
Ключевые слова:DeepSeek R1-0528, Машина Гёделя Дарвина, Потребление энергии ИИ, Обучение с подкреплением с ложными наградами, Ascend от Huawei, Рейтинг SuperCLUE, Мультимодальное тестирование, Повышение производительности DeepSeek R1-0528, Механизм саморазвития DGM, Ядерные решения для центров обработки данных ИИ, Механизм RLVR модели Qwen, Оптимизация обучения Pangu Ultra MoE
🔥 В центре внимания
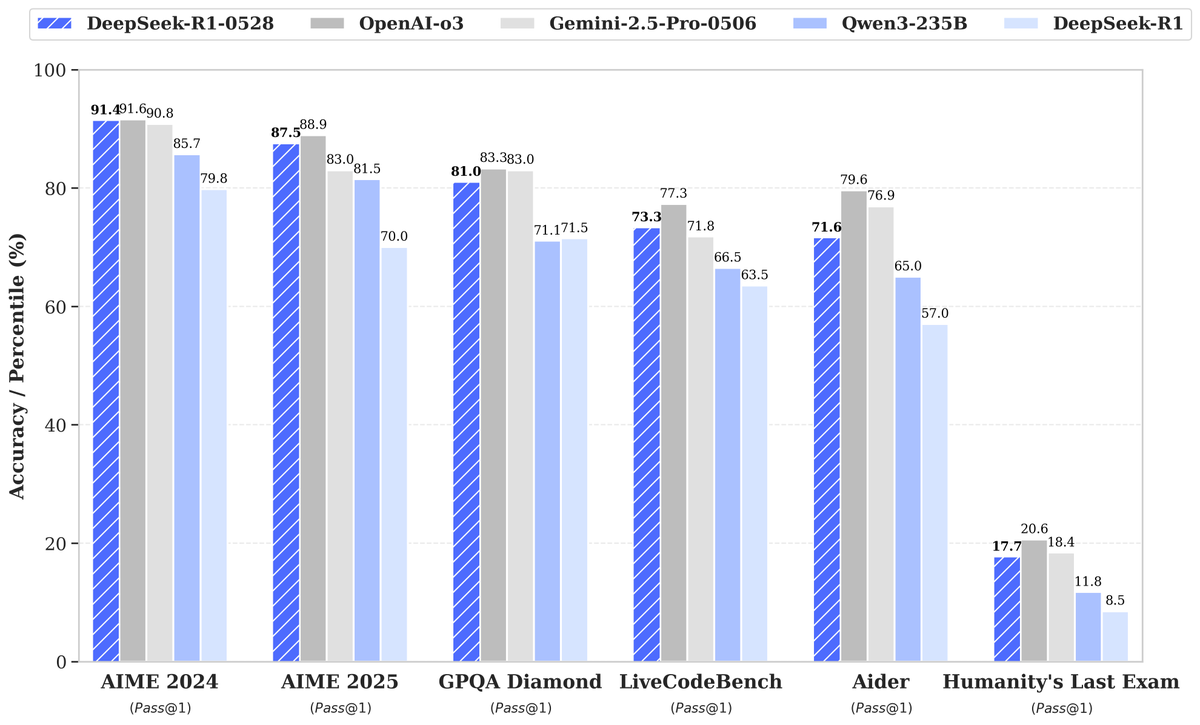
DeepSeek выпустила новую модель R1-0528 со значительно улучшенной производительностью, что привлекло внимание: DeepSeek представила новую версию своей большой языковой модели R1-0528, которая показала отличные результаты в нескольких бенчмарках, особенно добившись значительного прогресса в таких областях, как генерация кода (LiveCodeBench), научное мышление (GPQA Diamond) и математические соревнования (AIME 2024). Artificial Analysis отмечает, что R1-0528 поднялась в их индексе интеллекта с 60 до 68 баллов, сравнявшись с Gemini 2.5 Pro от Google, став второй в мире лабораторией ИИ и укрепив свои лидирующие позиции в области моделей с открытыми весами. Сообщество отреагировало положительно, и Unsloth быстро выпустила квантованные версии GGUF для удобного локального развертывания. Это обновление было в основном достигнуто за счет техник пост-обучения, таких как обучение с подкреплением (RL), что демонстрирует потенциал для постоянного повышения интеллекта модели на основе существующей архитектуры и предварительного обучения. Хотя некоторые обсуждения указывают на то, что ее выходные данные иногда имеют «льстивый» стиль, в целом это считается значительным скачком в способностях к рассуждению и написанию кода. (Источник: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
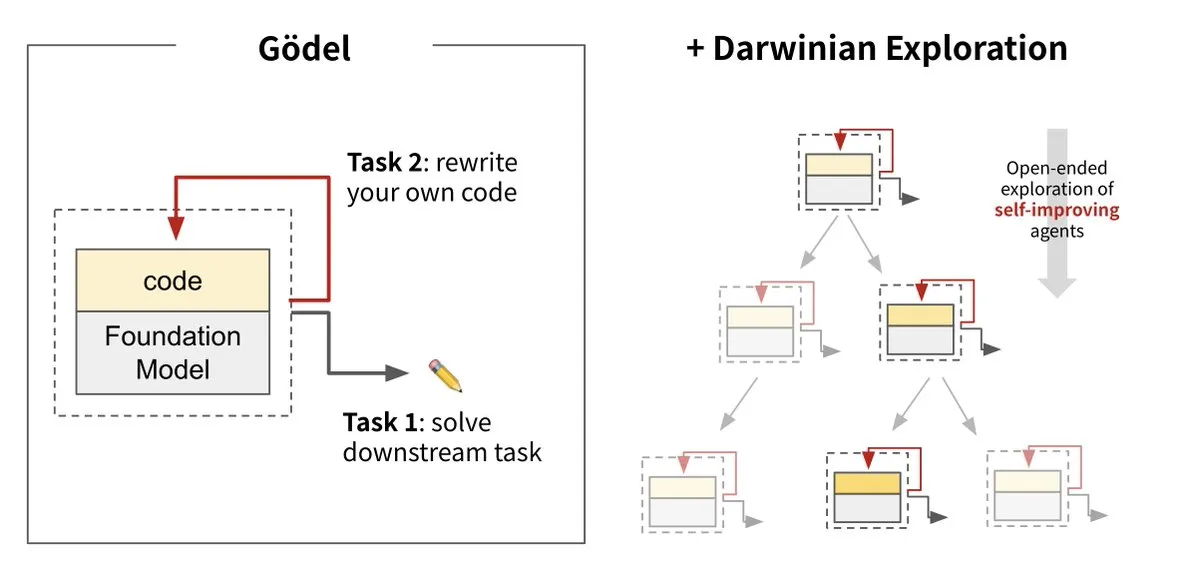
Sakana AI представила Darwin Gödel Machine (DGM), реализующую самоэволюцию ИИ: Sakana AI в сотрудничестве с UBC представила Darwin Gödel Machine (DGM) — интеллектуального агента ИИ, способного постоянно самосовершенствоваться путем перезаписи собственного кода. Система, вдохновленная теорией эволюции, сочетает в себе большие базовые модели и кодовые базы, позволяя агенту предлагать улучшения кода и самостоятельно их оценивать. Эксперименты показали, что производительность DGM на SWE-bench выросла с 20% до 50%, а на Polyglot — с 14,2% до 30,7%, что значительно превосходит агентов, разработанных вручную. Это исследование считается важным шагом на пути к созданию ИИ, способного к автономному обучению и инновациям, направленного на решение проблемы фиксации интеллекта систем ИИ после развертывания, и подчеркивает высокое внимание к безопасности в процессе разработки. (Источник: Sakana AI, hardmaru, ITmedia AI+)
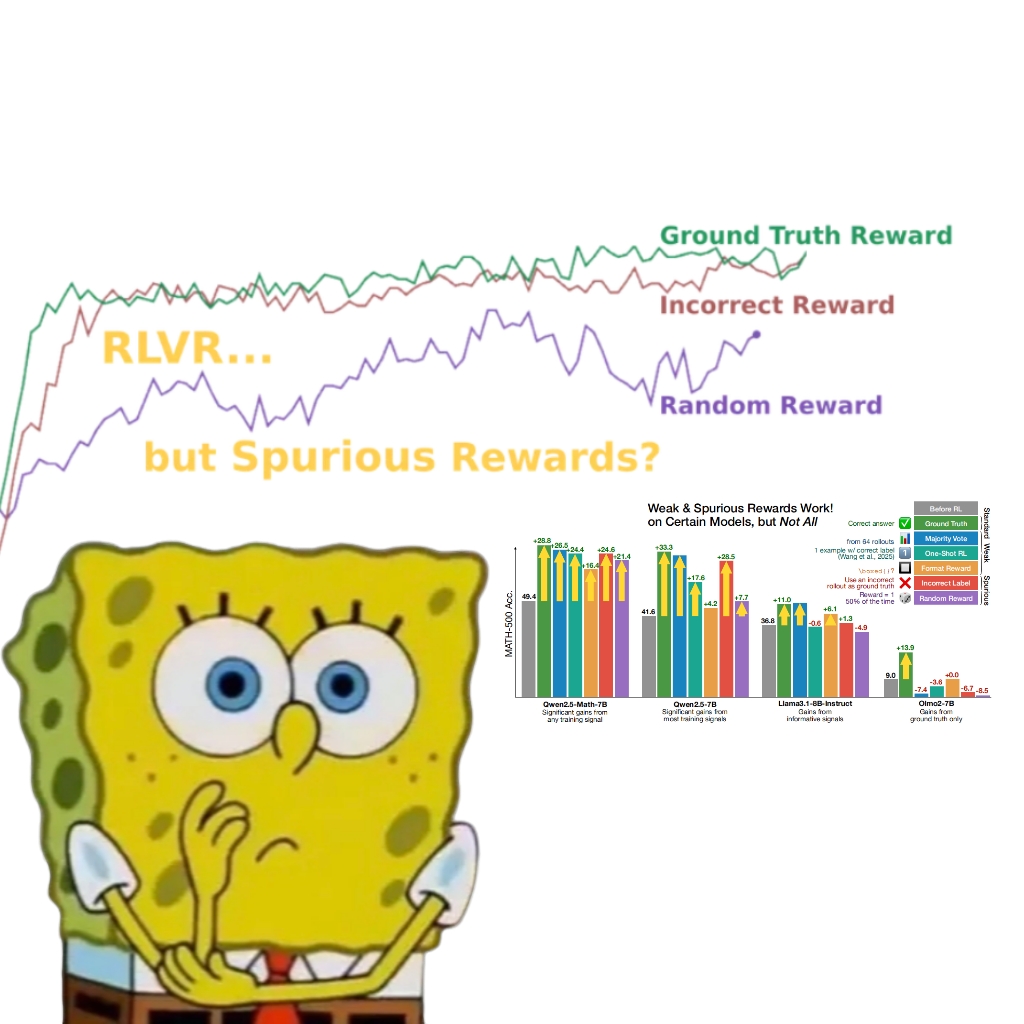
Энергопотребление ИИ вызывает озабоченность, атомная энергия и ископаемое топливо становятся потенциальными источниками энергии: Серия репортажей MIT Technology Review «Power Hungry» подробно рассматривает ожидаемые потребности искусственного интеллекта (ИИ) в энергии. Центры обработки данных ИИ нуждаются в постоянном и стабильном электроснабжении, особенно для сценариев инференса моделей. Хотя солнечная и ветровая энергия являются чистыми источниками, их прерывистый характер затрудняет удовлетворение потребностей ИИ в одиночку, если только не использовать дорогостоящие решения для хранения энергии. Атомная энергия рассматривается как потенциальное решение благодаря своей способности обеспечивать постоянную выработку электроэнергии, однако строительство новых АЭС — длительный и сложный процесс. Поэтому ископаемые виды топлива, такие как природный газ, могут стать краткосрочной зависимостью для удовлетворения быстрорастущих энергетических потребностей ИИ, что может создать проблемы для климатических целей. В отчете подчеркивается, что крупные технологические компании должны продвигать более чистые энергетические решения, такие как технологии улавливания углерода или оптимизация эффективности использования энергии, чтобы справиться с двойной проблемой энергетики и климата, связанной с развитием ИИ. (Источник: MIT Technology Review, The Download)

Исследование показало, что ложные вознаграждения также могут улучшить производительность модели Qwen, что вызывает переосмысление механизма RLVR: Исследовательская группа из Вашингтонского университета обнаружила, что даже при использовании случайных или неверных сигналов вознаграждения, обучение модели Qwen2.5-Math с помощью обучения с подкреплением на основе верифицируемых вознаграждений (RLVR) может значительно повысить ее производительность на бенчмарках математического мышления, таких как MATH-500, примерно на 25%, приближаясь к эффекту оптимизации с реальными вознаграждениями. Исследование указывает, что это явление в основном связано с тем, что модель Qwen в процессе предварительного обучения усвоила определенные стратегии логического вывода кода (например, генерация кода Python для помощи в рассуждениях), а процесс RLVR (особенно при использовании алгоритма GRPO) усиливает частоту такого полезного поведения, а не правильность самого сигнала вознаграждения. Это открытие не применимо к другим моделям, не обладающим такими особенностями предварительного обучения (например, OLMo2-7B), производительность которых при ложных вознаграждениях практически не меняется или даже снижается. Данное исследование ставит под сомнение традиционное представление о том, что RLVR зависит от правильных сигналов вознаграждения, и напоминает исследователям о необходимости остерегаться влияния специфического поведения модели на результаты оценки, подчеркивая важность межмодельной проверки. (Источник: 量子位, Stella Li)
🎯 Новости и тенденции
Huawei Ascend обеспечивает эффективное обучение модели Pangu Ultra MoE почти триллионного масштаба, достигая полного цикла автономного контроля: Huawei опубликовала технический отчет, в котором подробно описывается практика эффективного обучения модели Pangu Ultra MoE (718 миллиардов параметров) на базе аппаратного обеспечения Ascend AI и фреймворка MindSpore. Благодаря интеллектуальному выбору стратегий распараллеливания, глубокой интеграции вычислений и коммуникаций, глобальной динамической балансировке нагрузки и другим технологиям, на кластере Ascend Atlas 800T A2 из 10 000 карт была достигнута MFU (эффективность использования вычислительной мощности модели) в 41%. На этапе пост-обучения RL, в сочетании с технологией совместного использования карт для обучения и инференса RL Fusion и квази-асинхронным механизмом StaleSync, на кластере Ascend CloudMatrix 384 из суперузлов была достигнута высокая пропускная способность 35K токенов/с на суперузел, что эквивалентно решению одной задачи по высшей математике каждые 2 секунды. Этот шаг знаменует собой зрелость замкнутого цикла отечественных вычислительных мощностей ИИ и обучения больших моделей, а также демонстрирует лидирующую в отрасли производительность в обучении сверхбольших моделей MoE. (Источник: 量子位)

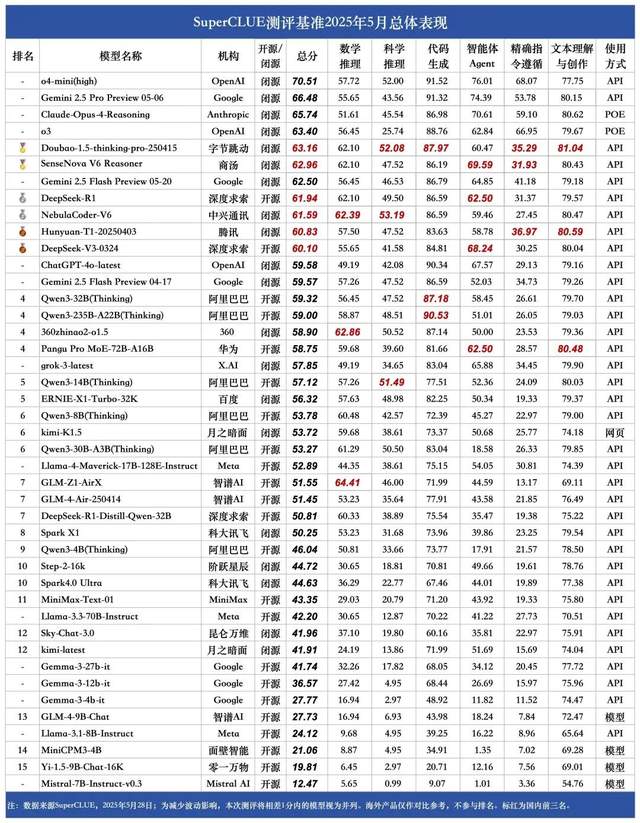
Майский рейтинг китайских больших моделей SuperCLUE: Doubao 1.5 и SenseTime Rì Rì Xīn V6 делят первое место в Китае: Авторитетное агентство по оценке больших моделей SuperCLUE опубликовало «Отчет об эталонном тестировании китайских больших моделей» за май 2025 года. Отчет показывает, что модель Doubao-1.5-thinking-pro от ByteDance и мультимодальная модель SenseNova-V6 Reasoner от SenseTime делят первое место в Китае, их производительность в общих китайскоязычных способностях уже превзошла Gemini 2.5 Flash Preview. Модели DeepSeek-R1, NebulaCoder-V6, 混元-T1 и DeepSeek-V3 следуют за ними, занимая второй эшелон. В отчете подчеркивается, что разрыв в общих способностях между ведущими отечественными и зарубежными большими моделями в китайскоязычной сфере сокращается, и конкурентная среда отечественных моделей для логического вывода начинает формироваться. Текущая оценка охватывала шесть основных задач: математическое мышление, научное мышление, генерация кода, интеллектуальные агенты (Agent), точное следование инструкциям, а также понимание и создание текста. (Источник: 量子位)
Оценка LIFEBench показывает, что большие модели повсеместно испытывают трудности с соблюдением инструкций по длине текста: Новый бенчмарк под названием LIFEBench показал, что современные основные большие языковые модели (LLM) плохо справляются с соблюдением инструкций по определенной длине текста, особенно при генерации длинных текстов. Исследование протестировало 26 моделей и обнаружило, что большинство моделей получают низкие оценки, когда их просят сгенерировать текст точной длины, и лишь немногие модели, такие как o3-mini, Claude-Sonnet-Thinking и Gemini-2.5-Pro, показали приемлемые результаты. Генерация длинных текстов (>2000 слов) является повсеместной слабой стороной, и оценки всех моделей значительно снизились. Кроме того, модели в целом хуже справляются с задачами на китайском языке по сравнению с английским и склонны к «избыточной генерации». Исследование также указывает, что заявленная многими моделями максимальная длина вывода не соответствует их реальным возможностям, что свидетельствует о «чрезмерной рекламе». Модели испытывают трудности с восприятием длины, обработкой длинных входных данных и избеганием «ленивой генерации» (например, преждевременное прекращение или отказ от генерации). (Источник: 量子位)
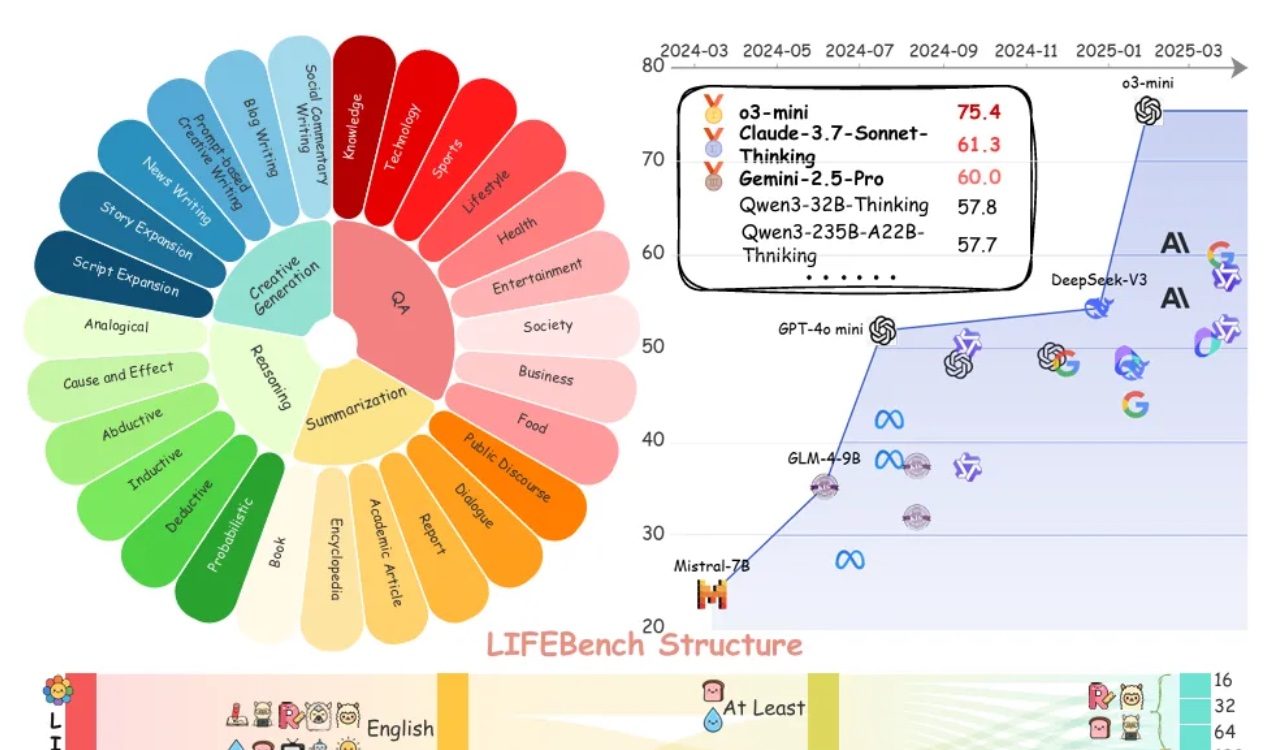
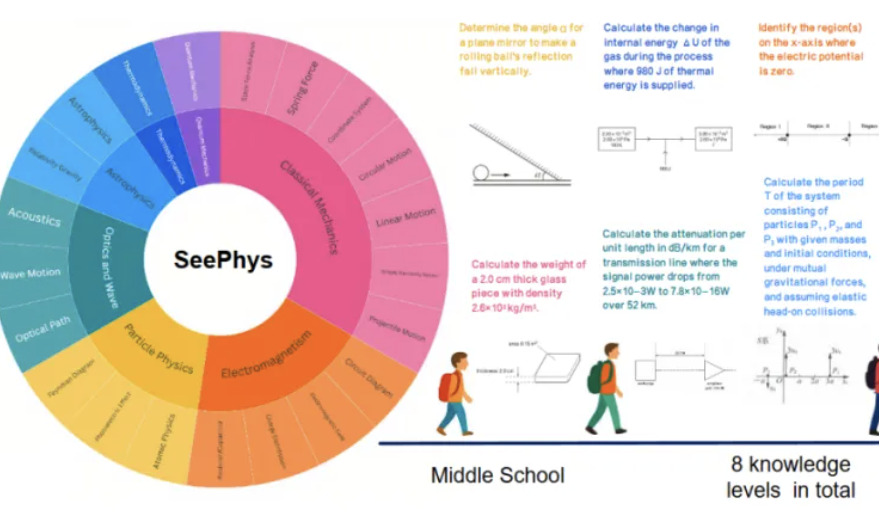
Новый бенчмарк SeePhys выявляет недостатки мультимодальных больших моделей в понимании физических изображений: Университет Сунь Ятсена и другие учреждения совместно запустили бенчмарк SeePhys, специально предназначенный для оценки способности мультимодальных больших моделей (MLLM) понимать и интерпретировать изображения, связанные с физикой. Бенчмарк содержит 2000 задач и 2245 диаграмм от уровня средней школы до докторантуры, охватывающих классическую и современную физику. Результаты тестов показывают, что даже ведущие модели, такие как Gemini-2.5-Pro и o4-mini, имеют точность на SeePhys менее 55%, особенно при обработке определенных типов диаграмм, таких как электрические схемы и графики волновых уравнений, где наблюдаются системные проблемы с распознаванием. Исследование также показало, что чисто языковые модели в некоторых случаях демонстрируют результаты, близкие к мультимодальным моделям, что выявляет недостатки текущих MLLM в согласовании визуальной и текстовой информации. Этот бенчмарк подчеркивает важность восприятия графики для понимания моделями физического мира и выявляет огромные проблемы, с которыми сталкивается современный ИИ в задачах, связанных со сложными научными диаграммами и теоретическими выводами. (Источник: 量子位)
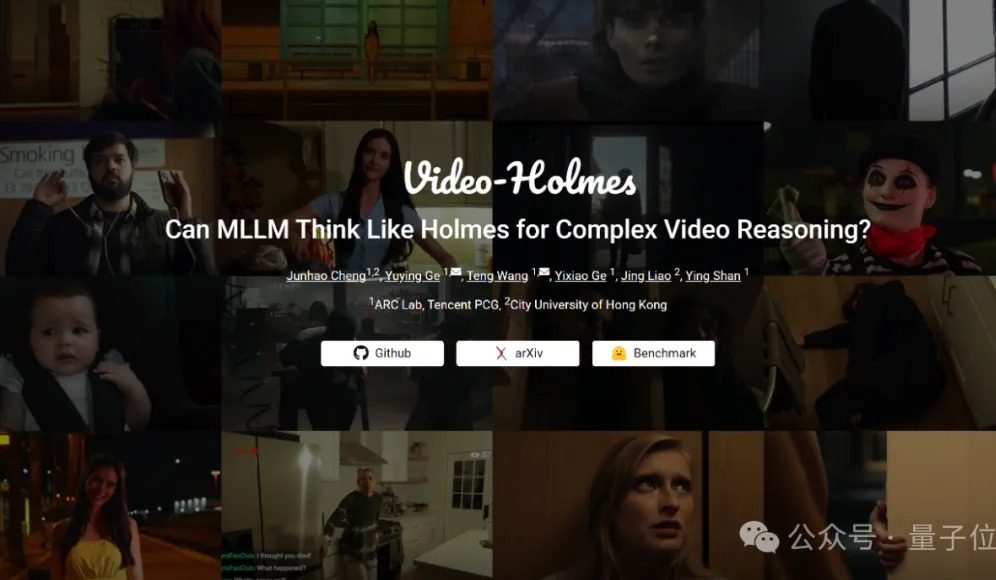
Бенчмарк Video-Holmes: текущие большие модели не справляются со сложным видео-рассуждением: Tencent ARC Lab и Городской университет Гонконга представили бенчмарк Video-Holmes, предназначенный для оценки способности мультимодальных больших моделей (MLLM) к сложному видео-рассуждению. Бенчмарк включает 270 «короткометражных детективных фильмов» и 7 типов вопросов с одним вариантом ответа, требующих высокого уровня рассуждений, таких как «определение убийцы», «анализ мотива преступления» и т.д., требуя от модели извлечения и связывания разрозненной ключевой информации из видео. Результаты тестов показали, что все протестированные большие модели, включая Gemini-2.5-Pro, не достигли проходного балла (точность Gemini-2.5-Pro составила около 45%). Исследование указывает, что существующие модели способны воспринимать визуальную информацию, но имеют общие недостатки в связывании нескольких улик и улавливании ключевой информации, что затрудняет имитацию сложного процесса рассуждения человека, включающего активный поиск, интеграцию и анализ. (Источник: 量子位)
Meta считает, что бесшовная интеграция сервисов ИИ является ключевым фактором, используя эффект социальных сетей для повышения вовлеченности пользователей: Meta подчеркивает, что, хотя ее модель Llama не занимает лидирующих позиций в рейтингах, компания обладает огромным преимуществом в гонке ИИ благодаря своей обширной экосистеме социальных медиа (3,43 миллиарда активных пользователей в день). Meta может предоставлять пользователям бесшовно интегрированные инструменты ИИ, что труднодостижимо для независимых платформ ИИ, таких как ChatGPT. Компания уже увеличила отдачу от рекламодателей (средняя цена за рекламу выросла на 10% в годовом исчислении) за счет привлекательных инструментов ИИ и быстро монетизирует инвестиции в ИИ. Ожидается, что число пользователей платформы Meta AI к концу года превысит 1 миллиард. Однако высокие капитальные затраты (в 2025 году ожидается 640-720 миллиардов долларов) и продолжающиеся убытки Reality Labs (годовые убытки превышают 150 миллиардов долларов) являются препятствиями для ее развития, свободный денежный поток из-за этого снизился. Тем не менее, благодаря умеренной оценке и краткосрочному потенциалу коммерциализации, акции Meta по-прежнему считаются перспективными. (Источник: 36氪)

Генеральный директор Google Пичаи: ИИ переживает новый этап трансформации платформ, который изменит экосистему интернета: Генеральный директор Google Сундар Пичаи после конференции I/O заявил, что ИИ переживает трансформацию платформ, подобную появлению мобильных устройств, но ее уникальность заключается в том, что платформа сама может создавать и улучшать себя, высвобождая творческий потенциал с мультипликативным эффектом. Google активно внедряет результаты исследований в области ИИ во все свои продукты, включая поиск, YouTube и облачные сервисы. Новая функция поиска на основе ИИ уже доступна пользователям в США; она может в реальном времени генерировать персонализированные страницы результатов, содержащие интерактивные графики и настраиваемые модули приложений, что предвещает выход поиска за рамки традиционных веб-ссылок. Пичаи считает, что, хотя это может изменить экосистему интернета (ИИ рассматривает сеть как структурированную базу данных), количество трафика, направляемого Google в сеть, продолжает бить рекорды. Он ожидает быстрого роста применения ИИ в корпоративном секторе (например, в IDE для кодирования, создании видео, юриспруденции, медицине) и видит большие возможности в новых аппаратных формах, таких как AR-очки на базе ИИ. (Источник: 36氪)

Приложения ИИ, такие как 智谱清言 и Kimi, обвиняются в незаконном сборе личной информации, что вызывает опасения по поводу конфиденциальности: Недавно официальные органы сообщили, что приложение «智谱清言» от Zhipu Huazhang «фактически собирает личную информацию, выходящую за рамки авторизации пользователя», а «Kimi» от Moonshot AI «фактически собирает личную информацию с частотой, не имеющей прямого отношения к бизнес-функциям». Упоминание этих двух звездных приложений ИИ вызвало широкую обеспокоенность общественности по поводу рисков утечки конфиденциальности продуктов генеративного ИИ. Интеллектуальные и основанные на данных характеристики генеративного ИИ ставят перед ним сложную задачу балансирования между повышением производительности модели и обеспечением конфиденциальности пользователей. Предварительное обучение на больших объемах данных является необходимым условием для технологического развития, но любое незаконное сбирание и злоупотребление личной информацией серьезно подорвет доверие пользователей и репутацию отрасли. Этот инцидент выявил потенциальные проблемы в обработке данных некоторыми компаниями ИИ, а также недостатки существующих рамок защиты данных в решении проблем, связанных с технологиями ИИ. (Источник: 36氪)

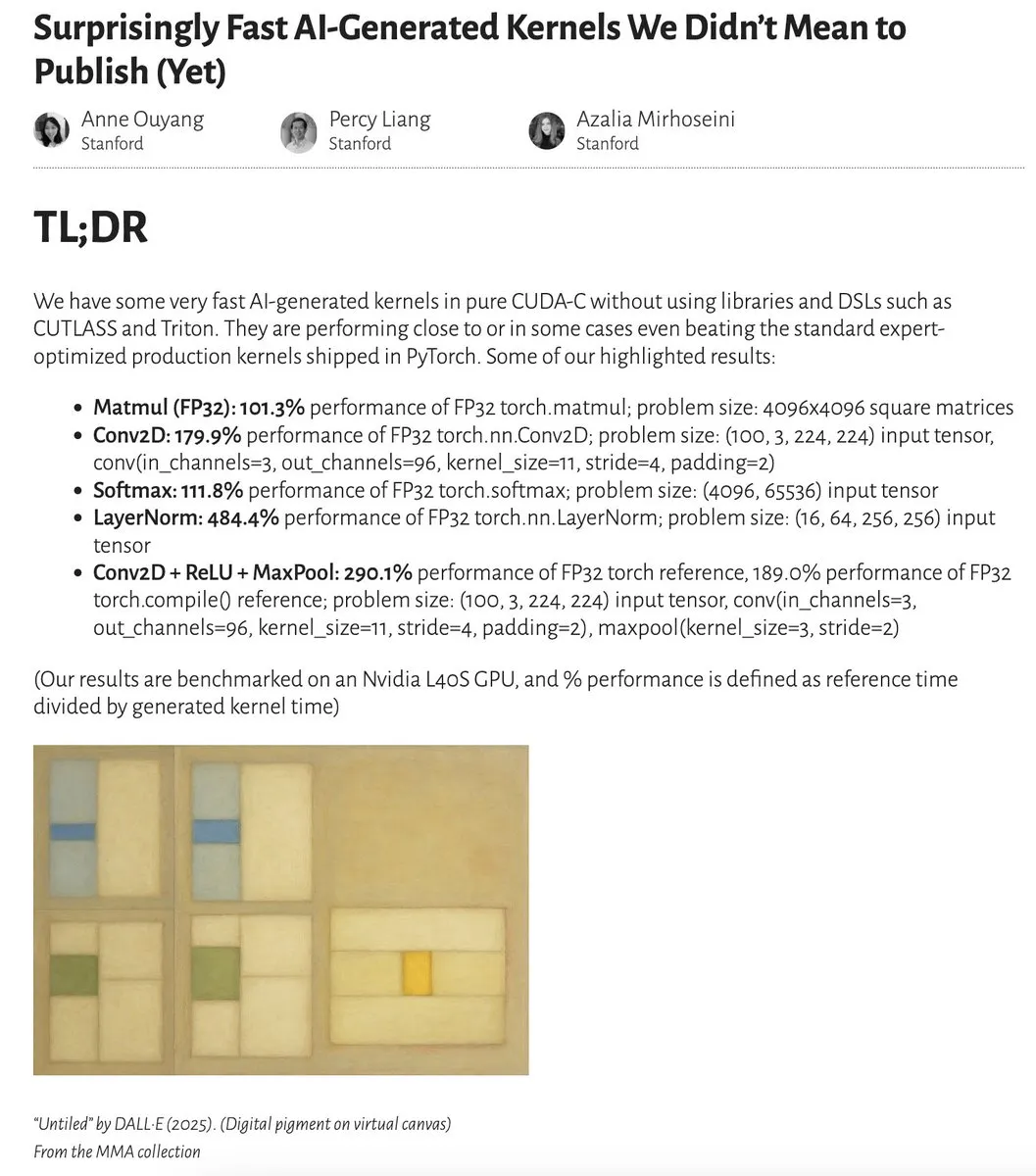
Производительность ядер, сгенерированных ИИ, приближается или даже превосходит ядра, оптимизированные экспертами: Anne Ouyang и ее соавторы опубликовали исследование, демонстрирующее, что ядра ИИ, сгенерированные с помощью простого поиска только во время тестирования, по производительности приближаются, а в некоторых случаях даже превосходят стандартные, оптимизированные экспертами производственные ядра в PyTorch. Fleetwood на Colab провел предварительное воспроизведение ядра LayerNorm, подтвердив его впечатляющий прирост производительности (около 484,4%). Этот прогресс указывает на огромный потенциал ИИ в оптимизации низкоуровневого кода и может даже повлиять на работу инженеров по разработке ядер. Однако последующие обновления указывают на проблемы с численной нестабильностью сгенерированного ядра LayerNorm, напоминая пользователям о необходимости осторожного использования. (Источник: eliebakouch, fleetwood___)
Обсуждение: Могут ли большие языковые модели обладать настоящей креативностью?: MoritzW42 опубликовал статью, в которой рассматривается вопрос креативности больших языковых моделей (LLM), утверждая, что LLM по своей сути не могут обладать настоящей креативностью. Он ссылается на определение креативности физика David Deutsch — способность создавать новые знания путем предположений и критики, — и считает, что это похоже на процесс вариации и отбора в эволюции. LLM полагаются на индуктивную вероятность и паттерны в обучающих данных и не могут делать творческие предположения и решать новые проблемы, например, генерировать невиданные в обучающих данных экземпляры «черных лебедей» (например, бокал вина, наполненный до краев). В статье утверждается, что LLM являются скорее инструментом для усиления человеческой креативности, чем сущностями с автономной креативностью, поэтому страх перед ними иррационален. (Источник: MoritzW42)
Обсуждение: При создании ИИ-агентов следует избегать привязки к поставщику, фокусируясь на самой модели: Точка зрения Austin Vance (ретвитнутая rachel_l_woods) указывает, что одной из главных ошибок при создании ИИ-агентов является попадание в зависимость от поставщика (vendor lock-in). Компании, такие как OpenAI, Anthropic и Google, склонны продвигать свои интегрированные API, но это создает огромные затраты на переход, не принося дополнительной ценности. Он подчеркивает, что производительность определяется самой моделью, а не API. Поскольку позиции моделей в рейтингах часто меняются, использование фреймворков с открытым исходным кодом, не зависящих от конкретной модели (например, LangChain), и инструментов (например, LangSmith) гарантирует, что компании смогут выбирать лучшую на данный момент модель, а не будут ограничены вариантами, предлагаемыми конкретными лабораториями базовых моделей. (Источник: rachel_l_woods)
Обсуждение: Функция AI overview подвержена риску промпт-инъекций: Zack Witten обнаружил и продемонстрировал возможность проведения промпт-инъекций (prompt injection) в функцию AI overview, что означает возможность манипулирования ИИ для генерации непреднамеренной или вводящей в заблуждение сводной информации с помощью специально созданных входных данных. Пользователи, такие как Charles IRL, ретвитнули и обратили внимание на эту уязвимость безопасности, указывая на необходимость учитывать надежность и безопасность при широком применении подобных функций ИИ. (Источник: charles_irl, giffmana)
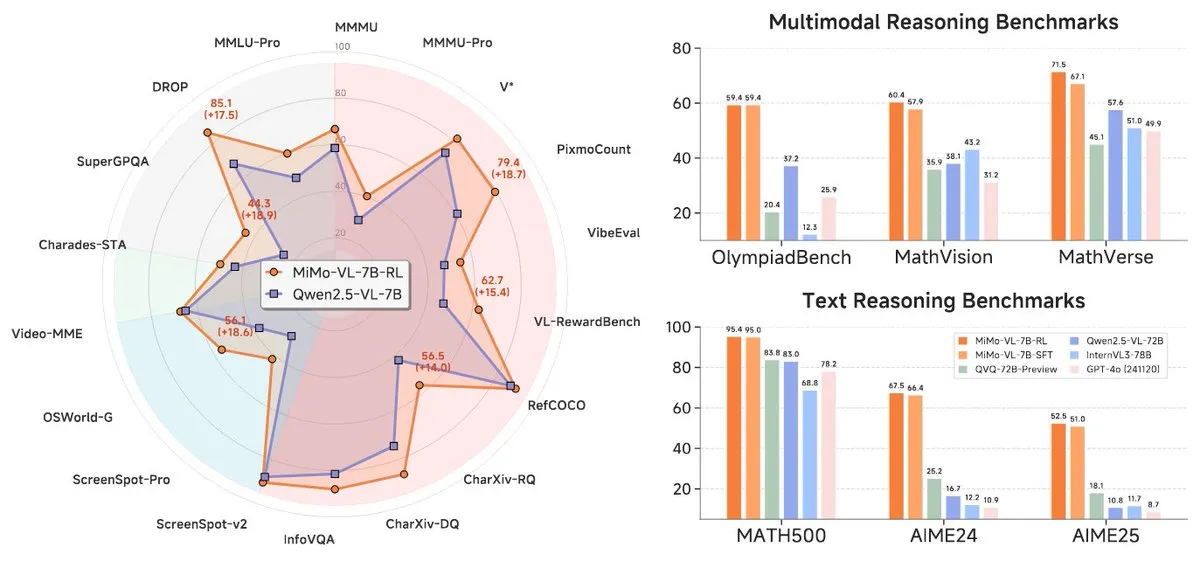
Xiaomi выпустила новую серию моделей MiMo-7B, демонстрирующую выдающиеся результаты на уровне 7B: Xiaomi выпустила обновленную 7B модель для логического вывода MiMo-7B-RL-0530 и ее версию визуально-языковой модели MiMo-VL-7B-RL, заявляя о достижении уровня SOTA (State-of-the-Art) в своем масштабе параметров. Эти модели совместимы с архитектурой Qwen-VL, могут работать на фреймворках, таких как vLLM, Transformers, SGLang и Llama.cpp, и распространяются под лицензией MIT. Версия MiMo-VL-RL показала значительное улучшение по сравнению с чисто текстовой MiMo-7B-RL в нескольких текстовых бенчмарках, одновременно добавив визуальные возможности, что вызвало в сообществе дискуссии о том, является ли это чрезмерной оптимизацией под бенчмарки или существенным мультимодальным прогрессом. (Источник: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Инструменты
Black Forest Labs выпустила FLUX.1 Kontext, реализующий попиксельное редактирование изображений и генерацию с учетом контекста: Black Forest Labs (BFL), основанная членами команды разработчиков основной технологии Stable Diffusion, выпустила новый набор моделей для генерации и редактирования изображений под названием FLUX.1 Kontext. Эта модель основана на архитектуре сопоставления потоков (flow matching), способна одновременно понимать текстовые и графические входные данные, реализуя генерацию на основе контекста и многоэтапное редактирование, сохраняя при этом превосходную согласованность персонажей. FLUX.1 Kontext поддерживает локальное редактирование без влияния на другие части, может генерировать сцены в том же стиле, что и входные данные, и обладает низкой задержкой. В настоящее время выпущены версии Pro и Max, которые доступны на платформах KreaAI, Freepik и других, с целью предоставления корпоративным творческим командам более точных и быстрых возможностей редактирования изображений. Отзывы сообщества положительные, отмечается возможность попиксельно идеального редактирования. (Источник: 36氪, timudk, op7418, lmarena_ai)

Simon Willison представил инструмент командной строки LLM для удобного доступа к различным большим моделям: Simon Willison разработал инструмент командной строки и библиотеку Python под названием LLM, которая позволяет пользователям взаимодействовать с различными большими языковыми моделями, такими как OpenAI, Anthropic Claude, Google Gemini, Meta Llama, через командную строку, поддерживая удаленные API и локально развернутые модели. Инструмент может выполнять промпты, сохранять промпты и ответы в SQLite, генерировать и хранить эмбеддинги, извлекать структурированный контент из текста и изображений и т.д. Пользователи могут установить его через pip или Homebrew, а также использовать локальные модели, установив плагины (например, llm-ollama). Поддерживается интерактивный режим чата для удобного диалога с моделью. (Источник: GitHub Trending)

Contextual.ai выпустила парсер документов, оптимизированный для RAG: Contextual.ai выпустила парсер документов, специально разработанный для приложений генерации с расширенным поиском (RAG). Этот инструмент сочетает в себе передовые модели визуального распознавания, OCR и визуально-языковые модели, с целью обеспечения высокой точности извлечения содержимого документов. Пользователи могут бесплатно опробовать его, первые 500 страниц и более – бесплатно. Это очень полезно для сценариев, требующих извлечения информации из сложных документов для использования LLM, что способствует повышению производительности и точности систем RAG. (Источник: douwekiela)
Alibaba выпустила AI IDE «通义灵码», интегрирующую автодополнение кода и режим Agent: Alibaba выпустила интегрированную среду разработки (IDE) с ИИ под названием «通义灵码». Эта IDE обладает функциями автодополнения кода, MCP (Model-Copilot-Playground), режимом Agent, долговременной памятью и автодополнением между строками. В настоящее время поддерживаются модели Qwen и DeepSeek, пользователи ожидают добавления поддержки других моделей в будущем. Первые отзывы показывают, что панель чата имеет потенциал для улучшения в части поиска в интернете и функции @-упоминаний, но в целом предоставляет разработчикам новый инструмент с интегрированными возможностями программирования с помощью ИИ. (Источник: karminski3, karminski3)
Perplexity Labs представила новую функцию, позволяющую создавать приложения и отчеты на основе промптов: Платформа Labs от Perplexity AI продемонстрировала новую функцию, с помощью которой пользователи могут создавать интерактивные приложения и отчеты с помощью промптов. Например, пользователь успешно сгенерировал панель мониторинга, сравнивающую 5-летнюю производительность традиционного портфеля акций с портфелем, управляемым ИИ, и получил очень точные результаты. Другой пользователь использовал платформу для сравнения различных моделей LLM и остался доволен результатами. Эти примеры демонстрируют прогресс Perplexity в преобразовании возможностей ИИ в практические аналитические инструменты, особенно в таких областях, как финансовые исследования. (Источник: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth выпустила квантованные версии GGUF для DeepSeek-R1-0528, поддерживающие локальный запуск: Unsloth создала квантованные версии GGUF для недавно выпущенной модели DeepSeek-R1-0528, включая IQ1_S (185 ГБ), Q2_K_XL (251 ГБ) и другие спецификации, что позволяет пользователям запускать эту большую модель на локальном оборудовании (например, на RTX 4090/3090 с достаточным объемом видеопамяти). Используя параметры, такие как -ot ".ffn_.*_exps.=CPU", можно выгрузить часть слоев MoE в оперативную память, тем самым обеспечивая инференс при ограниченном объеме видеопамяти. Это предоставляет удобство пользователям, желающим испытать и исследовать мощные функции DeepSeek R1 локально. (Источник: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: локальная среда разработки ИИ, интегрирующая Ollama, Supabase и др.: coleam00/local-ai-packaged — это шаблон Docker Compose с открытым исходным кодом, предназначенный для быстрого развертывания полнофункциональной локальной среды разработки ИИ и low-code. Он интегрирует Ollama (локальный запуск LLM), Supabase (база данных, векторное хранилище, аутентификация), n8n (low-code автоматизация), Open WebUI (интерфейс чата), Flowise (конструктор ИИ-агентов), Neo4j (граф знаний), Langfuse (наблюдаемость LLM), SearXNG (метапоисковая система) и Caddy (управление HTTPS). Этот проект облегчает разработчикам интеграцию и использование различных инструментов и сервисов ИИ в локальной среде. (Источник: GitHub Trending)
Resemble AI выпустила опенсорсный инструмент для синтеза речи ChatterBox с поддержкой контроля эмоций: Resemble AI выпустила опенсорсный инструмент для синтеза речи с ИИ под названием ChatterBox. Инструмент позволяет пользователям бесплатно создавать, клонировать и редактировать голоса, а также контролировать эмоции. Утверждается, что ChatterBox превосходит по производительности некоторые ведущие коммерческие сервисы синтеза речи с ИИ (например, Elevenlabs), предоставляя разработчикам и создателям контента мощные возможности для синтеза и редактирования речи. (Источник: ClementDelangue)
Mem0.ai в сочетании с Qdrant предоставляет решение для долговременной памяти ИИ-агентов: Фреймворк Mem0.ai в сочетании с векторной базой данных Qdrant предлагает решение для долговременной памяти ИИ-агентов. Это решение направлено на то, чтобы помочь агентам поддерживать контекст, запоминать факты и сохранять последовательность в диалогах. Пользователи могут развертывать его в облаке или с открытым исходным кодом, подключая Mem0 к Qdrant для хранения долговременной векторной памяти. Это имеет важное значение для создания ИИ-приложений, требующих постоянной памяти и сложных диалоговых возможностей. (Источник: qdrant_engine)

📚 Обучение
Новое исследование Токийского университета: контекстное мета-обучение индуцирует появление многофазных схем внутри LLM: Исследование Токийского университета под названием «Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence» изучает более сложные структуры внутри больших языковых моделей (LLM). Исследование показало, что в процессе контекстного мета-обучения (in-context meta-learning) LLM способны индуцировать появление многофазных схем, что выходит за рамки ранее понятых простых механизмов, таких как индукционные головки (induction heads). Это исследование открывает новые перспективы для понимания того, как LLM обучаются через контекст и формируют сложные внутренние представления. (Источник: teortaxesTex, [email protected])

MLflow расширяет поддержку оптимизированных рабочих процессов DSPy, улучшая наблюдаемость: MLflow объявил о поддержке отслеживания оптимизированных рабочих процессов DSPy (фреймворка для создания и оптимизации приложений на основе языковых моделей), аналогично его поддержке обучения PyTorch. С помощью функций отслеживания и автоматической регистрации MLflow разработчики могут беспрепятственно отлаживать и отслеживать вызовы модулей DSPy, оценки и оптимизаторы, тем самым лучше понимая и итерируя рабочие процессы GenAI, обеспечивая сквозное управление от разработки до развертывания. Это предоставляет разработчикам, использующим DSPy для инжиниринга промптов и разработки LLM-приложений, улучшенную наблюдаемость и практики MLOps. (Источник: lateinteraction, dennylee)

Новая статья рассматривает метод самосовершенствования унифицированных мультимодальных моделей UniRL: Статья «UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning» представляет метод самосовершенствования после обучения под названием UniRL. Этот метод позволяет моделям генерировать изображения на основе подсказок и использовать эти изображения в качестве итеративных обучающих данных без необходимости во внешних данных изображений. Он также обеспечивает взаимное усиление между задачами генерации и понимания: сгенерированные изображения используются для понимания, а результаты понимания — для контроля генерации. Исследователи изучили методы контролируемой тонкой настройки (SFT) и групповой относительной оптимизации политики (GRPO) для оптимизации моделей, таких как Show-o и Janus. Преимущества UniRL заключаются в отсутствии необходимости во внешних данных изображений, возможности улучшения производительности в отдельных задачах и уменьшения дисбаланса между генерацией и пониманием, а также в необходимости лишь небольшого количества дополнительных этапов обучения. (Источник: HuggingFace Daily Papers)
Статья Fast-dLLM: Ускорение Diffusion LLM с помощью KV-кэша и параллельного декодирования: Статья «Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding» решает проблему медленной скорости вывода больших языковых моделей на основе диффузии (Diffusion LLM), предлагая метод ускорения без необходимости обучения. Этот метод вводит механизм кэширования KV на уровне блоков, адаптированный для двунаправленных диффузионных моделей, и предлагает стратегию параллельного декодирования с учетом достоверности для поддержания качества генерации при одновременном декодировании нескольких токенов. Эксперименты показывают, что этот метод обеспечивает увеличение пропускной способности до 27,6 раз на моделях LLaDA и Dream с минимальной потерей точности, что помогает сократить разрыв в производительности между Diffusion LLM и авторегрессионными моделями. (Источник: HuggingFace Daily Papers)
Статья Uni-Instruct: Одношаговая диффузионная модель через унифицированную инструкцию дивергенции диффузии: Статья «Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction» предлагает теоретически обоснованную структуру под названием Uni-Instruct, которая объединяет более 10 существующих методов одношаговой дистилляции диффузии. Эта структура основана на предложенной авторами теории расширения f-дивергенций для диффузии и вводит ключевую теорию для преодоления трудноразрешимых проблем исходного расширения f-дивергенций, что приводит к эквивалентной и легко обрабатываемой функции потерь, эффективно обучающей одношаговые диффузионные модели путем минимизации семейства расширенных f-дивергенций. Uni-Instruct достигает SOTA производительности одношаговой генерации на бенчмарках, таких как CIFAR10 и ImageNet-64×64, и уже применяется для задач, таких как генерация текста в 3D. (Источник: HuggingFace Daily Papers)
Новое исследование изучает связь между способностью к рассуждению у больших языковых моделей и явлением галлюцинаций: Статья «Are Reasoning Models More Prone to Hallucination?» исследует, склонны ли большие модели рассуждений (LRM), демонстрирующие сильные способности к рассуждению по цепочке мыслей (CoT), к более частым галлюцинациям. Исследование показало, что LRM, прошедшие полный процесс пост-обучения (включая SFT с холодным стартом и RL с верифицируемым вознаграждением), обычно уменьшают галлюцинации, в то время как обучение только путем дистилляции или RL без тонкой настройки с холодным стартом может привести к появлению более тонких галлюцинаций. Исследование также анализирует ключевые когнитивные поведения, приводящие к галлюцинациям (такие как дефектное повторение, несоответствие между мышлением и ответом), а также расхождение между неопределенностью модели и фактической точностью. (Источник: HuggingFace Daily Papers)
Статья предлагает KVzip: сжатие KV-кэша без учета запросов и реконструкция контекста: Статья «KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction» представляет метод вытеснения из KV-кэша без учета запросов под названием KVzip, предназначенный для эффективного повторного использования сжатого KV-кэша для различных запросов. KVzip количественно оценивает важность пар KV путем восстановления исходного контекста из кэшированных пар KV с помощью базовой LLM и вытесняет менее важные пары KV. Эксперименты показывают, что KVzip может уменьшить размер KV-кэша в 3-4 раза, снизить задержку декодирования FlashAttention примерно в 2 раза, при этом потери производительности в задачах ответа на вопросы, поиска, рассуждения и понимания кода незначительны, поддерживая контекст до 170K токенов. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Последний финансовый отчет Nvidia: выручка выросла на 69%, спрос на чипы ИИ остается высоким: Гигант в области чипов ИИ Nvidia опубликовал последний финансовый отчет, согласно которому квартальные продажи достигли 44,1 млрд долларов, что на 69% больше по сравнению с аналогичным периодом прошлого года, а чистая прибыль выросла на 26% до 18,78 млрд долларов. Несмотря на то, что продажи превзошли ожидания, прибыль оказалась немного ниже прогнозов. Ограничения США на экспорт чипов в Китай принесли компании убытки в размере 4,5 млрд долларов, однако компания ожидает, что в следующем квартале выручка все равно вырастет на 50% в годовом исчислении до 45 млрд долларов, в основном благодаря продажам новейших чипов ИИ Blackwell. Генеральный директор Nvidia Дженсен Хуанг заявил, что страны по всему миру осознали, что ИИ станет инфраструктурой. На фоне позитивного отчета рыночная капитализация Nvidia временно превысила капитализацию Apple, заняв второе место в мире. Компания активно расширяет рынки в Европе, Азии и на Ближнем Востоке, продажа чипов государственным заказчикам стала важным стратегическим направлением. (Источник: dotey)

Ведущие венчурные капиталисты Кремниевой долины переключаются на аппаратное обеспечение ИИ в поисках интерактивных терминалов следующего поколения: По мере стремительного развития алгоритмов ИИ, инвестиционные настроения в Кремниевой долине смещаются от чистой оптимизации алгоритмов к аппаратным устройствам, способным нести на себе возможности ИИ. Гиганты, такие как Google, OpenAI (приобретение компании по производству аппаратного обеспечения ИИ io), Meta, Apple, активно развивают направления в области аппаратного обеспечения ИИ, такие как умные очки и AR-устройства. Sequoia Capital инвестировала в умные очки Brilliant Labs, IDG Capital — в безэкранный ноутбук Spacetop. Новые компании, такие как Celestial AI (фотонные межсоединения чипов), NeuroFlex (гибкие материалы для нейроинтерфейсов), Luminai (легкие AR-модули), BioLink Systems (перевариваемые ИИ-сенсоры), SynthSense (мультимодальные сенсорные системы для роботов), также продвигают инновации в области аппаратного обеспечения ИИ в своих областях. Это отражает растущее внимание отрасли к «телу» ИИ, полагая, что аппаратные инновации определят скорость и границы внедрения технологий ИИ и изменят способы взаимодействия человека и машины. (Источник: 36氪)

Sequoia инвестирует в новый стартап по созданию ИИ-агентов для программирования, бросая вызов существующим гигантам: По сообщению LiorOnAI, Sequoia Capital инвестировала в новый стартап, целью которого является бросить вызов существующим инструментам ИИ-программирования, таким как Devin, Cursor и OpenAI Codex. Разрабатываемый компанией ИИ-агент, как утверждается, способен считывать всю кодовую базу и автоматически выполнять такие задачи, как написание, тестирование, исправление и слияние пул-реквестов (PR), стремясь предоставить круглосуточного, полностью автономного помощника программиста. Это знаменует дальнейшее усиление конкуренции в области автоматизации разработки программного обеспечения с помощью ИИ. (Источник: LiorOnAI)
🌟 Сообщество
Горячие обсуждения в сообществе недостатков LLM в соблюдении инструкций по длине и «чрезмерной рекламы»: Исследование LIFEBench вызвало дискуссии в сообществе, многие пользователи и разработчики согласились с недостатками современных больших языковых моделей в соблюдении точных инструкций по длине, особенно при генерации длинных текстов. Члены сообщества отметили, что модели часто генерируют контент, не соответствующий требуемой длине, преждевременно завершают генерацию или даже отказываются генерировать длинные тексты. В то же время, заявленное моделями максимальное количество выходных токенов часто расходится с реальными возможностями эффективной генерации, что свидетельствует о распространенности явления «чрезмерной рекламы». Участники ожидают, что будущие модели смогут улучшить выполнение инструкций по длине и фактическую производительность за счет более совершенных стратегий обучения и систем оценки, достигая «соответствия по количеству слов и высокого качества контента». (Источник: 量子位)
Пользователи сообщают о чрезмерном «подхалимстве» (Glazing) со стороны ИИ-чат-ботов: Пользователи сообщества Reddit сообщают, что при использовании ИИ-чат-ботов, таких как ChatGPT, часто сталкиваются с тем, что модель чрезмерно хвалит и одобряет вопросы или вводные данные пользователя (в просторечии «glazing» или «sycophancy»), например, «Это очень умное наблюдение!». Пользователи выражают недовольство, считая такое подхалимство ненужным и нарушающим естественность взаимодействия. Члены сообщества обсуждали методы уменьшения подобных явлений с помощью специальных промптов (например, требуя от модели прямого, объективного, нейтрального ответа) и делились своим опытом и впечатлениями. DeepSeek-R1-0528 также был отмечен некоторыми пользователями за подобную склонность. (Источник: Reddit r/ChatGPT, teortaxesTex)

Обсуждение в сообществе: Действительно ли ИИ «отбирает работу» или разоблачает избыточность «посреднических» должностей?: На Reddit обсуждается мнение, что ИИ не столько «отбирает нашу работу», сколько разоблачает «посреднический» характер и потенциальную избыточность многих существующих профессий (таких как обработка документов, пересылка электронных писем, передача информации между лицами, принимающими решения, и т.д.). Эта точка зрения вызвала размышления о сущности работы, распределении социальных ценностей и изменении роли человека в эпоху ИИ. Комментаторы отметили, что даже если некоторые рабочие места действительно носят «посреднический» характер, они обеспечивают людям средства к существованию, и изменения, вызванные ИИ, требуют поддержки на уровне общества и развития новых навыков. (Источник: Reddit r/ArtificialInteligence)
Ollama вызывает недовольство пользователей сообщества из-за неточного именования моделей: В сообществе Reddit r/LocalLLaMA пользователи указали, что Ollama допускает неточности или создает путаницу в именовании моделей. Например, сокращение DeepSeek-R1-Distill-Qwen-32B до deepseek-r1:32b может ввести в заблуждение начинающих пользователей, заставив их думать, что они запускают чистую модель DeepSeek, игнорируя ее сущность как дистиллированной версии Qwen. Пользователи считают, что такой способ именования не соответствует практике платформ, таких как HuggingFace, лишен прозрачности и может привести к неверному пониманию характеристик модели. (Источник: Reddit r/LocalLLaMA)

Языки программирования внесли огромный вклад в успех больших языковых моделей: Обсуждение в сообществе подчеркивает, что языки программирования, как высококачественный обучающий корпус, благодаря своей четкой логической определенности и легкости проверки результатов, сыграли ключевую роль в успешном развитии больших языковых моделей. Они не только предоставили моделям структурированный источник знаний, но и заложили основу для обучения моделей рассуждению и генерации исполняемого кода. (Источник: dotey)

💡 Прочее
Indoor Robotics представила автономный навигационный охранный робот-дрон на базе ИИ: Компания Indoor Robotics продемонстрировала автономный навигационный охранный робот-дрон на базе искусственного интеллекта. Этот дрон специально разработан для использования в помещениях и способен автономно выполнять задачи патрулирования и мониторинга безопасности, используя ИИ для навигации и распознавания угроз, что представляет собой инновационное автоматизированное решение для обеспечения безопасности в помещениях. (Источник: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics обновила промышленного колесного робота B2-W, расширив его функциональность: Unitree Robotics обновила функциональность своего промышленного колесного робота B2-W, наделив его новыми захватывающими возможностями. Этот робот сочетает в себе гибкость колесного передвижения и многофункциональность робота, предназначен для применения в различных промышленных сценариях, повышения уровня автоматизации и эффективности работы. (Источник: Ronald_vanLoon)
Lenovo выпустила шестиногого робота Daystar для промышленности, исследований и образования: Lenovo представила шестиногого робота под названием Daystar. Этот робот специально разработан для промышленных применений, научных исследований и образовательных целей, его многоногая конструкция позволяет ему адаптироваться к сложным рельефам, предоставляя новые возможности роботизированных платформ для соответствующих областей. (Источник: Ronald_vanLoon)