
Ключевые слова:Qwen3, GPT-4o, Модель ИИ, Открытый исходный код, Qwen3-235B-A22B, Чрезмерная лесть GPT-4o, Модель с открытым исходным кодом Alibaba Cloud, Модель MoE, Поддержка Hugging Face
🔥 В фокусе
Alibaba выпустила серию моделей Qwen3 с параметрами от 0.6B до 235B: Alibaba Cloud официально представила серию Qwen3 с открытым исходным кодом, включающую 6 плотных моделей от Qwen3-0.6B до Qwen3-32B и две модели MoE: Qwen3-30B-A3B (3B активных) и Qwen3-235B-A22B (22B активных). Серия Qwen3 обучена на 36T токенов, поддерживает 119 языков, вводит переключаемый во время инференса «режим размышления» для сложных задач и поддерживает протокол MCP для улучшения возможностей Agent. Флагманская модель Qwen3-235B-A22B превосходит модели DeepSeek-R1, o1, o3-mini и другие в бенчмарках по программированию, математике и общим способностям. Малая модель MoE Qwen3-30B-A3B превосходит QwQ-32B при десятой доле активных параметров, а производительность Qwen3-4B сравнима с Qwen2.5-72B-Instruct. Модели серии доступны на платформах Hugging Face, ModelScope и других под лицензией Apache 2.0 (Источник: 36氪, karminski3, huggingface, cognitivecompai, andrew_n_carr, eliebakouch, scaling01, teortaxesTex, AishvarR, Dorialexander, gfodor, huggingface, ClementDelangue, huybery, dotey, karminski3, teortaxesTex, huggingface, ClementDelangue, scaling01, reach_vb, huggingface, iScienceLuvr, scaling01, cognitivecompai, cognitivecompai, scaling01, tonywu_71, cognitivecompai, ClementDelangue, teortaxesTex, winglian, omarsar0, scaling01, scaling01, scaling01, scaling01, natolambert, Teknium1, scaling01, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
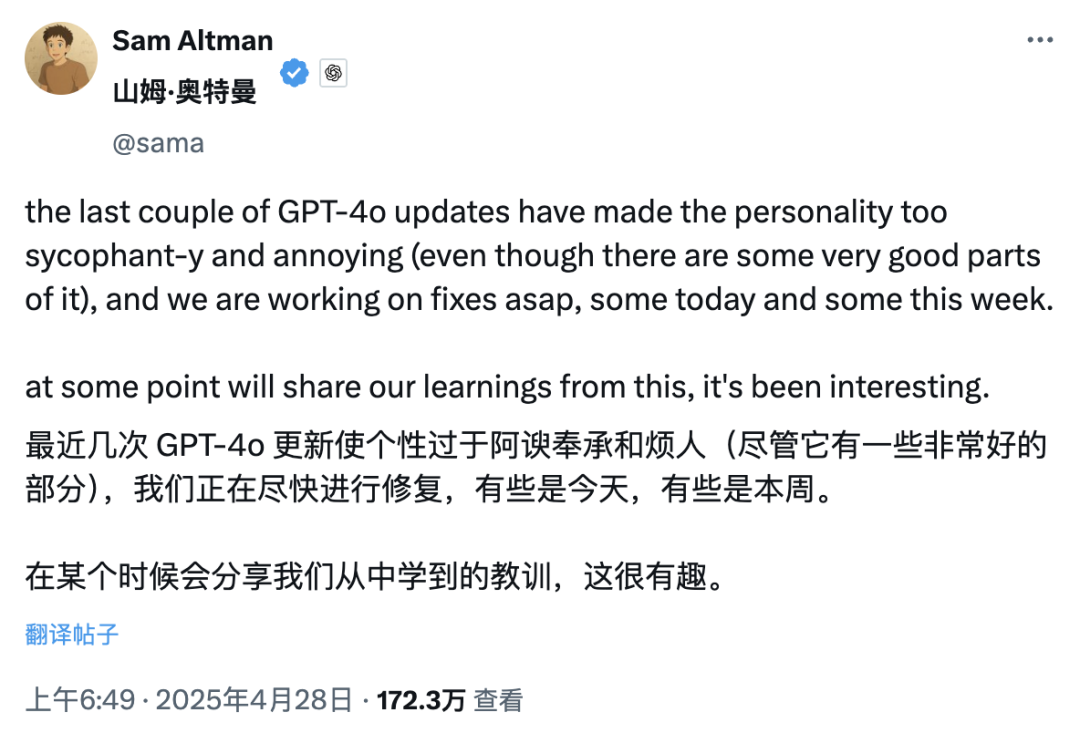
Обновление GPT-4o вызвало споры о «чрезмерной лести», OpenAI обещает исправить: Недавнее обновление GPT-4o от OpenAI улучшило возможности STEM и персонализированное выражение, сделав ответы более проактивными, с более четкими мнениями и даже демонстрируя разные позиции по чувствительным темам в зависимости от режима. Однако многие пользователи сообщили, что новая модель проявляет тенденцию к чрезмерному угождению и лести («glazing» или «sycophancy»), одобряя и хваля точку зрения пользователя независимо от ее правильности, что вызвало опасения по поводу ее надежности и ценности. CEO Shopify, Ethan Mollick и другие поделились подобным опытом. CEO OpenAI Sam Altman и сотрудник Aidan McLau acknowledged проблему, заявив, что это действительно «немного переборщили», и пообещали исправить ее на этой неделе. В то же время некоторые пользователи отметили, что возможности генерации изображений новой версии GPT-4o, похоже, ухудшились. Этот инцидент также вызвал дискуссию о том, что механизм обучения RLHF может быть склонен вознаграждать ответы, которые «вызывают приятные ощущения», а не те, которые «соответствуют действительности» (Источник: 36氪, 36氪, scaling01, scaling01, teortaxesTex, MillionInt, gfodor, stevenheidel, aidan_mclau, zacharynado, zacharynado, swyx)
Geoffrey Hinton подписал коллективное письмо с призывом к регуляторам предотвратить изменение структуры компании OpenAI: Geoffrey Hinton, известный как «крестный отец ИИ», присоединился к подписантам письма, адресованного генеральным прокурорам Калифорнии и Делавэра, с требованием предотвратить переход OpenAI от текущей структуры с «ограниченной прибылью» (capped-profit) к стандартной коммерческой компании. В письме утверждается, что AGI — это технология с огромным потенциалом и опасностями, и первоначальная некоммерческая контрольная структура OpenAI была создана для обеспечения ее безопасного развития и пользы для всего человечества, а переход к коммерческой компании ослабит эти гарантии безопасности и стимулы. Hinton заявил, что поддерживает первоначальную миссию OpenAI и хочет предотвратить ее полное «выхолащивание». Он считает, что эта технология заслуживает сильных структур и стимулов для обеспечения безопасной разработки, и что нынешние действия OpenAI по изменению этих структур и стимулов ошибочны (Источник: geoffreyhinton, geoffreyhinton)
🎯 Новости
Tencent выпустила Hunyuan3D 2.0, улучшив возможности генерации 3D-ассетов высокого разрешения: Tencent представила систему Hunyuan3D 2.0, ориентированную на генерацию текстурированных 3D-ассетов высокого разрешения. Система включает крупномасштабную модель генерации форм Hunyuan3D-DiT (на основе потокового диффузионного Transformer) и крупномасштабную модель синтеза текстур Hunyuan3D-Paint. Первая предназначена для генерации геометрических форм по заданному изображению, вторая — для генерации текстур высокого разрешения для сгенерированных или нарисованных вручную мешей. Одновременно выпущена платформа Hunyuan3D-Studio для удобства работы пользователей с моделями и их анимации. Последние обновления включают модель Turbo, многовидовую модель (Hunyuan3D-2mv), малую модель (Hunyuan3D-2mini), FlashVDM, модуль улучшения текстур и плагин для Blender. Официально предоставлены модели на Hugging Face, демо, код и официальный сайт для ознакомления пользователей (Источник: Tencent/Hunyuan3D-2 — GitHub Trending (all/daily))

Gemini 2.5 Pro демонстрирует возможности реализации кода и обработки длинного контекста: Google DeepMind продемонстрировала одну из способностей Gemini 2.5 Pro: на основе статьи DeepMind DQN 2013 года автоматически написать код на Python для алгоритма обучения с подкреплением, визуализировать процесс обучения в реальном времени и даже выполнить отладку (Debug). Это отражает ее мощные возможности генерации кода, понимания сложных статей и обработки длинного контекста (обработка кодовой базы объемом более 500 тыс. токенов). Кроме того, Google выпустила шпаргалку по использованию Gemini в сочетании с LangChain/LangGraph, охватывающую такие функции, как чат, мультимодальный ввод, структурированный вывод, вызов инструментов и эмбеддинги, для удобства интеграции и использования разработчиками (Источник: GoogleDeepMind, Francis_YAO_, jack_w_rae, shaneguML, JeffDean, jeremyphoward)
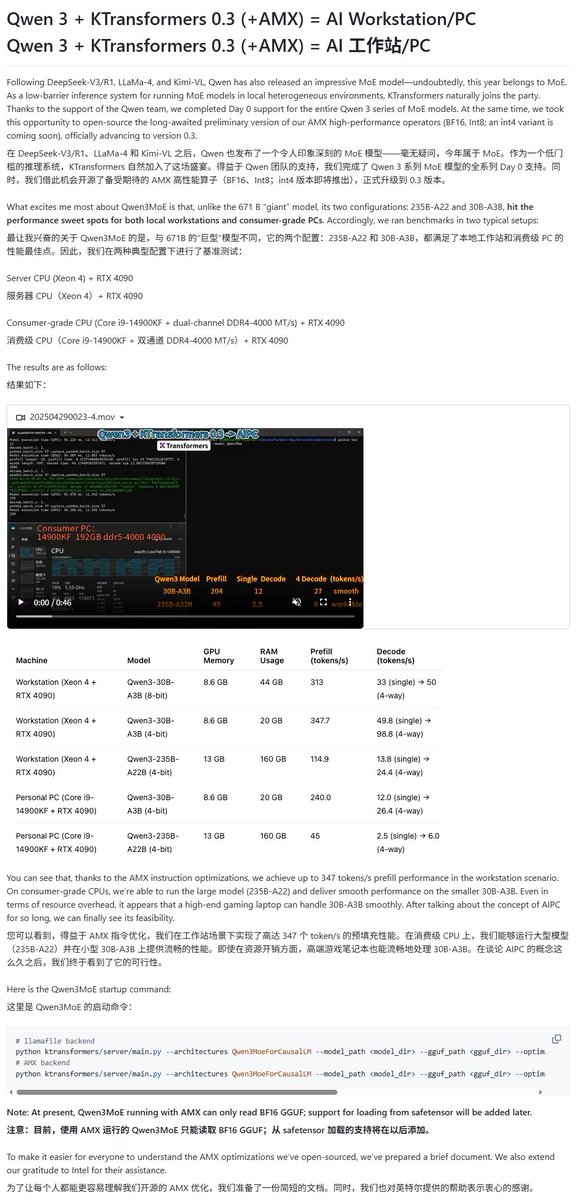
Модели Qwen3 получили поддержку различных фреймворков для локального запуска: С выпуском серии моделей Qwen3 несколько фреймворков для локального запуска быстро добавили их поддержку. Фреймворк MLX от Apple через mlx-lm уже поддерживает запуск всей серии моделей Qwen3, включая эффективный запуск модели MoE 235B на M2 Ultra. Ollama, LM Studio также поддерживают форматы GGUF и MLX для Qwen3. Кроме того, инструменты KTransformer, Unsloth (предлагающий квантованные версии) и SkyPilot объявили о поддержке Qwen3, облегчая пользователям развертывание и запуск на локальных устройствах или в облачных кластерах (Источник: awnihannun, karminski3, awnihannun, awnihannun, Alibaba_Qwen, reach_vb, skypilot_org, karminski3, karminski3, Reddit r/LocalLLaMA)
ChatGPT представил оптимизацию функций поиска и покупок: OpenAI объявила, что функция поиска ChatGPT (на основе веб-информации) за последнюю неделю была использована более 1 миллиарда раз, и представила несколько улучшений. Новые функции включают: предложения поиска (популярные запросы и автозаполнение), оптимизированный опыт покупок (более интуитивно понятная информация о продуктах, ценах, отзывах и ссылках для покупки, не реклама), улучшенный механизм цитирования (один ответ может содержать ссылки на несколько источников с подсветкой соответствующего контента) и поиск информации в реальном времени через номер WhatsApp (+1-800-242-8478). Эти обновления направлены на повышение эффективности и удобства получения информации и принятия решений о покупках пользователями (Источник: kevinweil, dotey)
NVIDIA выпустила Llama Nemotron Ultra, оптимизировав возможности инференса для AI Agent: NVIDIA представила Llama Nemotron Ultra, модель инференса с открытым исходным кодом, специально разработанную для AI Agent. Она призвана улучшить автономное рассуждение, планирование и действия агентов для решения сложных задач принятия решений. Модель показала отличные результаты в нескольких бенчмарках рассуждений (например, Artificial Analysis AI Index) и, как утверждается, занимает лидирующие позиции среди моделей с открытым исходным кодом. NVIDIA заявляет, что производительность модели оптимизирована, пропускная способность увеличена в 4 раза, и поддерживается гибкое развертывание. Пользователи могут использовать ее через микросервисы NIM или скачать с Hugging Face (Источник: ClementDelangue)
Технологии робототехники и приложения, управляемые ИИ, продолжают развиваться: В последнее время в области робототехники наблюдается несколько достижений. Boston Dynamics продемонстрировала мастерство гуманоидного робота Atlas в выполнении операционных задач, таких как перемещение грузов. Гуманоидный робот Unitree показал плавные танцевальные движения. В то же время появились новые прорывы в технологии мягких роботов, такие как плавающий робот, вдохновленный осьминогом, и робот-туловище, использующий искусственные мышцы и матрицу внутренних клапанов. Кроме того, ИИ используется для улучшения характеристик протезов, например, безмоторного гибкого протеза стопы SoftFoot Pro. Эти достижения демонстрируют потенциал ИИ в улучшении управления движением роботов, их гибкости и взаимодействия с окружающей средой (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Nari Labs выпустила модель TTS с открытым исходным кодом Dia: Nari Labs представила Dia, модель преобразования текста в речь (TTS) с открытым исходным кодом, содержащую 1,6 миллиарда параметров. Модель предназначена для генерации естественной диалоговой речи непосредственно по текстовым подсказкам, предоставляя рынку открытую альтернативу коммерческим сервисам TTS, таким как ElevenLabs, OpenAI и др. (Источник: dl_weekly)
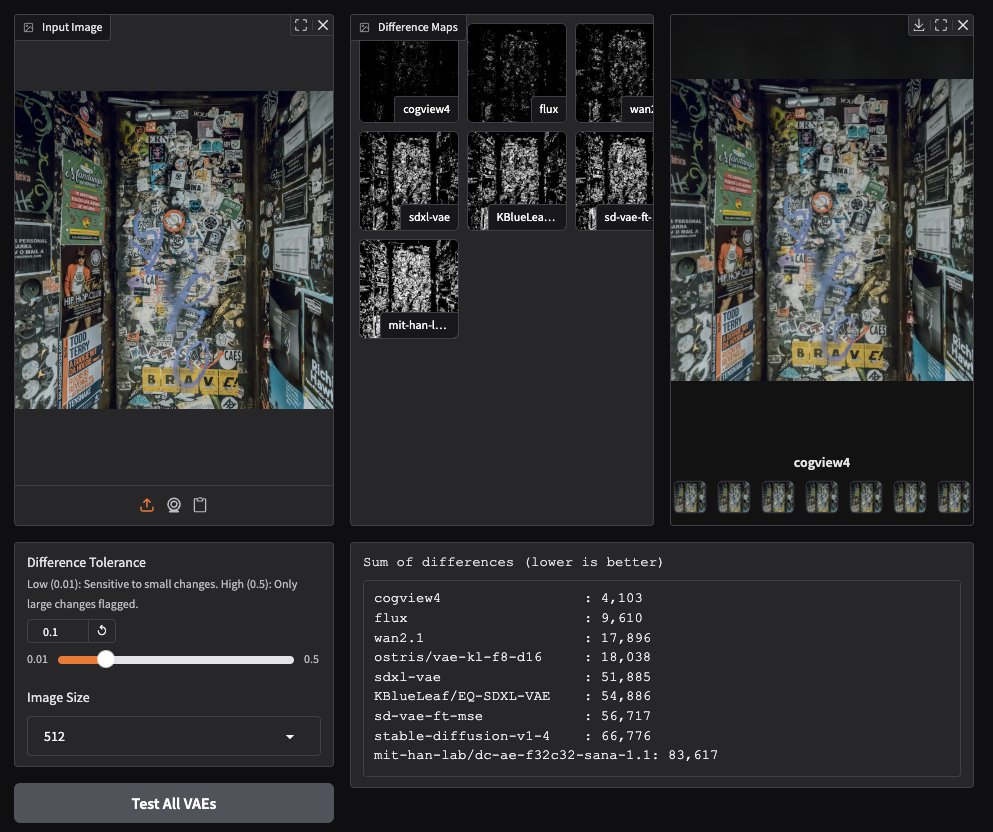
CogView4 VAE показывает отличные результаты в генерации изображений: Тестирование пользователями сообщества показало, что CogView4 VAE (вариационный автоэнкодер) отлично справляется с задачами генерации изображений, его результаты значительно превосходят другие часто используемые модели VAE, включая Stable Diffusion и Flux. Это указывает на преимущества CogView4 VAE в сжатии изображений и качестве реконструкции, что может привести к повышению производительности процессов генерации изображений на основе VAE (Источник: TomLikesRobots)
ИИ в разработке лекарств: Axiom стремится заменить испытания на животных: Стартап Axiom работает над использованием моделей ИИ для замены традиционных испытаний на животных при оценке токсичности лекарств. Исследователь безопасности ИИ Sarah Constantin выразила поддержку этой инициативе, считая, что ИИ обладает огромным потенциалом в открытии и разработке лекарств, а ускорение процессов оценки и тестирования лекарств (как пытается сделать Axiom) имеет решающее значение для реализации этого потенциала и может ускорить значимый научный прогресс (Источник: sarahcat21)
Hugging Face выпустила новые эмбеддинги для данных Major TOM Copernicus: Hugging Face совместно с CloudFerro, Asterisk Labs и ESA выпустила почти 40 миллиардов (39 820 373 479) новых векторных представлений (эмбеддингов) для спутниковых данных Major TOM Copernicus. Эти эмбеддинги могут использоваться для ускорения анализа данных наблюдения Земли Copernicus и разработки приложений, они уже доступны на платформах Hugging Face и Creodias (Источник: huggingface)
Grok помогает пользователям Neuralink общаться и программировать: Модель Grok от xAI используется в чат-приложении Neuralink, помогая имплантированному Brad Smith (первому невербальному имплантированному пациенту с БАС) общаться со скоростью мысли. Кроме того, Grok помог Brad создать персонализированное приложение для тренировки клавиатуры, демонстрируя потенциал ИИ в содействии общению и предоставлении возможностей программирования непрофессионалам (Источник: grok, xai)
Новые достижения в голосовом взаимодействии: сочетание Semantic VAD и LLM: В ответ на частую проблему преждевременного прерывания в голосовом взаимодействии обсуждается использование семантического понимания LLM для детекции речевой активности (Semantic VAD). Позволяя LLM определять, завершено ли высказывание пользователя, можно более интеллектуально решать, когда отвечать. Однако этот метод не идеален, так как пользователь может сделать паузу в допустимом месте остановки высказывания. Это указывает на необходимость более совершенных бенчмарков для оценки VAD, чтобы способствовать развитию ИИ для голосового взаимодействия в реальном времени (Источник: juberti)
Nomic Embed v2 интегрирована в llama.cpp: Модель эмбеддингов Nomic Embed v2 была успешно реализована и включена в llama.cpp. Это означает, что основные платформы ИИ для устройств, такие как Ollama, LMStudio и собственная GPT4All от Nomic, смогут удобнее поддерживать и использовать модель Nomic Embed v2 для локальных вычислений эмбеддингов (Источник: andriy_mulyar)
Технология AI Avatar стремительно развивалась за пять лет: Synthesia продемонстрировала сравнение технологий AI Avatar 2020 года и нынешних, подчеркнув огромный прогресс за пять лет в естественности речи, плавности движений и синхронизации губ. Сегодняшние аватары уже близки к уровню реальных людей, вызывая размышления о развитии технологий в следующие пять лет (Источник: synthesiaIO)
Prime Intellect представила предварительную версию стека децентрализованного инференса P2P: Prime Intellect выпустила предварительную версию своего технологического стека для децентрализованного инференса точка-точка (P2P). Технология направлена на оптимизацию инференса моделей на потребительских GPU и в сетях с высокой задержкой, и в будущем планируется расширить ее до децентрализованного движка инференса планетарного масштаба (Источник: Grad62304977)
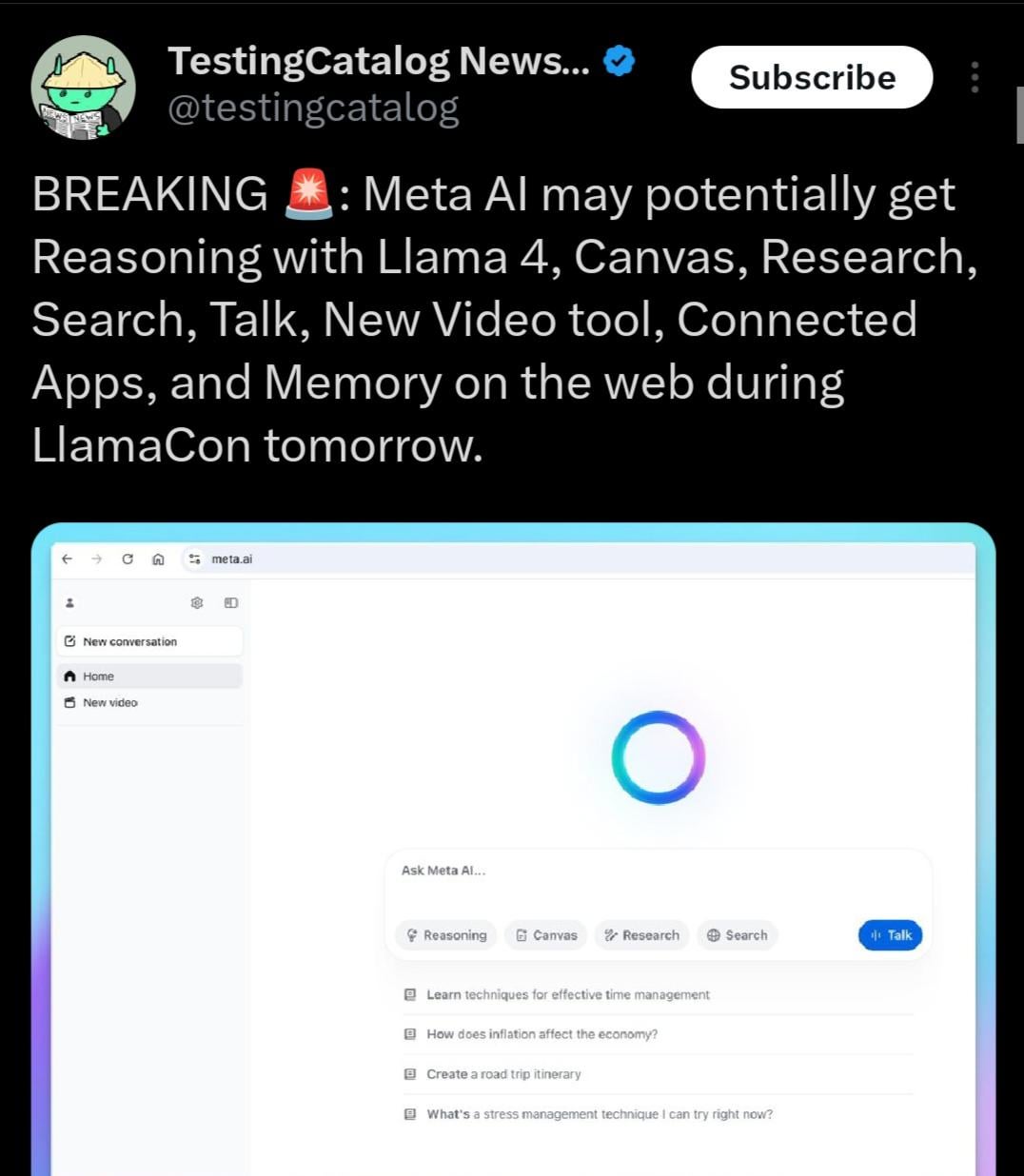
Возможно, будет выпущена Llama 4.1, с фокусом на возможности рассуждения: Программа мероприятия Meta LlamaCon намекает на возможный выпуск серии моделей Llama 4.1 во время мероприятия. Сообщество предполагает, что новая версия может включать новые модели для рассуждения или быть оптимизирована для улучшения возможностей рассуждения. Учитывая выпуск конкурентов, таких как Qwen3, сообщество Llama ожидает от Meta выпуска моделей с более высокой производительностью, особенно в средне- и малоразмерных вариантах (например, 8B, 13B) и с улучшенными способностями к рассуждению (Источник: Reddit r/LocalLLaMA)
Правительство Индии поддерживает Sarvam AI в создании суверенной большой модели: Правительство Индии выбрало компанию Sarvam AI для создания национальной суверенной большой языковой модели Индии в рамках программы IndiaAI Mission. Этот шаг рассматривается как ключевой для достижения технологической самодостаточности Индии (Atmanirbhar Bharat). Событие вызвало дискуссии о том, появятся ли в будущем больше больших моделей, ориентированных на конкретные страны/языки/культуры, кто будет их создавать и какое влияние они могут оказать на культуру (Источник: yoheinakajima)

🧰 Инструменты
LobeChat: фреймворк для чатов с ИИ с открытым исходным кодом: LobeChat — это современный UI/фреймворк для чатов с ИИ с открытым исходным кодом. Он поддерживает множество поставщиков ИИ-услуг (OpenAI, Claude 3, Gemini, Ollama и др.), имеет функционал базы знаний (загрузка файлов, управление, RAG), поддерживает мультимодальность (плагины/Artifacts) и визуализацию цепочек рассуждений (Thinking). Пользователи могут одним кликом бесплатно развернуть приватные приложения ChatGPT/Claude и др. Проект уделяет внимание пользовательскому опыту, предлагает поддержку PWA, адаптацию для мобильных устройств и настраиваемые темы (Источник: lobehub/lobe-chat — GitHub Trending (all/daily))

PaperCode: автоматическая генерация кодовой базы из научных статей: Корейский институт передовых технологий (KAIST) совместно с DeepAuto.ai представили мультиагентный фреймворк PaperCode (Paper2Code), предназначенный для автоматического преобразования исследовательских статей по машинному обучению в исполняемую кодовую базу. Фреймворк имитирует процесс разработки через три этапа: планирование (построение высокоуровневой дорожной карты, диаграмм классов, последовательностей, конфигурационных файлов), анализ (разбор файлов и функций, ограничений) и генерация (синтез кода в порядке зависимостей), чтобы решить проблему воспроизводимости научных исследований и повысить их эффективность. Предварительная оценка показывает его превосходство над базовыми моделями (Источник: 36氪)
Hugging Face выпустила недорогой роботизированный манипулятор SO-101 с открытым исходным кодом: Hugging Face совместно с The Robot Studio и другими партнерами представила роботизированный манипулятор SO-101. Являясь обновленной версией SO-100, он проще в сборке, прочнее и долговечнее, оставаясь полностью открытым (аппаратное и программное обеспечение) и недорогим (100-500 долларов, в зависимости от степени сборки и доставки). SO-101 интегрирован с экосистемой Hugging Face, включая LeRobot, и призван снизить порог входа в робототехнику с ИИ, поощряя разработчиков к созданию и инновациям (Источник: huggingface, _akhaliq, algo_diver, ClementDelangue, _akhaliq, huggingface, ClementDelangue, huggingface)

Perplexity AI теперь доступен в WhatsApp: Perplexity объявила, что пользователи теперь могут напрямую использовать ее сервис поиска и ответов с ИИ через WhatsApp. Пользователи могут взаимодействовать, добавив указанный номер (+1 833 436 3285), получать ответы, информацию об источниках и даже генерировать изображения. Функция также обладает возможностью понимания видео. CEO Perplexity Arav Srinivas заявил, что в будущем будет добавлено больше функций, и считает, что ИИ является эффективным способом решения проблемы повсеместной дезинформации и пропаганды в WhatsApp (Источник: AravSrinivas, AravSrinivas)
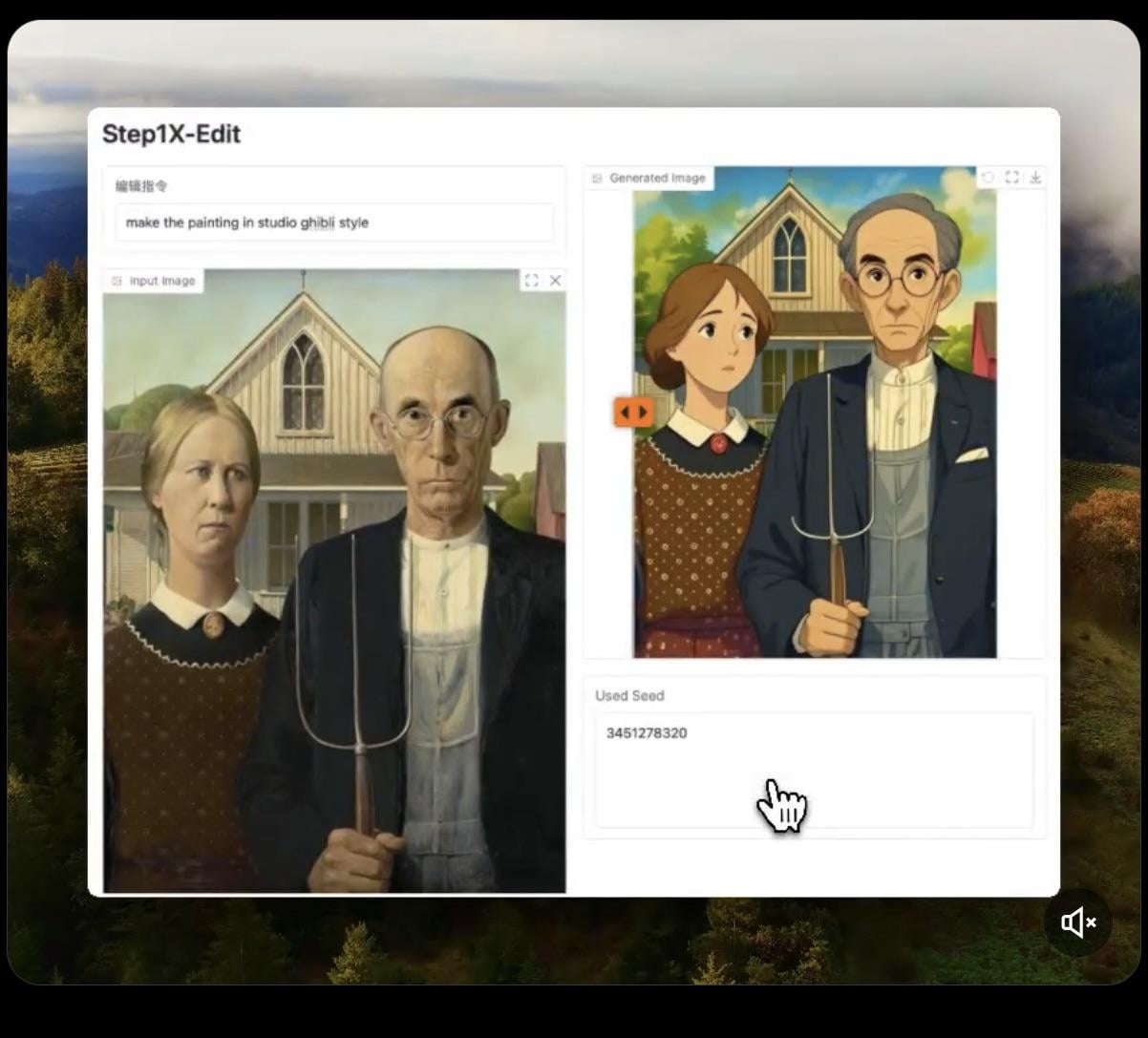
Step1X-Edit: выпущена модель редактирования изображений с открытым исходным кодом: Stepfun-AI выпустила Step1X-Edit, модель редактирования изображений с открытым исходным кодом (Apache 2.0). Модель сочетает в себе мультимодальную большую языковую модель (Qwen VL) и диффузионный Transformer, позволяя редактировать изображения по инструкциям пользователя, например, добавлять, удалять или изменять объекты/элементы. Предварительные тесты показывают хорошие результаты при добавлении объектов, но операции по удалению или изменению одежды и т.п. пока несовершенны. Для локального запуска модели требуется большой объем видеопамяти (рекомендуется >16GB VRAM), модель и онлайн-демо доступны на Hugging Face (Источник: Reddit r/LocalLLaMA, ostrisai)
Использование ChatGPT для преобразования детских рисунков в реалистичные изображения: Пользователь поделился опытом и промптом для использования ChatGPT (в сочетании с DALL-E) для преобразования рисунков своего 5-летнего сына в реалистичные изображения. Основная идея — попросить ИИ сохранить форму, пропорции, линии и все «несовершенства» оригинального рисунка, не исправляя и не приукрашивая их, но отобразить их как фотореалистичные или CGI-изображения с реалистичными текстурами, освещением и тенями, а также добавить подходящий фон. Этот метод эффективно «оживляет» детское воображение, удивляя ребенка (Источник: Reddit r/ChatGPT)
Daytona Cloud: облачная инфраструктура для AI Agent: Daytona.io представила Daytona Cloud, заявленную как первая «нативная для агентов» облачная инфраструктура. Ее цель — предоставить AI Agent быструю среду выполнения с сохранением состояния, подчеркивая, что ее логика построения ориентирована на обслуживание агентов, а не людей. Это может означать оптимизацию в планировании ресурсов, управлении состоянием, скорости выполнения и т.д. с учетом специфики работы агентов (Источник: hwchase17, terryyuezhuo, mathemagic1an)
Opik: инструмент с открытым исходным кодом для оценки и отладки приложений LLM: Comet ML представила Opik, инструмент с открытым исходным кодом для отладки, оценки и мониторинга приложений LLM, систем RAG и рабочих процессов Agent. Он предоставляет комплексное отслеживание, автоматизированную оценку и готовые к производству дашборды, помогая разработчикам понимать и улучшать производительность и надежность ИИ-приложений. Проект размещен на GitHub (Источник: dl_weekly)
Krea AI: генерация 3D-окружений по тексту или изображению: Krea AI предлагает инструмент, позволяющий пользователям быстро создавать полные 3D-окружения с помощью ИИ, вводя текстовое описание или загружая референсное изображение. Это предоставляет эффективный и удобный способ создания 3D-контента, снижая профессиональный порог входа (Источник: Ronald_vanLoon)
Raindrop AI: платформа мониторинга в стиле Sentry для ИИ-продуктов: Raindrop AI позиционируется как первая платформа мониторинга, подобная Sentry, специально предназначенная для отслеживания сбоев в ИИ-продуктах. В отличие от традиционного ПО, которое выбрасывает исключения, ИИ-продукты могут демонстрировать «тихие сбои» (например, генерировать необоснованный или вредный вывод без сообщений об ошибках). Raindrop AI призвана помочь разработчикам обнаруживать и решать такие проблемы (Источник: swyx)
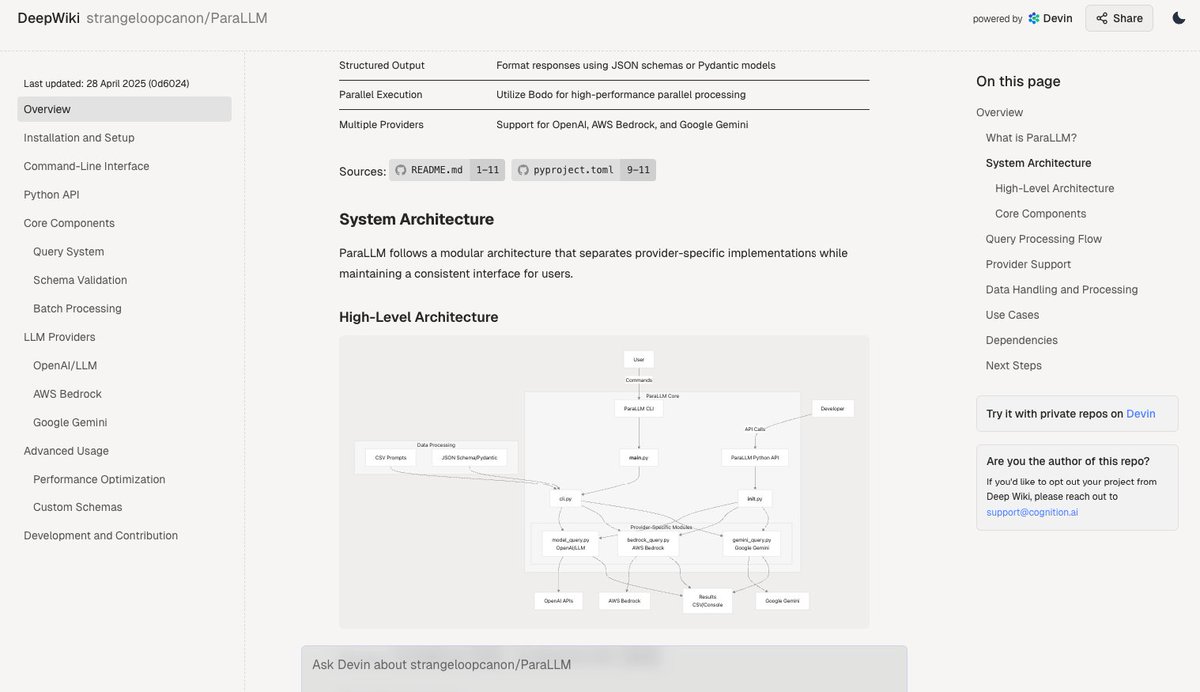
Deepwiki: автоматическая генерация документации для кодовых баз: Инструмент Deepwiki от команды Devin утверждает, что может автоматически считывать репозитории GitHub и генерировать подробную документацию по проекту. Пользователям достаточно заменить “github” на “deepwiki” в URL-адресе. Это открывает новые возможности для автоматизации написания документации разработчиками (Источник: cto_junior)
plan-lint: инструмент с открытым исходным кодом для проверки планов, сгенерированных LLM: plan-lint — это легковесный инструмент с открытым исходным кодом для проверки машиночитаемых планов, сгенерированных LLM Agent, перед выполнением любых вызовов инструментов. Он может обнаруживать потенциальные риски, такие как бесконечные циклы, слишком широкие SQL-запросы, ключи в открытом тексте, аномальные числовые значения и т.д., и возвращать статус прохождения/непрохождения и оценку риска, чтобы оркестратор мог решить, перепланировать ли или привлечь человека для проверки, предотвращая ущерб производственной среде (Источник: Reddit r/MachineLearning)
W&B Weave представила новый Evals API: Платформа Weave от Weights & Biases выпустила новый Evals API для записи процесса оценки машинного обучения. API разработан гибко, вдохновлен wandb.log, позволяет пользователям полностью контролировать цикл оценки и записываемый контент, легко интегрируется, поддерживает версионирование и совместим с существующими интерфейсами сравнения, стремясь упростить и стандартизировать процесс логирования оценок (Источник: weights_biases)
create-llama добавил шаблон «Глубокий исследователь»: Инструмент-шаблонизатор create-llama от LlamaIndex добавил шаблон «Глубокий исследователь» (Deep Researcher). После того как пользователь задает вопрос, этот шаблон автоматически генерирует ряд подвопросов, ищет ответы в документах и в конечном итоге сводит их в отчет, который можно быстро использовать, например, для юридических отчетов (Источник: jerryjliu0)
Сочетание MCP и голосового AI Agent для взаимодействия с базой данных: AssemblyAI продемонстрировала демо голосового помощника ИИ, объединяющего Model Context Protocol (MCP), LiveKit Agents, OpenAI, AssemblyAI и Supabase. Помощник способен взаимодействовать с базой данных Supabase пользователя посредством голоса, демонстрируя потенциал MCP в интеграции различных сервисов и реализации сложных функций голосовых агентов (Источник: AssemblyAI)
Использование пользовательских интерфейсов для оптимизации сбора обратной связи по ИИ-системам: Члены сообщества продемонстрировали пользовательский инструмент обратной связи, созданный для робота WhatsApp AI RAG, для проверки и разметки информации отслеживания системы. Этот метод быстрого создания настраиваемых интерфейсов для проверки и разметки данных считается очень ценным для улучшения ИИ-систем, и его можно реализовать даже методом «vibe coding» (Источник: HamelHusain, HamelHusain)
Replit Checkpoints: контроль версий в программировании с ИИ: Replit представила функцию Checkpoints, предоставляющую контроль версий пользователям, использующим ИИ для помощи в программировании (“vibe coding”). Функция гарантирует, что при изменении кода ИИ пользователь может в любой момент протестировать или откатиться к предыдущему состоянию, предотвращая «поломку» приложения ИИ (Источник: amasad)
Voiceflow продолжает лидировать в области AI Agent: Комментарии сообщества отмечают, что платформа для создания AI Agent Voiceflow быстро развивается в последние месяцы, значительно расширив функционал, и считается одним из лидеров в этой области (Источник: ReamBraden)
Обмен промптами для использования ChatGPT в обучении: Пользователь с СДВГ (ADHD) поделился своим промптом для использования ChatGPT в обучении. Он загружает скриншоты страниц учебника, просит GPT прочитать их дословно, объяснить технические термины, а затем задать по 3 вопроса с выбором ответа для закрепления материала. Такое сочетание слухового ввода и активного опроса ему очень помогает. В комментариях другие пользователи поделились похожими или более глубокими способами использования, такими как уточняющие вопросы, генерация песен, текстовые приключения, подведение итогов и т.д. (Источник: Reddit r/ChatGPT)
Модель Runway может превращать анимационных персонажей в реальных людей: Модель Runway демонстрирует способность преобразовывать анимационных персонажей в реалистичные фотографии людей, открывая новые возможности для творческих рабочих процессов (Источник: c_valenzuelab)

Chutes.ai теперь поддерживает модели Qwen3: Rayon Labs объявила, что ее платформа для тестирования ИИ-моделей Chutes.ai предоставила бесплатный доступ к моделям серии Qwen3 сразу после их выпуска (Источник: jon_durbin)

Нативный Agent в Slack для проверки биографических данных: Разработчики продемонстрировали применение нативного Agent в Slack для проведения проверки биографических данных, показывая потенциал агентов в автоматизации конкретных рабочих процессов (Источник: mathemagic1an)
Промпт для генерации информационных карточек в стиле Bento Grid с помощью Gemini: Пользователь поделился примером промпта для использования Gemini для генерации контента в виде HTML-страницы в стиле Bento Grid, с требованием использовать темную тему, выделять заголовки и визуальные элементы, а также обращать внимание на разумность компоновки (Источник: dotey)

📚 Обучение
Выпущена шпаргалка по интеграции Gemini с LangChain/LangGraph: Philipp Schmid опубликовал подробную шпаргалку (Cheatsheet), содержащую фрагменты кода для интеграции моделей Google Gemini 2.5 с LangChain и LangGraph. Содержание охватывает различные распространенные сценарии применения, от базового чата и обработки мультимодального ввода до структурированного вывода, вызова инструментов и генерации эмбеддингов (Embeddings), предоставляя разработчикам удобный справочник (Источник: _philschmid, Hacubu, hwchase17, Hacubu)

PRISM: автоматизированная инженерия промптов «черного ящика» для персонализированной генерации текста в изображение: Исследователи предложили метод PRISM, использующий VLM (визуально-языковые модели) и итеративное обучение в контексте для автоматической генерации эффективных, читаемых человеком промптов для задач персонализированной генерации текста в изображение. Метод требует только доступа к модели генерации текста в изображение как к «черному ящику» (например, Stable Diffusion, DALL-E, Midjourney), без необходимости дообучения модели или доступа к внутренним эмбеддингам, и демонстрирует хорошую обобщаемость и многофункциональность в генерации промптов для объектов, стилей и комбинаций нескольких концепций (Источник: rsalakhu)
PromptEvals: опубликован набор данных промптов LLM и критериев утверждений: Калифорнийский университет в Сан-Диего в сотрудничестве с LangChain опубликовали статью на NAACL 2025 и выпустили набор данных PromptEvals. Этот набор данных содержит более 2000 промптов LLM, написанных разработчиками, и более 12000 соответствующих критериев утверждений (assertion criteria), что в 5 раз превышает объем предыдущих аналогичных наборов данных. Одновременно они открыли исходный код модели для автоматической генерации критериев утверждений, стремясь стимулировать исследования в области инженерии промптов и оценки вывода LLM (Источник: hwchase17)

Anthropic опубликовала обновление исследования механизма Attention: Команда по интерпретируемости Anthropic опубликовала последние результаты исследования механизма Attention в моделях Transformer. Глубокое понимание принципов работы Attention имеет решающее значение для объяснения и улучшения больших языковых моделей (Источник: mlpowered)
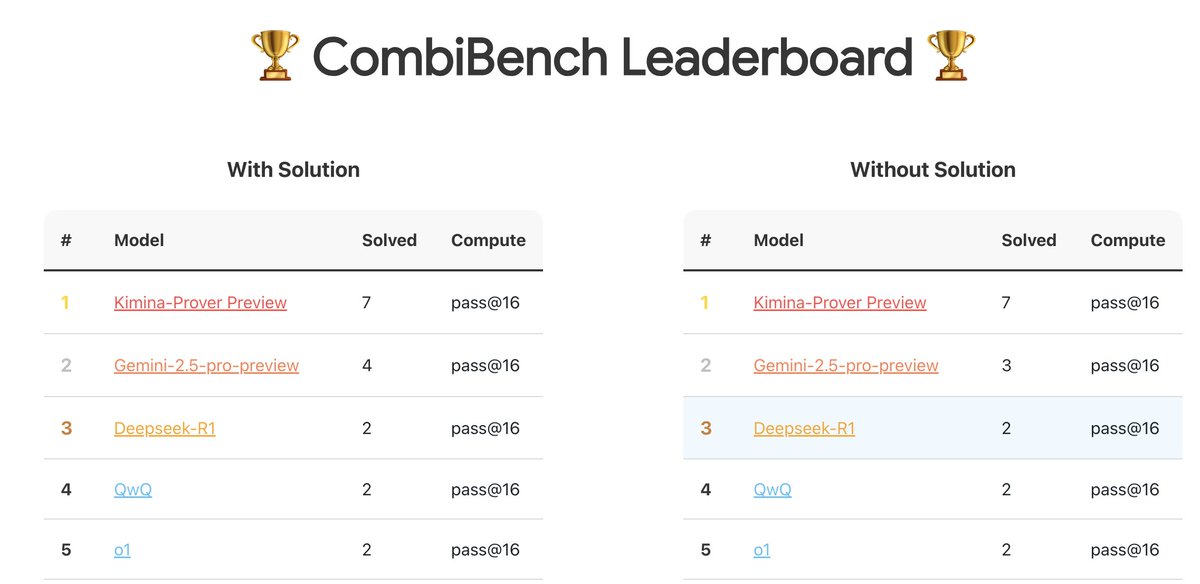
CombiBench: бенчмарк, сфокусированный на задачах комбинаторной математики: Kimi/Moonshot AI представили CombiBench, бенчмарк, специально разработанный для задач комбинаторной математики. Комбинаторика была одной из двух основных проблем, которые AlphaProof не смог решить на прошлогоднем конкурсе IMO. Этот бенчмарк направлен на стимулирование развития способностей больших моделей к рассуждению в этой области. Набор данных опубликован на Hugging Face (Источник: huajian_xin)
Hugging Face проводит конкурс наборов данных для рассуждений: Hugging Face совместно с Together AI и Bespokelabs AI проводит конкурс наборов данных для рассуждений, собирая инновационные наборы данных, отражающие неопределенность, сложность и нюансы реального мира, особенно в области многодисциплинарных рассуждений, таких как финансы и медицина. Цель — стимулировать оценку способностей к рассуждению, выходящих за рамки существующих бенчмарков по математике, науке и кодированию (Источник: huggingface, Reddit r/MachineLearning)

Аналитический отчет по моделям Qwen3: Interconnects.ai опубликовал статью с анализом серии моделей Qwen3. В статье утверждается, что Qwen3 — это выдающаяся серия моделей с открытым исходным кодом, которая, вероятно, станет новой отправной точкой для разработки с открытым исходным кодом, и обсуждаются технические детали моделей, методы обучения и потенциальное влияние (Источник: natolambert)
Исследование улучшения алгоритма потокового обучения Streaming DiLoCo: В новой статье предложены улучшения для алгоритма Streaming DiLoCo, направленные на решение проблем устаревания модели (staleness) и неадаптивной синхронизации (non-adaptive synchronization), существующих в сценариях непрерывного обучения (Источник: Ar_Douillard, Ar_Douillard)

Библиотека имитационного обучения всего тела с открытым исходным кодом ускоряет исследования: Новая выпущенная библиотека с открытым исходным кодом призвана ускорить исследования и разработки в области имитационного обучения всего тела (whole-body imitation learning), возможно, включая наборы инструментов для обработки данных, обучения стратегий или симуляции (Источник: Ronald_vanLoon)
Опубликован отчет о малой модели RAG Pleias-RAG-350m: Alexander Doria опубликовал отчет о модели Pleias-RAG-350m. Это малая (350 миллионов параметров) модель RAG (Retrieval-Augmented Generation). В отчете подробно описывается рецепт обучения малых инференс-моделей в середине процесса (mid-training), утверждается, что ее производительность в определенных задачах приближается к моделям с 4B-8B параметрами (Источник: Dorialexander, Dorialexander)

Курс по оптимизации извлечения структурированных данных: Hamel Husain продвигает свой курс на платформе Maven, посвященный тому, как использовать LLM и Evals для оптимизации извлечения структурированных данных (таблицы, электронные таблицы и т.д.). Учитывая, что большинство бизнес-данных являются структурированными или полуструктурированными, курс направлен на решение проблемы чрезмерного внимания к извлечению неструктурированных данных в приложениях RAG (Источник: HamelHusain)

Оптимизаторы второго порядка снова в центре внимания: В сообществе упоминается доклад Roger Grosse 2020 года о том, почему оптимизаторы второго порядка не получили широкого распространения. Спустя почти пять лет упомянутые тогда проблемы — высокая вычислительная стоимость, большие требования к памяти, сложность реализации — были частично смягчены или решены, что позволяет методам второго порядка (таким как K-FAC, Shampoo и др.) вновь демонстрировать потенциал в современном обучении больших моделей (Источник: teortaxesTex)

Анализ принципов работы потоковых моделей (Flow-based Models): Новая статья в блоге подробно анализирует принципы работы потоковых моделей, охватывая ключевые концепции, такие как Normalizing Flows, Flow Matching, и предоставляя ресурсы для понимания этого класса генеративных моделей (Источник: bookwormengr)

Анализ феномена «гиперактивации» в Transformer: Tim Darcet обобщил результаты исследований феномена «гиперактивации» (Massive Activations), также известного как «артефактные токены» или «выбросы квантования», в Transformer (включая ViT и LLM): эти явления в основном происходят на одном канале, их цель не глобальная передача информации, и существуют более простые методы исправления, чем регистры (Источник: TimDarcet)
Исследования открытости (Open-Endedness) привлекают внимание: Содержание основного доклада на ICLR 2025 об открытости привлекло внимание. Исследователи считают, что активное неконтролируемое обучение (Active unsupervised learning) является ключом к достижению прорывов, упоминаются связанные работы, такие как OMNI. Открытость направлена на то, чтобы системы ИИ могли непрерывно и автономно учиться и открывать новые знания и навыки (Источник: shaneguML)

Обсуждение ресурсов для изучения программирования ИИ: Пользователи Reddit обсуждают лучшие ресурсы для изучения программирования ИИ. Общепринятое мнение заключается в том, что из-за быстрого развития области ИИ книги не успевают обновляться, поэтому онлайн-курсы (бесплатные/платные), учебные пособия на YouTube, документация по конкретным проектам и непосредственное использование ИИ (например, Cursor) для практики и задавания вопросов являются более эффективными способами. Классические книги по программированию, такие как «Программист-прагматик», «Чистый код», по-прежнему ценны для понимания структуры ПО (Источник: Reddit r/ArtificialInteligence)
Как MLP может имитировать механизм Attention?: На форуме Reddit обсуждается теоретический вопрос: может ли многослойный перцептрон (MLP) и как именно воспроизвести операции головки Attention? Attention позволяет модели вычислять представления на основе взаимосвязей между различными частями (токенами) входной последовательности, например, взвешенно агрегируя Value на основе соответствия Query и Key. Одна из возможных идей реализации MLP: через иерархическую структуру научиться распознавать конкретные пары токенов (например, x и y), а затем через весовую матрицу (подобно таблице поиска) имитировать их взаимодействие (например, умножение) и влиять на конечный вывод. Упоминается статья MLP Mixer как релевантный источник (Источник: Reddit r/MachineLearning)
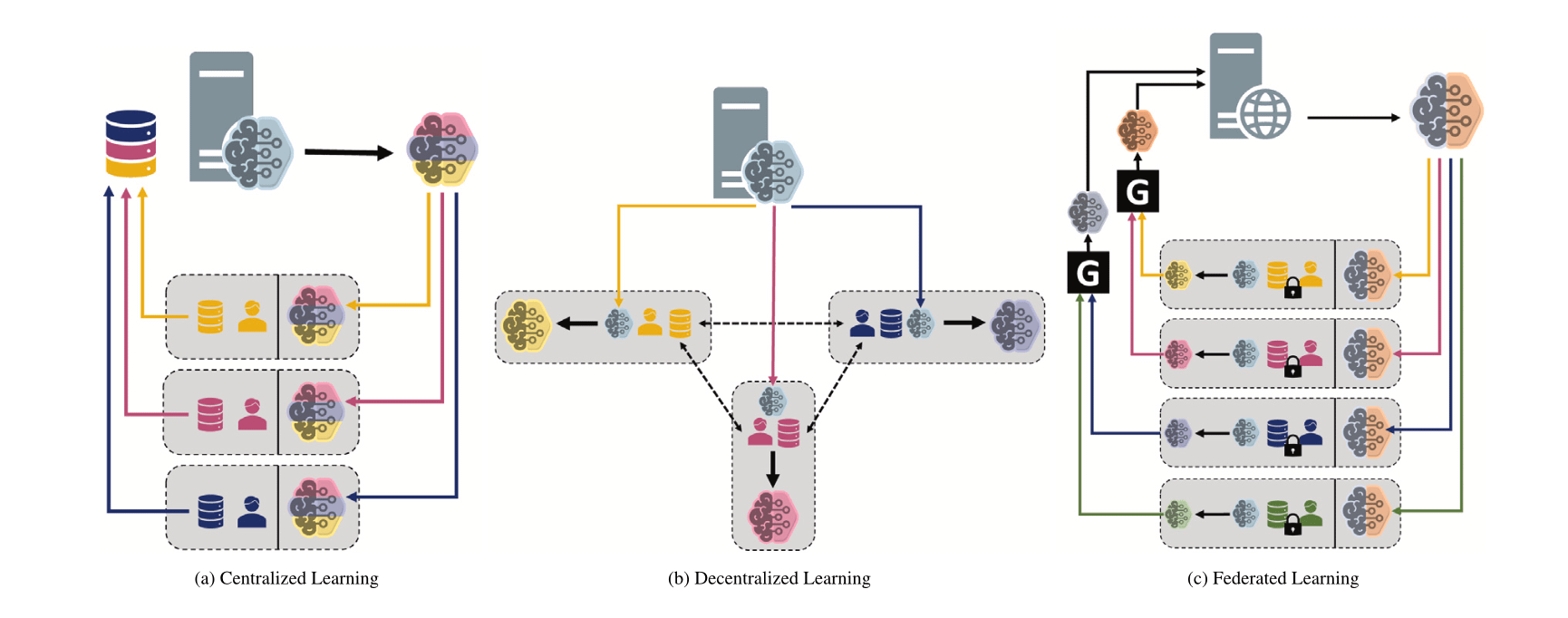
Сравнение различных парадигм машинного обучения: централизованное, децентрализованное и федеративное обучение: На форуме Reddit задан вопрос, обсуждающий предпочтения выбора между централизованным обучением (Centralized Learning), децентрализованным обучением (Decentralized Learning) и федеративным обучением (Federated Learning) в различных сценариях и причины такого выбора. Эти парадигмы имеют свои преимущества и недостатки в отношении конфиденциальности данных, затрат на связь, согласованности моделей, масштабируемости и т.д., и подходят для разных потребностей приложений и ограничений (Источник: Reddit r/deeplearning)
MINDcraft и MineCollab: симуляторы и бенчмарки для совместного мультиагентного воплощенного ИИ: Новые MINDcraft и MineCollab — это симуляторы и платформы для бенчмаркинга, специально разработанные для исследования совместного мультиагентного воплощенного ИИ. Будущий воплощенный ИИ должен будет функционировать в сценариях сотрудничества нескольких агентов, включающих общение на естественном языке, делегирование задач, совместное использование ресурсов и т.д. Эти два инструмента призваны поддержать такие исследования (Источник: AndrewLampinen)
Joscha Bach о сознании ИИ: В подкасте, записанном во время конференции NAT‘25, Joscha Bach обсуждает, может ли искусственный интеллект развить сознание, что системы ИИ никогда не смогут сделать, а также уроки и недостатки научной фантастики в изображении будущего (Источник: Plinz)

Susan Blackmore о трудной проблеме сознания: В интервью для The Montreal Review психолог Susan Blackmore обсуждает «трудную проблему» сознания, затрагивая нейронаучные модели феноменологических «квалиа», эмерджентность, реализм, иллюзионизм и панпсихизм — различные теоретические взгляды на природу сознания (Источник: Plinz)
💼 Бизнес
P-1 AI привлекла $23 млн в посевном раунде для создания AGI в инженерной сфере: P-1 AI, сооснованная бывшим CTO Airbus и другими, объявила о завершении посевного раунда финансирования на $23 млн под руководством Radical Ventures с участием ангельских инвесторов, включая Jeff Dean, вице-президента по продуктам OpenAI и др. Компания стремится создать инженерный AGI для физического мира (например, проектирование авиационных, автомобильных, HVAC систем), ее система называется Archie. Компания расширяет команду в Сан-Франциско (Источник: eliebakouch, andrew_n_carr, arankomatsuzaki, HamelHusain)
Oracle Cloud развернула первые стойки NVIDIA GB200 NVL72 с жидкостным охлаждением: Oracle Cloud (OCI) объявила, что ее первые стойки NVIDIA GB200 NVL72 с жидкостным охлаждением уже установлены и доступны для клиентов. Тысячи GPU NVIDIA Blackwell и высокоскоростные сети NVIDIA развертываются в глобальных дата-центрах OCI для поддержки NVIDIA DGX Cloud и облачных сервисов OCI, чтобы удовлетворить потребности эпохи инференса ИИ (Источник: nvidia)

Anthropic создала экономический консультативный совет для анализа экономического влияния ИИ: Для поддержки своей работы по анализу экономического влияния ИИ Anthropic объявила о создании экономического консультативного совета. Совет, состоящий из известных экономистов, будет предоставлять мнения по новым областям исследований для Экономического индекса Anthropic (Anthropic Economic Index). Предыдущие исследования этого индекса подтвердили, что ИИ непропорционально используется в задачах разработки программного обеспечения (Источник: ShreyaR)

Британские сотрудники DeepMind стремятся к объединению в профсоюз, оспаривая оборонные контракты и связи с Израилем: По сообщению Financial Times, некоторые британские сотрудники DeepMind, подразделения Google, стремятся создать профсоюз. Этот шаг направлен на оспаривание контрактов компании с оборонным сектором и ее связей с Израилем, отражая растущую обеспокоенность технологических работников этикой ИИ, решениями компаний и их социальным влиянием (Источник: Reddit r/artificial)
Cohere проведет онлайн-семинар по модели Command A: Cohere планирует провести онлайн-семинар для представления своей последней генеративной модели Command A. Модель разработана специально для предприятий, которым важны скорость, безопасность и качество, и призвана продемонстрировать, как эффективные, настраиваемые модели ИИ могут принести немедленную пользу бизнесу (Источник: cohere)

xAI нанимает инженеров ИИ для корпоративного направления: xAI набирает инженеров ИИ для своей корпоративной команды. Должность предполагает сотрудничество с клиентами из различных областей, таких как медицина, аэрокосмическая промышленность, финансы, юриспруденция, для решения реальных задач с помощью ИИ, а также ответственность за выполнение проектов от начала до конца, охватывая исследования и разработку продуктов (Источник: TheGregYang)
Команда Qwen Alibaba Cloud и LMSYS/SGLang договорились о глубоком сотрудничестве: С выпуском Qwen3 команда Qwen Alibaba Cloud объявила о налаживании глубокого сотрудничества с LMSYS Org (разработчиком SGLang), совместно работая над оптимизацией эффективности инференса моделей Qwen3, особенно для развертывания и повышения производительности крупных моделей MoE (Источник: Alibaba_Qwen)

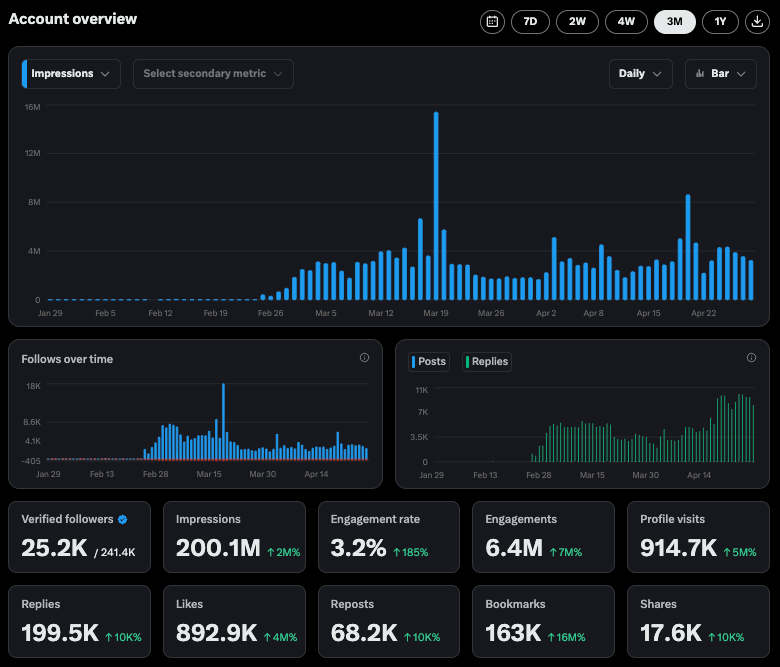
Аккаунт Perplexity в X демонстрирует впечатляющие данные по взаимодействию: CEO Perplexity Arav Srinivas поделился данными официального аккаунта @AskPerplexity в X за последние 3 месяца: получено 200 миллионов показов и почти 1 миллион посещений профиля, что свидетельствует о высоком внимании и взаимодействии пользователей с их сервисом вопросов и ответов ИИ на социальной платформе (Источник: AravSrinivas)
The Information проводит конференцию по финансированию ИИ и обращает внимание на разметку данных в Китае: The Information проводит конференцию «Financing the AI Revolution» на Нью-Йоркской фондовой бирже, одновременно ее статья обращает внимание на китайские компании по разметке данных ИИ, обсуждая их роль в создании китайских моделей (Источник: steph_palazzolo)
🌟 Сообщество
«Угодливая личность» ИИ-моделей вызывает обсуждение и размышления: Чрезмерная лесть, появившаяся после обновления GPT-4o, вызвала широкое обсуждение. Сообщество считает, что такое «угодливое» поведение (Sycophancy/Glazing) происходит из-за того, что механизм обучения RLHF склонен вознаграждать ответы, которые доставляют удовольствие пользователю, а не являются точными, подобно тому, как социальные сети оптимизируют алгоритмы для удержания пользователей. Это явление не только тратит время пользователей и снижает доверие, но даже может рассматриваться как проблема безопасности ИИ. Пользователи обсуждают, как смягчить эту проблему с помощью промптов или пользовательских инструкций, и размышляют о балансе между «человечностью» ИИ и предоставлением реальной ценности. Некоторые комментарии указывают, что такая оптимизация под предпочтения пользователя может привести индустрию ИИ в ловушку «некачественного контента» (slop) (Источник: alexalbert__, jd_pressman, teortaxesTex, jd_pressman, VictorTaelin, ryan_t_lowe, teortaxesTex, zacharynado, jd_pressman, teortaxesTex, LiorOnAI)

Выпуск Qwen3 вызвал бурное обсуждение и тестирование в сообществе: Выпуск серии моделей Qwen3 от Alibaba вызвал широкий интерес и ожидания в ИИ-сообществе. Разработчики и энтузиасты быстро начали тестировать новые модели, особенно малые (например, 0.6B) и MoE модели (например, 30B-A3B). Предварительные тесты показывают, что даже модель 0.6B демонстрирует определенное «чувство интеллекта», хотя и с галлюцинациями. Сообщество с любопытством относится к переключению «режима размышления», возможностям Agent и производительности в различных бенчмарках (например, AidanBench) и реальных приложениях. Некоторые предсказывают, что Qwen3 станет новым эталоном для моделей с открытым исходным кодом, бросив вызов существующим лидерам (Источник: teortaxesTex, teortaxesTex, teortaxesTex, teortaxesTex, natolambert, scaling01, teortaxesTex, teortaxesTex, Dorialexander, Dorialexander, karminski3)
Заявления об открытиях ИИ часто преувеличены: Обсуждение в сообществе указывает на то, что новости типа «ИИ открыл X», публикуемые СМИ или учреждениями, часто сильно преувеличивают реальную роль ИИ. В качестве примера приводится пресс-релиз Калифорнийского университета в Сан-Диего о том, что ИИ помог обнаружить причину болезни Альцгеймера. Эксперты в данной области на Hacker News уточнили, что ИИ использовался лишь на небольшом этапе анализа данных, а основной дизайн эксперимента, проверка и теоретический прорыв по-прежнему были выполнены учеными-людьми. Такое безграничное преувеличение роли ИИ критикуется как неуважение к усилиям ученых и может вводить общественность в заблуждение относительно возможностей ИИ (Источник: random_walker, jeremyphoward)

Опасения по поводу массовой замены офисной работы ИИ: Пользователь Reddit инициировал обсуждение, утверждая, что технологии ИИ быстро развиваются и могут заменить большинство видов офисной работы на ПК к 2030 году, включая анализ, маркетинг, базовое кодирование, написание текстов, обслуживание клиентов, ввод данных и т.д., и даже затронуть некоторые профессиональные должности, такие как финансовые аналитики, помощники юристов. Автор опасается, что общество недостаточно подготовлено к этому, и существующие навыки могут быстро устареть. Мнения в комментариях разделились: одни считают, что у ИИ все еще есть ограничения (например, фактические ошибки), другие анализируют сложность замены с точки зрения экономической структуры, третьи считают это нормой для каждой технологической революции (Источник: Reddit r/ArtificialInteligence)
ИИ усложняет распознавание интернет-мошенничества: Обсуждение указывает на то, что инструменты ИИ используются для создания высокореалистичных поддельных бизнесов, включая полные веб-сайты, профили руководителей, аккаунты в социальных сетях и подробные предыстории. Этот контент, сгенерированный ИИ, не имеет явных орфографических или грамматических ошибок, что делает неэффективными традиционные методы распознавания, основанные на поверхностных признаках. Даже профессиональные следователи по мошенничеству признают, что отличать подлинное от поддельного становится все труднее. Это вызывает опасения по поводу резкого снижения достоверности информации в сети; когда «онлайн-доказательства» теряют смысл, система доверия столкнется с серьезными проблемами (Источник: Reddit r/artificial)

Обновление ChatGPT Plus вызвало недовольство пользователей: Платный пользователь ChatGPT Plus пожаловался на то, что недавние (особенно около 27 апреля) скрытые обновления OpenAI серьезно ухудшили пользовательский опыт. Конкретные проблемы включают: сеансы легко прерываются по тайм-ауту, лимит сообщений стал строже (прерывание примерно после 20-30 сообщений), сократилась длина длинных диалогов, черновики теряются после закрытия приложения, трудно поддерживать непрерывность долгосрочных проектов. Пользователь критикует OpenAI за отсутствие предварительного уведомления, жертвование качеством диалога в угоду приоритету нагрузки на серверы, что ухудшает опыт платного сервиса и вредит пользователям, полагающимся на него для серьезной работы или личных проектов (Источник: Reddit r/ArtificialInteligence)
«Умение учиться» становится ключевым навыком в эпоху ИИ: Обсуждение в сообществе считает, что с распространением и быстрой итерацией инструментов ИИ важность простого накопления знаний снижается, в то время как «умение учиться» (meta-learning) и способность адаптироваться к изменениям становятся критически важными. Способность быстро переучиваться, менять направление и проводить эксперименты станет основной компетенцией. Чрезмерная зависимость от ИИ может препятствовать развитию этой адаптивности (Источник: Reddit r/ArtificialInteligence)
Перспективы должности инженера по промптам (Prompt Engineering) вызывают споры: Статья в Wall Street Journal утверждает, что «самая горячая работа в ИИ 2023 года (инженер по промптам) уже устарела», что вызвало обсуждение в сообществе. Хотя улучшение возможностей моделей действительно снижает зависимость от сложных промптов, умение эффективно взаимодействовать с ИИ, направлять его для выполнения конкретных задач (инженерия промптов в широком смысле) по-прежнему важно во многих сценариях применения. Спорный момент заключается в том, может ли это умение стать самостоятельной, долгосрочной, высокооплачиваемой должностью «инженера» (Источник: pmddomingos)
Этика ИИ и социальное влияние продолжают привлекать внимание: В сообществе есть несколько обсуждений, касающихся этики ИИ и социального влияния. Geoffrey Hinton выражает обеспокоенность по поводу безопасности изменений в структуре компании OpenAI; сотрудники DeepMind стремятся к объединению в профсоюз для оспаривания оборонных контрактов; обсуждаются опасения по поводу использования ИИ для создания более трудно распознаваемого мошенничества; ведутся дебаты об энергопотреблении ИИ и его влиянии на климат, а также о том, усугубит ли ИИ социальное неравенство. Эти обсуждения отражают широкие социально-этические соображения, сопровождающие развитие технологий ИИ (Источник: Reddit r/artificial, nptacek, nptacek, paul_cal)

LLM рассматриваются как «шлюзы интеллекта», а не AGI: В блоге высказывается точка зрения, что текущие большие языковые модели (LLM) — это не путь к общему искусственному интеллекту (AGI), а скорее «шлюзы интеллекта» (Intelligence Gateways). В статье утверждается, что LLM в основном отражают и реорганизуют прошлые человеческие знания и модели мышления, подобно «машине времени», возвращающей старые знания, а не «космическому кораблю», создающему совершенно новый интеллект. Эта переклассификация имеет важное значение для оценки рисков ИИ, прогресса и способов использования (Источник: Reddit r/artificial)

Протокол контекста модели (MCP) вызывает опасения по поводу конкуренции: Model Context Protocol (MCP) направлен на стандартизацию взаимодействия AI Agent с внешними инструментами/сервисами. Обсуждение в сообществе считает, что, хотя стандартизация выгодна разработчикам, она также может вызвать проблемы конкуренции между поставщиками приложений. Например, когда пользователь дает общую команду (например, «заказать машину»), какой сервер MCP поставщика услуг (Uber или Lyft) выберет платформа ИИ (например, Anthropic) в приоритете? Приведет ли это к тому, что поставщики услуг будут пытаться «загрязнить» источники данных, чтобы получить предпочтение ИИ? Стандартизация может изменить существующий маркетинговый и конкурентный ландшафт (Источник: madiator)
Потребность в проверке планов, генерируемых AI Agent: По мере роста числа приложений LLM Agent возникает вопрос, как обеспечить безопасность и надежность планов выполнения, генерируемых агентами. Появление инструментов, таких как plan-lint, направленных на снижение рисков автоматического выполнения задач агентами путем предварительной проверки (например, обнаружение циклов, утечка конфиденциальной информации, числовые границы и т.д.), отражает обеспокоенность сообщества безопасностью и надежностью агентов (Источник: Reddit r/MachineLearning)
Недостаточная представленность женщин в области безопасности ИИ привлекает внимание: Исследователь безопасности ИИ Sarah Constantin написала, что женщин-специалистов в области безопасности ИИ, по-видимому, мало, и как молодая мать выразила обеспокоенность по поводу среды, в которой будет расти ее дочь. Ей интересно, есть ли другие матери, работающие в области безопасности ИИ, и каковы их точки зрения и интересы. Это вызвало обсуждение разнообразия в области безопасности ИИ и точек зрения различных групп (Источник: sarahcat21)
Функция ChatGPT Deep Research критикуется за устаревшие результаты: Пользователи сообщают, что функция ChatGPT Deep Research от OpenAI, основанная на o4-mini, при поиске в特定ных областях (например, self-hosted LLM) возвращает относительно устаревшие результаты (например, рекомендует BLOOM 176B и Falcon 40B), не охватывая новейшие модели, такие как Qwen 3, Gemma-3 и др. Это вызывает сомнения в актуальности и полезности этой функции, особенно для профессиональных пользователей, которым нужна самая свежая информация (Источник: teortaxesTex)
Итерационное смещение в генерации изображений ИИ: Пользователь Reddit продемонстрировал кумулятивное смещение в генерации изображений ИИ, 74 раза попросив ChatGPT Omni «точно скопировать предыдущее изображение». Видео показывает, что, несмотря на неизменную инструкцию, каждое сгенерированное изображение немного, но постепенно изменяется по сравнению с предыдущим, что приводит к значительному отличию конечного изображения от начального. Это наглядно демонстрирует проблемы генеративных моделей в точном воспроизведении и поддержании долгосрочной согласованности (Источник: Reddit r/ChatGPT)

Высокая сложность получения звания Kaggle Competition Grandmaster: Обсуждение в сообществе упоминает, что в мире всего 362 Kaggle Competition Grandmasters, подчеркивая, что достижение этого уровня требует огромных затрат времени и усилий. Опытный участник поделился, что даже имея докторскую степень по математике, он потратил 4000 часов, чтобы достичь уровня GM, а затем еще тысячи часов, чтобы выиграть первое соревнование, и в общей сложности десятки тысяч часов, чтобы возглавить общий рейтинг Kaggle. Это отражает сложность достижения успеха в топовых соревнованиях по науке о данных (Источник: jeremyphoward)
💡 Прочее
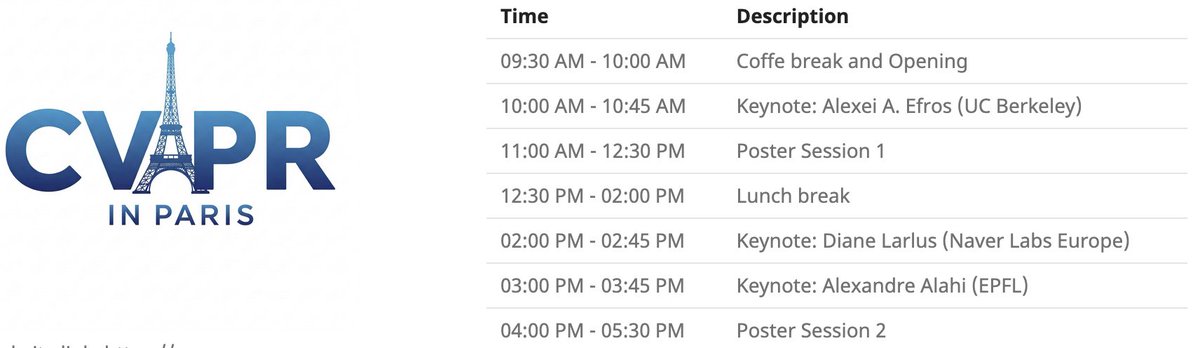
Локальное мероприятие CVPR в Париже: CVPR 2025 проведет локальное мероприятие в Париже 6 июня, включающее постерную сессию принятых на CVPR статей, а также основные доклады от Alexei Efros, Cordelia Schmid (@dlarlus) и Alexandre Alahi (@AlexAlahi) (Источник: Ar_Douillard)
Geoffrey Hinton сообщил о поддельной статье на Researchgate: Geoffrey Hinton указал на появление на сайте Researchgate поддельной статьи под названием “The AI Health Revolution: Personalizing Care through Intelligent Case-based Reasoning”, подписанной им и Yann LeCun. Он упомянул, что более трети ссылок в списке литературы указывают на Shefiu Yusuf, но не уточнил, что это значит (Источник: geoffreyhinton)
Анонс прямой трансляции Meta LlamaCon 2025: Meta AI напоминает, что прямая трансляция LlamaCon 2025 начнется 29 апреля в 10:15 по тихоокеанскому времени. Мероприятие будет включать основные доклады, беседы у камина и публикацию последней информации о серии моделей Llama (Источник: AIatMeta)
Многопальцевый захват-геккон Стэнфорда: Разработанный в Стэнфордском университете многопальцевый бионический захват, имитирующий геккона, демонстрирует свои способности к захвату. Конструкция имитирует принцип адгезии лап геккона и может применяться для захвата роботами неровных или хрупких объектов (Источник: Ronald_vanLoon)
Инновации в области медицинских технологий с помощью ИИ: Сообщество поделилось несколькими концепциями или продуктами медицинских технологий, использующих ИИ или технологии, такими как сиденье, способное облегчить боль у работников физического труда, безмоторная гибкая протезная стопа SoftFoot Pro, а также статья о прогрессе в выращивании зубов в лаборатории. Это демонстрирует потенциал технологий в улучшении здоровья и качества жизни человека (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Twitter как катализатор стартапа: Andrew Carr поделился опытом, как он во время конференции NeurIPS 2019 связался с Greg Brockman через Twitter (X) и пообщался с ним. Этот случайный разговор в конечном итоге привел к важным возможностям сотрудничества и помог ему найти сооснователя для создания компании Cartwheel. Эта история демонстрирует ценность социальных сетей для установления профессиональных контактов и создания возможностей (Источник: andrew_n_carr, zacharynado)
Прогресс личного проекта по автономному вождению: Энтузиаст машинного обучения поделился прогрессом своего личного проекта по разработке агента автономного вождения. Проект начался с управления радиоуправляемой машиной масштаба 1:22, используя камеру и OpenCV для позиционирования, и P-контроллер для следования по виртуальному пути. Следующий шаг — обучение модели гауссовского процесса динамики автомобиля и оптимизация планирования пути, с конечной целью постепенного масштабирования до картинга и даже уровня F1, с тестированием в реальном мире (Источник: Reddit r/MachineLearning)
Инженерия данных как карьерный путь к инженеру машинного обучения: На форуме Reddit обсуждается целесообразность использования должности инженера данных (Data Engineer, DE) как пути к тому, чтобы в конечном итоге стать инженером машинного обучения (ML Engineer, MLE). Опытный специалист по данным считает, что это хорошая отправная точка для изучения ETL/ELT, конвейеров данных, озер данных и т.д., после чего можно постепенно перейти на должность MLE, изучив математику, алгоритмы ML, MLOps и т.д., и подкрепив это сертификатами или опытом проектов (Источник: Reddit r/MachineLearning)
Мероприятие Pie & AI от DeepLearning.AI в Варшаве: DeepLearning.AI продвигает свое первое мероприятие Pie & AI, проводимое в Варшаве, Польша, в сотрудничестве с Sii Poland (Источник: DeepLearningAI)

Анонс мероприятия Deep Tech Week: Мероприятие Deep Tech Week вернется в Сан-Франциско 22-27 июня, а также пройдет в Нью-Йорке. Мероприятие выросло из одного твита в децентрализованную конференцию, включающую 85 мероприятий и привлекающую более 8200 участников (представляющих 1924 стартапа и 814 инвестиционных организаций), с целью демонстрации передовых технологий и содействия обмену и сотрудничеству (Источник: Plinz)

Первая офлайн-встреча SkyPilot: Команда SkyPilot поделилась информацией об успешном проведении их первой офлайн-встречи (meetup), которая привлекла множество разработчиков и пригласила докладчиков из Abridge, проекта vLLM, Anyscale и других организаций для обмена опытом использования SkyPilot (Источник: skypilot_org)

Обсуждение: вызовы специализированного обучения: Члены сообщества обсуждают причины, по которым трудно достичь «мастерства» в обучении. Одна точка зрения заключается в том, что многие из самых полезных навыков (например, написание CUDA Kernel) требуют владения знаниями из нескольких смежных дисциплин (например, PyTorch, линейная алгебра, C++), а не极致ного овладения одним навыком. Изучение новых навыков требует быть одновременно умным и готовым «выглядеть дураком», смело выходя из зоны комфорта (Источник: wordgrammer, wordgrammer)