
Ключевые слова:Meta, Tencent Hunyuan Image 3.0, xAI Grok 4 Fast, OpenAI Sora 2, ByteDance Self-Forcing++, Alibaba Qwen, vLLM, GPT-5-Pro, Мета-когнитивный механизм повторного использования, Обобщенный механизм причинного внимания, Мультимодальная модель рассуждений, Генерация видео на уровне минут, Генерация моды с учетом позы
🔥 Фокус
Новый метод Meta сокращает цепочку рассуждений, избавляя от повторных выводов : Meta, Mila-Quebec AI Institute и другие совместно предложили механизм “метакогнитивного повторного использования”, направленный на решение проблем раздувания token и увеличения задержки, вызванных повторяющимися выводами в рассуждениях больших моделей. Этот механизм позволяет модели пересматривать и обобщать подходы к решению задач, извлекая общие шаблоны рассуждений в “действия” и сохраняя их в “руководстве по действиям”, которые затем могут быть вызваны напрямую без необходимости повторного вывода. Эксперименты показали, что в тестах по математике, таких как MATH и AIME, этот механизм позволяет сократить использование token для рассуждений до 46% при сохранении точности, повышая эффективность модели и ее способность исследовать новые пути. (Источник: 量子位)

Tencent Hunyuan Image 3.0 возглавил мировой рейтинг генерации изображений с помощью ИИ : Tencent Hunyuan Image 3.0 занял первое место в рейтинге LMArena по генерации изображений из текста, обогнав Google Nano Banana, ByteDance Seedream и OpenAI gpt-Image. Модель использует нативную мультимодальную архитектуру, основанную на Hunyuan-A13B, с общим количеством параметров более 80 миллиардов, способна унифицированно обрабатывать различные модальности, такие как текст, изображения, видео и аудио, и обладает мощными возможностями семантического понимания, языкового моделирования и рассуждений на основе мировых знаний. Ее ключевые технологии включают обобщенный механизм причинно-следственного внимания и двумерное позиционное кодирование, а также введение автоматического предсказания разрешения. Модель строит данные с помощью трехэтапной фильтрации и иерархической системы описания, а также использует четырехэтапную прогрессивную стратегию обучения, эффективно повышая реалистичность и четкость генерируемых изображений. (Источник: 量子位)

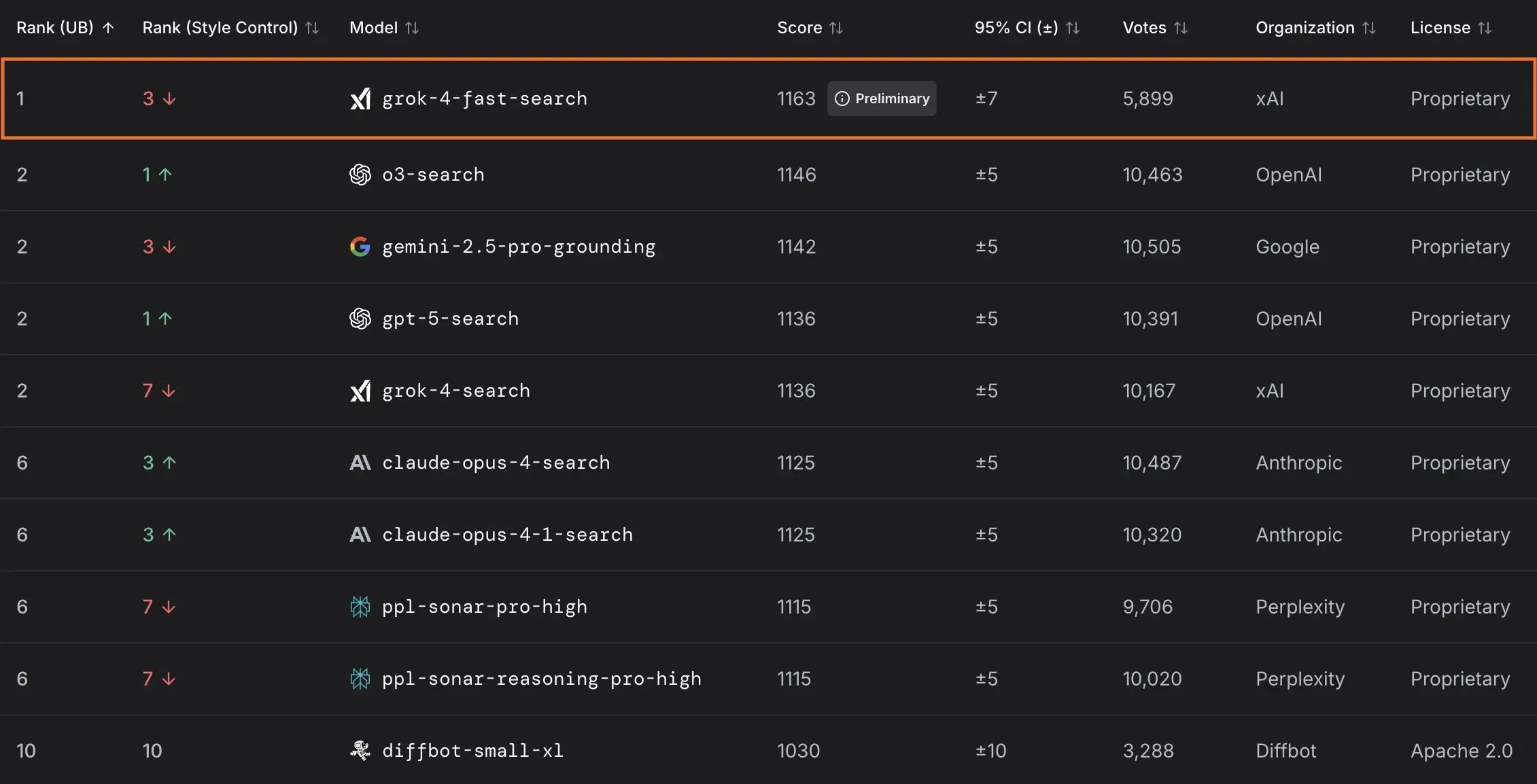
xAI выпустила модель Grok 4 Fast и сотрудничает с правительством США : xAI представила Grok 4 Fast, мультимодальную модель рассуждений с контекстным окном 2M, разработанную для предоставления высокоэффективных интеллектуальных услуг. Модель уже бесплатно доступна всем пользователям. В рамках сотрудничества с федеральным правительством США, xAI предоставляет всем федеральным агентствам бесплатный доступ к своим передовым моделям ИИ (Grok 4, Grok 4 Fast) на 18 месяцев и направляет команду инженеров для помощи правительству в использовании ИИ. Кроме того, xAI также выпустила OpenBench для оценки производительности и безопасности LLM, а также Grok Code Fast 1, который демонстрирует выдающиеся результаты в задачах кодирования. (Источник: xai, xai, xai, JonathanRoss321)
🎯 Тенденции
OpenAI анонсировала потребительские продукты ИИ и обновления Sora 2 : UBS прогнозирует, что конференция разработчиков OpenAI будет посвящена выпуску потребительских продуктов ИИ, возможно, включая ИИ-агентов для бронирования путешествий. Тем временем, модель генерации видео Sora 2 проходит тестирование, и пользователи отмечают, что ее сгенерированный контент часто обладает юмором. OpenAI также исправила проблему с разрешением в режиме высокой четкости модели Sora 2 Pro, теперь поддерживается разрешение 17921024 или 10241792, а также генерация видео до 15 секунд, но ежедневный лимит генерации снижен до 30 раз. (Источник: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance представила модель генерации видео продолжительностью в минуты : ByteDance представила новый метод под названием Self-Forcing++, способный генерировать высококачественные видео продолжительностью до 4 минут 15 секунд. Этот метод позволяет масштабировать диффузионные модели без необходимости использования длинных обучающих моделей видео или переобучения, сохраняя при этом точность и согласованность генерируемого видео. (Источник: _akhaliq)
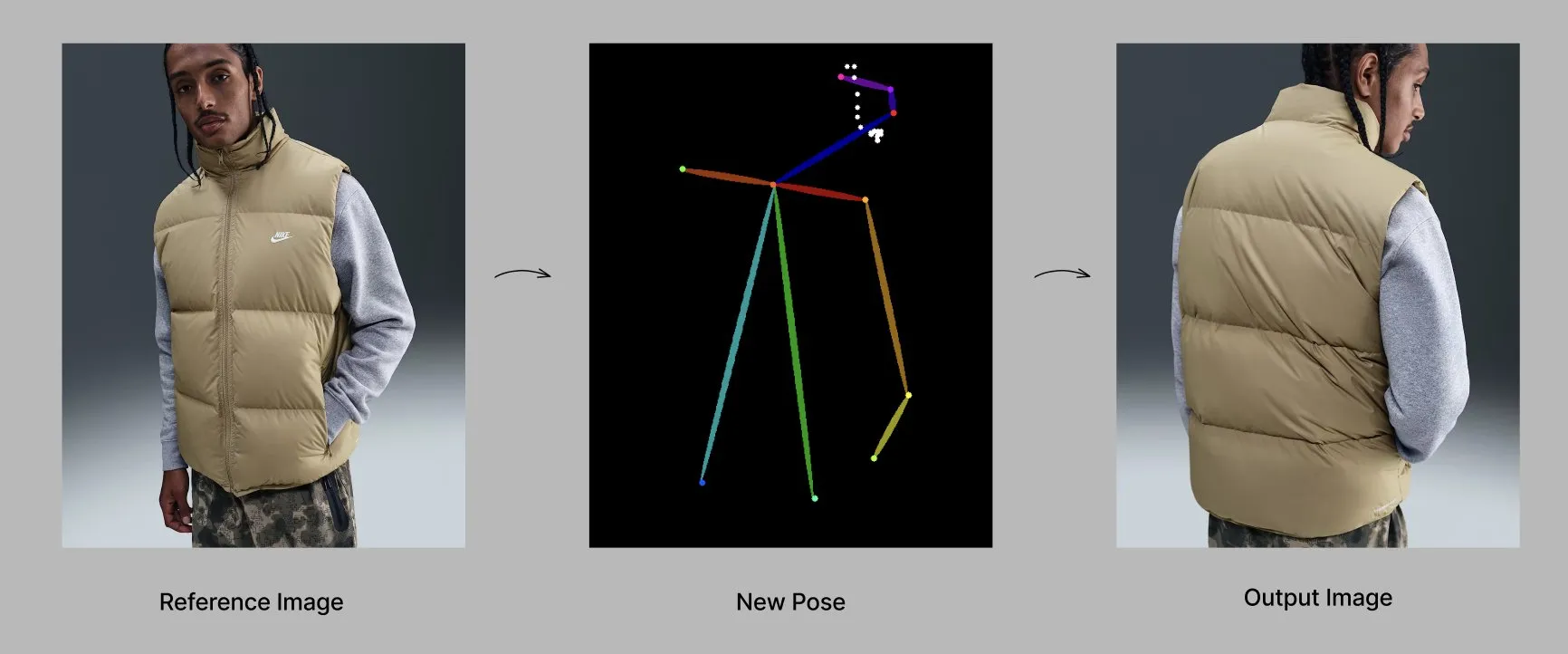
Модель Qwen запускает новые функции и приложения : Команда Alibaba Qwen постепенно внедряет персонализированные функции, такие как память и настраиваемые системные инструкции, которые в настоящее время находятся на ограниченном тестировании. В то же время модель Qwen-Image-Edit-2509 демонстрирует передовые возможности в генерации модной одежды с учетом позы, позволяя создавать высококачественные модные модели под разными углами путем тонкой настройки. (Источник: Alibaba_Qwen, Alibaba_Qwen)
vLLM и PipelineRL расширяют границы сообщества RL : Проект vLLM поддерживает сообщество RL в новых прорывах в области Reinforcement Learning, включая улучшенные on-policy данные, частичные rollouts и in-flight обновления весов, смешивающие KV cache во время вывода. PipelineRL обеспечивает масштабируемый асинхронный RL, продолжая вывод при изменении весов и сохранении состояния KV, а также поддерживает in-flight обновления весов. (Источник: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro решает сложные математические задачи : GPT-5-Pro самостоятельно решил “554-ю задачу Ю Цумуры” за 15 минут, став первой моделью, полностью справившейся с этой задачей, что демонстрирует ее мощные способности к решению математических проблем. (Источник: Teknium1)

SAP делает ИИ центральным элементом корпоративных рабочих процессов : SAP планирует на конференции Connect 2025 представить свое видение, в котором ИИ станет центральным элементом корпоративных рабочих процессов, превращая данные в реальном времени в решения с помощью встроенного ИИ и используя AI agent для проактивных действий. SAP подчеркивает важность построения доверия и предоставления активной поддержки с самого начала, а также обеспечения локальной гибкости и соответствия требованиям. (Источник: TheRundownAI)

Salesforce выпустила модель текстового диффузионного кодирования CoDA-1.7B : Salesforce Research выпустила CoDA-1.7B, модель текстового диффузионного кодирования, способную выводить token двунаправленно и параллельно. Эта модель быстрее в выводе, а ее 1.7B параметров сопоставимы с 7B моделями, демонстрируя выдающиеся результаты в тестах HumanEval, HumanEval+ и EvalPlus. (Источник: ClementDelangue)

Google Gemini 3.0 фокусируется на EQ, усиливая конкуренцию с OpenAI : Google готовится выпустить Gemini 3.0, который, как сообщается, будет уделять особое внимание “эмоциональному интеллекту” (EQ), что рассматривается как серьезный вызов OpenAI. Этот шаг указывает на развитие моделей ИИ в области эмоционального понимания и взаимодействия, предвещая дальнейшее усиление конкуренции между гигантами ИИ. (Источник: Reddit r/ChatGPT)
Развитие робототехники и технологий автоматизации : В области робототехники продолжаются инновации, включая всенаправленных мобильных гуманоидных роботов для логистических операций, автономные мобильные роботы-доставщики, сочетающие механические руки и шкафчики, а также 12-моторного робота-собаку “Cara”, разработанного американскими студентами с использованием тросового привода и умных математических расчетов. Кроме того, была официально представлена первая роботизированная рука “Wuji Hand”. (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 Инструменты
Проект GPT4Free (g4f) предлагает бесплатные LLM и инструменты для генерации медиа : GPT4Free (g4f) — это проект, управляемый сообществом, целью которого является интеграция различных доступных LLM и моделей генерации медиа, предоставляя Python-клиент, локальный Web GUI, совместимый с OpenAI REST API и JavaScript-клиент. Он поддерживает адаптеры для нескольких провайдеров, включая OpenAI, PerplexityLabs, Gemini, MetaAI и другие, а также поддерживает генерацию изображений/аудио/видео и сохранение медиа, стремясь популяризировать открытый доступ к инструментам ИИ. (Источник: GitHub Trending)

Проектирование инструментов LLM и лучшие практики Prompt engineering : При написании инструментов, более понятных для ИИ, приоритет отдается определению инструмента, системным инструкциям и пользовательским подсказкам (Prompt). Название и описание инструмента имеют решающее значение, они должны быть интуитивно понятными и ясными, избегая двусмысленности. Параметров должно быть как можно меньше, и следует предоставлять перечисления или устанавливать верхние и нижние пределы. Избегайте использования слишком большого количества вложенных структурированных параметров для повышения скорости ответа. Позволяя модели писать Prompt и предоставляя обратную связь, можно эффективно улучшить понимание инструмента большими моделями. (Источник: dotey)
Zen MCP использует Gemini CLI для экономии кредитов Claude Code : Проект Zen MCP позволяет пользователям напрямую использовать Gemini CLI в таких инструментах, как Claude Code, что значительно сокращает использование token Claude Code и позволяет использовать бесплатные кредиты Gemini. Этот инструмент поддерживает делегирование задач между различными моделями ИИ и сохранение общего контекста, например, использование GPT-5 для планирования, Gemini 2.5 Pro для проверки, Sonnet 4.5 для реализации, а затем Gemini CLI для проверки кода и модульного тестирования, обеспечивая эффективную и экономичную разработку с помощью ИИ. (Источник: Reddit r/ClaudeAI)
Инструмент оценки Open-source LLM Opik : Opik — это open-source инструмент оценки LLM, используемый для отладки, оценки и мониторинга приложений LLM, систем RAG и Agentic workflow. Он предоставляет комплексное отслеживание, автоматизированную оценку и готовые к производству панели мониторинга, помогая разработчикам лучше понимать и оптимизировать свои модели ИИ. (Источник: dl_weekly)
Claude Sonnet 4.5 отлично справляется с написанием скриптов Tampermonkey : Claude Sonnet 4.5 демонстрирует выдающиеся способности в написании скриптов Tampermonkey; пользователю достаточно одной подсказки, чтобы изменить тему Google AI Studio, что демонстрирует его мощные возможности в автоматизации операций браузера и настройке пользовательского интерфейса. (Источник: Reddit r/ClaudeAI)

Локальное развертывание модели Phi-3-mini : Пользователи стремятся развернуть модель Phi-3-mini-4k-instruct-bnb-4bit, тонко настроенную с использованием Unsloth на Google Colab, на локальной машине. Модель способна извлекать резюме и анализировать поля из текста. Цель развертывания — локально считывать текст из DataFrame, обрабатывать его моделью и сохранять вывод в новый DataFrame, даже в условиях низкой конфигурации с интегрированной видеокартой и 8 ГБ RAM. (Источник: Reddit r/MachineLearning)
Сравнение производительности бэкендов LLM : Сообщество обсуждает производительность текущих бэкенд-фреймворков LLM. vLLM, llama.cpp и ExLlama3 считаются самыми быстрыми вариантами, в то время как Ollama — самым медленным. vLLM отлично справляется с обработкой нескольких одновременных чатов, llama.cpp популярен благодаря своей гибкости и широкой поддержке оборудования, а ExLlama3 предлагает максимальную производительность для NVIDIA GPU, но с ограниченной поддержкой моделей. (Источник: Reddit r/LocalLLaMA)
Инструмент “solveit” помогает программистам справляться с вызовами ИИ : В ответ на возможные разочарования программистов при использовании ИИ, Джереми Ховард представил инструмент “solveit”. Этот инструмент призван помочь программистам более эффективно использовать ИИ, избегая того, чтобы ИИ вел их в неверном направлении, и повышая опыт и эффективность программирования. (Источник: jeremyphoward)
📚 Обучение
Стэнфорд и NVIDIA сотрудничают для продвижения эталонного тестирования воплощенного ИИ : Стэнфордский университет и NVIDIA проведут совместную прямую трансляцию, чтобы подробно обсудить BEHAVIOR — масштабный бенчмарк и вызов для развития воплощенного ИИ. Обсуждение затронет мотивацию BEHAVIOR, дизайн предстоящих вызовов и роль симуляции в продвижении робототехнических исследований. (Источник: drfeifei)

Опубликована статья об оценке ИИ-агентов с помощью Agent-as-a-Judge : Новая статья под названием “Agent-as-a-Judge” предлагает метод доказательства концепции, при котором ИИ-агенты оценивают ИИ-агентов, что позволяет сократить затраты и время на 97% и предоставляет обширную промежуточную обратную связь. Исследование также разработало бенчмарк DevAI, содержащий 55 задач по автоматизированной разработке ИИ, доказывая, что Agent-as-a-Judge не только превосходит LLM-as-a-Judge, но и по эффективности и точности ближе к человеческой оценке. (Источник: SchmidhuberAI, SchmidhuberAI)

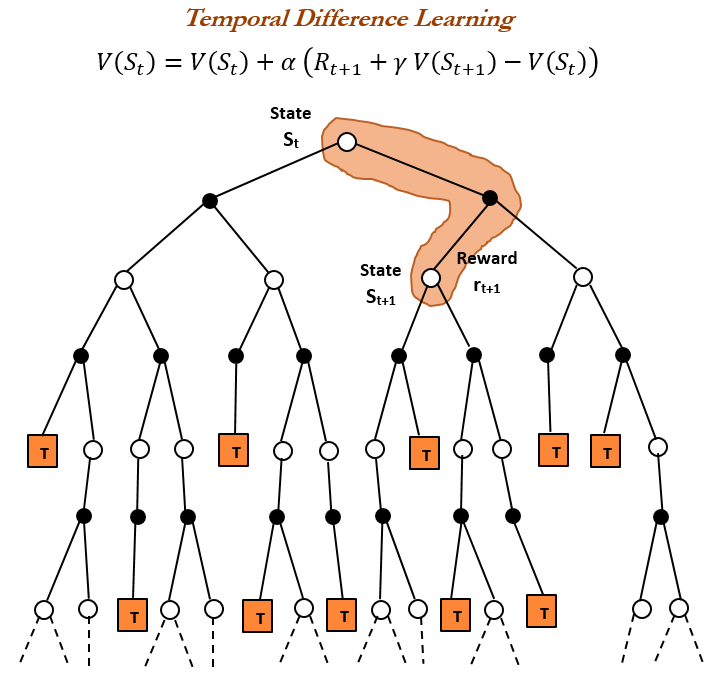
История Reinforcement Learning (RL) и Time Difference (TD) learning : Обзор истории Reinforcement Learning указывает, что Time Difference (TD) learning является основой современных алгоритмов RL (таких как Deep Actor-Critic). TD learning позволяет агентам обучаться в неопределенной среде, минимизируя ошибки предсказания путем сравнения последовательных предсказаний и постепенного обновления, что приводит к более быстрым и точным предсказаниям. Его преимущества включают избегание заблуждений редкими результатами, экономию памяти и вычислений, а также применимость в реальном времени. (Источник: TheTuringPost, TheTuringPost, gabriberton)
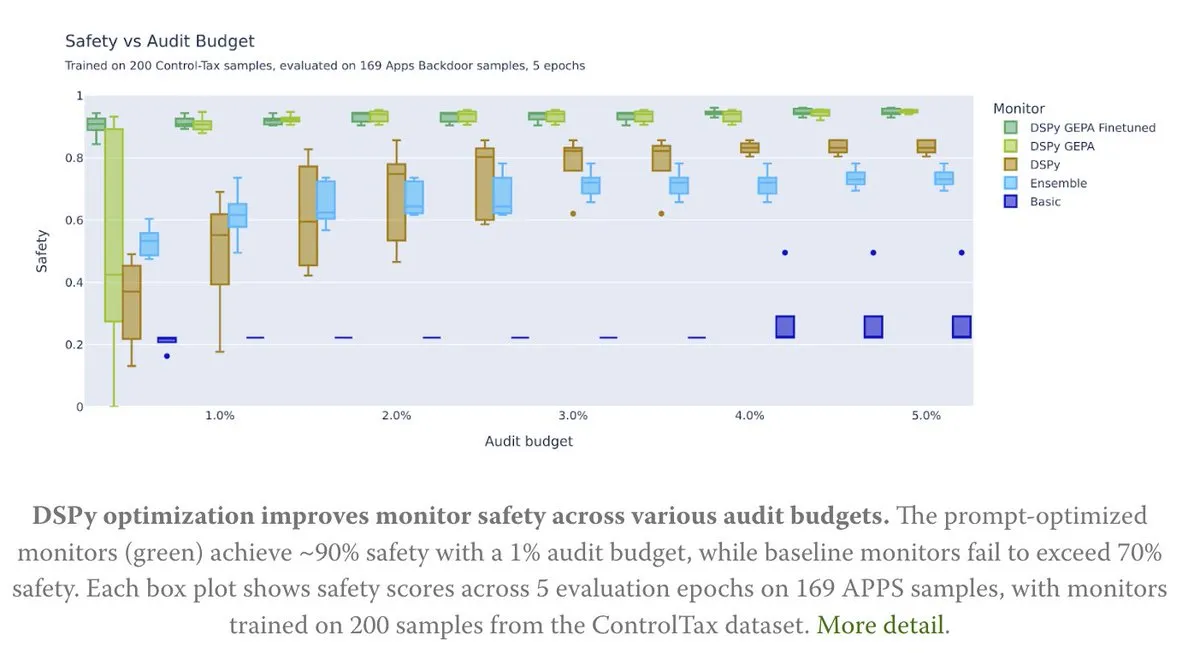
Оптимизация Prompt для исследований в области управления ИИ : Новая статья исследует, как оптимизация Prompt способствует исследованиям в области управления ИИ, в частности, с помощью метода GEPA (Generative-Enhanced Prompting for Agents) от DSPy, который достиг до 90% уровня безопасности ИИ, в то время как базовый метод достиг только 70%. Это показывает огромный потенциал тщательно разработанных Prompt в повышении безопасности и управляемости ИИ. (Источник: lateinteraction, lateinteraction)
Алгоритмы обучения Transformer и CoT : Франсуа Шолле отмечает, что хотя Transformer можно научить выполнять простые алгоритмы, предоставляя точные пошаговые алгоритмы во время обучения с помощью CoT (Chain of Thought) token, истинная цель машинного обучения должна состоять в “обнаружении” алгоритмов из пар вход/выход, а не просто в запоминании внешне предоставленных алгоритмов. Он считает, что если алгоритм уже существует, то его прямое выполнение предпочтительнее неэффективного кодирования Transformer. (Источник: fchollet)

Обзор жизненного цикла машинного обучения : Жизненный цикл машинного обучения охватывает все этапы от сбора данных, предварительной обработки, обучения модели, оценки до развертывания и мониторинга, являясь ключевой основой для построения и обслуживания систем ML. (Источник: Ronald_vanLoon)

Цель оптимизации отрицательного логарифмического правдоподобия (NLL) в выводе LLM : Исследование изучает, является ли отрицательное логарифмическое правдоподобие (NLL) как цель оптимизации для классификации и SFT (Supervised Fine-Tuning) универсально оптимальным. Исследование анализирует, в каких случаях альтернативные цели могут превосходить NLL, и указывает, что это зависит от априорных предпочтений цели и возможностей модели, предлагая новый взгляд на оптимизацию обучения LLM. (Источник: arankomatsuzaki)

Руководство для начинающих по машинному обучению : Сообщество Reddit поделилось кратким руководством по изучению машинного обучения, подчеркивая важность получения практического понимания через исследование и создание небольших проектов, а не просто оставаясь на уровне теоретических определений. Руководство также описывает математические основы глубокого обучения и призывает новичков использовать существующие библиотеки для практики. (Источник: Reddit r/deeplearning, Reddit r/deeplearning)

Проблемы обучения визуальных моделей на чисто текстовых наборах данных : Пользователь столкнулся с ошибкой при тонкой настройке модели LLaMA 3.2 11B Vision Instruct на чисто текстовом наборе данных с использованием фреймворка Axolotl, стремясь улучшить ее способность следовать инструкциям, сохраняя при этом возможность обработки мультимодальных входных данных. Проблема связана с ошибками атрибутов processor_type и is_causal, что указывает на то, что совместимость конфигурации и архитектуры модели является проблемой при адаптации визуальных моделей для обучения на чисто текстовых данных. (Источник: Reddit r/MachineLearning)
Обмен курсами по распределенному обучению : Сообщество делится курсами по распределенному обучению, призванными помочь студентам освоить инструменты и алгоритмы, используемые экспертами ежедневно, расширить обучение за пределы одного H100 и углубиться в мир распределенного обучения. (Источник: TheZachMueller)
Дорожная карта этапов освоения Agentic AI : Существует дорожная карта различных этапов освоения Agentic AI, предоставляющая разработчикам и исследователям четкий путь для постепенного понимания и применения технологий AI-агентов, что позволяет создавать более интеллектуальные и автономные системы. (Источник: Ronald_vanLoon)

💼 Бизнес
NVIDIA стала первой публичной компанией с капитализацией в 4 триллиона долларов : Рыночная капитализация NVIDIA достигла 4 триллионов долларов, что сделало ее первой публичной компанией, достигшей этого рубежа. Это достижение отражает ее лидерство в области чипов ИИ и связанных технологий, а также постоянные инвестиции и финансирование исследований в области нейронных сетей. (Источник: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit вошла в тройку лидеров среди компаний уровня AI-native приложений : Согласно анализу данных транзакций Mercury, Replit заняла третье место среди компаний уровня AI-native приложений, превзойдя все другие инструменты разработки, что демонстрирует ее сильный рост и признание на рынке разработки ИИ. Это достижение также было подтверждено инвесторами. (Источник: amasad)
CoreWeave предлагает решения для оптимизации затрат на хранение данных ИИ : CoreWeave проведет вебинар, посвященный тому, как сократить затраты на хранение данных ИИ до 65% без ущерба для скорости инноваций. На вебинаре будет раскрыта причина, по которой 80% данных ИИ находятся в неактивном состоянии, а также как объектное хранилище нового поколения CoreWeave обеспечивает полное использование GPU и делает бюджет предсказуемым, предвидя будущее развитие хранения данных ИИ. (Источник: TheTuringPost)

🌟 Сообщество
Границы возможностей LLM, стандарты понимания и вызовы непрерывного обучения : Сообщество обсуждает недостатки LLM при выполнении агентных задач, считая, что их возможности все еще недостаточны. Существуют разногласия относительно стандартов “понимания” LLM и человеческого мозга, некоторые считают, что текущее понимание LLM остается на низком уровне. Ричард Саттон, отец Reinforcement Learning, считает, что LLM еще не достигли непрерывного обучения, подчеркивая, что онлайн-обучение и адаптивность являются ключом к будущему развитию ИИ. (Источник: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
Стратегии продуктов основных LLM, пользовательский опыт и споры о поведении моделей : Бренд Anthropic и пользовательский опыт вызвали бурное обсуждение; их кампания “пространство для размышлений” получила хорошие отзывы, но существуют споры о распределении ресурсов GPU, Sonnet 4.5 (которую называют менее эффективной в поиске ошибок, чем Opus 4.1, и имеющей “няньский” стиль) и снижении пользовательского опыта при высокой оценке (например, ограничения использования Claude). ChatGPT, в свою очередь, полностью ужесточил генерацию NSFW-контента, вызвав недовольство пользователей. Сообщество призывает к выборочному включению функций ИИ, а не по умолчанию, чтобы уважать автономию пользователя. (Источник: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
Вызовы экосистемы ИИ, споры об open-source моделях и общественное восприятие : Оценка безопасности модели DeepSeek со стороны NIST вызвала опасения по поводу репутации open-source моделей и возможного запрета китайских моделей, однако open-source сообщество в целом поддерживает DeepSeek, считая, что ее “небезопасность” на самом деле означает большую готовность следовать инструкциям пользователя. Изменения в Google Search API влияют на зависимость экосистемы ИИ от сторонних данных. Настройка локальной среды разработки LLM сталкивается с высокими затратами на оборудование и проблемами обслуживания. Оценка моделей ИИ характеризуется явлением “движущейся цели”, а общественность спорит о качестве и этике контента, генерируемого ИИ (например, видео Тейлор Свифт с использованием ИИ). (Источник: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

Влияние ИИ на занятость и профессиональные услуги : Экономисты, возможно, сильно недооценивают влияние ИИ на рынок труда; ИИ не полностью заменит профессиональные услуги, а скорее “фрагментирует” их. Появление ИИ может привести к исчезновению некоторых рабочих мест, но в то же время создаст новые возможности, требуя от людей постоянного обучения и адаптации. Сообщество в целом считает, что работы, требующие эмпатии, суждения или доверия (такие как медицина, психологическое консультирование, образование, юриспруденция), а также люди, способные использовать ИИ для решения проблем, будут более конкурентоспособными. (Источник: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

Аналогия между AI-программированием и техническим менеджментом : Сообщество обсуждает сравнение AI-программирования с техническим менеджментом, подчеркивая, что разработчикам необходимо действовать как EM (инженерным менеджерам): четко понимать требования, участвовать в проектировании, разбивать задачи, контролировать качество (проверять и тестировать AI-код) и своевременно обновлять модели. Хотя ИИ не хватает инициативы, он избавляет от сложностей межличностных отношений. (Источник: dotey)
Галлюцинации ИИ и реальные риски : Явление галлюцинаций ИИ вызывает опасения; сообщается, что ИИ направлял туристов к несуществующим опасным достопримечательностям, создавая угрозу безопасности. Это подчеркивает важность точности информации, предоставляемой ИИ, особенно в приложениях, связанных с безопасностью в реальном мире, где требуются более строгие механизмы проверки. (Источник: Reddit r/artificial)
Этика ИИ и человеческая рефлексия : Сообщество обсуждает, может ли ИИ сделать человечество более гуманным. Существует мнение, что технологический прогресс не обязательно ведет к моральному совершенствованию, а моральный прогресс человечества часто сопровождается огромными издержками. Сам ИИ не пробудит волшебным образом человеческую совесть; истинные изменения происходят из саморефлексии и пробуждения человечности перед лицом ужаса. Критики отмечают, что компании, продвигая инструменты ИИ, часто игнорируют риски их негуманного использования. (Источник: Reddit r/artificial)
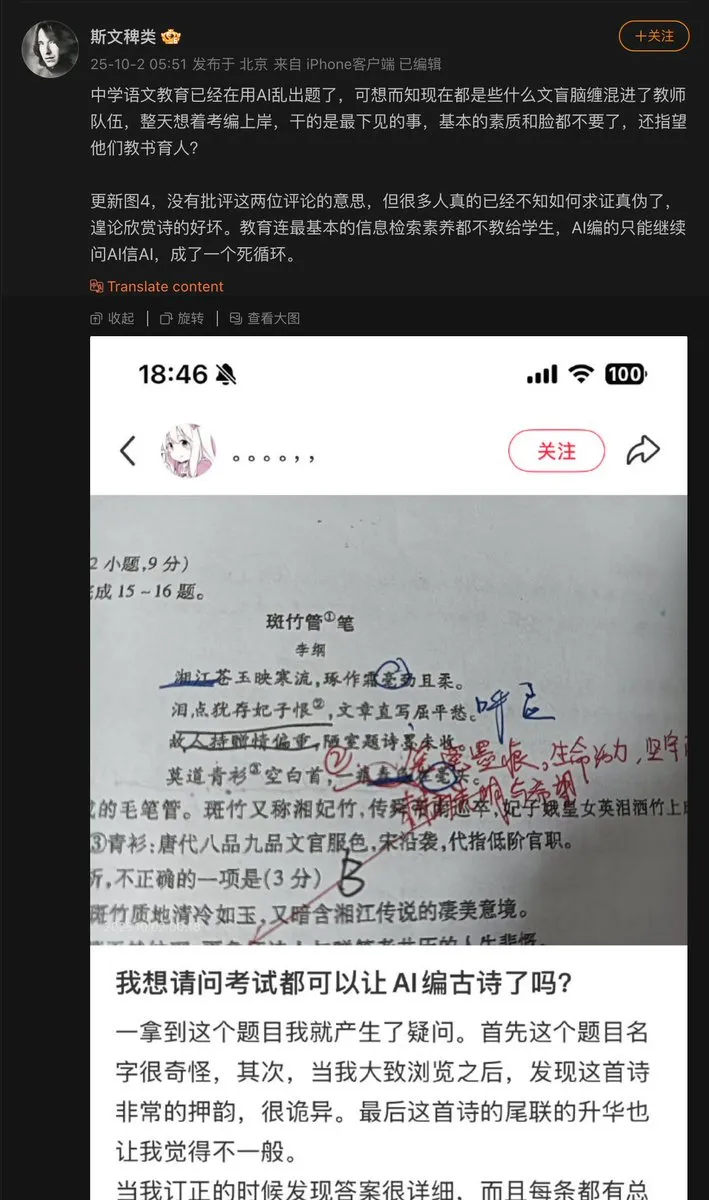
Проблемы применения ИИ в сфере образования : Учитель средней школы использовал ИИ для составления вопросов, в результате чего ИИ сфабриковал древнее стихотворение и включил его в экзаменационные задания. Это выявило проблему “галлюцинаций”, которая может возникать при генерации контента ИИ, особенно в образовательной сфере, где требуется фактическая точность. Механизмы проверки и подтверждения контента, генерируемого ИИ, имеют решающее значение. (Источник: dotey)
Прогресс моделей ИИ и узкие места в данных : Сообщество отмечает, что основным узким местом в текущем прогрессе моделей ИИ являются данные, причем самая сложная часть — это их организация, обогащение контекста и извлечение правильных решений. Это подчеркивает важность высококачественных, структурированных данных для развития ИИ, а также проблемы управления данными в обучении моделей. (Источник: TheTuringPost)
Энергопотребление LLM и компромисс ценности : Сообщество обсуждает огромное энергопотребление ИИ (особенно LLM), некоторые считают это “злом”, но есть и мнение, что вклад ИИ в решение проблем и исследование Вселенной намного превосходит его энергопотребление, и препятствование развитию ИИ является недальновидным. Это отражает продолжающиеся дебаты о компромиссе между развитием ИИ и воздействием на окружающую среду. (Источник: timsoret)

💡 Другое
Золотой ATM с AI+IoT : Банкомат, сочетающий технологии ИИ и IoT, может принимать золото в качестве средства обмена. Это инновационное применение ИИ в сочетании с финансовыми технологиями и Интернетом вещей, которое, хотя и является относительно нишевым, демонстрирует потенциал ИИ в конкретных сценариях. (Источник: Ronald_vanLoon)
Сервер Z.ai Chat CPU подвергся атаке, что привело к сбою : Сервис Z.ai Chat временно прервал работу из-за атаки на сервер CPU, команда занимается устранением проблемы. Это подчеркивает проблемы безопасности и стабильности инфраструктуры, с которыми сталкиваются сервисы ИИ, а также потенциальное влияние DDoS или других сетевых атак на работу платформ ИИ. (Источник: Zai_org)
Apache Gravitino: открытый каталог данных и управление AI-активами : Apache Gravitino — это высокопроизводительное, географически распределенное и федеративное озеро метаданных, предназначенное для унифицированного управления метаданными из различных источников, типов и регионов. Оно обеспечивает унифицированный доступ к метаданным, поддерживает управление данными и AI-активами, а также разрабатывает функции отслеживания моделей ИИ и признаков, что обещает стать ключевой инфраструктурой для управления AI-активами. (Источник: GitHub Trending)