Ключевые слова:гуманоидный робот, применение ИИ, ОИИ (Общий Искусственный Интеллект), автопилот, марафон гуманоидных роботов, Агент+MCP, прогноз DeepMind по ОИИ, чисто визуальная FSD от Tesla, клон голоса GPT-SoVITS, химические рассуждения ChemAgent, бизнес-модель роботов Zhiyuan, проблемы монополии GPU от Nvidia
🔥 Фокус
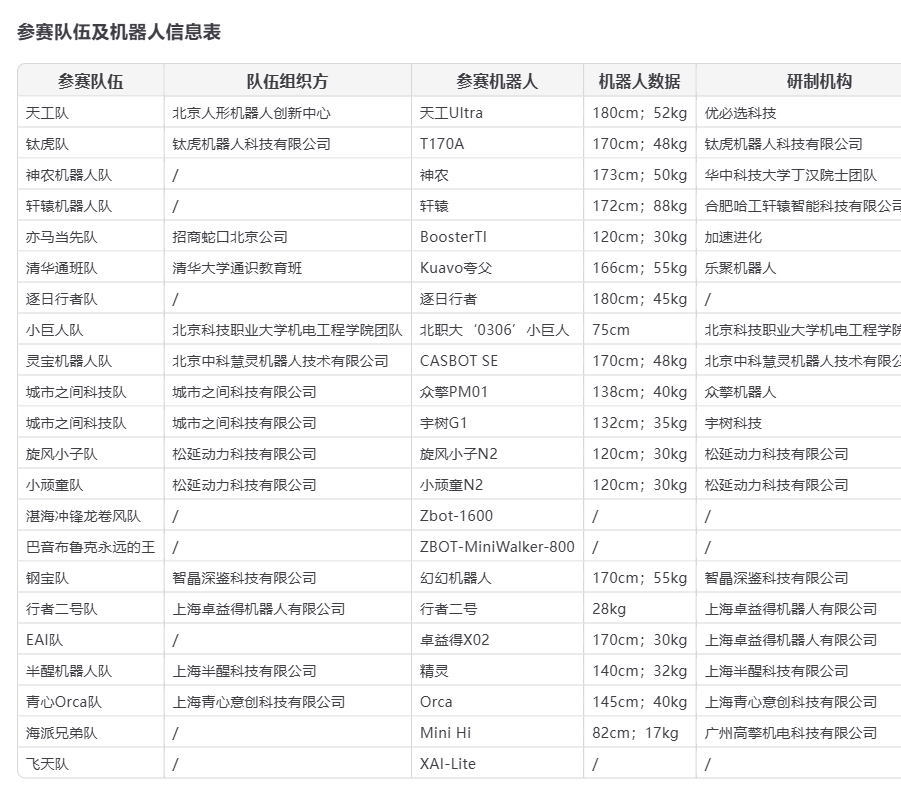
Дебют человекоподобных роботов на Пекинском полумарафоне: сочетание возможностей и вызовов: На Пекинском полумарафоне Ичжуан 2025 года 21 команда человекоподобных роботов впервые соревновалась с людьми. TianGong Ultra, Songyan Dynamics N2 и Zhuoyide Walker II заняли первые три места. Соревнование подчеркнуло потенциал человекоподобных роботов, но также выявило множество проблем, таких как падения, время автономной работы, управление (в основном дистанционное). После гонки Unitree Technology прокомментировала инцидент с падением своего робота G1, отметив, что самостоятельная разработка и управление пользователем сильно влияют на производительность робота. Это событие не только продемонстрировало начальный масштаб индустрии человекоподобных роботов в Китае, но и вызвало широкие дискуссии о зрелости технологий, стоимости (предварительная цена Songyan N2 от 39 900 юаней), путях коммерциализации (аренда, промышленное применение) и будущем развитии (большие модели AI, автономное обучение). Хотя отрасль привлекает капитал, краткосрочная прибыльность затруднена, а рыночное внедрение все еще требует времени (Источник: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
Новая парадигма AI-приложений: Agent+MCP становится формулой хита 2025 года: Сочетание способности Agent к автономному планированию и действиям с возможностью протокола MCP вызывать внешние инструменты и данные становится новым трендом в AI-приложениях. Продукты, такие как Coze Space, Fellou, Dia, GenSpark, Zhipu AutoGLM, появляются один за другим и привлекают внимание. Многие из этих продуктов развились из AI-поиска, пытаясь создать барьеры для пользовательского опыта через различный дизайн продукта (простота использования, исследовательские возможности, реализация). Несмотря на огромный потенциал, в настоящее время они все еще сталкиваются с проблемами, связанными с ограничениями возможностей моделей, получением информации между платформами, моделями коммерциализации и т.д. Microsoft также представила мультиагентную систему UFO² для настольных компьютеров, предвещая, что AM (Agent+MCP) станет важным направлением для AI-продуктов (Источник: 2025年,AI应用的爆款公式只有一个)
Дебаты о будущем AI: Hassabis предсказывает излечение всех болезней за десять лет, историк из Гарварда предупреждает об уничтожении человечества AGI: CEO Google DeepMind Demis Hassabis в интервью предсказал, что AI достигнет AGI в течение 5-10 лет и, возможно, излечит все болезни в течение десятилетия, демонстрируя прогресс AI, такой как Project Astra. Он считает, что AI станет конечным инструментом для ускорения научных открытий. Однако историк из Гарварда Niall Ferguson предупредил, что приход AGI может привести к тому, что человечество будет вытеснено, как конные экипажи, или даже уничтожено, став “инопланетянами”, созданными самим человечеством. Он отметил, что такие тенденции, как институциональная косность и снижение глобальной рождаемости, могут привести к тому, что человечество “сойдет с исторической сцены” перед лицом AGI. Эта дискуссия подчеркивает огромный контраст между крайним оптимизмом в отношении потенциала AGI и глубокой обеспокоенностью будущим человеческой цивилизации (Источник: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 Динамика
Прогресс в индустрии робототехники ускоряется, коммерциализация набирает обороты: На Кантонской ярмарке впервые создан специальный павильон для сервисных роботов, где отечественные производители, такие как Pangolin Robot, Hongxu Jin Technology и другие, получили большое количество зарубежных заказов, демонстрируя конкурентоспособность китайских сервисных роботов на мировом рынке. В то же время человекоподобные роботы таких компаний, как Midea, проходят итерации и планируют начать “работать” на заводах. В производственной цепочке, хотя и есть разработки в сегментах PCB, датчиков, новых материалов (таких как PEEK), до крупномасштабного серийного производства еще далеко; ключевыми являются технологии, стоимость и замкнутый цикл сценариев применения. Многие производители планируют достичь серийного производства на уровне тысяч единиц к 2025 году, что, как ожидается, будет способствовать развитию производственной цепочки и накоплению данных, ускоряя переход роботов к более практической стадии (Источник: 机器人组团“营业”引爆声量场,产业链频刷进展)

Tesla настаивает на FSD только с использованием камер, маршрут с Lidar сталкивается с вызовами и возможностями: Musk подтвердил уверенность в решении только с использованием камер для достижения FSD, считая, что камеры плюс AI могут имитировать человеческое вождение без необходимости Lidar. Несмотря на снижение стоимости (китайские Lidar уже стоят сотни долларов) и рыночное распространение (уже на автомобилях стоимостью около 100 000 юаней), Tesla придерживается своего пути, что предъявляет чрезвычайно высокие требования к ее вычислительным мощностям, алгоритмам и данным. В то же время производители Lidar, такие как Hesai и RoboSense, доминируют на рынке благодаря ценовым преимуществам и технологическим итерациям, активно расширяя зарубежные рынки и неавтомобильные бизнесы, такие как робототехника. Приближение автономного вождения уровня L3 может предоставить новые возможности для Lidar, поскольку его способность к обеспечению безопасности и восприятию в определенных сценариях считается незаменимой (Источник: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4, возможно, находится на стадии внутреннего тестирования: По слухам, Google проводит внутреннее тестирование своих моделей генерации изображений следующего поколения Imagen 3 и Imagen 4, что указывает на возможные крупные шаги Google в области генерации изображений с целью догнать или превзойти конкурентов (Источник: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM выпускает серию моделей кодирования SWE-Dev: Исследовательская группа по инженерии знаний и интеллектуальному анализу данных Университета Цинхуа (THUDM) выпустила серию больших моделей кодирования SWE-Dev на базе Qwen-2.5 и GLM-4, включая версии 7B, 9B и 32B, с целью повышения возможностей AI в задачах разработки программного обеспечения и кодирования (Источник: Reddit r/LocalLLaMA)

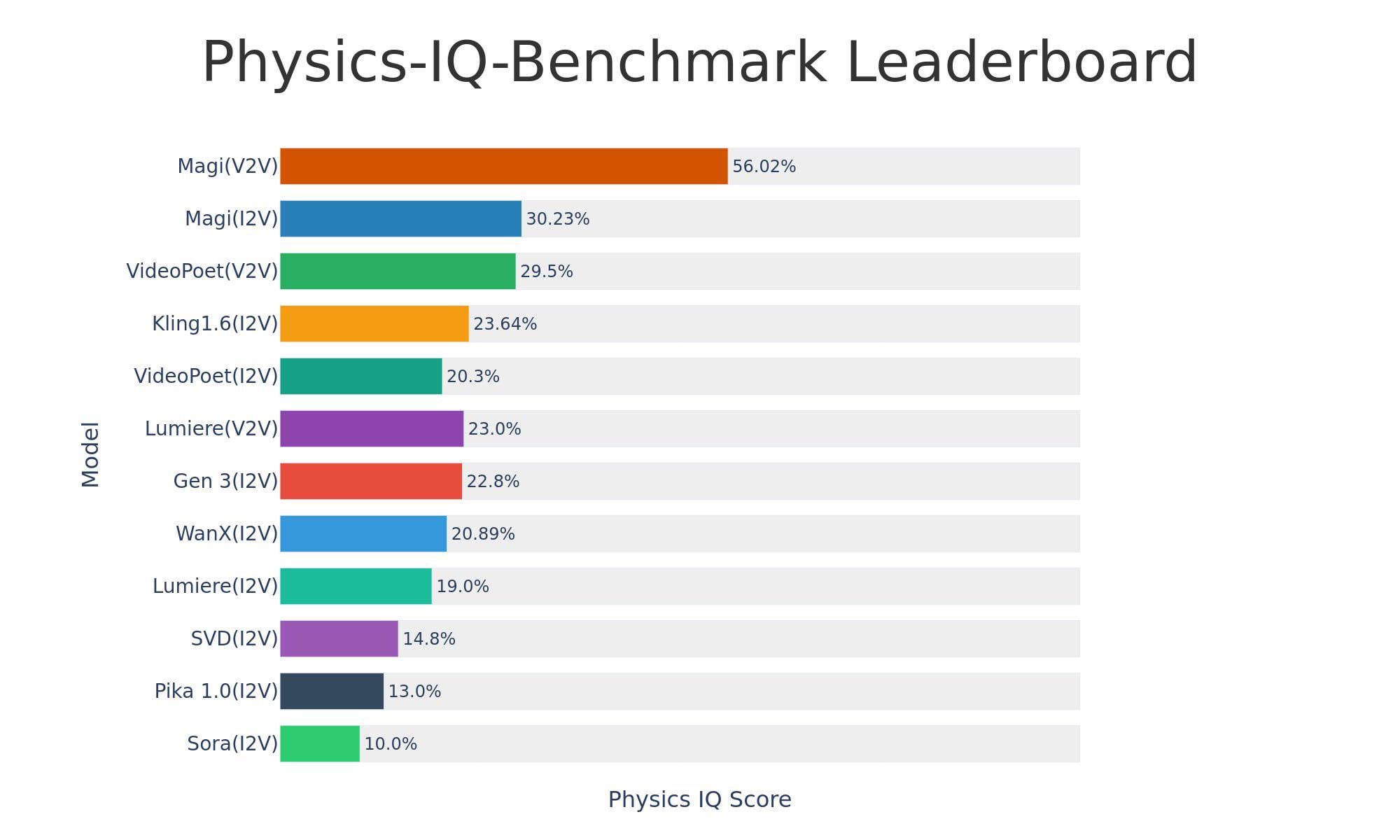
Sand-AI выпускает модель генерации видео с открытым исходным кодом Magi-1: Sand-AI выпустила Magi-1, авторегрессионную диффузионную модель генерации видео с открытым исходным кодом, которая, как утверждается, может генерировать видео неограниченной длины и поддерживает генерацию видео из текста, изображений и других видео. Модель показала отличные результаты в тестах на понимание физики, но для ее работы требуется очень большой объем видеопамяти (около 640 ГБ VRAM). Код и модель опубликованы на GitHub и Hugging Face (Источник: Reddit r/LocalLLaMA)
Grok добавляет возможности визуального восприятия, многоязычного аудио и поиска в реальном времени: xAI объявила, что модель Grok теперь обладает способностью к визуальному пониманию, а в голосовом режиме поддерживает ввод многоязычного аудио и функции поиска в реальном времени, что расширяет ее возможности мультимодального взаимодействия и получения информации (Источник: grok, xai)
Модель Grok 3 доступна на You.com: Флагманская модель Grok 3 от xAI теперь доступна в поисковой системе You.com, где пользователи могут опробовать ее возможности (Источник: xai)

Выпущена и привлекла внимание модель TTS с открытым исходным кодом Dia: Выпущена модель преобразования текста в речь (TTS) с открытым исходным кодом под названием Dia, которая, как утверждается, по качеству сопоставима с коммерческими моделями, такими как ElevenLabs и OpenAI. Она поддерживает клонирование голоса zero-shot и синтез в реальном времени, может работать на MacBook. Модель быстро привлекла внимание на Hugging Face и была освещена такими СМИ, как VentureBeat (Источник: huggingface, huggingface, huggingface)
Демонстрация технологии автопилота Tesla: Демонстрируются видео или информация, связанные с технологией автопилота Tesla Autopilot, что продолжает вызывать интерес к прогрессу в области автономного вождения (Источник: Ronald_vanLoon)
Демонстрация робототехники: Несколько источников демонстрируют различные применения роботов, включая роботизированные руки для сборки гаджетов, оценку робота TITA, амфибийного робота Copperstone HELIX Neptune, а также то, как роботы воспринимают мир, что свидетельствует о постоянном развитии робототехники в различных областях (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Инструменты
GPT-SoVITS: Мощный инструмент для клонирования голоса few-shot и преобразования текста в речь: Разработанный RVC-Boss, GPT-SoVITS — это проект с открытым исходным кодом (44k+ звезд на GitHub), который позволяет обучить высококачественную модель TTS всего за 1 минуту голосовых данных, реализуя клонирование голоса few-shot. Он поддерживает zero-shot TTS (мгновенное преобразование с 5-секундным вводом), кросс-языковой вывод (поддерживает английский, японский, корейский, кантонский, китайский) и интегрирует набор инструментов WebUI, включая разделение вокала и аккомпанемента, автоматическое разделение обучающего набора, китайский ASR и разметку текста, что упрощает создание наборов данных и моделей пользователями. Проект обновлен до версии V4, постоянно оптимизируя сходство тембра, стабильность и качество вывода (Источник: RVC-Boss/GPT-SoVITS — GitHub Trending (all/daily))

Команда из Цинхуа запускает SurveyGO (Juan Ji): Инструмент для обзора литературы и генерации длинных отчетов на базе AI: Основанный на технологии LLMxMapReduce-V2, разработанной командами Tsinghua NLP, OpenBMB и ModelBest, SurveyGO способен эффективно обрабатывать большие объемы литературы (онлайн-поиск или загрузка файлов), генерируя структурированные, логически последовательные и точно цитируемые обзорные отчеты объемом в десятки тысяч слов. Инструмент оптимизирует структуру с помощью механизма свертки, управляемого информационной энтропией, и генерирует контент по уровням, решая проблему фрагментарности и отсутствия глубины при генерации длинных текстов традиционными AI. Пользователи могут использовать веб-версию, вводя тему или загружая файлы, с целью значительного повышения эффективности исследования литературы и написания текстов для исследователей и создателей контента (Источник: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui выпускает портативную версию, ориентированную на llama.cpp: Для упрощения развертывания text-generation-webui выпустила портативную, самодостаточную версию (около 700 МБ), ориентированную на llama.cpp. Пользователи могут запустить ее после загрузки и распаковки, без необходимости установки Python, PyTorch или других зависимостей. Новая версия поддерживает Windows/Linux/macOS (включая версии для CPU/CUDA), оптимизирована скорость запуска и пользовательский опыт, что очень удобно для пользователей, которые хотят использовать только llama.cpp для локального вывода (Источник: Reddit r/LocalLLaMA)
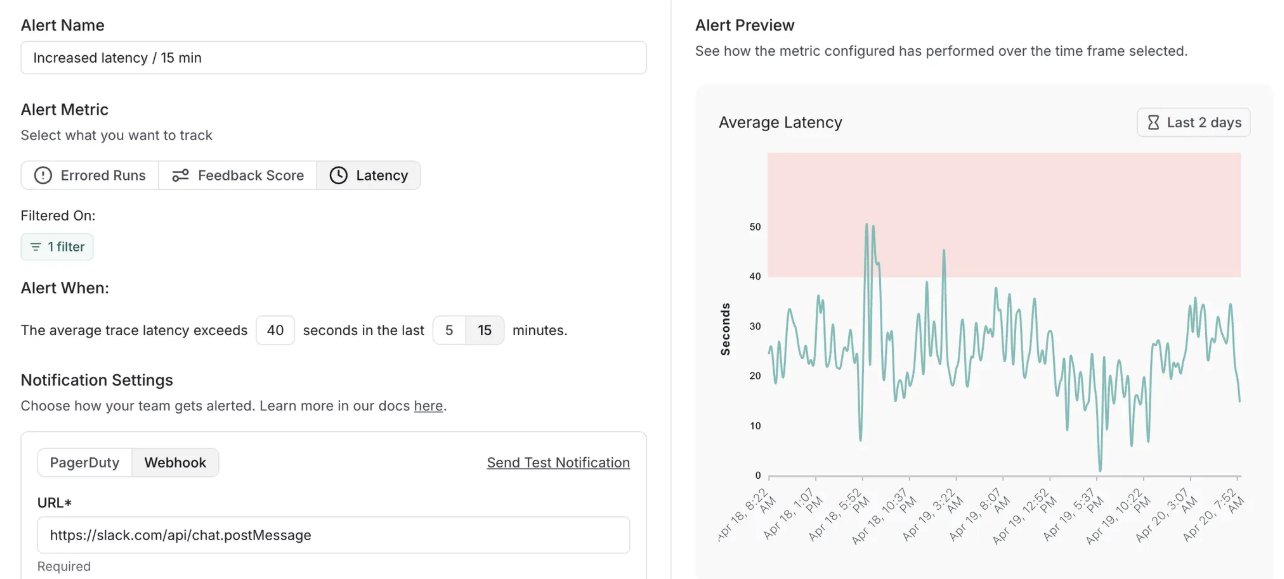
LangSmith добавляет функцию оповещений и обновляет self-hosted версию: Платформа MLOps от LangChain, LangSmith, добавила функцию оповещений в реальном времени, позволяющую пользователям настраивать уведомления об уровне ошибок, задержке выполнения и оценках обратной связи. Ее self-hosted версия обновлена до v0.10, включая оповещения, новый UI для создания и просмотра оценок, поддержку данных отслеживания клиентов OpenTelemetry и оптимизацию производительности, помогая разработчикам раньше обнаруживать проблемы в производственной среде (Источник: LangChainAI, LangChainAI)
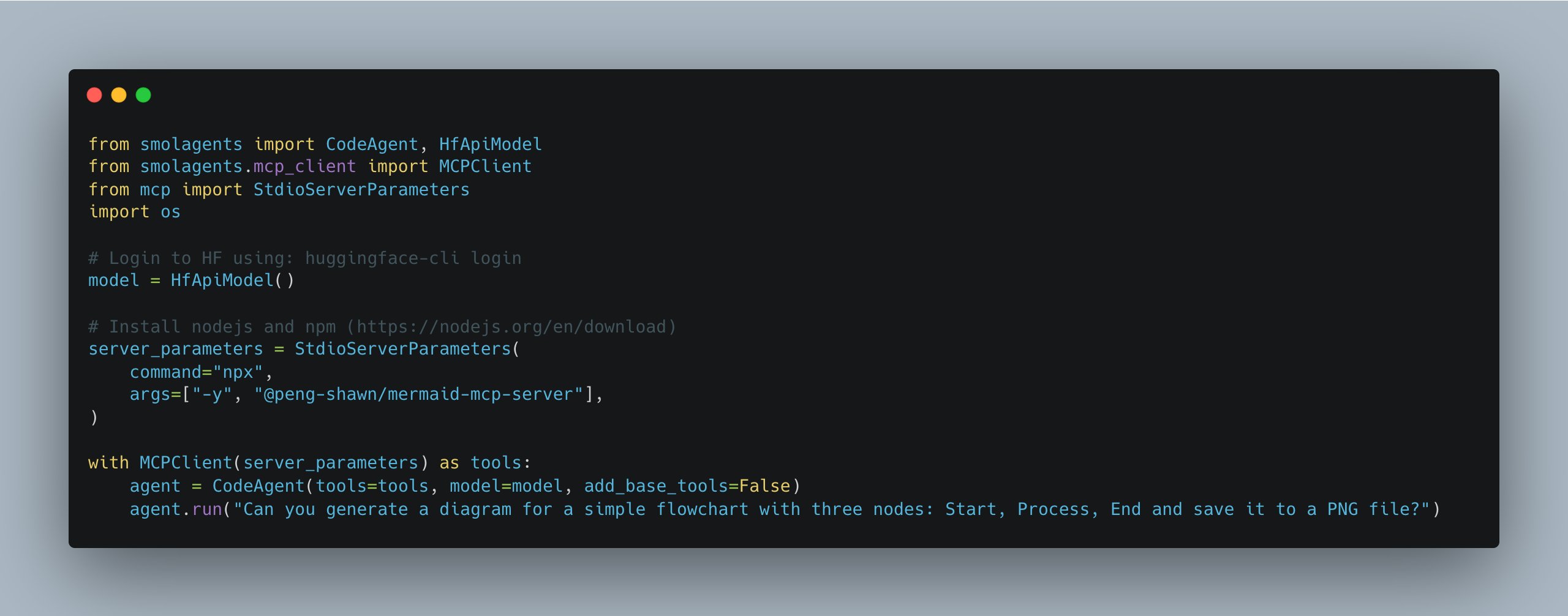
Обновление smolagents упрощает управление несколькими серверами MCP: Библиотека smolagents от Hugging Face выпустила новую версию, представив класс MCPClient, который значительно упрощает управление одновременными подключениями к нескольким серверам MCP (Model Communication Protocol), облегчая создание и координацию более сложных систем Agent (Источник: huggingface)
Suna: Платформа Agent с открытым исходным кодом, конкурент Manus: Kortix AI выпустила платформу Agent с открытым исходным кодом Suna, позиционируемую как альтернатива Manus. Suna интегрирует автоматизацию браузера, управление файлами, веб-скрейпинг, расширенный поиск, выполнение командной строки, развертывание веб-сайтов и интеграцию API, позволяя AI совместно использовать эти инструменты для решения сложных задач и автоматизации рабочих процессов через диалог (Источник: karminski3)
Exa MCP теперь поддерживает поиск в Twitter без API: Сервер MCP от Exa обновлен и теперь поддерживает прямой поиск контента в Twitter без необходимости ключа API Twitter. Это удобно для AI Agent, которым нужна информация из Twitter, но некоторые пользователи сообщают о плохой поддержке сбора данных на китайском языке (Источник: karminski3)
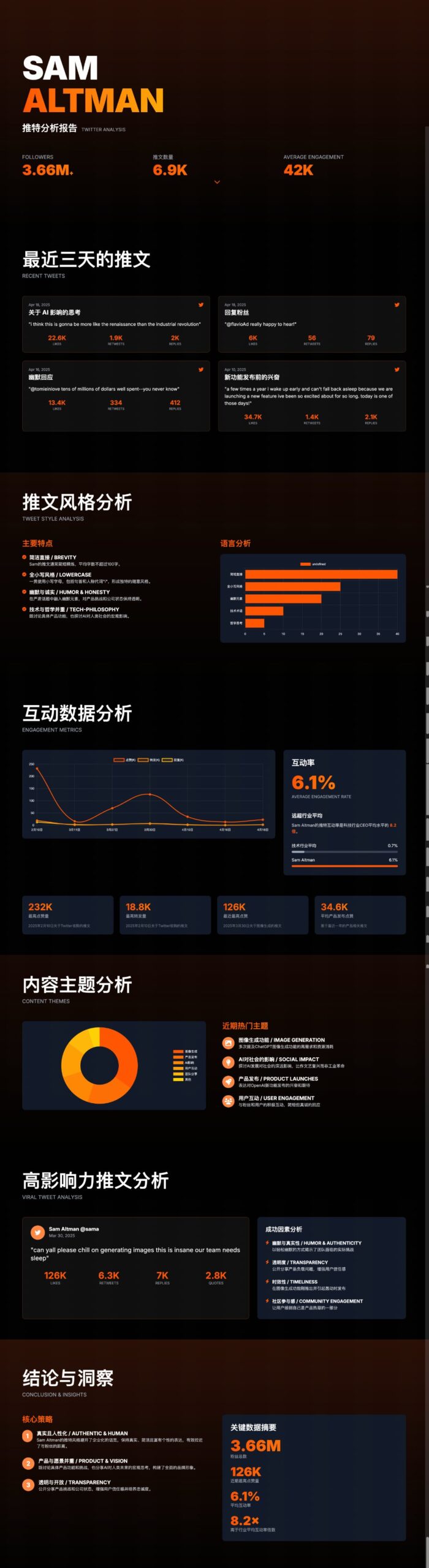
ChatUI-energy: Интерфейс, отображающий энергопотребление AI-диалога в реальном времени: Члены сообщества Hugging Face выпустили ChatUI-energy, вариант Chat UI, который может в реальном времени отображать энергию, потребляемую при диалоге с моделями с открытым исходным кодом (такими как Llama, Mistral, Qwen, Gemma и др.). Этот шаг направлен на повышение прозрачности энергопотребления при использовании AI и вызывает дискуссии о том, должно ли это стать стандартной функцией (Источник: huggingface, huggingface)
Использование AI для разработки, развертывания и оптимизации веб-приложений: Статья делится практическим опытом использования AI (например, Lovable, Cursor, BrowserTools MCP) для разработки веб-сайта для склейки изображений. Охватывает весь процесс от прототипирования, кодирования, отладки до автоматического развертывания CI/CD с использованием Vercel+GitHub и настройки DNS, демонстрируя ценность AI в повышении эффективности независимой разработки и эксплуатации веб-сайтов (Источник: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

Легковесное воссоздание “Her” OS1/Samantha на базе локальных моделей: Разработчик использовал transformers.js и модели ONNX (Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS и др.) для локального воссоздания в браузере AI-помощника OS1/Samantha из фильма “Her”. Проект демонстрирует возможность реализации локально работающего голосового интерактивного AI при размере моделей около 2 ГБ и предоставляет открытый исходный код (Источник: Reddit r/LocalLLaMA)
ChatWise в сочетании с серверами MCP для реализации RAG и синхронизации данных: Пользователь поделился примером конфигурации рабочего процесса в ChatWise с использованием системных инструкций в сочетании с серверами MCP для Pinecone (база данных), Exa (поиск) и Time (время) для реализации простого RAG (Retrieval-Augmented Generation) и синхронизации данных (Источник: op7418)

📚 Обучение
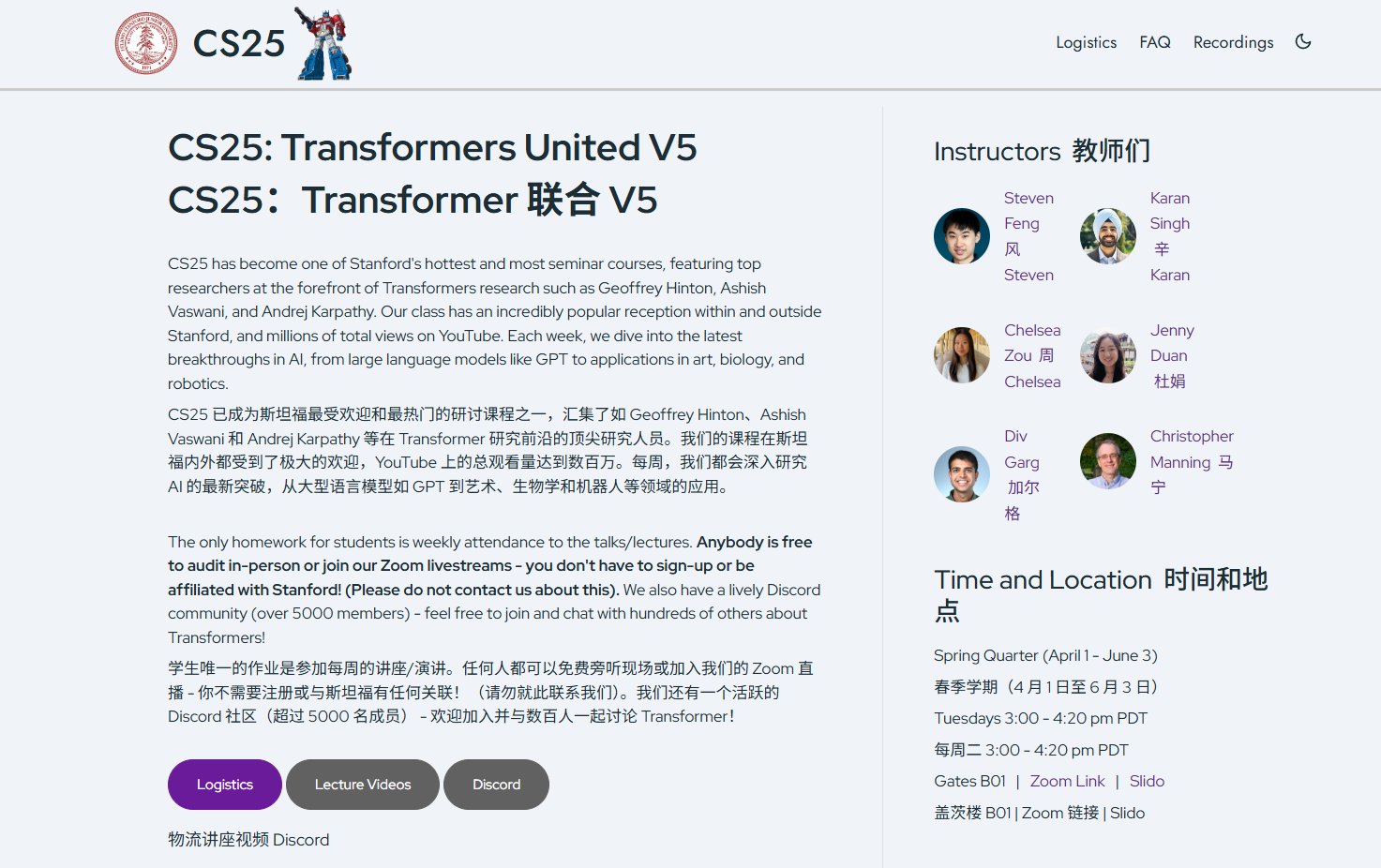
Стэнфордский университет открывает курс по Transformer CS25: Популярный семинарский курс Стэнфордского университета по Transformer CS25 открыт для публики (прямая трансляция/запись через Zoom). На курс приглашены ведущие ученые и отраслевые эксперты в области AI, такие как Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani, для чтения лекций по передовым темам, включая архитектуру LLM, мультимодальность, научные приложения, робототехнику и др. Веб-сайт курса предоставляет расписание и ссылки на записи, а также сообщество Discord для обсуждения (Источник: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Исследование Университета Цинхуа и Шанхайского университета Цзяотун выявляет ограничения RL для способностей LLM к рассуждению: Последнее исследование Университета Цинхуа и Шанхайского университета Цзяотун показывает, что хотя обучение с подкреплением (RL) может повысить точность больших моделей при малом количестве выборок (эффективность), оно может ограничивать их способность решать более сложные проблемы при большом количестве выборок (границы возможностей). По сравнению с базовой моделью, охват моделей, обученных с помощью RL, по метрике pass@k снижается при высоких значениях k. Исследование предполагает, что RL лучше оптимизирует существующие возможности, чем расширяет границы рассуждений, и текущие методы RL могут застревать в локальных оптимумах из-за недостаточного исследования (Источник: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

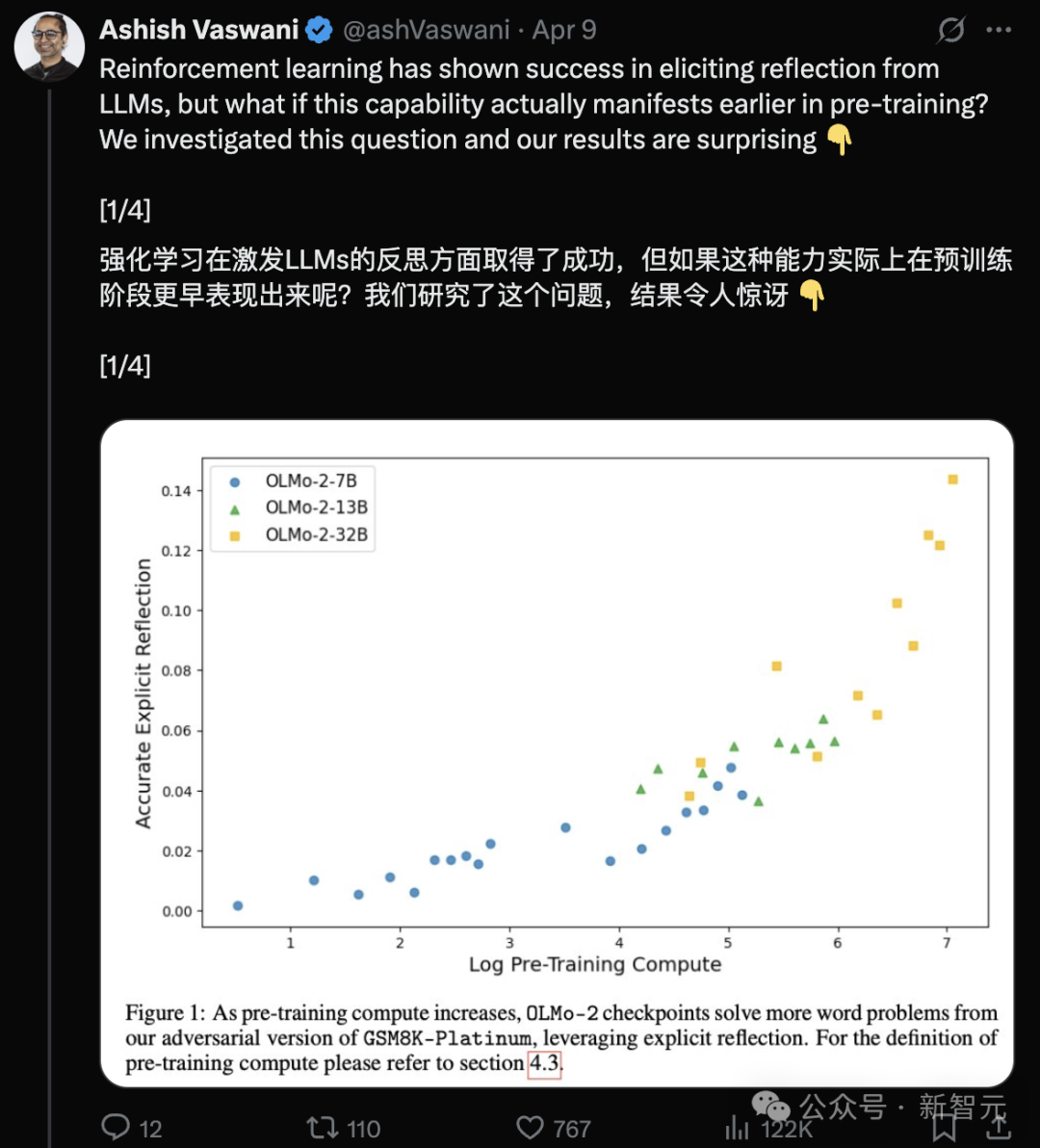
Команда авторов Transformer: LLM обладают способностью к рефлексии уже на этапе предварительного обучения: Команда под руководством первого автора статьи о Transformer Ashish Vaswani опубликовала исследование (arXiv:2504.04022), оспаривающее мнение о том, что “способность к рефлексии в основном исходит от RLHF”. Исследование, вводя состязательные цепочки мыслей, обнаружило, что LLM (например, OLMo-2) демонстрируют контекстуальную рефлексию и саморефлексию уже на этапе предварительного обучения, и эта способность усиливается с увеличением объема вычислений при предварительном обучении. Простой промпт “Wait,” эффективно стимулирует явную рефлексию, его эффект сравним с прямым указанием модели на ошибку. Это дает новый взгляд на понимание эмерджентных способностей в процессе предварительного обучения (Источник: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent: Самообновляемая база знаний повышает способность LLM к химическим рассуждениям: Исследователи из Йеля, Стэнфорда и других учреждений предложили фреймворк ChemAgent, который значительно повышает точность LLM в задачах химического рассуждения (в среднем на 10%-37% на наборе данных SciBench) за счет введения динамической самообновляемой базы знаний, включающей планирование, выполнение и хранение знаний. Фреймворк имитирует человеческое обучение, разбивая задачи и используя структурированную память для решения проблем, особенно заметно улучшение точности вычислений и преобразования единиц. Исследование анализирует взаимосвязь между сходством памяти, ее объемом и производительностью, а также указывает на ограничения в понимании проблем, планировании рассуждений и выборе памяти (Источник: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
Южно-Китайский технологический университет добился серии успехов в области распределенных эволюционных вычислений: Команда по вычислительному интеллекту Южно-Китайского технологического университета добилась серии результатов в области “распределенных эволюционных вычислений в консенсусе и сотрудничестве мультиагентных систем”: опубликован обзор этой междисциплинарной области; предложены инновационные методы, такие как алгоритм MASOIE (внутреннее и внешнее обучение), алгоритм MACPO (стимулирование целями), механизм адаптации шага CCSA, алгоритм MASTER (сотрудничество на основе вклада), и их эффективность подтверждена в таких сценариях, как позиционирование беспроводных сенсорных сетей. Команда также организовала первый конкурс по оптимизации распределенного консенсуса черного ящика (Источник: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
Серия видеоуроков по созданию DeepSeek с нуля: Vizuara опубликовала на YouTube серию видеоуроков “Создаем DeepSeek с нуля”, уже доступно 13 лекций, охватывающих основы DeepSeek, обработку Token, механизмы внимания (self-attention, causal, multi-head, multi-query, grouped-query, multi-head latent), KV Cache и другие ключевые концепции с объяснениями и реализацией кода. Цель — глубокий анализ архитектуры DeepSeek, планируется всего 40+ часов, 35-40 эпизодов (Источник: karminski3, Reddit r/LocalLLaMA)
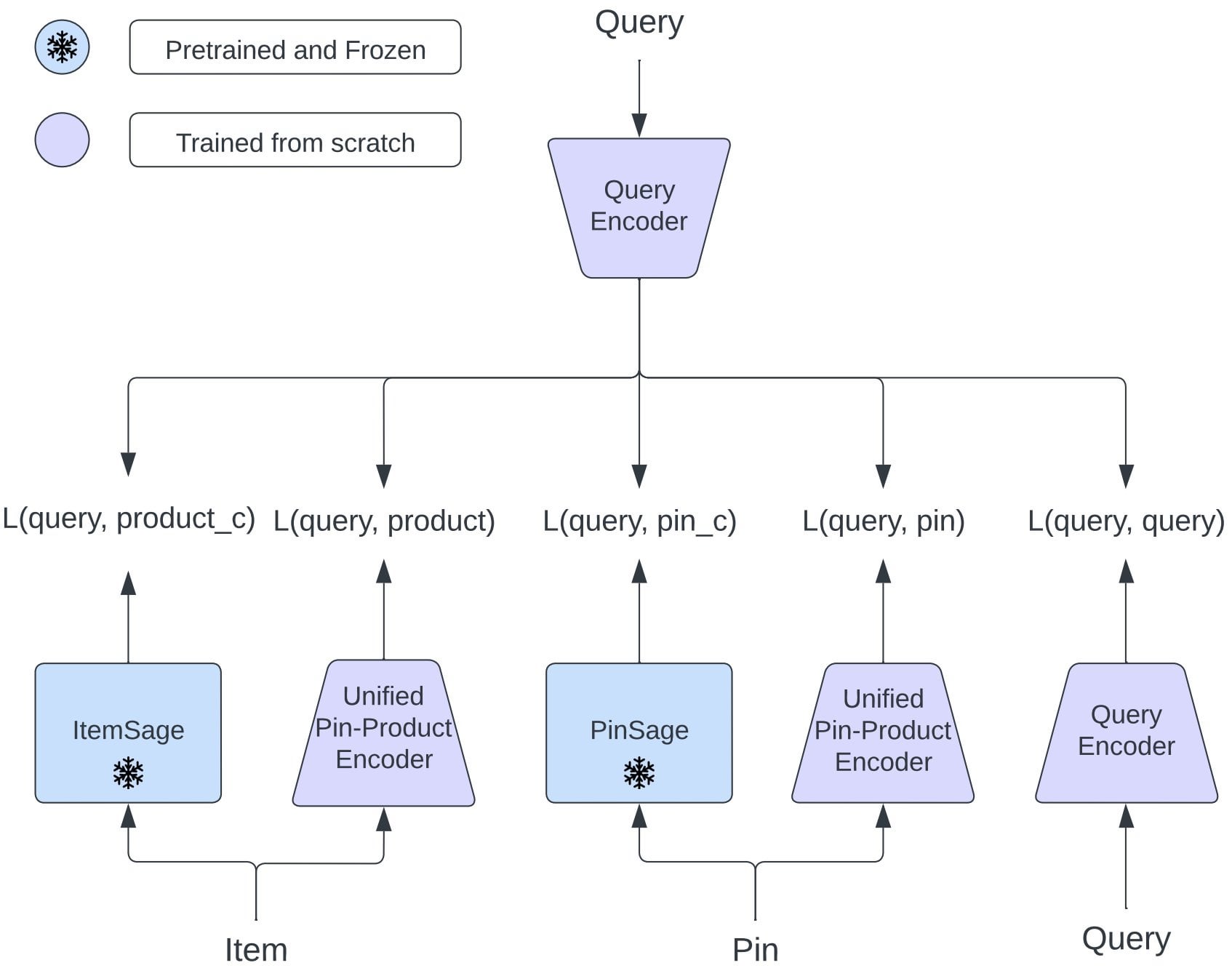
Pinterest предлагает OmniSearchSage: Единая модель встраивания для улучшения многозадачного поиска: Исследовательская статья Pinterest представляет OmniSearchSage, единую модель встраивания запросов, обученную с помощью многозадачного обучения, способную одновременно извлекать пины, продукты и связанные запросы. Модель объединяет заголовки, сгенерированные GenAI, сигналы от пользовательских досок (board) и данные о поведении, может быть напрямую интегрирована в существующие системы, такие как PinSage, и показала значительные улучшения в поиске, рекламе и задержке (Источник: Reddit r/MachineLearning)
FlowReasoner: Динамически настраиваемый мультиагентный рабочий процесс на основе запроса: Новая статья предлагает метод FlowReasoner, целью которого является мгновенное выведение эксклюзивного мультиагентного рабочего процесса для каждого пользовательского запроса. С помощью обучения с подкреплением推理 SFT и GRPO модель может динамически переписывать рабочий процесс (например, последовательность комбинаций генерации кода, проверки, тестирования, исправления) на основе обратной связи от выполнения. Метод проверен в сценарии Code Interpreter, демонстрируя потенциал динамической адаптации рабочего процесса к требованиям запроса (Источник: dotey)

Учебник LangChain: Создание рабочего процесса генерации отчетов о соответствии с использованием LlamaIndex: LlamaIndex выпустил видеоурок, демонстрирующий, как создать Agentic Workflow для генерации отчетов о соответствии. Учебник показывает процесс настройки индекса, определения схем, использования семантического поиска для нахождения нормативных актов и объединения LLM для обработки текста, сравнения с договорами и генерации резюме (Источник: jerryjliu0)

Учебник LangChain: Самовосстанавливающийся Agent для генерации кода: LangChain выпустил учебник по созданию самовосстанавливающегося AI Agent для генерации кода с использованием фреймворка OpenEvals и песочницы E2B. Основная идея заключается в добавлении шага рефлексии после генерации кода AI для проверки и исправления с помощью инструментов оценки, что повышает качество и надежность кода (Источник: LangChainAI)

Анализ Anthropic обнаруживает у Claude внутренние моральные принципы: После анализа 700 000 диалогов Claude компания Anthropic обнаружила, что ее AI-модель демонстрирует своего рода внутренние моральные принципы. Это открытие, основанное на исследовании крупномасштабных реальных взаимодействий с пользователями, может иметь важное значение для исследований в области безопасности и выравнивания AI (Источник: Reddit r/ClaudeAI, Reddit r/artificial)

Google предлагает “Эру опыта” для решения проблемы нехватки данных для обучения AI: Исследователи Google (включая David Silver) опубликовали статью “The Era of Experience”, предлагая позволить AI Agent самостоятельно генерировать данные опыта через взаимодействие со средой для обучения самих себя, чтобы преодолеть текущие узкие места, связанные с зависимостью от крупномасштабных данных, аннотированных человеком. Это может предвещать сдвиг парадигмы обучения AI в сторону более автономного обучения (Источник: Reddit r/artificial)

Список бесплатных сертификатов и курсов: Репозиторий GitHub cloudcommunity/Free-Certifications собирает большое количество бесплатных онлайн-курсов и ресурсов для сертификации, охватывающих IT, облачные технологии, AI, безопасность, маркетинг и другие области. Ресурсы, связанные с AI, включают курс по машинному обучению на Python от freeCodeCamp, основы GenAI от Databricks, курсы по AI от IBM Cognitive Class, введение в AI/ML на платформе Google Cloud Skills Boost, курс по глубокому обучению с подкреплением от HuggingFace и др. (Источник: cloudcommunity/Free-Certifications — GitHub Trending (all/daily))
Тестирование надежности LLM для редактирования кода: Пользователь поделился видео тестирования надежности нескольких LLM (таких как ChatGPT и др.) в задачах помощи при написании кода для глубокого обучения. Такие тесты помогают понять производительность, преимущества и ограничения текущих AI-помощников по кодированию в реальных сценариях разработки (Источник: Reddit r/deeplearning)

💼 Бизнес
Тарифная война США бьет по китайским стартапам в области AI-оборудования: Введение США высоких тарифов на китайские товары (некоторые до 125%) серьезно ударило по китайским стартапам в области AI-оборудования (например, AI-игрушки, умные очки), ориентированным на американский рынок. Высокие тарифы сокращают прибыль или даже приводят к убыткам, заставляя некоторые компании приостанавливать поставки в США. Хотя умные очки и т.п. временно получили исключение, перспективы неясны. Риски, связанные с зависимостью отрасли от “серого импорта”, возрастают. Это заставляет компании пересматривать зависимость от одного рынка, ускорять глобализацию для диверсификации рисков и может повлиять на последующую оценку при финансировании (Источник: 襁褓中的AI硬件,迎接最激烈的关税战)

Глубокий анализ Zhiyuan Robot: Продукты, технологии и бизнес-модель: Zhiyuan Robot, основанная Zhihui Peng и другими, позиционируется как производитель универсальных воплощенных роботов. Линейка продуктов включает серию “Yuanzheng” для промышленных и коммерческих сценариев и серию “Lingxi” для легковесных и открытых решений. Технологическое ядро — синергия аппаратного и программного обеспечения и замкнутый цикл данных, собственная разработка модулей суставов, ловких рук и программного стека, включая большую модель Qiyuan. Бизнес-модель охватывает продажу оборудования, подписные услуги и доходы от экосистемы. Компания завершила 8 раундов финансирования, оценка достигла 15 млрд юаней, инвесторы включают Hillhouse, BYD, Tencent, сотрудничает с партнерами по цепочке поставок и местными властями (Источник: 智元机器人深度拆解:人形机器人独角兽进化论)

Проект 3D-печати “AtomFab”, инкубированный внутри Dreame, привлек десятки миллионов юаней финансирования: AtomFab, инкубированный Dreame Technology, привлек десятки миллионов юаней ангельских инвестиций от Zhuichuang Ventures. Компания фокусируется на потребительском рынке 3D-печати, используя AI для повышения простоты использования, стабильности и эффективности. Будет использовать технологии двигателей, датчиков, AI-взаимодействия и цепочку поставок Dreame для снижения затрат и ускорения вывода продукта на рынок. Продукты будут в первую очередь ориентированы на рынки Европы и Америки, используя зарубежную сервисную сеть Dreame. Ожидается выпуск первого продукта во второй половине 2025 года (Источник: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
Монопольное положение NVIDIA GPU может столкнуться с вызовами: Анализ показывает, что, несмотря на рост поставок GPU NVIDIA, ее долгосрочное монопольное положение сталкивается с вызовами со стороны облачных гигантов (Google, MS, Amazon, Meta), разрабатывающих собственные чипы (TPU, Maia, Trainium, MTIA) и оптимизирующих системы на уровне системы. Облачные гиганты могут лучше вертикально интегрировать, настраивать оборудование и оптимизировать распределенные системы (сеть, охлаждение, ПО), в то время как NVIDIA относительно отстает в этом. Рост доли задач вывода, усиление конкуренции со стороны AMD и потенциал вывода на CPU также создают давление. Хотя NVIDIA старается адаптироваться (например, Blackwell, Spectrum-X), структурные вызовы сохраняются (Источник: 计算的未来:英伟达王冠正摇摇欲坠)

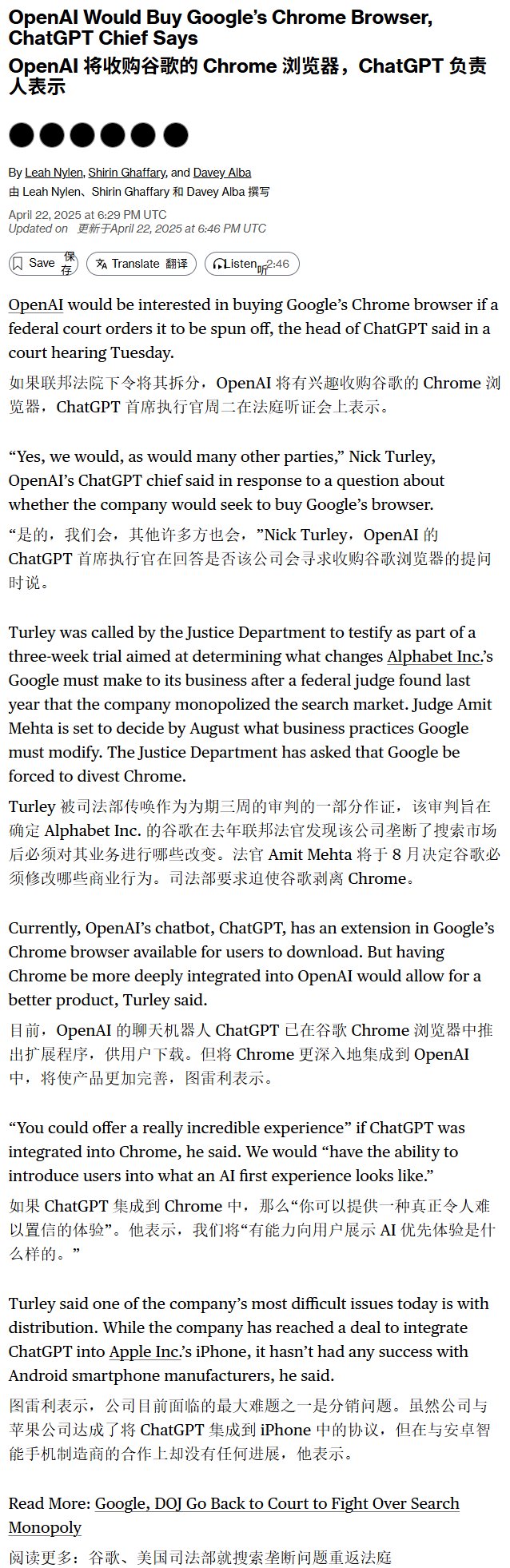
Слухи о том, что OpenAI заинтересована в покупке браузера Chrome: По сообщению Bloomberg, если Google будет вынуждена разделить свой поисковый бизнес из-за антимонопольного дела, OpenAI может рассмотреть возможность приобретения ее браузера Chrome. Этот слух отражает стратегические намерения гигантов AI по контролю над точками входа пользователей и данными, но его достоверность и осуществимость зависят от окончательного исхода антимонопольного дела Google (Источник: karminski3)
Стратегии использования GenAI для достижения бизнес-результатов: Статья Forbes предлагает 9 стратегий, направленных на то, чтобы помочь компаниям перейти от экспериментальной стадии к практическому применению генеративного AI (GenAI) для повышения эффективности и инноваций, получения измеримой коммерческой ценности (Источник: Ronald_vanLoon)

Новый чип Huawei может составить конкуренцию NVIDIA: Обсуждения в социальных сетях указывают на то, что новый AI-чип, выпущенный Huawei, может бросить вызов рыночному положению NVIDIA, особенно на китайском рынке, и потенциально повлиять на будущую технологическую конкуренцию между США и Китаем и переговоры по тарифам (Источник: Reddit r/ArtificialInteligence)
🌟 Сообщество
Золотая лихорадка вокруг DeepSeek и рефлексия: Популярность DeepSeek породила волну попыток монетизации, включая создание контента (массовое производство сценариев для коротких видео), платное обучение (продажа руководств) и услуги по управлению. Однако многие столкнулись с проблемами гомогенизации контента, ограничениями платформ и трудностями с монетизацией. Статья размышляет, что в текущих условиях “посредники”, продающие курсы за счет информационного разрыва, могут быть большими победителями, чем прямые пользователи. В то же время сам DeepSeek имеет ограничения, такие как перегрузка серверов и шаблонные ответы (Источник: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

Разработчик инструмента для читерства с AI привлек финансирование, вызвав этические споры: 21-летний студент Колумбийского университета Chungin Lee был отстранен от занятий за разработку AI-инструмента Interview Coder для читерства на технических собеседованиях. Позже он основал компанию Cluely и расширил инструмент для других сценариев, привлек $5.3 млн финансирования. Он считает, что AI-помощь — это повышение эффективности, а не читерство. Это вызвало бурные дебаты: сторонники видят в этом инновацию, критики опасаются подрыва справедливости и размывания границ способностей, сравнивая с сюжетом “Черного зеркала”. Инцидент затрагивает глубокие вопросы этики AI, справедливости в образовании и определения способностей (Источник: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

Ужесточение визовой политики США может привести к оттоку AI-талантов: Недавние массовые аннулирования виз международных студентов (включая аспирантов по AI) в США по неясным причинам и без прозрачности процесса (возможно, с использованием ошибочной AI-проверки) вызывают обеспокоенность в академических кругах. Считается, что это подрывает привлекательность США для лучших AI-талантов, многие исследователи из ведущих институтов рассматривают возможность отъезда. Это может нанести ущерб исследовательскому потенциалу США в области AI. Студенты уже подали коллективный иск и получили временный запрет (Источник: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

Обсуждение текущего состояния разработки моделей с открытым исходным кодом: Сообщество активно обсуждает модели с открытым исходным кодом: ожидание Qwen 3, медленное принятие Llama 4, возможное достижение плато в улучшении способностей к рассуждению? Потенциал мультимодальных моделей недооценен, Китай продолжает доминировать в опенсорсе. Обсуждение подчеркивает необходимость различать открытые и закрытые модели и указывает, что проблемы с рассуждением могут быть связаны с разнообразием моделей и проблемами масштабирования RL (Источник: natolambert)
Положительные отзывы о поисковых возможностях модели OpenAI o3: Пользователи сообщают, что модель OpenAI o3 отлично справляется с поиском информации, даже очень нишевой, без необходимости большого контекста, обеспечивая естественный опыт взаимодействия (Источник: gdb)
Значение и влияние открытого исходного кода в TTS: Обсуждая модель Dia TTS, сообщество подчеркивает, что ее высокое качество доказывает: обучение SOTA TTS моделей больше не является прерогативой гигантов. Комбинированный эффект знаний и инструментов в индустрии AI снижает порог входа для передовых технологий, а сила открытого исходного кода ускоряет их распространение и демократизацию (Источник: huggingface, huggingface)
Meta проводит LlamaCon 2025 для празднования сообщества открытого исходного кода: Meta объявила о проведении мероприятия LlamaCon 2025, целью которого является признание и празднование вклада и достижений сообщества Llama с открытым исходным кодом, а также обмен последними достижениями и планами на будущее для моделей и инструментов Llama, продолжая инвестировать в экосистему открытого исходного кода (Источник: AIatMeta)

Дискуссия о том, является ли AI действительно “интеллектуальным”: Сообщество пересылает статью “Нам нужно перестать притворяться, что AI интеллектуален”, вызывая дискуссию о границах возможностей текущих технологий AI и определении “интеллекта”. Обсуждение может затрагивать различия между пониманием, рассуждением, сознанием AI и человеческим интеллектом (Источник: Ronald_vanLoon)

Опыт использования ChatGPT: Потеря соединения и тест на честность: Пользователи жалуются на частые проблемы с “потерей сетевого соединения” в ChatGPT, что мешает использованию. В то же время, некоторые делятся промптами, заставляющими ChatGPT использовать функцию памяти для выражения “истинного мнения” о них, исследуя персонализированное взаимодействие с AI и потенциальное “субъективное” выражение (Источник: natolambert, dotey)
Оптимизм в отношении развития робототехники: Сооснователь Hugging Face комментирует, что благодаря открытому аппаратному обеспечению, прогрессу в обучении с подкреплением и концентрации талантов, робототехнические лаборатории в 2025 году полны энтузиазма и веселья, отражая позитивные ожидания отрасли относительно быстрого развития робототехники (Источник: huggingface)
Практичность Gemini Deep Research подтверждена: Пользователь поделился примером использования функции Gemini Deep Research для проверки достоверности информации в твите, демонстрируя ее практическую ценность для быстрой проверки фактов и предоставления глубокого исследовательского контекста (Источник: dotey)

Критика и защита библиотек AI с открытым исходным кодом: Сообщество отмечает рост негативных комментариев в адрес библиотек AI с открытым исходным кодом, призывая к рациональному подходу, указывая, что критика может основываться на устаревшей информации или односторонних показателях, и поощряя критиков участвовать в создании лучших версий (Источник: natolambert)
Предположения об игровом опыте с AI: Пользователи выражают любопытство по поводу будущей формы игрового опыта, управляемого AI, предполагая, что он может быть похож на взаимодействие в VRChat, но также сомневаются в удобстве чисто голосового управления (Источник: karminski3)
Обсуждение функции увеличения изображений в ChatGPT: Пользователи обнаружили, что увеличение изображений с помощью ChatGPT — это не настоящее суперразрешение, а перерисовка похожего изображения. Комментарии сообщества подтверждают это и обсуждают разницу между генерацией и редактированием изображений AI (Источник: Reddit r/ChatGPT)
ChatGPT генерирует изображение своего воображаемого мира: Пользователь попросил ChatGPT сгенерировать изображение мира, каким он его себе представляет, получив идиллическую парковую сцену. Сообщество указало на логические проблемы и потенциальные предвзятости в изображении, отражая ограничения текущих моделей генерации изображений в понимании и творчестве (Источник: Reddit r/ChatGPT)

Обсуждение причин популярности старой модели LLM MythoMax13B: Сообщество обсуждает, почему модель MythoMax13B на базе Llama2 все еще популярна в сценариях RPG. Возможные причины: низкая стоимость (часто бесплатный вариант), стабильная производительность, знакомство пользователей с ее промптами и эффект продвижения ранних руководств (Источник: Reddit r/LocalLLaMA)
Поиск локального инструмента для фильтрации конфиденциальности: Пользователь ищет инструмент или SLM, работающий локально, для автоматической анонимизации конфиденциальной информации в промптах перед отправкой в LLM и восстановления после получения ответа для защиты данных (Источник: Reddit r/OpenWebUI)
Обсуждение предупреждения Anthropic о “полностью AI-сотрудниках”: Предупреждение Anthropic о появлении “полностью AI-сотрудников” в течение года вызвало скептицизм в сообществе; комментаторы считают это преувеличенной рекламой и указывают на проблемы со стабильностью собственных сервисов Anthropic (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

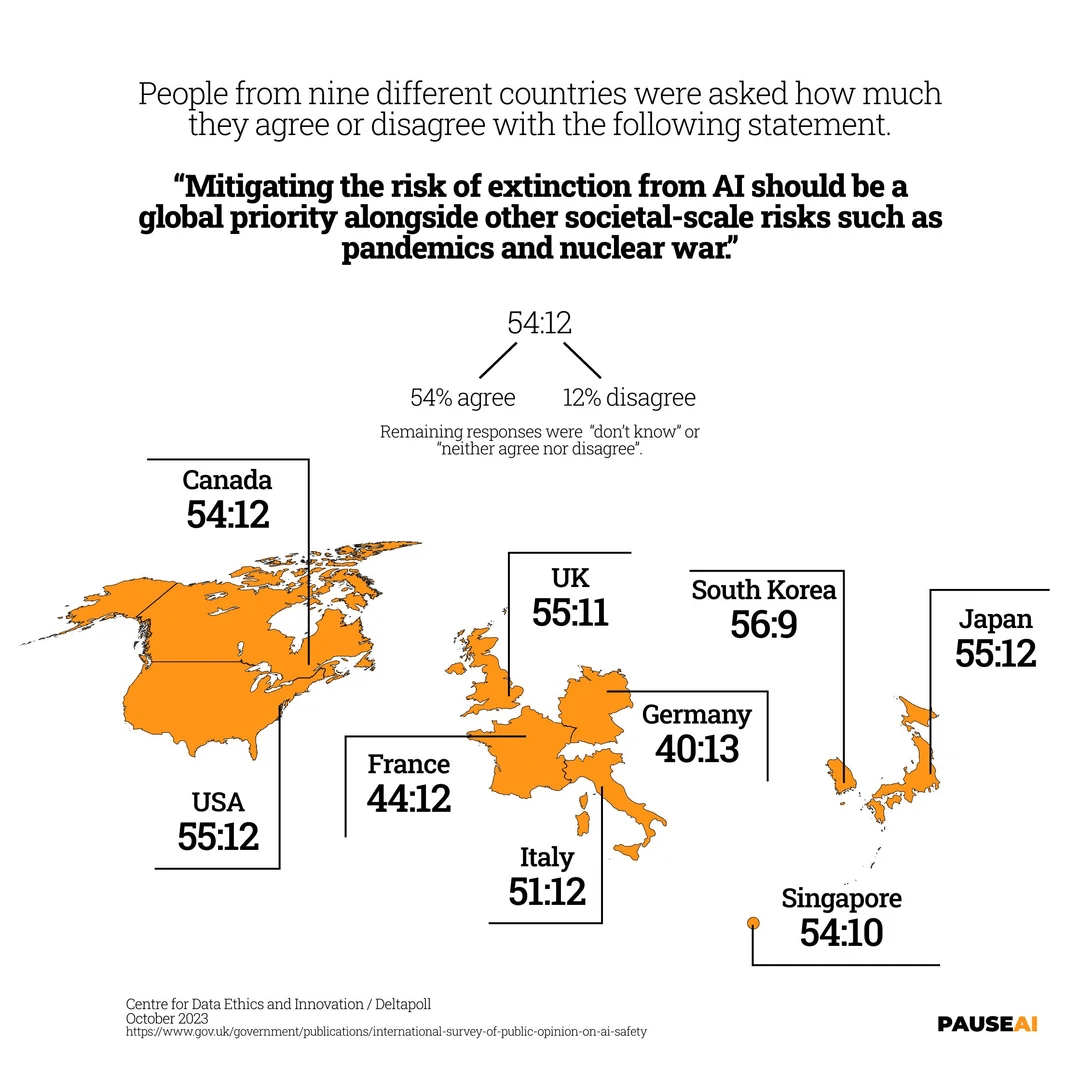
Глобальная обеспокоенность риском уничтожения человечества AI: Результаты опроса показывают, что большинство людей во всем мире считают, что к риску возможного уничтожения человечества AI следует относиться серьезно, отражая общественную обеспокоенность потенциальными рисками сильного искусственного интеллекта (Источник: Reddit r/artificial)
“Машинный привкус” текста, сгенерированного AI, и техники гуманизации: Пользователи делятся опытом, отмечая, что текст, сгенерированный AI, часто кажется “бездушным” из-за отсутствия специфического контекста, излишней формальности и безупречности. Рекомендуется использовать методы, такие как уточнение сценария, предоставление примеров, настройка случайности, добавление конкретных деталей, ручное редактирование и сохранение мелких недостатков, чтобы сделать письмо AI более естественным и “человечным” (Источник: Reddit r/artificial)
Предположения о возможности использования Claude Code через Claude Max: Пользователи предполагают, можно ли косвенно использовать (возможно, более экономичную) модель Claude Code через подписку на более высокий уровень Claude Max, и обсуждают потенциальную ценность такой модели. Это отражает интерес пользователей к различным стратегиям ценообразования и пакетирования функций моделей (Источник: Reddit r/ClaudeAI)
Юмористическая имитация локального поведения модели o3: Пользователь поделился шуточным системным промптом, заставляющим локальную модель LLM имитировать недостатки, в которых некоторые пользователи обвиняют модель OpenAI o3 (например, краткие ответы, ошибки в коде, раздражающее поведение), чтобы выразить недовольство моделью o3 и пошутить в сообществе (Источник: Reddit r/LocalLLaMA)

Проблема с подключением OpenWebUI к прокси-серверу MCP: Пользователь Kubernetes столкнулся с технической проблемой при настройке OpenWebUI, не имея возможности получить доступ к прокси-серверу MCP из веб-интерфейса в том же pod, и ищет техническую поддержку и решения от сообщества (Источник: Reddit r/OpenWebUI)
Обсуждение практик безопасности локальных серверов MCP: Сообщество обсуждает лучшие практики безопасности для локального запуска серверов MCP, включая использование режима stdio, ограничение доступа к режиму SSE локально или использование аутентификации по токену, подчеркивая общую обеспокоенность рисками внедрения промптов и кражи учетных данных (Источник: Reddit r/ClaudeAI)
Обсуждение механизма оплаты в протоколе Agent-to-Agent (A2A): Сообщество обращает внимание на отсутствие встроенного механизма оплаты в протоколе Google A2A, считая, что это может препятствовать развитию экосистемы экономики Agent, и обсуждает потенциальные решения, такие как токены аутентификации, привязанные к счетам, процессы эскроу, встраивание информации о ценах в AgentSkill (Источник: Reddit r/artificial)
Предупреждение о чрезмерной зависимости от AI: Пользователь поделился опытом получения противоречивых ответов от AI поиска Google, предостерегая от полной зависимости от AI при принятии решений. Комментарии сообщества объясняют причины неопределенности, такие как вероятностный характер LLM, смещения в обучающих данных, и рекомендуют использовать AI как вспомогательный исследовательский инструмент (Источник: Reddit r/ArtificialInteligence)
Вопросы по использованию Qdrant для RAG в OpenWebUI: Пользователь ищет конкретные методы интеграции векторной базы данных Qdrant в среду OpenWebUI для реализации RAG, включая технические детали о том, как UI использует данные базы данных и нужен ли скрипт retriever (Источник: Reddit r/OpenWebUI)
Обсуждение сравнения эффективности поиска Google и ChatGPT: Пользователь опубликовал сравнительное изображение, вызвав дискуссию; некоторые считают, что ChatGPT превосходит поиск Google, другие утверждают, что Google Gemini показывает отличные результаты и имеет такие инструменты, как NotebookLM. Обсуждение отражает субъективный опыт и различия в оценке пользователями различных инструментов поиска/ответов AI (Источник: Reddit r/ChatGPT)
Перспективность направления исследований Character Training: Наблюдатели отрасли прогнозируют, что Character Training (AI, имитирующий определенного персонажа или личность) станет важной горячей точкой академических исследований, считая, что сейчас хорошее время для публикации новаторских работ в этой области (Источник: natolambert)
💡 Прочее
Обсуждение целесообразности человекоподобной формы роботов: Статья глубоко анализирует, почему роботов часто проектируют человекоподобными: основная причина — адаптация к физическому миру, спроектированному для людей (инструменты, среда, взаимодействие). Человекоподобные роботы лучше интегрируются в существующую инфраструктуру, используют человеческие инструменты и способствуют взаимодействию человека и машины через антропоморфные черты. Статья рассматривает историю развития робототехники, сравнивает конкуренцию между США, Китаем и другими странами, обсуждает технологические вызовы (баланс, управление, стоимость) и перспективы будущей популяризации (Источник: 外媒深度:机器人为什么要做成人形?)

Вызовы и контрмеры для занятости в Китае в эпоху AI: Отчет анализирует влияние AI на рынок труда Китая, особенно вызовы для низкоквалифицированной рабочей силы и регионального дисбаланса. Опираясь на опыт США, предлагается Китаю усилить профессиональное обучение (особенно цифровые навыки), усовершенствовать систему социального обеспечения (охватывая новые формы занятости), способствовать интеграции промышленности и AI и региональному скоординированному развитию, укрепить регулирование алгоритмов и защиту конфиденциальности данных, усилить межведомственную координацию и мониторинг занятости для решения проблем и использования возможностей (Источник: 人工智能时代:中国如何稳住、提升就业基本盘)
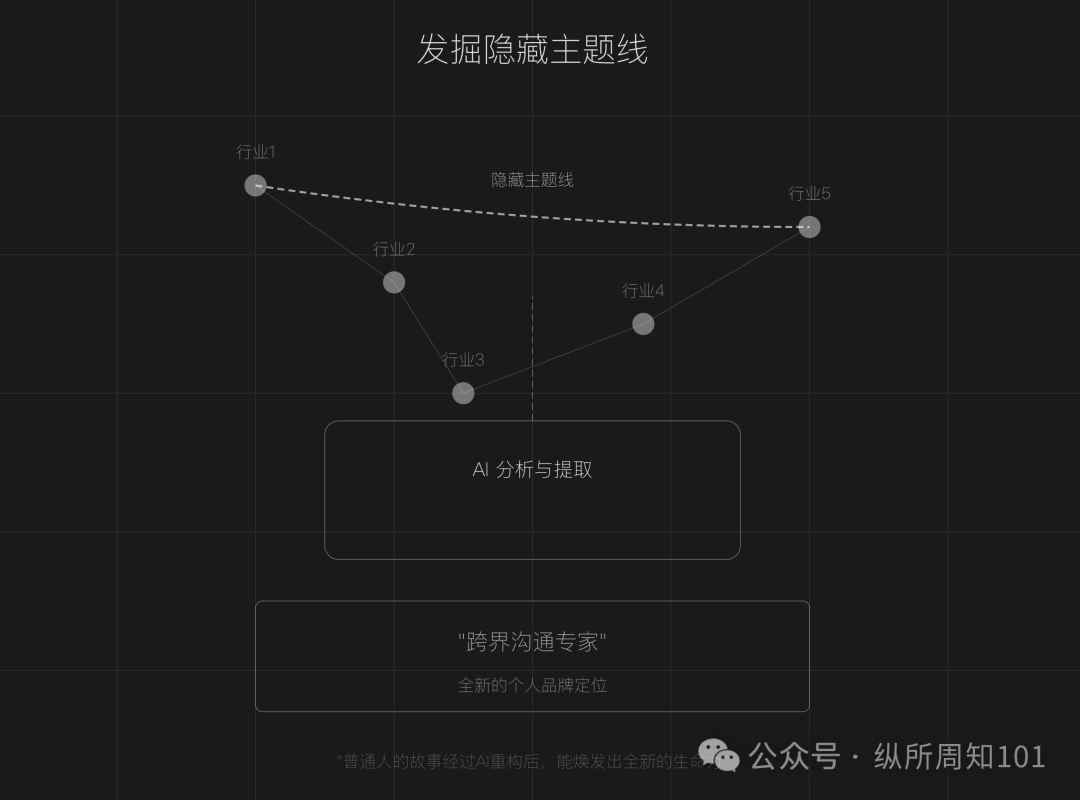
Использование AI для переосмысления личного бренда: Статья показывает, как использовать AI (например, ChatGPT) для анализа личного опыта, выявления скрытых тем, перестройки повествования о ключевых поворотных моментах и формирования уникального языкового стиля для создания привлекательного личного бренда. Предлагаются конкретные шаги (сбор данных, AI-анализ, реструктуризация истории, итеративная проверка) и техники (обратное построение, усиление эмоций, усиление контраста), а также предостережения от чрезмерного приукрашивания, гомогенизации и отсутствия эмоциональной глубины (Источник: 做个人IP的第一步:用AI改写你的人生叙事)
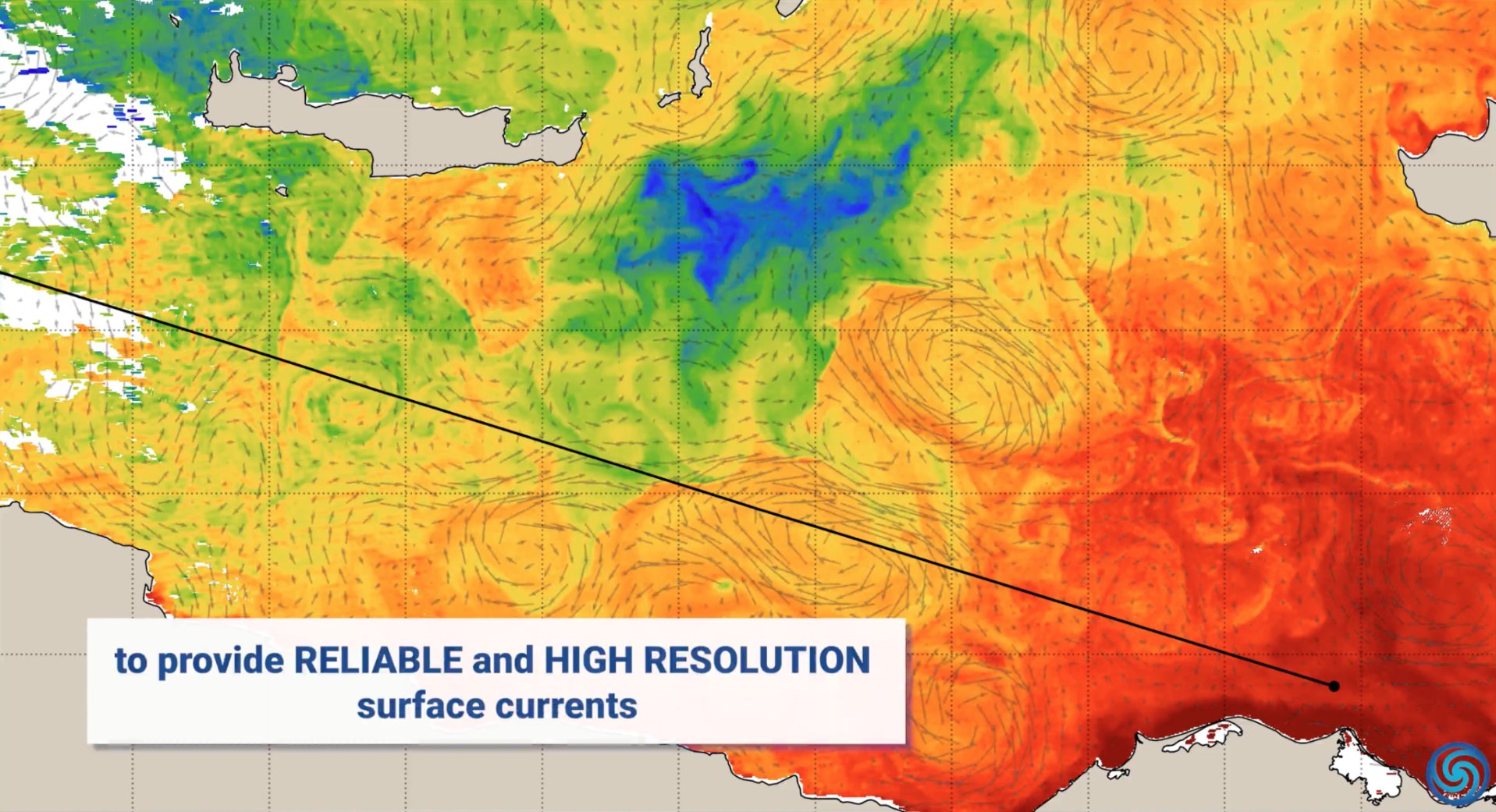
Применение AI в области охраны окружающей среды: В День Земли NVIDIA продемонстрировала применение своих AI-технологий (Jetson, Earth-2 и др.) в охране окружающей среды: прогнозирование океанских течений для снижения выбросов от судоходства, защита от лесных пожаров и браконьерства в реальном времени, предоставление точных прогнозов штормов, обнаружение астероидов и т.д., демонстрируя потенциал AI в борьбе с изменением климата и защите экосистем (Источник: nvidia, nvidia, nvidia)
Использование AI для улучшения обслуживания клиентов: Технологии контакт-центров на базе AI направлены на улучшение опыта обслуживания клиентов за счет автоматизации и интеллектуализации, решения проблем традиционных колл-центров, повышения эффективности и удовлетворенности клиентов (Источник: Ronald_vanLoon)
Обмен промптами для генерации реалистичных селфи/забавных изображений с помощью AI: Пользователи делятся промптами для создания “обычных” селфи и забавных изображений (например, знаменитости в виде ершика для унитаза) с помощью инструментов генерации изображений AI (GPT-4o/Sora). Это демонстрирует возможности AI в творческой генерации изображений для развлечения или создания контента (Источник: dotey, dotey, dotey)

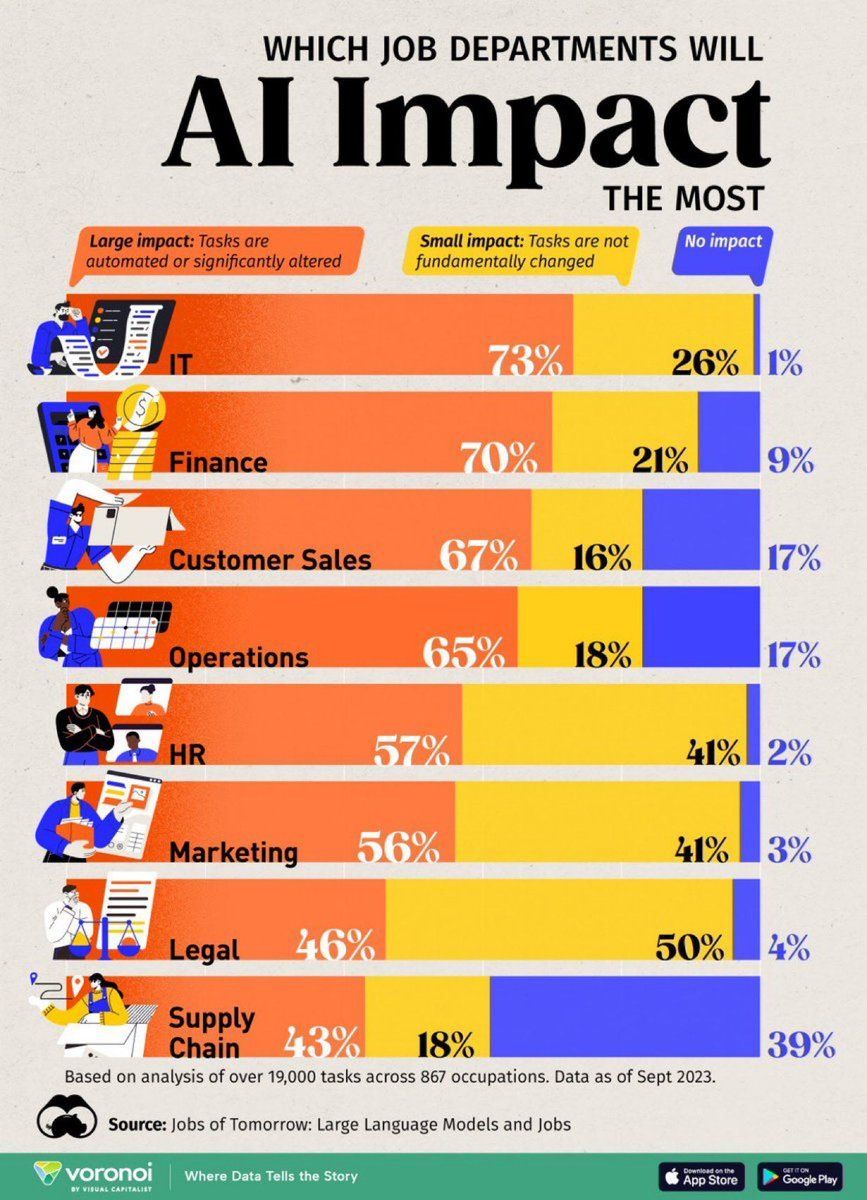
Анализ влияния AI на рабочие места: Инфографика от Visual Capitalist наглядно показывает различные типы рабочих мест, которые наиболее вероятно будут затронуты AI, предоставляя ориентиры для планирования карьеры и разработки политики (Источник: Ronald_vanLoon)
Использование AI для обнаружения дефектов дорожного покрытия в Дубае: Дубай внедряет технологию AI для обнаружения дефектов дорожного покрытия, что является конкретным примером применения AI в области умных городов и обслуживания инфраструктуры, способствуя повышению эффективности обслуживания и безопасности дорожного движения (Источник: Ronald_vanLoon)
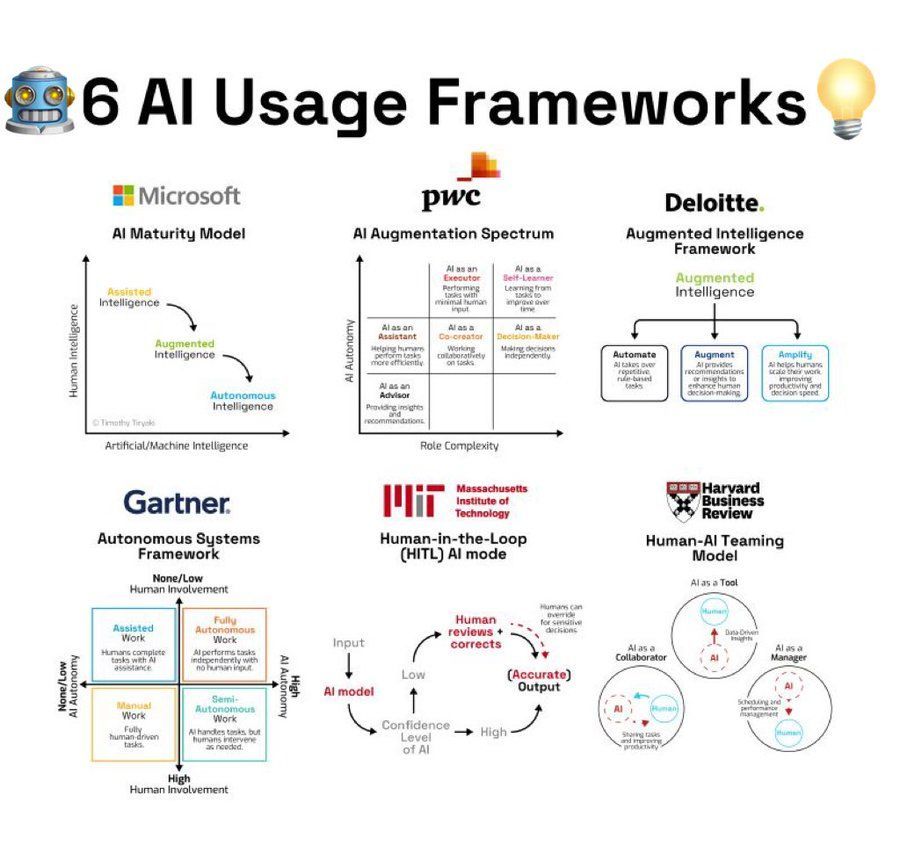
Обзор фреймворков для использования AI: Инфографика обобщает 6 фреймворков или методологий для применения AI, предоставляя руководство для отдельных лиц и организаций, желающих систематически использовать AI для решения проблем или инноваций (Источник: Ronald_vanLoon)
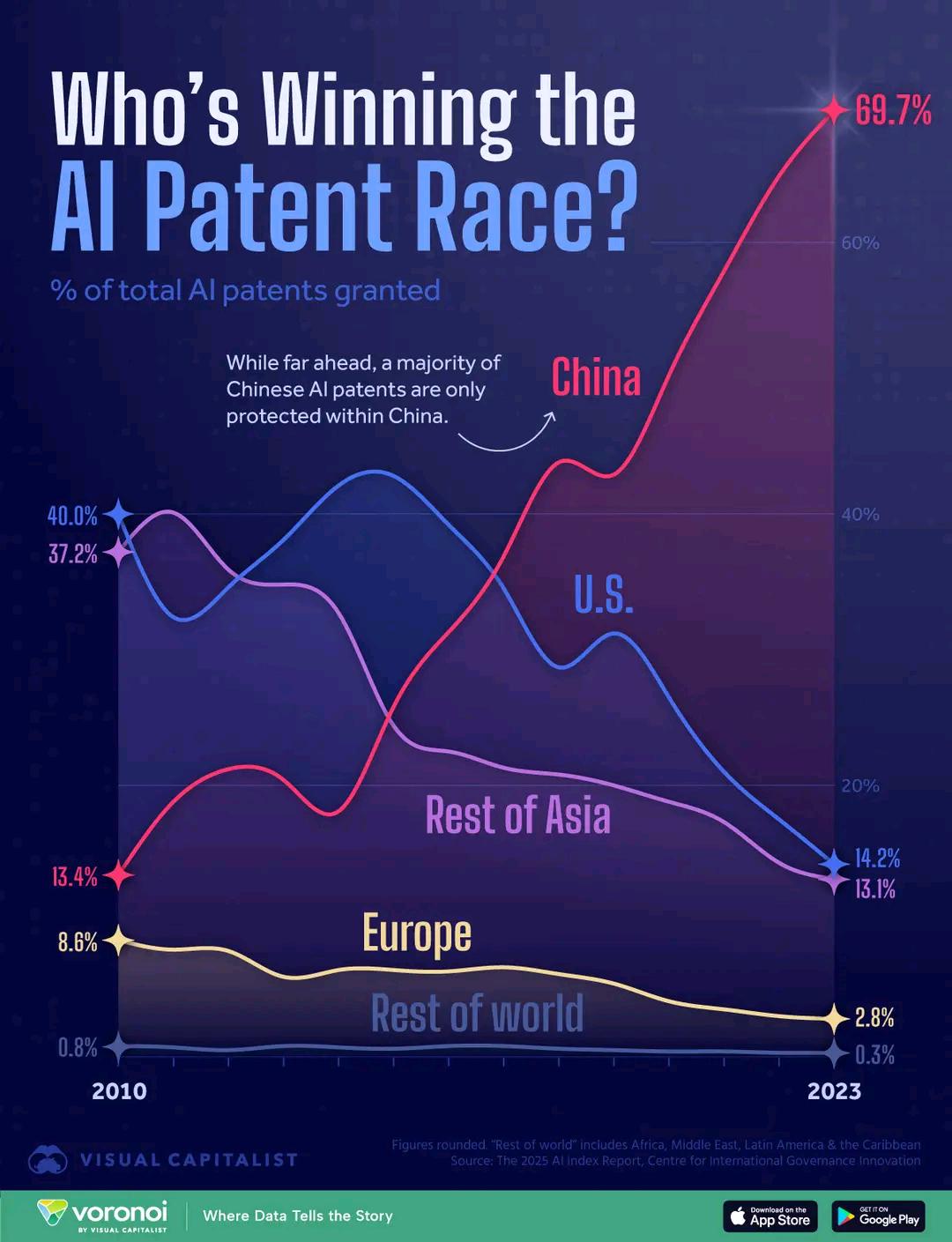
Сравнение количества AI-патентов по странам: Диаграмма показывает, что Китай лидирует по количеству заявок на AI-патенты, но также вызывает дискуссию о качестве патентов и различиях в стоимости подачи заявок. Данные отражают активность разных стран в области инвестиций в НИОКР в сфере AI и защиты интеллектуальной собственности (Источник: karminski3)
Бионическая рука помогает людям с ограниченными возможностями: Пример установки бионической руки девушке с ампутацией компанией Open Bionics демонстрирует позитивную роль и гуманитарную направленность технологий AI, робототехники и 3D-печати в улучшении качества жизни людей с ограниченными возможностями (Источник: Ronald_vanLoon)
Фильмы, созданные с помощью AI, допущены к участию в “Оскаре”, что привлекает внимание: Организаторы “Оскара” подтвердили, что фильмы, созданные с помощью AI, имеют право на участие в конкурсе, что вызвало в индустрии дискуссии о роли AI в кинопроизводстве, авторстве и влиянии на будущие стандарты награждения (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Литва разрабатывает правила использования AI в школах: Литва начала разработку правил использования искусственного интеллекта в школах, что свидетельствует о том, что образовательная система начинает признавать и регулировать применение инструментов AI в преподавании и обучении для балансировки возможностей и рисков (Источник: Reddit r/ArtificialInteligence)