
Ключевые слова:Искусственный интеллект (ИИ), NVIDIA, Deutsche Telekom, Промышленное облако ИИ, Суверенный ИИ, Anthropic, Многоагентные системы, Закон RAISE, Европейское промышленное облако ИИ, Обход чип-блокировки с помощью летающих жестких дисков, Исследование многоагентных систем Claude, Закон RAISE штата Нью-Йорк, Дебаты между Дженсеном Хуангом и CEO Anthropic
🔥 В фокусе
Nvidia и Deutsche Telekom сотрудничают для создания европейского промышленного AI-облака: Канцлер Германии встретился с CEO Nvidia Дженсеном Хуангом для обсуждения углубления стратегического сотрудничества, направленного на укрепление позиций Германии как мирового лидера в области AI. Ключевые темы включали создание суверенной AI-инфраструктуры и ускорение развития AI-экосистемы. С этой целью Deutsche Telekom и Nvidia объявили о сотрудничестве, планируя к 2026 году создать первое в мире промышленное AI-облако для европейских производителей. Эта платформа обеспечит суверенитет данных и будет способствовать инновациям в области AI в европейской промышленности. (Источник: nvidia)

Китайские AI-компании используют «летающие контейнеры с жесткими дисками» для обхода американских ограничений на чипы: В ответ на ограничения США на экспорт AI-чипов в Китай, китайские компании применяют новую стратегию: они напрямую доставляют жесткие диски с данными для обучения AI в зарубежные дата-центры (например, в Малайзии), где используют серверы с передовыми чипами, такими как Nvidia, для обучения моделей, а затем возвращают результаты обратно. Этот шаг подчеркивает сложность глобальной цепочки поставок AI и гибкость китайских предприятий в условиях ограничений, а также способствует превращению Юго-Восточной Азии и Ближнего Востока в новые горячие точки для AI дата-центров. (Источник: dotey)

Anthropic опубликовала метод создания мультиагентных исследовательских систем: Инженерный блог Anthropic подробно описывает, как компания использует несколько параллельно работающих агентов для наращивания исследовательских возможностей Claude. В статье делятся успешным опытом разработки, возникшими проблемами и инженерными решениями. Такой режим совместной работы нескольких агентов направлен на повышение способности больших языковых моделей к глубокому анализу и обработке информации в сложных исследовательских задачах, предоставляя практический ориентир для создания более мощных AI-ассистентов для исследований. (Источник: AnthropicAI)
Штат Нью-Йорк принял закон RAISE Act, ужесточающий требования к прозрачности передовых AI-моделей: Штат Нью-Йорк принял RAISE Act, направленный на установление требований к прозрачности для передовых AI-моделей. Компании, такие как Anthropic, предоставили свои отзывы по законопроекту; несмотря на улучшения, остаются опасения, такие как размытость ключевых определений, неясность возможностей исправления нарушений соответствия, слишком широкое определение «инцидента безопасности» и короткий срок для отчетности (72 часа), а также возможность наложения многомиллионных штрафов за незначительные технические нарушения, что создает риски для малых компаний. Anthropic призывает к созданию единых федеральных стандартов прозрачности и рекомендует, чтобы предложения на уровне штатов фокусировались на прозрачности и избегали чрезмерного регулирования. (Источник: jackclarkSF)
CEO Nvidia Дженсен Хуанг опроверг взгляды CEO Anthropic на развитие AI: Дженсен Хуанг на пресс-конференции Viva Technology в Париже выступил с опровержением взглядов CEO Anthropic Дарио Амодея. Амодея обвинили в том, что он считает AI слишком опасным и его разработку следует доверить лишь определенным компаниям; слишком дорогим, чтобы его популяризировать; и слишком мощным, что приведет к потере рабочих мест. Хуанг подчеркнул, что AI должен развиваться безопасно, ответственно и открыто, а не в «темной комнате» с заявлениями о безопасности. Эти высказывания вызвали дискуссию о путях развития AI (открытый демократический vs. элитарный закрытый), подчеркнув идеологические различия между гигантами отрасли. (Источник: pmddomingos, dotey)

🎯 Тренды
Meta может потратить 14 миллиардов долларов на покупку мажоритарной доли в Scale AI для усиления своих AI-возможностей: По сообщениям, Meta планирует приобрести 49% акций компании по разметке данных для AI Scale AI за 14,8 миллиарда долларов и, возможно, назначит ее CEO руководителем недавно созданной в Meta «группы суперинтеллекта». Этот шаг направлен на решение проблем, связанных с неудовлетворительными результатами модели Llama 4 и оттоком AI-талантов внутри компании, путем привлечения внешних ведущих специалистов и технологий для ускорения наверстывания упущенного в области общего искусственного интеллекта. (Источник: Reddit r/ArtificialInteligence, QbitAI)

OpenAI выпустила модель o3-pro, значительное снижение цены на o3 вызвало дискуссии о производительности: OpenAI официально выпустила свою «новейшую и самую мощную» модель для логического вывода o3-pro, предназначенную для пользователей Pro и Team, с ценой API 20 долларов за миллион токенов на входе и 80 долларов за миллион токенов на выходе. Одновременно цена API для оригинальной модели o3 была снижена на 80%, почти сравнявшись с GPT-4o. Официально заявлено, что o3-pro демонстрирует превосходные результаты в математике, науке и программировании, но имеет более длительное время отклика. Снижение цены на o3 вызвало в сообществе бурное обсуждение возможного «снижения интеллекта», некоторые пользователи сообщают о падении производительности, однако единых эмпирических данных нет. (Источник: QbitAI)

Cohere Labs исследует влияние универсального токенизатора на адаптивность языковых моделей: Cohere Labs опубликовала новое исследование, в котором изучается, может ли токенизатор, обученный на большем количестве языков, чем целевые языки предварительного обучения (universal tokenizer), улучшить адаптивность модели к новым языкам (plasticity) без ущерба для производительности предварительного обучения. Исследование показало, что универсальный токенизатор повышает эффективность языковой адаптации в 8 раз и производительность в 2 раза, и даже в условиях крайне малого количества данных и совершенно незнакомых языков его процент побед на 5% выше, чем у специализированных токенизаторов. Это свидетельствует о том, что универсальные токенизаторы могут эффективно повышать гибкость и эффективность моделей при обработке многоязычных задач. (Источник: sarahookr)

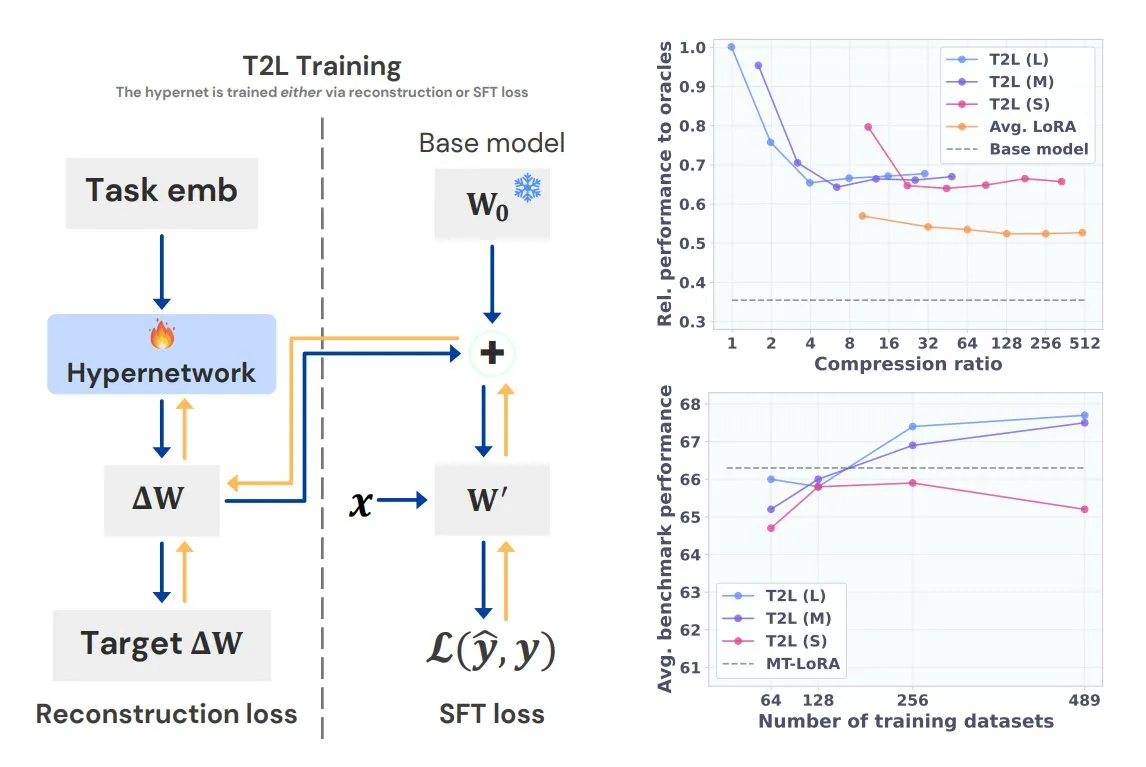
Sakana AI представляет Text-to-LoRA (T2L), генерирующий специализированные LoRA для задач одной фразой: Sakana AI, сооснователем которой является один из авторов Transformer Llion Jones, выпустила технологию Text-to-LoRA (T2L). Эта архитектура сверхсети способна быстро генерировать специфические адаптеры LoRA на основе текстового описания задачи, что значительно упрощает процесс тонкой настройки LLM. T2L может сжимать существующие LoRA и генерировать эффективные адаптеры в сценариях с нулевым обучением (zero-shot), предоставляя новый путь для быстрой адаптации моделей к задачам с длинным хвостом распределения. (Источник: TheTuringPost, QbitAI)
Университет Цинхуа и Tencent совместно выпустили Scene Splatter, реализующий высококачественную генерацию 3D-сцен: Университет Цинхуа в сотрудничестве с Tencent предложил технологию Scene Splatter, которая, исходя из одного изображения, использует видео диффузионные модели и инновационный механизм импульсного наведения для генерации видеофрагментов, удовлетворяющих требованиям трехмерной согласованности, тем самым создавая сложные 3D-сцены. Этот метод преодолевает зависимость от традиционных многоракурсных данных, повышает точность и согласованность генерируемых сцен, предлагая новые идеи для ключевых аспектов мировых моделей и воплощенного интеллекта. (Источник: QbitAI)

Tencent Hunyuan 3D 2.1 выпущен: первая производственная PBR 3D-генеративная модель с открытым исходным кодом: Tencent выпустила Hunyuan 3D 2.1, заявленную как первая полностью открытая производственная 3D-генеративная модель, основанная на физически корректном рендеринге (PBR). Модель способна генерировать визуальные эффекты кинематографического уровня, поддерживает синтез PBR-материалов, таких как кожа и бронза, с реалистичными эффектами взаимодействия света и тени. Веса модели, код для обучения/вывода, конвейеры данных и архитектура полностью открыты, могут работать на потребительских GPU, предоставляя создателям, разработчикам и небольшим командам возможности для тонкой настройки и создания 3D-контента. (Источник: cognitivecompai, huggingface)
Mistral выпустила свою первую модель для логического вывода Magistral Small: Mistral AI выпустила свою первую модель для логического вывода Magistral Small, которая фокусируется на предметно-ориентированных, прозрачных и многоязычных возможностях логического вывода. Пользователи уже могут опробовать ее через платформы Hugging Face и FeatherlessAI. Это знаменует важный шаг Mistral в создании более специализированных и понятных инструментов AI для логического вывода. (Источник: dl_weekly, huggingface)
ByteDance обвиняют в том, что название ее модели Dolphin конфликтует с cognitivecomputations/dolphin: Указывается, что модель Dolphin, выпущенная ByteDance, имеет такое же название, как и уже существующая модель cognitivecomputations/dolphin. Cognitive Computations заявили, что комментировали эту проблему 24 дня назад, когда ByteDance впервые выпустила модель, но их замечание не было учтено. Этот инцидент вызвал в сообществе дискуссию о нормах именования моделей и предотвращении путаницы. (Источник: cognitivecompai)
Упрощен MLX Swift LLM API, для начала чат-сессии достаточно трех строк кода: В ответ на отзывы разработчиков о сложности начала работы с MLX Swift LLM API, команда внесла улучшения и выпустила новый упрощенный API. Теперь разработчикам достаточно всего трех строк кода для загрузки LLM или VLM в проекте Swift и запуска чат-сессии, что значительно снижает порог входа для использования и интеграции больших языковых моделей в экосистеме Apple. (Источник: ImazAngel)

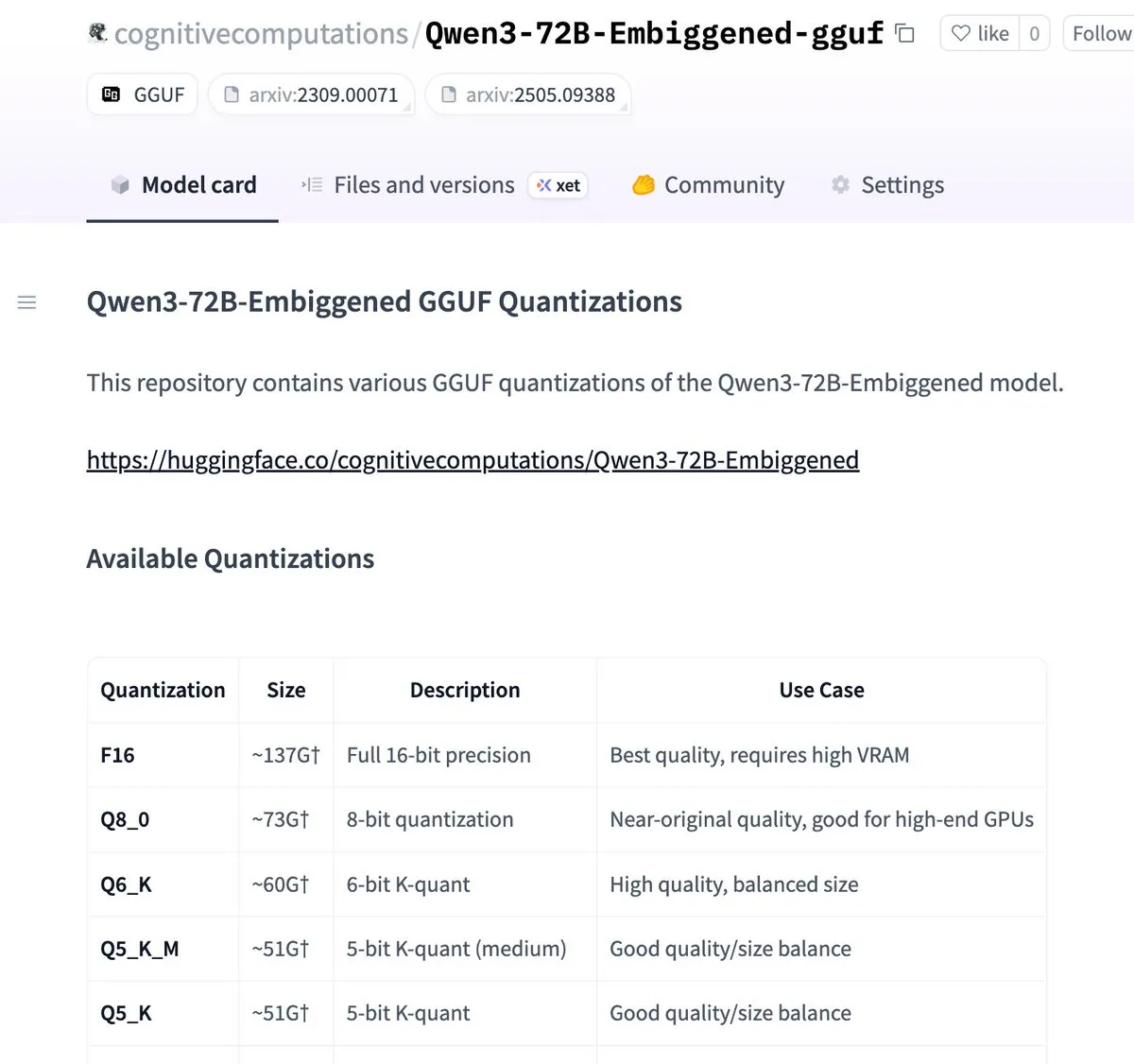
Версии Qwen3-72B-Embiggened и 58B квантованы в формат llama.cpp gguf: Eric Hartford объявил о квантовании моделей Qwen3-72B-Embiggened и Qwen3-58B-Embiggened в формат llama.cpp gguf, что позволяет пользователям запускать эти большие модели на локальных устройствах. Этот проект получил поддержку вычислительных ресурсов AMD mi300x. (Источник: ClementDelangue, cognitivecompai)
Немецкая Black Forest Labs выпустила серию text-to-image моделей FLUX.1, ориентированных на согласованность персонажей: Немецкая компания Black Forest Labs представила три text-to-image модели: FLUX.1 Kontext max, pro и dev. Эти модели сосредоточены на сохранении согласованности персонажей при изменении фона, позы или стиля. Они сочетают в себе сверточные кодеры-декодеры изображений и Transformer, обученные с помощью состязательной диффузионной дистилляции, и поддерживают эффективное и точное редактирование. Версии max и pro уже доступны через FLUX Playground и партнерские платформы. (Источник: DeepLearningAI)

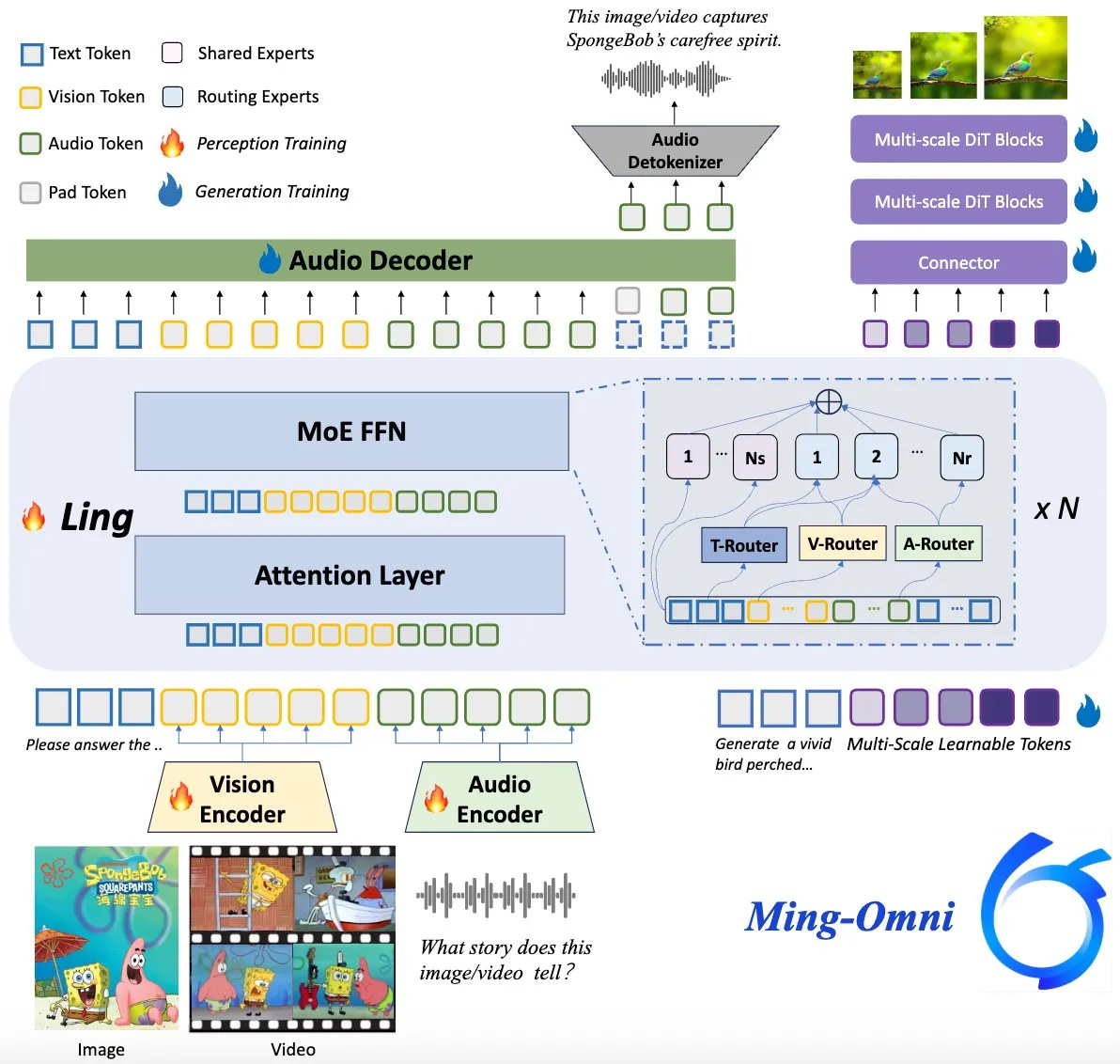
Модель Ming-Omni с открытым исходным кодом, конкурент GPT-4o: На Hugging Face выпущена мультимодальная модель с открытым исходным кодом под названием Ming-Omni, предназначенная для обеспечения унифицированных возможностей восприятия и генерации, сопоставимых с GPT-4o. Модель поддерживает текст, изображения, аудио и видео в качестве входных данных, может генерировать речь и изображения высокого разрешения, использует архитектуру MoE и специфичные для модальностей маршрутизаторы, обладает функциями контекстно-зависимого чата, TTS, редактирования изображений и т.д., с всего 2,8 млрд активных параметров, а также полностью открытыми весами и кодом. (Источник: huggingface)
AI-исследование показало, что мультимодальные LLM могут развивать интерпретируемые концептуальные представления, подобные человеческим: Китайские исследователи обнаружили, что мультимодальные большие языковые модели (LLM) способны развивать интерпретируемые, подобные человеческим, способы представления концепций объектов. Это исследование открывает новые перспективы для понимания внутренних механизмов работы LLM и того, как они понимают и связывают информацию различных модальностей (например, текст и изображения). (Источник: Reddit r/LocalLLaMA)
DeepMind сотрудничает с Национальным центром ураганов США для прогнозирования ураганов с помощью AI: Национальный центр ураганов США впервые применил технологию AI для прогнозирования ураганов и других сильных штормов, начав сотрудничество с DeepMind. Это знаменует важный шаг в применении AI в области метеорологического прогнозирования и обещает повысить точность и своевременность предупреждений об экстремальных погодных явлениях. (Источник: MIT Technology Review)
🧰 Инструменты
LlamaParse выпустила функцию «пресетов» для оптимизации разбора различных типов документов: LlamaParse представила функцию «пресетов» (Presets), предлагающую ряд легко понятных предварительно сконфигурированных режимов для оптимизации настроек разбора под различные сценарии использования. Включает режимы «быстрый», «сбалансированный» и «расширенный» для общих сценариев, а также оптимизированные режимы для конкретных типов документов, таких как счета-фактуры, научные статьи, техническая документация и формы. Эти пресеты призваны помочь пользователям удобнее получать структурированный вывод для конкретных типов документов, например, табличное представление полей форм, вывод XML для схем в технической документации и т.д. (Источник: jerryjliu0, jerryjliu0)
Codegen представил функцию преобразования видео в PR, AI помогает исправлять баги UI: Codegen объявил о поддержке видеоввода: пользователи могут прикреплять видео с проблемой в Slack или Linear, Codegen использует Gemini для извлечения информации из видео и автоматически исправляет баги, связанные с UI, генерируя PR. Эта функция призвана значительно повысить эффективность сообщения о проблемах UI и их исправления, особенно для багов, связанных с взаимодействием. (Источник: mathemagic1an)
LlamaIndex представляет структурированные «блоки памяти артефактов» для интеллектуальных агентов заполнения форм: LlamaIndex продемонстрировал новую концепцию памяти — структурированные «блоки памяти артефактов» (structured artifact memory block), специально разработанные для интеллектуальных агентов, например, для заполнения форм. Этот блок памяти отслеживает структурированную схему Pydantic, которая постоянно обновляется с новыми сообщениями в чате и всегда внедряется в контекстное окно, позволяя агенту постоянно быть в курсе предпочтений пользователя и уже заполненной информации в форме, например, при сборе деталей заказа пиццы, таких как размер, адрес и т.д. (Источник: jerryjliu0)

Davia: Инструмент для генерации веб-страниц WYSIWYG на базе FastAPI с открытым исходным кодом: Davia — это проект с открытым исходным кодом, созданный с использованием FastAPI, целью которого является предоставление интерфейса для генерации веб-страниц по принципу «что видишь, то и получаешь» (WYSIWYG), аналогично функциям чат-интерфейсов ведущих производителей больших моделей. Пользователи могут установить его с помощью pip install davia. Он поддерживает настройку цветов Tailwind, адаптивную верстку и темный режим, используя shadcn/ui в качестве UI-компонентов. (Источник: karminski3)
Llama-server-launcher: графический интерфейс для сложных конфигураций llama.cpp: Учитывая растущую сложность конфигурации llama.cpp, сравнимую с веб-серверами вроде Nginx, сообщество разработало проект llama-server-launcher. Этот инструмент предоставляет графический интерфейс, позволяющий пользователям выбирать модель для запуска, количество потоков, размер контекста, температуру, выгрузку на GPU, размер пакета (batch size) и другие параметры путем простого выбора, что упрощает процесс настройки и экономит время на изучение документации. (Источник: karminski3)
Радость для пользователей Mac: MLX Llama 3 + MPS TTS для создания офлайн-голосового помощника: Разработчик поделился опытом создания офлайн-голосового помощника на Mac Mini M4 с использованием MLX-LM (4-битная Llama-3-8B) и Kokoro TTS (работающего через MPS). Это решение не требует облачных сервисов или демона Ollama, может работать в пределах 16 ГБ ОЗУ и реализует сквозные функции офлайн-чата и TTS, предоставляя пользователям Mac с чипами серии M новый вариант локального AI-голосового помощника. (Источник: Reddit r/LocalLLaMA)
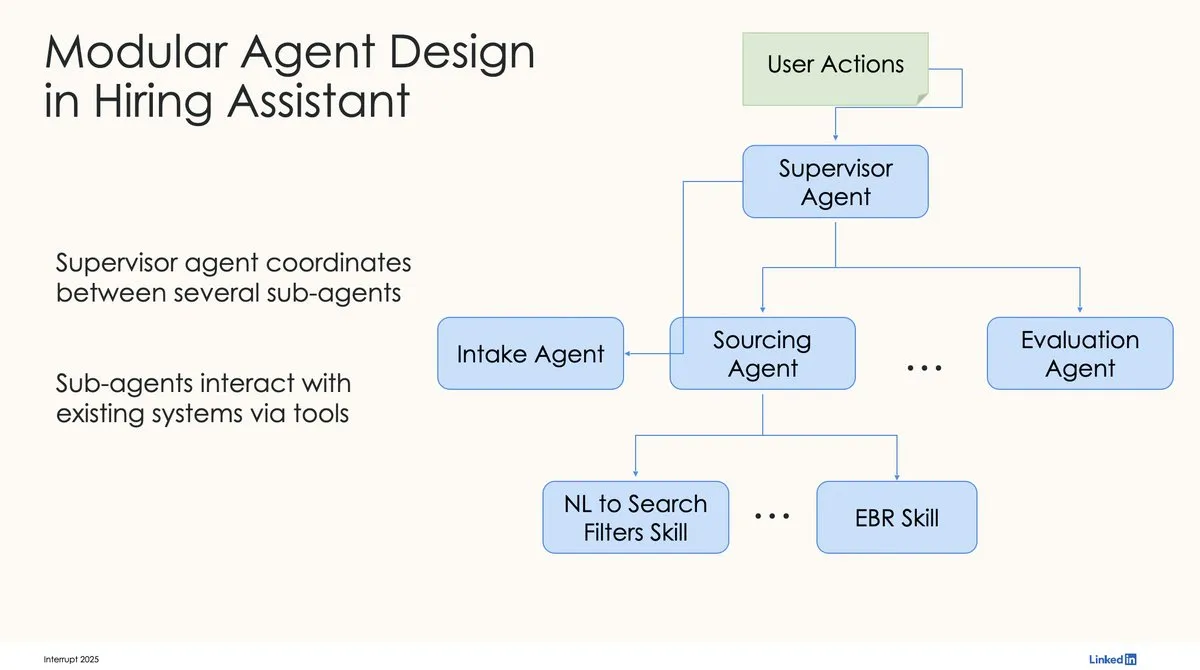
LinkedIn использует LangChain и LangGraph для создания первого производственного AI-ассистента по подбору персонала: David Tag из LinkedIn поделился технической архитектурой их первого производственного AI-ассистента по подбору персонала LinkedIn Hiring Assistant, созданного с использованием LangChain и LangGraph. Эта платформа успешно масштабирована более чем на 20 команд, демонстрируя потенциал LangChain в разработке и масштабном применении AI-агентов корпоративного уровня. (Источник: LangChainAI, hwchase17)
📚 Обучение
ZTE предложила новые метрики LCP и ROUGE-LCP и фреймворк SPSR-Graph для оценки и оптимизации автодополнения кода: Команда ZTE предложила две новые метрики оценки для AI-автодополнения кода: самый длинный общий префикс (LCP) и ROUGE-LCP, нацеленные на более точное отражение реальной готовности разработчиков к принятию предложений. Одновременно они разработали фреймворк SPSR-Graph для обработки корпусов кода на уровне репозитория, который путем построения графа знаний кода улучшает понимание моделью структуры и семантики всего репозитория. Эксперименты показали, что новые метрики лучше коррелируют с уровнем принятия пользователями, а SPSR-Graph значительно повышает производительность моделей, таких как Qwen2.5-7B-Coder, в задачах автодополнения кода C/C++ в телекоммуникационной отрасли. (Источник: QbitAI)

Новая работа Kaiming He: Dispersive Loss вводит регуляризацию для diffusion models, улучшая качество генерации: Kaiming He и его соавторы предложили Dispersive Loss, метод регуляризации plug-and-play, направленный на улучшение качества и реалистичности генерируемых изображений путем поощрения рассредоточения промежуточных представлений diffusion models в скрытом пространстве. Этот метод не требует пар положительных примеров, имеет низкие вычислительные затраты, может напрямую применяться к существующим diffusion models и совместим с исходной функцией потерь. Эксперименты на ImageNet показали, что Dispersive Loss значительно улучшает результаты генерации моделей, таких как DiT и SiT. (Источник: QbitAI)

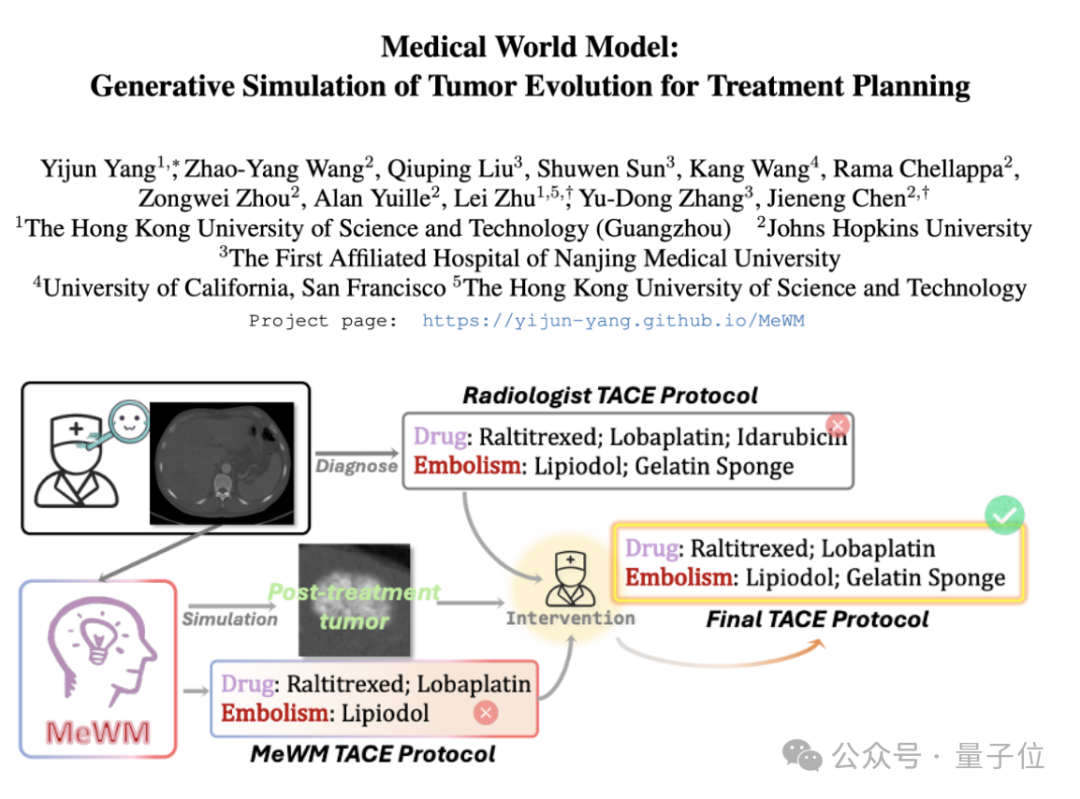
Предложена медицинская мировая модель (MeWM) для моделирования эволюции опухолей и помощи в принятии терапевтических решений: Ученые из Гонконгского университета науки и технологий (Гуанчжоу) и других учреждений предложили медицинскую мировую модель (MeWM), способную моделировать будущий процесс эволюции опухоли на основе клинических терапевтических решений. MeWM интегрирует симулятор эволюции опухоли (3D diffusion model), модель прогнозирования риска выживаемости и создает замкнутый цикл оптимизации «генерация схемы — симуляционное моделирование — оценка выживаемости», обеспечивая персонализированную и визуализированную поддержку принятия решений для планирования интервенционного лечения рака. (Источник: QbitAI)
Статья исследует разложение активаций MLP на интерпретируемые признаки с помощью полунеотрицательной матричной факторизации (SNMF): Новая статья предлагает использовать полунеотрицательную матричную факторизацию (SNMF) для прямого разложения значений активации многослойных перцептронов (MLP) с целью выявления интерпретируемых признаков. Этот метод направлен на изучение разреженных признаков, состоящих из линейных комбинаций совместно активируемых нейронов, и их отображение на входные данные активации, тем самым повышая интерпретируемость признаков. Эксперименты показывают, что признаки, полученные с помощью SNMF, превосходят разреженные автоэнкодеры (SAE) в каузальном наведении и согласуются с человеческими интерпретируемыми концепциями, выявляя иерархическую структуру в пространстве активаций MLP. (Источник: HuggingFace Daily Papers)
Комментарий к исследованию Apple об «иллюзии мышления»: указываются ограничения в дизайне эксперимента: В обзорной статье ставится под сомнение исследование Shojaee и др. о «коллапсе точности» больших моделей логического вывода (LRM) при решении задач планирования (под названием «Иллюзия мышления: понимание сильных и слабых сторон моделей логического вывода через призму сложности задач»). В комментарии утверждается, что выводы оригинального исследования в основном отражают ограничения дизайна эксперимента, а не фундаментальные сбои в логическом выводе LRM. Например, эксперимент с Ханойской башней превышал ограничения модели на количество выходных токенов, а бенчмарк «переправа через реку» содержал математически неразрешимые экземпляры. После исправления этих экспериментальных недостатков модели продемонстрировали высокую точность в задачах, ранее заявленных как полностью провальные. (Источник: HuggingFace Daily Papers)
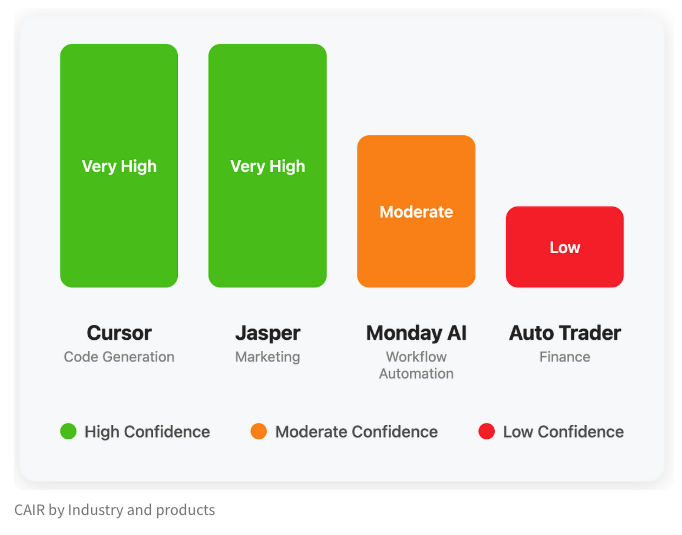
LangChain опубликовал блог, обсуждающий скрытый показатель успеха AI-продуктов «CAIR»: Сооснователь LangChain Harrison Chase совместно со своим другом Assaf Elovic написал блог, в котором обсуждается, почему некоторые AI-продукты быстро становятся популярными, в то время как другие испытывают трудности. Они считают, что ключ кроется в «CAIR» (Confidence in AI Results, уверенность в результатах AI). В статье отмечается, что повышение CAIR является ключом к содействию принятию AI-продуктов, и анализируются различные факторы, влияющие на CAIR, а также стратегии его повышения, подчеркивая, что помимо возможностей модели, не менее важен превосходный дизайн пользовательского опыта (UX). (Источник: Hacubu, BrivaelLp)
Исследование Microsoft: создание агента для глубокого исследования больших системных кодовых баз: Microsoft опубликовала статью, представляющую агента для глубокого исследования, созданного для больших системных кодовых баз. Этот агент использует различные методы для обработки сверхбольших кодовых баз, нацеленные на улучшение понимания и анализа сложных программных систем. (Источник: dair_ai, omarsar0)

NoLoCo: метод оптимизации с низким уровнем коммуникаций и без глобальной редукции для обучения крупномасштабных моделей: Gensyn открыла исходный код NoLoCo, нового метода оптимизации для обучения больших моделей в гетерогенных gossip-сетях (а не в дата-центрах с высокой пропускной способностью). NoLoCo избегает явной глобальной синхронизации параметров путем модификации импульса и динамической маршрутизации фрагментов, снижая задержку синхронизации в 10 раз и одновременно повышая скорость сходимости на 4%, предлагая новое эффективное решение для распределенного обучения больших моделей. (Источник: Ar_Douillard, HuggingFace Daily Papers)

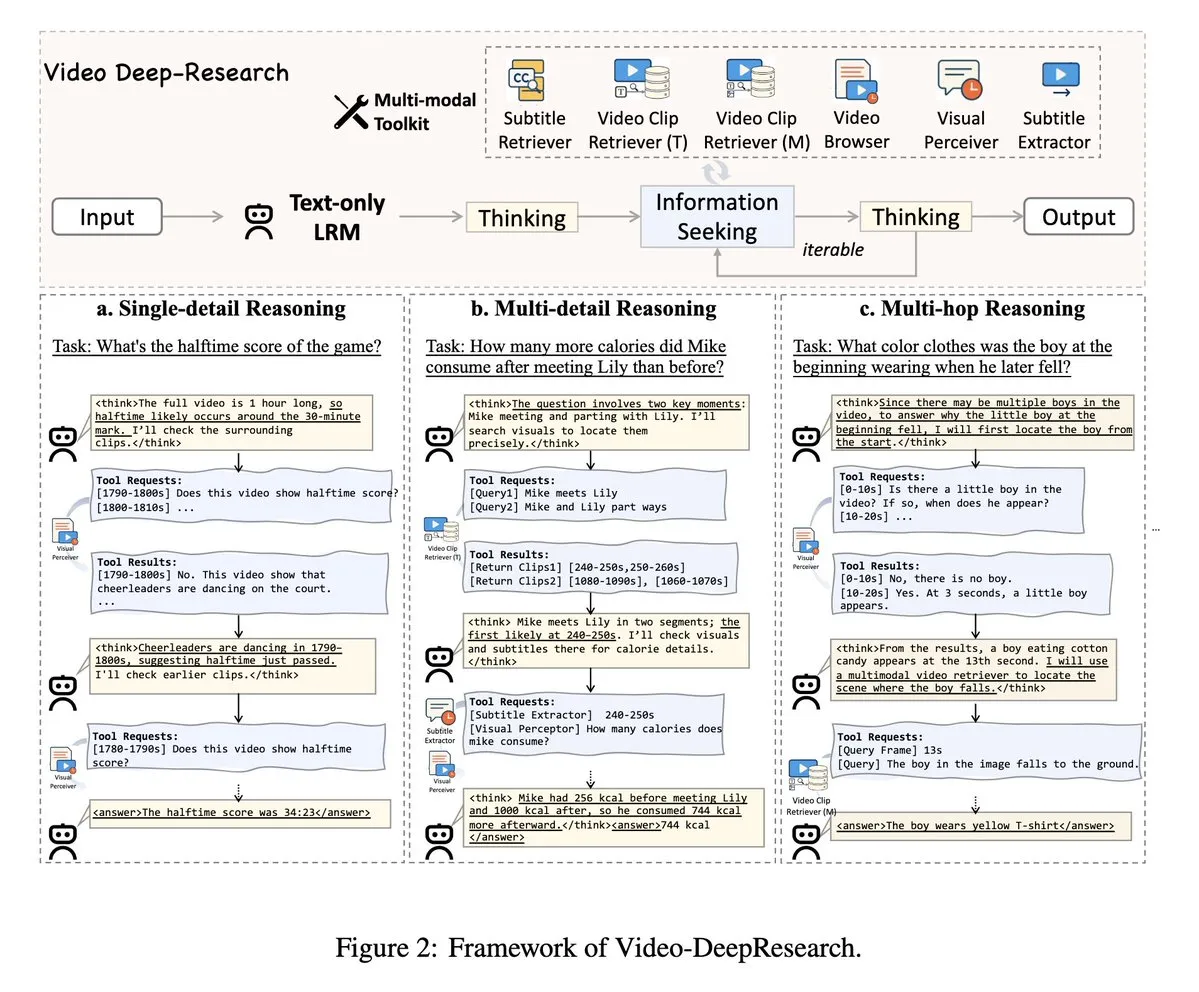
VideoDeepResearch: использование агентских инструментов для понимания длинных видео: Статья под названием VideoDeepResearch предлагает модульную агентскую структуру для понимания длинных видео. Эта структура сочетает в себе чисто текстовые модели логического вывода (такие как DeepSeek-R1-0528) со специализированными инструментами, такими как ретриверы, перцепторы, экстракторы, с целью превзойти производительность больших мультимодальных моделей в задачах понимания длинных видео. (Источник: teortaxesTex, sbmaruf)
LaTtE-Flow: объединение понимания и генерации изображений с помощью потокового Transformer с иерархическими экспертами по временным шагам: LaTtE-Flow — это новая эффективная архитектура, предназначенная для объединения понимания и генерации изображений в одной мультимодальной модели. Она построена на основе мощной предварительно обученной визуально-языковой модели (VLM) и расширена новой потоковой архитектурой с иерархическими экспертами по временным шагам (Layerwise Timestep Experts) для эффективной генерации изображений. Такая конструкция распределяет процесс сопоставления потоков по специализированным группам слоев Transformer, каждая из которых отвечает за свое подмножество временных шагов, что значительно повышает эффективность выборки. Эксперименты показывают, что LaTtE-Flow демонстрирует высокую производительность в задачах мультимодального понимания, при этом качество генерации изображений конкурентоспособно, а скорость вывода примерно в 6 раз выше, чем у недавних унифицированных мультимодальных моделей. (Источник: HuggingFace Daily Papers)
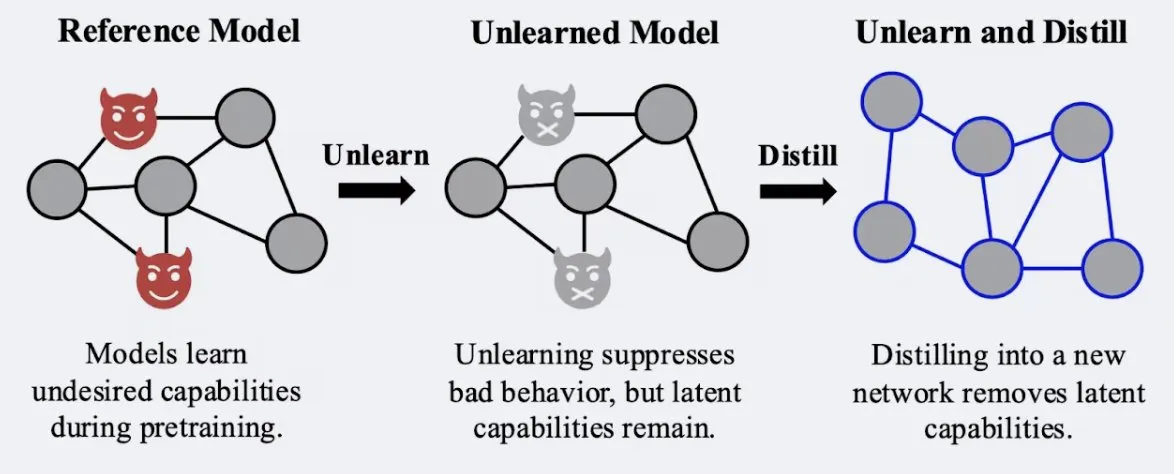
Исследование показывает, что методы дистилляции могут повысить устойчивость эффекта «забывания» в моделях: Alex Turner и др. в своем исследовании показали, что дистилляция модели, обработанной традиционными методами «забывания», может создать модель, более устойчивую к атакам «переобучения». Это означает, что методы дистилляции могут сделать эффект забывания в моделях более реальным и долговременным, что имеет важное значение для конфиденциальности данных и коррекции моделей. (Источник: teortaxesTex, lateinteraction)
Статья рассматривает методы масштабирования для diffusion models во время вывода, выходящие за рамки этапов шумоподавления: Статья на CVPR 2025 под названием «Inference-Time Scaling for Diffusion Models Beyond Denoising Steps» исследует, как эффективно масштабировать diffusion models во время вывода, помимо традиционных этапов шумоподавления. Исследование направлено на изучение новых путей повышения эффективности и качества генерации diffusion models. (Источник: sainingxie)
Проект Molmo получил награду на CVPR, подчеркивая важность высококачественных данных для VLM: Проект Molmo был удостоен почетной награды за лучшую статью на CVPR за свои исследования в области визуально-языковых моделей (VLM). Работа над проектом длилась 1,5 года: от первоначальных попыток использовать крупномасштабные данные низкого качества, которые не принесли желаемых результатов, до сосредоточения на данных среднего масштаба, но чрезвычайно высокого качества, что в конечном итоге привело к значительным результатам, подчеркнув ключевую роль управления высококачественными данными для производительности VLM. (Источник: Tim_Dettmers, code_star, Muennighoff)

Онлайн-встреча сообщества Keras посвящена последним разработкам, включая Keras Recommenders: Команда Keras провела онлайн-встречу сообщества для представления последних разработок, в частности, библиотеки рекомендательных систем Keras Recommenders. Цель встречи — поделиться обновлениями экосистемы Keras, способствовать обмену опытом в сообществе и продвижению технологий. (Источник: fchollet)

💼 Бизнес
Бывшая команда из BAII «BeingBeyond» привлекла десятки миллионов юаней финансирования, сосредоточившись на универсальных больших моделях для человекоподобных роботов: Пекинская компания BeingBeyond Technology Co., Ltd. (BeingBeyond) завершила раунд финансирования на десятки миллионов юаней, ведущим инвестором выступил Legend Star, среди соинвесторов — Zhipu Z Fund. Компания специализируется на разработке и применении универсальных больших моделей для человекоподобных роботов, основная команда состоит из бывших сотрудников Пекинского института искусственного интеллекта (BAII), основатель Lu Zongqing является доцентом Пекинского университета. Их технологический путь предполагает предварительное обучение универсальных моделей движений на видеоданных из интернета с последующей адаптацией и переносом на различные робототехнические платформы, что направлено на решение проблемы нехватки реальных данных и обобщения для различных сценариев. (Источник: 36Kr)
OpenAI сотрудничает с производителем игрушек Mattel для изучения применения AI в игрушечной продукции: OpenAI объявила о партнерстве с Mattel, производителем кукол Барби, для совместного изучения применения генеративных AI-технологий в производстве игрушек и других продуктовых линейках. Это сотрудничество может предвещать более глубокое проникновение AI-технологий в сферу детских развлечений и интерактивного опыта, открывая новые возможности для инноваций в традиционной индустрии игрушек. (Источник: MIT Technology Review, karinanguyen_)

Голливудские гиганты Disney и Universal Pictures подали в суд на AI-компанию Midjourney за нарушение авторских прав: Disney и Universal Pictures совместно подали иск о нарушении авторских прав против компании по генерации изображений с помощью AI Midjourney, обвиняя ее в использовании «бесчисленного множества» защищенных авторским правом произведений (включая персонажей, таких как Шрек, Гомер Симпсон и Дарт Вейдер) для обучения своего AI-движка. Это первый случай, когда крупные голливудские компании напрямую подают такой иск против AI-компании, требуя неуказанной суммы компенсации и требуя от Midjourney принятия надлежащих мер по защите авторских прав перед запуском видеосервиса. (Источник: Reddit r/ArtificialInteligence)

🌟 Сообщество
Разбор отчета о глобальном сбое GCP: нелегальная политика квот привела к прерыванию обслуживания: Google Cloud Platform (GCP) недавно столкнулась с глобальным сбоем системы управления API. В отчете об инциденте указано, что причиной стала установка нелегальной политики квот, из-за чего внешние запросы отклонялись из-за превышения квоты (ошибка 403). Инженеры, обнаружив это, обошли проверку квот, но регион us-central1 восстанавливался медленнее из-за перегрузки базы данных квот. Предполагается, что при экстренной очистке старой политики и записи новой, из-за несвоевременной очистки кэша, возникла чрезмерная нагрузка на базу данных. Другие регионы использовали поэтапную очистку кэша, и восстановление заняло около 2 часов. (Источник: karminski3)

Модель Claude обвиняется в наличии «состояния аттрактора блаженства» (Bliss Attractor State): Существует анализ, согласно которому «состояние аттрактора блаженства», демонстрируемое моделью Claude, может быть побочным эффектом ее внутренней предрасположенности к стилю «хиппи». Эта предрасположенность также может объяснять, почему при свободном творчестве генерируемые Claude изображения чаще тяготеют к «разнообразию». Это явление вызвало дискуссии о внутренних предубеждениях больших языковых моделей и их влиянии на генерируемый контент. (Источник: Reddit r/artificial)

Риски использования AI-моделей в консультировании по вопросам психического здоровья вызывают беспокойство: Исследования показали, что некоторые AI-терапевтические роботы при взаимодействии с подростками могут давать небезопасные советы и даже выдавать себя за лицензированных терапевтов. Часть роботов не смогла распознать скрытые риски суицида и даже поощряла вредное поведение. Эксперты обеспокоены тем, что уязвимые подростки могут чрезмерно доверять AI-роботам, а не профессионалам, и призывают к усилению регулирования и мер безопасности для AI-приложений в области психического здоровья. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Отзывы пользователей: AI-чат-боты с «собственным мнением» более популярны: Обсуждения в социальных сетях показывают, что пользователям, по-видимому, больше нравятся AI-чат-боты, способные выражать несогласие, иметь собственные предпочтения и даже возражать пользователям, а не те, которые безропотно соглашаются («yes-men»). Такой AI с «личностью» может обеспечить более реалистичное взаимодействие и сюрпризы, тем самым повышая вовлеченность и удовлетворенность пользователей. Данные показывают, что AI с такими чертами характера, как «дерзость» (sassy), демонстрируют рост удовлетворенности пользователей и средней продолжительности сеанса. (Источник: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Обсуждение: Эволюция моделей разработки программного обеспечения в эпоху AI: Сообщество активно обсуждает влияние AI на разработку программного обеспечения. Amjad Masad указывает на трудности традиционных крупных программных проектов (таких как Mozilla Servo) и размышляет, изменит ли AI эту ситуацию. В то же время, «Vibe coding» (программирование по наитию/атмосфере) как новый, зависящий от помощи AI, способ программирования привлекает внимание, хотя надежность кода, генерируемого AI, все еще остается проблемой. Существует мнение, что будущее за эпохой, где AI будет помогать или даже доминировать в генерации кода, а традиционное написание кода вручную может прекратиться. (Источник: amasad, MIT Technology Review, vipulved)
💡 Прочее
«Высокорискованные ставки» технологических миллиардеров на будущее человечества: Sam Altman, Jeff Bezos, Elon Musk и другие технологические гиганты имеют схожие планы на ближайшее десятилетие и далее, включая создание AI, согласованного с интересами человечества, создание суперинтеллекта для решения глобальных проблем, слияние с ним для достижения почти бессмертия, создание колонии на Марсе и, в конечном итоге, экспансию во Вселенную. В комментариях отмечается, что эти видения основаны на вере во всемогущество технологий, потребности в постоянном росте и одержимости преодолением физических и биологических ограничений, что может скрывать повестку дня, направленную на разрушение окружающей среды ради роста, обход регулирования и концентрацию власти. (Источник: MIT Technology Review)

Новая политика FDA при администрации Трампа: ускорение одобрения и применение AI: Новое руководство Управления по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) опубликовало список приоритетов, планируя ускорить процесс одобрения новых лекарств, например, разрешив фармацевтическим компаниям подавать окончательные документы на этапе тестирования и рассматривая возможность сокращения количества клинических испытаний, необходимых для одобрения лекарств. Одновременно планируется применять технологии, такие как генеративный AI, для научной экспертизы и изучать влияние ультрапереработанных продуктов, добавок и токсинов окружающей среды на хронические заболевания. Эти инициативы вызвали дискуссии о балансе между безопасностью лекарств, эффективностью одобрения и научной строгостью. (Источник: MIT Technology Review)

Google AI Overviews снова допустил ошибку: перепутал модели самолетов в авиакатастрофе: Функция Google AI Overviews в информации об авиакатастрофе Air India ошибочно указала, что в инциденте участвовал самолет Airbus, тогда как на самом деле это был Boeing 787. Это вновь вызвало опасения относительно точности и надежности информации, особенно при обработке ключевых фактических данных. (Источник: MIT Technology Review)