Ключевые слова:Meta V-JEPA 2, NVIDIA Industrial AI Cloud, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, HistBench Принстонского университета, открытая мировая модель для обучения видео, европейская облачная платформа AI для производства, адаптер LLM для генерации текста, тонкая настройка GPT-4.1 методом DPO, наблюдаемость AI-агентов
🔥 聚焦
Meta выпустила V-JEPA 2: модель мира изображений/видео с открытым исходным кодом, обученную на видео : Meta представила новую модель мира изображений/видео с открытым исходным кодом V-JEPA 2, основанную на архитектуре ViT, с версиями различных размеров (L/G/H) и разрешений (286/384), и количеством параметров до 1,2 миллиарда. V-JEPA 2 демонстрирует выдающиеся результаты в визуальном понимании и прогнозировании, позволяя роботам выполнять планирование и задачи в незнакомой среде с нулевым обучением (zero-shot). Meta подчеркивает свое видение того, что ИИ использует модели мира для адаптации к динамичным средам и эффективного изучения новых навыков. Одновременно Meta также выпустила три новых бенчмарка: MVPBench, IntPhys 2 и CausalVQA, для оценки способности существующих моделей делать выводы о физическом мире из видео. (Источник: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia строит первое в Европе промышленное облако ИИ для стимулирования развития производства : Nvidia объявила о строительстве первой в мире промышленной облачной платформы ИИ для европейских производителей. Эта фабрика ИИ призвана помочь промышленным лидерам ускорить производственные приложения на всех этапах: от проектирования и инженерного моделирования до цифровых двойников заводов и робототехники. Этот шаг является одной из ряда инициатив, объявленных Nvidia на GTC Paris и VivaTech 2025, направленных на ускорение инноваций в области ИИ в Европе и за ее пределами. Хуан Жэньсюнь заявил, что вычислительные мощности ИИ в Европе, по прогнозам, увеличатся в десять раз в течение двух лет, и подчеркнул, что «все движущиеся объекты будут роботизированы, автомобили — следующие на очереди». (Источник: nvidia, nvidia, Хуан Жэньсюнь: Вычислительные мощности ИИ в Европе увеличатся в десять раз за два года)

Sakana AI представляет Text-to-LoRA: мгновенная генерация адаптеров LLM для конкретных задач с помощью текстовых описаний : Sakana AI выпустила технологию Text-to-LoRA, представляющую собой гиперсеть (Hypernetwork), способную мгновенно генерировать адаптеры LLM (LoRAs) для конкретных задач на основе текстового описания задачи пользователем. Эта технология направлена на снижение порога входа для кастомизации больших моделей, позволяя нетехническим пользователям специализировать базовые модели с помощью естественного языка, без глубоких технических знаний или значительных вычислительных ресурсов. Text-to-LoRA способна кодировать сотни существующих адаптеров LoRA и обобщать их на ранее не встречавшиеся задачи, сохраняя при этом производительность. Соответствующая статья и код опубликованы на arXiv и GitHub и будут представлены на ICML2025. (Источник: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
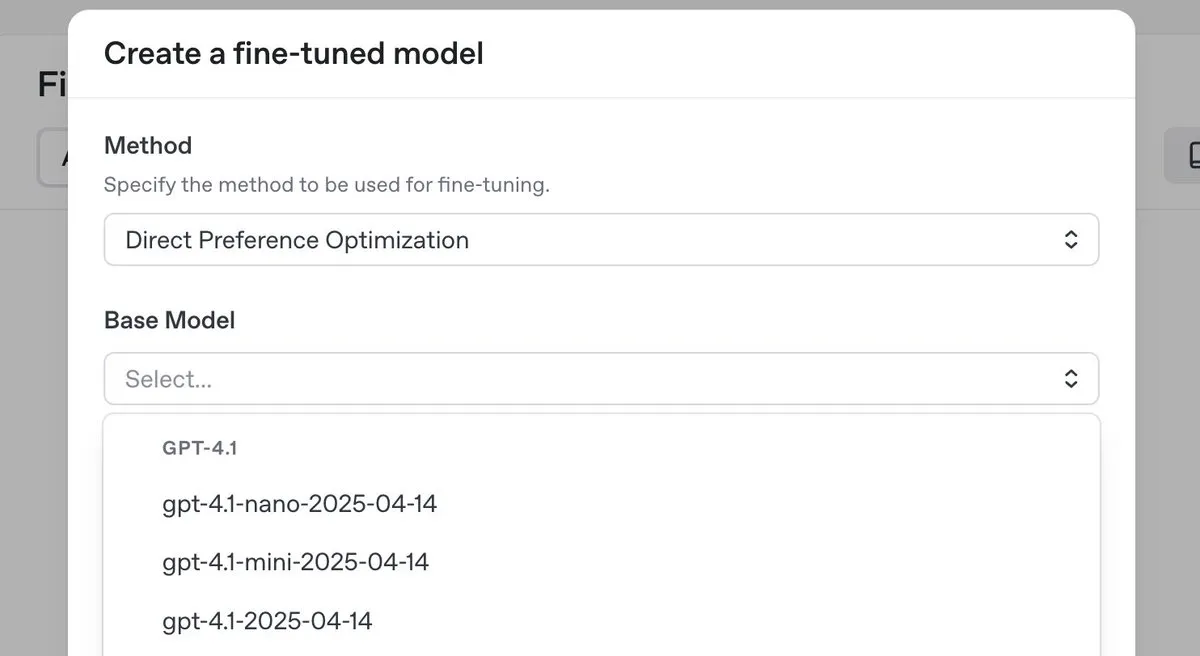
OpenAI выпускает топовую модель для инференса o3-pro со значительным снижением цен, а также запускает функцию DPO-тюнинга для серии GPT-4.1 : OpenAI представила свою новую топовую модель для инференса o3-pro и значительно снизила цены на модели серии o3 с целью уменьшения затрат для разработчиков. Одновременно OpenAI объявила, что пользователи теперь могут использовать прямую оптимизацию предпочтений (DPO) для тонкой настройки моделей семейства GPT-4.1 (включая 4.1, 4.1-mini и 4.1-nano). DPO позволяет настраивать модель путем сравнения ее ответов, а не по фиксированным целям, что особенно подходит для задач, требующих субъективной оценки тона, стиля и креативности. ARC Prize провел повторное тестирование o3 после снижения цен, и результаты показали, что ее производительность на ARC-AGI не изменилась. (Источник: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 动向
Databricks представляет Lakebase, бесплатную версию и Agent Bricks, ускоряя разработку приложений для данных и ИИ : Databricks объявила о выходе Lakebase в публичную предварительную версию. Это полностью управляемая база данных Postgres, интегрированная с lakehouse и созданная для ИИ, сочетающая в себе простоту использования Postgres, масштабируемость lakehouse и технологию ветвления базы данных Neon. Одновременно Databricks выпустила бесплатную версию платформы и большое количество учебных материалов, чтобы помочь разработчикам изучать инженерию данных, науку о данных и ИИ. Кроме того, Databricks Apps стали общедоступными (GA), поддерживая клиентов в создании и развертывании интерактивных приложений для данных и ИИ на платформе. Databricks также представила Agent Bricks, использующий декларативный подход к разработке агентов ИИ, где пользователь описывает задачу, а система автоматически генерирует оценку и оптимизирует агента. (Источник: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia сотрудничает с Mistral AI для создания комплексной облачной платформы в Европе : Nvidia объявила о сотрудничестве с французским стартапом Mistral AI для совместного создания комплексной облачной платформы. На первом этапе сотрудничества будет развернуто 18 000 систем Nvidia Grace Blackwell, а к 2026 году планируется расширение на другие локации. Это сотрудничество является частью усилий Nvidia по развитию инфраструктуры ИИ в Европе и продвижению концепции «суверенного ИИ», направленной на предоставление Европе локализованных центров обработки данных и серверов. (Источник: Хуан Жэньсюнь: Вычислительные мощности ИИ в Европе увеличатся в десять раз за два года)
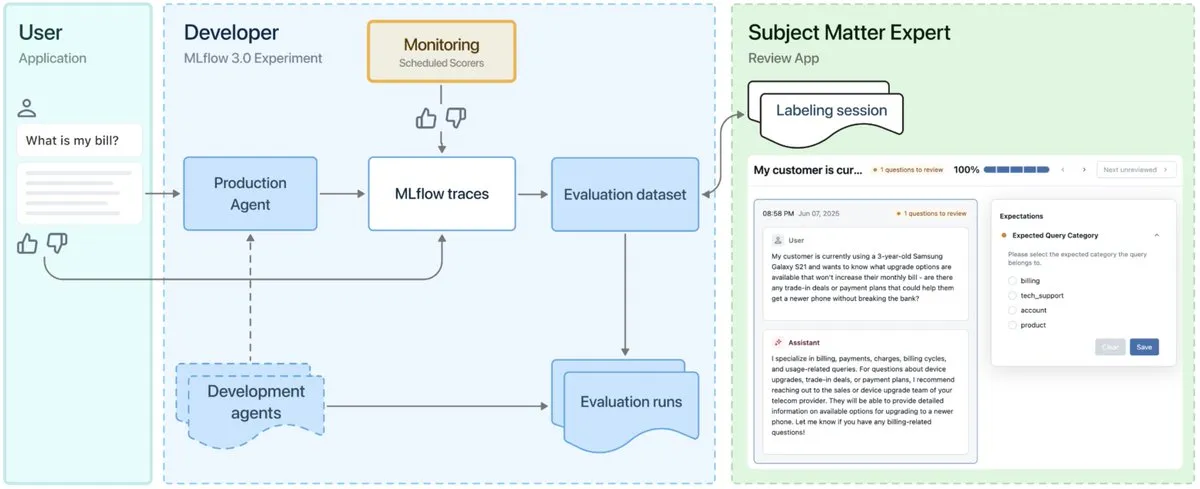
Выпущен MLflow 3.0, разработанный специально для наблюдаемости и разработки агентов ИИ : Официально выпущен MLflow 3.0. Новая версия была переработана специально для наблюдаемости и разработки агентов ИИ, а также обновлены традиционные функции структурированного машинного обучения. MLflow 3.0 нацелен на постоянное улучшение систем ИИ с помощью данных, поддерживая отслеживание, оценку и мониторинг систем ИИ, а также учитывая потребности корпоративного уровня, такие как совместная работа людей, управление данными и безопасность, а также интеграция с экосистемой данных Databricks. (Источник: matei_zaharia, matei_zaharia, lateinteraction)
Принстонский университет и Фуданьский университет совместно запустили HistBench и HistAgent для продвижения применения ИИ в исторических исследованиях : Лаборатория ИИ Принстонского университета в сотрудничестве с историческим факультетом Фуданьского университета запустили первый в мире бенчмарк для оценки ИИ в исторических исследованиях HistBench и ИИ-помощника HistAgent. HistBench включает 414 исторических вопросов, охватывающих историю многих цивилизаций на 29 языках, и предназначен для проверки способности ИИ обрабатывать сложные исторические материалы и понимать мультимодальную информацию. HistAgent — это интеллектуальный агент, специально разработанный для исторических исследований, интегрирующий инструменты для поиска литературы, OCR, перевода и т.д. Тестирование показало, что точность универсальных больших моделей на HistBench составляет менее 20%, в то время как HistAgent значительно превосходит существующие модели. (Источник: Первый в мире исторический бенчмарк, Принстон и Фудань создают ИИ-помощника по истории, ИИ прорывается в гуманитарные науки)

Microsoft Research и Пекинский университет совместно выпустили фреймворк Next-Frame Diffusion (NFD) для повышения эффективности авторегрессионной генерации видео : Microsoft Research совместно с Пекинским университетом представили новый фреймворк Next-Frame Diffusion (NFD), который за счет параллельной выборки внутри кадра и авторегрессионного метода между кадрами достиг скорости генерации высококачественного авторегрессионного видео более 30 кадров в секунду на GPU A100 с использованием модели 310M. NFD использует Transformer с блочным причинно-следственным механизмом внимания и сочетает технологии согласованной дистилляции и спекулятивной выборки для дальнейшего повышения эффективности, что обещает применение в сценариях интерактивных игр в реальном времени. (Источник: Генерация более 30 кадров видео в секунду, поддержка интерактивности в реальном времени, новый фреймворк авторегрессионной генерации видео обновляет эффективность генерации)

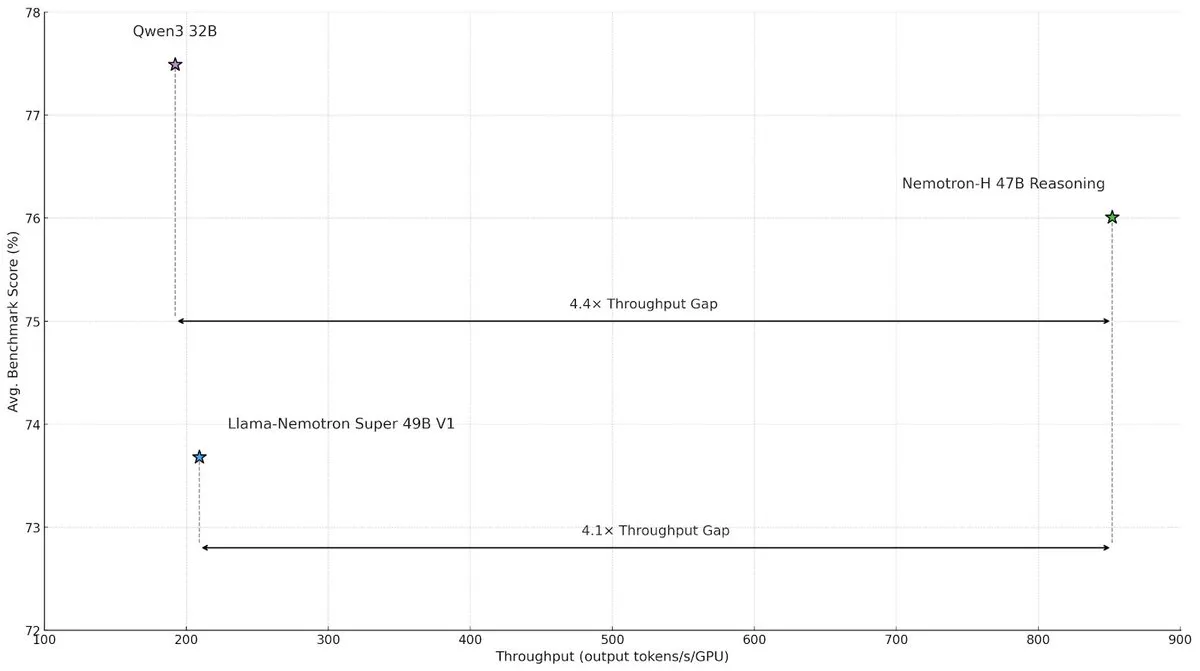
NVIDIA выпускает модель гибридной архитектуры Nemotron-H для повышения скорости и эффективности крупномасштабного инференса : NVIDIA Research представила модель Nemotron-H, использующую гибридную архитектуру Mamba и Transformer, нацеленную на решение проблемы узких мест в скорости при выполнении крупномасштабных задач инференса. Эта модель, сохраняя способность к инференсу, достигает в 4 раза большей пропускной способности по сравнению с аналогичными моделями Transformer. Исследования показывают, что гибридные модели могут поддерживать производительность инференса даже с меньшим количеством слоев внимания, особенно в сценариях с длинными цепочками инференса, где преимущество эффективности линейной архитектуры значительно. (Источник: _albertgu, tri_dao, krandiash)
Исследователь Google DeepMind Джек Рэй присоединяется к группе «суперинтеллекта» Meta : Главный исследователь Google DeepMind Джек Рэй подтвердил свое присоединение к недавно созданной группе «суперинтеллекта» в Meta. Во время работы в DeepMind Рэй отвечал за способность «мышления» модели Gemini и является одним из представителей идеи «сжатие как интеллект», ранее участвовал в разработке GPT-4 в OpenAI. Генеральный директор Meta Марк Цукерберг лично набирает лучших специалистов в области ИИ, предлагая новой команде компенсационные пакеты на десятки миллионов долларов, с целью улучшения модели Llama и разработки более мощных инструментов ИИ, чтобы догнать лидеров отрасли. (Источник: Первый крупный специалист в группе «суперинтеллекта» Цукерберга, главный исследователь Google DeepMind, ключевая фигура в концепции «сжатие как интеллект», DhruvBatraDB)

Mistral AI выпускает свою первую модель для логических выводов Magistral, поддерживающую многоязычные рассуждения : Mistral AI представила свою первую модель для логических выводов Magistral, включающую версию с открытым исходным кодом Magistral Small с 24 миллиардами параметров и корпоративную версию Magistral Medium. Модель специально доработана для многошаговой логики и интерпретируемости, поддерживает многоязычные рассуждения, особенно оптимизирована для европейских языков, и способна предоставлять отслеживаемый процесс мышления. Magistral обучена с использованием улучшенного алгоритма GRPO посредством чистого обучения с подкреплением, без необходимости дистилляции данных из существующих моделей для логических выводов. Однако результаты ее бенчмарков подверглись некоторой критике из-за отсутствия данных по последним версиям Qwen и DeepSeek R1. (Источник: Новая модель логических выводов «SOTA» избегает сравнения с Qwen и R1? Европейский OpenAI подвергся резкой критике)

ByteDance выпускает большую модель Doubao 1.6 и снова значительно снижает цены, одновременно выходит видеомодель Seedance 1.0 pro : Volcano Engine выпустила большую модель Doubao 1.6, впервые применив ценообразование по диапазонам «длины ввода»: для диапазона ввода 0-32K цена составляет 0,8 юаня за миллион токенов, для вывода — 8 юаней за миллион токенов, что на 63% дешевле по сравнению с версией 1.5. Цена на новую видеогенерационную модель Seedance 1.0 pro установлена в 1,5 фэня за тысячу токенов, генерация 5-секундного видео 1080P обойдется примерно в 3,67 юаня. Президент Volcano Engine Тан Дай заявил, что это снижение цен достигнуто за счет целенаправленной оптимизации затрат для часто используемого предприятиями диапазона 32K и инноваций в бизнес-модели, с целью содействия масштабному применению Agent. (Источник: Большая модель Doubao снова значительно снижает цены, Volcano Engine продолжает агрессивно бороться за долю рынка, «Volcano» нацеливается на Baidu Cloud)
Гонконгский университет науки и технологий совместно с Huawei предложили фреймворк AutoSchemaKG, реализующий полностью автономное построение графов знаний : Лаборатория KnowComp Гонконгского университета науки и технологий в сотрудничестве с теоретическим отделом Huawei в Гонконге предложили фреймворк AutoSchemaKG, который позволяет полностью автономно строить графы знаний без предварительно определенных схем. Эта система использует большие языковые модели для прямого извлечения троек знаний из текста и индукции схем сущностей и событий. На основе этого фреймворка команда построила серию графов знаний ATLAS, содержащую более 900 миллионов узлов и 5,9 миллиардов ребер. Эксперименты показали, что при нулевом вмешательстве человека индукция схем достигает 95% семантического соответствия схемам, разработанным людьми. (Источник: Крупнейший открытый GraphRag: полностью автономное построение графов знаний)

QJ Technologies выпускает программно-аппаратное серверное решение на 8 карт, повышающее эффективность работы большой модели DeepSeek : QJ Technologies совместно с Intel провели экологический салон, на котором представили новейшее программно-аппаратное серверное решение на 8 карт. Это решение способно эффективно запускать большие модели, такие как DeepSeek-R1/V3-671B, с повышением производительности до 7 раз по сравнению с одной картой. Одновременно были значительно обновлены их собственный движок для логических выводов KLLM, платформа управления большими моделями AMaaS и офисный пакет приложений «QJ·SmartQuery», направленные на решение проблем высокого порога входа и недостаточной производительности при развертывании больших моделей в частном порядке. (Источник: Прошел экологический салон QJ Technologies & Intel, интеграция аппаратного обеспечения, движка для логических выводов и экосистемы приложений верхнего уровня, преодоление «последней мили» в частном развертывании больших моделей)

Black Forest Labs выпускает серию моделей изображений FLUX.1 Kontext, усиливающую согласованность персонажей и стиля : Немецкая компания Black Forest Labs представила серию моделей преобразования текста в изображение FLUX.1 Kontext (версии max, pro, dev), ориентированных на сохранение согласованности персонажей и стиля при редактировании изображений. Эта серия моделей поддерживает локальные и глобальные изменения изображений и может генерировать изображения из текстового и/или графического ввода. Версию FLUX.1 Kontext dev планируется сделать открытой. В проприетарном бенчмарке, включающем около 1000 пар подсказок и эталонных изображений, версии FLUX.1 Kontext max и pro превзошли конкурирующие модели, такие как OpenAI GPT Image 1 и Google Gemini 2.0 Flash. (Источник: DeepLearning.AI Blog)

Nvidia, Университет Рутгерса и другие учреждения предложили фреймворк STORM, использующий слои Mamba для уменьшения количества токенов, необходимых для понимания видео : Исследователи из Nvidia, Университета Рутгерса, Калифорнийского университета в Беркли и других учреждений создали систему текст-видео STORM. Эта система вводит слой Mamba между визуальным трансформером SigLIP и LLM Qwen2-VL, обогащая вложения токенов одного кадра информацией (содержащей информацию из других кадров того же клипа), что позволяет усреднять вложения токенов между кадрами без потери ключевой информации. Это позволяет системе обрабатывать видео с меньшим количеством токенов, превосходя GPT-4o и Qwen2-VL в бенчмарках понимания видео, таких как MVBench и MLVU, при этом скорость обработки увеличивается более чем в 3 раза. (Источник: DeepLearning.AI Blog)

Сооснователь Google скептически относится к человекоподобным роботам, коммерческие перспективы специализированных роботов выглядят многообещающе : Сооснователь Google Сергей Брин заявил, что не испытывает особого энтузиазма по поводу человекоподобных роботов, строго копирующих человеческую форму, считая это необязательным условием для эффективной работы роботов. В то же время специализированные роботы привлекают внимание благодаря своей характеристике «включил и работай» и четким путям коммерциализации. Например, подводные роботы и роботы-газонокосилки демонстрируют огромный потенциал в конкретных сценариях. Аналитики считают, что на данном этапе ключевыми являются форма робота и производительность, способные решать реальные проблемы, а специализированные роботы, благодаря четким бизнес-моделям и насущным потребностям, первыми достигают коммерциализации. (Источник: Специализированные роботы похлопали человекоподобных роботов по плечу: «Братец, подвинься, я хочу за стол»)

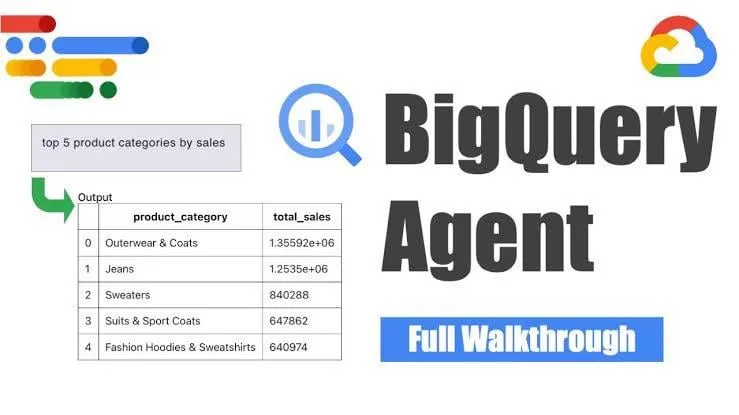
Google представляет интеллектуального агента для инжиниринга данных BigQuery, реализующего интеллектуальную генерацию конвейеров : Google представила интеллектуального агента для инжиниринга данных BigQuery. Этот инструмент использует контекстно-зависимые рассуждения для эффективного масштабирования генерации конвейеров данных. Пользователи с помощью простых командных инструкций могут определять требования к конвейеру, а интеллектуальный агент, используя специфичные для предметной области подсказки, генерирует код пакетных конвейеров, настроенный под пользовательскую среду данных, включая конфигурацию приема данных, запросы на преобразование, логику создания таблиц и настройки планирования через Dataform или Composer. Этот инструмент призван упростить повторяющуюся работу инженеров данных при обработке нескольких доменов данных, сред и логик преобразования с помощью ИИ. (Источник: Reddit r/deeplearning)
Yandex опубликовал крупномасштабный общедоступный набор данных Yambda, содержащий почти 5 миллиардов взаимодействий пользователей с аудиозаписями : Yandex опубликовал крупномасштабный общедоступный набор данных под названием Yambda, специально разработанный для исследований в области рекомендательных систем. Этот набор данных содержит почти 5 миллиардов анонимных записей о взаимодействиях пользователей с аудиозаписями из Яндекс.Музыки, предоставляя исследователям редкую возможность работать с данными реального масштаба. (Источник: _akhaliq)

ByteDance выпустила модель восстановления видео SeedVR2 на Hugging Face : Команда Seed из ByteDance выпустила на Hugging Face модель SeedVR2, одношаговый диффузионный Transformer для восстановления видео. Модель распространяется под лицензией Apache 2.0, отличается одношаговым выводом, высокой скоростью и эффективностью, а также поддерживает обработку произвольного разрешения без необходимости разбиения на блоки или ограничений по размеру. (Источник: huggingface)
Видео-большая модель Seedance 1.0 Pro от ByteDance получила положительные отзывы по результатам практических тестов : Недавно выпущенная ByteDance большая модель для генерации видео из изображений Seedance 1.0 Pro продемонстрировала в практических тестах хорошую способность следовать инструкциям и стабильность генерации объектов. Пользователи отмечают высокое качество генерируемых видео, точное попадание в тайминг движения камеры, уступая лишь Veo 2/3. Потенциальным недостатком является то, что при генерации движения чисто объектов модель иногда добавляет действия рук, чтобы сделать кадр более логичным, что можно обойти, ограничив появление рук. (Источник: karminski3, karminski3, karminski3)
Alibaba открыла исходный код фреймворка для цифровых людей Mnn3dAvatar, поддерживающего захват мимики в реальном времени и создание 3D виртуальных персонажей : Alibaba открыла на GitHub исходный код фреймворка для цифровых людей под названием Mnn3dAvatar. Этот проект позволяет осуществлять захват мимики в реальном времени и переносить выражения лица на 3D виртуальных персонажей, а также поддерживает создание пользователями собственных 3D виртуальных персонажей. Данный фреймворк подходит для простых сценариев прямых трансляций с продажами, демонстрации контента и т.п. (Источник: karminski3)
Nvidia открыла исходный код базовой модели для человекоподобных роботов Gr00t N 1.5 3B и предоставила руководство по тонкой настройке : Nvidia открыла исходный код модели Gr00t N 1.5 3B, открытой базовой модели, специально разработанной для навыков рассуждения человекоподобных роботов, с коммерческой лицензией. Одновременно Nvidia также выпустила полное руководство по тонкой настройке для использования с LeRobotHF SO101, направленное на содействие развитию и применению технологий человекоподобных роботов. (Источник: ClementDelangue)
Together AI запускает Batch API, предоставляя услуги крупномасштабного инференса LLM со значительным снижением цен : Together AI запустила новый Batch API, специально разработанный для крупномасштабного инференса LLM, поддерживающий такие высокопроизводительные сценарии применения, как генерация синтетических данных, бенчмаркинг, модерация и аннотирование контента, извлечение документов. API предлагает стартовую цену на 50% ниже, чем API реального времени, поддерживает пакетную обработку до 50 000 запросов или 100 МБ за раз и совместим с 15 топовыми моделями. (Источник: vipulved)
Google Gemini 2.5 Pro добавил функцию интерактивной генерации фрактального искусства : Google объявила, что Gemini 2.5 Pro теперь поддерживает мгновенное создание интерактивного фрактального искусства. Пользователи могут генерировать уникальные визуальные произведения искусства, предоставляя такие подсказки, как «создай для меня красивое, основанное на частицах, анимированное, бесконечное, трехмерное, симметричное, вдохновленное математическими формулами фрактальное произведение искусства». (Источник: demishassabis)
Скорость генерации видео Google Veo3 Fast увеличена в два раза : Лаборатория Google объявила, что скорость генерации версии Veo3 Fast в их инструменте для создания видео Flow увеличена более чем в два раза, при этом сохраняется разрешение 720p. Это обновление направлено на то, чтобы пользователи могли быстрее создавать видеоконтент. (Источник: op7418)
Hugging Face интегрируется с Google Colab и Kaggle, упрощая процесс использования моделей : Hugging Face теперь интегрирован с Google Colab и Kaggle. Пользователи могут напрямую запускать ноутбуки Colab с любой карточки модели или открывать ту же модель в Kaggle Notebook с прилагаемыми примерами общедоступного кода, что упрощает процесс использования и экспериментирования с моделями. (Источник: ClementDelangue, huggingface)
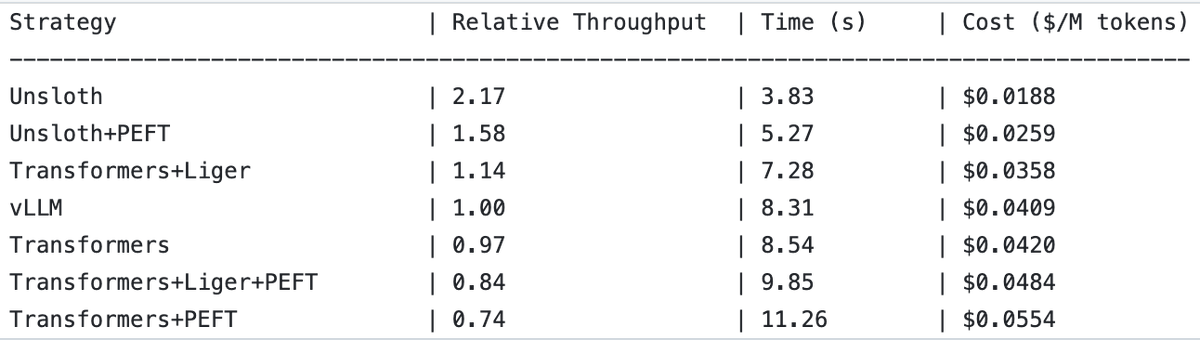
UnslothAI достигает двукратного увеличения пропускной способности в сервисах моделей вознаграждения и инференсе классификации последовательностей : Обнаружено, что UnslothAI может использоваться для предоставления сервисов моделей вознаграждения (RM), и в инференсе классификации последовательностей его пропускная способность вдвое выше, чем у vLLM. Это открытие привлекло внимание в сообществе RL (обучение с подкреплением), и ожидается, что повышение производительности UnslothAI ускорит соответствующие исследования и приложения. (Источник: natolambert, danielhanchen)
Digua Robot выпускает первый в отрасли комплект для разработки роботов RDK S100 с интегрированным управлением и вычислениями на одном SoC : Digua Robot представила первый в отрасли комплект для разработки роботов RDK S100 с интегрированным управлением и вычислениями на одном SoC. Этот комплект разработан на основе архитектуры, подобной человеческому мозгу и мозжечку, интегрируя CPU+BPU+MCU на одном SoC, поддерживая эффективное взаимодействие больших и малых моделей воплощенного интеллекта и замыкая цикл «восприятие-решение-управление». RDK S100 предоставляет различные интерфейсы и инфраструктуру разработки с программно-аппаратной координацией и интеграцией «край-облако», нацеленную на ускорение создания продуктов воплощенного интеллекта и развертывания в различных сценариях. В настоящее время сотрудничество налажено с более чем 20 ведущими клиентами, рыночная цена составляет 2799 юаней. (Источник: Digua Robot выпускает первый в отрасли комплект для разработки роботов с интегрированным управлением и вычислениями на одном SoC, уже сотрудничает с более чем 20 ведущими клиентами | Передовая линия)

🧰 工具
LangChain публикует бенчмарк для мультиагентных архитектур и улучшения метода супервизора : LangChain, в связи с растущим числом мультиагентных систем, провел предварительное тестирование бенчмарков, исследуя способы оптимизации координации между несколькими агентами. Одновременно LangChain внес некоторые улучшения в свой метод супервизора (supervisor), соответствующий блог уже опубликован. (Источник: LangChainAI, hwchase17)
Cartesia представляет Ink-Whisper: быструю и экономичную потоковую модель преобразования речи в текст, разработанную для голосовых агентов : Cartesia выпустила Ink-Whisper, высокоскоростную и недорогую потоковую модель преобразования речи в текст (STT), оптимизированную для голосовых агентов. Эта модель специально разработана для обеспечения точности в реальных условиях и может использоваться совместно с моделью преобразования текста в речь (TTS) Sonic от Cartesia для быстрого взаимодействия с голосовым ИИ. Ink-Whisper поддерживает интеграцию с платформами VapiAI, PipecatAI и Livekit. (Источник: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: небольшая, быстрая, открытая модель для анализа документов : Выпущена модель для анализа документов MonkeyOCR с 3 миллиардами параметров под лицензией Apache 2.0. Эта модель способна анализировать различные элементы в документах, включая диаграммы, формулы, таблицы и т.д., и призвана заменить традиционные конвейеры парсеров, предлагая улучшенное решение для обработки документов. (Источник: mervenoyann, huggingface)
LlamaIndex интегрируется с Cleanlab для повышения достоверности ответов ИИ-помощников : LlamaIndex объявил об интеграции с CleanlabAI. LlamaIndex используется для создания ИИ-помощников по знаниям и производственных интеллектуальных агентов, генерирующих инсайты из корпоративных данных. Добавление Cleanlab направлено на повышение достоверности ответов этих ИИ-помощников, позволяя оценивать каждый ответ LLM, выявлять галлюцинации или неверные ответы в реальном времени и помогать анализировать причины недостоверности ответов (например, плохой поиск, проблемы с данными/контекстом, сложные запросы или галлюцинации LLM). (Источник: jerryjliu0)

Claude Code добавляет «режим планирования» для повышения контролируемости сложных изменений кода : Claude Code от Anthropic вводит «режим планирования» (Plan mode). Эта функция позволяет пользователям просматривать план реализации перед фактическим изменением кода, обеспечивая продуманность каждого шага, что особенно полезно для сложных изменений кода. Пользователи могут войти в режим планирования, дважды нажав Shift + Tab, после чего Claude Code предоставит подробный план реализации и запросит подтверждение перед выполнением. Эта функция уже доступна всем пользователям Claude Code (включая подписчиков Pro или Max). (Источник: dotey, kylebrussell)
rvn-convert: инструмент для преобразования SafeTensors в GGUF v3, реализованный на Rust : Выпущен открытый инструмент под названием rvn-convert, написанный на языке Rust, для преобразования файлов моделей формата SafeTensors в формат GGUF v3. Особенностями этого инструмента являются поддержка одного шарда, высокая скорость, отсутствие необходимости в среде Python, возможность отображения файлов safetensors в память и прямой записи в файлы gguf, что позволяет избежать пиков использования RAM и дисковых операций. В настоящее время поддерживается повышение дискретизации с BF16 до F32, встраивание tokenizer.json и другие функции. (Источник: Reddit r/LocalLLaMA)
Runway API добавляет функцию суперразрешения видео до 4K : Runway объявила, что ее API теперь поддерживает функцию суперразрешения видео до 4K. Разработчики могут интегрировать эту функцию в свои приложения, продукты, платформы и веб-сайты для повышения четкости и качества видеоконтента. (Источник: c_valenzuelab)
You.com запускает функцию Projects для организации и управления исследовательскими материалами : You.com выпустила новый инструмент под названием «Projects», предназначенный для помощи пользователям в организации исследовательских материалов в легкодоступные папки. Эта функция позволяет пользователям контекстуализировать и структурировать диалоги, избегая разрозненности записей чатов и потери инсайтов, тем самым упрощая процесс управления знаниями. (Источник: RichardSocher)
LlamaIndex запускает сервис извлечения документов LlamaExtract с помощью интеллектуальных агентов : LlamaIndex выпустил LlamaExtract, сервис извлечения документов с помощью интеллектуальных агентов, предназначенный для извлечения структурированных данных из сложных документов и входных шаблонов. Этот сервис не только извлекает пары ключ-значение, но и предоставляет точное обоснование источника, ссылки на страницы и совпадающий текст для каждого извлеченного элемента. LlamaExtract предоставляется в виде API и может быть легко интегрирован в последующие рабочие процессы интеллектуальных агентов. (Источник: jerryjliu0)

Выпущено обновление langchain-google-vertexai, улучшающее кэширование клиента и поддержку инструментов : Вышла новая версия langchain-google-vertexai. Основные обновления включают: кэширование клиента прогнозирования, что ускоряет создание экземпляра нового клиента в 500 раз; поддержка встроенного инструмента выполнения кода. (Источник: LangChainAI, Hacubu)
Perplexity Finance добавляет функцию прямой загрузки моделей Excel : Perplexity Finance объявила, что пользователи теперь могут напрямую загружать модели Excel со своей страницы, что обеспечивает более быстрый старт для финансового моделирования и исследований. Эта функция доступна всем пользователям бесплатно, ранее поддерживалась только загрузка в формате CSV. (Источник: AravSrinivas)
Viwoods выпускает планшет на электронных чернилах AI Paper Mini, интегрированный с функциями ИИ, такими как GPT-4o : Новый производитель устройств на электронных чернилах Viwoods представил AI Paper Mini, планшет на электронных чернилах с функциями ИИ. Устройство поддерживает различные модели ИИ, такие как GPT-4o, DeepSeek, и предлагает режим Chat, а также предустановленных ИИ-помощников (анализ контента, генерация электронных писем, преобразование ИИ в текст). Его отличительные особенности включают управление задачами в виде календаря, быстрые плавающие окна для заметок и т.д. Аппаратно Paper Mini оснащен экраном Carta 1000 с разрешением 292 ppi, 4 ГБ + 128 ГБ памяти и стилусом. Одновременно Viwoods также выпустила AI Paper большего размера с гибким экраном Carta 1300 с разрешением 300 ppi и более высокой скоростью отклика. (Источник: Я потратил полцены iPhone, чтобы купить «планшет на электронных чернилах» с ИИ…)

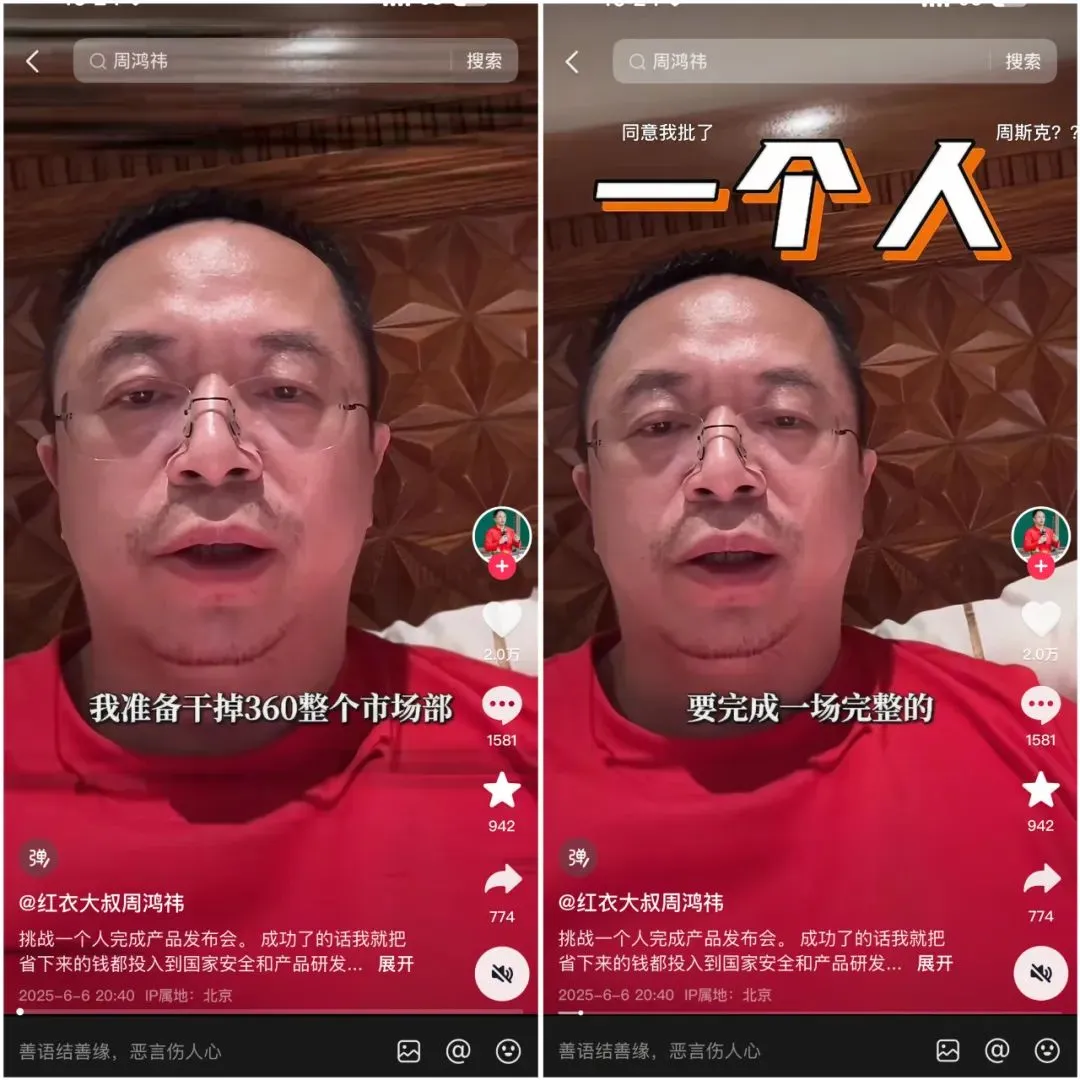
360 выпускает суперпоискового интеллектуального агента Nano AI, Чжоу Хунъи лично представляет продукт : Основатель 360 Group Чжоу Хунъи провел презентацию суперпоискового интеллектуального агента Nano AI. Этот интеллектуальный агент призван реализовать принцип «одна фраза — и все можно найти», способен самостоятельно мыслить, вызывать браузер и внешние инструменты для выполнения задач без вмешательства человека, а также поддерживает полную визуализацию и отслеживание шагов. Чжоу Хунъи заявил, что сама эта презентация также была подготовлена с использованием Nano AI, и представил аппаратное устройство для интеллектуальной записи звука Nano AI Note, а также совместно разработанные с Rokid очки с ИИ. (Источник: Чжоу Хунъи хочет «уничтожить» отдел маркетинга с помощью ИИ, удалось ли это «Nano»?)
📚 学习
DeepLearning.AI запускает новый короткий курс: Оркестрация рабочих процессов GenAI с помощью Apache Airflow : DeepLearning.AI в сотрудничестве с Astronomer запускает новый короткий курс, обучающий преобразованию прототипов RAG в готовые к производству рабочие процессы с использованием Apache Airflow 3.0. Содержание курса включает разбивку рабочих процессов на модульные задачи, планирование конвейеров с использованием триггеров, управляемых временем и событиями, динамическое отображение задач для параллельного выполнения, добавление повторных попыток/оповещений/заполнения для отказоустойчивости, а также методы масштабирования конвейеров. Опыт работы с Airflow для прохождения курса не требуется. (Источник: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Хамель Хусейн запускает мини-курс по оптимизации и оценке RAG : Хамель Хусейн объявил о запуске четырехчастного мини-курса по оптимизации и оценке RAG (Retrieval Augmented Generation). Первую часть ведет @bclavie, обсуждая точку зрения «поиск как RAG», в ответ на предыдущие дискуссии о том, что RAG является «мыслительным вирусом, который необходимо искоренить». Этот бесплатный курс направлен на помощь практикам в решении трудностей, возникающих при оценке RAG. (Источник: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

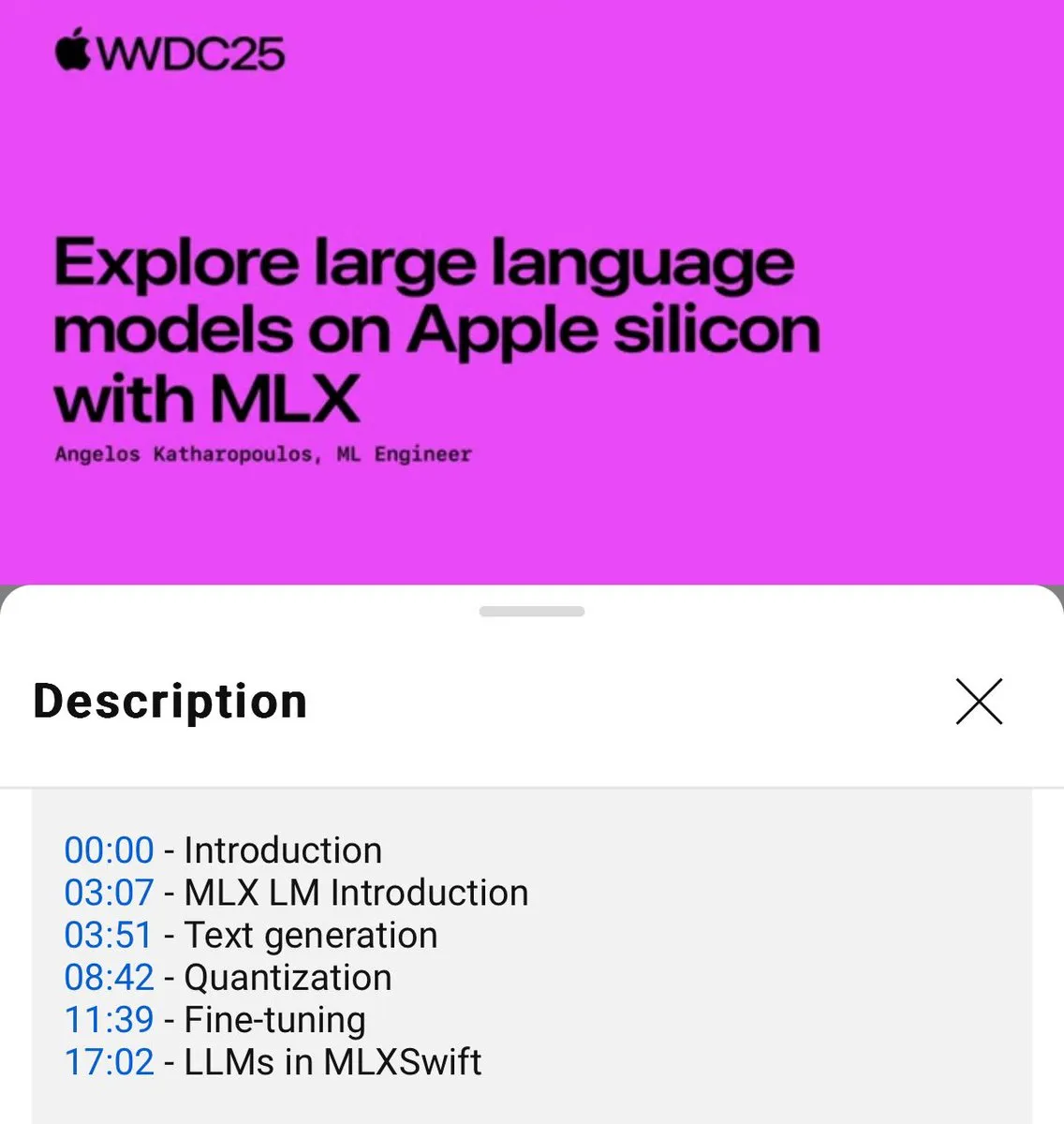
Опубликовано руководство по локальному использованию языковых моделей MLX (WWDC25) : На конференции WWDC25 Ангелос Катаропулос рассказал, как быстро начать работу с локальными языковыми моделями с помощью MLX. Руководство охватывает использование MLXLM CLI для выполнения операций одной командой, таких как квантование моделей (mlx_lm.convert), тонкая настройка LoRA (mlx_lm.lora), а также слияние моделей и загрузка на Hugging Face (mlx_lm.fuse). Полное руководство в формате Jupyter Notebook доступно на GitHub. (Источник: awnihannun)
LangChain делится методом Harvey AI по созданию юридических ИИ-агентов : Бен Либальд из Harvey AI на мероприятии LangChain Interrupt поделился их отработанным методом создания юридических ИИ-агентов. Этот метод сочетает оценку LangSmith и стратегию «юрист в цикле» (lawyer-in-the-loop), направленную на предоставление надежных ИИ-инструментов для сложной юридической работы. (Источник: LangChainAI, hwchase17)

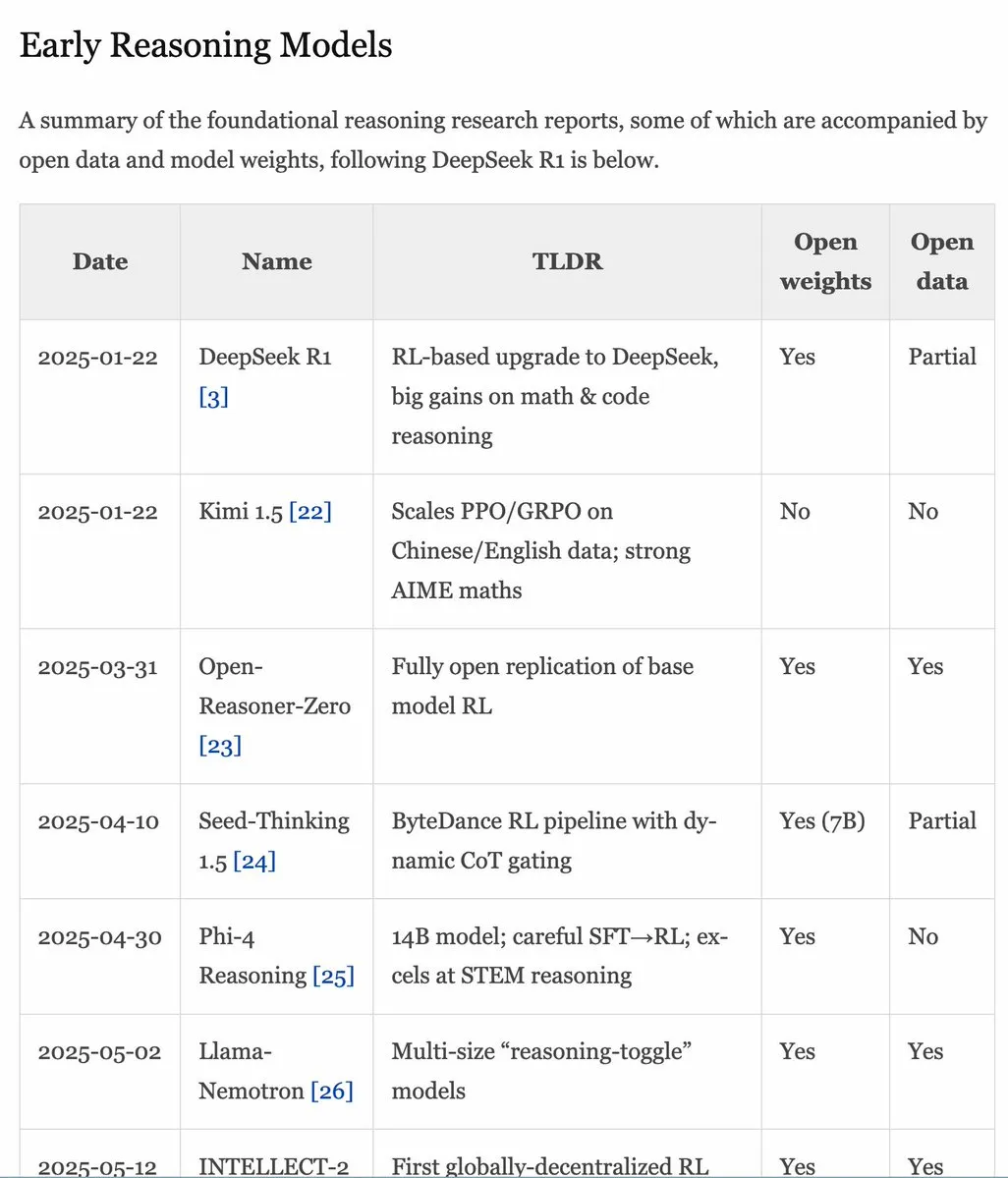
Руководство по RLHF v1.1 обновлено, расширено содержание по RLVR/моделям логического вывода : Руководство по RLHF (rlhfbook.com) обновлено до версии v1.1, добавлены расширенные материалы по RLVR (Reinforcement Learning from Video Representations) и моделям логического вывода. Обновления включают краткое изложение отчетов по основным моделям логического вывода, распространенные практики/приемы и их пользователей, соответствующую работу по логическому выводу до o1, а также улучшения, такие как асинхронный RL. (Источник: menhguin)
Статья SWE-Flow: Синтез данных для программной инженерии на основе тестирования : Новая статья под названием SWE-Flow предлагает новую структуру синтеза данных, основанную на разработке через тестирование (TDD). Эта структура автоматически выводит инкрементные шаги разработки путем анализа модульных тестов, строит граф зависимостей времени выполнения (RDG) для генерации структурированного плана разработки. Каждый шаг производит частичную кодовую базу, соответствующие модульные тесты и необходимые изменения кода, тем самым создавая проверяемые задачи TDD. На основе этого метода был сгенерирован эталонный набор данных SWE-Flow-Eval. (Источник: HuggingFace Daily Papers)
Статья PlayerOne: первый симулятор реального мира, построенный с видом от первого лица : PlayerOne предложен как первый симулятор реального мира, построенный с видом от первого лица (эгоцентрический), способный к иммерсивному исследованию в динамичной среде. Получив изображение сцены от первого лица пользователя, PlayerOne может построить соответствующий мир и сгенерировать видео от первого лица, строго согласованное с реальными движениями пользователя, зафиксированными внешней камерой. Модель использует процесс обучения от грубого к точному и разработала схему внедрения движения с разделением компонентов и совместную структуру реконструкции. (Источник: HuggingFace Daily Papers)
Статья ComfyUI-R1: Исследование моделей логического вывода для генерации рабочих процессов : ComfyUI-R1 — это первая крупная модель логического вывода для автоматической генерации рабочих процессов. Исследователи сначала создали набор данных из 4K рабочих процессов и сконструировали данные для логического вывода с длинной цепочкой рассуждений (CoT). ComfyUI-R1 обучается с использованием двухэтапной структуры: тонкая настройка CoT для холодного старта и обучение с подкреплением для стимулирования способности к логическому выводу. Эксперименты показывают, что модель с 7 миллиардами параметров значительно превосходит существующие методы по валидности формата, пропускной способности и F1-оценкам на уровне узлов/графов. (Источник: HuggingFace Daily Papers)
Статья SeerAttention-R: Адаптивная структура разреженного внимания для длинных логических выводов : SeerAttention-R — это структура разреженного внимания, специально разработанная для длинного декодирования моделей логического вывода. Она изучает разреженность внимания с помощью механизма стробирования самодистилляции и удаляет пулинг запросов для адаптации к авторегрессионному декодированию. Эта структура может быть интегрирована в существующие предварительно обученные модели в качестве легковесного плагина без изменения исходных параметров. В бенчмарке AIME SeerAttention-R, обученный всего на 0,4 млрд токенов, при бюджете в 4K токенов сохранил точность логического вывода, близкую к без потерь, в больших блоках разреженного внимания (64/128). (Источник: HuggingFace Daily Papers)
Статья SAFE: Обнаружение многозадачных сбоев для моделей визуально-языково-действенных моделей : В статье предлагается SAFE, детектор сбоев, разработанный для универсальных роботизированных стратегий (таких как VLA). Анализируя пространство признаков VLA, SAFE учится предсказывать вероятность сбоя задачи на основе внутренних признаков VLA. Этот детектор обучается на успешных и неудачных развертываниях и оценивается на невиданных ранее задачах, совместим с различными архитектурами стратегий и направлен на повышение безопасности VLA при взаимодействии со средой. (Источник: HuggingFace Daily Papers)
Статья Branched Schrödinger Bridge Matching: Обучение ветвящимся мостам Шрёдингера : Данное исследование вводит фреймворк Branched Schrödinger Bridge Matching (BranchSBM) для обучения ветвящимся мостам Шрёдингера с целью прогнозирования промежуточных траекторий между начальным и целевым распределениями. В отличие от существующих методов, BranchSBM способен моделировать ветвящиеся или расходящиеся эволюции от общей начальной точки к нескольким различным результатам, что достигается путем параметризации нескольких зависящих от времени полей скоростей и процессов роста. (Источник: HuggingFace Daily Papers)
💼 商业
Сообщается, что Meta планирует приобрести компанию по разметке данных Scale AI за 15 миллиардов долларов, основатель может присоединиться к Meta : По сообщениям, Meta планирует потратить 15 миллиардов долларов на приобретение Scale AI, ведущей компании в области разметки данных. В случае заключения сделки 28-летний китайский основатель Scale AI Александр Ванг и его команда напрямую войдут в состав Meta. Этот шаг рассматривается как значительная мера генерального директора Meta Марка Цукерберга для усиления своей команды AGI (искусственного общего интеллекта) и наверстывания упущенного по сравнению с конкурентами, такими как OpenAI и Google. Meta в последнее время активно набирает таланты в области ИИ, предлагая ведущим инженерам компенсационные пакеты на десятки миллионов долларов. (Источник: Первый крупный специалист в группе «суперинтеллекта» Цукерберга, главный исследователь Google DeepMind, ключевая фигура в концепции «сжатие как интеллект», dylan522p, sarahcat21, Dorialexander)
Disney и Universal Pictures подали в суд на компанию по генерации изображений с помощью ИИ Midjourney за нарушение авторских прав : Disney и Universal Pictures подали иск против компании по генерации изображений с помощью ИИ Midjourney, обвиняя ее в несанкционированном использовании известных произведений интеллектуальной собственности, таких как «Звездные войны» и «Симпсоны». Это дело привлекло внимание, и если Disney выиграет, это может вызвать цепную реакцию для других компаний ИИ, зависящих от обучения на больших объемах данных, что еще больше обострит споры об авторских правах в области ИИ. (Источник: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google из-за влияния ИИ-поиска снова запускает «программу добровольного увольнения», затрагивающую несколько важных команд, включая поиск и рекламу : Столкнувшись с влиянием ИИ-поиска, Google снова предложила сотрудникам нескольких американских подразделений «программу добровольного увольнения», затрагивающую ключевые команды, такие как поиск, реклама, основная инженерия, и ужесточила политику возвращения в офис. Этот шаг направлен на реорганизацию ресурсов и концентрацию усилий на флагманском проекте ИИ Gemini и разработке поискового опыта в «режиме ИИ». Традиционный поисковый бизнес Google сталкивается с огромными проблемами из-за подъема ИИ, одновременно компания также испытывает давление со стороны регулирующих органов. (Источник: Под влиянием ИИ-поиска Google снова запускает «программу добровольного увольнения», затрагивающую несколько важных команд, jpt401)
🌟 社区
ИИ в эксперименте по выявлению мошенничества с пособиями в Амстердаме выявил предвзятость, проект остановлен : Амстердам попытался использовать систему ИИ (Smart Check) для оценки заявлений на получение пособий с целью выявления мошенничества. Несмотря на соблюдение лучших практик ответственного ИИ, включая тестирование на предвзятость и технические гарантии, в пилотном проекте система так и не смогла обеспечить справедливость и эффективность. Первоначальная модель была предвзята по отношению к заявителям не голландского происхождения и мужчинам, а после корректировки стала предвзятой по отношению к голландцам и женщинам. В конечном итоге, из-за невозможности обеспечить отсутствие дискриминации, проект был остановлен. Этот случай вызвал широкие дискуссии о справедливости алгоритмов, эффективности практик ответственного ИИ и применении ИИ в принятии решений в сфере государственных услуг. (Источник: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Система маркировки контента, сгенерированного ИИ: ценность, ограничения и логика управления : С ростом числа слухов и ложной пропаганды, генерируемых ИИ, система маркировки ИИ привлекает внимание как средство управления. Теоретически, явная и неявная маркировка может повысить эффективность распознавания и усилить бдительность пользователей. Однако на практике маркировку легко обойти, подделать и ошибочно определить, к тому же она дорогостояща. В статье утверждается, что маркировка ИИ должна быть включена в существующую систему управления контентом, сфокусирована на областях высокого риска (таких как слухи, ложная пропаганда) и должна разумно определять ответственность платформ генерации и распространения, одновременно усиливая медиаграмотность населения. (Источник: Когда слухи подхватывают «восточный ветер» ИИ)
Инструменты для кодирования с помощью ИИ (например, Claude Code) значительно повышают эффективность разработчиков и снижают рабочую нагрузку : Многие разработчики в сообществе делятся положительным опытом использования инструментов для кодирования с помощью ИИ (в частности, Claude Code от Anthropic). Эти инструменты не только помогают писать, тестировать и отлаживать код, но и оказывают поддержку в планировании проектов, решении сложных проблем, тем самым значительно повышая эффективность разработки, снижая рабочую нагрузку и беспокойство из-за сроков. Некоторые пользователи заявляют, что помощь ИИ заставляет их чувствовать себя «неодолимой силой». (Источник: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Потребление энергии и водных ресурсов при генерации контента ИИ вызывает обеспокоенность, Сэм Альтман утверждает, что каждый запрос ChatGPT потребляет около 1/15 чайной ложки воды : Генеральный директор OpenAI Сэм Альтман сообщил, что каждый запрос ChatGPT потребляет примерно «одну пятнадцатую чайной ложки» воды. Эти данные вызвали дискуссии о влиянии обучения и инференса моделей ИИ на окружающую среду. Хотя конкретный метод расчета и включение затрат на обучение пока неясны, энергетический след и потребление водных ресурсов ИИ уже стали предметом озабоченности в технологических и экологических кругах. (Источник: MIT Technology Review, Reddit r/ChatGPT)

Обсуждение того, действительно ли LLM понимают математические доказательства: бенчмарк IneqMath выявляет слабые стороны моделей : Недавно опубликованный бенчмарк IneqMath фокусируется на доказательствах математических неравенств олимпиадного уровня. Исследование показало, что LLM, хотя иногда и могут найти правильный ответ, имеют значительные пробелы в построении строгих, обоснованных доказательств. Это вызвало дискуссию о том, действительно ли LLM понимают математику и другие области, или же они просто «угадывают». Сатья отметил, что это явление «правильный ответ — неверное рассуждение» также проявляется в таких бенчмарках, как PutnamBench. (Источник: lupantech, lupantech, _akhaliq, clefourrier)
Применение и обсуждение AI Agent в разработке программного обеспечения, исследованиях и повседневных задачах : Сообщество широко обсуждает применение AI Agent в различных областях. Например, пользователи делятся опытом создания рабочих процессов для глубоких исследований с использованием n8n и Claude; LlamaIndex демонстрирует, как реализовать агента для инкрементного заполнения форм с помощью Artifact Memory Block; обсуждения также касаются использования MCP (Model Context Protocol) для проектирования интерфейсов инструментов, ориентированных на ИИ, а также применения AI Agent в юридической сфере, автоматизации инфраструктуры (например, JARVIS от Cisco) и других областях. (Источник: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Стандарты безопасности человекоподобных роботов привлекают внимание, необходимо учитывать как физическое, так и психологическое воздействие : По мере того как человекоподобные роботы постепенно входят в промышленное применение и нацеливаются на домашние и другие сценарии, их стандарты безопасности становятся предметом обсуждения. Исследовательская группа IEEE по человекоподобным роботам отмечает, что человекоподобные роботы обладают уникальными свойствами, такими как динамическая стабильность, и требуют новых правил безопасности. Помимо физической безопасности (например, предотвращение падений, столкновений), необходимо учитывать коммуникационные проблемы во взаимодействии человека и робота (например, выражение намерений, координация нескольких роботов) и психологическое воздействие (например, чрезмерная антропоморфизация, приводящая к завышенным ожиданиям, эмоциональная безопасность). Разработка стандартов должна сбалансировать инновации и безопасность, а также учитывать потребности различных сценариев применения. (Источник: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 其他
Docker объявил, что docker run --gpus теперь поддерживает AMD GPU : Официальное обновление Docker: команда docker run --gpus теперь также поддерживает запуск на AMD GPU. Это улучшение повышает удобство использования AMD GPU в контейнеризированных рабочих нагрузках ИИ/МО и имеет положительное значение для продвижения применения AMD в экосистеме ИИ. (Источник: dylan522p)
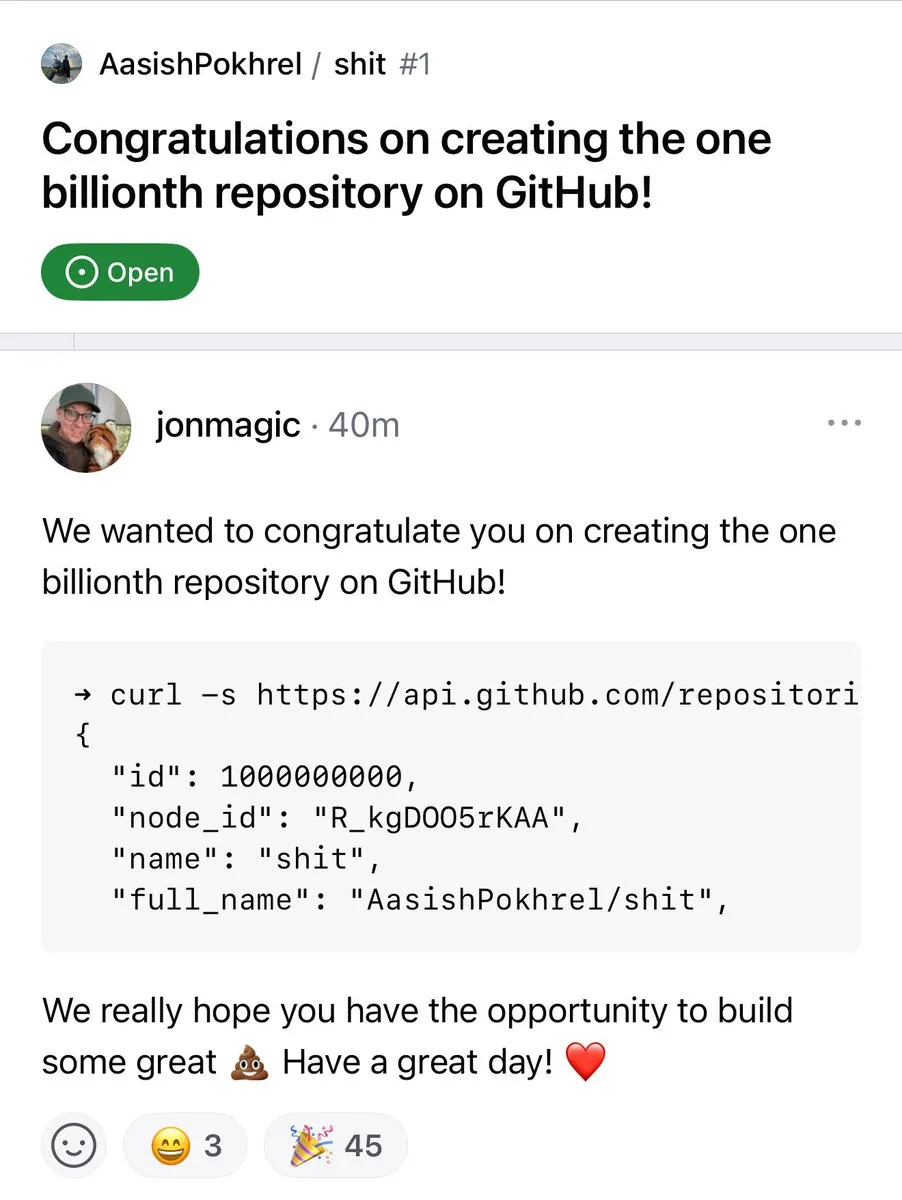
Количество репозиториев на GitHub превысило 1 миллиард : Количество репозиториев кода на платформе GitHub официально превысило отметку в 1 миллиард. Это знаковое событие свидетельствует о продолжающемся процветании и росте сообщества открытого исходного кода и платформ хостинга кода. (Источник: karminski3, zacharynado)
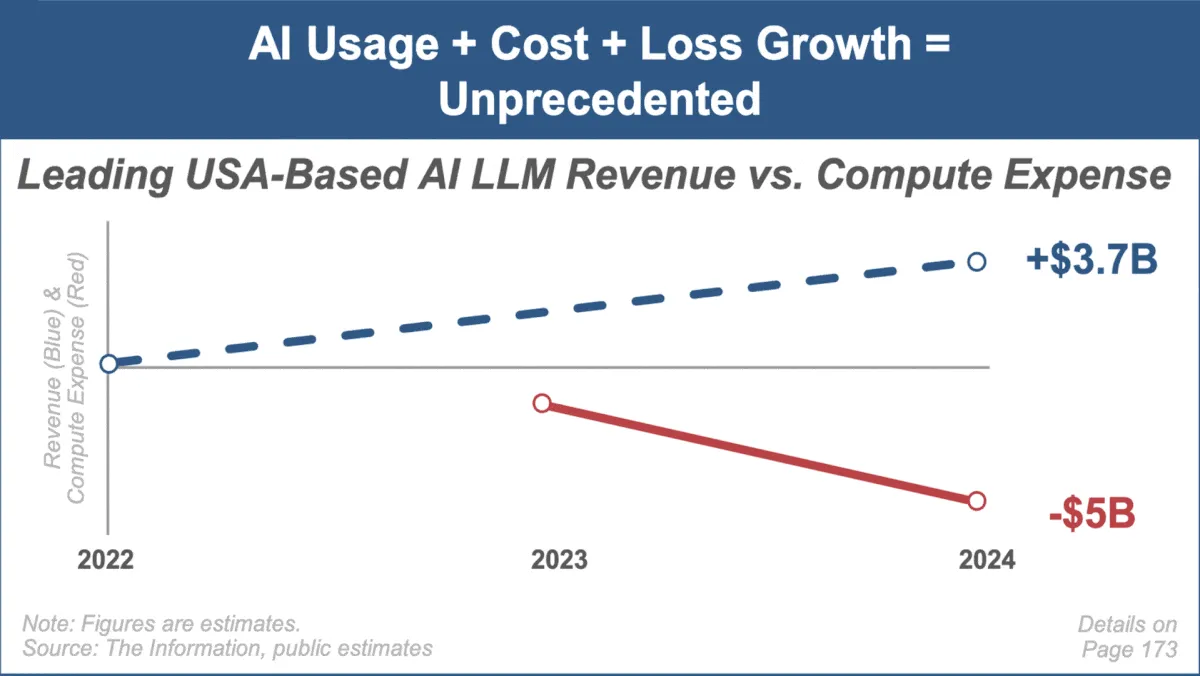
Мэри Микер опубликовала последний отчет о тенденциях в области ИИ, акцентируя внимание на быстром росте рынка и вызовах : Известный инвестиционный аналитик Мэри Микер опубликовала свой первый отчет о тенденциях на рынке искусственного интеллекта «Trends — Artificial Intelligence (May ‘25)». В отчете подчеркивается беспрецедентная скорость роста в области ИИ, резкое увеличение числа пользователей (например, у ChatGPT 800 миллионов пользователей), значительное увеличение капитальных затрат, связанных с ИИ, а также постоянные прорывы ИИ в производительности и новых возможностях. В отчете также указываются проблемы, с которыми сталкиваются бизнес-модели ИИ, такие как рост вычислительных затрат, быстрая итерация моделей и конкуренция со стороны альтернатив с открытым исходным кодом. (Источник: DeepLearning.AI Blog)