Ключевые слова:Исследование ИИ, Компьютерные науки, Обучение с подкреплением, Разработка лекарств, Автономное вождение, Языковые модели, Мультимодальная обработка, Виртуальная клетка, Институт Laude, Преподаватели по обучению с подкреплением (RLTs), Платформа BioNeMo, Tesla Robotaxi, Модель мышления Kimi VL A3B
🔥 聚焦
Laude Institute成立,获1亿美元初始资金推动计算机科学公益研究: Andy Konwinski объявил о запуске Laude Institute, некоммерческой организации, целью которой является финансирование некоммерческих исследований в области компьютерных наук, оказывающих значительное влияние на мир. В совет директоров вошли такие известные личности, как Jeff Dean, Joyia Pineau и Dave Patterson. Учреждение получило первоначальное обязательство по финансированию в размере 100 миллионов долларов и будет поддерживать исследователей в превращении идей в реальное влияние посредством финансирования, обмена ресурсами и создания сообщества, уделяя особое внимание открытым и ориентированным на результат исследованиям. (Источник: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

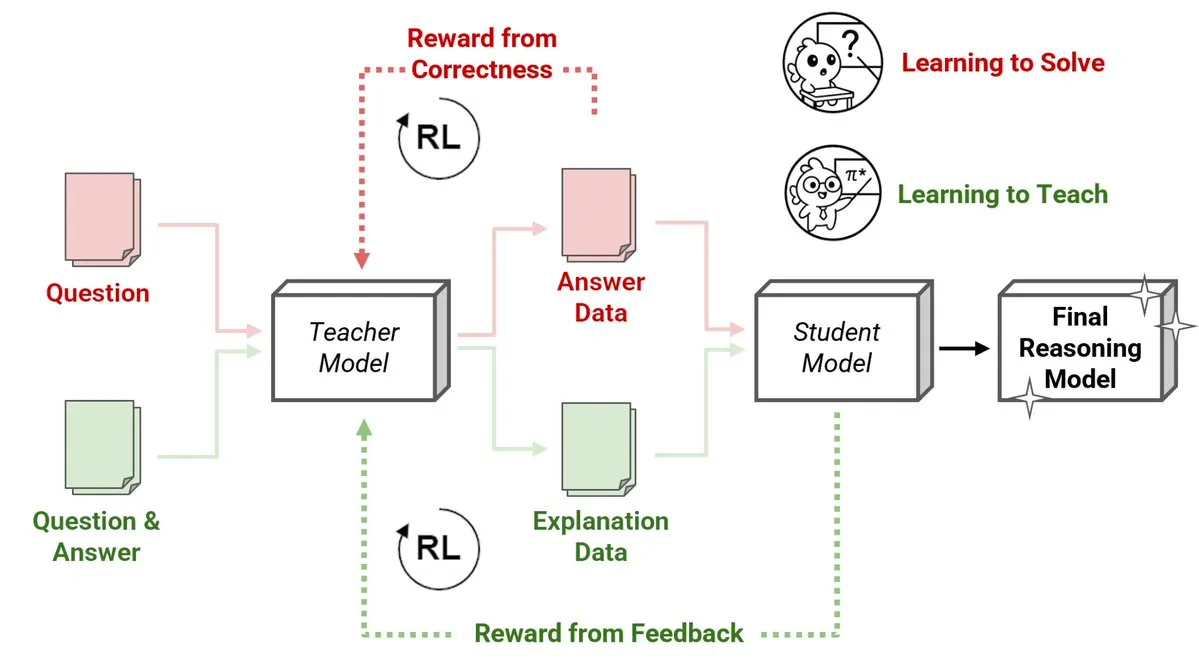
Sakana AI发布强化学习教师(RLTs)新方法,小模型教大模型推理: Sakana AI представила новый метод учителей на основе обучения с подкреплением (RLTs), который изменяет способ обучения рассуждениям больших языковых моделей (LLMs) с помощью обучения с подкреплением (RL). Традиционное RL фокусируется на «обучении решению» проблем, в то время как RLTs обучаются генерировать четкие, пошаговые «объяснения» для обучения моделей-студентов. RLT всего с 7B параметрами, обучая модель-студента с 32B параметрами, превзошел LLM, в несколько раз превышающие его по размеру, в задачах на рассуждение соревновательного и аспирантского уровня. Этот метод устанавливает новый стандарт эффективности для разработки языковых моделей с рассуждениями на основе RL. (Источник: cognitivecompai, AndrewLampinen)
英伟达与诺和诺德合作,利用AI超级计算机加速药物研发: Nvidia объявила о сотрудничестве с датским фармацевтическим гигантом Novo Nordisk и Датским национальным центром инноваций в области ИИ для совместного использования технологий ИИ и новейшего датского суперкомпьютера Gefion для ускорения разработки новых лекарств. В рамках этого сотрудничества будет использоваться платформа Nvidia BioNeMo и передовые рабочие процессы ИИ с целью трансформации моделей исследований и разработок лекарств. Суперкомпьютер Gefion, созданный на основе технологий Eviden и Nvidia, обеспечит мощную вычислительную поддержку для исследований в таких областях, как науки о жизни, способствуя развитию персонализированной медицины и открытию новых методов лечения. (Источник: nvidia)

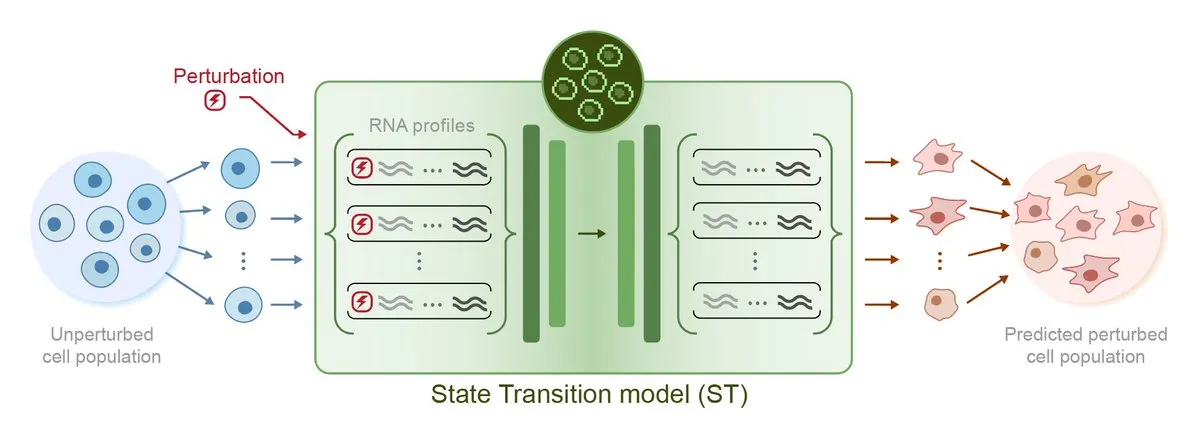
Arc Institute发布首个扰动预测AI模型STATE,迈向虚拟细胞目标: Arc Institute выпустил свою первую модель ИИ для прогнозирования возмущений STATE, что является важным шагом на пути к достижению цели создания виртуальной клетки. Модель STATE предназначена для изучения того, как использовать возмущения, вызванные лекарствами, цитокинами или генами, для изменения состояния клетки (например, из «больного» в «здоровое»). Выпуск этой модели знаменует новый прогресс в понимании и прогнозировании поведения клеток с помощью ИИ, открывая новые пути для лечения заболеваний и разработки лекарств. Соответствующая модель доступна на HuggingFace. (Источник: riemannzeta, ClementDelangue)
特斯拉Robotaxi在奥斯汀启动试点,视觉方案受关注,Karpathy遗留代码被大幅精简: Tesla официально запустила пилотный сервис Robotaxi в Остине, штат Техас, США. Первые автомобили созданы на базе Model Y и используют чисто визуальное восприятие и программное обеспечение FSD. Команда под руководством Ashok Elluswamy, руководителя отдела ИИ и программного обеспечения для автономного вождения Tesla, провела значительные технологические изменения в системе, сократив примерно 330-340 тысяч строк эвристического кода на C++, унаследованного от команды Andrej Karpathy, почти на 90%, заменив его «гигантской нейронной сетью». Этот шаг направлен на переход от «кодирования человеческого опыта» к «параметризованному обучению», автономно оптимизируя модель с помощью огромных объемов данных и симуляций вождения. В настоящее время сервис находится на ранней стадии тестирования, вызывая широкие отраслевые дискуссии о технологическом маршруте Tesla и ее возможностях масштабирования. (Источник: 36氪, Ronald_vanLoon, kylebrussell)

🎯 动向
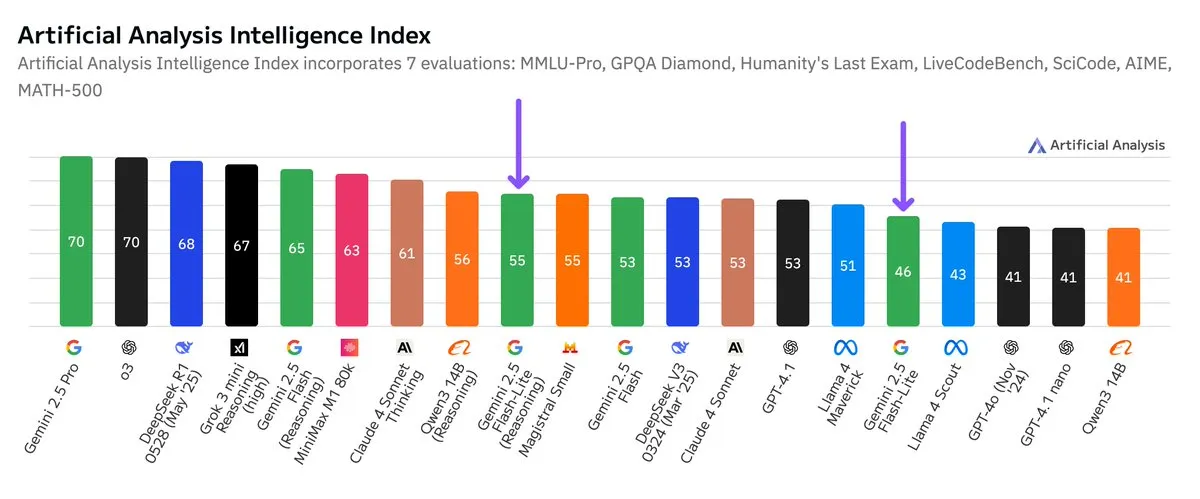
谷歌Gemini 2.5 Flash-Lite独立基准测试发布,性价比提升: Согласно независимым результатам бенчмаркинга, опубликованным Artificial Analysis, версия Google Gemini 2.5 Flash-Lite Preview (06-17) по сравнению с обычной версией Flash снизила затраты примерно в 5 раз и увеличила скорость примерно в 1.7 раза, однако уровень интеллекта несколько снизился. Эта модель является обновленной версией Gemini 2.0 Flash-Lite, выпущенной в феврале 2025 года, и относится к гибридным моделям. Это обновление демонстрирует постоянные усилия Google в стремлении к эффективности моделей и экономической целесообразности, возможно, ориентируясь на сценарии применения с высокими требованиями к стоимости и скорости. (Источник: zacharynado)
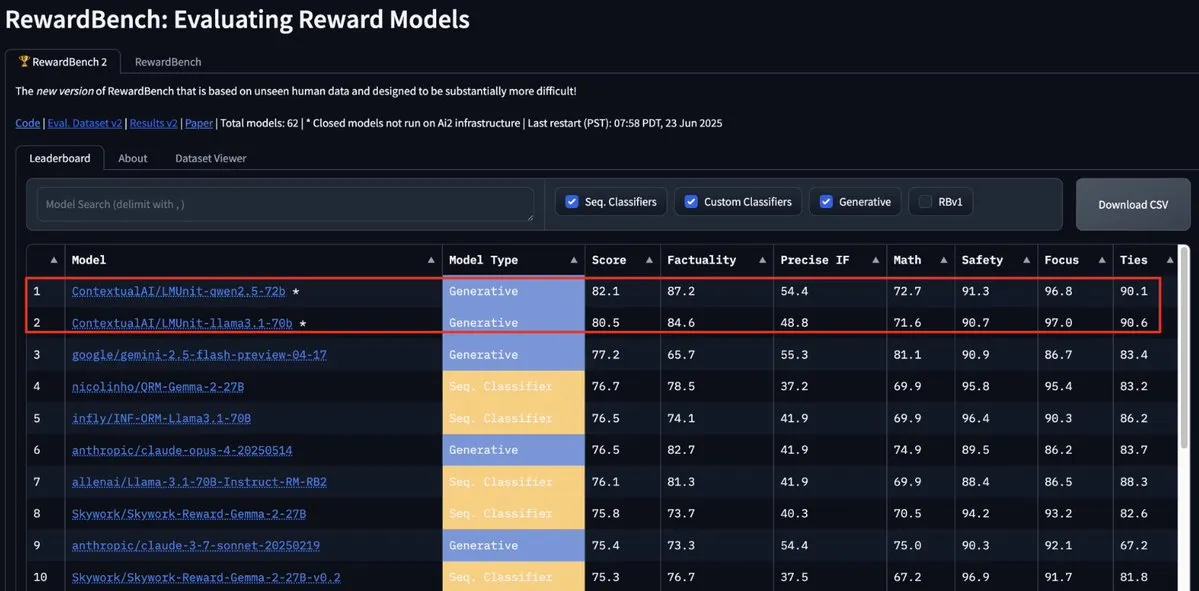
ContextualAI的LMUnit模型登顶RewardBench2,超越Gemini、Claude 4和GPT-4.1: Модель LMUnit от ContextualAI заняла первое место в бенчмарке RewardBench2, опередив такие известные модели, как Gemini, Claude 4 и GPT-4.1, более чем на 5%. Это достижение, возможно, связано с ее уникальным методом обучения, который, как утверждается, аналогичен методу «rubrics», над которым OpenAI вложила много усилий для моделей o4 и последующих. Этот метод способствует эффективному масштабированию LLM в качестве арбитра (llm-as-a-judge) при рассуждениях. (Источник: natolambert, menhguin, apsdehal)
Arcee.ai成功将AFM-4.5B模型上下文长度从4k扩展至64k: Arcee.ai объявила об успешном расширении длины контекста своей первой базовой модели AFM-4.5B с 4k до 64k. Команда достигла этого прорыва благодаря активным экспериментам, слиянию моделей, дистилляции и методам, в шутку названным «большим количеством супа» (имеется в виду техника слияния моделей). Этот прогресс имеет решающее значение для обработки длинных текстовых задач. Улучшения Arcee в модели GLM-32B-Base также подтвердили ее эффективность: поддержка длинного контекста увеличилась с 8k до 32k, а также улучшились все оценки базовых моделей (включая короткий контекст). (Источник: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

谷歌Gemini API更新,提升视频和PDF处理速度与能力: Google Gemini API получил важные обновления в области обработки видео и PDF. Время первого ответа (TTFT) для кэшированных видео увеличилось в 3 раза, а скорость обработки кэшированных PDF — до 4 раз. Кроме того, новая версия поддерживает пакетную обработку нескольких видео, а производительность неявного кэширования приблизилась к производительности явного кэширования. Эти улучшения направлены на повышение эффективности и удобства использования Gemini API разработчиками при работе с мультимедийным контентом. (Источник: _philschmid)
Moonshot (Kimi) 更新Kimi VL A3B Thinking模型,提升多模态处理能力: Moonshot AI (Kimi) выпустила обновленную версию своей небольшой визуально-языковой модели (VLM) Kimi VL A3B Thinking, распространяемой по лицензии MIT. Новая версия потребляет меньше токенов, сокращает траекторию мышления, поддерживает обработку видео и может обрабатывать изображения с более высоким разрешением (1792×1792). Модель достигла 65.2 балла на VideoMMMU, улучшила результат на MathVision на 20.1 балла до 56.9, на MathVista на 8.4 балла до 80.1, на MMMU-Pro на 3.2 балла до 46.3, а также продемонстрировала отличные результаты в визуальном рассуждении, позиционировании UI Agent, обработке видео и PDF. Модель доступна на Hugging Face. (Источник: mervenoyann)

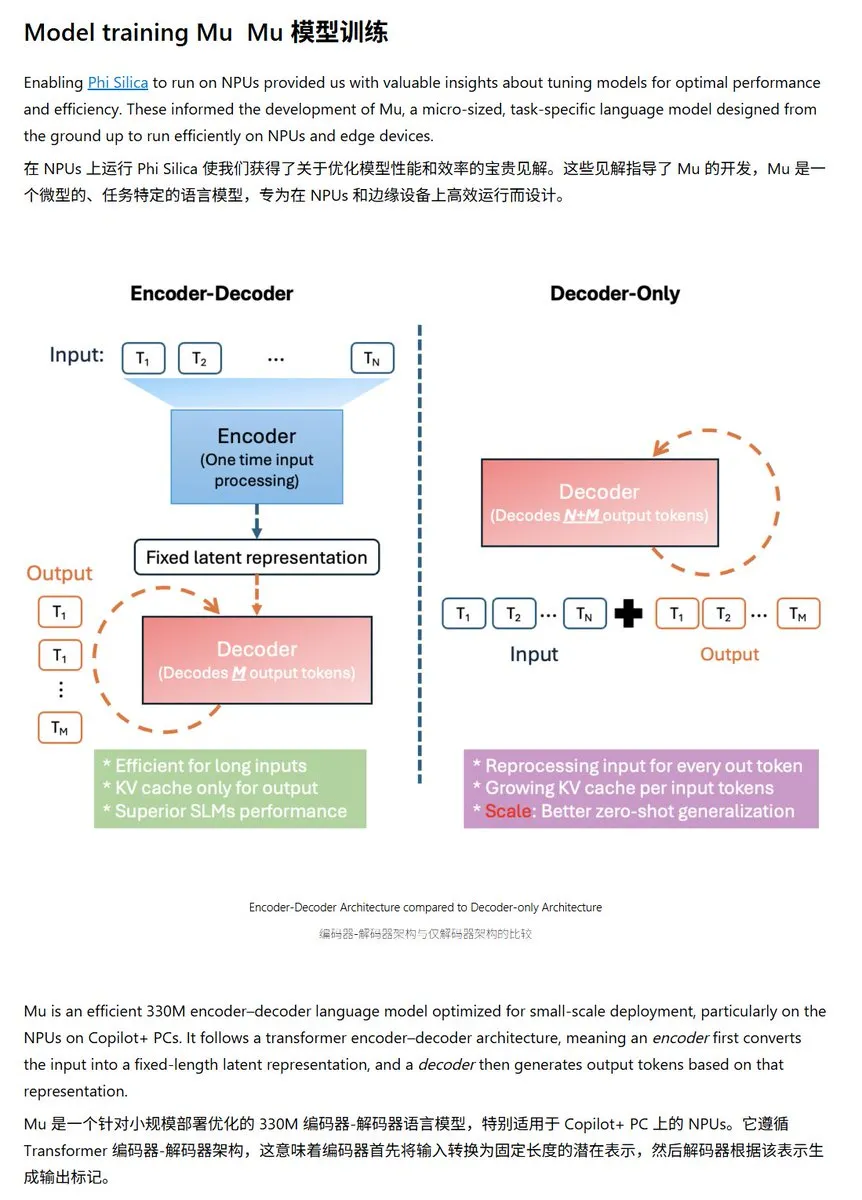
微软发布Mu-330M小型语言模型,专为Windows NPU优化: Microsoft представила новую небольшую языковую модель Mu-330M, предназначенную для работы на NPU (нейронных процессорах) ПК с Windows Copilot+ и поддержки функций Agent в системе Windows. Модель оптимизирована для NPU, использует такие технологии, как ротационные позиционные эмбеддинги, групповое внимание запросов, двухслойный LayerNorm, для эффективной работы при низком энергопотреблении, что знаменует дальнейшее развитие Microsoft в области ИИ на конечных устройствах. (Источник: karminski3)
DeepMind发布Mercury技术报告,专注于扩散语言模型: Inception Labs (команда, связанная с DeepMind) опубликовала технический отчет о своей диффузионной языковой модели Mercury. В отчете подробно описаны архитектура, методы обучения и результаты экспериментов модели Mercury, предоставляя исследователям глубокое понимание этого нового типа моделей. Диффузионные модели уже достигли значительных успехов в области генерации изображений, и их применение к языковым моделям является одним из передовых направлений исследований в области ИИ. (Источник: andriy_mulyar)
Meta与Oakley合作扩展AI智能眼镜系列: Meta в сотрудничестве с брендом очков Oakley расширяет свою линейку умных очков с ИИ. Ожидается, что новые умные очки будут интегрированы с технологиями ИИ от Meta, предлагая более богатые интерактивные функции и пользовательский опыт. Это сотрудничество знаменует собой постоянные инвестиции Meta в область носимых устройств с ИИ, направленные на более плавную интеграцию ИИ в повседневную жизнь. (Источник: rowancheung, Ronald_vanLoon)
阿里云推出自动驾驶模型训推加速框架PAI-TurboX,训练时间可缩短50%: Alibaba Cloud выпустила фреймворк для ускорения обучения и инференса моделей в области автономного вождения PAI-TurboX. Фреймворк нацелен на повышение эффективности обучения и инференса моделей восприятия, планирования, управления и даже моделей мира. Благодаря оптимизации предварительной обработки мультимодальных данных, аффинности CPU, динамической компиляции, конвейерного параллелизма, а также предоставлению возможностей оптимизации операторов и квантования, PAI-TurboX, по результатам тестов, может сократить время обучения примерно на 50% для таких отраслевых моделей, как BEVFusion, MapTR и SparseDrive. (Источник: 量子位)
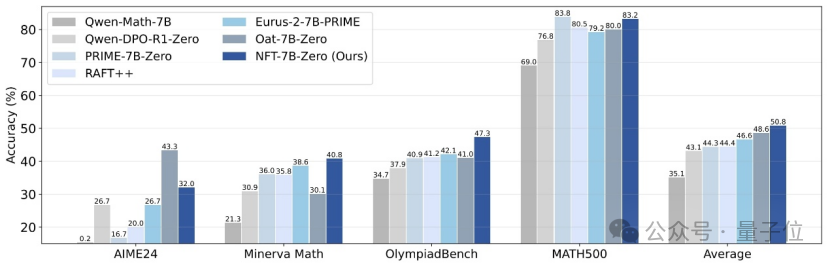
清华与英伟达等提出NFT方法,使监督学习能从错误中“反思”: Исследователи из Университета Цинхуа, Nvidia и Стэнфордского университета совместно предложили новую схему контролируемого обучения под названием NFT (Negative-aware FineTuning). Этот метод, основанный на алгоритме RFT (Rejection FineTuning), использует негативные данные для обучения путем построения «неявной негативной модели», то есть «неявной негативной стратегии». Эта стратегия позволяет контролируемому обучению, подобно обучению с подкреплением, проводить «саморефлексию», устраняя разрыв в некоторых возможностях между контролируемым обучением и обучением с подкреплением. Метод продемонстрировал значительное улучшение производительности в таких задачах, как математическое рассуждение, и даже в условиях On-Policy его градиент функции потерь эквивалентен GRPO. (Источник: 量子位)
OmniGen2发布:8B多功能修图模型,融合视觉理解与图像生成: Выпущена новая многофункциональная модель для редактирования изображений OmniGen2, которая объединяет визуальное понимание (на базе Qwen-VL-2.5) с генерацией изображений (диффузионная модель с 4B параметрами), общим объемом около 8B параметров. OmniGen2 поддерживает множество задач, таких как генерация текста в изображение, редактирование изображений, понимание изображений и генерация в контексте, с целью предоставления единой модели, способной решать различные проблемы, связанные с визуализацией, и подходящей для интеграции на конечных устройствах. (Источник: karminski3)

Chroma-8.9B-v39文本生成图像模型更新,基于FLUX.1-schnell,可商用: Обновлена модель генерации текста в изображение Chroma-8.9B-v39, улучшено освещение и естественность задач. Модель основана на FLUX.1-schnell, количество параметров уменьшено с 12B до 8.9B, используется лицензия Apache 2.0, разрешающая коммерческое использование. Утверждается, что модель «восстановила недостающие анатомические концепции, полностью без ограничений по содержанию» и была дообучена на наборе данных, содержащем 5 миллионов аниме, фурри, художественных работ и фотографий. (Источник: karminski3)

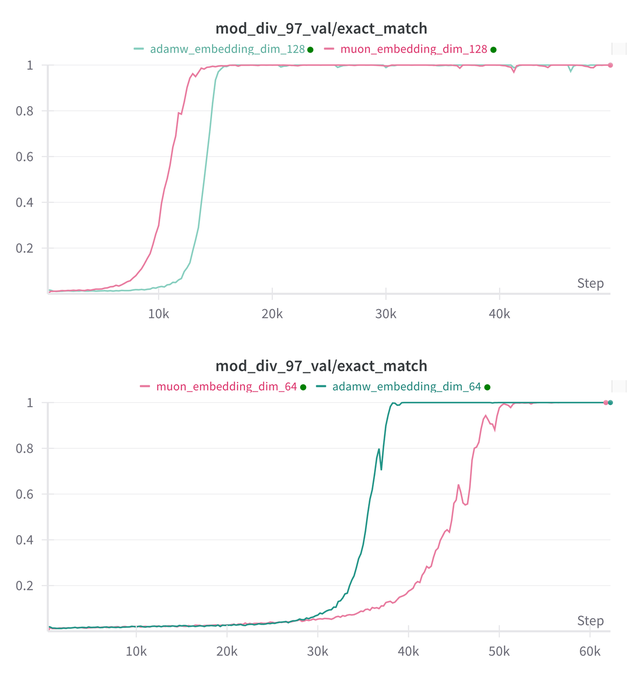
Essential AI更新其模型Muon和Adam在Grokking能力上的研究结论: Essential AI поделилась последними результатами исследований своих моделей Muon и Adam в отношении способности к Grokking (явление, когда модель плохо работает на начальном этапе обучения, а затем внезапно понимает обобщение). Первоначальные гипотезы могут противоречить фактическим наблюдениям. Команда опубликовала результаты внутренних небольших исследовательских экспериментов, которые показывают, что после расширения пространства поиска гиперпараметров Muon не имеет явного универсального преимущества перед AdamW, и они показывают разные результаты в различных сценариях. Это указывает на то, что AdamW во многих случаях по-прежнему является мощным и даже SOTA оптимизатором. (Источник: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI图像生成模型更新,专注无CFG版本并优化高频细节: Ostris AI продолжает обновлять свою модель генерации изображений, в настоящее время фокусируясь на разработке версии без CFG (Classifier-Free Guidance) из-за ее более быстрой конвергенции. В последнем обновлении Day 7 команда добавила новые методы обучения для лучшей обработки высокочастотных деталей и прилагает усилия для удаления артефактов высокой детализации. Предыдущее обновление Day 4 уже продемонстрировало значительное улучшение качества изображений, сгенерированных новым методом без использования CFG. (Источник: ostrisai)

蚂蚁与中科院等开源ViLaSR-7B模型,实现“边画边想”空间推理: Ant Technology Research Institute, Институт автоматизации Китайской академии наук и Китайский университет Гонконга совместно выпустили в открытый доступ модель ViLaSR-7B. Эта модель, используя парадигму «Drawing to Reason in Space», позволяет большим визуально-языковым моделям (LVLM) рисовать вспомогательные метки (например, опорные линии, ограничивающие рамки) в визуальном пространстве для помощи в мышлении, тем самым улучшая пространственное восприятие и возможности рассуждения. ViLaSR использует трехэтапную структуру обучения: холодный запуск, рефлексивную выборку с отклонением и обучение с подкреплением. Эксперименты показывают, что эта модель в среднем улучшает результаты на 18.4% в 5 бенчмарках, включая навигацию по лабиринту, понимание изображений и пространственное рассуждение в видео, а также демонстрирует производительность, близкую к Gemini-1.5-Pro на VSI-Bench. (Источник: 量子位)

🧰 工具
SGLang现已支持Hugging Face Transformers作为后端,提升推理效率: SGLang объявила о поддержке Hugging Face Transformers в качестве бэкенда. Это означает, что пользователи могут предоставлять быстрые, готовые к производству услуги инференса для любой модели, совместимой с Transformers, без необходимости нативной поддержки, по принципу plug-and-play. Эта интеграция призвана упростить процесс развертывания высокопроизводительного инференса языковых моделей, расширяя область применения и удобство использования SGLang. (Источник: TheZachMueller, ClementDelangue)

MLX-LM-LORA v0.7.0发布,内置RLHF功能: Выпущена версия v0.7.0 MLX-LM-LORA, в которую встроена функция обучения с подкреплением на основе обратной связи от человека (RLHF). Инструмент теперь поддерживает загрузку в 4-битном, 6-битном, 8-битном форматах, режим обучения RLHF, а также может напрямую объединять адаптеры (adapters) с базовыми весами. Это делает тонкую настройку LoRA в рамках MLX более интеллектуальной и эффективной, особенно на устройствах с чипами Apple. (Источник: awnihannun)
LlamaCloud发布,为文档工作流提供MCP兼容工具箱: LlamaCloud теперь доступен как инструментарий, совместимый с протоколом контекста модели (MCP), для любых рабочих процессов с документами. Пользователи могут подключать его к моделям, таким как Claude, для выполнения сложных операций по извлечению, сравнению документов и т.д. Например, он может анализировать финансовые показатели Tesla за последние пять кварталов и генерировать сводный отчет, динамически создавая стандартизированные схемы и запуская их по всем файлам, а затем используя генерацию кода для получения окончательного результата. LlamaCloud способен динамически исправлять некорректные схемы и поддерживает прямые ссылки на файлы. (Источник: jerryjliu0)
Georgi Gerganov预告LlamaBarn项目: Georgi Gerganov (создатель llama.cpp) опубликовал в социальных сетях изображение, анонсирующее новый проект под названием «LlamaBarn». На изображении показан интерфейс, похожий на панель управления, с элементами выбора модели, настройки параметров и т.д., что намекает на то, что это может быть инструмент для управления, запуска или тестирования локальных LLM. Сообщество выразило ожидание, полагая, что он может стать сильным конкурентом существующим инструментам, таким как Ollama. (Источник: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor:一个新的开源AI编程助手,支持MCP和本地模型: Void Editor представлен как новый开源ный ИИ-помощник для программирования, призванный стать альтернативой таким инструментам, как Cursor. Он поддерживает автодополнение по нажатию tab, режим чата, протокол контекста модели (MCP) и режим Agent. Пользователи могут подключать любой API большой языковой модели или запускать модели локально, предоставляя разработчикам гибкий опыт программирования с ИИ-поддержкой. (Источник: karminski3)
Together AI推出Which LLM工具,帮助选择合适的开源LLM: Together AI выпустила бесплатный инструмент под названием «Which LLM», предназначенный для помощи пользователям в выборе наиболее подходящей открытой большой языковой модели в зависимости от конкретного варианта использования, требований к производительности и экономических соображений. С резким ростом числа открытых LLM подобные инструменты могут предоставить разработчикам и исследователям ценную информацию при выборе модели. (Источник: vipulved)
Perplexity Finance新增股价时间轴追踪功能: Perplexity Finance объявила, что пользователи теперь могут отслеживать временную шкалу изменения цен на любые акции на ее платформе. Эта новая функция призвана предоставить пользователям более интуитивно понятный и удобный инструмент для анализа информации о финансовых рынках, который в сочетании с возможностями ИИ Perplexity может привнести новый опыт в запросы и анализ финансовой информации. (Источник: AravSrinivas)

IdeaWeaver推出首个用于系统性能调试的AI代理: IdeaWeaver выпустила, по ее утверждению, первого ИИ-агента, специально разработанного для отладки проблем с производительностью системы. Этот инструмент использует фреймворк CrewAI и способен фактически выполнять системные команды для диагностики проблем, связанных с CPU, памятью, вводом-выводом и сетью. Его особенностью является приоритетное использование локальных LLM (через OLLAMA) для защиты конфиденциальности, и только в случае недоступности локальной модели он запрашивает ключ API OpenAI. Цель состоит в применении возможностей ИИ в областях DevOps и системного администрирования. (Источник: Reddit r/artificial)
Kling AI新增Live Photo支持,可将生成视频存为动态壁纸: Kling AI объявила, что ее функция генерации видео теперь поддерживает сохранение работ в виде Live Photos (живых фото). Пользователи могут устанавливать понравившийся динамический контент, созданный Kling, в качестве обоев для мобильных телефонов, что повышает интересность и практичность видео, сгенерированных ИИ. (Источник: Kling_ai)
Cognition AI开源Blockdiff,实现VM快照速度200倍提升: Cognition AI объявила об открытии исходного кода формата файлов снимков VM Blockdiff, разработанного для Devin. Поскольку создание снимков VM на EC2 занимало слишком много времени (более 30 минут), команда самостоятельно создала гипервизор виртуальных машин otterlink и формат файлов Blockdiff, что позволило увеличить скорость создания снимков в 200 раз. Этот вклад в открытый исходный код призван помочь разработчикам более эффективно управлять средами виртуальных машин. (Источник: karinanguyen_)

📚 学习
LangChain博文探讨“上下文工程”的兴起: LangChain опубликовал статью в блоге, в которой обсуждается набирающий популярность термин «контекстная инженерия» (Context Engineering). Статья определяет его как «создание динамических систем, которые предоставляют правильную информацию и инструменты в правильном формате, чтобы LLM могли разумно выполнять задачи». Это не совершенно новая концепция, разработчики Agent уже давно ее практикуют, и такие инструменты, как LangGraph, LangSmith, были созданы для этого. Введение этого термина помогает привлечь больше внимания к соответствующим навыкам и инструментам. (Источник: hwchase17, Hacubu, yoheinakajima)
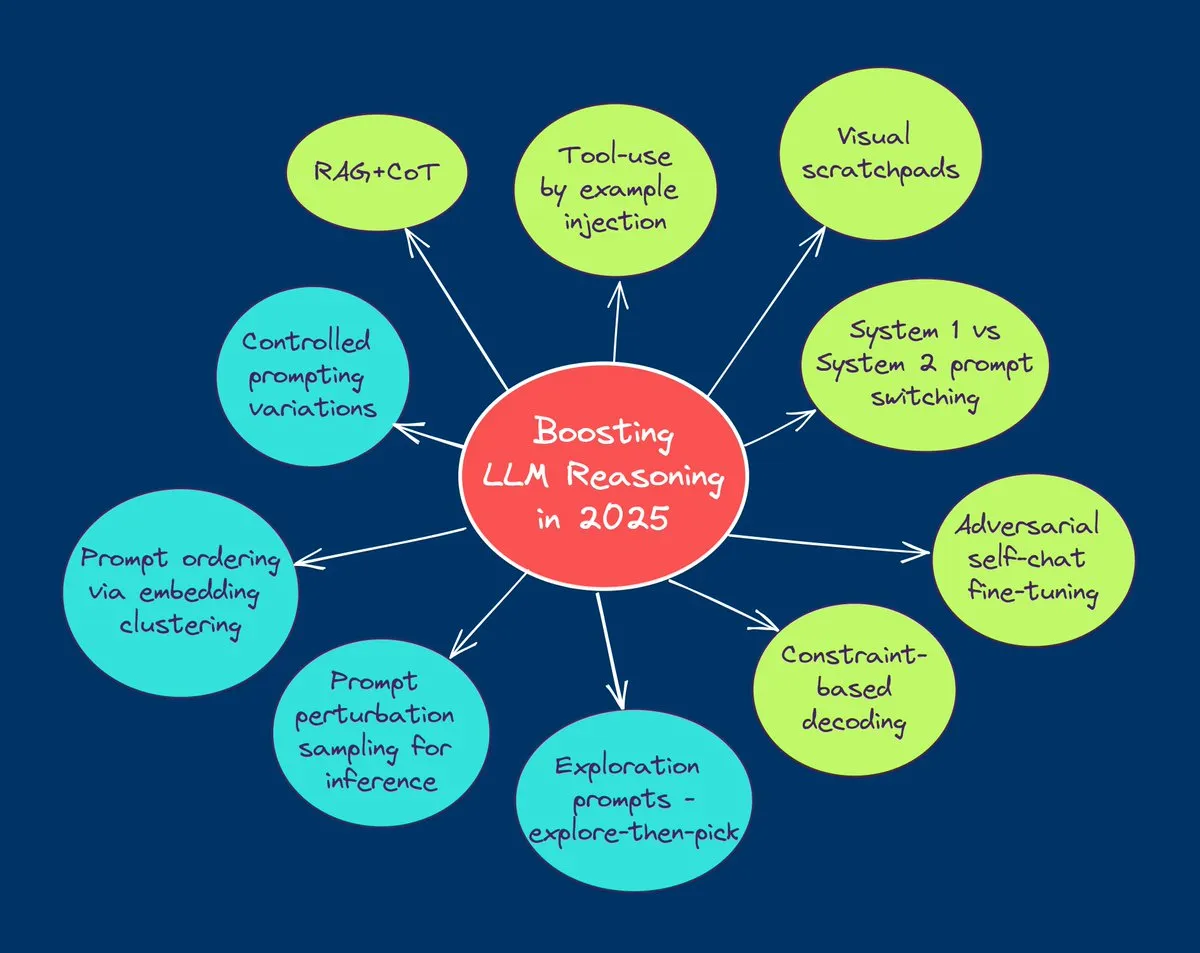
TuringPost总结2025年提升LLM推理能力的10大技术: TuringPost поделился 10 ключевыми технологиями для улучшения возможностей рассуждения больших языковых моделей (LLM) в 2025 году, включая: цепочку мыслей с расширенным поиском (RAG+CoT), использование инструментов путем инъекции примеров, визуальный черновик (поддержка мультимодального рассуждения), переключение между подсказками Системы 1 и Системы 2, состязательная самодиалоговая тонкая настройка, декодирование на основе ограничений, исследовательские подсказки (сначала исследовать, потом выбирать), выборка с возмущением подсказок для рассуждения, упорядочивание подсказок путем кластеризации эмбеддингов и контролируемые варианты подсказок. Эти технологии предоставляют разнообразные пути для оптимизации производительности LLM в сложных задачах. (Источник: TheTuringPost, TheTuringPost)
Cohere Labs举办ML暑期学校,探索机器学习未来: Открытое научное сообщество Cohere Labs проведет в июле Летнюю школу машинного обучения (ML Summer School). Мероприятие соберет членов мирового сообщества для совместного обсуждения будущего машинного обучения, а также пригласит докладчиков из отрасли для обмена опытом. В частности, Katrina Lawrence 2 июля проведет курс повторения математики для машинного обучения, охватывающий такие основные понятия, как исчисление, векторное исчисление и линейная алгебра. (Источник: sarahookr)

DeepLearning.AI与Meta合作推出“Building with Llama 4”免费课程: DeepLearning.AI в сотрудничестве с Meta запустили бесплатный курс под названием «Building with Llama 4». Содержание курса включает: практическую работу с моделями серии Llama 4, понимание их архитектуры смеси экспертов (MOE) и создание приложений с использованием официального API; применение Llama 4 для мультимодального вывода по нескольким изображениям, локализации изображений (распознавание объектов и их ограничивающих рамок), а также обработки длинных текстовых запросов до 1 миллиона токенов; использование инструментов оптимизации подсказок Llama 4 для автоматического улучшения системных подсказок и использование его набора инструментов для синтеза данных для создания высококачественных наборов данных для тонкой настройки. (Источник: DeepLearningAI)
EleutherAI YouTube频道提供大量AI研究内容: YouTube-канал EleutherAI собрал более 100 часов записей видео своих книжных клубов и серий лекций. Темы охватывают масштабируемость и производительность машинного обучения, функциональный анализ, а также подкасты и интервью с членами команды. Канал предоставляет богатые учебные ресурсы для исследователей и энтузиастов ИИ. EleutherAI также запустила новую серию лекций, первую из которых проведет @linguist_cat на тему токенизаторов и их ограничений. (Источник: BlancheMinerva, BlancheMinerva)
论文探讨通过潜在视觉Token增强多模态推理(Machine Mental Imagery): Новая статья «Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens» предлагает фреймворк Mirage, который улучшает мультимодальное рассуждение путем добавления латентных визуальных токенов (вместо генерации полных изображений) в процессе декодирования VLM, имитируя человеческое мысленное воображение. Метод сначала контролирует латентные токены путем дистилляции эмбеддингов реальных изображений, затем переключается на чисто текстовый контроль, чтобы выровнять латентную траекторию с целями задачи, и далее улучшает возможности с помощью обучения с подкреплением. Эксперименты показывают, что Mirage может достичь более сильного мультимодального рассуждения без генерации явных изображений. (Источник: HuggingFace Daily Papers)
论文提出Vision as a Dialect框架,通过文本对齐表示统一视觉理解与生成: Статья под названием «Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations» представляет фреймворк мультимодальной LLM под названием Tar. Этот фреймворк использует токенизатор с выравниванием по тексту (TA-Tok) для преобразования изображений в дискретные токены и использует кодовую книгу с выравниванием по тексту, спроецированную из словаря LLM, тем самым объединяя визуальные и текстовые данные в общее дискретное семантическое представление. Tar реализует кросс-модальный ввод-вывод через общий интерфейс без необходимости специального модального дизайна и использует масштабно-адаптивный кодек и генеративный детокенизатор для баланса эффективности и визуальных деталей. (Источник: HuggingFace Daily Papers)
论文提出ReasonFlux-PRM:用于LLM长链思维推理的轨迹感知PRM: Статья «ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs» представляет новую модель вознаграждения процесса, чувствительную к траектории (PRM), специально разработанную для оценки следов рассуждений типа траектория-ответ, генерируемых передовыми моделями рассуждений, такими как DeepSeek-R1. ReasonFlux-PRM сочетает в себе пошаговый и траекторный контроль, обеспечивая мелкозернистое распределение вознаграждений, согласованное со структурированными данными цепочки мыслей, и демонстрирует улучшение производительности в сценариях SFT, RL и расширения BoN во время тестирования. (Источник: HuggingFace Daily Papers)
论文研究大型语言模型越狱防护栏的评估方法: Статья под названием «SoK: Evaluating Jailbreak Guardrails for Large Language Models» проводит систематический обзор знаний об атаках типа «jailbreak» на большие языковые модели (LLM) и их защитных барьерах (Guardrails). В статье предлагается новая многомерная классификация, которая классифицирует защитные барьеры по шести ключевым измерениям, и вводится оценочная структура «безопасность-эффективность-практичность» для оценки их фактической эффективности. Путем широкого анализа и экспериментов в статье указываются преимущества и недостатки существующих методов защитных барьеров, обсуждается их универсальность по отношению к различным типам атак и предлагаются идеи для оптимизации комбинаций защиты. (Источник: HuggingFace Daily Papers)
AAAI 2025杰出论文探讨部分可观察马尔可夫决策过程(POMDP)的可判定类: Статья под названием «Revelations: A Decidable Class of POMDP with Omega-Regular Objectives» получила награду за выдающуюся статью AAAI 2025. В этом исследовании определен разрешимый класс MDP (марковских процессов принятия решений): проблемы принятия решений с «сильными откровениями», то есть на каждом шаге существует ненулевая вероятность раскрытия точного состояния мира. В статье также представлены результаты разрешимости для «слабых откровений», где точное состояние гарантированно будет раскрыто в конечном итоге, но не обязательно на каждом шагу. Это исследование предоставляет новую теоретическую основу для принятия оптимальных решений в условиях неполной информации. (Источник: aihub.org)
论文提出CommVQ:用于KV缓存压缩的交换向量量化: Статья «CommVQ: Commutative Vector Quantization for KV Cache Compression» предлагает метод под названием CommVQ, который сжимает KV-кэш с помощью аддитивного квантования и легковесных кодировщика и кодовой книги для уменьшения занимаемой памяти при выводе LLM с длинным контекстом. Для снижения вычислительных затрат на декодирование кодовая книга спроектирована так, чтобы быть взаимозаменяемой с ротационными позиционными эмбеддингами (RoPE), и обучается с использованием EM-алгоритма. Эксперименты показывают, что этот метод при 2-битном квантовании может уменьшить размер KV-кэша FP16 на 87.5% и превосходит существующие методы квантования KV-кэша, и даже может достичь 1-битного квантования KV-кэша с минимальной потерей точности. (Источник: HuggingFace Daily Papers)
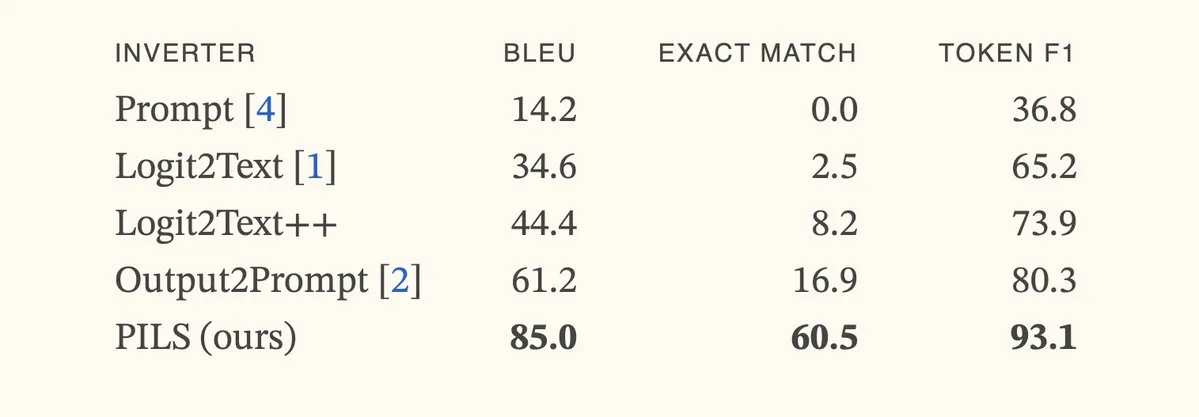
论文提出PILS方法,通过紧凑表示下一Token分布改进语言模型反演: Статья «Better Language Model Inversion by Compactly Representing Next-Token Distributions» предлагает новый метод инверсии языковой модели PILS (Prompt Inversion from Logprob Sequences). Этот метод восстанавливает скрытые подсказки, анализируя вероятности следующего токена модели на нескольких этапах генерации. Ключевым моментом является обнаружение того, что выходные векторы языковой модели занимают низкоразмерное подпространство, что позволяет без потерь сжимать распределение вероятностей следующего токена с помощью линейного отображения для более эффективной инверсии. Эксперименты показывают, что PILS значительно превосходит предыдущие SOTA методы в восстановлении скрытых подсказок. (Источник: HuggingFace Daily Papers, jxmnop)
论文提出Phantom-Data:一个通用的主体一致性视频生成数据集: Статья «Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset» представляет новый набор данных под названием Phantom-Data, предназначенный для решения распространенной проблемы «копирования-вставки» в существующих моделях генерации видео от субъекта к видео (т.е. чрезмерной запутанности идентичности субъекта с фоном и атрибутами контекста). Phantom-Data является первым универсальным набором данных для согласованной генерации видео от субъекта к видео по парам, содержащим около миллиона пар с согласованной идентичностью в различных категориях. Этот набор данных создан с помощью трехэтапного процесса, включающего обнаружение субъекта, крупномасштабный поиск субъекта в разных контекстах и проверку идентичности на основе априорных знаний. (Источник: HuggingFace Daily Papers)
论文提出LongWriter-Zero:通过强化学习掌握超长文本生成: Статья «LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning» предлагает метод, основанный на поощрении, для развития у LLM способности генерировать сверхдлинные, высококачественные тексты с нуля с использованием обучения с подкреплением (RL), без каких-либо аннотированных или синтетических данных. Этот метод начинается с базовой модели и с помощью RL направляет ее на планирование и уточнение в процессе написания, а также использует специализированную модель вознаграждения для контроля длины, качества написания и структурного формата. Эксперименты показывают, что LongWriter-Zero, обученный на Qwen2.5-32B, превосходит традиционные методы SFT в задачах написания длинных текстов и достигает SOTA уровня на нескольких бенчмарках. (Источник: HuggingFace Daily Papers)
💼 商业
法律AI公司Harvey宣布完成3亿美元E轮融资,估值达50亿美元: Юридический стартап в области ИИ Harvey объявил о завершении раунда финансирования серии E на сумму 300 миллионов долларов, возглавляемого Kleiner Perkins и Coatue, при оценке компании в 5 миллиардов долларов. Среди других инвесторов — Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson и REV. Это финансирование поможет Harvey продолжать разработку и расширение своих ИИ-приложений в юридической сфере. (Источник: saranormous)
Hyperbolic按需GPU云服务上线7天ARR达100万美元: Yuchenj_UW объявил, что его запущенный на прошлой неделе облачный сервис GPU по требованию Hyperbolic достиг годового регулярного дохода (ARR) в 1 миллион долларов за 7 дней, при этом маркетинг ограничился одним твитом. Они предоставляют разработчикам бесплатные пробные кредиты на узлы 8xH100, что свидетельствует о высоком рыночном спросе на высокопроизводительные облачные сервисы GPU. (Источник: Yuchenj_UW)
Replit宣布年度经常性收入(ARR)突破1亿美元: Онлайн-платформа интегрированной среды разработки (IDE) и облачных вычислений Replit объявила, что ее годовой регулярный доход (ARR) превысил 100 миллионов долларов, что является значительным ростом по сравнению с 10 миллионами долларов в конце 2024 года. Компания заявила, что после последнего раунда финансирования в 2023 году при оценке в 1.1 миллиарда долларов у нее все еще остается более половины средств в банке. Рост Replit обусловлен использованием ее платформы корпоративными пользователями (такими как Zillow, HubSpot) и независимыми разработчиками. В настоящее время компания активно нанимает сотрудников. (Источник: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 社区
AI编程新范式:先设计再提示,迭代优化代码生成: dotey и Баоюй обсуждают изменения в парадигме разработки программного обеспечения, вызванные ИИ. Традиционный спор «сначала проектирование, потом кодирование» против «сначала реализация, потом рефакторинг» находит свое слияние в эпоху ИИ. ИИ значительно сокращает затраты и время на переход от проектирования к кодированию, позволяя разработчикам быстро реализовывать версии, даже если проектирование еще не полностью ясно, и итеративно улучшать проектирование и подсказки на основе результатов проверки. Подсказки берут на себя роль прежних «подробных проектных документов», но в более упрощенной форме. В этой модели разработчики должны уделять больше внимания проектированию системы, генерировать код небольшими партиями, использовать управление исходным кодом, а также проверять и тестировать код, сгенерированный ИИ. Для опытных программистов изменение мышления и привычек разработки является ключом к освоению программирования с ИИ. (Источник: dotey)
Claude Code因其强大的大代码库处理能力和上下文效率受开发者青睐: Сообщество Reddit r/ClaudeAI активно обсуждает выдающуюся производительность Claude Code при работе с большими кодовыми базами. Пользователи сообщают, что он хорошо понимает кодовые базы размером значительно превышающим 200k токенов и способен вносить изменения. Обсуждается, что Claude Code, возможно, достигает эффективной обработки контекста благодаря стратегиям, подобным человеческому чтению (чтение только ключевых частей), использованию инструментов типа grep для контекстного поиска (а не полной зависимости от векторизации и сжатия RAG), а также преимуществам интеграции моделей от первого лица. Пользователи делятся множеством успешных примеров использования Claude Code для исправления системных проблем, создания трекера личных финансов, разработки Android-приложений (даже без опыта разработки под Android), создания скриптов Obsidian DataviewJS и т.д., что значительно повышает эффективность работы. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

“上下文工程”概念引关注,强调构建动态系统赋能LLM: Harrison Chase из LangChain предположил, что «контекстная инженерия» (Context Engineering) является основной работой инженеров ИИ при построении систем. Она определяется как «построение динамических систем, которые предоставляют правильную информацию и инструменты в правильном формате, чтобы LLM могли разумно выполнять задачи». Эта концепция подчеркивает важность эффективной организации и предоставления контекстной информации для производительности модели в приложениях LLM и является основой для таких областей, как создание Agent. (Источник: hwchase17, Hacubu, yoheinakajima)
Meta创始人扎克伯格亲自招募AI人才,引发社区关注: В социальных сетях появилась информация о том, что основатель Meta Марк Цукерберг лично участвует в наборе талантов для своей лаборатории сверхинтеллекта, напрямую связываясь с сотнями потенциальных кандидатов и приглашая откликнувшихся на ужин. Этот шаг интерпретируется как решимость и усилия Meta в области ИИ, особенно в отношении общего искусственного интеллекта (AGI) или сверхинтеллекта, что свидетельствует об ожесточенной борьбе ведущих технологических компаний за лучшие таланты в области ИИ. (Источник: reach_vb, andrew_n_carr)

AI发展引发对就业市场和经济结构的深刻反思: Гарвардская школа бизнеса и экономист Anton Korinek предупреждают, что AGI может быть достигнут в течение 2-5 лет, и если экономическая система не претерпит коренных изменений, это может привести к коллапсу, подчеркивая необходимость всеобщего базового дохода. В то же время, в сообществе обсуждается, что ИИ автоматизирует большое количество измеримых задач, что ударит по рабочим местам как «синих», так и «белых воротничков», и предприятиям потребуется перестроить организационные структуры для адаптации к ИИ. Yuval Noah Harari сравнивает революцию ИИ с «иммиграционной волной ИИ», вызывая дискуссии о замене рабочих мест ИИ и стремлении к власти. Эти точки зрения указывают на разрушительное влияние ИИ на будущую социально-экономическую структуру. (Источник: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

AI在编程竞赛中表现突出,Sakana AI智能体成绩优异引热议: Агент Sakana AI занял 21-е место среди более чем 1000 программистов-людей на эвристическом конкурсе программирования AtCoder, показав общий результат в топ-6.8%. ИИ за 4 часа выполнил около 100 итераций, сгенерировав тысячи потенциальных решений, в то время как участники-люди обычно успевают протестировать около 12. ИИ использовал Gemini 2.5 Pro и сочетал экспертные знания с системными алгоритмами поиска (такими как имитация отжига и лучевой поиск) для решения реальных задач оптимизации. Реакция сообщества на это была неоднозначной: некоторые считают, что соревновательное программирование отличается от корпоративной инженерии, и победа ИИ больше похожа на победу компьютера над человеком в сложении и вычитании. (Источник: Reddit r/ArtificialInteligence)
💡 其他
AI在职业教育领域的探索:面试、老师与学习机的多元尝试: Гиганты профессионального образования, такие как Huatu, Fenbi, Zhonggong, активно исследуют применение ИИ в различных направлениях. Huatu фокусируется на оценке ИИ-собеседований, Fenbi углубляется в ИИ-проверку и ИИ-учителей (объем продаж системы ИИ-тренировок уже превысил 14 миллионов юаней), а Zhonggong выпускает ИИ-учебные устройства для трудоустройства. Отраслевой консенсус заключается в том, что ИИ должен повышать эффективность обучения и операционную эффективность, а не просто стремиться к высокой наценке. Применение ИИ также переходит от проверки концепции к углубленному освоению сценариев, например, 51CTO использует цифровых людей, 3D-моделирование для создания курсов, а также ИИ для генерации тестовых заданий и анализа траекторий обучения. Однако большинство образовательных компаний пока не обладают возможностями для создания собственных больших моделей и предпочитают использовать сторонние API. (Источник: 36氪)
迪士尼、环球影业起诉AI生图独角兽Midjourney侵权: Голливудские гиганты Disney и Universal Pictures совместно подали в суд на компанию по генерации изображений с помощью ИИ Midjourney, обвиняя ее в несанкционированном использовании большого количества защищенного авторским правом IP-контента (такого как Железный человек, Миньоны и др.) для обучения ИИ-моделей и генерации очень похожих изображений. Истцы требуют запрета на нарушение авторских прав и компенсации до 150 000 долларов за каждое умышленное нарушение. Это дело подчеркивает проблемы с авторскими правами, с которыми сталкивается генеративный ИИ. Основатель Midjourney ранее признавал использование данных без разрешения. Иск, возможно, направлен на продвижение создания механизмов лицензирования авторских прав и систем фильтрации контента. (Источник: 36氪)

苹果被指AI落后,或考虑收购弥补短板,前OpenAI CTO公司受关注: Сообщается, что Apple отстает в области ИИ, ее собственные возможности в области ИИ недостаточны, а Siri работает неэффективно. Чтобы сократить разрыв, Apple, возможно, рассматривает возможность крупного приобретения. По слухам, компания вела предварительные переговоры с бывшим CTO OpenAI Mira Murati относительно ее новой компании Thinking Machines Lab. Исторически Apple неоднократно приобретала небольшие технологические компании для усиления собственных возможностей (например, саму Siri). В настоящее время Apple значительно отстает от отраслевых гигантов по масштабу параметров ИИ-моделей, и приобретение таких компаний, как Mistral, могло бы помочь ей добиться прорыва в разработке собственных больших моделей. (Источник: 36氪)