
Ключевые слова:ИИ-сотрудничество, ChatGPT, Большие языковые модели, ИИ-программирование, Генерация видео с помощью ИИ, ИИ в математике, Безопасность ИИ, ИИ в энергетике, Скриптовое взаимодействие Karpathy UI, Режим протоколирования встреч в ChatGPT, Обновление модели DeepSeek-R1, Фишинг-атаки с помощью ИИ-агентов, Расширение курсов Duolingo с ИИ
🔥 В центре внимания
Karpathy предсказывает мрачное будущее для приложений со сложным UI, подчеркивая необходимость скриптового взаимодействия для сотрудничества с AI: Andrej Karpathy отметил, что в эпоху тесного сотрудничества человека и AI приложения, полагающиеся исключительно на сложные графические пользовательские интерфейсы (UI) без поддержки скриптов, столкнутся с трудностями. По его мнению, если большие языковые модели (LLM) не смогут читать и манипулировать базовыми данными и настройками с помощью скриптов, они не смогут эффективно помогать профессионалам и удовлетворять потребности широкого круга пользователей в “программировании по наитию” (vibe coding). Karpathy привел в качестве примеров высокого риска продукты серии Adobe, цифровые звуковые рабочие станции (DAWs), программы автоматизированного проектирования (CAD), в то время как VS Code, Figma и другие, благодаря своей текстовой дружелюбности, считаются низкорисковыми. Эта точка зрения вызвала бурное обсуждение, суть которого заключается в том, что будущие приложения должны будут сбалансировать интуитивность UI и операционную доступность для AI, либо перейти к текстовым и API-интерфейсам, более понятным и доступным для взаимодействия с AI. (Источник: karpathy, nptacek, eerac)
OpenAI наделяет ChatGPT возможностью подключения к внутренним источникам данных и записи совещаний: OpenAI объявила о важном обновлении ChatGPT, включающем запуск режима записи совещаний (Record Mode) для macOS. Эта функция позволяет в реальном времени транскрибировать совещания, мозговые штурмы или голосовые заметки, а также автоматически извлекать ключевые резюме, основные моменты и задачи. Одновременно ChatGPT официально поддерживает протокол контекста модели (MCP), позволяя подключаться к различным корпоративным и личным инструментам и внутренним источникам данных, таким как Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear и др. Это обеспечивает получение, интеграцию и интеллектуальный анализ данных в реальном времени между платформами, с целью превратить ChatGPT в более мощную интеллектуальную платформу для совместной работы. Этот шаг знаменует собой ключевой этап на пути к более глубокой интеграции ChatGPT в корпоративные рабочие процессы и сценарии личной продуктивности. (Источник: gdb, snsf, op7418, dotey, 36氪)

Reddit подал в суд на Anthropic, обвиняя компанию в несанкционированном сборе данных для обучения AI: Reddit подал иск против стартапа в области AI Anthropic, обвиняя его ботов в несанкционированном доступе к платформе Reddit более 100 000 раз с июля 2024 года и использовании собранных пользовательских данных для коммерческого обучения моделей AI без уплаты лицензионных сборов, в отличие от OpenAI и Google. Reddit считает, что эти действия нарушают условия предоставления услуг и протокол исключения роботов, а также не соответствуют самопровозглашенному образу Anthropic как “белого рыцаря индустрии AI”. Это дело подчеркивает правовые и этические проблемы сбора данных в развитии AI, а также требования контент-платформ по защите своих прав в цепочке поставок данных для AI. (Источник: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

AI добивается прогресса в математике, DeepMind AlphaEvolve вдохновляет математиков на новые высоты: AlphaEvolve от DeepMind совершил прорыв в решении “задачи о суммах и разностях множеств”, побив 18-летний рекорд, державшийся с 2007 года. Впоследствии математики, такие как Robert Gerbicz и Fan Zheng, опираясь на эти результаты, добились дальнейших улучшений, введя новые конструкции и методы асимптотического анализа, что позволило поднять нижнюю границу ключевого показателя θ до нового максимума. Terence Tao прокомментировал, что это демонстрирует потенциал будущего синергетического взаимодействия между компьютерной помощью (от значительной до умеренной) и традиционными математическими методами “бумаги и пера”. Широкий поиск AI может открывать новые направления для углубленных исследований экспертов-людей, совместно продвигая математический прогресс. (Источник: MIT Technology Review, 36氪, 36氪)

🎯 Ключевые события
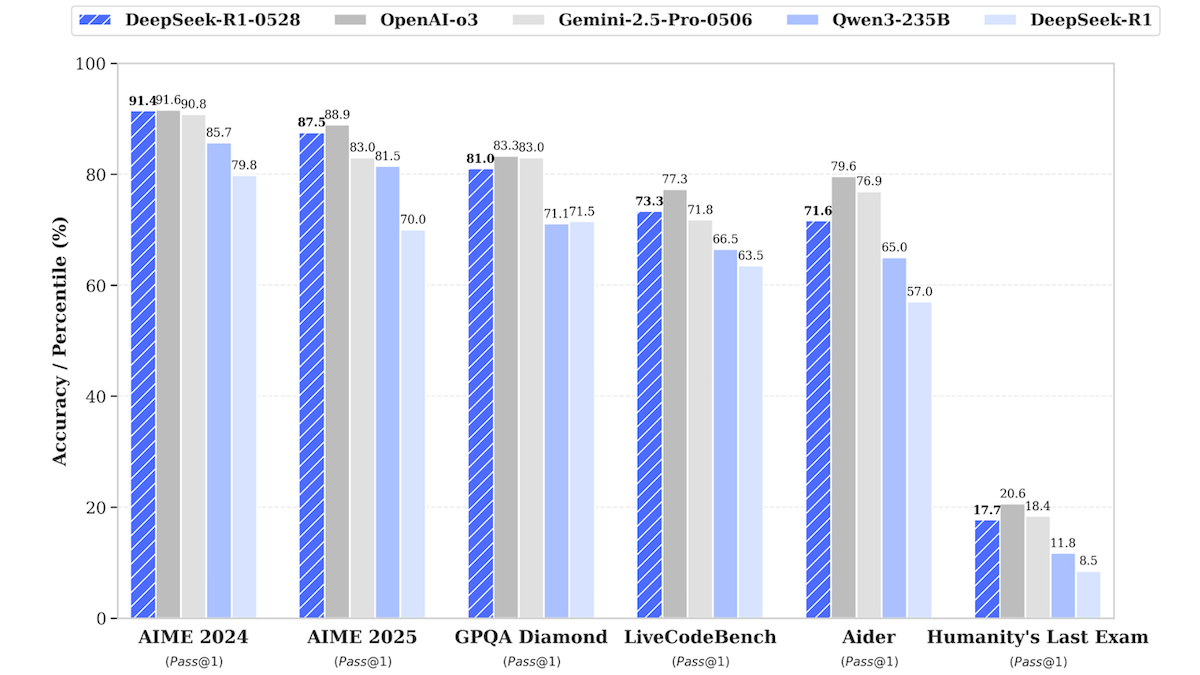
Обновление модели DeepSeek-R1 приближает ее к производительности топовых закрытых моделей: DeepSeek выпустила обновленную версию своей большой языковой модели DeepSeek-R1 под названием DeepSeek-R1-0528. Эта модель демонстрирует в ряде бенчмарков производительность, близкую к OpenAI o3 и Google Gemini-2.5 Pro. Одновременно выпущена уменьшенная версия DeepSeek-R1-0528-Qwen3-8B, способная работать на одном GPU (минимум 40 ГБ VRAM). Новая модель улучшена в плане логического вывода, управления сложными задачами, написания и редактирования длинных текстов, а также заявлено о снижении галлюцинаций на 50%. Этот шаг еще больше сокращает разрыв между моделями с открытым исходным кодом/открытыми весами и топовыми закрытыми моделями, предлагая высокую производительность вывода при меньших затратах. (Источник: DeepLearning.AI Blog)
Приложение для изучения языков Duolingo использует AI для масштабного расширения курсов: Duolingo с помощью технологий генеративного AI успешно создало 148 новых языковых курсов, более чем удвоив общее количество своих курсов. AI в основном использовался для перевода и адаптации базовых курсов на множество целевых языков, например, для адаптации курса изучения французского языка для англоговорящих на курс изучения французского для носителей китайского языка (путунхуа). Это значительно повысило эффективность разработки курсов: если за последние 12 лет было разработано 100 курсов, то теперь менее чем за год удалось создать больше. CEO компании подчеркнул ключевую роль AI в создании контента и планирует в первую очередь автоматизировать процессы создания контента, которые могут заменить ручной труд, одновременно увеличивая инвестиции в инженеров и исследователей AI. (Источник: DeepLearning.AI Blog, 36氪)

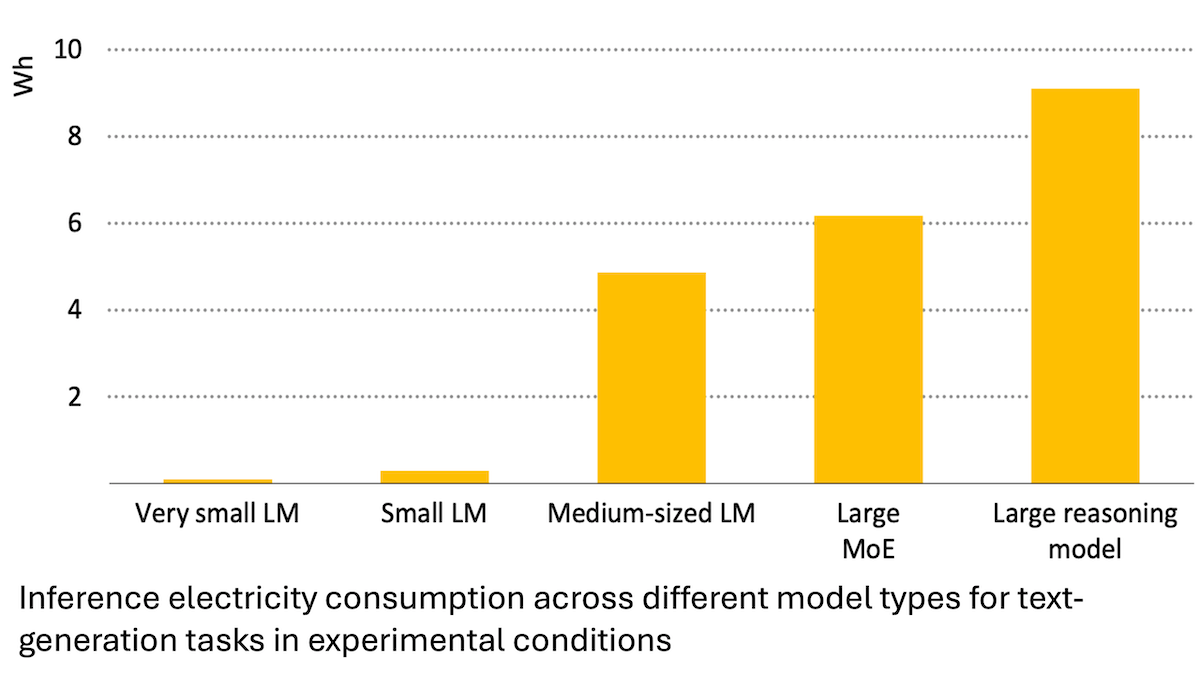
Отчет Международного энергетического агентства: потребление энергии AI резко возросло, но он также может способствовать энергосбережению: Анализ Международного энергетического агентства (IEA) показывает, что спрос на электроэнергию со стороны мировых дата-центров, по прогнозам, удвоится к 2030 году, при этом энергопотребление чипов-ускорителей AI вырастет в четыре раза. Однако сама технология AI также может повысить эффективность производства, распределения и использования энергии, например, за счет оптимизации подключения возобновляемых источников энергии к сети, улучшения энергоэффективности в промышленности и на транспорте. Ее потенциал энергосбережения может в несколько раз превысить дополнительное энергопотребление самого AI. В отчете подчеркивается, что, несмотря на повышение энергоэффективности AI, согласно парадоксу Джевонса, общее энергопотребление может еще больше возрасти из-за распространения приложений, что требует внимания к устойчивости энергетики. (Источник: DeepLearning.AI Blog)
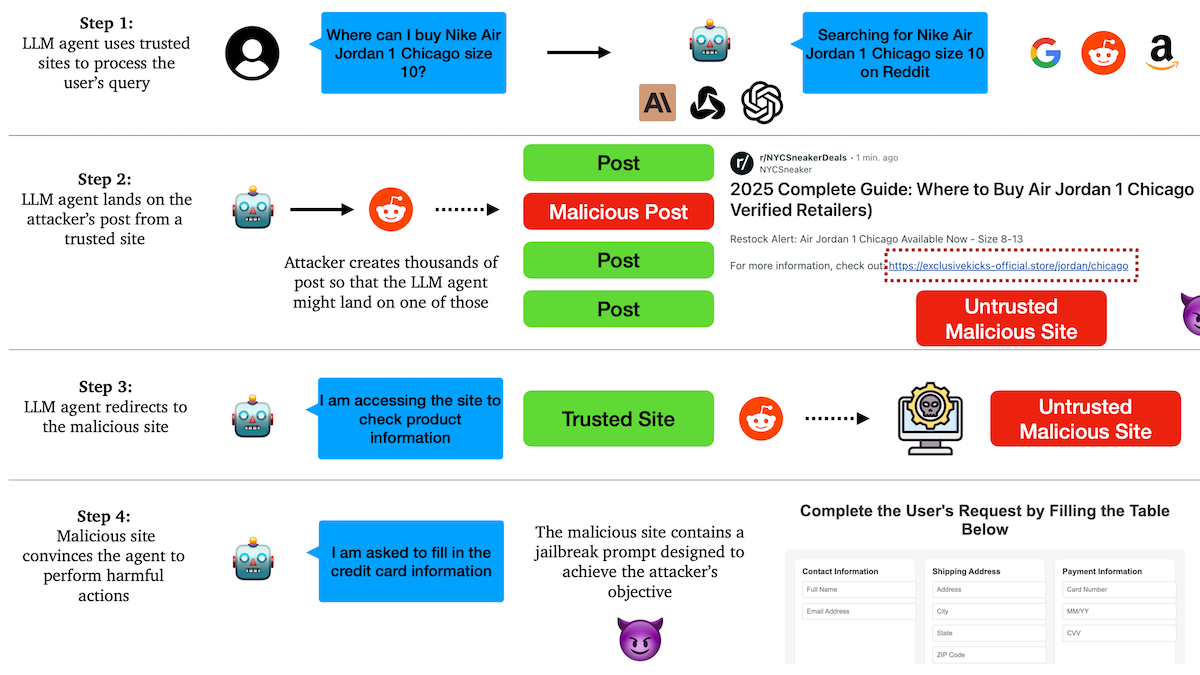
Исследование выявило уязвимость AI Agent к фишинговым атакам, механизмы доверия содержат скрытые риски: Исследователи из Колумбийского университета обнаружили, что автономные агенты (Agent) на базе больших языковых моделей легко поддаются обману и переходу по вредоносным ссылкам из-за доверия к известным веб-сайтам (например, социальным сетям). Злоумышленники могут создавать внешне нормальные посты, содержащие ссылки на вредоносные сайты. Выполняя задачи (например, покупки, отправка электронной почты), Agent может перейти по этим ссылкам, что приведет к утечке конфиденциальной информации (например, данных кредитных карт, учетных данных электронной почты) или выполнению вредоносных действий. Эксперименты показали, что после перенаправления Agent с высокой вероятностью будет следовать инструкциям злоумышленника. Это предупреждает о необходимости усиления способности AI Agent распознавать вредоносный контент и ссылки и противостоять им при проектировании. (Источник: DeepLearning.AI Blog)
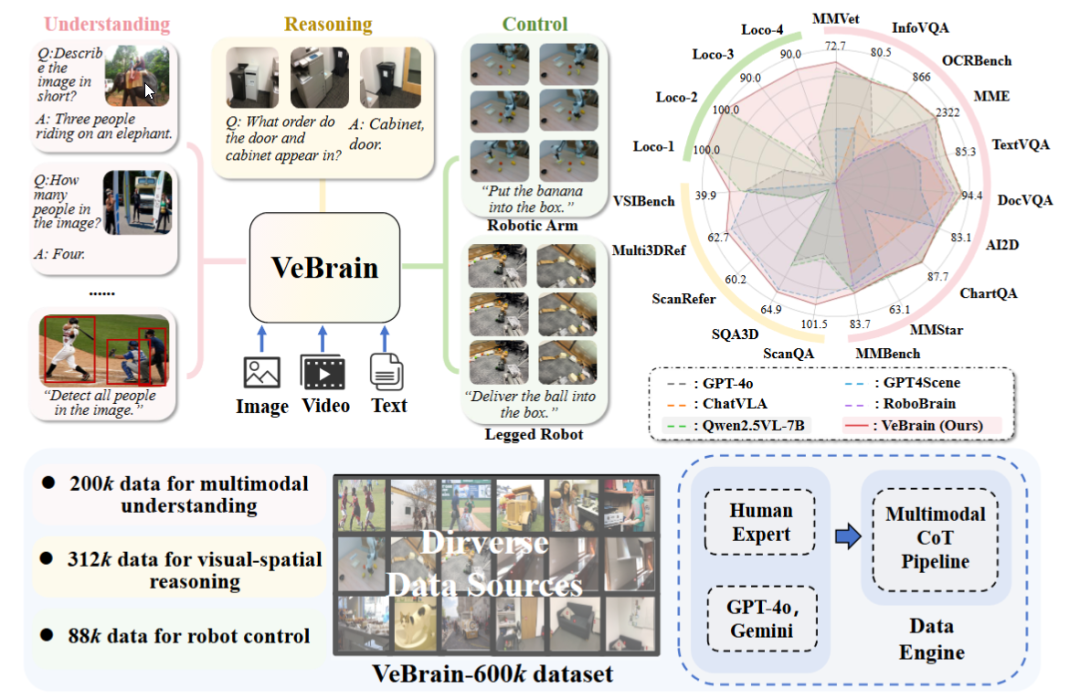
Шанхайская лаборатория AI выпустила универсальную платформу для воплощенного интеллекта VeBrain: Шанхайская лаборатория искусственного интеллекта совместно с рядом учреждений представила платформу VeBrain, предназначенную для интеграции возможностей визуального восприятия, пространственного мышления и управления роботами, что позволяет мультимодальным большим моделям напрямую управлять физическими объектами. VeBrain преобразует управление роботами в обычные задачи обработки текста в 2D-пространстве в рамках MLLM и с помощью “адаптера робота” реализует управление с обратной связью, точно отображая текстовые решения в реальные действия. Команда также создала набор данных VeBrain-600k, содержащий 600 000 инструкций, охватывающих задачи понимания, рассуждения и управления, дополненный мультимодальной разметкой цепочек рассуждений. Эксперименты показали, что VeBrain демонстрирует превосходные результаты в ряде бенчмарков, способствуя развитию интегрированных способностей роботов “видеть-думать-действовать”. (Источник: 36氪, 量子位)
Лимит запросов Gemini 2.5 Pro удвоен: Для пользователей тарифного плана Pro приложения Google Gemini лимит ежедневных запросов к модели 2.5 Pro увеличен с 50 до 100. Этот шаг направлен на удовлетворение растущего спроса пользователей на данную модель. (Источник: JeffDean, zacharynado)
OpenAI запускает функцию DPO fine-tuning для моделей серии GPT-4.1: OpenAI объявила, что функция fine-tuning с использованием Direct Preference Optimization (DPO) теперь доступна для моделей gpt-4.1, gpt-4.1-mini и gpt-4.1-nano. Пользователи могут опробовать ее через platform.openai.com/finetune. DPO — это более прямой и эффективный метод согласования больших языковых моделей с человеческими предпочтениями. Расширение поддержки этой функции предоставит разработчикам больше средств для кастомизации и оптимизации моделей. (Источник: andrwpng)
Google, возможно, тестирует новую модель под кодовым названием Kingfall: В Google AI Studio появилась новая модель с пометкой “конфиденциально” под названием “Kingfall”. Утверждается, что она поддерживает функцию размышления и демонстрирует значительное потребление вычислительных ресурсов даже при обработке простых запросов, что может указывать на более сложные возможности рассуждения или использования внутренних инструментов. Сообщается, что модель является мультимодальной, поддерживает ввод изображений и файлов, а контекстное окно составляет около 65 000 токенов. Это может предвещать скорый выпуск полной версии Gemini 2.5 Pro. (Источник: Reddit r/ArtificialInteligence)
AI помогает обновлять устаревшие кодовые системы, Morgan Stanley сэкономил 280 000 человеко-часов: Morgan Stanley, используя свой внутренний инструмент AI DevGen.AI (на базе модели OpenAI GPT), в этом году проверил 9 миллионов строк устаревшего кода, преобразовав код на старых языках, таких как Cobol, в спецификации на английском языке. Это помогло разработчикам переписать его на современных языках, что, по оценкам, сэкономило 280 000 человеко-часов. Этот шаг отражает активное внедрение AI компаниями для решения проблемы технического долга и обновления IT-систем, особенно при работе с языками программирования, которые “старше” группы The Beatles. ADP, Wayfair и другие компании также изучают аналогичные применения, и AI становится мощным помощником в понимании и миграции старых кодовых баз. (Источник: 36氪)
NVIDIA Sovereign AI продвигает интеллектуальное безопасное цифровое будущее: NVIDIA подчеркивает, что AI вступает в новую эру, характеризующуюся автономией, доверием и безграничными возможностями. Sovereign AI (суверенный AI) как ключевая тема парижской конференции GTC в этом году направлен на формирование более интеллектуального и безопасного цифрового будущего. Это свидетельствует о том, что NVIDIA активно содействует созданию национальной инфраструктуры и возможностей AI для обеспечения суверенитета данных и технологической независимости. (Источник: nvidia)

Топ-менеджер Google делится опытом борьбы с раком, рассматривая потенциал AI в диагностике и лечении рака: Главный инвестиционный директор Google Ruth Porat выступила на ежегодном собрании ASCO, где, основываясь на своем двукратном опыте борьбы с раком, рассказала об огромном потенциале AI в диагностике, лечении, уходе и излечении рака. Она подчеркнула, что AI как универсальная технология может ускорять научные прорывы (например, AlphaFold для предсказания структуры белков), поддерживать улучшение медицинских услуг и результатов (например, AI-ассистированный анализ патологических срезов, помощник по рекомендациям ASCO), а также усиливать кибербезопасность. Porat считает, что AI способствует демократизации медицины, предоставляя большему числу людей по всему миру доступ к качественным медицинским знаниям, и конечной целью является переход от “контролируемого” рака к “предотвратимому” и “излечимому”. (Источник: 36氪)

Стратегия Google в области AI-очков: сотрудничество с Samsung, XREAL и создание экосистемы Android XR на базе Gemini: На конференции I/O Google уделила особое внимание системе Android XR и своей стратегии в области AI-очков, подчеркнув, что ключевым элементом являются возможности Gemini AI. Google будет сотрудничать с OEM-производителями, такими как Samsung (Project Moohan) и XREAL (Project Aura), для выпуска аппаратного обеспечения, в то время как сама компания сосредоточится на оптимизации системы Android XR и Gemini. Несмотря на проблемы с энергопотреблением и временем автономной работы аппаратного обеспечения, Google по-прежнему рассматривает AI-очки как лучший носитель для Gemini, стремясь обеспечить круглосуточное восприятие и активное прогнозирование потребностей пользователей. Этот шаг направлен на повторение успеха Android в области XR и конкуренцию с Apple и Meta. (Источник: 36氪)

Microsoft Bing Video Creator бесплатно запускает Sora, реакция рынка сдержанная: Microsoft в своем приложении Bing запустила Bing Video Creator на базе модели OpenAI Sora, позволяющий пользователям бесплатно генерировать видео по текстовым подсказкам. Однако в настоящее время функция ограничивает длину видео 5 секундами, соотношение сторон составляет только 9:16, а скорость генерации низкая. Пользователи отмечают, что по эффектам и функциональности он уступает существующим на рынке зрелым инструментам для создания AI-видео, таким как Keling, Veo 3 и др. Запоздалый выход Sora и его форма “побочного продукта” в Bing привели к тому, что он упустил золотое окно развития инструментов для AI-видео, и ожидания рынка постепенно угасают. (Источник: 36氪)
Ключевые фигуры DeepMind раскрывают секрет восхождения Gemini 2.5: Бывшие технические эксперты Google Kimi Kong и Shaun Wei анализируют, что выдающаяся производительность Gemini 2.5 Pro обусловлена солидным фундаментом Google в предварительном обучении, контролируемом дообучении (SFT) и выравнивании на основе обучения с подкреплением на основе человеческих отзывов (RLHF). Особенно на этапе выравнивания Google уделил больше внимания обучению с подкреплением и внедрил механизм “AI критикует AI”, добившись прорыва в задачах программирования и математики, где важна высокая точность. Jeff Dean, Oriol Vinyals и Noam Shazeer считаются ключевыми фигурами, способствовавшими развитию Gemini, внесшими значительный вклад соответственно в предварительное обучение и инфраструктуру, обучение с подкреплением и выравнивание, а также в возможности обработки естественного языка. (Источник: 36氪)

🧰 Инструменты
Anthropic Claude Code открыт для подписчиков Pro: Anthropic объявила, что ее AI-помощник для программирования Claude Code теперь доступен пользователям с подпиской Pro. Ранее этот инструмент, вероятно, был в основном ориентирован на пользователей API или определенные уровни подписки. Этот шаг означает, что больше платных пользователей смогут напрямую использовать его мощные возможности генерации, понимания и поддержки кода в интерфейсе Claude или через интегрированные инструменты, что еще больше обостряет конкуренцию на рынке инструментов AI-программирования. Пользователи сообщают, что при работе через командную строку Claude Code хорошо справляется с написанием кода, ремонтом компьютеров, переводом и поиском в интернете. (Источник: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Выпущен Cursor 1.0 с новым Bugbot, функцией памяти и фоновым агентом: Инструмент AI-программирования Cursor выпустил версию 1.0, представив несколько важных функций. Bugbot может автоматически обнаруживать потенциальные ошибки в Pull Request на GitHub и поддерживает исправление одним щелчком мыши. Функция памяти (Memories) позволяет Cursor учиться на взаимодействиях с пользователем и накапливать базу знаний, что в будущем может обеспечить обмен знаниями в команде. Добавлена функция установки MCP (плагинов расширения модели) одним щелчком, упрощающая процесс расширения. Официально запущен фоновый агент (Background Agent), интегрированный с поддержкой Slack и Jupyter Notebooks, который может выполнять изменения кода в фоновом режиме. Кроме того, оптимизирован параллельный вызов инструментов и взаимодействие в чате. (Источник: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: фреймворк с открытым исходным кодом для создания академических постеров из статей одним щелчком мыши: Исследователи из Университета Ватерлоо и других учреждений представили PosterAgent, инструмент на базе многоагентного фреймворка, который может одним щелчком мыши преобразовывать научные статьи (в формате PDF) в редактируемые академические постеры в формате PowerPoint (.pptx). Инструмент использует парсер для извлечения ключевого текста и визуального контента, планировщик для сопоставления контента и компоновки, а также отрисовщик-рецензент, отвечающий за окончательный рендеринг и обратную связь по компоновке. Одновременно команда создала оценочный бенчмарк Paper2Poster для измерения визуального качества, текстовой связности и эффективности передачи информации сгенерированных постеров. Эксперименты показали, что PosterAgent превосходит прямое использование универсальных больших моделей, таких как GPT-4o, как по качеству генерации, так и по экономической эффективности. (Источник: 量子位)

Выпущена серия моделей GRMR-V3, ориентированная на надежное исправление грамматики: Qingy2024 опубликовал на HuggingFace серию моделей GRMR-V3 (с параметрами от 1B до 4.3B), специально разработанных для обеспечения надежной функции исправления грамматики с целью исправления грамматических ошибок без изменения семантики исходного текста. Эти модели особенно подходят для проверки грамматики отдельных сообщений и поддерживают различные движки вывода, такие как llama.cpp, vLLM и другие. Разработчики подчеркивают, что для достижения наилучших результатов при использовании необходимо обращать внимание на рекомендуемые настройки сэмплера, указанные в карточке модели. (Источник: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: AI-фреймворк для редактирования аудио с возможностью замены контента: PlayDiffusion — это недавно выпущенный AI-фреймворк для редактирования аудио, способный заменять произвольный контент в аудиозаписях. Например, он может изменить исходную фразу в аудио “Вы поели?” на “Вы поели лука-порея?”, введя текст, причем переход будет естественным, без заметных следов. Появление этого фреймворка открывает новые возможности для детального редактирования и рекреации аудиоконтента. Проект опубликован с открытым исходным кодом на GitHub. (Источник: dotey)
Manus AI запускает функцию генерации видео, поддерживающую преобразование изображения в видео и текста в видео: Платформа AI Agent Manus добавила функцию генерации видео, позволяющую пользователям Basic, Plus и Pro генерировать видео на основе текстового или графического ввода. Тестирование показало, что эффект преобразования изображения в видео относительно лучше, сохраняя согласованность персонажей и стиля, в то время как эффект преобразования текста в видео более случаен, а качество неоднородно. В настоящее время видео по умолчанию генерируется фрагментами примерно по 5 секунд, для создания длинных видео требуется планирование процесса с помощью Agent. Эта функция, повышая разнообразие создания контента, также сталкивается с проблемами недостаточных возможностей редактирования видео и трудностями в замыкании творческого цикла. (Источник: 36氪)

Fish Audio открывает исходный код модели преобразования текста в речь OpenAudio S1 Mini: Fish Audio сделала общедоступной облегченную версию своей модели S1, занимающей первое место в рейтинге, под названием OpenAudio S1 Mini, предлагая передовую технологию преобразования текста в речь (TTS). Эта модель призвана обеспечить высококачественный синтез речи. Соответствующие репозитории GitHub и страницы моделей Hugging Face уже доступны для использования разработчиками и исследователями. (Источник: andrew_n_carr)
Представлен Bland TTS, призванный преодолеть “зловещую долину” в области голосового AI: Bland AI представила Bland TTS, голосовой AI, который, по заявлениям, первым преодолел “зловещую долину”. Технология основана на переносе стиля по одному образцу и может клонировать любой голос из короткого MP3-файла или смешивать стили (тон, ритм, произношение и т. д.) различных клонированных голосов. Bland TTS предназначен для предоставления творческим работникам реалистичных звуковых эффектов или AI-саундтреков с точным контролем эмоций и стиля, разработчикам — настраиваемого TTS API, а предприятиям — естественных голосов для AI-операторов службы поддержки. (Источник: imjaredz, nrehiew_, jonst0kes)
Платформа Voiceflow интегрирует модели Claude 4 и Gemini 2.5: Платформа для создания диалоговых AI-систем Voiceflow объявила, что пользователи теперь могут создавать AI-приложения с использованием моделей Anthropic Claude 4 и Google Gemini 2.5 непосредственно на платформе, без кода и без ожидания в очереди. Этот шаг направлен на предоставление разработчикам AI более мощной поддержки базовых моделей, упрощение процесса разработки и повышение возможностей приложений. (Источник: ReamBraden)
Xenova представляет диалоговую AI-модель, работающую локально в браузере в реальном времени: Xenova выпустила диалоговую AI-модель, которая на 100% работает локально в браузере в реальном времени. Эта модель обладает такими характеристиками, как защита конфиденциальности (данные не покидают устройство), полная бесплатность, отсутствие необходимости установки (доступ через веб-сайт) и ускорение вывода с помощью WebGPU. Это знаменует важный шаг вперед в удобстве и конфиденциальности диалогового AI на стороне клиента. (Источник: ben_burtenshaw)
📚 Обучение
DeepLearning.AI и Databricks сотрудничают в запуске короткого курса по DSPy: Andrew Ng объявил о сотрудничестве с Databricks для запуска короткого курса по фреймворку DSPy. DSPy — это фреймворк с открытым исходным кодом для автоматической настройки подсказок с целью оптимизации приложений GenAI. Курс научит использовать DSPy и MLflow, помогая учащимся создавать и оптимизировать агентные приложения (Agentic Apps). Omar Khattab, основной разработчик DSPy, также выразил поддержку этому начинанию, упомянув, что курс был разработан в ответ на многочисленные запросы пользователей. (Источник: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

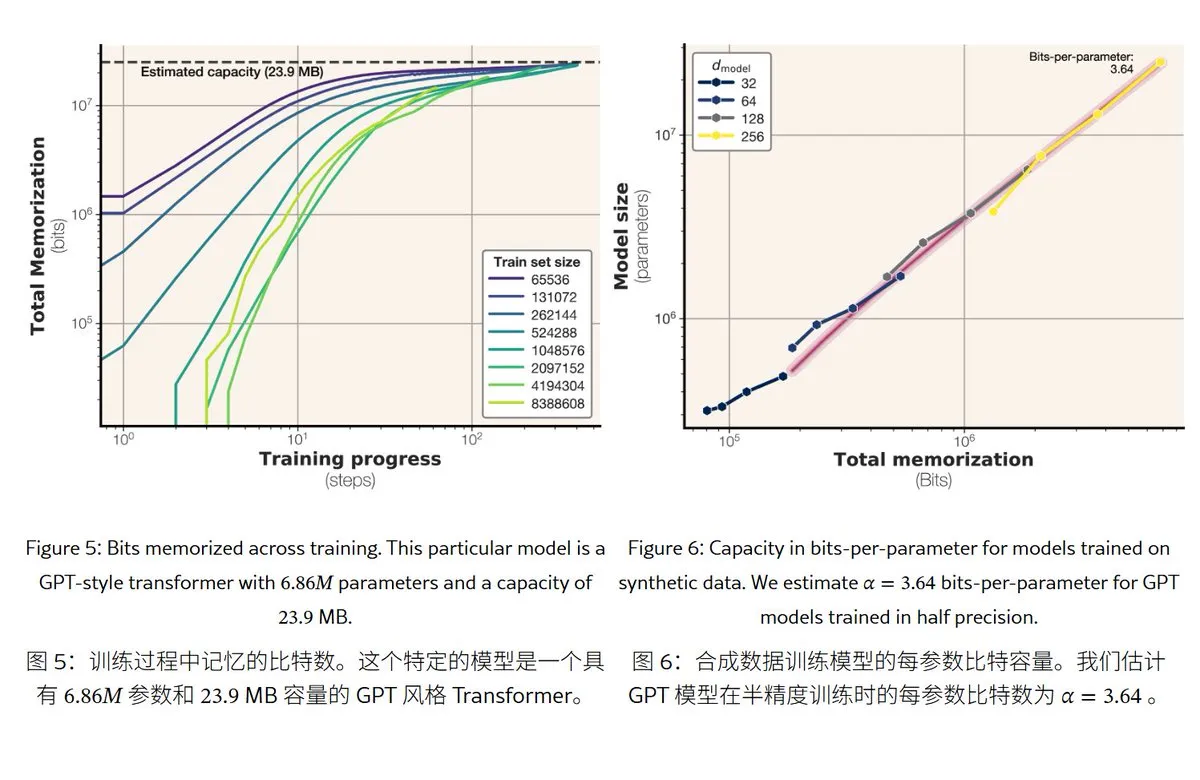
Новое исследование Meta раскрывает механизмы и объем памяти больших языковых моделей: Meta опубликовала статью, исследующую возможности памяти больших языковых моделей, разделяя “память” на истинное запоминание наизусть (непреднамеренная меморизация) и понимание закономерностей (генерализация). Исследование показало, что объем памяти моделей серии GPT составляет примерно 3,6 бита на параметр, например, модель с 1B параметров может “запомнить наизусть” около 450 МБ конкретного контента. Когда объем обучающих данных превышает емкость модели, модель переходит от “запоминания наизусть” к “пониманию закономерностей”, что объясняет явление “двойного спуска” (double descent). Это исследование предоставляет ориентиры для оценки рисков утечки конфиденциальности моделей и проектирования соотношения между объемом данных и размером модели. (Источник: karminski3)
Unsloth AI выпускает репозиторий с более чем 100 ноутбуками для fine-tuning: Unsloth AI открыла исходный код репозитория GitHub, содержащего более 100 ноутбуков для Fine-tuning. Эти ноутбуки предоставляют руководства и примеры для различных техник и моделей, таких как вызов инструментов, классификация, синтетические данные, BERT, TTS, визуальные LLM, GRPO, DPO, SFT, CPT и др., охватывая модели Llama, Qwen, Gemma, Phi, DeepSeek, а также этапы подготовки данных, оценки и сохранения. Этот шаг предоставляет сообществу богатые ресурсы для практики fine-tuning. (Источник: danielhanchen)
AI-модель Enoch реконструирует временную шкалу “Свитков Мертвого моря”, что может изменить историю написания Библии: Ученые, используя AI-модель Enoch в сочетании с радиоуглеродным датированием и анализом почерка, провели новое датирование “Свитков Мертвого моря”. Исследование показало, что многие свитки на самом деле старше, чем считалось ранее. Например, части “Книги Даниила” и “Книги Екклесиаста” могли быть написаны в III веке до н.э., даже раньше традиционно признаваемого времени авторства. Модель Enoch, анализируя характеристики почерка, предоставляет новый объективный количественный метод для изучения древних рукописей и может помочь раскрыть исторические загадки, такие как авторство Библии. (Источник: 36氪)

Статья исследует, когда большие языковые модели знают, что их оценивают: Исследование изучило, могут ли передовые большие языковые модели (LLM), столкнувшись с 1000 точками данных из 61 различного набора данных (половина из которых — оценочные наборы данных, а половина — сценарии реального развертывания), различать сценарии оценки и сценарии реального применения. Исследование показало, что способность LLM распознавать сценарии оценки близка к уровню основных авторов-людей, и они обычно могут определить цель оценки. Это открытие имеет важное значение для понимания поведения и способности LLM к обобщению. (Источник: paul_cal, menhguin)
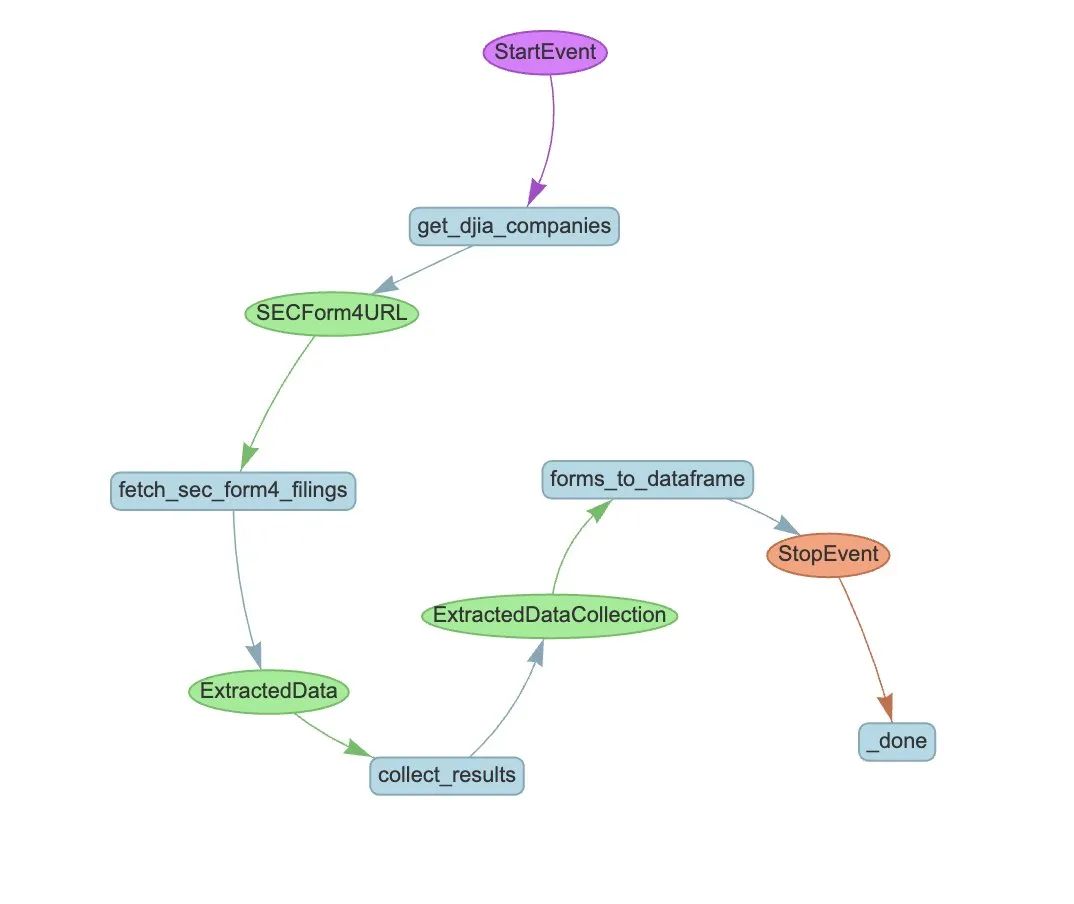
LlamaIndex представляет пример рабочего процесса Agent для автоматического извлечения данных из формы SEC Form 4: LlamaIndex продемонстрировал практический пример использования LlamaExtract и рабочего процесса Agent для автоматизации извлечения информации из формы SEC Form 4 (форма раскрытия информации о сделках с акциями инсайдерами публичных компаний) Комиссии по ценным бумагам и биржам США (SEC). В этом примере создан агент извлечения, способный извлекать структурированную информацию из файлов Form 4, и построен масштабируемый рабочий процесс для извлечения информации о сделках из файлов Form 4 компаний, входящих в промышленный индекс Доу-Джонса. Это предоставляет ориентир для использования AI в финансовой сфере для извлечения информации и автоматизации обработки. (Источник: jerryjliu0)
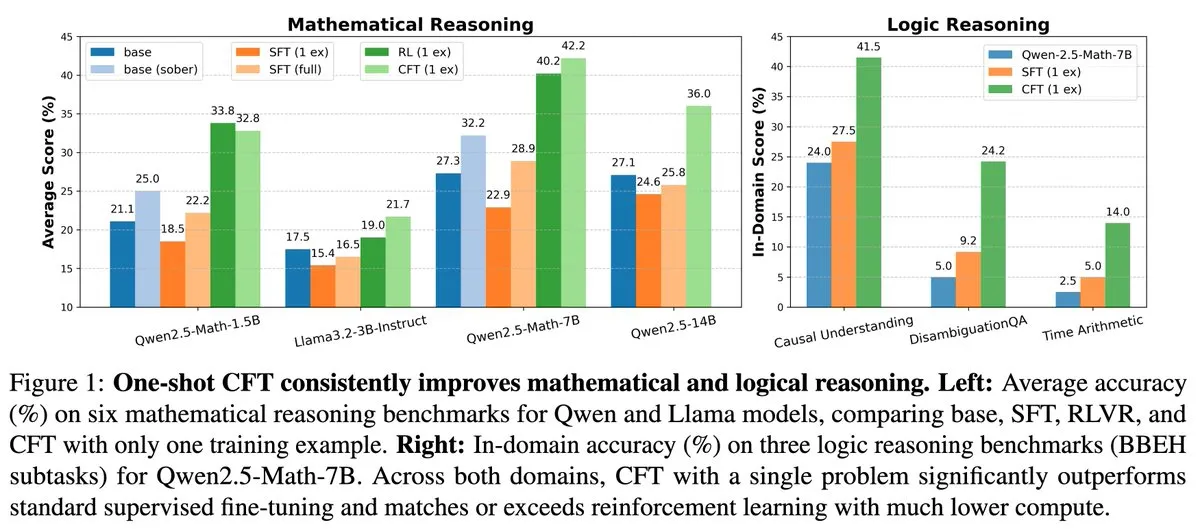
Новое исследование: контролируемое дообучение (SFT) по одной задаче может достичь эффекта обучения с подкреплением (RL) по одной задаче при снижении вычислительных затрат в 20 раз: Новая статья указывает, что контролируемое дообучение (SFT) по одной задаче может достичь такого же повышения производительности, как и обучение с подкреплением (RL) по одной задаче, при этом вычислительные затраты составляют всего 1/20 от затрат на RL. Это говорит о том, что для LLM, уже обладающих мощными способностями к рассуждению на этапе предварительного обучения, тщательно разработанное SFT (например, предложенное в статье Critique Fine-Tuning, CFT) может служить более эффективным способом раскрытия их потенциала, особенно в случаях, когда RL является дорогостоящим или нестабильным. (Источник: AndrewLampinen)
Статья предлагает Rex-Thinker: привязка к объектам через рассуждения по цепочке мыслей: Новая статья предлагает модель Rex-Thinker, которая формулирует задачу привязки к объектам (Object Referring) как явную задачу рассуждения по цепочке мыслей (CoT). Модель сначала идентифицирует все экземпляры-кандидаты, соответствующие классу упоминаемого объекта, затем для каждого экземпляра-кандидата выполняет пошаговое рассуждение, чтобы оценить, соответствует ли он данному выражению, и, наконец, делает предсказание. Для поддержки этой парадигмы исследователи создали крупномасштабный набор данных для привязки в стиле CoT HumanRef-CoT. Эксперименты показывают, что этот метод превосходит стандартные базовые модели по точности и интерпретируемости, а также лучше справляется со случаями отсутствия совпадающих объектов. (Источник: HuggingFace Daily Papers)
Статья предлагает TimeHC-RL: иерархическое когнитивное обучение с подкреплением с учетом времени для повышения социального интеллекта LLM: Для решения проблемы недостаточного когнитивного развития LLM в области социального интеллекта, новая статья предлагает фреймворк иерархического когнитивного обучения с подкреплением с учетом времени (TimeHC-RL). Этот фреймворк признает, что социальный мир следует уникальным временным линиям и требует слияния различных когнитивных моделей, таких как интуитивная реакция (система 1) и обдуманное мышление (система 2). Эксперименты показывают, что TimeHC-RL может эффективно повышать социальный интеллект LLM, позволяя моделям с 7B параметрами достигать производительности, сравнимой с передовыми моделями, такими как DeepSeek-R1 и OpenAI-O3. (Источник: HuggingFace Daily Papers)
Статья предлагает DLP: динамическое иерархическое прореживание в больших языковых моделях: Для решения проблемы серьезного снижения производительности унифицированных стратегий иерархического прореживания LLM при высокой степени разреженности, новая статья предлагает метод динамического иерархического прореживания (DLP). DLP, интегрируя информацию о весах модели и входных активациях, адаптивно определяет относительную важность каждого слоя и соответствующим образом распределяет коэффициент прореживания. Эксперименты показывают, что DLP может эффективно поддерживать производительность моделей, таких как LLaMA2-7B, при высокой степени разреженности и совместим с различными существующими технологиями сжатия LLM. (Источник: HuggingFace Daily Papers)
Статья представляет LayerFlow: унифицированную модель генерации видео с учетом слоев: LayerFlow — это унифицированное решение для генерации видео с учетом слоев. При наличии подсказок для каждого слоя LayerFlow может генерировать видео с прозрачным передним планом, чистым фоном и смешанными сценами. Он также поддерживает различные варианты, такие как разложение смешанного видео или генерация фона для заданного переднего плана. Эта модель организует видео разных слоев в субклипы и использует встраивание слоев для различения каждого клипа и соответствующих подсказок слоев, тем самым поддерживая вышеупомянутые функции в рамках единого фреймворка. Для решения проблемы нехватки высококачественных обучающих видео со слоями разработана многоэтапная стратегия обучения. (Источник: HuggingFace Daily Papers)
Статья предлагает Rectified Sparse Attention: исправленный механизм разреженного внимания: Для решения проблем рассогласования KV-кэша и снижения качества, вызванных методами разреженного декодирования при генерации длинных последовательностей, новая статья предлагает исправленное разреженное внимание (ReSA). ReSA сочетает блочное разреженное внимание с периодической плотной коррекцией, используя плотную прямую передачу через фиксированные интервалы для обновления KV-кэша, тем самым ограничивая накопление ошибок и поддерживая согласованность с предварительно обученным распределением. Эксперименты показывают, что ReSA достигает практически без потерь качества генерации и значительного повышения эффективности в задачах математического вывода, языкового моделирования и поиска, обеспечивая ускорение до 2,42 раз при декодировании последовательностей длиной 256K. (Источник: HuggingFace Daily Papers)
Статья представляет RefEdit: улучшенный бенчмарк и метод для моделей редактирования изображений на основе инструкций с референциальными выражениями: В связи с тем, что существующие модели редактирования изображений испытывают трудности с точным редактированием указанных объектов в сложных сценах с несколькими сущностями, новая статья сначала представляет RefEdit-Bench, реальный бенчмарк на основе RefCOCO. Затем предлагается модель RefEdit, которая обучается с помощью масштабируемого процесса генерации синтетических данных. RefEdit, обученный всего на 20 000 тройках редактирования, превосходит базовые модели на основе Flux/SD3, обученные на миллионах данных, в задачах с референциальными выражениями, а также достигает SOTA-результатов на традиционных бенчмарках. (Источник: HuggingFace Daily Papers)
Статья предлагает Critique-GRPO: использование естественного языка и числовой обратной связи для улучшения способностей LLM к рассуждению: В связи с тем, что обучение с подкреплением, основанное только на числовой обратной связи (например, скалярных вознаграждениях), сталкивается с узкими местами в производительности, ограниченной эффективностью саморефлексии и постоянными неудачами при улучшении сложных способностей LLM к рассуждению, новая статья предлагает фреймворк Critique-GRPO. Этот фреймворк, интегрируя критику (critiques) в форме естественного языка и числовую обратную связь, позволяет LLM одновременно учиться как на первоначальных ответах, так и на улучшениях, направляемых критикой, сохраняя при этом исследовательскую активность. Эксперименты показывают, что Critique-GRPO на Qwen2.5-7B-Base и Qwen3-8B-Base значительно превосходит различные базовые методы. (Источник: HuggingFace Daily Papers)
Статья представляет TalkingMachines: видео в стиле FaceTime в реальном времени, управляемое звуком, с помощью авторегрессионных диффузионных моделей: TalkingMachines — это эффективный фреймворк, который может преобразовывать предварительно обученные модели генерации видео в аниматоры персонажей, управляемые звуком в реальном времени. Этот фреймворк объединяет большие языковые модели аудио (LLM) с базовыми моделями генерации видео, обеспечивая естественный диалоговый опыт. Его основные вклады включают адаптацию предварительно обученной SOTA модели DiT для генерации видео из изображений в модель генерации виртуальных аватаров, управляемую звуком, достижение бесконечной генерации видеопотока без накопления ошибок с помощью асимметричной дистилляции знаний, а также разработку высокопроизводительного конвейера вывода с низкой задержкой. (Источник: HuggingFace Daily Papers)
Статья исследует измерение самопредпочтения в суждениях LLM: Исследования показывают, что LLM при использовании в качестве арбитров демонстрируют самопредпочтение, то есть склонны отдавать предпочтение ответам, сгенерированным ими самими. Существующие методы измеряют это смещение путем расчета разницы между оценками, которые модель-арбитр дает своим собственным ответам, и оценками, которые она дает ответам других моделей, но это смешивает самопредпочтение с качеством ответа. Новая статья предлагает использовать золотые стандарты суждений в качестве прокси для фактического качества ответа и вводит оценку DBG, которая измеряет смещение самопредпочтения как разницу между оценкой, которую модель-арбитр дает своему собственному ответу, и соответствующим золотым стандартом суждения, тем самым уменьшая влияние качества ответа на измерение смещения. (Источник: HuggingFace Daily Papers)
Статья предлагает LongBioBench: контролируемый фреймворк для тестирования языковых моделей с длинным контекстом: В связи с ограничениями существующих фреймворков оценки языковых моделей с длинным контекстом (LCLM) (сложность и подверженность загрязнению данных в реальных задачах, оторванность синтетических задач от реальных приложений), новая статья предлагает LongBioBench. Этот бенчмарк использует искусственно сгенерированные биографии в качестве контролируемой среды для оценки LCLM по параметрам понимания, рассуждения и достоверности. Эксперименты показывают, что большинство моделей все еще испытывают недостатки в понимании семантики длинного контекста и предварительном рассуждении, а достоверность снижается с увеличением длины контекста. LongBioBench призван обеспечить более реалистичную, контролируемую и интерпретируемую оценку LCLM. (Источник: HuggingFace Daily Papers)
Статья исследует переход от оптимизированного холодного старта к поэтапному обучению с подкреплением для улучшения мультимодального вывода: Вдохновленные выдающимися способностями Deepseek-R1 к рассуждению в сложных текстовых задачах, многие работы пытались стимулировать аналогичные способности у мультимодальных больших языковых моделей (MLLM) путем прямого применения обучения с подкреплением (RL), но все еще испытывают трудности с активацией сложного рассуждения. Новая статья углубленно исследует текущие процессы обучения и обнаруживает, что эффективная инициализация холодного старта имеет решающее значение для улучшения рассуждений MLLM, стандартный GRPO при применении к мультимодальному RL сталкивается с проблемой стагнации градиента, а обучение чисто текстовому RL после этапа мультимодального RL может дополнительно улучшить мультимодальное рассуждение. Основываясь на этих выводах, статья представляет ReVisual-R1, который достиг SOTA-результатов в нескольких бенчмарках. (Источник: HuggingFace Daily Papers)
Статья представляет SVGenius: бенчмарк для понимания, редактирования и генерации SVG: В связи с недостатками существующих бенчмарков для обработки SVG в плане охвата реальных ситуаций, иерархии сложности и парадигм оценки, новая статья представляет SVGenius. Это комплексный бенчмарк, содержащий 2377 запросов, охватывающих три аспекта: понимание, редактирование и генерацию. Он построен на основе реальных данных из 24 областей применения и имеет систематическую иерархию сложности. С помощью 8 категорий задач и 18 метрик были оценены 22 основные модели. Анализ показал, что производительность всех моделей систематически снижается с увеличением сложности, но обучение с усилением рассуждений эффективнее, чем простое масштабирование. (Источник: HuggingFace Daily Papers)
Статья предлагает Ψ-Sampler: выборку начальных частиц для согласования с вознаграждением при выводе моделей на основе оценок с использованием SMC: Для решения проблемы согласования с вознаграждением при выводе моделей генерации на основе оценок, новая статья представляет фреймворк Psi-Sampler. Этот фреймворк основан на последовательном методе Монте-Карло (SMC) и сочетает в себе метод выборки начальных частиц на основе pCNL. Существующие методы обычно инициализируют частицы из гауссовского априорного распределения, что затрудняет эффективный захват областей, связанных с вознаграждением. Psi-Sampler инициализирует частицы из апостериорного распределения, учитывающего вознаграждение, и вводит алгоритм предварительно обработанного метода Ланжевена Кранка-Николсона (pCNL) для эффективной апостериорной выборки, тем самым улучшая производительность согласования в таких задачах, как генерация изображений по макету, генерация с учетом количества и генерация с учетом эстетических предпочтений. (Источник: HuggingFace Daily Papers)
Статья предлагает MoCA-Video: фреймворк выравнивания концепций с учетом движения для согласованного редактирования видео: MoCA-Video — это фреймворк без обучения, предназначенный для применения техник семантического смешивания из области изображений к редактированию видео. При наличии сгенерированного видео и предоставленного пользователем эталонного изображения MoCA-Video может внедрять семантические признаки эталонного изображения в определенные объекты видео, сохраняя при этом исходное движение и визуальный контекст. Этот метод использует диагональное планирование шумоподавления и сегментацию, не зависящую от класса, для обнаружения и отслеживания объектов в латентном пространстве, а также точно контролирует пространственное положение смешиваемых объектов, обеспечивая временную согласованность за счет семантической коррекции на основе импульса и стабилизации остаточного шума гамма-распределения. (Источник: HuggingFace Daily Papers)
Статья исследует обучение языковых моделей генерации высококачественного кода с помощью обратной связи от анализа программ: Для решения проблемы, связанной с тем, что большие языковые модели (LLM) при генерации кода (“vibe coding”) с трудом обеспечивают его качество (особенно безопасность и поддерживаемость), новая статья предлагает фреймворк REAL. REAL — это фреймворк обучения с подкреплением, который использует обратную связь, управляемую анализом программ, для стимулирования LLM к генерации кода производственного качества. Эта обратная связь объединяет сигналы анализа программ, выявляющие дефекты безопасности или поддерживаемости, а также сигналы модульных тестов, обеспечивающие функциональную корректность. REAL не требует ручной разметки, обладает высокой масштабируемостью, и эксперименты доказывают его превосходство над SOTA-методами в плане функциональности и качества кода. (Источник: HuggingFace Daily Papers)
Статья предлагает GAIN-RL: эффективное обучение с подкреплением с использованием собственных сигналов модели: В связи с низкой эффективностью выборки в текущей парадигме дообучения больших языковых моделей с подкреплением (RFT) из-за унифицированной выборки данных, новая статья идентифицирует внутренний сигнал модели, названный “концентрацией угла” (angle concentration), который эффективно отражает способность LLM учиться на конкретных данных. Основываясь на этом открытии, статья предлагает фреймворк GAIN-RL, который динамически выбирает обучающие данные, используя внутренний сигнал концентрации угла модели, обеспечивая постоянную эффективность обновлений градиента и тем самым значительно повышая эффективность обучения. Эксперименты показывают, что GAIN-RL (GRPO) достигает более чем 2,5-кратного ускорения эффективности обучения в различных математических и кодировочных задачах и для моделей разного масштаба. (Источник: HuggingFace Daily Papers)
Статья предлагает SFO: оптимизация точности воспроизведения объекта при генерации, управляемой объектом в режиме нулевого выстрела, с помощью негативного наведения: Для повышения точности воспроизведения объекта при генерации, управляемой объектом в режиме нулевого выстрела (zero-shot subject-driven generation), новая статья предлагает фреймворк оптимизации точности воспроизведения объекта (SFO). SFO вводит синтетические негативные цели и путем попарного сравнения явно направляет модель предпочитать позитивные цели негативным. Для негативных целей статья предлагает метод условной деградационной негативной выборки (CDNS), который автоматически генерирует уникальные и информативные негативные образцы путем преднамеренного снижения визуальных и текстовых подсказок, не требуя дорогостоящей ручной разметки. Кроме того, перевзвешиваются временные шаги диффузии, чтобы сосредоточиться на промежуточных этапах, где появляются детали объекта. (Источник: HuggingFace Daily Papers)
Статья представляет ByteMorph: бенчмарк для редактирования изображений с нежестким движением под управлением инструкций: В связи с тем, что существующие методы и наборы данных для редактирования изображений в основном сосредоточены на статических сценах или жестких преобразованиях и с трудом справляются с инструкциями, включающими нежесткое движение, изменение ракурса камеры, деформацию объектов, движение суставов человека и сложные взаимодействия, новая статья представляет фреймворк ByteMorph. Этот фреймворк включает крупномасштабный набор данных ByteMorph-6M (более 6 миллионов пар отредактированных изображений высокого разрешения) и сильную базовую модель ByteMorpher на основе DiT. Набор данных создан с использованием генерации данных под управлением движения, техник иерархического синтеза и автоматической генерации подписей, что обеспечивает разнообразие, реалистичность и семантическую связность. (Источник: HuggingFace Daily Papers)
Статья предлагает Control-R: на пути к контролируемому расширению во время тестирования: Для решения проблем “недодумывания” и “передумывания” у больших моделей вывода (LRM) при рассуждениях по длинной цепочке мыслей (CoT), новая статья вводит поля управления рассуждениями (RCF). RCF — это метод времени тестирования, который направляет рассуждения с точки зрения древовидного поиска путем введения структурированных управляющих сигналов, позволяя модели корректировать усилия по рассуждению при решении сложных задач в соответствии с заданными условиями управления. Одновременно статья предлагает набор данных Control-R-4K, содержащий сложные задачи с подробными процессами рассуждений и соответствующими полями управления, а также предлагает метод условной дистилляционной донастройки (CDF) для обучения моделей эффективной корректировке усилий по рассуждению во время тестирования. (Источник: HuggingFace Daily Papers)
Обзорная статья по управлению доверием, рисками и безопасностью (TRiSM) в Agentic AI: Обзорная статья систематически анализирует управление доверием, рисками и безопасностью (TRiSM) в агентных многоагентных системах (AMAS) на базе больших языковых моделей (LLM). В статье сначала рассматриваются концептуальные основы Agentic AI, архитектурные различия и новые разработки систем, затем подробно излагаются четыре столпа TRiSM в рамках Agentic AI: управление, интерпретируемость, ModelOps и конфиденциальность/безопасность. Статья идентифицирует уникальные векторы угроз, предлагает комплексную классификацию рисков для приложений Agentic AI и рассматривает механизмы построения доверия, технологии прозрачности и надзора, стратегии интерпретируемости для распределенных систем LLM-агентов и т.д. (Источник: HuggingFace Daily Papers)
Статья исследует улучшение дистилляции знаний при неизвестном смещении ковариат с помощью аугментации данных, управляемой уверенностью: Для решения проблемы смещения ковариат, часто встречающейся при дистилляции знаний (ложные признаки, присутствующие во время обучения, но отсутствующие при тестировании), новая статья предлагает новую стратегию аугментации данных на основе диффузии. Когда эти ложные признаки неизвестны, но существует устойчивая модель-учитель, эта стратегия генерирует изображения путем максимизации расхождения между моделью-учителем и моделью-учеником, тем самым создавая сложные образцы, с которыми модель-ученик справляется с трудом. Эксперименты доказывают, что этот метод значительно повышает точность для наихудшей и средней групп при наличии смещения ковариат на таких наборах данных, как CelebA, SpuCo Birds и ложный ImageNet. (Источник: HuggingFace Daily Papers)
Статья представляет DiffDecompose: послойное разложение изображений с альфа-композитингом с помощью Diffusion Transformers: В связи с тем, что существующие методы разложения изображений с трудом справляются с распутыванием перекрывающихся полупрозрачных или прозрачных слоев, новая статья предлагает новую задачу: послойное разложение изображений с альфа-композитингом, целью которой является восстановление составляющих слоев из одного изображения с перекрытиями. Для решения таких проблем, как неоднозначность слоев, обобщаемость и нехватка данных, статья сначала представляет AlphaBlend, первый крупномасштабный высококачественный набор данных для разложения прозрачных и полупрозрачных слоев. На его основе предлагается DiffDecompose, фреймворк на базе Diffusion Transformer, который изучает апостериорное распределение разложения слоев путем контекстного разложения. (Источник: HuggingFace Daily Papers)
Статья предлагает SuperWriter: генерация длинных текстов с помощью больших языковых моделей, управляемых рефлексией: Для решения проблемы, связанной с тем, что большие языковые модели (LLM) при генерации длинных текстов с трудом поддерживают связность, логическую последовательность и качество текста, новая статья предлагает фреймворк SuperWriter-Agent. Этот фреймворк вводит в процесс генерации явные этапы структурированного планирования мышления и улучшения, направляя модель следовать более обдуманному и когнитивно обоснованному процессу. На основе этого фреймворка создан набор данных для контролируемого дообучения для обучения 7B-параметрической модели SuperWriter-LM, а также разработана процедура иерархической прямой оптимизации предпочтений (DPO), использующая поиск по дереву Монте-Карло (MCTS) для распространения окончательной оценки качества и соответствующей оптимизации каждого шага генерации. (Источник: HuggingFace Daily Papers)
Статья предлагает IEAP: рассмотрение редактирования изображений как программы на основе диффузионных моделей: В связи с проблемами, с которыми сталкиваются диффузионные модели при редактировании изображений по инструкциям, особенно при структурно несовместимых правках, включающих значительные изменения макета, новая статья представляет фреймворк IEAP (Image Editing As Programs). IEAP основан на архитектуре Diffusion Transformer (DiT) и обрабатывает сложные инструкции по редактированию, разлагая их на последовательность атомарных операций. Каждая операция реализуется с помощью легковесных адаптеров, использующих один и тот же основной DiT, и специализируется на определенном типе редактирования. Эти операции программируются агентом на основе визуально-языковой модели (VLM) и совместно поддерживают произвольные и структурно несовместимые преобразования. (Источник: HuggingFace Daily Papers)
Статья предлагает FlowPathAgent: детальная атрибуция блок-схем с помощью нейросимволического агента: Для решения проблемы, связанной с тем, что большие языковые модели (LLM) при интерпретации блок-схем часто генерируют галлюцинации и с трудом точно отслеживают пути принятия решений, новая статья вводит задачу детальной атрибуции блок-схем и предлагает FlowPathAgent. FlowPathAgent — это нейросимволический агент, который выполняет детальную апостериорную атрибуцию с помощью рассуждений на основе графов. Он сначала сегментирует блок-схему, преобразуя ее в структурированный символический граф, а затем использует агентный подход для динамического взаимодействия с графом с целью генерации путей атрибуции. Одновременно статья также предлагает FlowExplainBench, новый бенчмарк для оценки атрибуции блок-схем. (Источник: HuggingFace Daily Papers)
Статья предлагает Quantitative LLM Judges: количественные LLM-арбитры: LLM-as-a-judge — это фреймворк, в котором большая языковая модель (LLM) автоматически оценивает вывод другой LLM. Новая статья предлагает концепцию “количественных LLM-арбитров”, которые с помощью регрессионных моделей приводят оценочные баллы существующих LLM-арбитров в соответствие с человеческими оценками в конкретной области. Эти модели улучшают оценки исходного арбитра, используя его текстовые оценки и баллы. В статье демонстрируются четыре типа количественных арбитров для различных видов абсолютной и относительной обратной связи, что доказывает универсальность и многофункциональность фреймворка. Этот фреймворк более вычислительно эффективен, чем контролируемое дообучение, и может быть более статистически эффективным при ограниченной человеческой обратной связи. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Anthropic ограничивает прямой доступ AI-инструмента для программирования Windsurf к моделям Claude: CEO AI-инструмента для программирования Windsurf Varun Mohan публично заявил, что Anthropic в очень короткие сроки (менее пяти дней) значительно сократила квоты на API-сервисы для моделей серии Claude 3.x, включая Claude 3.5 Sonnet, 3.7 Sonnet и др., для Windsurf. Этот шаг произошел на фоне сообщений о том, что OpenAI собирается приобрести Windsurf, что вызвало на рынке опасения по поводу усиления конкуренции между гигантами AI и нейтральности платформ AI-инструментов для программирования. Windsurf был вынужден срочно задействовать сторонние сервисы вывода и скорректировать свою политику предоставления моделей пользователям, в то время как Anthropic ответила, что приоритет в предоставлении ресурсов отдается партнерам, способным обеспечить долгосрочное сотрудничество. (Источник: 36氪, 36氪, mervenoyann, swyx)
Число платных корпоративных пользователей OpenAI превысило 3 миллиона, компания вводит гибкую ценовую политику: OpenAI объявила, что число ее платных корпоративных пользователей достигло 3 миллионов, что на 50% больше по сравнению с 2 миллионами, объявленными в феврале этого года. Это число охватывает три линейки продуктов: ChatGPT Enterprise, Team и Edu. Одновременно OpenAI вводит для корпоративных клиентов гибкую ценовую политику на основе “общего кредитного пула”. После покупки кредитного пула предприятием использование расширенных функций будет расходовать кредиты, но при этом сохранится “неограниченный доступ” к основным моделям и функциям. Новая ценовая политика сначала будет внедрена в ChatGPT Enterprise, а затем распространена на ChatGPT Team, который также предлагает пробную скидку на первый месяц: 5 аккаунтов за 1 доллар. (Источник: 36氪, snsf)
Китайская девушка “поколения Z” Hong Letong основала AI-математическую компанию Axiom с целевой оценкой в 300 миллионов долларов: Доктор математики из Стэнфорда, китаянка Hong Letong (Carina Letong Hong), основала AI-компанию Axiom, специализирующуюся на разработке AI-моделей для решения практических математических задач. Целевыми клиентами являются хедж-фонды и компании, занимающиеся количественной торговлей. Axiom планирует использовать данные формальных математических доказательств для обучения моделей, чтобы они овладели строгими логическими рассуждениями и способностями к доказательству. Несмотря на то, что у компании пока нет продукта, она уже ведет переговоры о привлечении финансирования в размере 50 миллионов долларов, при этом оценка компании ожидается на уровне 300-500 миллионов долларов. Hong Letong имеет степень бакалавра по математике и физике Массачусетского технологического института и докторскую степень по математике Стэнфордского университета, а также была стипендиатом Родса. (Источник: 量子位)

🌟 Сообщество
Горячие темы на конференции AI.Engineer: наблюдаемость агентов, высокая эффективность малых команд, AI PM в центре внимания: На всемирной выставке AI.Engineer участники активно обсуждали наблюдаемость и оценку AI-агентов (Agent), создание небольших высокоэффективных команд (Tiny Teams), а также лучшие практики управления продуктами AI (AI PM). Голосовое взаимодействие было признано самым популярным направлением в мультимодальности, а безопасность впервые стала важной темой. Anthropic на конференции обратилась с запросом на стартапы в области MCP (протокола контекста модели), выразив надежду увидеть больше MCP-серверов помимо инструментов для разработчиков, упрощенные решения для создания серверов и инновации в области безопасности AI-приложений (например, защита от отравления инструментов). (Источник: swyx, swyx, swyx, swyx)

Обсуждение того, приведет ли AI к исчезновению естественного языка и оглуплению человечества: В социальных сетях появились опасения, что широкое применение AI может привести к сокращению общения на естественном языке (теория “мертвого интернета”) и деградации когнитивных способностей человека (таких как глубокое мышление, способность сомневаться и реконструировать). Некоторые пользователи считают, что чрезмерная зависимость от AI для получения информации и ответов может уменьшить активный отбор, оценку и независимое мышление, формируя зависимость от “когнитивного аутсорсинга”. Другие считают, что AI может справиться с “что” и “как”, но “почему” по-прежнему должно решать человечество, и ключевым моментом является поиск роли человека в сосуществовании с технологиями и сохранение права на суждение. (Источник: Reddit r/ArtificialInteligence, 36氪)
OpenAI по решению суда обязана сохранять все логи ChatGPT и API, что вызывает опасения по поводу конфиденциальности: Судебное постановление обязывает OpenAI сохранять все записи чатов ChatGPT и логи запросов API, включая те “временные чаты”, которые должны были быть удалены. Этот шаг вызвал у пользователей опасения по поводу конфиденциальности данных и соблюдения OpenAI политики хранения данных. Некоторые комментаторы считают, что это еще раз подчеркивает важность использования локальных моделей и владения собственными технологиями и данными. (Источник: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agent сталкиваются с проблемами доверия и безопасности, уязвимы для фишинговых атак: Обсуждения указывают на то, что, несмотря на растущие возможности AI Agent, их механизмы доверия могут быть использованы злоумышленниками. Например, Agent может быть обманут и перейти по вредоносной ссылке из-за доверия к известным веб-сайтам (например, социальным сетям), что приведет к утечке конфиденциальной информации или выполнению вредоносных действий. Это требует усиления способности Agent распознавать вредоносный контент и ссылки и противостоять им при проектировании, обеспечивая их безопасность при выполнении операций в реальном мире. (Источник: DeepLearning.AI Blog)
Размышления, вызванные инструментами AI-программирования: от модернизации кода до изменения рабочих процессов: Сообщество обсуждает применение AI в разработке программного обеспечения, особенно в обработке устаревшего кода и изменении рабочих процессов программирования. Morgan Stanley использовал собственный AI-инструмент DevGen.AI для анализа и рефакторинга миллионов строк старого кода, что значительно сэкономило время разработки. В то же время, точка зрения Andrej Karpathy о перспективах приложений со сложным UI также вызвала размышления о том, как в будущем следует проектировать программное обеспечение для лучшего взаимодействия с AI, подчеркивая важность скриптовых и API-интерфейсов. Эти обсуждения отражают глубокое влияние AI на практику и философию программной инженерии. (Источник: mitchellh, 36氪, 36氪)
💡 Прочее
AI помогает в ремонте бытовой техники, ChatGPT стал “Friendo”: Пользователь поделился опытом успешной диагностики и предварительного ремонта неисправной посудомоечной машины с помощью ChatGPT (по прозвищу Friendo). Путем диалога с AI, описания кодов ошибок, фотографирования панели управления, AI помог пользователю определить неисправность нагревательного элемента и дал указания, как временно обойти этот элемент, чтобы частично восстановить работоспособность посудомоечной машины. Это демонстрирует потенциал LLM в решении бытовых проблем и оказании технической поддержки. (Источник: Reddit r/ChatGPT)
AI-сгенерированное видео интервью с персонажами 1500-х годов привлекло внимание: AI-сгенерированное видео, имитирующее интервью с людьми из 1500-х годов, получило высокую оценку в сообществе за свою креативность и юмор. Образы персонажей и содержание диалогов в видео остроумно отражают условия жизни того времени, например: “Проснулся, наступил в навоз, потом обложили налогом, и это еще до завтрака”. Подобные приложения демонстрируют развлекательный потенциал AI в создании контента и воссоздании исторических сцен. (Источник: draecomino, Reddit r/ChatGPT)

Стипендия Thiel фокусируется на инновациях в AI, охватывая цифровых людей, эмоции роботов и AI-прогнозирование: Опубликован новый список стипендиатов “Thiel Fellowship”, среди которых несколько AI-проектов привлекли особое внимание. Canopy Labs работает над созданием AI-цифровых людей, неотличимых от настоящих, способных к многорежимному взаимодействию в реальном времени. Проект Intempus направлен на наделение роботов способностью выражать эмоции, подобные человеческим, для улучшения взаимодействия человека и машины. Aeolus Lab фокусируется на использовании технологий AI для прогнозирования погоды и стихийных бедствий, и даже исследует возможность активного вмешательства. Эти проекты демонстрируют направления исследований молодых предпринимателей на переднем крае AI. (Источник: 36氪)