
Ключевые слова:Всемирная конференция робототехники, Гуманоидные роботы, Воплощенный искусственный интеллект, GPT-5, Очки с искусственным интеллектом, Google DeepMind, LangChain, Очки Reality Proxy с ИИ, Генератор симуляторов мира Genie 3, Векторный индекс LEANN, Бесплатный доступ к Qwen Code, Приоритетный доступ к GPT-5
🔥 В центре внимания
«Весенний фестиваль» в мире воплощенного ИИ: 200 роботов на одной сцене: Всемирная конференция робототехники (WRC 2025) торжественно состоялась в Пекине, привлекая более 220 компаний-участников, представивших более 1500 экспонатов, включая более 100 новых продуктов от 50 компаний, специализирующихся на гуманоидных роботах. На конференции были продемонстрированы последние достижения гуманоидных роботов в таких областях, как бытовые услуги (например, застилание кроватей, складывание одежды), коммерческие услуги (например, кассовые операции, приготовление кофе, смешивание напитков), промышленное применение (например, точная сборка, сортировка, перемещение) и медицинское обслуживание (например, реабилитационные тренировки, массаж). Кроме того, значительные инновации были продемонстрированы в компонентах цепочки поставок робототехники (например, планетарные роликовые винты, ловкие руки, тактильные датчики), что свидетельствует об ускоренной интеграции воплощенного ИИ в физический мир, что, как ожидается, будет способствовать глубокой интеграции AI с реальными сценариями. (Источник: 36氪)
AI-очки «удаленно берут» объекты: Reality Proxy: Команда выпускников Чжэцзянского университета разработала технологию AI-очков под названием «Reality Proxy», которая позволяет пользователям «удаленно брать» объекты из реального мира и интуитивно взаимодействовать с ними через «цифровых двойников». Эта технология способна захватывать структуру сцены и генерировать интерактивные цифровые прокси, поддерживая разнообразные функции взаимодействия, такие как просмотр предварительных изображений, выбор нескольких объектов, фильтрация по атрибутам, семантическая группировка и пространственное масштабирование групп. Это нововведение объединяет физический и цифровой миры, значительно повышая эффективность и точность взаимодействия устройств XR в сложных сценариях, таких как поиск книг, навигация по зданиям и управление дронами, и рассматривается как ключевой шаг на пути к AI-помощнику в стиле «Jarvis». (Источник: 量子位)

🎯 Тенденции
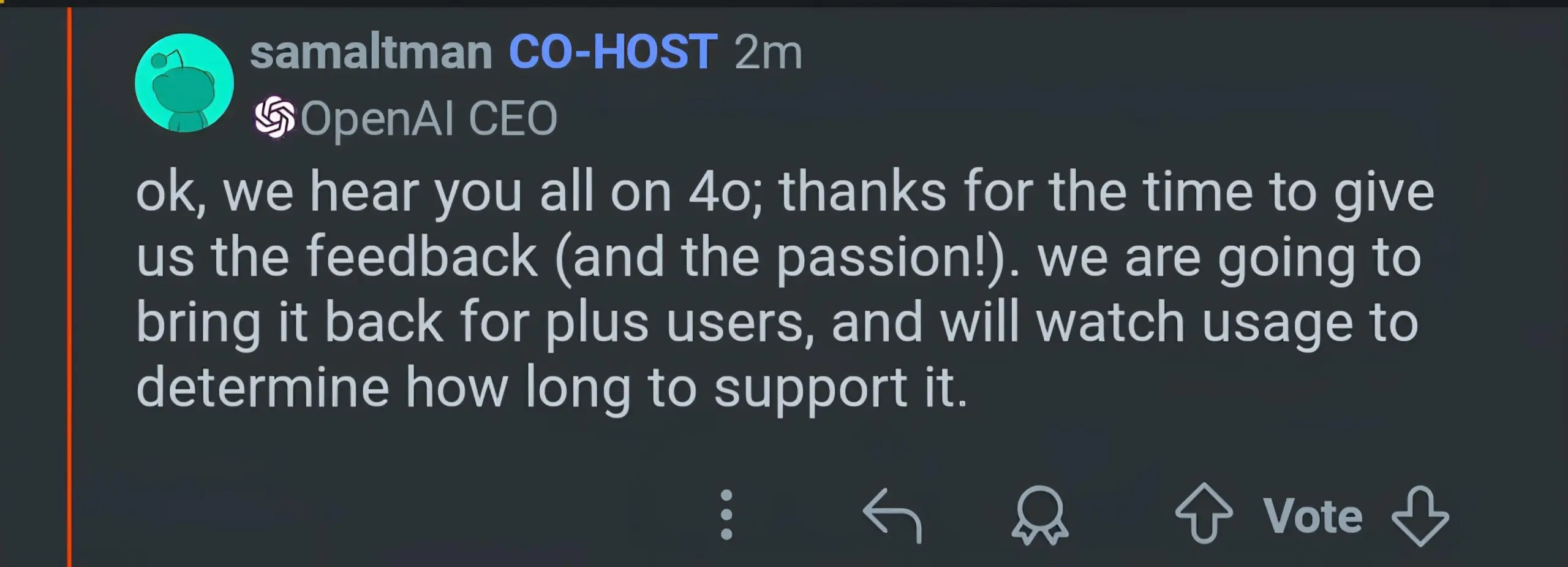
OpenAI GPT-5: выпуск и последующие корректировки: OpenAI официально выпустила GPT-5, подчеркнув, что ее «система маршрутизации» может динамически распределять ресурсы модели в зависимости от сложности задачи и намерений пользователя, обеспечивая «бесшовную мультимодальную координацию» и значительно снижая частоту фактических ошибок и галлюцинаций. Однако после выпуска пользователи сообщили о «поглупении» модели. Sam Altman объяснил это сбоем автоматического переключателя и пообещал исправить его, а также восстановить GPT-4o для пользователей Plus и планирует добавить опции «температуры» и персонализации для GPT-5, чтобы учесть предпочтения пользователей в отношении «характера» модели. (Источник: 36氪, The Verge, The Verge, sama, openai, nickaturley, sama, openai, dotey, dotey, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
Google DeepMind: сводка последних достижений: Google DeepMind недавно представила ряд достижений в области AI, включая самый передовой симулятор мира Genie 3, открытый для Ultra-подписчиков Gemini 2.5 Pro Deep Think, бесплатный доступ к Gemini Pro для студентов университетов и инвестиции в размере 1 миллиарда долларов в поддержку образования в США, выпуск глобальной геопространственной модели AlphaEarth, а также модель Aeneas для расшифровки древних текстов. Кроме того, Gemini достиг уровня золотой медали на IMO (Международной математической олимпиаде), выпустил приложение для создания интерактивных книг Storybook с искусством и аудио, добавил бенчмарк LLM для игровой арены Kaggle, асинхронный кодирующий Agent Jules вышел из бета-версии, в Великобритании запущен режим AI-поиска, опубликован видеообзор NotebookLM, а количество загрузок модели Gemma превысило 200 миллионов. (Источник: demishassabis, Google, Ar_Douillard, _rockt, quocleix)
Модели серии GLM-4.5 скоро будут с открытым исходным кодом: Zhipu AI (GLM) объявила о скором открытии исходного кода своих новых моделей серии GLM-4.5 и сообщила, что эта модель за 16 часов победила 99% реальных игроков в конкурсе по поиску на картах. Этот шаг предвещает новые достижения в области визуальных моделей и может повлиять на приложения для геолокации и распознавания изображений. Сообщество проявляет большой интерес к конкретным возможностям новой модели и деталям открытого исходного кода. (Источник: Reddit r/LocalLLaMA)

Выпущен Cohere Command A Vision: Команда Cohere представила Command A Vision — передовую генеративную модель, разработанную для обеспечения выдающейся производительности в мультимодальных визуальных задачах для предприятий, сохраняя при этом мощные возможности обработки текста. Выпуск этой модели будет способствовать дальнейшему повышению эффективности и результативности корпоративных приложений, объединяющих изображения и текст. (Источник: dl_weekly)
Выпущен Meta V-JEPA 2: Meta AI выпустила V-JEPA 2 — прорывную модель мира, ориентированную на визуальное понимание и прогнозирование. Ожидается, что эта модель принесет значительные успехи в области робототехники и искусственного интеллекта, поскольку она поможет AI-системам лучше понимать и прогнозировать визуальную среду, что позволит им выполнять более сложные автономные действия. (Источник: Ronald_vanLoon)
OpenAI GPT-5 запускает услугу приоритетной обработки: OpenAI представила услугу «Priority Processing» для GPT-5, позволяющую разработчикам получать более высокую скорость генерации первого токена, установив "service_tier": "priority". Эта функция критически важна для приложений, чувствительных к задержкам в миллисекундах, но требует дополнительной оплаты, что отражает стремление OpenAI оптимизировать опыт использования модели и ее коммерциализацию. (Источник: jeffintime, OpenAIDevs, swyx, juberti)

🧰 Инструменты
Qwen Code предлагает бесплатные вызовы: Alibaba Tongyi Qianwen объявила, что Qwen Code предоставляет 2000 бесплатных вызовов в день, а международные пользователи могут получить 1000 вызовов через OpenRouter. Этот шаг значительно снижает порог входа для разработчиков, использующих инструменты генерации кода, и, как ожидается, будет способствовать распространению инновационных приложений на базе Qwen Code и «vibe coding», делая его сильным конкурентом в области AI-помощи в программировании. (Источник: huybery, jeremyphoward, op7418, Reddit r/LocalLLaMA)

Genie 3 исследует мир живописи: Genie 3 от Google DeepMind продемонстрировал удивительные возможности: пользователи могут «войти» и исследовать свои любимые картины, превращая их в интерактивные 3D-миры. Эта функция открывает новые измерения для наслаждения искусством, образования и виртуального опыта, например, можно прогуляться по «Полуночникам» Эдварда Хоппера или «Смерти Сократа» Жака-Луи Давида, ощущая полное погружение в искусство. (Источник: cloneofsimo, jparkerholder, BorisMPower, francoisfleuret, shlomifruchter, _rockt, Vtrivedy10, rbhar90, fchollet, bookwormengr)

LangChain запускает GPT-5 Playground: LangChain интегрировала новейшие модели OpenAI GPT-5 (включая gpt-5, gpt-5-mini, gpt-5-nano) в свой LangSmith Playground, а также встроила функцию отслеживания затрат. Это предоставляет разработчикам удобную платформу для тестирования и создания приложений на базе GPT-5, а также для мониторинга затрат на использование API, что помогает оптимизировать процесс разработки и управление ресурсами. (Источник: LangChainAI, hwchase17)

Claude Code помогает с мобильными «горячими» исправлениями: Один разработчик успешно справился с экстренным «горячим» исправлением в производственной среде, используя Claude Code через мобильный браузер в ресторане Taco Bell. Это демонстрирует мощную практичность инструментов AI-кодирования в мобильных сценариях, позволяя разработчикам освободиться от привязки к рабочему столу и отлаживать код и решать проблемы в любое время и в любом месте, повышая гибкость работы. (Источник: Reddit r/ClaudeAI)

Функция удаленного доступа Clode Studio: Clode Studio выпустила обновление, добавив встроенный Relay Server и поддержку нескольких туннелей, что позволяет пользователям удаленно получать доступ к настольному IDE с любого устройства и управлять Claude Code Chat. Эта функция предлагает различные варианты туннелей (Clode, Cloudflare, Custom), поддерживает сенсорное управление на телефонах и планшетах и обеспечивает безопасную аутентификацию, что направлено на улучшение опыта удаленной разработки и повышение гибкости. (Источник: Reddit r/ClaudeAI)
LEANN: чрезвычайно легкий векторный индекс: LEANN — это инновационный, чрезвычайно легкий векторный индекс, который обеспечивает быструю, точную и 100% приватную RAG (Retrieval Augmented Generation) на MacBook без подключения к интернету, при этом размер индексных файлов на 97% меньше, чем у традиционных методов. Он позволяет пользователям выполнять семантический поиск на локальных устройствах, обрабатывать личные данные, такие как электронные письма и записи чатов, предоставляя опыт, подобный личному Jarvis. (Источник: matei_zaharia)

Qwen-Image LoRA Trainer запущен: Платформа WaveSpeedAI запустила Qwen-Image LoRA Trainer, став первой в мире платформой, предлагающей онлайн-тренажер Qwen-Image LoRA. Теперь пользователи могут обучать свои собственные стили за считанные минуты, что значительно упрощает процесс создания AI-искусства и повышает возможности персонализации моделей генерации изображений. (Источник: Alibaba_Qwen)

Jules запускает Interactive Plan: Асинхронный кодирующий Agent Jules от Google выпустил функцию Interactive Plan, которая позволяет Jules читать кодовые базы, задавать уточняющие вопросы и сотрудничать с пользователями для совершенствования плана разработки. Этот совместный подход увеличивает вероятность того, что пользователи четко определят цели, обеспечивая согласованность взаимодействия человека и машины в генерации кода и построении решений, тем самым повышая качество и надежность кода. (Источник: julesagent)

Улучшены возможности Grok 4 по обработке PDF: xAI объявила о значительном улучшении возможностей Grok 4 по обработке PDF, теперь он может бесшовно обрабатывать сверхбольшие PDF-файлы объемом в сотни страниц и лучше понимать содержимое PDF благодаря более острому распознаванию. Это обновление уже доступно в веб- и мобильных приложениях Grok, значительно повышая эффективность пользователей при обработке и анализе сложных документов. (Источник: xai, Yuhu_ai_, Yuhu_ai_, Yuhu_ai_)

📚 Обучение
HuggingFace запускает AI-курсы: HuggingFace выпустила 9 бесплатных курсов AI элитного уровня, охватывающих основные темы, такие как LLMs, Agent и AI-системы. Эти курсы призваны помочь разработчикам и исследователям освоить передовые AI-технологии, снизить порог входа в обучение и способствовать развитию сообщества открытого исходного кода AI. (Источник: huggingface)

Attention Basin: исследование чувствительности LLM к контекстному положению: Исследование выявило значительную чувствительность больших языковых моделей (LLMs) к контекстному положению входной информации, названную феноменом «бассейна внимания»: модель склонна уделять больше внимания информации в начале и конце последовательности, игнорируя среднюю часть. Исследование предлагает фреймворк Attention-Driven Reranking (AttnRank), который значительно улучшил производительность 10 различных LLM в задачах многошагового вопросно-ответного поиска и Few-shot обучения путем калибровки предпочтений внимания модели и переранжирования извлеченных документов или Few-shot примеров. (Источник: HuggingFace Daily Papers)

MLLMSeg: легковесный декодер маски улучшает сегментацию референциальных выражений: MLLMSeg — это новый фреймворк, разработанный для решения проблем плотного пиксельного прогнозирования в задачах сегментации референциальных выражений (RES) для мультимодальных больших моделей (MLLMs). Этот фреймворк полностью использует внутренние визуальные детали, присущие визуальным кодировщикам MLLM, и предлагает модули с улучшением деталей и семантически согласованным слиянием признаков, в сочетании с легковесным декодером маски, достигая лучшего баланса между производительностью и стоимостью, превосходя существующие SAM-основанные и SAM-free методы. (Источник: HuggingFace Daily Papers)

Обучение рассуждению для повышения фактической точности: Исследование предложило новую функцию вознаграждения, направленную на решение проблемы высокой частоты галлюцинаций у больших языковых моделей с рассуждениями (R-LLMs) в длинных задачах, требующих фактической точности. Эта функция вознаграждения одновременно учитывает фактическую точность, уровень детализации ответа и релевантность ответа. Обучение с подкреплением в режиме онлайн позволило модели снизить средний уровень галлюцинаций на 23,1 процентных пункта и повысить уровень детализации ответа на 23% в шести бенчмарках по фактической точности, не влияя на общую полезность ответа. (Источник: HuggingFace Daily Papers)

LangChain проводит Hacking Hours: LangChain проведет мероприятие «LangChain Hacking Hours», предлагая целенаправленную совместную рабочую среду, где разработчики смогут добиться реального прогресса в проектах LangChain или LangGraph, получить прямые технические консультации от команды и общаться с другими разработчиками сообщества. (Источник: LangChainAI)

DSPy: достоверность конвейеров RAG: В социальных сетях обсуждались преимущества фреймворка DSPy в поддержании достоверности в конвейерах RAG (Retrieval Augmented Generation). С помощью DSPy разработчики могут проектировать системы таким образом, чтобы они активно выводили «Я не знаю», когда контекст не содержит необходимой информации, тем самым избегая галлюцинаций модели и упрощая сложность проектирования подсказок, разделяя бизнес-цели, модели, процессы и обучающие данные. (Источник: lateinteraction, lateinteraction, lateinteraction)

AI Evals: идеи курса: Hamel Husain поделился 14 ключевыми моментами из своего курса AI Evals, особенно выделяя идеи, касающиеся Retrieval (RAG). Курс подчеркивает важность оценки в разработке AI-систем и то, как эффективно использовать технологии Retrieval для повышения производительности моделей, особенно при работе со сложными данными и многоисточниковой информацией. (Источник: HamelHusain)

Anthropic обязуется развивать AI-образование: Anthropic присоединилась к инициативе «Pledge to America’s Youth», совместно с более чем 100 организациями, стремящимися развивать AI-образование. Они будут сотрудничать с педагогами, студентами и сообществами по всей стране, чтобы развивать необходимые навыки в области AI и кибербезопасности у следующего поколения, чтобы справиться с вызовами будущего технологического развития. (Источник: AnthropicAI)

Суть рассуждений Chain-of-Thought (CoT): Активно обсуждается вопрос, является ли рассуждение Chain-of-Thought (CoT) «миражом». Одно исследование, анализируя с точки зрения распределения данных, ставит под сомнение истинные способности CoT к пониманию, указывая на то, что оно может переобучаться на бенчмарковых задачах и легко генерировать галлюцинации. В то же время, существует мнение, что CoT все еще может предоставлять ценную информацию в сложных когнитивных задачах, и его «следы мышления» остаются достоверными при определенных условиях. (Источник: togelius, METR_Evals, rao2z, METR_Evals, METR_Evals)

Как LLM предсказывают следующее слово: В социальных сетях было опубликовано видео, наглядно демонстрирующее, как большие языковые модели (LLMs) генерируют текст, предсказывая следующее слово. Это помогает пользователям понять основной принцип работы LLM: выбор наиболее вероятного следующего слова на основе распределения вероятностей для построения связных и осмысленных последовательностей. (Источник: Reddit r/deeplearning)
Необходимость независимых проекций Q, K, V в модели Transformer: В сообществе обсуждались причины независимого проецирования Query (Q), Key (K) и Value (V) в модели Transformer. В ходе обсуждения было отмечено, что прямое связывание Q и V с входными эмбеддингами приведет к потере выразительной способности и гибкости модели, поскольку независимое проецирование позволяет модели запрашивать, сопоставлять и извлекать информацию в различных семантических пространствах, тем самым улавливая более сложные зависимости и механизмы многоголового внимания. (Источник: Reddit r/deeplearning)
Adaptive Classifiers: новая архитектура для Few-Shot обучения: Исследование предложило архитектуру «Adaptive Classifiers», которая позволяет текстовым классификаторам обучаться на небольшом количестве примеров (5-10 на класс), непрерывно адаптироваться к новым данным без катастрофического забывания и динамически добавлять новые категории без переобучения. Это решение сочетает прототипное обучение и интеграцию эластичных весов, достигая 90-100% точности в задачах корпоративного уровня, обеспечивая высокую скорость вывода и решая проблемы развертывания ML в сценариях с дефицитом данных и быстрыми изменениями. (Источник: Reddit r/MachineLearning)

Динамическая тонкая настройка (DFT) улучшает SFT: Исследование предложило «Dynamic Fine-Tuning» (DFT), которое переопределяет SFT (Supervised Fine-Tuning) как обучение с подкреплением и вводит однострочное изменение кода для стабилизации обновления токенов, повышая производительность SFT. DFT в некоторых случаях превосходит методы RL, такие как PPO, DPO, GRPO, предлагая более эффективный и стабильный новый подход к тонкой настройке моделей. (Источник: TheTuringPost)

💼 Бизнес
Ценовая стратегия OpenAI GPT-5 вызывает предположения о ценовой войне: OpenAI выпустила GPT-5, чьи цены на API ($1.25/1M входных токенов, $10/1M выходных токенов) значительно ниже, чем у конкурента Anthropic Claude Opus 4.1 ($15/1M входных токенов, $75/1M выходных токенов). Этот шаг рассматривается как «козырь», который может спровоцировать ценовую войну на рынке LLM. Отрасль задается вопросом, является ли это краткосрочным ударом по доле рынка или началом долгосрочного снижения затрат на AI, а также как это повлияет на разработку AI-инструментов, бизнес-модели и доступность AI. (Источник: Reddit r/ArtificialInteligence)

Концентрация ресурсов GPU и ландшафт AI-индустрии: Комментарии указывают на то, что высокая концентрация ресурсов GPU привела к доминированию «богатых GPU-лабораторий» в области общего AI, с которыми открытые модели не могут конкурировать. В статье утверждается, что 2025 год станет годом Agent и прикладного уровня, и предприятиям следует сосредоточиться на создании приемлемых решений на минимальных LLM, а не тратить огромные средства на обучение больших моделей, что отражает стратегический сдвиг в AI-индустрии от обучения моделей к их практическому применению. (Источник: Reddit r/artificial)
Хаос в сделках с акциями AI-компаний: В социальных сетях были выявлены явления «низовых хищников» и «мошенников» в сделках с акциями AI-лабораторий. Эти многоуровневые брокеры SPV (Special Purpose Vehicle) не имеют прямого отношения к самим компаниям, но занимаются мошеннической деятельностью, что служит предупреждением для инвесторов и общественности о растущем иррациональном буме и потенциальных рисках в области AI. (Источник: saranormous)
🌟 Сообщество
Выпуск GPT-5 вызывает сильный отклик и споры среди пользователей: После выпуска GPT-5 от OpenAI в сообществе развернулись широкие дискуссии. Некоторые пользователи выразили разочарование производительностью GPT-5 (особенно в программировании и творческом письме), считая, что она уступает GPT-4o или Claude Code, и даже ощутили «откат», а также выразили недовольство функцией «автоматического переключателя» OpenAI, прозрачностью модели и изменениями в ограничениях использования для пользователей Plus. Многие пользователи выразили ностальгию по «личности» и «эмоциям» GPT-4o, считая ее не просто инструментом, а «другом» или «партнером», и даже запустили петицию с требованием к OpenAI восстановить опцию 4o. Sam Altman ответил, что компания недооценила предпочтения пользователей в отношении «личности» 4o, и пообещал восстановить 4o для пользователей Plus, а также улучшить «температуру» и функции персонализации GPT-5, объяснив, что плохое поведение модели на ранних этапах выпуска было вызвано техническими сбоями. (Источник: maithra_raghu, teortaxesTex, teortaxesTex, teortaxesTex, SebastienBubeck, SebastienBubeck, shaneguML, OfirPress, cloneofsimo, TheZachMueller, scaling01, Smol_AI, natolambert, teortaxesTex, Vtrivedy10, tokenbender, ClementDelangue, TheZachMueller, TomLikesRobots, METR_Evals, Ronald_vanLoon, teortaxesTex, teortaxesTex, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, Teknium1, Teknium1, Teknium1, Teknium1