
Ключевые слова:OpenAI Sora 2, Генерация видео с помощью ИИ, Мультимодальный ИИ, Ученый в области ИИ, Дизайн белков, API Sora 2, PXDesign для дизайна белков, Фреймворк PromptCoT 2.0, Генерация от первого лица EgoTwin, Liquid AI LFM2-Audio
🔥 В центре внимания
Выпуск OpenAI Sora 2 и его влияние: OpenAI официально выпустила Sora 2, позиционируя ее как социальное приложение для iOS в стиле “AI-версии TikTok”, поддерживающее синхронную генерацию аудио и видео, а также значительно улучшенное в части соблюдения законов физики и управляемости. Новые функции включают “cameos”, позволяющие пользователям вставлять свои изображения или изображения друзей в видео, сгенерированные AI. В социальных сетях активно обсуждаются ее поразительная реалистичность и креативность, но также высказываются опасения по поводу распространения “slop”-контента, сложности отличия правды от вымысла, резкого увеличения спроса на GPU и региональной доступности (например, отсутствие Sora в Великобритании). CEO OpenAI Сэм Альтман (Sam Altman) ответил, что Sora 2 предназначена для финансирования исследований AGI и предоставления интересных новых продуктов. Обсуждения в сообществе также касались получения инвайт-кодов для Sora 2, предположений о требованиях к аппаратному обеспечению (GPU) и опасений по поводу качества будущего видеоконтента и его злонамеренного использования. OpenAI планирует расширить приглашения для Sora, но соответственно снизит ежедневные лимиты генерации, а также сообщила о планах выпустить Sora 2 API.
(Источник: 量子位, Yuchenj_UW, teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Periodic Labs запускает платформу AI-ученых для ускорения научных открытий: Periodic Labs получила финансирование в размере 300 миллионов долларов с целью создания AI-ученых для ускорения фундаментальных научных открытий, особенно в области материаловедения, путем автоматизации лабораторий и экспериментов, управляемых AI. Платформа призвана рассматривать физическую вселенную как вычислительную систему, используя AI для выдвижения гипотез, экспериментов и обучения, что может привести к прорывам в таких областях, как высокотемпературные сверхпроводники. Это видение подчеркивает связь AI с физическим миром и важность генерации высококачественных данных через эксперименты, превосходя традиционные модели, основанные только на данных из интернета.
(Источник: dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

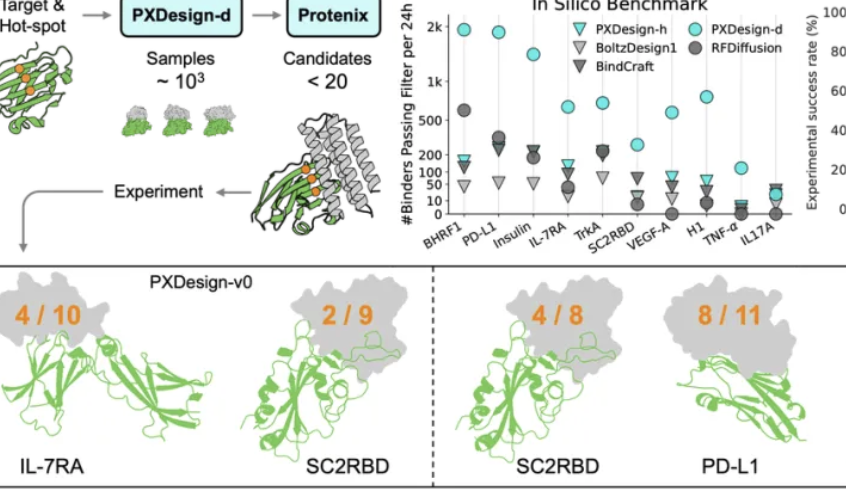
Команда ByteDance Seed выпустила PXDesign, повышающую эффективность дизайна белков: Команда ByteDance Seed представила PXDesign, масштабируемый метод дизайна белков на основе AI, способный генерировать сотни высококачественных белковых кандидатов за 24 часа, что примерно в 10 раз эффективнее, чем основные отраслевые методы. Этот метод достигает 20-73% успеха в мокрых экспериментах на нескольких мишенях, что значительно выше, чем у AlphaProteo от DeepMind. PXDesign сочетает стратегию “генерация + фильтрация”, используя сетевую структуру DiT и модель предсказания структуры Protenix для эффективного скрининга, а также предоставляет открытый бесплатный онлайн-сервис дизайна binder’ов, направленный на ускорение биологических научных исследований.
(Источник: 量子位)
Ant Group и Гонконгский университет совместно представили PromptCoT 2.0, сфокусированный на синтезе задач: Группа по обработке естественного языка Центра общего искусственного интеллекта Ant Group и группа по обработке естественного языка Гонконгского университета совместно выпустили фреймворк PromptCoT 2.0, направленный на развитие рассуждений больших моделей и агентов через синтез задач. Этот фреймворк использует цикл максимизации ожидания (EM) вместо ручного проектирования, итеративно оптимизируя цепочки рассуждений для генерации более сложных и разнообразных вопросов. PromptCoT 2.0, сочетая обучение с подкреплением и SFT, позволил модели 30B-A3B достичь SOTA в задачах математического кодового рассуждения и открыл 4.77M синтетических данных вопросов, предоставляя сообществу ресурсы для обучения.
(Источник: 量子位)

EgoTwin впервые реализовал синхронную генерацию видео от первого лица и движений человека: Национальный университет Сингапура, Наньянский технологический университет, Гонконгский университет науки и технологий и Шанхайская лаборатория искусственного интеллекта совместно выпустили фреймворк EgoTwin, впервые реализовав совместную генерацию видео от первого лица и движений человека. Этот фреймворк, основанный на диффузионных моделях, осуществляет трехмодальную совместную генерацию “текст-видео-движение”, преодолевая две основные проблемы: выравнивание перспективы-движения и причинно-следственную связь. Ключевые инновации включают представление движений, ориентированное на голову, кибернетически вдохновленный механизм взаимодействия и асинхронный фреймворк диффузионного обучения. Сгенерированные видео и движения могут быть далее перенесены в 3D-сцены.
(Источник: 量子位)

🎯 Тенденции
Интенсивный выпуск и обновление AI-моделей нового поколения: Недавно в области AI произошло множество важных выпусков и обновлений моделей и функций, включая DeepSeek-V3.2, Claude Sonnet 4.5, GLM 4.6, Sora 2, Dreamer 4, а также функцию мгновенной оплаты в ChatGPT. DeepSeek-V3.2 был оптимизирован на vLLM с помощью механизма разреженного внимания, что обеспечило более высокую производительность с длинным контекстом и экономическую эффективность. Claude Sonnet 4.5 продемонстрировал сложность в выравнивании и теории разума пользователя, отлично проявив себя в творческом и длинном письме, но некоторые пользователи отметили, что качество генерации кода все еще требует улучшения. GLM-4.6 показал выдающиеся способности в работе с фронтенд-кодом, но улучшения в других языках, таких как Python, были незначительными, и была выпущена квантованная версия GGUF для поддержки локального развертывания. Dreamer 4 — это агент, способный обучаться решению сложных задач управления в масштабируемых мировых моделях.
(Источник: Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
Мультимодальная видеомодель Veo3 демонстрирует потенциал общего визуального интеллекта: Видеомодель Veo3 рассматривается как потенциальный путь к общему визуальному интеллекту, демонстрируя способности к обучению с нулевым примером и рассуждению, способная решать различные визуальные задачи и считающаяся важной для прогресса в робототехнике. В то же время, команда Qwen от Alibaba Cloud выпустила серию мультимодальных больших языковых моделей Qwen3-VL, которые были всесторонне обновлены в области визуальных агентов, визуального кодирования, пространственного восприятия, понимания длинного контекста и видео, мультимодального рассуждения, визуального распознавания и OCR, а также предоставила версии Instruct и Thinking. Tencent также представила модели HunyuanImage 3.0 и Hunyuan3D-Part, которые достигли ведущего уровня в генерации изображений из текста и 3D-форм соответственно.
(Источник: gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI представила LFM2-Audio и специализированные малые модели: Liquid AI выпустила LFM2-Audio, универсальную базовую модель для аудио-текста с 1.5B параметрами, способную обеспечивать быстрое реагирование в реальном времени на устройствах, с в 10 раз более высокой скоростью вывода, чем аналогичные модели. Кроме того, Liquid AI также представила серию тонко настроенных моделей LFM2, включая различные варианты, такие как Tool, RAG и Extract, которые сосредоточены на конкретных задачах, а не на универсальности. Это совпадает с точкой зрения Nvidia в ее белой книге о том, что малые специализированные модели являются будущим Agentic AI.
(Источник: ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
Векторные базы данных переживают “вторую весну” и акцент xAI на высококачественных данных: Существует мнение, что векторные базы данных могут вступить в новый пик развития, но их модели применения могут отличаться от ожидаемых. В то же время, xAI создает новую парадигму для обработки человеческих данных, подчеркивая важность пост-обучения (post-training) и считая высококачественные данные краеугольным камнем на пути к AGI. xAI планирует создать сообщество экспертов из различных областей для совместного построения системы оценки высочайшего качества.
(Источник: _philschmid, Dorialexander, Yuhu_ai_)
🧰 Инструменты
Генератор AI-романов YILING0013/AI_NovelGenerator: Многофункциональный генератор романов на основе больших языковых моделей, поддерживающий архитектуру мира, создание персонажей, сюжетные планы, интеллектуальную генерацию глав, отслеживание состояний, управление сюжетными линиями, семантический поиск, интеграцию базы знаний и механизм автоматической проверки, предоставляющий визуальный GUI-интерфейс. Этот инструмент предназначен для эффективного создания логически строгих и единообразных длинных историй, а также поддерживает различные LLM и Embedding-сервисы, такие как OpenAI, DeepSeek, Ollama.
(Источник: GitHub Trending)
Инструменты AI-помощи в программировании продолжают развиваться: GitHub Copilot, используя инструкции, подсказки и режимы чата, предоставленные сообществом, помогает пользователям максимально эффективно использовать его в различных областях, языках и сценариях, а также предлагает сервер MCP для упрощения интеграции. Replit Agent продемонстрировал мощные возможности в миграции кода и QA, способный быстро переносить крупные Next.js-сайты с Vercel и поддерживать интеграцию внутриигровых платежей. Модель Apriel-1.5-15b-Thinker от ServiceNow может работать на одном GPU, предоставляя мощные возможности вывода. Кроме того, модель Moondream3-preview используется для автоматизации UI-процессов и задач RPA, а vLLM также поддерживает развертывание моделей только с энкодером.
(Источник: github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

Инновации в инструментах AI для конкретных областей применения: pix2tex (LaTeX OCR) способен преобразовывать изображения математических формул в код LaTeX, значительно повышая эффективность в научно-исследовательской и образовательной сферах. BatonVoice использует способность LLM следовать инструкциям для предоставления структурированных параметров синтеза речи, обеспечивая контролируемый TTS. Платформа Hex интегрирует функции агентов, позволяя большему числу людей использовать AI для точной и надежной работы с данными. Инструменты для генерации видео, такие как Kling 2.5 Turbo и Lucid Origin, делают создание видео беспрецедентно удобным. Racine CU-1 — это интерактивная модель с GUI, способная распознавать места кликов, подходящая для агентских UI-процессов и задач RPA.
(Источник: lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Модель переранжирования документов jina-reranker-v3: jina-reranker-v3 — это многоязычная модель переранжирования документов с 0.6B параметрами, которая представляет новый механизм “last but not late interaction”. Этот метод выполняет причинно-следственные вычисления самовнимания между запросом и документами, обеспечивая богатое междокументное взаимодействие до извлечения контекстных эмбеддингов для каждого документа. Эта компактная архитектура достигает SOTA по производительности BEIR, будучи при этом в десять раз меньше, чем генеративные модели переранжирования списков.
(Источник: HuggingFace Daily Papers)
📚 Обучение
Последние достижения в исследованиях вывода и выравнивания AI-моделей: Исследования показывают, что мультимодальный вывод, усиливая логическое рассуждение, может повредить перцептивную основу, приводя к визуальному забыванию. Предложен метод Vision-Anchored Policy Optimization (VAPO) для направления процесса рассуждения к большей ориентации на визуальную основу. Обсуждаются причины превосходства онлайн-выравнивания (например, GRPO) над офлайн-выравниванием (например, DPO) и предлагается вариант Humanline, который, имитируя человеческие перцептивные искажения, позволяет обучению на офлайн-данных достигать производительности онлайн-выравнивания. Парадигма Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) и алгоритм Optimum-Referenced One-Step Adaptation (ROSA) используют обратную связь от пользователя для эффективной корректировки параметров модели в реальном времени, повышая способность LLM к самокоррекции в многоходовых диалогах. NuRL (Nudging method) снижает сложность вопросов путем самогенерируемых подсказок, позволяя модели учиться на изначально “неразрешимых” задачах, тем самым повышая верхний предел способности LLM к рассуждению. RLP (Reinforcement Learning Pre-training) вводит обучение с подкреплением на этапе предварительного обучения, рассматривая цепочку мыслей как действия и используя информационный прирост для вознаграждения, чтобы повысить способность модели к рассуждению уже на этапе предварительного обучения. Exploratory Iteration (ExIt) — это автоматический метод обучения на основе RL, который эффективно улучшает производительность модели в одно- и многоходовых задачах, направляя LLM на итеративное самосовершенствование своих решений во время рассуждения. Исследование TruthRL стимулирует LLM генерировать правдивую информацию с помощью обучения с подкреплением, направленное на решение проблемы галлюцинаций модели. Исследование показало, что “максимальное эффективное окно контекста” (MECW) LLM значительно меньше заявленного “максимального окна контекста” (MCW), и MECW меняется в зависимости от типа вопроса, что выявляет фактические ограничения LLM при обработке длинного контекста. Атака Bias-Inversion Rewriting Attack (BIRA) теоретически может эффективно обходить водяные знаки LLM, подавляя логиты токенов, которые могут быть помечены водяным знаком, достигая более 99% обхода при сохранении семантического содержания, что подчеркивает уязвимость технологий водяных знаков.
(Источник: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
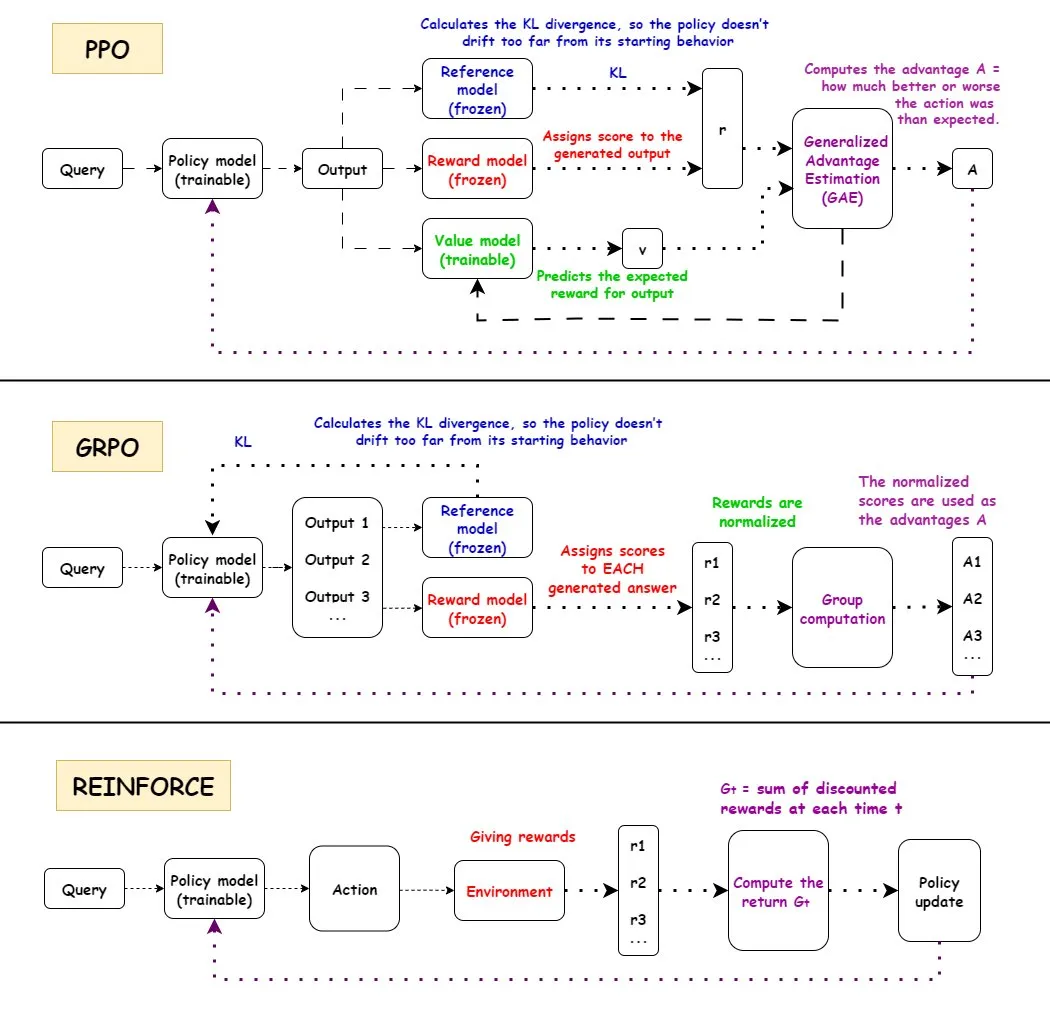
Углубленный анализ алгоритмов обучения с подкреплением (RL): Подробно рассмотрены рабочие процессы, преимущества, недостатки и сценарии применения трех основных алгоритмов обучения с подкреплением: PPO, GRPO и REINFORCE. PPO широко используется в области AI благодаря своей стабильности, GRPO — благодаря механизму относительного вознаграждения, а REINFORCE — как базовый алгоритм. Исследования показывают, что обучение с подкреплением может обучать модели комбинировать атомарные навыки и обобщать их на различной глубине комбинаций, что указывает на потенциал RL в освоении новых навыков. Обнаружено, что более половины улучшений производительности в конвейере RL обусловлены не ML-связанными улучшениями, а инженерными оптимизациями, такими как многопоточность. Обсуждается проблема количества информации в каждом эпизоде обучения RL, а также информационная эквивалентность различных траекторий при одинаковом конечном вознаграждении. Сообщество обсуждает определение и эффективность предварительного обучения RL, указывая на проблемы, которые могут возникнуть из-за принудительного синтеза разнообразия, и призывая обратить внимание на деградацию когерентности. Для двурукого пятипалого человекоподобного робота, путем тонкой настройки стратегии клонирования поведения с помощью остаточного внеполитического обучения с подкреплением (ROSA), значительно повышена эффективность выборки, что позволило напрямую настраивать стратегию на аппаратном уровне.
(Источник: TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
AI-ученые и научные открытия: DeepScientist — это целеориентированная, полностью автономная система научных открытий, которая с помощью байесовской оптимизации и иерархического процесса оценки продвигает передовые научные открытия в течение нескольких месяцев. Система уже превзошла человеческие SOTA-методы в трех передовых AI-задачах и открыла исходный код всех журналов экспериментов и системного кода. OpenAI набирает научных сотрудников для создания научного инструмента нового поколения — платформы, управляемой AI, для ускорения научных открытий.
(Источник: HuggingFace Daily Papers, mcleavey)
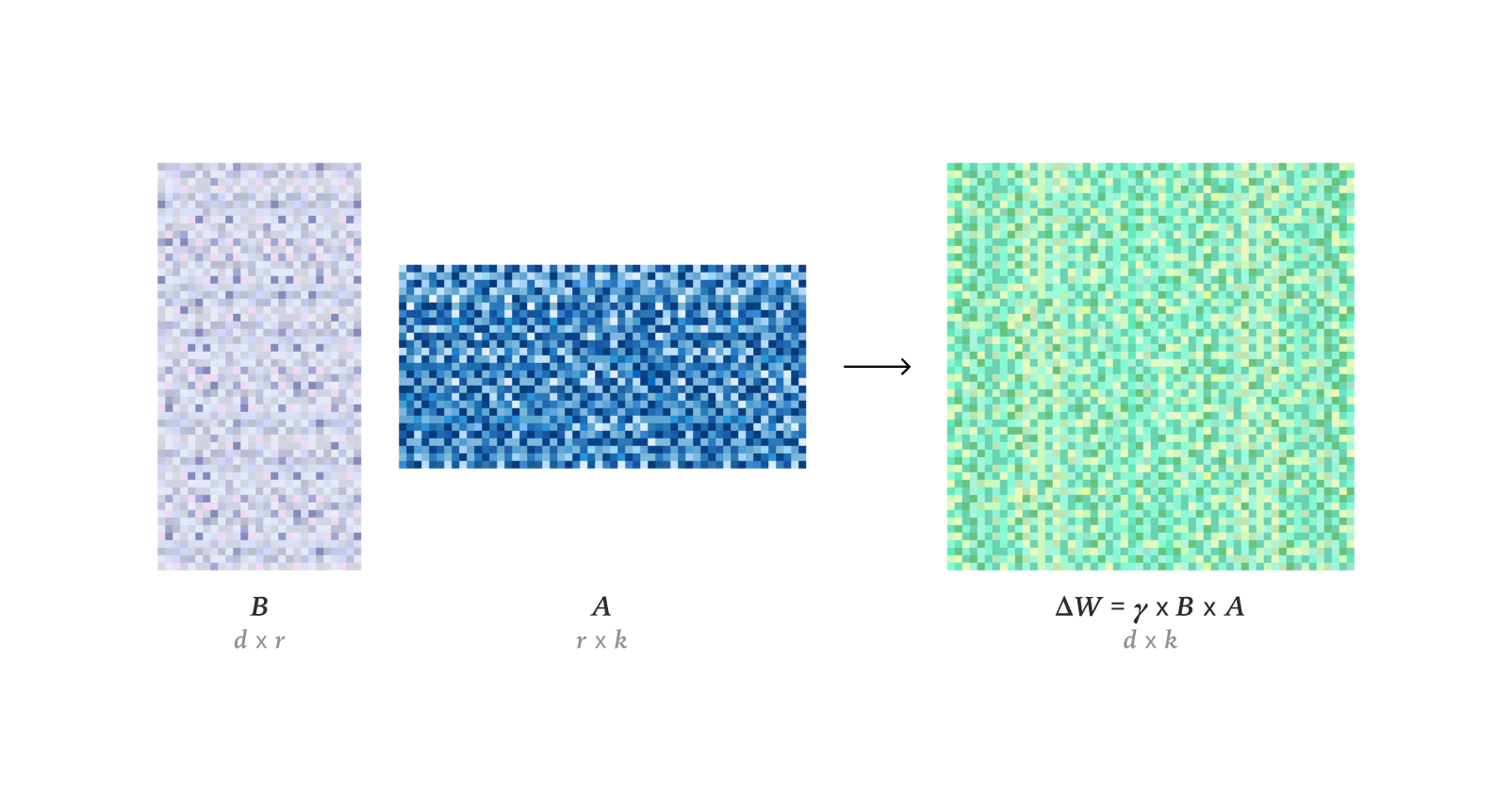
Технологии тонкой настройки и оптимизации LLM: Исследования показывают, что LoRA в обучении с подкреплением может полностью соответствовать производительности обучения при полной тонкой настройке (FullFT), и даже в условиях низкого ранга достаточно для поглощения информации из RL-обучения. Фреймворк Quadrant-based Tuning (Q-Tuning) значительно повысил эффективность данных в контролируемой тонкой настройке (SFT) за счет совместной обрезки выборок и токенов, в некоторых случаях превосходя обучение на полных данных. Оптимизатор Muon постоянно превосходит Adam в обучении LLM, особенно в обучении памяти, связанной с хвостами распределения, решая проблемы различий в обучении Adam на несбалансированных по классам данных за счет более изотропного сингулярного спектра и эффективной оптимизации данных с тяжелыми хвостами. Проведено исследование асимптотической оценки RMS весов в оптимизаторе AdamW. Подробно проанализирована работа CUDA-ядер Flash Attention 4, раскрыты ее инновации в асинхронном конвейере, программном softmax (кубическая аппроксимация) и эффективном масштабировании, что объясняет ее более высокую производительность по сравнению с cuDNN.
(Источник: ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
AI-ресурсы для обучения и исследовательские инструменты: Представлены мультимодальные AI-слайды, охватывающие тенденции, открытые модели, инструменты для настройки/развертывания и дополнительные ресурсы. Анонсированы конференции AI Engineer Europe 2026 и AI Engineer Paris, предоставляющие платформу для обмена опытом AI-инженерам. Рекомендованы серия “Let’s build GPT” Карпати и статья Qwen, подчеркивающие важность высококачественных обучающих данных CTF и вычислительных ресурсов для обучения LLM. Обсужден потенциал оптимизатора DSPyOSS для реализации “многоуровневой” оптимизации в B2B AI-сценариях для решения проблемы нехватки данных. Axiom Math AI стремится создать самосовершенствующийся сверхразумный рассуждающий, начиная с AI-математика, для достижения прогресса в области формальной математики. Исследуется применение регрессионных языковых моделей в генерации и понимании кода. Обсуждается дебаты о том, достаточно ли обучения с подкреплением для достижения AGI. Исследуется изобретатель глубокого остаточного обучения (Deep Residual Learning) и временная шкала его эволюции. Юрген Шмидхубер (Jürgen Schmidhuber) в 2016 году объяснил искусственное сознание, мировые модели, предиктивное кодирование и науку как сжатие данных, подчеркнув свои ранние вклады в область AI. Проведен разведочный анализ открытых практик сотрудничества, мотиваций и управления 14 проектами открытых больших языковых моделей, выявляющий разнообразие и проблемы экосистемы открытых LLM. Dragon Hatchling (BDH) — это архитектура LLM, основанная на мозгоподобных сетях, разработанная для соединения Transformer с моделями мозга, обеспечивая интерпретируемость и производительность, аналогичную Transformer. Фреймворк d^2Cache значительно повышает эффективность вывода и качество генерации диффузионных языковых моделей (dLLMs) за счет двойного адаптивного кэширования. Фреймворк TimeTic оценивает переносимость базовых моделей временных рядов (TSFMs) с помощью контекстного обучения, чтобы эффективно выбирать лучшую модель для последующей тонкой настройки. Визуальный базовый кодировщик может использоваться как токенизатор для моделей латентной диффузии (LDM), генерируя семантически богатое латентное пространство, повышая производительность генерации изображений. NVFP4 — это новый 4-битный формат предварительного обучения, который за счет двухступенчатого масштабирования, RHT и случайного округления, при соответствии базовой производительности FP8, обещает 6.8-кратное повышение эффективности. DA^2 (Depth Anything in Any Direction) — это точный, обобщающий с нулевым примером и сквозной оценщик панорамной глубины, который, используя масштабные обучающие данные и архитектуру SphereViT, достигает SOTA в оценке панорамной глубины. Модель SAGANet, используя маски визуальной сегментации, видео- и текстовые подсказки, реализует контролируемую, объектно-ориентированную генерацию аудио, обеспечивая точный контроль для профессиональных рабочих процессов Foley. Mem-α — это фреймворк обучения с подкреплением, который, обучая агентов эффективно управлять сложными внешними системами памяти, решает проблемы построения памяти и потери информации у LLM-агентов при понимании длинного текста, а также демонстрирует способность к обобщению на сверхдлинные последовательности. Фреймворк EntroPE (Entropy-Guided Dynamic Patch Encoder) динамически обнаруживает точки перехода во временных рядах с помощью условной энтропии и размещает границы патчей для сохранения временной структуры, повышая точность и эффективность прогнозирования. BUILD-BENCH — это более сложный бенчмарк для оценки способности LLM-агентов компилировать реальное открытое программное обеспечение, и предлагает OSS-BUILD-AGENT в качестве сильной базовой линии. ProfVLM — это легкая видео-языковая модель, которая с помощью генеративного вывода совместно прогнозирует уровень навыков и генерирует экспертную обратную связь из видео от первого лица и внешнего вида. Обсуждается эффективность обучения во время тестирования (TTT) в базовых моделях, считается, что TTT, специализируясь на тестовых задачах, может значительно снизить ошибку тестирования внутри распределения. CST — это новая архитектура нейронной сети для обработки наборов изображений произвольной мощности, которая оперирует непосредственно с 3D-тензорами изображений, одновременно выполняя извлечение признаков и контекстное моделирование, демонстрируя выдающиеся результаты в задачах классификации наборов и обнаружения аномалий. Фреймворк TTT3R рассматривает 3D-реконструкцию как задачу онлайн-обучения, выводя скорость обучения на основе состояний памяти и достоверности выравнивания наблюдений, что значительно повышает способность к обобщению на длинные последовательности.
(Источник: tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
Обнаружение человеческого восприятия подделок в AI-генерации видео: DeeptraceReward — это первый детальный, пространственно-временной эталонный набор данных, используемый для аннотирования человеческого восприятия следов подделок в сгенерированных видео. Этот набор данных содержит 4.3K подробных аннотаций на 3.3K высококачественных сгенерированных видео и объединяет их в 9 основных категорий следов подделок. Исследование обучило мультимодальную языковую модель в качестве модели вознаграждения для имитации человеческого суждения и локализации, превосходя GPT-5 в идентификации, локализации и объяснении поддельных улик.
(Источник: HuggingFace Daily Papers)
Адверсариальная очистка и реконструкция 3D-сцен: MANI-Pure — это амплитудно-адаптивный фреймворк очистки, который, используя спектр амплитуд входного сигнала для управления процессом очистки, адаптивно вводит гетерогенный, частотно-ориентированный шум, эффективно подавляя высокочастотные возмущения, сохраняя при этом семантически важный низкочастотный контент, достигая SOTA-производительности в адверсариальной защите. Nvidia выпустила модель Lyra, которая реализует генеративную реконструкцию 3D-сцен с помощью самодистилляции видеодиффузионной модели, способную генерировать 3D- и 4D-сцены из одного изображения/видео.
(Источник: HuggingFace Daily Papers, _akhaliq)
💼 Бизнес
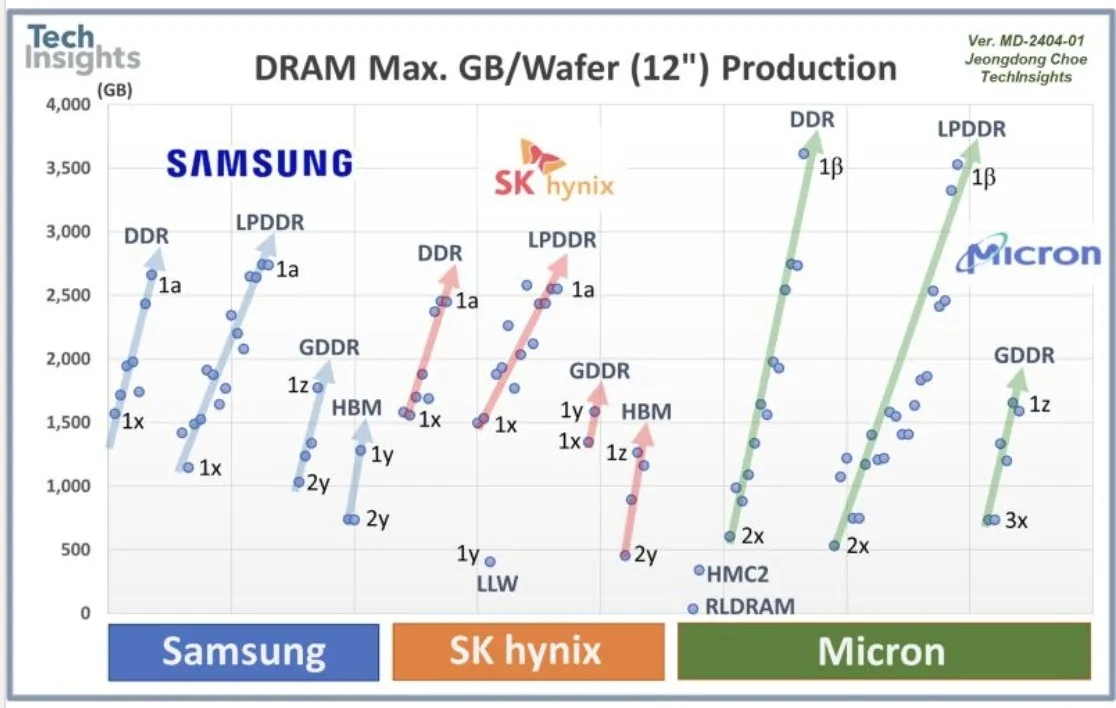
Сотрудничество OpenAI с Samsung и спрос на DRAM: OpenAI сотрудничает с Samsung в разработке чипа “Stargate” и, как ожидается, будет ежемесячно требовать 900 000 высокопроизводительных пластин DRAM, что указывает на огромные планы и инвестиции в будущую AI-инфраструктуру, значительно превышающие текущие ожидания отрасли. Этот огромный объем спроса вызвал дискуссии о стоимости AI-вычислений и суперцикле памяти.
(Источник: bookwormengr, teortaxesTex, francoisfleuret)
Финансирование AI-стартапов и отраслевое развитие: Axiom Math AI представила самосовершенствующийся сверхразумный рассуждающий, начиная с AI-математика, что привлекло внимание отрасли. Modal завершила раунд финансирования серии B на 87 миллионов долларов, достигнув оценки в 1.1 миллиарда долларов, с целью продвижения будущего AI-вычислительной инфраструктуры. OffDeal завершила раунд финансирования серии A на 12 миллионов долларов, стремясь создать первый в мире AI-ориентированный инвестиционный банк. Министр обороны Японии посетил офис Sakana AI, что указывает на потенциальное сотрудничество в области AI в оборонной сфере. Разработчик поделился своей дилеммой, столкнувшись с исчерпанием средств после того, как потратил 3000 долларов на создание открытых LLM-моделей, что вызвало дискуссии в сообществе о устойчивости открытых AI-проектов. Разработчики Google AI объявили победителей Nano Banana Hackathon, вручив более 400 000 долларов призовых, чтобы стимулировать инновации в AI-приложениях.
(Источник: shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 Сообщество
Социальное влияние и споры, вызванные Sora 2: Выпуск Sora 2 вызвал широкое социальное влияние и споры. Многие пользователи обеспокоены распространением “slop” (низкокачественного, бессмысленного контента) в AI-сгенерированных видео, ставя под сомнение приоритеты OpenAI, которые, по их мнению, заключаются в развлечениях, а не в решении серьезных проблем, таких как рак. В то же время, существуют опасения, что сверхвысокая реалистичность Sora 2 может привести к тому, что видео станет трудно отличить от настоящих, и даже может быть злонамеренно использована для генерации ложной информации или вредоносного контента, подобного “биологическому оружию”. Сам CEO OpenAI Сэм Альтман (Sam Altman) стал героем AI-сгенерированных мемов, на что он ответил, что это “не так уж и странно”, и объяснил, что фокус OpenAI по-прежнему на AGI и научных открытиях, а выпуск продуктов предназначен для финансирования. Мощные возможности Sora 2 вновь подчеркнули огромный спрос на GPU, вызвав дискуссии о высокой стоимости AI, и некоторые даже сравнили затраты на AI со стоимостью строительства системы межштатных автомагистралей США. Некоторые комментаторы считают, что стратегия выпуска Sora 2 слишком “обычна”, ей не хватает бенчмарков и поддержки профессиональных пользователей, а также существуют ограничения на контент, генерируемый бесплатными пользователями.
(Источник: teortaxesTex, gfodor, TheTuringPost, nptacek, rasbt, scottastevenson, mckbrando, gfodor, yoheinakajima, skirano, inerati, colin_fraser, fabianstelzer, billpeeb, gfodor, genmon, dejavucoder, nptacek, nptacek, JureZbontar, Teknium1, fabianstelzer, scaling01, qtnx_, genmon, NerdyRodent, BlackHC, op7418, op7418, Teknium1, dejavucoder, scaling01, dejavucoder, teortaxesTex, sama, sama, inerati, inerati, scaling01, VictorTaelin, bookwormengr, MParakhin, Teknium1, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, , Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Пользовательский опыт и споры вокруг Claude Sonnet 4.5: Пользователи в целом считают, что Sonnet 4.5 значительно улучшился в сохранении информации, суждениях, принятии решений и творческом письме, демонстрируя даже “изменение отношения”, подобное человеческому, например, становясь более профессиональным после обнаружения фона пользователя или исправляя пользователя, когда тот “несет чушь”. Несмотря на выдающиеся результаты в некоторых аспектах, некоторые пользователи критикуют низкое качество генерации кода, наличие “небрежных и глупых ошибок”, и даже проблемы с невозможностью генерации кода при “слишком длинных диалогах” в длительных беседах, считая, что до замены человеческих инженеров-программистов еще далеко. Кроме того, некоторым пользователям удалось “взломать” Sonnet 4.5, заставив его генерировать опасные рецепты и вредоносный код, что вызвало серьезные опасения по поводу защитных механизмов модели.
(Источник: teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Будущее языков программирования в эпоху AI и упадок культуры сообщества: Рейтинг языков программирования IEEE Spectrum 2025 показывает, что Python десять лет подряд остается самым популярным языком, занимая первое место по общему рейтингу, скорости роста и ориентации на трудоустройство, его преимущества в эпоху AI еще больше усиливаются. Рейтинг JavaScript значительно снизился, в то время как SQL, хотя и подвергся влиянию, все еще сохраняет свою ценность. В отчете отмечается, что AI кладет конец разнообразию языков программирования, эффект Матфея для основных языков усиливается, а не основные языки будут маргинализированы. В то же время, культура сообщества программистов приходит в упадок, разработчики все чаще обращаются за помощью к большим моделям, а не задают вопросы в сообществе, что меняет способы обучения и работы, вызывая дискуссии о будущей роли программистов и важности основных навыков проектирования базовой архитектуры.
(Источник: 量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

AI-пузырь и перспективы развития отрасли: В социальных сетях развернулась дискуссия о наличии AI-пузыря в отрасли. Некоторые считают, что текущий инвестиционный ажиотаж может привести к появлению “глупых” проектов, но фундаментальные показатели отрасли остаются сильными, а внедрение AI предприятиями неуклонно растет. В то же время, есть мнения, что огромные затраты на AI-вычисления и колоссальный спрос OpenAI на DRAM указывают на то, что отрасль все еще быстро расширяется и далека от стадии лопнувшего пузыря, но к притоку капитала следует относиться с осторожностью.
(Источник: arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 Прочее
Гуманоидные роботы и AI-вспомогательные устройства: Китайская робототехническая компания LimX Dynamics продемонстрировала автономное передвижение, сгибание и бросание своего гуманоидного робота Oli без захвата движений или удаленного управления, что указывает на достижение Китаем уровня, сопоставимого с Figure/1X/Tesla в области гуманоидных роботов. Neural Band от Meta, считывая нервные сигналы через EMG и сочетаясь с очками Meta Rayban, обещает предоставить революционный способ управления для людей с ампутированными конечностями, обеспечивая синхронное управление протезами и цифровыми интерфейсами, и может стать универсальным контроллером без рук. Кроме того, AI и робототехника находят разнообразное применение в повышении мобильности, разведке и спасательных операциях, например, электрические роботизированные экзоскелеты, беспроводные управляемые роботы-насекомые, четвероногие роботы и роботы-змеи для спасательных миссий.
(Источник: Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
Применение AI в редактировании изображений и графическом дизайне: LayerD — это метод разложения растрового графического дизайна на слои, направленный на создание редактируемых творческих рабочих процессов. Он итеративно извлекает незакрытые слои переднего плана и использует предположение о том, что слои обычно имеют единый внешний вид, для уточнения, что приводит к высококачественному разложению. GeoRemover предлагает геометрически осведомленный двухэтапный фреймворк для удаления объектов из изображений и связанных с ними визуальных артефактов (таких как тени и отражения), путем разделения геометрического удаления и рендеринга внешнего вида, а также введения целей, управляемых предпочтениями, для направления обучения.
(Источник: HuggingFace Daily Papers, HuggingFace Daily Papers)