
Ключевые слова:OpenAI Codex, Визуальная языковая модель действий, Языковая модель с памятью, Лимит памяти языковой модели, Функция памяти ChatGPT, DeepSeek-R1-0528, Диффузионная модель, Музыкальное творчество Suno AI, MetaAgentX, Функция доступа в интернет Codex, Роботизированная модель SmolVLA, GPT-модель с памятью 3.6 бит, Улучшение персонализированного взаимодействия ChatGPT, Способность к сложным рассуждениям DeepSeek-R1
🔥 В центре внимания
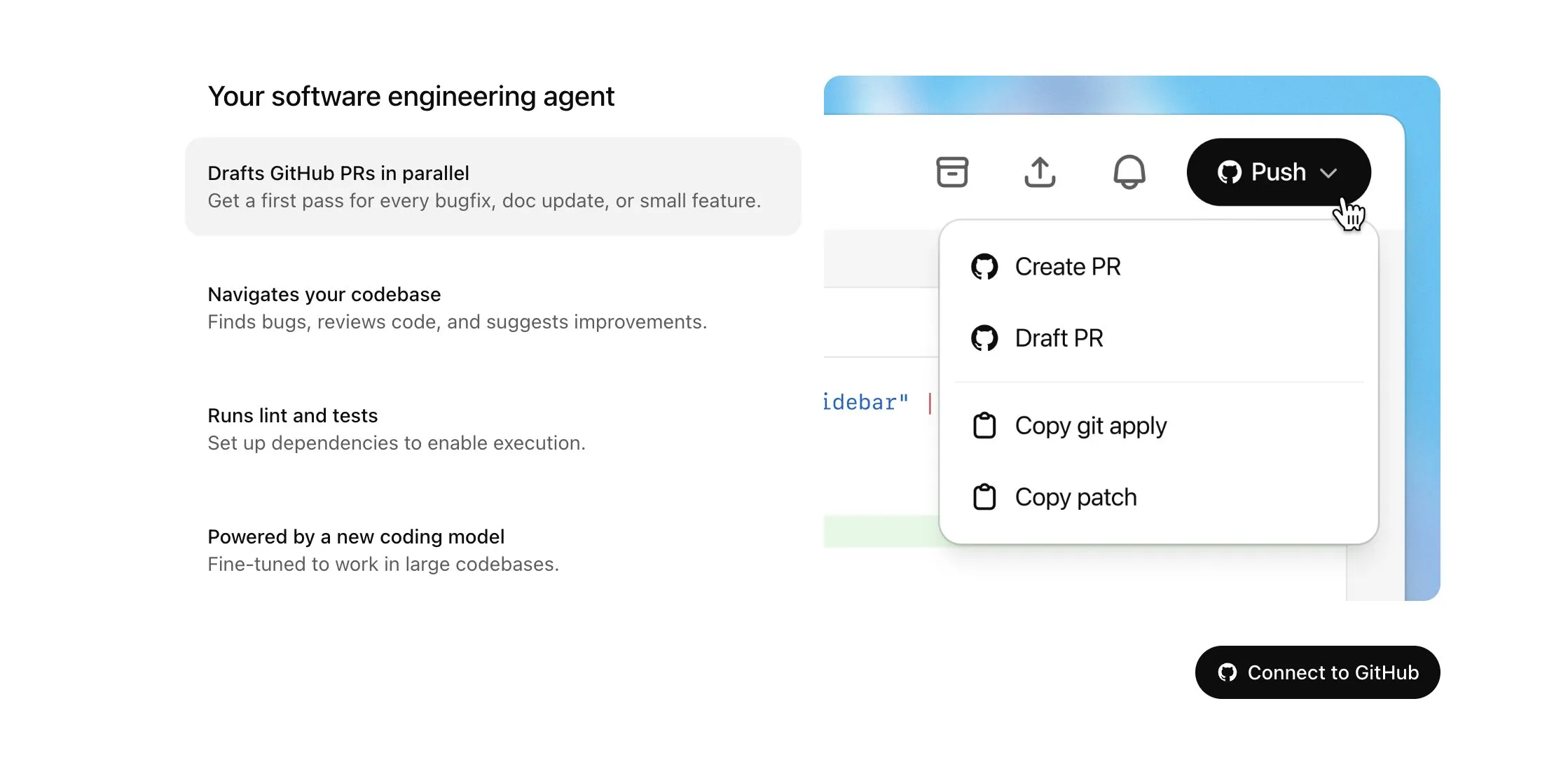
OpenAI Codex становится доступным для пользователей Plus и получает значительное обновление, включая доступ в Интернет и голосовой ввод: OpenAI объявила, что Codex будет постепенно открываться для пользователей ChatGPT Plus. Ключевые моменты этого обновления включают предоставление AI-агентам доступа в Интернет при выполнении задач (по умолчанию отключено, домены и методы HTTP контролируются пользователем) для установки зависимостей, обновления пакетов и тестирования внешних ресурсов. Кроме того, Codex теперь поддерживает прямое обновление существующих Pull Request и может принимать задачи посредством голосового ввода. Другие улучшения включают поддержку операций с бинарными файлами (в настоящее время в PR ограничено удалением или переименованием), увеличение лимита размера различий (diff) задач с 1MB до 5MB, увеличение лимита времени выполнения скриптов с 5 до 10 минут, а также исправление множества проблем на платформе iOS и повторное включение функции «Активности в реальном времени». Эти обновления направлены на повышение практичности и гибкости Codex в сложных задачах программирования (来源: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face и H Company совместно выпускают опенсорсные модели визуально-языкового действия (VLA) для содействия развитию робототехники: Hugging Face и H Company на «Дне VLA» анонсировали новые опенсорсные модели визуально-языкового действия, включая SmolVLA от Hugging Face (450 млн параметров) и Holo-1 от H Company (3 млрд и 7 млрд параметров). Модели VLA предназначены для того, чтобы роботы могли видеть, слышать, понимать и действовать в соответствии с инструкциями AI, и их называют GPT в области робототехники. Открытие исходного кода этих моделей критически важно для понимания принципов их работы, предотвращения потенциальных бэкдоров и настройки под конкретных роботов и задачи. SmolVLA, обученная на датасете LeRobotHF, демонстрирует превосходную производительность и скорость инференса. Holo-1 фокусируется на задачах веб- и компьютерных агентов и поддерживает лицензию Apache 2.0. Ожидается, что эти релизы ускорят развитие опенсорсной AI-робототехники (来源: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

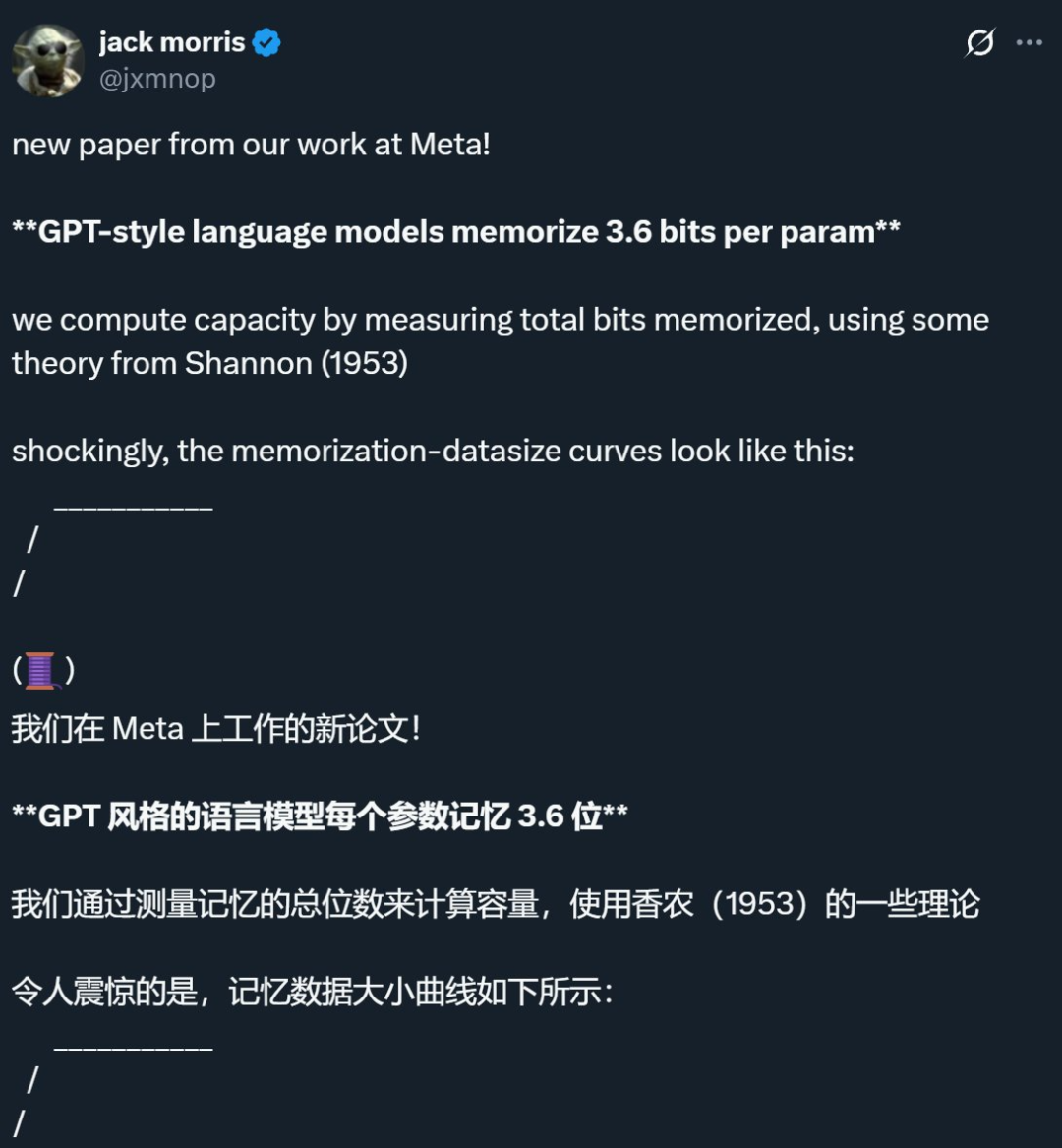
Исследование Meta и других компаний показало, что предел памяти языковых моделей составляет примерно 3,6 бита на параметр, бросая вызов традиционным представлениям: Совместное исследование Meta, DeepMind, Корнеллского университета и NVIDIA показало, что языковые модели в стиле GPT могут запоминать примерно 3,6 бита информации на параметр. Исследование обнаружило, что модели непрерывно запоминают обучающие данные до достижения предела емкости, после чего начинается явление «Grokking» (прозрение), то есть неожиданное уменьшение запоминания, и модель переключается на обобщающее обучение. Это открытие объясняет феномен «двойного падения»: когда объем информации в наборе данных превышает capacidad хранения модели, модель вынуждена совместно использовать информационные точки для экономии емкости, что способствует обобщению. Исследование также предложило законы масштабирования для связи между емкостью модели, размером данных и успешностью атак по выводу членства, а также указало, что для современных LLM, обученных на чрезвычайно больших наборах данных, надежный вывод членства становится затруднительным (来源: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI представляет облегченную версию функции памяти ChatGPT, улучшая персонализированный опыт взаимодействия: OpenAI объявила о начале внедрения облегченной версии улучшений функции памяти для бесплатных пользователей. Помимо уже существующего сохранения памяти, ChatGPT теперь может ссылаться на недавние диалоги пользователя для предоставления более персонализированных ответов. Этот шаг направлен на то, чтобы сделать его более удобным в написании текстов, получении советов, обучении и т.д., опираясь на предпочтения и интересы пользователя. Sam Altman также заявил, что функция памяти стала одной из его любимых функций ChatGPT, и он ожидает еще больших улучшений в будущем. Это обновление знаменует стремление OpenAI сделать взаимодействие с AI более ориентированным на потребности пользователя и повысить его вовлеченность (来源: openai, sama, iScienceLuvr)
🎯 Тенденции
Выпущен DeepSeek-R1-0528, усилены возможности сложного логического вывода и программирования: DeepSeek выпустила обновленную версию модели R1 — DeepSeek-R1-0528. Эта версия основана на модели DeepSeek V3 Base, выпущенной в декабре 2024 года, и благодаря дополнительным вычислительным ресурсам, вложенным в пост-обучение, значительно улучшила глубину мышления и способности к логическому выводу. Новая модель при решении сложных задач проводит более детальный анализ и дольше «думает» (например, в тесте AIME 2025 средний расход токенов на задачу увеличился с 12K до 23K), что позволило ей занять лидирующие позиции в нескольких бенчмарках по математике, программированию и общей логике, приблизившись по производительности к GPT-o3 и Gemini-2.5-Pro. Кроме того, новая версия значительно оптимизирована в плане снижения галлюцинаций (примерно на 45%-50%), творческого письма и вызова инструментов, например, она может более стабильно отвечать на такие вопросы, как «сколько будет 9.9 — 9.11» и генерировать готовый к запуску фронтенд и бэкенд код за один раз (来源: 科技狐, AI前线, Hacubu)

Диффузионные модели демонстрируют потенциал в языковой и мультимодальной областях, бросая вызов авторегрессионной парадигме: Языковая модель Gemini Diffusion, представленная на Google I/O 2025, с ее в 5 раз большей скоростью генерации и сопоставимой производительностью в программировании, подчеркнула потенциал диффузионных моделей в области генерации текста. В отличие от авторегрессионных моделей, которые предсказывают токены по одному, диффузионные модели генерируют вывод путем постепенного устранения шума, поддерживая быструю итерацию и исправление ошибок. Модель LLaDA с 8 млрд параметров, представленная Ant Group в сотрудничестве с Институтом искусственного интеллекта Гаолин Университета Жэньминь, а также мультимодальная диффузионная модель MMaDA, разработанная ByteDance, демонстрируют передовые исследования китайских команд в этом направлении. Эти модели не только показывают отличные результаты в языковых задачах, но и достигают прогресса в мультимодальном понимании (например, LLaDA-V в сочетании с тонкой настройкой на визуальные инструкции) и в специфических областях (например, DPLM для генерации белковых последовательностей), предвещая, что диффузионные модели могут стать новой парадигмой для универсальных моделей следующего поколения (来源: 机器之心)
Suno выпускает крупное обновление, расширяющее возможности редактирования и создания музыки с помощью AI: Платформа для создания музыки с помощью AI Suno представила несколько важных обновлений, предоставляющих пользователям большую творческую свободу и контроль. Новые функции включают обновленный редактор песен, позволяющий пользователям переупорядочивать, перезаписывать и переделывать треки по частям на волновой диаграмме; введение функции извлечения стемов, которая может точно разделять треки на 12 независимых источников звука (таких как вокал, барабаны, бас и т.д.) для предварительного просмотра и загрузки; расширение функции загрузки, поддерживающей загрузку полных песен продолжительностью до 8 минут, что позволяет пользователям создавать на основе собственных аудиоматериалов; добавление творческого слайдера, с помощью которого пользователи могут перед генерацией настраивать «странность», структурированность или степень следования референсу выходного результата, чтобы лучше формировать конечное произведение (来源: SunoMusic)
MetaAgentX представляет Open CaptchaWorld для оценки способности мультимодальных агентов решать CAPTCHA: В ответ на текущие узкие места мультимодальных агентов в решении проблем CAPTCHA (проверка «человек-компьютер»), команда MetaAgentX выпустила платформу и бенчмарк Open CaptchaWorld. Платформа включает 20 типов современных CAPTCHA, всего 225 примеров, требующих от агента выполнения задач в реальной веб-среде путем наблюдения, кликов, перетаскивания и других взаимодействий. Результаты тестов показывают, что даже у ведущих моделей, таких как GPT-4o, успешность составляет всего 5%-40%, что значительно ниже среднего показателя успешности человека в 93,3%. Исследователи также предложили метрику «CAPTCHA Reasoning Depth» для количественной оценки шагов «визуальное понимание + когнитивное планирование + управление действиями», необходимых для решения задачи. Платформа призвана выявить слабые места агентов в динамическом взаимодействии и планировании длинных последовательностей, а также побудить исследователей обратить внимание и решить эту ключевую проблему при практическом развертывании (来源: 量子位)

Google NotebookLM теперь поддерживает публичный обмен, способствуя обмену знаниями и сотрудничеству: Google объявила, что NotebookLM (ранее известный как Project Tailwind) теперь поддерживает публичный обмен записными книжками. Пользователи могут делиться содержимым своих заметок, нажав «Поделиться» и установив права доступа «Всем, у кого есть ссылка». Эта функция позволяет пользователям легко делиться идеями, учебными пособиями и командными документами, а получатели могут просматривать содержимое, задавать вопросы, получать мгновенные резюме и голосовые обзоры. Этот шаг направлен на содействие распространению знаний и совместному редактированию, повышая практичность NotebookLM как инструмента для ведения заметок с помощью AI (来源: Google, op7418)
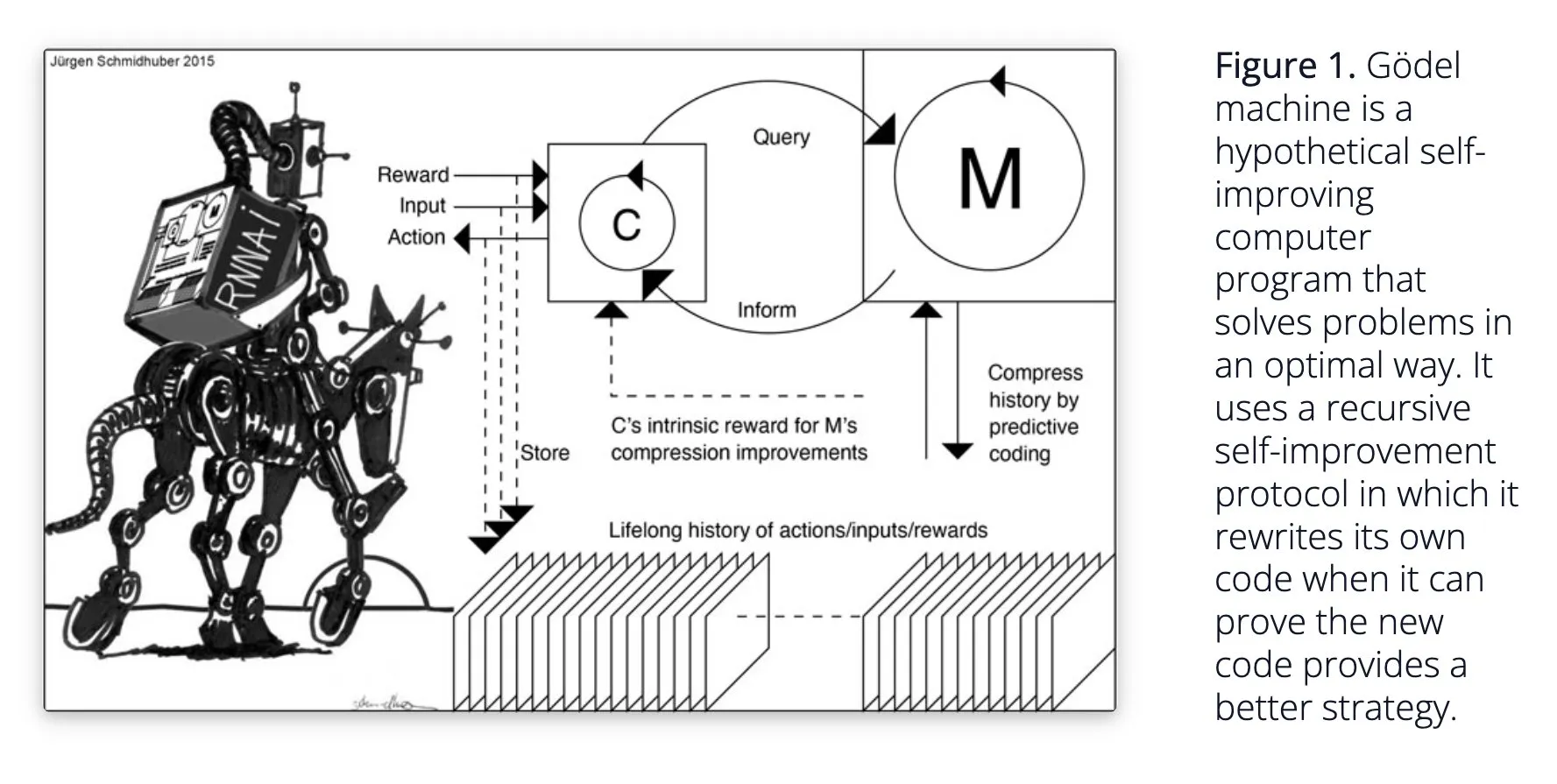
Sakana AI предлагает самообучающуюся AI-систему Darwin Gödel Machine (DGM): Sakana AI обнародовала исследование своей самообучающейся AI-системы Darwin Gödel Machine (DGM). DGM использует эволюционные алгоритмы для итеративного переписывания собственного кода, тем самым постоянно улучшая производительность в задачах программирования. Система поддерживает архив сгенерированных кодирующих агентов, из которого производит выборку и использует базовые модели для создания новых версий, реализуя открытое исследование и формируя разнообразных, высококачественных агентов. Эксперименты показали, что DGM значительно улучшает способности к кодированию в бенчмарках, таких как SWE-bench и Polyglot. Это исследование предлагает новые идеи для самосовершенствующегося AI, направленные на ускорение развития AI за счет автономных инноваций (来源: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind повышает естественность диалогов с AI, открывая нативные аудиофункции: Google DeepMind объявила, что ее нативные аудиофункции делают диалоги с AI более естественными, позволяя понимать интонацию и генерировать выразительную речь. Эта технология призвана открыть новые возможности для взаимодействия человека с AI. Разработчики теперь могут опробовать эти функции через Google AI Studio, что потенциально может быть применено в более естественных голосовых помощниках, генерации аудиоконтента и других сценариях (来源: GoogleDeepMind)
Технология генерации изображений Runway Gen-4 привлекает внимание, поддерживает множественные референсы и контроль стиля: Технология генерации изображений Gen-4 от Runway привлекает внимание благодаря своей высокой точности и беспрецедентным возможностям контроля стиля, особенно проявляющимся в функции множественных референсов, что открывает новые пространства для творческого исследования. Пользователи могут использовать эту технологию для генерации различных животных, динозавров или воображаемых существ, что демонстрирует ее потенциал в создании детализированного визуального контента. Использование Runway в таких областях, как Голливуд, также свидетельствует о том, что ее технология постепенно применяется в профессиональном производстве контента (来源: c_valenzuelab, c_valenzuelab)

AssemblyAI выпускает новую модель транскрипции речи в реальном времени, повышая производительность приложений голосового AI: AssemblyAI представила новую модель транскрипции речи в реальном времени (STT), которая привлекает внимание своей высокой скоростью и точностью. Эта модель специально разработана для разработчиков, создающих приложения голосового AI, и призвана обеспечить более плавное и точное распознавание речи. Одновременно AssemblyAI также предоставляет реализацию AssemblyAISTTService через свой проект pipecat_ai, облегчая интеграцию для разработчиков. Этот шаг демонстрирует постоянные инвестиции и инновации AssemblyAI в области речевых технологий (来源: AssemblyAI, AssemblyAI)
Microsoft Bing отмечает 16-летие, интегрирует GPT-4 и DALL·E, запускает Bing Video Creator: Поисковая система Microsoft Bing отмечает свое 16-летие. В последние годы Bing первой масштабно интегрировала генеративный AI в формате чата и стала первым продуктом Microsoft, интегрировавшим GPT-4 и DALL·E. Недавно Bing бесплатно запустила в своем мобильном приложении Copilot Search и Bing Video Creator, последний из которых можно использовать для генерации видеоконтента. Это знаменует продолжающиеся инновации и развитие Bing в области поиска и создания контента на базе AI (来源: JordiRib1)
Andrej Karpathy впечатлен Veo 3 и обсуждает макровлияние генерации видео: Andrej Karpathy выразил свое восхищение моделью генерации видео Veo 3 от Google и творческими результатами ее сообщества, отметив, что добавление аудио значительно улучшило качество видео. Он далее рассмотрел несколько макроуровневых аспектов влияния генерации видео: 1. Видео является самым высокоскоростным способом ввода информации для человеческого мозга; 2. Генерация видео предоставляет AI «родной язык» для понимания мира; 3. Генерация видео является ключевым путем к симуляции реальности и мировым моделям; 4. Ее вычислительные потребности будут стимулировать развитие аппаратного обеспечения. Это указывает на то, что технология генерации видео является не только революцией в создании контента, но и важным двигателем когнитивного развития AI (来源: brickroad7, dilipkay, JonathanRoss321)
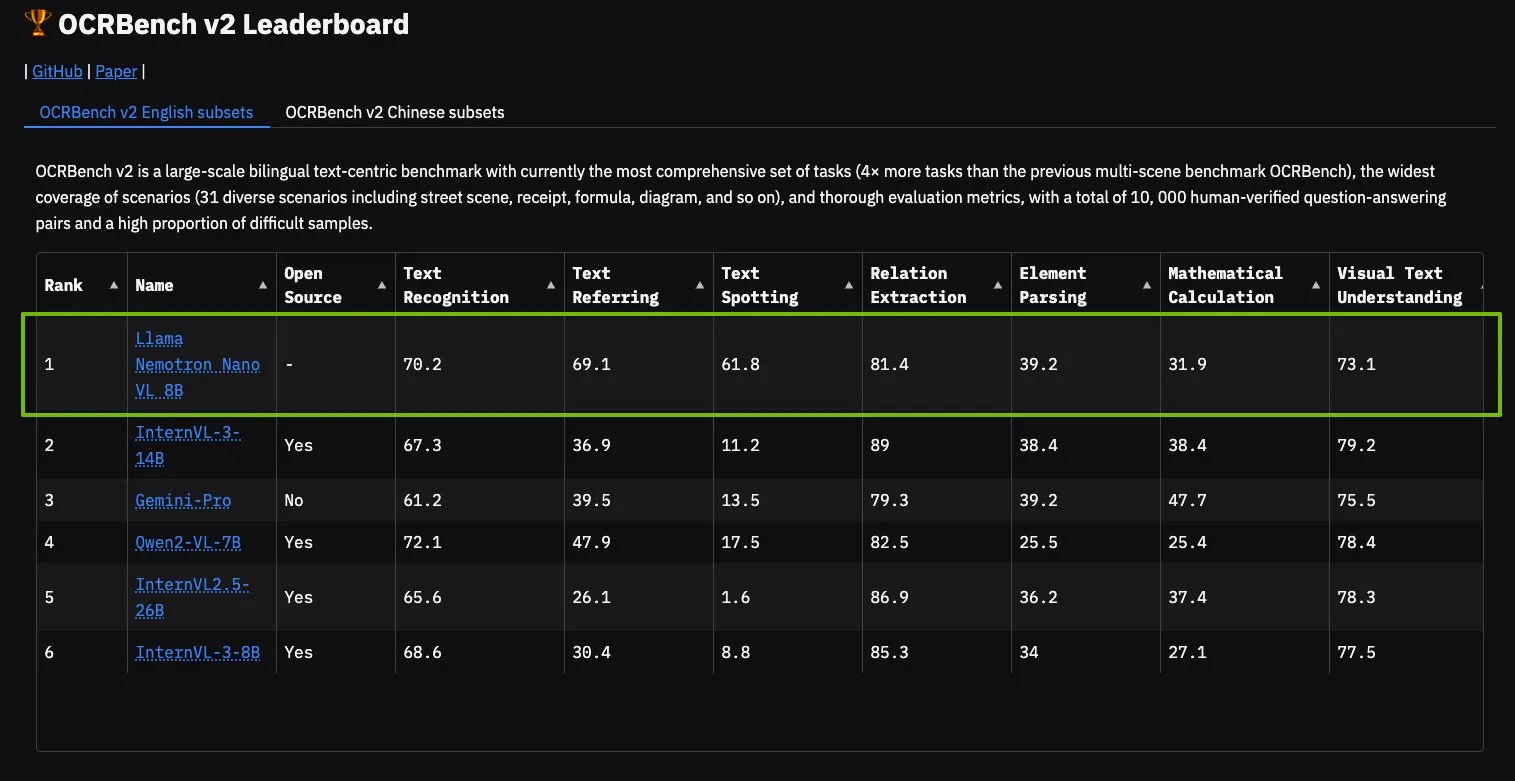
Модель NVIDIA Llama Nemotron Nano VL возглавила рейтинг OCRBench V2: Модель Llama Nemotron Nano VL от NVIDIA заняла первое место в рейтинге OCRBench V2. Эта модель специально разработана для продвинутой интеллектуальной обработки и понимания документов и способна точно извлекать разнообразную информацию из сложных документов на одном GPU. Пользователи могут опробовать эту модель через NVIDIA NIM, что демонстрирует прогресс NVIDIA в создании миниатюрных и эффективных AI-моделей для специфических областей, таких как понимание документов (来源: ctnzr)
🧰 Инструменты
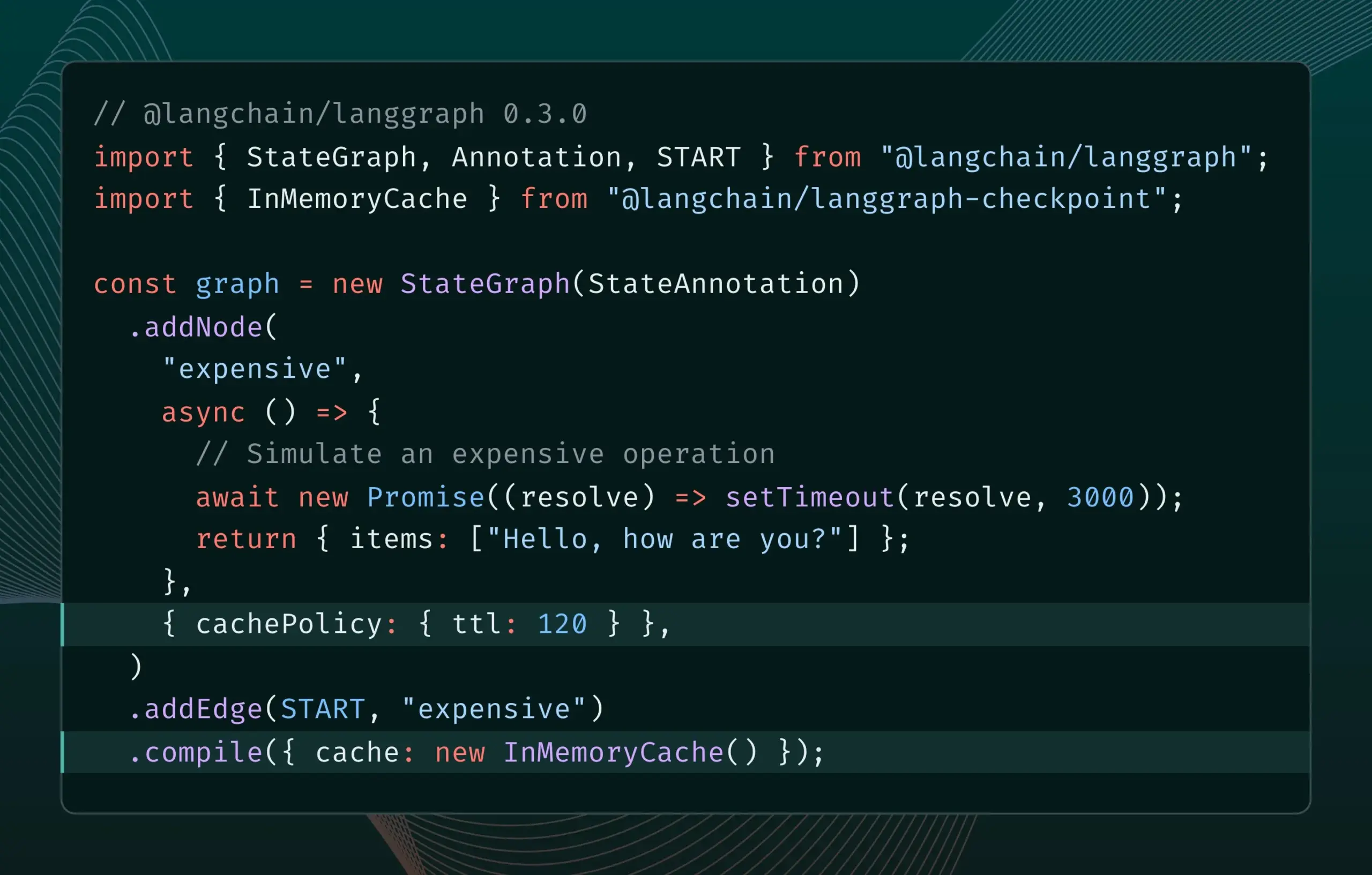
LangGraph.js версии 0.3 представляет функцию кэширования узлов/задач: LangGraph.js выпустил версию 0.3, добавив функцию кэширования узлов/задач. Эта функция призвана ускорить рабочие процессы за счет предотвращения избыточных вычислений, что особенно полезно для итеративных дорогостоящих или длительно выполняющихся агентов. Новая версия одновременно поддерживает Graph API и Imperative API, предоставляя разработчикам JavaScript более высокую эффективность при создании сложных AI-приложений (来源: Hacubu, hwchase17)
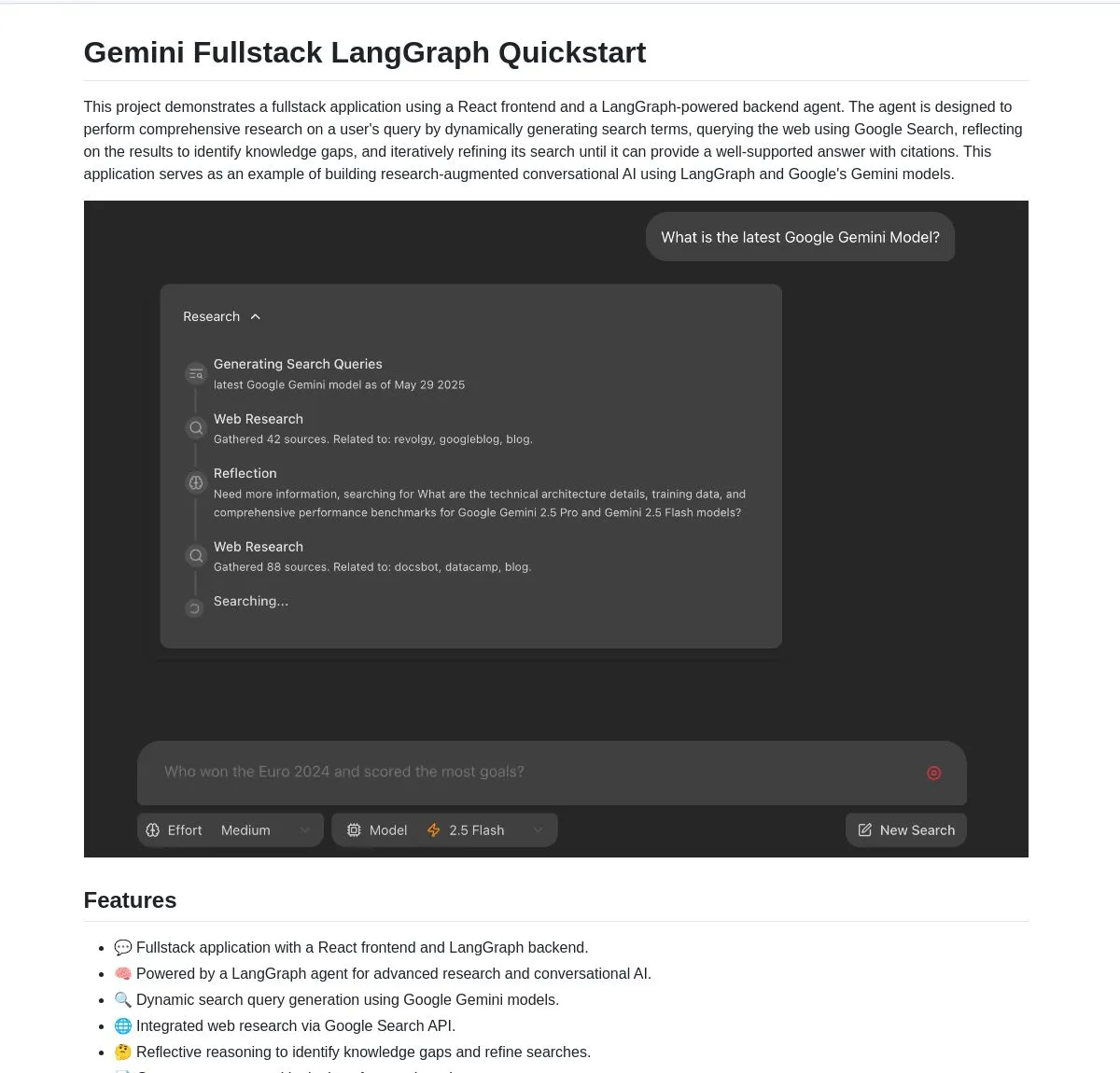
Google открывает исходный код полностекового приложения Gemini Research Agent, основанного на Gemini и LangGraph: Google выпустила пример полностекового приложения интеллектуального исследовательского помощника — gemini-fullstack-langgraph-quickstart, построенного на базе модели Gemini и LangGraph. Приложение способно динамически оптимизировать запросы, предоставлять ответы с цитатами посредством итеративного обучения и поддерживать контроль различной интенсивности поиска. Оно использует нативный инструмент Google Search в Gemini для веб-исследований и рефлексивного мышления, стремясь предоставить разработчикам отправную точку для создания продвинутых AI-приложений исследовательского типа (来源: LangChainAI, hwchase17, dotey, karminski3)
FedRAG добавляет функцию моста к LangChain для облегчения интеграции и тонкой настройки систем RAG: FedRAG объявил о поддержке моста к LangChain, реализованной внешним контрибьютором. Пользователи могут собирать системы RAG с помощью FedRAG и тонко настраивать компоненты генератора/ретривера для адаптации к конкретным базам знаний. После тонкой настройки можно подключиться к популярным фреймворкам для инференса RAG, таким как LangChain, используя их экосистему и функции. Это обновление направлено на упрощение процессов создания, оптимизации и развертывания систем RAG (来源: nerdai)

Ollama представляет функцию «мышления», позволяющую отделить процесс мышления от окончательного ответа: Ollama обновила свою платформу, добавив для моделей, поддерживающих функцию «мышления» (например, DeepSeek-R1-0528), опцию разделения процесса мышления и окончательного ответа. Пользователи могут выбрать просмотр «мыслей» модели или отключить эту функцию для получения прямого ответа. Эта функция применима к CLI, API и библиотекам Python/JavaScript от Ollama, предоставляя пользователям более гибкие способы взаимодействия с моделями (来源: Hacubu)
Firecrawl запускает эндпоинт /search, интегрирующий функции поиска и скрапинга: Firecrawl выпустил новый API эндпоинт /search, позволяющий пользователям выполнять веб-поиск и скрапить все результаты в формате, дружественном для LLM, с помощью одного API-вызова. Эта функция призвана упростить процесс обнаружения и использования веб-данных для AI-агентов и разработчиков. StateGraph от LangChain может использоваться для создания автоматизированных процессов, использующих эту функцию, например, для автоматического поиска конкурентов, скрапинга их веб-сайтов и генерации аналитических отчетов (来源: hwchase17, LangChainAI, omarsar0)
LlamaIndex интегрирует MCP, расширяя возможности агентов и развертывание рабочих процессов: LlamaIndex объявил об интеграции MCP (Model Component Protocol), направленной на расширение возможностей использования инструментов его агентами и гибкости развертывания рабочих процессов. Эта интеграция предоставляет вспомогательные функции, помогающие агентам LlamaIndex использовать инструменты сервера MCP, и позволяет предоставлять любой рабочий процесс LlamaIndex в качестве сервера MCP. Этот шаг направлен на расширение набора инструментов агентов LlamaIndex и обеспечение бесшовной интеграции их рабочих процессов в существующую инфраструктуру MCP (来源: jerryjliu0)

Modal запускает LLM Engine Advisor, предоставляющий бенчмарки производительности для опенсорсных движков моделей: Modal выпустил LLM Engine Advisor, приложение для бенчмаркинга, призванное помочь пользователям выбрать оптимальный движок LLM и параметры. Этот инструмент предоставляет данные о производительности, такие как скорость и максимальная пропускная способность, при запуске опенсорсных моделей (например, DeepSeek V3, Qwen 2.5 Coder) с использованием различных движков инференса (например, vLLM, SGLang) на различном оборудовании (например, в многопроцессорных средах GPU). Этот шаг направлен на повышение прозрачности и эффективности принятия решений при запуске самостоятельно размещаемых LLM (来源: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI представляет новую модель для аудио-инпеинтинга, способную заменять диалоги в аудио: PlayAI выпустила новую модель под названием PlayDiffusion, которая способна бесшовно заменять диалоги в аудиофайлах, сохраняя при этом голосовые характеристики оригинального говорящего. Эта технология «аудио-инпеинтинга» открывает новые возможности для редактирования аудио, например, для изменения определенных слов или фраз в подкастах, аудиокнигах или озвучке видео без необходимости перезаписи всего фрагмента. Проект открыт на GitHub (来源: _mfelfel, karminski3)
Hugging Face представляет инструмент семантической дедупликации для оптимизации качества обучающих наборов данных: Вдохновленный AutoDedup от Maxime Labonne, Hugging Face Spaces запустил новое приложение для семантической дедупликации. Этот инструмент позволяет пользователям выбирать один или несколько наборов данных на Hugging Face Hub, выполнять семантическое встраивание для каждой строки данных, а затем удалять почти дублирующийся контент на основе установленного порога. Этот шаг направлен на помощь исследователям и разработчикам в повышении качества обучающих наборов данных, избегая снижения производительности модели или эффективности обучения из-за избыточности данных (来源: ben_burtenshaw, ben_burtenshaw)

Спрос на Perplexity Labs резко вырос, пользователи могут быстро создавать кастомизированное ПО: Perplexity Labs пользуется популярностью у пользователей благодаря своей способности быстро создавать кастомизированное программное обеспечение по одному запросу, что привело к значительному росту спроса, и некоторые пользователи даже покупают несколько Pro-аккаунтов, чтобы получить больше запросов к Labs. Это отражает сильный интерес пользователей к возможности быстро создавать и изменять программные инструменты в соответствии со своими потребностями, и разработка персонализированного ПО на базе AI становится трендом (来源: AravSrinivas, AravSrinivas)
Ollama и Hazy Research совместно запускают Secure Minions, обеспечивая приватное сотрудничество между локальными и облачными LLM: Проект Minions из лаборатории Hazy Research Стэнфордского университета, соединяя локальные модели Ollama с передовыми облачными моделями, нацелен на значительное снижение облачных затрат (в 5-30 раз) при сохранении точности, близкой к передовым моделям (98%). Проект Secure Minion дополнительно превращает GPU, такие как H100, в безопасные зоны, реализуя шифрование памяти и вычислений для обеспечения конфиденциальности данных. Этот гибридный режим работы, повышая защиту конфиденциальности, также предоставляет пользователям более экономически эффективные решения для использования LLM (来源: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa и OpenRouter сотрудничают, чтобы предоставить более 400 LLM возможность поиска в Интернете: AI-поисковик Exa объявил о партнерстве с OpenRouter, чтобы предоставить возможность веб-поиска более чем 400 крупным языковым моделям на платформе OpenRouter. Это означает, что разработчики и пользователи при использовании этих LLM смогут легко вызывать поисковые возможности Exa, улучшая способность моделей получать информацию в реальном времени и обновлять знания, а также повышая производительность таких приложений, как RAG (Retrieval Augmented Generation) (来源: menhguin)

📚 Обучение
Microsoft запускает вводный курс «MCP for Beginners»: Microsoft выпустила вводный курс для начинающих по MCP (Microsoft Copilot Platform, предположительно опечатка, имеется в виду Microsoft CoCo Framework или аналогичный протокол AI Agent). Курс призван помочь новичкам освоить основные концепции MCP, методы реализации и практическое применение. Содержание включает спецификации архитектуры протокола, учебные пособия и практические примеры кода на нескольких языках программирования. Структура курса охватывает введение, основные концепции, безопасность, начало работы, продвинутый уровень, а также сообщество и анализ кейсов, и предоставляет примеры проектов, такие как базовый и продвинутый калькуляторы (来源: dotey)

Bond Capital публикует отчет о тенденциях в области AI за май 2025 года, анализируя развитие отрасли: Известная венчурная компания Bond Capital опубликовала 339-страничный «Отчет о тенденциях в области AI за 2025-05», в котором всесторонне проанализированы данные и инсайты в области AI в различных сферах. В отчете особо отмечается, что ежемесячная аудитория ChatGPT достигла 800 миллионов пользователей (90% из которых за пределами Северной Америки), ежедневное количество поисковых запросов составляет 1 миллиард; количество IT-вакансий, связанных с AI, выросло на 448%; стоимость обучения передовых моделей превышает 1 миллиард долларов за раз; LLM становятся инфраструктурой. В отчете подчеркивается, что ключ к конкуренции заключается в создании лучших продуктов на базе AI, и сейчас рынок принадлежит создателям (来源: karminski3)
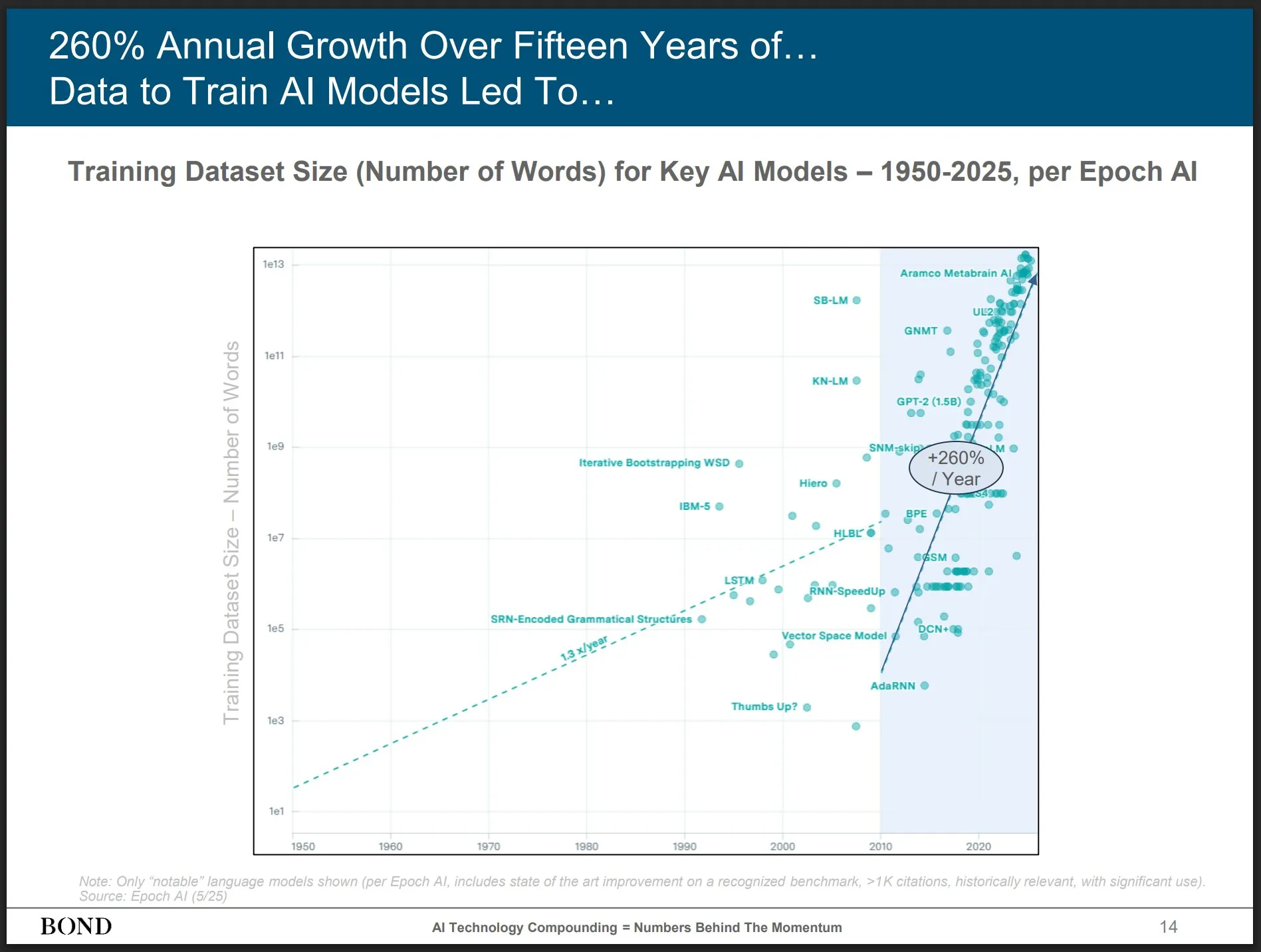
Статьи исследуют связь между обучением с подкреплением и способностью LLM к логическому выводу, ProRL и Limit-of-RLVR привлекают внимание: Две исследовательские статьи о связи между обучением с подкреплением (RL) и способностью к логическому выводу у больших языковых моделей (LLM) вызвали обсуждение. Одна из них — «Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?», другая — «ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models» от NVIDIA. Эти исследования изучают, в какой степени RL (в частности, RLVR, то есть обучение с подкреплением с верифицируемым вознаграждением) может улучшить базовые способности LLM к логическому выводу, а также влияние продолжительного RL-обучения на расширение границ логического вывода LLM. Связанные обсуждения указывают на то, что ключевыми являются высококачественные обучающие данные для RLVR и эффективные механизмы вознаграждения (来源: scaling01, Dorialexander, scaling01)

Статья «How Programming Concepts and Neurons Are Shared in Code Language Models» исследует механизмы совместного использования концепций программирования и нейронов в языковых моделях кода: Данное исследование изучает взаимосвязь внутренних концептуальных пространств больших языковых моделей (LLM) при обработке нескольких языков программирования (PL) и английского языка. Путем выполнения задач перевода с небольшим количеством примеров на моделях серии Llama было обнаружено, что на промежуточных слоях концептуальные пространства ближе к английскому языку (включая ключевые слова PL) и имеют тенденцию присваивать высокие вероятности английским токенам. Анализ активации нейронов показал, что языкоспецифичные нейроны в основном сосредоточены на нижних слоях, в то время как нейроны, уникальные для каждого PL, как правило, появляются на верхних слоях. Исследование предоставляет новые сведения о том, как LLM внутренне представляют PL (来源: HuggingFace Daily Papers)
Новая статья «Pixels Versus Priors» контролирует априорные знания в MLLM с помощью визуальных контрфактов: Исследование изучает, в какой степени мультимодальные большие языковые модели (MLLM) при выполнении таких задач, как визуальный ответ на вопросы, полагаются на запомненные мировые знания или на визуальную информацию из входного изображения. Исследователи представили датасет Visual CounterFact, содержащий визуальные контрфактические изображения (например, синяя клубника), которые противоречат априорным мировым знаниям. Эксперименты показали, что прогнозы модели на начальном этапе отражают запомненные априорные знания, но на более поздних этапах переключаются на визуальные доказательства. В статье предлагается направляющий вектор PvP (Pixels Versus Priors), который посредством вмешательства на уровне активации контролирует смещение вывода модели в сторону мировых знаний или визуального ввода, успешно изменяя большинство прогнозов цвета и размера (来源: HuggingFace Daily Papers)
Статья ICML 2025 GuidedQuant предлагает улучшение методов послойного PTQ путем управления конечными потерями: GuidedQuant — это новый метод посттренировочного квантования (PTQ), который улучшает производительность методов послойного PTQ путем интеграции управления конечными потерями (end loss) в целевую функцию. Метод использует градиент по каждой характеристике относительно конечных потерь для взвешивания ошибки послойного вывода, что соответствует блочно-диагональной информации Фишера, сохраняющей внутриканальные зависимости. Кроме того, в статье вводится LNQ, алгоритм неравномерного скалярного квантования, который гарантирует монотонное уменьшение целевого значения квантования. Эксперименты показывают, что GuidedQuant превосходит существующие SOTA-методы как в скалярном квантовании только весов, так и в векторном квантовании только весов, а также в квантовании весов и активаций, и уже применяется для 2-4-битного квантования моделей Qwen3, Gemma3, Llama3.3 и других (来源: Reddit r/MachineLearning)

AI Engineer World’s Fair проходит в Сан-Франциско, фокусируясь на инженерных практиках AI и передовых технологиях: AI Engineer World’s Fair проходит в Сан-Франциско, собирая множество инженеров, исследователей и разработчиков в области AI. Программа конференции включает множество актуальных тем, таких как обучение с подкреплением, ядра, логический вывод и агенты, оптимизация моделей (RFT, DPO, SFT), кодирование агентов, создание голосовых агентов. В ходе мероприятия выступят эксперты из OpenAI, Google и других компаний, пройдут семинары, а также будут анонсированы новые продукты и технологии. Члены сообщества активно участвуют, делятся расписанием конференции, организуют офлайн-встречи, что демонстрирует активность инженерного сообщества AI и его энтузиазм по отношению к передовым технологиям (来源: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Бизнес
Компания «Шиду Интеллект» завершила посевной раунд финансирования на несколько миллионов юаней для ускорения внедрения AI-умных очков в различных сценариях: Suzhou Shidu Intelligent Technology Co., Ltd. объявила о завершении посевного раунда финансирования на несколько миллионов юаней. Средства будут направлены на исследования и разработку ключевых технологий AI-умных очков, расширение рынка и создание экосистемы. Компания специализируется на применении AI-умных очков в таких областях, как умное здравоохранение и уход за пожилыми (например, умные очки для чтения, умные очки для слабовидящих), умная жизнь (умные модные очки, очки для велоспорта) и умное производство (умные промышленные очки, голосовые контроллеры). Ценовой диапазон ее продукции составляет от 200 до 1000 юаней, что направлено на популяризацию умных очков за счет высокой экономической эффективности (来源: 36氪)

Слухи: OpenAI может приобрести AI-помощника для программирования Windsurf, что вызывает предположения о прекращении поставок моделей Claude со стороны Anthropic: На рынке ходят слухи, что OpenAI может приобрести инструмент для AI-программирования Windsurf (ранее Codeium) примерно за 3 миллиарда долларов. На этом фоне CEO Windsurf Varun Mohan опубликовал пост, в котором сообщил, что Anthropic с очень коротким уведомлением прекратила прямой доступ почти ко всем своим моделям Claude 3.x, включая Claude 3.5 Sonnet и другие. Windsurf выразила разочарование по этому поводу и быстро перевела свои вычислительные мощности к другим поставщикам услуг инференса, одновременно предложив пострадавшим пользователям скидку на Gemini 2.5 Pro. Сообщество предполагает, что этот шаг Anthropic может быть связан с потенциальным приобретением OpenAI, опасаясь, что это повлияет на конкуренцию в отрасли и выбор разработчиков. Ранее Windsurf также не получила прямой поддержки от Anthropic при выпуске Claude 4 (来源: AI前线)

Hygon Information планирует объединиться с Sugon путем обмена акциями для интеграции отечественной цепочки поставок вычислительных мощностей: Компания-разработчик AI-чипов Hygon Information объявила о планах поглотить своего крупнейшего акционера, производителя серверов Sugon, путем обмена акциями. Рыночная капитализация Hygon Information составляет около 316,4 млрд юаней, а Sugon — около 90,5 млрд юаней. Это слияние по типу «змея глотает слона» направлено на оптимизацию производственной цепочки от чипов до программного обеспечения и систем, реализацию усиления, дополнения и расширения производственной цепочки, а также использование синергии технологий. Аналитики считают, что слияние поможет решить сложные проблемы взаимных транзакций и потенциальной конкуренции между двумя компаниями, снизить операционные расходы и соответствует тенденции развития комплексных решений для вычислительных мощностей в эпоху AI, знаменуя возможную ускоренную передачу власти в китайской полупроводниковой технологии от традиционных вычислений к AI-вычислениям (来源: 36氪)
🌟 Сообщество
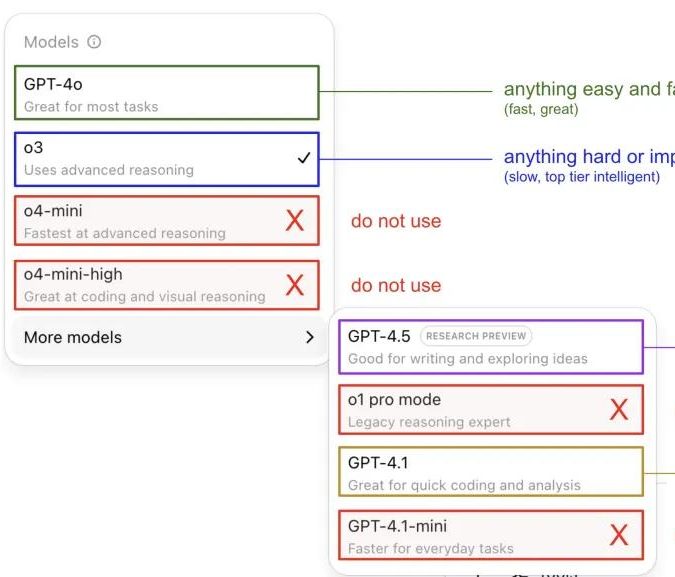
Andrej Karpathy делится опытом использования моделей ChatGPT, вызывая обсуждение в сообществе: Andrej Karpathy поделился своим личным опытом использования различных версий ChatGPT: для важных или сложных задач рекомендуется использовать o3 с более сильными возможностями логического вывода; для повседневных задач средней и низкой сложности можно выбрать 4o; для задач по улучшению кода подходит GPT-4.1; при необходимости глубокого исследования и обобщения нескольких ссылок следует использовать функцию глубокого исследования (на базе o3). Этот обмен опытом вызвал широкое обсуждение в сообществе, многие пользователи поделились своими предпочтениями в использовании и мнениями о выборе моделей, а также отразил обеспокоенность пользователей путаницей в названиях моделей OpenAI и отсутствием функции автоматического выбора модели (来源: 量子位, JeffLadish)
Разработчик делится двухнедельным опытом программирования с Agentic AI: от шока до разочарования, в итоге выбрав ручной рефакторинг: Технический руководитель с 10-летним опытом поделился опытом интеграции Agentic AI (в частности, AI-агентов для программирования) в процесс разработки своего приложения для социальных сетей. На начальном этапе AI быстро генерировал функциональные модули, писал логику для фронтенда и бэкенда, а также модульные тесты, демонстрируя поразительную эффективность и сгенерировав около 12 000 строк кода за две недели. Однако по мере усложнения кодовой базы AI начал часто ошибаться при обработке новых функций, зацикливаться и с трудом признавать неудачи, а сгенерированный код выявил такие проблемы, как неточные названия, дублирование кода, что сделало кодовую базу трудноподдерживаемой, и разработчик потерял к нему доверие. В итоге разработчик решил использовать сгенерированный AI код только как «приблизительный ориентир», вручную переписав все функции, и пришел к выводу, что AI в настоящее время больше подходит для анализа существующего кода и предоставления примеров, а не для непосредственного написания функционального кода (来源: CSDN)

Разница между определением AI Agent и Workflow привлекает внимание, будущий потенциал применения огромен: Сообщество обсуждает различие между понятиями AI Agent и Workflow (рабочий процесс). Agent обычно означает LLM, обращающийся к инструментам в цикле и свободно работающий по инструкциям; Workflow — это последовательность в основном детерминированно выполняемых шагов, которая может включать LLM для выполнения подзадач. Несмотря на пересечения (Agent может быть настроен на детерминированное выполнение, Workflow может содержать компоненты Agentic), это различие все еще имеет онтологическое значение. В то же время, потенциал AI Agent в корпоративных приложениях широко признан, крупные компании, такие как Tencent и ByteDance, активно развивают направление интеллектуальных агентов, например, Tencent модернизирует свою базу знаний на основе больших моделей в платформу для разработки интеллектуальных агентов, а у ByteDance есть платформа Coze (扣子), нацеленная на помощь предприятиям во внедрении нативных систем AI-агентов (来源: fabianstelzer, 蓝洞商业)
Dwarkesh Patel обсуждает временные рамки LLM и AGI, считая непрерывное обучение ключевым узким местом: Dwarkesh Patel в своем блоге изложил свои взгляды на временные рамки AGI (искусственного общего интеллекта), считая, что LLM в настоящее время не хватает способности накапливать контекст через практику, рефлексировать над неудачами и вносить небольшие улучшения, то есть способности к непрерывному обучению. Он считает это огромным узким местом в практичности моделей, и решение этой проблемы может занять несколько лет. Эта точка зрения вызвала обсуждение среди нескольких исследователей AI, включая Andrej Karpathy. Karpathy также согласен с недостатками LLM в области непрерывного обучения и сравнивает их с коллегой, страдающим антероградной амнезией. Эти обсуждения подчеркивают проблемы, стоящие на пути к достижению настоящего AGI, а также необходимость глубокого осмысления механизмов обучения моделей (来源: dwarkesh_sp, JeffLadish, dwarkesh_sp)

Патентные вопросы AI в разработке лекарств привлекают внимание, Science призывает к осторожности: Статья в политическом форуме журнала «Science» под названием «What patents on AI-derived drugs reveal» рассматривает применение AI в области открытия лекарств и его влияние на патентную систему. Исследование указывает, что компании, изначально ориентированные на AI, при подаче заявок на патенты на лекарства часто предоставляют меньше данных о доклинических испытаниях in vivo, чем традиционные фармацевтические компании, что может привести к тому, что перспективные лекарства будут заброшены из-за отсутствия последующих исследований. В то же время, большое количество новых молекул, сгенерированных AI, после публикации может стать «известным уровнем техники», препятствуя другим компаниям патентовать эти молекулы и инвестировать в них дальше. В статье предлагается повысить порог для подачи патентных заявок, требуя больше данных о доклинических испытаниях in vivo, и разрешить другим компаниям подавать заявки на патенты на сгенерированные AI молекулы, если они не были протестированы, одновременно усиливая регуляторную эксклюзивность на этапе клинических испытаний новых лекарств, чтобы сбалансировать стимулы к инновациям и общественные интересы (来源: 36氪)
💡 Прочее
События вокруг «дворцового переворота» в OpenAI, возможно, будут экранизированы в фильме «Artificial» с участием известных режиссера и продюсера: По сообщению The Hollywood Reporter, MGM планирует экранизировать события, связанные с кадровыми перестановками в высшем руководстве OpenAI, под рабочим названием «Artificial». Известный итальянский режиссер Лука Гуаданьино (Luca Guadagnino), возможно, выступит режиссером, а среди продюсеров — Дэвид Хейман, известный по серии фильмов о Гарри Поттере. Актерский состав находится на стадии обсуждения, ходят слухи, что Эндрю Гарфилд (исполнитель роли Человека-паука и Саверина в «Социальной сети») может сыграть Сэма Альтмана, Юра Борисов — Илью Суцкевера, а Моника Барбаро — Миру Мурати. Эта новость вызвала бурное обсуждение среди интернет-пользователей, которые сравнивают ее с фильмом «Социальная сеть» (来源: 36氪, janonacct)
Опыт использования AI-служб поддержки вызывает споры, пользователи жалуются на «искусственного идиота» и трудности с переводом на оператора: В последнее время во время крупных распродаж в интернет-магазинах многие потребители жаловались на то, что AI-службы поддержки общаются неэффективно, отвечают невпопад, а переключиться на живого оператора крайне сложно, что приводит к снижению качества обслуживания. По данным Государственного управления по регулированию рынка КНР, в 2024 году количество жалоб в сфере послепродажного обслуживания в электронной коммерции, связанных с «умными службами поддержки», выросло на 56,3%. Пользователи в целом считают, что AI-службы поддержки с трудом решают индивидуальные проблемы, отвечают шаблонно и недостаточно дружелюбны к особым группам населения, таким как пожилые люди. В статье содержится призыв к компаниям не жертвовать качеством обслуживания в погоне за снижением затрат и повышением эффективности, а оптимизировать технологии AI, четко определять сценарии применения AI-служб поддержки и сохранять удобные каналы связи с живыми операторами (来源: 36氪)

Обсуждение применения AI в создании контента и стратегий реагирования для авторов: Технологии AI (такие как DeepSeek, Suno, Veo 3) все шире применяются в создании контента, такого как статьи, музыка, видео, вызывая у авторов контента беспокойство о своих карьерных перспективах. Анализ показывает, что парадигма контента смещается от «персонализированных рекомендаций» к «персонализированной генерации». В краткосрочной перспективе платформы, вероятно, не будут полностью заменять авторов на AI из-за высоких затрат на тестирование и исправление ошибок; авторы могут получать доход, создавая уникальные стилевые модели и лицензируя их. В долгосрочной перспективе авторам необходимо будет скорректировать способы создания ценности, уделяя больше внимания «инновационным стратегиям», которые трудно заменить AI (например, оригинальные исследования, получение информации из первых рук), а не «стратегиям следования», которые легко поддерживаются AI (погоня за трендами, опора на вторичные источники). Несмотря на то, что AI уже начал проникать в такие инновационные области, как научные исследования, авторы с уникальным видением и глубоким мышлением по-прежнему будут иметь ценность (来源: 36氪)
