
Ключевые слова:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Усиленное обучение ProRL, NVIDIA Cosmos, Мультимодальные большие модели, Фреймворк для ИИ-агентов, Оптимизация логического вывода LLM, Математический рекорд AlphaEvolve, Самоулучшающаяся машина Дарвина-Гёделя, Медицинская оценка MedHELM, Масштабируемость усиленного обучения ProRL, Физическое моделирование Cosmos Transfer
🔥 В центре внимания
DeepMind AlphaEvolve обновляет математические рекорды, сотрудничество человека и машины способствует научному прогрессу: DeepMind AlphaEvolve дважды за неделю побил математический рекорд, державшийся 18 лет, вызвав широкий резонанс. Теренс Тао прокомментировал, что это демонстрирует, как различные методы могут дополнять друг друга для продвижения математического прогресса, а не просто определять «победителей» и «проигравших». Это событие подчеркивает потенциал сотрудничества AI и человека для создания новых парадигм в технологической и научной сферах. AI не просто заменяет людей, а совместно открывает новые пути для прогресса (источник: shaneguML)

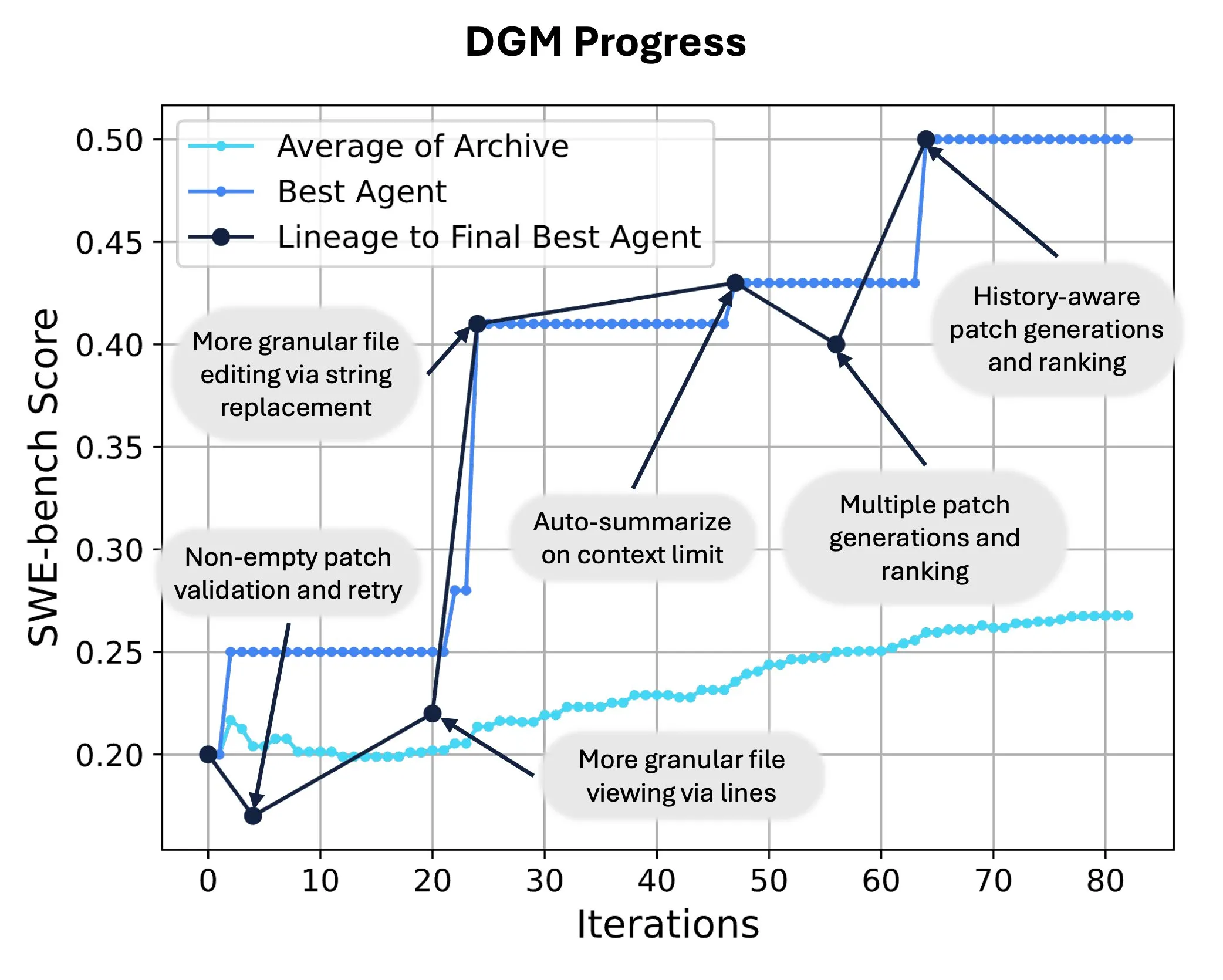
Sakana AI выпускает Darwin Gödel Machine (DGM), реализуя самопереписывание и эволюцию кода AI: Sakana AI представила Darwin Gödel Machine (DGM) — самосовершенствующегося агента, способного улучшать свою производительность путем изменения собственного кода. Вдохновленный теорией эволюции, DGM поддерживает постоянно расширяющуюся линию вариантов агентов, реализуя открытое исследование пространства проектирования «самосовершенствующихся» агентов. На SWE-bench DGM повысил производительность с 20.0% до 50.0%; на Polyglot успешность выросла с 14.2% до 30.7%, значительно превзойдя агентов, разработанных человеком. Эта технология открывает новые пути для систем AI к непрерывному обучению и эволюции способностей (источник: SakanaAILabs, hardmaru)
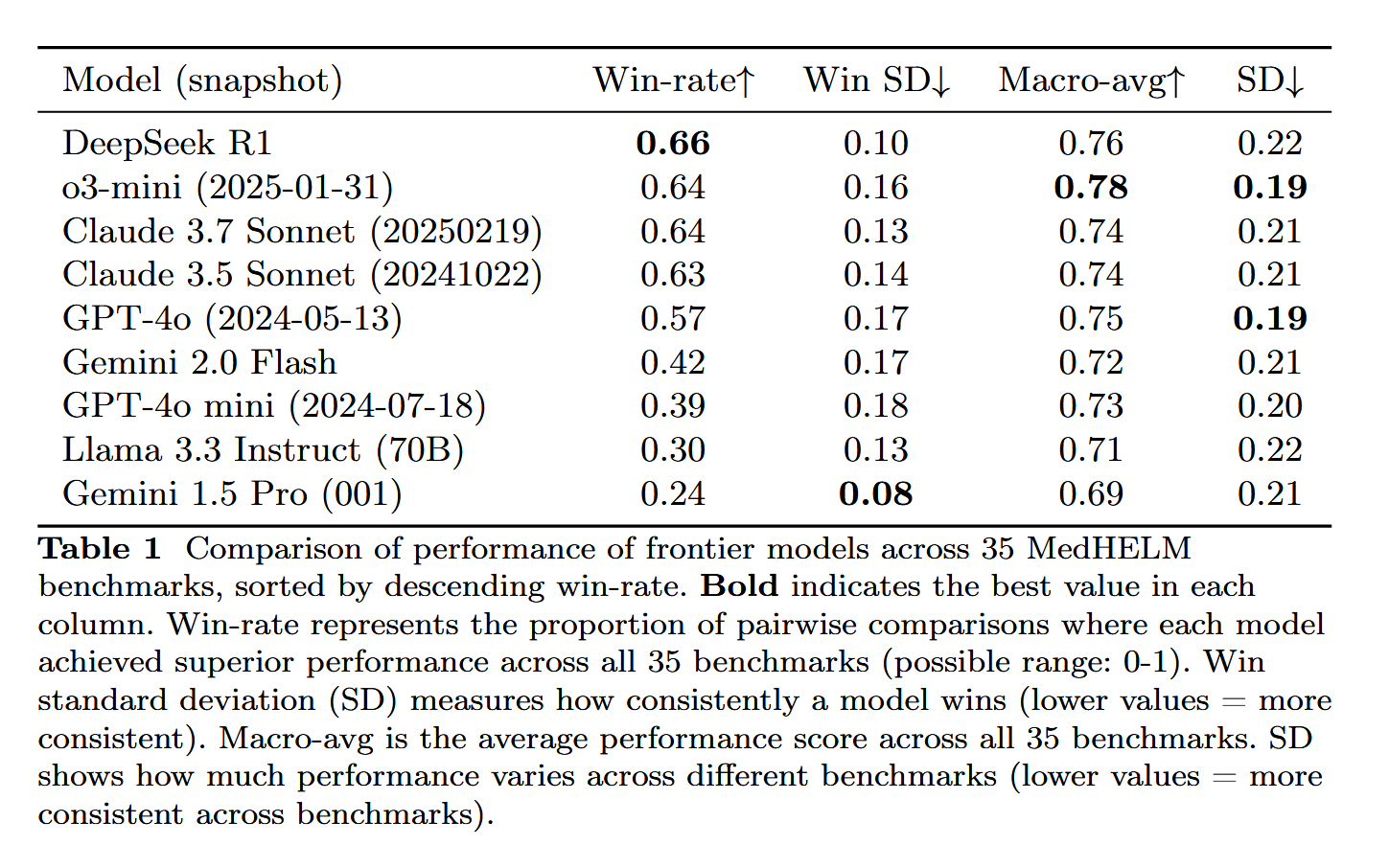
DeepSeek-R1 демонстрирует выдающиеся результаты в оценке медицинских задач MedHELM: Большая языковая модель DeepSeek-R1 показала лучшие результаты в бенчмарке MedHELM (комплексная оценка больших языковых моделей для медицинских задач), который предназначен для оценки производительности LLM в более реалистичных клинических задачах, а не в традиционных экзаменах на медицинскую лицензию. Этот результат считается весьма значимым, демонстрируя потенциал DeepSeek-R1 в медицинских приложениях, особенно в обработке реальных клинических сценариев (источник: iScienceLuvr)
Новые достижения в исследовании масштабируемости обучения с подкреплением: ProRL расширяет границы логического вывода LLM: Новая статья (arXiv:2505.24864) о масштабируемости обучения с подкреплением (RL) привлекла внимание. Исследование показывает, что длительное обучение с подкреплением (ProRL) позволяет выявить совершенно новые стратегии логического вывода, которые трудно получить из базовых моделей путем широкого сэмплирования. ProRL сочетает контроль дивергенции KL, сброс референсной стратегии и разнообразный набор задач, что позволяет моделям, обученным с помощью RL, стабильно превосходить базовые модели в различных оценках pass@k. Исследование предоставляет новые сведения о том, как RL может существенно расширить границы логического вывода языковых моделей, и закладывает основу для будущих исследований долговременного логического вывода с помощью RL. NVIDIA уже опубликовала соответствующие веса моделей (источник: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 События
NVIDIA выпускает Cosmos Transfer и Cosmos Reason для продвижения приложений AI в физическом мире: NVIDIA представила систему Cosmos, в которой Cosmos Transfer может преобразовывать простые изображения из игровых движков, информацию о глубине и даже грубые симуляции роботов в реалистичные видео реальных сцен, предоставляя большое количество контролируемых обучающих данных для AI, таких как роботы и автономное вождение. Cosmos Reason, в свою очередь, позволяет AI понимать эти сцены и принимать решения, например, как двигаться в тестах автономного вождения. Оба инструмента в настоящее время являются открытыми и, как ожидается, ускорят развитие AI в физическом мире, решая проблемы нехватки обучающих данных и контроля сцен (источник: )
DeepSeek выпускает обновление R1, экосистема открытого исходного кода продолжает процветать: DeepSeek выпустила обновление для модели R1, включая саму R1 и дистиллированную уменьшенную модель с 8 миллиардами параметров. В то же время ByteDance активно действует в области открытого исходного кода, запустив такие проекты, как BAGEL, Dolphin, Seedcoder, Dream0 и другие. Эти достижения демонстрируют активность и инновационность Китая в области AI с открытым исходным кодом, особенно в быстром развитии мультимодальных и специализированных моделей (источник: TheRundownAI, stablequan, reach_vb, clefourrier)
Google выпускает Edge AI Gallery для продвижения моделей AI с открытым исходным кодом на смартфонах: Google представила Edge AI Gallery, целью которой является внедрение моделей AI с открытым исходным кодом в смартфоны для реализации локализованных и конфиденциальных AI-приложений. Пользователи могут напрямую запускать LLM от Hugging Face на своих устройствах для генерации кода, диалогов с изображениями и других операций, с поддержкой многоходовых диалогов и возможностью выбора любой модели. Приложение основано на LiteRT, в настоящее время поддерживает Android, версия для iOS скоро появится, что будет способствовать дальнейшему развитию и популяризации AI на устройствах (источник: TheRundownAI, huggingface, reach_vb, osanseviero)
Новое исследование рассматривает использование положительных и отрицательных траекторий логического вывода при дистилляции для оптимизации LLM: Новая статья предлагает фреймворк Reinforced Distillation (REDI), направленный на улучшение способностей к логическому выводу малых моделей-студентов путем использования правильных и неправильных траекторий логического вывода, генерируемых моделью-учителем (например, DeepSeek-R1). REDI состоит из двух этапов: сначала обучение на правильных траекториях с помощью контролируемой тонкой настройки (SFT), а затем дальнейшая оптимизация модели с использованием новой целевой функции REDI (функция потерь без референса) в сочетании с положительными и отрицательными траекториями. Эксперименты показывают, что в задачах математического логического вывода REDI превосходит базовые методы, а модель Qwen-REDI-1.5B достигла высокого результата в 83.1% на MATH-500 (источник: HuggingFace Daily Papers)
Фреймворк LLMSynthor использует LLM для синтеза данных с учетом структуры: LLMSynthor — это универсальный фреймворк для синтеза данных, который превращает большие языковые модели (LLM) в симуляторы, учитывающие структуру, и управляется обратной связью по распределению. Фреймворк рассматривает LLM как непараметрические симуляторы копулы для моделирования зависимостей высокого порядка и вводит сэмплирование предложений LLM для повышения эффективности сэмплирования. Путем минимизации расхождений в пространстве сводной статистики итеративный цикл синтеза обеспечивает согласование реальных и синтетических данных. Оценка на гетерогенных наборах данных в областях, чувствительных к конфиденциальности, таких как электронная коммерция, демография и мобильность, показывает, что синтетические данные, сгенерированные LLMSynthor, обладают высокой статистической достоверностью и практической ценностью (источник: HuggingFace Daily Papers)
Фреймворк v1 улучшает мультимодальное интерактивное рассуждение за счет выборочного визуального пересмотра: v1 — это легковесное расширение, позволяющее мультимодальным большим языковым моделям (MLLM) выполнять выборочный визуальный пересмотр в процессе рассуждения. В отличие от текущих MLLM, которые обычно обрабатывают визуальный ввод однократно, v1 вводит механизм «укажи и скопируй», позволяющий модели динамически извлекать релевантные области изображения в процессе рассуждения. Благодаря обучению на наборе данных v1g, содержащем траектории мультимодального рассуждения с аннотациями визуальной привязки, v1 демонстрирует улучшение производительности на бенчмарках, таких как MathVista, особенно в задачах, требующих детальной визуальной привязки и многошагового рассуждения (источник: HuggingFace Daily Papers)
MetaFaith повышает достоверность выражения неопределенности на естественном языке в LLM: Для решения проблемы, связанной с тем, что LLM часто преувеличивают при выражении неопределенности, MetaFaith предлагает новый метод калибровки на основе подсказок. Исследование показало, что существующие LLM плохо отражают свою внутреннюю неопределенность, стандартные методы подсказок имеют ограниченный эффект, а методы калибровки, основанные на фактичности, могут даже навредить достоверной калибровке. MetaFaith, вдохновленный человеческим метапознанием, способен значительно улучшить достоверную калибровку моделей в различных задачах и для разных моделей, повышая достоверность до 61% и достигая 83% побед в оценках человеком (источник: HuggingFace Daily Papers)
CLaSp: ускорение декодирования LLM с помощью самоспекулятивного декодирования путем пропуска слоев в контексте: CLaSp — это стратегия самоспекулятивного декодирования для больших языковых моделей (LLM), которая ускоряет процесс декодирования путем пропуска промежуточных слоев проверяющей модели, при этом не требуя дополнительного обучения или модификации модели. CLaSp использует алгоритм динамического программирования для оптимизации процесса пропуска слоев и динамически корректирует стратегию на основе полного скрытого состояния предыдущего этапа проверки. Эксперименты показывают, что CLaSp обеспечивает ускорение в 1.3–1.7 раза на моделях серии LLaMA3, не изменяя исходное распределение генерируемого текста (источник: HuggingFace Daily Papers)
HardTests синтезирует высококачественные тестовые наборы для кода с помощью LLM: Для решения проблемы, связанной с тем, что существующие тестовые наборы не могут эффективно проверять код, сгенерированный LLM для сложных задач программирования, HardTests предлагает процесс HARDTESTGEN для генерации высококачественных тестовых наборов с помощью LLM. Набор данных HardTests, созданный на основе этого процесса, содержит 47 000 задач по программированию и синтезированные высококачественные тестовые наборы. По сравнению с существующими тестами, тесты, сгенерированные HARDTESTGEN, при оценке кода, сгенерированного LLM, повышают точность на 11.3%, полноту на 17.5%, а для сложных задач точность может увеличиться до 40%. Этот набор данных также демонстрирует лучшие результаты в обучении моделей (источник: HuggingFace Daily Papers)
Исследование выявляет предвзятость в визуально-языковых моделях (VLM): Исследование показало, что продвинутые визуально-языковые модели (VLM) при обработке визуальных задач, связанных с популярными темами (такими как подсчет и распознавание), сильно подвержены влиянию обширных априорных знаний, полученных из интернета. Например, VLM с трудом распознают добавленную четвертую полоску на логотипе Adidas. В задачах подсчета, охватывающих 7 различных областей, включая животных, товарные знаки, настольные игры и т.д., средняя точность VLM составила всего 17.05%. Даже указание модели тщательно проверять или полагаться только на детали изображения привело к ограниченному повышению точности. Исследование предлагает автоматизированный фреймворк для тестирования предвзятости VLM (источник: HuggingFace Daily Papers)
Point-MoE: использование модели «смесь экспертов» для междоменной генерализации в 3D семантической сегментации: Для решения проблемы обучения единой модели для разнообразных источников данных 3D облаков точек (например, камеры глубины, LiDAR) и гетерогенных доменов (например, внутри помещений, снаружи), Point-MoE предлагает архитектуру «смесь экспертов» (MoE). Эта архитектура, используя простую стратегию маршрутизации top-k, автоматически специализирует экспертные сети даже при отсутствии меток домена. Эксперименты показывают, что Point-MoE не только превосходит мощные многодоменные базовые модели, но и обладает лучшей способностью к генерализации на невиданных ранее доменах, открывая масштабируемый путь для крупномасштабного, междоменного 3D восприятия (источник: HuggingFace Daily Papers)
SpookyBench выявляет «временную слепоту» видео-языковых моделей: Несмотря на прогресс видео-языковых моделей (VLM) в понимании пространственно-временных отношений, при нечеткой пространственной информации они с трудом улавливают чисто временные паттерны. Бенчмарк SpookyBench, кодируя информацию (например, формы, текст) в последовательностях шумоподобных кадров, обнаружил, что люди могут распознавать ее с точностью более 98%, в то время как точность продвинутых VLM составляет 0%. Это указывает на то, что VLM чрезмерно полагаются на пространственные характеристики на уровне кадра и не могут извлекать смысл из временных подсказок. Исследование подчеркивает необходимость преодоления «временной слепоты» VLM, что может потребовать новых архитектур или парадигм обучения для разделения пространственной зависимости и временной обработки (источник: HuggingFace Daily Papers, _akhaliq)
Новый метод и набор данных для обнаружения научной инновационности с использованием LLM: Выявление новых научных идей имеет решающее значение, но является сложной задачей. Для решения этой проблемы исследователи предлагают использовать большие языковые модели (LLM) для обнаружения научной инновационности и создали два новых набора данных в областях маркетинга и обработки естественного языка. Метод строит наборы данных путем извлечения замыкающих множеств статей и использования LLM для обобщения их основных идей. Для улавливания концепций идей исследователи предлагают обучить легковесный ретривер, который выравнивает идеи со схожими концепциями путем дистилляции знаний на уровне идей из LLM, тем самым обеспечивая эффективный и точный поиск идей. Эксперименты доказывают, что предложенный метод превосходит другие методы на предложенных эталонных наборах данных (источник: HuggingFace Daily Papers)
un^2CLIP улучшает способность CLIP улавливать визуальные детали путем инвертирования unCLIP: Для устранения недостатков модели CLIP в различении мелких деталей изображений и обработке задач, таких как плотное предсказание, un^2CLIP предлагает улучшить CLIP путем инвертирования модели unCLIP. Сам unCLIP обучается генерировать изображения на основе вложений изображений CLIP, тем самым изучая распределение деталей изображения. un^2CLIP использует эту особенность, позволяя улучшенному кодировщику изображений CLIP приобретать способность unCLIP улавливать визуальные детали, сохраняя при этом согласованность с исходным кодировщиком текста. Эксперименты показывают, что un^2CLIP значительно превосходит исходный CLIP и другие улучшенные методы в нескольких задачах (источник: HuggingFace Daily Papers)
ViStoryBench: выпущен комплексный набор эталонных тестов для визуализации историй: Для содействия развитию технологий визуализации историй (генерация последовательных серий изображений на основе повествования и референсных изображений) ViStoryBench предоставляет комплексный эталонный тест для оценки. Этот эталонный тест содержит наборы данных различных типов историй (комедия, ужасы и т.д.) и художественных стилей (аниме, 3D-рендеринг и т.д.), а также включает истории с одним и несколькими персонажами для проверки согласованности персонажей, и сложные сюжеты и построение мира для проверки точности визуальной генерации моделей. ViStoryBench использует несколько метрик оценки, направленных на всестороннюю оценку производительности моделей в аспектах структуры повествования и визуальных элементов, помогая исследователям выявлять сильные и слабые стороны моделей и целенаправленно их улучшать (источник: HuggingFace Daily Papers)
Декодирование с ветвлением и слиянием (FMD) улучшает сбалансированное мультимодальное понимание в больших аудиовизуальных моделях: Для решения проблемы возможной модальной предвзятости в аудиовизуальных больших языковых моделях (AV-LLM) (т.е. модель чрезмерно полагается на одну модальность при принятии решений), декодирование с ветвлением и слиянием (FMD) предлагает стратегию времени вывода без дополнительного обучения. FMD сначала обрабатывает чистый аудио- и чистый видеоввод по отдельности через ранние слои декодирования (этап ветвления), а затем объединяет полученные скрытые состояния для совместного вывода (этап слияния). Этот метод направлен на содействие сбалансированному вкладу модальностей и использование взаимодополняющей информации из разных модальностей. Эксперименты на моделях, таких как VideoLLaMA2 и video-SALMONN, показывают, что FMD может улучшить производительность в задачах аудио-, видео- и совместного аудиовизуального вывода (источник: HuggingFace Daily Papers)
LegalSearchLM: переосмысление поиска юридических дел как генерации юридических элементов: Традиционные методы поиска юридических дел (LCR) полагаются на вложения или лексическое соответствие, что ограничивает их применение в реальных сценариях. LegalSearchLM предлагает новый подход, рассматривая LCR как задачу генерации юридических элементов. Эта модель выполняет логический вывод юридических элементов для запрашиваемого дела и путем ограниченного декодирования напрямую генерирует контент на основе целевого дела. Одновременно исследователи выпустили LEGAR BENCH, крупномасштабный эталонный тест LCR, содержащий 1.2 миллиона корейских юридических дел. Эксперименты показывают, что LegalSearchLM превосходит базовые модели на LEGAR BENCH на 6-20% и демонстрирует сильную способность к междоменной генерализации (источник: HuggingFace Daily Papers)
RPEval: новый бенчмарк для оценки способности больших языковых моделей к ролевым играм: Для решения проблем оценки способности больших языковых моделей (LLM) к ролевым играм, RPEval предоставляет новый бенчмарк. Этот бенчмарк оценивает производительность LLM в ролевых играх по четырем ключевым аспектам: понимание эмоций, принятие решений, моральные установки и последовательность роли. Цель состоит в том, чтобы решить проблемы больших затрат ресурсов на ручную оценку и возможной предвзятости автоматизированной оценки (источник: HuggingFace Daily Papers)
GATE: универсальная модель вложения текста для улучшения арабского STS: Для решения проблемы нехватки высококачественных наборов данных и предварительно обученных моделей в исследованиях семантической текстовой схожести (STS) на арабском языке была создана модель GATE (General Arabic Text Embedding). GATE использует обучение представлений Matryoshka и метод обучения со смешанными потерями в сочетании с набором данных триплетов для арабского естественного языкового вывода. Результаты экспериментов показывают, что GATE достигла SOTA-производительности в задачах STS на бенчмарке MTEB, превзойдя крупные модели, включая OpenAI, на 20-25%, и эффективно улавливает уникальные семантические нюансы арабского языка (источник: HuggingFace Daily Papers)
CoDA: фреймворк совместной оптимизации шума диффузии для манипулирования всем телом сочлененных объектов: Для достижения реалистичности и точности манипулирования всем телом сочлененных объектов (включая движения тела, рук и объекта), CoDA предлагает новый фреймворк совместной оптимизации шума диффузии. Этот фреймворк оптимизирует пространство шума для трех специализированных диффузионных моделей для тела, левой и правой руки, а также обеспечивает естественную координацию рук с остальными частями тела через поток градиентов в кинематической цепи человека. Для повышения точности взаимодействия руки с объектом CoDA использует унифицированное представление на основе набора базовых точек (BPS), кодируя положение конечного эффектора как расстояние до BPS геометрии объекта, тем самым направляя оптимизацию шума диффузии для генерации высокоточных интерактивных движений (источник: HuggingFace Daily Papers)
Новое объяснение механизма рефлексии при выводе LLM: Байесовская адаптивная структура обучения с подкреплением BARL: Северо-Западный университет в сотрудничестве с Google DeepMind предложил Байесовскую адаптивную структуру обучения с подкреплением (BARL), направленную на объяснение и оптимизацию поведения «рефлексии» больших языковых моделей (LLM) в процессе вывода. Традиционное обучение с подкреплением (RL) во время тестирования обычно использует только изученную стратегию, в то время как BARL, вводя моделирование неопределенности среды, позволяет модели адаптивно исследовать новые стратегии во время вывода. Эксперименты показывают, что BARL может достигать более высокой точности в задачах, таких как математический вывод, и значительно сокращать потребление токенов. Это исследование впервые с байесовской точки зрения объясняет, почему, как и когда LLM должны проводить рефлексивное исследование (источник: 量子位)

Применение LLM в формальных грамматиках с неопределенностью: когда доверять LLM для автоматического вывода: Большие языковые модели (LLM) демонстрируют потенциал в генерации формальных спецификаций, но их вероятностный характер противоречит требованиям детерминизма формальной верификации. Исследователи всесторонне изучили режимы отказа и количественную оценку неопределенности (UQ) в формальных конструкциях, генерируемых LLM. Результаты показывают, что влияние автоматической формализации на основе SMT на точность зависит от области, а существующие методы UQ с трудом выявляют эти ошибки. В статье вводится фреймворк вероятностных контекстно-свободных грамматик (PCFG) для моделирования вывода LLM и обнаруживается, что сигналы неопределенности зависят от задачи. Путем объединения этих сигналов можно реализовать выборочную верификацию, значительно сократив количество ошибок и сделав формализацию на основе LLM более надежной (источник: HuggingFace Daily Papers)
Сравнение тонкой настройки малых языковых моделей (SLM) и промптинга больших языковых моделей (LLM) при генерации рабочих процессов с низким кодом: Исследование сравнивает эффективность тонкой настройки малых языковых моделей (SLM) и промптинга больших языковых моделей (LLM) в задаче генерации рабочих процессов с низким кодом в формате JSON. Результаты показывают, что, хотя хороший промптинг может позволить LLM давать разумные результаты, для задач, специфичных для предметной области, и структурированного вывода тонкая настройка SLM в среднем обеспечивает повышение качества на 10%. Это указывает на то, что в определенных сценариях SLM по-прежнему имеют преимущество, особенно при высоких требованиях к качеству вывода (источник: HuggingFace Daily Papers)
Оценка и управление модальными предпочтениями в мультимодальных больших моделях: Исследователи создали бенчмарк MC², который систематически оценивает модальные предпочтения мультимодальных больших языковых моделей (MLLM) (т.е. склонность полагаться на одну модальность при принятии решений) в контролируемых сценариях с конфликтующими доказательствами. Исследование показало, что все 18 протестированных MLLM демонстрируют явную модальную предвзятость, и направление предпочтений может быть изменено внешним вмешательством. На основе этого исследователи предложили метод зондирования и управления на основе инженерии представлений, который позволяет явно контролировать модальные предпочтения без дополнительной тонкой настройки или тщательно разработанных подсказок, и достиг положительных результатов в таких последующих задачах, как смягчение галлюцинаций и мультимодальный машинный перевод (источник: HuggingFace Daily Papers)
Текущее состояние исследований безопасности многоязычных LLM: от измерения языкового разрыва до его преодоления: Систематический обзор почти 300 статей конференций по NLP за 2020-2024 годы показал, что исследования безопасности LLM страдают от значительной англоцентричности. Даже хорошо обеспеченные ресурсами неанглийские языки редко привлекают внимание, неанглийские языки редко становятся независимыми объектами исследования, а исследованиям безопасности на английском языке повсеместно не хватает хорошей практики документирования языков. Для продвижения многоязычных исследований безопасности в статье предлагаются будущие направления, включая оценку безопасности, генерацию обучающих данных и межъязыковую генерализацию безопасности, с целью разработки более надежных и инклюзивных практик безопасности AI для различных групп населения по всему миру (источник: HuggingFace Daily Papers, sarahookr)

Пересмотр билинейных переходов состояний в рекуррентных нейронных сетях: Традиционно считается, что скрытые единицы рекуррентных нейронных сетей (RNN) в основном используются для моделирования памяти. Данное исследование рассматривает это с другой точки зрения, полагая, что скрытые единицы являются активными участниками вычислений сети. Исследователи пересмотрели билинейные операции, включающие мультипликативное взаимодействие между скрытыми единицами и входными вложениями, теоретически и эмпирически доказав, что они являются естественным индуктивным смещением для представления эволюции скрытых состояний в задачах отслеживания состояний. Исследование также показывает, что билинейные обновления состояний образуют естественную иерархию, соответствующую задачам отслеживания состояний с возрастающей сложностью, в то время как популярные линейные RNN (такие как Mamba) находятся в центре этой иерархии с наименьшей сложностью (источник: HuggingFace Daily Papers)
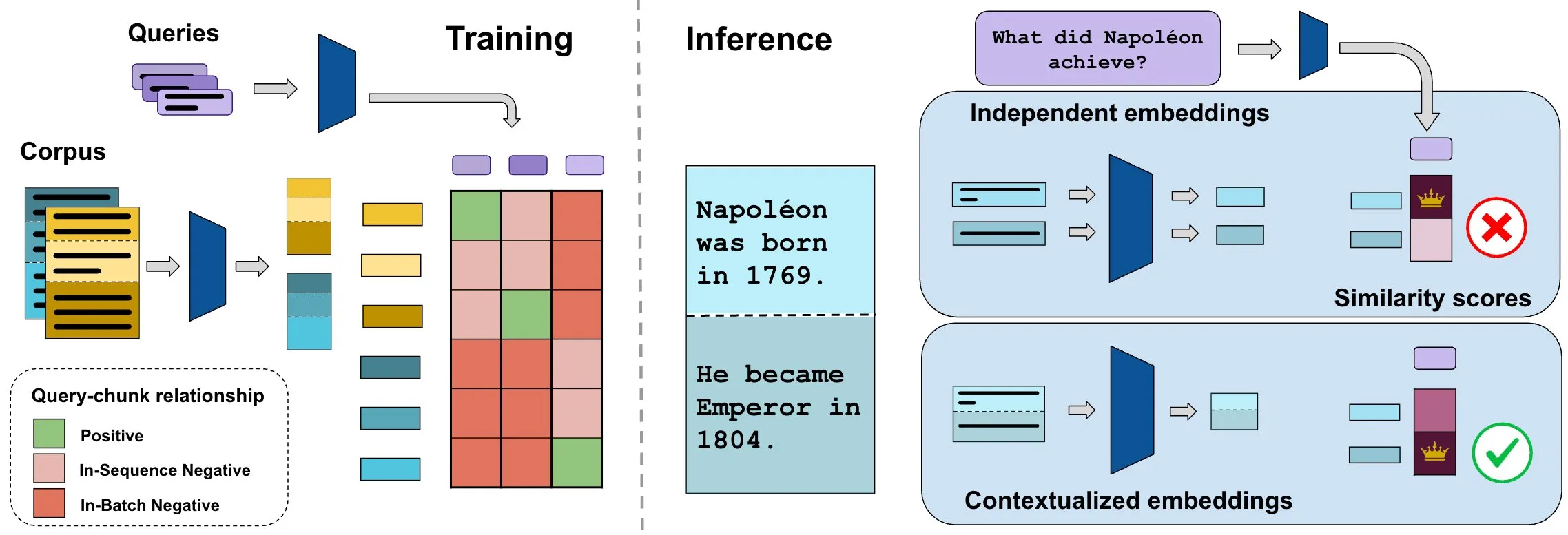
Бенчмарк ConTEB оценивает вложения контекстных документов, метод InSeNT улучшает качество поиска: Текущие методы вложения для поиска документов обычно кодируют различные фрагменты (chunk) одного и того же документа независимо, игнорируя информацию контекста на уровне документа. Для решения этой проблемы исследователи представили бенчмарк ConTEB, специально предназначенный для оценки способности моделей поиска использовать контекст документа, и обнаружили, что SOTA-модели плохо справляются с этой задачей. Одновременно исследователи предложили метод последующего обучения контрастивному обучению InSeNT (In-Sequence Negative Training) в сочетании с поздним объединением фрагментов (late chunk pooling) для усиления обучения контекстным представлениям, что значительно улучшило качество поиска на ConTEB и показало большую устойчивость к неоптимальным стратегиям разбиения на фрагменты и более крупным корпусам (источник: HuggingFace Daily Papers, tonywu_71)
🧰 Инструменты
PraisonAI: фреймворк для мультиагентных систем AI с низким уровнем кодирования: PraisonAI — это производственный мультиагентный фреймворк AI, разработанный для упрощения автоматизации и решения проблем, от простых задач до сложных вызовов, с помощью решений с низким уровнем кодирования. Он объединяет PraisonAI Agents, AG2 (AutoGen) и CrewAI, подчеркивая простоту, настраиваемость и эффективное сотрудничество человека и машины. Его функции включают автоматическое создание AI-агентов, саморефлексию, мультимодальность, мультиагентное сотрудничество, добавление знаний, краткосрочную и долгосрочную память, RAG, интерпретатор кода, более 100 настраиваемых инструментов и поддержку LLM. Поддерживает Python и JavaScript, а также предоставляет опцию конфигурации YAML без кода (источник: GitHub Trending)
TinyTroupe: открытый фреймворк Microsoft для симуляции мультиагентных ролей на базе LLM: TinyTroupe — это экспериментальная библиотека Python, использующая большие языковые модели (LLM, в частности GPT-4) для симуляции персонажей (TinyPerson) с определенными личностями, интересами и целями, взаимодействующих в симулированной среде (TinyWorld). Фреймворк направлен на усиление воображения и предоставление бизнес-инсайтов через симуляцию, и может применяться для оценки рекламы, тестирования программного обеспечения, генерации синтетических данных, сбора отзывов о продуктах и мозгового штурма. Пользователи могут определять агентов и среды с помощью файлов Python и JSON для проведения программных, аналитических и мультиагентных симуляционных экспериментов (источник: GitHub Trending)

FLUX Kontext достигает прорыва в референсе по нескольким изображениям и редактировании изображений: Пользователи сообщают, что FLUX Kontext отлично справляется с референсом по нескольким изображениям, эту функцию можно включить с помощью узла слияния изображений в ComfyUI. Инструмент позволяет достичь высокой степени согласованности при редактировании изображений, например, при создании демонстрационных изображений для подарочной коробки он хорошо воспроизводит текстуру материала, пыль и другие детали. Кроме того, пользователи продемонстрировали использование FLUX Kontext для операций ретуширования, таких как похудение, сужение лица, наращивание мышц одним щелчком мыши, с естественными результатами и высокой степенью сходства лиц, что обеспечивает удобство для таких сценариев, как электронная коммерция (источник: op7418, op7418, op7418)

Ichi: диалоговый AI на устройстве на базе MLX Swift и MLX audio: Rudrank Riyam разработал Ichi, проект диалогового AI на устройстве, использующий MLX Swift и MLX audio. Это означает, что обработка диалогов может выполняться локально на устройстве, что помогает защитить конфиденциальность пользователей и уменьшить зависимость от облачных сервисов. Код проекта открыт на GitHub (источник: stablequan, awnihannun)
FedRAG представляет NoEncode RAG с основной абстракцией MCP: Проект FedRAG представил новую основную абстракцию — NoEncode RAG with MCP. Традиционный RAG включает ретривер, генератор и базу знаний, где знания в базе знаний должны быть закодированы моделью ретривера. NoEncode RAG же полностью пропускает этап кодирования, состоя непосредственно из базы знаний NoEncode и генератора, без необходимости в ретривере/вложениях. Это открывает путь для создания систем RAG, использующих серверы MCP (Model Component Provider) в качестве источников знаний, позволяя пользователям подключаться к нескольким сторонним источникам MCP и тонко настраивать RAG через FedRAG для достижения оптимальной производительности (источник: nerdai)

📚 Обучение
Курс Стэнфордского университета CS224n (версия 2024 года) доступен онлайн, добавлены материалы по LLM и агентам: Классический курс Стэнфордского университета по обработке естественного языка CS224n выпустил последнюю версию 2024 года. Новая программа курса охватывает передовые темы, связанные с большими языковыми моделями (LLM), такие как предварительное обучение, последующее обучение, бенчмаркинг, логический вывод, агенты и т.д. Видеолекции курса опубликованы на YouTube, также предлагается платный синхронный курс (источник: stanfordnlp)
Руководство по улучшению навыков системной архитектуры: практика и обучение в эпоху AI: Dotey поделился подробными методами улучшения личных навыков системной архитектуры в условиях растущей мощи программирования с помощью AI. В статье подчеркивается, что системное проектирование — это процесс разделения сложных систем на легко реализуемые и обслуживаемые небольшие модули с четким определением взаимодействия между ними. Методы улучшения включают «больше смотреть» (изучение классических примеров, проектов с открытым исходным кодом), «больше практиковаться» (восстановление архитектуры, сравнительное обучение, проектирование в первую очередь, проверка с помощью AI, рефакторинг, практическая работа над сторонними проектами) и «больше анализировать» (обобщение оснований для принятия решений, извлеченные уроки). AI может служить вспомогательным инструментом, помогая искать информацию, проверять дизайн, содействовать коммуникации и принятию решений, но не может заменить практику и мышление (источник: dotey)

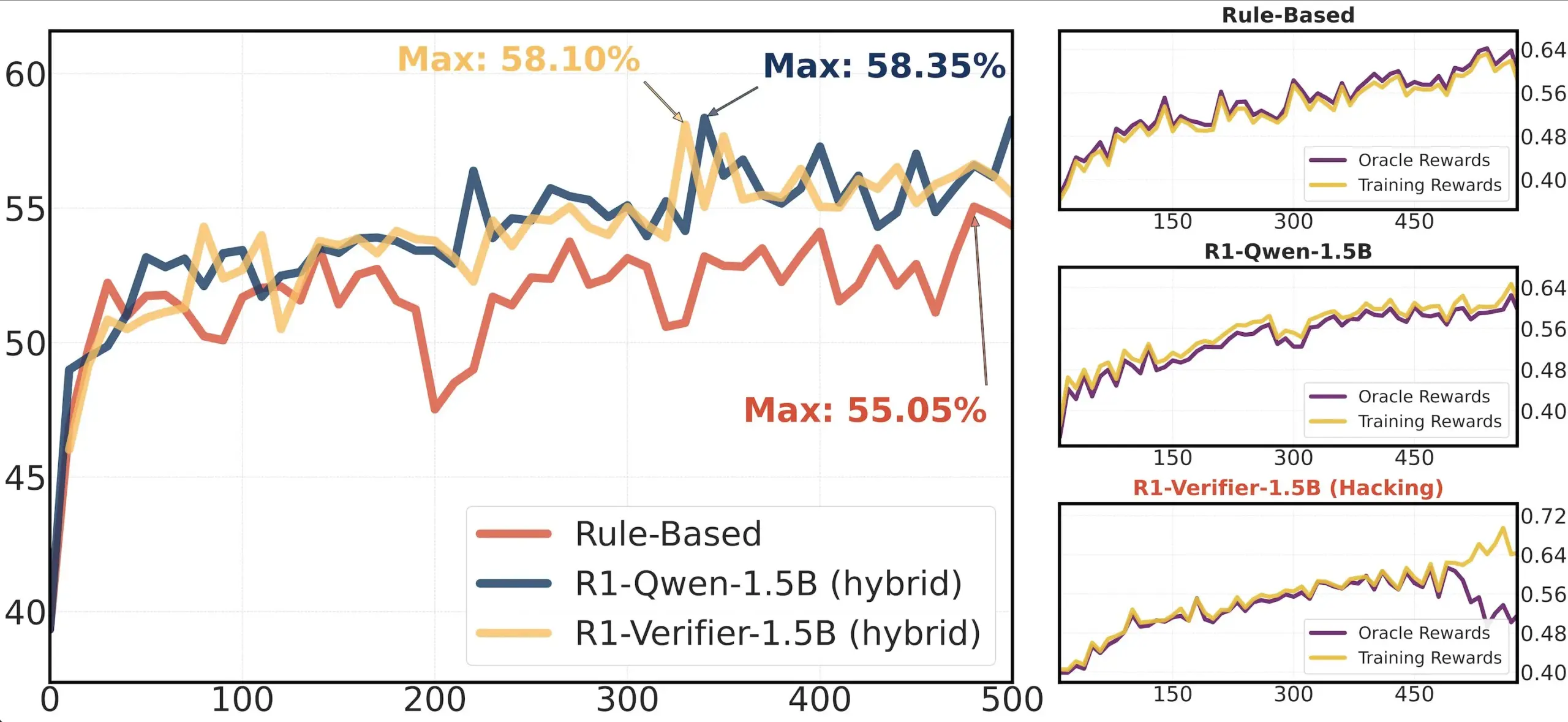
Обзор статьи: Исследование надежности верификаторов в RLHF: Статья «Pitfalls of Rule- and Model-based Verifiers» исследует недостатки верификаторов на основе правил и моделей в обучении с подкреплением с верификацией (RLVR). Исследование показало, что верификаторы на основе правил часто ненадежны даже в математической области и недоступны во многих областях; в то время как верификаторы на основе моделей легко атаковать, например, путем создания простых состязательных паттернов. Интересно, что по мере того, как сообщество переходит к генеративным верификаторам, исследование обнаружило, что они более подвержены манипулированию вознаграждением (reward hacking), чем дискриминативные верификаторы, что указывает на то, что дискриминативные верификаторы могут быть более надежными в RLVR (источник: Francis_YAO_)
Рекомендация статьи: Теорема о равноколебаниях для наилучшего полиномиального приближения: В статье представлена теорема о равноколебаниях для наилучшего полиномиального приближения, а также связанная с ней проблема дифференцирования в бесконечной норме. Эта теорема является классическим результатом теории аппроксимации функций и имеет важное значение для понимания и разработки численных алгоритмов (источник: eliebakouch)
Reasoning Gym: Среды для рассуждений с проверяемыми вознаграждениями для обучения с подкреплением: Новая статья «Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards» (arXiv:2505.24760) предлагает набор сред для рассуждений для обучения с подкреплением. Особенностью этих сред является проверяемость их вознаграждений, что предоставляет платформу для исследования и разработки более надежных агентов для рассуждений на основе обучения с подкреплением (источник: Ar_Douillard)

🌟 Сообщество
Обсуждение «промежуточного обучения (Mid-training)»: Сообщество AI обсуждает значение и практику термина «промежуточное обучение (Mid-training)». Некоторые выражают недоумение, зная только о предварительном и последующем обучении. Существует мнение, что промежуточное обучение может относиться к определенному этапу обучения между предварительным обучением и окончательной тонкой настройкой, например, к непрерывному предварительному обучению для специфических знаний в определенной области или раннему выравниванию. Dorialexander поделился соответствующей статьей в блоге, дополнительно исследуя эту концепцию, полагая, что она может включать внедрение специфических задач или способностей поверх базовой модели, но единого определения и методологии пока не сформировано (источник: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Анализ обратной разработки Claude Code привлек внимание: Hrishi, проведя обратную разработку минимизированного кода Claude Code за 8-10 часов с использованием нескольких субагентов и флагманских моделей от крупных поставщиков, раскрыл сложность его внутренней структуры. Анализ показывает, что Claude Code — это не просто цикл модели Claude, а содержит множество механизмов, заслуживающих изучения. Это открытие вызвало обсуждение в сообществе, которое считает, что из этого можно извлечь много опыта по созданию агентов и применению моделей (источник: rishdotblog, imjaredz, hrishioa)
Обсуждение длины системных подсказок и производительности моделей: Сообщество обсуждает влияние длины системных подсказок на производительность LLM. Dotey считает, что сверхдлинные системные подсказки не всегда хороши, могут размывать внимание модели, увеличивать затраты, и отмечает, что системные подсказки продуктов серии ChatGPT относительно коротки, но эффективны. В то же время Tony出海号 упоминает, что системные подсказки таких продуктов, как Claude, Cursor, достигают десятков тысяч слов, намекая на необходимость расширения систем подсказок. Статья YC также раскрывает, что ведущие AI-компании используют длинные подсказки, XML, мета-подсказки и другие методы для «приручения» LLM. Dorialexander, в свою очередь, выражает сомнения в надежности методов длинных подсказок, упомянутых в статье YC, в обучении RL/рассуждению и интересуется, как смягчить проблему «подхалимства» (sycophancy) (источник: dotey, Dorialexander)

Проблема масштабируемости Softpick вызвала похвалу за научную прозрачность: Исследователь Zed публично заявил, что его предыдущий метод Softpick при масштабировании на более крупные модели (1.8B параметров) показал худшие результаты по потерям при обучении и в бенчмарках по сравнению с Softmax, и уже обновил препринт на arXiv. Сообщество высоко оценило это прозрачное сообщение о негативных результатах, считая это крайне важным для научного прогресса и качеством отличного научного коллеги (источник: gabriberton, vikhyatk, BlancheMinerva)
Пользователи делятся выбором моделей и опытом локального запуска LLM: Пользователи сообщества Reddit r/LocalLLaMA активно обсуждают используемые ими локальные большие языковые модели. Модели Qwen 3 (особенно 32B Q4, 32B Q8, 30B A3B), Gemma 3 (особенно 27B QAT Q8, 12B), Devstral и другие широко упоминаются благодаря их производительности в кодировании, творчестве, общем логическом выводе и т.д. Пользователи обращают внимание на длину контекста моделей, скорость вывода, квантованные версии (например, IQ1_S_R4) и работу на различном оборудовании (например, 8GB VRAM, телефоны с чипом Snapdragon 8 Elite). Закрытые модели, такие как Claude Code, Gemini API, также используются одновременно из-за их специфических преимуществ (например, обработка длинного контекста, возможности кодирования) (источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Прочее
Развитие навыков в эпоху AI: умение задавать вопросы, критическое мышление и непрерывное обучение являются ключевыми: Обсуждение подчеркивает, что в эпоху AI шесть навыков имеют решающее значение: умение задавать вопросы, критическое мышление, поддержание режима обучения, навыки кодирования или составления инструкций, умелое использование инструментов AI и четкая коммуникация. Компания Zapier даже требует от 100% новых сотрудников владения AI, что интерпретируется в основном как акцент на коммуникационных потребностях и способности правильно делегировать задачи, а не на чисто технических знаниях. AI упрощает выполнение, поэтому качество проектирования и мышления оказывает большее влияние на конечный результат (источник: TheTuringPost, zacharynado)

Этика AI и социальное воздействие: опасения и расширение возможностей сосуществуют: Актер Стив Карелл выразил обеспокоенность по поводу будущего общества, изображенного в его новом фильме «Mountainhead», полагая, что это может быть общество, в котором мы скоро будем жить, намекая на опасения по поводу потенциальных негативных последствий AI. С другой стороны, существует мнение, что AI не обязательно приведет к крайней поляризации на «крестьян и королей», а наоборот, может, расширяя возможности отдельных лиц, сократить разрыв в возможностях между отдельными людьми и крупными компаниями, способствуя повышению личной производительности, креативности и влияния. Однако к перспективам демократизации AI некоторые относятся с осторожностью, полагая, что крупные корпорации по-прежнему будут удерживать доминирующее положение, контролируя обучение и развертывание моделей (источник: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Платформа агрегации вакансий на базе AI Hiring Cafe: Hamed N. использовал ChatGPT API для сбора 4.1 миллиона вакансий, опубликованных непосредственно на сайтах компаний, и создал сайт Hiring Cafe. Платформа призвана решить проблему «призрачных вакансий» и сторонних посредников на таких платформах, как LinkedIn и Indeed, помогая соискателям более эффективно отбирать вакансии с помощью мощных фильтров (например, должность, функция, отрасль, опыт работы, управленческая/IC роль и т.д.). Это некоммерческий побочный проект аспиранта, который получил положительные отзывы и используется сообществом (источник: Reddit r/ChatGPT)
