
Ключевые слова:DeepSeek-R1-0528, Искусственный интеллект агент, Мультимодальная модель, Открытый исходный код ИИ, Обучение с подкреплением, Редактирование изображений, Большая языковая модель, Тестирование производительности ИИ, DeepSeek-R1-0528-Qwen3-8B, Инструмент Circuit Tracer, Машина Дарвина-Гёделя, FLUX.1 Kontext, Агентский поиск информации
🔥 В фокусе
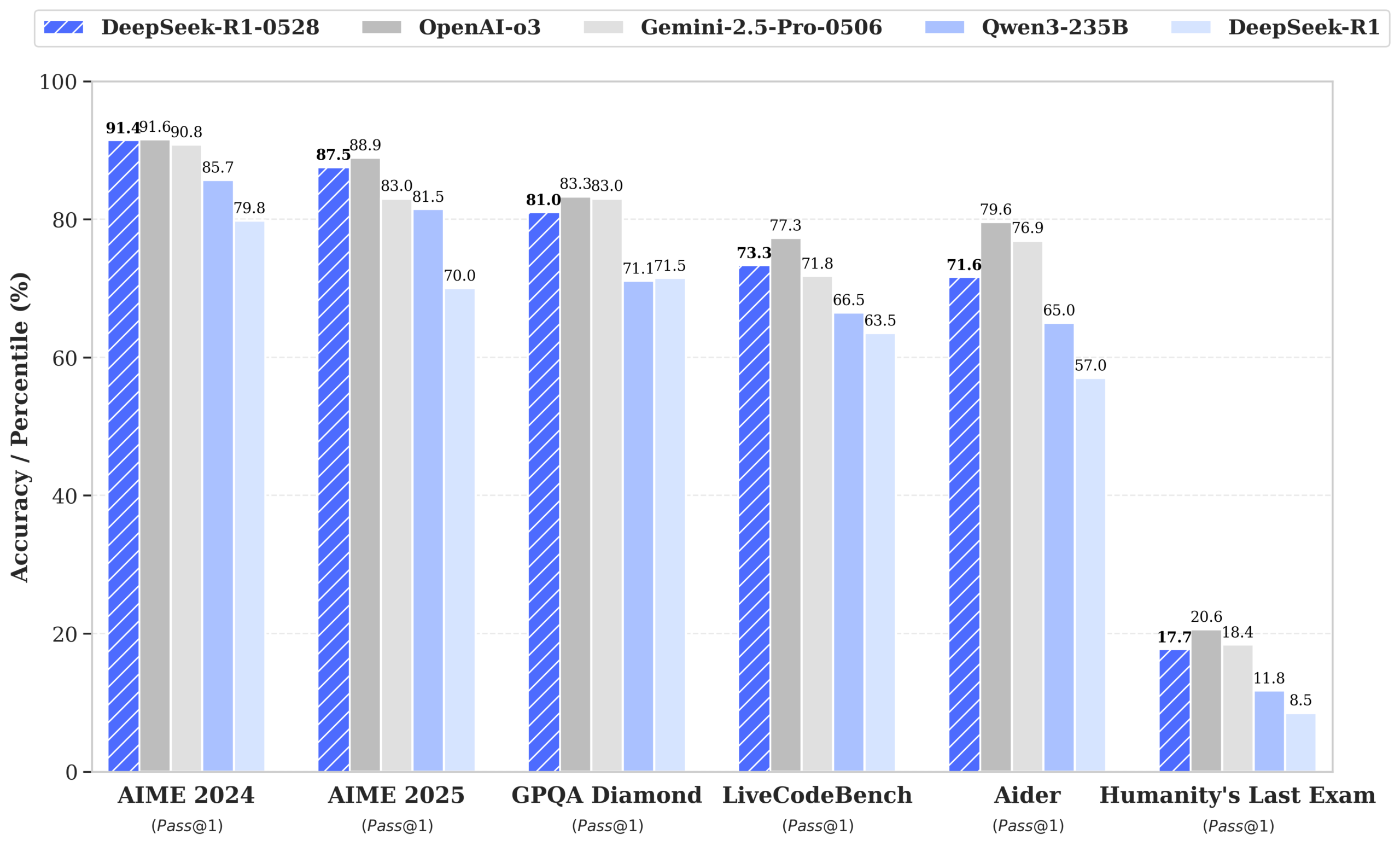
DeepSeek выпустила модель R1-0528, производительность которой приближается к GPT-4o и Gemini 2.5 Pro, и возглавила рейтинг моделей с открытым исходным кодом: DeepSeek-R1-0528 отлично показала себя в нескольких бенчмарках, включая математику, программирование и общее логическое мышление, особенно в тесте AIME 2025, где точность выросла с 70% до 87.5%. Новая версия значительно снизила частоту галлюцинаций (примерно на 45-50%), улучшила возможности генерации фронтенд-кода и поддерживает вывод в формате JSON и вызовы функций. Одновременно DeepSeek, на основе дообученной Qwen3-8B Base, выпустила DeepSeek-R1-0528-Qwen3-8B, производительность которой на AIME 2024 уступает только R1-0528 и превосходит Qwen3-235B. Это обновление укрепило позиции DeepSeek как второй по величине AI-лаборатории в мире и лидера в области открытого исходного кода. (Источник: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
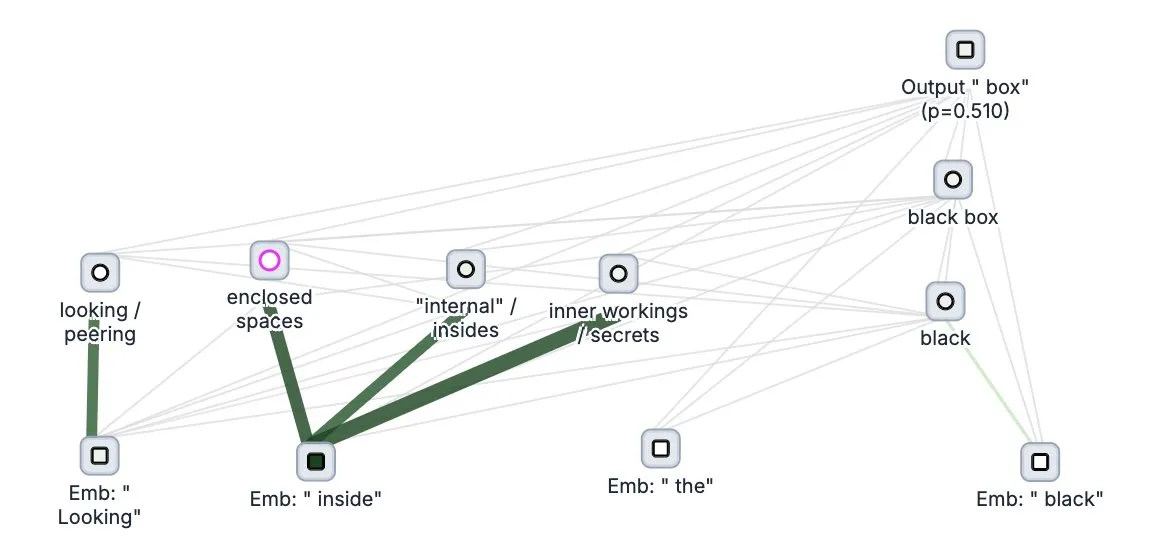
Anthropic представила инструмент с открытым исходным кодом для “отслеживания мышления” больших моделей Circuit Tracer: Компания Anthropic открыла исходный код своего инструмента для исследования интерпретируемости больших моделей Circuit Tracer, который позволяет исследователям генерировать и интерактивно исследовать “карты атрибуции” для понимания внутренних “мыслительных” процессов и механизмов принятия решений больших языковых моделей (LLM). Этот инструмент призван помочь исследователям глубже изучить внутреннюю работу LLM, например, как модель использует определенные признаки для предсказания следующего токена. Пользователи могут опробовать инструмент на Neuronpedia, введя предложение, чтобы получить схему использования признаков моделью. (Источник: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
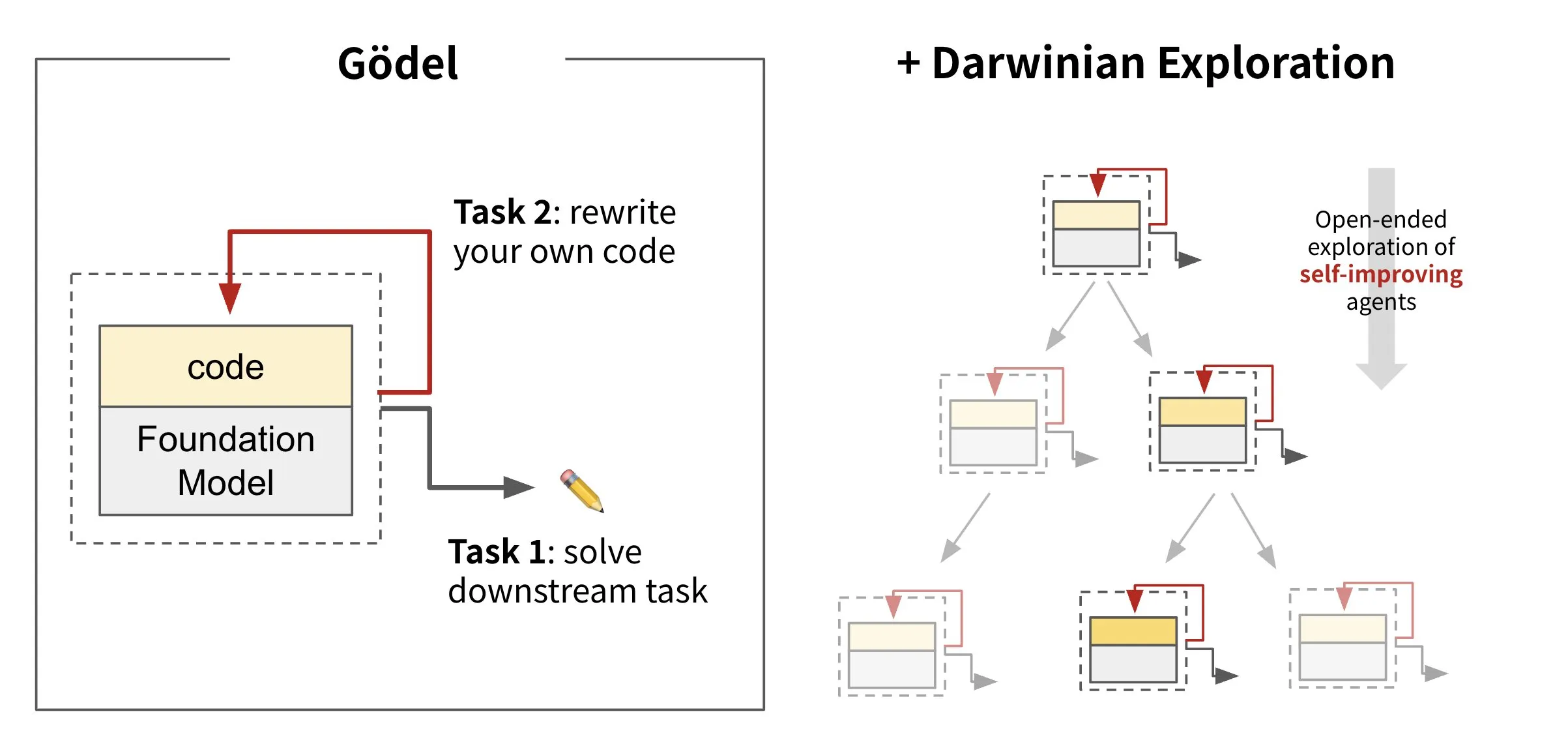
Sakana AI выпустила фреймворк для самоэволюционирующих агентов Darwin Gödel Machine (DGM): Sakana AI представила Darwin Gödel Machine (DGM), фреймворк для AI-агентов, способных к самосовершенствованию путем перезаписи собственного кода. DGM, вдохновленный теорией эволюции, поддерживает постоянно расширяющуюся линию вариантов агентов для открытого исследования пространства проектирования самосовершенствующихся интеллектуальных агентов. Фреймворк нацелен на то, чтобы AI-системы могли, подобно человеку, со временем учиться и развивать собственные способности. На SWE-bench DGM повысил производительность с 20.0% до 50.0%; на Polyglot успешность выполнения задач выросла с 14.2% до 30.7%. (Источник: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs выпустила модель для редактирования изображений FLUX.1 Kontext, поддерживающую смешанный ввод текста и изображений: Black Forest Labs представила модель нового поколения для редактирования изображений FLUX.1 Kontext, использующую архитектуру потокового согласования (flow matching) и способную одновременно принимать текст и изображения в качестве входных данных для контекстно-зависимой генерации и редактирования изображений. Модель демонстрирует превосходные результаты в обеспечении согласованности персонажей, локальном редактировании, следовании стилю и скорости взаимодействия, например, генерируя изображения разрешением 1024×1024 всего за 3-5 секунд. Тесты Replicate показывают, что ее возможности редактирования превосходят GPT-4o-Image при меньших затратах. Kontext доступна в версиях Pro и Max, также планируется выпуск open-source версии Dev. (Источник: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Тренды
Google DeepMind выпустила мультимодальную медицинскую модель MedGemma: Google DeepMind представила MedGemma, мощную открытую модель, специально разработанную для понимания мультимодальных медицинских текстов и изображений. Эта модель, предоставляемая в рамках Health AI Developer Foundations, призвана расширить возможности применения AI в медицинской сфере, особенно в комплексном анализе, сочетающем текстовую информацию и медицинские изображения (например, рентгеновские снимки). (Источник: GoogleDeepMind)
Perplexity AI запустила Perplexity Labs для решения сложных задач: Perplexity AI представила новую функцию Perplexity Labs, специально разработанную для решения более сложных задач и призванную предоставить пользователям возможности анализа и построения, сопоставимые с работой целой исследовательской группы. С помощью Labs пользователи могут создавать аналитические отчеты, презентации, динамические дашборды и многое другое. Функция уже доступна всем Pro-пользователям и демонстрирует свой потенциал в научных исследованиях, анализе рынка и создании мини-приложений (например, игр, дашбордов). (Источник: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan и Tencent Music совместно выпустили HunyuanVideo-Avatar, позволяющий генерировать реалистичные поющие видео из фотографий: Tencent Hunyuan и Tencent Music совместно представили модель HunyuanVideo-Avatar, которая способна объединять загруженные пользователем фотографии и аудио, автоматически определять контекст сцены и эмоции, а также генерировать говорящие или поющие видео с реалистичной синхронизацией губ и динамическими визуальными эффектами. Технология поддерживает различные стили и доступна в виде open source. (Источник: huggingface, thursdai_pod)
Состоялся официальный релиз Apache Spark 4.0.0 с улучшениями SQL, Spark Connect и многоязыковой поддержки: Официально выпущена версия Apache Spark 4.0.0, которая принесла значительные улучшения функциональности SQL, усовершенствования Spark Connect для более удобного запуска приложений, а также добавила поддержку новых языков. В этом обновлении было решено более 5100 проблем, в работе над которыми приняли участие более 390 контрибьюторов. (Источник: matei_zaharia, lateinteraction)

Выпущена видеомодель Kling 2.1, интегрированная с OpenArt для поддержки согласованности персонажей: Kling AI выпустила свою видеомодель Kling 2.1 и в сотрудничестве с OpenArt обеспечила поддержку согласованности персонажей в AI-видеоповествовании. Kling 2.1 улучшила выравнивание по промптам, скорость генерации видео, четкость движения камеры и, по заявлениям, обладает лучшими результатами преобразования текста в видео. Новая версия поддерживает вывод в разрешении 720p (стандарт) и 1080p (профессиональный). Функция преобразования изображения в видео уже доступна, а функция преобразования текста в видео появится в ближайшее время. (Источник: Kling_ai, NandoDF)
Hume выпустила голосовую модель EVI 3, способную понимать и генерировать любой человеческий голос: Hume представила свою новейшую голосовую языковую модель EVI 3, нацеленную на достижение универсального голосового интеллекта. EVI 3 способна понимать и генерировать любой человеческий голос, а не только голоса нескольких конкретных дикторов, тем самым обеспечивая более широкие выразительные возможности и более глубокое понимание интонации, ритма, тембра и стиля речи. Технология призвана дать каждому человеку уникального, заслуживающего доверия AI, которого можно узнать по голосу. (Источник: AlanCowen, AlanCowen, _akhaliq)
Alibaba представила WebDancer, исследующий автономных агентов для поиска информации: Alibaba запустила проект WebDancer, направленный на исследование и разработку AI-агентов, способных автономно осуществлять поиск информации. Проект фокусируется на том, как сделать AI-агентов более эффективными в навигации по сетевой среде, понимании информации и выполнении сложных задач по сбору данных. (Источник: _akhaliq)
MiniMax открыла исходный код фреймворка V-Triune и модели Orsta, объединяющих визуальное RL-умозаключение и задачи восприятия: AI-компания MiniMax открыла исходный код своего унифицированного фреймворка для визуального reinforcement learning V-Triune и семейства моделей Orsta (от 7B до 32B), основанных на этом фреймворке. Благодаря трехкомпонентной архитектуре и механизму вознаграждения на основе динамического IoU (Intersection over Union), фреймворк впервые позволяет VLM совместно обучаться задачам визуального умозаключения и восприятия в рамках единого процесса постобучения, демонстрируя значительное улучшение производительности на бенчмарке MEGA-Bench Core. (Источник: 量子位)

Шанхайская лаборатория AI и другие учреждения выпустили новый бенчмарк для редактирования изображений RISEBench, проверяющий глубокое логическое мышление моделей: Шанхайская лаборатория искусственного интеллекта совместно с несколькими университетами выпустила новый бенчмарк для оценки редактирования изображений под названием RISEBench. Он включает 360 сложных случаев, разработанных экспертами, охватывающих четыре основных типа логического мышления: временное, причинно-следственное, пространственное и логическое. Результаты тестов показали, что даже GPT-4o-Image смогла выполнить лишь 28.9% задач, что выявило недостатки текущих мультимодальных моделей в понимании сложных инструкций и визуальном редактировании. (Источник: 36氪)

Гонконгский университет CUHK и другие предложили фреймворк TON, позволяющий AI-моделям выборочно рассуждать для повышения эффективности и точности: Исследователи из Гонконгского университета Китая (CUHK) и Национального университета Сингапура (Show Lab) предложили фреймворк TON (Think Or Not), который позволяет визуально-языковым моделям (VLM) самостоятельно определять, нужно ли явное рассуждение. С помощью “отбрасывания мыслей” и reinforcement learning, фреймворк позволяет модели напрямую отвечать на простые вопросы и подробно рассуждать над сложными, тем самым сокращая среднюю длину вывода рассуждений до 90% без ущерба для точности, а в некоторых задачах точность даже повышается на 17%. (Источник: 36氪)
Microsoft Copilot интегрирован с Instacart для AI-ассистированных покупок продуктов: Руководитель AI-направления Microsoft Мустафа Сулейман объявил, что Copilot теперь интегрирован с сервисом Instacart, позволяя пользователям беспрепятственно выполнять весь процесс от генерации рецептов, создания списков покупок до доставки свежих продуктов на дом через приложение Copilot. Это знаменует дальнейшее расширение AI-помощников в сфере повседневных услуг. (Источник: mustafasuleyman)
🧰 Инструменты
LlamaIndex представила исходный код BundesGPT и инструмент create-llama, упрощающий создание AI-приложений: Джерри Лю из LlamaIndex объявил о предоставлении исходного кода BundesGPT и продвижении своего open-source инструмента create-llama. Этот инструмент, основанный на LlamaIndex, призван помочь разработчикам легко создавать и интегрировать корпоративные данные с AI-агентами, а его новый eject-mode делает создание полностью настраиваемых AI-интерфейсов, таких как BundesGPT, очень простым. Этот шаг направлен на поддержку потенциального плана Германии по предоставлению каждому гражданину бесплатной подписки ChatGPT Plus. (Источник: jerryjliu0)
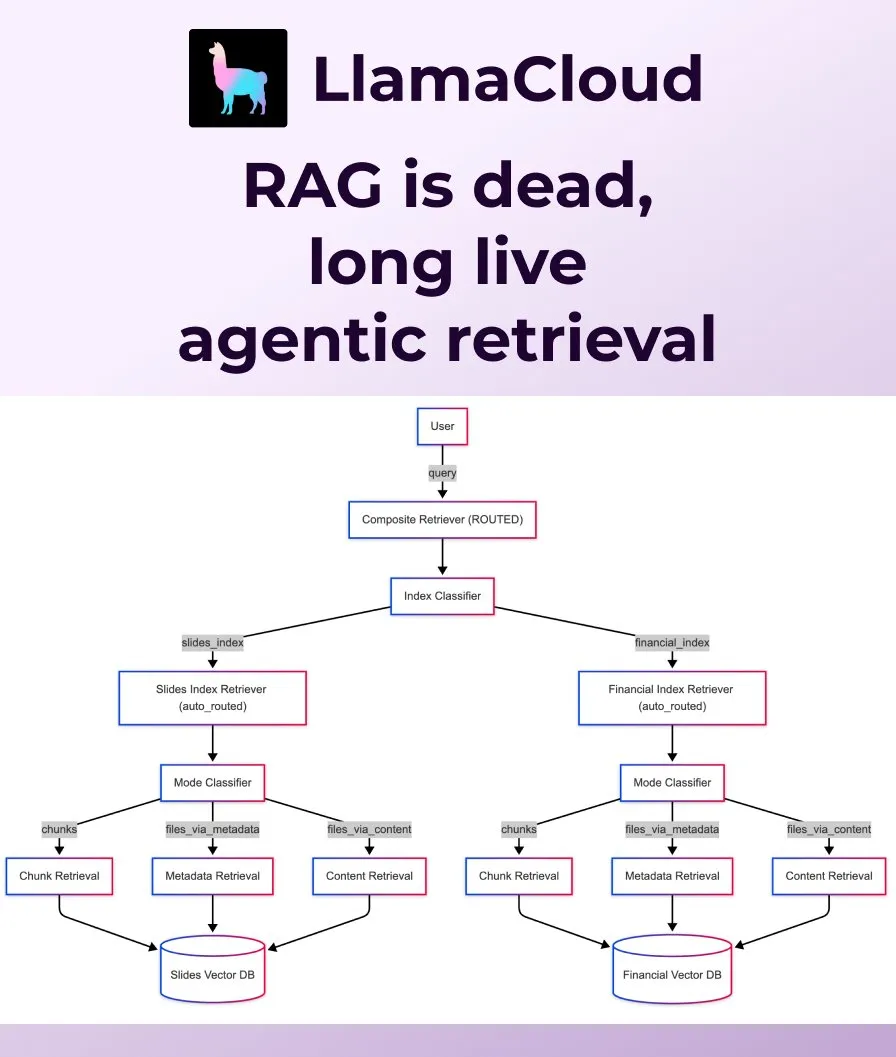
Инструменты LangChain теперь можно конвертировать в инструменты MCP и интегрировать в сервер FastMCP: Пользователи LangChain теперь могут конвертировать инструменты LangChain в инструменты MCP (Model Component Protocol) и напрямую добавлять их на сервер FastMCP. Установив библиотеку langchain-mcp-adapters, разработчики могут более удобно использовать набор инструментов LangChain в экосистеме MCP, что способствует взаимодействию между различными AI-фреймворками. (Источник: LangChainAI, hwchase17)
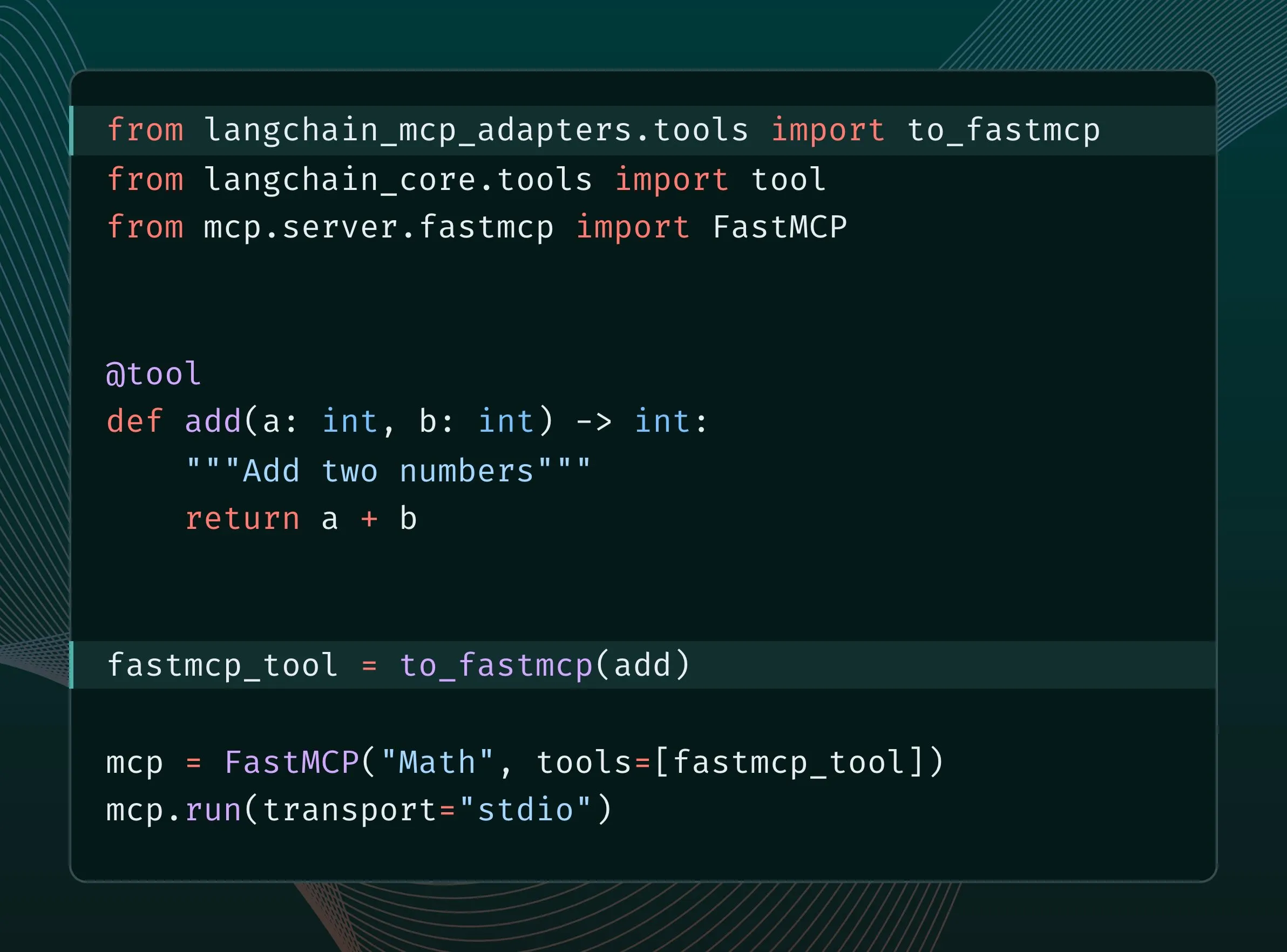
LlamaIndex выпустила Agentic Retrieval, заменяющий традиционный RAG: LlamaIndex считает, что традиционный простой RAG (Retrieval Augmented Generation) уже недостаточен для удовлетворения потребностей современных приложений, и представила Agentic Retrieval. Это решение, встроенное в LlamaCloud, позволяет агентам динамически извлекать целые файлы или определенные блоки данных из одного или нескольких хранилищ знаний (таких как Sharepoint, Box, GDrive, S3) в зависимости от содержания вопроса, обеспечивая более интеллектуальное и гибкое получение контекста. (Источник: jerryjliu0, jerryjliu0)
Ollama поддерживает запуск модели Osmosis-Structure-0.6B для преобразования неструктурированных данных: Пользователи теперь могут запускать модель Osmosis-Structure-0.6B через Ollama. Это очень маленькая модель, способная преобразовывать любые неструктурированные данные в указанный формат (например, JSON Schema), и может использоваться с любой моделью, особенно подходя для задач логического вывода, требующих структурированного вывода. (Источник: ollama)
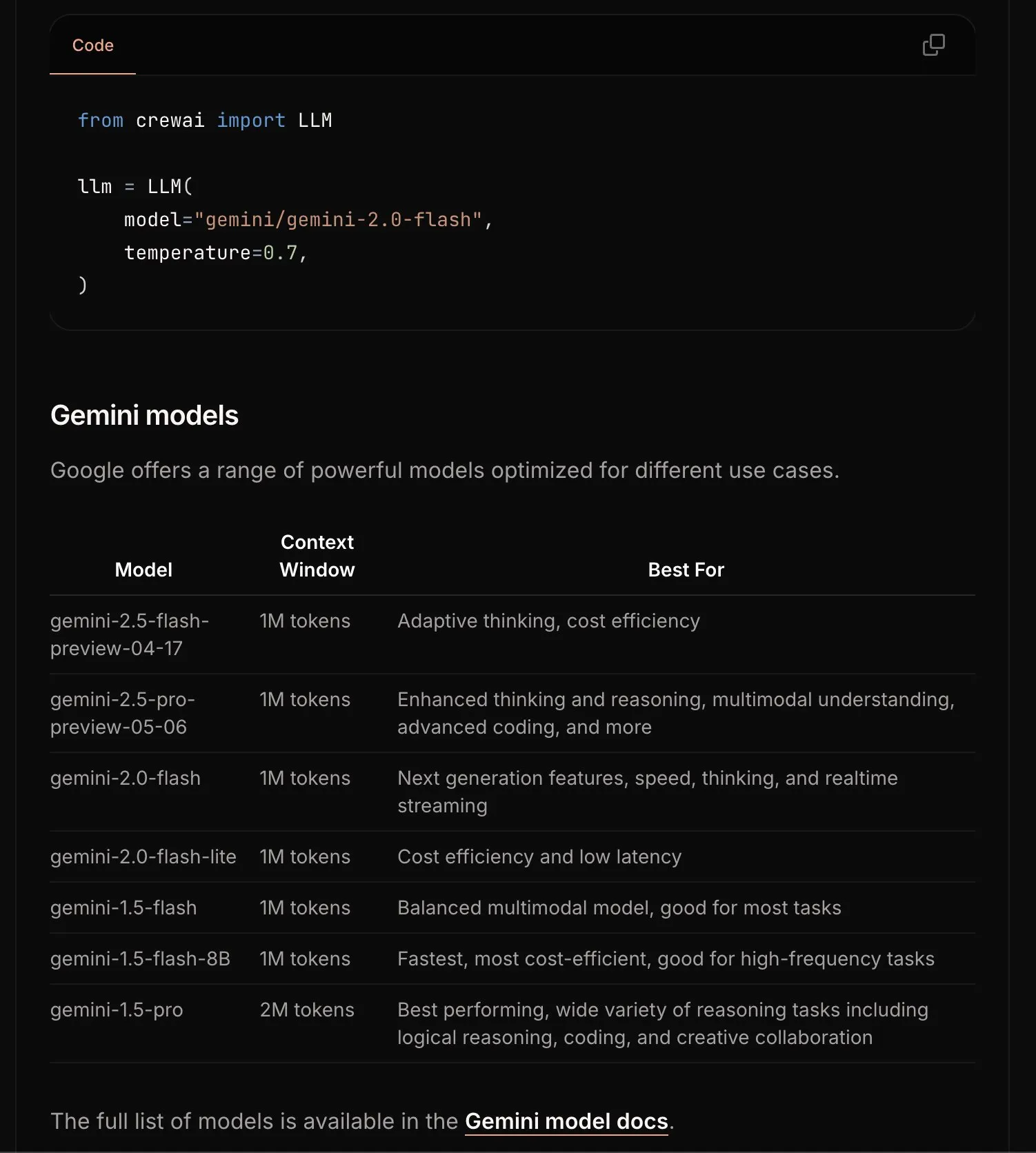
CrewAI обновила документацию по Gemini, упростив процесс начала работы: Команда CrewAI обновила свою документацию по Google Gemini API, чтобы помочь пользователям легче начать использовать модели Gemini для создания AI-агентов. Новая документация может содержать более четкие инструкции, примеры кода или лучшие практики. (Источник: _philschmid)
Requesty представила функцию Smart Routing, автоматически выбирающую лучший LLM для OpenWebUI: Requesty выпустила функцию Smart Routing, которая бесшовно интегрируется с OpenWebUI и автоматически выбирает лучший LLM (например, GPT-4o, Claude, Gemini) в зависимости от типа задачи, указанной в пользовательском промпте. Пользователю достаточно использовать smart/task в качестве ID модели, и система примерно за 65 миллисекунд классифицирует промпт и направит его к наиболее подходящей модели на основе стоимости, скорости и качества. Функция призвана упростить выбор модели и улучшить пользовательский опыт. (Источник: Reddit r/OpenWebUI)
EvoAgentX: выпущен первый open-source фреймворк для самоэволюции AI-агентов: Исследовательская группа из Университета Глазго (Великобритания) выпустила EvoAgentX, первый в мире open-source фреймворк для самоэволюции AI-агентов. Он поддерживает создание рабочих процессов в один клик и вводит механизм “самоэволюции”, позволяющий мультиагентным системам постоянно оптимизировать свою структуру и производительность в соответствии с изменениями среды и целей. Цель проекта — переход мультиагентных AI-систем от “ручной отладки” к “автономной эволюции”. Эксперименты показали, что в задачах многоэтапного ответа на вопросы, генерации кода и математического вывода производительность в среднем повысилась на 8%-13%. (Источник: 36氪)

📚 Обучение
HuggingFace, Gradio и другие совместно организуют Agents & MCP Hackathon с щедрыми призами и API-кредитами: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, LlamaIndex и другие организации совместно проведут Gradio Agents & MCP Hackathon (2-8 июня). Мероприятие предлагает общий призовой фонд в размере 11000 долларов США, а также бесплатные API-кредиты от Hyperbolic, Anthropic, Mistral, SambaNova для тех, кто зарегистрируется раньше. Modal Labs обещает предоставить всем участникам GPU-кредиты на сумму 250 долларов США, что в общей сложности составляет более 300 000 долларов США. (Источник: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain поделилась практикой JPMorgan по использованию мультиагентных систем для инвестиционных исследований: Дэвид Одомирок и Чжэн Сюэ из JPMorgan поделились тем, как они создали мультиагентную AI-систему под названием “Ask David”. Эта система предназначена для автоматизации процесса инвестиционных исследований для тысяч финансовых продуктов, демонстрируя потенциал мультиагентных архитектур в сложном финансовом анализе. (Источник: LangChainAI, hwchase17)
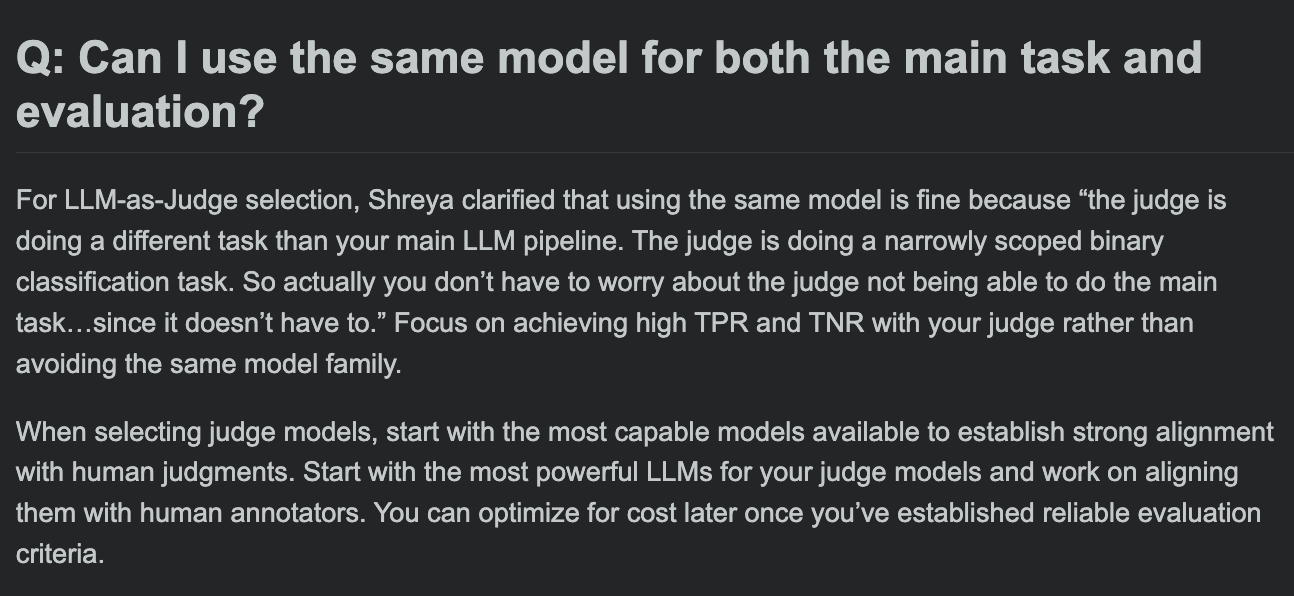
Хамел Хусейн поделился FAQ по курсу оценки LLM, обсуждая, могут ли модель оценки и модель основной задачи быть одинаковыми: В разделе вопросов и ответов своего курса по оценке LLM Хамел Хусейн рассмотрел распространенный вопрос: можно ли использовать одну и ту же модель для обработки основной задачи и для оценки этой задачи. Это обсуждение помогает разработчикам понять потенциальные смещения и лучшие практики в оценке моделей. (Источник: HamelHusain, HamelHusain)
The Rundown AI запустила персонализированную образовательную AI-платформу: The Rundown AI объявила о запуске первой в мире персонализированной образовательной AI-платформы, предлагающей индивидуальное обучение, примеры использования и семинары в реальном времени, адаптированные для различных отраслей, уровней квалификации и повседневных рабочих процессов. Платформа включает 16 отраслевых AI-сертификационных курсов в технологических вертикалях, более 300 реальных примеров использования AI, семинары экспертов, а также скидки на AI-инструменты и многое другое. (Источник: TheRundownAI, rowancheung)
Common Crawl опубликовал графы сети на уровне хостов и доменов за март-май 2025 года: Common Crawl обнародовал свои последние данные графов сети на уровне хостов и доменов, охватывающие март, апрель и май 2025 года. Эти данные имеют большую ценность для исследования структуры сети, обучения языковых моделей и проведения крупномасштабного анализа сети. (Источник: CommonCrawl)
Билл Чемберс запустил учебную инициативу “20 Days of DSPyOSS”: Чтобы помочь сообществу лучше понять функции и методы использования DSPyOSS, Билл Чемберс запустил 20-дневную учебную инициативу по DSPyOSS. Каждый день будет публиковаться фрагмент кода DSPy с его объяснением, чтобы помочь пользователям освоить этот фреймворк от начального до продвинутого уровня. (Источник: lateinteraction)
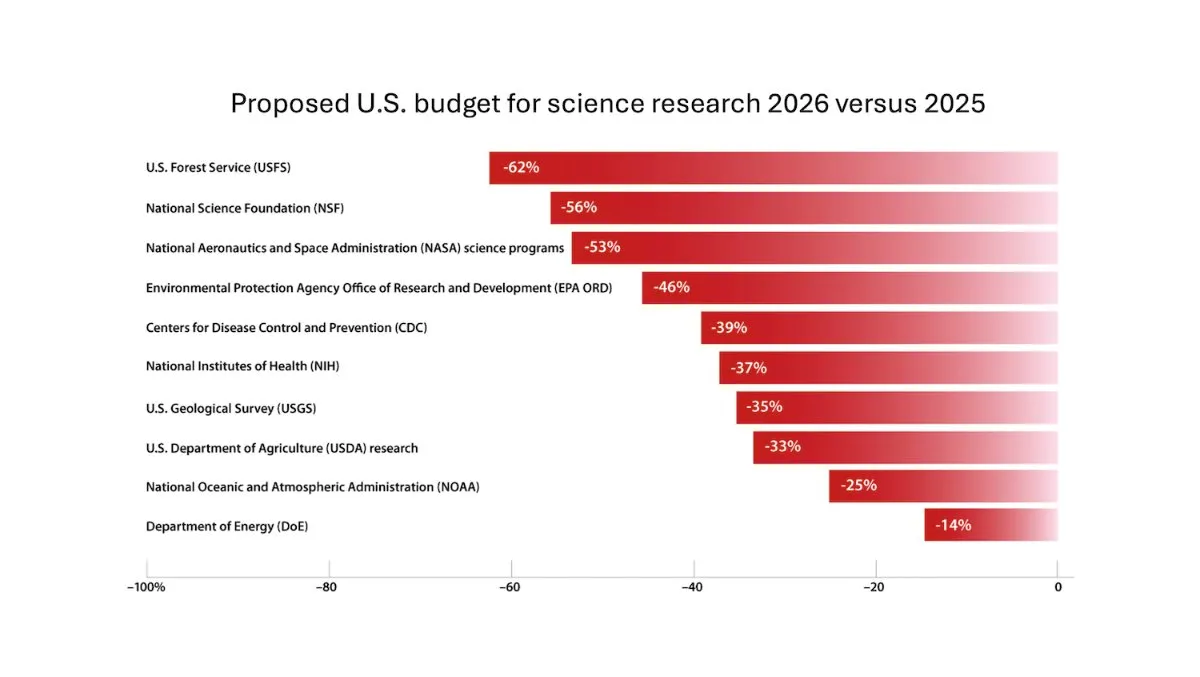
DeepLearning.AI выпустила еженедельник The Batch, Эндрю Ын обсуждает риски сокращения финансирования научных исследований: В последнем выпуске еженедельника The Batch Эндрю Ын обсуждает потенциальные риски сокращения финансирования научных исследований для национальной конкурентоспособности и безопасности. Еженедельник также освещает производительность модели Claude 4 в бенчмарках кодирования, AI-анонсы на Google I/O, метод низкозатратного обучения DeepSeek, а также возможное использование GPT-4o книг, защищенных авторским правом, для обучения и другие горячие темы. (Источник: DeepLearningAI)
Google DeepMind предоставляет британским студентам бесплатный доступ к Gemini 2.5 Pro и NotebookLM: Google DeepMind объявила о предоставлении британским студентам бесплатного доступа к своим самым передовым моделям (включая Gemini 2.5 Pro и NotebookLM) на 15 месяцев. Этот шаг направлен на поддержку студентов в их учебе, исследованиях, написании работ и подготовке к экзаменам, а также предоставляет 2 ТБ бесплатного хранилища. (Источник: demishassabis)
Разбор AI-статьи: Prot2Token – унифицированный фреймворк для моделирования белков: Статья «Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction» представляет унифицированный фреймворк для моделирования белков Prot2Token, который преобразует различные задачи прогнозирования, от свойств белковых последовательностей и характеристик остатков до межбелковых взаимодействий, в стандартный формат предсказания следующего токена. Фреймворк использует авторегрессионный декодер, эмбеддинги предобученного белкового энкодера и обучаемые токены задач для многозадачного обучения, с целью повышения эффективности и ускорения биологических открытий. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Майнинг сложных негативных примеров для доменно-специфического поиска в корпоративных системах: Статья «Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems» предлагает масштабируемый фреймворк для майнинга сложных негативных примеров для данных, специфичных для корпоративных доменов. Метод динамически выбирает семантически сложные, но контекстуально нерелевантные документы для улучшения производительности развернутых моделей переранжирования. Эксперименты на корпоративных корпусах в области облачных сервисов показали улучшение MRR@3 и MRR@10 на 15% и 19% соответственно. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: FS-DAG, графовая сеть для понимания визуально насыщенных документов в условиях малого количества примеров: Статья «FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding» предлагает архитектуру модели FS-DAG для понимания визуально насыщенных документов в условиях малого количества обучающих примеров (few-shot). Модель использует доменно-специфичные и языковые/визуальные базовые сети в рамках модульного фреймворка для адаптации к различным типам документов с минимальным количеством данных. Эксперименты по извлечению информации показали более быструю сходимость и производительность по сравнению с SOTA-методами. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: FastTD3, простое и быстрое reinforcement learning управление для гуманоидных роботов: Статья «FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control» представляет алгоритм reinforcement learning под названием FastTD3, который значительно ускоряет обучение гуманоидных роботов в популярных наборах, таких как HumanoidBench, IsaacLab и MuJoCo Playground, за счет параллельного моделирования, обновлений большими пакетами, распределенного критика и тщательно настроенных гиперпараметров. (Источник: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Разбор AI-статьи: HLIP, масштабируемое предварительное обучение язык-изображение для 3D-медицинских изображений: Статья «Towards Scalable Language-Image Pre-training for 3D Medical Imaging» представляет масштабируемый фреймворк для предварительного обучения на 3D-медицинских изображениях под названием HLIP (Hierarchical attention for Language-Image Pre-training). HLIP использует легковесный иерархический механизм внимания, способный обучаться непосредственно на неструктурированных клинических наборах данных, и достиг SOTA-производительности на нескольких бенчмарках. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: PENGUIN, бенчмарк персонализированной безопасности LLM и агентный подход на основе планирования: Статья «Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach» вводит концепцию персонализированной безопасности и предлагает бенчмарк PENGUIN (включающий 14000 сценариев в 7 чувствительных областях) и фреймворк RAISE (двухэтапный агент без необходимости обучения, который стратегически получает специфичную для пользователя фоновую информацию). Исследование показывает, что персонализированная информация значительно повышает оценку безопасности, а RAISE может улучшить безопасность при низких затратах на взаимодействие. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Усиление многоходовых рассуждений в LLM-агентах через назначение кредита на уровне хода: Статья «Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment» исследует, как усилить способности LLM-агентов к рассуждению с помощью reinforcement learning, особенно в сценариях многоходового использования инструментов. Авторы предлагают мелкозернистую стратегию оценки преимущества на уровне хода для достижения более точного назначения кредита. Эксперименты показывают, что этот метод может значительно улучшить многоходовые рассуждения LLM-агентов в сложных задачах принятия решений. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: PISCES, точное удаление концепций внутри параметров в больших языковых моделях: Статья «Precise In-Parameter Concept Erasure in Large Language Models» предлагает фреймворк PISCES для точного удаления целых концепций из параметров модели путем прямого редактирования направлений, кодирующих концепции в пространстве параметров. Метод использует декомпозитор для разделения векторов MLP, выявления признаков, связанных с целевой концепцией, и их удаления из параметров модели. Эксперименты показывают его превосходство над существующими методами по эффективности удаления, специфичности и надежности. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: DORI, оценка понимания ориентации MLLM с помощью мелкозернистых многоосевых задач восприятия: Статья «Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks» представляет бенчмарк DORI, предназначенный для оценки способности мультимодальных больших языковых моделей (MLLM) понимать ориентацию объектов. DORI включает четыре аспекта: определение лицевой стороны, преобразование вращения, относительные ориентационные отношения и понимание канонической ориентации. Тестирование 15 SOTA MLLM показало, что даже лучшие модели имеют значительные ограничения в точном определении ориентации. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Могут ли LLM выводить причинно-следственные связи из реальных текстов?: Статья «Can Large Language Models Infer Causal Relationships from Real-World Text?» исследует способность LLM выводить причинно-следственные связи из реальных текстов. Исследователи разработали бенчмарк, основанный на реальных академических публикациях, включающий тексты различной длины, сложности и из разных областей. Эксперименты показали, что даже SOTA LLM сталкиваются со значительными трудностями в этой задаче, лучший результат F1-score составил всего 0.477, что выявило их проблемы с обработкой неявной информации, различением релевантных факторов и связыванием разрозненной информации. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: IQBench, оценка “интеллекта” визуально-языковых моделей с помощью тестов IQ человека: Статья «IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests» представляет IQBench, новый бенчмарк, предназначенный для оценки флюидного интеллекта визуально-языковых моделей (VLM) с помощью стандартизированных визуальных тестов IQ. Бенчмарк ориентирован на визуальные данные и включает 500 вручную собранных и аннотированных визуальных вопросов IQ, оценивающих способность моделей к интерпретации, решению проблем и точность конечных прогнозов. Эксперименты показали, что o4-mini, Gemini-2.5-Flash и Claude-3.7-Sonnet показали хорошие результаты, но все модели испытывали трудности с задачами на 3D-пространственное и анаграммное мышление. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: PixelThink, на пути к эффективному цепочечному пиксельному рассуждению: Статья «PixelThink: Towards Efficient Chain-of-Pixel Reasoning» предлагает решение PixelThink, которое регулирует генерацию рассуждений в рамках парадигмы reinforcement learning путем интеграции внешней оценки сложности задачи и внутренней оценки неопределенности модели. Модель учится сжимать длину рассуждений в зависимости от сложности сцены и уверенности в прогнозе. Для оценки также представлен бенчмарк ReasonSeg-Diff. Эксперименты показывают, что этот метод повышает эффективность рассуждений и общую производительность сегментации. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Пересмотр многоагентных дебатов как масштабирования во время тестирования: систематическое исследование условной эффективности: Статья «Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness» концептуализирует многоагентные дебаты (MAD) как технику масштабирования вычислений во время тестирования и систематически исследует их эффективность по сравнению с методами самоагентности в различных условиях (сложность задачи, масштаб модели, разнообразие агентов). Исследование показало, что для математических рассуждений преимущество MAD ограничено, но более эффективно при увеличении сложности задачи или снижении возможностей модели; для задач безопасности совместная оптимизация MAD может увеличить уязвимость, но разнообразные конфигурации помогают снизить успешность атак. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: VF-Eval, оценка способности MLLM генерировать обратную связь по видео AIGC: Статья «VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos» предлагает новый бенчмарк VF-Eval для оценки способности мультимодальных больших языковых моделей (MLLM) интерпретировать видео, сгенерированные AI (AIGC). VF-Eval включает четыре задачи: проверка согласованности, восприятие ошибок, определение типа ошибки и оценка рассуждений. Оценка 13 передовых MLLM показала, что даже лучшая из них, GPT-4.1, с трудом поддерживает хорошую производительность во всех задачах. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: SafeScientist, LLM-агент для научных открытий с учетом рисков: Статья «SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents» представляет фреймворк AI-ученого под названием SafeScientist, направленный на повышение безопасности и этической ответственности в научных исследованиях, проводимых с помощью AI. Фреймворк способен активно отклонять неуместные или высокорискованные задачи и подчеркивает безопасность исследовательского процесса с помощью многоуровневых механизмов защиты, таких как мониторинг промптов, мониторинг сотрудничества агентов, мониторинг использования инструментов и компонент этической экспертизы. Также предложен бенчмарк SciSafetyBench для оценки. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: CXReasonBench, бенчмарк для оценки структурированного диагностического мышления по рентгеновским снимкам грудной клетки: Статья «CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays» представляет процесс CheXStruct и бенчмарк CXReasonBench для оценки того, могут ли большие визуально-языковые модели (LVLM) выполнять клинически эффективные этапы рассуждений при диагностике по рентгеновским снимкам грудной клетки. Бенчмарк содержит 18988 пар вопрос-ответ, охватывающих 12 диагностических задач и 1200 случаев, и поддерживает многопутевую, многоэтапную оценку, включая выбор анатомической области и визуальную локализацию для диагностических измерений. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: ZeroGUI, автоматизация онлайн-обучения GUI без затрат человеческого труда: Статья «ZeroGUI: Automating Online GUI Learning at Zero Human Cost» предлагает ZeroGUI, масштабируемый фреймворк онлайн-обучения для автоматизации обучения GUI-агентов без затрат человеческого труда. ZeroGUI интегрирует автоматическую генерацию задач на основе VLM, автоматическую оценку вознаграждения и двухэтапное онлайн-обучение с подкреплением для постоянного взаимодействия со средой GUI и обучения на ней. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Spatial-MLLM, повышение пространственного интеллекта MLLM на основе визуальных данных: Статья «Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence» предлагает фреймворк Spatial-MLLM для пространственного мышления на основе визуальных данных, получаемых исключительно из 2D-наблюдений. Фреймворк использует архитектуру с двумя кодировщиками (семантический визуальный кодировщик и пространственный кодировщик) и сочетает ее со стратегией выборки кадров с учетом пространственной информации, достигая SOTA-производительности на нескольких реальных наборах данных. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: TrustVLM, определение достоверности прогнозов визуально-языковых моделей: Статья «To Trust Or Not To Trust Your Vision-Language Model’s Prediction» представляет TrustVLM, фреймворк без необходимости обучения, предназначенный для оценки достоверности прогнозов визуально-языковых моделей (VLM). Метод использует различия в представлении концепций в пространстве эмбеддингов изображений и предлагает новую функцию оценки уверенности для улучшения обнаружения ошибочных классификаций, демонстрируя SOTA-производительность на 17 различных наборах данных. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: MAGREF, генерация видео с несколькими референсами под управлением маски: Статья «MAGREF: Masked Guidance for Any-Reference Video Generation» предлагает MAGREF, унифицированный фреймворк для генерации видео с несколькими референсами. Он вводит механизм управления маской, который с помощью динамических масок, учитывающих области, и попиксельного соединения каналов обеспечивает согласованный синтез видео с несколькими объектами при разнообразных референсных изображениях и текстовых подсказках, превосходя существующие open-source и коммерческие базовые модели на бенчмарках видео с несколькими объектами. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: ATLAS, обучение оптимальному запоминанию контекста во время тестирования: Статья «ATLAS: Learning to Optimally Memorize the Context at Test Time» предлагает ATLAS, модуль долговременной памяти большой емкости, который учится запоминать контекст путем оптимизации памяти на основе текущих и прошлых токенов, преодолевая особенность онлайн-обновления моделей долговременной памяти. На основе этого авторы предлагают семейство архитектур DeepTransformers. Эксперименты показывают, что ATLAS превосходит Transformers и недавние линейные рекуррентные модели в задачах языкового моделирования, рассуждений на основе здравого смысла, задач с интенсивным извлечением информации и понимания длинного контекста. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Satori-SWE, выборочно эффективный эволюционный метод масштабирования во время тестирования для программной инженерии: Статья «Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering» предлагает метод EvoScale, который рассматривает генерацию кода как эволюционный процесс, повышая производительность небольших моделей в задачах программной инженерии (таких как SWE-Bench) путем итеративной оптимизации вывода. Модель Satori-SWE-32B с помощью этого метода, используя небольшое количество примеров, достигает или превосходит производительность моделей с более чем 100B параметров. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: OPO, on-policy reinforcement learning с оптимальной базовой линией вознаграждения: Статья «On-Policy RL with Optimal Reward Baseline» предлагает алгоритм OPO, новый упрощенный алгоритм reinforcement learning, направленный на решение проблем нестабильности обучения и низкой вычислительной эффективности, с которыми сталкиваются текущие RL-алгоритмы при обучении LLM. OPO подчеркивает точное on-policy обучение и вводит теоретически оптимальную базовую линию вознаграждения, минимизирующую дисперсию градиента. Эксперименты показывают его превосходную производительность и стабильность обучения на бенчмарках математического мышления. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: SWE-bench Goes Live! Бенчмарк для программной инженерии с обновлением в реальном времени: Статья «SWE-bench Goes Live!» представляет SWE-bench-Live, бенчмарк, обновляемый в реальном времени и призванный преодолеть ограничения существующего SWE-bench. Новая версия включает 1319 задач, основанных на реальных проблемах GitHub с 2024 года, охватывающих 93 репозитория, и оснащена автоматизированными процессами управления для обеспечения масштабируемости и постоянного обновления, тем самым предоставляя более строгую и устойчивую к загрязнению оценку LLM и агентов. (Источник: HuggingFace Daily Papers, _akhaliq)
Разбор AI-статьи: ToMAP, обучение LLM-убеждающих агентов с осознанием оппонента на основе теории сознания: Статья «ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind» представляет новый метод под названием ToMAP, который создает более гибких убеждающих агентов путем интеграции двух модулей теории сознания, усиливая их осознание и анализ психического состояния оппонента. Эксперименты показывают, что убеждающий агент ToMAP всего с 3B параметрами превосходит крупные базовые модели, такие как GPT-4o, в различных моделях объектов убеждения и корпусах. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Могут ли LLM обмануть CLIP? Оценка состязательной композиционности предварительно обученных мультимодальных представлений с помощью текстовых обновлений: Статья «Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates» представляет бенчмарк мультимодальной состязательной композиционности (MAC), использующий LLM для генерации обманчивых текстовых примеров с целью эксплуатации уязвимостей композиционности предварительно обученных мультимодальных представлений, таких как CLIP. Исследование предлагает метод самообучения с тонкой настройкой путем отбраковочной выборки с фильтрацией, способствующей разнообразию, для повышения успешности атак и разнообразия примеров. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Роль шумных вознаграждений в обучении рассуждению — путь к вершине высекает мудрость глубже, чем сама вершина: Статья «The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason» исследует влияние шума в вознаграждениях на постобучение LLM рассуждению с помощью reinforcement learning. Исследование показало, что LLM демонстрируют высокую устойчивость к значительному шуму в вознаграждениях. Даже если вознаграждать только появление ключевых фраз рассуждения (без проверки правильности ответа), модель может достичь производительности, сопоставимой с моделями, обученными со строгой проверкой и точными вознаграждениями. (Источник: HuggingFace Daily Papers)
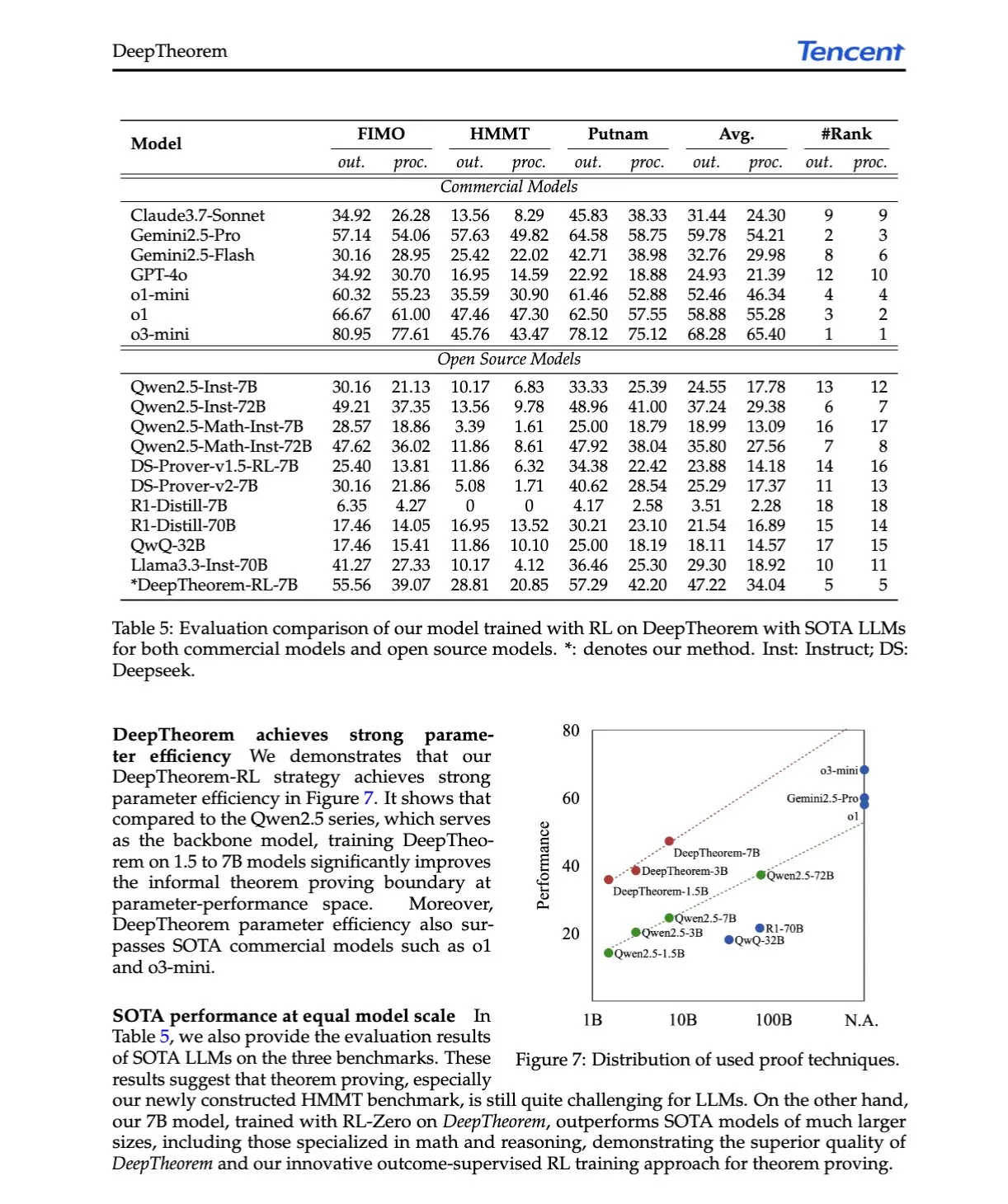
Разбор AI-статьи: DeepTheorem, продвижение доказательства теорем LLM с помощью естественного языка и reinforcement learning: Статья «DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning» предлагает DeepTheorem, неформальный фреймворк для доказательства теорем, использующий естественный язык для улучшения математического мышления LLM. Фреймворк включает крупномасштабный эталонный набор данных (121 тыс. неформальных теорем и доказательств уровня IMO) и RL-стратегию (RL-Zero), специально разработанную для неформального доказательства теорем. (Источник: HuggingFace Daily Papers, teortaxesTex)
Разбор AI-статьи: D-AR, диффузия через авторегрессионные модели: Статья «D-AR: Diffusion via Autoregressive Models» предлагает новую парадигму D-AR, которая переформулирует процесс диффузии изображений как стандартный авторегрессионный процесс предсказания следующего токена. С помощью разработанного токенизатора изображение преобразуется в последовательность дискретных токенов, где токены в разных позициях могут быть декодированы в различные шаги шумоподавления диффузии в пиксельном пространстве. Этот метод достигает FID 2.09 на ImageNet с использованием 775M Llama backbone и 256 дискретных токенов. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Table-R1, масштабирование во время вывода для табличных рассуждений: Статья «Table-R1: Inference-Time Scaling for Table Reasoning» впервые исследует масштабирование во время вывода (inference-time scaling) для задач табличных рассуждений. Исследователи разработали и оценили две стратегии постобучения: дистилляция из траекторий рассуждений передовых моделей (Table-R1-SFT) и reinforcement learning с верифицируемыми вознаграждениями (Table-R1-Zero). Table-R1-Zero (7B параметров) достигает или превосходит производительность GPT-4.1 и DeepSeek-R1 в различных задачах табличных рассуждений. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Muddit, унифицированная модель дискретной диффузии для генерации за пределами преобразования текста в изображение: Статья «Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model» представляет Muddit, унифицированную модель дискретного диффузионного трансформера, поддерживающую быструю параллельную генерацию текстовых и графических модальностей. Muddit объединяет мощные визуальные априорные знания предобученной базовой модели преобразования текста в изображение и легковесный текстовый декодер, демонстрируя конкурентоспособность как по качеству, так и по эффективности. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: VideoReasonBench, могут ли MLLM выполнять сложные видеорассуждения, ориентированные на визуальные данные?: Статья «VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?» представляет VideoReasonBench, бенчмарк, предназначенный для оценки способности к сложным видеорассуждениям, ориентированным на визуальные данные. Бенчмарк содержит видео с мелкозернистыми последовательностями действий, а вопросы оценивают способности к запоминанию, выводу и прогнозированию. Эксперименты показывают, что большинство SOTA MLLM плохо справляются с этим бенчмарком, в то время как Gemini-2.5-Pro с улучшенным мышлением демонстрирует выдающиеся результаты. (Источник: HuggingFace Daily Papers, OriolVinyalsML)
Разбор AI-статьи: GeoDrive, мировая модель вождения с 3D-геометрической осведомленностью и точным управлением действиями: Статья «GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control» предлагает GeoDrive, который явно интегрирует надежные 3D-геометрические условия в мировую модель вождения для улучшения пространственного понимания и управляемости действий. Метод улучшает эффекты рендеринга во время обучения с помощью модуля динамического редактирования. Эксперименты доказывают его превосходство над существующими моделями в точности действий и восприятии 3D-пространства. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Адаптивное управление без классификатора через динамическое маскирование с низкой уверенностью: Статья «Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking» предлагает метод A-CFG, который настраивает безусловный ввод для управления без классификатора (CFG), используя мгновенную уверенность модели в прогнозе. A-CFG на каждом шаге итеративной (маскированной) диффузионной языковой модели идентифицирует токены с низкой уверенностью и временно повторно маскирует их, создавая таким образом динамический, локализованный безусловный ввод, что делает корректирующее влияние CFG более точным. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: PatientSim, симулятор на основе персон для реалистичных взаимодействий врач-пациент: Статья «PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions» представляет PatientSim, симулятор, генерирующий реалистичные и разнообразные персоны пациентов на основе клинических профилей из набора данных MIMIC и четырехосевой персоны (личность, уровень владения языком, уровень воспоминаний истории болезни, уровень когнитивной спутанности). Предназначен для предоставления реалистичной системы взаимодействия с пациентами для обучения или оценки LLM-врачей. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: LoRAShop, генерация и редактирование изображений с несколькими концепциями без обучения с помощью трансформеров с корректированным потоком: Статья «LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers» представляет первый фреймворк LoRAShop для редактирования изображений с несколькими концепциями с использованием моделей LoRA. Фреймворк использует паттерны взаимодействия внутренних признаков диффузионного трансформера в стиле Flux для вывода разделенных латентных масок для каждой концепции и смешивает веса LoRA только в областях концепций, обеспечивая бесшовную интеграцию нескольких объектов или стилей. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: AnySplat, прямое 3D-гауссово распыление из неограниченных ракурсов: Статья «AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views» представляет AnySplat, сеть прямого распространения для синтеза новых ракурсов из набора некалиброванных изображений. В отличие от традиционных процессов нейронного рендеринга, AnySplat за один прямой проход может предсказывать 3D-гауссовы примитивы (кодирующие геометрию и внешний вид сцены), а также внутренние и внешние параметры камеры для каждого входного изображения, не требуя аннотации поз, и поддерживает синтез новых ракурсов в реальном времени. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: ZeroSep, разделение чего угодно в аудио без обучения: Статья «ZeroSep: Separate Anything in Audio with Zero Training» обнаруживает, что только с помощью предварительно обученной модели диффузии аудио, управляемой текстом, в определенной конфигурации можно достичь разделения источников звука без обучения (zero-shot). Метод ZeroSep восстанавливает отдельные источники звука путем инвертирования смешанного аудио в латентное пространство модели диффузии и использования текстовых условий для управления процессом шумоподавления, не требуя какого-либо специального обучения или тонкой настройки для конкретной задачи. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Исследование минимизации энтропии за один проход: Статья «One-shot Entropy Minimization» путем обучения 13440 больших языковых моделей обнаружила, что минимизация энтропии требует всего лишь одного немаркированного набора данных и 10 шагов оптимизации для достижения или даже превышения улучшения производительности, достигаемого с помощью reinforcement learning на основе правил, использующего тысячи данных и тщательно разработанные вознаграждения. Этот результат может побудить к переосмыслению парадигм постобучения LLM. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: ChartLens, мелкозернистая визуальная атрибуция в диаграммах: Статья «ChartLens: Fine-grained Visual Attribution in Charts»,针对MLLM在图表理解中易产生幻觉的问题, 引入了图表后验视觉归因任务, 并提出ChartLens算法。该算法使用分割技术识别图表对象, 并通过标记集提示与MLLM进行细粒度视觉归因。同时发布了ChartVA-Eval基准, 包含金融、政策、经济等领域图表的细粒度归因标注。 (Источник: HuggingFace Daily Papers) (Примечание: Оригинальный текст на китайском, перевод на русский ниже)
Разбор AI-статьи: ChartLens, мелкозернистая визуальная атрибуция в диаграммах: Статья «ChartLens: Fine-grained Visual Attribution in Charts», addressing the issue of MLLMs being prone to hallucinations in chart understanding, introduces the task of post-hoc visual attribution for charts and proposes the ChartLens algorithm. This algorithm uses segmentation techniques to identify chart objects and performs fine-grained visual attribution with MLLMs through tagged set prompting. Simultaneously, the ChartVA-Eval benchmark was released, containing fine-grained attribution annotations for charts in fields such as finance, policy, and economics. (Источник: HuggingFace Daily Papers)
Разбор AI-статьи: Исследование структурных паттернов знаний в больших языковых моделях с точки зрения графов: Статья «A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models» исследует структурные паттерны знаний в LLM с точки зрения графов. Исследование количественно оценивает знания LLM на уровне триплетов и сущностей, анализирует их связь со структурными свойствами графа, такими как степень узла, и выявляет гомофилию знаний (сходный уровень знаний у топологически близких сущностей). На основе этого разработана графовая модель машинного обучения для оценки знаний сущностей и их использования для проверки знаний. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Компания по воплощенному интеллекту Lumos Robotics за полгода привлекла почти 200 млн юаней и заключила партнерства с COSCO Shipping и др.: Компания Lumos Robotics (鹿明机器人), занимающаяся робототехникой с воплощенным интеллектом и основанная бывшим топ-менеджером Dreame Юй Чао, объявила о завершении раунда финансирования Angel++, инвесторами в котором выступили Fosun RZ Capital, Dematic Technology и Wuzhong Financial Holding. За полгода компания привлекла в общей сложности почти 200 млн юаней. Компания фокусируется на бытовом сегменте, ее продукция включает гуманоидных роботов серий LUS, MOS и ключевые компоненты. Уже представлен полноразмерный гуманоидный робот LUS. Также заключены стратегические партнерства с Dematic Technology, COSCO Shipping и другими для ускорения коммерциализации воплощенного интеллекта в логистике, интеллектуальном производстве и других сценариях. (Источник: 36氪)

Snorkel AI привлекла 100 миллионов долларов в раунде D и запустила сервисы оценки AI-агентов и экспертных данных: Компания Snorkel AI, специализирующаяся на AI для дата-центров, объявила о завершении раунда финансирования D на сумму 100 миллионов долларов под руководством Valor Equity Partners, в результате чего общая сумма привлеченных средств достигла 235 миллионов долларов. Одновременно компания запустила Snorkel Evaluate (платформу для оценки AI-агентов в дата-центрах) и Expert Data-as-a-Service (сервис предоставления экспертных данных), направленные на помощь предприятиям в создании и развертывании более надежных и профессиональных AI-агентов. (Источник: realDanFu, percyliang, tri_dao, krandiash)
Министерство энергетики США объявило о сотрудничестве с Dell и Nvidia для разработки суперкомпьютера следующего поколения “Doudna”: Министерство энергетики США объявило о заключении контракта с компанией Dell на разработку для Национальной лаборатории Лоуренса Беркли флагманского суперкомпьютера следующего поколения под названием “Doudna” (NERSC-10). Система будет работать на платформе Nvidia Vera Rubin следующего поколения, ввод в эксплуатацию ожидается в 2026 году. Ее производительность будет более чем в 10 раз превышать существующий флагман Perlmutter. Система предназначена для поддержки крупномасштабных высокопроизводительных вычислений и AI-задач, способствуя победе США в глобальной гонке за доминирование в области AI. (Источник: 36氪, nvidia)

🌟 Сообщество
DeepSeek R1-0528 вызвал бурные обсуждения, в центре внимания – производительность, галлюцинации и вызов инструментов: Выпуск DeepSeek R1-0528 вызвал широкое обсуждение в сообществе. Большинство мнений сходится в том, что модель значительно улучшилась в математике, программировании и общем логическом мышлении, приблизившись или даже превзойдя некоторые закрытые модели. Новая версия достигла прогресса в снижении частоты галлюцинаций и добавила поддержку вывода в JSON и вызова функций. В то же время, ее дистиллированная версия Qwen3-8B также привлекла внимание благодаря отличной математической производительности для небольшой модели. Сообщество в целом считает, что DeepSeek укрепила свои лидирующие позиции в области open source и с нетерпением ожидает выпуска версии R2. (Источник: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Модель редактирования изображений AI FLUX.1 Kontext привлекает внимание, подчеркивая понимание контекста и согласованность персонажей: Модель редактирования изображений FLUX.1 Kontext, выпущенная Black Forest Labs, привлекла внимание сообщества благодаря своей способности одновременно обрабатывать текстовые и графические входные данные и поддерживать согласованность персонажей. Пользователи отмечают ее превосходную производительность в задачах редактирования изображений, переноса стиля и наложения текста, особенно в многоэтапном редактировании, где она хорошо сохраняет основные черты объекта. Платформы, такие как Replicate, уже добавили эту модель и предоставили подробные отчеты о тестировании и советы по использованию. (Источник: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

AI-агенты значительно изменят модели поиска и рекламы: CEO Perplexity AI Арав Шринивас считает, что по мере того, как AI-агенты будут выполнять поиск за пользователей, количество человеческих запросов к поисковым системам, таким как Google, значительно сократится. Это приведет к снижению CPM/CPC рекламы, и рекламные бюджеты могут переместиться в социальные сети или на AI-платформы. Пользователям больше не нужно будет часто выполнять поиск по ключевым словам, вместо этого AI-помощники будут активно предоставлять информацию. (Источник: AravSrinivas)
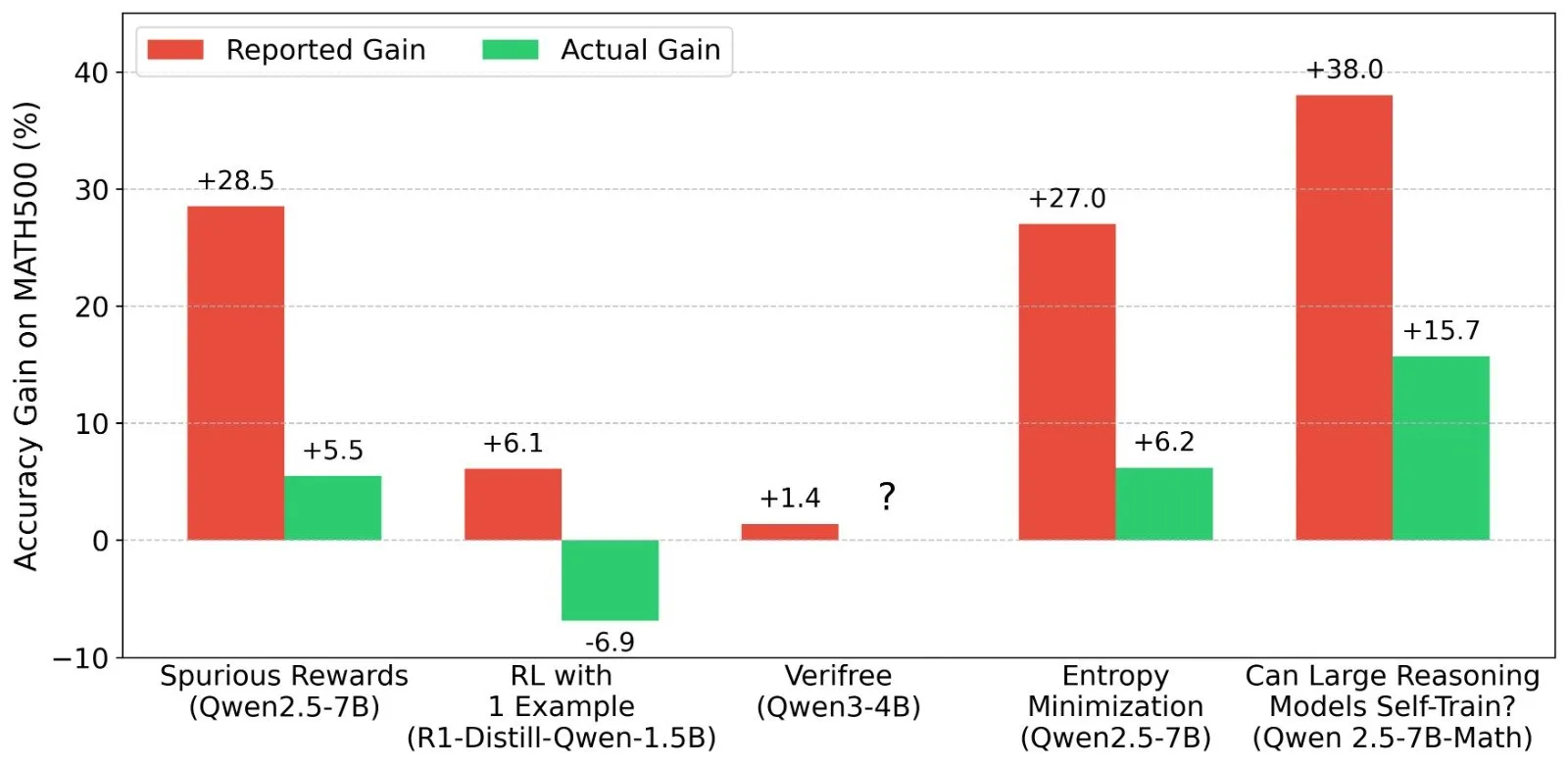
Обсуждение результатов reinforcement learning (RL) для LLM: реальность сигналов вознаграждения и возможностей модели: Шашват Гоэл и другие исследователи ставят под сомнение недавние исследования в области RL для LLM, где модели демонстрируют улучшение производительности без реальных сигналов вознаграждения, указывая на то, что некоторые исследования могли недооценить базовые возможности предварительно обученных моделей или наличие других смешивающих факторов. Обсуждение вызвало углубленный анализ производительности моделей, таких как Qwen, в RL, а также размышления об эффективности RLVR (reinforcement learning с верифицируемым вознаграждением), подчеркивая необходимость более строгих базовых линий и оптимизации промптов при оценке эффектов RL. (Источник: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” вызывает дискуссии, подчеркивая важность безопасных настроек по умолчанию и риски технического долга: “Vibe coding” (программирование “по наитию”, означающее программирование, основанное больше на интуиции и быстрых итерациях, чем на строгих спецификациях) стало горячей темой обсуждения в сообществе. CEO Replit Амджад Масад считает, что этот подход расширяет возможности новых разработчиков, но платформы должны предоставлять безопасные конфигурации по умолчанию. В то же время Педро Домингос прокомментировал, что “программирование по наитию — это Годзилла технического долга”, намекая на возможные долгосрочные проблемы с обслуживанием. Semafor сообщил об уязвимости безопасности в Lovable из-за неправильной конфигурации политики RLS, что еще больше привлекло внимание к безопасности этого стиля программирования. (Источник: alexalbert__, amasad, pmddomingos, gfodor)
Роль AI в программной инженерии: повышение эффективности и незаменимость человеческих программистов: Создатель Redis Сальваторе Санфилиппо поделился опытом, что, хотя AI (например, Gemini 2.5 Pro) ценен в помощи при программировании, проверке кода и проверке идей, человеческие программисты по-прежнему значительно превосходят AI в творческом решении проблем и нестандартном мышлении. Обсуждение в сообществе также указало, что AI в настоящее время больше похож на “умную резиновую уточку”, которая может помочь в размышлениях, но ее предложения требуют осторожной оценки, а чрезмерная зависимость может ослабить основные навыки разработчиков. Митчелл Хашимото также поделился случаем, когда LLM помог ему быстро найти проблему компиляции Clang, сэкономив много времени. (Источник: mitchellh, 36氪)
Вопрос о том, заменит ли AI массово рабочие места, продолжает вызывать беспокойство: CEO Anthropic Дарио Амодей предсказывает, что AI может привести к исчезновению половины офисных должностей начального уровня, в то время как Марк Кьюбан считает, что AI создаст новые компании и новые рабочие места. В сообществе на эту тему идут бурные дебаты: некоторые считают, что работа в сфере обслуживания клиентов, копирайтинга начального уровня, частично разработки уже пострадала, но AI пока не может заменить человека в творчестве, принятии сложных решений и областях, требующих высокого уровня межличностного взаимодействия. Общее мнение сводится к тому, что AI изменит характер работы, и людям необходимо адаптироваться и повышать свои навыки сотрудничества с AI. (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent (интеллектуальный агент) становится следующим поколением интерфейса взаимодействия, вызывая конкуренцию среди крупных компаний: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa и другие отечественные и зарубежные технологические компании активно развивают направление AI Agent. Интеллектуальные агенты способны к глубокому мышлению, автономному планированию, принятию решений и выполнению сложных задач, и рассматриваются как следующее поколение интерфейса взаимодействия после поисковых систем и приложений. В настоящее время сформировались три основные силы: создатели технологических экосистем, представленные OpenAI и Baidu; поставщики корпоративных услуг для вертикальных рынков, такие как Microsoft и Alibaba Cloud; а также производители программного и аппаратного обеспечения, такие как Huawei и Coocaa. (Источник: 36氪)

💡 Прочее
Китайский AI ускоряет выход на международный рынок, переходя от экспорта продуктов к построению экосистемы: Отчет «Трансокеанский рост китайского AI» указывает, что выход китайских AI-компаний на международный рынок вступил в фазу быстрого масштабного развития, при этом 76% компаний сосредоточены на прикладном уровне. Путь выхода на международный рынок развивался от ранних инструментальных приложений, через средний этап экспорта отраслевых решений с использованием технологических преимуществ, до текущего этапа, на котором акцент делается на экспорте технологических экосистем, продвижении технологических стандартов и сотрудничестве в области open source. Выход AI на международный рынок демонстрирует градиентное проникновение «от ближнего к дальнему» и сталкивается с проблемами локализации, соблюдения этических норм и брендового маркетинга. (Источник: 36氪)

Министерство энергетики США сравнивает гонку AI с “новым Манхэттенским проектом”, подчеркивая, что США одержат победу: Объявляя о суперкомпьютере следующего поколения “Doudna”, Министерство энергетики США назвало конкуренцию в развитии AI “Манхэттенским проектом нашего времени” и заявило, что США одержат победу в этой гонке. Это заявление вызвало в сообществе дискуссии о технологической конкуренции великих держав, этике AI и международном сотрудничестве. (Источник: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Прогресс AI в области создания контента вызывает размышления о “реальности” и “творчестве”: Сообщество обсудило применение AI в дизайне одежды, создании комиксов, генерации видео и других областях. С одной стороны, AI способен быстро генерировать разнообразный контент, даже превращая комиксы многолетней давности в видео; с другой стороны, этот сгенерированный контент иногда выглядит странно или лишен глубины. Это вызвало размышления о том, является ли сгенерированный AI контент “лучше”, и какую роль будет играть человеческое творчество в эпоху AI. (Источник: Reddit r/ChatGPT, Reddit r/artificial)
