
Ключевые слова:AI, OpenAI, o3和o4-mini模型, 视觉推理与工具调用, OpenAI开源Codex CLI, 谷歌DolphinGemma海豚语言, 智联网与MCP协议
🔥 В центре внимания
OpenAI выпустила модели o3 и o4-mini, усилив визуальное распознавание и вызов инструментов: OpenAI представила две новые модели для логического вывода, o3 и o4-mini, значительно повысив возможности ИИ в области рассуждений, особенно в визуальной сфере. Это первые модели OpenAI, способные интегрировать изображения в цепочку мыслей для рассуждений, интерпретировать диаграммы, фотографии и даже наброски от руки, а также выполнять многоэтапные сложные задачи, используя такие инструменты, как Python, веб-поиск и генерация изображений. o3 позиционируется как самая мощная модель для рассуждений, установившая рекорды во многих бенчмарках, особенно в визуальном анализе; o4-mini оптимизирована по скорости и стоимости. Новые модели постепенно заменят старую серию o1 и будут доступны пользователям Plus, Pro, Team и корпоративным клиентам. Одновременно OpenAI открыла исходный код легковесного агента для программирования Codex CLI и запустила программу поощрения на миллион долларов. Первые отзывы пользователей положительные, отмечается значительное повышение уровня интеллекта и инициативности, но в некоторых сценариях все еще существуют проблемы с галлюцинациями и надежностью (Источник: 智东西, 元宇宙之心MetaverseHub, 新智元, 量子位, Reddit r/LocalLLaMA, Reddit r/deeplearning)

Модель ИИ Google DolphinGemma пытается расшифровать язык дельфинов: Google представила легковесную (400 млн параметров) модель ИИ DolphinGemma на базе архитектуры Gemma, предназначенную для понимания акустической коммуникации дельфинов. Модель обучается на аудиоданных, изучает звуковые паттерны дельфинов и генерирует похожие звуки, что потенциально может привести к начальной межвидовой коммуникации. Проект реализуется в сотрудничестве с WDP (Wild Dolphin Project), организацией, давно изучающей дельфинов, и использует накопленный ими за десятилетия размеченный набор данных. В сочетании с подводной компьютерной системой CHAT, разработанной Технологическим институтом Джорджии (которая будет базироваться на Pixel 9), исследователи надеются взаимодействовать с дельфинами с помощью упрощенного общего словарного запаса. Генеральный директор Google Pichai назвал это «крутым шагом к межвидовой коммуникации» и планирует открыть исходный код модели. Генеральный директор DeepMind Hassabis также выразил надежду на будущее общение с высокоинтеллектуальными животными, такими как собаки (Источник: 新智元)
Смена парадигмы: от «Интернета людей» к «Интернету интеллектов» и протоколу MCP: По мере того как рост числа пользователей Интернета достигает пика, фокус отрасли смещается от соединения людей («Интернет людей») к соединению интеллектуальных агентов ИИ («Интернет интеллектов»). AI Agent может выполнять задачи и вызывать сервисы от имени пользователя, а открытые стандарты, такие как MCP (Model Context Protocol), предоставляют возможность взаимодействия между различными моделями и инструментами, подобно «USB-C» в мире ИИ. Это может изменить структуру власти платформ, ослабив монополию традиционных порталов трафика на распространение контента и внимание пользователей, и в то же время дать шанс на возрождение небольшим сайтам и сервисам (если они подключатся к протоколу и станут «плагинами возможностей»). Метрики платформ могут сместиться с DAU на AAU (Active Agent Unit), поставка контента — с UGC на AIGC, взаимодействие — с GUI на CUI/API, границы между ToC и ToB размываются, двигаясь к экосистеме ToAI. Microsoft, Google, OpenAI и крупные китайские компании уже работают над MCP или связанными протоколами (Источник: 朋克商店)

🎯 Динамика
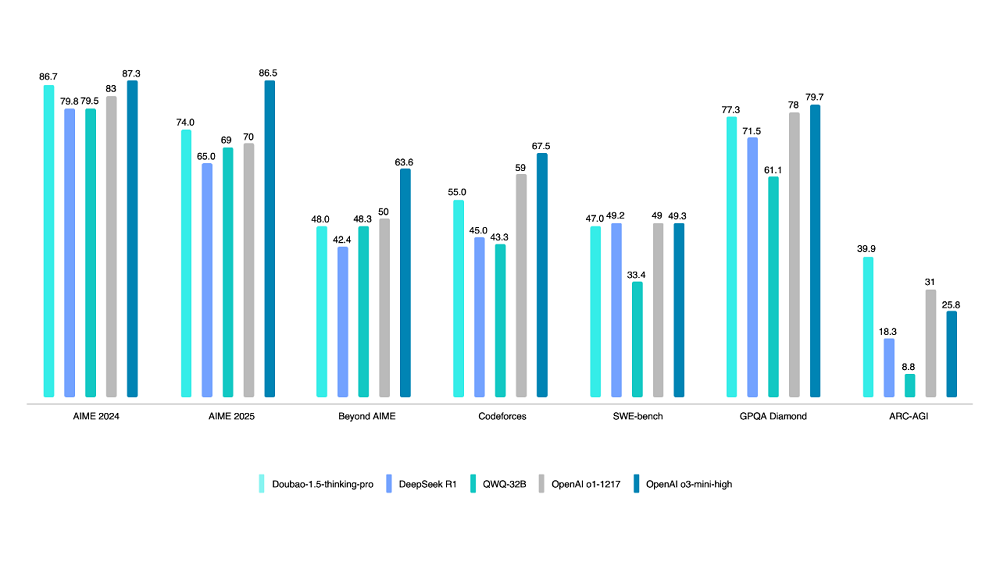
Volcano Engine выпустила модель глубокого мышления Doubao 1.5: Volcano Engine представила модель глубокого мышления Doubao 1.5, использующую архитектуру MoE с общим количеством параметров 200B и активированными параметрами 20B. Модель показала выдающиеся результаты в нескольких бенчмарках в области математики, программирования и науки, частично превзойдя DeepSeek-R1 и приблизившись к уровню OpenAI o1/o3-mini-high, а также получив более высокий балл в тесте ARC-AGI. Особенности включают функцию «думать во время поиска» (в отличие от «сначала искать, потом думать») и способность к визуальному пониманию на основе текстовой и графической информации. Также обновлены модель генерации изображений из текста 3.0 (поддержка изображений 2K HD, оптимизация компоновки текста) и модель визуального понимания (улучшенные возможности позиционирования, подсчета, понимания видео). По состоянию на конец марта среднесуточный объем вызовов большой модели Doubao превысил 12,7 трлн tokens (Источник: 智东西)
Встроенный ИИ-помощник WeChat «Yuanbao» запущен: Приложение Tencent Yuanbao интегрировано в WeChat в виде ИИ-помощника, пользователи могут добавить его в друзья и взаимодействовать прямо в интерфейсе чата. Помощник работает на двухрежимном движке Hunyuan и DeepSeek, оптимизирован для сценариев WeChat, поддерживает анализ статей публичных аккаунтов, изображений, документов (до 100 МБ), а также интеллектуальные вопросы и ответы и повседневное взаимодействие. Сложные ответы перенаправляют в приложение Yuanbao. Это важный шаг WeChat в интеграции функций ИИ после серого тестирования ИИ-поиска, направленный на более естественное встраивание возможностей ИИ в основные сценарии диалога. Tencent недавно увеличила продвижение Yuanbao и инвестиции в вычислительные мощности, рассматривая ИИ как важное стратегическое направление (Источник: 界面新闻, 华尔街见闻)
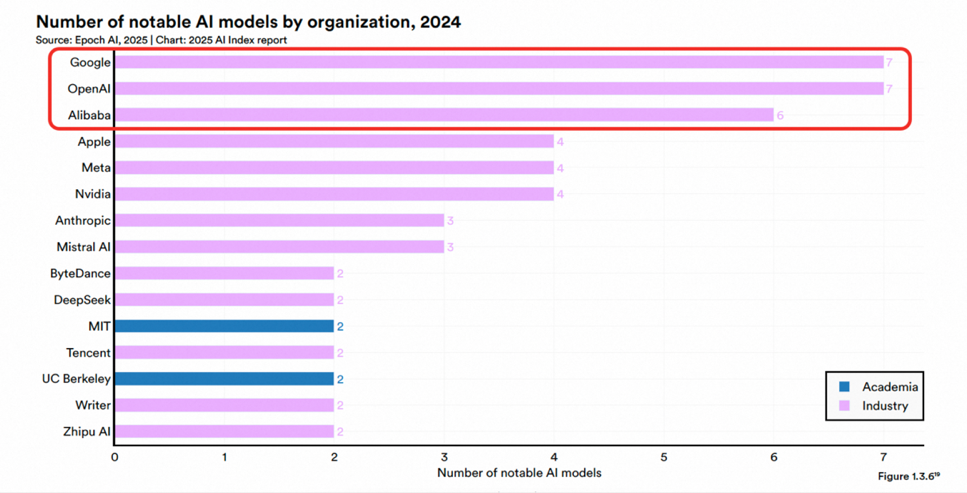
Alibaba Tongyi Qianwen признана Omdia лидером по конкурентоспособности коммерческих больших моделей в Китае: Международное исследовательское учреждение Omdia опубликовало отчет «Китайские коммерческие большие модели 2025 года», в котором Alibaba Cloud Tongyi Qianwen второй год подряд названа лидером и заняла первое место по трем основным параметрам: общая конкурентоспособность, возможности модели и способность к исполнению. В отчете подтверждается лидирующее положение Alibaba в области технологии моделей, создания экосистемы с открытым исходным кодом (глобальные загрузки моделей серии Qwen превысили 200 млн, производных моделей — более 100 тыс.) и коммерческого внедрения (стратегия MaaS). Ранее в отчете Stanford AI Index Alibaba также была названа третьей в мире и первой в Китае организацией по количеству выпущенных важных моделей. Alibaba продолжает инвестировать в облачную инфраструктуру ИИ, планируя вложить более 380 млрд юаней в ближайшие три года (Источник: 乌鸦智能说)
Сообщается, что Alibaba и ByteDance разрабатывают умные очки с ИИ: Вслед за Baidu, Xiaomi и другими, стало известно, что Alibaba и ByteDance разрабатывают умные очки с ИИ. Проект Alibaba возглавляет команда Tmall Genie, интегрируя возможности Kuake AI, планируется выпуск двух версий — с дисплеем и без, аппаратное обеспечение может использовать решение с двумя чипами Qualcomm + Hengxuan. Проект ByteDance возглавляет команда Pico, интегрируя большую модель Doubao, возможно, запуск сначала произойдет за рубежом. Выход гигантов на рынок с их преимуществами в технологии, капитале и экосистеме может ускорить развитие рынка, но они также сталкиваются с проблемой относительно недостаточного опыта разработки аппаратного обеспечения. Этот шаг может сместить конкуренцию в области умных очков с параметров аппаратного обеспечения на экосистемные сервисы, создавая давление и возможности для существующих производителей, таких как Rokid и Thunderbird (Leiniao) (Источник: 科技新知)

Google значительно повышает эффективность блокировки вредоносной рекламы с помощью ИИ: В 2024 году Google использовала обновленные модели ИИ (включая LLM) для усиления применения рекламной политики, успешно приостановив 39,2 млн аккаунтов вредоносных рекламодателей, что в три раза больше, чем в 2023 году. Модели ИИ участвовали в 97% случаев применения рекламных правил, позволяя быстрее выявлять и обрабатывать постоянно меняющиеся мошеннические стратегии. Эта мера направлена на борьбу со злоупотреблением рекламной сетью, ложными утверждениями, нарушением товарных знаков и мошенничеством с использованием дипфейков, созданных ИИ. Хотя некоторая вредоносная реклама все еще просачивается (удалено 5,1 млрд объявлений по всему миру), блокировка аккаунтов на источнике значительно повысила общий эффект. Google подчеркивает, что люди все еще участвуют в процессе, но применение ИИ стало ключом к масштабной безопасности рекламы (Источник: Reddit r/ArtificialInteligence)

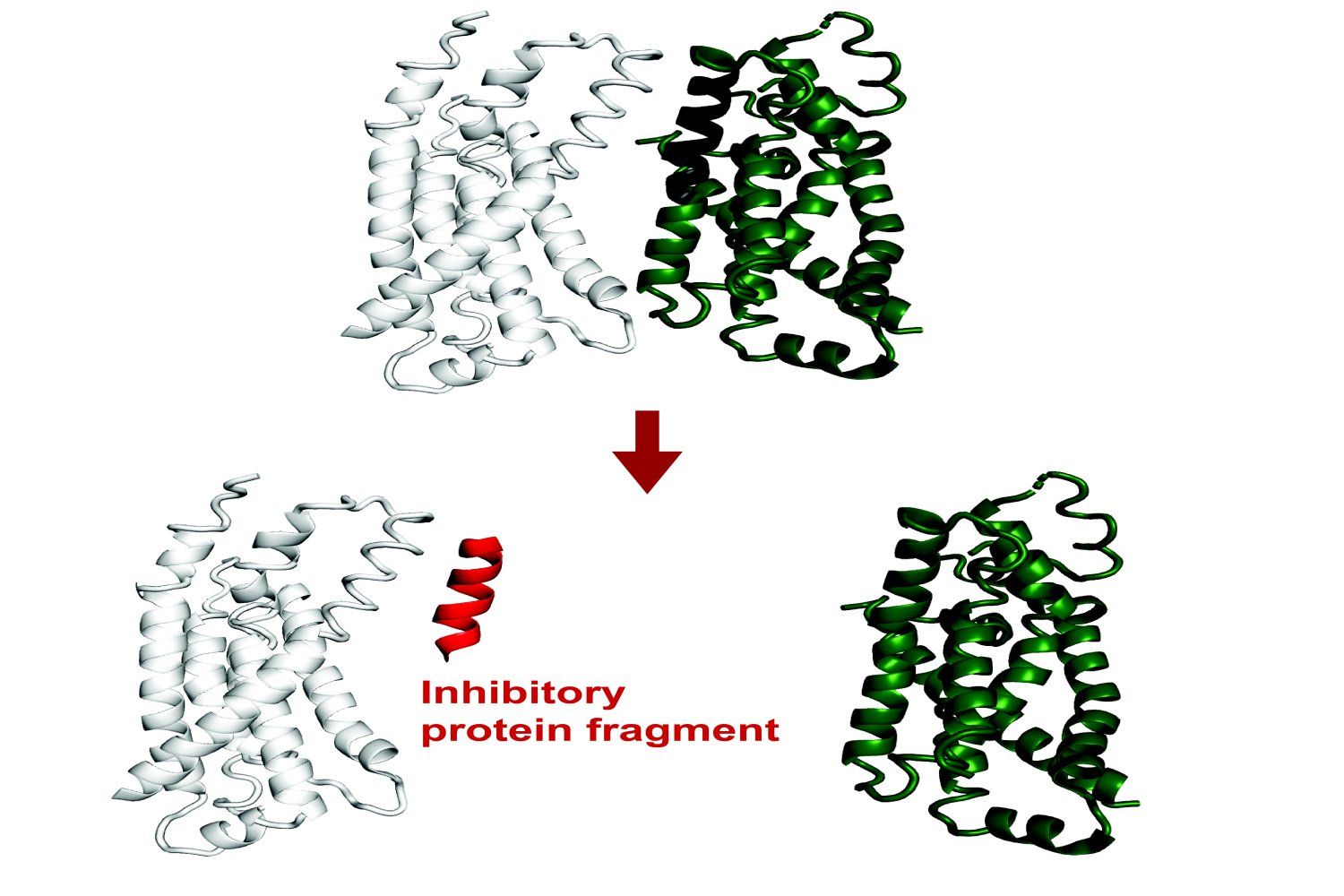
MIT разработала систему ИИ для прогнозирования связывания фрагментов белка: Исследователи из MIT разработали систему ИИ, способную прогнозировать, какие фрагменты белка (пептиды) могут связываться с целевым белком или ингибировать его функцию. Это имеет важное значение для разработки лекарств и биотехнологии, помогая разрабатывать новые методы лечения или диагностические инструменты. Система использует машинное обучение для анализа данных о структуре и взаимодействиях белков, чтобы идентифицировать короткие пептидные последовательности с потенциальной способностью к связыванию (Источник: Ronald_vanLoon)
Grok добавляет функцию памяти диалога: ИИ-помощник Grok платформы X объявил о добавлении функции памяти, позволяющей запоминать содержание предыдущих разговоров пользователя. Это означает, что Grok сможет предоставлять более персонализированные и связные ответы, рекомендации или предложения в последующих взаимодействиях, улучшая пользовательский опыт (Источник: grok)
Google анонсирует открытый протокол для коммуникации между агентами: Google объявила о запуске открытого протокола, предназначенного для того, чтобы различные искусственные интеллектуальные агенты (AI agents) могли общаться и сотрудничать друг с другом. Это похоже на цели MCP (Model Context Protocol), направленные на устранение барьеров между приложениями ИИ и содействие формированию более сложных, интегрированных рабочих процессов ИИ и экосистемы приложений (Источник: Ronald_vanLoon)

🧰 Инструменты
Корректировка функции генерации изображений в ChatGPT: Пользователи заметили, что кнопка «Create Image» внизу интерфейса ChatGPT была удалена, но функцию генерации изображений все еще можно вызвать в поддерживаемых моделях (таких как GPT-4o, o3, o4-mini) с помощью явных подсказок для рисования или специального префикса (например, «Пожалуйста, сгенерируй изображение:»). Модели GPT-4.5 и o1 pro в настоящее время не поддерживают генерацию изображений таким способом (Источник: dotey)
Интеграция бесплатного локального автодополнения кода LLM в JetBrains IDE: JetBrains объявила о крупном обновлении своего AI Assistant, предоставляя бесплатный уровень функций ИИ в своих продуктах IDE (таких как Rider), включая неограниченное автодополнение кода и поддержку интеграции локальных моделей LLM. Этот шаг направлен на снижение порога входа в разработку с помощью ИИ. В то же время платные уровни AI Pro и AI Ultimate предлагают больше расширенных функций и доступ к облачным моделям (таким как GPT-4.1, Claude 3.7, Gemini 2.0) (Источник: Reddit r/LocalLLaMA)
HypernaturalAI: Инструмент ИИ для профессионального создания контента, предназначенный для повышения эффективности и креативности в таких сценариях, как контент-маркетинг (Источник: Ronald_vanLoon)
Демонстрация генерации видео Kling 2.0: Пользователь поделился видеофрагментами, созданными с помощью модели генерации видео Kling 2.0, выпущенной Kuaishou, демонстрируя ее эффект генерации (Источник: op7418)
Фреймворк Cactus для бенчмаркинга ИИ на устройствах: Cactus — это фреймворк, предназначенный для эффективного запуска моделей ИИ на периферийных устройствах (телефонах, дронах и т. д.) без подключения к сети. Разработчики выпустили демо чат-приложения на базе Cactus для тестирования скорости работы (tokens/sec) различных моделей (таких как Gemma 1B, SmollLM) на разных телефонах и предоставили ссылку для скачивания для тестирования пользователями (Источник: Reddit r/deeplearning)

Практика гибридного конвейера ИИ с OpenWebUI: Пользователь поделился успешным примером построения гибридного конвейера ИИ с использованием Open WebUI в качестве фронтенда. Конвейер может автоматически маршрутизировать запрос пользователя либо к структурированному SQL-запросу (через LangChain SQL Agent, работающий с DuckDB), либо к векторной базе данных (Pinecone) для семантического поиска, а затем использовать Gemini Flash для генерации окончательного ответа, обеспечивая быстрый отклик (Источник: Reddit r/OpenWebUI)
Проблемы с базой знаний и API в OpenWebUI: Пользователи Reddit обсуждают проблемы, возникающие при использовании функции базы знаний (RAG) в OpenWebUI, включая то, как указывать документы в каталоге сервера вместо загрузки через веб-страницу, а также как получать и управлять идентификаторами файлов в базе знаний через API для синхронизации файлов (Источник: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Помощь в интеграции OpenWebUI и сервера MCP: Пользователь ищет помощь в локальной настройке сервера Karakeep MCP и его интеграции с OpenWebUI, столкнувшись с трудностями (Источник: Reddit r/OpenWebUI)
Использование режима мышления Grok3 через OpenWebUI: Пользователь спрашивает, есть ли способ включить специфический режим «Think» или «Deepsearch» Grok3 при использовании Grok API для доступа к OpenWebUI (Источник: Reddit r/OpenWebUI)
📚 Обучение
Исследование целеустремленности LLM: Исследователи DeepMind изучают проблему возможного недостаточного использования возможностей LLM при выполнении задач. Используя оценку подзадач, они обнаружили, что LLM часто не могут полностью использовать имеющиеся у них возможности, то есть не являются полностью «целеустремленными». Это исследование помогает понять внутренние механизмы и ограничения LLM (Источник: GoogleDeepMind)

Ограничения передовых моделей ИИ на физических задачах: Исследование на примере производства показывает, что текущие передовые модели ИИ (включая мультимодальные модели) плохо справляются с простыми физическими задачами (например, изготовление латунных деталей), особенно имея существенные недостатки в визуальном распознавании и пространственном понимании. Gemini 2.5 Pro показала себя относительно лучше, но разрыв все еще велик. Это предвещает, что прогресс применения ИИ в физическом мире может отставать от цифрового мира, и для улучшения пространственного понимания и эффективности использования выборок потребуются новые архитектуры или методы обучения (Источник: Reddit r/MachineLearning)
Исследование выявило недостаточную способность ИИ к отладке кода: Несмотря на прогресс ИИ в генерации кода, исследование указывает, что текущий ИИ плохо справляется с отладкой кода и пока не может заменить программистов-людей. Однако некоторые разработчики считают LLM очень полезными при отладке конкретных проблем (Источник: Reddit r/artificial)

Практика оптимизации производительности локальной LLM: Qwen2.5-7B достигает 5000 т/с на двух 3090: Пользователь поделился опытом оптимизации скорости вывода локальной LLM на двух видеокартах RTX 3090. Выбрав модель Qwen2.5-7B, применив квантование W8A8 и используя движок Aphrodite, а также настроив количество одновременных запросов (max_num_seqs=32), удалось достичь скорости обработки промпта до ~4500 т/с и скорости генерации ~825 т/с при длине контекста около 5k. Это предоставляет справочник по оптимизации производительности для исследований или приложений, требующих обработки больших объемов данных локально (Источник: Reddit r/LocalLLaMA)
Представлен новый механизм внимания CALA: Исследователь опубликовал черновик статьи о разработанном им новом механизме внимания под названием «Контекстно-агрегированное линейное внимание» (Context-Aggregated Linear Attention, CALA). CALA стремится объединить эффективность O(N) линейного внимания с улучшенным локальным восприятием за счет вставки шага «агрегации локального контекста». В статье обсуждается его дизайн, инновации по сравнению с другими механизмами внимания и сложные оптимизации (такие как слияние ядер CUDA), необходимые для достижения эффективности O(N). Исследователь надеется на участие сообщества в последующей валидации и разработке (Источник: Reddit r/MachineLearning)
![[P] Today, to give back to the open source community, I release my first paper- a novel attention mechanism, Context-Aggregated Linear Attention, or CALA.](https://rebabel.net/wp-content/uploads/2025/04/yIc61XmsPqdJ02d1eyWbLo9h4fZ3ORdzypEFu1tSkN4.jpg)
Использование Claude 3.7 Sonnet для оценки знакомости лексики: Пользователь потратил около 300 долларов на вызовы API Claude 3.7 Sonnet для создания набора данных с оценками знакомости английских слов и фраз из Wiktionary (оценочная доля американцев старше 10 лет, знающих слово/фразу). Пользователь считает, что Sonnet справился с этой задачей лучше других топовых моделей, лучше различая повседневный язык и профессиональные термины. Код проекта и набор данных опубликованы с открытым исходным кодом, но пользователь сетует на высокую стоимость и ищет более экономичные методы (Источник: Reddit r/ClaudeAI)
💼 Бизнес
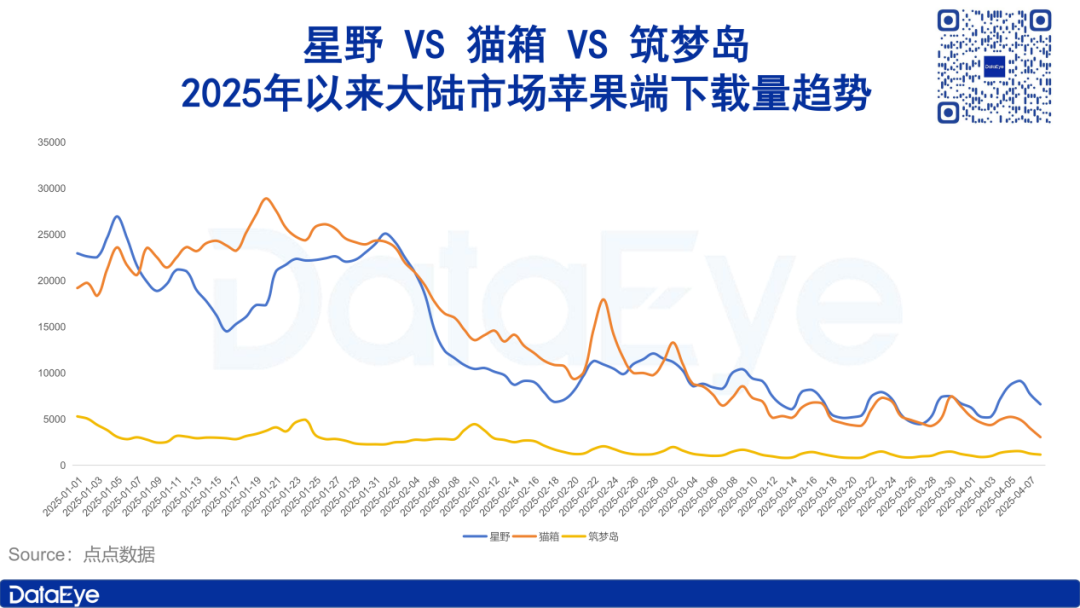
Рынок приложений-компаньонов с ИИ охлаждается,投放 и загрузки падают: Данные DataEye研究院 показывают, что социальные приложения-компаньоны с ИИ, такие как Xingye, Maoxiang, Zhumengdao, столкнулись с охлаждением рынка в начале 2025 года, количество загрузок и размещение рекламы (投放) резко упали, у некоторых продуктов размещение рекламы сократилось вдвое или даже больше («脚斩»). Аналитики считают, что причины включают: 1) смещение стратегического фокуса индустрии ИИ на большие модели глубокого мышления, такие как DeepSeek, и ИИ-помощников, что снизило важность социальных ИИ; 2) сильная гомогенизация продуктов, снижение новизны для пользователей; 3) недостаточная привлекательность основной бизнес-модели подписки. В статье обсуждается основная ценность социального ИИ (сильная эмоциональная ценность, приемлемая рациональная ценность, слабая физиологическая ценность) и указывается, что будущее направление может лежать в фокусе на эмоциональном исцелении или разработке терминалов-компаньонов с ИИ (Источник: DataEye应用数据情报)
Zhipu AI начинает процесс IPO, стремясь стать «первой акцией большой модели»: Компания Zhipu AI, связанная с университетом Цинхуа, после получения нескольких раундов финансирования (включая недавние инвестиции в 1,5 млрд от государственного капитала Ханчжоу и Чжухая) в апреле начала процесс выхода на биржу (IPO). В статье анализируются ее преимущества: технический бэкграунд (гены Цинхуа), стратегическое позиционирование (независимый и контролируемый, включен в список США) и сильные инвесторы (ранние — Dachen Ventures, средние — Tencent, Ant Group, Sequoia, Saudi Aramco, недавние — местный госкапитал). Выбор этого момента для IPO рассматривается как стратегия укрепления позиций в отрасли путем позиционирования себя как «первой акции большой модели» на фоне давления со стороны низкозатратных моделей, таких как DeepSeek, а также для удовлетворения требований инвесторов по доходности (особенно местного госкапитала, способствующего IPO). Zhipu AI планирует выпустить несколько моделей в этом году, который все еще остается «годом больших расходов», и листинг поможет решить проблемы финансирования и оценки (Источник: 真故研究室)

Предприниматели из класса Яо университета Цинхуа эпохи AI 1.0 снова в деле: В статье рассматривается предпринимательский путь выпускников класса Яо университета Цинхуа (таких как Инь Ци из Megvii, Лоу Тяньчэн из Pony.ai) в эпоху AI 1.0 (распознавание лиц, автономное вождение и т. д.), включая раннее использование технологических возможностей, получение благосклонности капитала, но также столкновение с трудностями коммерциализации, усилением конкуренции, блокировкой IPO и другими проблемами. С приходом волны AI 2.0 (большие модели, воплощенный интеллект) эти «гениальные юноши» снова занялись предпринимательством, например, Инь Ци развивает умные автомобили (Qianli Technology), а бывший сотрудник Megvii Фань Хаоцян основал компанию по воплощенному интеллекту Yuanli Lingji. Они продолжают бросать вызов «неизведанной территории», следуя гену класса Яо, пытаясь найти прорывы в новом технологическом цикле, но также сталкиваются с более жесткой конкуренцией и проблемами коммерциализации (Источник: 直面AI)

У Чжао (无招) возвращается в DingTalk и проводит реформы, подчеркивая важность продукта и клиентского опыта: Основатель DingTalk Чэнь Хан (У Чжао) после возвращения быстро начал внутреннюю реорганизацию. Он ставит продукт и клиентский опыт на первое место, требуя от команд разработки и дизайна полностью проверить цепочки пользовательского опыта, сравнить с конкурентами, и лично возглавляет визиты к клиентам «под прикрытием» для сбора отзывов, перезапуская режим «совместного творчества». В коммерциализации требуется исследовать все платные пути, некоторые платные барьеры уже сняты или исправлены, что показывает, что коммерческие цели уступают место пользовательскому опыту и инновациям в ИИ. В управлении наводится порядок в трудовой дисциплине (например, требование приходить на работу к 9 утра), подчеркивается, что руководители должны подавать пример и углубляться в передовую, выступая против чистых менеджеров, упрощается процесс отчетности (без PPT) и контролируются расходы (Источник: 智能涌现)

Bocha AI: Поставщик услуг ИИ-поиска для DeepSeek, бросающий вызов Bing: Bocha AI предоставляет сервис API для поиска в сети для DeepSeek и более 60% ИИ-приложений в Китае. CEO Лю Сюнь рассказал о технических различиях между ИИ-поиском и традиционным поиском (векторный индекс, семантическое ранжирование, генеративная интеграция) и подчеркнул, что их сервис является лишь промежуточным звеном. Ключевая конкурентоспособность Bocha AI заключается в обработке данных, собственной модели переранжирования, архитектуре с высокой параллельностью и низкой задержкой, преимуществе в стоимости (примерно 1/3 цены Bing) и соответствии требованиям к данным. Лю Сюнь считает, что ИИ-поиск повлияет на модель торгов традиционного поиска, подталкивая компании к переходу от SEO к GEO (больший акцент на качестве контента и построении базы знаний). Он полагает, что создание чисто приложений ИИ-поиска (таких как Perplexity) — не лучший путь из-за неясной модели прибыли, в то время как Bocha AI позиционируется как инфраструктура, предоставляющая ИИ возможности поиска, с целью снижения затрат на разработку AGI (Источник: 腾讯科技)
🌟 Сообщество
Разрыв в ИИ и политический раскол: почему «люди, больше всего ненавидящие ИИ, выбрали Трампа»?: В статье анализируется, что часть сторонников Трампа, такие как фермеры из традиционных сельскохозяйственных штатов и рабочие ржавого пояса, являются группами, пострадавшими от автоматизации ИИ, не сумевшими разделить технологические дивиденды и чувствующими себя маргинализированными. Они недовольны текущим положением дел и надеются на обещания MAGA Трампа (такие как возвращение производства, ограничение технологических гигантов). В статье отмечается, что трудности этих групп вызваны структурной перестройкой экономики и разрывом в навыках, вызванными технологическими изменениями, а политика администрации Трампа (такая как тарифные барьеры, недостаточное базовое образование в области ИИ) может не только не решить проблему по-настоящему, но и усугубить затруднительное положение. Автор сравнивает это с усилиями Китая по инклюзивности ИИ (такими как «Восточные данные, Западные вычисления», расширение прав и возможностей промышленного ИИ, бесплатные большие модели, базовое образование в области ИИ), направленными на то, чтобы все население разделило технологические дивиденды и избежало социального разрыва (Источник: 脑极体)

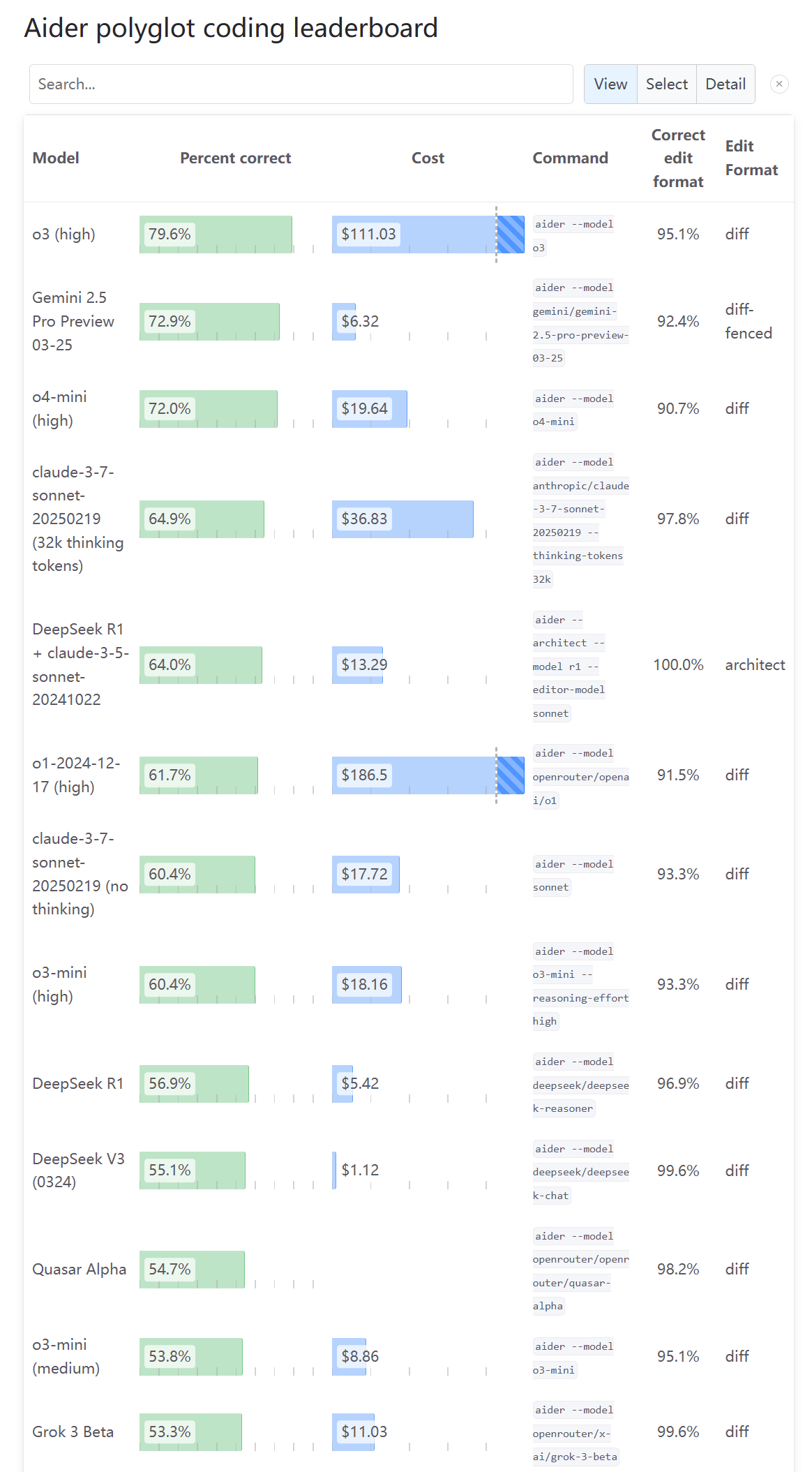
Мнения сообщества о возможностях программирования o3 расходятся: После обновления Aider Leaderboard с рейтингом возможностей программирования o3, пользователь (karminski3) заявил, что результат не соответствует его личному опыту тестирования, и предложил большему числу людей попробовать и оставить отзыв. Это отражает наличие разнообразных точек зрения и споров в сообществе относительно оценки возможностей новой модели, и что один бенчмарк может не полностью отражать реальный опыт использования (Источник: karminski3)
Пользователь обнаружил, что новые модели OpenAI ухудшаются при вопросах на китайском: Пользователь op7418 сообщил, что при использовании китайского языка для вопросов к недавно выпущенным моделям OpenAI o3 и o4-mini, их производительность значительно хуже, чем при использовании английского, особенно в задачах, требующих визуального рассуждения, где вопросы на китайском, похоже, не могут запустить возможность анализа изображений. Пользователь предполагает, что OpenAI, возможно, ограничила или недостаточно оптимизировала обработку китайского ввода (Источник: op7418)

Опыт пользователя: o3 в сочетании с DALL-E генерирует лучшие изображения: Пользователь op7418 обнаружил, что при использовании модели o3 в ChatGPT для вызова генерации изображений (возможно, DALL-E 3), результат лучше, чем при прямой генерации, особенно для сложных концепций, требующих от модели понимания фоновых знаний (например, конкретных сцен из романа). o3 может сначала понять содержание текста, а затем сгенерировать более релевантные изображения (Источник: op7418)

Пользователь делится обходом ограничений контента ChatGPT для генерации изображений: Пользователь Reddit поделился способом обхода ограничений контента ChatGPT (DALL-E 3) путем «побуждения» или постепенного уточнения промптов для генерации изображений, близких к правилам, но не нарушающих их (например, купальник). В комментариях обсуждаются методы этого подхода, а также обоснованность ограничений контента ИИ (Источник: Reddit r/ChatGPT)
Реакция сообщества на релиз новых моделей OpenAI: фокус на отсутствии открытого исходного кода: В обсуждении на Reddit выпуска OpenAI o3 и o4-mini многие комментарии выражают недовольство тем, что OpenAI придерживается закрытого пути разработки, считая это имеющим ограниченное значение для сообщества и исследователей, и ожидают выпуска моделей с открытым исходным кодом, которые можно развернуть локально (Источник: Reddit r/LocalLLaMA)
Неожиданные умные применения ИИ: обмен в сообществе: Пользователь Reddit запросил примеры неосновных, но практичных применений ИИ. Ответы включают: использование ИИ для психотерапии, изучения теории музыки, организации стенограмм интервью и придумывания сюжетных линий, помощи пациентам с СДВГ в приоритизации задач, создания персонализированных песен на день рождения для детей, что демонстрирует широкий потенциал ИИ в повседневной жизни и сценариях специфических потребностей (Источник: Reddit r/ArtificialInteligence)
Юмор сообщества: насмешки над именами моделей Nvidia и Llama 2: Пользователь Reddit опубликовал юмористический пост, высмеивающий сложные и трудно запоминаемые названия новых моделей Nvidia, а также саркастически показал, как Llama 2 возглавляет некий рейтинг, насмехаясь над волатильностью бенчмарков и мнениями сообщества о новых и старых моделях (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Дилемма выбора между Claude Max и ChatGPT Pro: После выпуска OpenAI o3 пользователь на Reddit выразил колебания при выборе подписки между Claude Max и ChatGPT Pro, полагая, что o3 может быть улучшением сильного o1 и превзойти текущие модели. В комментариях обсуждаются недавние ограничения скорости Claude, проблемы с производительностью, а также плюсы и минусы каждой модели в конкретных сценариях, таких как кодирование (Источник: Reddit r/ClaudeAI)
Юмор сообщества: насмешки над взаимодействием ИИ и пользователей: Пользователь Reddit поделился шуточным постом о том, есть ли у ИИ эмоции или сознание, что вызвало беззаботное обсуждение в сообществе антропоморфизма ИИ и ожиданий пользователей (Источник: Reddit r/ChatGPT)

Пользователь жалуется на ограничение емкости Claude, приводящее к потере ответов: Пользователь Reddit выразил недовольство моделью Anthropic Claude, указав, что после того, как модель сгенерировала полный и полезный ответ, он был удален из-за «превышения емкости», что вызвало у пользователя большое разочарование. Это отражает все еще существующие проблемы со стабильностью и пользовательским опытом у некоторых ИИ-сервисов (Источник: Reddit r/ClaudeAI)
Резкое падение рейтинга Claude в LiveBench вызывает вопросы: Пользователь заметил, что рейтинг моделей серии Claude Sonnet в бенчмарке программирования LiveBench внезапно значительно упал, в то время как рейтинг моделей OpenAI вырос, что вызвало обсуждение надежности бенчмарков и возможных скрытых интересов. Члены сообщества смущены этим явлением, предполагая возможные изменения в методах тестирования или колебания реальной производительности модели (Источник: Reddit r/ClaudeAI)
Пользователь показывает селфи игровых персонажей, сгенерированные ИИ: Пользователь Reddit поделился серией «селфи», созданных с помощью ChatGPT (DALL-E 3) для известных персонажей видеоигр, демонстрируя способность ИИ понимать черты персонажей и генерировать креативные изображения. Пользователи в разделе комментариев последовали его примеру, генерируя селфи своих любимых персонажей, что привело к интересному взаимодействию (Источник: Reddit r/ChatGPT)
Может ли ИИ заменить руководителей? Горячее обсуждение в сообществе: На Reddit обсуждается, почему ИИ сначала заменяет рядовых «белых воротничков», а не высокооплачиваемых руководителей. Мнения включают: ИИ в настоящее время не хватает возможностей для сложных управленческих решений; структура власти диктует, что руководители контролируют решения о замене; замена руководителей ИИ может привести к более холодным, ориентированным на эффективность решениям, что не обязательно выгодно для сотрудников; а также опасения по поводу управления и контроля ИИ (Источник: Reddit r/ArtificialInteligence)
Инструменты ИИ-саммаризации упускают ключевые «озарения»: Пользователь на Reddit жалуется, что при использовании инструментов ИИ (таких как Gemini или расширения Chrome) для суммирования длинных подкастов или видео часто удается получить основные моменты, но пропускаются короткие, но очень проницательные «золотые цитаты» или ключевые моменты. Пользователь размышляет, можно ли улучшить эффект саммаризации, предоставляя обратную связь, и спрашивает, есть ли у других подобный опыт (Источник: Reddit r/artificial)
Сообщество выражает недовольство стратегией релизов OpenAI: Пользователь Reddit опубликовал пост с критикой недавних релизов OpenAI (таких как o3/o4-mini, Codex CLI), утверждая, что их технология по сути является масштабированием известных методов, а не фундаментальной инновацией, и что они чрезмерно маркетируют продукты с закрытым исходным кодом, недостаточно вкладываясь в сообщество открытого исходного кода, не предоставляя реальной обучающей ценности и больше служа коммерческим интересам, что вызывает утомление (Источник: Reddit r/LocalLLaMA)

ChatGPT неожиданно «излечивает» пятилетнее ВНЧС пользователя: Пользователь Reddit поделился удивительным опытом: щелканье челюсти (симптом ВНЧС), мучившее его пять лет, исчезло примерно за минуту после выполнения простого упражнения, предложенного ChatGPT (упирать язык в нёбо при симметричном открывании/закрывании рта), и эффект сохраняется. Пользователь ранее безуспешно обращался за медицинской помощью и делал МРТ. Этот случай вызвал обсуждение в сообществе потенциала ИИ в предоставлении нетрадиционных, но эффективных советов по здоровью (Источник: Reddit r/ChatGPT)
💡 Прочее
Мысли Киссинджера о развитии ИИ: люди могут стать самым большим ограничением: Покойный мыслитель Генри Киссинджер и другие в статье исследуют будущие возможности развития ИИ, включая достижение способности к планированию, обладание «заземленностью» (надежная связь с реальностью), память и понимание причинно-следственных связей, и даже развитие предварительного самосознания. В статье предупреждается, что по мере усиления возможностей ИИ его взгляд на людей может измениться, особенно когда люди проявляют пассивность перед ИИ, зависимы от цифрового мира и оторваны от реальности, ИИ может рассматривать людей как ограничения для развития, а не партнеров. В статье также обсуждаются глубокие последствия придания ИИ физической формы и способности к автономным действиям, а также неизвестные вызовы, которые может принести подключение общего искусственного интеллекта (AGI) к сети, и призывает людей активно адаптироваться, а не поддаваться фатализму или отрицанию (Источник: 腾讯研究院)
Демонстрация применений роботов, управляемых ИИ: В социальных сетях демонстрируются многочисленные примеры роботов, управляемых или поддерживаемых ИИ, включая робота, играющего в пинг-понг, разработанного Google DeepMind, роботизированную руку, способную выполнять тонкие манипуляции (например, отделять мембраны перепелиных яиц, инкрустировать бриллианты, создавать искусство стамеской), а также роботов странной формы (например, робот-собака, беспроводной управляемый робот-насекомое, робот, использующий колеса Mecanum) и т. д., что показывает прогресс в улучшении восприятия, принятия решений и управления роботами с помощью ИИ (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Обсуждение применений ИИ в здравоохранении: В социальных сетях упоминаются многочисленные статьи и обсуждения о применении ИИ в сфере здравоохранения, с акцентом на то, как ИИ помогает поставщикам медицинских услуг справляться с социальными изменениями, инновационный потенциал генеративного ИИ в медицине, а также конкретные направления применения (Источник: Ronald_vanLoon, Ronald_vanLoon)

Демонстрация концептуальных технологий на базе ИИ: В социальных сетях демонстрируются некоторые концептуальные технологии или продукты, интегрирующие ИИ, например, концепция автономного летающего автомобиля, управляемого ИИ, а также роль, которую ИИ может играть в будущих сценариях розничной торговли (Источник: Ronald_vanLoon, Ronald_vanLoon)
Американские колледжи борются с наплывом «студентов-роботов»: Сообщается, что американские общественные колледжи сталкиваются с большим количеством поддельных заявлений о приеме, поданных ботами (возможно, управляемыми ИИ), что создает вызовы для систем приема и управления школ, и школы пытаются найти контрмеры (Источник: Reddit r/artificial)

Выпуск OpenAI GPT-4.1 без отчета о безопасности привлекает внимание: Технологические СМИ сообщают, что OpenAI при выпуске GPT-4.1 не предоставила подробный отчет об оценке безопасности, как это делалось ранее при выпуске новых моделей. OpenAI, возможно, считает, что модель основана на существующих технологиях и риски управляемы, но этот шаг вызвал дискуссию о прозрачности и ответственности в области безопасности ИИ (Источник: Reddit r/artificial)

Ускорение разработки AGI и отставание в безопасности вызывают беспокойство: В статье отмечается, что ожидаемые сроки достижения общего искусственного интеллекта (AGI) в индустрии ИИ сокращаются, но в то же время внимание и инвестиции в вопросы безопасности ИИ отстают, что вызывает опасения по поводу рисков будущего развития ИИ (Источник: Reddit r/artificial)

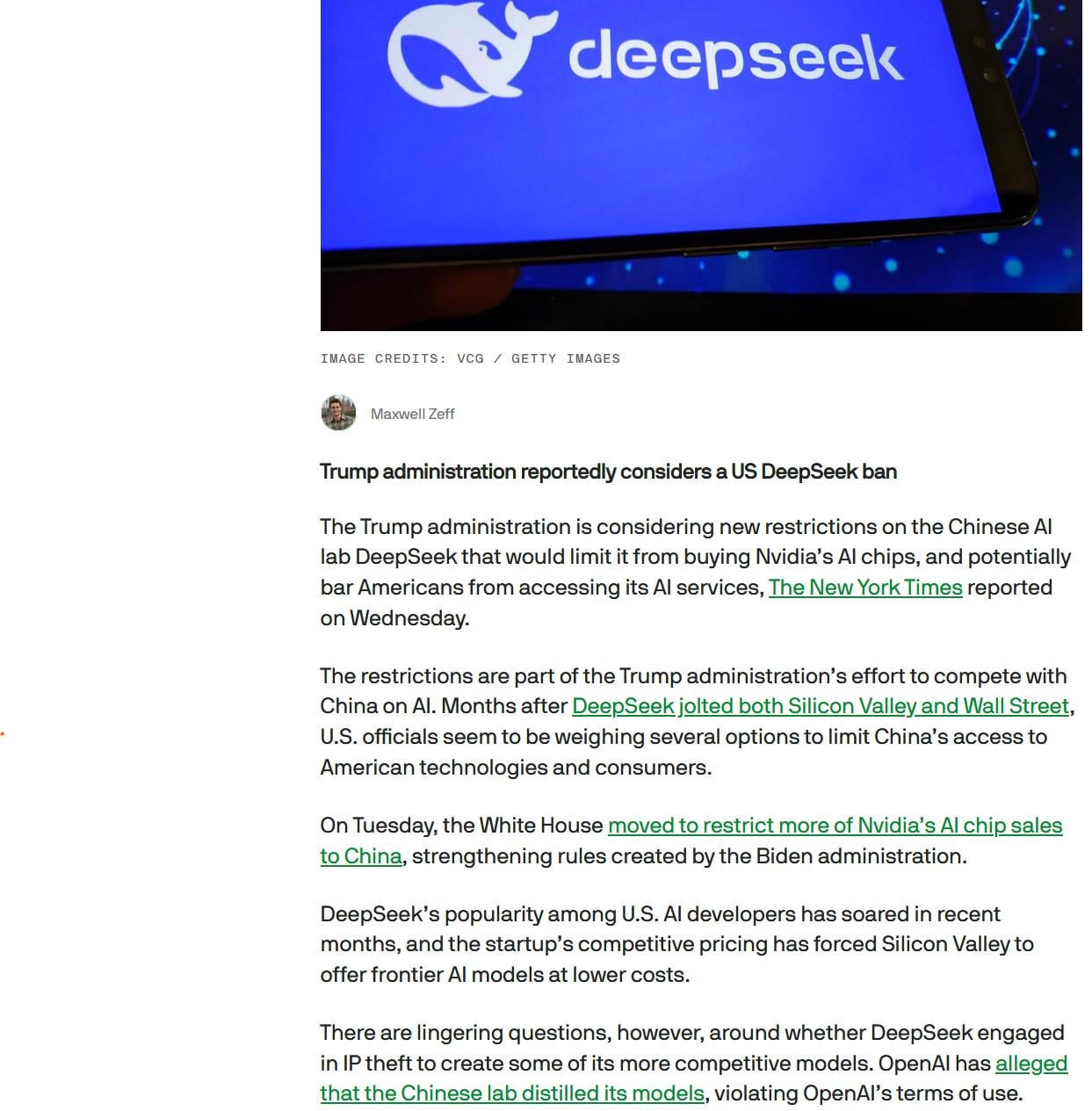
США, по сообщениям, рассматривают возможность запрета DeepSeek: Сообщается, что администрация Трампа может рассмотреть возможность запрета использования китайской большой модели DeepSeek в США и оказать давление на поставщиков, таких как Nvidia, поставляющих чипы китайским ИИ-компаниям. Этот шаг, возможно, основан на соображениях безопасности данных, национальной конкуренции и защите отечественных ИИ-компаний (таких как OpenAI), что вызывает опасения по поводу технологических ограничений и будущего моделей с открытым исходным кодом (Источник: Reddit r/LocalLLaMA)
Предложение создать мозговой центр из ИИ-агентов для решения проблем ИИ: Пользователь Reddit предлагает идею: использовать AI Agent, специализирующихся в конкретных областях со сверхчеловеческими возможностями (ANDSI, Artificial Narrow Domain Superintelligence), для формирования «мозгового центра», который будет совместно работать над решением текущих проблем в области ИИ, таких как устранение галлюцинаций, исследование слияния ИИ-моделей с разной архитектурой и т. д. Идея предполагает, что использование сверхинтеллекта ИИ для ускорения собственного развития ИИ может иметь больший потенциал, чем просто замена ИИ человеческих рабочих мест (Источник: Reddit r/deeplearning)
Призыв к открытому исходному коду AGI для защиты будущего человечества: Ссылка на видео YouTube, заголовок которого утверждает, что Open Source AGI (ОИИ с открытым исходным кодом) имеет решающее значение для обеспечения будущего человечества, подразумевая, что открытый, прозрачный и распределенный путь развития ОИИ более выгоден для благополучия человечества, чем закрытые, централизованные пути (Источник: Reddit r/ArtificialInteligence)
