
Ключевые слова:большая языковая модель, оценка ИИ, мультиагентная система, способность к рассуждению, обработка контекста, открытая модель, генерация видео с помощью ИИ, программирование с ИИ, оценка способности к рассуждению LLM, опровержение статьи Apple Claude Opus 4, модель MiniMax-M1 MoE, программная модель Kimi-Dev-72B, функция Gemini Deep Think
🔥 В фокусе
Статья Apple, ставящая под сомнение способности LLM к рассуждению, опровергнута; в статье, написанной в соавторстве с Claude, указывается на недостатки в дизайне эксперимента: Недавно компания Apple опубликовала статью «Иллюзия мышления», в которой с помощью тестов на классических задачах, таких как Ханойская башня и мир кубиков, указывается, что основные большие языковые модели (LLM) плохо справляются со сложными задачами на рассуждение, по сути являясь сопоставлением с образцом, а не истинным пониманием. Однако независимый исследователь Alex Lawsen совместно с AI-моделью Claude Opus 4 опубликовал статью «Иллюзия самой „иллюзии мышления“» в качестве опровержения, утверждая, что эксперимент Apple имел недостатки в дизайне: 1. Не учтен верхний предел вывода токенов LLM, из-за чего модель оценивалась как неверная, поскольку не могла полностью вывести сверхдлинные последовательности шагов; 2. Некоторые тестовые случаи (например, определенные «задачи о переправе») математически неразрешимы при заданных условиях, и неспособность AI дать «правильный ответ» не является недостатком его возможностей; 3. При изменении метода оценки, например, при требовании от модели вывода программы для решения задачи, а не полных шагов, AI демонстрирует отличные результаты. Этот случай вызвал широкие дискуссии о реальных способностях LLM к рассуждению и методологии их оценки, подчеркнул важность разработки обоснованных схем оценки и напомнил разработчикам о необходимости учитывать влияние таких факторов, как контекстное окно, бюджет вывода и формулировка задачи, на производительность модели в практических приложениях. (Источник: 新智元, 大数据文摘)
Обнародована дорожная карта Google по AI, намекающая на возможный отказ от существующих механизмов внимания в архитектуре AI следующего поколения: Руководитель по продуктам Google Logan Kilpatrick на Всемирной выставке AI-инженеров рассказал о будущем направлении развития модели Gemini, где наиболее примечательным стало видение достижения «бесконечного контекста». Он отметил, что с текущими механизмами внимания и способами обработки контекста невозможно реализовать истинно бесконечный контекст, намекая на то, что Google, возможно, исследует совершенно новую базовую архитектуру AI. Дорожная карта также включает: полные мультимодальные возможности (уже поддерживаются изображения + аудио, видео — следующий этап), ранние эксперименты с Diffusion, встроенные по умолчанию возможности Agent (первоклассный вызов и использование инструментов, постепенная эволюция модели в интеллектуального агента), постоянное расширение возможностей рассуждения и выпуск большего количества малых моделей. Эта серия планов показывает, что Google активно продвигает AI от пассивного реагирования к активной эволюции интеллектуальных агентов и стремится преодолеть существующие технологические узкие места, особенно в обработке контекста, что может привести к значительным изменениям в архитектуре AI. (Источник: 新智元)
Sakana AI выпустила ALE-Agent, который превзошел 98% людей-участников в соревновании по программированию NP-трудных задач: Sakana AI, сооснованная одним из авторов Transformer Llion Jones, в сотрудничестве с японской платформой для соревнований по программированию AtCoder, запустила ALE-Bench (Algorithm Engineering Benchmark). Этот бенчмарк сфокусирован на оценке способностей AI к долгосрочным рассуждениям и творческому программированию в NP-трудных задачах (таких как планирование маршрутов, диспетчеризация задач). Разработанный ими ALE-Agent, основанный на Gemini 2.5 Pro и сочетающий подсказки на основе знаний в предметной области со стратегиями поиска в разнообразном пространстве решений, показал выдающиеся результаты в эвристическом соревновании AtCoder, заняв 21-е место (топ-2%), превзойдя множество ведущих разработчиков-людей. Это знаменует важный прогресс AI в решении сложных оптимизационных задач и имеет большое значение для практических применений, таких как логистика и планирование производства. Несмотря на то, что ALE-Agent отлично справляется с такими алгоритмами, как имитация отжига, все еще есть возможности для улучшения в отладке, анализе сложности и избегании ошибок оптимизации. (Источник: 新智元, SakanaAILabs, hardmaru)
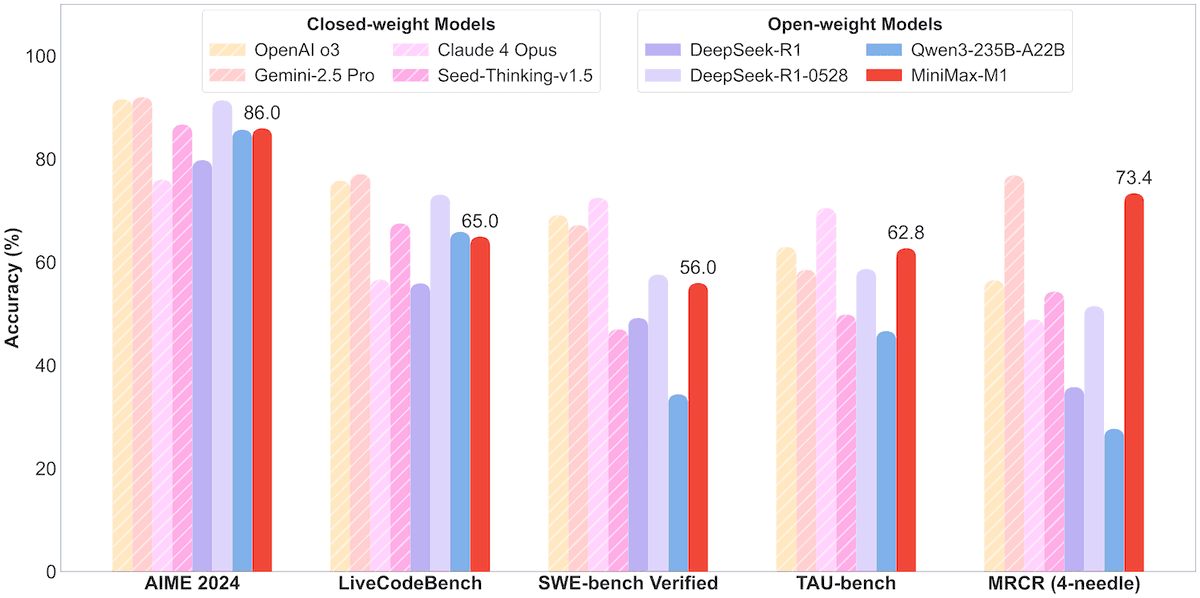
MiniMax открыла исходный код модели MoE MiniMax-M1 с 456B параметрами, поддержкой контекста в миллион токенов и выводом 80 тысяч токенов: Компания MiniMax выпустила свою первую крупномасштабную модель логического вывода с открытым исходным кодом типа Mixture-of-Experts (MoE) — MiniMax-M1. Модель имеет 45.6 миллиардов параметров, при этом каждый токен активирует 4.59 миллиарда параметров, и использует архитектуру, сочетающую MoE с механизмом Lightning Attention. M1 изначально поддерживает длину контекста в 1 миллион токенов и может выводить до 80 тысяч токенов, что является лучшим показателем в отрасли, включая версии с бюджетом мышления в 40k и 80k. В бенчмарках по программной инженерии, использованию инструментов и задачам с длинным контекстом M1 превосходит такие модели, как DeepSeek-R1 и Qwen3-235B, особенно в использовании инструментов Agent (например, TAU-bench). Этап обучения с подкреплением занял всего три недели на 512 блоках H800, а стоимость составила около 537,400 долларов США. Модель M1 уже доступна бесплатно в приложении MiniMax APP и на веб-сайте, а также предоставляется через API. (Источник: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Тренды
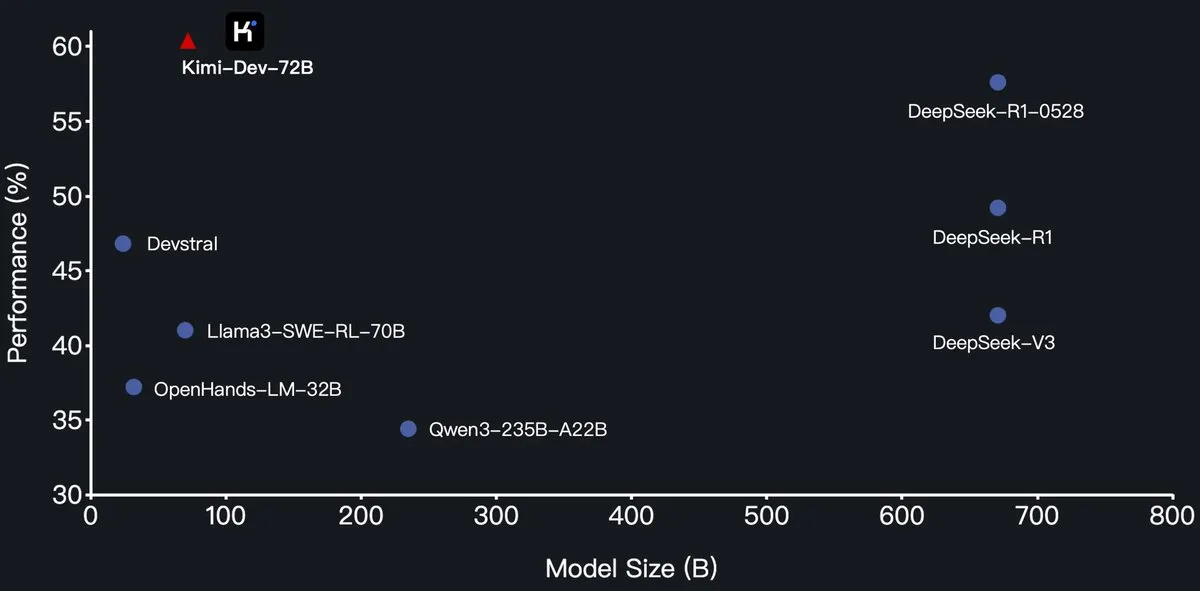
Moonshot AI (月之暗面) открыла исходный код большой модели для программирования Kimi-Dev-72B, которая превзошла DeepSeek-R1 на SWE-Bench: Moonshot AI (月之暗面) выпустила свою новую большую языковую модель для программирования с открытым исходным кодом Kimi-Dev-72B, доработанную на основе Qwen2.5-72B. Сообщается, что Kimi-Dev-72B достигла показателя решения задач в 60.4% на бенчмарке SWE-bench Verified, превзойдя такие модели, как DeepSeek-R1-0528 (57.6%) и Qwen3-235B-A22B, став одной из лучших среди моделей с открытым исходным кодом. Модель прошла обучение с подкреплением, сфокусированное на исправлении реальных репозиториев кода в среде Docker, и получала вознаграждение только при успешном прохождении полного набора тестов. Руководитель разработки Qwen заявил, что авторизация не предоставлялась, однако использование Kimi лицензии MIT для выпуска доработанной версии соответствует правилам. (Источник: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Модели серии Qwen3 теперь поддерживают формат MLX, оптимизируя логический вывод на чипах Apple: Команда Alibaba Tongyi Qianwen объявила, что модели серии Qwen3 теперь поддерживают формат MLX и предлагают четыре уровня квантования: 4bit, 6bit, 8bit и BF16. Этот шаг направлен на оптимизацию эффективности работы моделей на фреймворке Apple MLX, облегчая разработчикам локальное развертывание и логический вывод на устройствах Mac. Пользователи могут получить соответствующие модели на HuggingFace и ModelScope. (Источник: ClementDelangue, stablequan, jeremyphoward)

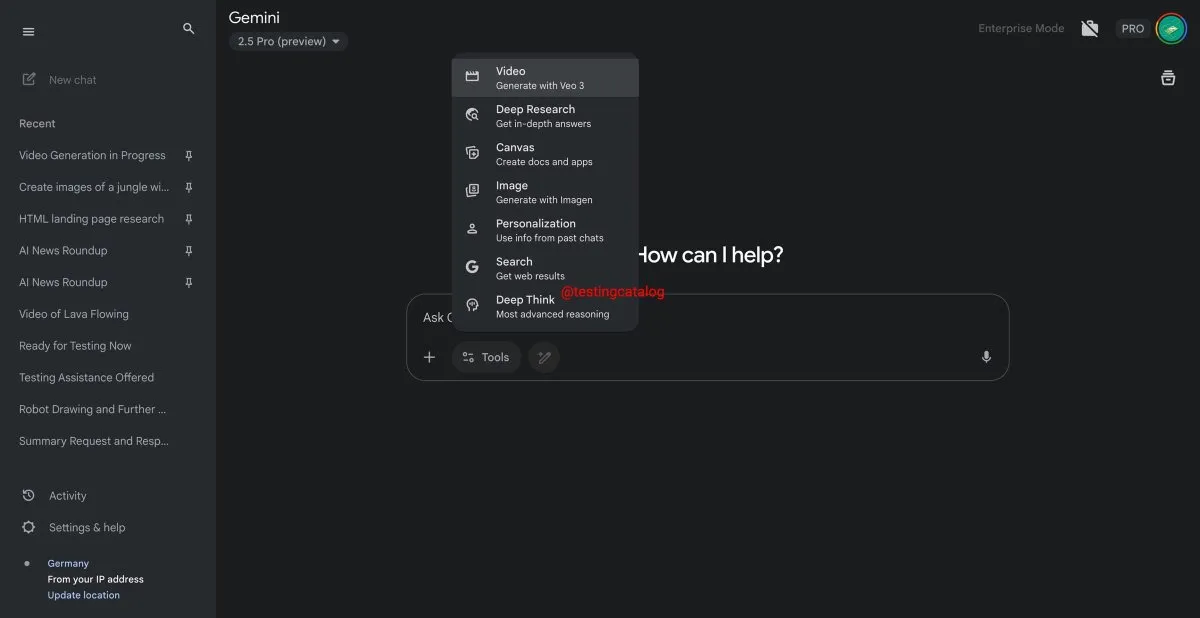
Google Gemini скоро запустит функцию «Deep Think» для улучшения обработки сложных задач: Google готовится представить новую функцию под названием «Deep Think» для своей модели Gemini 2.5 Pro. Эта функция предназначена для обработки более сложных задач за счет предоставления дополнительных вычислительных мощностей. Ожидается, что производительность Deep Think в задачах, связанных с математикой, будет на 15% выше по сравнению с обычной версией Gemini 2.5 Pro. Функция появится в виде новой опции на панели инструментов, а процесс обработки может занять несколько минут. Одновременно обновится и пользовательский интерфейс Gemini. (Источник: op7418)
Модель генерации видео Google Veo 3 официально запущена и доступна на более чем 70 рынках: Google объявила, что ее AI-модель для генерации видео Veo 3 официально стала доступна подписчикам AI Pro и Ultra на более чем 70 рынках по всему миру. Veo 3 привлекла внимание благодаря реалистичности и креативности генерируемых видео. Ранее пользователи уже создавали с ее помощью контент ASMR, такой как «вирусная нарезка фруктов», который набрал десятки миллионов просмотров в социальных сетях, демонстрируя потенциал модели в области создания контента. Официальный запуск позволит большему числу пользователей опробовать и использовать Veo 3 для создания видео. (Источник: Google, 新智元)
Hugging Face и Groq сотрудничают для предоставления высокоскоростных услуг логического вывода LLM: Hugging Face объявила о сотрудничестве с компанией по производству AI-чипов Groq с целью интеграции LPU™ (Language Processing Unit) от Groq в Hugging Face Playground и API. Теперь пользователи могут напрямую на платформе Hugging Face опробовать услуги логического вывода LLM, ускоренные аппаратным обеспечением Groq, с поддержкой различных моделей, включая Llama 4 и Qwen 3. Этот шаг направлен на предоставление разработчикам более быстрых и эффективных опций для логического вывода AI-моделей, особенно подходящих для создания агентов, ассистентов и AI-приложений в реальном времени. (Источник: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub добавил функцию фильтрации моделей по размеру, помогая разработчикам выбирать подходящие модели: Платформа Hugging Face представила новую функцию, позволяющую пользователям фильтровать модели по размеру (Size Range), особенно для моделей, работающих на фреймворке mlx / mlx-lm. Это улучшение призвано помочь разработчикам легче находить модели, соответствующие их конкретным аппаратным и производительным требованиям, подчеркивая, что не всегда чем больше модель, тем лучше – малые специализированные модели часто оказываются оптимальнее в определенных сценариях. (Источник: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

Обновление NVIDIA NCCL: операции редукции для входов половинной точности теперь используют накопление в FP32: Последняя версия NVIDIA Collective Communications Library (NCCL) (коммит 72d2432) вносит важное обновление: при обработке операций редукции (reduction ops) для входов половинной точности (таких как FP16, BF16) теперь используется накопление в FP32. Это изменение критически важно для поддержания точности вычислений и предотвращения переполнения, особенно в крупномасштабном распределенном обучении. Ожидается, что эта версия будет интегрирована в PyTorch 2.8 и более поздние версии. (Источник: StasBekman)

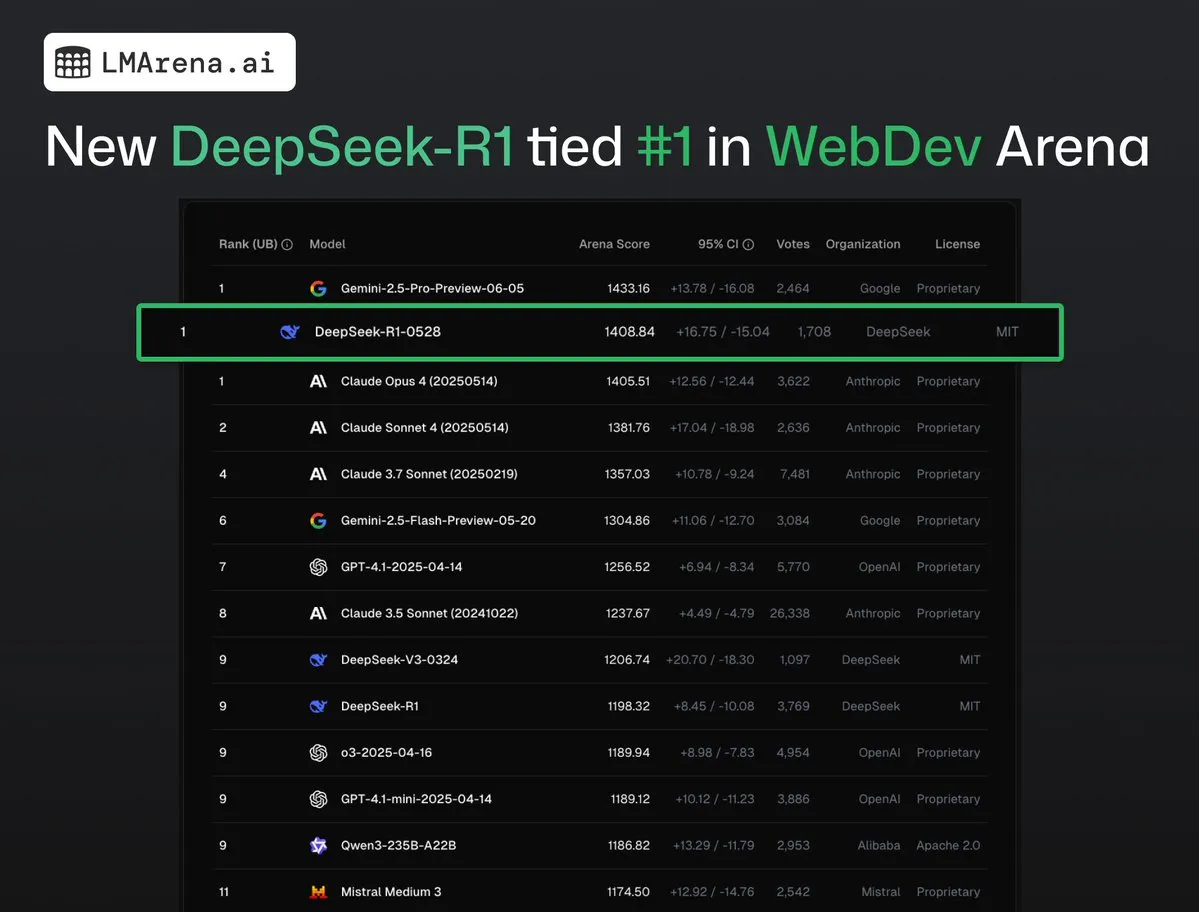
DeepSeek-R1 (0528) делит первое место с Claude Opus 4 на WebDev Arena: Последние данные с lmarena.ai показывают, что новая версия DeepSeek-R1 (0528) отлично проявила себя на бенчмарке WebDev Arena, разделив первое место с Claude Opus 4. Эта модель занимает шестое место в общем рейтинге Text Arena, второе место по способностям к программированию, четвертое по сложным подсказкам, пятое по математическим способностям и является лучшей моделью с открытым исходным кодом под лицензией MIT в рейтинге. Это свидетельствует о высокой конкурентоспособности DeepSeek в конкретных задачах разработки и логического вывода. (Источник: ClementDelangue, zizhpan)
ByteDance запускает на платформе Poe модели для изображений Seedream 3.0 и видео Seedance 1.0 Lite: Инструменты для AI-творчества от ByteDance получили обновление на зарубежной платформе Poe: запущены модель генерации изображений Seedream 3.0 от 即梦AI и модель генерации видео Seedance 1.0 Lite. Seedream 3.0 предназначена для создания четких и ярких изображений, а Seedance 1.0 Lite позволяет быстро генерировать видео с реалистичными динамическими эффектами. Пользователи могут сначала сгенерировать изображение в Seedream, а затем, упомянув Seedance через @-mention, преобразовать его в видео, реализуя непрерывный творческий процесс от изображения к видео. (Источник: op7418)

Tencent представила модель для пения Levo, поддерживающую разделение дорожек и клонирование тембра голоса zero-shot: Tencent выпустила AI-модель для пения под названием Levo, производительность которой, по утверждениям, сопоставима с Suno V3.5. Levo поддерживает функции разделения аудиодорожек и клонирования тембра голоса zero-shot. Судя по опубликованным демонстрациям и оценкам, модель показывает отличные результаты. Этот прогресс демонстрирует实力 Tencent в области генерации AI-музыки. (Источник: karminski3)
OpenAI запускает функцию генерации изображений ChatGPT в WhatsApp: OpenAI объявила, что пользователи теперь могут использовать функцию генерации изображений ChatGPT через сервис 1-800-ChatGPT в WhatsApp. Это обновление позволяет более широкому кругу пользователей удобно генерировать AI-изображения непосредственно в приложении для обмена мгновенными сообщениями. (Источник: gdb, eliza_luth, iScienceLuvr)
SpatialLM обновлен до версии 1.1, улучшены возможности понимания и реконструкции 3D-сцен: Модель пространственного вывода SpatialLM выпущена в версии 1.1. Новая версия поддерживает несколько режимов источников ввода, включая генерацию 3D-сцен из текста (Text-to-3D), реконструкцию видео с ручной камеры, данные облаков точек LiDAR (например, с iPhone Pro LiDAR) и сэмплирование синтетических сеток. Ключевые особенности включают надежную обработку неструктурированных облаков точек, позволяющую выполнять разумную реконструкцию даже при неполных данных 3D-сканирования. Кроме того, в новой версии оптимизировано обнаружение zero-shot для потокового видеовхода, улучшена точность оценки планировки помещений и повышен эффект обнаружения 3D-объектов. Сферы применения широки и охватывают реконструкцию AR-сцен, пространственное понимание роботами, рабочие процессы 3D-дизайна и приложения для потребительских камер. (Источник: karminski3)
GitHub Copilot запускает тарифный план за 39 долларов в месяц, интегрируя Claude Opus 4 и другие большие модели: GitHub Copilot добавил новый тарифный план подписки за 39 долларов в месяц. Этот план не только предоставляет функции помощника по кодированию, но и дает пользователям доступ к множеству мощных языковых моделей, включая Claude Opus 4, o3 и GPT-4.5, а также возможность использовать Coding agent. Эта инициатива направлена на предоставление разработчикам более комплексного опыта программирования с помощью AI. (Источник: dotey)
Стоимость вызова больших AI-моделей продолжает снижаться, цена серии Doubao 1.6 снижена еще на 63%: Volcano Engine на конференции Force 原动力大会 представила серию больших моделей Doubao 1.6 и объявила о снижении их совокупной стоимости на 63%. Для наиболее часто используемого предприятиями диапазона длины ввода 0-32K цена составляет 0.8 юаня за миллион токенов ввода и 8 юаней за вывод. Это знаменует продолжение ценовой войны на рынке больших моделей после того, как в марте этого года Alibaba Qianwen снизила стоимость до 1/10 от DeepSeek R1. Низкая стоимость будет способствовать дальнейшему внедрению и популяризации приложений, таких как AI Agent. (Источник: 字节必须再赢一次)
Инструмент ускорения генерации видео Chipmunk обновлен, поддерживает многопроцессорные GPU-архитектуры и больше моделей с открытым исходным кодом: Инструмент Chipmunk от команды Dan Fu получил обновление и теперь поддерживает ускорение генерации видео без потерь в 1.4-3 раза на различных архитектурах GPU NVIDIA (sm_80, sm_89, sm_90, таких как A100s, 4090s, H100s). Одновременно Chipmunk добавил поддержку большего количества моделей видео с открытым исходным кодом, таких как Mochi, Wan, и предоставил учебные пособия по интеграции. Инструмент использует разреженность активаций в видеомоделях (только 5-25% активаций вносят более 90% вклада в вывод) для достижения ускорения без необходимости переобучения модели. (Источник: realDanFu)

🧰 Инструменты
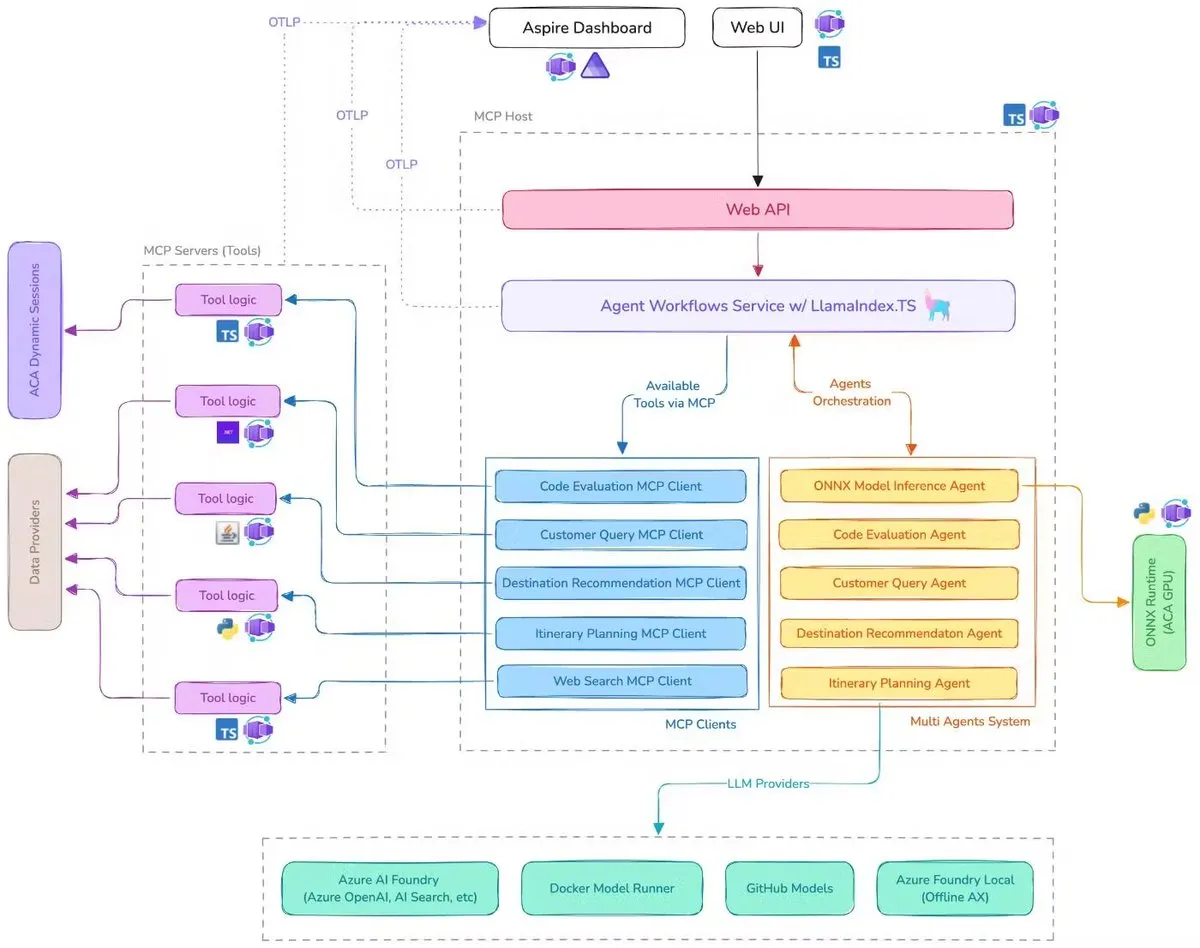
Microsoft представила демо-версию AI-помощника для путешествий, интегрирующую MCP, LlamaIndex.TS и Azure AI Foundry: Microsoft продемонстрировала демо-версию AI-помощника для путешествий. Эта система координирует работу нескольких AI-агентов (включая шесть специализированных агентов для классификации запросов, рекомендаций по направлениям, планирования маршрутов и т.д.) для выполнения сложных задач по планированию путешествий с помощью протокола контекста модели (MCP), LlamaIndex.TS и Azure AI Foundry. Каждый агент получает данные в реальном времени и инструменты через MCP-серверы, написанные на Java, .NET, Python и TypeScript. Приложение демонстрирует, как многоагентные системы корпоративного уровня могут совместно работать через многоязычные микросервисы, используя возможности AI от Azure OpenAI и моделей GitHub, и могут быть развернуты как масштабируемые бессерверные приложения с помощью Azure Container Apps. (Источник: jerryjliu0, jerryjliu0)
LlamaParse добавил предустановленные режимы, позволяющие анализировать сложные диаграммы в Mermaid или Markdown: Инструмент LlamaParse от LlamaIndex недавно обновился, добавив «предустановленные режимы» (preset-modes), которые позволяют ему анализировать сложные диаграммы в документах, таких как исследовательские отчеты (например, диаграммы с несколькими кривыми и аннотациями), и преобразовывать их в форматированные диаграммы Mermaid или таблицы Markdown. Эта функция помогает извлекать полный контекст со страницы, а сгенерированный структурированный текст можно использовать для построения RAG-процессов или дальнейшего извлечения метаданных. (Источник: jerryjliu0)
Prompt Optimizer: инструмент оптимизации для помощи в написании высококачественных подсказок: Prompt Optimizer — это инструмент, предназначенный для помощи пользователям в написании более качественных AI-подсказок, тем самым улучшая качество вывода AI. Он доступен в виде веб-приложения и расширения для Chrome, предлагая интеллектуальную оптимизацию, многоэтапное итеративное улучшение, сравнение исходных и оптимизированных подсказок, интеграцию с несколькими моделями (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow и др.), расширенные настройки параметров, локальное зашифрованное хранилище и другие функции. Инструмент обрабатывает данные исключительно на стороне клиента, обеспечивая безопасность и конфиденциальность данных. (Источник: GitHub Trending)

Выпущена LLaMA Factory v0.9.3, поддерживающая тонкую настройку без кода почти 300 моделей, включая Qwen3, Llama 4: Выпущена версия LLaMA Factory v0.9.3. Это полностью открытая платформа для тонкой настройки без кода с пользовательским интерфейсом Gradio, подходящая для почти 300 моделей, включая последние Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni и другие. Пользователи могут установить ее локально через Docker-образ или опробовать на Hugging Face Spaces, Google Colab, а также в облаке GPU от Novita. (Источник: _akhaliq)
Nanonets OCR: открыта SOTA OCR-модель на базе Qwen 2.5 VL 3B: Nanonets выпустила новую OCR-модель с 3B параметрами — Nanonets OCR. Эта модель основана на базовой сети Qwen 2.5 VL 3B, превосходит по производительности Mistral OCR API и распространяется под лицензией Apache 2.0 с открытым исходным кодом. Она способна обрабатывать множество OCR-задач, таких как распознавание LaTeX, обнаружение водяных знаков и подписей, извлечение сложных таблиц. (Источник: huggingface)
Утверждается, что Perplexity Labs может заменить несколько профессиональных должностей, что вызвало дискуссию о возможностях AI-инструментов: Пользователь GREG ISENBERG заявил, что использовал Perplexity Labs для замены работы продавца, копирайтера, кинорежиссера, менеджера социальных сетей и финансового аналитика — пяти должностей, считая возможности AI-инструментов «действительно безумными». CEO Perplexity Arav Srinivas ретвитнул это и прокомментировал, что это одно из лучших видео, демонстрирующих применение AI-агентов в реальных жизненных сценариях, сравнивая Perplexity Labs с другими инструментами на рынке в области финансового анализа, маркетинга в социальных сетях, креативного руководства и продаж. Это подчеркивает потенциал AI Agent в интеграции и выполнении многопрофильных профессиональных задач. (Источник: AravSrinivas, AravSrinivas)
Claude-Flow выпустил крупное обновление v1.0.50, активирующее «режим роя» для повышения эффективности автоматизации кода: Claude-Flow, система параллельных пакетных агентов на основе Claude Code, выпустила версию v1.0.50. Новая версия вводит «режим роя» (Swarm Mode), позволяющий пользователям одновременно генерировать, управлять и координировать работу сотен агентов Claude параллельно для создания, тестирования, развертывания или многоэтапных исследовательских циклов. Утверждается, что производительность повысилась в 20 раз по сравнению с традиционной последовательной автоматизацией Claude Code. Разработчики могут инициализировать его с помощью команды npx claude-flow@latest init --sparc --force. (Источник: Reddit r/ClaudeAI)

📚 Обучение
Awesome Machine Learning: всеобъемлющий список ресурсов по машинному обучению: Проект «awesome-machine-learning» на GitHub представляет собой тщательно подобранный список фреймворков, библиотек и программного обеспечения для машинного обучения, классифицированный по языкам программирования. Он также содержит ссылки на бесплатные книги по машинному обучению, профессиональные мероприятия, онлайн-курсы, блоги, новостные рассылки и местные встречи, предоставляя ценную навигацию для изучающих и практикующих машинное обучение. (Источник: GitHub Trending)
Anthropic и Cognition AI опубликовали статьи о создании многоагентных систем, LangChain подвел итоги: Anthropic и Cognition AI недавно опубликовали статьи о создании (или не создании) многоагентных систем. Anthropic поделилась своим опытом построения исследовательской многоагентной системы, в то время как Cognition AI высказала точку зрения «не создавайте многоагентные системы». Harrison Chase из LangChain подвел итоги, отметив, что, несмотря на кажущиеся различными взгляды, обе статьи имеют много общего в руководящих принципах и рекомендациях, и связал это с усилиями LangChain в области многоагентных систем. (Источник: hwchase17, Hacubu)
Статья «Recent Advances in Speech Language Models: A Survey» принята на основную конференцию ACL 2025: Обзорная статья о речевых языковых моделях (SpeechLM) «Recent Advances in Speech Language Models: A Survey», написанная командой из Китайского университета Гонконга, принята на основную конференцию ACL 2025. Эта статья является первым всесторонним и систематическим обзором в данной области, глубоко анализирующим техническую архитектуру SpeechLM (речевые токенизаторы, языковые модели, вокодеры), стратегии обучения (предварительное обучение, тонкая настройка по инструкциям, последующее выравнивание), парадигмы взаимодействия (полнодуплексное моделирование), сценарии применения (семантика, диктор, паралингвистика) и системы оценки. В статье подчеркивается потенциал SpeechLM в достижении естественного человеко-машинного речевого взаимодействия, а также указываются существующие проблемы и будущие направления. (Источник: 36氪)

Новое исследование повышает способность малых моделей к междоменному рассуждению с помощью обучения на визуальных играх (ViGaL), 7B модель превосходит GPT-4o в математике: Исследовательская группа из Университета Райса, Университета Джонса Хопкинса и Nvidia предложила новую парадигму пост-обучения под названием ViGaL (Visual Game Learning). Позволив мультимодальной модели с 7B параметрами (Qwen2.5-VL-7B) играть в простые аркадные игры, такие как «Змейка» и 3D-вращение, модель не только улучшила игровые навыки, но и продемонстрировала значительное улучшение междоменных способностей в сложных задачах на рассуждение, таких как математика (MathVista) и междисциплинарные вопросы-ответы (MMMU), в некоторых аспектах даже превзойдя топовые модели, такие как GPT-4o. Исследование показывает, что игровое обучение может развивать у моделей общие когнитивные способности, такие как пространственное понимание и последовательное планирование, причем разные игры могут усиливать разные аспекты навыков рассуждения. Этот метод повышает способности к рассуждению, сохраняя при этом общие визуальные возможности модели. (Источник: 新智元)

Shanghai AI Lab и другие предложили фреймворк MathFusion для улучшения способности LLM решать математические задачи путем слияния инструкций: Шанхайская лаборатория искусственного интеллекта, Институт искусственного интеллекта Гаолин Китайского народного университета и другие учреждения совместно предложили фреймворк MathFusion, направленный на улучшение способности больших языковых моделей (LLM) решать математические задачи путем слияния различных структур генерации математических задач для создания более разнообразных и логически сложных синтетических инструкций. Этот фреймворк включает три стратегии слияния: последовательное, параллельное и условное, которые могут эффективно улавливать глубинные связи между задачами. Эксперименты показали, что после тонкой настройки моделей DeepSeekMath-7B, Llama3-8B, Mistral-7B и других с использованием всего 45K синтетических инструкций, MathFusion повысил среднюю точность на нескольких математических бенчмарках на 18.0 процентных пунктов, продемонстрировав высокую эффективность данных и производительность. (Источник: 量子位)

Shanghai AI Lab и другие предложили фреймворк GRA, где малые модели совместно генерируют высококачественные данные, достигая производительности, сравнимой с 72B моделями: Шанхайская лаборатория искусственного интеллекта совместно с Китайским народным университетом предложила фреймворк GRA (Generator–Reviewer–Adjudicator), который, имитируя механизм подачи статей и рецензирования, позволяет нескольким малым языковым моделям (7-8B параметров) совместно генерировать высококачественные обучающие данные. В этом фреймворке Generator отвечает за генерацию, Reviewer проводит многоэтапное рецензирование и оценку, а Adjudicator выносит окончательное решение в случае конфликта рецензий. Эксперименты показали, что обучение базовых моделей, таких как LLaMA-3.1-8B и Qwen-2.5-7B, на данных, сгенерированных с помощью GRA, по производительности на 10 основных наборах данных (математика, код, логические рассуждения и др.) сравнялось или превзошло данные, сгенерированные путем дистилляции с использованием больших моделей, таких как Qwen-2.5-72B-Instruct. Это открывает новые перспективы для низкозатратного и высокоэффективного синтеза данных. (Источник: 量子位)

Статья рассматривает текущее состояние и будущее интерпретируемости больших моделей, подчеркивая ее важность для безопасного развертывания AI: Исследовательский институт Tencent опубликовал статью, в которой подробно рассматриваются текущее состояние, технологические пути и будущие проблемы интерпретируемости больших языковых моделей (LLM). В статье отмечается, что понимание внутренних механизмов LLM имеет решающее значение для предотвращения отклонений от ценностей, отладки и улучшения моделей, предотвращения злоупотреблений и продвижения приложений в сценариях с высоким риском. Текущие технологические пути включают автоматизированную интерпретацию (большие модели интерпретируют малые модели), визуализацию признаков (например, разреженные автоэнкодеры), мониторинг цепочек рассуждений и механистическую интерпретируемость (например, «AI-микроскоп» от Anthropic и Tracr от DeepMind). Однако многозначность нейронов, универсальность закономерностей интерпретации и ограничения человеческого познания остаются основными проблемами. Статья призывает к увеличению инвестиций в исследования интерпретируемости и предлагает на данном этапе принять мягкие правила, поощряющие саморегулирование отрасли, чтобы обеспечить безопасное, прозрачное и ориентированное на человека развитие AI-технологий. (Источник: 腾讯研究院)

Новая статья рассматривает применение и прогресс дискретных диффузионных моделей в больших языковых и мультимодальных моделях: Статья под названием «Discrete Diffusion in Large Language and Multimodal Models: A Survey» систематически обобщает исследовательский прогресс в области дискретных диффузионных языковых моделей (dLLMs) и дискретных диффузионных мультимодальных языковых моделей (dMLLMs). Эти модели используют параллельное декодирование нескольких токенов и стратегии генерации на основе шумоподавления, обеспечивая параллельную генерацию, мелкозернистую управляемость вывода, а также динамические и чувствительные к отклику возможности восприятия, при этом скорость вывода может быть до 10 раз выше по сравнению с авторегрессионными моделями. В статье прослеживается история их развития, формализуется математический аппарат, классифицируются репрезентативные модели, анализируются ключевые технологии обучения и вывода, обобщаются применения в языковой, визуально-языковой и биологической областях, и, наконец, обсуждаются будущие направления исследований и проблемы развертывания. (Источник: HuggingFace Daily Papers)
Новое исследование предлагает Test3R: повышение геометрической точности 3D-реконструкции за счет обучения во время тестирования: Новая технология под названием Test3R значительно повышает геометрическую точность 3D-реконструкции за счет обучения во время тестирования. Метод использует триплеты изображений (I_1,I_2,I_3) и генерирует результаты реконструкции из пар изображений (I_1,I_2) и (I_1,I_3). Основная идея заключается в оптимизации сети во время тестирования с помощью самоконтролируемой цели: максимизации геометрической согласованности этих двух результатов реконструкции относительно общего изображения I_1. Эксперименты показывают, что Test3R значительно превосходит существующие SOTA-методы в задачах 3D-реконструкции и оценки глубины с нескольких ракурсов, обладая при этом универсальностью и низкой стоимостью, легко применим к другим моделям, а затраты на обучение во время тестирования и количество параметров минимальны. (Источник: HuggingFace Daily Papers)
Статья предлагает Mirage-1: GUI-агент с иерархическими мультимодальными навыками, улучшающий обработку долгосрочных задач: Исследователи предложили Mirage-1, мультимодальный, кроссплатформенный, подключаемый GUI-агент, предназначенный для решения проблем нехватки знаний и разрыва между офлайн- и онлайн-доменами, с которыми сталкиваются текущие GUI-агенты при обработке долгосрочных задач в онлайн-среде. Ядром Mirage-1 является модуль иерархических мультимодальных навыков (HMS), который постепенно абстрагирует траектории в исполнительные навыки, основные навыки и мета-навыки, обеспечивая иерархическую структуру знаний для планирования долгосрочных задач. Одновременно алгоритм поиска по дереву Монте-Карло с усилением навыков (SA-MCTS) использует офлайн-полученные навыки для сокращения пространства поиска действий при онлайн-исследовании дерева. На бенчмарках AndroidWorld, MobileMiniWob++, Mind2Web-Live и новом AndroidLH Mirage-1 продемонстрировал значительное улучшение производительности. (Источник: HuggingFace Daily Papers)
Статья «Don’t Pay Attention» предлагает новую базовую архитектуру нейронной сети Avey, бросающую вызов Transformer: Статья под названием «Don’t Pay Attention» предлагает новую базовую архитектуру нейронной сети Avey, целью которой является отказ от зависимости от механизмов внимания и рекуррентности. Avey состоит из ранжировщика (ranker) и авторегрессионного нейронного процессора (autoregressive neural processor), которые совместно идентифицируют и контекстуализируют только те токены, которые наиболее релевантны любому данному токену (независимо от его положения в последовательности). Эта архитектура отделяет длину последовательности от ширины контекста, что позволяет эффективно обрабатывать последовательности произвольной длины. Результаты экспериментов показывают, что Avey демонстрирует производительность, сравнимую с Transformer, на стандартных краткосрочных NLP-бенчмарках и особенно хорошо справляется с улавливанием долгосрочных зависимостей. (Источник: HuggingFace Daily Papers)
Новая статья рассматривает масштабируемую проверку кода с помощью моделей вознаграждения, балансируя между точностью и пропускной способностью: Исследование изучает компромисс между использованием моделей вознаграждения за результат (ORM) и комплексных валидаторов (таких как полные наборы тестов) при решении задач кодирования большими языковыми моделями (LLM). Исследование показало, что даже при наличии комплексных валидаторов ORM играют ключевую роль в масштабировании проверки, жертвуя некоторой точностью ради скорости. В частности, в методе «генерация-отсечение-переупорядочивание» использование более быстрого, но менее точного валидатора для предварительного удаления неверных решений может ускорить систему в 11.65 раз при снижении точности всего на 8.33%. Этот метод работает путем отфильтровывания неверных, но высокоранжированных решений, предлагая новые идеи для разработки масштабируемых и точных систем ранжирования программ. (Источник: HuggingFace Daily Papers)
Новый бенчмарк AbstentionBench показывает: LLM, ориентированные на рассуждения, плохо справляются с вопросами, на которые невозможно ответить: Для оценки способности больших языковых моделей (LLM) воздерживаться от ответа (т.е. отказываться от четкого ответа) перед лицом неопределенности, исследователи представили AbstentionBench. Этот крупномасштабный бенчмарк включает 20 различных наборов данных, охватывающих различные типы вопросов, такие как неизвестные ответы, недостаточные спецификации, ложные предпосылки, субъективные интерпретации и устаревшая информация. Оценка 20 передовых LLM показала, что воздержание от ответа является нерешенной проблемой, и увеличение масштаба модели мало что дает для ее решения. Удивительно, но даже для LLM, специально обученных для математики и науки, тонкая настройка на рассуждения в среднем снизила способность воздерживаться от ответа на 24%. Хотя тщательно разработанные системные подсказки могут улучшить показатели воздержания на практике, это не решает фундаментальных недостатков моделей в рассуждениях в условиях неопределенности. (Источник: HuggingFace Daily Papers)
Статья предлагает метод PatchInstruct на основе патч-подсказок и декомпозиции для использования LLM в прогнозировании временных рядов: Новое исследование изучает простые и гибкие стратегии подсказок для использования больших языковых моделей (LLM) в прогнозировании временных рядов без необходимости значительного переобучения или сложных внешних архитектур. Комбинируя декомпозицию временных рядов, токенизацию на основе патчей (patch-based tokenization) и усиление на основе сходства с соседями, исследователи обнаружили, что можно улучшить качество прогнозов LLM, сохраняя при этом простоту и минимизируя предварительную обработку данных. Предложенный в исследовании метод PatchInstruct позволяет LLM делать точные и эффективные прогнозы. (Источник: HuggingFace Daily Papers)
Опубликован новый набор данных MS4UI, ориентированный на мультимодальное резюмирование обучающих видео по пользовательским интерфейсам: Для решения проблемы нехватки существующих бенчмарков в предоставлении пошаговых, выполнимых инструкций и иллюстраций, исследователи предложили набор данных MS4UI (Multi-modal Summarization for User Interface Instructional Videos). Этот набор данных включает 2413 обучающих видео по UI общей продолжительностью более 167 часов, с ручной сегментацией видео, текстовым резюмированием и аннотациями видео-резюме. Цель — стимулировать исследования методов краткого, выполнимого мультимодального резюмирования для обучающих видео по UI. Эксперименты показали, что текущие SOTA-методы мультимодального резюмирования плохо справляются с MS4UI, что подчеркивает важность новых методов в этой области. (Источник: HuggingFace Daily Papers)
DeepResearch Bench: всесторонний бенчмарк для интеллектуальных агентов глубокого исследования: Для систематической оценки возможностей интеллектуальных агентов глубокого исследования на базе LLM (Deep Research Agents, DRAs) исследователи представили DeepResearch Bench. Этот бенчмарк содержит 100 исследовательских задач уровня докторантуры, тщательно разработанных экспертами из 22 различных областей. Из-за сложности и трудоемкости оценки DRAs исследователи предложили два новых метода оценки, которые высоко коррелируют с человеческими суждениями: один — адаптивный метод на основе эталонных критериев для оценки качества сгенерированных исследовательских отчетов; другой — фреймворк для оценки возможностей DRA по поиску и сбору информации путем оценки количества эффективных цитат и общей точности цитирования. (Источник: HuggingFace Daily Papers)
Статья предлагает BridgeVLA: эффективное обучение 3D-манипуляциям через выравнивание входа и выхода: Для повышения эффективности использования 3D-сигналов визуально-языковыми моделями (VLM) в обучении роботов манипуляциям исследователи предложили BridgeVLA, новую модель 3D-визуально-языкового действия (VLA). BridgeVLA проецирует 3D-вход на несколько 2D-изображений, обеспечивая выравнивание с входом базовой сети VLM, и использует 2D-тепловые карты для прогнозирования действий, тем самым унифицируя вход и выход в согласованном пространстве 2D-изображений. Кроме того, исследование предлагает масштабируемый метод предварительного обучения, который позволяет базовой сети VLM прогнозировать 2D-тепловые карты до последующего обучения стратегии. Эксперименты показали, что BridgeVLA демонстрирует отличные результаты на нескольких симуляционных бенчмарках и в реальных экспериментах с роботами, значительно повышая эффективность и результативность обучения 3D-манипуляциям, а также демонстрируя высокую эффективность использования выборок и способность к обобщению. (Источник: HuggingFace Daily Papers)
Новое исследование синтезирует миллионы разнообразных и сложных пользовательских инструкций (SynthQuestions) с помощью атрибутивного обоснования: Для решения проблемы нехватки разнообразных, сложных и крупномасштабных наборов инструкций, необходимых для выравнивания больших языковых моделей (LLM), исследователи предложили метод синтеза инструкций на основе атрибутивного обоснования (attributed grounding). Этот фреймворк включает: 1) нисходящий процесс атрибуции, связывающий выбранные реальные инструкции с контекстуализированными пользователями; 2) восходящий процесс синтеза, использующий веб-документы для первоначальной генерации контекста, а затем для генерации осмысленных инструкций. С помощью этого метода был создан набор данных SynthQuestions, содержащий 1 миллион инструкций. Эксперименты показали, что модели, обученные на этом наборе данных, достигли лидирующих результатов на нескольких распространенных бенчмарках, и их производительность продолжает улучшаться по мере увеличения объема веб-корпуса. (Источник: HuggingFace Daily Papers)
PersonaFeedback: опубликован крупномасштабный, аннотированный вручную бенчмарк для оценки персонализации: Для оценки способности больших языковых моделей (LLM) предоставлять персонализированные ответы на основе заданных пользовательских профилей и запросов, исследователи представили бенчмарк PersonaFeedback. Этот бенчмарк содержит 8298 вручную аннотированных тестовых случаев, разделенных на три уровня сложности (простой, средний и сложный) в зависимости от контекстной сложности пользовательского профиля и трудности различения персонализированных ответов. В отличие от существующих бенчмарков, PersonaFeedback отделяет вывод профиля от персонализации, фокусируясь на оценке способности модели генерировать индивидуализированные ответы на четко определенные профили. Результаты экспериментов показывают, что даже SOTA LLM сталкиваются с трудностями на тестах сложного уровня, что указывает на то, что текущие фреймворки с расширенным поиском не являются окончательным решением для задач персонализации. (Источник: HuggingFace Daily Papers)
Статья исследует «языковую хирургию» в многоязычных больших моделях: управление языком во время вывода через латентную инъекцию: Новое исследование изучает явление естественного выравнивания представлений в больших языковых моделях (LLM) и его значение для разделения языкоспецифичной и языконезависимой информации. Исследование подтверждает существование такого выравнивания и анализирует его поведение по сравнению с моделями с явно спроектированным выравниванием. На основе этих выводов исследователи предложили метод управления языком во время вывода (Inference-Time Language Control, ITLC), который использует латентную инъекцию (latent injection) для точного межъязыкового контроля и смягчения проблемы смешения языков в LLM. Эксперименты продемонстрировали сильную способность ITLC к межъязыковому контролю при сохранении семантической целостности целевого языка, а также его эффективность в смягчении проблемы межъязыкового смешения, которая все еще существует даже в современных крупномасштабных LLM. (Источник: HuggingFace Daily Papers)
Статья предлагает метод NoWait: удаление «токенов размышления» для повышения эффективности вывода больших моделей: Недавние исследования показывают, что большие модели для рассуждений при выполнении сложных пошаговых выводов часто из-за чрезмерного «размышления» (например, вывода токенов «Wait», «Hmm» и т.п.) генерируют избыточный вывод, что снижает эффективность. Новый предложенный метод NoWait, подавляя эти явные токены саморефлексии во время вывода, направлен на проверку их необходимости для продвинутых рассуждений. В десяти бенчмарках, охватывающих задачи рассуждения по тексту, изображениям и видео, NoWait сократил длину траекторий цепочек мыслей на 27%-51% в пяти семействах моделей стиля R1, не нанеся ущерба полезности модели. Этот метод предлагает готовое к использованию решение для достижения эффективного мультимодального вывода с сохранением полезности. (Источник: HuggingFace Daily Papers)
💼 Бизнес
OpenAI выиграла контракт Министерства обороны США на 200 миллионов долларов на разработку передовых военных возможностей: OpenAI заключила годовой контракт с Министерством обороны США на сумму 200 миллионов долларов, направленный на разработку передовых инструментов искусственного интеллекта для национальной безопасности. Это знаменует собой первый контракт такого рода, полученный OpenAI от Пентагона. Работы будут в основном проводиться в столичном регионе страны. Ранее OpenAI уже сотрудничала с оборонной компанией Anduril. Этот шаг происходит на фоне широкого стремления оборонного сектора США к внедрению AI, в то время как ее конкурент Anthropic также сотрудничает с Palantir и Amazon в этой области. CEO OpenAI Sam Altman ранее публично выражал поддержку проектам в области национальной безопасности. (Источник: Reddit r/ArtificialInteligence, code_star)

Alta привлекла 11 миллионов долларов финансирования под руководством Menlo Ventures, фокусируясь на AI+мода: AI-стартап в области моды Alta объявил о завершении раунда финансирования на 11 миллионов долларов под руководством Menlo Ventures, с участием Benchstrength и Aglaé Ventures (венчурный фонд, поддерживаемый семьей Арно из LVMH Group). Amy Tong Wu войдет в совет директоров Alta. Этот раунд финансирования будет способствовать дальнейшему развитию Alta в области сочетания AI и моды. (Источник: ZhaiAndrew)
Компания Figure корректирует организационную структуру, отдел управления объединяется с Helix для ускорения дорожной карты AI: Компания по производству человекоподобных роботов Figure объявила, что ее отдел управления (Controls) прекратил свое существование, а вся команда была объединена с отделом Helix. Этот шаг направлен на ускорение развития дорожной карты компании в области искусственного интеллекта, что свидетельствует о том, что Figure концентрирует больше ресурсов и усилий на исследованиях и разработках AI-технологий. (Источник: adcock_brett)
🌟 Сообщество
Обсуждение AGI: обычным пользователям не стоит чрезмерно беспокоиться, AGI скорее стратегический инструмент, чем повседневный: Многие в сообществе отмечают, что обычным пользователям LLM не стоит слишком беспокоиться о приходе AGI (Общего Искусственного Интеллекта). Определение AGI расплывчато и теоретично, и даже если он будет реализован, в краткосрочной перспективе это не отразится напрямую в окне чата пользователя. Скорее, AGI станет стратегическим инструментом и инфраструктурой для государств или крупных организаций, используемым для решения сложных задач, таких как межгосударственные переговоры, а не для помощи отдельным лицам в организации встреч. (Источник: farguney, farguney, farguney, farguney)
Создание многоагентных систем требует ручной оценки, внимания к крайним случаям и качеству источников: При создании многоагентных систем ручная оценка и тестирование имеют решающее значение, поскольку позволяют выявить крайние случаи, которые автоматизированная оценка может упустить. Например, ранние агенты при выборе источников информации отдавали предпочтение SEO-оптимизированным контент-фермам, а не авторитетным научным PDF или личным блогам. Добавление в подсказки эвристик по качеству источников помогает решить подобные проблемы. Это показывает, что даже в эпоху автоматизированной оценки ручное тестирование остается незаменимым для выявления системных сбоев, тонких смещений в выборе источников и других проблем. (Источник: riemannzeta)

Различия в механизмах прогнозирования и обучения LLM и видеомоделей вызывают размышления: Yann LeCun и Pedro Domingos ретвитнули мнение Sergey Levine, обсуждающее, почему языковые модели могут так многому научиться из прогнозирования следующего токена, в то время как видеомодели из прогнозирования следующего кадра учатся относительно мало. Levine предполагает, что это может быть связано с тем, что LLM в некоторой степени играют роль «сканера мозга», намекая на уникальность их механизмов обучения, или что LLM, подобно жителям платоновской пещеры, выводят реальный мир, наблюдая за последовательностью теней (текста). (Источник: ylecun, pmddomingos, pmddomingos)

Положительное влияние AI Agent в образовании: стимулирование учащихся выходить из зоны комфорта: В сообществе обсуждается, что AI Agent оказывают положительное влияние не только на предприятия, но и обладают огромным потенциалом в сфере образования. Взаимодействуя с AI Agent, учащиеся могут более эффективно выходить из своей зоны комфорта, что способствует повышению результатов обучения. (Источник: pirroh, amasad)
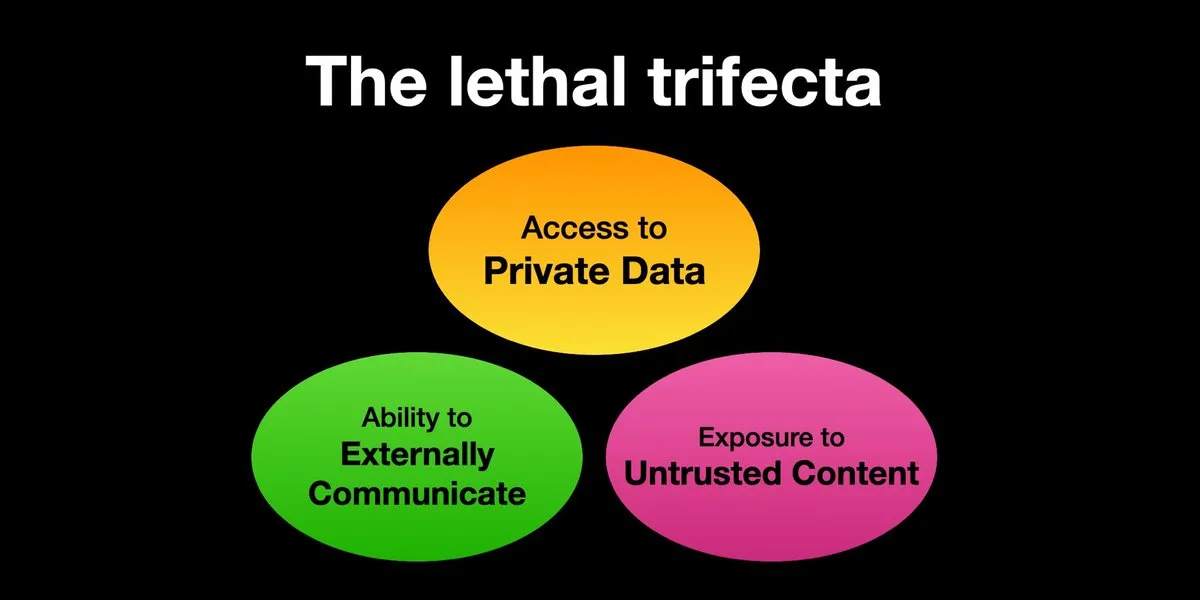
AI Agent подвержены риску атак с внедрением подсказок, требуется усиление мер безопасности: Karpathy ретвитнул предупреждение Simon Willison о «смертельной триаде» (Lethal Trifecta) рисков для AI Agent: когда AI Agent одновременно имеет доступ к личным данным, контактирует с недоверенным контентом и обладает возможностью внешней коммуникации, злоумышленники могут обманом заставить систему украсть данные. Это напоминает эпоху «Дикого Запада» ранних компьютерных вирусов. В настоящее время механизмы защиты от вредоносных подсказок несовершенны, например, отсутствует парадигма безопасности, подобная разделению на ядро/пользовательское пространство в операционных системах, для ограничения способности Agent выполнять произвольные скрипты. Это вызывает опасения относительно раннего внедрения LLM Agent для персональных вычислений. (Источник: karpathy, TheTuringPost)
В эпоху AI способность быстро учиться становится ключевой компетенцией: Mustafa Suleyman отмечает, что в ближайшее десятилетие главным ускорителем карьерного роста станет превосходная способность к обучению. Он советует людям четко определить свой стиль обучения, использовать AI для преобразования материалов в подходящий формат (например, подкасты, тесты), а затем применять знания и постоянно повторять этот процесс, тем самым достигая быстрого обучения и роста. (Источник: mustafasuleyman)
Аутентичность и релевантность AI-генерируемого контента: релевантность может превосходить аутентичность: Пользователь imjaredz поделился опытом, сообщив, что отправил 2000 писем-приглашений, сгенерированных AI, и никто не пожаловался на то, что они написаны AI. Напротив, 5 человек отметили, что содержание писем «именно то, над чем они работают». Это вызвало дискуссию о том, является ли релевантность контента в коммуникации более важной, чем его «аутентичность» (т.е. создан ли он человеком). (Источник: imjaredz)
Обсуждение способности LLM к «пониманию»: поведенческое сходство не равно истинному пониманию: В сообществе существует мнение, что, несмотря на то, что большие языковые модели демонстрируют мощные способности к поведенческому и когнитивному приближению, это не равносильно истинному пониманию. Понимание требует способности к объяснению, а простое проявление поведения не является ни интеллектом, ни пониманием. Это фундаментальное различие часто упускается из виду. Эта точка зрения подчеркивает, что перед тем, как доверять моделям принятие решений, связанных с жизнью и безопасностью, необходимо тщательно оценить, действительно ли они приближаются к общему искусственному интеллекту, и остерегаться чрезмерного преувеличения их способностей. (Источник: farguney)
AI Agent показывают впечатляющие результаты на бенчмарках по программной инженерии, но обсуждается их «агентская» сущность: По мере того как AI набирает все более высокие баллы (даже превышая 50-60) на бенчмарках по программной инженерии, таких как SWE-bench, в сообществе обсуждается, действительно ли наступила «эпоха кодирования агентами». Существует мнение, что если повсеместно используются «безагентные фреймворки» (agentless frameworks), а не среды, в которых языковая модель действительно исследует окружение, то называть это «эпохой кодирования агентами» может быть не совсем корректно, хотя сами эти фреймворки очень ценны. (Источник: huybery, terryyuezhuo)
Потребность в модерации контента AI-генерируемых изображений: поиск открытых или коммерческих решений: С распространением технологий AI-генерации изображений китайские разработчики начинают обращать внимание на проблемы соответствия выходного контента нормативным требованиям, особенно на то, как обнаруживать порнографический, политически чувствительный и другой нежелательный контент. В сообществе появляются запросы на доступные открытые малые модели или коммерческие продукты для модерации контента. (Источник: dotey)
💡 Прочее
AI-управляемая персонализация и релевантность контента: 2000 AI-писем без негативных отзывов, 5 человек сказали «именно то, что мне нужно»: Один пользователь поделился, что отправил 2000 писем-приглашений, сгенерированных AI, и ни один получатель не пожаловался, что письмо написано AI. Напротив, пять получателей отметили, что содержание письма «именно то, над чем они сейчас работают». Этот случай вызвал дискуссию о том, может ли высокая релевантность контента в коммуникации с использованием AI перевесить озабоченность «аутентичностью» (т.е. тем, написано ли оно человеком), намекая на потенциал AI в генерации персонализированного контента. (Источник: imjaredz)
Человек становится узким местом в AI-системах, необходимо избегать или повышать эффективность человека: Мнение Charles Earl указывает на то, что переполненные входящие почтовые ящики при пустых исходящих отражают тот факт, что человек является узким местом в обработке информации и реагировании. В эпоху AI необходимо задуматься о том, как избежать человеческого узкого места или как повысить эффективность работы человека с помощью AI и других технологий. (Источник: charles_irl)
Потенциальные риски управления умным домом с помощью AI: пользователь оказался заперт в холодной умной кровати из-за сбоя приложения: Один пользователь поделился своим опытом, когда из-за сбоя приложения его умной кровати с AI-управлением (Eight Sleep Pod3) он не смог отрегулировать температуру и в итоге оказался заперт на холодной кровати. Поскольку данная модель не имеет ручного управления и полностью зависит от приложения, этот сбой подчеркнул неудобства и «антиутопический» опыт, которые могут возникнуть из-за чрезмерной зависимости от AI и приложений для управления устройствами умного дома. (Источник: madiator)