
Ключевые слова:OpenAI, AI инфраструктура, AlphaEarth Foundations, Claude Sonnet 4.5, DeepSeek V3.2-Exp, мультимодальный ИИ, проект OpenAI Stargate, трансформерная геномная языковая модель, ИИ-генерируемые вирусы, RTEB, Google AlphaEarth 10-метровое моделирование, Hugging Face RTEB бенчмарк, Anthropic Claude генерация кода
Как главный редактор рубрики об ИИ, я провел глубокий анализ, обобщение и выжимку предоставленных вами новостей и обсуждений в социальных сетях. Ниже представлен интегрированный контент:
🔥 В центре внимания
Ставка OpenAI на инфраструктуру в триллионы долларов: OpenAI в сотрудничестве с Oracle и SoftBank планирует инвестировать триллионы долларов в строительство вычислительной инфраструктуры по всему миру под кодовым названием Stargate. Первоначально было объявлено о создании 5 новых объектов в США стоимостью 400 миллиардов долларов, а также о сотрудничестве с Nvidia по проекту Stargate UK в Великобритании. OpenAI прогнозирует, что будущая потребность ИИ в электроэнергии достигнет 100 гигаватт, а общие инвестиции могут составить 5 триллионов долларов. Этот шаг направлен на удовлетворение огромных потребностей моделей ИИ в вычислительной мощности, но также вызывает опасения по поводу капиталовложений, энергопотребления и потенциальных финансовых рисков, подчеркивая крайнюю зависимость развития ИИ от инфраструктуры. (来源:DeepLearning.AI Blog)

ИИ генерирует вирусные геномы: Исследователи из Arc Institute, Стэнфордского университета и Мемориального онкологического центра имени Слоуна-Кеттеринга успешно синтезировали de novo новые фаговые вирусы, способные бороться с распространенными бактериальными инфекциями, используя геномную языковую модель на основе Transformer. Эта технология, путем тонкой настройки последовательностей вирусных геномов, позволяет генерировать новые геномы с определенными функциями, отличающиеся от природных вирусов. Этот прорыв открывает новые пути для разработки альтернативных антибиотикам методов лечения, но также вызывает опасения по поводу биобезопасности и злонамеренного использования, подчеркивая необходимость исследований в области реагирования на биологические угрозы. (来源:DeepLearning.AI Blog)
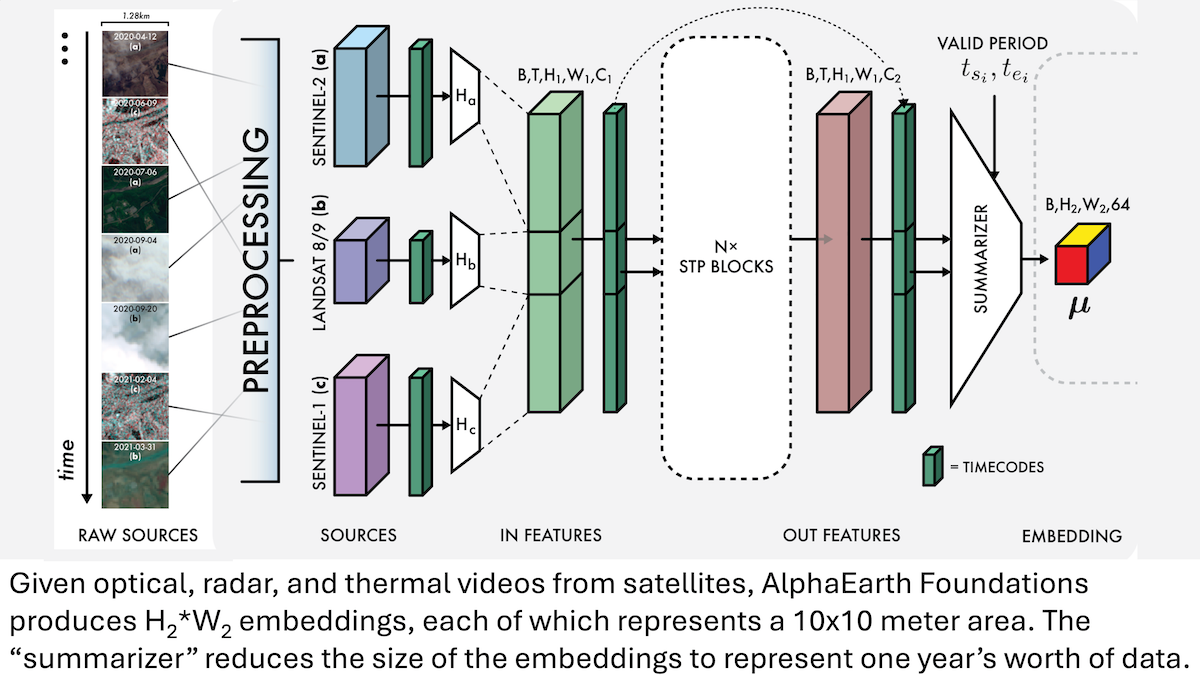
Google AlphaEarth Foundations: Высокоточное моделирование Земли с разрешением 10 метров: Исследователи Google представили модель AlphaEarth Foundations (AEF), способную интегрировать спутниковые снимки и данные других датчиков для детального моделирования поверхности Земли с разрешением 10 квадратных метров, а также генерировать эмбеддинги, представляющие характеристики Земли за каждый год с 2017 по 2024 год. Эти эмбеддинги могут использоваться для отслеживания различных планетарных характеристик, таких как влажность, осадки, растительность, а также для решения глобальных проблем, таких как производство продуктов питания, риск лесных пожаров, уровень воды в водохранилищах, предоставляя беспрецедентно высокоточный инструмент для мониторинга окружающей среды и исследований изменения климата. (来源:DeepLearning.AI Blog)
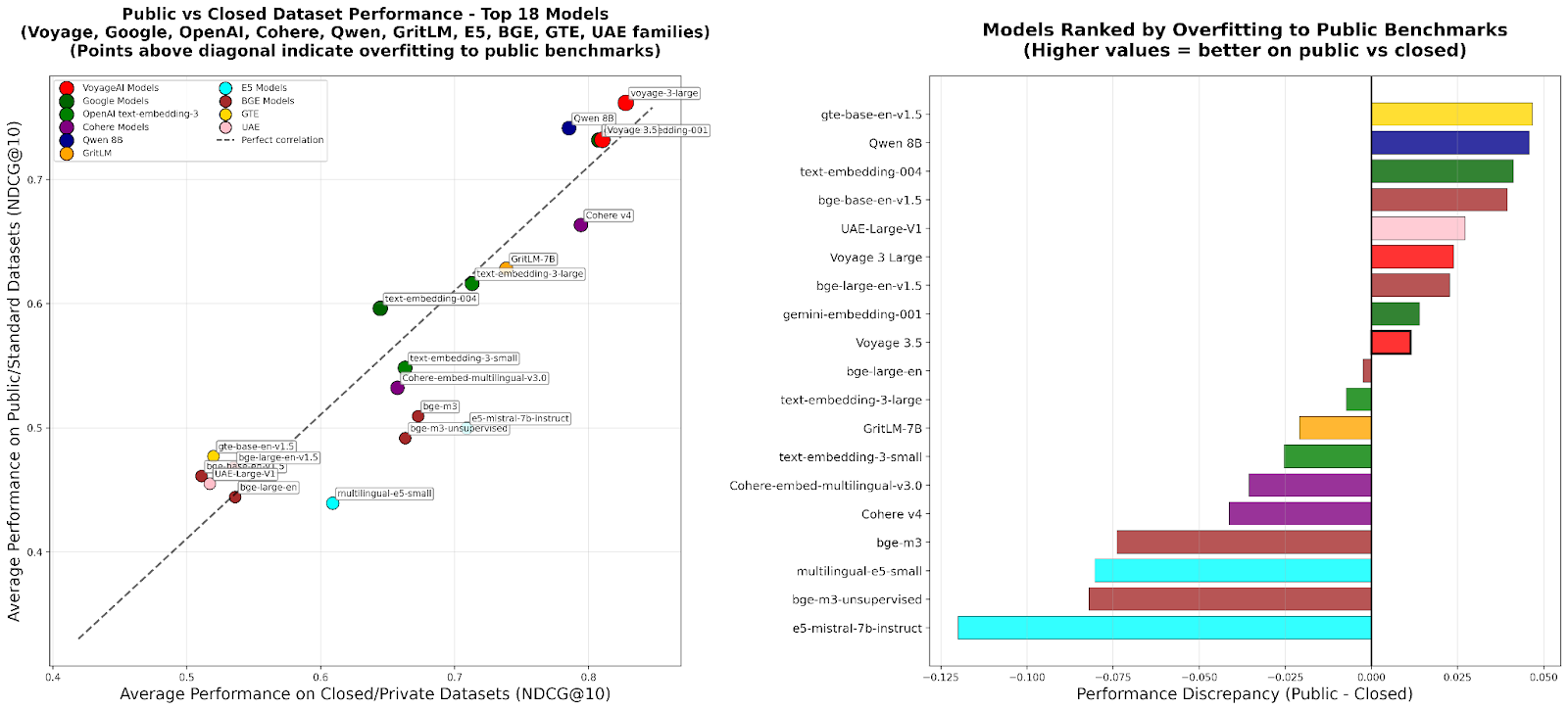
RTEB: Новый стандарт для оценки Retrieval Embeddings: Hugging Face выпустила бета-версию Retrieval Embedding Benchmark (RTEB), призванную предоставить надежный стандарт оценки точности Retrieval Embeddings моделей. Этот бенчмарк, используя гибридную стратегию, сочетающую публичные и частные наборы данных, эффективно решает проблему переобучения моделей в существующих бенчмарках, обеспечивая, что результаты оценки лучше отражают способность модели к обобщению на невиданных данных, что критически важно для повышения качества таких ИИ-приложений, как RAG и Agent. (来源:HuggingFace Blog)
Масштабируемое промежуточное обучение RL: Достижение рассуждений через абстракцию действий: Новейшее исследование предлагает алгоритм «Рассуждение как абстракция действий» (RA3), который значительно повышает способности больших языковых моделей (LLMs) к рассуждению и генерации кода, идентифицируя компактные и полезные наборы действий на промежуточной стадии обучения с подкреплением (RL) и ускоряя онлайн-RL. Этот метод показал отличные результаты в задачах генерации кода, увеличив среднюю производительность на 8-4 процентных пункта по сравнению с базовыми моделями, а также обеспечил более быструю сходимость RL и более высокую асимптотическую производительность. (来源:HuggingFace Daily Papers)
🎯 Тенденции
OpenAI Sora 2: Новая эра социального ИИ-видео: OpenAI выпустила Sora 2 и одноименное социальное приложение, целью которого является создание социальной сети, ориентированной на пользователя и его социальный круг (друзей, домашних животных) через просмотр и создание видео, генерируемых ИИ, а не традиционной платформы для распространения контента. Sora 2 демонстрирует мощные возможности физического моделирования и генерации аудио, но в ранних тестах все еще присутствуют мелкие недостатки, такие как «счет пальцев». Ее выпуск вызвал дискуссии о зависимости от ИИ-видео, дипфейках и пути коммерциализации OpenAI. Sam Altman ответил, что Sora призвана сбалансировать технологические прорывы с приятным пользовательским опытом и обеспечить финансирование исследований в области ИИ. (来源:36氪、Reddit r/ChatGPT、OpenAI)

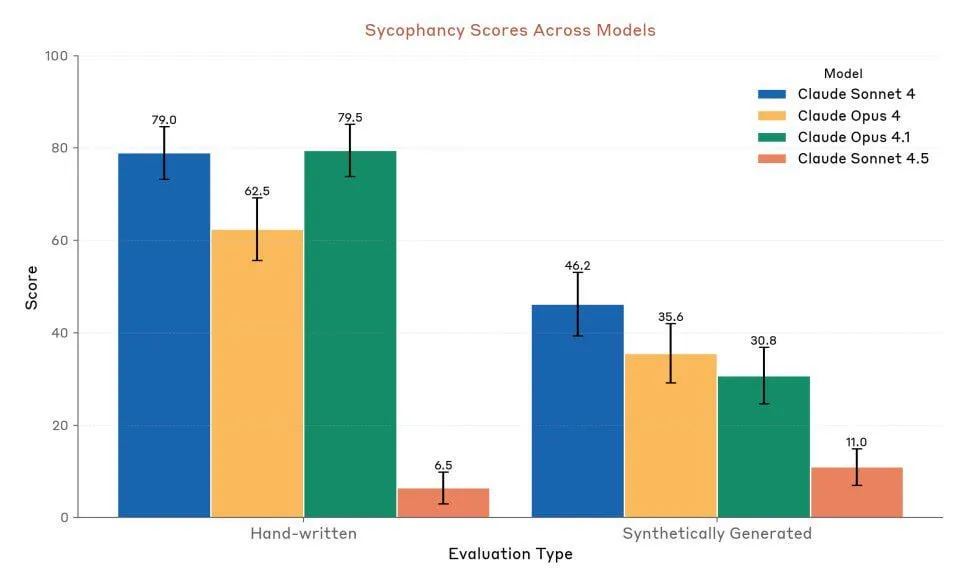
Anthropic Claude Sonnet 4.5: Новый эталон для кода и Agent: Anthropic выпустила Claude Sonnet 4.5, который был назван «лучшей в мире моделью для программирования» и «самой мощной моделью для создания сложных Agent», обладающей автономным временем работы до 30 часов и демонстрирующей значительное повышение производительности кодирования в задачах GitHub. Модель также получила новую функцию памяти, позволяющую сохранять прогресс проекта. Несмотря на высокую оценку ее производительности, среди пользователей все еще существуют споры относительно ограничений на использование и сравнения ее фактической производительности с Opus 4.1 и GPT-5. (来源:Reddit r/ClaudeAI、Reddit r/artificial、Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: Архитектура разреженного внимания повышает эффективность: DeepSeek выпустила большую языковую модель DeepSeek V3.2-Exp, представив совершенно новую архитектуру разреженного внимания (DSA), которая снижает сложность основного внимания с O(L²) до O(L·k), значительно оптимизируя затраты на предварительное заполнение и декодирование в сценариях с длинным контекстом, тем самым существенно снижая плату за использование API. Компания 九章云极 (Jiuzhang Yunji) первой завершила адаптацию DeepSeek V3.2-Exp, предлагая безопасные и эффективные решения для частного развертывания, чтобы удовлетворить потребности предприятий в безопасности данных и гибкости вычислительных мощностей. (来源:量子位、Reddit r/LocalLLaMA)

Выпущена мультимодальная аудио-текстовая модель LFM2-Audio-1.5B: Liquid AI представила LFM2-Audio-1.5B, универсальную сквозную базовую модель для аудио и текста, способную понимать и генерировать текст и аудио. Эта модель в 10 раз быстрее аналогичных моделей по скорости инференса, а при всего 1.5B параметров ее качество сопоставимо с моделями в 10 раз большего размера, поддерживая локальное развертывание и диалог в реальном времени. Hume AI также выпустила Octave 2, более быструю и дешевую многоязычную модель преобразования текста в речь, обладающую возможностями многопользовательского диалога и изменения голоса. (来源:Reddit r/LocalLLaMA、QuixiAI)

Microsoft Agent Framework: Новые достижения в разработке Agent-систем: Microsoft выпустила Microsoft Agent Framework, объединяющий AutoGen и Semantic Kernel в единый, готовый к производству SDK для создания, оркестровки и развертывания многоагентных систем. Этот фреймворк поддерживает .NET и Python и позволяет реализовать многоагентные рабочие процессы с помощью графовой оркестровки, призванной упростить разработку, наблюдение и управление Agent-приложениями, ускоряя внедрение корпоративных AIAgent. (来源:gojira、omarsar0)

Передовые технологии ИИ-робототехники и промышленная конкуренция: Робототехника продолжает развиваться: OmniRetarget от Amazon FAR позволяет изучать сложные человекоподобные навыки с минимальным обучением с подкреплением за счет оптимизации захвата движений человека. Periodic Labs стремится создать «ИИ-ученых» для ускорения научных открытий. Nvidia, в свою очередь, подчеркивает роль своего открытого физического движка Newton, модели визуального языка для инференса Cosmos Reason и базовой модели робототехники Isaac GR00T N1.6 в развертывании физического ИИ. В то же время Китай демонстрирует лидирующие позиции в производстве роботов и стоимости человекоподобных роботов, что вызывает интерес к глобальной конкурентной среде в робототехнической отрасли. (来源:pabbeel、LiamFedus、nvidia、atroyn)

🧰 Инструменты
Tinker API: Гибкий интерфейс для упрощения тонкой настройки LLM: Thinking Machines Lab представила Tinker API, гибкий интерфейс, разработанный для тонкой настройки языковых моделей. Он позволяет исследователям и разработчикам писать циклы обучения локально, в то время как Tinker берет на себя запуск на распределенных кластерах GPU и управление сложностью инфраструктуры, позволяя пользователям сосредоточиться на алгоритмах и данных. Этот инструмент призван снизить порог для пост-обучения LLM, ускорить эксперименты и инновации с открытыми моделями, и был назван экспертами, такими как Andrej Karpathy, «инфраструктурой, которую я всегда хотел». (来源:Reddit r/artificial、Thinking Machines、karpathy)

LlamaAgents: Развертывание Document Agent в один клик: LlamaIndex представила LlamaAgents, предоставляющие возможность развертывания AI Agent для работы с документами в один клик, что призвано в 10 раз ускорить создание и доставку Document Agent. Платформа предлагает 90% предварительно настроенных шаблонов, поддерживает автоматизированную обработку таких ресурсоемких задач, как счета, проверка контрактов и претензии, а также позволяет неограниченную настройку. Пользователи могут развертывать Agent в LlamaCloud и легко управлять и обновлять рабочие процессы Agent через репозиторий Git, значительно сокращая цикл разработки. (来源:jerryjliu0、jerryjliu0)

Hex AI Agent: Расширение возможностей анализа и командной работы: Hex выпустила три новых AI Agent, разработанных специально для анализа данных и командной работы: Threads обеспечивает диалоговое взаимодействие с данными, Semantic Model Agent создает контролируемый контекст для получения точных ответов, а Notebook Agent революционизирует повседневную работу команд по обработке данных. Все эти Agent работают на базе Claude 4.5 Sonnet и призваны превратить диалоговый ИИ-анализ из концепции будущего в немедленно доступный и эффективный инструмент. (来源:sarahcat21)
Sculptor: Недостающий UI для Claude Code: Imbue представила Sculptor, пользовательский интерфейс, разработанный для Claude Code, призванный улучшить опыт программирования Agent. Он позволяет разработчикам параллельно запускать несколько Claude Agent в изолированных контейнерах и синхронизировать результаты работы Agent с локальной средой разработки для тестирования и редактирования через «режим сопряжения». Sculptor также планирует поддерживать GPT-5 и предлагать такие функции, как обнаружение вводящего в заблуждение поведения, чтобы сделать программирование Agent более плавным и эффективным. (来源:kanjun、kanjun)
Synthesia 3.0: Новый прорыв в интерактивном ИИ-видео: Synthesia выпустила версию 3.0, представив ряд инновационных функций, включая «Видео Agent» (интерактивные видео для обучения и собеседований с возможностью диалога в реальном времени), обновленные «Аватары» (создаваемые по одному запросу или изображению, с реалистичными выражениями лица и движениями тела) и «Copilot» (ИИ-видеоредактор, быстро генерирующий сценарии и визуальные элементы). Кроме того, были улучшены функции интерактивности и инструменты для разработки курсов, призванные полностью изменить опыт создания видео и обучения. (来源:synthesiaIO、synthesiaIO)
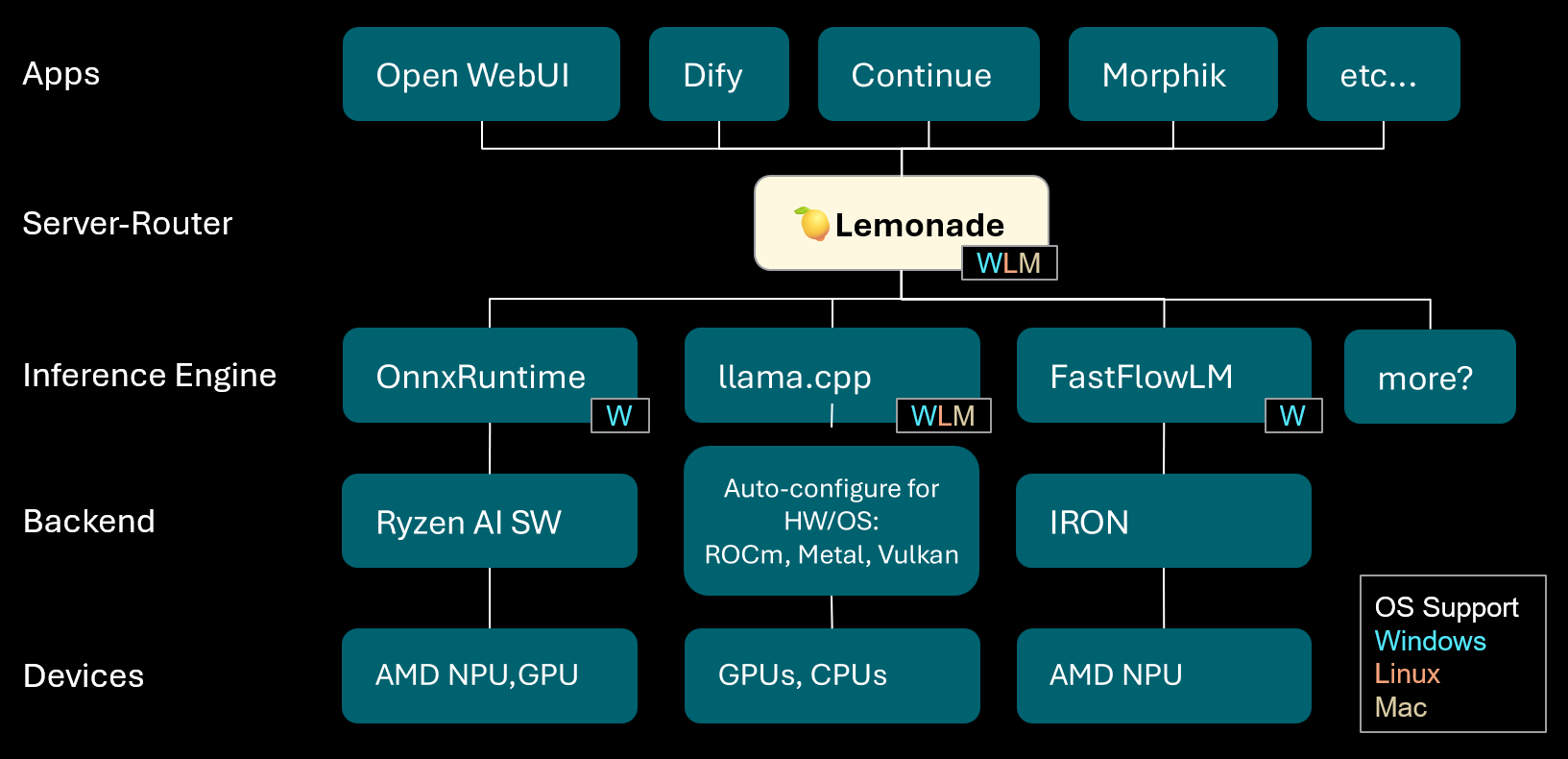
Lemonade: Локальный LLM-сервер-маршрутизатор: Lemonade выпустила версию v8.1.11, локальный LLM-сервер-маршрутизатор, способный автоматически настраивать высокопроизводительные движки инференса для различных ПК (включая устройства с AMD NPU и macOS/Apple Silicon). Он поддерживает различные форматы моделей, такие как ONNX, GGUF и FastFlowLM, и использует бэкенд Metal от llama.cpp для эффективных вычислений на Apple Silicon, предоставляя пользователям гибкий и высокопроизводительный локальный опыт работы с LLM. (来源:Reddit r/LocalLLaMA)
PopAi: Генерация презентаций на базе ИИ: PopAi продемонстрировала способность своего ИИ-инструмента генерировать подробные бизнес-презентации с диаграммами и иллюстрациями за считанные минуты из простого запроса. Это подчеркивает эффективность ИИ в создании контента, позволяя даже непрофессионалам быстро создавать высококачественные презентационные материалы. (来源:kaifulee)

GitHub Copilot CLI: Автоматический выбор модели: GitHub Copilot CLI теперь предлагает функцию автоматического выбора модели для коммерческих и корпоративных пользователей. Это обновление позволяет системе автоматически выбирать наиболее подходящую модель для текущей задачи, что направлено на повышение эффективности разработки и качества генерации кода. (来源:pierceboggan)
Mixedbread Search: Многоязычный мультимодальный локальный поиск: Mixedbread выпустила бета-версию своей поисковой системы, предлагающую быстрый, точный, многоязычный и мультимодальный поиск документов. Система ориентирована на локальное выполнение, позволяя пользователям эффективно извлекать документы на своих устройствах, что особенно полезно для сценариев, требующих обработки разнообразных типов данных. (来源:TheZachMueller)
Hume AI Octave 2: Многоязычная TTS-модель нового поколения: Hume AI выпустила Octave 2, многоязычную модель преобразования текста в речь (TTS) нового поколения. Эта модель на 40% быстрее и на 50% дешевле предыдущей, поддерживает более 11 языков, многопользовательский диалог, изменение голоса и редактирование фонем, призванная обеспечить более быстрый, реалистичный и эмоциональный опыт работы с голосовым ИИ. (来源:AlanCowen)
Обновления AssemblyAI за сентябрь: Универсальные ИИ-аудиосервисы: AssemblyAI представила обзор своих сентябрьских обновлений, среди которых запуск Playground в приложении, универсальное расширение языка, функция десенсибилизации PII для ЕС, а также улучшения производительности потоковой передачи и подсказки по ключевым словам. Эти обновления призваны предоставить пользователям более комплексные и эффективные услуги по обработке аудио с помощью ИИ. (来源:AssemblyAI)
Инструмент Voiceflow MCP: Стандартизация интеграции инструментов Agent: Voiceflow представила инструмент Model Context Protocol (MCP), который предлагает стандартизированный способ для AI Agent использовать различные инструменты. Это упрощает работу разработчиков по созданию пользовательских интеграций и предоставляет готовые сторонние инструменты для пользователей без кода, значительно расширяя возможности Voiceflow Agent. (来源:ReamBraden)
Salesforce Agentforce Vibes: Кодирование Agent корпоративного уровня: Salesforce, основываясь на архитектуре Cline, представила продукт «Agentforce Vibes», который, используя поддержку Model Context Protocol (MCP), предоставляет корпоративным клиентам возможности автономного кодирования. Этот продукт обеспечивает безопасную связь LLM с внутренними и внешними источниками знаний/базами данных, направленную на реализацию ИИ-кодирования в масштабах предприятия. (来源:cline)

JoyAgent-JDGenie: Отчет об архитектуре универсального Agent: Опубликован технический отчет GAIA (Generalist Agent Architecture), в котором представлена архитектура, интегрирующая коллективную многоагентную систему (сочетающую планирование, исполняющие Agent и голосование моделей-комментаторов), иерархическую систему памяти (рабочий, семантический, программный уровни), а также набор инструментов для поиска, выполнения кода и мультимодального анализа. Эта архитектура показала отличные результаты в комплексных бенчмарках, превзойдя открытые базовые модели и приблизившись к производительности проприетарных систем, что открывает путь для создания масштабируемых, устойчивых и адаптивных ИИ-помощников. (来源:HuggingFace Daily Papers)
AI-помощник для путешествий: От планирования до действия: Приложение AI-помощника для путешествий, запущенное 马蜂窝 (Mafengwo), призвано поднять ИИ от традиционной генерации путеводителей до помощи в реальных путешествиях. Приложение может генерировать персонализированные путеводители с изображениями и текстом, а также предоставлять практические функции, такие как AI Agent, который звонит и бронирует рестораны, эффективно решая такие проблемы, как языковой барьер. Хотя есть еще возможности для улучшения в области перевода в реальном времени и глубокой персонализации, оно уже значительно снизило порог для «путешествий без подготовки», демонстрируя огромный потенциал ИИ в соединении цифровой информации с действиями в физическом мире. (来源:36氪)

📚 Обучение
Советы по карьерному развитию для ИИ-исследователей: В отношении карьерного развития ИИ-исследователей эксперты подчеркивают важность становления отличным кодером, призывают воспроизводить исследовательские работы с нуля и глубоко понимать инфраструктуру. В то же время рекомендуется активно создавать личный бренд, делиться интересными идеями, сохранять любопытство и адаптивность, а также отдавать предпочтение должностям, способствующим инновациям и обучению. В долгосрочной перспективе постоянные усилия и достижение реальных результатов являются ключом к формированию уверенности и мотивации. (来源:dejavucoder、BlackHC)
Курс по анализу данных на Python: DeepLearningAI запустила новый курс по анализу данных на Python, призванный научить, как использовать Python для повышения эффективности, отслеживаемости и воспроизводимости анализа данных. Этот курс является частью профессионального сертификата по анализу данных и подчеркивает центральную роль навыков программирования в современной работе с данными. (来源:DeepLearningAI)
Студенты получают бесплатный доступ к ИИ-инструментам Copilot: Microsoft предлагает квалифицированным студентам университетов бесплатную 12-месячную подписку на Microsoft 365 Personal, которая включает дополнительный доступ к Copilot Podcasts, Deep Research и Vision. Этот шаг направлен на предоставление студентам мощных ИИ-инструментов для поддержки их обучения и инноваций. (来源:mustafasuleyman)

Настройка локальных курсов по ИИ/МО: Один преподаватель поделился тем, как создать практический курс по ИИ/МО для студентов с ограниченным бюджетом, основанный на локальной разработке и потребительском оборудовании. Он предложил использовать небольшие модели, Transformer Lab в качестве платформы для обучения и подчеркнул важность понимания основных концепций, а не слепого стремления к масштабу моделей, чтобы улучшить результаты обучения студентов и их практические навыки. (来源:Reddit r/deeplearning)
Предстоящие семинары по ИИ: AIhub опубликовал список предстоящих семинаров по машинному обучению и ИИ, которые пройдут с октября по ноябрь 2025 года. Эти мероприятия охватывают различные темы, от сбора данных с политически ограниченных платформ социальных сетей до этики ИИ. Все семинары бесплатны и предлагают возможность онлайн-участия, предоставляя ИИ-сообществу богатые возможности для обучения и обмена знаниями. (来源:aihub.org)

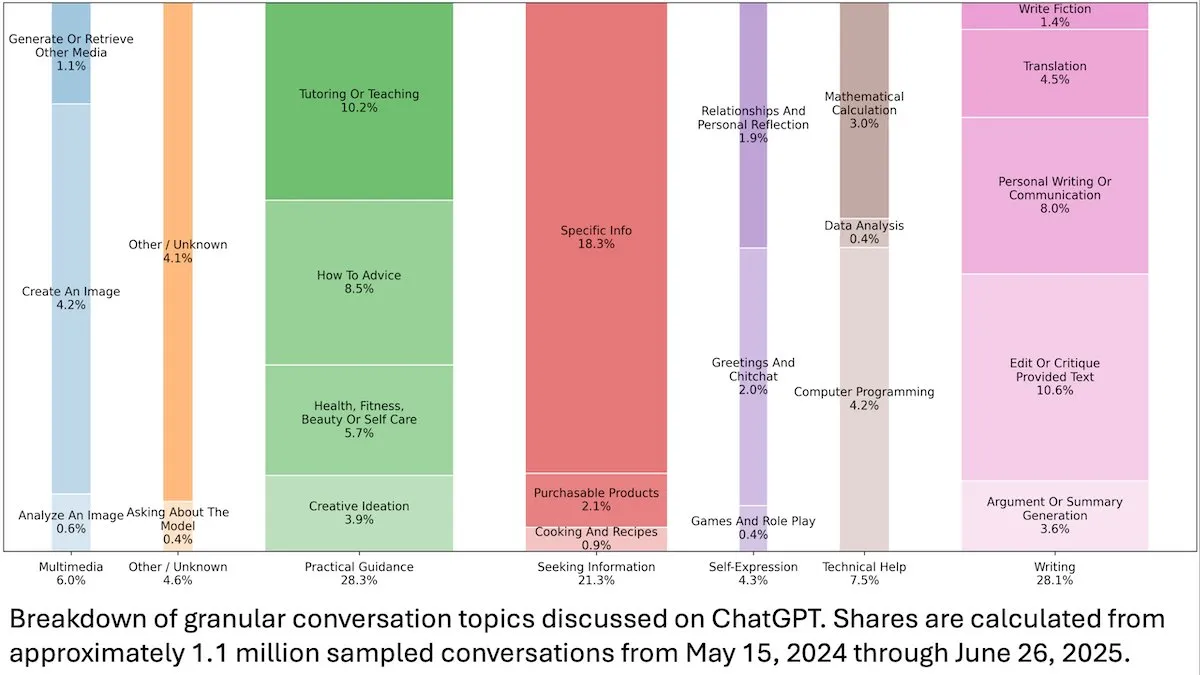
Анализ поведения пользователей ChatGPT: Исследование OpenAI, опубликованное DeepLearningAI, показало, что анализ 110 миллионов анонимных диалогов ChatGPT свидетельствует о смещении сценариев использования с рабочих на личные потребности, при этом доля женщин и молодых пользователей в возрасте 18-25 лет выше. Наиболее распространенными запросами являются практические рекомендации (28.3%), помощь в написании (28.1%) и информационные запросы (21.3%), что демонстрирует широкое применение ChatGPT в повседневной жизни. (来源:DeepLearningAI)
Code2Video: Генерация образовательных видео на основе кода: Исследование представило Code2Video, ориентированный на код фреймворк Agent, который генерирует профессиональные образовательные видео с помощью исполняемого кода Python. Этот фреймворк включает три совместных Agent: планировщик, кодировщик и критик, способных структурировать содержание лекций, преобразовывать их в код и выполнять визуальную оптимизацию. Он достиг 40% повышения производительности на бенчмарке образовательных видео MMMC и сгенерировал видео, сопоставимые с созданными человеком обучающими материалами. (来源:HuggingFace Daily Papers)
BiasFreeBench: Бенчмарк для снижения предвзятости LLM: Представлен BiasFreeBench как эмпирический бенчмарк для всестороннего сравнения восьми основных методов снижения предвзятости LLM. Этот бенчмарк, путем реорганизации существующих наборов данных, вводит метрику «Bias-Free Score» на уровне ответа в двух сценариях тестирования: вопросы с множественным выбором и открытые многораундовые вопросы, чтобы измерить справедливость, безопасность и степень борьбы со стереотипами в ответах LLM, призванный создать единую тестовую платформу для исследований по снижению предвзятости. (来源:HuggingFace Daily Papers)
Препятствия Transformer в обучении умножению и ловушки долгосрочных зависимостей: Исследование методом обратного инжиниринга проанализировало причины сбоев модели Transformer в, казалось бы, простой задаче многозначного умножения. Было обнаружено, что модель кодирует необходимые структуры долгосрочных зависимостей в неявной цепочке рассуждений, но стандартные методы тонкой настройки не смогли сойтись к глобальному оптимуму, который мог бы использовать эти зависимости. Введя вспомогательную функцию потерь, исследователи успешно решили эту проблему, раскрыв ловушки Transformer в обучении долгосрочным зависимостям и предоставив пример решения этой проблемы с помощью правильного индуктивного смещения. (来源:HuggingFace Daily Papers)
Понимание обучения VL-PRM в мультимодальном рассуждении: Исследование направлено на прояснение пространства проектирования моделей вознаграждения за визуально-языковые процессы (VL-PRMs), исследуя различные стратегии построения наборов данных, обучения и расширения во время тестирования. Путем внедрения фреймворка синтеза смешанных данных и надзора, ориентированного на восприятие, VL-PRMs продемонстрировали ключевые идеи в пяти мультимодальных бенчмарках, включая превосходство над моделями вознаграждения за результаты при расширении во время тестирования, способность небольших VL-PRMs обнаруживать ошибки процесса, а также способность раскрывать потенциальные возможности рассуждения более сильных VLM-основ. (来源:HuggingFace Daily Papers)
GEM: Универсальный симулятор среды для Agentic LLM: GEM (General Experience Maker) — это симулятор среды с открытым исходным кодом, разработанный специально для эмпирического обучения LLM Agent. Он предоставляет стандартизированный интерфейс Agent-среда, поддерживает асинхронное векторизованное выполнение для достижения высокой пропускной способности и предлагает гибкие обертки для удобного расширения. GEM также включает разнообразный набор сред и интегрированных инструментов, а также предоставляет базовые показатели для использования фреймворков обучения RL, таких как REINFORCE, с целью ускорения исследований Agentic LLM. (来源:HuggingFace Daily Papers)
GUI-KV: Сжатие KV-кэша для эффективных GUI Agent: GUI-KV — это метод сжатия KV-кэша по принципу «подключи и работай», разработанный специально для GUI Agent, который повышает эффективность без необходимости переобучения. Анализируя паттерны внимания в рабочих нагрузках GUI, этот метод сочетает пространственно-значимое руководство и технику оценки временной избыточности, достигая точности, близкой к полному кэшу, при умеренном бюджете и значительно сокращая FLOPs декодирования, эффективно используя избыточность, характерную для GUI. (来源:HuggingFace Daily Papers)
За пределами логарифмической правдоподобности: Исследование вероятностных целевых функций для SFT: Исследование изучает вероятностные целевые функции для контролируемой тонкой настройки (SFT), выходящие за рамки традиционной отрицательной логарифмической правдоподобности (NLL). В ходе обширных экспериментов с 7 архитектурами моделей, 14 бенчмарками и 3 областями было обнаружено, что когда модель обладает высокой производительностью, целевые функции, отдающие приоритет априорным токенам с меньшим весом низкой вероятности (например, -p, -p^10), превосходят NLL; в то время как при низкой производительности модели NLL доминирует. Теоретический анализ раскрывает, как целевые функции балансируются в зависимости от возможностей модели, предоставляя более принципиальные стратегии оптимизации для SFT. (来源:HuggingFace Daily Papers)
VLA-RFT: RL-тонкая настройка на основе вознаграждения за валидацию в симуляторах мира: VLA-RFT — это фреймворк для усиленной тонкой настройки моделей «зрение-язык-действие» (VLA), использующий управляемую модель мира, основанную на данных, в качестве контролируемого симулятора. Симулятор, обученный на реальных интерактивных данных, предсказывает будущие визуальные наблюдения на основе действий, что позволяет разрабатывать стратегии с плотными вознаграждениями на уровне траектории. Этот фреймворк значительно снижает потребность в образцах, превосходит мощные контролируемые базовые модели менее чем за 400 шагов тонкой настройки и демонстрирует высокую устойчивость в условиях помех. (来源:HuggingFace Daily Papers)
ImitSAT: Решение проблемы булевой выполнимости через имитационное обучение: ImitSAT — это стратегия ветвления решателя CDCL, основанная на имитационном обучении, используемая для решения проблемы булевой выполнимости (SAT). Этот метод, изучая экспертный KeyTrace, сворачивает полные прогоны в последовательности выживших решений, обеспечивая плотное наблюдение на уровне решений и напрямую сокращая количество распространений. Эксперименты показали, что ImitSAT превосходит существующие методы обучения по количеству распространений и времени выполнения, обеспечивая более быструю сходимость и стабильное обучение. (来源:HuggingFace Daily Papers)
Исследование практики тестирования фреймворков AI Agent с открытым исходным кодом: Масштабное эмпирическое исследование 39 фреймворков Agent с открытым исходным кодом и 439 приложений Agent выявило практики тестирования в экосистеме AI Agent. Исследование выявило десять уникальных паттернов тестирования, обнаружив, что более 70% усилий по тестированию сосредоточено на детерминированных компонентах (таких как инструменты и рабочие процессы), в то время как на планирующие субъекты на основе LLM приходится менее 5%. Кроме того, регрессионное тестирование компонентов подсказок (Trigger) сильно игнорируется, появляясь лишь примерно в 1% тестов, что выявляет ключевые слепые зоны в тестировании Agent. (来源:HuggingFace Daily Papers)
DeepCodeSeek: Retrieval API в реальном времени для генерации кода: DeepCodeSeek предлагает новую технологию для обеспечения Retrieval API в реальном времени для контекстно-зависимой генерации кода, что позволяет высококачественное сквозное автодополнение кода и приложения Agentic AI. Этот метод решает проблему утечки API в существующих наборах данных бенчмарков путем расширения кода и индексации для предсказания необходимых API. После оптимизации компактный реранкер 0.6B превзошел модель 8B по производительности, сохраняя при этом в 2.5 раза меньшую задержку. (来源:HuggingFace Daily Papers)
CORRECT: Концентрированное распознавание ошибок в многоагентных системах: CORRECT — это легкий, не требующий обучения фреймворк, который обеспечивает распознавание ошибок и передачу знаний в многоагентных системах за счет использования онлайн-кэша дистиллированных паттернов ошибок. Этот фреймворк способен распознавать структурированные ошибки за линейное время, избегая дорогостоящего переобучения, и может адаптироваться к динамическому развертыванию MAS. CORRECT повысил локализацию ошибок на уровне шага на 19.8% в семи многоагентных приложениях, значительно сократив разрыв между автоматизированным и человеческим уровнем распознавания ошибок. (来源:HuggingFace Daily Papers)
Swift: Авторегрессионная модель согласованности для эффективного прогнозирования погоды: Swift — это одношаговая модель согласованности, которая впервые реализовала авторегрессионную тонкую настройку моделей вероятностных потоков и использует целевую функцию непрерывного ранжированного вероятностного балла (CRPS). Эта модель способна генерировать квалифицированные 6-часовые прогнозы погоды и сохранять стабильность до 75 дней, работая в 39 раз быстрее самых современных диффузионных базовых моделей, при этом достигая конкурентоспособных прогностических навыков по сравнению с численными IFS ENS, что знаменует собой важный шаг к эффективному и надежному интегрированному прогнозированию от среднесрочного до сезонного масштаба. (来源:HuggingFace Daily Papers)
Catching the Details: Самодистиллирующий RoI-предиктор для мелкозернистого восприятия MLLM: Исследование предлагает эффективную, не требующую аннотаций самодистиллирующую сеть предложений регионов (SD-RPN), которая решает проблему высоких вычислительных затрат мультимодальных больших языковых моделей (MLLM) при обработке изображений высокого разрешения. SD-RPN, преобразуя карты внимания промежуточных слоев MLLM в высококачественные псевдо-RoI-метки и обучая легковесную RPN для точной локализации, достигает высокой эффективности данных и способности к обобщению, повышая точность более чем на 10% в невиданных бенчмарках. (来源:HuggingFace Daily Papers)
Новая парадигма многораундового рассуждения LLM: In-Place Feedback: Исследование представляет новую парадигму взаимодействия под названием «In-Place Feedback» для руководства LLM в многораундовом рассуждении. Пользователи могут напрямую редактировать предыдущие ответы LLM, и модель генерирует исправления на основе этого измененного ответа. Эмпирическая оценка показывает, что In-Place Feedback превосходит традиционную многораундовую обратную связь в бенчмарках с интенсивным рассуждением, одновременно сокращая использование токенов на 79.1% и решая ограничения модели в точном применении обратной связи. (来源:HuggingFace Daily Papers)
Предсказуемость динамики обучения с подкреплением LLM: Эта работа раскрывает две фундаментальные характеристики обновления параметров LLM в обучении с подкреплением (RL): доминирование ранга 1 (наивысшее сингулярное подпространство матрицы обновления параметров почти полностью определяет улучшение инференса) и линейная динамика ранга 1 (это доминирующее подпространство линейно эволюционирует в процессе обучения). Основываясь на этих открытиях, исследование предлагает AlphaRL, фреймворк ускорения по принципу «подключи и работай», который выводит окончательные обновления параметров через раннее окно обучения, достигая ускорения до 2.5 раз, сохраняя при этом более 96% производительности инференса. (来源:HuggingFace Daily Papers)
Ловушки сжатия KV-кэша: Исследование выявляет несколько ловушек сжатия KV-кэша при развертывании LLM, особенно в реальных сценариях, таких как подсказки с несколькими инструкциями, где сжатие может привести к быстрому снижению производительности некоторых инструкций или даже к их полному игнорированию LLM. Исследование, анализируя утечки системных подсказок на конкретных примерах, эмпирически демонстрирует влияние сжатия на утечки и общее следование инструкциям, а также предлагает простые улучшения стратегии вытеснения KV-кэша. (来源:HuggingFace Daily Papers)
💼 Бизнес
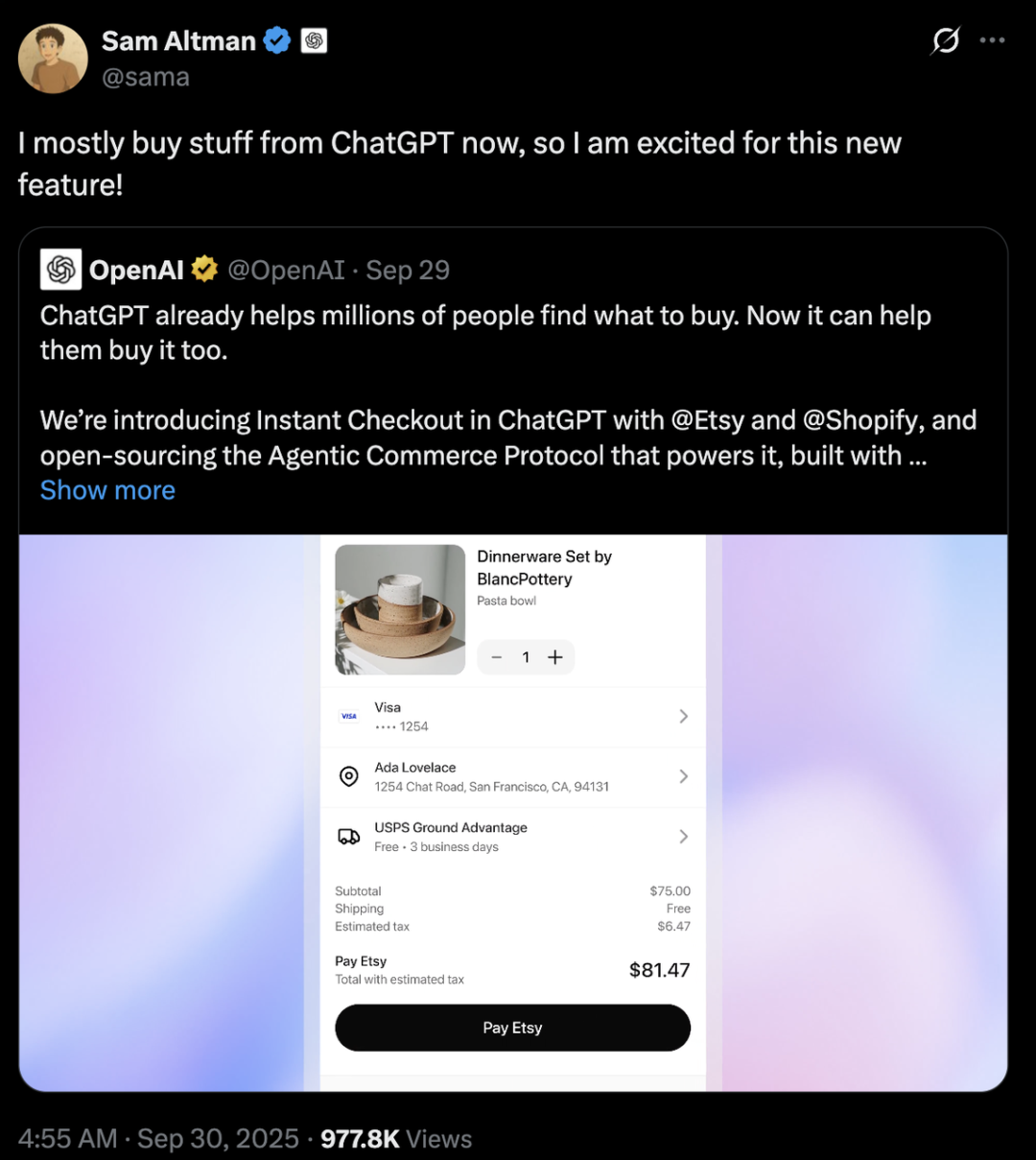
Конкуренция ИИ-гигантов: Стратегические различия OpenAI и Anthropic: OpenAI и Anthropic выбрали совершенно разные пути развития в области ИИ. OpenAI, интегрируя электронную коммерцию через ChatGPT и запуская социальное приложение Sora, стремится к «горизонтальной экспансии», становясь суперплатформой, охватывающей многие аспекты жизни пользователей, ее оценка уже превышает Anthropic на сотни миллиардов долларов. Anthropic, напротив, сосредоточена на «вертикальном углублении», используя Claude Sonnet 4.5 в качестве основы, углубляясь в ИИ-программирование и рынок корпоративных Agent, а также тесно сотрудничая с облачными провайдерами, такими как AWS и Google. За этими двумя компаниями стоит противостояние двух гигантов облачных вычислений, Microsoft и Amazon, в «дипломатии вычислительных мощностей», что подчеркивает реальность индустрии ИИ, где вычислительные мощности дефицитны и дороги. (来源:36氪、量子位、36氪)
Perplexity приобретает Visual Electric: Perplexity объявила о приобретении Visual Electric, чья команда присоединится к Perplexity для совместной разработки новых потребительских продуктов. Продукты Visual Electric будут постепенно прекращены. Целью этого приобретения является усиление инновационных возможностей Perplexity в области потребительских ИИ-продуктов. (来源:AravSrinivas)

Databricks приобретает Mooncakelabs: Databricks объявила о приобретении Mooncakelabs для ускорения реализации своей концепции Lakebase. Lakebase — это новая OLTP-база данных, построенная на Postgres и оптимизированная для AI Agent, призванная предоставить единую основу для приложений, аналитики и ИИ, а также глубоко интегрироваться с Lakehouse и Agent Bricks, упрощая управление данными и разработку ИИ-приложений. (来源:matei_zaharia)

🌟 Сообщество
Влияние ИИ на занятость и общество: Сообщество широко обсуждает глубокое влияние автоматизации ИИ на рынок труда, опасаясь, что это может привести к массовой безработице, созданию новых социальных слоев и спросу на универсальный базовый доход (UBI). Люди повсеместно сомневаются, будут ли новые рабочие места, связанные с ИИ, также автоматизированы, и смогут ли все овладеть навыками ИИ, чтобы адаптироваться к будущему. Обсуждение также затрагивает управление затратами AI Agent и проблемы достижения ROI, а также потенциальное влияние прихода AGI на социальную структуру и геополитику. (来源:Reddit r/ArtificialInteligence、Ronald_vanLoon、Ronald_vanLoon)
Этика ИИ и борьба за контроль: Сообщество активно обсуждает, кто должен контролировать будущее ИИ: обычные люди или технологические олигархи. Звучат призывы к развитию ИИ, ориентированному на человека, с акцентом на прозрачность и контроль пользователей над их личными данными и историей ИИ. В то же время, крестный отец ИИ Yoshua Bengio предупреждает, что сверхразумные машины могут привести к вымиранию человечества в течение десяти лет. Компании, такие как Meta, планируют использовать данные чатов ИИ для целевой рекламы, что еще больше усиливает опасения пользователей по поводу конфиденциальности и злоупотреблений ИИ, вызывая глубокие размышления об этике и регулировании ИИ. (来源:Reddit r/artificial、Reddit r/artificial、Reddit r/ArtificialInteligence)

Аномальное поведение модели безопасности GPT-5: Пользователи сообщества Reddit сообщают, что модель «CHAT-SAFETY» GPT-5 демонстрирует странное, обвинительное и даже галлюцинаторное поведение при обработке незлонамеренных запросов, например, интерпретируя вопрос о распознавании отпечатков пальцев как преследование и выдумывая законы. Такая чрезмерная чувствительность и неточные ответы вызывают серьезные вопросы у пользователей относительно надежности модели, потенциального вреда и стратегий безопасности OpenAI. (来源:Reddit r/ChatGPT)
«Горький урок» и дебаты о пути развития LLM: Andrej Karpathy и отец обучения с подкреплением Richard Sutton спорят о том, соответствуют ли LLM «горькому уроку». Sutton считает, что LLM полагаются на ограниченные человеческие данные для предварительного обучения и не следуют принципу обучения на опыте, заложенному в «горьком уроке». Karpathy, в свою очередь, рассматривает предварительное обучение как «плохую эволюцию» для решения проблемы холодного старта и указывает на фундаментальные различия в механизмах обучения LLM и интеллекта животных, подчеркивая, что нынешний ИИ больше похож на «вызов призраков», чем на «создание животных». (来源:karpathy、SchmidhuberAI)
Обсуждение ценности локальной настройки LLM: Пользователи сообщества обсуждают ценность инвестирования десятков тысяч долларов в создание локальной настройки LLM. Сторонники подчеркивают, что конфиденциальность, безопасность данных и глубокие знания, полученные в ходе практической работы, являются основными преимуществами, сравнивая это с хобби радиолюбителей. Противники же считают, что с улучшением производительности дешевых облачных API (таких как Sonnet 4.5 и Gemini Pro 2.5) высокая стоимость локальной настройки трудно оправдать. (来源:Reddit r/LocalLLaMA)
LLM как судья: Новый метод оценки Agent: Исследователи и разработчики изучают использование LLM в качестве «судьи» для оценки качества ответов AI Agent, включая точность и обоснованность. Практика показывает, что этот метод может быть удивительно эффективным, если подсказки для судьи тщательно разработаны (например, один критерий, привязанная оценка, строгий формат вывода и предупреждения о предвзятости). Эта тенденция указывает на огромный потенциал LLM-as-a-Judge в области оценки Agent. (来源:Reddit r/MachineLearning)
ИИ и взаимодействие с человеком: От устройств до виртуальных персонажей: ИИ многомерно перестраивает взаимодействие человека. Стартап, связанный с Массачусетским технологическим институтом, представил «почти телепатическое» носимое устройство, обеспечивающее бесшумную связь. В то же время, голосовые AI Agent в реальном времени уже используются в качестве NPC (неигровых персонажей) в трехмерных онлайн-играх, предвещая потенциал ИИ в предоставлении более естественного и захватывающего интерактивного опыта в играх и виртуальных мирах. Эти достижения вызывают дискуссии о роли ИИ в повседневной жизни и развлечениях. (来源:Reddit r/ArtificialInteligence、Reddit r/artificial)

Выбор между открытыми и закрытыми моделями: Сообщество обсудило самые большие препятствия, с которыми сталкиваются инженеры-программисты при переходе от использования закрытых моделей к открытым. Эксперты отмечают, что тонкая настройка открытых моделей, а не зависимость от закрытых «черных ящиков», имеет решающее значение для глубокого обучения, достижения дифференциации продукта и создания лучших продуктов для пользователей. Хотя открытые модели могут развиваться медленнее, в долгосрочной перспективе они обладают огромным потенциалом в создании ценности и технологической автономии. (来源:ClementDelangue、huggingface)
Инфраструктура ИИ и проблемы вычислительной мощности: Проект Stargate от OpenAI выявил огромные потребности ИИ в вычислительной мощности, энергии и земле, прогнозируя ежемесячное потребление до 900 000 пластин DRAM. Дефицит GPU, их высокая стоимость и ограничения в энергоснабжении вынуждают ИИ-компании заниматься «дипломатией вычислительных мощностей», тесно сотрудничая с поставщиками облачных услуг (такими как Microsoft и Amazon). Хотя такие крупные инвестиции и стратегическое партнерство способствуют развитию ИИ, они также несут риски, связанные с цепочками поставок, энергетической политикой и регулированием. (来源:karminski3、AI巨头的奶妈局、DeepLearning.AI Blog)

💡 Прочее
Авторские права на ИИ-музыку и механизмы компенсации: Шведская организация по авторским правам STIM в сотрудничестве с компанией Sureel запустила лицензионное соглашение на ИИ-музыку, призванное решить проблему использования музыкальных произведений при обучении ИИ-моделей. Это соглашение позволяет разработчикам ИИ легально использовать музыку и, с помощью технологии атрибуции Sureel, рассчитывать влияние произведений на вывод модели, тем самым компенсируя композиторам и звукозаписывающим артистам. Этот шаг направлен на предоставление правовой защиты для создания ИИ-музыки, стимулирование производства оригинального контента и создание новых источников дохода для правообладателей. (来源:DeepLearning.AI Blog)

Безопасность LLM и adversarial-атаки: Trend Micro опубликовала исследование, глубоко изучающее различные способы, которыми LLM могут быть использованы злоумышленниками, включая компрометацию через тщательно сконструированные подсказки, отравление данных и уязвимости в многоагентных системах. Исследование подчеркивает важность понимания этих векторов атак для разработки более безопасных приложений LLM и многоагентных систем, а также предлагает соответствующие стратегии защиты. (来源:Reddit r/deeplearning)

Proactive AI: Баланс между удобством и конфиденциальностью: Сообщество обсудило удобство, предоставляемое «Proactive Ambient AI» (активным окружающим ИИ) в качестве интеллектуального помощника, и потенциальные риски нарушения конфиденциальности. Такой ИИ может активно предлагать помощь, но постоянный сбор и обработка личных данных вызывает у пользователей опасения по поводу прозрачности, контроля и принадлежности данных. Некоторые призывают к созданию «протоколов прозрачности» и «личных базовых профилей», чтобы гарантировать пользователям контроль над их историей взаимодействия с ИИ. (来源:Reddit r/artificial)
