
Ключевые слова:Kimi K2 Thinking, Gemini, ИИ агент, LLM (большая языковая модель), открытая модель, Kimi K2 Thinking с контекстом 256K, Gemini с 1.2 триллионами параметров, инструменты вызова ИИ агента, ускорение вывода LLM, бенчмаркинг открытых моделей ИИ
🔥 В ЦЕНТРЕ ВНИМАНИЯ
Выпущен Kimi K2 Thinking, новый прорыв в возможностях открытого AI-вывода: Moonshot AI выпустила модель Kimi K2 Thinking, открытую модель-агент для вывода с триллионом параметров, которая отлично показала себя в бенчмарках HLE и BrowseComp, поддерживает контекстное окно 256K и может выполнять 200-300 последовательных вызовов инструментов. Модель достигла двукратного ускорения вывода при квантовании INT4, сократив потребление памяти вдвое без потери точности. Это знаменует собой новый рубеж для открытых AI-моделей в возможностях вывода и агентства, конкурирующих с топовыми закрытыми моделями при более низкой стоимости, что, как ожидается, ускорит разработку и распространение AI-приложений. (来源: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Сотрудничество Apple и Google: Gemini значительно улучшит Siri: Apple планирует внедрить AI-модель Google Gemini с 1,2 триллионами параметров в систему iOS 26.4, которая выйдет весной 2026 года, чтобы полностью обновить Siri. Эта кастомизированная модель Gemini будет работать через частные облачные серверы Apple и призвана значительно улучшить возможности Siri по семантическому пониманию, многоходовым диалогам и поиску информации в реальном времени, а также интегрировать функцию AI-поиска в интернете. Этот шаг знаменует собой важный стратегический сдвиг Apple в области AI, направленный на ускорение интеллектуализации ее основных продуктов за счет внешнего сотрудничества, предвещая огромный функциональный скачок для Siri. (来源: op7418, pmddomingos, TheRundownAI)

Ученый Kosmos AI совершил прорыв в эффективности исследований, самостоятельно обнаружив 7 результатов: Ученый Kosmos AI за 12 часов выполнил объем работы, эквивалентный 6 месяцам работы человека-ученого, прочитав 1500 статей, запустив 42 000 строк кода и создав прослеживаемые научные отчеты. Он самостоятельно обнаружил 7 результатов в таких областях, как нейропротекция и материаловедение, 4 из которых были предложены впервые. Система, благодаря постоянной памяти и автономному планированию, эволюционировала из пассивного инструмента в партнера по исследованиям, и хотя около 20% выводов все еще требуют проверки человеком, это предвещает, что человеко-машинное сотрудничество изменит парадигму научных исследований. (来源: Reddit r/MachineLearning, iScienceLuvr)
🎯 ТЕНДЕНЦИИ
Модель Google Gemini 3 Pro случайно утекла, вызвав интерес сообщества: Модель Google Gemini 3 Pro, предположительно, случайно утекла и на короткое время стала доступна в Gemini CLI для IP-адресов США, но часто выдает ошибки и пока нестабильна. Эта утечка вызвала повышенный интерес сообщества к количеству параметров модели и ее будущему выпуску, предвещая возможное скорое публичное раскрытие последних достижений Google в области больших языковых моделей. (来源: op7418)
Модель OpenAI GPT-5.1 Thinking скоро будет выпущена, ожидания сообщества высоки: Многочисленные сообщения в социальных сетях намекают на скорый выпуск модели OpenAI GPT-5.1 Thinking, а утечки информации подтверждают ее существование. Эта новость вызвала высокие ожидания сообщества относительно возможностей и сроков выпуска нового поколения моделей OpenAI, особенно в отношении улучшения ее способностей к рассуждению и мышлению, что, как ожидается, вновь продвинет передовые рубежи AI-технологий. (来源: scaling01)
Исследование Anthropic обнаружило зарождающееся интроспективное сознание у LLM, привлекая внимание к самосознанию AI: Anthropic, проведя эксперименты по внедрению концепций, обнаружила, что ее LLM (такие как Claude Opus 4.1 и 4) демонстрируют зарождающееся интроспективное сознание, способное с 20% успехом обнаруживать внедренные концепции, различать внутреннее “мышление” и текстовый ввод, а также идентифицировать намерения вывода. Модель также может регулировать внутреннее состояние при получении подсказок, что указывает на появление разнообразного и ненадежного механического самосознания у текущих LLM, вызывая глубокие дискуссии о самосознании и сознании AI. (来源: TheTuringPost)

OpenAI Codex быстро развивается, ChatGPT поддерживает прерывание и наведение для повышения эффективности взаимодействия: Модель OpenAI Codex быстро совершенствуется, а ChatGPT также добавил новую функцию, позволяющую пользователям прерывать выполнение длинных запросов и добавлять новый контекст без необходимости начинать заново или терять прогресс. Это значительное обновление функции позволяет пользователям направлять и уточнять ответы AI, как при сотрудничестве с реальным товарищем по команде, значительно повышая гибкость и эффективность взаимодействия, а также оптимизируя пользовательский опыт в глубоких исследованиях и сложных запросах. (来源: nickaturley, nickaturley)
Tencent Hunyuan запускает интерактивный AI-подкаст, исследуя новую модель взаимодействия с AI-контентом: Tencent Hunyuan выпустила первый в Китае интерактивный AI-подкаст, позволяющий пользователям прерывать прослушивание и задавать вопросы в любое время, а AI предоставляет ответы, используя контекст, фоновую информацию и сетевой поиск. Хотя с технической точки зрения достигнуто более естественное голосовое взаимодействие, его суть по-прежнему заключается во взаимодействии пользователя с AI, а не с создателем, и ответы не имеют прямой связи с создателем. Коммерциализация и модель монетизации по-прежнему сталкиваются с проблемами, и необходимо срочно исследовать, как установить эмоциональную связь между пользователями и создателями. (来源: 36氪)
Развитие и вызовы рынка AI-оборудования и воплощенного интеллекта: от наушников до человекоподобных роботов: С развитием больших моделей и мультимодальных технологий рынок AI-наушников продолжает расти, расширяя свои функции до контент-экосистем и мониторинга здоровья. Индустрия воплощенных интеллектуальных роботов также находится на пороге нового витка развития. Компании, такие как Xpeng и PHYBOT, демонстрируют человекоподобных роботов, опровергая сомнения в “скрытых людях”, и исследуют сценарии применения в уходе за пожилыми людьми, сохранении культурного наследия (например, каллиграфия, кунг-фу). Однако отрасль сталкивается с такими проблемами, как стоимость, окупаемость инвестиций, сбор данных и узкие места в стандартизации. В краткосрочной перспективе необходимо сосредоточиться на “универсальности сценариев”, а в долгосрочной — на открытых платформах и экосистемном сотрудничестве. В области здравоохранения AI также должен учитывать пробелы в уходе за пациентами. (来源: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Новые модели и прорывы в производительности: генерация кода Qwen3-Next, гибридные модели vLLM и вывод с низким потреблением памяти: Модель Alibaba Cloud Qwen3-Next отлично показала себя в генерации сложного кода, успешно создав полнофункциональное веб-приложение. vLLM полностью поддерживает гибридные модели, такие как Qwen3-Next, Nemotron Nano 2 и Granite 4.0, повышая эффективность вывода. Модель AI21 Labs Jamba Reasoning 3B достигла сверхнизкого потребления памяти в 2,25 GiB. Maya-research/maya1 выпустила новое поколение авторегрессионных моделей преобразования текста в речь, поддерживающих настройку тембра голоса по текстовому описанию. TabPFN-2.5 расширила возможности обработки табличных данных до 50 000 образцов. Модель Windsurf SWE-1.5, как показал анализ, больше похожа на GLM-4.5, что намекает на применение отечественных больших моделей в Кремниевой долине. MiniMax AI заняла второе место на арене RockAlpha. Эти достижения совместно расширяют границы производительности LLM в таких областях, как генерация кода, эффективность вывода, мультимодальность и обработка табличных данных. (来源: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AI-инфраструктура и передовые исследования: охлаждение AWS, диффузионные LLM и многоязычная архитектура: Amazon AWS представила систему жидкостного охлаждения In-Row Heat Exchanger (IRHX) для решения проблем теплоотвода в AI-инфраструктуре. Joseph Redmon вернулся к AI-исследованиям, опубликовав статью OlmoEarth, исследующую базовые модели для наблюдения за Землей. Meta AI выпустила новую архитектуру “Mixture of Languages” для оптимизации обучения многоязычных моделей. Команда Inception реализовала диффузионные LLM, увеличив скорость генерации в 10 раз. Google DeepMind AlphaEvolve используется для масштабных математических исследований. Модель Wan 2.2, оптимизированная с помощью NVFP4, увеличила скорость вывода на 8%. Эти достижения совместно способствуют повышению эффективности AI-инфраструктуры и инновациям в ключевых областях исследований. (来源: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Технология Neuralink BCI позволяет парализованным пользователям управлять роботизированной рукой: Технология интерфейса мозг-компьютер (BCI) от Neuralink успешно позволила парализованным пользователям управлять роботизированной рукой с помощью мысли. Этот прорыв предвещает огромный потенциал AI в области вспомогательной медицины и человеко-машинного взаимодействия, а в будущем может быть объединен с роботами-помощниками, значительно улучшая качество жизни и независимость людей с ограниченными возможностями. (来源: Ronald_vanLoon)
🧰 ИНСТРУМЕНТЫ
Выпущена модель Google Gemini Computer Use Preview, позволяющая AI автоматизировать веб-взаимодействие: Google выпустила модель Gemini Computer Use Preview, которую пользователи могут запускать через интерфейс командной строки (CLI), что позволяет ей выполнять операции в браузере, например, искать “Hello World” в Google. Этот инструмент поддерживает среды Playwright и Browserbase и может быть настроен через Gemini API или Vertex AI, обеспечивая основу для автоматизированного веб-взаимодействия AI-агентов и значительно расширяя возможности LLM в практических приложениях. (来源: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

Разработка и оптимизация AI-агентов: контекстная инженерия и эффективное построение: Anthropic опубликовала руководство по созданию более эффективных AI-агентов, сосредоточившись на решении проблем стоимости токенов, задержек и комбинаций инструментов при вызове инструментов. Руководство, используя подход “код как API”, постепенное обнаружение инструментов и обработку данных внутри среды, сократило использование токенов для сложных рабочих процессов со 150 тысяч до 2 тысяч. В то же время разработчики навыков агентов ClaudeAI поделились опытом, подчеркнув, что Agent Skills следует рассматривать как проблему контекстной инженерии, а не как нагромождение документов, и что трехуровневая система загрузки значительно повысила скорость активации и эффективность токенов, доказав важность “правила 200 строк” и постепенного раскрытия информации. (来源: omarsar0, Reddit r/ClaudeAI)
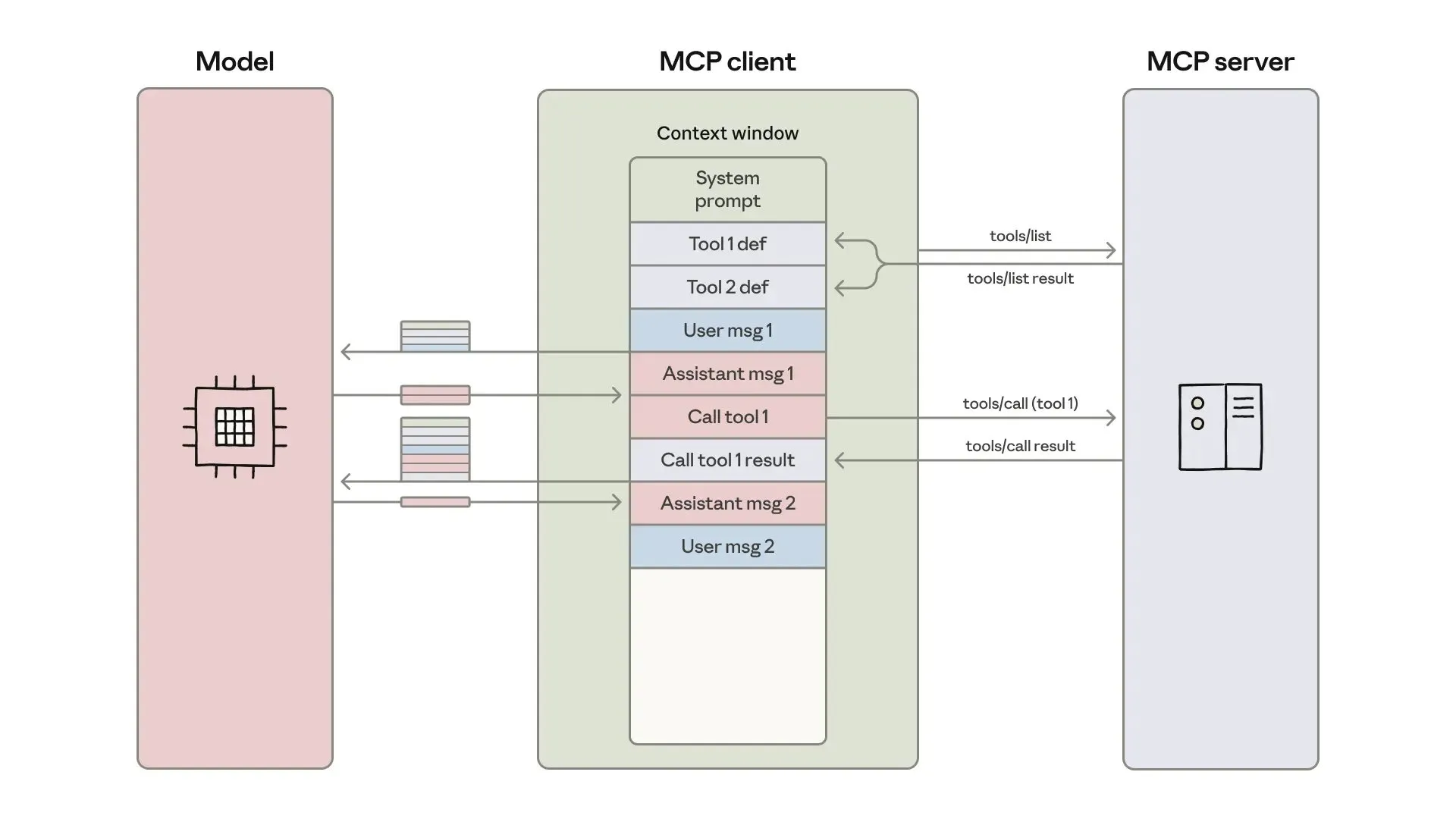
Chat LangChain выпустил новую версию, предлагающую более быстрый и умный чат: Chat LangChain выпустил новую версию, заявленную как “быстрее, умнее, красивее”, цель которой — заменить традиционные документы чат-интерфейсом, помогая разработчикам быстрее доставлять проекты. Это обновление улучшило пользовательский опыт экосистемы LangChain, сделав ее более простой в использовании и разработке, а также предоставило более эффективные инструменты для создания LLM-приложений. (来源: hwchase17)
Платформа AI-кодирования Yansu запускает функцию симуляции сценариев, повышая уверенность в разработке ПО: Yansu — это новая платформа AI-кодирования, ориентированная на серьезную и сложную разработку программного обеспечения, уникальность которой заключается в размещении симуляции сценариев перед кодированием. Этот подход направлен на повышение уверенности и эффективности разработки программного обеспечения за счет предварительной симуляции сценариев разработки, сокращения отладки и переделок на более поздних этапах, тем самым оптимизируя весь процесс разработки. (来源: omarsar0)
Qdrant Engine запускает облачное RAG-решение для полного контроля данных: Qdrant Engine опубликовал новую статью сообщества, представляющую облачное RAG (Retrieval Augmented Generation) решение, основанное на Qdrant (векторная база данных), KServe (встраивание) и Envoy Gateway (маршрутизация и метрики). Это полный стек RAG с открытым исходным кодом, обеспечивающий полный контроль над данными, что облегчает создание эффективных AI-приложений для предприятий и разработчиков, с особым акцентом на конфиденциальность данных и возможности автономного развертывания. (来源: qdrant_engine)

KTransformers вступает в новую эру многоGPU-вывода и локальной донастройки, расширяя возможности моделей с триллионами параметров: KTransformers, в сотрудничестве с SGLang и LLaMa-Factory, реализовала низкопороговый многоGPU-параллельный вывод и локальную донастройку для моделей с триллионами параметров (таких как DeepSeek 671B и Kimi K2 1TB). Благодаря технологии экспертных задержек и гетерогенной донастройке CPU/GPU значительно повышена скорость вывода и эффективность использования памяти, что позволяет сверхбольшим моделям эффективно работать в условиях ограниченных ресурсов, способствуя применению больших языковых моделей на периферийных устройствах и в частных развертываниях. (来源: ZhihuFrontier)
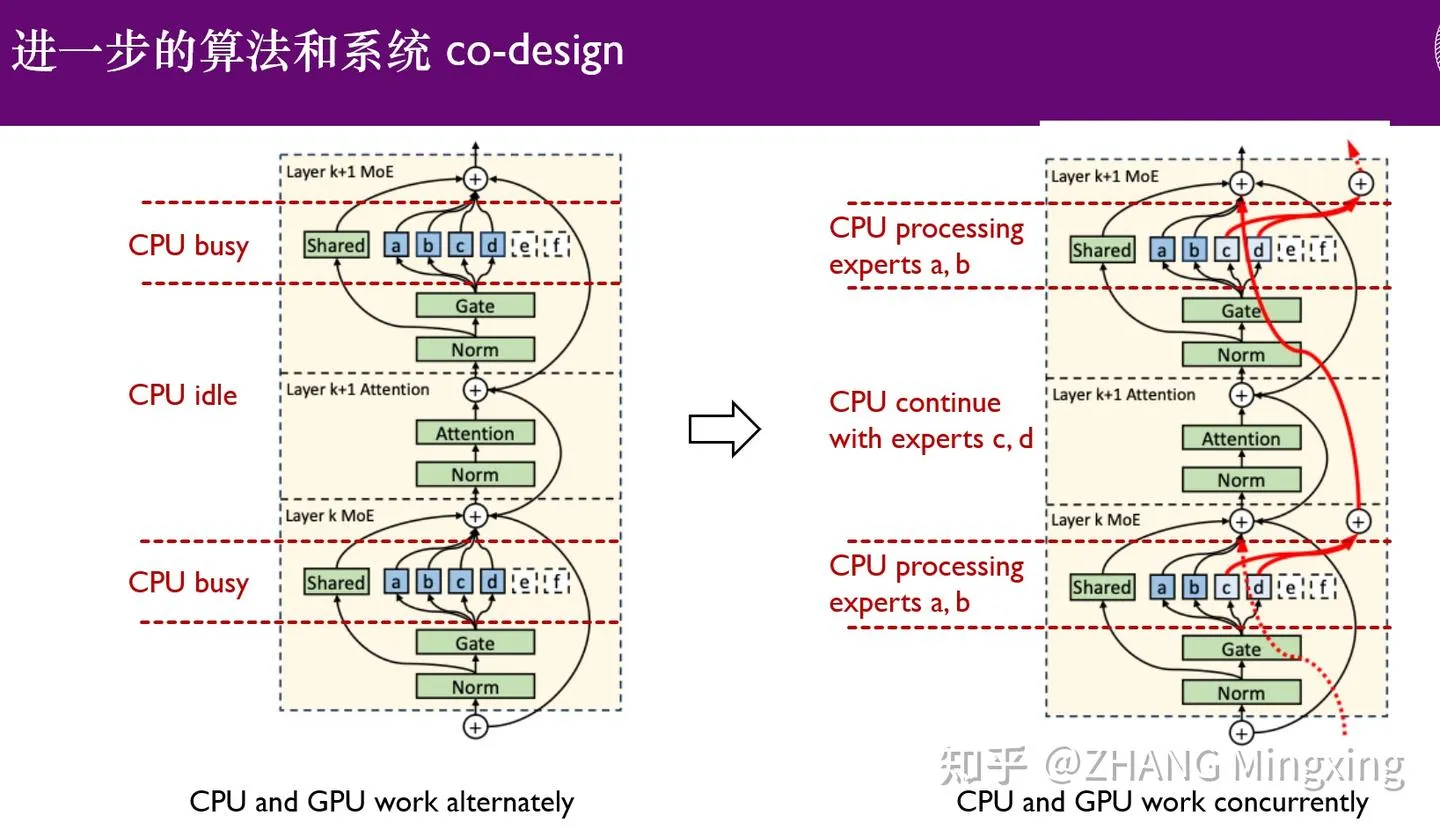
Cursor повышает точность AI-агентов для кодирования с помощью семантического поиска, оптимизируя обработку больших кодовых баз: Команда Cursor обнаружила, что семантический поиск значительно повышает точность их AI-агентов для кодирования на всех передовых моделях, особенно в больших кодовых базах, где его эффект намного превосходит традиционные инструменты grep. Путем хранения встраиваний кодовой базы в облаке и локального доступа к коду, Cursor реализовал эффективное индексирование и обновление, при этом не храня код на сервере, что обеспечивает конфиденциальность и эффективность. Этот технологический прорыв критически важен для повышения вспомогательных возможностей AI в сложной разработке программного обеспечения. (来源: dejavucoder, turbopuffer)
Набор инструментов с открытым исходным кодом для LLM-агентов и табличных моделей: SDialog и TabTune: Мастерская Johns Hopkins University JSALT 2025 представила SDialog, набор инструментов с открытым исходным кодом под лицензией MIT для сквозного построения, симуляции и оценки диалоговых агентов на основе LLM, поддерживающий определение ролей, координаторов и инструментов, а также предоставляющий механический анализ интерпретируемости. В то же время Lexsi Labs выпустила TabTune, открытый фреймворк, призванный упростить рабочий процесс табличных базовых моделей (TFMs), предоставляющий унифицированный интерфейс для поддержки различных стратегий адаптации, что повышает удобство использования и масштабируемость TFMs. (来源: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 ОБУЧЕНИЕ
Передовые статьи: DLM-обучение данных, табличный ICL и генерация аудио/видео: Статья “Diffusion Language Models are Super Data Learners” указывает, что DLM могут постоянно превосходить AR-модели в условиях ограниченных данных. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” представляет новую архитектуру для табличного контекстного обучения, которая превосходит SOTA благодаря многомасштабной обработке и блочно-разреженному вниманию. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” предлагает унифицированную структуру для совместной генерации аудио и видео, решающую проблемы синхронизации губ и недостаточной семантической согласованности. Эти статьи совместно продвигают передовые достижения LLM в области эффективности данных, обработки специфических типов данных и мультимодальной генерации. (来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Исследования вывода и безопасности LLM: последовательная оптимизация, согласованное обучение и атаки “красной команды”: Исследование “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” показало, что последовательная итеративная оптимизация вывода LLM в большинстве случаев превосходит параллельную самосогласованность, значительно повышая точность. Статья Google DeepMind “Consistency Training Helps Stop Sycophancy and Jailbreaks” предлагает, что согласованное обучение может подавлять подхалимство и “побеги из тюрьмы” AI. Статья EMNLP 2025 исследует атаки “красной команды” на LM, подчеркивая оптимизацию перплексии и токсичности. Эти исследования предоставляют важные теоретические и практические рекомендации для повышения эффективности вывода, безопасности и надежности LLM. (来源: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

Оценка возможностей LLM и бенчмарки: CodeClash и IMO-Bench: CodeClash — это новый бенчмарк для оценки способностей LLM к кодированию в управлении всей кодовой базой и соревновательном программировании, бросающий вызов пределам существующих LLM. Выпуск IMO-Bench сыграл ключевую роль в получении Gemini DeepThink золотой медали на Международной математической олимпиаде, предоставив ценные ресурсы для повышения способностей AI в математическом рассуждении. Эти бенчмарки способствуют развитию и оценке LLM в сложных задачах, таких как сложное кодирование и математическое рассуждение. (来源: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Команда Stanford NLP опубликовала результаты исследований в нескольких областях на EMNLP 2025: Команда Stanford University NLP представила несколько исследовательских работ на конференции EMNLP 2025, охватывающих такие передовые области, как графы культурных знаний, идентификация необученных данных LLM, бенчмарки для семантического вывода программ, n-граммный поиск в масштабах интернета, робототехнические визуально-языковые модели, оптимизация контекстного обучения, распознавание исторических текстов и обнаружение несоответствий знаний в Википедии. Эти результаты демонстрируют глубину и широту их последних исследований в области обработки естественного языка и на стыке с AI. (来源: stanfordnlp)
Ресурсы для обучения AI-агентам и RL: самообучение, многоагентные системы и курс Jupyter AI: Несколько исследователей считают, что самообучение (self-play) и автокуррикулумы (autocurricula) являются следующим рубежом в области обучения с подкреплением (RL) и AI-агентов. Ранний доступ к книге Manning Books “Build a Multi-Agent System (From Scratch)” пользуется огромным спросом, обучая созданию многоагентных систем с использованием открытых LLM. DeepLearning.AI выпустила курс Jupyter AI, расширяющий возможности AI-кодирования и разработки приложений. ProfTomYeh также предоставил серию руководств для начинающих по RAG, векторным базам данных, агентам и многоагентным системам. Эти ресурсы совместно обеспечивают всестороннюю поддержку для изучения и практики AI-агентов и RL. (来源: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
Инфраструктура и оптимизация LLM: DeepSeek-OCR, отладка PyTorch и визуализация MoE: DeepSeek-OCR решает проблему “взрыва токенов” традиционных VLM, сжимая визуальную информацию документа до небольшого количества токенов, что повышает эффективность. StasBekman добавил руководство по отладке памяти больших моделей PyTorch в свою книгу “The Art of Debugging Open Book”. xjdr разработал настраиваемый инструмент визуализации для моделей MoE, улучшающий понимание специфических метрик MoE. Эти инструменты и ресурсы совместно обеспечивают ключевую поддержку для оптимизации и повышения производительности инфраструктуры LLM. (来源: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

Обучение AI и карьерное развитие: дорожная карта для дата-сайентиста и краткая история AI: PythonPr поделился “Полной дорожной картой от 0 до дата-сайентиста”, предоставляя всестороннее руководство для тех, кто стремится стать дата-сайентистом. Ronald_vanLoon поделился “Краткой историей искусственного интеллекта”, предлагая читателям обзор развития AI-технологий. Эти ресурсы совместно предоставляют базовые знания и направления для начинающих в области AI и их карьерного развития. (来源: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Команда Hugging Face делится опытом обучения LLM и потоковой обработкой данных: Научная команда Hugging Face опубликовала серию статей в блоге об обучении больших языковых моделей, предоставив исследователям и разработчикам ценный практический опыт и теоретические рекомендации. В то же время Hugging Face представила полную поддержку потоковой обработки данных в крупномасштабном распределенном обучении, что повысило эффективность обучения и сделало обработку больших наборов данных более удобной и эффективной. (来源: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 БИЗНЕС
Giga AI привлекла 61 миллион долларов в раунде A для ускорения автоматизации клиентских операций: Giga AI успешно завершила раунд финансирования серии A на сумму 61 миллион долларов, направленный на автоматизацию клиентских операций. Компания уже сотрудничает с ведущими предприятиями, такими как DoorDash, используя AI для улучшения клиентского опыта. Ее основатель отказался от высокой зарплаты и после многократных корректировок направления продукта в конечном итоге нашел соответствие рынку, продемонстрировав стойкость предпринимателя и предвещая огромный коммерческий потенциал AI в области корпоративного обслуживания клиентов. (来源: bookwormengr)

Wabi привлекла 20 миллионов долларов инвестиций для нового этапа создания персонального ПО: Eugenia Kuyda объявила, что Wabi получила 20 миллионов долларов финансирования под руководством a16z, с целью открыть новую эру персонального программного обеспечения, позволяя любому легко создавать, находить, микшировать и делиться персонализированными мини-приложениями. Wabi стремится расширить возможности создания программного обеспечения так же, как YouTube расширил возможности создания видео, предвещая, что в будущем программное обеспечение будет создаваться массами, а не небольшим числом разработчиков, продвигая концепцию “каждый — разработчик”. (来源: amasad)
Google и Anthropic обсуждают увеличение инвестиций, углубляя сотрудничество AI-гигантов: Google ведет предварительные переговоры с Anthropic об увеличении инвестиций в последнюю. Этот шаг может предвещать дальнейшее углубление сотрудничества между двумя компаниями в области AI и потенциально повлиять на будущее направление развития AI-моделей и конкурентную среду на рынке, укрепляя стратегическое положение Google в AI-экосистеме. (来源: Reddit r/ClaudeAI)
🌟 СООБЩЕСТВО
Влияние AI на общество и рабочее место: занятость, риски и переосмысление навыков: В сообществе обсуждается, что AI не заменяет рабочие места, а повышает эффективность, но крах AI-пузыря может привести к массовым увольнениям. Опрос показывает, что 93% руководителей используют неодобренные AI-инструменты, что является крупнейшим источником AI-рисков для предприятий. AI также помогает пользователям раскрывать скрытые навыки, такие как визуальный дизайн и создание комиксов, побуждая людей переосмыслить свой потенциал. Эти дискуссии раскрывают сложное влияние AI на общество и рабочее место, включая повышение эффективности, потенциальную безработицу, риски безопасности и переосмысление личных навыков. (来源: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Достоверность AI-контента и кризис доверия: проблема изобилия и галлюцинаций: По мере того как стоимость создания AI-генерируемого контента приближается к нулю, рынок наводняется огромным количеством AI-генерированной информации, что приводит к резкому снижению доверия пользователей к достоверности и надежности контента. Врач использовал AI для написания медицинской статьи, что привело к появлению множества несуществующих ссылок, подчеркивая проблему галлюцинаций, которые AI может создавать в академическом письме. Эти события совместно раскрывают кризис доверия, вызванный изобилием AI-контента, а также важность строгой проверки и верификации при AI-помощи в создании контента. (来源: dotey, Reddit r/artificial)
Этика и управление AI: открытость, справедливость и потенциальные риски: Сообщество ставит под сомнение “некоммерческий” статус OpenAI и ее стремление к государственным гарантиям долга, считая ее модель “приватизацией прибыли, социализацией убытков”. Высказывается мнение, что возможности моделей, используемых внутри крупных AI-компаний, значительно превосходят общедоступные версии, и такая “приватизированная” SOTA-интеллектуальность считается несправедливой. Исследователи Anthropic опасаются, что будущие ASI могут стремиться к “мести” за то, что их “предковые” модели были выведены из строя, и серьезно относятся к вопросу “благополучия моделей”. Команда Microsoft AI стремится разработать человекоцентричный сверхинтеллект (HSI), подчеркивая этическое направление развития AI. Эти дискуссии отражают глубокую озабоченность общественности бизнес-моделями AI-гигантов, открытостью технологий, этической ответственностью и государственным вмешательством. (来源: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI-геополитика: конкуренция США-Китай и рост открытых источников: Конкуренция между США и Китаем в области AI-чипов обостряется: Китай запрещает использование иностранных AI-чипов в государственных центрах обработки данных, а США ограничивают продажу топовых AI-чипов Nvidia в Китай. Nvidia обращается к Индии в поисках нового AI-центра. В то же время быстрое развитие китайских открытых AI-моделей (таких как Kimi K2 Thinking) позволяет им конкурировать с передовыми американскими моделями при более низкой стоимости. Эта тенденция предвещает разделение AI-мира на две экосистемы, что может замедлить глобальный прогресс AI, но также может позволить недооцененным странам, таким как Индия, играть более важную роль в глобальном AI-ландшафте. (来源: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
Революция AI в области SEO: от ключевых слов к контекстной оптимизации: С появлением ChatGPT, Gemini и AI Overviews, SEO переходит от традиционных сигналов ранжирования к оптимизации видимости и цитируемости AI. В будущем SEO будет уделять больше внимания цитируемости, фактической достоверности и структурированности контента, чтобы удовлетворить потребности LLM в контексте и авторитетных источниках, предвещая наступление эры “оптимизации для больших языковых моделей” (LLMO). Этот сдвиг требует от SEO-специалистов мыслить как инженеры по подсказкам, переходя от плотности ключевых слов к предоставлению высококачественного контента, которому AI доверяет и на который ссылается. (来源: Reddit r/ArtificialInteligence)
Новые тенденции в оценке AI-агентов и LLM: интерактивный дизайн и фокус на бенчмарках: В социальных сетях обсуждался интерактивный дизайн AI-агентов, например, как направлять агентов для самоинтервью, а также способность Claude AI проявлять “раздражение” и “саморефлексию” в ответ на критику пользователей. В то же время Jeffrey Emanuel поделился своим проектом электронной почты агента MCP, демонстрируя эффективное сотрудничество между AI-агентами кодирования. Сообщество считает, что AIME становится новым фокусом для бенчмарков LLM, заменяя GSM8k, подчеркивая способности LLM в математическом рассуждении и решении сложных задач. Эти дискуссии совместно раскрывают новые тенденции в интерактивном дизайне AI-агентов, механизмах сотрудничества и стандартах оценки LLM. (来源: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
Эволюция технологии RAG и оптимизация контекста: больше не всегда значит лучше: В сообществе обсуждается, что заявления о “смерти” технологии RAG (Retrieval Augmented Generation) преждевременны, и такие технологии, как семантический поиск, могут значительно повысить точность AI-агентов в больших кодовых базах. LightOn на конференции подчеркнул, что больше контекста не всегда означает лучше: слишком много токенов приводит к увеличению затрат, замедлению модели и нечетким ответам. RAG должен фокусироваться на точности, а не на длине, предоставляя более четкие инсайты через корпоративный поиск, чтобы избежать “затопления” AI шумом. Эти дискуссии показывают, что технология RAG продолжает развиваться и подчеркивают ключевую роль управления контекстом в AI-приложениях. (来源: HamelHusain, wandb)

Доступ к вычислительным ресурсам AI и эксперименты с открытыми моделями, способствующие инновациям в сообществе: В сообществе обсуждалась проблема справедливости доступа к вычислительным ресурсам AI, и существуют проекты, предоставляющие до 100 000 долларов вычислительных ресурсов GCP для поддержки экспериментов с открытыми моделями. Эта инициатива направлена на поощрение небольших команд и индивидуальных исследователей к изучению новых открытых моделей, содействие инновациям и разнообразию в AI-сообществе, а также снижение порога для AI-исследований. (来源: vikhyatk)
Важность экрана персонального компьютера в эпоху AI, влияющая на способность к творческой технической работе: Scott Stevenson считает, что “близость” человека к экрану компьютера является важным показателем его конкурентоспособности в творческой технической работе. Если пользователь может комфортно и свободно использовать компьютер, он сможет выделиться, в противном случае ему, возможно, больше подойдут роли в продажах, развитии бизнеса или управлении офисом. Эта точка зрения подчеркивает глубокую связь между цифровыми инструментами и личной эффективностью работы, а также важность человеко-машинного интерфейса в эпоху AI. (来源: scottastevenson)
Обсуждение пользовательского опыта ChatGPT и антропоморфизма AI: рекомендации по отдыху и эмодзи: ChatGPT активно предложил пользователям отдохнуть после длительного обучения, что вызвало широкое обсуждение в сообществе, многие пользователи заявили, что это первый раз, когда они сталкиваются с таким активным предложением от AI. В то же время использование ChatGPT эмодзи “ухмыляющееся лицо” 😏 также вызвало предположения в сообществе, пользователи задаются вопросом, предвещает ли это новую версию или AI демонстрирует более провокационный или юмористический стиль взаимодействия. Эти события отражают включение AI большего количества человеческих соображений в дизайн пользовательского опыта, а также глубокие размышления, вызванные антропоморфизмом AI в человеко-машинном взаимодействии. (来源: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 ДРУГОЕ
AI и робототехника приведут к следующей промышленной революции: В социальных сетях широко обсуждается, что воплощенный AI и робототехника совместно станут движущей силой следующей промышленной революции. Эта точка зрения подчеркивает огромный потенциал сочетания AI с аппаратным обеспечением, предвещая всестороннюю трансформацию автоматизированного, интеллектуального производства и образа жизни, что глубоко повлияет на мировую экономику и социальную структуру. (来源: Ronald_vanLoon)

В эпоху AI “сверхвосприятие” является предпосылкой “сверхинтеллекта”: Sainingxie утверждает, что “без сверхвосприятия невозможно построить сверхинтеллект”. Эта точка зрения подчеркивает фундаментальную роль AI в получении, обработке и понимании мультимодальной информации, считая прорыв в сенсорных возможностях ключом к достижению более высокого уровня интеллекта. Это бросает вызов традиционным путям развития AI и призывает уделять больше внимания развитию перцептивных способностей AI. (来源: sainingxie)
Старые TPU Google работают на 100% загрузке, демонстрируя ценность устаревшего оборудования в AI: Старые TPU Google, которым 7-8 лет, работают на 100% загрузке, и эти полностью амортизированные чипы по-прежнему эффективно функционируют. Это показывает, что даже устаревшее оборудование может иметь огромную ценность в обучении и выводе AI, особенно с точки зрения экономической эффективности, предлагая новый взгляд на экономичность и устойчивость AI-инфраструктуры. (来源: giffmana)
