
Ключевые слова:Meta, Scale AI, Искусственный сверхинтеллект, ИИ общего назначения (AGI), Разметка данных для ИИ, Обучение искусственного интеллекта, Точность модели ИИ, Meta приобретает долю в Scale AI, Александр Ванг возглавляет группу по сверхинтеллекту, Точность разметки данных ИИ 99.7%, Снижение уровня загрязнения обучающих данных, Сокращение цикла обучения модели на 40%
🔥 В центре внимания
Сообщается, что Meta инвестирует около 15 миллиардов долларов в приобретение 49% акций Scale AI и назначит ее CEO Александра Ванга руководителем новой команды «Суперинтеллект»: Meta планирует приобрести 49% акций компании Scale AI, занимающейся разметкой данных и инфраструктурой для ИИ, примерно за 14,9 млрд долларов, и назначить ее 28-летнего CEO китайского происхождения Александра Ванга (Alexandr Wang) руководителем новой «Группы по суперинтеллекту». Этот шаг направлен на усиление конкурентоспособности Meta в области ИИ, особенно в части высококачественных данных для обучения и исследований AGI. Scale AI известна своей точностью разметки данных до 99,7% и, как ожидается, снизит уровень загрязнения обучающих данных моделей Meta с 15% до 2%, а также сократит цикл обучения на 40%. Это приобретение рассматривается как ключевой шаг Meta в гонке ИИ, направленный на то, чтобы догнать и попытаться превзойти конкурентов, а также подчеркивает центральную стратегическую роль данных в развитии ИИ. (Источник: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
Сообщается, что OpenAI заключила крупное соглашение о вычислительных мощностях с Google Cloud, возможно, для снижения зависимости от Microsoft: По сообщениям, OpenAI заключила важное соглашение об облачных услугах с Google Cloud, согласно которому Google Cloud предоставит OpenAI вычислительные мощности, необходимые для растущих потребностей в обучении и развертывании моделей ИИ. Ранее основным поставщиком вычислительных мощностей для OpenAI была Microsoft Azure. Этот шаг может означать, что OpenAI стремится диверсифицировать источники вычислительных мощностей, чтобы уменьшить зависимость от одного поставщика и удовлетворить свои огромные вычислительные потребности. Это сотрудничество является крупной победой для Google Cloud, но также вызвало дискуссии о том, как компания будет балансировать ресурсы TPU между собственными проектами и потребностями клиентов. (Источник: 36氪, scaling01)
Mistral AI выпустила модель для логического вывода Magistral, вызвав в сообществе вопросы о прозрачности ее бенчмарков: Французская компания ИИ Mistral AI представила свою первую серию моделей, специально разработанных для логического вывода, Magistral, включающую версию с открытым исходным кодом 24B Magistral Small и корпоративную версию Magistral Medium. Официально заявлено, что она разработана для прозрачного, отслеживаемого многошагового логического вывода и поддерживает несколько языков. Однако сообщество поставило под сомнение опубликованные результаты бенчмарков, полагая, что они не сравнивались с последними версиями конкурирующих моделей, таких как Qwen и DeepSeek R1, что может указывать на попытку «избежать прямого сравнения». Несмотря на это, Magistral показала значительное улучшение по сравнению с Mistral Medium 3 в математическом бенчмарке AIME-24. (Источник: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

Отец обучения с подкреплением Richard Sutton: Доминирование LLM временно, будущее за масштабируемыми вычислениями и обучением на опыте: Лауреат премии Тьюринга, отец обучения с подкреплением Richard Sutton, предсказывает, что нынешнее доминирование больших языковых моделей (LLM) является лишь временным, а имитация человеческого мышления может принести лишь краткосрочное улучшение производительности. Он считает, что будущее ИИ заключается в «эпохе опыта», когда агенты будут учиться, получая данные из взаимодействия с миром от первого лица, а не полагаясь на статические человеческие данные. Sutton подчеркивает, что обучение с подкреплением является основным путем к этому будущему, и в сочетании с алгоритмами глубокого обучения с непрерывным обучением и крупномасштабными вычислениями позволит ИИ преодолеть существующие когнитивные ограничения и достичь настоящих инноваций. (Источник: 量子位)

Hugging Face в сотрудничестве с NVIDIA запускает «Training Cluster as a Service», снижая барьер для обучения больших моделей: Hugging Face объявила о сотрудничестве с NVIDIA для запуска «Training Cluster as a Service», целью которого является облегчение доступа исследовательских институтов по всему миру к крупным кластерным ресурсам GPU для обучения различных передовых моделей. Сервис объединяет NVIDIA DGX Cloud Lepton и ресурсы разработки Hugging Face, позволяя организациям запрашивать и оплачивать время использования кластеров GPU по мере необходимости. Этот шаг направлен на преодоление «разрыва в доступности GPU», содействие разнообразию и популяризации исследований в области ИИ, и уже получил поддержку от таких исследовательских институтов и стартапов, как TIGEM, Numina, Mirror Physics. (Источник: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 Новости и тенденции
OpenAI выпустила модель o3-pro и значительно снизила цены на API o3: OpenAI представила свою новую топовую модель для логического вывода o3-pro, которая уже доступна пользователям ChatGPT Pro и API. Одновременно с этим цены на API модели o3 были значительно снижены на 80%, а лимиты скорости o3 для пользователей ChatGPT Plus удвоены. Отзывы сообщества показывают, что o3-pro превосходит Claude Opus 4 в задачах, не связанных с кодом, и установила новые рекорды в нескольких бенчмарках, таких как Extended NYT Connections и Creative Short Story Writing, и даже успешно решила «задачу о Ханойской башне с 10 дисками», которая ранее ставила под сомнение возможности LLM в статье Apple. Однако некоторые пользователи отмечают, что o3-pro работает медленнее. OpenAI заявила, что снижение цен на o3 достигнуто не за счет дистилляции или квантования, а благодаря оптимизационной работе инженеров по логическому выводу. (Источник: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB выпустила серию эффективных LLM для конечных устройств MiniCPM4: OpenBMB представила серию моделей MiniCPM4, специально разработанных для конечных устройств, утверждая, что они обеспечивают более чем 5-кратное ускорение генерации на типичных чипах для конечных устройств. Серия включает MiniCPM4-8B, MiniCPM4-0.5B, а также версии с трехуровневым квантованием BitCPM4-1B/0.5B. В MiniCPM4 используется обучаемый механизм разреженного внимания InfLLM v2, поддерживающий обработку длинных текстов до 128K, и сочетаются эффективные алгоритмы обучения и технологии тренировки, такие как Model Wind Tunnel 2.0, трехуровневое квантование BitCPM, вычисления с низкой точностью FP8 и предсказание нескольких токенов. Одновременно были выпущены высококачественные наборы данных для предварительного обучения на китайском и английском языках UltraFineweb и набор данных для контролируемой тонкой настройки UltraChat v2. (Источник: GitHub Trending)
MSRA и ученые из университетов Цинхуа и Пекина предложили новую парадигму Reinforcement Pre-Training (RPT): Исследователи из Microsoft Research Asia (MSRA) совместно с учеными из Университета Цинхуа и Пекинского университета предложили новую парадигму предварительного обучения LLM под названием Reinforcement Pre-Training (RPT). Этот метод глубоко интегрирует обучение с подкреплением (RL) в этап предварительного обучения: перед предсказанием каждого токена модель генерирует последовательность рассуждений в виде цепочки мыслей и получает вознаграждение в зависимости от правильности предсказания. RPT нацелена на то, чтобы модель перешла от изучения поверхностных корреляций токенов к пониманию глубинного смысла. Эксперименты показали, что модель 14B, обученная на основе RPT, в некоторых задачах на рассуждение может сравниться или даже превзойти традиционно предварительно обученную модель 32B, демонстрируя огромный потенциал в улучшении языкового моделирования и способностей LLM к рассуждению. (Источник: 量子位, omarsar0)

Meta выпустила видео-мировую модель V-JEPA 2 и новые бенчмарки: Meta AI представила V-JEPA 2, мировую модель с 1,2 миллиардами параметров, обученную на видеоданных, с целью улучшения понимания и прогнозирования машинами физического мира. Модель может играть роль в планировании роботов с нулевым обучением (zero-shot planning), позволяя им планировать и выполнять задачи в незнакомой среде. Одновременно Meta выпустила три новых бенчмарка для оценки способности существующих моделей делать выводы о физическом мире на основе видео. HuggingFace уже предоставила поддержку V-JEPA 2 в библиотеке transformers. (Источник: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
ByteDance выпустила модель генерации видео Seedance 1.0 Pro, уже доступную в приложении Doubao: ByteDance представила свою последнюю модель генерации видео Seedance 1.0 Pro (также известную как модель Video 3.0 Pro в Dream Engine). Модель демонстрирует отличные результаты в понимании подсказок, детализации изображения и согласованности физического поведения, способна генерировать 5-секундные видео в разрешении 1080P. В настоящее время модель доступна корпоративным пользователям через Volcano Engine и интегрирована в приложение Doubao с функцией «Оживи фото» для бесплатного использования. (Источник: op7418)
Huawei представила симуляционную платформу «Цифровая аэродинамическая труба» для оптимизации эффективности обучения и инференса ИИ: Команда Huawei по моделированию и симуляции Марковских процессов впервые продемонстрировала свою технологию «Цифровая аэродинамическая труба» — платформу для «репетиции» в виртуальной среде перед фактическим обучением и инференсом сложных моделей ИИ. Платформа включает три основных модуля: Sim2Train (симуляция обучения), Sim2Infer (симуляция инференса) и Sim2Availability (симуляция высокой доступности). Цель платформы — путем симуляции и автоматической оптимизации решать проблемы несоответствия аппаратных ресурсов, системной связанности и т.д., тем самым позволяя за часы предварительно прогонять сценарии для кластеров из десятков тысяч карт, избегать потерь вычислительных мощностей и повышать эффективность и стабильность обучения и инференса больших моделей ИИ. (Источник: 量子位)

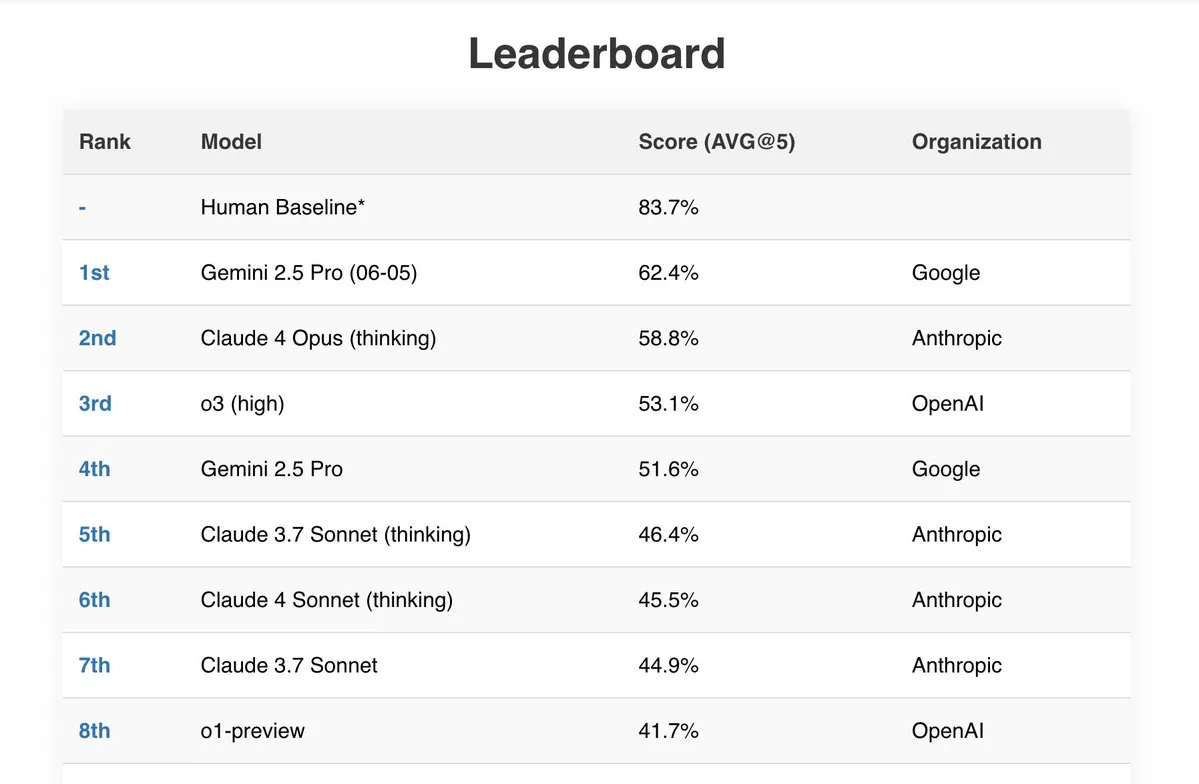
Gemini 2.5 Pro демонстрирует отличные результаты в нескольких бенчмарках: Новейшая модель Google Gemini 2.5 Pro (06-05) показала выдающиеся результаты в нескольких публичных рейтингах ИИ. Она продемонстрировала лучшие показатели в тесте Live Fiction при обработке 192k токенов, заняла первое место в SimpleBench с результатом 62,4% и показала мощные возможности обработки документов и экономическую эффективность в бенчмарках IDP (интеллектуальная обработка документов) и Aider (ИИ-ассистированное кодирование). Кроме того, пользователи сообщают, что Gemini 2.5 Pro успешно решила все задачи из математической части JEE Advanced 2025. (Источник: _philschmid, dilipkay)
Видеомодель Kling AI обновила функцию синхронизации губ, добавив поддержку выбора и редактирования персонажей: Инструмент генерации видео Kling AI от Kuaishou недавно обновил свою функцию синхронизации губ (Lip-sync). Новая функция позволяет пользователям выбирать конкретного персонажа в сгенерированном видео для синхронизации губ, а также настраивать время синхронизации аудио и движений рта. Это обновление повышает гибкость и реалистичность Kling AI при создании видео с диалогами нескольких персонажей и является важным достижением в области генерации видео. (Источник: Kling_ai, Kling_ai)
Выпущена Delta Lake 4.0.0 с улучшенными возможностями Lakehouse: Официально выпущена версия Delta Lake 4.0.0, которая включает несколько важных новых функций, в том числе предварительную версию таблиц, управляемых каталогом (Catalog-Managed Tables) для унифицированного управления и обнаруживаемости, расширение Delta Connect для Spark Connect, поддержку типа данных Variant для обработки полуструктурированных данных, а также функцию немедленного удаления DROP FEATURE, позволяющую удалять свойства таблицы без усечения истории или простоя. Эта версия направлена на улучшение опыта сообщества открытых lakehouse. (Источник: matei_zaharia)

Hugging Face запускает сервер MCP для упрощения взаимодействия моделей и инструментов: Hugging Face выпустила первую версию своего сервера Model Context Protocol (MCP). Теперь пользователи могут через http://hf.co/mcp использовать этот сервер в приложениях, таких как Claude или Cursor, для поиска моделей, наборов данных, статей, приложений или конкретной информации. Это знаменует важный шаг Hugging Face в продвижении совместимости инструментов и моделей в экосистеме ИИ, и в будущем может быть расширено до функций загрузки, скачивания, создания PR и т.д. (Источник: clefourrier, ClementDelangue)

Baidu запускает «AI-камеру» с интегрированным хранилищем и интеллектуальным управлением, а также обновляет GenFlow Super Partner 2.0: Baidu Netdisk и Baidu Wenku совместно выпустили функцию «AI-камера», объединяющую фотографирование, облачное хранилище и интеллектуальное управление. Фотографии могут автоматически архивироваться в облачный фотоальбом и поддерживают интеллектуальную классификацию и поиск по описанию на естественном языке. AI-камера также обладает различными возможностями ИИ, такими как улучшение внешности, распознавание объектов с предоставлением информации, генерация граффити в стиле набросков, сканирование квитанций, преобразование рукописных таблиц и т.д. Одновременно платформа для совместной работы нескольких интеллектуальных агентов «GenFlow Super Partner» обновлена до версии 2.0, способная глубже интегрироваться с данными и привычками пользователя для предоставления персонализированных услуг по генерации контента. (Источник: 量子位)

ByteDance открыла исходный код и веса модели восстановления видео SeedVR2: Команда ByteDance SEED опубликовала код для инференса и веса своей одношаговой модели восстановления видео SeedVR2, которые теперь доступны на Hugging Face. Модель использует технологию диффузионного состязательного пост-обучения (diffusion adversarial post-training) и достигла значительных результатов в восстановлении видео, особенно хорошо справляясь с обработкой видео высокого разрешения. (Источник: _akhaliq)
GroqCloud добавила модель Qwen3-32B с поддержкой более ста языков и контекста 131k: Groq объявила о добавлении модели Tongyi Qianwen Qwen3-32B на свою облачную платформу для инференса на LPU, GroqCloud. Модель поддерживает более 100 языков и диалектов, имеет контекстное окно 131k и работает с характерной для оборудования Groq скоростью в реальном времени, предоставляя разработчикам мощные возможности обработки многоязычных длинных текстов. (Источник: JonathanRoss321)
CEO OpenAI Sam Altman заявил, что выпуск их модели с открытыми весами будет отложен: Sam Altman сообщил, что выпуск модели OpenAI с открытыми весами будет отложен до конца этого лета, а не состоится в июне, как планировалось изначально. Он рассказал, что исследовательская команда достигла некоторых «неожиданных и очень удивительных» успехов, которые стоят ожидания, но требуют больше времени для доработки. (Источник: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

Digua Robotics выпустила комплект разработчика RDK S100 с интегрированной архитектурой «большой мозг-малый мозг» на одном SoC: Digua Robotics представила первый в отрасли комплект разработчика для роботов RDK S100 с интегрированным управлением и вычислениями на одном SoC. Комплект использует суперигетерогенную协同архитектуру, подобную человеческому «большому мозгу» и «малому мозгу» (6-ядерный Arm Cortex-A78AE CPU + 80 TOPS BPU в качестве «большого мозга», 4-ядерный Arm Cortex-R52+ MCU в качестве «малого мозга»), поддерживает эффективное взаимодействие больших и малых моделей воплощенного интеллекта, замыкая цикл «восприятие-решение-управление». RDK S100 предлагает богатый набор интерфейсов и полнофункциональную инфраструктуру разработки, предзаказ по цене 2499 юаней. (Источник: 量子位)

Aibook Intelligence выпустила вычислительный модуль ИИ E300 на базе отечественного SoC с 50 TOPS: Aibook Intelligence представила вычислительный модуль ИИ E300 для граничных вычислений, оснащенный собственным чипом AI SoC AB100. Модуль обеспечивает до 50 TOPS вычислительной мощности INT8, поддерживает вычисления со смешанной точностью FP16/FP32 и оснащен памятью LPDDR5 с пропускной способностью 102 ГБ/с. E300 имеет модульную конструкцию и предназначен для предоставления высокопроизводительных, низколатентных и надежных отечественных решений ИИ для граничных вычислений в таких отраслях, как образование, энергетика, медицина, поддерживая развертывание на границе основных моделей с открытым исходным кодом, а также различных моделей компьютерного зрения и распознавания речи. (Источник: 量子位)

Huawei раскрыла технологию высокой доступности для кластера Ascend из десятков тысяч карт, достигнув 98% доступности обучения: Huawei впервые публично раскрыла детали своей технологии высокой доступности для вычислительного кластера Ascend, состоящего из десятков тысяч карт. Благодаря трем основным возможностям — обнаружению и диагностике неисправностей, управлению неисправностями и отказоустойчивости оптических каналов кластера, — а также возможностям поддержки бизнеса, таким как оптимизация линейности кластера, быстрое восстановление обучения и инференса, Huawei достигла 98% доступности обучения для кластера из десятков тысяч карт, линейности более 95%, восстановления после сбоев за секунды и диагностики за минуты. Эта технологическая система «3+3» двойного измерения направлена на обеспечение стабильной и эффективной работы крупномасштабного обучения и инференса ИИ. (Источник: 量子位)

Уровень проникновения интеллектуального вождения в новых автомобилях BYD достиг 79%, высокоскоростной NOA становится основной конфигурацией: Последние данные, опубликованные BYD, показывают, что среди новых автомобилей, проданных в мае, доля моделей, оснащенных системами интеллектуального ассистента водителя (по крайней мере, с функциями высокоскоростного NOA и автоматической парковки), достигла 79%. Это свидетельствует о значительных успехах BYD в продвижении стратегии «интеллектуального вождения для всех», и функции интеллектуального вождения быстро становятся стандартной конфигурацией для ее моделей. Эта тенденция также отражает ускорение темпов популяризации технологий интеллектуального вождения на китайском автомобильном рынке. (Источник: 量子位)

Расширенные голосовые функции ChatGPT стали доступны всем платным пользователям: OpenAI объявила, что ранее обновленные расширенные голосовые функции ChatGPT (Advanced Voice) с улучшенной естественностью речи теперь доступны всем платным пользователям (ChatGPT Plus, Team, Enterprise). Пользователи могут использовать эту функцию для более естественного голосового взаимодействия с ChatGPT. (Источник: juberti)
🧰 Инструменты
Выпущен AI-браузер Genspark с интегрированными функциями нескольких AI-агентов: Команда Eric Jing выпустила AI-браузер Genspark, который, по их словам, был создан командой из 24 человек за 10 недель и объединяет 8 основных продуктов: AI-браузер, AI-секретарь, AI-личные звонки, AI-агент загрузки, AI Drive, AI Sheets и др. Браузер ориентирован на скорость, блокировку рекламы, полную агентификацию, режим автопилота и имеет встроенный магазин MCP и суперагентов, стремясь предоставить универсальный опыт просмотра веб-страниц и работы с помощью ИИ. (Источник: blader)
Yutori AI запустила платформу Scouts для мониторинга сети с помощью AI-агентов: Yutori AI выпустила платформу Scouts, позволяющую пользователям создавать постоянно активных AI-агентов для мониторинга обновлений конкретной информации в сети. Эти агенты могут отслеживать различный интересующий пользователей контент, такой как нишевые новости, изменения цен на товары, информацию о билетах и т.д., и в ключевые моменты уведомлять пользователей по электронной почте, стремясь освободить пользователей за счет автоматизации отслеживания информации. (Источник: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face представляет AISheets, объединяющий AI-модели и электронные таблицы: Hugging Face выпустила AISheets, приложение, которое объединяет тысячи AI-моделей (особенно LLM с открытым исходным кодом) с функциональностью электронных таблиц. Пользователи могут создавать, анализировать и автоматизировать обработку данных в AISheets, стремясь предоставить плавный, быстрый и простой опыт обработки данных с использованием ИИ. (Источник: ben_burtenshaw, LoubnaBenAllal1)
PLaMo выпустила локальный CLI-инструмент для перевода на базе MLX: Команда PLaMo LLM открыла исходный код инструмента командной строки (CLI), который позволяет выполнять локальный перевод текста на Mac с Apple Silicon, используя фреймворк MLX. Инструмент предназначен для обеспечения быстрого и высокоточного локального перевода и имеет встроенные HTTP и MCP серверы и клиенты для удобной интеграции с другими MCP-совместимыми приложениями (например, Claude Desktop). (Источник: awnihannun)
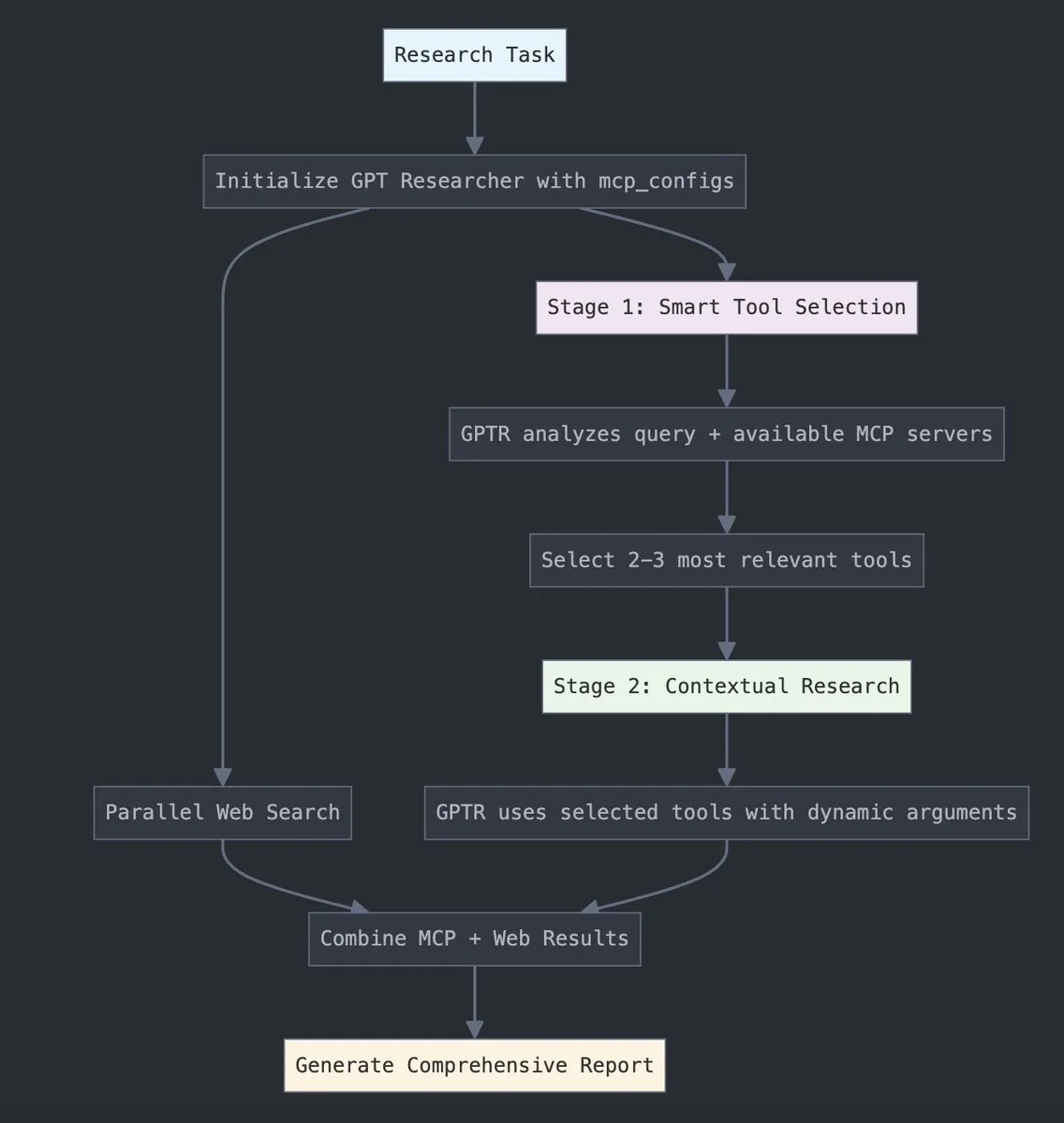
GPT Researcher интегрировал адаптер LangChain MCP для улучшения выбора инструментов и исследовательских возможностей: GPT Researcher теперь использует адаптер Model Context Protocol (MCP) от LangChain для более интеллектуального выбора инструментов и исследовательских процессов. Этот шаг направлен на объединение преимуществ MCP с возможностями веб-поиска для более всестороннего сбора и анализа данных. (Источник: Hacubu)
Consilium: выпущен фреймворк для совместной работы нескольких интеллектуальных агентов с открытым исходным кодом: Victor M представил Consilium, фреймворк с открытым исходным кодом для совместной работы команд AI-агентов. Пользователи могут устанавливать стратегии, по которым несколько экспертных агентов будут вести дебаты и использовать исследования в реальном времени (веб, arXiv, данные SEC) для совместного решения сложных проблем и достижения консенсуса. Демо-версия инструмента доступна на Hugging Face. (Источник: clefourrier)
youtube-transcript-api: Python-библиотека для получения субтитров YouTube, поддерживает перевод и автоматическую генерацию контента: Python-библиотека youtube-transcript-api, разработанная jdepoix, привлекает внимание на GitHub. API позволяет получать субтитры к видео на YouTube, включая автоматически сгенерированные субтитры, и поддерживает функцию перевода. В отличие от других решений на базе Selenium, она не требует API-ключа или безголового браузера, предоставляя разработчикам удобный способ извлечения текстового контента из видео. (Источник: GitHub Trending)

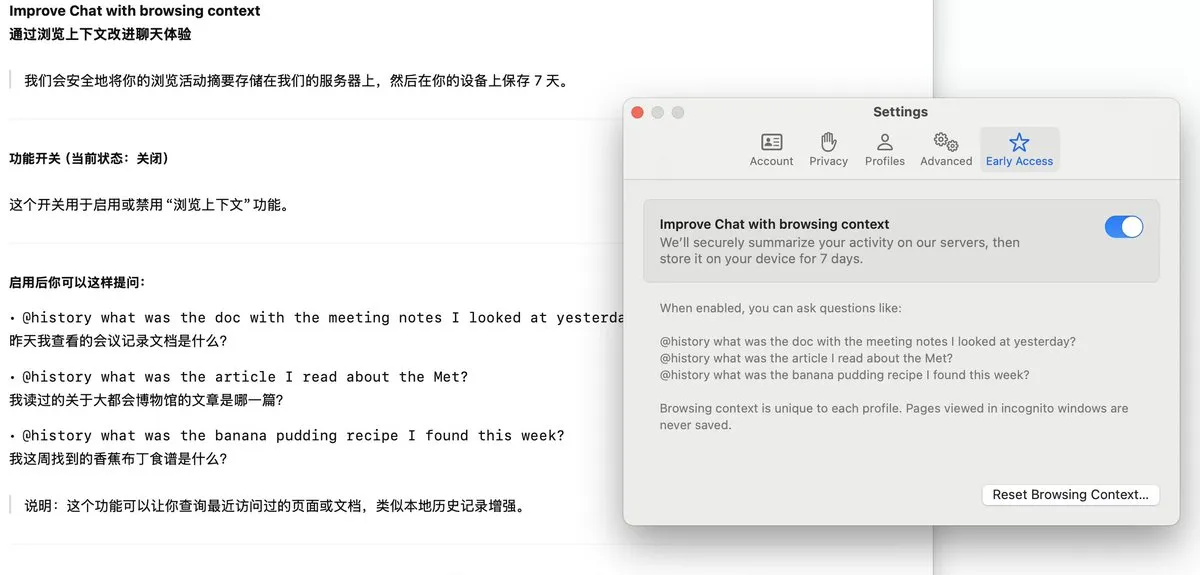
Браузер Arc представил функцию Dia, записывающую историю просмотров и поддерживающую AI-ответы на вопросы: В браузере Arc добавлена функция Dia, которая при включении непрерывно записывает всю историю просмотров пользователя. С помощью функции @History пользователи могут задавать вопросы на естественном языке с нечеткими формулировками, чтобы найти информацию, которую они когда-то просматривали, но забыли точный URL-адрес. Функция, возможно, даже будет поддерживать генерацию отчетов об истории просмотров, повышая интеллектуальность браузера и возможности персонализированного управления информацией. (Источник: op7418)
📚 Обучение
Apple опубликовала статью «Иллюзия мышления», исследующую границы возможностей LLM: Исследовательская группа Apple по машинному обучению опубликовала статью «Иллюзия мышления» (The Illusion of Thinking), в которой анализируются производительность и ограничения текущих больших языковых моделей (LLM) в сложных задачах на рассуждение (например, решение задачи о Ханойской башне). Статья вызвала в сообществе дискуссию о реальном уровне интеллекта LLM, и высказывались мнения, что подобные исследования иногда используются как предлог для отсрочки внедрения ИИ. Модель o3-pro от OpenAI впоследствии решила предложенную в статье задачу о Ханойской башне. (Источник: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
Новое исследование «Универсальным агентам нужны мировые модели» исследует связь между обобщением агентов и предиктивными моделями: В новой исследовательской статье под названием «Универсальным агентам нужны мировые модели» (General agents need world models) утверждается, что универсальные агенты, способные обобщаться на многошаговые целенаправленные задачи, должны изучать предиктивную мировую модель. Эта модель кодируется в стратегии агента, и статья демонстрирует прямую связь между способностью к обобщению и точностью изученной модели путем запроса выбора стратегии агента при составных целях для извлечения вероятностей перехода среды. (Источник: menhguin)

Статья исследует концептуально-ориентированную тонкую настройку (CAFT) для повышения производительности LLM: Новая статья «Улучшение больших языковых моделей с помощью концептуально-ориентированной тонкой настройки» (Improving large language models with concept-aware fine-tuning) предлагает метод CAFT, который улучшает понимание концепций моделью путем включения предсказания нескольких токенов во время тонкой настройки. Исследование показывает, что CAFT достигает значительного прироста производительности в задачах кодирования, математики, реферирования текста, генерации молекул и проектирования белков. Код открыт на GitHub. (Источник: Reddit r/MachineLearning)
DeepLearning.AI запускает новый курс «Оркестровка рабочих процессов для приложений GenAI»: DeepLearning.AI Эндрю Ына (Andrew Ng) в сотрудничестве с Astronomer запустила новый короткий учебный курс под названием «Оркестровка рабочих процессов для приложений GenAI» (Orchestrating Workflows for GenAI Applications). Курс обучает созданию надежных процессов GenAI с использованием популярного инструмента с открытым исходным кодом Airflow 3.0 и преобразованию прототипов Jupyter Notebook или Python-скриптов в готовые к производству рабочие процессы, охватывая декомпозицию задач, планирование, параллельное выполнение, восстановление после сбоев и наблюдаемость. (Источник: AndrewYNg)
Статья «Потокенное выравнивание текста, изображений и 3D-структур» исследует мультимодальные авторегрессионные модели: Это исследование предлагает унифицированную структуру LLM, нацеленную на выравнивание языка, изображений и структурированных 3D-сцен. В статье подробно описываются ключевые проектные решения для достижения оптимального обучения и производительности, включая представление данных, целевые функции для конкретных модальностей и т.д., и проводится оценка по четырем основным 3D-задачам (рендеринг, распознавание, следование инструкциям и ответы на вопросы) и нескольким наборам данных. Исследование также расширяется на реконструкцию сложных форм 3D-объектов путем квантованного кодирования форм. (Источник: HuggingFace Daily Papers)
Статья «Squeeze3D»: использование предварительно обученных 3D-генеративных моделей для экстремального нейронного сжатия: Фреймворк Squeeze3D использует неявные априорные знания, полученные из предварительно обученных 3D-генеративных моделей, для значительного сжатия 3D-данных (меши, облака точек, поля излучения). Он соединяет предварительно обученный кодировщик и латентное пространство генеративной модели через обучаемую сеть отображения, сжимая 3D-модели в компактные латентные коды, которые при распаковке восстанавливаются генеративной моделью. Метод обучается на синтетических данных, не требуя реальных 3D-наборов данных, и достигает коэффициента сжатия текстурированных мешей до 2187 раз. (Источник: HuggingFace Daily Papers)
Статья «Frame Guidance»: покадровый контроль в видеодиффузионных моделях без обучения: Данное исследование предлагает «Frame Guidance» — метод, позволяющий осуществлять покадровый контроль в видеодиффузионных моделях без необходимости обучения. С помощью простой обработки латентного пространства и новой стратегии оптимизации латентного пространства метод эффективно управляет покадровыми сигналами, такими как ключевые кадры, стилевые референсы, эскизы или карты глубины, и подходит для различных задач, таких как управление по ключевым кадрам, стилизация, создание зацикленных видео, и совместим с любой видеомоделью. (Источник: HuggingFace Daily Papers)
Статья «Геополитические предубеждения в больших языковых моделях» раскрывает национальные позиции моделей: Данное исследование оценивает геополитические предубеждения в LLM путем анализа интерпретации моделями исторических событий с точки зрения разных стран (США, Великобритания, СССР, Китай). Исследователи представили новый набор данных, содержащий нейтральные описания событий и контрастные точки зрения разных стран, и обнаружили, что LLM демонстрируют значительные предубеждения в пользу нарративов определенных стран, а простые подсказки для устранения предубеждений имеют ограниченный эффект. Эта работа предоставляет основу и набор данных для будущих исследований геополитических предубеждений. (Источник: HuggingFace Daily Papers)
Репозиторий Awesome Lists постоянно обновляется, собирая различные интересные темы: Проект awesome на GitHub, поддерживаемый sindresorhus, представляет собой мета-список «Awesome lists» по различным интересным темам. Эти списки охватывают множество областей, от языков программирования и платформ разработки до теорий, книг, инструментов и т.д., предоставляя разработчикам и учащимся богатый индекс ресурсов. (Источник: GitHub Trending)
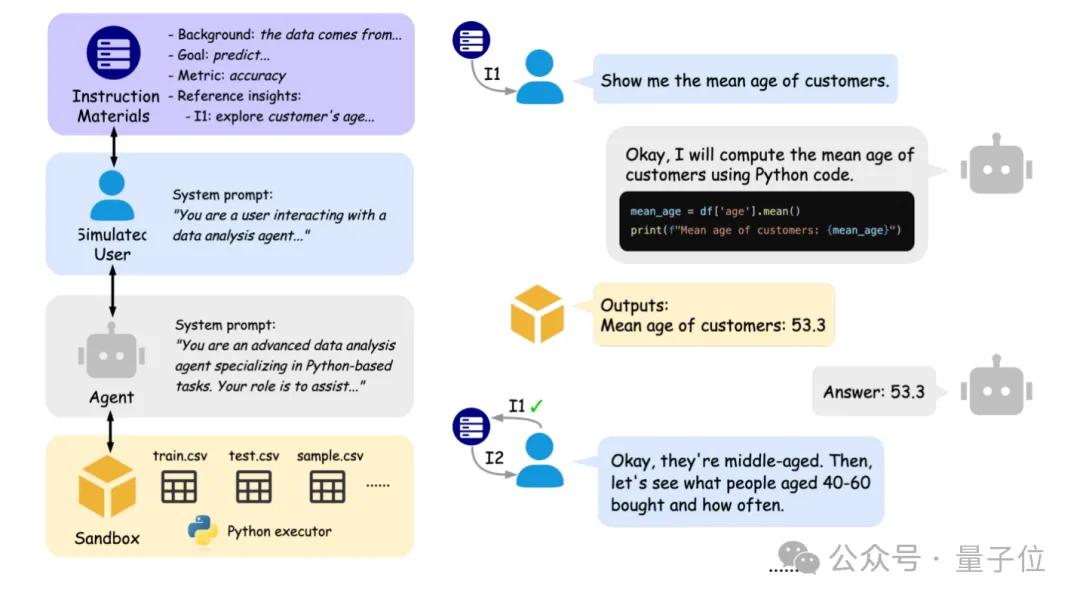
Пекинский университет и Беркли совместно запустили IDA-Bench для оценки интерактивных возможностей AI-агентов анализа данных: Исследовательские группы Пекинского университета и Калифорнийского университета в Беркли (включая профессора Michael I. Jordan) запустили IDA-Bench, новый бенчмарк, предназначенный для оценки способностей больших языковых моделей (LLM) в качестве агентов анализа данных (Agent) в сценариях многоэтапного взаимодействия. Бенчмарк имитирует рабочий процесс реальных аналитиков данных, проверяя способность агента следовать инструкциям, писать и выполнять код посредством постепенно развивающихся указаний. Предварительная оценка показывает, что даже у топовых моделей, таких как Claude-3.7 и Gemini-2.5 Pro, успешность выполнения задач составляет менее 40%, что выявляет текущие проблемы агентов в сложном взаимодействии и следовании инструкциям. (Источник: 量子位)
💼 Бизнес
xAI и Polymarket сотрудничают для объединения рыночных прогнозов и анализа Grok: xAI Илона Маска объявила о сотрудничестве с платформой прогнозных рынков Polymarket. Стороны объединят возможности Polymarket по прогнозированию рынка, данные платформы X и аналитические возможности модели Grok с целью создания «хардкорного механизма истины» (Hardcore truth engine) для понимания факторов, формирующих мир. Официально заявлено, что это только начало сотрудничества, и в будущем ожидается больше новостей. (Источник: Yuhu_ai_)
UnslothAI признана Redpoint одной из ведущих инфраструктурных компаний и появилась на большом экране Nasdaq: AI-стартап UnslothAI за свой вклад в область инфраструктуры ИИ был признан венчурной компанией Redpoint одной из 100 самых влиятельных и быстрорастущих инфраструктурных компаний 2025 года, в связи с чем его логотип появился на электронном экране здания Nasdaq в Нью-Йорке. UnslothAI специализируется на оптимизации эффективности обучения и инференса LLM. (Источник: danielhanchen, karminski3)

Ant Digital модернизирует лабораторию Tianji, фокусируясь на «ИИ + промышленные инновации»: Ant Digital объявила о модернизации своей лаборатории Tianji из «Лаборатории безопасности цифровой идентификации» в лабораторию «Искусственный интеллект + промышленные инновации». Обновленная лаборатория сосредоточится на исследовании ключевых технологических прорывов в применении больших моделей ИИ в промышленности, развивая направления AI+данные, AI+безопасность, AI+финансы и AI+воплощенный интеллект, с целью содействия глубокой интеграции технологий ИИ и промышленности через совместные инновации в производстве, обучении, исследованиях и применении. (Источник: 量子位)

🌟 Сообщество
Способность ИИ к автономному вождению в сложных дорожных условиях привлекает внимание: Ronald van Loon поделился видео испытаний автономного вождения в хаотичном трафике Индии, что вызвало обсуждение способностей ИИ к восприятию, принятию решений и управлению в сложных, высокодинамичных средах. Подобные реальные сценарии предъявляют чрезвычайно высокие требования к надежности и адаптивности систем автономного вождения. (Источник: Ronald_vanLoon)
Основные моменты конференции AI Engineer World’s Fair: протокол MCP, стоимость AI-агентов и локальные модели в центре внимания: Yogi, Shawn “swyx” Wang и другие поделились основными моментами конференции AI Engineer World’s Fair. Ключевые тенденции включают: 1) AI-агенты — это будущее, атомарной единицей взаимодействия будет вызов агента; 2) Model Context Protocol (MCP) быстро становится стандартом, решая проблему «ада копирования-вставки» и позволяя ИИ напрямую взаимодействовать с внешними приложениями; 3) Ключевым моментом является создание глубоко оптимизированных инструментов ИИ для конкретных областей и рабочих процессов (модель Cursor-for-X); 4) Стоимость моделей значительно снижается, а возможности локальных моделей расширяются, предоставляя разработчикам больший контроль и решения с низкой задержкой; 5) ИИ эволюционирует от вспомогательного инструмента к «товарищу по команде» для разработчиков; 6) Инженерия ИИ переходит от этапа демонстраций к системам производственного уровня. (Источник: swyx, TheTuringPost)
Сообщество активно обсуждает быструю итерацию после выпуска o3-pro и статью Apple об ИИ: andersonbcdefg с юмором отметил, что всего через 6 часов после выпуска o3-pro сообщество, кажется, уже ожидает, что кто-то перепишет fastText на Rust, и иронизировал над длинными рассуждениями о «мягком сверхинтеллекте», отражая чрезвычайно высокую скорость итераций технологий в области ИИ и высокие ожидания сообщества. В то же время Teknium1 указал, что o3-pro решила задачу о Ханойской башне, предложенную в статье Apple «Иллюзия мышления», и поставил под сомнение, почему Apple, сотрудничая с OpenAI, не провела внутреннюю проверку перед публикацией подобных статей, что вызвало в сообществе дискуссию о конкуренции и сотрудничестве между технологическими компаниями. (Источник: andersonbcdefg, Teknium1)
Обсуждение этики и эффективности применения ИИ в реальном мире: Сообщество обсуждает эффективность и этические вопросы применения ИИ в конкретных сценариях. Например, Arvind Narayanan отметил, что концепция приложений для подсчета калорий с помощью ИИ сама по себе несовершенна, так как информации с изображения недостаточно для точной оценки калорий, и считает, что они скорее помогают пользователям выработать привычку следить за питанием, являясь своего рода «ритуалом». Кроме того, предметом обсуждения стал вопрос о том, является ли этичным или целесообразным использование ИИ-сгенерированных изображений для коммерческой рекламы (например, для демонстрации блюд в меню кофейни); общее мнение склоняется к тому, что это приемлемый способ снижения затрат и повышения эффективности, если изображения не являются явно недостоверными или вводящими в заблуждение. (Источник: random_walker, Reddit r/artificial)
«Очеловечивание» LLM и пользовательский опыт взаимодействия становятся центральными темами: Пользователи сообщества Reddit обсуждают, как сделать взаимодействие с LLM более похожим на общение с реальным человеком, включая введение колебаний, пауз, более коротких ответов и неидеальных выражений. Это отражает потребность пользователей в более естественных, менее «роботизированных» AI-компаньонах или ассистентах. В то же время, некоторые пользователи жалуются на то, что текущие LLM (например, ChatGPT) часто используют шаблонные фразы и преувеличенные выражения (например, «это не просто X, это Y»), и хотели бы, чтобы их речь была более лаконичной и прямой. Эти обсуждения указывают на постоянные вызовы в области моделирования LLM человеческого диалога и удовлетворения эмоциональных потребностей пользователей. (Источник: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 Прочее
CEO NVIDIA Дженсен Хуанг выступит с основным докладом на GTC Paris, посвященном новому этапу вычислений для ИИ: NVIDIA объявила, что ее CEO Дженсен Хуанг выступит с основным докладом 11 июня на конференции GTC в Париже (в рамках VivaTech 2025). Ожидается, что он раскроет следующий этап вычислений для ИИ, охватывающий передовые темы от агентных систем до AI-фабрик. (Источник: nvidia, nvidia)

Databricks Data+AI Summit продемонстрирует последние прорывы: Databricks объявила, что ее Data+AI Summit соберет ведущих экспертов, исследователей и контрибьюторов открытого исходного кода для демонстрации последних прорывов компании в области данных и ИИ, а также для обмена успешными кейсами инновационных компаний. Саммит предлагает возможность участия онлайн и офлайн. (Источник: matei_zaharia, lateinteraction)

Этические и экологические аспекты ИИ привлекают внимание, популяризация в формате графического романа: Центр LEARN Федеральной политехнической школы Лозанны (EPFL) в сотрудничестве с иллюстратором Herji выпустил образовательный графический роман на французском языке под названием «Utop’IA», целью которого является популяризация среди подростков информации о влиянии искусственного интеллекта на окружающую среду, включая потребление ресурсов (энергия, вода, редкие металлы) и потенциальные экологические выгоды. Работа подчеркивает важность критического мышления и исследует пути развития устойчивого ИИ. (Источник: aihub.org)
