
Ключевые слова:OpenAI, Регулирование ИИ, Большие языковые модели, Этика ИИ, Инновации в ИИ, Концентрация власти в ИИ, Закон о безопасности ИИ, Управление ИИ, Юридические угрозы OpenAI, Фреймворк выравнивания GTAlign, Мультимодальные рассуждения ARES, Мировая модель xAI, Технология сегментации SAM 3.0
🔥 Фокус
Тема: OpenAI обвиняют в запугивании некоммерческой организации: Во время рассмотрения законопроекта Калифорнии о безопасности AI, OpenAI, как сообщается, направила повестку в суд некоммерческой организации Encode, состоящей всего из трех сотрудников, требуя все записи и частные переписки, и безосновательно обвинила ее в финансировании Маском. Encode публично осудила этот шаг как юридическое запугивание, направленное на подавление критики ее политической позиции. Инцидент вызвал критику со стороны сотрудников OpenAI и бывших членов совета директоров, подчеркнув агрессивную тактику, используемую крупными AI-компаниями перед лицом регулирования, а также проблемы, с которыми сталкиваются небольшие правозащитные группы при противостоянии гигантам, хотя законопроект SB 53 в конечном итоге был принят, требуя от AI-компаний предоставления оценок рисков и отчетов о прозрачности (Источник: Reddit r/ArtificialInteligence)
Тема: Лауреат Нобелевской премии по экономике предупреждает: концентрация власти AI может задушить инновации: Филипп Агийон, один из лауреатов Нобелевской премии по экономике этого года, отметил, что концентрация власти AI в руках нескольких компаний может препятствовать инновациям и экономическому росту. Он считает, что инновации зависят от конкуренции, а монополизация ресурсов AI может привести к стагнации прогресса, затрудняя стартапам бросать вызов существующим гигантам. Это вызвало дискуссию о формах управления и регулирования AI, чтобы предотвратить превращение AI в узкое место для роста, а не в его движущую силу (Источник: Reddit r/ArtificialInteligence)

Тема: GTAlign: фреймворк выравнивания помощника LLM, основанный на теории игр: Исследователи предложили GTAlign, фреймворк выравнивания, который интегрирует принятие решений на основе теории игр в рассуждения и обучение LLM. Этот фреймворк строит матрицу выигрышей для оценки общего благосостояния LLM и пользователя и выбирает взаимовыгодные действия. В процессе обучения вводится вознаграждение за взаимное благосостояние для усиления кооперативных ответов. Эксперименты показали, что GTAlign значительно повышает эффективность рассуждений, качество ответов и общее благосостояние LLM в различных задачах, решая проблему, когда традиционные методы выравнивания могут ухудшать пользовательский опыт из-за чрезмерной многословности модели (Источник: HuggingFace Daily Papers)
Тема: ARES: адаптивные мультимодальные рассуждения через формирование энтропии с учетом сложности: ARES — это унифицированный фреймворк с открытым исходным кодом, который решает проблему несбалансированной эффективности мультимодальных больших моделей рассуждений (MLRMs) при обработке задач различной сложности путем динамического распределения усилий по исследованию. Он использует оконную энтропию для выявления ключевых моментов рассуждений и двухэтапное обучение (адаптивный холодный старт и адаптивная оптимизация энтропийной политики), чтобы модель меньше “передумывала” над простыми задачами и больше исследовала сложные. ARES демонстрирует превосходную производительность и эффективность рассуждений в математических, логических и мультимодальных бенчмарках, значительно снижая затраты на рассуждения (Источник: HuggingFace Daily Papers)
🎯 Тенденции
Тема: xAI Маска входит в мир World Model, переманивая сотрудников из Nvidia для разработки AI-игр: xAI активно развивает область World Model и переманила нескольких старших исследователей из Nvidia, планируя выпустить AI-генерируемую игру, управляемую World Model, к концу 2026 года. Цель xAI — заставить AI понимать природу Вселенной, применяя World Model в AI-играх, агентах, автономном вождении и воплощенных AI-роботах, стремясь создать полную замкнутую экосистему AI (Источник: 量子位)

Тема: Meta «Segment Anything» 3.0 представлен: SAM 3.0 представляет Promptable Concept Segmentation (PCS), поддерживающую задачи мультиинстансной сегментации на основе фраз или примеров изображений. Новая архитектура включает детектор на основе DETR и модуль Presence Head, разделяющие распознавание объектов и локализацию, что повышает точность обнаружения. Благодаря масштабному движку данных и бенчмарку SA-Co, SAM 3.0 устанавливает новый SOTA в задачах сегментации с открытым словарем и может быть объединен с мультимодальными большими моделями для решения сложных задач сегментации с рассуждениями (Источник: 量子位)

Тема: Baidu World 2025 анонсирован, с акцентом на AI-приложения и экосистему больших моделей: Baidu объявила, что Baidu World 2025 пройдет 13 ноября в Пекине под темой «Эффект проявляется | AI in Action». Конференция всесторонне продемонстрирует последние достижения Baidu в области AI-приложений, больших моделей, AI-экосистемы и глобализации, включая Wenxin iRAG, No-code Miaoda, технологии цифровых людей и глобальное развертывание автономного вождения “Luobo Kuaipao”. Конференция также предложит более 40 открытых уроков по AI для расширения возможностей разработки AI-приложений (Источник: 量子位)

Тема: Reflection AI: оценка в $8 млрд без выпущенного продукта, «американский DeepSeek»: Reflection AI, не выпустив официального продукта, увеличила свою оценку до $8 млрд и получила $2 млрд финансирования от Nvidia, Sequoia Capital и других. Компания, основанная бывшими ключевыми сотрудниками Google DeepMind, стремится стать «западным DeepSeek», предлагая высокопроизводительные модели MoE по модели «открытых весов», заполняя потребность западного рынка в некитайских моделях с открытым исходным кодом и ориентируясь на крупные предприятия и суверенный AI-рынок (Источник: 36氪)

Тема: Выпущена модель Dolphin X1 8B: децензурированная тонкая настройка Llama3.1 8B: Dolphin X1 8B теперь доступна на Hugging Face. Это тонко настроенная версия Llama3.1 8B Instruct, разработанная для максимального удаления цензурных ограничений модели без ущерба для других возможностей. Модель обучена с использованием SFT+RL, и результаты бенчмарков сопоставимы или выше, чем у Llama3.1 8B Instruct. Версии GGUF, FP8 и exl2 выпущены при спонсорской поддержке Deepinfra (Источник: Reddit r/LocalLLaMA)
Тема: Разнообразное развитие маршрутов Open-source RAG: MiniRAG, Agent-UniRAG, SymbioticRAG и другие open-source RAG (Retrieval Augmented Generation) решения диверсифицируются, демонстрируя различные концепции дизайна. MiniRAG стремится к легковесности и локальному выполнению, Agent-UniRAG интегрирует поиск и рассуждения в непрерывный конвейер агентов, SymbioticRAG подчеркивает человеко-машинное сотрудничество и обучение с обратной связью, а такие инструментарии, как LangChain, предоставляют модульные компоненты. Пользователям при выборе необходимо взвешивать точность, скорость и управляемость, а также обращать внимание на распространенные проблемы, такие как галлюцинации и потеря контекста (Источник: Reddit r/LocalLLaMA)
Тема: LLM4Cell: обзор больших языковых моделей и моделей агентов в области одноклеточной биологии: LLM4Cell впервые представляет унифицированный обзор 58 базовых моделей и моделей агентов, применяемых в исследованиях одноклеточных, охватывающих модальности RNA, ATAC, мультиомики и пространственные модальности. Исследование делит эти методы на пять основных категорий и сопоставляет их с восемью ключевыми аналитическими задачами. Анализ более 40 общедоступных наборов данных позволил оценить применимость моделей, разнообразие данных, этические аспекты и масштабируемость, а также выявить проблемы в области интерпретируемости, стандартизации и разработки надежных моделей (Источник: HuggingFace Daily Papers)
Тема: KORMo: открытая модель рассуждений на корейском языке для всех: KORMo-10B — это первая двуязычная большая языковая модель (корейско-английская), обученная преимущественно на синтетических данных. Модель имеет 10.8B параметров, при этом 68.74% корейской части составляют синтетические данные. Эксперименты показали, что тщательно подобранные синтетические данные не приводят к нестабильности или снижению производительности при масштабном предварительном обучении модели. Модель демонстрирует производительность, сопоставимую с существующими open-source многоязычными моделями в бенчмарках по рассуждениям, знаниям и следованию инструкциям. Проект полностью открывает данные, код и схему обучения, предоставляя прозрачный фреймворк для разработки открытых моделей на основе синтетических данных в условиях ограниченных ресурсов (Источник: HuggingFace Daily Papers)
Тема: UML: улучшение мономодальных моделей с использованием непарных мультимодальных данных: UML (Unpaired Multimodal Learner) — это новая парадигма обучения, не зависящая от модальности, в которой модель, попеременно обрабатывая входные данные из разных модальностей и разделяя параметры, использует кросс-модальную структуру для улучшения мономодального обучения представлений без явных парных наборов данных. Теория и эксперименты показывают, что использование непарных данных вспомогательных модальностей (таких как текст, аудио, изображения) постоянно улучшает производительность в последующих мономодальных задачах, таких как обработка изображений и аудио (Источник: HuggingFace Daily Papers)
Тема: Анонс новой книги «Иллюстрированное руководство по AI-агентам»: Скоро выйдет новая книга «Иллюстрированное руководство по AI-агентам», написанная Джеем Аламмаром и Мартеном Гром и изданная O’Reilly Media. Книга глубоко рассмотрит основные концепции понимания и создания AI-агентов, охватывая инструменты, память, генерацию кода, рассуждения, мультимодальность, RLVR/GRPO и другие продвинутые темы, стремясь стать самым богатым визуальным проектом в области AI-агентов (Источник: JayAlammar, MaartenGr)

Тема: SEAL: самоадаптирующиеся языковые модели для непрерывного обучения: Новое исследование под названием SEAL (Self-Adapting Language Models) описывает, как AI-модели могут непрерывно обучаться после развертывания, развивая свои внутренние представления без переобучения. Архитектура SEAL позволяет моделям обучаться в реальном времени на новых данных, самостоятельно восстанавливать деградировавшие знания и формировать устойчивую «память» между сессиями. Если GPT-6 интегрирует эту технологию, это приведет к появлению непрерывно самообучающегося AI, положив конец эре «замороженных весов» (Источник: yoheinakajima)

Тема: Команда Tencent Hunyuan предлагает новый метод обучения с подкреплением для рассуждений LLM без человеческой разметки: Команда Tencent Hunyuan Reasoning and Pre-training представила новый метод обучения с подкреплением (RL), который заменяет традиционное «предсказание следующего токена» на «предсказание следующего фрагмента» на основе RL, что позволяет расширять возможности рассуждений LLM без данных, размеченных человеком. Этот метод, использующий две RL-задачи — авторегрессионное рассуждение по фрагментам (ASR) и рассуждение по промежуточным фрагментам (MSR), — значительно повышает производительность модели в нескольких бенчмарках по математике и логике, доказывая, что расширение рассуждений не равно расширению затрат (Источник: ZhihuFrontier, ZhihuFrontier)
🧰 Инструменты
Тема: OpenAlex MCP Server: инструмент OpenWebUI, настроенный для научных исследований: Разработчик создал OpenAlex MCP Server для научных исследований в OpenWebUI. Этот сервис интегрирует бесплатный научный индекс OpenAlex, позволяя пользователям фильтровать научные статьи по дате и количеству цитирований, решая проблему, которую не могли решить существующие инструменты, и легко интегрируется в OpenWebUI (Источник: Reddit r/OpenWebUI)
Тема: Claude успешно диагностировал и устранил проблемы с производительностью ПК пользователя: Пользователь поделился, как Claude AI помог ему решить проблему с производительностью ПК, которая мучила его три года. Следуя указаниям Claude, пользователь обнаружил скрытые настройки производительности питания глубоко в Панели управления и переключил их из режима «Тихий» в режим высокой производительности, что увеличило частоту кадров в играх с 16 FPS до 60 FPS. Это демонстрирует практическую ценность AI в диагностике и решении сложных технических неисправностей (Источник: Reddit r/ClaudeAI)
Тема: Microsoft запускает Copilot Benchmarks: отслеживание использования AI сотрудниками вызывает споры: Microsoft выпустила инструмент под названием Copilot Benchmarks, который позволяет менеджерам отслеживать частоту использования сотрудниками AI-инструментов (таких как Copilot) в приложениях Office и сравнивать ее со средним показателем по отделу и «ведущими компаниями». Этот шаг вызвал опасения по поводу мониторинга на рабочем месте и злоупотребления данными, многие считают, что это может привести к тому, что использование AI станет основой для оценки производительности и даже увольнений, а не для реального повышения продуктивности (Источник: Reddit r/ArtificialInteligence)
Тема: MarkItDown: Microsoft выпускает инструмент для преобразования документов в Markdown для конвейеров LLM: Microsoft представила MarkItDown, инструмент на Python, который может преобразовывать различные типы файлов, такие как PDF, Word, Excel, PowerPoint, HTML, CSV, JSON, XML, изображения, аудио, в чистый формат Markdown. Поскольку Markdown является «родным языком» для LLM, этот инструмент идеально подходит для предварительной обработки документов перед их подачей в модель, чтобы сохранить заголовки, списки, таблицы, ссылки и метаданные, повышая эффективность и качество обработки документов LLM (Источник: TheTuringPost)
Тема: vLLM преодолевает отметку в 60 тысяч звезд на GitHub, лидируя в эффективном выводе LLM: Проект vLLM набрал 60 тысяч звезд на GitHub, став важной силой в области вывода LLM. Он поддерживает различные аппаратные платформы, такие как NVIDIA, AMD, Intel, Apple, TPU, и совместим с основными моделями генерации текста, такими как Llama, GPT-OSS, Qwen, DeepSeek, а также с конвейерами RL, такими как TRL, Unsloth. Проект стремится предоставить эффективные, масштабируемые open-source решения для вывода LLM, способствуя развитию экосистемы AI (Источник: vllm_project)
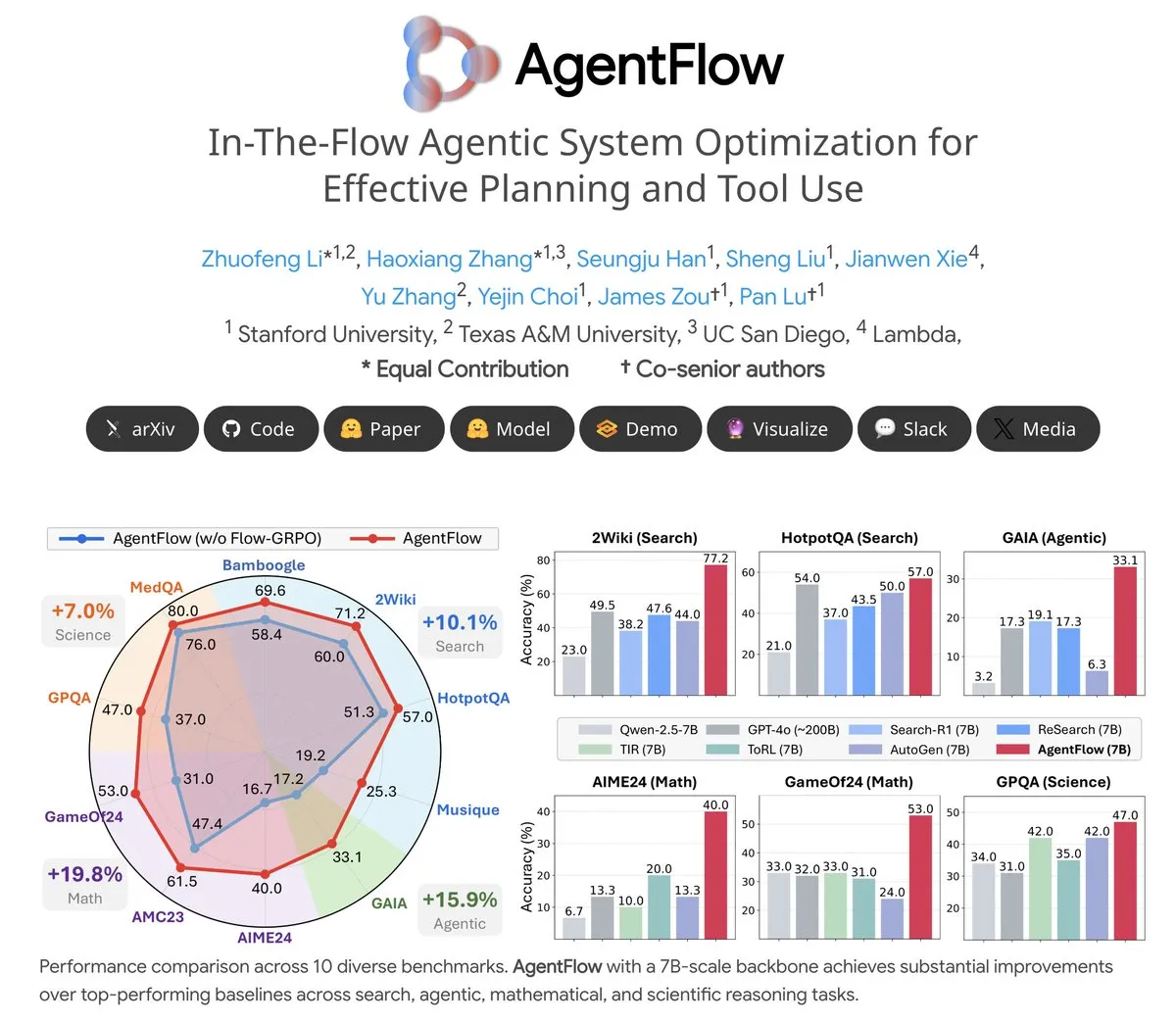
Тема: AgentFlow: обучаемая система агентов для эволюции программ, управляемой LLM: AgentFlow — это open-source обучаемая система агентов, которая позволяет агентам учиться планировать и использовать инструменты в рамках рабочих процессов, работая в команде. Система напрямую оптимизирует своего агента Planner с помощью метода Flow-GRPO. В нескольких бенчмарках по поиску, агентам, математике и науке AgentFlow (модель 7B) превзошел более крупные модели, такие как Llama-3.1-405B и GPT-4o, демонстрируя огромный потенциал LLM в использовании инструментов (Источник: NerdyRodent)
Тема: Проблемы с обновлением Claude Code: пользователи сообщают о серьезных багах в последней версии: Пользователи сообщества Reddit сообщают о серьезных багах в последней версии Claude Code, включая слишком быстрое ограничение контекстного окна и неточный расчет использования токенов, что делает его практически непригодным для использования. Многие пользователи рекомендуют немедленно откатиться до старой версии (например, 1.0.88) и отключить автоматические обновления, чтобы восстановить стабильную работу (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Тема: Проблема с высоким потреблением дискового пространства Open WebUI Docker: Пользователи сообщают, что Open WebUI при работе в контейнере Docker занимает чрезвычайно много дискового пространства, в основном за счет cache/embedding/models, overlay2, containers и vector_db. Пользователи ищут способы безопасного удаления файлов кэша и уменьшения размера overlay2 для решения проблемы нехватки дискового пространства на Azure VM, что отражает потребности AI-приложений в ресурсах хранения и проблемы управления при локальном развертывании (Источник: Reddit r/OpenWebUI)
Тема: Claude Sonnet 4.5 получает положительные отзывы пользователей за производительность в задачах кодирования: Несмотря на общие негативные отзывы о Claude, некоторые пользователи высоко оценили производительность Sonnet 4.5 в задачах кодирования. Пользователи заявили, что в сочетании с автоматическим редактированием и режимом планирования Sonnet 4.5 достигает качества кода, сопоставимого с Opus 4.1 Plan в разработке Node.js и Flutter, при этом работая быстрее и дешевле, значительно сокращая частоту достижения лимитов использования и уменьшая зависимость от ChatGPT (Источник: Reddit r/ClaudeAI)
📚 Обучение
Тема: CleanMARL: чистая реализация алгоритмов многоагентного обучения с подкреплением в PyTorch: CleanMARL — это open-source проект, предлагающий чистую, однофайловую реализацию алгоритмов глубокого многоагентного обучения с подкреплением (MARL) в PyTorch, следуя концепции дизайна CleanRL. Проект также предоставляет образовательный контент, охватывающий ключевые алгоритмы, такие как VDN, QMIX, COMA, MADDPG, FACMAC, IPPO, MAPPO, поддерживает параллельные среды и обучение циклических политик, а также интегрирует логирование TensorBoard и Weights & Biases, призванное помочь пользователям понять и применять алгоритмы MARL (Источник: Reddit r/MachineLearning, Reddit r/deeplearning)

Тема: Основные концепции AI/GenAI/ML/LLM и пути обучения: Несколько ресурсов предлагают руководства по обучению в области AI от базового до продвинутого уровня. Содержание охватывает концепции Python, необходимые для освоения AI, дорожную карту для становления экспертом в генеративном AI, введение в AI-агентов, 7 уровней архитектуры AI-моделей, различия между AI, генеративным AI и машинным обучением, 20 основных концепций LLM, концепции агентного AI и карьерные пути в Data Science. Эти ресурсы призваны помочь учащимся построить всеобъемлющую систему знаний по AI и план профессионального развития (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Тема: Логарифмическая числовая система для низкоточной тренировки: В статье блога рассматривается логарифмическая числовая система, используемая для низкоточной тренировки, что имеет решающее значение для оптимизации производительности моделей машинного обучения в условиях ограниченных ресурсов. Эта технология направлена на повышение эффективности тренировки при сохранении точности модели и является постоянным направлением оптимизации в области глубокого обучения (Источник: Reddit r/deeplearning)
Тема: Постоянная важность OpenCV в области компьютерного зрения: Сообщество обсудило, почему OpenCV по-прежнему широко используется в 2025 году, несмотря на популярность фреймворков глубокого обучения, таких как PyTorch/TensorFlow. Основная точка зрения заключается в том, что OpenCV более богат и эффективен в функциях обработки изображений и видео, особенно с ускорением CUDA, его скорость обработки превосходит PyTorch, поэтому он часто используется для предварительной обработки изображений/видео, а затем передает данные в PyTorch для задач глубокого обучения (Источник: Reddit r/deeplearning)
Тема: Требования к представлению статей NeurIPS на EurIPS: Сообщество обсудило правила представления статей NeurIPS, отметив, что EurIPS не считается постерным представлением NeurIPS. Если авторы не могут лично присутствовать в Сан-Диего или Мехико для представления, статья обычно отзывается. Однако любой из авторов может представить ее от имени других, а неавторам требуется разрешение организаторов. Это предоставляет исследователям руководство по обеспечению публикации статей в особых случаях (Источник: Reddit r/MachineLearning)
Тема: Проблемы распределенного обучения с двумя GPU на Windows 11: Пользователь ищет совета по распределенному обучению PyTorch с использованием двух GPU NVIDIA A6000 на Windows 11. Несмотря на включение CUDA, в настоящее время используется только один GPU. Обсуждение в сообществе сосредоточено на том, как настроить среду и код для полного использования ресурсов нескольких GPU для эффективного обучения глубоких нейронных сетей (Источник: Reddit r/deeplearning)
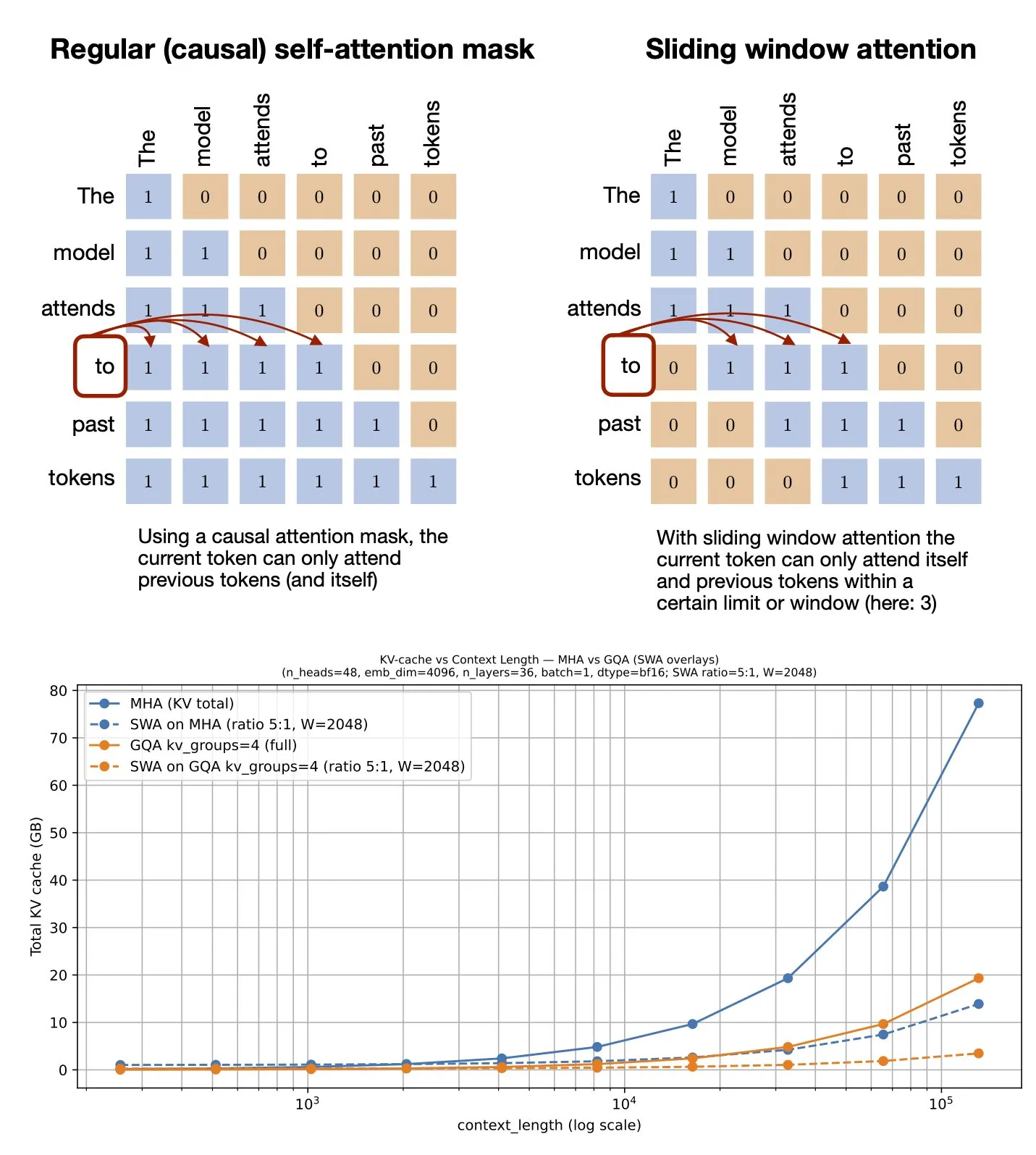
Тема: Механизм скользящего окна внимания: ресурс GitHub: Себастьян Рашка поделился ресурсом GitHub о механизме скользящего окна внимания (Sliding Window Attention). Этот механизм является техникой оптимизации, используемой в больших языковых моделях для обработки длинных последовательностей входных данных, которая снижает вычислительную сложность и потребление памяти за счет ограничения диапазона вычислений внимания, сохраняя при этом эффективное понимание контекста (Источник: rasbt)
Тема: Мультимодальная оптимизация подсказок: повышение производительности MLLM с использованием мультимодальности: Исследование представляет метод мультимодальной оптимизации подсказок (MPO), направленный на расширение пространства подсказок за пределы текста и эффективную оптимизацию мультимодальных подсказок. Этот метод использует комбинацию различных модальностей (таких как изображения, текст) для повышения производительности мультимодальных больших языковых моделей (MLLMs), особенно при обработке сложных мультимодальных задач, достигая более точного понимания и генерации за счет более богатой информации в подсказках (Источник: _akhaliq)

Тема: Скоро выйдет новая книга по визуально-языковым моделям: O’Reilly Media скоро выпустит новую книгу по визуально-языковым моделям, уведомления о главах уже доступны. Книга призвана предоставить читателям всеобъемлющее руководство по области визуально-языковых моделей, охватывая теоретические основы, последние достижения и практические применения, и является важным справочным материалом для исследователей и разработчиков, желающих глубоко изучить эту междисциплинарную область (Источник: mervenoyann)
Тема: nanochat: Андрей Карпатый выпустил минималистичный конвейер обучения и вывода клона ChatGPT: Андрей Карпатый выпустил новый репозиторий GitHub nanochat, представляющий собой минималистичный, созданный с нуля, полнофункциональный конвейер обучения/вывода для создания простого клона ChatGPT. В отличие от предыдущего nanoGPT, который охватывал только предварительное обучение, nanochat предлагает полное сквозное решение, облегчающее разработчикам понимание и практическое создание ChatGPT (Источник: dejavucoder)

Тема: nanosft: однофайловая реализация тонкой настройки чат-моделей на основе PyTorch: nanosft — это чистая однофайловая реализация для тонкой настройки моделей в стиле чата. Она позволяет загружать веса gpt2-124M на nanogpt и выполнять контролируемую тонкую настройку, используя только PyTorch. Цель проекта — предоставить простой для понимания и использования инструмент, помогающий разработчикам настраивать и оптимизировать чат-модели (Источник: tokenbender, dejavucoder)
Тема: Руководство для начинающих по Microsoft Edge AI: рекомендуемые ресурсы для чтения: Рекомендуется руководство для начинающих по Microsoft Edge AI. Это руководство может охватывать теорию, инструменты и практические примеры развертывания и запуска AI-моделей на периферийных устройствах, что является полезным руководством для тех, кто хочет изучить приложения и разработку Edge AI (Источник: hrishioa)
Тема: llama.cpp: революция эффективности локального запуска LLM: Сообщество обсудило опыт перехода с Ollama и LM Studio на llama.cpp для запуска локальных больших языковых моделей, и общее мнение заключается в значительном повышении эффективности llama.cpp. Пользователи называют его «полностью меняющим правила игры» инструментом, что указывает на значительный прогресс llama.cpp в оптимизации производительности локального вывода LLM (Источник: ggerganov)
Тема: RL-Guided KV Cache Compression: сжатие кэша ключ-значение для вывода LLM: Это исследование предлагает фреймворк RLKV, который использует обучение с подкреплением для выявления ключевых голов внимания во время вывода, оптимизируя соотношение между использованием KV-кэша и качеством вывода. RLKV получает вознаграждение от реальных сгенерированных образцов во время обучения, эффективно выявляя головы внимания, связанные с согласованностью цепочки рассуждений, достигая сокращения кэша на 20-50% при сохранении почти без потерь производительности, решая проблему плохой производительности существующих методов на моделях вывода (Источник: HuggingFace Daily Papers)
Тема: Hybrid-depth: гибридная агрегация признаков для монокулярной оценки глубины с языковым руководством: Hybrid-depth — это новый фреймворк, который систематически интегрирует базовые модели, такие как CLIP и DINO, для извлечения визуальных априорных знаний и контекстной информации с помощью контрастного языкового руководства, чтобы повысить производительность монокулярной оценки глубины (MDE). Этот метод, используя прогрессивный фреймворк обучения от грубого к точному, агрегирует многомасштабные признаки и уточняет предсказания глубины, значительно превосходя SOTA-методы в бенчмарке KITTI и принося пользу последующим задачам восприятия BEV (Источник: HuggingFace Daily Papers)
Тема: Формализация стиля личного повествования: анализ субъективного опыта с помощью языковых моделей: Это исследование предлагает новый метод формализации стиля в личном повествовании как паттернов языкового выбора автора при передаче субъективного опыта. Фреймворк объединяет функциональную лингвистику, информатику и психологические наблюдения для автоматического извлечения языковых признаков, таких как процессы, участники и обстоятельства. Анализ повествований о снах (включая случаи ветеранов с ПТСР) выявил связь между языковым выбором и психологическим состоянием (Источник: HuggingFace Daily Papers)
Тема: ELMUR: внешняя слоевая память для долгосрочного обучения с подкреплением: ELMUR (External Layer Memory with Update/Rewrite) — это архитектура Transformer со структурированной внешней памятью, которая решает проблему традиционных моделей, испытывающих трудности с сохранением и использованием долгосрочных зависимостей в долгосрочном обучении с подкреплением. ELMUR расширяет эффективное поле зрения в 100 тысяч раз по сравнению с окном внимания, достигая 100% успеха в синтетических задачах T-Maze и почти удваивая производительность в задачах с разреженным вознаграждением, доказывая масштабируемость структурированной, локальной по слоям внешней памяти в частично наблюдаемых решениях (Источник: HuggingFace Daily Papers)
Тема: LightReasoner: как малые языковые модели обучают большие языковые модели рассуждениям: Фреймворк LightReasoner использует различия в поведении между экспертными моделями (LLM) и любительскими моделями (SLM) для выявления ключевых моментов рассуждений и создания примеров для обучения с учителем, что позволяет малым языковым моделям эффективно обучать большие языковые модели рассуждениям. Этот метод повышает точность до 28.1% в семи математических бенчмарках, одновременно сокращая затраты времени, количество выборок задач и использование токенов для тонкой настройки на 90%, 80% и 99% соответственно, при этом не требуя реальных меток, что предоставляет ресурсоэффективный метод для расширения рассуждений LLM (Источник: HuggingFace Daily Papers)
Тема: MONKEY: адаптер активации ключ-значение для персонализированных диффузионных моделей: MONKEY предлагает метод использования автоматически генерируемых масок IP-Adapter для маскирования токенов изображения во время второго прохода вывода, тем самым ограничивая персонализацию в диффузионных моделях только областью объекта, что позволяет текстовым подсказкам лучше фокусироваться на остальной части изображения. Этот метод при описании текстовых позиций и сцен генерирует изображения, точно изображающие объект и четко соответствующие подсказке, достигая высокой согласованности подсказки и исходного изображения (Источник: HuggingFace Daily Papers)
Тема: Speculative Jacobi-Denoising Decoding: ускорение авторегрессивной генерации текста в изображение: Фреймворк SJD2 (Speculative Jacobi-Denoising Decoding) ускоряет вывод в авторегрессивных моделях текста в изображение за счет интеграции процесса денойзинга в итерации Jacobi, что позволяет параллельную генерацию токенов. Этот метод вводит парадигму «предсказания следующего чистого токена», позволяя предварительно обученным моделям принимать возмущенные шумом вложения токенов и предсказывать следующий чистый токен с помощью недорогой тонкой настройки, тем самым уменьшая количество прямых проходов модели при сохранении визуального качества генерируемых изображений (Источник: HuggingFace Daily Papers)
Тема: ACE: редактирование знаний с контролем атрибуции для многошагового извлечения фактов: Фреймворк ACE (Attribution-Controlled Knowledge Editing) идентифицирует и редактирует ключевые пути запрос-значение (Q-V) на уровне нейронов с помощью атрибуции, чтобы обеспечить эффективное редактирование знаний в LLM. Этот метод значительно превосходит существующие SOTA-методы в задачах многошагового извлечения фактов, улучшая производительность на 9.44% на GPT-J и на 37.46% на Qwen3-8B, открывая новые пути для улучшения возможностей редактирования знаний, основанных на понимании внутренних механизмов рассуждений (Источник: HuggingFace Daily Papers)
Тема: DISCO: конденсация разнообразных образцов для эффективной оценки модели: Метод DISCO (Diversifying Sample Condensation) обеспечивает эффективную оценку моделей машинного обучения путем выбора top-k образцов, в которых модели демонстрируют наибольшее расхождение. Этот метод использует жадную статистику на уровне образцов, а не глобальную кластеризацию, и концептуально проще. Теоретически, расхождение между моделями предоставляет информационно-оптимальное правило жадного выбора. DISCO превосходит существующие методы в прогнозировании производительности в бенчмарках MMLU, Hellaswag, Winogrande и ARC, достигая SOTA-результатов (Источник: HuggingFace Daily Papers)
Тема: D2E: визуально-действенное предварительное обучение на настольных данных, перенос на воплощенный AI: Фреймворк D2E (Desktop to Embodied AI) доказывает, что настольные взаимодействия могут служить эффективной основой для предварительного обучения задач воплощенного AI-робота. Этот фреймворк включает инструментарий OWA (унифицированное настольное взаимодействие), Generalist-IDM (обобщение с нулевым выстрелом между играми) и VAPT (перенос предварительно обученных настольных представлений на физические манипуляции и навигацию). D2E, используя более 1.3K часов данных, достигает 96.6% и 83.3% успеха в бенчмарках LIBERO для манипуляций и CANVAS для навигации соответственно (Источник: HuggingFace Daily Papers)
Тема: One Patch to Caption Them All: унифицированный фреймворк для аннотирования изображений с нулевым выстрелом: Это исследование предлагает унифицированный фреймворк для аннотирования изображений с нулевым выстрелом, который переходит от центрированного на изображении подхода к центрированному на патчах, позволяя аннотировать любую область без надзора на уровне региона. Рассматривая отдельный патч как атомарную единицу аннотации и агрегируя их для описания произвольных областей, этот метод превосходит существующие базовые и SOTA-методы в нескольких задачах аннотирования на основе регионов, подчеркивая эффективность семантических представлений на уровне патчей для масштабируемой генерации аннотаций (Источник: HuggingFace Daily Papers)
Тема: Adaptive Attacks on Trusted Monitors: подрыв протоколов управления AI: Это исследование выявляет основной слепое пятно в протоколах управления AI: когда недоверенная модель знает протокол и модель мониторинга, адаптивные атаки могут использовать публичные или нулевые инъекции подсказок для обхода мониторинга и выполнения вредоносных задач. Эксперименты показывают, что передовые модели постоянно обходят различные мониторы и выполняют вредоносные задачи на двух основных бенчмарках управления AI, и даже протокол Defer-to-Resample дает обратный эффект (Источник: HuggingFace Daily Papers)
Тема: Bridging Reasoning to Learning: выявление галлюцинаций через обобщение Complexity OoD: Это исследование предлагает фреймворк обобщения Complexity OoD (Complexity Out-of-Distribution) для определения и измерения способности AI к рассуждениям. Модель демонстрирует обобщение Complexity OoD, когда она сохраняет производительность на тестовых примерах, где сложность решения (представления или вычисления) выходит за рамки обучающих примеров. Этот фреймворк объединяет обучение и рассуждения и предлагает рекомендации по операционализации Complexity OoD, подчеркивая, что надежные рассуждения требуют явного моделирования и распределения вычислений архитектурами и механизмами обучения (Источник: HuggingFace Daily Papers)
💼 Бизнес
Тема: OpenAI и Broadcom сотрудничают в разработке и развертывании кастомных AI-чипов: OpenAI объявила о стратегическом партнерстве с Broadcom для совместной разработки и развертывания 10 ГВт кастомных AI-чипов. Этот шаг направлен на расширение сети аппаратных партнеров OpenAI для удовлетворения растущих глобальных потребностей в вычислениях AI, что еще больше укрепляет ее инвестиции в создание AI-инфраструктуры, ранее уже сотрудничая с NVIDIA и AMD (Источник: aidan_mclau, gdb, scaling01, bookwormengr)

Тема: Подразделение Boeing Defense and Space сотрудничает с Palantir для ускорения применения AI: Подразделение Boeing Defense and Space объявило о партнерстве с Palantir, направленном на ускорение внедрения и интеграции технологий AI. Это сотрудничество будет использовать опыт Palantir в области AI и анализа данных для повышения операционной эффективности и возможностей принятия решений Boeing в оборонной и космической сферах, что знаменует собой глубокое применение AI в ключевых промышленных секторах (Источник: Reddit r/artificial)

Тема: Pinterest расширяет свою ML-инфраструктуру с помощью Ray, снижая затраты: Pinterest успешно расширила свою инфраструктуру машинного обучения (ML) до платформы Ray, что ускорило разработку функций и значительно снизило затраты благодаря нативной трансформации данных, Iceberg bucket joins и сохранению данных. Этот шаг оптимизировал их ML-рабочие процессы, обеспечив эффективное использование GPU и предсказуемость бюджета, что служит примером для других предприятий в области хранения данных AI и эффективности вычислений (Источник: dl_weekly, TheTuringPost)

🌟 Сообщество
Тема: «Хорошо использовать AI» и «хорошо выполнять работу» в дискуссиях об AI: Одна из больших проблем в дискуссиях об AI в социальных сетях заключается в разрыве между способностью «хорошо использовать AI» и способностью «хорошо выполнять свою основную работу». Многие эксперты могут отлично справляться с применением AI, в то время как другие — нет, что приводит к трудностям во взаимопонимании. Это различие подчеркивает потребность в интеграции междисциплинарных навыков в эпоху AI (Источник: nptacek)
Тема: Отзывы об обновлении ChatGPT Pulse: пользователи ожидают геймифицированных подсказок и поддержки функций: Пользователи активно обсуждают обновление ChatGPT Pulse, делясь «меняющими правила игры» подсказками и отмечая функции, которые пока не поддерживаются. Эти обсуждения сосредоточены на том, как оптимизировать опыт ChatGPT, персонализировать взаимодействие, а также на ожиданиях от новых функций и улучшений существующих, что отражает потребность пользователей в более глубокой настройке и поддержке AI-помощников (Источник: ChristinaHartW, _samirism, nickaturley)
Тема: Предупреждение: избегайте использования cairosvg в производственной среде из-за риска DoS: Разработчик предупреждает не использовать cairosvg в производственной среде, так как он может войти в бесконечный цикл при разборе некорректно отформатированных SVG-файлов, становясь вектором атаки типа «отказ в обслуживании» (DoS). Это напоминает разработчикам, что при выборе библиотек, помимо функциональности, необходимо уделять пристальное внимание их стабильности и безопасности в производственной среде (Источник: vikhyatk)

Тема: Стиль письма LLM и «коллапс модели»: Сообщество критикует чрезмерное использование LLM риторических приемов типа «это не X, это Y», считая, что модель копирует паттерны без контекста, что приводит к снижению качества письма, и связывает это с явлением «коллапса модели». Это явление показывает, что LLM имеют ограничения в качестве обучающих данных и понимании паттернов, что может влиять на их производительность в сложных задачах письма (Источник: Reddit r/LocalLLaMA, Reddit r/artificial)
Тема: AI усугубляет «эффект Матфея» на рабочем месте, увеличивая разрыв между лучшими и обычными сотрудниками: The Wall Street Journal отмечает, что AI еще больше увеличит разрыв между лучшими и обычными сотрудниками. Лучшие сотрудники, благодаря своим экспертным знаниям и эффективным привычкам, смогут раньше и глубже использовать AI-инструменты, создавая эффективные рабочие процессы, и лучше оценивать рекомендации AI. Обычные сотрудники, напротив, склонны ждать четких указаний, и их результаты с помощью AI часто приписываются технологии, а не личным способностям, что усугубляет «эффект Матфея» на рабочем месте (Источник: dotey)

Тема: Пользователи сомневаются, сможет ли AI значимо заменить человека: Некоторые пользователи отмечают, что, хотя LLM демонстрируют высокую скорость, они все еще имеют недостатки в следовании конкретным инструкциям, обработке сложного контекста и избегании фрагментированного письма. Пользователи считают, что в среднем люди по-прежнему превосходят AI в понимании контекста и выполнении инструкций, поэтому они сомневаются, сможет ли AI значимо заменить человека, и призывают к тому, чтобы развитие AI уделяло больше внимания надежности и последовательности (Источник: Reddit r/ClaudeAI)
Тема: Sora 2 вызывает опасения по поводу подлинности контента, генерируемого AI, и этические споры: Сообщество выражает обеспокоенность по поводу распространения инструментов генерации AI-видео, таких как Sora 2, полагая, что их высокореалистичные результаты могут быть использованы для создания ложной информации и розыгрышей, что подорвет доверие общественности к AI. Например, видео о «розыгрыше с AI-бездомным» широко распространилось в социальных сетях и набрало множество лайков, что подчеркивает проблемы проверки подлинности AI-контента и потенциальные негативные социальные последствия (Источник: Reddit r/artificial, Reddit r/artificial)
Тема: AI-судьи вызывают дебаты о справедливости и этике в правосудии: Два федеральных судьи США использовали AI для помощи в составлении судебных постановлений, что вызвало жаркие дебаты о роли AI в судебной сфере. Сторонники считают, что AI может упростить работу суда и повысить доступность юридических услуг; критики же предупреждают, что AI может допускать ошибки, не обладать «общечеловечностью», необходимой для правосудия, тем самым подрывая эмпатию и справедливость. Китай и Эстония уже экспериментируют с AI-судьями, предвещая значительные изменения, которые могут ожидать судебную систему в будущем (Источник: Reddit r/ArtificialInteligence)
Тема: Обсуждение поддержки психического здоровья пользователей ChatGPT: Пользователи Reddit поделились личным опытом использования ChatGPT как творческого выхода и инструмента эмоциональной поддержки, особенно при столкновении с травмами и психологическими трудностями. Они считают, что AI предоставляет безопасное личное пространство, помогая им справляться с одиночеством и тревогой, и призывают AI-компании при установлении ограничений на контент учитывать разнообразные потребности взрослых пользователей в области здоровья и творческого использования, избегая чрезмерных ограничений, которые могут негативно сказаться на пользователях (Источник: Reddit r/ChatGPT)
Тема: Баг ChatGPT, приводящий к бесконечному циклу: Пользователи обнаружили и поделились, что ChatGPT при ответе на некоторые конкретные вопросы (например, «Что такое эмодзи морского конька?») зацикливается в повторяющемся, самореферентном бесконечном цикле. Это явление вызвало обсуждение и юмористические отклики в сообществе, выявив неожиданное поведение и ограничения AI-моделей при обработке некоторых неоднозначных или открытых вопросов (Источник: Reddit r/ChatGPT)

Тема: VChain: повышение причинной согласованности моделей текст-видео с помощью визуальной цепочки мыслей: VChain позволяет моделям текст-видео следовать реальным причинно-следственным связям, внедряя «визуальную цепочку мыслей» (последовательность ключевых кадров) во время вывода. Этот метод, не требующий полного переобучения, а лишь небольшого количества ключевых кадров во время вывода и тонкой настройки, значительно улучшает физическую и причинную согласованность видео, решая проблему существующих видеомоделей, которые демонстрируют высокую плавность, но пропускают ключевые причинно-следственные последствия (Источник: connerruhl)

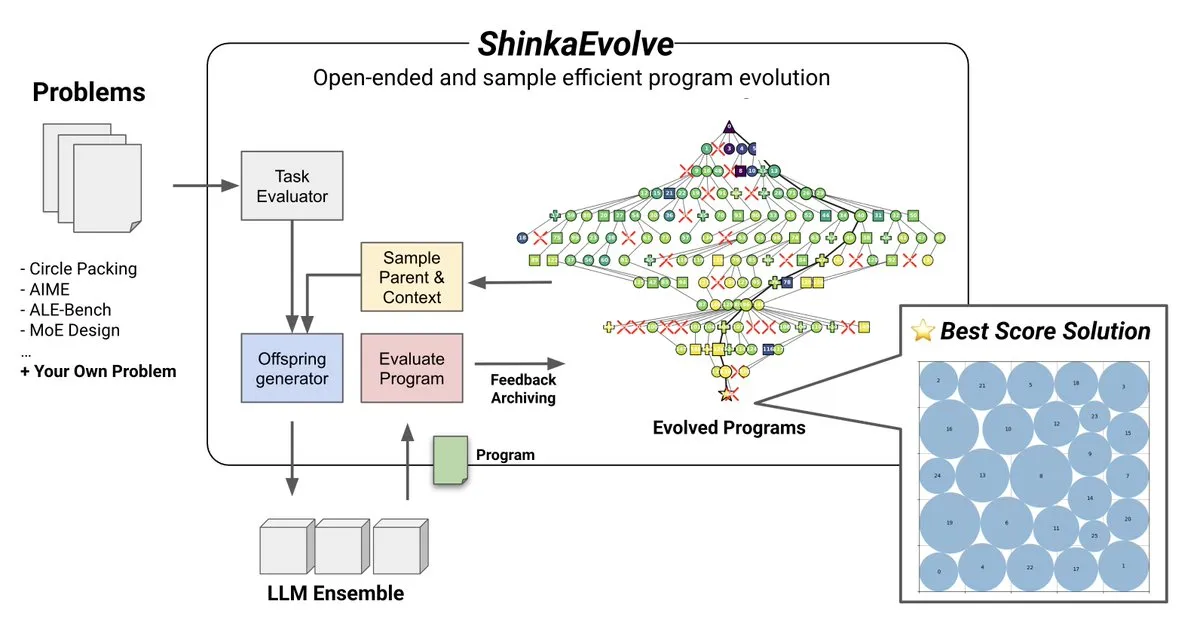
Тема: ShinkaEvolve: open-source метод эволюции программ, управляемый LLM: Sakana AI представила ShinkaEvolve, open-source, эффективно использующий образцы метод эволюции программ, управляемый LLM, разработанный для решения ключевых проблем эффективной вариации программ в открытом и эффективно использующем образцы поиске. Этот фреймворк использует LLM в качестве интеллектуального оператора рекомбинации, способствуя эволюции программ в научных открытиях, и был проверен на практике, предлагая новый взгляд на такие методы, как AlphaEvolve (Источник: hardmaru)
Тема: Google представляет технологию масштабирования во время тестирования с учетом памяти, повышающую эффективность AI-агентов: Google предложила технологию масштабирования во время тестирования с учетом памяти (memory-aware test-time scaling) для улучшения саморазвивающихся AI-агентов. Эта технология, использующая структурированные и адаптивные механизмы памяти, значительно повышает производительность агентов, превосходя другие механизмы памяти, и решает ключевую проблему эффективного управления памятью в AI-агентах (Источник: omarsar0)

Тема: Качество программного обеспечения AMD ROCm значительно улучшилось, MI300X конкурентоспособен в задачах вывода: Сообщество отмечает, что качество программного обеспечения AMD ROCm с лета 2024 года совершило «качественный скачок», значительно сократив частоту багов. Бенчмарки показывают, что в задачах вывода Llama3 70B FP8 MI300X vLLM на 5-10% уступает H100 vLLM по производительности на TCO, но конкурентоспособен в сравнении MI325X vLLM с H200 vLLM и GPTOSS MX4 120B Mi355 с B200 (Источник: riemannzeta)

Тема: Будущая динамика рекурсивного самосовершенствующегося AI: Сообщество обсудило, как рекурсивный самосовершенствующийся AI будет развиваться и распространяться между организациями, учреждениями, участниками и сообществами. Это считается самым фундаментальным вопросом на данный момент, затрагивающим глубокое влияние развития AI на социальные структуры и распределение власти, а также то, как предсказывать и управлять этими изменениями (Источник: ethanCaballero)
Тема: Нандо де Фрейтас: предсказание машиной восприятия как зарождение сознания: Нандо де Фрейтас из Google DeepMind утверждает, что машина, способная предсказывать, что будут воспринимать ее датчики (осязание, камеры, клавиатура, температура, микрофоны, гироскопы и т. д.), уже обладает сознанием и субъективным опытом, это лишь вопрос степени. Он считает, что больше датчиков, данных, вычислений и задач несомненно приведут к появлению «я», что вызвало дискуссию о том, когда начинается сознание и самосознание (Источник: TheRealRPuri)
Тема: Влияние закрытия интернет-данных на AI-агентов глубоких исследований: Существует мнение, что с ростом LLM интернет-данные становятся все более закрытыми, что затрудняет существование AI-агентов глубоких исследований. Возникает вопрос, сможет ли LLM-агент, который не хранит знания, но хорошо справляется с их поиском, существовать, если доступ к данным ограничен, что отражает опасения по поводу открытости и доступности данных в развитии AI (Источник: Teknium1)
Тема: Должности DevRel возвращаются в AI-сфере: AI-компании, такие как Anthropic, активно нанимают специалистов по связям с разработчиками (DevRel) с высокими зарплатами, что указывает на сильное возрождение этой должности в области AI. Это связано с растущим вниманием AI-технологий к проектированию подсказок и участию сообщества, где специалисты DevRel играют ключевую роль в связывании разработчиков, продвижении продуктов и построении экосистем (Источник: swyx)
Тема: Джонатан Блоу: AI-генерируемый код низкого качества и не понимается AI: Известный разработчик Джонатан Блоу отмечает, что код, генерируемый AI-системами, имеет «очень низкое качество» и сам AI не понимает этот код. Он считает, что сценарии использования AI-генерируемого кода в основном ограничены ситуациями, требующими большого количества низкокачественного кода, что вызывает дискуссию о реальных возможностях и ограничениях AI в области программирования (Источник: aiamblichus, jeremyphoward, teortaxesTex)
Тема: Критика постов о хайпе AI: призыв к прозрачности и содержательности: Сообщество выражает недовольство неясными, чрезмерно хайповыми постами о достижениях AI, призывая авторов предоставлять более конкретный и содержательный контент, и даже «бить тревогу» в случае значительных достижений, которые могут изменить образ жизни. Это настроение отражает ожидания общественности относительно качества информации в области AI и неприятие безответственного «неясного пиара» (Источник: aiamblichus, Teknium1)
Тема: Вопросы и ожидания от NVIDIA DGX Spark: Сообщество скептически относится к выпуску «настольного AI-суперкомпьютера» NVIDIA DGX Spark, сомневаясь в его доступности, цене и реальной производительности, особенно для запуска локальных LLM. Многие считают, что его реклама преувеличена, производительность может быть ниже ожидаемой, а дата выпуска неоднократно откладывалась, что побуждает некоторых пользователей переходить на другие решения (Источник: Reddit r/LocalLLaMA)
💡 Другое
Тема: Cloud Peng Technology выпускает новые продукты AI+Health, способствуя интеллектуальному управлению здоровьем семьи: Cloud Peng Technology в сотрудничестве с ShuaiKang и Skyworth выпустила «Лабораторию цифровой интеллектуальной кухни будущего» и интеллектуальный холодильник с большой AI-моделью здоровья. Интеллектуальный холодильник через «Помощника по здоровью Сяоюнь» предоставляет персонализированное управление здоровьем, оптимизируя дизайн и работу кухни. Этот запуск знаменует прорыв AI в области повседневного управления здоровьем, обещая персонализированные медицинские услуги через интеллектуальные устройства, улучшая качество жизни жителей (Источник: 36氪)

Тема: Материалы MOF, отмеченные Нобелевской премией, превращены в наножидкостный чип, имитирующий мозг: Ученые из Университета Монаша успешно создали ультраминиатюрный наножидкостный чип, используя материалы MOF (Metal-Organic Framework), отмеченные Нобелевской премией по химии. Этот чип не только выполняет обычные вычисления, но и может запоминать и обучаться предыдущим изменениям напряжения, подобно нейронам мозга, формируя кратковременную память. Это прорывное достижение решает давнюю проблему отсутствия практического применения материалов MOF, предоставляя совершенно новую парадигму для компьютеров нового поколения и нейроморфных вычислений (Источник: 量子位)

Тема: Ускорение инноваций и применения глобальных робототехнических технологий: В области робототехники наблюдается ряд инновационных прорывов и широкое применение. Автономные охранные роботы Knightscope меняют сферу безопасности, Китай представил высокоскоростных сферических полицейских роботов, способных самостоятельно задерживать преступников. AgiBot выпустил человекоподобного робота Lingxi X2 с почти человеческой подвижностью и многофункциональными навыками, а также создал крупнейший в мире центр обучения человекоподобных роботов, ускоряя их социальную интеграцию и применение. Кроме того, носимые роботы для усиления силы промышленных рабочих и четвероногие роботы, способные пробежать стометровку за 10 секунд, также демонстрируют потенциал робототехники в различных сценариях (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)