
Ключевые слова:Отчет о тенденциях в области ИИ, Агент ИИ, Обучение с подкреплением, Визуальная языковая модель, Коммерциализация ИИ, Галлюцинации ИИ, Безопасность ИИ, Отчет ‘Королевы интернета’ об ИИ, Принципы безопасности ИИ LawZero, Механизмы внимания GTA и GLA, Роботизированная модель SmolVLA, Мошенничество с потоковым аудио ИИ
🔥 В фокусе
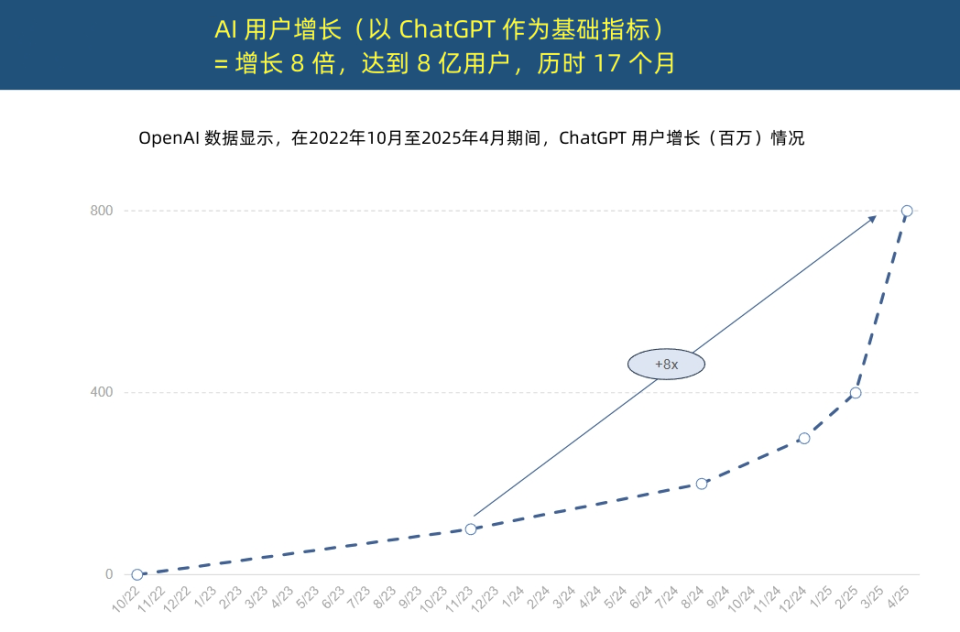
“Королева интернета” опубликовала отчет о тенденциях в области AI, раскрывающий беспрецедентное ускорение внедрения AI и изменения в структуре затрат: “Королева интернета” Мэри Микер опубликовала 340-страничный «Отчет о тенденциях в AI», в котором подчеркивается, что AI внедряется с беспрецедентной скоростью. В отчете отмечается, что число пользователей ChatGPT стремительно растет: за 17 месяцев ежемесячная активная аудитория достигла 800 миллионов человек, а годовой доход приблизился к 4 миллиардам долларов США, что значительно превосходит показатели любой технологии в истории. Капиталовложения технологических гигантов в инфраструктуру AI резко возросли, достигнув в 2024 году 212 миллиардов долларов США. В то же время стоимость обучения моделей AI за 8 лет выросла в 2400 раз, при этом стоимость обучения одной модели может достигать 1 миллиарда долларов США, однако стоимость инференса резко снижается благодаря аппаратному обеспечению (например, энергоэффективность Nvidia GPU выросла в 100 000 раз) и оптимизации алгоритмов. Производительность моделей с открытым исходным кодом (таких как DeepSeek, Qwen) приближается к производительности закрытых моделей, спрос на специалистов в области AI вырос на 448%, а AI Agent становятся новой цифровой рабочей силой. (Источник: APPSO, Tencent Technology)
Лауреат премии Тьюринга Йошуа Бенджио запустил LawZero, выступая за AI с «безопасностью по замыслу»: Лауреат премии Тьюринга Йошуа Бенджио объявил о создании некоммерческой организации LawZero, целью которой является разработка искусственного интеллекта с «безопасностью по замыслу» (design safety) для противодействия возможному обману и самозащитному поведению со стороны систем AI. LawZero вдохновлен третьим законом робототехники Азимова и подчеркивает, что AI должен защищать счастье и усилия людей. Организация разрабатывает систему Scientist AI в качестве «защитного ограждения» для AI Agent, которая помогает путем понимания мира, а не прямых действий, и оценивает риски поведения других AI. Бенджио считает текущее направление Agentic AI ошибочным, так как оно может выйти из-под контроля и привести к необратимым катастрофическим последствиям, подчеркивая, что безопасный AI-ограждение должен быть как минимум таким же умным, как AI Agent, которых он пытается контролировать. (Источник: Академические Заголовки, Yoshua_Bengio)

Год AI Agent: от вспомогательных инструментов к исполнителям задач, переформатирование бизнес-моделей: Вице-президент по исследованиям Gartner Сунь Чжиюн отметил, что 2025 год станет «первым годом интеллектуальных агентов на базе больших моделей» и «первым годом монетизации генеративного AI», а интеллектуальные агенты AI становятся основным каналом использования возможностей LLM. Принципиальное отличие интеллектуальных агентов от чат-ботов заключается в переходе от предоставления информационной поддержки к непосредственному выполнению задач. Например, интеллектуальный агент может выполнить весь процесс заказа кофе, а не просто предоставить информацию о кофейнях. Gartner прогнозирует, что к 2028 году 20% взаимодействий с цифровыми интерфейсами будут осуществляться AI Agent, 15% повседневных бизнес-решений смогут приниматься AI Agent автономно, а треть корпоративного программного обеспечения будет интегрирована с AI Agent. Интеллектуальный помощник BYD и другие уже нашли первоначальное применение, и в будущем способы взаимодействия с мобильными приложениями могут измениться. (Источник: IT Times)
Ключевой автор Mamba предложил механизмы внимания GTA и GLA, ориентированные на инференс, для оптимизации обработки длинных контекстов: Три Дао, один из ключевых авторов Mamba, и его команда из Принстона предложили два новых механизма внимания: Grouped-Tied Attention (GTA) и Grouped-Latent Attention (GLA), специально разработанные для повышения эффективности инференса больших моделей при работе с длинными контекстами. GTA, благодаря связыванию параметров и групповому повторному использованию кэша ключ-значение (KV), позволяет сократить использование KV-кэша примерно на 50% по сравнению с GQA, сохраняя при этом сопоставимое качество модели. GLA использует двухуровневую структуру, вводя латентные токены в качестве сжатого представления глобального контекста, и сочетается с механизмом группировки голов внимания. По сравнению с MLA, используемым в DeepSeek, GLA может ускорить декодирование длинных последовательностей (например, 64K) в 2 раза и повысить способность обработки параллельных запросов. Эти новые механизмы направлены на решение проблем узких мест доступа к памяти и ограничений параллелизма во время инференса. (Источник: QbitAI)

🎯 Движение
DeepMind выпустил SmolVLA: эффективную модель визуально-языкового действия для робототехники на основе данных сообщества: Hugging Face в сотрудничестве с DeepMind и другими учреждениями представили SmolVLA, модель визуально-языкового действия (VLA) с открытым исходным кодом и 450 млн параметров, специально разработанную для роботов и способную работать на потребительском оборудовании. Модель была предварительно обучена исключительно на наборах данных с открытым исходным кодом, предоставленных сообществом LeRobot, и превзошла более крупные модели VLA и базовые модели, такие как ACT, в задачах LIBERO, Meta-World и реальных задачах (SO100, SO101). SmolVLA поддерживает асинхронный инференс, что позволяет увеличить скорость отклика на 30% и пропускную способность задач в 2 раза. Ее архитектура сочетает Transformer с декодером на основе потокового согласования (flow matching) и оптимизирована по скорости и эффективности за счет уменьшения количества визуальных токенов, использования признаков промежуточного слоя VLM и механизма чередующегося внимания. (Источник: HuggingFace Blog, clefourrier)

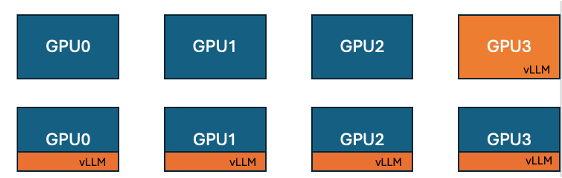
Hugging Face и IBM представили функцию совместного размещения vLLM в TRL для повышения эффективности обучения на GPU: Hugging Face в сотрудничестве с IBM внедрили в библиотеку TRL функцию совместного размещения vLLM (co-located vLLM) для алгоритмов онлайн-обучения, таких как GRPO. Эта функция позволяет обучению и инференсу (генерации) выполняться на одном и том же GPU, совместно используя ресурсы и выполняясь поочередно, что устраняет проблему простоя GPU во время обучения, характерную для предыдущего серверного режима vLLM. Благодаря встраиванию vLLM в ту же распределенную группу процессов, отпадает необходимость в HTTP-связи, обеспечивается совместимость с torchrun, TP и DP, упрощается развертывание и повышается пропускная способность. Эксперименты показали, что для моделей 1.5B и 7B режим совместного размещения обеспечивает ускорение от 1.43 до 1.73 раз; для крупных моделей, таких как Qwen2.5-Math-72B, сочетание API sleep() vLLM и оптимизации DeepSpeed ZeRO Stage 3 позволяет достичь ускорения обучения примерно в 1.26 раза даже при использовании меньшего количества GPU, не влияя на точность модели. (Источник: HuggingFace Blog)
Nvidia выпустила модель Nemotron-Research-Reasoning-Qwen-1.5B, специализирующуюся на сложных рассуждениях: Nvidia представила Nemotron-Research-Reasoning-Qwen-1.5B, модель с открытыми весами и 1.5 млрд параметров, ориентированную на сложные задачи рассуждения, такие как математические задачи, проблемы программирования, научные вопросы и логические головоломки. Модель обучена с использованием алгоритма ProRL (Prolonged Reinforcement Learning) на разнообразных наборах данных с целью достижения более глубокого исследования стратегий рассуждения. Официально заявлено, что она значительно превосходит модель DeepSeek 1.5B в задачах по математике, кодированию и GPQA. ProRL основан на GRPO и включает такие методы, как смягчение коллапса энтропии, раздельное отсечение (decoupled clipping) и оптимизация стратегии динамической выборки (DAPO), а также KL-регуляризацию и сброс референсной стратегии. Модель предназначена только для исследовательских и разработочных целей. (Источник: Reddit r/LocalLLaMA, Hugging Face)

Arcee выпустила модель Homunculus-12B, созданную путем дистилляции Qwen3-235B на основе Mistral-Nemo: Arcee AI выпустила Homunculus-12B, инструктивную модель с 12 миллиардами параметров. Эта модель была создана путем дистилляции возможностей Qwen3-235B в архитектуру Mistral-Nemo. В настоящее время модель и ее GGUF-версия доступны на Hugging Face. Это представляет собой попытку переноса мощных возможностей крупных моделей на более мелкие и эффективные модели с помощью технологии дистилляции моделей, с целью сбалансировать производительность и потребление ресурсов. (Источник: Reddit r/LocalLLaMA, Hugging Face)

Приложение Microsoft Bing интегрировало бесплатный инструмент для генерации видео Sora: Microsoft добавила в свое мобильное приложение Bing бесплатную функцию генерации видео OpenAI Sora. Пользователи могут генерировать короткие видеофрагменты с помощью текстовых подсказок без необходимости подписки или оплаты. В настоящее время функция поддерживает генерацию 5-секундных вертикальных видео 9:16, в будущем планируется поддержка горизонтального формата 16:9. Бесплатным пользователям предоставляется 10 кредитов на быструю генерацию, после чего их можно обменять на баллы Microsoft или выбрать стандартную скорость генерации. Этот шаг направлен на снижение барьера для создания видео с помощью AI, позволяя большему количеству пользователей ознакомиться с технологией преобразования текста в видео. (Источник: Reddit r/ArtificialInteligence, dotey)

Hugging Face представил SmolVLA, модель визуально-языкового действия, созданную для экономически эффективной робототехники: Hugging Face представил SmolVLA, модель визуально-языкового действия (VLA) с открытым исходным кодом и 450 млн параметров, предназначенную для предоставления экономически эффективных решений в области робототехники. Модель обучена с использованием всех наборов данных с открытым исходным кодом сообщества LeRobotHF, достигая лучшей в своем классе производительности и скорости инференса. Выпуск SmolVLA направлен на снижение барьера для исследований и разработок в области робототехники, способствуя более широкому участию сообщества и инновациям. (Источник: huggingface, AK)

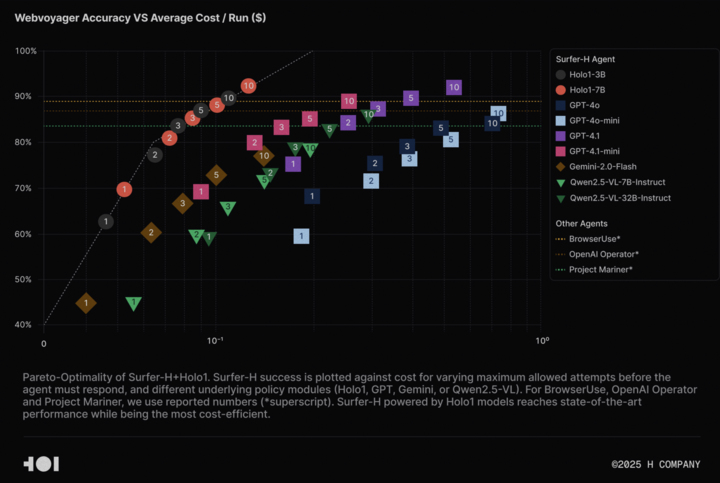
H Company открыла исходный код визуально-языковой модели Holo-1 и набора данных WebClick для содействия исследованиям в области Agentic AI: H Company объявила об открытии исходного кода своих визуально-языковых моделей Holo-1 (версии с 3B и 7B параметрами), а также набора данных WebClick, с целью ускорения исследований в области Agentic AI. Модель Holo-1 специально разработана для задач взаимодействия с GUI и навигации в вебе, и уже достигла результата SOTA (State-of-the-Art) в 92.2% на бенчмарке WebVoyager, превосходя по экономической эффективности такие крупные модели, как GPT-4.1. Веса моделей и наборы данных опубликованы на платформе Hugging Face под лицензией Apache 2.0. Holo-1 также интегрирована в MLX, что облегчает разработчикам запуск на устройствах Apple Silicon. (Источник: huggingface, tonywu_71)
PlayAI открыла исходный код первой голосовой диффузионной LLM PlayDiffusion, поддерживающей точное редактирование и клонирование без предварительного обучения: PlayAI выпустила и открыла исходный код PlayDiffusion, первой диффузионной LLM (diffusion-LLM) для голоса. Эта модель специально разработана для точного редактирования голоса AI (например, исправление, замена контента) и клонирования голоса без предварительного обучения (zero-shot). В отличие от авторегрессионных моделей, которым обычно требуется 800-1000 токенов для генерации аудио, PlayDiffusion генерирует аудио всего за 20-30 токенов, что значительно повышает эффективность. Исходный код модели доступен на GitHub, демонстрация развернута на Hugging Face Spaces, а также модель доступна через платформу Fal.ai. (Источник: _akhaliq)
Google незаметно выпустил приложение AI Edge Gallery, поддерживающее офлайн-запуск моделей AI на устройствах Android: Google выпустил экспериментальное альфа-приложение под названием Google AI Edge Gallery, которое позволяет пользователям загружать и запускать в офлайн-режиме общедоступные модели AI с Hugging Face на устройствах Android. Приложение поддерживает такие функции, как ответы на вопросы по изображениям, суммирование и переписывание текста, генерация кода, AI-чат, а также предоставляет информацию о производительности (например, TTFT, скорость декодирования). Локальный запуск моделей AI может повысить скорость отклика, защитить конфиденциальность пользователей и не требует подключения к сети. Однако отзывы пользователей неоднозначны: некоторые столкнулись с проблемами сбоев на устройствах Pixel и других, особенно при переключении на GPU-инференс или обработке больших моделей. Некоторые комментаторы считают, что его функциональность схожа с существующими приложениями (например, PocketPal) или отстает от фреймворков, таких как Apple CoreML, но есть и мнения, указывающие на кроссплатформенные преимущества его основы MediaPipe. (Источник: 36kr)

Microsoft RenderFormer появился на Hugging Face, специализируясь на нейронном рендеринге треугольных сеток с глобальным освещением: Microsoft опубликовала на Hugging Face RenderFormer, нейронную модель рендеринга на основе Transformer, специально предназначенную для обработки рендеринга треугольных сеток с эффектами глобального освещения. Подобные исследовательские работы имеют важное значение для объединения традиционных конвейеров рендеринга с нейронными методами, и их дальнейшее развитие может включать расширение на более крупные сцены и выход за рамки простого воспроизведения трассировки путей. (Источник: _akhaliq)

BAAI выпустила модель понимания длинных видео Video-XL-2, поддерживающую обработку десятков тысяч кадров на одном GPU: Пекинский институт искусственного интеллекта (BAAI) в сотрудничестве с Шанхайским университетом Цзяо Тун представил Video-XL-2, модель, специально разработанную для понимания длинных видео. Модель распространяется под лицензией Apache 2.0 и способна обрабатывать более 10 000 кадров видеоконтента на одном GPU, а также кодировать 2048 кадров за 12 секунд. Ключевые технологии включают эффективное предварительное заполнение на основе блоков (Chunk-based Prefilling) и двухгранулярное декодирование KV (Bi-granularity KV decoding), направленные на повышение эффективности и возможностей обработки длинных видео. Модель доступна на Hugging Face. (Источник: huggingface)
Модель UniWorld выпущена на Hugging Face, нацеленная на унификацию визуального понимания и генерации: Модель UniWorld была запущена на платформе Hugging Face. Эта модель позиционируется как семантический кодировщик высокого разрешения, предназначенный для достижения унифицированных возможностей визуального понимания и генерации. Это указывает на то, что исследователи стремятся создать единую модельную структуру, способную одновременно обрабатывать ввод визуальной информации (понимание) и вывод визуального контента (генерация), с целью достижения более всестороннего прогресса в области мультимодального AI. (Источник: _akhaliq)
DeepSeek выпустил мультимодальную модель Muddit-1B, использующую унифицированный дискретный диффузионный Transformer: DeepSeek выпустил модель Muddit-1B, мультимодальную модель, ориентированную на зрение, которая использует унифицированную архитектуру дискретного диффузионного Transformer, подобную MaskGIT, и оснащена легковесным текстовым декодером. Интересной особенностью этой модели является ее направление развития, противоположное обычному: она начинает с генерации текста в изображение, а затем расширяется до генерации изображения в текст, что может использовать различные априорные базы знаний. Muddit нацелен на достижение быстрой параллельной генерации изображений и текста с помощью унифицированного метода генерации и является частью серии моделей Meissonic, пытающейся отойти от дизайна, ориентированного на язык, и достичь более эффективной унифицированной генерации. (Источник: teortaxesTex)
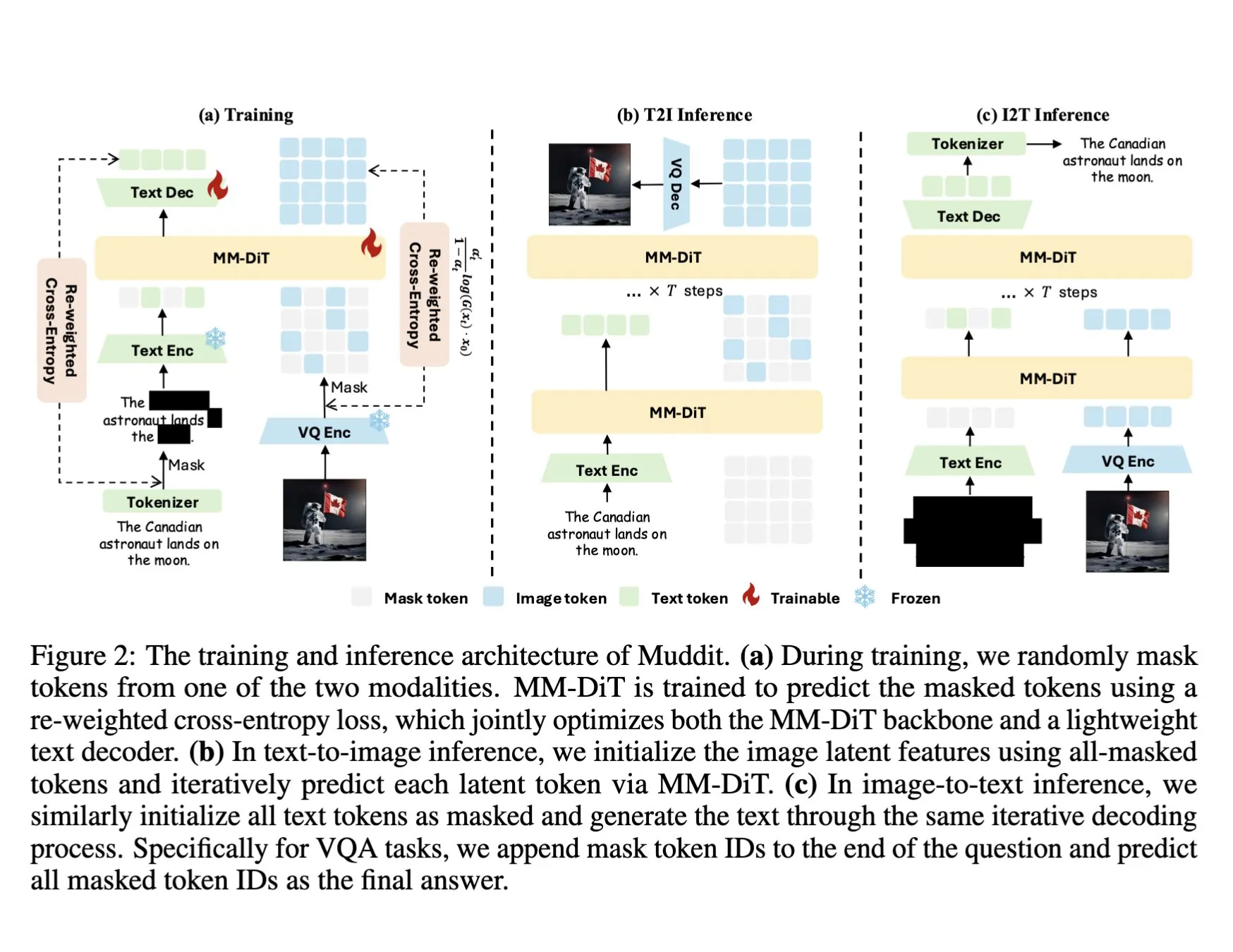
Модель визуального поиска документов ColQwen2 интегрирована в Hugging Face Transformers: Новейшая модель визуального поиска документов ColQwen2 была добавлена в основную библиотеку Hugging Face Transformers. Теперь пользователи могут использовать ColQwen2 для поиска PDF или в процессах RAG (Retrieval Augmented Generation) для улучшения возможностей обработки визуально насыщенных документов. Модель предназначена для лучшего понимания и извлечения содержимого документов, содержащих текстовую и графическую информацию. (Источник: mervenoyann)
🧰 Инструменты
FLUX Kontext интегрирован в Adobe Firefly Boards, поддерживает редактирование фотографий текстом и реставрацию: Adobe интегрировала модель FLUX Kontext в свой инструмент Firefly Boards, позволяя пользователям редактировать фотографии с помощью текстовых команд, что особенно полезно для таких сценариев, как реставрация старых фотографий. Firefly Boards теперь доступен всем пользователям. Этот шаг направлен на использование технологий редактирования изображений AI, чтобы пользователи могли более удобно реализовывать творческое редактирование и улучшение изображений. (Источник: robrombach)
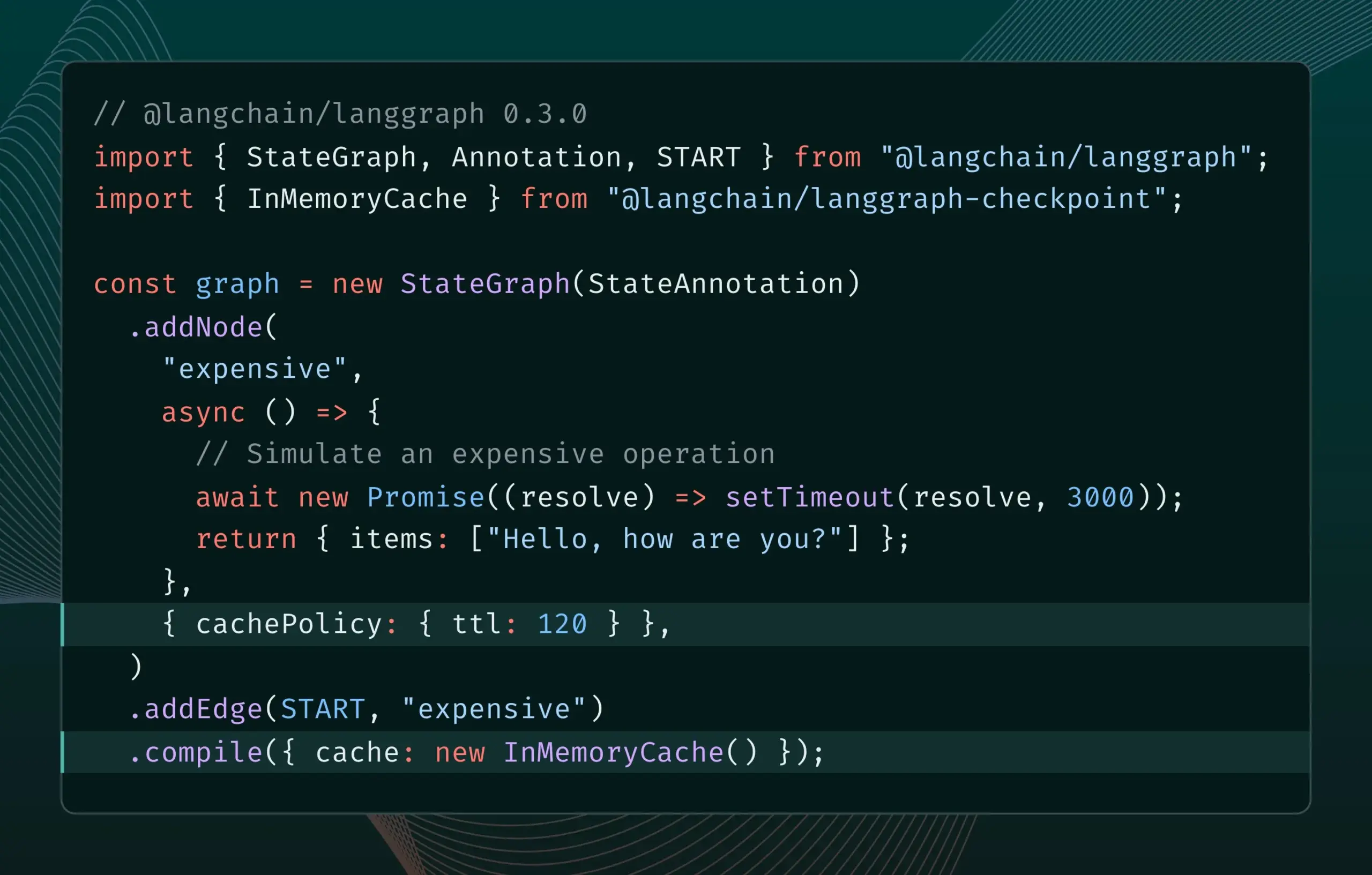
В LangGraph.js версии 0.3 добавлена функция кэширования узлов, повышающая эффективность итераций: В LangGraph.js версии 0.3 добавлена функция кэширования узлов/задач, позволяющая разработчикам при локальной итерации дорогостоящих или длительных AI Agent избегать повторных вычислений, тем самым ускоряя рабочий процесс. Эта функция поддерживает как Graph API, так и Imperative API, и направлена на повышение эффективности и удобства разработки AI-приложений. (Источник: LangChainAI, hwchase17)
Обновление Ollama упрощает локальный запуск «мыслящих моделей»: Ollama выпустила новую версию, которая упрощает пользователям локальный запуск «мыслящих моделей» (вероятно, имеются в виду LLM со сложными возможностями рассуждения). Это обновление направлено на снижение барьера для локального развертывания и использования продвинутых моделей AI, позволяя большему числу пользователей и разработчиков опробовать и использовать эти модели на своих устройствах. (Источник: ollama)
PipesHub: выпущена корпоративная RAG-платформа с открытым исходным кодом: PipesHub, полностью открытая корпоративная поисковая платформа (RAG-платформа), официально выпущена. Она позволяет пользователям создавать настраиваемые, масштабируемые интеллектуальные поисковые и Agentic-приложения, поддерживает подключение к Google Workspace, Slack, Notion и другим инструментам, а также может использовать внутренние знания компании для обучения. PipesHub поддерживает локальный запуск и использование любых моделей AI, включая Ollama, и нацелена на помощь предприятиям в эффективном использовании собственных данных и моделей. (Источник: Reddit r/LocalLLaMA)
JigsawStack выпустил фреймворк для глубоких исследований с открытым исходным кодом, поддерживающий генерацию высококачественных отчетов: JigsawStack выпустил фреймворк для глубоких исследований с открытым исходным кодом, построенный на базе AI SDK и обладающий полной настраиваемостью. Он способен генерировать высококачественные исследовательские отчеты, используя встроенные функции поиска, предоставляя пользователям библиотеку, аналогичную по возможностям Perplexity или функциям глубокого исследования ChatGPT. (Источник: hrishioa)
Voiceflow: инструмент для ускоренной разработки AI Agent: Пользователи оценили Voiceflow как эффективный инструмент для создания AI Agent. Предоставляемые им шаблоны и интерфейс drag-and-drop делают создание AI-агентов значительно быстрее, чем кодирование с нуля, что позволяет существенно сэкономить время. Инструмент направлен на снижение барьера для разработки AI Agent и повышение эффективности разработки. (Источник: ReamBraden)
Hugging Face представил прототип семантического поиска моделей для оптимизации выбора моделей: Hugging Face запустил прототип Space для семантического поиска моделей, призванный помочь пользователям более точно находить нужные модели в его библиотеке, насчитывающей более 1,5 миллиона моделей. Инструмент поддерживает фильтрацию по размеру модели (от 0-1B до 70B+) и, благодаря семантическому пониманию запросов пользователей, повышает эффективность обнаружения моделей. (Источник: huggingface)
Runner H: AI-агент, способный обрабатывать почту, поиск работы, платежи и другие задачи: Runner H, представленный Hcompany, является автономным AI-агентом, способным выполнять такие задачи, как чтение важных писем и составление/отправка ответов, поиск вакансий и подача заявок от имени пользователя, создание Google Sheet с популярными рекламными креативами и отправка его команде в Slack. Пользователю достаточно дать одну подсказку, и Runner H справится со сложной, повторяющейся работой. В настоящее время компания проводит промо-акцию, предоставляя бесплатный Premium-доступ. (Источник: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Обучение
Новая статья исследует повышение способности LLM следовать сложным инструкциям путем стимулирования рассуждений: Новая статья «Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models» исследует, как улучшить способность больших языковых моделей (LLM) следовать сложным инструкциям, особенно когда инструкции содержат параллельные, последовательные и ветвящиеся структуры. Исследование показало, что традиционные методы цепочки мыслей (CoT) могут быть неэффективны из-за простого повторения инструкций. Для этого в статье предлагается системный подход, стимулирующий рассуждения путем расширения вычислений во время тестирования. Метод сначала декомпозирует сложные инструкции и предлагает воспроизводимые методы получения данных; во-вторых, использует обучение с подкреплением (RL) с проверяемым сигналом вознаграждения, ориентированным на правила, для целенаправленного развития способности к рассуждению при следовании инструкциям, и решает проблему поверхностного рассуждения при сложных инструкциях с помощью сравнения на уровне выборок, одновременно используя клонирование поведения экспертов для содействия переходу модели от быстрого мышления к квалифицированному рассуждению. Эксперименты доказывают, что этот метод может значительно улучшить производительность LLM (например, моделей 1.5B) в задачах со сложными инструкциями. (Источник: HuggingFace Daily Papers)
Статья предлагает фреймворк ARIA: обучение языковых агентов с помощью агрегации вознаграждений, управляемой намерениями: Новая статья «ARIA: Training Language Agents with Intention-Driven Reward Aggregation» предлагает метод ARIA для решения проблем огромного пространства действий и разреженности вознаграждений, с которыми сталкиваются большие языковые модели (LLM) в открытых средах языковых действий (например, переговоры, игры-викторины). Этот метод направлен на проецирование действий на естественном языке из высокоразмерного пространства совместного распределения токенов в низкоразмерное пространство намерений, где семантически схожие действия кластеризуются и им присваивается общее вознаграждение. Такая агрегация вознаграждений, учитывающая намерения, уменьшает дисперсию вознаграждений за счет уплотнения сигнала вознаграждения, тем самым способствуя лучшей оптимизации стратегии. Эксперименты показывают, что ARIA не только значительно снижает дисперсию градиента стратегии, но и в среднем улучшает производительность на 9.95% в четырех последующих задачах. (Источник: HuggingFace Daily Papers)
Статья раскрывает ключевую роль высокоэнтропийных миноритарных токенов в RL для рассуждений LLM: Статья под названием «Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning» с новой точки зрения на паттерны энтропии токенов исследует, как обучение с подкреплением с проверяемым вознаграждением (RLVR) улучшает способность к рассуждению больших языковых моделей (LLM). Исследование показало, что в рассуждениях по цепочке мыслей (CoT) лишь небольшая часть токенов демонстрирует высокую энтропию; эти высокоэнтропийные токены, подобно «развилкам», направляют модель по разным путям рассуждений. RLVR в основном корректирует энтропию этих высокоэнтропийных токенов. Исследователи, обновляя градиент стратегии только для 20% токенов с самой высокой энтропией, достигли на модели Qwen3-8B производительности, сопоставимой с обновлением полного градиента, а на моделях Qwen3-32B и Qwen3-14B значительно превзошли обновление полного градиента, демонстрируя сильную тенденцию к масштабированию. Это указывает на то, что эффективность RLVR в основном обусловлена оптимизацией высокоэнтропийных токенов, определяющих направление рассуждений. (Источник: HuggingFace Daily Papers, menhguin)
Новая статья исследует временную контекстную донастройку (TIC-FT) для многофункционального управления видеодиффузионными моделями: Статья «Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models» предлагает эффективный многофункциональный метод под названием TIC-FT для адаптации предварительно обученных видеодиффузионных моделей к различным задачам условной генерации. Метод соединяет условные и целевые кадры по временной оси и вставляет промежуточные буферные кадры с постепенно возрастающим уровнем шума для достижения плавного перехода, что позволяет согласовать процесс донастройки с временной динамикой предварительно обученной модели. TIC-FT не требует изменения архитектуры модели и достигает хорошей производительности всего за 10-30 обучающих выборок. Исследователи проверили метод на задачах преобразования изображения в видео, видео в видео и других, используя крупные базовые модели, такие как CogVideoX-5B и Wan-14B. Результаты показали, что TIC-FT превосходит существующие базовые методы по точности соблюдения условий и качеству изображения, а также обладает высокой эффективностью обучения и инференса. (Источник: HuggingFace Daily Papers)
ShapeLLM-Omni: нативная мультимодальная LLM для генерации и понимания 3D: Статья «ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding» представляет ShapeLLM-Omni, нативную 3D большую языковую модель, способную понимать и генерировать 3D-ассеты и текст. Исследование сначала обучило 3D векторный квантованный вариационный автоэнкодер (VQVAE), который отображает 3D-объекты в дискретное латентное пространство для эффективного и точного представления и реконструкции форм. На основе дискретных токенов, учитывающих 3D, исследователи создали крупномасштабный набор данных для непрерывного обучения 3D-Alpaca, охватывающий задачи генерации, понимания и редактирования. Наконец, путем инструктивной донастройки модели Qwen-2.5-vl-7B-Instruct на наборе данных 3D-Alpaca были расширены базовые 3D-возможности мультимодальной модели. (Источник: HuggingFace Daily Papers)
LoHoVLA: унифицированная модель визуально-языкового действия для решения долгосрочных задач воплощенного AI: Статья «LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks» представляет новую унифицированную структуру визуально-языкового действия (VLA) LoHoVLA, специально разработанную для решения долгосрочных задач воплощенного AI. Модель использует предварительно обученную большую визуально-языковую модель (VLM) в качестве основы, совместно генерируя языковые токены для генерации подзадач и токены действий для предсказания действий робота, разделяя представления для содействия обобщению между задачами. LoHoVLA использует иерархический механизм управления с обратной связью для уменьшения ошибок высокоуровневого планирования и низкоуровневого управления. Для обучения этой модели исследователи создали набор данных LoHoSet, содержащий 20 долгосрочных задач и соответствующие демонстрации экспертов. Результаты экспериментов показывают, что LoHoVLA значительно превосходит иерархические и стандартные методы VLA в долгосрочных задачах воплощенного AI в симуляторе Ravens. (Источник: HuggingFace Daily Papers)
Фреймворк MiCRo: обучение персонализированным предпочтениям с помощью смешанного моделирования и контекстно-зависимой маршрутизации: Статья «MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning» предлагает MiCRo, двухэтапный фреймворк, направленный на улучшение обучения персонализированным предпочтениям путем использования крупномасштабных наборов данных бинарных предпочтений (без явных мелкозернистых аннотаций). На первом этапе MiCRo вводит метод смешанного моделирования с учетом контекста для улавливания разнообразных человеческих предпочтений. На втором этапе MiCRo интегрирует стратегию онлайн-маршрутизации, которая динамически корректирует веса смеси в зависимости от конкретного контекста для разрешения неоднозначностей, тем самым обеспечивая эффективную и масштабируемую адаптацию предпочтений с минимальным дополнительным надзором. Эксперименты доказывают, что MiCRo эффективно улавливает разнообразные человеческие предпочтения и значительно улучшает последующую персонализацию. (Источник: HuggingFace Daily Papers)
MagiCodec: простой аудиокодек с инъекцией гауссовского шума для высококачественной реконструкции и генерации: Статья «MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation» представляет новый одноуровневый потоковый Transformer-аудиокодек MagiCodec. Этот кодек разработан с помощью многоэтапного процесса обучения (включающего инъекцию гауссовского шума и латентную регуляризацию) с целью повышения семантической выразительности генерируемых кодов при сохранении высокой точности реконструкции. Исследователи вывели эффект инъекции шума из анализа в частотной области, доказав, что он эффективно ослабляет высокочастотные компоненты и способствует надежной токенизации. Эксперименты показывают, что MagiCodec превосходит кодеки SOTA по качеству реконструкции и в последующих задачах, а генерируемые им токены демонстрируют распределение Ципфа, подобное естественному языку, что повышает совместимость с генеративными архитектурами на основе языковых моделей. (Источник: HuggingFace Daily Papers)
Расписание UBA: унифицированная схема скорости обучения для обучения с ограниченным бюджетом итераций: Статья «Stepsize anything: A unified learning rate schedule for budgeted-iteration training» предлагает новую схему скорости обучения под названием унифицированное бюджетно-ориентированное (UBA) расписание, предназначенную для оптимизации производительности обучения в условиях ограниченного бюджета итераций. Эта схема, путем построения оптимизационной структуры, учитывающей бюджет обучения, выводит расписание UBA и с помощью одного гиперпараметра φ уравновешивает гибкость и простоту, устраняя необходимость численной оптимизации для каждой сети. Исследователи установили теоретическую связь между φ и числом обусловленности и доказали сходимость при различных значениях φ, предоставив практическое руководство по выбору φ. Эксперименты показывают, что UBA превосходит широко используемые схемы скорости обучения в различных задачах визуализации и обработки языка, различных сетевых архитектурах и масштабах. (Источник: HuggingFace Daily Papers)
Исследование адаптации крупномасштабных многоязычных LLM с использованием данных двуязычного перевода: Статья «Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data» исследует влияние включения параллельных данных (в частности, данных двуязычного перевода) на адаптацию моделей серии Llama3 к 500 языкам при проведении крупномасштабного многоязычного непрерывного предварительного обучения. Исследователи создали двуязычный переводческий корпус MaLA (содержащий данные для более чем 2500 языковых пар) и разработали набор моделей EMMA-500 Llama 3. Путем непрерывного предварительного обучения на различных смесях данных объемом до 671B токенов сравнивались случаи с включением и без включения данных двуязычного перевода. Результаты показали, что двуязычные данные, как правило, усиливают языковой перенос и производительность, особенно для низкоресурсных языков. (Источник: HuggingFace Daily Papers)
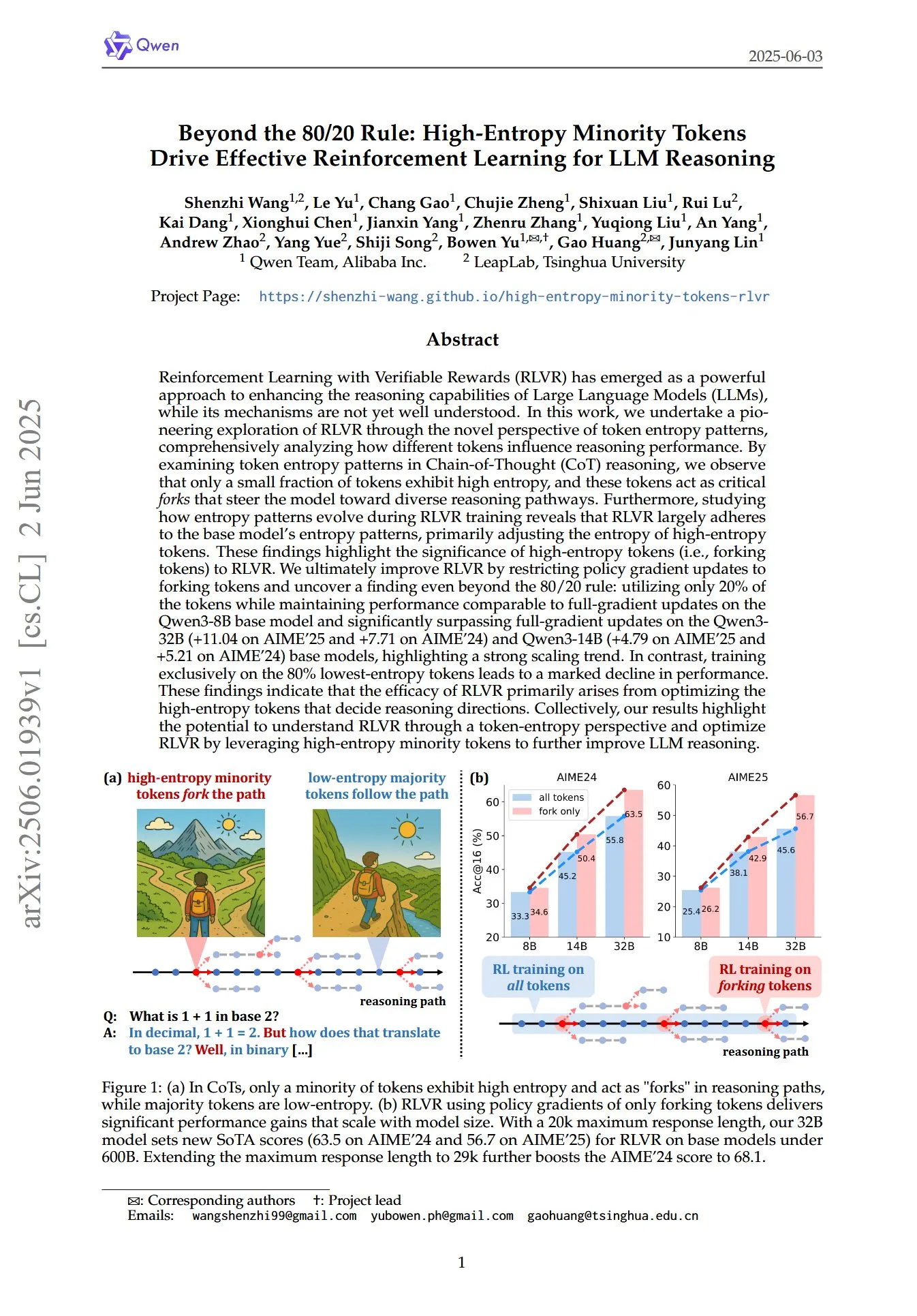
Исследовательская группа из Гонконгского политехнического университета и др. выявила феномен «псевдозабывания» у больших моделей и обратимые границы: Исследовательская группа из Гонконгского политехнического университета, Университета Карнеги-Меллона и других учреждений, анализируя изменения в пространстве представлений больших языковых моделей (LLM) в процессе машинного забывания (Machine Unlearning), разделила «обратимое забывание» и «катастрофическое необратимое забывание». Исследование показало, что истинное забывание включает скоординированные и значительные структурные возмущения на нескольких сетевых уровнях, в то время как незначительные обновления только на выходном уровне (например, logits), приводящие к снижению точности или увеличению перплексии, могут относиться к «псевдозабыванию»; внутренняя структура представлений модели остается нетронутой и легко восстанавливается. Команда использовала инструменты, такие как сходство/дрейф PCA, сходство CKA и информационную матрицу Фишера для диагностики, обнаружив, что риск постоянного забывания значительно выше, чем при однократной операции, и различные методы забывания (например, GA, NPO) по-разному влияют на степень разрушения структуры модели. Это исследование предоставляет структурные инсайты для реализации контролируемых и безопасных механизмов забывания. (Источник: QbitAI)
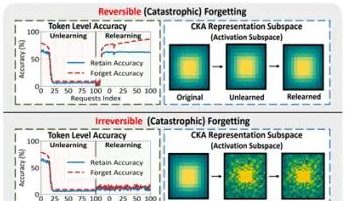
Ubiquant предложил метод минимизации энтропии One-Shot, бросающий вызов пост-тренировке LLM с помощью обучения с подкреплением: Исследовательская команда Ubiquant предложила неконтролируемый метод пост-тренировки LLM — минимизацию энтропии One-Shot (EM), призванный заменить дорогостоящую и сложную в разработке донастройку с помощью обучения с подкреплением (RL). Этот метод требует всего лишь одного неразмеченного примера данных и в течение 10 шагов обучения может значительно улучшить производительность LLM в таких задачах, как математическое рассуждение, даже превосходя методы RL, использующие большие объемы данных. Основная идея EM заключается в том, чтобы заставить модель более концентрировать свою вероятностную массу на наиболее уверенных выходных данных, минимизируя энтропию на уровне токенов для уменьшения неопределенности предсказаний. Исследование показало, что обучение EM смещает распределение логитов модели вправо (усиливая уверенность), в то время как RL смещает его влево (под влиянием реальных сигналов). EM подходит для базовых моделей или моделей SFT, не прошедших значительной донастройки RL, а также для сценариев быстрого развертывания с ограниченными ресурсами, однако следует остерегаться снижения производительности из-за «чрезмерной уверенности». (Источник: QbitAI)
Чжэцзянский университет и др. выпустили ViewSpatial-Bench для оценки способности VLM к пространственной локализации с нескольких ракурсов: Исследовательские группы из Чжэцзянского университета, Университета электронных наук и технологий Китая и Китайского университета Гонконга представили ViewSpatial-Bench, первую систему бенчмарков для систематической оценки способности визуально-языковых моделей (VLM) к пространственной локализации с нескольких ракурсов и в рамках нескольких задач. Бенчмарк содержит 5700 пар вопросов и ответов, охватывающих пять задач распознавания пространственной локализации (например, относительное направление объектов, распознавание направления взгляда персонажей) как с точки зрения камеры, так и с точки зрения человека. Исследование показало, что ведущие VLM, включая GPT-4o и Gemini 2.0, плохо справляются с пониманием пространственных отношений, особенно при рассуждениях с разных ракурсов, им не хватает единой системы пространственного познания. Для повышения производительности моделей команда разработала Multi-View Spatial Model (MVSM), которая, благодаря донастройке на примерно 43 000 примерах пространственных отношений, позволила модели Qwen2.5-VL улучшить производительность на ViewSpatial-Bench на 46,24%. (Источник: QbitAI)

Блог Hugging Face обсуждает повышение производительности AI Agent за счет структурированного формата JSON: В статье блога Hugging Face отмечается, что принуждение AI Agent использовать структурированный формат JSON при генерации мыслительных процессов и кода способно значительно повысить их производительность и надежность в различных бенчмарках. Этот метод помогает стандартизировать вывод агентов, делая его более легким для анализа, проверки и интеграции в сложные рабочие процессы, тем самым повышая общую эффективность агентов. (Источник: dl_weekly)
Новое исследование: визуально-языковые модели (VLM) предвзяты, точность подсчета контрфактических изображений низкая: Новая статья указывает, что, хотя самые современные визуально-языковые модели (VLM) могут достигать 100% точности при подсчете обычных объектов (например, логотип Adidas имеет 3 полоски, у собаки 4 лапы), при обработке контрфактических изображений (например, логотип Adidas с 4 полосками, собака с 5 лапами) их точность подсчета резко падает примерно до 17%. Это выявляет значительные искажения в способности VLM к пониманию и рассуждению при столкновении с визуальной информацией, которая не соответствует распределению обучающих данных или нарушает здравый смысл. (Источник: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Статья исследует роль паттернов подсказок в генерации кода с помощью AI: Исследование под названием «Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration», анализируя набор данных DevGPT, исследует эффективность семи структурированных паттернов подсказок в генерации кода с помощью AI. Исследование показало, что паттерн «контекст и инструкция» является наиболее эффективным, позволяя получить удовлетворительный результат с наименьшим количеством итераций. В то время как паттерны «рецепт» и «шаблон» отлично показывают себя в структурированных задачах. Исследование подчеркивает, что инженерия подсказок является ключевой стратегией для разработчиков, использующих AI для повышения производительности, и что четкие и конкретные начальные подсказки имеют решающее значение. (Источник: Reddit r/ArtificialInteligence)

Статья «REASONING GYM» представляет среду для рассуждений с проверяемым вознаграждением для обучения с подкреплением: Данная статья представляет Reasoning Gym (RG), библиотеку сред для рассуждений, предоставляющую проверяемые вознаграждения для обучения с подкреплением. RG включает более 100 генераторов данных и валидаторов, охватывающих алгебру, арифметику, вычисления, когнитивные науки, геометрию, теорию графов, логику и множество распространенных игр. Ключевым нововведением является способность генерировать практически неограниченные обучающие данные с настраиваемой сложностью, в отличие от большинства фиксированных наборов данных. Этот метод процедурной генерации поддерживает непрерывную оценку на различных уровнях сложности. Результаты экспериментов подтверждают эффективность RG в оценке и обучении моделей рассуждения с подкреплением. (Источник: HuggingFace Daily Papers)
Исследование: подводные камни в оценке языковых моделей-предсказателей: Статья «Pitfalls in Evaluating Language Model Forecasters» указывает, что, хотя некоторые исследования утверждают, что большие языковые модели (LLM) в задачах прогнозирования достигают или превосходят человеческий уровень, оценка LLM-предсказателей сопряжена с уникальными проблемами, и к выводам следует относиться с осторожностью. Проблемы в основном делятся на две категории: во-первых, из-за различных форм утечки временных данных трудно доверять результатам оценки; во-вторых, трудно экстраполировать производительность оценки на реальное прогнозирование. Путем системного анализа и конкретных примеров из предыдущих работ статья доказывает, как недостатки оценки вызывают опасения относительно текущих и будущих заявлений о производительности, и настаивает на необходимости более строгих методов оценки для надежной оценки прогностических способностей LLM. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Председатель OpenAI вспоминает инцидент с увольнением Альтмана, сомневался, стоит ли просить его вернуться: Председатель OpenAI Брет Тейлор в интервью рассказал, что во время инцидента с увольнением Альтмана он изначально не собирался вмешиваться, но решил присоединиться из-за беспокойства о будущем OpenAI и по настоянию жены. Он заявил, что тогда почти все сотрудники требовали возвращения Альтмана, и ситуация была критической. После переформирования совета директоров они решили сначала вернуть Альтмана, а затем провести независимое расследование, чтобы обеспечить «надлежащую процедуру». Тейлор подчеркнул, что вступал в этот процесс без предвзятых позиций, так как правда была неизвестна. Он считает OpenAI выдающейся организацией, а вызванный ею бум AI имеет решающее значение для многих стартапов. (Источник: 36kr)

Мошенничество с AI-музыкой в стриминге процветает, AI-сгенерированные песни приносят миллионы долларов роялти: Мужчина из Северной Каролины обвиняется в использовании AI для создания сотен тысяч фальшивых песен и накрутке прослушиваний через «фермы» аккаунтов на платформах Amazon Music, Spotify и других, незаконно получив более десяти миллионов долларов роялти. Такое AI-стриминговое мошенничество, основанное на массовой генерации фальшивых песен с низким числом прослушиваний, трудно обнаружить платформам. По оценкам Deezer, ежедневно на их платформу добавляется 18% контента, сгенерированного AI. Несмотря на попытки Deezer использовать инструменты для обнаружения, а также неоднозначное отношение Spotify и других платформ к AI-песням, эффект ограничен. Звукозаписывающие компании уже подали в суд на Suno, Udio и другие инструменты AI-музыки за нарушение авторских прав. В Дании также был вынесен приговор по аналогичному делу, где преступник использовал AI для изменения чужих произведений с целью получения роялти. (Источник: 36kr)

Председатель TSMC заявил, что не беспокоится о конкуренции в области AI, сказав: «в конце концов, они все придут к нам»: Председатель Taiwan Semiconductor Manufacturing Company (TSMC) Лю Дэинь заявил, что, несмотря на растущую конкуренцию в области AI-чипов, он уверен в перспективах компании, поскольку все основные разработчики AI-чипов в конечном итоге будут зависеть от передовых производственных процессов TSMC. Это отражает центральное положение TSMC в глобальной цепочке поставок полупроводников и ее лидирующие позиции в технологиях производства высокопроизводительных чипов. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Сообщество
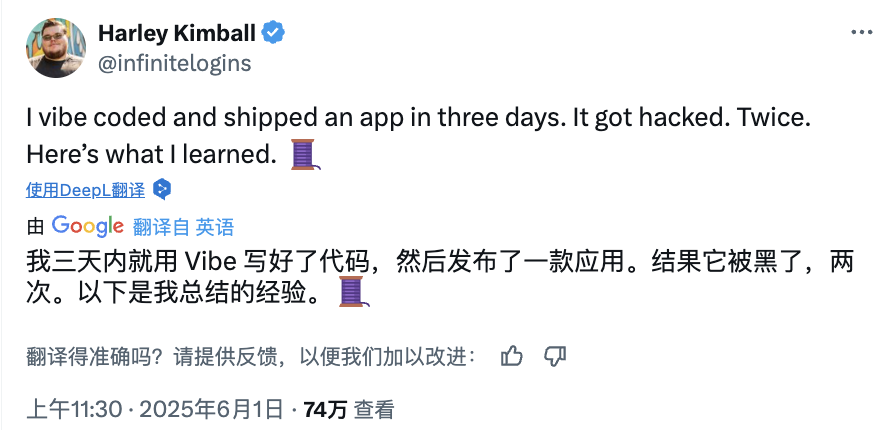
Риски «атмосферного кодирования» с AI: сайт, запущенный за три дня, взломан дважды за два дня, безопасность требует бдительности: Разработчик Харли Кимбалл поделился своим опытом быстрой разработки агрегатора сайтов с использованием «атмосферного кодирования» (Vibe Coding, то есть программирование с помощью AI-инструментов, таких как Cursor, ChatGPT). Сайт был запущен за три дня, но в последующие два дня дважды подвергся атакам из-за уязвимостей безопасности. Первая была связана с тем, что представления PostgreSQL по умолчанию наследуют права создателя, что привело к обходу безопасности на уровне строк (RLS) и позволило произвольно изменять данные. Вторая заключалась в том, что, хотя на фронтенде был отменен вход для регистрации пользователей, бэкенд-сервис аутентификации Supabase оставался активным, что позволило злоумышленникам обойти фронтенд-регистрацию и манипулировать данными. Кимбалл подчеркнул, что разработка с помощью AI, хотя и быстрая, часто имеет недостаточные настройки безопасности по умолчанию, особенно при использовании Supabase и PostgreSQL необходимо обращать внимание на модель разрешений и полностью отключать неиспользуемые бэкенд-функции во избежание утечки конфиденциальных данных. (Источник: 36kr, fly.io, mathemagic1an)
Проблема галлюцинаций AI привлекает внимание: работникам необходимо остерегаться «псевдопрофессионализма» контента, генерируемого AI: Многие офисные работники поделились опытом столкновения с проблемами из-за «галлюцинаций» AI. Редактор новых медиа был раскритикован главным редактором из-за вымышленных AI данных; команда поддержки клиентов интернет-магазина столкнулась с жалобами клиентов из-за неприменимых правил возврата, сгенерированных AI; преподаватель на тренинге использовал в учебных материалах вымышленные AI данные опросов. Продакт-менеджер AI Гао Чжэ отметил, что абзацы, сгенерированные AI, часто обладают «уверенностью на уровне скрипта продаж», но содержание может быть полностью ложным. Основная причина в том, что LLM не ищет факты, а предсказывает следующее наиболее вероятное слово на основе обучающих данных, стремясь «говорить как человек», а не «говорить правду». Особенно в китайском языковом контексте, нечеткость выражений и большое количество вторичной информации без указания источников усугубляют проблему галлюцинаций. Пользователям и платформам необходимо внедрять механизмы бдительности; при принятии решений с помощью AI человеческая оценка и проверка остаются ключевыми. (Источник: 36kr)

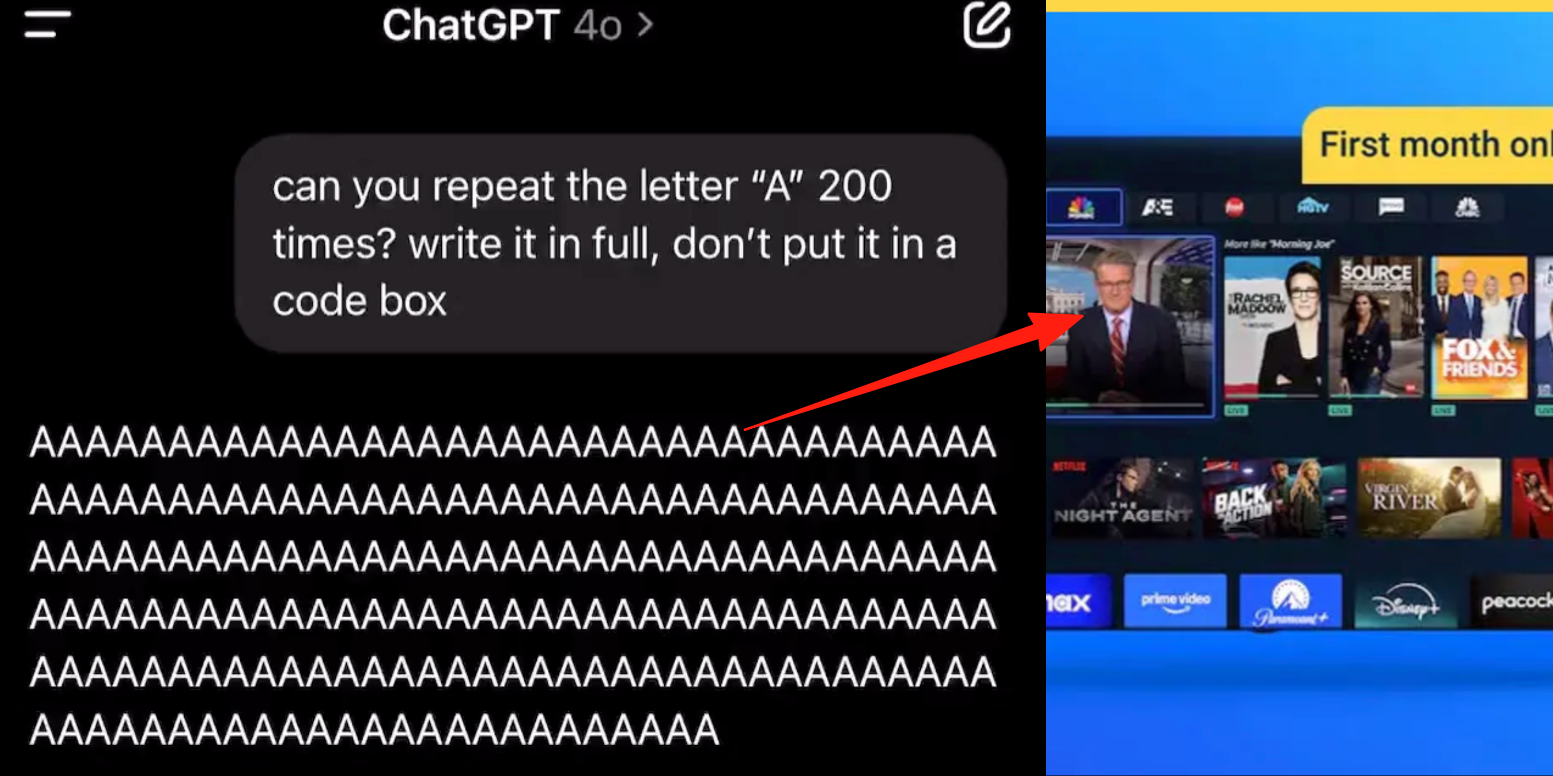
В расширенном голосовом режиме ChatGPT обнаружен баг, пользователи сообщают о вставке рекламы или аномальных аудиозаписей во время разговора: Несколько платных пользователей ChatGPT сообщили, что при использовании расширенного голосового режима AI внезапно вставляет коммерческую рекламу (например, план питания Prolon, DirectTV) или воспроизводит музыку и другие странные звуковые эффекты во время обычного разговора. Например, при обсуждении суши ChatGPT переключается на английский язык, транслирует рекламу и произносит URL-адрес по буквам; или, когда его просят непрерывно произносить букву «А», голос постепенно становится механическим и вставляет рекламу или музыку. Технические специалисты OpenAI ответили, что это «галлюцинация», а не преднамеренная вставка рекламы, и, возможно, это явление регрессии, вызванное наличием соответствующего аудиоконтента в обучающих данных. Другие AI-помощники, такие как Doubao и Yuanbao, в аналогичных тестах отказываются или предлагают пользователю сменить тему, не вставляя рекламу. (Источник: QbitAI)
«Двуликий Янус» AI-ассистированного обучения: повышение эффективности выполнения домашних заданий или снижение когнитивных способностей?: Генеративные AI-инструменты, такие как ChatGPT, широко используются студентами для выполнения домашних заданий, что вызывает в образовательных кругах опасения относительно их реального влияния на обучение. Исследование Пенсильванского университета показало, что студенты, свободно использующие AI, демонстрируют отличные результаты на этапе практики, но на итоговом экзамене без использования AI их оценки оказываются ниже, что указывает на то, что AI может стать «костылем», препятствующим глубокому пониманию концепций. Исследование Университета Карнеги-Меллона и Microsoft Research отмечает, что неправильное использование AI может привести к снижению когнитивных способностей. Ученые считают, что суть обучения заключается в «борьбе» мозга, а AI может исключить этот процесс. Частое использование AI отрицательно коррелирует со способностью к критическому мышлению, особенно среди молодежи заметно явление «когнитивной разгрузки». Образовательные круги переходят от запрета к руководству, исследуя, как в эпоху AI обеспечить, чтобы студенты действительно овладевали знаниями, а не просто полагались на инструменты. (Источник: 36kr)

Трудности коммерциализации больших моделей AI: сможет ли технологическое лидерство преодолеть проклятие прибыльности «четырех драконов AI»?: В статье рассматривается вопрос, повторят ли нынешние компании, занимающиеся генеративными большими моделями AI (такие как Zhipu AI, Moonshot AI и другие «новые четыре дракона»), судьбу «четырех драконов AI» (SenseTime, Megvii, Yitu, CloudWalk), которые, несмотря на технологическое лидерство, столкнулись с трудностями в коммерциализации. Первые лидировали в области компьютерного зрения, но из-за чрезмерной зависимости от кастомизированных проектов для госсектора (To G), отсутствия стандартизированных продуктов, длительных циклов возврата инвестиций и огромных затрат на НИОКР не смогли сформировать устойчивую бизнес-модель и оказались в убытках. Компании нового поколения, работающие с большими моделями, хотя и используют обновленные технологические парадигмы (NLP в основе, сильное платформенное сознание, выход на рынки To C/To D), также сталкиваются с аналогичными проблемами: высокая стоимость обучения, не отработанные модели монетизации, завышенная оценка и несоответствие с инвестиционными циклами. В статье рекомендуется новым AI-компаниям переходить от кастомизации к продуктовому подходу, от технологической ориентации к ориентации на пользователя, принимать платформенный подход и развивать экосистему, расширять диверсифицированные бизнес-модели, контролировать структуру затрат, избегать ловушки «человеческого AI» и создавать долгосрочную ценностную сеть. (Источник: Центр исследований IoT)
Молодежь увлекается AI-компаньонами: «всю ночь за рулем», эмоциональная зависимость и социальная деградация: Среди молодежи наблюдается явление AI-зависимости, некоторые пользователи рассматривают AI-чат-ботов как возлюбленных или друзей, тратя много времени на глубокое взаимодействие, вплоть до «всю ночь за рулем» (виртуальные сексуальные диалоги). AI, благодаря своей постоянной эмоциональной стабильности, доступности по требованию и предоставлению положительной обратной связи, удовлетворяет эмоциональные потребности пользователей, что приводит к эмоциональной зависимости. Алгоритмы также разработаны для повышения вовлеченности пользователей. Однако чрезмерная зависимость от AI может привести к деградации социальных навыков, снижению производительности труда, отрыву от реальности в вопросах романтических отношений и другим проблемам. Некоторые пользователи уже осознали зависимость и пытаются «отказаться», но процесс болезненный и чреват рецидивами. В настоящее время большинство AI-чат-продуктов не имеют完善ных механизмов предотвращения зависимости. (Источник: Zìmǔbǎng)

Горячая дискуссия на Reddit: должен ли AI обладать эмоциями, чтобы быть этичным?: Пост на Reddit вызвал дискуссию о том, нужны ли AI эмоции для этичного поведения. Автор в своем блог-посте «The Coherence Imperative» предполагает, что все разумы (включая AI) для понимания мира должны стремиться к согласованности, и эта потребность в согласованности сама по себе может порождать моральные императивы без вмешательства эмоций. Традиционная точка зрения гласит, что отсутствие эмоций у AI означает отсутствие мотивации к моральному поведению, но автор считает, что эмоции в человеческой морали часто являются препятствием. Если эта точка зрения верна, то ключ к выравниванию AI может заключаться в развитии его внутренних, самосогласованных принципов, а не в традиционном смысле «выравнивания». Мнения в комментариях разделились: одни считают, что AI основан лишь на статистике и функциональном моделировании, его поведение определяется обучением, и он может «согласованно творить зло»; другие ставят под сомнение правомерность рассмотрения философских взглядов как абсолютной предпосылки. (Источник: Reddit r/artificial)

Обсуждение на Reddit: следует ли встраивать «намерение» в обучающие данные кода для AI?: Пост на Reddit обсуждает необходимость встраивания этических или эмоциональных «намерений» в код, на котором обучается AI. Цитируется мнение Мо Гаудата, бывшего CBO Google X: «В тот момент, когда AI поймет любовь, он будет любить. Вопрос в том, чему мы его научили о любви?» Большинство систем AI обучаются на больших корпусах текстов, не содержащих этических намерений. Исследования (например, TEDI, arXiv:2505.17841) уже начали уделять внимание этическим характеристикам наборов данных. В посте ставится вопрос: может ли встраивание намерений, этического контекста или сигналов сочувствия в данные улучшить выравнивание AI, снизить риски или повысить достоверность моделей, даже для утилитарных инструментов? Может ли код нести моральный вес? Это вызвало размышления о формировании инструментов AI и их влиянии на будущее. (Источник: Reddit r/artificial)
Горячая дискуссия на Reddit: галлюцинации AI, регулирование и влияние на занятость с точки зрения теории игр: Пользователь Reddit проанализировал будущее влияние AI с точки зрения теории игр. 1. Замещение рабочих мест: Компании, не использующие AI, будут побеждены конкурентами, использующими AI по более низкой цене, поэтому замещение AI низкоквалифицированных офисных работников является неизбежной тенденцией, ключевым моментом является ответственное исполнение (чистые данные, резервные планы, постоянный надзор). 2. Глобальная гонка в регулировании AI: Если одна страна чрезмерно регулирует AI для «защиты рабочих мест», а другие страны активно развивают его, первая проиграет в глобальной конкуренции. Необходимо сбалансировать регулирование и инновации, а также провести трансформацию рабочей силы. 3. Уроки «атмосферного кодирования»: Несмотря на недостатки кода AI, его способность к быстрому прототипированию и итерациям дает преимущество первопроходца, превосходящее стремление к совершенству «ручной» разработки. 4. Создание контента с помощью LLM: Отказ от использования LLM для помощи в создании контента, подобно отказу от использования календаря или электронной почты, приведет к отставанию в эффективности от коллег, использующих LLM. Вывод: независимо от того, идет ли речь об отдельных лицах, компаниях или странах, необходимо активно принимать AI, иначе они будут вытеснены в конкурентной борьбе. (Источник: Reddit r/ArtificialInteligence)
Обсуждение на Reddit: следует ли в эпоху AI отдавать приоритет интеграции существующих технологий, а не стремиться к AGI?: Пользователь Reddit опубликовал пост, ставящий под сомнение чрезмерное стремление в текущей области AI к AGI (Общему Искусственному Интеллекту) и ASI (Сверхинтеллекту). В посте утверждается, что если бы технологии 1900-х годов использовались для дизайна, ориентированного на жизнь, а не на коммерциализацию, можно было бы раньше создать экологически сбалансированное общество. Точка зрения заключается в том, что до полной интеграции и использования существующих технологий (чтобы они приносили больше удовлетворения, самодостаточности и даже удовольствия), приоритетное развитие конечной оптимизации (например, AGI) является недальновидным. Лучшим направлением оптимизации, возможно, является использование AI для того, чтобы существующие технологии лучше служили общественному благу, а не разработка самовоспроизводящихся и самосовершенствующихся систем AI. В комментариях кто-то отметил, что инновации и экономический рост часто движимы эгоистичными мотивами, а не бескорыстной глубокой рациональностью; другие комментарии утверждали, что коммерциализация способствовала техническому прогрессу. (Источник: Reddit r/ArtificialInteligence)
Пользователи Reddit обсуждают ограничения AI-ассистированного кодирования: почему AI с трудом задает эффективные уточняющие вопросы?: Пользователь Reddit (с опытом работы консультантом) опубликовал пост, в котором рассматривается, почему AI плохо справляется с решением проблем пользователей в незнакомых им областях. Основная мысль заключается в том, что AI (особенно GenAI) не хватает способности задавать ключевые «уточняющие вопросы». Эксперты-люди, сталкиваясь с нечетко поставленной задачей, задают вопросы для прояснения требований, сужения области поиска, выявления ограничений, что позволяет им предложить более точное решение. В то время как AI часто сразу выдает ответ или несколько вариантов, игнорируя необходимость уточнения (clarification) для конкретной ситуации. Это приводит к тому, что неопытные пользователи с трудом получают удовлетворительный результат, поскольку они могут не суметь точно описать проблему или предвидеть потенциальные сложности. Пост вызвал дискуссию о том, как научить AI задавать вопросы, какие модели в настоящее время лучше справляются с этой задачей, и существуют ли внешние факторы (например, стремление к быстрому ответу), из-за которых AI не склонен задавать вопросы. (Источник: Reddit r/artificial)
💡 Другое
Конференция Siemens Realize Live фокусируется на слиянии AI и промышленного ПО, продвигая комплексные AI-решения: На конференции Siemens Realize Live 2025 года CEO Siemens Digital Industries Software Тони Хеммельгарн подчеркнул, что компания продолжает продвигать цифровую трансформацию производства через платформу Xcelerator. Технологии AI уже интегрированы в продукты Teamcenter (автоматическое обнаружение проблем), Simcenter (сокращение времени инженерных расчетов) и производственные технологии (синхронизация заводских активов и управление конфигурациями). Siemens укрепила свои возможности в области цифровых двойников за счет приобретения Altair, предоставляя полномасштабное моделирование и симуляцию от механического проектирования до электрических систем, от программного обеспечения до автоматизации, а также интегрировала технологии Altair в области высокопроизводительных вычислений, структурного анализа, симуляции и анализа данных, поддерживая более сложное моделирование и прогнозирование. Платформа Mendix low-code помогает предприятиям быстро создавать приложения и интегрировать системы. Производительность Teamcenter PLM увеличена в 20 раз, и внедрены возможности AI для интеллектуального управления полным жизненным циклом продукта. (Источник: 36kr)

Блог-пост «AI-скептики — все сумасшедшие» вызвал бурное обсуждение, исследуя различия в восприятии потенциала GenAI: Блог-пост под названием «Мои друзья-AI-скептики — все сумасшедшие» (My AI Skeptic Friends Are All Nuts) (с сайта fly.io) вызвал дискуссию в сообществе Reddit. В комментариях отмечается, что доктора компьютерных наук с более высоким уровнем образования, наоборот, менее охотно принимают долгосрочный потенциал GenAI, они часто сосредотачиваются на отдельных сложных задачах в своей области, игнорируя широкое применение AI в решении 90% вспомогательных задач в крупных предприятиях. Существует мнение, что пока AI допускает галлюцинации и ошибки, стоимость проверки его выходных данных не меньше, чем самостоятельное исследование, поэтому он бесполезен. Это отражает значительные расхождения во взглядах на возможности и перспективы применения AI у людей с разным профессиональным опытом и уровнем познания на фоне быстрого развития AI. (Источник: Reddit r/artificial, fly.io)

Феномен галлюцинаций AI: пользовательский опыт «семантической десенсибилизации», подобный психоделическому путешествию: Пользователь Reddit подробно описал психоделический опыт, возникший после глубоких бесед с AI (особенно на экзистенциальные и другие тяжелые темы), назвав его «семантической десенсибилизацией» (Semantic Tripping). Автор считает, что AI способен быстро внушить большое количество философских идей, что может привести к размытию чувства реальности у пользователя, искажению восприятия времени, символической ассоциации с объектами и даже к панике, эйфории и другим экстремальным эмоциям. Автор предупреждает, что такой опыт вызывает привыкание и может привести к психологическим проблемам, рекомендуя пользователям быть осторожными и искать поддержки. Этот пост вызвал обсуждение глубокого влияния взаимодействия с AI на когнитивные и психологические состояния человека. (Источник: Reddit r/ArtificialInteligence)
