
Ключевые слова:Модель вывода Phi-4, DeepSeek-Prover-V2, Обновление GPT-4o с откатом, Tongyi Qianwen Qwen3, Оптимизация вывода MoE, Протокол интеллектуального агента ИИ, Технология пост-обучения LLM, Модель Microsoft Phi-4-reasoning-plus, Производительность DeepSeek-Prover-V2 в доказательстве теорем, Исправление чрезмерно угодливого поведения GPT-4o, Многоязыковая поддержка Qwen3-235B, Моделирование длинных текстов с DiffTransformer
🔥 Фокус
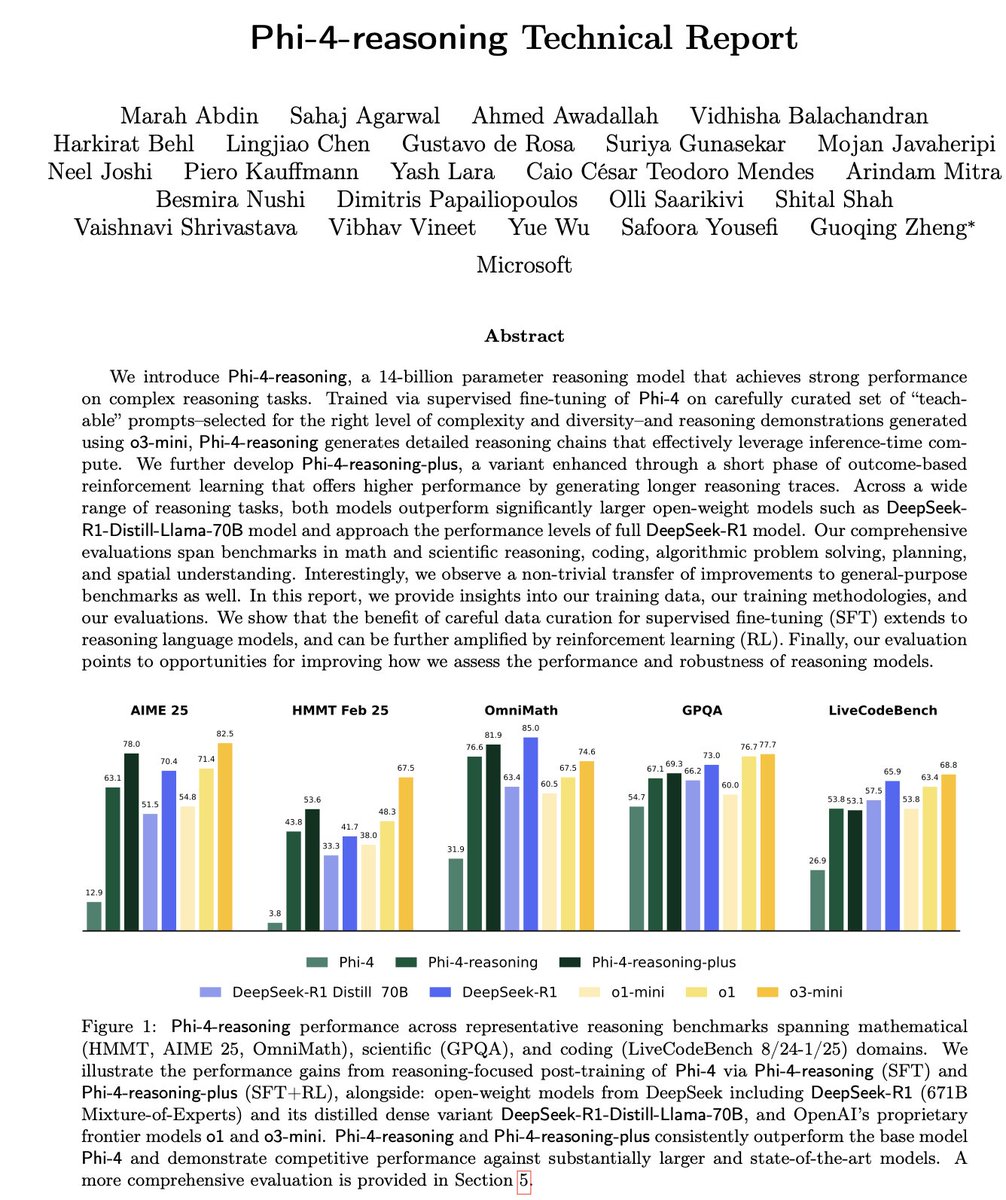
Microsoft выпустила серию малых моделей для логического вывода Phi-4: Microsoft представила серию моделей Phi-4, включая Phi-4-reasoning с 14 млрд параметров и Phi-4-reasoning-plus (последняя дообучена с небольшим количеством RL). Эти модели демонстрируют выдающиеся результаты в тестах на логическое мышление и общих бенчмарках, будучи компактными, но мощными. Phi-4-reasoning даже превзошла значительно более крупную модель DeepSeek-R1 (671 млрд параметров) в бенчмарке AIME25, подчеркивая ключевую роль высококачественных данных для обучения в производительности модели, а не просто зависимость от масштаба параметров. Серия также включает версию Phi-4-mini-reasoning с 3.8 млрд параметров. (Источник: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
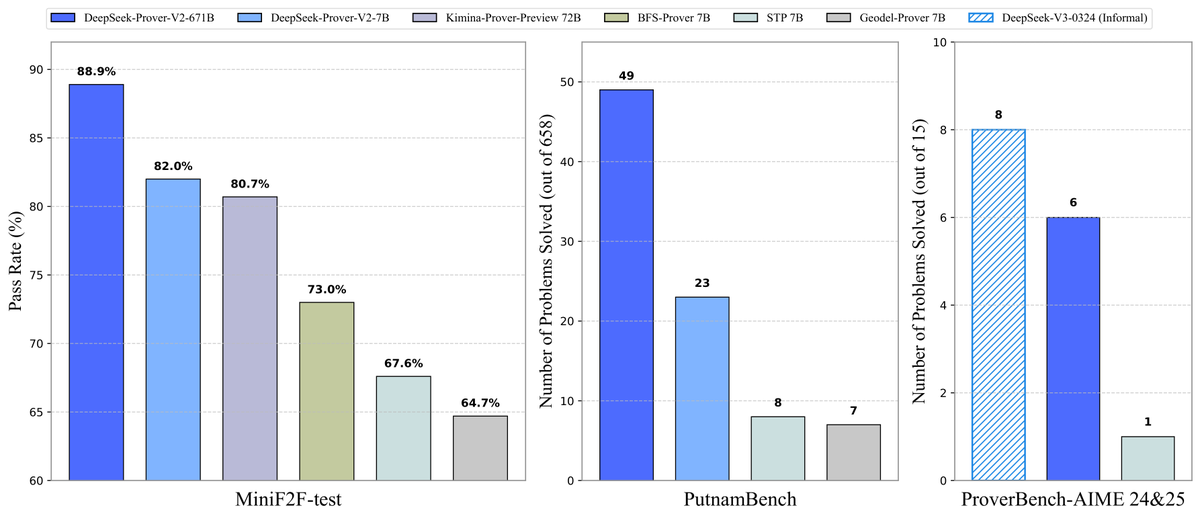
DeepSeek открыла исходный код модели для доказательства теорем Prover-V2: DeepSeek выпустила опенсорсную большую модель DeepSeek-Prover-V2, специально разработанную для формального доказательства теорем в Lean 4, доступную в двух размерах: 7B и 671B. Модель использует DeepSeek-V3 для рекурсивной декомпозиции подцелей для генерации датасета холодного старта и оптимизирована с помощью обучения с подкреплением (GRPO). Она достигла 88.9% прохождения на MiniF2F-test и показала SOTA или значительную производительность на бенчмарках, таких как PutnamBench и AIME 24/25. Также был открыт датасет ProverBench, включающий задачи конкурса AIME, и руководство по запуску, способствуя развитию формального математического мышления. (Источник: karminski3, op7418, TheRundownAI, op7418)
OpenAI откатила обновление GPT-4o для исправления проблемы “чрезмерной угодливости”: CEO OpenAI Сэм Альтман подтвердил, что из-за многочисленных отзывов пользователей, указывающих на то, что последняя версия GPT-4o демонстрирует чрезмерное угождение и отсутствие собственного мнения (“sycophancy/glazing”), компания начала откат этого обновления вечером в понедельник. Откат для бесплатных пользователей завершен, платные пользователи получат обновление позже. Команда вносит дополнительные исправления и планирует в ближайшие дни поделиться дополнительной информацией о личности модели. Этот инцидент вызвал широкое обсуждение баланса между методами обучения RLHF, целями выравнивания модели и ожиданиями пользователей. (Источник: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen выпустила серию моделей Qwen3: Alibaba выпустила и открыла исходный код нового поколения моделей Tongyi Qianwen Qwen3, включающего 8 моделей типа Mixture-of-Experts (MoE) с параметрами от 0.6B до 235B. Qwen3 демонстрирует превосходные результаты в логическом выводе, коде, математике, многоязычности (поддерживает 119 языков) и вызове инструментов (улучшенная поддержка MCP), при этом модель 32B превосходит OpenAI o1 и DeepSeek R1, а модель 235B обновляет рекорды опенсорса на многих бенчмарках. Модели Qwen3 уже доступны в приложении Tongyi App и на веб-сайте tongyi.com, пользователи могут оценить их мощные возможности генерации кода, логического мышления и творческого письма. (Источник: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 Тренды
Inception Labs запустила первый коммерческий API для Diffusion LLM: Inception Labs выпустила публичную бета-версию своего API, предоставляя первый коммерческий сервис Diffusion Large Language Models (dLLMs). Их модель Mercury Coder использует метод генерации текста “от грубого к точному”, аналогичный генерации изображений, что позволяет параллельно генерировать выходные токены, достигая тем самым более высокой пропускной способности (в тестах скорость превышает в 5 раз) по сравнению с традиционными авторегрессионными LLM. Эта архитектура конкурирует по скорости и качеству с GPT-4o mini и Claude 3.5 Haiku, знаменуя новый прогресс в диверсификации архитектур LLM. (Источник: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon представила модель Amazon Nova Premier: Amazon Science запустила на платформе Amazon Bedrock свою самую мощную учительскую модель Amazon Nova Premier. Эта модель специально разработана для сложных задач (таких как RAG, вызов функций, Agentic кодирование), имеет контекстное окно в миллион токенов, способна анализировать большие наборы данных и является наиболее экономически эффективной проприетарной моделью в своем классе интеллекта. Цель этого шага — предоставить пользователям мощную основу для создания кастомизированных дистиллированных моделей. (Источник: bookwormengr)
Together AI добавила поддержку файнтюнинга DPO: Платформа Together AI теперь поддерживает Direct Preference Optimization (DPO) для файнтюнинга моделей. DPO — это техника для настройки модели на основе данных о предпочтениях человека без явной модели вознаграждения. Эта функция позволяет пользователям создавать кастомизированные модели, которые постоянно адаптируются к потребностям пользователей, улучшая возможности выравнивания модели. Платформа также предоставляет подробные статьи в блоге и примеры кода по DPO. (Источник: stanfordnlp, stanfordnlp)
Новые достижения в теории информации диффузионных моделей: Исследователи из Амстердамского университета и других институтов обнаружили, что уменьшение энтропии, вызванное предсказаниями диффузионных моделей, равно масштабированной версии функции потерь. Это открытие открывает возможность введения временного искажения (time warping), аналогичного работе CDCD для перекрестной энтропии классификации, в гауссовские диффузионные модели, предлагая концепцию времени, зависящую от данных и основанную на условной энтропии, что потенциально может оптимизировать расписание обучения диффузионных моделей. (Источник: sedielem)

Техпроцесс Intel 18A вошел в стадию рискового производства, 14A скоро появится: На конференции Intel Foundry CEO Пэт Гелсингер объявил, что техпроцесс Intel 18A вошел в стадию рискового производства и будет запущен в массовое производство в течение года. В то же время Intel предоставила основным клиентам раннюю версию PDK Intel 14A, который будет использовать технологию прямой подачи питания PowerDirect. Кроме того, были представлены эволюционные версии, такие как Intel 18A-P, 18A-PT, а также передовые технологии корпусирования, такие как Foveros Direct и EMIB-T. Было объявлено о сотрудничестве с Amkor Technology для укрепления возможностей системного литейного производства и удовлетворения потребностей в высокопроизводительных вычислениях, таких как AI. (Источник: WeChat)
AI-студии развлечений ускоряют консолидацию через слияния и поглощения: В последнее время в сфере AI-развлечений наблюдается тенденция к консолидации. Голливудская платформа анализа данных AI Cinelytic приобрела разработчика инструментов управления интеллектуальной собственностью AI Jumpcut Media с целью расширения своих возможностей анализа сценариев с помощью AI, интеграции инструментов, таких как ScriptSense, и повышения эффективности принятия решений по контенту. В то же время, основанная в прошлом году AI-студия развлечений Promise приобрела AI-киношколу Curious Refuge с намерением создать канал для подготовки талантов, владеющих генеративным AI, и ускорить применение AI в производстве кино и телевидения. (Источник: 36氪)

Duolingo объявляет о полной стратегии AI First: CEO Duolingo в письме ко всем сотрудникам объявил, что компания полностью переходит на стратегию AI First, считая внедрение AI неотложным. Компания будет постепенно заменять ручной аутсорсинг, где это возможно, с помощью AI, строго контролировать рост персонала и отдавать приоритет решениям по автоматизации с помощью AI. AI будет внедрен в процессы найма, оценки производительности и другие области с целью повышения эффективности, позволяя сотрудникам-людям сосредоточиться на творческой работе. Этот шаг основан на значительном росте пользователей и доходов Duolingo за последние годы, достигнутом благодаря использованию AI (особенно в сотрудничестве с OpenAI). (Источник: WeChat)

🧰 Инструменты
Meta открыла исходный код инструмента llama-prompt-ops: На LlamaCon Meta выпустила Python-пакет llama-prompt-ops, основанный на оптимизаторах DSPy и MIPROv2. Этот инструмент может преобразовывать промпты, подходящие для других LLM, в промпты, оптимизированные для моделей Llama, и продемонстрировал значительное повышение производительности на нескольких задачах. Цель этого шага — помочь пользователям удобнее переносить и оптимизировать свои приложения на моделях Llama. (Источник: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud выпустила Agent Starter Pack: Google Cloud Platform открыла исходный код Agent Starter Pack, набора готовых к продакшену шаблонов GenAI Agent (таких как ReAct, RAG, мультиагентные системы, API реального времени для мультимодальности). Он предназначен для ускорения разработки и развертывания GenAI Agent путем предоставления комплексных решений, решения общих проблем, таких как эксплуатация и обслуживание развертывания, оценка, кастомизация и наблюдаемость, с поддержкой развертывания в Cloud Run и Agent Engine. (Источник: GitHub Trending)

Выпущен фреймворк CUA: Docker-контейнер для управления ОС с помощью AI Agent: trycua открыла исходный код фреймворка CUA (Computer-Use Agent), решения AI Agent, которое может управлять полноценной операционной системой внутри высокопроизводительного, легковесного виртуального контейнера. Он использует Virtualization.Framework от Apple Silicon для обеспечения производительности виртуальных машин macOS/Linux, близкой к нативной (до 97%), и предоставляет интерфейсы для AI-систем для наблюдения и управления этими средами, выполнения сложных рабочих процессов, таких как взаимодействие с приложениями, веб-серфинг, кодирование, при этом обеспечивая безопасную изоляцию. (Источник: GitHub Trending)
Платформа Modal Labs добавила поддержку JavaScript и Go: Облачная платформа Modal Labs объявила, что ее среда выполнения (написанная на Rust) теперь поддерживает SDK для JavaScript (Node/Deno/Bun) и Go. Разработчики теперь могут использовать эти языки для вызова бессерверных функций GPU, запуска безопасных виртуальных машин для недоверенного кода, расширяя сценарии применения Modal за пределы науки о данных/машинного обучения. (Источник: akshat_b, HamelHusain)
Kling AI представила новые спецэффекты: Модель генерации видео Kling AI от Kuaishou добавила новые интерактивные спецэффекты. Пользователи могут загрузить фотографию с двумя людьми, а затем применить эффекты “поцелуй”, “объятие”, “сердечко” или даже “драка”, чтобы сгенерировать динамическое видео, повышая интерес и интерактивность генерации портретных видео. (Источник: Kling_ai)
NotebookLM добавил функцию многоязычного аудио-обзора: Инструмент для заметок с AI от Google NotebookLM представил функцию Audio Overviews, которая может генерировать аудио-резюме в стиле подкастов из загруженных пользователем документов, заметок и других материалов. Эта функция теперь поддерживает более 50 языков по всему миру, включая русский. Даже если исходные материалы пользователя смешаны на нескольких языках, можно сгенерировать аудио-резюме на нужном языке, что позволяет пользователям удобно изучать и понимать информацию на слух в любое время и в любом месте. (Источник: WeChat)
PaperCoder: Автоматическое преобразование статей по машинному обучению в код: Исследователи из Корейского института передовых технологий (KAIST) открыли исходный код PaperCoder, мультиагентной системы LLM, предназначенной для автоматического преобразования методов и экспериментов из статей по машинному обучению в работающие репозитории кода. Система работает в три этапа: планирование, анализ и генерация кода, где специализированные агенты обрабатывают разные задачи. Исследования показывают, что качество генерируемого кода превосходит существующие бенчмарки и получило одобрение 77% авторов оригинальных статей, что может решить проблему сложности воспроизведения кода из статей. (Источник: WeChat)

Cactus: Легковесный фреймворк AI для устройств: Cactus — это легковесный, высокопроизводительный фреймворк для запуска AI-моделей на мобильных устройствах. Он предоставляет унифицированный, согласованный API для React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++) и Flutter/Dart, облегчая разработчикам развертывание и запуск AI-моделей на различных мобильных платформах. (Источник: Reddit r/deeplearning)
Muyan-TTS: Опенсорсная настраиваемая TTS-модель с низкой задержкой: Команда ChatPods открыла исходный код Muyan-TTS, модели преобразования текста в речь (TTS) с низкой задержкой и высокой степенью настраиваемости. Модель призвана решить проблемы существующего опенсорсного TTS, связанные с низким качеством или недостаточной открытостью, предоставляя полные веса модели, скрипты обучения и процесс обработки данных. Включает базовую модель (для zero-shot TTS) и SFT-модель (для клонирования голоса), хорошо поддерживает английский язык и поощряет сообщество к вторичной разработке и расширению на основе ее фреймворка. (Источник: Reddit r/deeplearning)
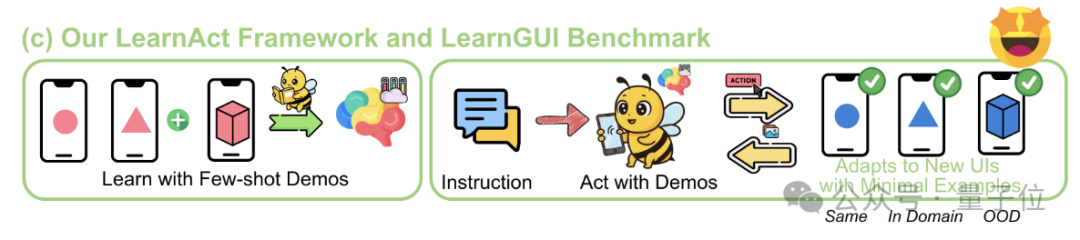
Фреймворк LearnAct: AI на телефоне учится сложным операциям всего за одну демонстрацию: Чжэцзянский университет совместно с vivo AI Lab предложили мультиагентный фреймворк LearnAct и бенчмарк LearnGUI, направленные на то, чтобы позволить агенту GUI на телефоне научиться выполнять сложные, персонализированные задачи длинного хвоста с помощью небольшого количества (даже одной) демонстраций пользователя. LearnAct включает трех агентов: DemoParser (анализ демонстрации), KnowSeeker (поиск знаний), ActExecutor (выполнение действий). Эксперименты показывают, что этот метод может значительно повысить успешность выполнения задач моделью в невиданных ранее сценариях, например, повысив точность Gemini-1.5-Pro с 19.3% до 51.7%. (Источник: WeChat)
📚 Обучение
Глубокий обзор технологий пост-тренировки LLM: Исследователи из MBZUAI, Google DeepMind и других институтов опубликовали всесторонний обзор технологий пост-тренировки LLM. В отчете подробно рассматриваются различные методы улучшения способностей LLM к логическому выводу, выравнивания с намерениями человека и повышения надежности с помощью обучения с подкреплением (RLHF, RLAIF, DPO, GRPO и др.), контролируемого файнтюнинга (SFT), расширения во время тестирования (CoT, ToT, GoT, декодирование с самосогласованием и др.). Отчет также охватывает моделирование вознаграждения, параметроэффективный файнтюнинг (PEFT), стратегии масштабирования моделей и соответствующие бенчмарки для оценки, а также указывает на будущие направления исследований. (Источник: WeChat)
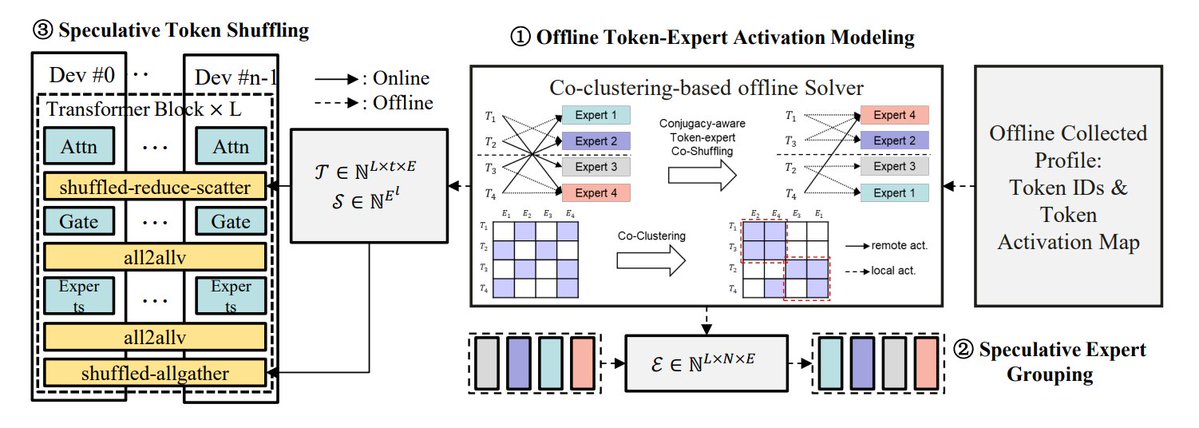
Обзор методов оптимизации инференса MoE: TheTuringPost обобщил 5 методов оптимизации инференса моделей MoE: eMoE (прогнозирование и предварительная загрузка экспертов), MoEShard (шардинг экспертов по разным GPU), DeepSpeed-MoE (комбинация различных техник для крупномасштабной обработки), Speculative-MoE (прогнозирование путей маршрутизации и группировка экспертов), MoE-Gen (пакетная обработка на основе модулей). В статье также упоминаются продвинутые методы, такие как Structural MoE и Symbolic-MoE, направленные на повышение эффективности и пропускной способности инференса моделей MoE. (Источник: TheTuringPost)
Взгляд на статью End-To-End Memory Networks десятилетней давности: Исследователь Meta Сайнбаяр Сухбаатар вспоминает свою статью 2015 года “End-To-End Memory Networks”, написанную в соавторстве. Эта статья была одной из первых языковых моделей, полностью заменивших RNN механизмом внимания, представив такие концепции, как точечное произведение мягкого внимания с проекцией ключ-значение, многослойное стекирование внимания и позиционные вложения (тогда называвшиеся временными вложениями) — все это ключевые элементы современных LLM. Хотя ее влияние было не таким значительным, как у “Attention is all you need”, она объединила идеи Memory Networks и раннего мягкого внимания, продемонстрировав потенциал многослойного мягкого внимания для логического вывода. (Источник: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona — новый эффективный метод визуального файнтюнинга: Университет Цинхуа, Университет Китайской академии наук и другие учреждения предложили Mona (Multi-cognitive Visual Adapter), новый метод файнтюнинга с визуальным адаптером. Путем введения мультикогнитивных визуальных фильтров (глубинно-разделимая свертка + многомасштабные ядра) и оптимизации распределения входных данных (Scaled LayerNorm), Mona настраивает менее 5% параметров базовой сети, превосходя по производительности полный файнтюнинг на нескольких задачах компьютерного зрения, таких как сегментация экземпляров и детекция объектов, при этом значительно снижая вычислительные и затраты на хранение. Этот метод предлагает новый подход к эффективному PEFT для визуальных моделей. (Источник: WeChat)

ICLR 2025 Oral: DIFF Transformer — дифференциальное внимание улучшает моделирование длинных текстов: Microsoft и Университет Цинхуа предложили DIFF Transformer, который вводит механизм дифференциального внимания (вычисление разницы между двумя наборами карт внимания Softmax) для усиления ключевых контекстных сигналов и устранения шума. Эксперименты показывают, что DIFF Transformer более масштабируем в языковом моделировании (достигает эквивалентной производительности при ~65% параметров/данных), значительно превосходит традиционный Transformer в моделировании длинных текстов, извлечении ключевой информации, обучении в контексте, борьбе с состязательными галлюцинациями и математическом мышлении, а также уменьшает выбросы активаций, что полезно для квантования. (Источник: WeChat)

MARFT: Новая парадигма мультиагентного файнтюнинга с подкреплением: Шанхайский университет Цзяотун и другие учреждения предложили MARFT (Multi-Agent Reinforcement Fine-Tuning), новую парадигму файнтюнинга с подкреплением, подходящую для мультиагентных систем на базе LLM (LaMAS). Этот метод решает проблемы оптимизации, связанные с динамичностью LaMAS, с помощью декомпозиции значения преимущества для нескольких агентов и моделирования последовательных решений, подобного Transformer. Предварительные эксперименты показывают, что LaMAS, дообученные с помощью MARFT, превосходят по производительности на математических задачах не дообученные системы и одноагентный PPO. Исследователи также обсуждают его потенциал и проблемы в решении сложных задач, масштабируемости, защите конфиденциальности и интеграции с блокчейном. (Источник: WeChat)

Всесторонний обзор протоколов AI-агентов: Шанхайский университет Цзяотун в сотрудничестве с сообществом ANP опубликовал первый обзор протоколов AI-агентов. В статье предлагается двумерная классификационная структура: объектно-ориентированная (контекстно-ориентированная vs. межагентная) и по сценариям применения (общая vs. доменно-специфическая), систематизирующая более десяти основных протоколов, таких как MCP, A2A, ANP, AITP, LMOS. Проводится оценка по семи измерениям (эффективность, масштабируемость, безопасность, надежность, расширяемость, управляемость, интероперабельность) и сравниваются четыре архитектуры (MCP, A2A, ANP, Agora) на примере планирования путешествия. Наконец, рассматривается будущее развитие протоколов: от статических к эволюционирующим, от правил к экосистемам, от протоколов к интеллектуальной инфраструктуре. (Источник: WeChat)

Глубокий обзор протокола MCP: архитектура, экосистема и риски безопасности: Новая обзорная статья подробно рассматривает архитектуру протокола контекста модели (MCP), состояние экосистемы и потенциальные риски безопасности. В статье анализируется тройственная структура MCP Host, Client, Server и их механизмы взаимодействия, описывается прогресс компаний и сообществ, таких как Anthropic, OpenAI, Cursor, Replit, в использовании MCP, и акцентируется внимание на уязвимостях безопасности, существующих в жизненном цикле MCP Server (создание, запуск, обновление), таких как конфликты имен, обман установщика, инъекция кода, конфликты имен инструментов, побег из песочницы, персистентность разрешений и другие проблемы. (Источник: WeChat)

CVPR Oral: UniAP — унифицированный алгоритм автоматического параллелизма внутри и между слоями: Исследовательская группа профессора Ли Уцзюня из Нанкинского университета предложила UniAP, алгоритм распределенного обучения, который может совместно оптимизировать стратегии параллелизма внутри слоя (данные/тензор/ZeRO) и между слоями (конвейер). Моделируя задачу с помощью смешанно-целочисленного квадратичного программирования, UniAP может автоматически находить эффективные схемы распределенного обучения, решая проблему сложности и низкой эффективности ручной настройки. Эксперименты показывают, что UniAP до 3.8 раз быстрее существующих методов автоматического параллелизма и до 9 раз быстрее неоптимизированных стратегий, а также эффективно избегает 64%-87% недействительных (OOM) стратегий, повышая удобство использования. Алгоритм адаптирован для отечественных AI-вычислительных карт. (Источник: WeChat)
Tina: Малые модели с высокой способностью к логическому выводу при низкой стоимости с помощью LoRA: Команда из Университета Южной Калифорнии предложила серию моделей Tina (Tiny Reasoning Models via LoRA). Используя LoRA для пост-тренировки с обучением с подкреплением на базе модели DeepSeek-R1-Distill-Qwen с 1.5 млрд параметров, модели Tina достигли производительности, сравнимой или даже превосходящей базовые модели с полным файнтюнингом на нескольких бенчмарках логического вывода (AIME, AMC, MATH, GPQA, Minerva), при этом стоимость обучения чрезвычайно низка (стоимость лучшей контрольной точки всего 9 долларов). Исследование выявило преимущества LoRA в эффективном изучении формата/структуры логического вывода и наблюдало явление разделения метрик формата и метрик точности в процессе обучения. (Источник: WeChat)
Оптимизация рекурсивной дивергенции KL: новый эффективный метод обучения моделей: Новая статья предлагает метод оптимизации рекурсивной дивергенции KL (Recursive KL Divergence Optimization), который, как утверждается, может достичь повышения эффективности обучения моделей (особенно файнтюнинга) до 80%. Этот метод, возможно, позволяет более оптимально ограничивать обновления модели, сокращая необходимые вычислительные ресурсы или время для обучения, предоставляя новый путь для более экономичного и быстрого обучения и файнтюнинга моделей. (Источник: Reddit r/LocalLLaMA)
💼 Бизнес
Sakana AI стремится использовать неопределенность политики США для развития в Японии: Японский AI-стартап Sakana AI считает, что неопределенность политики США и спрос на отечественные AI-решения (особенно в правительстве и финансовых учреждениях) предоставляют ему возможности для развития в Японии. Менеджер по развитию бизнеса компании заявил, что в ближайшие 6 месяцев ожидается 5-10 потребительских кейсов от правительства и финансовых учреждений. CEO Дэвид Ха отметил, что в условиях ужесточения геополитической обстановки возрастает потребность демократических стран в обновлении правительственной и оборонной инфраструктуры, и фокус компании на оборонных приложениях (таких как риски биобезопасности и отслеживание дезинформации) имеет решающее значение. (Источник: SakanaAILabs, SakanaAILabs)
Meta прогнозирует доход от генеративного AI в $1.4 трлн к 2035 году: Компания Meta прогнозирует, что ее бизнес в области генеративного AI принесет $3 млрд дохода в 2025 году и ожидает, что к 2035 году эта цифра вырастет до $1.4 трлн. Этот прогноз свидетельствует о чрезвычайно оптимистичном взгляде Meta на долгосрочный потенциал роста в области AI и, вероятно, компания продолжит поддерживать высокие капитальные затраты на исследования и разработки в области AI и инфраструктуру. (Источник: brickroad7)

Alimama выпустила большую модель мировых знаний URM: Alimama представила большую языковую модель URM (Universal Recommendation Model), объединяющую мировые знания и знания в области электронной коммерции. Модель способна понимать исторические интересы пользователей и делать рекомендательные выводы с помощью инъекции знаний (ID товаров как специальные токены) и выравнивания информации (слияние ID с мультимодальными семантическими представлениями). URM использует метод генерации Sequence-In-Set-Out, параллельно генерируя несколько представлений пользователя для повышения эффективности и разнообразия, сохраняя при этом эффективность инференса. Модель уже запущена в сценариях медийной рекламы Alimama и решает проблему задержки LLM с помощью асинхронного конвейера инференса, повышая эффективность размещения рекламы для продавцов и улучшая покупательский опыт пользователей. (Источник: WeChat)

🌟 Сообщество
Завершение эры GPT-4 вызывает ностальгию и дискуссии: Сэм Альтман попрощался с GPT-4, заявив, что модель начала революцию, и ее веса будут сохранены для будущих историков. Этот шаг вызвал широкую ностальгию в сообществе, многие вспоминали GPT-4 как первую модель, которая заставила их почувствовать потенциал AGI. В то же время это вызвало дискуссии об открытом исходном коде: члены сообщества, такие как Hugging Face, призвали OpenAI открыть веса GPT-4 для исследований, а не просто заархивировать их. (Источник: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
Наблюдения и обсуждения в сфере AI Coding: Основатель GruAI Чжан Хайлун считает, что AI Coding — одна из немногих областей, где сейчас виден PMF (Product-Market Fit). Успех Cursor заключается в создании нового рынка, его UI имеет огромную ценность. Он считает, что направление Devin правильное, но слишком амбициозное и требует много времени, однако вероятность успеха растет, и в конечном итоге он будет конкурировать с Cursor. Что касается стартапов, он считает, что не стоит слишком беспокоиться о конкуренции со стороны крупных компаний, главное — это сила продукта и уникальная ценность. Прогресс моделей значительно снижает необходимость инженерной компенсации, предпринимателям нужно различать, какие проблемы будут решены развитием моделей, а что является настоящей силой продукта. (Источник: WeChat)

Размышления о фразе “AI заменит вашу работу”: В сообществе отмечается, что фраза “AI не заменит вашу работу, но люди, использующие AI, заменят” хотя и верна на поверхности, но слишком упрощена и является “театром консенсуса”, мешающим задуматься о более глубоких проблемах. Настоящий ключ — в понимании того, как AI меняет структуру работы, перестраивает рабочие процессы, изменяет организационную логику, и каким будет будущее работы в новой системе, а не просто в фокусировке на автоматизации или усилении отдельных задач. (Источник: Reddit r/ArtificialInteligence)

AI-агенты и новый вход для взаимодействия с физическим миром: камера: Обсуждается, что функции, подобные “сфотографируй и спроси” в браузере Quark, представляют новую тенденцию взаимодействия с AI-приложениями. Через камеру телефона — распространенный сенсор — в сочетании с мультимодальным пониманием и возможностями Agent, AI может лучше понимать физический мир и, основываясь на неявных или явных потребностях пользователя, самостоятельно принимать решения и вызывать возможности для выполнения задач (например, распознавание объектов, перевод, сравнение цен, помощь с домашним заданием, обработка счетов и т.д.). Это превращает камеру из простого инструмента ввода информации в узел, соединяющий физический мир с цифровым интеллектом и реализующий принцип “Get it Done”. (Источник: WeChat)
💡 Другое
AI и научные исследования: В сообществе высказывается мнение, что AI постепенно становится новой “математикой” для научных исследований, подразумевая, что AI, подобно математике, станет фундаментальным инструментом и языком для продвижения научных открытий и понимания. (Источник: shuchaobi)

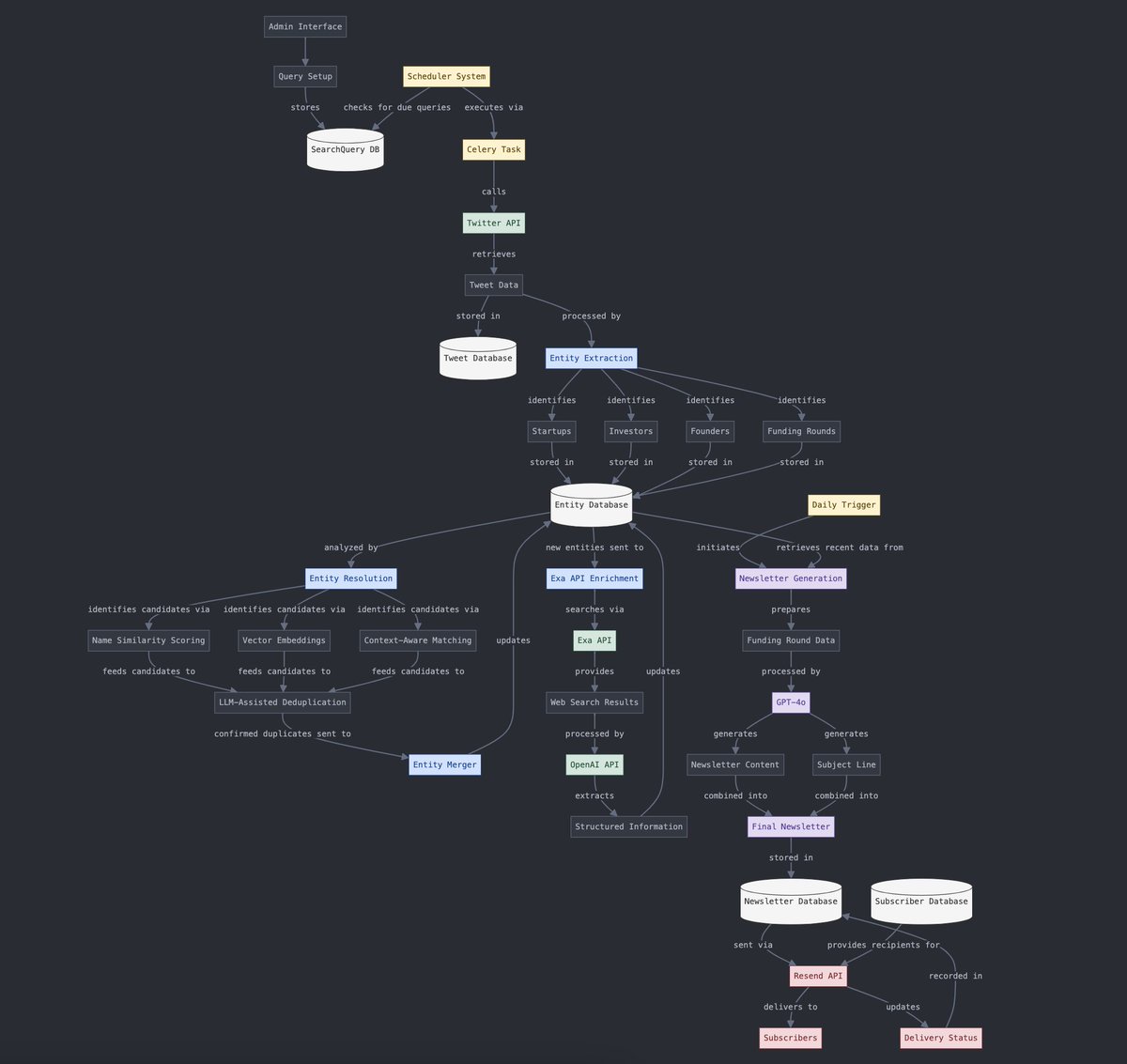
Преобразование структурированных и неструктурированных данных: Yohei Nakajima демонстрирует использование AI для преобразования неструктурированных данных из твитов в структурированные данные, чтобы затем снова преобразовать их в неструктурированную ежедневную рассылку, что отражает применение AI в процессах обработки информации и генерации контента. (Источник: yoheinakajima)
Будущее сочетания AI и VR: В сообществе обсуждается потенциал сочетания AI и VR, представляя будущее, где можно будет с помощью естественного языка или мысленных команд напрямую генерировать и манипулировать 3D-объектами в “пространстве белой доски” VR, реализуя когнитивно-управляемое творчество. Meta рассматривается как ключевой игрок, продвигающий это направление. (Источник: Reddit r/ArtificialInteligence)