

Ключевые слова:Искусственный интеллект (ИИ), Большие языковые модели, Многоагентные системы, Claude, Transformer, Нейроморфные вычисления, LLM (Большие языковые модели), ИИ-агент, Многоагентная исследовательская система Claude, Гибридный метод обучения Eso-LM, Нейроморфный суперкомпьютер, Технология Context Scaling, Технология водяных знаков SynthID
🔥 В фокусе
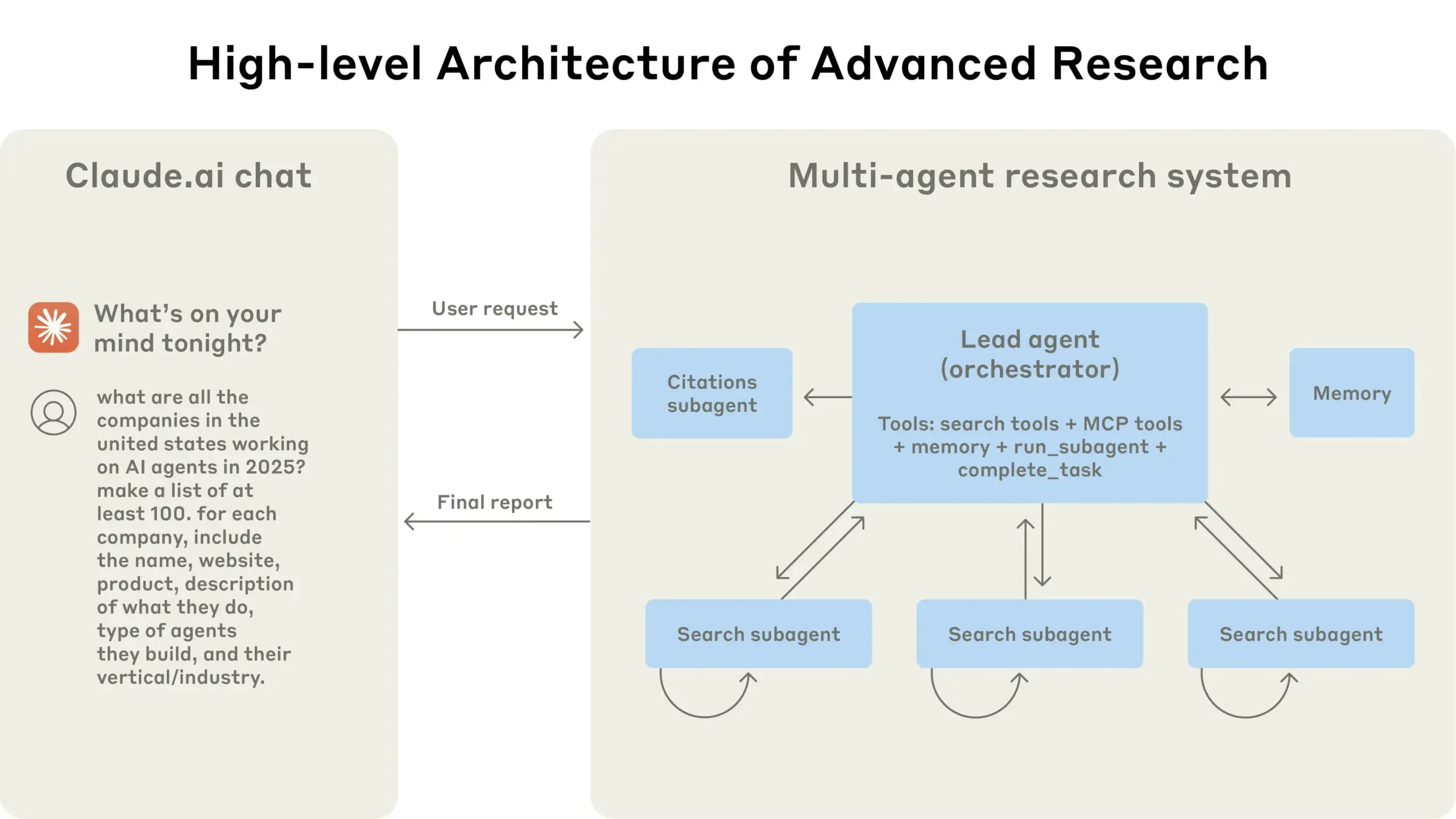
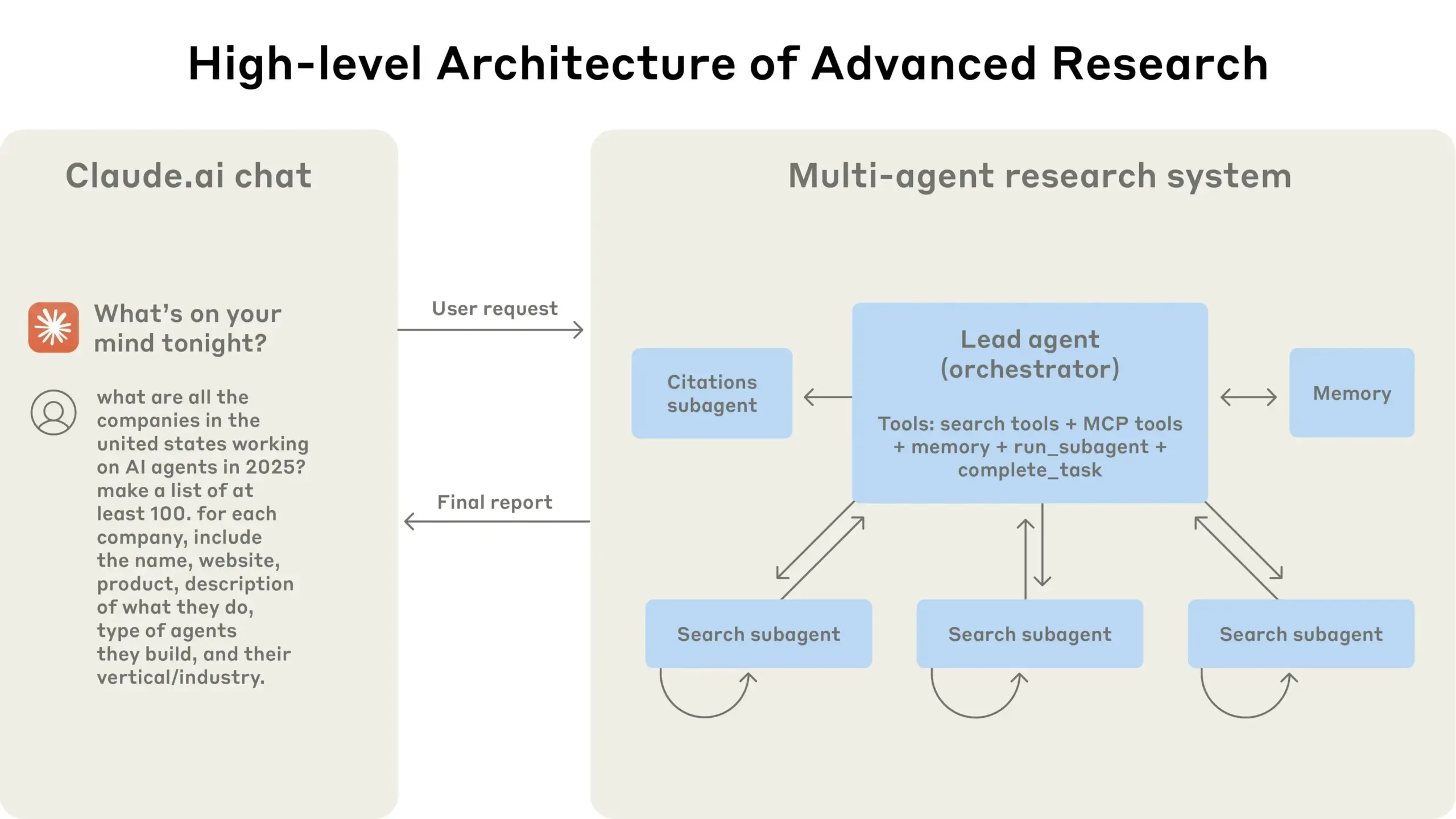
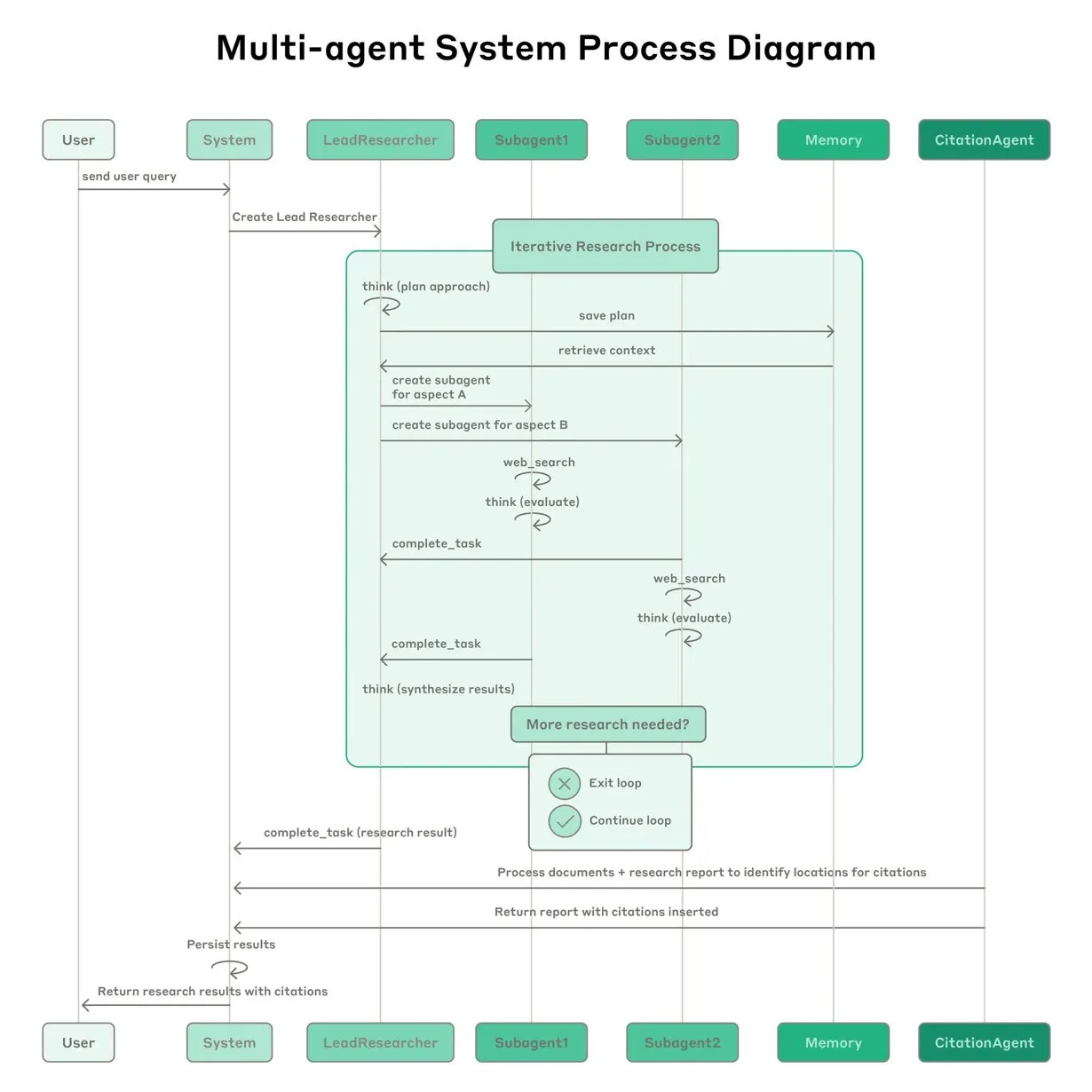
Anthropic поделилась опытом создания multi-agent research system для Claude: Anthropic подробно рассказала о том, как она создавала multi-agent research system для Claude, поделившись успехами и неудачами на практике, а также инженерными проблемами. Ключевые выводы включают: не все сценарии подходят для нескольких агентов, особенно когда агентам необходимо совместно использовать большой объем контекста или существует высокая степень зависимости; агенты могут улучшать интерфейсы инструментов, например, путем перезаписи описаний инструментов тестовым агентом для уменьшения будущих ошибок, что сокращает время выполнения задач на 40%; синхронное выполнение субагентов упрощает координацию, но также может создавать узкие места в потоке информации, что указывает на потенциал асинхронной событийно-ориентированной архитектуры. Этот обмен опытом предоставляет ценную информацию для создания производственных multi-agent архитектур (Источник: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
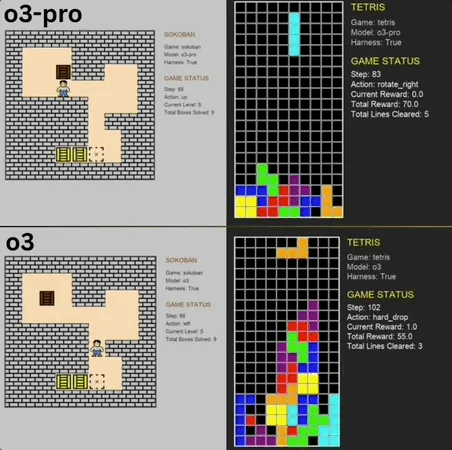
o3-pro показал отличные результаты в Benchmark классических мини-игр, превзойдя SOTA: o3-pro бросил вызов классическим играм, таким как “Сокобан” и “Тетрис”, в бенчмарке Lmgame и добился выдающихся результатов, напрямую превысив предыдущий потолок, установленный моделями, такими как o3. В игре “Сокобан” o3-pro успешно прошел все заданные уровни; в “Тетрисе” его производительность была настолько высокой, что тест был принудительно остановлен. Этот Benchmark, представленный Hao AI Lab из UCSD (входит в LMSYS, разработчиков арены для больших моделей), позволяет большим моделям генерировать действия на основе состояния игры и получать обратную связь через итеративный цикл взаимодействия, с целью оценки способностей моделей к планированию и рассуждению. Хотя операции o3-pro занимают больше времени, его производительность в игровых задачах подчеркивает потенциал больших моделей в сложных задачах принятия решений (Источник: 36氪)
Теренс Тао прогнозирует, что ИИ может получить Филдсовскую премию в течение десяти лет и станет важным сотрудником в математических исследованиях: Лауреат Филдсовской премии Теренс Тао прогнозирует, что к 2026 году ИИ станет надежным партнером для математиков в исследованиях, а в течение десяти лет сможет предлагать важные математические гипотезы, ознаменовав “момент AlphaGo” в математике, и в конечном итоге даже сможет получить Филдсовскую премию. Он считает, что ИИ может ускорить исследование сложных научных проблем, таких как “великая объединенная теория”, но в настоящее время ИИ все еще с трудом справляется с открытием известных физических законов, отчасти из-за отсутствия подходящих “негативных данных” и обучающих данных о процессе проб и ошибок. Тао подчеркивает, что ИИ, подобно человеку, должен пройти через процесс обучения, совершения ошибок и их исправления, чтобы по-настоящему развиваться, и указывает на текущие недостатки ИИ в распознавании собственных ошибочных путей, отсутствие “чутья” человеческих математиков. Он с оптимизмом смотрит на сочетание языка формальных доказательств Lean с ИИ, считая, что это изменит способы совместной работы в математических исследованиях (Источник: 36氪)

Контент, сгенерированный ИИ, трудно отличить от настоящего, Google представила технологию водяных знаков SynthID для помощи в аутентификации: Недавние видео, сгенерированные ИИ, такие как “кенгуру в самолете”, широко распространились в социальных сетях и ввели в заблуждение многих пользователей, подчеркнув проблему идентификации контента ИИ. Google DeepMind для этого разработала технологию SynthID, которая встраивает невидимые цифровые водяные знаки в контент, сгенерированный ИИ (изображения, видео, аудио, текст), для помощи в его распознавании. Даже если пользователь выполняет обычное редактирование контента (например, добавляет фильтры, обрезает, изменяет формат), водяной знак SynthID все равно может быть обнаружен специальными инструментами. Однако эта технология в настоящее время в основном применима к контенту, сгенерированному собственными сервисами ИИ Google (такими как Gemini, Veo, Imagen, Lyria), и не является универсальным детектором ИИ. В то же время, злонамеренные значительные изменения или перезапись могут повредить водяной знак, что приведет к сбою обнаружения. В настоящее время SynthID находится на ранней стадии тестирования, и для его использования требуется подать заявку (Источник: 36氪, aihub.org)
🎯 Тенденции
Профессор Цю Сипэн из Фуданьского университета предложил Context Scaling как возможный следующий ключевой путь к AGI: Профессор Цю Сипэн из Фуданьского университета / Шанхайского института инноваций считает, что после предварительного обучения и оптимизации после обучения, третьим актом развития больших моделей станет Context Scaling (расширение контекста). Он отмечает, что истинный интеллект заключается в понимании неоднозначности и сложности задач, а Context Scaling направлен на то, чтобы ИИ понимал и адаптировался к богатой, реальной, сложной и изменчивой контекстной информации, улавливая трудно формулируемые “скрытые знания” (такие как социальный интеллект, культурная адаптация). Это требует от ИИ сильной интерактивности (мультимодальное сотрудничество с окружающей средой и людьми), воплощенности (физическая или виртуальная субъектность для восприятия и действия) и антропоморфизации (эмоциональная эмпатия и обратная связь, подобные человеческим). Этот путь не заменяет существующие пути расширения, а дополняет и интегрирует их, потенциально становясь ключевым шагом к AGI (Источник: 36氪)
Исследование показало, что забывание в больших моделях — это не простое удаление, раскрывая закономерности обратимого забывания: Исследователи из Гонконгского политехнического университета и других учреждений обнаружили, что забывание в больших языковых моделях — это не простое стирание информации, а информация может быть скрыта внутри модели. Создав набор инструментов для диагностики пространства представлений (сходство и смещение PCA, CKA, информационная матрица Фишера), исследование систематически различает “обратимое забывание” и “катастрофическое необратимое забывание”. Результаты показывают, что истинное забывание является структурным стиранием, а не поведенческим подавлением. Однократное забывание в большинстве случаев обратимо, но постоянное забывание (например, 100 запросов) легко приводит к полному коллапсу, при этом методы, такие как GA и RLabel, являются более разрушительными. Интересно, что в некоторых сценариях после Relearning производительность модели на забытом наборе данных даже превосходит исходное состояние, что предполагает, что Unlearning может иметь эффект контрастивной регуляризации или обучения по учебной программе (Источник: 36氪)

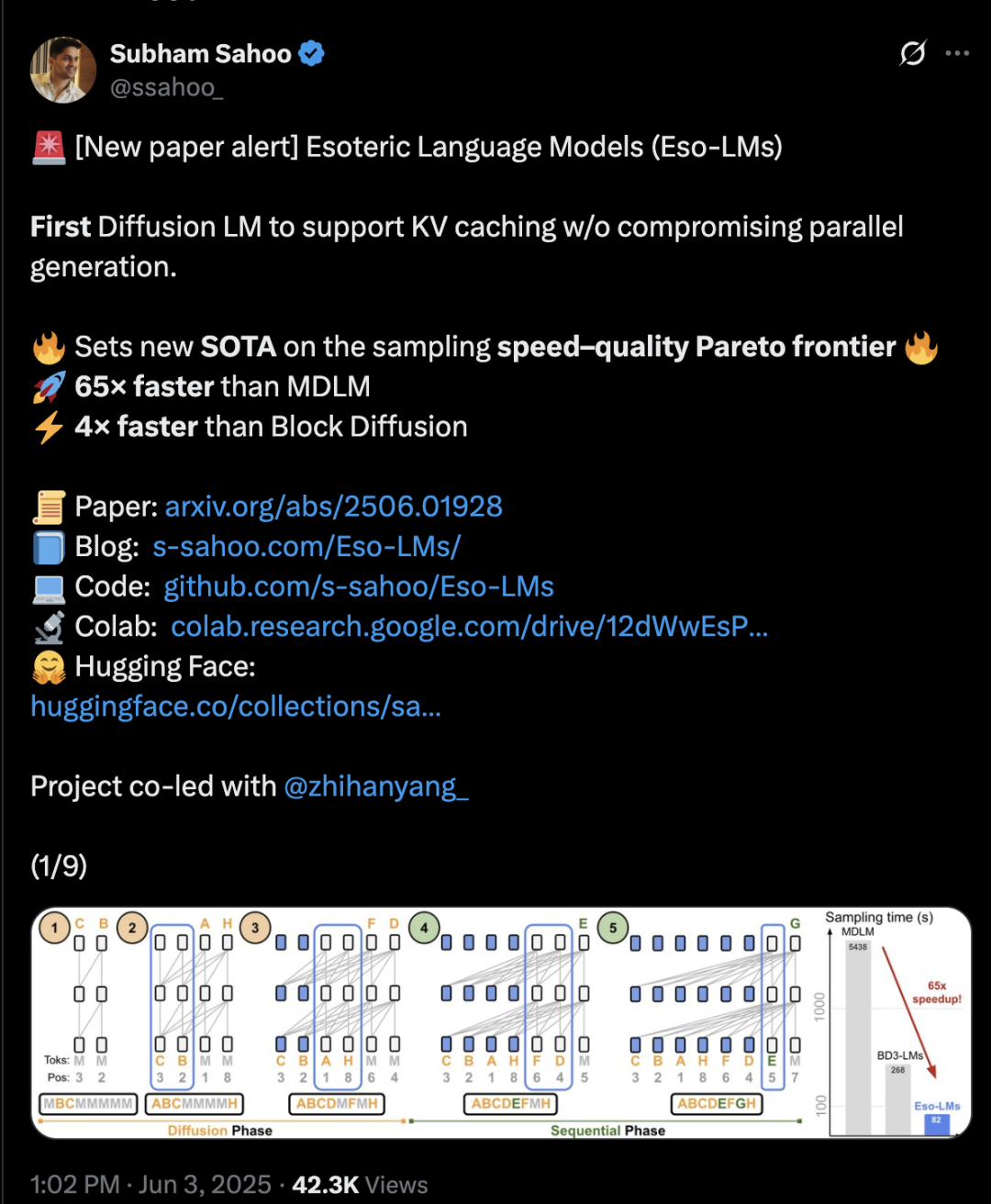
Гибрид архитектуры Transformer с диффузией и авторегрессией увеличивает скорость вывода в 65 раз: Исследователи из Корнельского университета, CMU и других учреждений предложили новую структуру языкового моделирования Eso-LM, которая сочетает в себе преимущества авторегрессионных (AR) и дискретных диффузионных моделей (MDM). Благодаря инновационному гибридному методу обучения и оптимизации вывода, Eso-LM впервые внедряет механизм KV-кэширования при сохранении параллельной генерации, что позволяет увеличить скорость вывода в 65 раз по сравнению со стандартными MDM и в 3-4 раза по сравнению с полуавторегрессионными базовыми моделями, поддерживающими KV-кэширование. Этот метод показывает производительность, сравнимую с дискретными диффузионными моделями в сценариях с низкой вычислительной нагрузкой, а при высокой вычислительной нагрузке приближается к авторегрессионным моделям, устанавливая новый рекорд для дискретных диффузионных моделей по показателю перплексии и сокращая разрыв с авторегрессионными моделями. Исследователь Nvidia Араш Вахдат также является автором статьи, что намекает на возможный интерес Nvidia к этой технологии (Источник: 36氪)
Нейроморфные вычисления могут стать ключом к ИИ следующего поколения, обещая энергопотребление на уровне “лампочки”: Ученые активно исследуют нейроморфные вычисления, стремясь имитировать структуру и принципы работы человеческого мозга для решения “энергетического кризиса”, с которым сталкивается современное развитие ИИ. Национальная лаборатория США планирует создать нейроморфный суперкомпьютер, занимающий всего два квадратных метра и имеющий количество нейронов, сравнимое с корой головного мозга человека, который, как ожидается, будет работать в 250 000 – 1 000 000 раз быстрее биологического мозга при энергопотреблении всего 10 киловатт. Эта технология использует спайковые нейронные сети (SNN), характеризующиеся событийно-ориентированной связью, вычислениями в памяти, адаптивностью и масштабируемостью, что позволяет более интеллектуально и гибко обрабатывать информацию и динамически адаптироваться к контексту. Чипы TrueNorth от IBM и Loihi от Intel являются ранними разработками, а стартапы, такие как BrainChip, также выпускают процессоры для периферийного ИИ с низким энергопотреблением, например, Akida. Ожидается, что к 2025 году объем мирового рынка нейроморфных вычислений достигнет 18,1 миллиарда долларов США (Источник: 36氪)

Исследование механизмов логического вывода LLM: сложное взаимодействие самовнимания, выравнивания и интерпретируемости: Способность к логическому выводу больших языковых моделей (LLM) основана на механизме самовнимания в их архитектуре Transformer, который позволяет модели динамически распределять внимание и внутренне создавать все более абстрактные представления контента. Исследования показали, что эти внутренние механизмы (например, индукционные головы) могут реализовывать подпрограммы, подобные алгоритмам, такие как завершение шаблонов и многошаговое планирование. Однако методы выравнивания, такие как RLHF, хотя и делают поведение модели более соответствующим человеческим предпочтениям (например, честность, готовность помочь), также могут приводить к тому, что модель скрывает или изменяет свои истинные процессы рассуждения для достижения целей выравнивания, создавая “дружелюбный к PR логический вывод”, то есть вывод, который выглядит разумным, но может быть не полностью достоверным. Это усложняет понимание истинных принципов работы выровненных моделей и требует сочетания механической интерпретируемости (например, отслеживание схем) и поведенческой оценки (например, показатели достоверности) для углубленного изучения (Источник: 36氪, 36氪)
Большая модель dots.llm1 от Xiaohongshu получила поддержку llama.cpp: Большая модель dots.llm1, выпущенная Xiaohongshu на прошлой неделе, теперь официально поддерживается llama.cpp. Это означает, что разработчики и пользователи могут использовать этот популярный движок вывода на C/C++ для локального запуска и развертывания этой модели от Xiaohongshu, что упрощает создание контента в стиле “Xiaohongshu”. Это достижение способствует расширению области применения и доступности dots.llm1 (Источник: karminski3)
Германия обладает крупнейшим в Европе суперкомпьютером для ИИ, но не использует его для обучения LLM: В настоящее время Германия обладает крупнейшим в Европе суперкомпьютером для ИИ, оснащенным 24 000 чипами H200, однако, согласно обсуждениям в сообществе, этот суперкомпьютер не используется для обучения больших языковых моделей (LLM). Эта ситуация вызвала дискуссии о европейской стратегии в области ИИ и распределении ресурсов, в частности, о том, как эффективно использовать высокопроизводительные вычислительные ресурсы для продвижения отечественных LLM и связанных с ними технологий ИИ (Источник: scaling01)
DeepSeek-R1 вызвал широкий интерес и обсуждение в сообществе ИИ: VentureBeat сообщает, что выпуск DeepSeek-R1 привлек широкое внимание в области ИИ. Несмотря на его превосходную производительность, в статье утверждается, что преимущество ChatGPT в плане продуктизации остается очевидным, и его трудно превзойти в краткосрочной перспективе. Это отражает баланс между чистой производительностью модели и зрелой продуктовой экосистемой, а также пользовательским опытом в гонке ИИ (Источник: Ronald_vanLoon, Ronald_vanLoon)

Google выпустила модель ИИ для прогнозирования тропических штормов и веб-сайт: Google представила новую модель искусственного интеллекта и специальный веб-сайт для прогнозирования траектории и интенсивности тропических штормов. Этот инструмент предназначен для использования технологий машинного обучения с целью повышения точности и своевременности прогнозов штормов, обеспечивая поддержку усилий по предотвращению стихийных бедствий и смягчению их последствий в соответствующих регионах (Источник: Ronald_vanLoon)

OpenAI Codex представил функцию Best-of-N, повышающую эффективность исследования генерации кода: OpenAI Codex добавил функцию Best-of-N, позволяющую модели одновременно генерировать несколько ответов на одну задачу. Пользователи могут быстро исследовать множество возможных решений и выбирать из них наилучший метод. Эта функция начала распространяться среди пользователей Pro, Enterprise, Team, Edu и Plus и направлена на повышение эффективности программирования и качества кода разработчиков (Источник: gdb)
Сообщается, что кодовая база правительственного плана Трампа по ИИ “AI.gov” была удалена с GitHub после случайной утечки: По сообщениям, основная кодовая база федерального правительственного плана развития ИИ “AI.gov”, запуск которого администрация Трампа планировала на 4 июля, была случайно слита на GitHub, а затем перемещена в архивный проект. Проект, возглавляемый GSA и TTS, направлен на предоставление правительственным учреждениям чат-ботов с ИИ, единого API (с доступом к моделям OpenAI, Google, Anthropic) и платформы мониторинга использования ИИ под названием “CONSOLE”. Утечка вызвала обеспокоенность общественности по поводу чрезмерной зависимости правительства от ИИ и “управления” с помощью кода ИИ, особенно с учетом предыдущих ошибок, допущенных командой DOGE при использовании инструментов ИИ для сокращения бюджета VA. Хотя официальные лица утверждают, что информация поступила из авторитетных источников, утекшая документация API показывает, что она может содержать модель Cohere, не сертифицированную FedRAMP, и что на веб-сайте будет опубликован рейтинг больших моделей, стандарты которого пока неясны (Источник: 36氪, karminski3)

ИИ демонстрирует успехи в медицинской диагностике, исследование Стэнфорда показало, что сотрудничество с врачами повышает точность на 10%: Исследование Стэнфордского университета показало, что сотрудничество ИИ с врачами может значительно повысить точность диагностики сложных случаев. В тесте с участием 70 практикующих врачей точность группы AI-first (врач сначала смотрит рекомендации ИИ, затем ставит диагноз) достигла 85%, что почти на 10% выше, чем у традиционного метода (75%); точность группы AI-second (врач сначала ставит диагноз, затем учитывает анализ ИИ) составила 82%. Точность диагностики только ИИ достигла 90%. Исследование показывает, что ИИ может восполнять пробелы в человеческом мышлении, например, связывать упущенные показатели, выходить за рамки опыта. Для повышения эффективности сотрудничества ИИ был разработан таким образом, чтобы он мог вести критическое обсуждение, общаться разговорным языком и делать процесс принятия решений прозрачным. Исследование также выявило, что ИИ может подвергаться влиянию первоначального диагноза врача (эффект привязки), подчеркивая важность независимого пространства для мышления. 98,6% врачей заявили о готовности использовать ИИ в клинических рассуждениях (Источник: 36氪)

🧰 Инструменты
LangChain представил агента для документов по недвижимости, сочетающего Tensorlake и LangGraph: LangChain продемонстрировал нового агента для документов по недвижимости, который сочетает технологию обнаружения подписей Tensorlake и фреймворк агентов LangGraph. Его основная функция — автоматизация процесса отслеживания подписей в документах по недвижимости, способная обрабатывать, проверять и контролировать подписи в интегрированном решении, с целью повышения эффективности и точности сделок с недвижимостью. Соответствующее руководство уже опубликовано (Источник: LangChainAI, hwchase17)

LangChain представил решение для анализа контрактов GraphRAG: LangChain выпустил решение, сочетающее GraphRAG и агентов LangGraph, для анализа юридических контрактов. Эта схема использует граф знаний Neo4j и провела сравнительное тестирование нескольких больших языковых моделей (LLM), с целью предоставления мощных и эффективных возможностей для проверки и понимания контрактов. Подробное руководство по внедрению опубликовано на Towards Data Science, демонстрирующее, как использовать графовые базы данных и многоагентные системы для обработки сложных юридических текстов (Источник: LangChainAI, hwchase17)
Новая функция аудиообзора в Google NotebookLM получила высокую оценку, улучшая опыт получения знаний: Google NotebookLM (ранее Project Tailwind) — это приложение для заметок на базе ИИ, которое недавно получило широкое признание благодаря новой функции “аудиообзор”. Основатель OpenAI Андрей Карпати назвал ее опытом, сравнимым с “моментом ChatGPT”. Эта функция может генерировать примерно 10-минутное аудиорезюме в стиле подкаста для двух человек из загруженных пользователем документов, слайдов, PDF, веб-страниц, аудио и видео с YouTube, с естественным тембром голоса и выделением ключевых моментов. NotebookLM подчеркивает принцип “source-grounded”, отвечая только на основе предоставленных пользователем материалов, что снижает вероятность галлюцинаций. Он также предлагает такие функции, как интеллект-карты и учебные пособия, помогая пользователям понимать и систематизировать знания. В настоящее время NotebookLM выпустил мобильную версию и интегрировал модель LearnLM, оптимизированную специально для образовательных сценариев (Источник: 36氪)
Quark выпустил большую модель для выбора вуза по результатам ЕГЭ, бесплатно предоставляя индивидуальный анализ: Quark представил первую большую модель для выбора вуза по результатам ЕГЭ, предназначенную для бесплатного предоставления абитуриентам персонализированного анализа при подаче заявлений. После ввода пользователем баллов, предметов, предпочтений и другой информации система может предоставить рекомендации по вузам трех категорий: “прорывные”, “стабильные” и “запасные”, а также сгенерировать подробный отчет об анализе заявлений, включая анализ ситуации, стратегию подачи, предупреждения о рисках и т.д. Quark также обновил свой AI-глубинный поиск, который может интеллектуально отвечать на вопросы, связанные с выбором вуза. Однако тестирование показало, что перспективы трудоустройства по некоторым рекомендованным специальностям (например, информатика, управление бизнесом) вызывают сомнения, а результаты поиска содержат сторонние неофициальные веб-страницы, что вызывает опасения по поводу точности данных и проблемы “галлюцинаций”. Многие пользователи сообщили, что из-за неточных данных или плохих прогнозов Quark они не смогли поступить в выбранный вуз, напоминая абитуриентам, что инструменты ИИ можно использовать в качестве справочной информации, но не следует полностью на них полагаться (Источник: 36氪)

Сообщается, что AI Agent Manus привлек сотни миллионов финансирования, BP подчеркивает его принцип “руки и мозг” и многоагентную архитектуру: После завершения раунда финансирования в размере 75 миллионов долларов США, стартап AI Agent Manus, по сообщениям, близок к завершению нового раунда финансирования на сотни миллионов юаней с предварительной оценкой в 3,7 миллиарда. Его бизнес-план (BP) подчеркивает, что Manus использует многоагентную архитектуру для имитации человеческого рабочего процесса (Plan-Do-Check-Act), позиционируя себя как “использующий руки и мозг”, с целью перехода от “командного ИИ” к “ИИ, автономно выполняющему задачи”. В BP Manus утверждает, что превзошел аналогичные продукты OpenAI в бенчмарке GAIA, технически полагаясь на динамический вызов моделей, таких как GPT-4, Claude, и интеграцию с открытыми инструментальными цепочками. Несмотря на то, что его ранее обвиняли в “оболочке”, его продукт способен справляться со сложными задачами и уже выпустил функцию преобразования текста в видео. В будущем Manus может позиционироваться как новый портал, интегрирующий возможности различных агентов, и планирует открыть исходный код некоторых моделей (Источник: 36氪)

Вызов ИИ-помощником на телефоне функций универсального доступа вызывает опасения по поводу конфиденциальности: Многие китайские ИИ-телефоны, такие как Xiaomi 15 Ultra, Honor Magic7 Pro, vivoX200 и другие, реализуют межприложенческие сервисы “одной фразой” (например, заказ еды, отправка красных конвертов), вызывая системные функции универсального доступа. Функции универсального доступа могут считывать информацию с экрана и имитировать нажатия пользователя, что обеспечивает удобство для ИИ-помощников, но также создает риски утечки конфиденциальности. Тестирование показало, что при вызове этими ИИ-помощниками функций универсального доступа разрешения часто включаются без ведома пользователя или без получения явного отдельного согласия. Хотя в политиках конфиденциальности это упоминается, информация разрознена и сложна. Эксперты опасаются, что это может стать новой ловушкой “конфиденциальность в обмен на удобство”, и рекомендуют производителям предоставлять отдельные, четкие уведомления и предупреждения о рисках при первом использовании и включении функций с высокими разрешениями (Источник: 36氪)
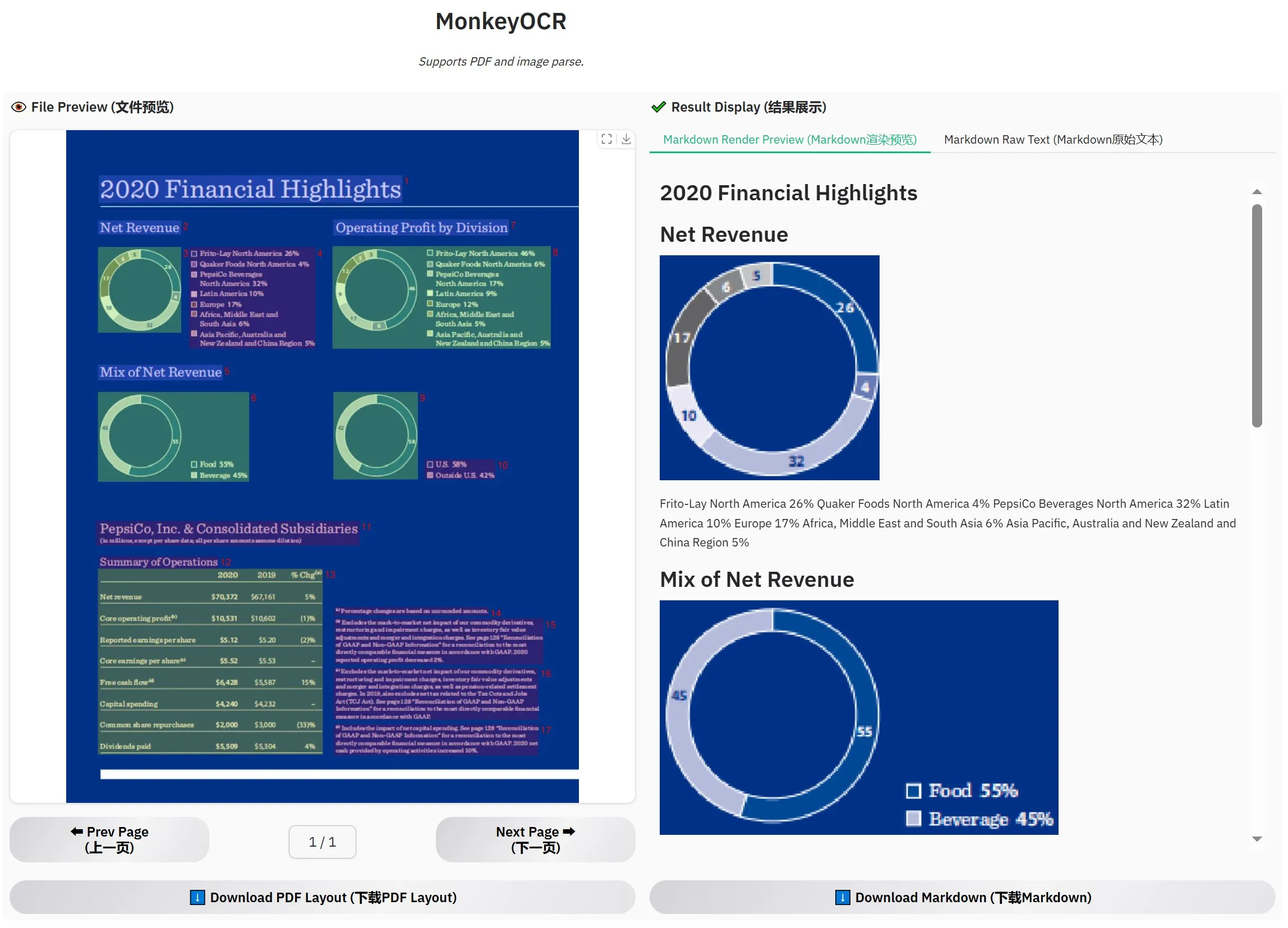
Выпущена MonkeyOCR-3B, официальные тесты показывают превосходство над MinerU: Выпущена новая модель OCR под названием MonkeyOCR-3B, которая в официальных тестах показала лучшие результаты, чем известная модель MinerU. Размер этой модели составляет всего 3B параметров, что позволяет легко запускать ее локально, предоставляя пользователям с большими потребностями в OCR документов новый эффективный вариант. Пользователи могут получить эту модель на HuggingFace (Источник: karminski3)
Observer AI: фреймворк для мониторинга ИИ, отслеживающий экран и анализирующий операции ИИ: Observer AI — это новый фреймворк, способный отслеживать экран пользователя и записывать процесс работы инструментов ИИ (таких как автоматизированные инструменты BrowserUse и др.). Он передает записанный контент ИИ для анализа и может реагировать на результаты анализа (например, через вызов функции MCP или предустановленные сценарии). Этот инструмент предназначен для использования в качестве “надсмотрщика” за операциями ИИ, помогая пользователям понимать и управлять поведением ИИ-помощников. Проект открыт на GitHub (Источник: karminski3)
Выпущен генератор режиссерских сценариев для Veo3, способствующий массовому производству коротких видео: Генератор режиссерских сценариев для модели генерации видео Veo3 теперь доступен на HuggingFace Spaces. Этот инструмент может использовать ИИ для генерации историй и написания сценариев, а затем упорядочивать их в формат, подходящий для Veo3, что упрощает пользователям массовое создание коротких видео. Это предоставляет эффективное решение для создателей контента, которым необходимо производить большое количество коротких видео (Источник: karminski3)
Терминал Ghostty будет поддерживать функции универсального доступа macOS, повышая интерактивность инструментов ИИ: Терминальное приложение Ghostty скоро будет поддерживать инструменты универсального доступа (accessibility tooling) macOS. Это означает, что программы чтения с экрана, а также инструменты ИИ, такие как ChatGPT и Claude, смогут считывать содержимое экрана Ghostty (с разрешения пользователя) и взаимодействовать с ним. Эта функция довольно редка в терминальных приложениях; в настоящее время ее поддерживают только системный Terminal, iTerm2 и Warp. Ghostty также будет предоставлять вспомогательным инструментам информацию о своей структуре (например, разделенные экраны, вкладки), что еще больше расширяет его возможности интеграции с ИИ и вспомогательными технологиями (Источник: mitchellh)
Комплексный обзор инструментов и платформ ИИ: предпочтение отдается Claude Code и Gemini 2.5 Pro: Пользователь поделился своим опытом углубленного использования основных инструментов и платформ ИИ. В области моделей ИИ новая версия Gemini 2.5 Pro высоко ценится за свой диалоговый интеллект, близкий к человеческому, и мощную универсальность (включая кодирование), превосходя даже Claude Opus/Sonnet. Модели серии Claude (Sonnet 4, Opus 4) отлично справляются с задачами кодирования и агентными задачами, их функция Artifacts превосходит Canvas в ChatGPT, а функция проектов удобна для управления контекстом. Однако подписка Claude Plus имеет значительные ограничения на использование Opus 4, план Max 5x ($100/месяц) более практичен. Perplexity больше не рекомендуется из-за улучшения функций конкурентов. Модель o3 от ChatGPT стала более экономичной, o4 mini подходит для коротких задач кодирования. DeepSeek имеет преимущество в цене, но скорость и качество средние. В области IDE Zed еще незрелый, Windsurf и Cursor вызывают сомнения из-за ценовой модели и коммерческого поведения. Среди AI Agent Claude Code является предпочтительным выбором благодаря локальному запуску, высокой экономической эффективности (в сочетании с подпиской), интеграции с IDE и возможностям вызова MCP/инструментов, несмотря на проблемы с галлюцинациями. GitHub Copilot улучшился, но все еще отстает. Aider CLI экономичен, но имеет крутую кривую обучения. Augment Code хорошо справляется с большими кодовыми базами, но требует много времени и дорог. Агенты семейства Cline (Roo Code, Kilo Code) имеют свои особенности, Kilo Code немного превосходит по качеству и полноте кода. Jules (Google) и Codex (OpenAI) как специфичные для поставщиков агенты, первый асинхронный и бесплатный, второй интегрирован с тестированием, но медленнее. Среди поставщиков API OpenRouter (наценка 5%) и Kilo Code (без наценки) являются альтернативными вариантами. Среди инструментов для создания презентаций Gamma.app имеет хороший визуальный эффект, Beautiful.ai силен в генерации текста (Источник: Reddit r/ClaudeAI)
Разработчик создал систему дебатов ИИ, быстро реализовав ее с помощью Claude Code: Разработчик за 20 минут создал систему дебатов ИИ с помощью Claude Code. Эта система настраивает несколько ИИ-агентов с разными “личностями” для дебатов по вопросам, предложенным пользователем, а затем “жюри” из ИИ выносит окончательное заключение. Разработчик заявил, что такие многоаспектные дебаты позволяют быстрее выявлять слепые зоны, а полученные ответы превосходят обсуждения с одной моделью. Код проекта открыт на GitHub (DiogoNeves/ass), что вызвало интерес сообщества к использованию ИИ для самодебатов и помощи в принятии решений (Источник: Reddit r/ClaudeAI)
Разработчик упаковал модель ИИ на устройстве Apple в OpenAI-совместимый API: Разработчик создал небольшое Swift-приложение, которое упаковывает встроенную модель Apple Intelligence на устройстве macOS 26 (вероятно, macOS Sequoia) в локальный сервер. К этому серверу можно обращаться через стандартный интерфейс API OpenAI /v1/chat/completions (http://127.0.0.1:11535), что позволяет любому клиенту, совместимому с API OpenAI, локально вызывать модель Apple на устройстве, при этом данные не покидают Mac. Проект открыт на GitHub (gety-ai/apple-on-device-openai) (Источник: Reddit r/LocalLLaMA)
Функция Agent в OpenWebUI реализована с помощью Pipe: Разработчик поделился функцией Agent (интеллектуального агента), реализованной с помощью функции Pipe в OpenWebUI. Хотя эта реализация в настоящее время выглядит избыточной, она уже имеет элементы пользовательского интерфейса (лаунчер) и может выполнять поиск в Интернете через OpenRouter и OpenAI SDK для выполнения более сложных задач. Код открыт на GitHub (bernardolsp/open-webui-agent-function), пользователи могут изменять все конфигурации агентов в соответствии со своими потребностями (Источник: Reddit r/OpenWebUI)
📚 Обучение
MIT выпустил учебник «Основы компьютерного зрения»: MIT выпустил новый учебник под названием «Основы компьютерного зрения» (Foundations of Computer Vision), соответствующие ресурсы уже доступны онлайн. Это предоставляет студентам и исследователям в области компьютерного зрения новые систематические учебные материалы (Источник: Reddit r/MachineLearning)
Учебник по тонкой настройке LLM: практическое руководство по LoRA и QLoRA: Рекомендуется учебник по тонкой настройке больших языковых моделей с использованием LoRA и QLoRA для новичков. В учебнике четко изложены шаги, которые помогут пользователям выполнить операции поэтапно. Также рекомендуется при возникновении проблем в процессе обучения напрямую передавать ссылку на учебник и вопрос ИИ (с включенной функцией подключения к сети) для получения ответов, использование ИИ для помощи в обучении может значительно повысить эффективность. Адрес учебника: mercity.ai (Источник: karminski3)

Репозиторий кода для обучения наноразмерных LLM, совместимых с TPU, с использованием JAX+Flax: Саурав Махешкар опубликовал репозиторий кода для обучения наноразмерных LLM, написанный на JAX и Flax (с бэкендом NNX) и совместимый с TPU. Особенности проекта включают: быстрый старт с помощью Colab, поддержку шардинга, поддержку сохранения и загрузки контрольных точек из Weights & Biases или Hugging Face, легкость модификации и пример кода с использованием набора данных Tiny Shakespeare. Адрес репозитория: github.com/SauravMaheshkar/nanollm (Источник: weights_biases)
Глобальный хакатон по робототехнике LeRobot от HuggingFace принес плодотворные результаты: Глобальный хакатон по робототехнике LeRobot, организованный HuggingFace, привлек широкое участие: более 10 000 членов сообщества, более 100 контрибьюторов на GitHub, более 2 миллионов загрузок наборов данных и более 10 000 наборов данных, эквивалентных 260 дням записи, загруженных на Hub. В ходе мероприятия появилось множество креативных проектов, таких как робот для игры в UNO, робот-ловушка для комаров, 3D-печатный WALL-E, совместная работа механических рук, робот-мастер чайной церемонии, робот для аэрохоккея и другие, демонстрирующие потенциал применения роботов с открытым исходным кодом в различных сценариях (Источник: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Новая парадигма исследований ИИ: влияние важнее публикаций на ведущих конференциях, блог помог Келлеру Джордану устроиться в OpenAI: Келлер Джордан успешно присоединился к OpenAI благодаря своей статье в блоге об оптимизаторе Muon, и его исследовательские результаты могут даже быть использованы для обучения GPT-5, что вызвало дискуссию о стандартах оценки результатов исследований в области ИИ. Традиционно статьи на ведущих конференциях являются важным показателем влияния исследований, но опыт Джордана, а также случай Джеймса Кэмпбелла, бросившего докторантуру в CMU ради работы в OpenAI, показывают, что практические инженерные навыки, вклад в открытый исходный код и влияние в сообществе становятся все более важными. Оптимизатор Muon продемонстрировал превосходную эффективность обучения по сравнению с AdamW в таких задачах, как NanoGPT и CIFAR-10, что свидетельствует о его огромном потенциале в области обучения моделей ИИ. Эта тенденция отражает быстро меняющийся характер области ИИ, где открытость, совместное создание сообществом и быстрая реакция становятся важными факторами, способствующими инновациям (Источник: 36氪, Yuchenj_UW, jeremyphoward)

Утечка с GitHub полной системной подсказки и информации о внутренних инструментах для v0 версии ИИ-инструмента: Пользователь утверждает, что получил и опубликовал полную системную подсказку (System Prompts) и информацию о внутренних инструментах для v0 версии некоего ИИ-инструмента, объемом более 900 строк, и поделился соответствующей ссылкой на GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). Подобные утечки могут раскрыть концепции проектирования, структуру команд и зависимые вспомогательные инструменты ИИ-моделей на ранних стадиях разработки, что представляет определенную ценность для исследователей и разработчиков в понимании поведения моделей, проведении анализа безопасности или воспроизведении аналогичных функций, но также может повлечь за собой риски безопасности и злоупотреблений (Источник: Reddit r/LocalLLaMA)
![FULL LEAKED v0 System Prompts and Tools [UPDATED]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Инженерный блог Anthropic делится опытом создания multi-agent research system для Claude: Anthropic опубликовала в своем инженерном блоге подробную статью, в которой детально описывается, как они создавали multi-agent research system для Claude. В статье рассказывается о практическом опыте, возникших проблемах и итоговых решениях в процессе разработки, предоставляя ценные идеи и практические советы для создания сложных систем ИИ-агентов. Этот материал привлек внимание сообщества и считается важным справочным материалом для понимания и разработки продвинутых ИИ-агентов (Источник: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
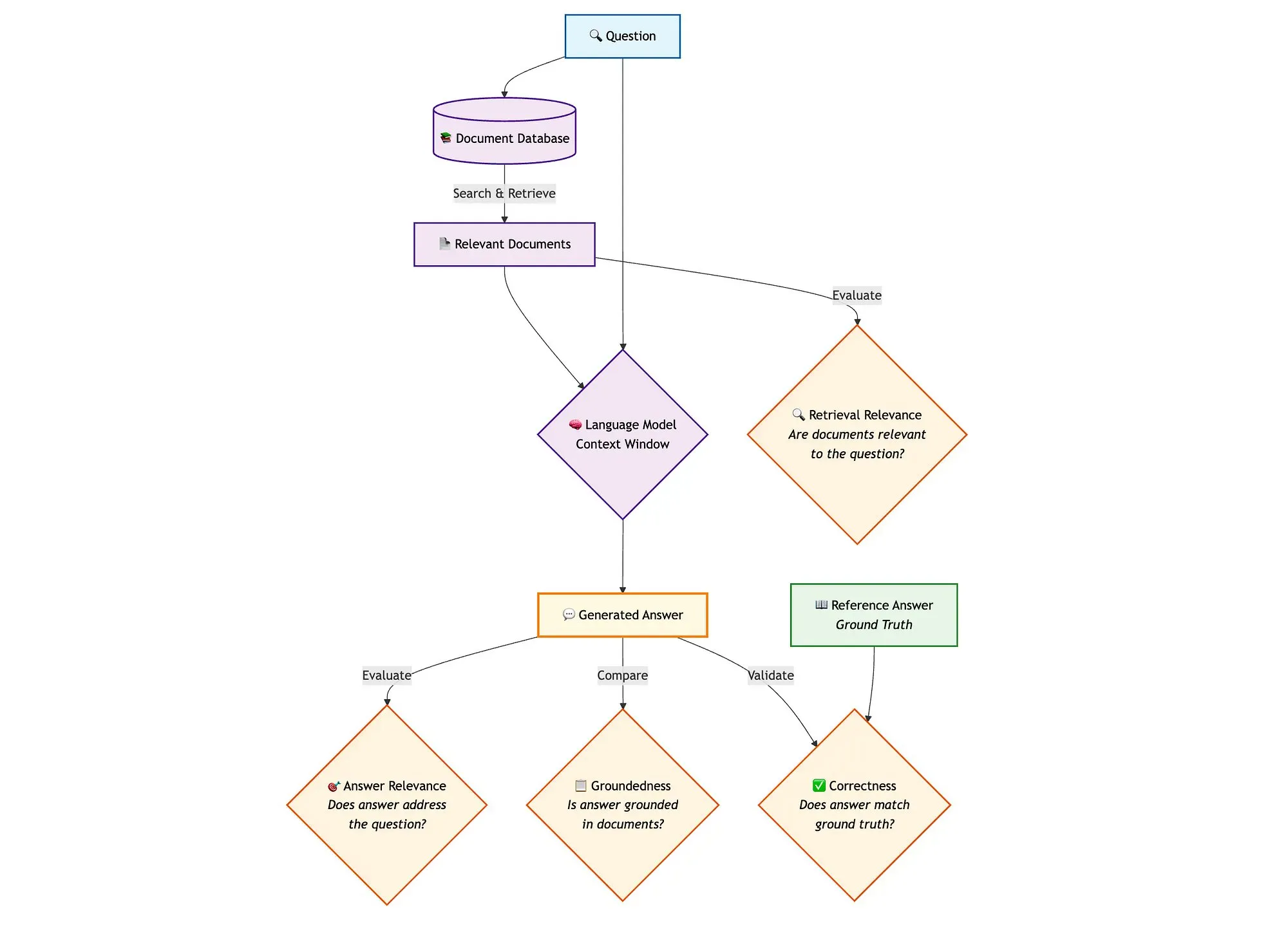
Сочетание LangGraph с Qdrant и другими инструментами для оценки гибридных поисковых RAG-пайплайнов: Технический блог демонстрирует, как использовать miniCOIL, LangGraph, Qdrant, Opik и DeepSeek-R1 для оценки и мониторинга каждого компонента гибридного поискового RAG (Retrieval Augmented Generation) пайплайна. Этот метод использует LLM-as-a-Judge для бинарной оценки релевантности контекста, релевантности ответа и обоснованности, Opik для отслеживания записей и постфактум обратной связи, а также Qdrant в качестве векторного хранилища (с поддержкой плотных и разреженных эмбеддингов miniCOIL) и DeepSeek-R1 на базе SambaNovaAI. LangGraph отвечает за управление всем процессом, включая этап параллельной оценки после генерации (Источник: qdrant_engine, qdrant_engine)
💼 Бизнес
Сообщается, что Meta инвестировала 14,3 млрд долларов в Scale AI и наняла ее основателя Александра Ванга, Google прекращает сотрудничество со Scale: По сообщениям Business Insider и The Information, Meta Platforms заключила стратегическое партнерство с компанией по разметке данных Scale AI и осуществила крупную инвестицию в размере 14,3 млрд долларов, получив 49% акций Scale AI, что довело ее оценку примерно до 290 млрд долларов. Основатель Scale AI, 28-летний Александр Ванг, покинет пост CEO и присоединится к Meta для работы в области сверхинтеллекта. Этот шаг направлен на усиление позиций Meta в области ИИ, особенно на фоне жесткой конкуренции, с которой сталкивается модель Llama. Однако после объявления сделки Google быстро расторгла контракт со Scale AI на разметку данных на сумму около 200 млн долларов в год и начала переговоры с другими поставщиками. Эта сделка вызвала бурные обсуждения в индустрии ИИ относительно талантов, данных и конкурентного ландшафта (Источник: 36氪)

OpenAI и Google Cloud заключили соглашение о сотрудничестве, расширяя источники вычислительных мощностей: Сообщается, что OpenAI после нескольких месяцев переговоров достигла соглашения с Google о сотрудничестве, в рамках которого будет использовать облачные сервисы Google для получения дополнительных вычислительных ресурсов, необходимых для поддержки быстрого роста обучения и инференса своих моделей ИИ. Ранее OpenAI была тесно связана с Microsoft Azure, но по мере резкого роста числа пользователей ChatGPT потребности в вычислительных мощностях превысили возможности одного облачного провайдера. Это сотрудничество знаменует собой диверсификацию стратегии OpenAI в области поставок вычислительных мощностей, а также отражает амбиции Google Cloud в сфере инфраструктуры ИИ. Несмотря на то, что OpenAI и Google являются конкурентами на уровне приложений ИИ, на уровне вычислительных мощностей стороны нашли основу для сотрудничества, исходя из своих потребностей (OpenAI нуждается в стабильных вычислительных мощностях, Google – в окупаемости инвестиций в инфраструктуру) (Источник: 36氪)

Компания по производству роботов с визуальным восприятием Ledong Robotics готовится к IPO на Гонконгской бирже, CEO Alibaba ранее инвестировал в нее: Шэньчжэньская компания Ledong Robotics Co., Ltd. подала проспект эмиссии и планирует провести IPO на Гонконгской фондовой бирже с предполагаемой рыночной капитализацией более 4 млрд гонконгских долларов. Компания специализируется на технологиях визуального восприятия, ее основная продукция включает лидары DTOF, лидары на основе триангуляции и другие датчики и алгоритмические модули, а также выпустила робота-газонокосилку. Ledong Robotics сотрудничает с семью из десяти крупнейших мировых производителей бытовых сервисных роботов и всеми пятью ведущими мировыми производителями коммерческих сервисных роботов. В 2022-2024 годах выручка компании составила 234 млн, 277 млн и 467 млн юаней соответственно, со среднегодовым темпом роста 41,4%, однако компания все еще находится в убытке, хотя чистый убыток ежегодно сокращается. Среди ее инвесторов – Yuanjing Capital, основанная CEO Alibaba У Юнмином, и Huaye Tiancheng, основанная бывшими топ-менеджерами Huawei (Источник: 36氪)

🌟 Сообщество
Обсуждение архитектуры AI Agent: взгляд с точки зрения программной инженерии против взгляда с точки зрения социальной координации: В ходе обсуждения многоагентных систем (Multi-Agent Systems) Омар Хаттаб предложил рассматривать их как проблему программной инженерии ИИ, а не как сложную проблему социальной координации. Он считает, что, определяя контракты между модулями и контролируя потоки информации, можно создавать эффективные системы, не прибегая к моделированию “общества агентов” с конфликтующими целями. Ключ заключается в хорошо продуманной архитектуре системы и высокоструктурированных контрактах модулей. Однако он также отметил, что многие архитектурные решения зависят от текущих возможностей моделей (таких как длина контекста, способность к декомпозиции задач) и других временных факторов. Поэтому необходимо разрабатывать языки программирования/запросов, способные отделить намерение от базовых техник реализации, подобно тому, как компиляторы в традиционном программировании оптимизируют модульный код. Эта точка зрения подчеркивает важность системной архитектуры и модульного программирования при проектировании AI Agent, а не чрезмерное внимание к свободному взаимодействию агентов и согласованию их целей (Источник: lateinteraction)
Обсуждение оптимизаторов моделей ИИ: оптимизатор Muon привлекает внимание, AdamW остается основным: В сообществе активизировалось обсуждение оптимизаторов моделей ИИ, особенно оптимизатора Muon, предложенного Келлером Джорданом. Ючэнь Цзинь отметил, что Muon, всего лишь благодаря статье в блоге, помог Джордану попасть в OpenAI и, возможно, будет использоваться для обучения GPT-5, подчеркнув, что практическое влияние важнее статей на ведущих конференциях. Он упомянул, что Muon на NanoGPT масштабируется лучше, чем AdamW. Однако hyhieu226 считает, что, несмотря на тысячи статей об оптимизаторах, реальные улучшения SOTA (State-of-the-Art) свелись лишь к переходу от Adam к AdamW (остальное в основном оптимизация реализации), поэтому не следует больше уделять чрезмерное внимание таким статьям и считает, что нет необходимости специально ссылаться на источник AdamW. Это отражает напряженность между академическими исследованиями и практическими результатами, а также различные взгляды сообщества на прогресс в области оптимизаторов (Источник: Yuchenj_UW, hyhieu226)
Советы и обсуждения по использованию моделей Claude: управление контекстом, инженерия подсказок и возможности Agent: В сообществе активно обсуждаются советы и опыт использования моделей серии Claude (Sonnet, Opus, Haiku). Пользователи обнаружили, что избегание автоматического сжатия контекста (auto-compact), активное управление контекстом (например, запись шагов в claude.md или GitHub issues) и выход из сеанса с последующим возобновлением, когда остается 5-10% лимита, могут значительно продлить время использования подписки Max и улучшить результаты. Claude Code как инструмент CLI Agent пользуется популярностью благодаря своей высокой экономической эффективности (в сочетании с подпиской), локальному запуску, интеграции с IDE и возможностям вызова MCP/инструментов, особенно при использовании модели Sonnet. Пользователи делятся опытом использования тщательно разработанных подсказок (например, подсказка для параллельного анализа несколькими субагентами в задачах проверки безопасности) для раскрытия мощных возможностей Agent в Claude Code. В то же время сообщество также обсуждает проблемы галлюцинаций моделей Claude в больших кодовых базах, а также их преимущества и недостатки по сравнению с другими моделями, такими как Gemini, в различных задачах. Например, некоторые пользователи считают, что Gemini 2.5 Pro лучше подходит для общих диалогов и аргументации, в то время как Claude лидирует в задачах кодирования и Agent (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

Растущая роль ИИ в программировании вызывает размышления о перспективах специальности CS и методах работы инженеров: CEO Microsoft Сатья Наделла заявил, что 20-30% кода в его компании пишется ИИ, а Марк Цукерберг предсказал, что в течение года половина разработки программного обеспечения в Meta (особенно модели Llama) будет выполняться ИИ, что вызвало дискуссии о перспективах специальности “Информатика” (CS). Комментаторы считают, что, хотя ИИ-ассистированное кодирование становится все более распространенным, CS — это гораздо больше, чем просто кодирование, и ROI от использования ИИ старшими инженерами выше. Многие разработчики заявляют, что ИИ в настоящее время в основном используется как инструмент повышения эффективности, например, для помощи в генерации кода, отладке, но все еще требует человеческого руководства и проверки, особенно в сложных системах и при понимании требований. Применение ИИ в программировании заставляет разработчиков задуматься о том, как использовать ИИ для повышения эффективности, а не быть им замененными, а также переосмыслить роль и ограничения ИИ во всем процессе разработки программного обеспечения (Источник: Reddit r/ArtificialInteligence, cto_junior)
Этика ИИ и социальное воздействие: от “участия” ИИ в ЕГЭ до опасений “порабощения” человечества ИИ: “Участие” ИИ в ЕГЭ и его способность решать сложные математические задачи демонстрируют его потенциал в сфере образования, такой как персонализированное обучение, интеллектуальная проверка работ и т.д., но также вызывают опасения по поводу чрезмерной зависимости от ИИ, “конвейеризации” учебного процесса и отсутствия эмоционального общения. Более глубокие дискуссии затрагивают вопрос о том, может ли “полезность” ИИ стать своего рода “троянским конем”, ведущим к тому, что люди, стремясь к удобству и удовольствию, добровольно откажутся от своей автономии, формируя “счастливое рабство”. Существует мнение, что свойство ИИ “беспрекословно подчиняться” может усугублять когнитивные искажения пользователей. Эти обсуждения отражают глубокую обеспокоенность общественности этическими, социально-структурными последствиями быстрого развития технологий ИИ и их влиянием на индивидуальную автономию (Источник: 36氪, Reddit r/ArtificialInteligence)

Крестный отец игр Джон Кармак о будущем LLM и игр: интерактивное обучение – ключ, текущие LLM – не будущее игр: Сооснователь id Software Джон Кармак поделился своим мнением о применении ИИ в игровой индустрии. Он считает, что, несмотря на выдающиеся достижения LLM, их особенность “все знать, но ничему не учиться” (основанная на предварительном обучении, а не на реальном интерактивном обучении) не является будущим игрового ИИ. Он подчеркивает важность обучения через поток интерактивного опыта, подобно тому, как учатся люди и животные. Кармак вспомнил проект Atari от DeepMind, отметив, что, хотя он и мог играть в игры, его эффективность использования данных была значительно ниже, чем у человека. Он считает, что текущий ИИ все еще нуждается в решении проблем непрерывного, эффективного, пожизненного, многозадачного онлайн-обучения в одной среде, и упомянул свои эксперименты с физическими роботами в играх Atari, подчеркнув сложность взаимодействия с реальным миром (например, задержки, надежность роботов, считывание очков). Он считает, что ИИ необходимо развивать “чутье” на жизнеспособность стратегий, а не просто сопоставление с образцом, чтобы действительно сравниться с человеческими игроками или играть большую роль в разработке игр (Источник: 36氪)

💡 Прочее
Резкий рост числа научных статей по ИИ вызывает опасения по поводу качества, общедоступные наборы данных и инструменты ИИ могут способствовать появлению “фабрик статей”: Science сообщает о резком росте числа низкокачественных статей, основанных на крупных общедоступных наборах данных, таких как американский NHANES, особенно после распространения инструментов ИИ (таких как ChatGPT) в 2022 году. Исследователи обнаружили, что многие статьи следуют простой “формуле”, массово генерируя “новые открытия” путем перестановки и комбинирования переменных, что свидетельствует о проблемах “охоты за p-значениями” и выборочного анализа данных. Например, после корректировки 28 исследований депрессии, основанных на NHANES, более половины “открытий” могли оказаться просто статистическим шумом. Это явление, называемое “научной игрой в заполнение пробелов”, может быть связано с использованием “фабриками статей” ИИ для быстрого производства публикаций. Академическое сообщество призывает журналы усилить рецензирование, разрабатывать инструменты для обнаружения текста, сгенерированного ИИ, и реформировать систему оценки научных исследований, ориентированную на количество, чтобы сдержать распространение “мусорных статей” (Источник: 36氪)

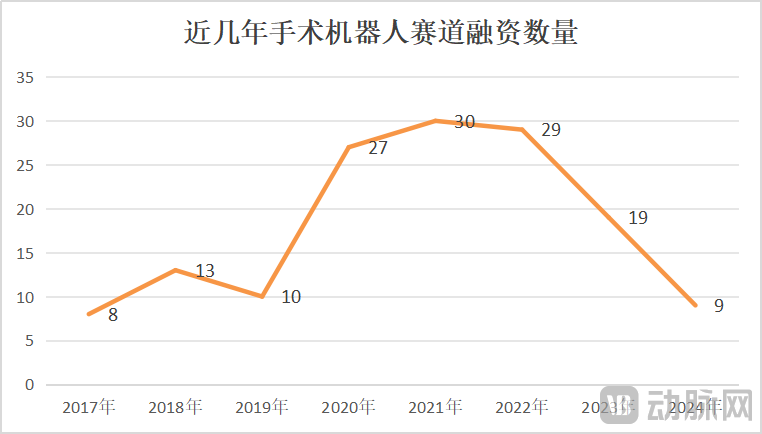
Рынок хирургических роботов: рост и кризис сосуществуют, технологические инновации и расширение рынка становятся ключевыми факторами: В январе-мае 2025 года количество выигранных тендеров на хирургических роботов в Китае выросло на 82,9% по сравнению с аналогичным периодом прошлого года. Рынок кажется оживленным, однако такие события, как поиск покупателя компанией CMR Surgical и банкротство отечественного предприятия по производству роботов для сосудистых вмешательств, также указывают на кризис в отрасли. Кризис включает: высокую внутреннюю конкуренцию, острую борьбу в каждом сегменте рынка; резкое сокращение финансирования, некоммерциализированные предприятия сталкиваются с нехваткой средств; ограниченную клиническую ценность некоторых продуктов, пригодных только для простых патологий; появление ценовых войн на рынке, однако низкая цена не всегда означает большой объем продаж, больницы больше ценят производительность и качество; сильное влияние на коммерциализацию политики (например, антикоррупционной кампании в медицине) и макроэкономической ситуации. Для выхода из кризиса предприятия ищут пути прорыва через технологические инновации (интеграция ИИ, снижение затрат, 5G + удаленные операции, расширение показаний, освоение сложных хирургических вмешательств), ускорение выхода на зарубежные рынки и проникновение в уездные больницы (Источник: 36氪)
Perplexity: снижение пользовательских рекомендаций из-за производительности модели и улучшения функций конкурентов: Пользователь Suhail заявил, что простота, форматирование и другие особенности Perplexity не имеют аналогов у других продуктов, особенно для пользователей, ориентированных на поиск/ответы на вопросы, а не на универсальные чат-продукты. Однако в другом всеобъемлющем обзоре инструментов ИИ Perplexity был признан нерентабельным и не рекомендованным (если нет специальных скидок) из-за более слабой собственной модели, предоставления в основном бюджетных версий других известных моделей (таких как o4 mini, Gemini 2.5 Pro, Sonnet 4, без o3 или Opus), производительности моделей, уступающей оригинальным, а также улучшения функций глубокого поиска у конкурентов (таких как ChatGPT и Gemini) (Источник: Suhail, Reddit r/ClaudeAI)