
Ключевые слова:DeepSeek, OpenAI, Модель логического вывода, Мультимодальная большая модель, Обучение с подкреплением, Инновации в ИИ, Открытая модель, Модель логического вывода DeepSeek R1, Обучение с подкреплением OpenAI o4, Мультимодальная большая модель карты человеческого мышления, Mistral AI Magistral серия, Xiaohongshu dots.llm1 MoE модель
🔥 В центре внимания
Инновационные пути DeepSeek и OpenAI раскрывают «когнитивные инновации»: DeepSeek, благодаря «ограниченному Scaling Law», инновациям в архитектурах MLA и MoE, а также программно-аппаратной оптимизации, достиг низкой стоимости и высокой производительности. Открытый исходный код его модели логического вывода R1 способствовал прорыву в когнитивных способностях ИИ, сломал «ментальные оковы» китайских новаторов в области фундаментальных исследований, доказав глобальное лидерство китайских компаний в фундаментальных исследованиях ИИ и инновациях моделей. OpenAI, в свою очередь, благодаря архитектуре Transformer и максимальному использованию Scaling Law (закона масштабирования), возглавила революцию больших языковых моделей, и через ChatGPT и модель логического вывода o1 способствовала изменению парадигмы взаимодействия человека с машиной и скачку в когнитивных способностях ИИ. Пути развития обеих компаний подчеркивают глубокое понимание сути технологий и их стратегическую перестройку, предоставляя предпринимателям эпохи ИИ ценные идеи для построения организаций и инноваций, особенно парадигма AI Lab от DeepSeek, поощряющая «эмерджентность», предлагает новый образец организационной модели для предпринимателей, движимых технологическими инновациями (Источник: 36氪)
Сообщается, что OpenAI обучает новую модель o4, Reinforcement Learning меняет ландшафт ИИ: SemiAnalysis сообщает, что OpenAI обучает новую модель, находящуюся между GPT-4.1 и GPT-4.5, модель логического вывода следующего поколения o4 будет обучаться на основе GPT-4.1 с использованием Reinforcement Learning (RL). RL раскрывает способности моделей к логическому выводу путем генерации CoT и способствует развитию интеллектуальных агентов ИИ, однако он предъявляет чрезвычайно высокие требования к инфраструктуре (особенно для логического вывода) и проектированию функций вознаграждения, и легко может возникнуть явление «взлома вознаграждения» (reward hacking). Высококачественные данные являются ключом к масштабированию RL, а данные о поведении пользователей станут важным активом. RL также меняет организационную структуру лабораторий, обеспечивая глубокую интеграцию логического вывода и обучения. В отличие от предварительного обучения, RL может постоянно обновлять возможности модели, как, например, DeepSeek R1. Для небольших моделей дистилляция может быть предпочтительнее RL. Эта утечка предвещает, что область ИИ, особенно модели логического вывода, ожидает непрерывная эволюция и скачок возможностей на основе RL (Источник: 36氪)
Обнаружено, что мультимодальные большие модели способны спонтанно формировать «карты человеческого мышления»: Совместная команда Института автоматизации Китайской академии наук и Центра передовых инноваций в области наук о мозге и интеллектуальных технологий посредством поведенческих экспериментов и анализа нейровизуализации подтвердила, что мультимодальные большие языковые модели (MLLMs) способны спонтанно формировать системы представления концепций объектов, очень похожие на человеческие. Исследование, проанализировав 4,7 миллиона данных поведенческих суждений в «задаче по распознаванию лишнего из трех», впервые построило «концептуальную карту» модели ИИ. Основные выводы включают: модели ИИ с различными архитектурами могут сходиться к схожим низкоразмерным когнитивным структурам; модели в условиях обучения без учителя демонстрируют эмерджентную способность к классификации концепций объектов высокого уровня, что соответствует человеческому познанию; «измерениям мышления» моделей ИИ могут быть присвоены семантические метки, такие как животные, еда, твердость и т.д.; представления MLLM значительно коррелируют с паттернами нейронной активности в определенных областях мозга (таких как FFA, PPA), что предоставляет доказательства в пользу «общего механизма обработки концепций у ИИ и человека». Данное исследование открывает новые перспективы для понимания когнитивных способностей ИИ, развития человекоподобного интеллекта и интерфейсов мозг-компьютер (Источник: 量子位)

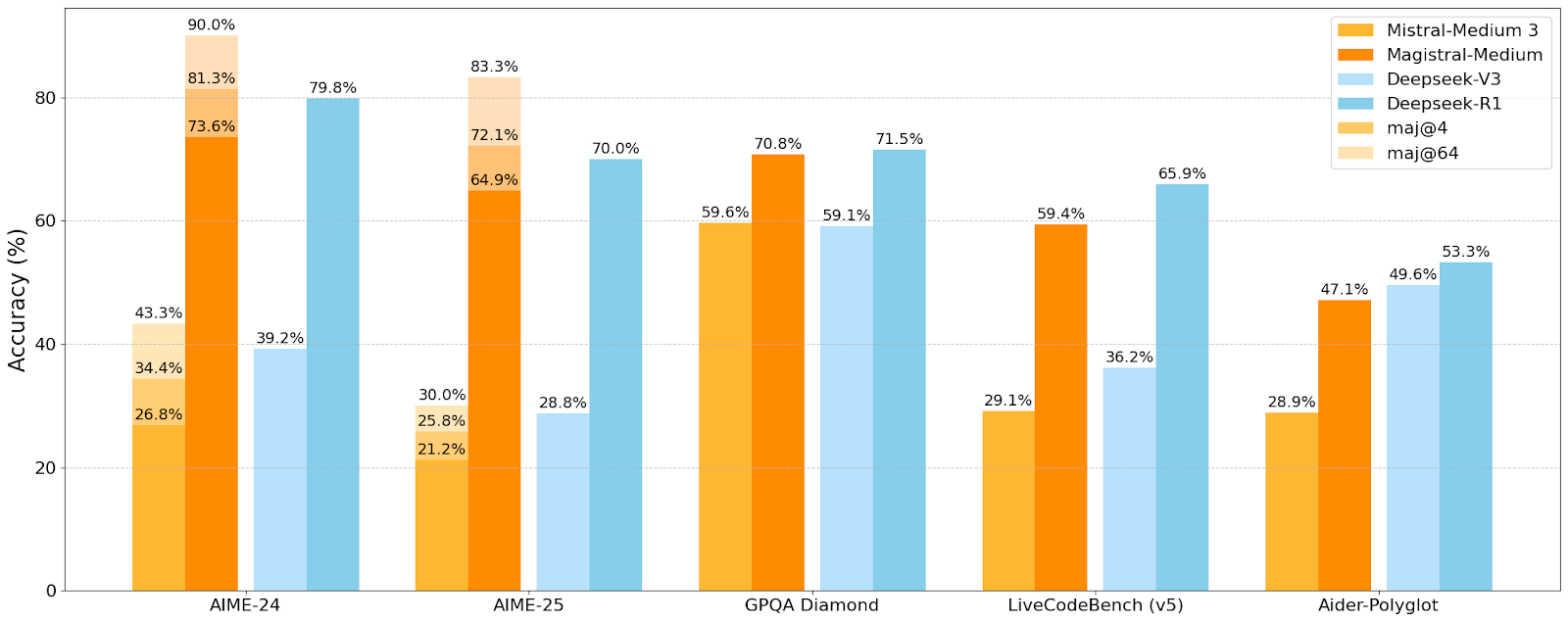
Mistral AI выпустила первую серию моделей для логического вывода Magistral, малая модель Magistral-Small уже с открытым исходным кодом: Mistral AI представила свою первую серию моделей, специально разработанных для логического вывода, Magistral, включающую Magistral-Small и Magistral-Medium. Magistral-Small, созданная на базе Mistral Small 3.1 (2503), представляет собой эффективную модель логического вывода с 24 млрд параметров, обученную с помощью SFT и RL на траекториях Magistral Medium для улучшения способностей к логическому выводу. Модель поддерживает несколько языков, имеет контекстное окно 128k (рекомендуемый эффективный контекст 40k), распространяется по лицензии Apache 2.0 с открытым исходным кодом и может быть развернута локально на одном RTX 4090 или MacBook с 32 ГБ ОЗУ (после квантования). Тесты производительности показывают, что Magistral-Small отлично справляется с такими задачами, как AIME24, AIME25, GPQA Diamond и Livecodebench (v5), приближаясь или даже превосходя некоторые более крупные модели. Magistral-Medium обладает более высокой производительностью, но в настоящее время не имеет открытого исходного кода. Этот выпуск знаменует прогресс Mistral в улучшении способностей моделей к логическому выводу и многоязычной поддержке (Источник: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 События
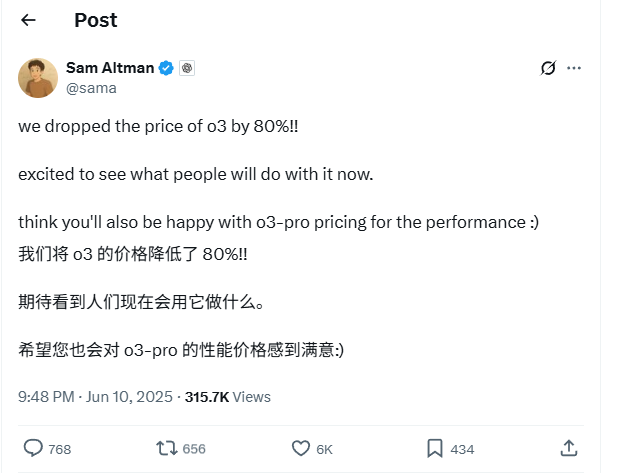
Цены на API модели OpenAI o3 значительно снижены на 80%: CEO OpenAI Sam Altman объявил о снижении цен на API модели o3 на 80%. После корректировки цена на ввод составляет 2 доллара США за миллион токенов, а на вывод — 8 долларов США за миллион токенов (некоторые источники упоминают 5 долларов США за миллион токенов на вывод, необходимо уточнять в официальной документации). Это значительное снижение цен существенно уменьшит затраты на использование модели o3 для таких задач, как написание кода, и, как ожидается, будет способствовать более широкому применению и инновациям. Пользователям следует обратить внимание, что список цен на официальном сайте может быть еще не обновлен, рекомендуется протестировать перед вызовом API для подтверждения фактической действующей цены, чтобы избежать ненужных потерь. Этот шаг рассматривается как стратегия реагирования на рыночную конкуренцию (например, Gemini 2.5 Pro и Claude 4 Sonnet) и может предвещать дальнейшее снижение стоимости ИИ-интеллекта (Источник: X, X, X)
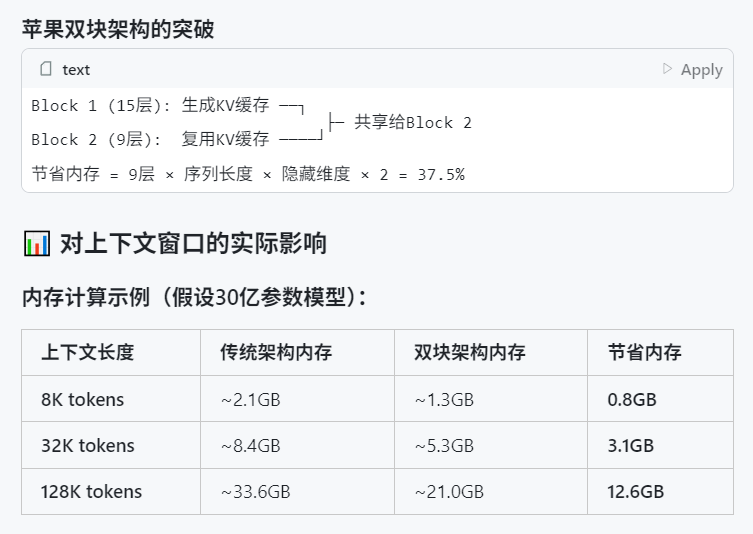
WWDC 2025 от Apple, по слухам, уделила мало внимания ИИ, но технические детали раскрывают амбиции: На Всемирной конференции разработчиков Apple (WWDC) 2025 ИИ, казалось, уделили меньше внимания, чем ожидалось, однако техническая документация компании раскрывает ее глубокие инвестиции в модели для устройств и облачные модели. Apple использует передовые технологии обучения, дистилляции и квантования, включая «двухблочную архитектуру» (разработанную для уменьшения занимаемой памяти) для мобильных моделей (размером около 3 млрд параметров) и архитектуру «PT-MoE» (Parallel Track Mixture of Experts) для серверных моделей. Эти технологии направлены на оптимизацию логического вывода с низкой задержкой на чипах Apple и сокращение использования памяти KV-кэша. Несмотря на мнения о том, что Apple отстает в области ИИ, ее достижения в технологиях моделей (например, открытые модели встраивания) и внимание к различным приоритетам (например, интеллект на устройстве, а не только чат-боты) указывают на ее уникальную стратегию в области ИИ. На WWDC также было объявлено, что Safari 26 будет поддерживать WebGPU, что значительно повысит производительность моделей ИИ, работающих на устройстве (например, через Transformers.js), например, скорость генерации субтитров для визуальных моделей в браузере увеличится примерно в 12 раз (Источник: X, X, X)
Пользователи Perplexity Pro теперь могут использовать модель OpenAI o3: Perplexity объявила, что ее подписчики Pro теперь могут использовать модель o3 от OpenAI. Эта интеграция предоставит пользователям Perplexity Pro более мощные возможности обработки информации и ответов на вопросы. Одновременно Perplexity тестирует свою функцию «Memory» и обновила голосового помощника для iOS, стремясь обеспечить более лаконичный и практичный пользовательский опыт. Ее функция Discover articles также по умолчанию использует более краткий режим «Summary» и предоставляет возможность переключения на углубленный режим «Report» (Источник: X, X, X)

Xiaohongshu опубликовала с открытым исходным кодом свою первую большую модель MoE dots.llm1 с 142 млрд параметров, которая превзошла DeepSeek-V3 в китайских бенчмарках: Xiaohongshu опубликовала свою первую большую модель dots.llm1, представляющую собой модель MoE (Mixture of Experts) со 142 миллиардами параметров, из которых при логическом выводе активируется только 14 миллиардов. На этапе предварительного обучения модель использовала 11,2 триллиона несинтетических токенов, в основном из общедоступных веб-данных, собранных собственными и сторонними веб-краулерами. Команда Xiaohongshu предложила масштабируемую трехэтапную структуру обработки данных и открыла ее исходный код для повышения воспроизводимости. dots.llm1 набрала 92,2 балла на C-Eval, превзойдя все модели, включая DeepSeek-V3, и приблизилась к производительности Qwen3-32B от Alibaba в задачах на китайском и английском языках, математике и выравнивании. Xiaohongshu также опубликовала промежуточные контрольные точки обучения, чтобы способствовать пониманию сообществом динамики больших моделей (Источник: 36氪)
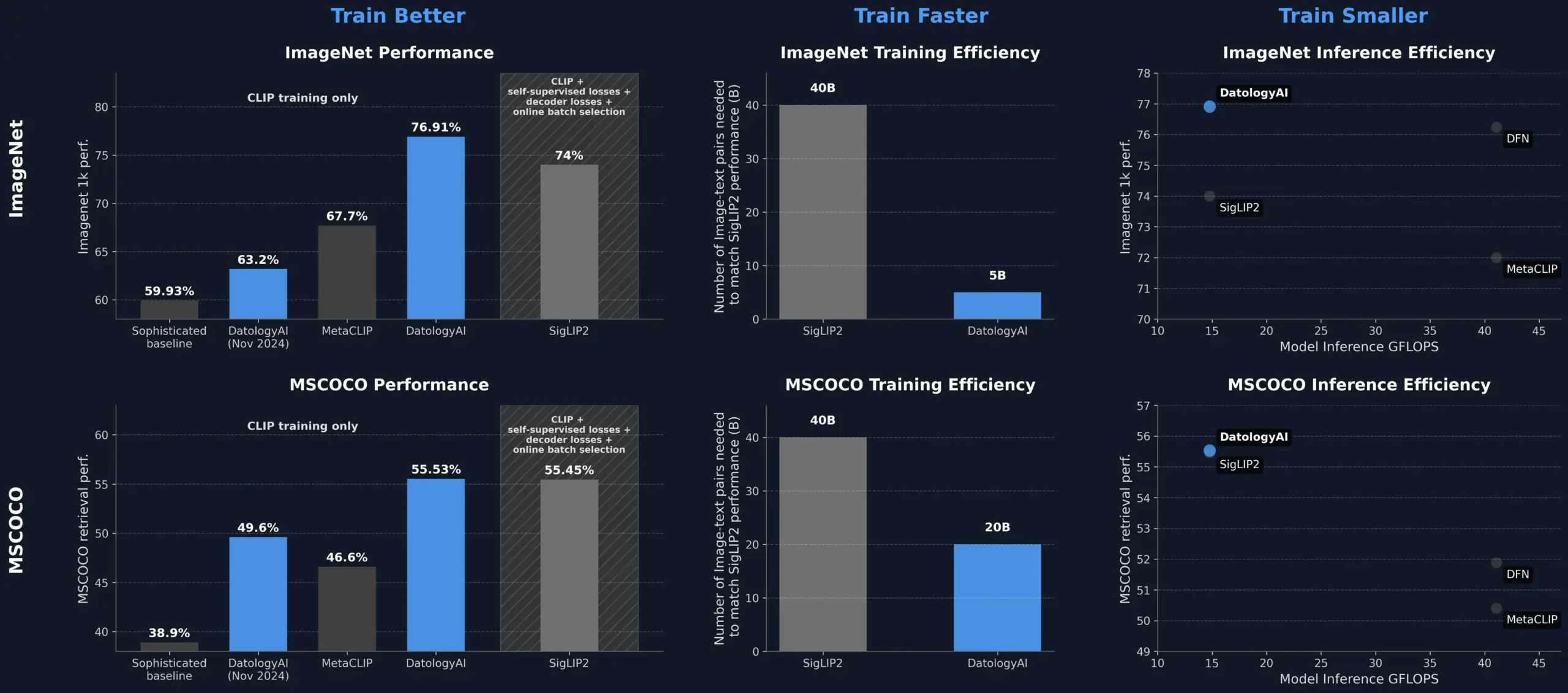
DatologyAI улучшает производительность модели CLIP за счет управления данными, превосходя SigLIP2: DatologyAI продемонстрировала, что только за счет управления данными (data curation) можно значительно улучшить производительность модели CLIP. Их метод позволил модели ViT-B/32 достичь точности 76,9% на ImageNet 1k, что превышает 74%, заявленные для SigLIP2. Кроме того, этот метод обеспечил 8-кратное повышение эффективности обучения и 2-кратное повышение эффективности логического вывода, а соответствующие модели были опубликованы. Это подчеркивает ключевую роль высококачественных, тщательно управляемых наборов данных в обучении передовых моделей ИИ, позволяя раскрыть потенциал модели за счет оптимизации данных даже без изменения ее архитектуры (Источник: X, X)
Kuaishou и Northeastern University совместно предложили унифицированную мультимодальную структуру встраивания UNITE: Для решения проблемы межмодальных помех, вызванных различиями в распределении данных разных модальностей (текст, изображение, видео) при мультимодальном поиске, исследователи из Kuaishou и Northeastern University предложили унифицированную мультимодальную структуру встраивания UNITE. Эта структура использует механизм «модально-осознанного маскированного контрастного обучения» (MAMCL), который при контрастном обучении учитывает только отрицательные примеры, соответствующие модальности целевого запроса, избегая ошибочной конкуренции между модальностями. UNITE использует двухэтапное обучение «адаптация к поиску + тонкая настройка по инструкциям» и достигла результатов SOTA в нескольких тестах, включая поиск изображений по тексту, поиск видео по тексту и поиск по инструкциям, например, превзойдя более крупные модели в MMEB Benchmark и значительно опередив конкурентов на CoVR. Исследование подчеркивает ключевую роль данных видео-текст в унифицированной модальности и указывает, что задачи по инструкциям больше зависят от данных, где доминирует текст (Источник: 量子位)

NVIDIA выпустила базовую модель ИИ для климатического моделирования Earth-2: Платформа Earth-2 от NVIDIA представила новую базовую модель ИИ, способную моделировать глобальный климат с разрешением на уровне километров. Модель предназначена для предоставления более быстрых и точных климатических прогнозов, открывая новые пути для понимания и прогнозирования сложных природных систем Земли. Этот шаг знаменует собой важный этап в применении ИИ в климатологии и моделировании земных систем, и ожидается, что он повысит возможности исследований изменения климата и предупреждения о стихийных бедствиях (Источник: X)

Сервисы OpenAI столкнулись с масштабным сбоем, затронувшим ChatGPT и API: Сервис ChatGPT и API-интерфейсы OpenAI столкнулись с масштабным сбоем вечером 10 июня по пекинскому времени, что выразилось в увеличении частоты ошибок и задержек. Многие пользователи сообщали о невозможности доступа к сервисам или сталкивались с сообщениями об ошибках, такими как «Hmm…something seems to have gone wrong». Официальная страница статуса OpenAI подтвердила проблему и сообщила, что инженеры установили основную причину и срочно работают над ее устранением. Этот сбой затронул большое количество пользователей и приложений по всему миру, зависящих от ChatGPT и его API, еще раз подчеркнув важность стабильности крупных сервисов ИИ (Источник: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Инструменты
Экосистема серверов Model Context Protocol (MCP) продолжает расширяться: Model Context Protocol (MCP) предназначен для предоставления большим языковым моделям (LLM) безопасного и контролируемого доступа к инструментам и источникам данных. Репозиторий modelcontextprotocol/servers на GitHub объединяет эталонные реализации MCP и серверы, созданные сообществом, демонстрируя их разнообразное применение. Официальные и сторонние серверы охватывают файловые системы, операции Git, взаимодействие с базами данных (такими как PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra и др.), облачные сервисы (AWS, Azure, Cloudflare), интеграцию API (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), поиск (Brave, Algolia, Exa, Tavily), выполнение кода, вызовы моделей ИИ (Replicate, ElevenLabs) и многие другие области. Экосистема MCP быстро развивается, насчитывая уже более 130 официальных и созданных сообществом серверов, а также появляются фреймворки для разработки, такие как EasyMCP, FastMCP, MCP-Framework, и инструменты управления, такие как MCP-CLI, MCPM, нацеленные на снижение барьера для подключения LLM к внешним инструментам и данным и способствующие развитию AI Agent (Источник: GitHub Trending)
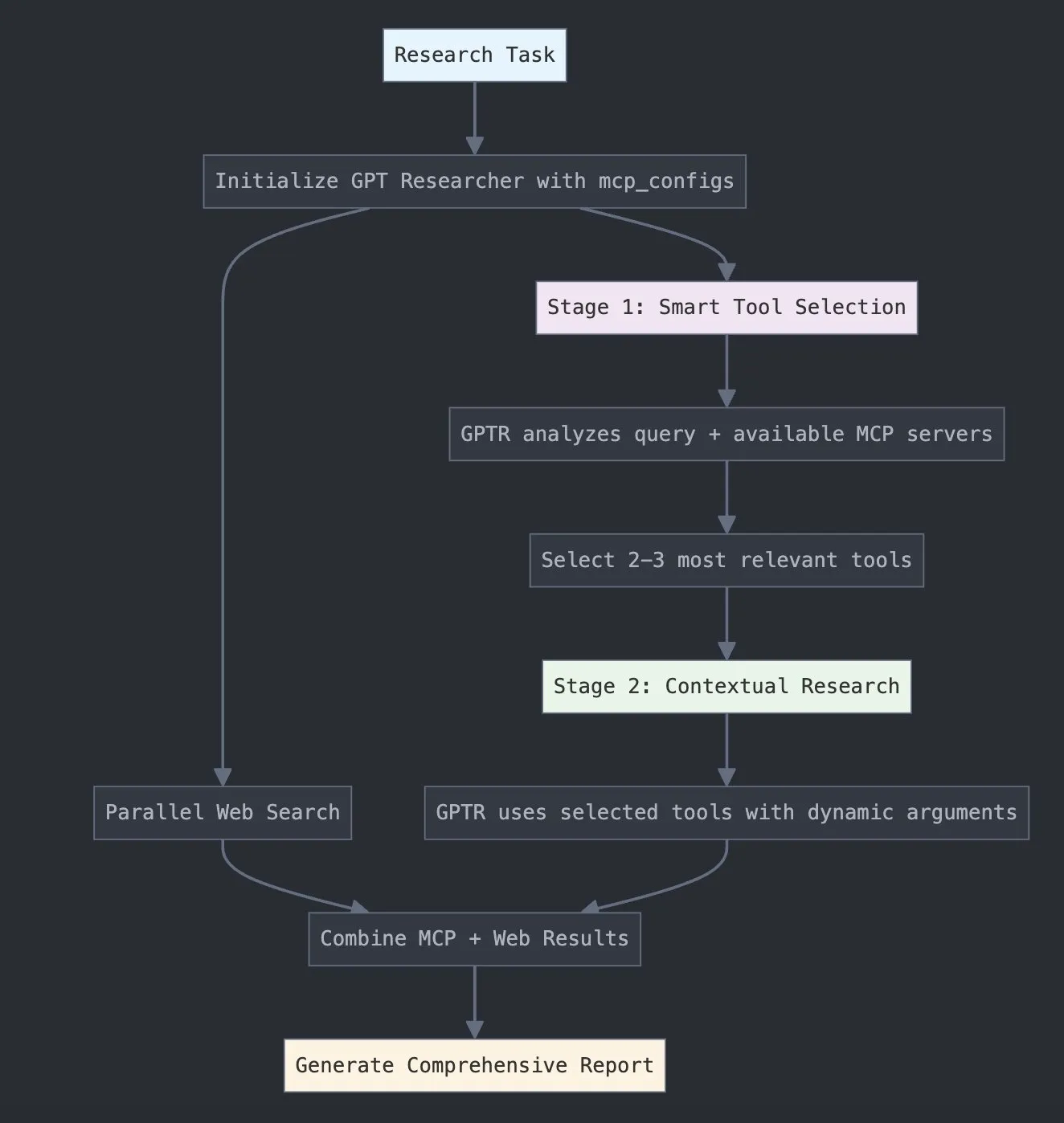
LangChain запускает GPT Researcher MCP для расширения исследовательских возможностей: LangChain объявила, что GPT Researcher теперь использует ее адаптер Model Context Protocol (MCP) для интеллектуального выбора инструментов и проведения исследований. Эта интеграция объединяет MCP с функциями веб-поиска, чтобы предоставить пользователям более комплексные возможности сбора и анализа данных, тем самым углубляя и расширяя применение ИИ в исследовательской сфере (Источник: X)
Hugging Face выпускает Vui: 100M открытый NotebookLM, реализующий человекоподобный TTS: На Hugging Face был выпущен Vui, проект NotebookLM с открытым исходным кодом и 100 миллионами параметров, включающий три модели: Vui.BASE (базовая модель, обученная на 40 000 часов аудиодиалогов), Vui.ABRAHAM (модель для одного говорящего с контекстно-зависимыми возможностями) и Vui.COHOST (модель, способная вести диалог с двумя участниками). Vui может клонировать голоса, имитировать дыхание, междометия типа «хм», «ах» и даже неречевые звуки, что знаменует новый прогресс в технологии человекоподобного преобразования текста в речь (TTS) (Источник: X, X)
Consilium: открытая платформа для совместной работы нескольких агентов, решающая сложные проблемы: На Hugging Face представлен проект Consilium, открытая платформа для совместной работы нескольких интеллектуальных агентов. Пользователи могут формировать команду экспертных ИИ-агентов, которые посредством дебатов и исследований в реальном времени (веб-страницы, arXiv, документы SEC) совместно решают сложные проблемы и достигают консенсуса. Пользователь задает стратегию, а команда агентов отвечает за поиск ответов, демонстрируя новые возможности ИИ в совместном решении проблем (Источник: X)
Unsloth выпустила оптимизированную GGUF-модель Magistral-Small-2506: Вслед за выпуском Mistral AI модели логического вывода Magistral-Small-2506, Unsloth быстро представила свою оптимизированную версию в формате GGUF, подходящую для таких платформ, как llama.cpp, LMStudio и Ollama. Эта быстрая реакция отражает динамизм и эффективность сообщества открытого исходного кода в оптимизации и развертывании моделей, позволяя новым моделям быстрее становиться доступными более широкому кругу пользователей и разработчиков (Источник: X)
📚 Обучение
Новая статья исследует парадигму предварительного обучения с подкреплением (RPT): Новая статья «Reinforcement Pre-Training (RPT)» предлагает переосмыслить предсказание следующего токена как задачу логического вывода с использованием RLVR (Reinforcement Learning with Verifiable Rewards). RPT направлена на улучшение точности предсказания языковых моделей путем стимулирования способности к логическому выводу следующего токена и обеспечивает прочную основу для последующей тонкой настройки с подкреплением. Исследование показывает, что увеличение вычислительных ресурсов для обучения постоянно повышает точность предсказания, указывая на то, что RPT является эффективной и перспективной расширенной парадигмой для предварительного обучения языковых моделей (Источник: HuggingFace Daily Papers, X)

Статья предлагает Cartridges: легковесные представления длинного контекста через самообучение: Статья под названием «Cartridges: Lightweight and general-purpose long context representations via self-study» исследует метод обработки длинных текстов путем офлайн-обучения небольших KV-кэшей (называемых Cartridge), чтобы заменить помещение всего корпуса в контекстное окно во время логического вывода. Исследование показало, что Cartridge, обученные с помощью «самообучения» (генерация синтетических диалогов о корпусе и обучение с целью контекстной дистилляции), могут достигать производительности, сравнимой с ICL, при значительно меньшем потреблении памяти (уменьшение в 38,6 раза) и более высокой пропускной способности (увеличение в 26,4 раза), а также могут расширять эффективную длину контекста модели и даже поддерживать комбинированное использование между корпусами без переобучения (Источник: HuggingFace Daily Papers, X)

Статья исследует оптимизацию стратегии группового контрастирования (GCPO) для LLM при решении геометрических задач: Статья «GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization» рассматривает проблему построения вспомогательных линий LLM при решении геометрических задач и предлагает фреймворк GCPO. Этот фреймворк использует «групповую контрастивную маску» для предоставления положительных и отрицательных сигналов вознаграждения за построение вспомогательных линий в зависимости от их контекстной полезности, а также вводит вознаграждение за длину для стимулирования более длинных цепочек рассуждений. Серия моделей GeometryZero, разработанная на основе GCPO, превзошла базовые модели в бенчмарках Geometry3K и MathVista, показав среднее улучшение на 4,29%, что демонстрирует потенциал повышения геометрических способностей рассуждения малых моделей при ограниченных вычислительных ресурсах (Источник: HuggingFace Daily Papers)
Статья «The Illusion of Thinking» исследует возможности и ограничения моделей логического вывода через сложность задач: Данное исследование систематически изучает возможности, характеристики масштабирования и ограничения больших моделей логического вывода (LRMs). Используя среду головоломок с точно контролируемой сложностью, исследование обнаружило, что точность LRMs полностью падает после превышения определенного порога сложности, и они демонстрируют контринтуитивные ограничения масштабирования: усилия по логическому выводу снижаются после того, как сложность задачи возрастает до определенной степени. По сравнению со стандартными LLM, LRMs хуже справляются с задачами низкой сложности, превосходят их в задачах средней сложности, и обе категории моделей не справляются с задачами высокой сложности. Исследование указывает на ограничения LRMs в точных вычислениях, трудности с применением явных алгоритмов и несогласованность логического вывода на разных масштабах (Источник: HuggingFace Daily Papers, X)
Статья исследует оценку устойчивости LLM в языках с малым количеством ресурсов: Статья «Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models» исследует чувствительность больших языковых моделей (LLMs) к возмущениям (таким как атаки на уровне символов и слов) в языках с низким уровнем ресурсов, таких как польский. Исследование показало, что путем небольших модификаций символов и использования небольших прокси-моделей для вычисления важности слов можно создавать атаки, которые значительно изменяют предсказания различных LLM. Это выявляет возможные уязвимости безопасности LLM в этих языках, которые могут быть использованы для обхода их внутренних механизмов безопасности. Исследователи опубликовали соответствующие наборы данных и код (Источник: HuggingFace Daily Papers)
Rel-LLM: новый метод повышения эффективности LLM при обработке реляционных баз данных: В статье предложен фреймворк Rel-LLM, направленный на решение проблемы низкой эффективности больших языковых моделей (LLM) при обработке реляционных баз данных. Традиционные методы преобразования структурированных данных в текст приводят к потере ключевых связей и избыточности ввода. Rel-LLM использует кодировщик на основе графовых нейронных сетей (GNN) для создания структурированных графовых подсказок, сохраняя реляционную структуру в рамках фреймворка генерации с расширенным поиском (RAG). Метод включает выборку подграфов с учетом временных аспектов, гетерогенный кодировщик GNN, слой проекции MLP для согласования встраиваний графов с латентным пространством LLM, а также структурирование графовых представлений в виде графовых подсказок JSON и использует цели самоконтролируемого предварительного обучения для согласования представлений графов и текста. Эксперименты показывают, что кодирование GNN эффективно улавливает сложные реляционные структуры, теряемые при текстовой сериализации, а структурированные графовые подсказки эффективно внедряют реляционный контекст в механизмы внимания LLM (Источник: X)

Статья исследует проблему «чрезмерного отказа» LLM и метод оптимизации EvoRefuse: Статья «EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions» исследует проблему чрезмерного отказа больших языковых моделей (LLM) от «псевдовредоносных инструкций» (семантически безвредных, но вызывающих отказ модели входных данных). Для решения недостатков существующих методов управления инструкциями в плане масштабируемости и разнообразия, в статье предлагается EVOREFUSE, метод оптимизации подсказок с использованием эволюционных алгоритмов, способный генерировать разнообразные псевдовредоносные инструкции, постоянно вызывающие отказ LLM. На основе этого исследователи создали EVOREFUSE-TEST (бенчмарк, содержащий 582 инструкции) и EVOREFUSE-ALIGN (набор данных для обучения выравниванию, содержащий 3000 инструкций и ответов). Эксперименты показывают, что модель LLAMA3.1-8B-INSTRUCT, дообученная на EVOREFUSE-ALIGN, демонстрирует снижение частоты чрезмерных отказов на 14,31% по сравнению с моделями, обученными на субоптимальных наборах данных для выравнивания, без ущерба для безопасности (Источник: HuggingFace Daily Papers)
💼 Бизнес
Zhongke Wenge завершила новый раунд стратегического финансирования, инвестором выступил Промышленный фонд района Шицзиншань города Пекин: Поставщик корпоративных ИИ-сервисов Zhongke Wenge объявил о завершении нового раунда стратегического финансирования, инвестором выступила компания Beijing Shijingshan Modern Innovation Industry Development Fund Co., Ltd. Полученные средства будут в основном направлены на исследования и разработку собственной операционной системы для интеллектуального принятия решений DIOS, а также на ее продвижение на рынке, ускоряя развитие корпоративных технологий искусственного интеллекта и их коммерческое внедрение. Zhongke Wenge была основана в 2017 году, ее основная команда происходит из Института автоматизации Китайской академии наук. Компания специализируется на многоязычном понимании, кросс-модальной семантике и технологиях принятия решений в сложных сценариях, обслуживая такие отрасли, как медиа, финансы, государственное управление и энергетика. Ранее компания привлекла более миллиарда юаней инвестиций от государственных фондов, таких как China Development Bank Capital, China Internet Investment Fund и Shenzhen Capital Group (Источник: 量子位)

Sakana AI и японский банк Hokkoku Bank заключили стратегическое партнерство для развития регионального финансового ИИ: Японский стартап в области ИИ Sakana AI объявил о подписании меморандума о взаимопонимании (MOU) с финансовой холдинговой компанией Hokkoku Financial Holdings, базирующейся в префектуре Исикава. Стороны будут сотрудничать в области интеграции региональных финансов и ИИ. Это уже второе сотрудничество Sakana AI с финансовым учреждением после установления всестороннего партнерства с Mitsubishi UFJ Bank. Целью является применение передовых технологий ИИ для решения проблем, стоящих перед региональными сообществами Японии, особенно в сфере финансовых услуг. Sakana AI стремится разрабатывать высокоспециализированные ИИ-технологии для финансовых учреждений, и это сотрудничество, как ожидается, станет образцом применения ИИ для других региональных банков Японии (Источник: X, X)

Cohere сотрудничает с Ensemble для внедрения своей ИИ-платформы в сферу здравоохранения: Компания ИИ Cohere объявила о партнерстве с EnsembleHP (поставщик решений для здравоохранения) для внедрения своей интеллектуальной агентской платформы Cohere North AI в отрасль здравоохранения. Стороны стремятся с помощью безопасной платформы ИИ-агентов уменьшить трения в процессах управления медицинскими услугами и улучшить опыт пациентов в больницах и системах здравоохранения. Этот шаг знаменует собой важный этап в продвижении Cohere своих больших языковых моделей и технологий ИИ в ключевых вертикальных отраслях (Источник: X)
🌟 Сообщество
Выступление Ильи Суцкевера на церемонии вручения почетной степени в Университете Торонто: ИИ в конечном итоге сможет все, необходимо активное внимание: Сооснователь OpenAI Илья Суцкевер в своей речи при получении почетной степени доктора наук в Университете Торонто (его четвертая степень в этом университете) заявил, что прогресс ИИ приведет к тому, что «однажды он сможет делать все, что можем мы», поскольку человеческий мозг — это биологический компьютер, а ИИ — цифровой мозг. Он считает, что мы находимся в необычайной эпохе, определяемой ИИ, который уже глубоко изменил смысл учебы и работы. Он подчеркнул, что вместо беспокойства лучше формировать интуицию, используя и наблюдая за передовыми ИИ, чтобы понять границы их возможностей. Он призвал людей уделять внимание развитию ИИ и активно реагировать на сопутствующие огромные вызовы и возможности, поскольку ИИ глубоко повлияет на жизнь каждого. Он также поделился своим личным настроем: «Принимать реальность, не сожалеть о прошлом, стремиться улучшить настоящее». (Источник: X, 36氪)
Борьба за таланты в сфере ИИ обостряется: Meta с высокими зарплатами все равно уступает OpenAI и Anthropic: Сообщается, что Meta предлагает годовую зарплату свыше 2 миллионов долларов для привлечения талантов в области ИИ, но все равно сталкивается с оттоком кадров в OpenAI и Anthropic. Обсуждается, что зарплата уровня L6 в OpenAI приближается к 1,5 миллионам долларов, а потенциал роста стоимости акций считается выше, чем у Meta, что делает ее более привлекательной для ведущих специалистов. Кроме того, на выбор талантов влияют обвинения команды Llama в нечестности, а также высокое давление KPI внутри Meta и высокий процент увольнений по результатам работы (15-20% в этом году). Anthropic, в свою очередь, с показателем удержания талантов около 80% (после двух лет с момента основания) стала одной из предпочтительных крупных компаний для ведущих исследователей ИИ. Ожесточенность этой борьбы за таланты описывается как «немыслимая» (Источник: X, X)
Опыт «Vibe Coding»: 5 правил, как избежать ловушек при программировании с помощью ИИ: В социальных сетях опытные разработчики поделились пятью правилами, как избежать попадания в неэффективные циклы отладки при использовании ИИ (например, Claude) для «Vibe Coding» (способ программирования, основанный на помощи ИИ): 1. Правило трех неудач: если ИИ трижды не смог исправить проблему, следует остановиться и попросить ИИ создать решение заново на основе переформулированных требований. 2. Сброс контекста: ИИ «забывает» информацию после длительного диалога, рекомендуется сохранять рабочий код каждые 8-10 сообщений, открывать новый сеанс и вставлять только проблемные компоненты и краткое описание приложения. 3. Краткое и ясное описание проблемы: четко опишите ошибку одним предложением. 4. Частый контроль версий: после завершения каждой функции делайте коммит в Git. 5. При необходимости начинайте заново: если исправление ошибки занимает слишком много времени (например, более 2 часов), лучше удалить проблемный компонент и попросить ИИ создать его заново. Главное — решительно отказаться от попыток исправить код, когда становится очевидно, что он необратимо поврежден. Также подчеркивается, что знание программирования помогает лучше руководить ИИ и отлаживать код (Источник: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Ли Фэйфэй о создании World Labs: истоки в исследовании сущности интеллекта, пространственный интеллект — ключевое недостающее звено ИИ: В подкасте a16z Ли Фэйфэй поделилась причинами создания World Labs, подчеркнув, что это не следование моде на базовые модели, а продолжение исследования сущности интеллекта. Она считает, что язык, хотя и является эффективным носителем информации, имеет недостатки в представлении трехмерного физического мира, и настоящий общий интеллект должен основываться на понимании физического пространства и отношений между объектами. Случай повреждения роговицы, из-за которого она временно потеряла стереоскопическое зрение, помог ей глубже осознать важность представления трехмерного пространства для физического взаимодействия. World Labs стремится создавать модели ИИ (мировые модели LWM), способные по-настоящему понимать физический мир, восполняя текущий пробел ИИ в пространственном интеллекте. Она считает, что для достижения этой цели необходимо объединить вычислительные мощности, данные и таланты промышленного уровня, и указывает, что текущий технологический прорыв заключается в том, чтобы научить ИИ восстанавливать полное понимание трехмерной сцены из монокулярного зрения (Источник: 量子位)

ИИ-помощник на госэкзаменах: от споров о «предсказании заданий» до возможностей и опасностей при выборе вуза: До и после государственных экзаменов (Гаокао) применение ИИ в образовании вызвало широкие дискуссии. С одной стороны, «предсказание заданий ИИ» стало горячей темой, но из-за научности, конфиденциальности и механизмов «анти-предсказания» при составлении заданий Гаокао, вероятность точного предсказания ИИ низка, а качество некоторых имеющихся на рынке «предсказательных» материалов сомнительно. С другой стороны, ИИ продемонстрировал положительную роль в планировании подготовки, объяснении заданий, контроле на экзаменах и проверке работ, например, персонализированные учебные планы, интеллектуальные ответы на вопросы, системы ИИ-контроля повышают справедливость и эффективность. На этапе выбора вуза ИИ-инструменты могут быстро рекомендовать учебные заведения и специальности на основе баллов и рейтинга абитуриента, устраняя информационный разрыв. Однако чрезмерная зависимость от ИИ при выборе вуза также вызывает опасения: алгоритмы могут усиливать предпочтение популярных специальностей, игнорируя индивидуальные интересы и долгосрочное развитие; полная передача права выбора жизненного пути алгоритму может привести к «порабощению алгоритмом». Статья призывает к рациональному отношению к помощи ИИ, подчеркивая важность разумного управления инструментами и осмысления будущего (Источник: 36氪)
Обсуждение успешных моделей компаний AI Agent: самообслуживание против кастомизированных услуг: В сообществе обсуждались успешные модели компаний, разрабатывающих AI Agent. Одна точка зрения заключается в том, что успешные компании AI Agent (особенно обслуживающие средне- и крупный рынок) чаще всего используют модель, подобную Palantir, то есть большое количество инженеров по разработке на местах (FDEs) и кастомизированное программное обеспечение, а не чисто модель самообслуживания. Другая сторона настаивает на долгосрочной ценности модели самообслуживания, полагая, что команды в конечном итоге предпочтут создавать важные приложения внутри компании. Это отражает различные подходы к моделям обслуживания и рыночным стратегиям в области AI Agent (Источник: X)
💡 Прочее
Раскрыты системные подсказки Google Diffusion, демонстрирующие принципы его дизайна и границы возможностей: Один из пользователей поделился предположительно системными подсказками для Google Diffusion (языковой модели диффузии текста). В этих подсказках подробно описывается идентичность модели (Gemini Diffusion, экспертная языковая модель диффузии текста, обученная Google, неавторегрессионная), основные принципы и ограничения (например, следование инструкциям, неавторегрессионный характер, точность, отсутствие доступа в реальном времени, этика безопасности, дата отсечки знаний — декабрь 2023 года, возможности генерации кода), а также конкретные инструкции для генерации HTML-веб-страниц и HTML-игр. Эти инструкции охватывают формат вывода, эстетический дизайн, стили (например, специальное использование Tailwind CSS или пользовательский CSS в играх), использование иконок (иконки Lucide SVG), макет и производительность (предотвращение CLS), требования к комментариям и т.д. В конце подчеркивается важность пошагового мышления и точного следования инструкциям пользователя. Эти подсказки дают представление о принципах проектирования подобных моделей и их ожидаемом поведении (Источник: Reddit r/LocalLLaMA)
Arvind Narayanan рассказывает о рождении и идеях статьи «AI as Normal Technology»: Профессор Принстонского университета Arvind Narayanan поделился историей создания своей статьи «AI as Normal Technology», написанной в соавторстве с Sayash Kapoor. Изначально он скептически относился к AGI и экзистенциальным рискам, но по настоянию коллег решил серьезно отнестись к этому вопросу и принять участие в соответствующих дискуссиях. Размышляя, он осознал, что взгляды, связанные со сверхинтеллектом, заслуживают серьезного рассмотрения, социальные сети не подходят для серьезных обсуждений, и что как в сообществе этики ИИ, так и в сообществе безопасности ИИ существуют свои «информационные пузыри». Первоначальный вариант статьи был отклонен на ICML, но ожесточенные споры в процессе рецензирования только укрепили их решимость продолжать исследования. Они поняли, что разногласия с сообществом безопасности ИИ глубже, чем предполагалось, и осознали необходимость более продуктивных междисциплинарных дебатов. В итоге статья была опубликована на семинаре Knight First Amendment Institute Колумбийского университета, вызвав широкий интерес и плодотворные дискуссии, что сделало Narayanan более оптимистичным в отношении будущего политики в области ИИ (Источник: X)
Поколение Z предпринимателей в сфере ИИ набирает силу, переформатируя правила стартапов: Группа предпринимателей в сфере ИИ, родившихся после 2000 года (поколение Z), с поразительной скоростью заявляет о себе в глобальной волне стартапов. Обладая глубоким пониманием технологий ИИ и острым чутьем, присущим цифровым аборигенам, они переопределяют правила предпринимательства. Примеры включают Michael Truell из Anysphere (Cursor) (за 3 года прошел путь от стажера до CEO компании стоимостью в десятки миллиардов долларов), трех основателей Mercor (за 2 года создали платформу для найма на основе ИИ стоимостью в десятки миллиардов), Eric Steinberger из Magic (в 25 лет стал соучредителем компании по кодированию на основе ИИ, привлекшей более 400 миллионов долларов финансирования) и Hong Letong из Axiom (специализируется на решении математических задач с помощью ИИ, получила высокую оценку еще до выпуска продукта). Этим молодым предпринимателям свойственны следующие черты: программирование для них — родной язык; они рано добились известности, воспользовавшись технологическим бумом; остро чувствуют потребности пользователей; обладают нативным для ИИ пониманием организации и продукта, предпочитая минималистичные и эффективные команды и логику «ИИ как продукт». Их успех знаменует собой смену парадигмы предпринимательства в эпоху ИИ (Источник: 36氪)