
Ключевые слова:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Deep Think режим, Универсальная инфраструктура воплощенного интеллекта VeBrain, Сегментация изображений и видео SAM 2, Qwen3-Embedding с контекстом 32k, Мультимодальное понимание AI Agent
🔥 В фокусе
Google анонсировала множество новых разработок в области ИИ, режим Deep Think в Gemini 2.5 Pro повышает способность к сложным рассуждениям: На конференции Google I/O компания Google анонсировала режим Deep Think для Gemini 2.5 Pro, предназначенный для значительного улучшения способностей ИИ к рассуждениям при решении сложных задач (таких как математические задачи уровня USAMO). Одновременно Google представила AlphaEvolve, агента для кодирования на базе Gemini, предназначенного для открытия алгоритмов, который уже достиг успехов в разработке алгоритмов умножения матриц и решении открытых математических проблем, а также применяется для оптимизации внутренних дата-центров Google, проектирования чипов и эффективности обучения ИИ. Кроме того, были представлены видеомодель Veo 3, модель изображений Imagen 4 и инструмент для редактирования видео с ИИ FLOW, демонстрирующие всесторонний охват и быстрый прогресс Google в области мультимодального ИИ. (Источник: OriolVinyalsML, demishassabis, demishassabis, op7418)
Шанхайская лаборатория ИИ совместно выпустила универсальную платформу для воплощенного интеллектуального мозга VeBrain: Шанхайская лаборатория искусственного интеллекта совместно с несколькими организациями представила VeBrain (Visual Embodied Brain) — универсальную платформу для воплощенного интеллектуального мозга, целью которой является объединение возможностей визуального восприятия, пространственного мышления и управления роботами. Эта платформа преобразует задачи управления роботами в задачи обработки 2D-пространственного текста в MLLM (например, обнаружение ключевых точек и распознавание воплощенных навыков) и вводит «роботизированный адаптер» для точного отображения текстовых решений в реальные действия и управления с обратной связью. Для поддержки обучения модели команда создала набор данных VeBrain-600k, содержащий 600 000 записей инструкций, охватывающих три типа задач: мультимодальное понимание, визуально-пространственное мышление и управление роботами. Тестирование показало, что VeBrain достигает уровня SOTA в мультимодальном понимании, пространственном мышлении и управлении реальными роботами (манипуляторами и робособаками). (Источник: 量子位)

Anthropic опубликовала в открытом доступе инструмент визуализации LLM «circuit tracing» для повышения интерпретируемости моделей: Anthropic представила инструмент с открытым исходным кодом «circuit tracing», предназначенный для помощи исследователям в понимании внутренних механизмов работы больших языковых моделей (LLM). Инструмент генерирует «графы атрибуции» (attribution graphs), визуализирующие внутренние суперузлы и их связи при обработке информации моделью, подобно схемам нейронных сетей. Исследователи могут проверять функции каждого узла, вмешиваясь в значения активации узлов и наблюдая за изменениями в поведении модели, чтобы расшифровать логику принятия решений LLM. Инструмент поддерживает генерацию графов атрибуции на основных моделях с открытым исходным кодом и предоставляет интерактивный интерфейс Neuronpedia для визуализации, аннотирования и обмена данными. Этот шаг направлен на продвижение исследований в области интерпретируемости ИИ, позволяя более широкому сообществу исследовать и понимать поведение моделей. (Источник: 量子位, swyx)
Meta выпустила Segment Anything Model 2 (SAM 2), улучшив возможности сегментации изображений и видео: Meta AI Research (FAIR) представила SAM 2, обновленную версию своей популярной модели Segment Anything Model. SAM 2 — это базовая модель, ориентированная на задачи визуальной сегментации изображений и видео по подсказкам, способная точно идентифицировать и сегментировать определенные объекты или области на изображении или видео на основе подсказок (таких как точки, рамки, текст). Модель теперь доступна с открытым исходным кодом под лицензией Apache, что позволяет исследователям и разработчикам бесплатно использовать ее и создавать приложения, способствуя дальнейшему развитию компьютерного зрения. (Источник: AIatMeta)
🎯 События
Институт искусственного интеллекта Пекина (BAAI) опубликовал в открытом доступе Video-XL-2, обеспечивающий понимание видео из десятков тысяч кадров на одной видеокарте: Институт искусственного интеллекта Пекина совместно с Шанхайским университетом Цзяо Тун и другими учреждениями выпустил модель нового поколения для понимания сверхдлинных видео Video-XL-2. Модель значительно улучшена по эффективности, длине обработки и скорости: одна видеокарта может обрабатывать видеовход из десятков тысяч кадров, а кодирование 2048 кадров видео занимает всего 12 секунд. Video-XL-2 использует визуальный кодировщик SigLIP-SO400M, модуль динамического синтеза токенов (DTS) и большую языковую модель Qwen2.5-Instruct, а также достигает высокой производительности благодаря четырехэтапному прогрессивному обучению и стратегиям оптимизации эффективности (таким как сегментированная предварительная загрузка и двухуровневое декодирование KV). Модель показала отличные результаты в бенчмарках MLVU, Video-MME и других, веса опубликованы в открытом доступе. (Источник: 量子位)

Character.ai запустила функцию генерации видео AvatarFX, позволяющую оживлять и взаимодействовать с персонажами с изображений: Ведущее приложение для ИИ-компаньонов Character.ai (c.ai) представило функцию AvatarFX, которая позволяет пользователям анимировать персонажей со статических изображений (включая нечеловеческие образы, такие как домашние животные), чтобы они могли говорить, петь и взаимодействовать с пользователями. Функция основана на архитектуре DiT и делает акцент на высокой точности и временной согласованности, сохраняя стабильность даже в сложных сценариях с несколькими персонажами и длинными диалогами. В настоящее время AvatarFX доступна всем пользователям в веб-версии, скоро появится и в приложении. Одновременно c.ai анонсировала новые функции, такие как Scenes (интерактивные сюжетные сцены), Imagine Animated Chat (анимированные истории чатов) и Stream (генерация историй между персонажами), что еще больше обогащает опыт создания контента с помощью ИИ. (Источник: 量子位)

Nvidia представила визуально-языковую модель Llama-3.1 Nemotron-Nano-VL-8B-V1: Nvidia выпустила новую модель преобразования визуальной информации в текст Llama-3.1-Nemotron-Nano-VL-8B-V1, которая способна обрабатывать изображения, видео и текстовый ввод, а также генерировать текстовый вывод, обладая определенной степенью возможностей для анализа и распознавания изображений. Выпуск этой модели является отражением постоянных инвестиций Nvidia в область мультимодального ИИ. В то же время, в сообществе обсуждается, что отказ Llama-4 от моделей менее 70B может создать возможности для таких моделей, как Gemma3 и Qwen3, на рынке тонкой настройки. (Источник: karminski3)
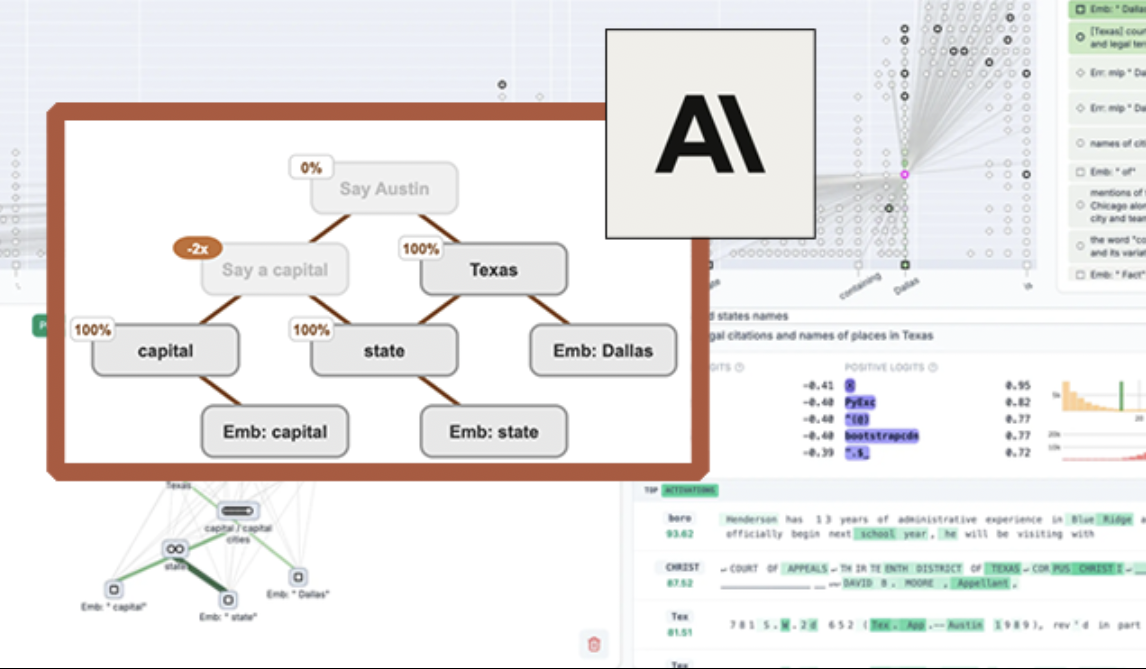
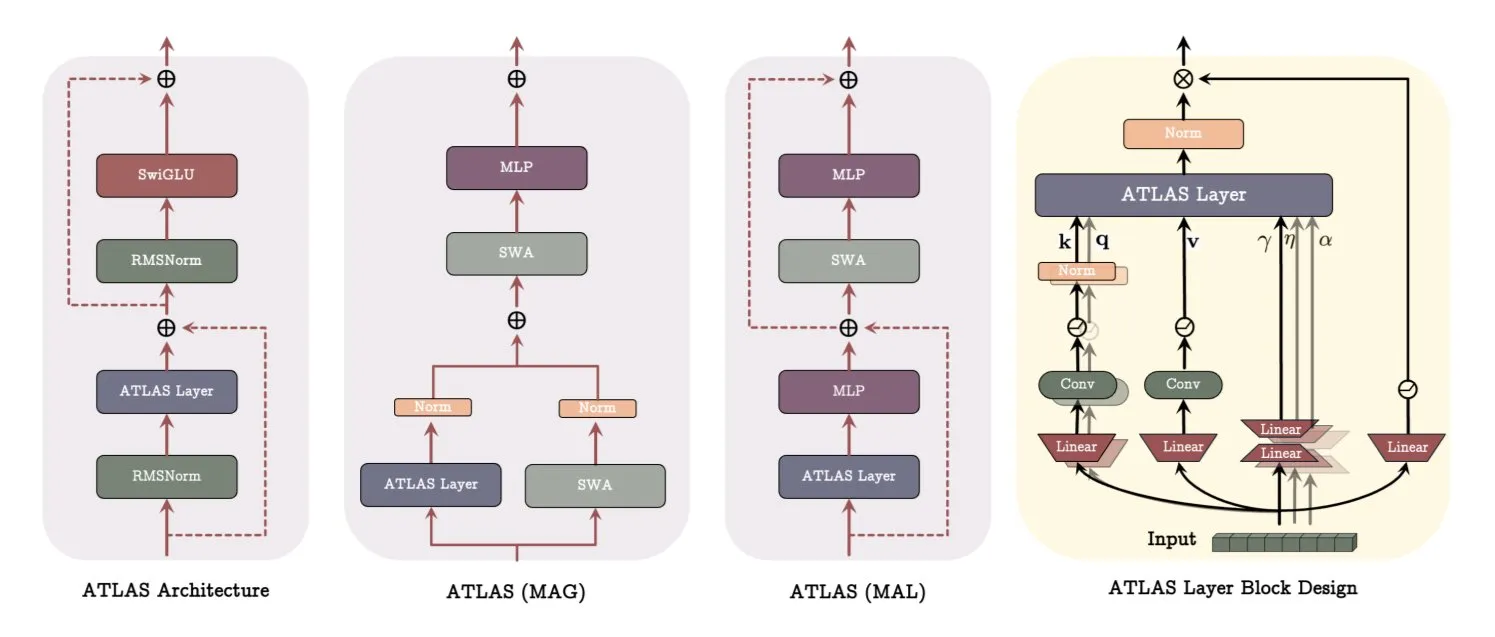
Google опубликовала статью об архитектуре ATLAS, революционизирующей способы обучения и запоминания моделей: В последней статье Google представлена новая архитектура модели под названием ATLAS, направленная на оптимизацию способностей модели к обучению и запоминанию за счет активной памяти (правило Omega обрабатывает последние c токенов) и более интеллектуального управления объемом памяти (полиномиальное и экспоненциальное отображение признаков). ATLAS использует оптимизатор Muon для более эффективного обновления памяти и вводит такие разработки, как DeepTransformers и Dot (Deep Omega Transformers), заменяя традиционное фиксированное внимание обучаемыми механизмами, управляемыми памятью. Это исследование знаменует собой шаг ИИ к более интеллектуальным, контекстно-зависимым системам и обещает улучшить способность ИИ обрабатывать и использовать крупномасштабные наборы данных. (Источник: TheTuringPost)
Qwen выпустила серию моделей Qwen3-Embedding, значительно улучшив производительность встраивания: Команда Qwen выпустила новую серию моделей Qwen3-Embedding, включающую три версии: 0.6B, 4B и 8B. Эти модели поддерживают длину контекста до 32k и 100 языков, достигнув результатов SOTA на MTEB (Massive Text Embedding Benchmark), причем по некоторым показателям опережая ближайшего конкурента на 10 пунктов. Этот прогресс знаменует собой еще один важный прорыв в технологии встраивания текста, предоставляя более мощную основу для таких приложений, как семантический поиск, RAG и др. (Источник: AymericRoucher, ClementDelangue)

Microsoft Bing Video Creator запущен, бесплатно доступен на базе модели OpenAI Sora: Microsoft запустила в своем приложении Bing функцию Bing Video Creator, которая основана на модели Sora от OpenAI и позволяет пользователям бесплатно генерировать видео по текстовым подсказкам. Это первый случай, когда модель Sora стала массово доступна широкой публике бесплатно. Несмотря на бесплатность, в настоящее время функциональность ограничена: например, длина видео составляет всего 5 секунд, соотношение сторон 9:16, а скорость генерации довольно низкая. Отзывы пользователей показывают, что ее эффект уступает текущим SOTA видеомоделям (таким как Kuaishou Kling, Veo3), что вызвало дискуссии о скорости итераций технологии Sora и продуктовой стратегии Microsoft. (Источник: 36氪)
OpenAI представила ряд функций корпоративного уровня для улучшения интеграции на рабочем месте: OpenAI выпустила серию новых функций, ориентированных на корпоративных пользователей, включая предоставление выделенных коннекторов для приложений, таких как Google Drive, а также реализацию функций записи совещаний, транскрипции и резюмирования в ChatGPT, с поддержкой SSO (единого входа) и корпоративного ценообразования на основе кредитов. Эти обновления направлены на более глубокую интеграцию ChatGPT в корпоративные рабочие процессы и повышение эффективности офисной работы. (Источник: TheRundownAI, EdwardSun0909)
Hugging Face выпустила эффективную модель для робототехники SmolVLA, способную работать на MacBook: Hugging Face представила модель для робототехники под названием SmolVLA, отличающуюся чрезвычайно высокой эффективностью и способную работать даже на MacBook. После тонкой настройки на небольшом количестве (например, 31) демонстрационных данных модель может достигать или превосходить производительность однозадачных базовых моделей в конкретных задачах (например, управление манипулятором Koch Arm), демонстрируя свой потенциал для развертывания ИИ в робототехнике в условиях ограниченных ресурсов. (Источник: mervenoyann, sytelus)
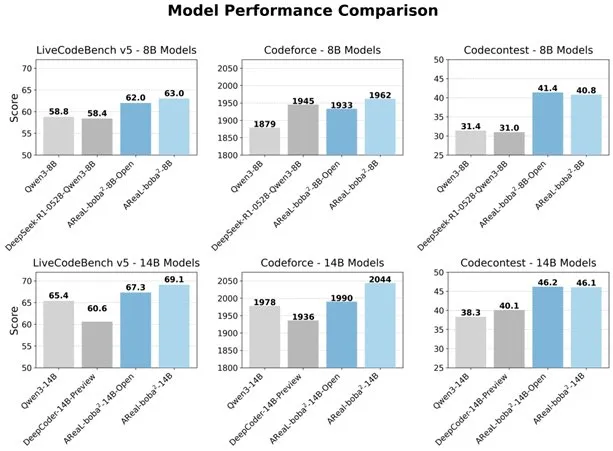
Alibaba опубликовала полностью асинхронную систему RL AReaL-boba², улучшающую способности LLM к написанию кода: Команда Qwen из Alibaba опубликовала в открытом доступе полностью асинхронную систему обучения с подкреплением (RL) AReaL-boba², специально разработанную для больших языковых моделей (LLM), и достигла SOTA-эффекта в обучении с подкреплением для кода на Qwen3-14B. Благодаря совместному проектированию системы и алгоритма, система достигла ускорения обучения в 2,77 раза, набрала 69,1 балла на LiveCodeBench и поддерживает многоэтапное обучение с подкреплением. (Источник: _akhaliq)
DuckDB представила расширение DuckLake, интегрирующее озера данных и форматы каталогов: DuckDB выпустила расширение DuckLake, представляющее собой открытый формат озера данных, основанный на SQL и Parquet. DuckLake хранит метаданные в базе данных каталога, а данные — в файлах Parquet. С помощью этого расширения DuckDB может напрямую читать и записывать данные в DuckLake, поддерживая создание, изменение, запросы к таблицам, перемещение во времени и эволюцию схемы, с целью упрощения создания и управления озерами данных. (Источник: GitHub Trending)
Выпущен Ruby SDK для Model Context Protocol (MCP): Model Context Protocol (MCP) выпустил официальный Ruby SDK, который поддерживается совместно с Shopify и предназначен для реализации серверов MCP. MCP нацелен на предоставление стандартизированного способа для моделей ИИ (особенно агентов) обнаруживать и вызывать инструменты, получать доступ к ресурсам и выполнять предопределенные подсказки. SDK поддерживает JSON-RPC 2.0 и предоставляет основные функции, такие как регистрация инструментов, управление подсказками, доступ к ресурсам, что облегчает разработчикам создание ИИ-приложений, соответствующих спецификации MCP. (Источник: GitHub Trending)
Технологии ИИ помогли достичь 99,8% эффективности и 4300 часов работы цинковых аккумуляторов: Благодаря оптимизации с помощью искусственного интеллекта, цинковые аккумуляторы нового поколения достигли кулоновской эффективности 99,8% и времени работы до 4300 часов. Применение ИИ в области материаловедения, особенно в проектировании аккумуляторов и прогнозировании их характеристик, способствует прорывам в технологиях хранения энергии и обещает более эффективные и долговечные энергетические решения для электромобилей, портативной электроники и других областей. (Источник: Ronald_vanLoon)

🧰 Инструменты
LlamaIndex представила LlamaExtract и рабочий процесс Agent для автоматического извлечения данных из форм SEC Form 4: LlamaIndex продемонстрировала, как использовать LlamaExtract и рабочий процесс Agent для автоматического извлечения структурированной информации из файлов SEC Form 4. SEC Form 4 — это важный документ, в котором руководители, директора и основные акционеры публичных компаний раскрывают информацию о сделках с акциями. Создавая агентов для извлечения данных и масштабируемые рабочие процессы, можно эффективно обрабатывать декларации Form 4 всех компаний из индекса Dow Jones Industrial Average, повышая прозрачность рынка и эффективность анализа данных. (Источник: jerryjliu0)
Cognee: инструмент с открытым исходным кодом для обеспечения динамической памяти AI Agent: Cognee — это проект с открытым исходным кодом, предназначенный для обеспечения AI Agent возможностями динамической памяти, который, по утверждению разработчиков, интегрируется всего за 5 строк кода. Он создает масштабируемые, модульные конвейеры ECL (Extract, Cognify, Load), помогая агентам связывать и извлекать прошлые диалоги, документы, изображения и аудио транскрипции, чтобы заменить традиционные системы RAG, снизить сложность и стоимость разработки, а также поддерживать обработку и загрузку данных из более чем 30 источников. (Источник: GitHub Trending)
Claude Code теперь доступен пользователям Pro, также выпущена общественная версия GitHub Action: AI-помощник для программирования Claude Code от Anthropic стал доступен подписчикам Pro, которые могут использовать его, например, через плагин для JetBrains IDE. Разработчики из сообщества также выпустили форк-версию Claude Code GitHub Action, позволяющую платным пользователям напрямую вызывать Claude Code в GitHub Issues или PR, используя свою подписную квоту для выполнения таких задач, как ревью кода, ответы на вопросы, без дополнительной платы за API. (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
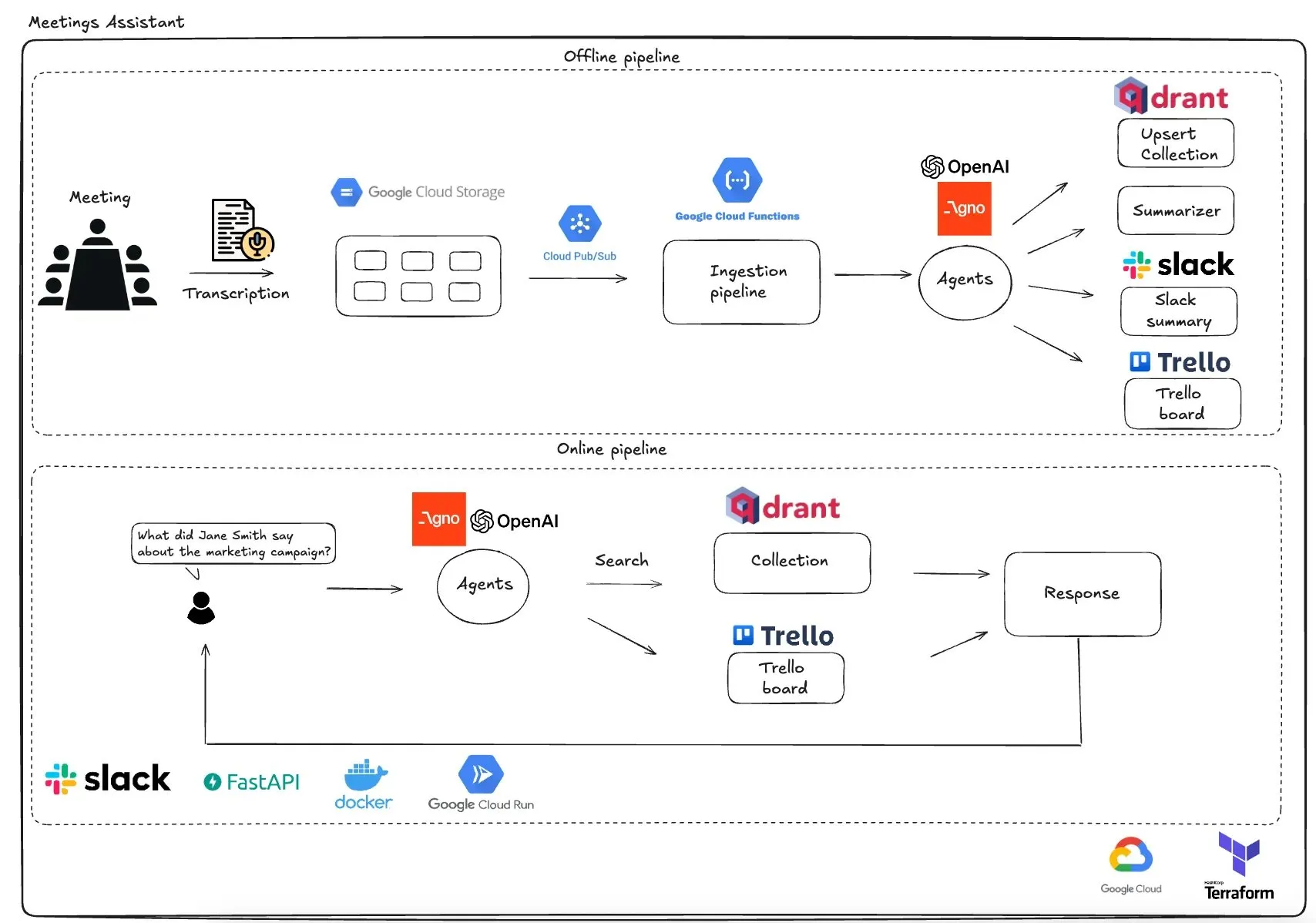
Qdrant представила мультиагентного помощника для совещаний на базе GCP: Qdrant продемонстрировала полностью бессерверную систему мультиагентного помощника для совещаний. Система способна транскрибировать содержание совещаний, использовать LLM-агентов для составления резюме, сохранять контекстную информацию в векторной базе данных Qdrant, синхронизировать задачи с Trello и доставлять конечные результаты непосредственно в Slack. Система использует AgnoAgi для оркестровки агентов, FastAPI работает на Cloud Run, а для встраивания и логического вывода используется OpenAI. (Источник: qdrant_engine)
Microsoft выпустила GUI-Actor для позиционирования элементов GUI без координат: Microsoft опубликовала на Hugging Face GUI-Actor — метод позиционирования элементов графического пользовательского интерфейса (GUI) без использования координат. Этот метод позволяет AI-агентам напрямую указывать на нативные визуальные блоки (visual patches) с помощью специального токена <actor>, вместо того чтобы полагаться на предсказание координат на основе текста, что направлено на повышение точности и надежности операций GUI-агентов. (Источник: _akhaliq)

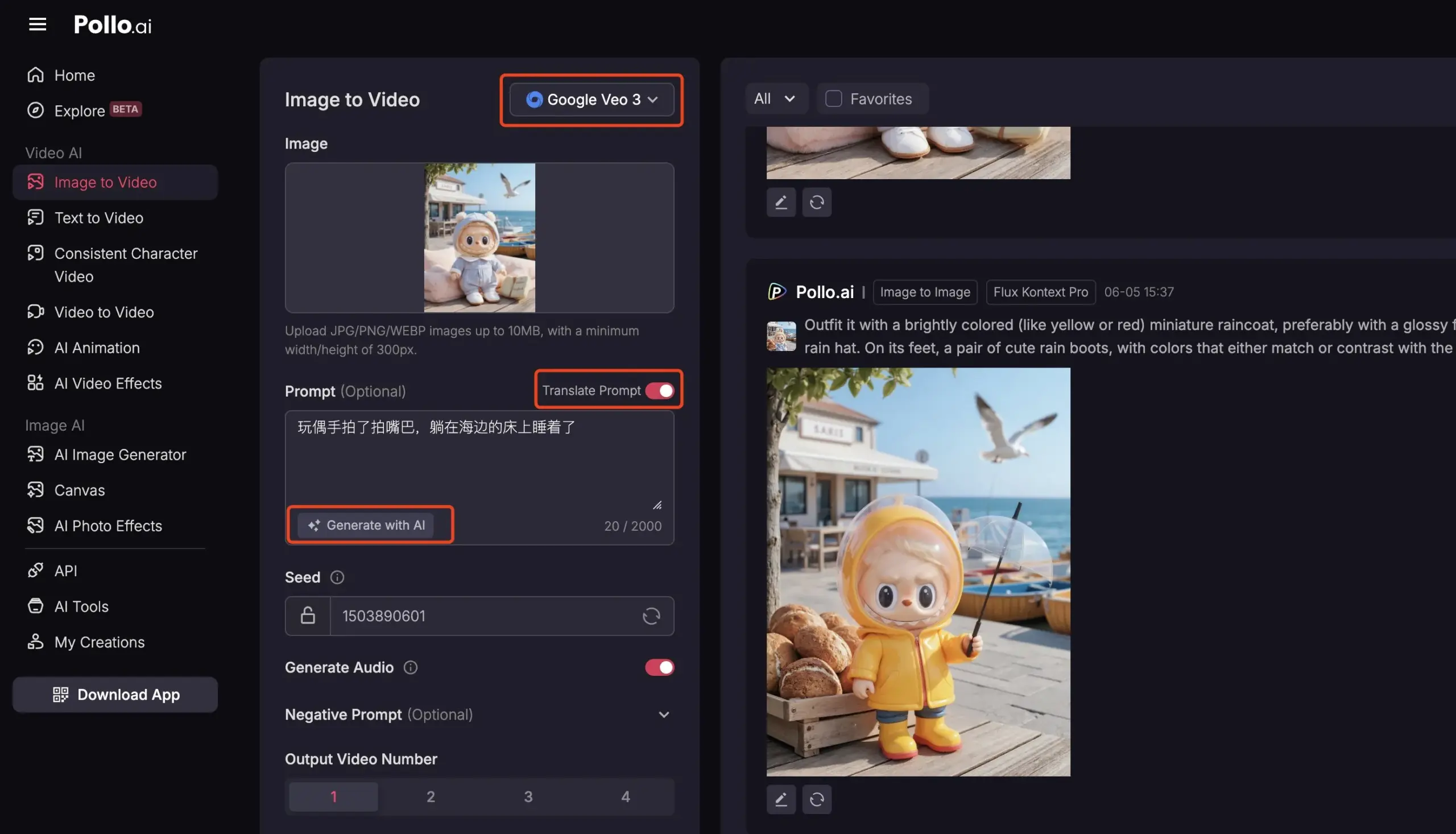
Pollo AI интегрировала Veo3 и FLUX Kontext, предоставляя комплексные услуги видео с ИИ: Платформа инструментов ИИ Pollo AI в последнее время часто обновляется, интегрировав модель генерации видео Google Veo3 и функции редактирования изображений FLUX Kontext. Пользователи могут на этой платформе редактировать изображения с помощью FLUX Kontext, а затем напрямую отправлять их в Veo3 для генерации видео. Платформа также предоставляет API-интерфейс, поддерживающий одновременный доступ к различным основным видео-моделям на рынке, и имеет встроенные вспомогательные функции, такие как генерация подсказок ИИ, многоязычный перевод, с целью повышения удобства и эффективности создания видео с ИИ. (Источник: op7418)
📚 Обучение
Глубокий анализ Meta-Learning: научить ИИ учиться учиться: Meta-Learning (метаобучение), также известное как «обучение обучению», заключается в обучении модели таким образом, чтобы она могла быстро адаптироваться к новым задачам, даже при наличии небольшого количества примеров. Этот процесс обычно включает две модели: базовый ученик (base-learner) быстро адаптируется к конкретным задачам (например, классификация изображений с малым количеством примеров) во внутреннем цикле обучения, а мета-ученик (meta-learner) управляет и обновляет параметры или стратегии базового ученика во внешнем цикле обучения, чтобы улучшить его способность решать новые задачи. После завершения обучения базовый ученик инициализируется с использованием знаний, полученных мета-учеником. (Источник: TheTuringPost, TheTuringPost)

Разбор статьи «A Controllable Examination for Long-Context Language Models»: Данная статья рассматривает ограничения существующих фреймворков оценки языковых моделей с длинным контекстом (LCLM) (сложность и трудноразрешимость задач реального мира, подверженность загрязнению данных; синтетические задачи, такие как NIAH, лишены контекстной связности) и предлагает три характеристики, которыми должен обладать идеальный фреймворк оценки: бесшовный контекст, контролируемые условия и надежная оценка. Также представлен LongBioBench, новый бенчмарк, использующий искусственно сгенерированные биографии в качестве контролируемой среды для оценки LCLM по таким аспектам, как понимание, рассуждение и достоверность. Эксперименты показывают, что большинство моделей все еще имеют недостатки в семантическом понимании, начальном рассуждении и достоверности при работе с длинным контекстом. (Источник: HuggingFace Daily Papers)
Разбор статьи «Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning»: Вдохновленное выдающимися способностями Deepseek-R1 к рассуждению в сложных текстовых задачах, это исследование изучает, как улучшить сложные способности к рассуждению мультимодальных больших языковых моделей (MLLM) путем оптимизации холодного старта и поэтапного обучения с подкреплением (RL). Исследование показало, что эффективная инициализация холодного старта имеет решающее значение для улучшения рассуждений MLLM, и инициализация только тщательно отобранными текстовыми данными может превзойти многие существующие модели. Стандартный GRPO при применении к мультимодальному RL сталкивается с проблемой стагнации градиента, в то время как последующее обучение RL только на тексте может дополнительно улучшить мультимодальные рассуждения. На основе этих выводов исследователи представили ReVisual-R1, который достиг SOTA-результатов на нескольких сложных бенчмарках. (Источник: HuggingFace Daily Papers)
Разбор статьи «Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem»: В данном исследовании предлагается эффективный метод раскрытия потенциала рассуждений предварительно обученных LLM: критическая тонкая настройка на одной задаче (Critique Fine-Tuning, CFT). Собирая различные решения, сгенерированные моделью для одной задачи, и используя LLM-учителя для предоставления подробной критики, создаются критические данные для тонкой настройки. Эксперименты показывают, что после CFT на одной задаче для моделей серий Qwen и Llama наблюдается значительное улучшение производительности в различных задачах на рассуждение. Например, Qwen-Math-7B-CFT показал среднее улучшение на 15-16% в бенчмарках по математике и логическому мышлению, при этом вычислительные затраты значительно ниже, чем при обучении с подкреплением. (Источник: HuggingFace Daily Papers)
Разбор статьи «SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation»: Для решения проблем ограниченного охвата существующих бенчмарков обработки SVG (масштабируемой векторной графики), отсутствия иерархии сложности и фрагментированной парадигмы оценки был создан SVGenius. Это комплексный бенчмарк, содержащий 2377 запросов, охватывающий три аспекта: понимание, редактирование и генерацию. Он построен на основе реальных данных из 24 областей применения и имеет систематическую иерархию сложности. С помощью 8 категорий задач и 18 метрик были оценены 22 основные модели, что выявило ограничения текущих моделей при обработке сложных SVG и указало на то, что обучение, усиленное рассуждениями, более эффективно, чем простое масштабирование. (Источник: HuggingFace Daily Papers)
Опубликован журнал изменений Hugging Face Hub: Hugging Face Hub опубликовал свой последний журнал изменений, где пользователи могут ознакомиться с новыми функциями платформы, обновлениями библиотеки моделей, расширением наборов данных, улучшениями инструментария и другими последними новостями. Это помогает пользователям сообщества своевременно узнавать и использовать новейшие ресурсы и возможности экосистемы Hugging Face. (Источник: huggingface, _akhaliq)
Maxime Labonne и другие авторы опубликовали в открытом доступе большое количество LLM Notebooks: Авторы руководства для LLM-инженеров Maxime Labonne и Iustin Paul опубликовали в открытом доступе серию Jupyter Notebooks, связанных с LLM. Эти Notebooks содержат богатый материал, включающий не только базовые техники тонкой настройки, но и такие продвинутые темы, как автоматическая оценка, ленивое слияние (lazy merges), создание моделей смеси экспертов (frankenMoEs) и методы снятия цензуры, предоставляя ценные практические ресурсы для разработчиков и исследователей LLM. (Источник: maximelabonne)
DeepLearningAI выпустила еженедельник The Batch, обсуждающий, как AI Fund готовит разработчиков ИИ: Andrew Ng в своем последнем выпуске еженедельника The Batch поделился опытом и стратегиями AI Fund в подготовке талантов и разработчиков в области ИИ. В этом выпуске также освещаются такие актуальные темы, как производительность новой модели DeepSeek с открытым исходным кодом, сравнимая с ведущими LLM, использование ИИ Duolingo для расширения языковых курсов, компромиссы в энергопотреблении ИИ и потенциальное введение в заблуждение AI Agent вредоносными ссылками. (Источник: DeepLearningAI)

💼 Бизнес
Reddit подал в суд на Anthropic, обвиняя в несанкционированном использовании пользовательских данных для обучения ИИ: Reddit подал иск против компании Anthropic, занимающейся разработкой ИИ, обвиняя ее в несанкционированном использовании автоматических ботов для сбора контента Reddit с целью обучения своих моделей ИИ (таких как Claude), что представляет собой нарушение контракта и недобросовестную конкуренцию. Этот случай подчеркивает текущие споры о законности сбора данных и обучения моделей в развитии ИИ, а также отражает растущее внимание контент-платформ к защите ценности своих данных. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon планирует инвестировать 10 миллиардов долларов в строительство дата-центра ИИ в Северной Каролине: Amazon объявила о планах инвестировать 10 миллиардов долларов в строительство нового дата-центра в Северной Каролине для поддержки растущих потребностей своего бизнеса в области ИИ. Этот шаг отражает постоянные инвестиции крупных технологических компаний в инфраструктуру ИИ, направленные на удовлетворение масштабных вычислительных и хранилищных ресурсов, необходимых для обучения и логического вывода моделей ИИ. (Источник: Reddit r/artificial)

Anthropic сократила доступ к API моделей Claude для Windsurf.ai, вызвав опасения по поводу рисков платформы: Платформа разработки ИИ-приложений Windsurf.ai сообщила, что Anthropic, уведомив менее чем за 5 дней, значительно сократила ее доступ к API моделей Claude 3.x и Claude 4. Этот шаг вынудил Windsurf.ai срочно искать сторонних поставщиков для обеспечения обслуживания платных пользователей и предложить бесплатным и Pro-пользователям опцию BYOK (использовать собственный ключ). Этот инцидент усилил опасения разработчиков относительно рисков, связанных с платформами поставщиков ИИ-моделей, а именно, что поставщики моделей могут в любой момент изменить свою сервисную политику или даже конкурировать с нижестоящими приложениями. (Источник: swyx, scaling01, mervenoyann)
🌟 Сообщество
Конференция AI-инженеров (@aiDotEngineer) вызвала бурное обсуждение, в центре внимания — дизайн агентов и стартапы в области ИИ: Конференция AI-инженеров (@aiDotEngineer), прошедшая в Сан-Франциско, стала предметом активного обсуждения в сообществе. LlamaIndex поделилась эффективными паттернами проектирования агентов для производственной среды; Anthropic на конференции представила «список потребностей» для стартапов, уделяя внимание применению серверов MCP в новых областях, упрощению создания серверов и безопасности ИИ-приложений (например, отравление инструментов); Graphite продемонстрировала инструмент для рецензирования кода на основе ИИ. На конференции также обсуждались фундаментальные исследовательские проблемы, связанные с масштабированием моделей GPT следующего поколения. (Источник: swyx, swyx, swyx, iScienceLuvr)

Присоединение исследователя Rohan Anil к Anthropic привлекло внимание: Исследователь Rohan Anil объявил о своем присоединении к команде Anthropic, что вызвало широкое внимание и обсуждение в сообществе ИИ. Многие инсайдеры отрасли и наблюдатели поздравили его с этим и выразили надежду на его новый вклад в исследовательскую работу Anthropic. Это также отражает потенциальное влияние перемещения ведущих талантов в области ИИ на отраслевой ландшафт. (Источник: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Суд обязал OpenAI сохранять все логи ChatGPT, что вызвало обсуждение политики хранения данных: Сообщается, что суд обязал OpenAI сохранять все логи ChatGPT, включая «временные чаты» и API-запросы, которые должны были быть удалены. Эта новость вызвала в сообществе обсуждение политики хранения данных, особенно для приложений, использующих API OpenAI. Это может означать, что их собственные политики хранения данных не смогут полностью соблюдаться, что создает новые проблемы для конфиденциальности пользователей и управления данными. Пользователям рекомендуется по возможности отдавать предпочтение локальным моделям для защиты данных. (Источник: code_star, TomLikesRobots)

Распространение контента, сгенерированного ИИ, и явление «AI Slop» вызывают беспокойство: Растущее количество низкокачественного, привлекающего внимание контента, сгенерированного ИИ (известного как «AI Slop») в социальных сетях, от постов, сгенерированных ИИ на Reddit, до изображений ИИ, таких как «креветочный Иисус» на Facebook, вызывает у пользователей беспокойство по поводу качества информации и ухудшения сетевой среды. Этот контент обычно дешево генерируется ботами или теми, кто ищет трафик, с целью получения лайков и репостов с помощью «приманки для вовлечения». Исследования показывают, что значительная часть интернет-трафика уже состоит из «плохих ботов», которые распространяют ложную информацию и крадут данные. Это явление не только влияет на пользовательский опыт, но и представляет угрозу для демократии и политической коммуникации, а также может загрязнить данные для обучения будущих моделей ИИ. (Источник: aihub.org)

Обсуждение стоимости LLM: Gemini экономически выгоден, стоимость кодирования Claude 4 вызывает вопросы: В сообществе отмечается значительная разница в стоимости использования LLM. Например, стоимость обработки целого страхового документа и задания большого количества вопросов с помощью Gemini составляет всего около 0,01 доллара США, что демонстрирует высокую экономическую эффективность. В то же время, модель Claude 4, хотя и показывает отличные результаты в таких задачах, как кодирование, на платформах вроде Cursor.ai в режиме максимальной производительности (max mode) обходится дорого, что побуждает пользователей переходить на более экономически выгодные варианты, такие как Google Gemini 2.5 Pro. (Источник: finbarrtimbers, Teknium1)
AI Agent сталкиваются с трудностями при решении CAPTCHA (проверки «человек-компьютер») в реальных веб-сценариях: Команда MetaAgentX выпустила платформу Open CaptchaWorld, специализирующуюся на оценке способности мультимодальных интерактивных агентов решать CAPTCHA. Тесты показали, что даже SOTA-модели, такие как GPT-4o, при обработке 20 типов интерактивных капч в реальных веб-средах имеют успешность всего 5%-40%, что значительно ниже среднего показателя успешности человека в 93,3%. Это указывает на то, что текущие AI Agent все еще имеют узкие места в визуальном понимании, многошаговом планировании, отслеживании состояния и точном взаимодействии, и CAPTCHA становится серьезным препятствием для их практического развертывания. (Источник: 量子位)

Рынок обучения AI-агентов на подъеме, качество курсов и перспективы трудоустройства вызывают вопросы: С ростом популярности концепции AI Agent появилось большое количество соответствующих обучающих курсов. Некоторые учебные заведения утверждают, что предоставляют всестороннее обучение от начального уровня до трудоустройства, и даже обещают «гарантированное трудоустройство», при этом стоимость обучения варьируется от нескольких сотен до десятков тысяч юаней. Однако качество курсов на рынке неоднородно, некоторые из них обвиняются в поверхностном содержании, чрезмерном маркетинге и даже схожести с курсами быстрого обучения ИИ, направленными на «сбор денег». Слушатели и наблюдатели с осторожностью относятся к реальной эффективности такого обучения, квалификации преподавателей и достоверности обещаний «гарантированного трудоустройства», опасаясь, что это может стать очередным «псевдоспросом» в переходный период развития ИИ. (Источник: 36氪)

💡 Прочее
Прогресс в применении ИИ в робототехнике: тактильно-чувствительная рука, амфибийный робот и робот-пожарный: Технологии ИИ расширяют границы возможностей роботов. Исследователи разработали механическую руку с тактильным восприятием, позволяющую ей лучше взаимодействовать с окружающей средой. Copperstone HELIX Neptune продемонстрировала амфибийного робота на базе ИИ, способного работать на различных типах местности. В Китае представили робота-собаку для пожаротушения, способного выбрасывать струю воды на 60 метров, подниматься по лестницам и вести прямую трансляцию спасательных работ. Эти достижения демонстрируют потенциал ИИ в улучшении восприятия, принятия решений и выполнения сложных задач роботами. (Источник: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Обсуждение сравнения AI Agent и генеративного ИИ: В сообществе возникло обсуждение различий и связей между AI Agent (интеллектуальными агентами ИИ) и генеративным ИИ (Generative AI). Генеративный ИИ в основном сосредоточен на создании контента, в то время как AI Agent больше ориентированы на автономное принятие решений и выполнение задач на основе восприятия, планирования и действий. Понимание различий между ними помогает лучше把握лять направления развития технологий ИИ и сценарии их применения. (Источник: Ronald_vanLoon, Ronald_vanLoon)
Обсуждение проблем автоматизации сложных организационных процессов с помощью ИИ: ИИ достиг прогресса в автоматизации или поддержке конкретных задач, но замена людей или команд для достижения более широкой экономической трансформации сталкивается с огромной сложностью. Во многих организациях существуют неявно задокументированные, но критически важные процессы, которые являются высокорискованными, но редкими, и, возможно, стали рутиной до такой степени, что их причины забыты. AI-агентам трудно изучать такие неявные знания методом проб и ошибок, поскольку это дорого и возможности для обучения ограничены. Это требует новой технологической парадигмы, а не простого машинного обучения. (Источник: random_walker)