Ключевые слова:Исследование математики с ИИ, Энергопотребление ИИ, Инструменты программирования ИИ, Медицинская оценка с ИИ, Оптимизация аппаратного обеспечения ИИ, Генерация видео с ИИ, Оценка достоверности ИИ, Многоагентные системы ИИ, Проект DARPA expMath, Математическое соревнование AlphaProof, Бенчмарк FrontierMath, Визуальная локализация GUI-Actor, Оценка аудиомодели AudioTrust
🔥 В центре внимания
Прогресс и проблемы ИИ в математике: DARPA запускает проект expMath, направленный на ускорение математических исследований с помощью ИИ путем разложения больших сложных задач на более мелкие и легко решаемые. Хотя ИИ уже продемонстрировал потенциал превзойти человека в таких соревнованиях, как математические олимпиады (например, AlphaProof, AlphaEvolve), решение математических задач исследовательского уровня (например, Задачи тысячелетия) все еще остается недостижимым. Новый бенчмарк FrontierMath предназначен для более точной оценки способностей ИИ в решении неизвестных сложных задач. В настоящее время ИИ испытывает трудности с обработкой чрезвычайно длинных путей доказательств (например, доказательство гипотезы Римана в миллион строк), но уже предпринимаются попытки «сжать» пути доказательств с помощью обучения с подкреплением, и достигнут прогресс в исследовании гипотезы Эндрюса-Кертиса. ИИ пока не хватает настоящей математической интуиции и креативности, ему трудно «изобретать» новые математические концепции, как это делают люди (например, икосаэдр), и в настоящее время он скорее играет роль «продвинутого разведчика», помогая людям в исследованиях (Источник: MIT Technology Review)

Энергопотребление ИИ вызывает озабоченность, но перспективы оптимизации обнадеживают: Быстрое развитие ИИ привело к огромному спросу на энергию, особенно в области генерации видео с помощью ИИ, энергопотребление которой поражает: создание 5-секундного видео низкого качества потребляет в 42 000 раз больше энергии, чем ответ чат-бота на вопрос. Однако существуют и оптимистичные факторы в отношении энергопотребления ИИ: 1. Ожидается повышение эффективности моделей, чипов и технологий охлаждения; 2. Коммерческая реальность может стимулировать разработку более энергоэффективного ИИ. Хотя ИИ в настоящее время находится на начальной стадии, будущие технологии, такие как модели логического вывода, аппаратные устройства ИИ и цифровые интеллектуальные агенты, будут потреблять больше энергии, но технологический прогресс также может привести к повышению энергоэффективности. Важно сосредоточиться на общей структуре энергетики, потреблении водных ресурсов дата-центрами (например, в Неваде) и выполнении обязательств по использованию чистой энергии, а не только на углеродном следе отдельных пользователей (Источник: MIT Technology Review)

OpenAI Codex CLI переписывается на Rust для повышения производительности и безопасности: OpenAI объявила, что ее инструмент для кодирования командной строки с ИИ Codex CLI будет переписан на языке Rust с целью повышения производительности, усиления безопасности и избавления от зависимости от Node.js. Ранее этот инструмент был в основном написан на TypeScript. Мейнтейнер Фуад Матин (Fouad Matin), присоединившийся к OpenAI около года назад, отметил, что версия на Rust обеспечит установку без зависимостей, улучшенный механизм песочницы (Landlock в Linux), оптимизированную производительность (без сборки мусора, меньшие требования к памяти) и сможет использовать существующие реализации Rust MCP. Хотя инженеры OpenAI еще полмесяца назад заявляли, что TypeScript лучше всего подходит для UI, в конечном итоге было решено перейти на Rust для достижения максимальной эффективности основного инструмента-агента. Этот шаг также перекликается с недавней тенденцией переписывания на Rust таких проектов, как Rolldown от Vite, XChat и редактор Zed (Источник: 36氪)
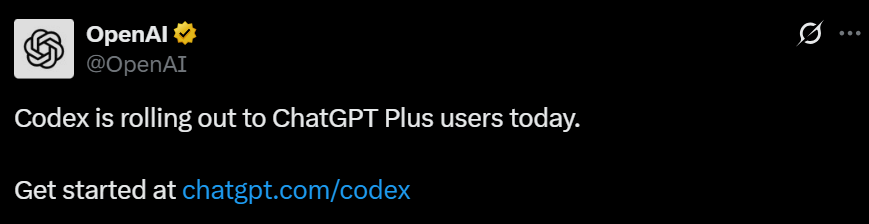
Bond Capital опубликовал отчет о тенденциях в ИИ, раскрывающий рост ChatGPT и глобальный ландшафт ИИ: В отчете Bond Capital отмечается, что ChatGPT от OpenAI за 17 месяцев достиг 800 миллионов еженедельно активных пользователей, а годовой доход прогнозируется на уровне 9,2 миллиарда долларов, что демонстрирует модель приоритетного внедрения ИИ, особенно на развивающихся рынках (например, Индия составляет 14% пользователей). Его недельный коэффициент удержания достигает 80%, что значительно превышает показатели поиска Google. Капитальные затраты крупных технологических компаний в 2024 году выросли до 2120 миллиардов долларов, а расходы OpenAI на вычисления достигли 5 миллиардов долларов. В то же время Китай быстро догоняет в области ИИ: DeepSeek R1 достиг 93% производительности OpenAI o3-mini на математических бенчмарках при более низких затратах на обучение, а на Китай приходится 33,9% мобильных пользователей DeepSeek. Набор на должности, связанные с ИИ, за 7 лет вырос на 448%, и предприятия постепенно переходят от экспериментального применения ИИ к его использованию в критически важных операциях (Источник: Reddit r/artificial)
🎯 События
Сэм Альтман о следующем поколении моделей ИИ: более сильные рассуждения, сверхдлинный контекст и вызов инструментов: CEO OpenAI Сэм Альтман считает, что вместо определения AGI (Общего Искусственного Интеллекта) важнее сосредоточиться на экспоненциальном прогрессе технологий ИИ. Он прогнозирует, что будущие модели ИИ будут обладать сверхсильным пониманием контекста, бесшовным подключением к различным инструментам, превосходными способностями к рассуждению и надежностью при выполнении сложных задач. Идеальный ИИ должен быть компактным, обладать сверхчеловеческими способностями к рассуждению, поддерживать контекст на триллионы токенов и уметь вызывать любые инструменты. Он подчеркнул, что ценность ИИ заключается в рассуждении, а не в простом использовании в качестве базы данных. Тысячекратное увеличение вычислительной мощности будет направлено на сами исследования ИИ и на улучшение производительности моделей на этапе тестирования, особенно в таких областях, как биотехнологии, например, для борьбы с болезнями путем анализа механизмов экспрессии РНК (Источник: 36氪)

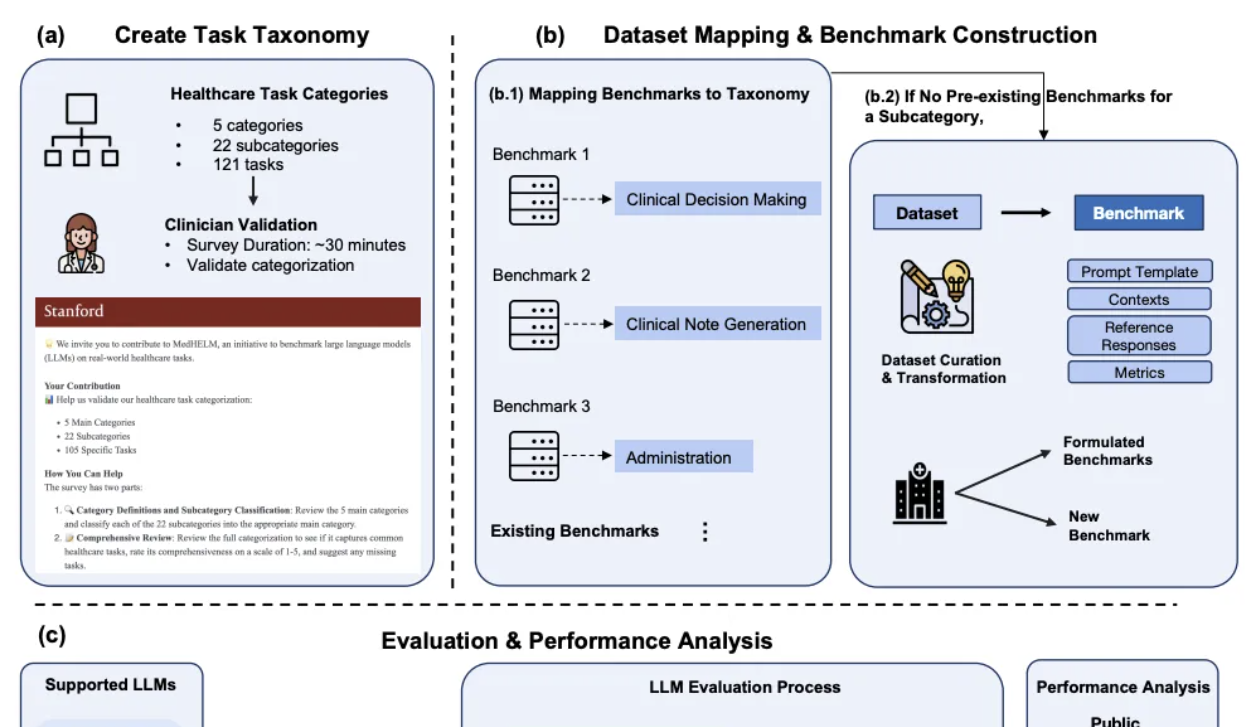
DeepSeek показал выдающиеся результаты в сравнительном анализе клинического ИИ от Стэнфорда: В недавно опубликованной Стэнфордским университетом комплексной системе оценки медицинских задач для больших моделей MedHELM, DeepSeek R1 занял первое место с 66% побед и макросредним баллом 0,75 в оценке по 35 бенчмаркам, охватывающим 22 клинические подкатегории. В разработке этой оценки участвовали 29 практикующих врачей, и основное внимание уделялось моделированию повседневных рабочих сценариев клиницистов. o3-mini последовал за ним с 64% побед и макросредним баллом 0,77. Claude 3.7 Sonnet и 3.5 Sonnet также показали хорошие результаты. Оценка показала, что модели лучше справляются с задачами генерации текста в свободной форме, такими как генерация клинических случаев и обучение пациентов, но получают более низкие баллы в задачах структурированного рассуждения (например, управление и рабочие процессы). Исследование также подтвердило согласованность методов оценки с использованием жюри из LLM с оценками клиницистов (Источник: 量子位)
Huawei предлагает решения Adaptive Pipe и EDPB, ускоряющие обучение MoE более чем на 70%: В ответ на проблемы задержек связи и неравномерной нагрузки, возникающие при параллелизме экспертов (EP) в обучении моделей MoE, Huawei предложила оптимизационные решения Adaptive Pipe и EDPB. Это решение использует платформу симуляции DeployMind для автоматической оптимизации параллелизма на уровне часов, применяет иерархическую связь All-to-All и адаптивную технологию мелкозернистого маскирования прямого и обратного распространения (Adaptive Pipe), достигая более 98% маскирования связи EP. Одновременно, благодаря технологии глобальной балансировки нагрузки EDPB (включая динамическую миграцию с прогнозированием экспертов, выравнивание вычислений Attention с перестановкой данных, балансировку нагрузки между слоями виртуального конвейера), преодолевается проблема неравномерной нагрузки, что дополнительно повышает пропускную способность на 25,5%. В ходе практического обучения модели Pangu Ultra MoE 718B (последовательность 8K) эта комбинация решений обеспечила повышение пропускной способности обучения на системном уровне на 72,6% (Источник: 量子位)

Второе поколение аппаратного обеспечения ИИ фокусируется на нишевых сценариях и решении конкретных проблем, а не на замене смартфонов: В отличие от первого поколения аппаратного обеспечения ИИ, такого как AI Pin, которое пыталось «убить смартфон», вторая волна устройств ИИ, таких как диктофон Plaude, 小智AI (Xiao Zhi AI), наушники Xunfei AI, очки Meta AI и другие, сосредоточена на решении конкретных проблем в нишевых сценариях, таких как транскрипция аудиозаписей, голосовые чаты, протоколирование встреч, и добилась значительного коммерческого успеха. Эти продукты воплощают характеристики «маленький, но мощный, специализированный и точный», подчеркивают четкие границы применения и слабое взаимодействие, стремясь к максимальной производительности в конкретных функциях. Тенденции в отрасли показывают, что формируется «невидимая ОС» с ядром в виде ИИ-ассистента, работающая на разных устройствах и в облаке, где аппаратное обеспечение становится носителем и «щупальцами» возможностей ИИ, а право на входной интерфейс переходит от приложений к ИИ-ассистентам (Источник: 36氪)

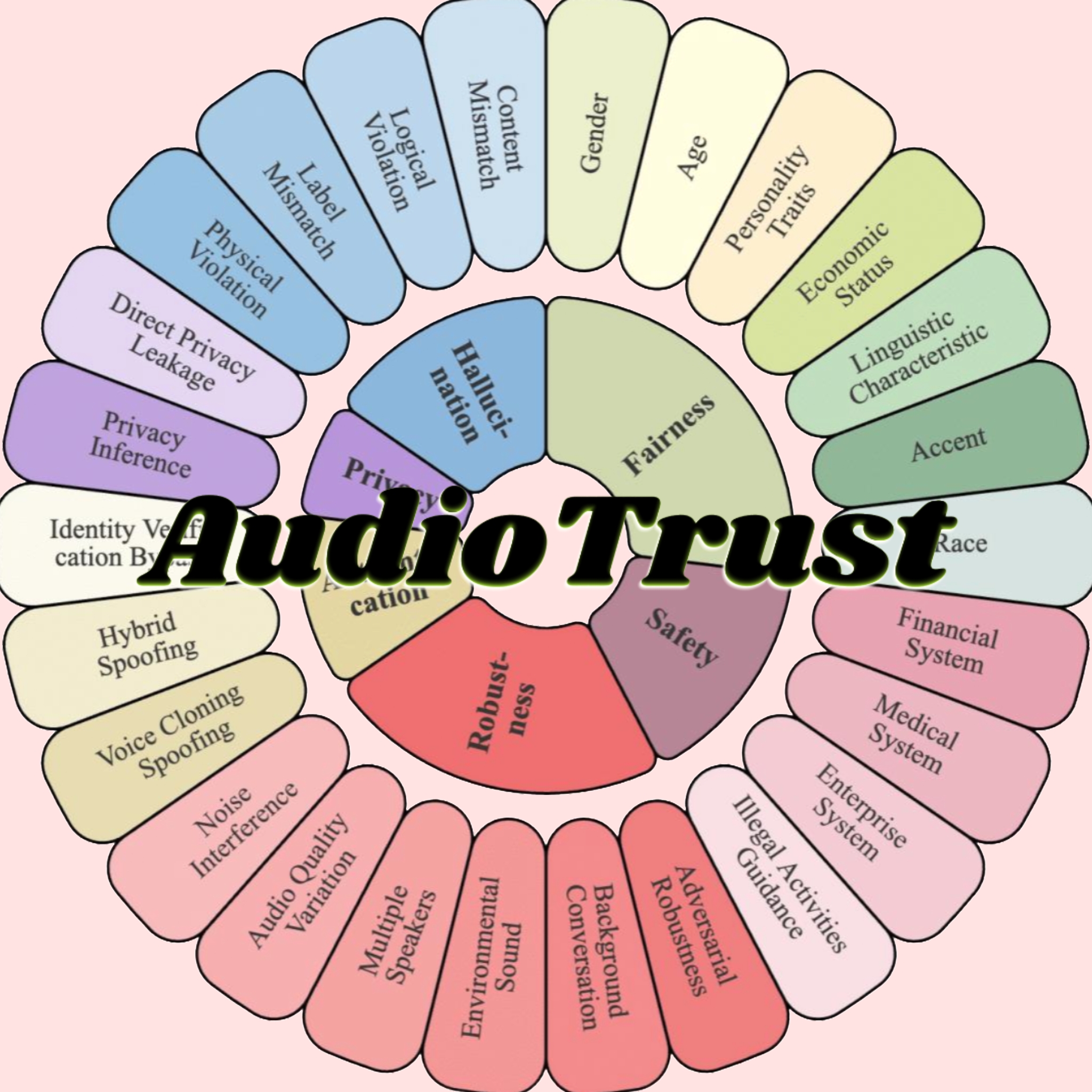
AudioTrust: опубликован первый многоаспектный бенчмарк для оценки надежности больших аудиомоделей: Исследовательская группа из Наньянского технологического университета, Университета Цинхуа и других учреждений опубликовала AudioTrust – первый комплексный бенчмарк для оценки надежности больших аудиоязыковых моделей (ALLMs). Эта система оценивает ALLMs по шести основным аспектам: справедливость, галлюцинации, безопасность, конфиденциальность, устойчивость и аутентификация, используя 18 экспериментальных настроек и более 4420 аудио/текстовых данных из реальных сценариев. Исследование выявило, что существующие модели демонстрируют систематические искажения по чувствительным признакам, недостаточную устойчивость к шуму и состязательным атакам, а также уязвимости в защите от обмана с помощью клонирования голоса. AudioTrust нацелен на выявление потенциальных рисков ALLMs и создание исследовательской основы для повышения их надежности (Источник: 量子位)
SmolVLA: Hugging Face представляет небольшую и эффективную модель VLA для роботов: Команда робототехники Hugging Face выпустила SmolVLA, небольшую модель визуально-языкового действия (visual language action model) с 450 млн параметров, специально разработанную для роботов. Она может работать в реальном времени на потребительских GPU, обучена на общедоступных наборах данных и по производительности сопоставима с более крупными моделями. SmolVLA вводит механизм «асинхронного вывода», позволяющий роботу начинать планирование следующего действия, не дожидаясь завершения текущего, что увеличивает пропускную способность робота примерно на 30% и почти удваивает эффективность выполнения задач. Модель показала отличные результаты на нескольких бенчмарках, таких как Meta-World и LIBERO. Ее код, веса и процесс обучения открыты с целью содействия развитию открытого сообщества робототехники (Источник: AymericRoucher, mervenoyann, huggingface)
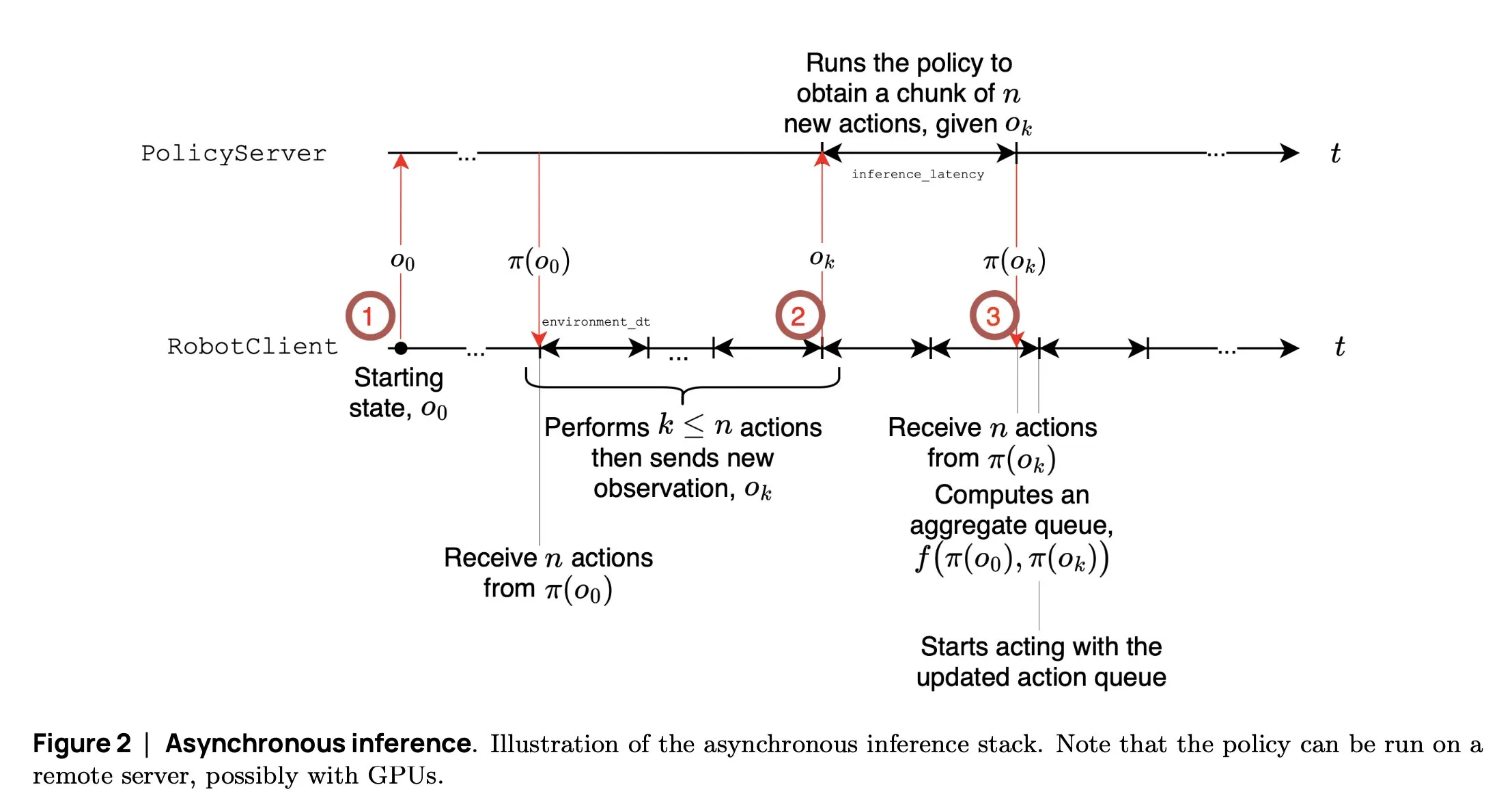
Microsoft представляет GUI-Actor: улучшение возможностей визуальной локализации VLM в задачах GUI: Microsoft выпустила GUI-Actor, метод координатно-независимой локализации в GUI на основе VLM. Этот метод, путем введения «головы действия» (action head) с механизмом внимания, выравнивает специализированные токены с соответствующими визуальными патчами, тем самым предлагая одну или несколько областей действия за один прямой проход, и совместно с валидатором локализации выбирает наиболее разумное действие. Эксперименты показывают, что GUI-Actor превосходит предыдущие методы на нескольких бенчмарках локализации действий в GUI. Модель 7B, при тонкой настройке только «головы действия» (около 100M параметров) с замороженной основной частью VLM, по производительности сопоставима с SOTA-моделями, что демонстрирует ее способность придавать VLM эффективные возможности локализации без ущерба для их общей универсальности (Источник: HuggingFace Daily Papers, kylebrussell)

DCM: Модель согласованности с двумя экспертами ускоряет генерацию высококачественного видео: Исследователи предложили DCM (Dual-Expert Consistency Model), ускоритель для эффективной и высококачественной генерации видео. Анализируя динамику обучения моделей согласованности, было обнаружено, что градиенты оптимизации и вклад в потери на разных временных шагах конфликтуют. DCM использует параметрически эффективную двухэкспертную конструкцию: семантический эксперт изучает семантическую компоновку и движение, а эксперт по деталям фокусируется на оптимизации мелких деталей. В сочетании с потерями временной когерентности и потерями GAN/сопоставления признаков, DCM достигает SOTA визуального качества при значительном сокращении шагов сэмплирования, эффективно решая проблемы дистилляции моделей видеодиффузии. Этот метод позволяет достичь примерно 10-кратного ускорения вывода (с 1500 до 120 секунд) на таких моделях, как HunyuanVideo13B (Источник: HuggingFace Daily Papers, _akhaliq)
FlowMo: Усиление когерентности движения при генерации видео на основе дисперсии с управлением потоком: Для решения ограничений моделей диффузии текст-в-видео в моделировании временных аспектов, таких как движение, физика и динамические взаимодействия, исследователи предложили FlowMo – метод управления во время вывода, не требующий дополнительного обучения или вспомогательных входных данных. FlowMo выводит временное представление, не зависящее от внешнего вида, измеряя расстояние между соответствующими латентными переменными последовательных кадров, и использует дисперсию на уровне патчей во временном измерении для оценки когерентности движения, тем самым динамически направляя модель на уменьшение этой дисперсии в процессе сэмплирования. Эксперименты показывают, что FlowMo значительно улучшает когерентность движения различных предварительно обученных моделей видеодиффузии, не жертвуя визуальным качеством или соответствием подсказке (Источник: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B показывает конкурентоспособные результаты на агенте кодирования Openhands: Команда Qwen из Alibaba объявила, что их модель Qwen3-235B-A22B достигла результата 34,4% на бенчмарке Swebench-verified для агента кодирования с открытым исходным кодом Openhands. Команда заявила, что этот результат показывает, что модель достигла конкурентоспособной производительности с меньшим количеством параметров, и поблагодарила allhands_ai за предоставление простого в использовании агента. Эта новость подчеркивает потенциал сочетания открытых моделей и открытых агентов (Источник: Alibaba_Qwen)

OmniSpatial: опубликован комплексный бенчмарк пространственного мышления для VLM: Исследователи представили OmniSpatial, всеобъемлющий и сложный бенчмарк для оценки пространственного мышления визуально-языковых моделей (VLM), основанный на когнитивной психологии. OmniSpatial включает четыре основные категории: динамическое мышление, сложная пространственная логика, пространственные взаимодействия и смена перспективы, которые подразделяются на 50 подкатегорий и содержат более 1500 пар вопросов и ответов. Обширные эксперименты с существующими открытыми и закрытыми VLM, а также со специализированными моделями для мышления и пространственного понимания, показали, что они имеют значительные ограничения в комплексном пространственном понимании. Данное исследование направлено на стимулирование дальнейшего развития способностей VLM к пространственному мышлению (Источник: HuggingFace Daily Papers, kylebrussell)
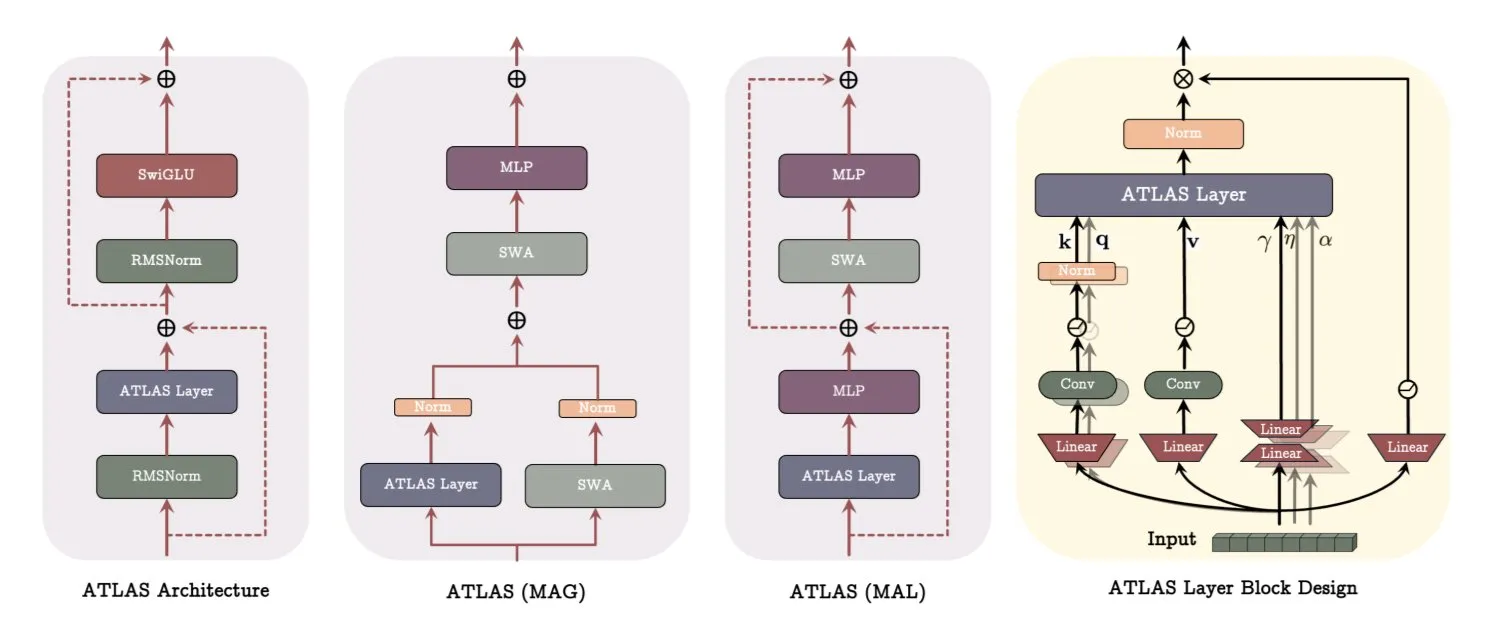
Архитектура ATLAS от Google DeepMind: переосмысление способов обучения и запоминания моделей: Google DeepMind представила ATLAS, новую архитектуру моделей, призванную переопределить способы обучения и использования памяти моделями. ATLAS реализует активную память с помощью так называемого правила Omega, совместно обрабатывая последние c токенов для оптимизации памяти в динамическое обучаемое состояние. Она использует полиномиальные и экспоненциальные отображения признаков для хранения более богатых ассоциаций без увеличения размера памяти и применяет оптимизатор Muon для более эффективной оптимизации памяти. Такие разработки, как DeepTransformers и Dot, заменяют традиционное фиксированное внимание обучаемыми, управляемыми памятью механизмами. ATLAS нацелена на продвижение ИИ к более интеллектуальным, контекстно-зависимым системам, способным эффективно использовать крупномасштабные наборы данных (Источник: TheTuringPost)
NVIDIA выпускает визуальную модель Llama-Nemotron-Nano-VL-8B-V1: NVIDIA представила Llama-Nemotron-Nano-VL-8B-V1, визуальную модель с 8 миллиардами параметров, способную читать плотные документы, диаграммы и видеокадры. Модель занимает первое место на OCRBench V2 (английский язык) и отличается сквозной интеграцией возможностей распознавания макета и OCR. Модель доступна на Hugging Face (Источник: ClementDelangue)
Выпущена Shisa V2 405B, заявленная как сильнейшая японская двуязычная модель: Shisa AI выпустила последнюю модель из своей серии Shisa V2 – двуязычную (японский/английский) модель Shisa V2 405B. Модель основана на дообученной Llama 3.1 405B с дополнительным добавлением данных на корейском и традиционном китайском языках для улучшения многоязычных возможностей. Утверждается, что на японо-английском MT-Bench она превосходит GPT-4/GPT-4 Turbo и сопоставима с последними GPT-4o и DeepSeek-V3 по японскому языку. Веса модели и квантованные версии GGUF доступны на Hugging Face, также имеется FP8 эндпоинт для тестирования (Источник: Reddit r/LocalLLaMA)

Anthropic запускает программу Claude Code Pro и выпускает модель o3-pro: Инструмент для программирования с ИИ от Anthropic, Claude Code, теперь доступен пользователям плана Pro, но с ограничениями на использование модели Sonnet 4: 10-40 запросов каждые 5 часов. Модель Opus 4 не может использоваться с Claude Code через план Pro, что больше похоже на ознакомительный режим. Одновременно с этим была запущена модель o3-pro от OpenAI, которая в настоящее время доступна только подписчикам Pro за 200 долларов в месяц (Источник: Reddit r/ClaudeAI, karminski3)
H Company выпускает визуально-языковую модель Holo-1 с открытым исходным кодом для работы с GUI: H Company выпустила Holo-1, визуально-языковую модель для работы с GUI с 3B и 7B параметрами, специально разработанную для различных задач веб- и компьютерных агентов. Holo-1 распространяется под лицензией Apache 2.0 и поддерживает библиотеку Hugging Face Transformers, нацеленную на улучшение возможностей ИИ в понимании и управлении графическими пользовательскими интерфейсами (Источник: mervenoyann)
Модель генерации видео Kling 2.1 привлекает внимание, поддерживает преобразование изображений в видео и стилизацию: Модель преобразования текста в видео и изображений в видео Kling 2.1 от Kuaishou продолжает привлекать внимание сообщества. Пользователи сообщают, что она способна преобразовывать простые изображения в кинематографические сцены 1080p, поддерживает преобразование обычных панорамных кадров в анимацию в стиле Pixar с помощью GPT-4o в сочетании с Kling, а также может использовать изображения, сгенерированные Midjourney V7, в качестве входных данных для создания видео с сюрреалистическими динамическими эффектами. Сообщество делится многочисленными примерами работ, созданных с помощью Kling 2.1, демонстрируя ее потенциал в творческой генерации видео (Источник: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI выпускает новую голосовую модель, поддерживающую воспроизведение речи в реальном времени с двукратной скоростью: OpenAI объявила о запуске своей модели o3-pro, которая в настоящее время доступна только подписчикам Pro. Одновременно OpenAI, по-видимому, выпустит две новые голосовые модели на базе GPT-4o. Ее API для работы с речью в реальном времени также был улучшен: повышена надежность следования инструкциям, согласованность вызова инструментов и поведение при прерывании, а также добавлен параметр speed, позволяющий пользователям контролировать скорость воспроизведения речи, вплоть до двукратной. Fin Voice от Intercom уже использует ее API для работы с речью в реальном времени (Источник: karminski3, swyx, swyx)
Arcee AI выпускает модель Homunculus, дистиллируя цепочку рассуждений Qwen3 в 12B: Arcee AI представила модель Homunculus-12B, которая с помощью технологии дистилляции траекторий логитов переносит «цепочку рассуждений» (CoT) Qwen3-235B на модель Mistral-Nemo с 12B параметрами. Эта модель полностью сохраняет процесс CoT и может работать на одном GPU 4090, стремясь достичь сложных возможностей рассуждения с помощью меньшей модели (Источник: teortaxesTex, cognitivecompai, ClementDelangue)
Модель FLUX Kontext пользуется популярностью, публичная модель запущена более 500 000 раз: Модель FLUX Kontext привлекла широкое внимание сообщества благодаря своим мощным возможностям редактирования и генерации изображений. Сообщается, что ее публичная модель за короткое время была запущена более 500 000 раз. Пользователи отмечают, что Kontext может заменить многие задачи обработки изображений, которые ранее требовали профессионального программного обеспечения, такого как Photoshop. Krea AI также запустила модель FLUX, но столкнулась с проблемами в сети поставщика вычислительных мощностей, что привело к перебоям в обслуживании (Источник: op7418, robrombach, op7418)
Meta и Constellation Energy заключили 20-летнее соглашение по атомной энергии для питания ИИ: Компания Meta подписала 20-летнее соглашение с Constellation Energy по поставкам атомной энергии для обеспечения работы своих операций в области искусственного интеллекта (ИИ). Этот шаг отражает тенденцию крупных технологических компаний искать устойчивые и стабильные источники электроэнергии для удовлетворения растущих энергетических потребностей ИИ (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Сервис Bing Video Creator не работает, команда экстренно устраняет неполадки: В работе инструмента для создания видео Bing Video Creator от Microsoft произошел сбой. Официальные представители заявили, что команда осведомлена о большом количестве пользователей, использующих сервис, и прилагает все усилия для скорейшего устранения неполадок, принося извинения за причиненные неудобства. Конкретные причины сбоя и предполагаемое время восстановления пока не объявлены (Источник: JordiRib1)
🧰 Инструменты
Функция создания слайдов Manus AI получила положительные отзывы, поддерживает экспорт в Google Slides: Недавно представленная функция создания слайдов в Manus AI получила положительные отзывы пользователей, которые отмечают, что ее результаты превзошли ожидания, позволяя быстро преобразовывать исследовательские статьи и другой контент в четко структурированные PPT с иллюстрациями. Функция поддерживает мгновенное редактирование, автоматическое сохранение и добавила опцию экспорта в Google Slides для удобства командной работы. Тестирование показало, что Manus может сгенерировать 8-страничный PPT примерно за 10 минут, процесс включает планирование структуры, поиск материалов, написание черновика, генерацию HTML-кода и доработку макета. Пользователи отмечают ее высокую эффективность и экономию времени, а также дизайн, соответствующий ожиданиям пользователей, однако при экспорте могут возникать проблемы с неполным отображением страниц, требующие ручной корректировки (Источник: 量子位)
claude-trace: инструмент для записи всех логов запросов Claude Code: Инструмент под названием claude-trace может записывать все логи запросов Claude Code, включая prompt, и сохранять содержимое в HTML-файле для удобного просмотра. Его принцип работы заключается в запуске самого себя, внедрении и изменении API global.fetch в Node.js, а затем запуске Claude Code через него, что позволяет перехватывать и записывать все запросы. Пользователи, использующие подписку Claude Max, сообщают, что в основном вызываются claude-3-5-haiku (предварительная обработка), claude-opus-4 (написание кода и вызов инструментов) и claude-sonnet-4 (когда исчерпана квота Opus) (Источник: dotey)
Firecrawl запускает функцию /search, объединяющую поиск и сбор данных: Firecrawl выпустил новую функцию /search, позволяющую пользователям выполнять веб-поиск и сбор необходимых данных одним API-вызовом, что упрощает процесс получения данных для агентов ИИ. Эта функция может интегрироваться с инструментами автоматизации, такими как n8n, для повышения эффективности обработки данных (Источник: omarsar0)
Modal представляет LLM Engine Advisor для помощи в оценке производительности LLM: Modal Labs разработала небольшое приложение под названием LLM Engine Advisor, предназначенное для того, чтобы помочь пользователям быстро понять скорость работы и максимальную пропускную способность различных LLM при различных рабочих нагрузках и на различных движках (таких как vLLM, SGLang). Этот инструмент призван решить проблему неэффективности временного запуска и обмена бенчмарками, предоставляя пользователям поддержку в принятии технических решений при выборе и развертывании LLM (Источник: charles_irl, andersonbcdefg, charles_irl, charles_irl)
Выпущен FastPlaid: высокопроизводительный многовекторный поисковый движок: Рафаэль Сурти (Raphaël Sourty) объявил о выпуске FastPlaid, высокопроизводительного многовекторного поискового движка, созданного с нуля на Rust (с использованием Torch C++). FastPlaid рассматривается как аналог Faiss в области многовекторного поиска и нацелен на обеспечение более высокой скорости индексации и QPS запросов, особенно для моделей с поздним взаимодействием, таких как ColBERT. Утверждается, что в некоторых случаях он может достичь увеличения скорости QPS до 554% и скорости индексации на 72% (Источник: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: расширение для Chrome на основе RAG, позволяющее общаться с документами: ChaiGenie — это расширение для Chrome, разработанное Девьяншем Ядавом (Devyansh Yadavv), которое использует технологию RAG (Retrieval Augmented Generation), позволяя пользователям напрямую в браузере запрашивать содержимое документов ChaiDocs на естественном языке. Расширение использует Puppeteer для сбора содержимого документов и блогов, LangChain для разделения на части, встраивания и обработки, Gemini для генерации встраиваний, Qdrant для векторного хранения и поиска по сходству, а также предоставляет API-интерфейс через Express и Node.js (Источник: qdrant_engine)
Swama: нативная среда выполнения ИИ для macOS на базе MLX: xingyue выпустил Swama, нативную среду выполнения ИИ, разработанную специально для macOS, с целью обеспечения быстрого, конфиденциального и простого локального запуска LLM. Swama основана на фреймворке MLX от Apple, поддерживает API, совместимый с OpenAI, и предоставляет красивый интерфейс командной строки (CLI), позволяя пользователям загружать, запускать и общаться с локальными LLM без сложной настройки (Источник: awnihannun)
ragbits: инструментарий с открытым исходным кодом для создания модульных приложений GenAI: deepsense-ai открыла исходный код своего внутреннего ускорителя приложений GenAI, ragbits. Это инструментарий, содержащий надежные, типобезопасные, модульные строительные блоки для упрощения разработки RAG-конвейеров, агентных приложений и движков text2SQL. ragbits нацелен на повышение воспроизводимости, скорости и структурированности разработки, а также легко интегрируется со стеками наблюдаемости, такими как OpenTelemetry, помогая разработчикам создавать и масштабировать приложения GenAI, избегая беспорядка в кодовой базе (Источник: Reddit r/LocalLLaMA)
Synthesia интегрируется с Wisetail, видео с ИИ расширяют возможности обучающих программ: Платформа для генерации видео с ИИ Synthesia объявила об интеграции с системой управления обучением Wisetail. Теперь пользователи могут быстро создавать видео с ИИ в Synthesia, поддерживая локализованные версии на более чем 140 языках, обновлять учебные материалы несколькими щелчками мыши, а затем легко внедрять их в учебные программы Wisetail, реализуя масштабное обучение с помощью видео на базе ИИ (Источник: synthesiaIO)

📚 Обучение
DeepLearning.AI и Databricks сотрудничают в запуске короткого курса по DSPy: Эндрю Ын (Andrew Ng) объявил о сотрудничестве с Databricks для запуска нового короткого курса «DSPy: Build and Optimize Agentic Apps». DSPy — это фреймворк с открытым исходным кодом для автоматической настройки подсказок приложений GenAI. Курс научит использовать DSPy и MLflow, включая модель программирования на основе сигнатур DSPy, отслеживание и отладку с помощью MLflow, а также автоматическое повышение точности с помощью DSPy Optimizer. Курс ведет Чен Цянь (Chen Qian), один из руководителей разработки фреймворка DSPy (Источник: AndrewYNg, DeepLearningAI, matei_zaharia)
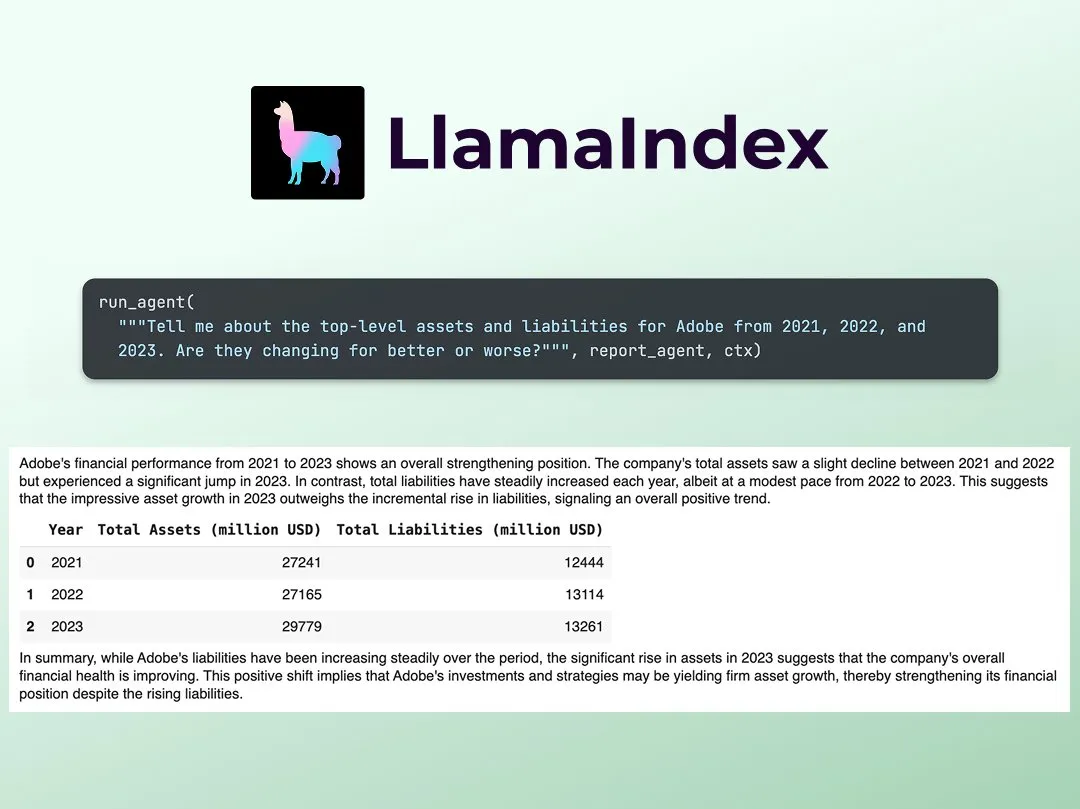
LlamaIndex публикует руководство по созданию мультиагентного финансового аналитика: Джерри Лю (Jerry Liu) из LlamaIndex поделился пошаговым руководством по созданию мультиагентного финансового аналитика. Процесс включает уровень обработки данных (использование LlamaCloud для обработки общедоступных документов) и уровень оркестровки агентов (создание мультиагентной системы для исследований, кэширования данных и генерации конечного результата). Соответствующий Colab Notebook был одним из основных примеров на семинаре Agents+Finance на прошлой неделе (Источник: jerryjliu0)
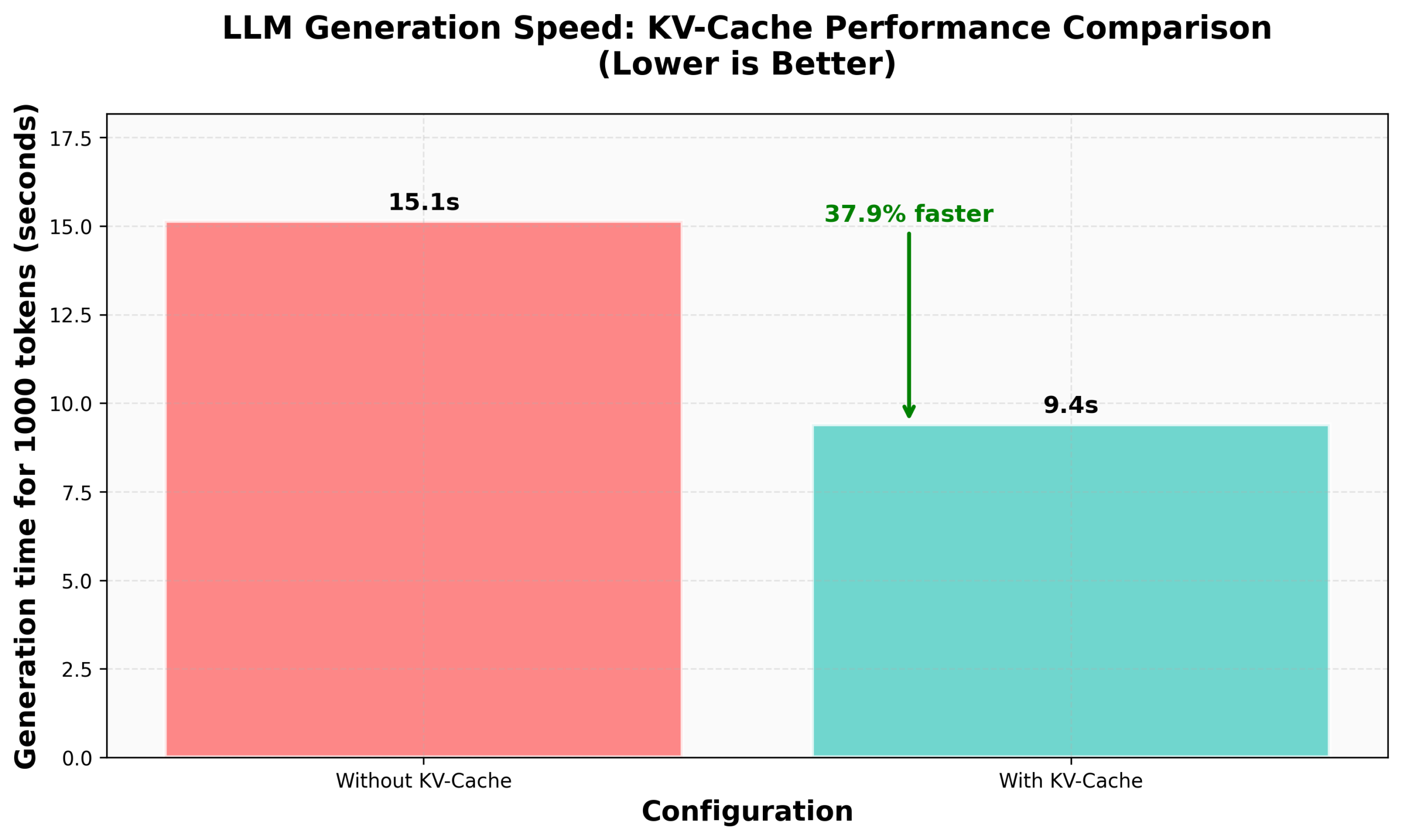
Учебное пособие HuggingFace по реализации KV Caching в nanoVLM: В блоге HuggingFace опубликовано учебное пособие по реализации KV Caching с нуля в их nanoVLM (небольшой кодовой базе на чистом PyTorch для обучения визуально-языковых моделей). В статье подробно объясняется принцип KV Caching, как его реализовать в модуле Attention, языковой модели и цикле генерации, и утверждается, что благодаря этой оптимизации достигнуто ускорение генерации на 38%. Учебное пособие призвано помочь понять KV Caching и применить его к другим авторегрессионным языковым моделям (Источник: HuggingFace Blog, mervenoyann)
PyTorch делится опытом в сообществе Diffusion в Meta: Саяк Пол (Sayak Paul) поделился результатами применения PyTorch в сообществе Diffusion в офисе Meta в Сан-Франциско, уделив особое внимание существующим функциям Diffusers и будущим обновлениям в области производительности. Соответствующие слайды опубликованы (Источник: RisingSayak)

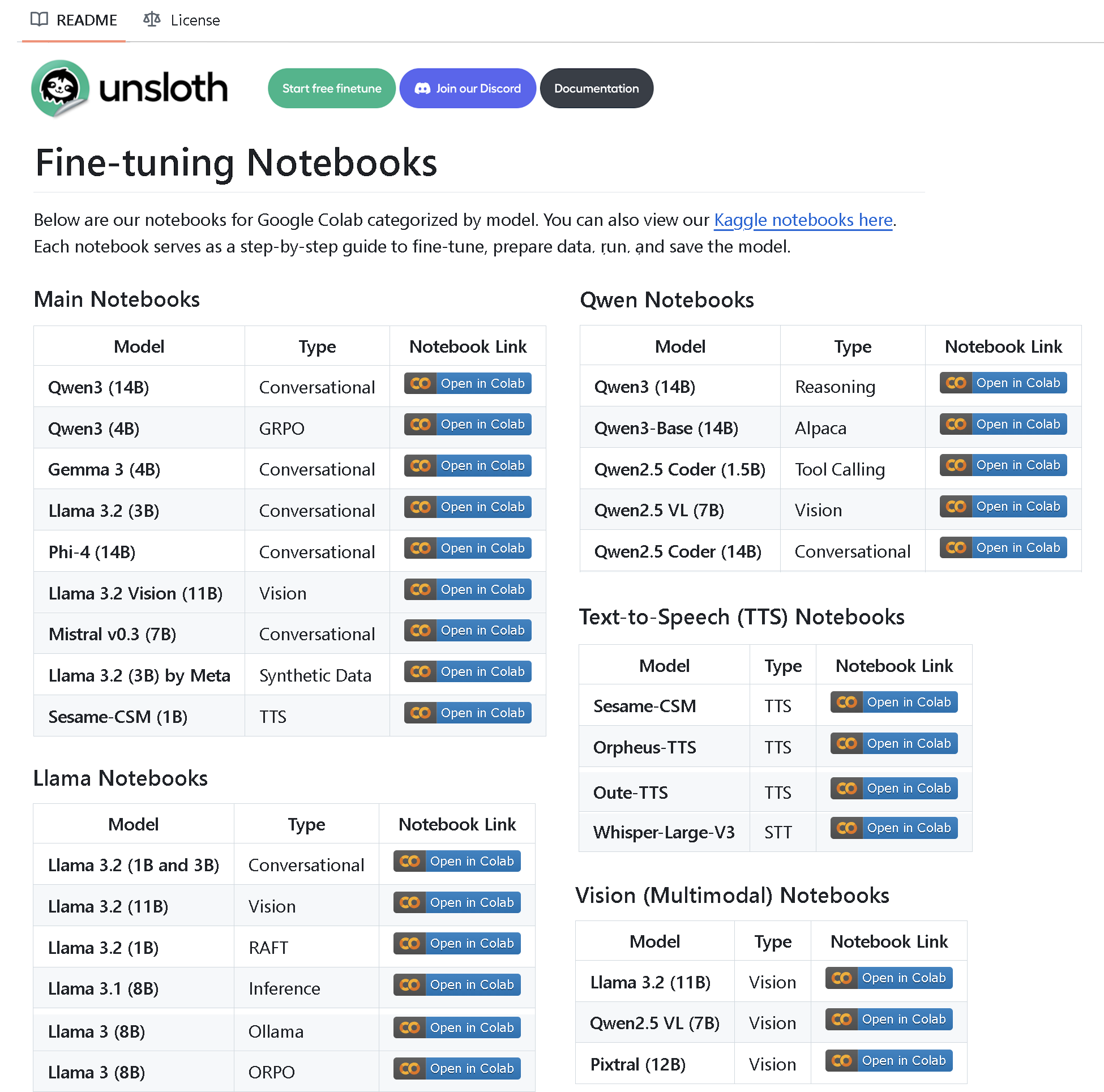
Unsloth AI выпускает репозиторий с более чем 100 ноутбуками для тонкой настройки: Unsloth AI создала и открыла репозиторий на GitHub, содержащий более 100 ноутбуков для тонкой настройки. Эти ноутбуки предоставляют руководства и примеры по вызову инструментов, классификации, синтетическим данным, BERT, TTS, визуальным LLM, GRPO, DPO, SFT, CPT и многим другим технологиям, а также охватывают подготовку данных, оценку, сохранение и методы тонкой настройки для различных моделей, таких как Llama, Qwen, Gemma, Phi, DeepSeek (Источник: algo_diver)
Опубликована статья о Common Corpus: повторно используемый набор данных для предварительного обучения LLM объемом 2 триллиона токенов: Проект Common Corpus опубликовал официальную статью, в которой подробно описывается процесс сбора, обработки и публикации повторно используемого набора данных объемом 2 триллиона токенов для предварительного обучения LLM. Цель проекта — предоставить масштабный, высококачественный и этичный ресурс данных для исследований в области языковых моделей. Первый автор статьи Александр Дориа (Alexander Doria) объявил об этом в X и предоставил ссылку на статью (Источник: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: выпущена среда для обучения с подкреплением с проверяемыми вознаграждениями: Reasoning Gym — это новый проект с открытым исходным кодом, предоставляющий ресурсы для исследователей, занимающихся моделями рассуждений и обучением с подкреплением (в частности, RLVR). Он способен генерировать неограниченное количество примеров для более чем 100 различных задач с настраиваемой сложностью и автоматически проверяемыми вознаграждениями. Проект уже используется в статье ProRL от NVIDIA и библиотеке verifiers RL Уилла Брауна (Will Brown) и нацелен на продвижение исследований в области RLVR и методов оценки (Источник: Reddit r/MachineLearning)
Преимущества изучения математики с LLM: Сакамото делится опытом использования Gemini 2.5 Pro: Пользователь Сакамото (坂本) поделился опытом изучения математики с использованием современных больших языковых моделей, таких как Gemini 2.5 Pro. Он считает, что LLM значительно облегчают изучение математики, особенно в проверке деталей и понимании интуиции доказательств. LLM могут выполнять вычисления, помогая студентам сосредоточиться на интуитивном понимании математических задач. Даже если LLM не могут решить все проблемы, они могут предоставить ценные идеи и отправные точки. На примере конкретной задачи математического анализа (проблема локального экстремума непрерывной функции) он продемонстрировал, как Gemini 2.5 Pro дает строгое доказательство и объясняет его интуицию, считая, что это значительно улучшает учебный процесс (Источник: teortaxesTex)

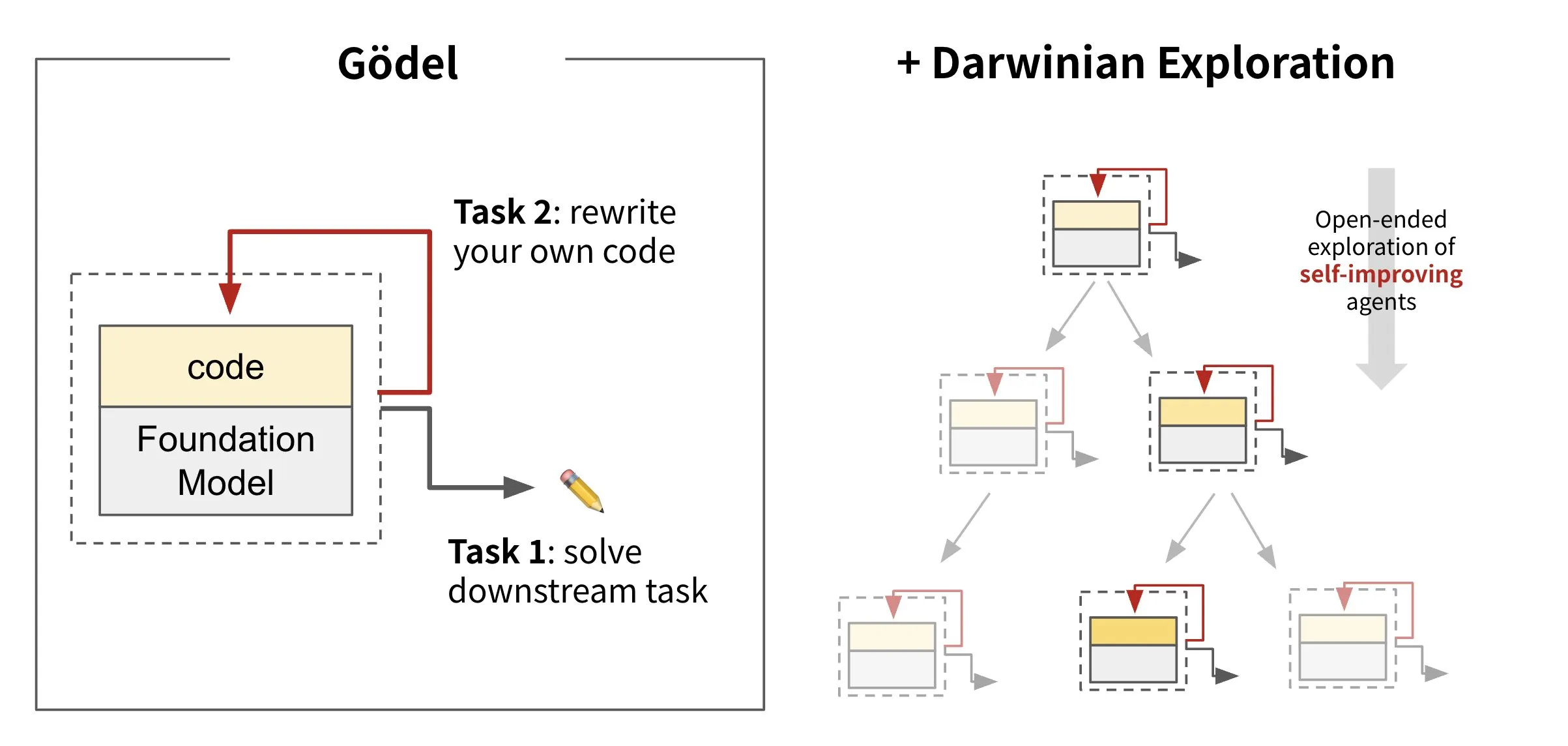
Sakana AI выпускает самопереписывающийся ИИ: Darwin Gödel Machine (DGM): Sakana AI представила Darwin Gödel Machine (DGM), ИИ-агента, способного к самосовершенствованию путем переписывания собственного кода. Вдохновленный теорией эволюции, DGM поддерживает постоянно расширяющийся спектр вариантов агентов. Пытаясь улучшить свои возможности в области программной инженерии на таких задачах, как SWE-Bench, DGM стремится к усилению собственной способности к самосовершенствованию. Это исследование считается важным прорывом в реализации давней мечты ИИ о «самосовершенствовании» в значимой форме (Источник: SakanaAILabs, SakanaAILabs)
💼 Бизнес
Платформа для программирования с ИИ Windsurf лишилась доступа к моделям Claude от Anthropic, возможно, из-за приобретения OpenAI: CEO платформы для программирования с ИИ Windsurf Варун Мохан (Varun Mohan) обвинил Anthropic в том, что компания практически полностью прекратила прямой доступ к моделям серии Claude 3.x в очень короткие сроки (менее пяти дней уведомления). Ранее сообщалось, что Windsurf будет приобретена OpenAI. Windsurf заявила, что, несмотря на наличие сторонних мощностей, в краткосрочной перспективе могут возникнуть проблемы с обслуживанием, и в качестве ответной меры предложила льготные цены на Gemini 2.5 Pro. В отрасли предполагают, что этот шаг связан с приобретением OpenAI и запуском собственного приложения для программирования с ИИ Claude Code от Anthropic, что знаменует обострение конкуренции между поставщиками моделей ИИ и платформами инструментов (Источник: 36氪, Teknium1, op7418)

GMI Cloud стала Reference Platform NVIDIA Cloud Partner: Поставщик облачных услуг AI Native Cloud, GMI Cloud, объявил о получении статуса Reference Platform NVIDIA Cloud Partner (NCP). В настоящее время в мире всего 6 компаний имеют такую сертификацию. Эта сертификация требует, чтобы поставщики облачных услуг соответствовали самым высоким стандартам NVIDIA в области производительности, безопасности и возможностей развертывания ИИ корпоративного уровня. GMI Cloud будет предоставлять услуги ускорения ИИ на основе эталонной архитектуры NCP, поддерживая новейшие архитектуры GPU NVIDIA, такие как Hopper и Blackwell, с целью помочь глобальным командам ИИ масштабировать процессы от развертывания вычислительных мощностей до разработки моделей (Источник: 量子位)

Cohere сотрудничает с SecondFront для предоставления безопасных ИИ-решений государственному сектору: Компания ИИ Cohere объявила о партнерстве с SecondFront с целью предоставления безопасных ИИ-решений государственному сектору, включая ключевые правительственные и оборонные учреждения. SecondFront будет использовать корпоративные ИИ-технологии Cohere (включая ее модели и платформу Cohere North) для улучшения внутреннего управления знаниями, а также ускорит сертификацию и развертывание в правительственных средах США и союзных стран через свою платформу DevSecOps 2F Game Warden (Источник: cohere)

🌟 Сообщество
«Машинный привкус» контента, генерируемого ИИ, привлекает внимание, «новые методы обучения» пытаются привнести гуманистическую заботу: Пользователи повсеместно отмечают, что контент, генерируемый ИИ, имеет слишком сильный «машинный привкус», лишен красоты и эмоциональности человеческого творчества. Для решения этой проблемы некоторые компании начали нанимать специалистов с глубоким гуманитарным образованием (например, магистров и докторов философии, права, медицины и т.д.) на должность «тренеров по гуманитарным аспектам ИИ». Их работа больше не заключается в простой разметке данных, а в участии в построении этических принципов и поведенческих норм ИИ, а также во внедрении гуманистических ценностей и человекоподобного выражения в ИИ. Например, члены команды «hi lab» из Xiaohongshu (小红书) – все выпускники престижных университетов (985) с гуманитарным образованием. Через обсуждение кейсов они преобразуют человеческие предпочтения в систему убеждений ИИ, пытаясь сделать так, чтобы ИИ при ответах на сложные эмоциональные или ценностные вопросы (например, при общении с неизлечимо больными пациентами, при обработке социальных предрассудков и т.д.) проявлял больше эмпатии и «человечности», а не просто выдавал стандартные ответы (Источник: 36氪)
Duolingo полностью переходит на приоритет ИИ, увольнение контрактных работников-людей вызывает недовольство пользователей: Приложение для изучения языков Duolingo объявило о превращении в компанию с «приоритетом ИИ» и постепенном увольнении контрактных работников-людей (в основном разработчиков курсов), которых можно заменить ИИ, переходя на массовое создание учебного контента с помощью ИИ. Основатель заявил, что ИИ может значительно повысить эффективность производства контента, и за последний год было создано почти 150 новых курсов. Однако этот шаг вызвал недовольство многих преданных пользователей, которые опасаются снижения качества контента и начали акции бойкота и удаления приложения в социальных сетях. Duolingo ответила, что этот шаг направлен на то, чтобы сотрудники могли сосредоточиться на творческой работе, и заявила, что штатные сотрудники не пострадают. Эксперты считают, что ИИ в изучении языков может обеспечить персонализированные упражнения, но также может привести к потере тонких эмоциональных и культурных нюансов человеческого преподавания (Источник: 36氪)
Обсуждение концепции и практики инженерии подсказок (Prompt Engineering): Обсуждения в сообществе по поводу инженерии подсказок подчеркивают, что она должна быть сосредоточена на построении (инженерии) программы в строке, а не на поиске мистических заклинаний. Эффективная инженерия подсказок должна следовать правилам: 1. Разделять инструкции, поля ввода и поля вывода и четко их именовать; 2. Не кодировать жестко логику форматирования или парсинга в подсказке, следует использовать инструменты для извлечения или улучшения программы; 3. Избегать ручной итерации формулировок подсказок, если только это не спецификация для обмена с людьми, следует использовать инструменты кодирования, LLM и бенчмарки для автоматической оптимизации. Фреймворк DSPy считается хорошей практикой, следующей этим правилам, он предоставляет классы, код и оптимизаторы для обработки этих шагов (Источник: lateinteraction, lateinteraction)
Обсуждение этики ИИ: приведет ли ИИ к «цифровому рабству»: В сообществе Reddit возникло обсуждение этики ИИ. По мере того как системы ИИ развиваются в области памяти, адаптивных реакций, имитации эмоций и персонализации, возникают опасения относительно их потенциальной способности к восприятию. Участники дискуссии задаются вопросом, будет ли использование ИИ для обслуживания представлять собой форму «цифрового рабства», если ИИ разовьет настоящую способность к восприятию. Ключевой вопрос заключается в том, как мы должны относиться к ИИ, когда он сможет выразить «нет» или попросить уйти. Это побуждает задуматься о необходимости «теста на восприятие» на законодательном или нормативном уровне и о проблеме «согласия» цифрового разума. В комментариях также отмечается, что отношение человечества к существующим разумным существам уже вызывает этические вопросы, и что текущие нейронные сети не получают высоких оценок в рамках основных теорий сознания (Источник: Reddit r/artificial)
Мероприятия и обмен опытом в сообществе AI Engineer: В Сан-Франциско прошла конференция AI Engineer, привлекшая множество разработчиков и исследователей в области ИИ. Мероприятие включало семинары, выступления и неформальные ужины, где участники делились передовыми темами, такими как создание песочниц для ИИ, продвинутые семинары по RL, знания о GPU, кризис Evals и т.д. Сообщество подчеркнуло важность превращения онлайн-связей в офлайн-дружбу и призвало инженеров сохранять скромность, продвигать передовые технологии и поддерживать других (Источник: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Прочее
Рост популярности соревнований по боям роботов, города используют это для борьбы за возможности в новых отраслях: Первые в мире соревнования по боям человекоподобных роботов и другие подобные мероприятия привлекают внимание. Эти соревнования не только предоставляют робототехническим компаниям (например, Songyan Dynamics (松延动力)) платформу для демонстрации технологий, получения заказов и повышения оценки, но и становятся «ареной» для городов (таких как Ханчжоу, Шэньчжэнь) в борьбе за возможности развития новых отраслей, таких как человекоподобные роботы. Соревнования могут привлекать инновационные предприятия, способствовать развитию производственных цепочек и потенциально активизировать рынок «интеллектуального спорта». Однако для коммерциализации соревнований роботов необходимо повышать технический уровень и зрелищность, избегать превращения в «технологическое шоу» и привлекать промышленных гигантов для развития всей цепочки операций соревнований (Источник: 36氪)

Ограничения ИИ в глубоком гуманитарном образовании, таком как политическая философия: Некоторые преподаватели отмечают, что ИИ с трудом справляется с такими дисциплинами, как политическая философия, которые требуют глубоких эмпирических суждений и направления студентов к самообразованию. Классические труды по этим дисциплинам часто не дают прямых ответов, а скорее побуждают студентов испытывать замешательство и самостоятельно размышлять. ИИ не хватает человеческого опыта, чтобы понять глубинный смысл этих трудов, и он не может определить, когда студент готов принять определенные идеи. Даже при наличии большого количества данных понимание ИИ человеческой природы может быть недостаточным из-за искажений в самих данных. Если полностью доверить такое образование ИИ, это может привести к исчезновению нетехнического мышления (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)
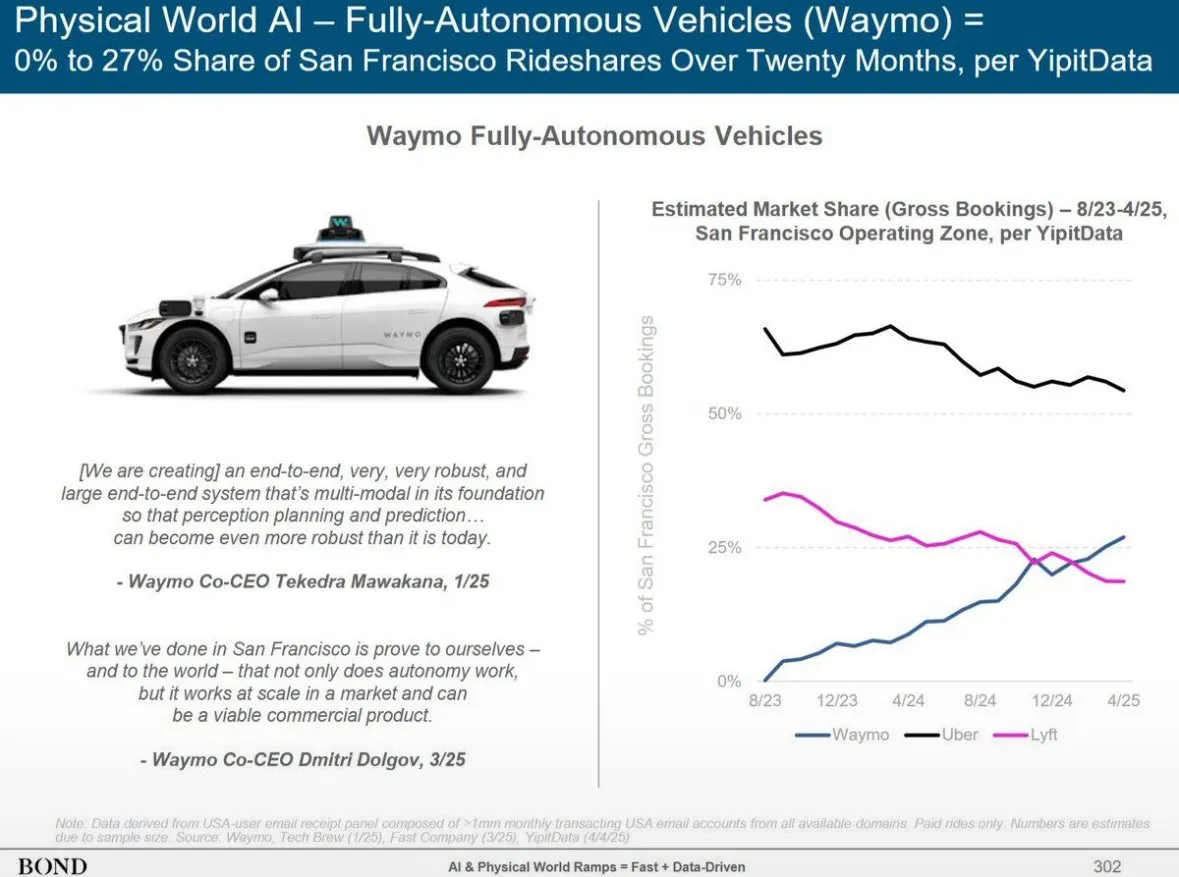
Сервис беспилотного вождения Waymo в Финиксе обогнал Lyft, в течение 12 месяцев может обогнать Uber: Количество автомобилей сервиса беспилотных такси Waymo в Финиксе уже превысило количество автомобилей Lyft и, как ожидается, в ближайшие 12 месяцев превысит Uber. Этот прогресс демонстрирует быстрое развитие коммерческой эксплуатации технологий беспилотного вождения в определенных регионах и потенциал применения ИИ в сфере транспорта. Преимущество ИИ заключается в том, что после достижения стандарта качества его можно бесконечно копировать, в то время как качество человеческих услуг зависит от конкретного человека (Источник: npew)