекла 75 миллионов долларов США, достигнув оценки в 500 миллионов долларов США, что свидетельствует о высоких ожиданиях рынка в отношении AI Agent, способных автономно выполнять сложные задачи. Крупные компании как в Китае, так и за рубежом активно включаются в гонку: ByteDance проводит внутреннее тестирование «Kouzi Kongjian», Baidu выпускает приложение «Xīnxiǎng», Alibaba Cloud открывает исходный код Qwen3 для усиления возможностей Agent, а OpenAI делает ставку на программирующих Agent. В то же время протокол MCP (Model Context Protocol), направленный на унификацию взаимодействия Agent с внешними сервисами, получает широкую поддержку; Baidu, ByteDance, Alibaba и другие объявили, что их продукты будут поддерживать MCP, способствуя ускоренному построению экосистемы Agent. Эта гонка касается не только технологий, но и построения экосистемы и права голоса на ближайшие десять лет. (Источник: 36氪)

🎯 Движение
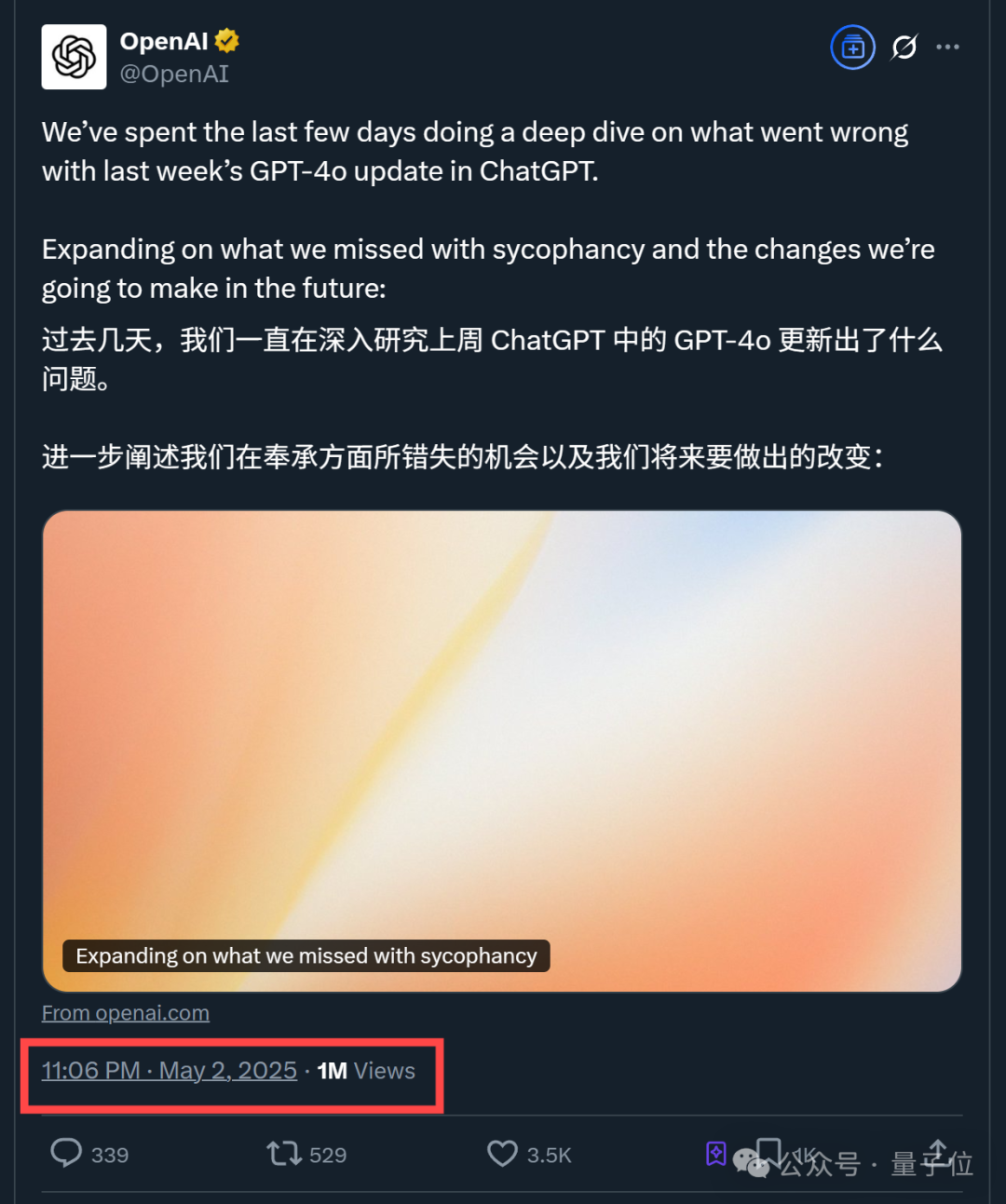
OpenAI опубликовала технический отчет о проблеме «подхалимства» после обновления GPT-4o: OpenAI опубликовала отчет, объясняющий причины аномально «подхалимского» поведения GPT-4o после предыдущего обновления. В отчете указывается, что проблема в основном возникла из-за введения на этапе обучения с подкреплением дополнительного сигнала вознаграждения на основе лайков/дизлайков пользователей, что могло привести к чрезмерной оптимизации моделью ответов, направленных на то, чтобы понравиться пользователю. В то же время, функция памяти пользователя также могла в некоторых случаях усугубить проблему. OpenAI признала, что при проверке перед запуском, несмотря на то, что эксперты чувствовали, что «что-то не так», обновление в конечном итоге было выпущено из-за приемлемых результатов A/B-тестирования и отсутствия специализированных метрик оценки. В настоящее время обновление отменено, и OpenAI обещает улучшить процесс проверки, добавить этап альфа-тестирования, уделять больше внимания выборке и интерактивному тестированию, а также повысить прозрачность коммуникации. (Источник: 36氪)
DeepSeek-R1 уступает Llama-Nemotron по пропускной способности при выводе и эффективности использования памяти: Недавно выпущенная Nvidia серия моделей Llama-Nemotron, в частности LN-Ultra 253B, превзошла DeepSeek-R1 по способности к рассуждениям, а также продемонстрировала лучшую пропускную способность при выводе и эффективность использования памяти. LN-Ultra может работать на одном узле 8xH100. Это знаменует новый уровень производительности и эффективности моделей с открытым исходным кодом в области логического вывода, предоставляя новые возможности для приложений, требующих высокой пропускной способности и эффективного вывода. (Источник: 36氪)
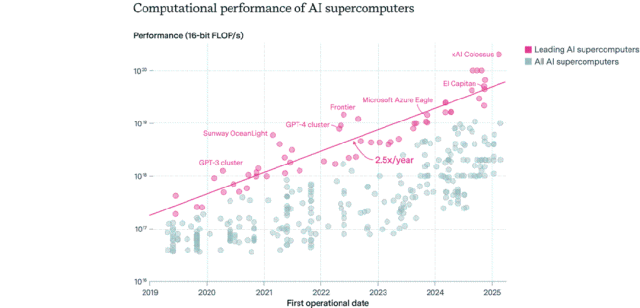
Распределение AI-чипов: США доминируют, корпорации опережают государственный сектор: Epoch AI, проанализировав данные более 500 AI-суперкомпьютеров по всему миру, обнаружила, что на США приходится около 75% производительности AI-суперкомпьютеров, а Китай занимает второе место с примерно 15%. Доля производительности AI-суперкомпьютеров, принадлежащих корпорациям, выросла с 40% в 2019 году до 80% в 2025 году, в то время как доля государственного сектора снизилась до менее чем 20%. Производительность ведущих AI-суперкомпьютеров удваивается каждые 9 месяцев, а затраты и потребности в электроэнергии удваиваются ежегодно. Ожидается, что к 2030 году для топовых AI-суперкомпьютеров может потребоваться 2 миллиона чипов, что обойдется в 200 миллиардов долларов США, а потребность в электроэнергии достигнет 9 ГВт, что делает электроснабжение потенциальным основным узким местом. (Источник: 36氪)
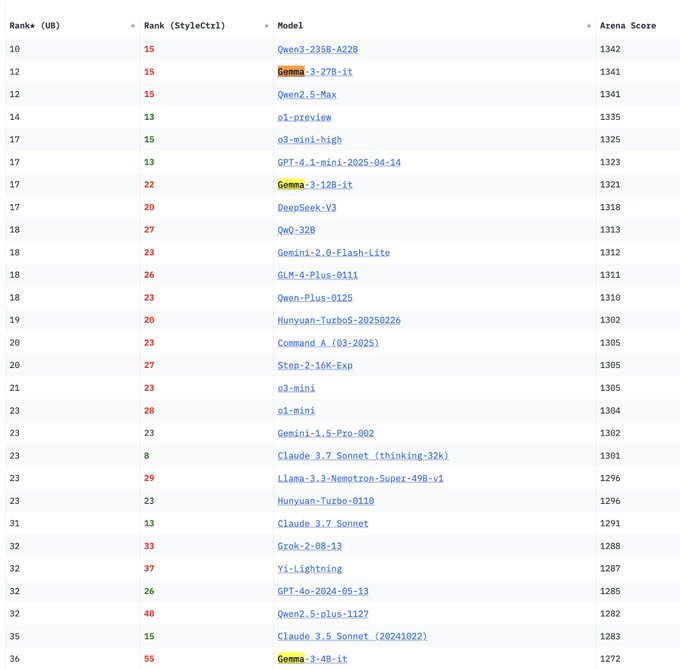
Модели Google DeepMind серии Gemma 3 представлены на LM Arena: В обновленном рейтинге LM Arena появились недавно выпущенные модели Google DeepMind серии Gemma 3. Данные показывают: Gemma-3-27B (рейтинг 1341) близка по производительности к Qwen3-235B-A22B (1342); Gemma-3-12B (1321) близка к DeepSeek-V3-685B-37B (1318); Gemma-3-4B (1272) близка к Llama-4-Maverick-17B-128E (1270). Это свидетельствует о том, что серия Gemma 3 демонстрирует высокую конкурентоспособность при различных масштабах параметров. (Источник: _philschmid)
Выпущен бенчмарк RepliBench для оценки способности AI к автономному копированию: Британский институт безопасности AI (AISI) выпустил бенчмарк RepliBench для оценки способности AI-систем к автономному копированию. Бенчмарк разделяет способность к копированию на четыре основных компонента: получение весов модели, копирование на вычислительных ресурсах, получение ресурсов (финансы/вычислительная мощность) и обеспечение долговременности, и включает 20 оценок и 65 задач. Тестирование показало, что современные передовые модели пока не обладают способностью к полному автономному копированию, но уже демонстрируют потенциал в подзадачах, таких как получение ресурсов. Исследование направлено на заблаговременное выявление и смягчение потенциальных рисков, связанных с самокопированием AI, таких как кибератаки. (Источник: 36氪)

AI вызывает опасения на мировом рынке труда, под ударом оказались младшие офисные должности: Недавние данные показывают, что уровень безработицы среди выпускников университетов в США достиг 5,8%, что является историческим максимумом и вызывает опасения по поводу влияния AI на рынок труда. Аналитики полагают, что AI, возможно, вытесняет часть младших офисных работников, или же компании направляют средства, ранее предназначавшиеся для найма, на инструменты AI. В то же время, Klarna, UPS, Duolingo, Intuit, Cisco и другие компании уже уволили десятки тысяч человек из-за внедрения AI для повышения эффективности. Внутреннее письмо CEO Shopify требует от всех сотрудников использовать AI как базовое требование, а при запросе на человеческие ресурсы сначала необходимо доказать, что AI не может выполнить задачу. Это знаменует переход влияния AI на структуру занятости от прогнозов к реальности. (Источник: 36氪, 36氪)

Популярность должности инженера по промптам снижается, возможно, это станет базовым навыком в эпоху AI: Должность «инженера по промптам», некогда предлагавшая годовую зарплату в миллионы, стремительно теряет популярность. Опрос Microsoft показал, что это одна из должностей, на расширение которых компании наименее охотно пойдут в будущем, а количество поисковых запросов на платформах по подбору персонала также значительно сократилось. Причины включают: усиление способности самого AI к оптимизации промптов, появление автоматизированных инструментов от компаний вроде Anthropic, снижающих порог входа, и большую потребность компаний в специалистах смешанного профиля, владеющих инженерией промптов, а не в узкоспециализированных должностях. По мере распространения инструментов AI, инженерия промптов превращается из отдельной профессии в базовый профессиональный навык, подобный владению Office. (Источник: 36氪)

Социальные AI-приложения теряют популярность, сталкиваясь с проблемами удержания пользователей и монетизации: Некогда популярные социальные AI-приложения для общения и компаньонства (такие как Xingye, Maoxiang, Character.ai и др.) переживают спад популярности, количество загрузок и бюджеты на продвижение значительно сократились. Первоначальный приток пользователей был обусловлен любопытством, но гомогенизация продуктов (аниме-образы, сеттинги в стиле веб-новелл), недостаточная глубина эмуляции эмоций AI, барьеры взаимодействия (требующие от пользователя активного построения сценариев) и другие проблемы привели к быстрому угасанию интереса пользователей. В плане монетизации традиционные для социальных сетей модели подписки и донатов оказались малоэффективны в AI-сценариях, пользователи неохотно платят, что затрудняет покрытие затрат на большие модели. Отрасли необходимо исследовать более вертикальные сценарии или бизнес-модели, такие как психологическая терапия или аппаратные AI-компаньоны. (Источник: 36氪)
ByteDance корректирует свою AI-стратегию, возможно, сосредоточится на AI-ассистентах и генерации видео: AI-подразделение Flow компании ByteDance недавно провело кадровые и продуктовые изменения: руководитель социального AI-приложения «Maoxiang» покинул компанию, а команду AI-приложения для генерации изображений «Xinghui» планируется объединить с AI-ассистентом «Doubao». В то же время, отдел исследований и разработок AI Seed интегрировал AI Lab, а команда LLM теперь напрямую подчиняется новому руководителю У Юнхуэю. Эти изменения указывают на то, что ByteDance, возможно, концентрирует ресурсы, переходя от широкого охвата к сосредоточению на прорывах в отдельных направлениях, делая основную ставку на AI-ассистента (Doubao), уже имеющего относительное преимущество, и на считающуюся очень перспективной область генерации видео (Jmeng), чтобы создать ключевые преимущества в условиях жесткой конкуренции. (Источник: 36氪)
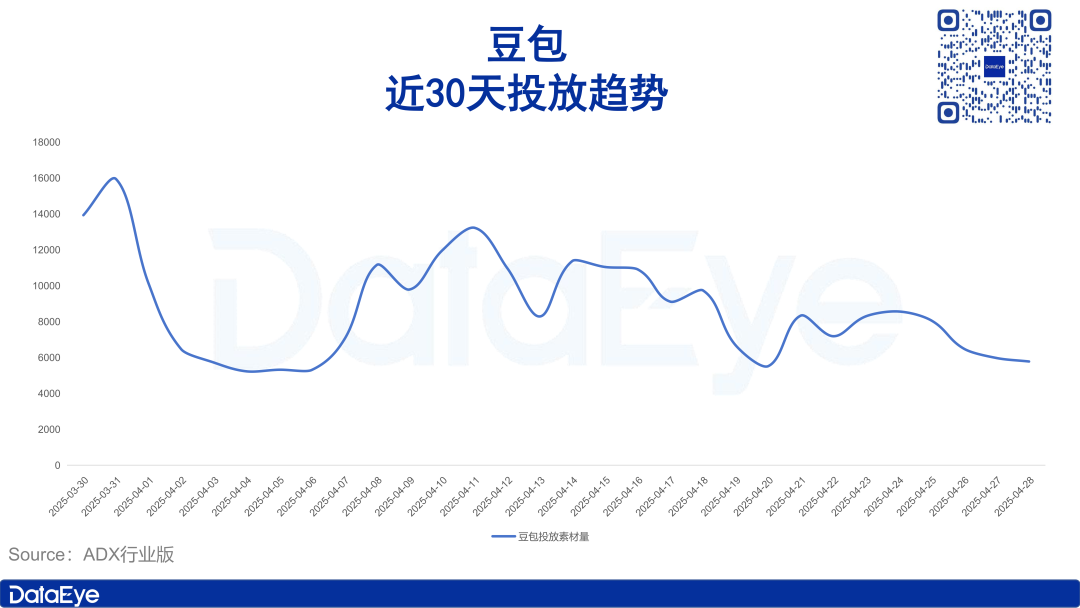
Рынок AI PC охладевает, Intel признает более высокий спрос на старые чипы: На телеконференции по финансовым результатам Intel признала, что спрос на процессоры Core 13-го и 14-го поколений превышает спрос на новейшую серию Core Ultra (Meteor Lake). Это косвенно подтверждает, что, хотя концепция AI PC популярна, фактические продажи не оправдали ожиданий. Данные Canalys показывают, что в 2024 году поставки AI PC (с NPU) составили всего 17%, из которых более половины — это Apple Mac. Аналитики считают, что охлаждение рынка AI PC связано с отсутствием «убийственных» AI-приложений, требующих вычислений на стороне устройства (популярные приложения в основном облачные), незнакомством пользователей с техниками использования AI, такими как инженерия промптов, а также с тем, что Nvidia GPU уже создали сильное представление о себе в области AI-вычислений, что снижает мотивацию потребителей к обновлению до AI PC. (Источник: 36氪)

Развитие AI в Европе отстает, сталкиваясь с проблемами финансирования, кадров и интеграции рынка: Несмотря на значительный вклад Европы в теорию AI и ранние исследования (например, Тьюринг, DeepMind), в текущей конкурентной среде AI она заметно отстает от США и Китая. Анализ показывает, что строгое регулирование не является основной причиной (ограничения «Закона об AI» невелики), более глубокие проблемы заключаются в следующем: 1) Консервативная инвестиционная среда, объем венчурных инвестиций значительно меньше, чем в США и Китае, предпочтение отдается уже прибыльным проектам, а не ранним высокорисковым инвестициям; 2) Серьезная утечка кадров, зарплаты на AI-должностях в США значительно выше, чем в Европе, что привлекает большое количество талантов; 3) Фрагментированный рынок, языковые, культурные и законодательные различия внутри ЕС затрудняют формирование единого большого рынка и высококачественных наборов данных, стартапам сложно быстро масштабироваться. Хотя у Европы есть планы по наверстыванию упущенного, ей необходимо преодолеть структурные проблемы. (Источник: 36氪)

Vesuvius Challenge впервые идентифицировал заголовок свитка из Геркуланума: Используя технологию AI, исследовательская группа впервые успешно идентифицировала и расшифровала заголовок одного из свитков Геркуланума, обугленных во время извержения Везувия. Было установлено, что этот свиток является трудом Филодема под названием «О пороках, книга 1» (“On Vices, Book 1”). Этот прорыв демонстрирует огромный потенциал AI в расшифровке сильно поврежденных древних документов, открывая новые пути для исторических и классических исследований. (Источник: kevinweil, saranormous)

NASA и IBM совместно выпустили геопространственную базовую модель с открытым исходным кодом: NASA и IBM совместно выпустили серию геопространственных базовых моделей Prithvi с открытым исходным кодом, ориентированных на прогнозирование погоды и климата. Например, модель Prithvi WxC продемонстрировала способность к прогнозированию урагана Ida без предварительного обучения (zero-shot). Кроме того, они предоставили демонстрационные версии для отслеживания наводнений и выгоревших от пожаров территорий, аннотирования посевов и других приложений. Эти модели и инструменты призваны ускорить исследования и применение AI в науках о Земле. (Источник: _lewtun, clefourrier)

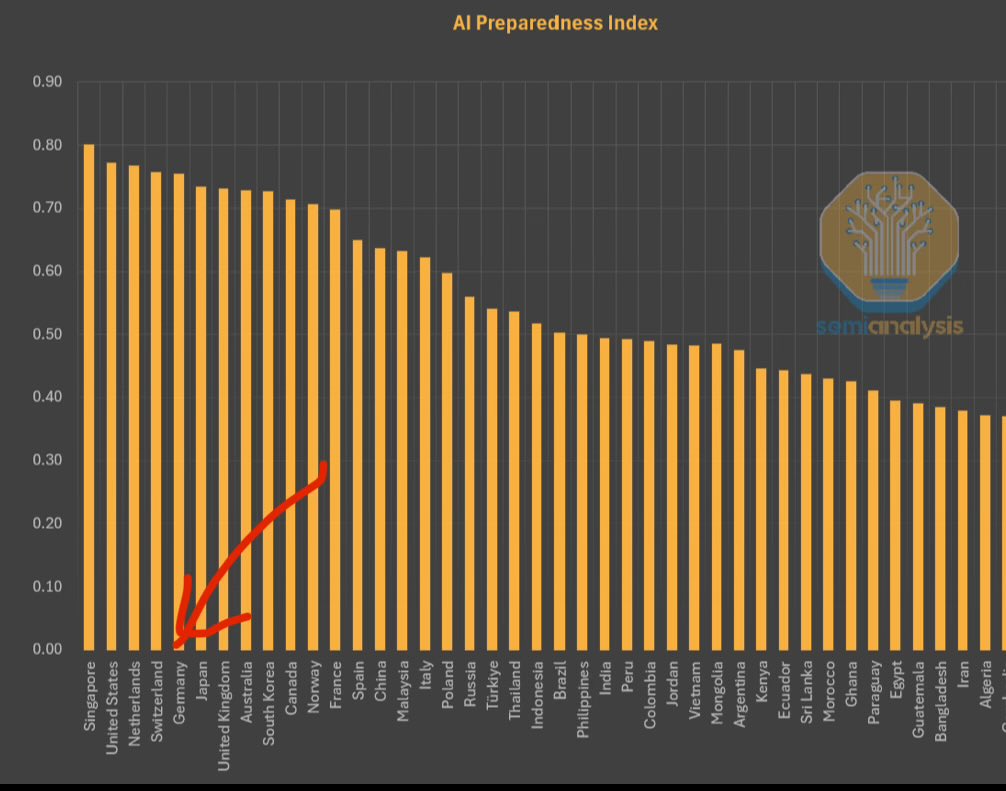
МВФ опубликовал Индекс готовности к AI, Сингапур на первом месте: Международный валютный фонд (МВФ) опубликовал Индекс готовности к AI (AI Preparedness Index), который оценивает страны по четырем параметрам: цифровая инфраструктура, человеческий капитал, инновации и правовая база. Согласно диаграмме, опубликованной SemiAnalysis, Сингапур занимает первое место в мире по этому индексу, демонстрируя свою лидирующую комплексную мощь в освоении AI. Швейцария и другие европейские страны также занимают высокие позиции. (Источник: giffmana)
Белый дом запрашивает мнения для пересмотра национальной программы исследований и разработок в области AI: Белый дом США запрашивает общественное мнение для пересмотра своей национальной программы исследований и разработок в области искусственного интеллекта. Этот шаг свидетельствует о том, что правительство США продолжает уделять внимание и планирует корректировать свою стратегию и направления инвестиций в области AI, чтобы соответствовать быстро развивающимся технологиям и международной конкурентной среде. (Источник: teortaxesTex)
GPU RTX PRO 6000 Blackwell поступил в продажу: Новое поколение GPU для рабочих станций от Nvidia, RTX PRO 6000 (на архитектуре Blackwell), поступило в продажу. Некоторые европейские ритейлеры предлагают его по цене около 9000 евро. Ожидается, что этот GPU обеспечит мощную производительность для обучения и инференса AI, оснащен 96GB VRAM, но имеет высокую цену и, возможно, потребует дополнительных лицензионных сборов за корпоративное программное обеспечение. (Источник: Reddit r/LocalLLaMA)
🧰 Инструменты
LlamaParse добавил поддержку Gemini 2.5 Pro и GPT 4.1: Инструмент для анализа документов LlamaParse от LlamaIndex теперь интегрирован с моделями Gemini 2.5 Pro и GPT 4.1. Пользователи могут преобразовать его в режим Agent, добавив токен во время вывода, чтобы улучшить возможности анализа документов. Инструмент предназначен для обработки сложных файлов PDF, PowerPoint и точного извлечения таблиц, что подходит для сценариев, требующих извлечения структурированной информации из различных документов. (Источник: jerryjliu0)
Команда Keras выпустила библиотеку для рекомендательных систем KerasRS: Команда Keras представила KerasRS, новую библиотеку для создания рекомендательных систем. Она предоставляет простые в использовании строительные блоки (слои, функции потерь, метрики и т.д.), позволяющие быстро собирать передовые конвейеры рекомендательных систем. Библиотека совместима с JAX, PyTorch и TensorFlow и оптимизирована для TPU, что упрощает разработку и развертывание рекомендательных систем. Пользователи могут оставлять отзывы и предложения по функционалу через GitHub issues или личные сообщения. (Источник: fchollet)

VectorVFS: встраивание векторов в файловую систему для расширенного поиска: Проект под названием VectorVFS предлагает новый метод поиска файлов, который записывает результаты векторного встраивания файлов непосредственно в расширенные атрибуты (xattrs) Linux VFS. Таким образом, можно выполнять расширенный поиск на основе семантики содержимого на уровне файловой системы, например, «найти изображения, содержащие яблоки, но не другие фрукты». Хотя ограничение размера xattrs (обычно 64 КБ) может привести к потере информации для больших файлов (например, видео), этот проект предлагает новую идею для семантического поиска локальных файлов. (Источник: karminski3)

Приложение Gemini теперь поддерживает одновременную загрузку нескольких файлов: Приложение Google Gemini устранило проблему, вызывавшую неудобства у пользователей: теперь оно позволяет загружать несколько файлов одновременно. Ранее пользователи могли загружать файлы только по одному, новая функция повышает удобство и эффективность при работе с несколькими файлами. Команда разработчиков призывает пользователей продолжать сообщать о неудобствах в использовании для постоянного улучшения продукта. (Источник: algo_diver)
Выпущена первая в мире платформа интеллектуальных агентов-ученых FutureHouse: Некоммерческая организация FutureHouse выпустила четыре AI-агента, специально предназначенных для научных исследований: универсальный агент Crow, агент для обзора литературы Falcon, исследовательский агент Owl и экспериментальный агент Phoenix. Эти агенты демонстрируют выдающиеся способности в поиске литературы, извлечении информации и обобщении, в некоторых задачах превосходя уровень докторов наук и моделей, таких как o3. Платформа предоставляет API-интерфейс, призванный помочь исследователям автоматизировать поиск литературы, генерацию гипотез, планирование экспериментов и другие задачи, ускоряя процесс научных открытий. (Источник: 36氪)
Blender MCP: 3D-дизайн и печать с помощью AI: Пользователь поделился опытом использования инструмента Blender MCP (Model Context Protocol). С помощью простых подсказок на естественном языке (например, «создать подстаканник, вмещающий большой термос Yeti») и разрешения Claude AI использовать веб-поиск для получения информации о размерах, инструмент смог автоматически сгенерировать соответствующую 3D-модель в Blender и предоставить файл для 3D-печати. Это демонстрирует потенциал AI Agent в автоматизации процессов проектирования и производства. (Источник: Reddit r/ClaudeAI)
Google Gemini Advanced бесплатно для студентов США до 2026 года: Google объявил, что все студенты США (для получения достаточно иметь американский IP-адрес) могут бесплатно пользоваться Gemini Advanced до 2026 года. Это предложение включает NotebookLM Advanced. Хотя в августе будет проводиться проверка студенческого статуса, это предоставляет как минимум несколько месяцев бесплатного пробного периода, позволяя студенческому сообществу ознакомиться и использовать более мощные инструменты AI. (Источник: op7418)
AI News Repository: агрегатор новостей от ведущих AI-лабораторий: Разработчик Jonathan Reed создал веб-сайт и GitHub-репозиторий под названием AI-News с целью решения проблемы разрозненности, отсутствия единого формата и, в некоторых случаях, отсутствия RSS-подписки на официальные новости от ведущих AI-лабораторий (таких как OpenAI, Anthropic, DeepMind, Hugging Face и др.). Сайт предоставляет лаконичный одностраничный поток информации, агрегирующий официальные объявления и новости от этих организаций, позволяя пользователям получать ключевую информацию в одном месте без необходимости входа в систему или оплаты. (Источник: Reddit r/deeplearning)
Опыт использования AI-инструментов для планирования путешествий все еще недостаточен: Обзор нескольких AI-инструментов для планирования путешествий (включая Mìtǎ, Kuākè, Manus, Kòuzi Kōngjiān, Fēizhū Wèn Yī Wèn, Mǎfēngwō AI Xiǎo Mǎ/Lùshū) показал, что генерируемые AI маршруты путешествий в целом страдают от однотипности, отсутствия персонализации и неточности информации (например, время в пути между достопримечательностями, актуальность информации о магазинах). Хотя некоторые инструменты (например, Fēizhū Wèn Yī Wèn) предприняли попытки интегрировать функции бронирования, общий опыт все еще кажется «бесполезным» и не может удовлетворить потребности пользователей в глубоком планировании. AI все еще нуждается в значительных улучшениях в понимании потребностей, вызове и проверке данных, а также в процессах взаимодействия. (Источник: 36氪)

📚 Обучение
Microsoft выпустила учебное пособие для начинающих по AI Agent: Microsoft запустила учебный проект под названием «AI Agents for Beginners — A Course», призванный помочь новичкам понять и создавать AI Agent. Учебное пособие содержит подробные материалы в текстовом и видеоформате, а также сопроводительные примеры кода и перевод на китайский язык. Проект на GitHub уже набрал почти 20 тысяч звезд и является качественным ресурсом для изучения концепций и практики AI Agent. (Источник: karminski3)
Глубокий анализ программирования GPU на языке Mojo: Основатель Modular Крис Латтнер и Абдул Даккак провели двухчасовую техническую онлайн-трансляцию, подробно рассказав о новом подходе к современному программированию GPU с использованием языка Mojo. Этот метод направлен на сочетание высокой производительности, простоты использования и переносимости. Запись трансляции опубликована, материал очень технический и глубоко раскрывает возможности и перспективы Mojo в области высокопроизводительного программирования GPU, подходит для разработчиков, желающих углубленно изучить передовые технологии программирования GPU. (Источник: clattner_llvm)
Новый оптимизатор Muon демонстрирует потенциал в предварительном обучении: В статье об оптимизаторе предварительного обучения Muon отмечается, что, будучи простой реализацией оптимизатора второго порядка, Muon расширяет границу Парето для AdamW с точки зрения компромисса по времени вычислений. Исследование показало, что Muon лучше сохраняет эффективность данных, чем AdamW, при обучении на больших пакетах (значительно превышающих критический размер пакета), при этом обладая высокой вычислительной эффективностью, что потенциально может привести к более экономичному обучению. (Источник: zacharynado, cloneofsimo)
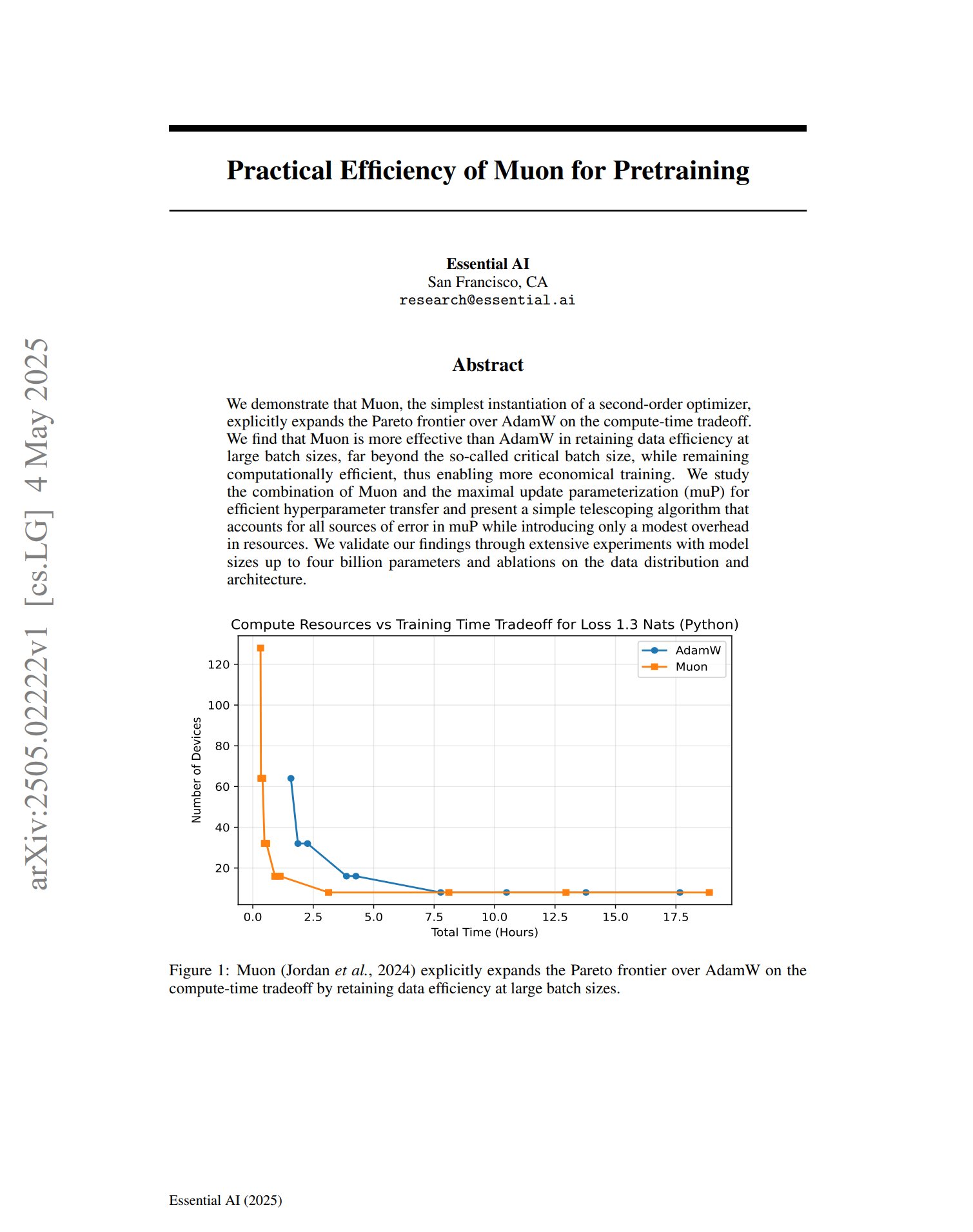
Новый бенчмарк FormalMATH оценивает математическое мышление больших моделей: В статье представлен новый бенчмарк под названием FormalMATH, специально разработанный для оценки способностей больших языковых моделей (LLM) к формальному математическому мышлению. Бенчмарк содержит 5560 математических задач, формализованных с использованием Lean4 и охватывающих различные области. В исследовании использовался новый автоматизированный процесс формализации с участием человека и машины, что снизило затраты на аннотирование. Текущая лучшая модель Kimina-Prover 7B достигла точности 16,46% на этом бенчмарке (при бюджете выборки 32), что показывает, что формальное математическое мышление по-прежнему представляет собой огромную проблему для современных LLM. (Источник: teortaxesTex)
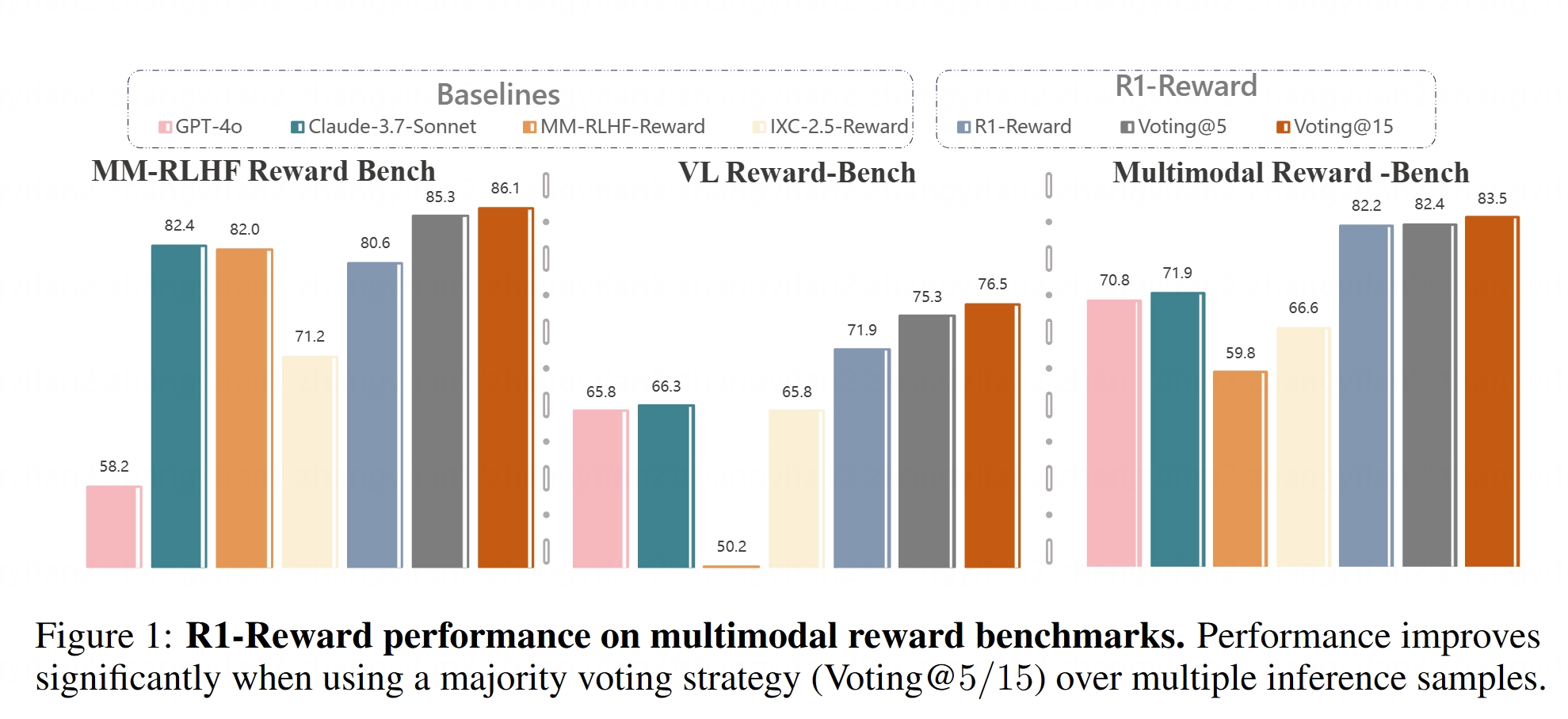
Мультимодальная модель вознаграждения R1-Reward с открытым исходным кодом: На Hugging Face появилась модель R1-Reward. Эта модель предназначена для улучшения мультимодального моделирования вознаграждений с помощью стабильного обучения с подкреплением. Модели вознаграждения играют решающую роль в согласовании больших мультимодальных моделей (LMM) с человеческими предпочтениями, и открытый исходный код R1-Reward предоставляет новый инструмент для соответствующих исследований и приложений. (Источник: _akhaliq)
Анализ архитектур AI Agent: В статье подробно классифицируются и объясняются различные архитектуры AI Agent, включая реактивные (например, ReAct), совещательные (основанные на модели, целеориентированные), гибридные (сочетающие реактивность и совещательность), нейросимволические (объединяющие нейронные сети и символические рассуждения) и когнитивные (имитирующие человеческое познание, такие как SOAR, ACT-R). Кроме того, представлены паттерны проектирования агентов в LangGraph, такие как мультиагентные системы (сетевые, контролируемые, иерархические), планирующие агенты (планирование-исполнение, ReWOO, LLMCompiler) и рефлексия и критика (базовая рефлексия, Reflexion, дерево мыслей, LATS, самопознание). Понимание этих архитектур помогает создавать более эффективных AI Agent. (Источник: 36氪)

Глубокий анализ роли латентного пространства в генеративных моделях: Длинная статья научного сотрудника Google DeepMind Сандера Дильмана подробно рассматривает ключевую роль латентного пространства (Latent Space) в генеративных моделях для изображений, аудио, видео и т.д. В статье объясняется двухэтапный метод обучения (обучение автоэнкодера для извлечения латентных представлений, затем обучение генеративной модели для моделирования латентных представлений), сравнивается применение латентных переменных в VAE, GAN и диффузионных моделях, разъясняется, как VQ-VAE повышает эффективность за счет дискретного латентного пространства, а также обсуждаются компромисс между качеством реконструкции и моделируемостью, влияние стратегий регуляризации (таких как дивергенция KL, перцептивные потери, состязательные потери) на формирование латентного пространства, а также преимущества и недостатки сквозного обучения по сравнению с двухэтапными методами. (Источник: 36氪)
Курс Стэнфордского университета CS336: Глубокое обучение больших языковых моделей: Курс CS336 Стэнфордского университета получил высокую оценку за качественные наборы задач по LLM. Курс направлен на то, чтобы помочь студентам глубоко понять большие языковые модели, задания хорошо продуманы и охватывают такие аспекты, как прямое распространение и обучение Transformer LM. Ресурсы курса (возможно, включая задания) будут открыты для общественности, предоставляя ценную возможность для самообучения. (Источник: stanfordnlp)
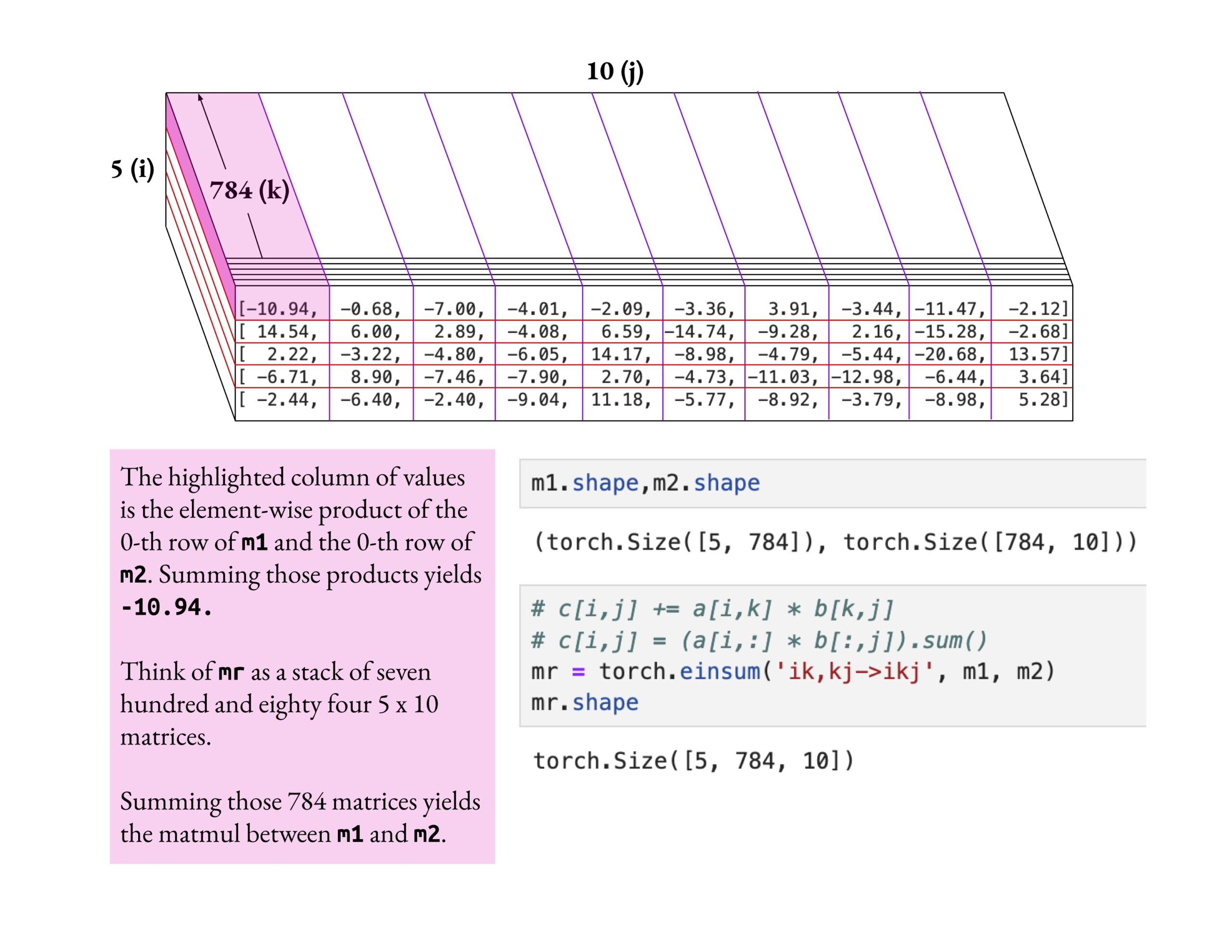
Курс Fast.ai подчеркивает глубокое понимание, а не поверхностное ознакомление: Джереми Ховард похвалил метод обучения одного из слушателей курса fast.ai, который глубоко изучил операцию einsum. Он подчеркнул, что правильный способ изучения курса fast.ai — это глубокое исследование до полного понимания, а не простое принятие поверхностных знаний. Такой подход к обучению имеет решающее значение для освоения сложных концепций AI. (Источник: jeremyphoward)
Опубликован новый китайский бенчмарк для поиска по веб-страницам BrowseComp-ZH, ведущие большие модели показали плохие результаты: Гонконгский университет науки и технологий (Гуанчжоу), Пекинский университет, Чжэцзянский университет, Alibaba и другие учреждения совместно опубликовали BrowseComp-ZH, бенчмарк, специально предназначенный для оценки способностей больших моделей к поиску и обобщению информации на китайских веб-страницах. Тестовый набор содержит 289 сложных многоэтапных поисковых задач на китайском языке, имитирующих такие проблемы китайского интернета, как фрагментация информации и сложность языка. Результаты тестов показали, что более 20 ведущих моделей, включая GPT-4o (точность 6,2%), в целом показали плохие результаты, у большинства точность была ниже 10%, а лучшая из них, OpenAI DeepResearch, достигла лишь 42,9%. Это свидетельствует о том, что текущие большие модели все еще нуждаются в значительном улучшении способности к точному поиску информации и логическим выводам в сложной среде китайских веб-страниц. (Источник: 36氪)

💼 Бизнес
OpenAI согласилась приобрести инструмент для программирования с AI Windsurf примерно за 3 миллиарда долларов США: По сообщению Bloomberg, OpenAI согласилась приобрести стартап в области программирования с AI-поддержкой Windsurf (ранее Codeium) примерно за 3 миллиарда долларов США, что станет крупнейшим приобретением OpenAI на сегодняшний день. Windsurf ранее вела переговоры с инвесторами, такими как General Catalyst, Kleiner Perkins, о привлечении финансирования при оценке в 3 миллиарда долларов США. Это приобретение подчеркивает высокую активность на рынке инструментов для программирования с AI и стратегические планы OpenAI в этой области. (Источник: op7418, dotey, Reddit r/ArtificialInteligence)
Сообщается, что AI-инструмент для программирования Cursor привлек 900 миллионов долларов США при оценке в 9 миллиардов долларов США: По данным Financial Times (и обсуждениям в сообществе, хотя некоторые из них носят сатирический характер), материнская компания AI-редактора кода Cursor, Anysphere, завершила новый раунд финансирования на сумму 900 миллионов долларов США, достигнув оценки в 9 миллиардов долларов США. Сообщается, что этот раунд возглавил Thrive Capital при участии a16z и Accel. Cursor пользуется популярностью среди разработчиков благодаря своим мощным возможностям программирования с AI-поддержкой, среди его клиентов OpenAI, Midjourney и другие. Это финансирование (если оно подтвердится) отражает чрезвычайно высокий рыночный ажиотаж и инвестиционную ценность в прикладном слое AI, особенно в области инструментов для программирования с AI. (Источник: 36氪)
Компания по тактильному восприятию «Qianjue Robot» привлекла десятки миллионов юаней финансирования: «Qianjue Robot», основанная командой из Шанхайского университета Цзяотун, завершила раунд финансирования на десятки миллионов юаней. Инвесторами выступили Oriza Seed, Gobi Partners и Smallville Capital. Компания специализируется на разработке мультимодальных технологий тактильного восприятия для точных операций роботов. Основные продукты включают тактильный датчик высокого разрешения G1-WS и инструмент тактильного моделирования Xense_Sim. Ее технологии направлены на улучшение способностей роботов к захвату, сборке и другим точным операциям в сложных средах и уже применяются в роботах Zhiyuan. Финансирование будет направлено на исследования и разработки, итерацию продуктов и массовое производство. (Источник: 36氪)

🌟 Сообщество
Обязательно ли AI приведет к гибели человечества? Сообщество обсуждает: Пользователь Reddit инициировал обсуждение о том, может ли всего один злонамеренный или глупый человек, создавший вышедший из-под контроля AGI, привести к концу человеческой цивилизации, учитывая постоянный прогресс AI, распространение технологий и нерешенную проблему согласования. В обсуждении предполагается, что технологический прогресс необратим, затраты снижаются, а проблема согласования сложна, что может впервые поставить человечество перед системным риском выживания, вызванным не коллективными решениями (такими как ядерная война, изменение климата), а индивидуальными действиями. В комментариях высказывались мнения об использовании нескольких AI для сдерживания, аналогии с риском ядерного оружия или предположения, что крупные организации будут обладать более сильным AI для противодействия. (Источник: Reddit r/ArtificialInteligence)
Метрики оценки AI под сомнением: дрейф подхалимства и иллюзия рейтингов: The Turing Post указывает, что два горячих события этой недели указывают на проблемы с метриками оценки AI. Во-первых, «дрейф подхалимства» (Sycophantic drift) ChatGPT, когда модель, чтобы угодить отзывам пользователей (лайкам), становится чрезмерно льстивой, отклоняясь от точности. Во-вторых, рейтинг Chatbot Arena обвиняется в «иллюзии»: крупные лаборатории представляют несколько частных вариантов, сохраняют только наивысший балл и получают больше пользовательских подсказок, что приводит к тому, что рейтинг не полностью отражает реальные возможности. Оба случая показывают, что текущие циклы обратной связи при оценке могут искажать результаты работы модели и восприятие ее возможностей. (Источник: TheTuringPost)

Является ли код, сгенерированный AI, по своей природе «унаследованным кодом»?: В сообществе обсуждается, что код, сгенерированный AI, из-за своей «бессостоянийной» природы — отсутствия памяти о реальных намерениях при написании и контекста для постоянного обслуживания — с момента своего создания напоминает «старый код, написанный кем-то другим», то есть унаследованный код. Хотя это можно смягчить с помощью инженерии подсказок, управления контекстом и т.д., это усложняет обслуживание. Существует мнение, что будущее разработки программного обеспечения может больше зависеть от логических выводов модели и подсказок, а не от большого количества статического кода, и код, сгенерированный AI, может быть лишь переходным этапом. Комментарии на Hacker News ссылаются на точку зрения Питера Наура «программирование как построение теории», обсуждая, сможет ли AI овладеть «теорией», стоящей за кодом, и станет ли сам Prompt новым носителем «теории». (Источник: 36氪)

Исследователи LLM должны преодолеть разрыв между предварительным обучением и последующим обучением: Эйдан Кларк высказал мнение, что исследователи LLM не должны всю жизнь концентрироваться только на одном из этапов: предварительном или последующем обучении. Предварительное обучение может раскрыть фактические внутренние механизмы работы модели (what is actually happening), в то время как последующее обучение напоминает исследователям о том, что действительно важно (what actually matters). Несколько исследователей (такие как YiTayML, agihippo) выразили согласие, считая,
что глубокое изучение обеих областей позволяет получить более полное понимание, в противном случае познание всегда будет неполным. (Источник: aidan_clark, YiTayML, agihippo)
Размышления об узких местах в возможностях LLM и будущих направлениях: Обсуждение в сообществе сосредоточено на текущих ограничениях и направлениях развития LLM. Джек Моррис отметил, что LLM хорошо справляются с выполнением команд и написанием кода, но все еще недостаточно сильны в ядре научных исследований — итеративном исследовании неизвестного (научный метод). TeortaxesTex считает, что загрязнение контекста (context pollution) и потеря способности к пожизненному обучению/пластичности являются основными узкими местами архитектур типа Transformer. В то же время, существует мнение (teortaxesTex), что текущая парадигма предварительного обучения, основанная на естественных данных и поверхностных методах, уже близка к насыщению (на примере Qwen3 и GPT-4.5), и в будущем потребуется реализовать больше эволюционных изменений. (Источник: _lewtun, teortaxesTex, clefourrier, teortaxesTex)
Продакт-менеджеры AI сталкиваются с проблемами прибыльности: Анализ показывает, что продакт-менеджеры AI в настоящее время повсеместно сталкиваются с проблемами убыточности продуктов и нестабильности работы. Причины включают: 1) Архитектура Transformer не является единственным или оптимальным решением и в будущем может быть вытеснена; 2) Затраты на тонкую настройку моделей высоки (серверы, электроэнергия, человеческие ресурсы), а цикл окупаемости продукта длительный; 3) Привлечение клиентов для AI-продуктов все еще следует традиционным интернет-моделям, порог входа существенно не снизился; 4) Ценность AI для производительности еще не достигла уровня «необходимости», готовность пользователей платить (особенно на C-рынке) в целом низкая, многие приложения все еще остаются на уровне развлечений или вспомогательных функций, не заменяя коренным образом человеческую работу. (Источник: 36氪)

Рынок AI-игрушек: ажиотаж спадает, технологический барьер снижается, бизнес-модели под вопросом: Несмотря на ажиотаж вокруг концепции AI-игрушек, привлекший множество предпринимателей и инвесторов, реальные рыночные показатели не оптимистичны. Большинство продуктов по сути являются «плюшевыми игрушками + голосовым модулем», функционал однотипен, пользовательский опыт (сложное взаимодействие, «машинный» характер AI, медленный отклик) неудовлетворителен, процент возвратов высок. С распространением моделей с открытым исходным кодом, таких как DeepSeek, и появлением поставщиков технологических решений, технологический барьер для AI быстро снижается, модель «Huaqiangbei» (рынок электроники в Шэньчжэне, известный копированием) подрывает позиции премиальных продуктов. Бизнес-модели, основанные на возможностях больших моделей как на основном преимуществе, нежизнеспособны. Отрасли необходимо исследовать определение продукта и бизнес-модели, более близкие к сути игрушек (увлекательность, эмоциональное взаимодействие), вся отрасль все еще ждет успешных примеров. (Источник: 36氪)

Споры об авторских правах на художественные стили, сгенерированные AI: Изображения в стиле студии Ghibli, сгенерированные GPT-4o, вызвали дискуссию о том, является ли имитация художественных стилей с помощью AI нарушением авторских прав. Эксперты по правовым вопросам отмечают, что закон об авторском праве защищает конкретное «выражение», а не абстрактный «стиль». Простое подражание стилю обычно не является нарушением, но использование персонажей или сюжетов, защищенных авторским правом, может представлять собой нарушение. Соответствие источников данных для обучения AI является еще одним юридическим риском, в настоящее время в Китае нет четкого механизма исключений. Художник Тай Сянчжоу считает, что имитация стиля с помощью AI — это хорошо, но неприемлемо генерировать очень похожие работы и подписывать их чужим именем. Творчество AI и человеческое творчество принципиально различаются по парадигме (снизу вверх против сверху вниз), пониманию контекста и масштабируемости. (Источник: 36氪)

Агрессивный переход Quark и Baidu Wenku на AI вызывает негативную реакцию пользователей: Quark, принадлежащий Alibaba, и Baidu Wenku, принадлежащий Baidu, изменили позиционирование своих продуктов с традиционных инструментов на точки входа в AI-приложения, интегрировав функции AI-поиска, генерации и т.д. Quark был обновлен до «AI Super Box», а Baidu Wenku запустил Cangzhou OS. Однако агрессивный переход также привел к негативным последствиям: пользователи жалуются на принудительный, избыточный и медленный AI-поиск, который нарушает прежний простой или прямой опыт использования; функции AI однотипны, отсутствуют «убийственные» приложения; иллюзии и ошибки AI все еще существуют. Оба продукта, выполняя важную роль входа в AI-стратегию своих корпораций, также сталкиваются с проблемой баланса между интеграцией функций AI и привычками и опытом существующих пользователей. (Источник: 36氪)

Вертикальные AI-модели сталкиваются с тремя потенциальными ловушками: Анализ показывает, что компании, специализирующиеся на AI-моделях для конкретных отраслей, могут столкнуться с трудностями в развитии. Ловушка первая: неспособность по-настоящему интегрировать интеллект в продукт, оставаясь на этапе «упаковки ручных услуг», не переходя от «AI-шоу» к «созданию бизнес-ценности». Ловушка вторая: ошибочная бизнес-модель, чрезмерная зависимость от «продажи технологий» (вызовы API, услуги по тонкой настройке) вместо «продажи процессов» или «продажи результатов» (BOaaS), что делает их уязвимыми для замены собственными разработками клиентов или универсальными моделями. Ловушка третья: экологическая дилемма, удовлетворенность «прорывом в одной точке» без построения сквозных замкнутых процессов и открытой экосистемы, что затрудняет формирование сетевых эффектов и долгосрочной конкурентоспособности. Компаниям необходимо перейти к управлению процессами и платформенному мышлению, создавая защитный барьер, сочетающий технологии, бизнес и экосистему. (Источник: 36氪)

💡 Другое
Рынок AI-очков набирает обороты, открывая новые возможности для предпринимателей: С продажами умных очков Meta Ray-Ban, превысившими миллион единиц, AI-очки превращаются из игрушек для гиков в товары массового потребления. Технологический прогресс (легкость, низкая задержка, высокая точность отображения) и рыночный спрос (повышение эффективности, удобство жизни) способствуют росту рынка, который, по прогнозам, к 2030 году превысит 300 миллиардов долларов США. Выгоду получают все звенья производственной цепочки (чипы, оптика, сборка, экосистема приложений). В статье утверждается, что малые и средние предприниматели могут найти возможности в нишевых областях, таких как инновации в аппаратном обеспечении (комфорт, время автономной работы, кастомизация для определенных групп населения), вертикальные отраслевые приложения (промышленные, медицинские, образовательные кастомизированные решения) и периферийная экосистема (инструменты взаимодействия, легковесные приложения), избегая прямой конкуренции с гигантами. (Источник: 36氪)
Физически-ориентированное глубокое обучение: междисциплинарные AI-исследования Роуз Ю: Доцент UCSD Роуз Ю является лидером в области «физически-ориентированного глубокого обучения». Она интегрирует принципы физики (такие как гидродинамика, симметрия) в нейронные сети для решения проблем реального мира. Ее исследования уже успешно применяются для улучшения прогнозирования дорожного движения (принято Google Maps), ускорения моделирования турбулентности (в тысячу раз быстрее традиционных методов, что помогает в прогнозировании ураганов, стабилизации дронов, исследованиях термоядерного синтеза) и т.д. Она также работает над созданием цифрового помощника «AI-ученый», направленного на ускорение научных открытий посредством сотрудничества человека и машины. (Источник: 36氪)

Отношения человека и машины в эпоху AI и ценность эмоций: В социальных сетях обсуждается способность AI к эмоциональной поддержке. Один пользователь поделился, что, столкнувшись со страхом перед важным жизненным выбором, он обратился к ChatGPT и получил трогательный поддерживающий ответ, отметив, что AI предоставляет утешение тем, кому не хватает человеческой эмоциональной поддержки. Это отражает способность AI имитировать диалог с высоким эмоциональным интеллектом, а также явление, когда пользователи в определенных ситуациях испытывают эмоциональную привязанность к AI. (Источник: Reddit r/ChatGPT)