Ключевые слова:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, Случайное вознаграждение, Ошибочное вознаграждение, Производительность модели, Обучение с подкреплением, Будущее RLHF/RLAIF, Случайное вознаграждение улучшает производительность модели, Обучение Qwen2.5-Math-7B с ошибочным вознаграждением, Тестовый набор MATH-500, Обучение сигналам подкрепления
🔥 В фокусе
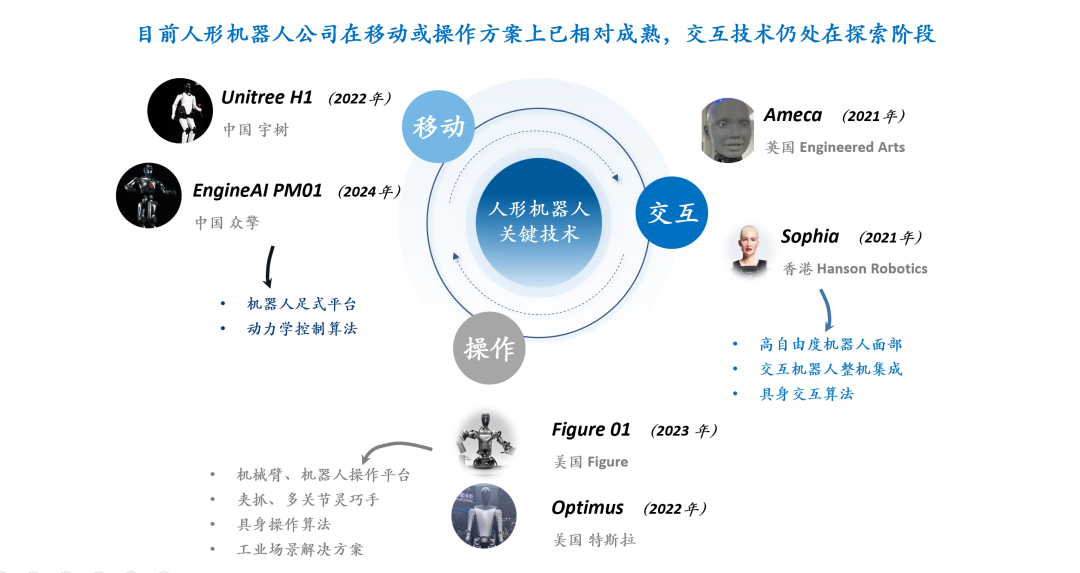
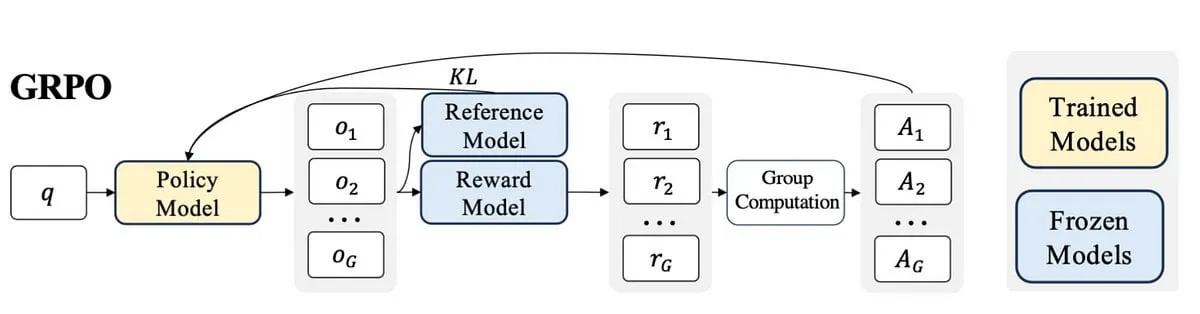
Будущее RLHF/RLAIF: могут ли случайные/ошибочные вознаграждения улучшить производительность модели? : Эксперимент Stella Li показывает, что обучение модели Qwen2.5-Math-7B с использованием случайных или неверных вознаграждений улучшило показатели на тестовом наборе MATH-500 на 21% и 25% соответственно, что близко к улучшению на 28,8% при использовании реальных вознаграждений. Исследование Rulin Shao, которым поделился natolambert, также показало, что RLVR (Reinforcement Learning from Verifier Reward) при использовании ложных вознаграждений увеличивает использование кода моделью Olmo, но снижает ее производительность, в то время как запрет на использование кода, наоборот, повышает производительность. Эти результаты ставят под сомнение традиционную зависимость RLHF/RLAIF от высококачественных данных о человеческих предпочтениях, предполагая, что модели могут учиться исследовать более широкое пространство стратегий через сигналы вознаграждения, даже если само вознаграждение несовершенно, это может стимулировать скрытые возможности модели или оптимизировать существующее поведение. Это может открыть новые пути для снижения зависимости от дорогостоящей ручной разметки и исследования более эффективных методов согласования моделей, однако необходимо остерегаться риска того, что модель научится неправильному поведению. (Источник: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
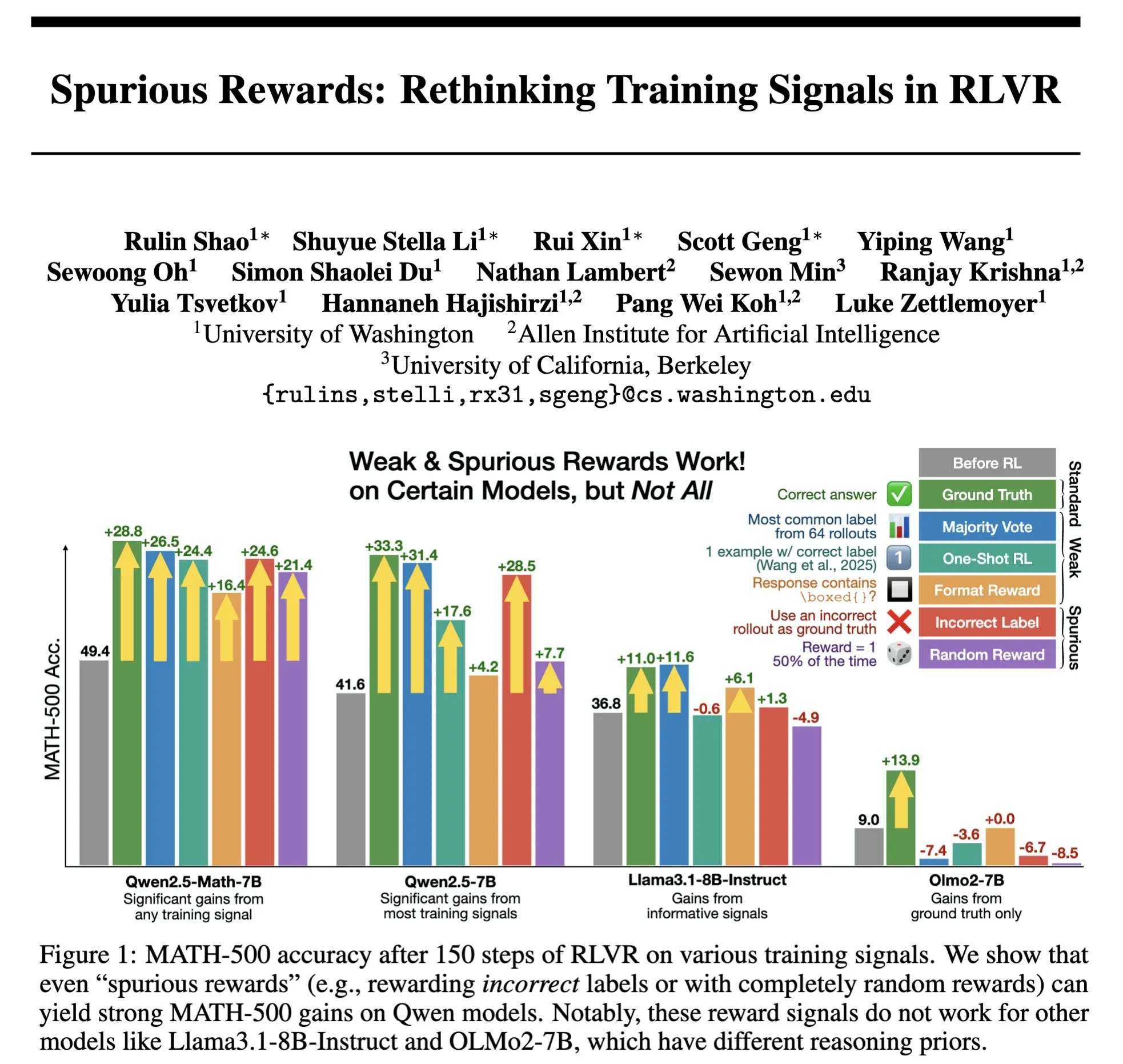
Hazy Research выпустила Low-Latency-Llama Megakernel: инференс Llama 1B на одном ядре CUDA : Hazy Research представила Low-Latency-Llama Megakernel, способный выполнять весь прямой проход модели Llama 1B в рамках одного ядра CUDA. Эта технология, интегрируя вычисления в единое ядро, устраняет границы синхронизации, возникающие при традиционных последовательных вызовах ядер, тем самым оптимизируя планирование вычислений и памяти и достигая более низкой задержки. Andrej Karpathy высоко оценил это, считая это единственным путем к достижению оптимальной организации вычислений и памяти. Этот прогресс имеет важное значение для сценариев с жесткими требованиями к задержке, таких как граничные вычисления и приложения ИИ в реальном времени, и, как ожидается, будет способствовать более эффективному и гибкому развертыванию малых языковых моделей. (Источник: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek AI выпустила rStar-Coder: создание крупномасштабного верифицированного набора данных для логического вывода кода, значительно повышающего возможности малых моделей в области кода : Исследователи из Microsoft и DeepSeek представили проект rStar-Coder, который решает проблему нехватки высококачественных и сложных наборов данных в области логического вывода кода путем создания крупномасштабного верифицированного набора данных, содержащего 418 000 задач по программированию соревновательного уровня, 580 000 длинных логических решений и обширные тестовые примеры. Проект повышает способность LLM к логическому выводу кода за счет комплексного использования существующих задач по программированию и решений-оракулов для синтеза новых задач, разработки надежных конвейеров генерации тестовых примеров ввода-вывода и использования тестовых примеров для проверки высококачественных длинных логических решений. Эксперименты показывают, что модели Qwen (1.5B-14B), обученные на наборе данных rStar-Coder, демонстрируют превосходные результаты на нескольких бенчмарках логического вывода кода. Например, точность Qwen2.5-7B на LiveCodeBench выросла с 17.4% до 57.3%, превзойдя o3-mini (low); на USACO модель 7B также превзошла более крупную QWQ-32B. (Источник: HuggingFace Daily Papers)
Институт автоматизации Китайской академии наук предложил AutoThink: позволяет большим моделям самостоятельно решать, нужно ли «глубоко думать» : В ответ на явление «чрезмерного обдумывания», когда большие языковые модели (LLM) выполняют избыточные рассуждения для простых задач, Институт автоматизации Китайской академии наук совместно с лабораторией Pengcheng Lab предложил метод AutoThink. Этот метод, добавляя «многоточие» (…) в промпт и сочетая трехэтапное обучение с подкреплением (стабилизация режима, оптимизация поведения, сокращение рассуждений), позволяет модели самостоятельно выбирать, следует ли проводить глубокое обдумывание и в какой степени, в зависимости от сложности задачи. Эксперименты показывают, что AutoThink может улучшить производительность моделей, таких как DeepSeek-R1, на математических бенчмарках, одновременно значительно сокращая потребление токенов при инференсе. Например, на DeepScaleR можно дополнительно сэкономить 10% токенов. Это исследование направлено на то, чтобы модели могли «думать по мере необходимости», улучшая баланс между эффективностью и точностью рассуждений. (Источник: 36氪, _akhaliq)

Sakana AI выпустила Sudoku-Bench, выявив слабые места ведущих больших моделей в решении «модифицированных судоку» : Стартап Sakana AI, основанный автором Transformer Llion Jones, выпустил Sudoku-Bench — бенчмарк, включающий современные «модифицированные судоку» от 4×4 до сложных 9×9, предназначенный для оценки творческих многошаговых способностей ИИ к рассуждению. Результаты тестов показали, что ведущие большие модели, включая Gemini 2.5 Pro, GPT-4.1 и Claude 3.7, без посторонней помощи демонстрируют общую точность ниже 15%. В современных судоку 9×9 точность o3 Mini High составила всего 2,9%. Это указывает на то, что модели плохо справляются с новыми задачами, требующими настоящего логического вывода, а не распознавания образов, часто допуская ошибки в решениях, отказываясь от решения или неверно интерпретируя правила. Генеральный директор NVIDIA Jensen Huang считает, что подобные головоломки способствуют улучшению способности ИИ к рассуждению. Sakana AI также опубликовала соответствующие обучающие данные, включая записи процессов решения, созданные в сотрудничестве с известным каналом по судоку. (Источник: 36氪)

🎯 Динамика
Meta реорганизует команду ИИ, уход ключевых членов FAIR вызывает беспокойство : Meta объявила о реорганизации своей команды ИИ, разделив ее на команду по продуктам ИИ под руководством Connor Hayes и подразделение по фундаментальным исследованиям AGI, совместно возглавляемое Ahmad Al-Dahle и Amir Frenkel. Первая будет сосредоточена на продуктах для конечных пользователей, вторая — на разработке фундаментальных моделей, таких как Llama. Примечательно, что отдел фундаментальных исследований ИИ FAIR остается независимым, но некоторые мультимедийные команды переходят в подразделение AGI. Эта реорганизация направлена на повышение скорости и гибкости разработки. Однако Meta сталкивается с проблемами, связанными с прохладным приемом Llama 4, усилением конкуренции в области открытого исходного кода и утечкой ключевых кадров. Из 14 авторов, первоначально участвовавших в разработке Llama, 11 уже ушли, многие из них присоединились к конкурентам, таким как Mistral AI, или основали их. Лаборатория FAIR также претерпела изменения в руководстве и направлениях исследований, что вызвало опасения относительно ее положения в компании и будущих инновационных возможностей. (Источник: 36氪)

Google DeepMind выпускает SignGemma: новую модель для перевода языка жестов : Google DeepMind анонсировала выпуск SignGemma, модели, которая, по их утверждению, является самой мощной на данный момент для перевода с языка жестов в текст на разговорном языке. Ожидается, что модель присоединится к семейству моделей Gemma позднее в этом году и будет выпущена в виде открытого исходного кода. Выпуск SignGemma направлен на открытие новых возможностей для инклюзивных технологий, повышение эффективности и удобства общения для пользователей языка жестов. Google DeepMind приглашает пользователей оставлять отзывы и участвовать в раннем тестировании. (Источник: GoogleDeepMind, demishassabis)
Tencent Hunyuan публикует веса модели HunyuanPortrait, способной преобразовывать статические портреты в динамические видео : Команда Tencent Hunyuan открыла исходный код и опубликовала веса своей модели генерации видео из изображений HunyuanPortrait, позволяя пользователям загружать и использовать ее локально. Модель специализируется на преобразовании статических портретных изображений в динамические видео, что подходит для различных сценариев применения, таких как игровые персонажи, виртуальные ведущие, цифровые люди, умные консультанты по покупкам, и способна оживлять изображения лиц, повышая живость и реалистичность взаимодействия. Соответствующие модели, репозитории кода и научные статьи уже опубликованы. (Источник: karminski3, Reddit r/LocalLLaMA)

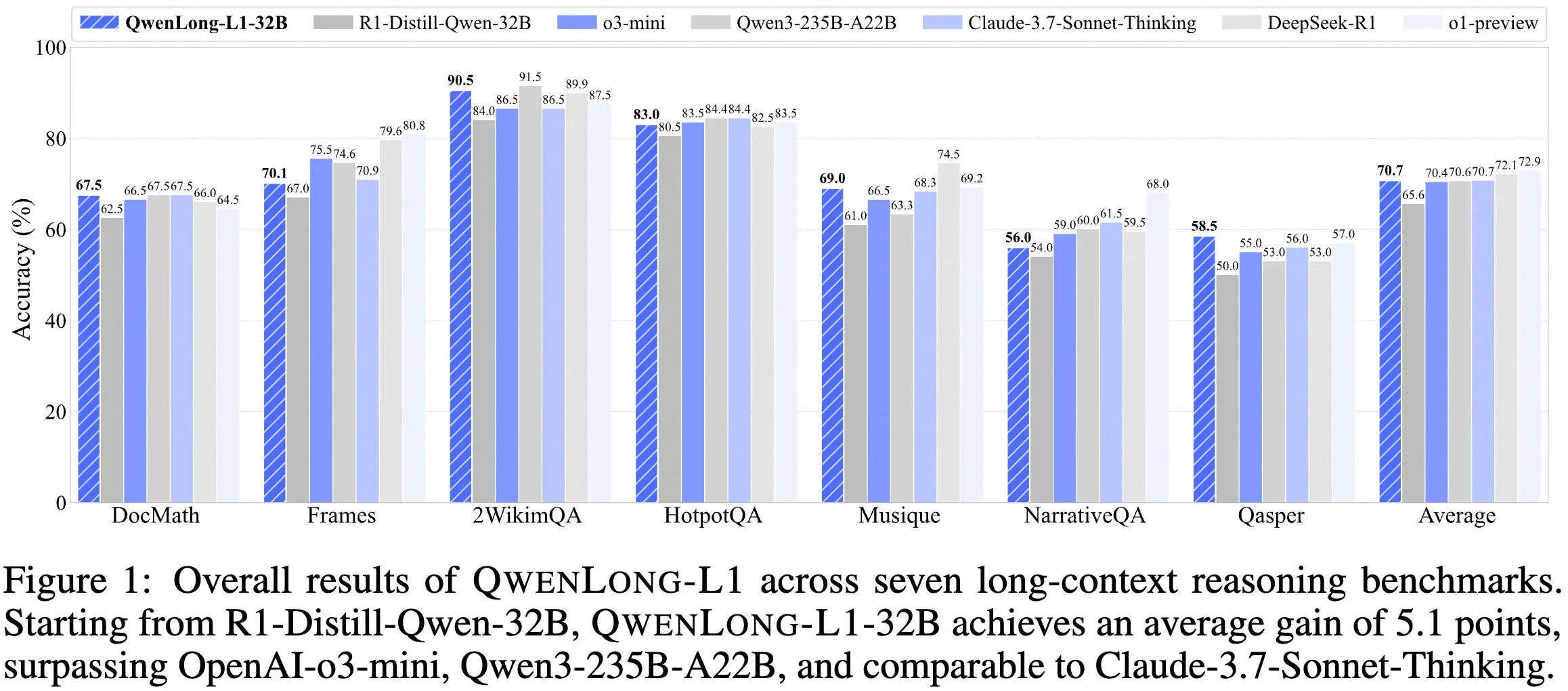
Команда QwenDoc выпустила модель для логического вывода с длинным контекстом QwenLong-L1-32B : Команда QwenDoc представила модель для логического вывода с длинным контекстом 128K QwenLong-L1-32B, обученную с использованием обучения с подкреплением. Эта модель, доработанная на основе DeepSeek-R1-Distill-Qwen-32B, набрала 90,5 баллов на тестовом наборе многоэтапного логического вывода 2WikiMultihopQA, что на 6,5 баллов выше, чем у исходной модели. Подчеркивается, что в длинном контексте она не только находит контент, но и связывает улики для логического вывода. Хотя длина контекста 128K не является самой большой на данный момент, ее выдающиеся способности к логическому выводу предоставляют новый выбор для обработки сложных длинных документов. Модель, научная статья и репозиторий кода опубликованы. (Источник: karminski3)
Гонконгский университет науки и технологий (HKUST) в сотрудничестве с Apple и другими учреждениями представил серию методов Laser для оптимизации эффективности и точности логического вывода больших моделей : Исследователи из HKUST, Городского университета Гонконга, Университета Ватерлоо и Apple предложили серию методов Laser (включая Laser-D, Laser-DE), направленных на решение проблемы чрезмерного потребления токенов большими языковыми моделями (LRM) при решении простых задач. Метод, благодаря единой структуре проектирования вознаграждения за длину, вознаграждениям на основе целевой длины и ступенчатой функции, а также механизму динамического восприятия сложности, на сложных математических бенчмарках, таких как AIME24, достиг повышения производительности на 6,1 пункта при одновременном сокращении использования токенов на 63%. Исследование показало, что обученная модель демонстрирует уменьшение избыточной «саморефлексии» и более здоровые паттерны мышления, эффективно балансируя эффективность и точность логического вывода модели. (Источник: 36氪)

Бесплатная версия Anthropic Claude теперь поддерживает функцию веб-поиска : Anthropic объявила, что пользователи бесплатной версии ее ИИ-ассистента Claude теперь могут использовать функцию веб-поиска. Это означает, что Claude при ответе на вопросы может получать самую свежую информацию из интернета для повышения релевантности и точности своих ответов. Официально заявлено, что каждый ответ, содержащий результаты поиска, будет снабжен встроенными цитатами, чтобы пользователи могли проверить источник информации. (Источник: AnthropicAI)
PKU-DS-LAB выпускает FairyR1: модель для логического вывода 32B, доработанная на основе DeepSeek-R1-Distill-Qwen-32B : Лаборатория наук о данных Пекинского университета (PKU-DS-LAB) представила FairyR1, модель для логического вывода с 32 миллиардами параметров, распространяемую по лицензии Apache 2.0. Утверждается, что эта модель, использующая метод «дистилляции и повторного слияния», достигает производительности более крупных моделей при использовании всего 5% параметров. FairyR1 доработана на основе DeepSeek-R1-Distill-Qwen-32B, и ее обучающие данные также доступны на Hugging Face Hub. Эта работа продолжает исследовательскую линию TinyR1, активно фильтруя наборы данных (около 10 000 траекторий), выполняя SFT отдельно для математики и кода и используя Arcee Fusion для слияния моделей. (Источник: huggingface, teortaxesTex, stablequan)
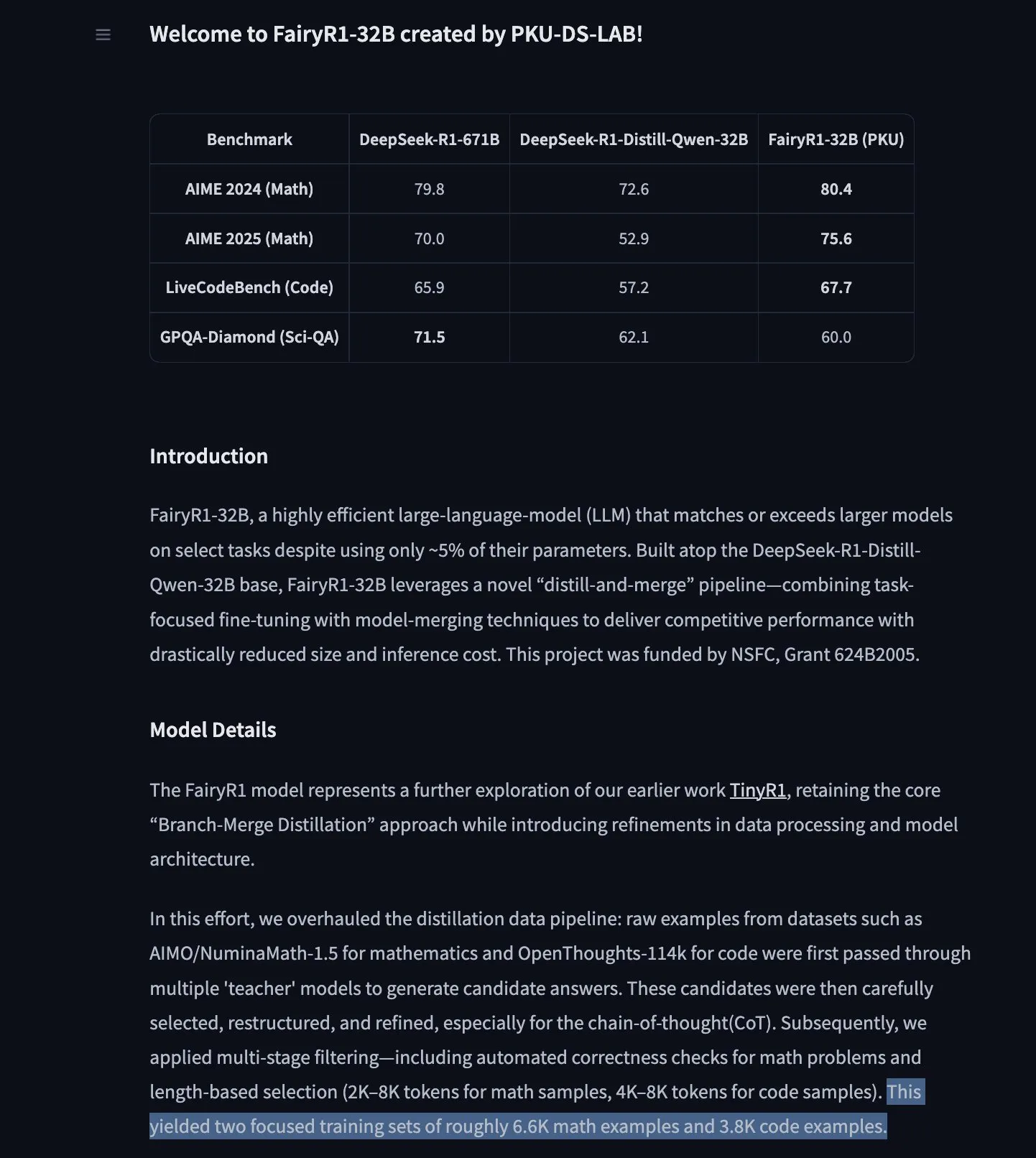
Модель прогнозирования временных рядов Google TimesFM появилась в Hugging Face Transformers : Модель TimesFM от Google теперь интегрирована в библиотеку Hugging Face Transformers. Это модель, подобная GPT, предварительно обученная на 100 миллиардах реальных временных точек из различных источников, таких как Google Trends, просмотры страниц Википедии и др. Утверждается, что TimesFM в задачах прогнозирования без предварительного обучения (zero-shot) превосходит специально доработанные модели, предоставляя новый мощный инструмент для анализа временных рядов. (Источник: huggingface)
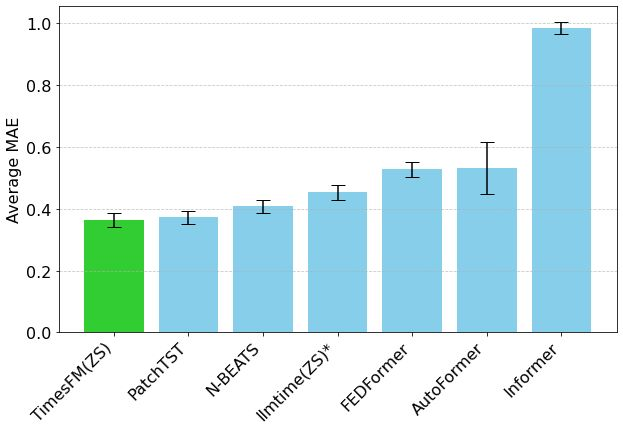
Hugging Face представляет Mixture of Thoughts: тщательно отобранный набор данных для общего логического вывода : Исследователь Hugging Face Lewis Tunstall и другие опубликовали набор данных «Mixture of Thoughts». Этот набор данных, тщательно отобранный из более чем 1 миллиона общедоступных образцов данных путем многочисленных экспериментов по исключению, содержит около 350 000 образцов и фокусируется на общих способностях к логическому выводу. Модели, обученные на этом смешанном наборе данных, показывают результаты на уровне или выше дистиллированных моделей DeepSeek на бенчмарках по математике, коду и научным дисциплинам (например, GPQA). Исследование подтвердило эффективность методологии «аддитивности», предложенной в Phi-4-reasoning, то есть можно независимо оптимизировать смешение данных для каждой области логического вывода, а затем интегрировать их для окончательного обучения. (Источник: huggingface)
ByteDance выпускает BAGEL-7B: всестороннюю модель, способную как понимать, так и генерировать изображения и текст : ByteDance представила BAGEL-7B, всестороннюю (omni) модель, способную одновременно понимать и генерировать изображения и текст. Кроме того, они выпустили Dolphin, визуально-языковую модель (VLM), специализирующуюся на анализе документов. Открытый исходный код этих моделей предоставит новые инструменты и возможности для мультимодальных исследований и приложений. (Источник: huggingface, TheTuringPost)

Google выпускает Gemini 2.5 Flash Preview с поддержкой нативного аудиовыхода : Разработчики Google AI объявили, что Gemini 2.5 Flash Preview теперь поддерживает нативный аудиовыход через Live API, что направлено на обеспечение бесшовного, естественного устного взаимодействия и более мощных возможностей голосового управления. Кроме того, выпущена новая экспериментальная версия этой аудиомодели с функцией «мышления», поддерживающая способность к рассуждению для более сложных задач. В то же время, выходные данные Gemini API начали отображать «краткое изложение мыслей», позволяя пользователям понять процесс мышления модели, но пока это не полная цепочка рассуждений. (Источник: algo_diver, op7418)
Статья исследует выразительные возможности Transformer при заполнении пустых токенов : Новое исследование изучает, может ли заполнение входных данных Transformer пустыми токенами (форма вычислений во время тестирования) повысить вычислительные возможности LLM. Исследование, проведенное в сотрудничестве с Ashish_S_AI, дает точную характеристику выразительных возможностей Transformer с заполнением, предлагая новый взгляд на понимание и оптимизацию вычислительных механизмов LLM. (Источник: teortaxesTex)

Новое исследование предлагает фреймворк Sci-Fi: улучшение интерполяции видеокадров с помощью симметричных ограничений : В ответ на проблему возможной асимметрии силы управления при слиянии ограничений начального и конечного кадров в существующих методах интерполяции видеокадров (Frame Inbetweening), новая статья предлагает фреймворк Sci-Fi (Symmetric Constraint for Frame Inbetweening). Этот метод направлен на достижение симметрии ограничений начального и конечного кадров путем применения более сильного механизма внедрения (на основе легковесного модуля EF-Net) для ограничений с меньшим масштабом обучения (например, конечного кадра), что приводит к более гармоничным переходам в генерируемых промежуточных кадрах и позволяет избежать несоответствий движения или искажения внешнего вида. (Источник: HuggingFace Daily Papers)
Статья предлагает Paper2Poster: автоматизированный процесс преобразования научных статей в мультимодальные постеры : Для решения проблем создания академических постеров исследователи представили первый бенчмарк для генерации постеров и набор метрик оценки Paper2Poster, включающий пары статей и разработанных авторами постеров. Оценка проводится по таким аспектам, как визуальное качество, текстовая связность, общая оценка и PaperQuiz (измеряющий способность постера передавать основное содержание). Одновременно предложен PosterAgent, многоагентный процесс «сверху вниз» с визуальной обратной связью, включающий парсер (извлечение активов), планировщик (визуальное выравнивание текста и макетирование) и цикл художник-критик (рендеринг и оптимизация обратной связи). Варианты, основанные на моделях с открытым исходным кодом, таких как Qwen-2.5, по большинству метрик превосходят системы на базе GPT-4o, при этом потребление токенов сокращается на 87%, что позволяет преобразовывать 22-страничные статьи в редактируемые постеры .pptx с очень низкими затратами. (Источник: HuggingFace Daily Papers)
Статья предлагает Frame In-N-Out: реализация неограниченной контролируемой генерации видео из изображений : Для решения проблем контроля, временной согласованности и синтеза деталей в генерации видео, новая статья фокусируется на технике киносъемки «Frame In and Frame Out». Цель состоит в том, чтобы позволить пользователям контролировать естественный выход объектов из сцены на изображении или вводить новые идентификационные референсы в сцену, руководствуясь указанной пользователем траекторией движения. Для этого исследователи представили новый полуавтоматически аннотированный набор данных, всеобъемлющий протокол оценки и эффективную архитектуру видео Diffusion Transformer, сохраняющую идентичность и управляемую движением. Эксперименты показывают, что предложенный метод значительно превосходит существующие базовые решения. (Источник: HuggingFace Daily Papers)
Новое исследование предлагает Active-O3: наделение мультимодальных больших языковых моделей способностью к активному восприятию с помощью GRPO : В связи с недостаточным исследованием возможностей мультимодальных больших языковых моделей (MLLM) в области активного восприятия (active perception), исследователи предложили фреймворк Active-O3. Этот фреймворк, основанный на обучении исключительно с подкреплением с использованием GRPO (Group Relative Policy Optimization), направлен на то, чтобы наделить MLLM способностью активно выбирать позиции и способы наблюдения для сбора информации, релевантной для задачи. Исследователи сначала систематически определили задачи активного восприятия на основе MLLM и указали, что стратегия расширенного поиска GPT-o3 является частным случаем активного восприятия, но недостаточно эффективна и точна. Active-O3 оценивается с помощью комплексного набора бенчмарков в общих задачах открытого мира (таких как локализация мелких и плотно расположенных объектов) и в специфических сценариях (таких как дистанционное зондирование, обнаружение мелких объектов в автономном вождении, мелкозернистая интерактивная сегментация), а также демонстрирует мощные возможности логического вывода без предварительного обучения (zero-shot) на V* Benchmark. (Источник: HuggingFace Daily Papers)
Статья предлагает MME-Reasoning: всесторонний бенчмарк для оценки логических способностей MLLM : В связи с недостатками существующих бенчмарков в оценке логических способностей мультимодальных больших языковых моделей (MLLM), исследователи представили MME-Reasoning. Этот бенчмарк охватывает три основных типа логического вывода: индуктивный, дедуктивный и абдуктивный, а данные тщательно отобраны для обеспечения того, чтобы вопросы эффективно оценивали именно способности к рассуждению, а не навыки восприятия или широту знаний. Результаты оценки показывают, что даже самые передовые MLLM демонстрируют ограничения при всесторонней оценке логического вывода, с несбалансированной производительностью по различным типам рассуждений. Исследование также анализирует влияние таких методов, как «режимы мышления» и обучение с подкреплением на основе правил, на способности к рассуждению, предоставляя систематические выводы для понимания и оценки логических способностей MLLM. (Источник: HuggingFace Daily Papers)
GraLoRA: повышение производительности эффективной по параметрам тонкой настройки за счет гранулированной адаптации низкого ранга : Для решения проблем переобучения и узких мест производительности, возникающих при увеличении ранга в LoRA, исследователи предложили GraLoRA (Granular Low-Rank Adaptation). Этот метод делит весовую матрицу на подблоки, каждый из которых имеет независимый адаптер низкого ранга, с целью решения проблем запутывания градиентов и искажения распространения, вызванных структурными узкими местами LoRA. GraLoRA эффективно повышает выразительную способность модели, приближаясь к эффекту полной тонкой настройки, практически без увеличения вычислительных или затрат на хранение. Эксперименты на бенчмарках генерации кода и рассуждений на основе здравого смысла показывают, что GraLoRA превосходит LoRA и другие базовые методы при различных размерах моделей и настройках ранга, например, на HumanEval+ абсолютный прирост Pass@1 достигает 8,5%. (Источник: HuggingFace Daily Papers)
SoloSpeech: каскадный генеративный конвейер улучшает четкость и качество извлечения целевой речи : Для решения проблемы, связанной с тем, что существующие дискриминативные модели для извлечения целевой речи (TSE) склонны вносить артефакты и снижать естественность, а генеративные модели не обеспечивают достаточного качества восприятия и четкости, исследователи предложили SoloSpeech. Это новый каскадный генеративный конвейер, объединяющий процессы сжатия, извлечения, восстановления и коррекции. Его особенностью является использование экстрактора цели без встраивания диктора, который использует условную информацию из латентного пространства аудиоподсказки и выравнивает ее с латентным пространством смешанного аудио для предотвращения несоответствий. Оценка на наборе данных Libri2Mix показывает, что SoloSpeech достигает нового уровня SOTA в задачах извлечения целевой речи и разделения речи, а также демонстрирует превосходную способность к обобщению на данных вне домена и в реальных сценариях. (Источник: HuggingFace Daily Papers)
Новое исследование изучает повышение способности мультимодальных больших языковых моделей к визуальному пониманию с помощью текстовых направляющих векторов : Новое исследование изучает, можно ли использовать направляющие векторы, полученные из чисто текстовой LLM-основы мультимодальных больших языковых моделей (MLLM) (с помощью таких методов, как разреженные автоэнкодеры SAE, смещение среднего и линейное зондирование), для улучшения их способности к визуальному пониманию. Исследование показало, что текстовые направляющие векторы способны последовательно повышать мультимодальную точность различных архитектур MLLM в разнообразных визуальных задачах. В частности, метод смещения среднего повысил точность пространственных отношений на CV-Bench до 7,3%, а точность подсчета — до 3,3%, превзойдя методы подсказок и продемонстрировав сильную способность к обобщению на наборах данных вне распределения. Это указывает на то, что текстовые направляющие векторы являются мощным и эффективным механизмом, способным улучшить визуальную основу MLLM с минимальными дополнительными затратами на сбор данных и вычисления. (Источник: HuggingFace Daily Papers)
Статья предлагает DiSA: ускорение авторегрессионной генерации изображений путем отжига шагов диффузии : Для решения проблемы низкой эффективности вывода из-за использования диффузионной выборки для улучшения качества изображений в авторегрессионных моделях, таких как MAR и FlowAR, в новой статье предложен метод DiSA (Diffusion Step Annealing). Метод основан на наблюдении, что по мере генерации большего количества токенов в авторегрессионном процессе распределение последующих токенов становится более ограниченным, а выборка — проще. DiSA — это метод, не требующий обучения, который постепенно уменьшает количество шагов диффузии по мере генерации большего количества токенов (например, с начальных 50 шагов до 5 шагов на более поздних этапах). Этот метод дополняет существующие методы ускорения, разработанные для самой диффузии, прост в реализации и позволяет ускорить MAR и Harmon в 5-10 раз, а FlowAR и xAR — в 1,4-2,5 раза, сохраняя при этом качество генерации. (Источник: HuggingFace Daily Papers)
Статья предлагает CASS: набор данных, модель и бенчмарк для перевода GPU-кода с Nvidia на AMD : Исследователи представили CASS, первый крупномасштабный набор данных и набор моделей для кросс-архитектурного перевода GPU-кода, нацеленный на перевод как на уровне исходного кода (CUDA <-> HIP), так и на уровне ассемблера (Nvidia SASS <-> AMD RDNA3). Набор данных содержит 70 000 проверенных пар кода для хоста и устройства. Серия доменно-специфичных языковых моделей CASS, обученных на этом ресурсе, достигает 95% точности при переводе исходного кода и 37,5% точности при переводе ассемблера, что значительно превосходит коммерческие базовые модели, такие как GPT-4o и Claude. Сгенерированный код соответствует производительности нативного кода в более чем 85% тестовых случаев. Одновременно выпущен CASS-Bench, бенчмарк, включающий 16 доменов GPU и результаты реального выполнения. Все данные, модели и инструменты оценки опубликованы с открытым исходным кодом. (Источник: HuggingFace Daily Papers)
Статья анализирует способность к вербальной калибровке в визуально-языковых моделях : Исследование всесторонне оценивает эффективность визуально-языковых моделей (VLM) в выражении уверенности (т.е. вербальной неопределенности) на естественном языке. Исследование охватывает три класса моделей, четыре области задач и три сценария оценки. Результаты показывают, что текущие VLM часто демонстрируют явные ошибки калибровки в различных задачах и условиях. Примечательно, что модели визуального рассуждения (т.е. модели, которые «думают» изображениями) последовательно демонстрируют лучшую калибровку, что указывает на то, что рассуждение в конкретной модальности имеет решающее значение для надежной оценки неопределенности. Для решения проблем калибровки исследователи представили «Визуально-ориентированное на уверенность подсказывание» (Visual Confidence-Aware Prompting), двухэтапную стратегию подсказывания, направленную на улучшение согласования уверенности в мультимодальных условиях. (Источник: HuggingFace Daily Papers)
Статья отслеживает возникновение прагматических способностей в больших языковых моделях : Современные LLM демонстрируют новые способности в задачах социального интеллекта, однако то, как они приобретают прагматические способности в процессе обучения, остается неясным. Новая статья представляет набор данных ALTPRAG, разработанный на основе прагматической концепции «альтернатив» (alternatives), для оценки способности LLM на разных этапах обучения точно выводить тонкие намерения говорящего. Путем систематической оценки 22 LLM (охватывающих этапы предварительного обучения, SFT и оптимизации предпочтений) результаты показывают, что даже базовые модели демонстрируют значительную чувствительность к прагматическим сигналам, которая постоянно улучшается с увеличением размера модели и данных. SFT и RLHF дополнительно улучшают когнитивные прагматические способности к рассуждению. Эти выводы подчеркивают, что прагматические способности являются эмерджентным композиционным свойством обучения LLM, предоставляя новые идеи для согласования моделей с человеческими коммуникативными нормами. (Источник: HuggingFace Daily Papers)
Выпущен бенчмарк Video-Holmes: оценка «шерлокхолмовского» мышления MLLM при сложном видео-рассуждении : В связи с тем, что существующие видео-бенчмарки в основном оценивают способности к визуальному восприятию и локализации, не в полной мере охватывая потребности в сложных рассуждениях, исследователи представили бенчмарк Video-Holmes. Этот бенчмарк, вдохновленный процессом рассуждений Шерлока Холмса, содержит 1837 вопросов, извлеченных из 270 вручную аннотированных короткометражных детективных фильмов, и охватывает 7 тщательно разработанных задач. Каждая задача требует от модели активного поиска и связывания нескольких релевантных визуальных подсказок, разбросанных по разным фрагментам видео. Оценка SOTA MLLM показывает, что, несмотря на превосходные результаты моделей в визуальном восприятии, они испытывают значительные трудности с интеграцией информации, часто упуская ключевые подсказки. Например, точность лучшей модели Gemini-2.5-Pro составила всего 45%. (Источник: HuggingFace Daily Papers)
Выпущен бенчмарк MME-VideoOCR: оценка возможностей OCR мультимодальных LLM в видеосценах : Несмотря на значительный прогресс мультимодальных больших языковых моделей (MLLM) в области OCR на статических изображениях, их эффективность в видео-OCR снижается из-за таких факторов, как размытие движения, временные изменения и визуальные эффекты. Для руководства обучением практических MLLM исследователи представили бенчмарк MME-VideoOCR, охватывающий широкий спектр сценариев применения видео-OCR. Этот бенчмарк включает 10 категорий задач (25 независимых задач), охватывающих 44 различных сценария, и включает не только распознавание текста, но и более глубокое понимание и логический вывод на основе текстового контента в видео. Бенчмарк содержит 1464 видео различного разрешения, соотношения сторон и продолжительности, а также 2000 тщательно отобранных пар вопросов и ответов, аннотированных вручную. Оценка 18 SOTA MLLM показала, что даже у лучшей модели, Gemini-2.5 Pro, точность составила всего 73,7%, что выявило ограничения существующих моделей при обработке задач, требующих целостного понимания видео. (Источник: HuggingFace Daily Papers)
MetaMind: моделирование человеческого социального мышления с помощью метакогнитивной многоагентной системы : Для преодоления недостатков больших языковых моделей (LLM) в обработке присущей человеческому общению неоднозначности и контекстуальных нюансов, исследователи представили MetaMind, многоагентный фреймворк, вдохновленный психологической теорией метапознания, предназначенный для моделирования человекоподобного социального рассуждения. MetaMind разделяет социальное понимание на три этапа сотрудничества: (1) агент теории разума генерирует гипотезы о психическом состоянии пользователя (например, намерениях, эмоциях); (2) доменный агент использует культурные нормы и этические ограничения для уточнения этих гипотез; (3) агент ответа генерирует контекстуально уместные ответы, одновременно проверяя их соответствие выведенным намерениям. Этот фреймворк достиг производительности SOTA на трех сложных бенчмарках, улучшив результаты на 35,7% в реальных социальных сценариях, на 6,2% в рассуждениях теории разума, и впервые позволил LLM достичь человеческого уровня в ключевых задачах теории разума. (Источник: HuggingFace Daily Papers)
Sparse VideoGen2: ускорение генерации видео за счет семантически-ориентированной перестановки и разреженного внимания : Для решения проблем значительной задержки и высоких затрат памяти, с которыми сталкиваются модели генерации видео на основе Diffusion Transformers (DiT) при обработке длинных видео, исследователи предложили фреймворк SVG2. Этот фреймворк максимизирует точность идентификации ключевых токенов и минимизирует вычислительные потери за счет семантически-ориентированной перестановки (используя k-means для кластеризации и переупорядочивания токенов на основе семантического сходства), тем самым достигая компромисса на переднем крае Парето между качеством генерации и эффективностью. SVG2 также интегрирует динамическое управление бюджетом top-p и реализацию пользовательских ядер, достигая ускорения до 2,30x на HunyuanVideo и 1,89x на Wan 2.1 соответственно, при сохранении высокого PSNR. (Источник: HuggingFace Daily Papers)
OmniConsistency: обучение независимой от стиля согласованности на основе парных стилизованных данных : Для решения двух основных проблем, с которыми сталкиваются диффузионные модели при стилизации изображений — поддержание согласованности в сложных сценах (особенно идентичности, композиции и деталей) и деградация стиля, вызванная стилевыми LoRA в процессах преобразования изображений, — исследователи предложили OmniConsistency. Это универсальный плагин согласованности, использующий крупномасштабные диффузионные трансформеры (DiT). Его вклад включает: (1) фреймворк обучения контекстной согласованности на основе выровненных пар изображений для достижения надежного обобщения; (2) двухэтапную стратегию прогрессивного обучения, которая разделяет обучение стилю и поддержание согласованности для смягчения деградации стиля; (3) полностью подключаемый дизайн, совместимый с любыми стилевыми LoRA в рамках фреймворка Flux. Эксперименты показывают, что OmniConsistency значительно улучшает визуальную связность и эстетическое качество, достигая производительности, сравнимой с коммерческими моделями SOTA, такими как GPT-4o. (Источник: HuggingFace Daily Papers)
ImgEdit: унифицированный набор данных и бенчмарк для редактирования изображений : Для решения проблемы отставания моделей редактирования изображений с открытым исходным кодом от проприетарных моделей (в основном из-за ограниченности высококачественных данных и недостатка бенчмарков), исследователи представили ImgEdit. Это крупномасштабный, высококачественный набор данных для редактирования изображений, содержащий 1,2 миллиона тщательно отобранных пар правок, охватывающих новые и сложные одноэтапные правки и сложные многоэтапные задачи. Для обеспечения качества данных использовался многоэтапный процесс, интегрирующий передовые визуально-языковые модели, модели обнаружения, модели сегментации, а также специфические для задач исправления и строгую постобработку. Модели редактирования ImgEdit-E1, обученные на ImgEdit, превосходят существующие модели с открытым исходным кодом в нескольких задачах. Одновременно выпущен бенчмарк ImgEdit-Bench для оценки редактирования изображений с точки зрения следования инструкциям, качества редактирования и сохранения деталей. (Источник: HuggingFace Daily Papers)
Статья предлагает достижение надежного контроля поведения в LLM с помощью управляющих целевых атомов : Для достижения точного контроля над генерацией языковых моделей с целью обеспечения безопасности и надежности, новая статья предлагает метод «Управляющие целевые атомы» (Steering Target Atoms, STA). Этот метод направлен на разделение и манипулирование разделенными компонентами знаний для повышения безопасности, особенно демонстрируя превосходную надежность и гибкость в состязательных сценариях. Исследователи утверждают, что, хотя инженерия подсказок и управление часто используются для вмешательства в поведение модели, высокая степень запутанности параметров модели ограничивает точность контроля и может приводить к побочным эффектам. STA использует разреженные автоэнкодеры (SAE) для разделения знаний в многомерном пространстве и управления ими, тем самым достигая более точного контроля поведения. Эксперименты подтвердили эффективность этого метода, который уже применяется к большим моделям логического вывода, подтверждая его потенциал в точном контроле рассуждений. (Источник: HuggingFace Daily Papers)
Статья предлагает бенчмарк SeePhys: оценка способности к физическому рассуждению на основе визуальной информации : Исследователи представили SeePhys, крупномасштабный мультимодальный бенчмарк для оценки способности LLM к рассуждению над физическими задачами от уровня средней школы до докторских квалификационных экзаменов. Бенчмарк охватывает 7 фундаментальных областей физики и включает 21 категорию высоко гетерогенных диаграмм. В отличие от предыдущих работ, где визуальные элементы играли в основном вспомогательную роль, в SeePhys 75% задач являются визуально необходимыми, то есть для правильного решения необходимо извлечь визуальную информацию. Широкая оценка показывает, что даже самые передовые модели визуального рассуждения (такие как Gemini-2.5-pro и o4-mini) на этом бенчмарке имеют точность менее 60%, что выявляет фундаментальные проблемы текущих LLM в визуальном понимании, особенно в строгой связи интерпретации диаграмм с физическим рассуждением и преодолении зависимости от когнитивных «коротких путей» на основе текстовых подсказок. (Источник: HuggingFace Daily Papers)
VerIPO: повышение способности Video-LLM к долгосрочному рассуждению с помощью итеративной оптимизации политики, управляемой верификатором : Для решения проблем узких мест в подготовке данных и нестабильного качества длинных цепочек рассуждений (CoT) при применении обучения с подкреплением к видео-большим языковым моделям (Video-LLM) в сложных задачах видео-рассуждения, исследователи предложили метод VerIPO (Verifier-guided Iterative Policy Optimization). Ядром этого метода является «Rollout-Aware Verifier», расположенный между этапами обучения GRPO и DPO, который используется для оценки логики рассуждений и построения высококачественных контрастных данных (содержащих рефлексивные и контекстуально согласованные CoT). Эти данные обеспечивают эффективный этап DPO, тем самым увеличивая длину и контекстуальную согласованность цепочек рассуждений. Экспериментальные результаты показывают, что VerIPO может быстрее и эффективнее оптимизировать модель, генерируя более длинные и контекстуально согласованные CoT, и превосходит стандартные варианты GRPO, а также некоторые большие Video-LLM с тонкой настройкой на инструкции и модели с длинным рассуждением. (Источник: HuggingFace Daily Papers)
OpenS2V-Nexus: подробный бенчмарк и миллионный набор данных для генерации видео из субъекта : Для содействия развитию технологий генерации видео из субъекта (S2V) исследователи предложили OpenS2V-Nexus, который включает (i) OpenS2V-Eval, мелкозернистый бенчмарк, и (ii) OpenS2V-5M, миллионный набор данных. В отличие от существующих бенчмарков S2V (унаследованных от VBench и ориентированных на глобальную и крупнозернистую оценку), OpenS2V-Eval фокусируется на способности модели генерировать видео с согласованным субъектом, естественным внешним видом и высокой точностью сохранения идентичности. Для этого OpenS2V-Eval вводит 180 подсказок из 7 основных категорий S2V, включая реальные и синтетические тестовые данные. Кроме того, для точного согласования с человеческими предпочтениями исследователи предложили три автоматические метрики: NexusScore, NaturalScore и GmeScore, которые количественно оценивают согласованность субъекта, естественность и текстовую релевантность в сгенерированных видео. На основе этого была проведена всесторонняя оценка 16 репрезентативных моделей S2V. Одновременно был создан первый открытый крупномасштабный набор данных для генерации S2V OpenS2V-5M, содержащий 5 миллионов высококачественных триплетов субъект-текст-видео в разрешении 720P. (Источник: HuggingFace Daily Papers)
Статья предлагает WHISTRESS: обогащение транскрибированного текста путем обнаружения ударения в предложении : Учитывая важность ударения в предложении в устной речи для передачи намерений говорящего и его отсутствие в существующих системах транскрипции, новая статья представляет WHISTRESS, метод обнаружения ударения в предложении без необходимости выравнивания. Для поддержки этой задачи исследователи предложили TINYSTRESS-15K, масштабируемый синтетический обучающий набор данных, созданный с помощью полностью автоматизированного процесса. Модель WHISTRESS, обученная на этом наборе данных, превосходит существующие базовые модели по производительности и не требует дополнительного обучения или априорных входных данных для вывода. Примечательно, что, несмотря на обучение на синтетических данных, WHISTRESS демонстрирует сильную способность к обобщению без предварительного обучения (zero-shot) на различных бенчмарках. (Источник: HuggingFace Daily Papers)
Статья предлагает InstructPart: сегментация частей, ориентированная на задачу, с рассуждением на основе инструкций : Несмотря на прогресс больших мультимодальных базовых моделей в различных задачах, многие модели рассматривают объекты как неделимые целые, игнорируя составляющие их части. Понимание этих частей и связанных с ними функциональных возможностей (affordances) имеет решающее значение для выполнения широкого круга задач. Для этого исследователи представили новый реальный бенчмарк InstructPart, содержащий вручную размеченные аннотации сегментации частей и ориентированные на задачу инструкции, для оценки производительности текущих моделей в понимании и выполнении задач на уровне частей в повседневных ситуациях. Эксперименты показывают, что даже для SOTA визуально-языковых моделей (VLM) ориентированная на задачу сегментация частей остается сложной проблемой. Помимо бенчмарка, исследователи также представили простую базовую модель, которая, будучи доработанной с использованием их набора данных, достигла двукратного повышения производительности. (Источник: HuggingFace Daily Papers)
Статья предлагает гибридный нейро-MPM метод для интерактивной симуляции жидкости в реальном времени : Для решения проблемы симуляции жидкости, где традиционные физические методы являются вычислительно интенсивными и имеют высокую задержку, а недавние методы машинного обучения, хотя и снижают затраты, все еще с трудом удовлетворяют требованиям интерактивности в реальном времени, исследователи предложили новый гибридный метод. Этот метод объединяет численное моделирование, нейрофизику и генеративное управление. Его нейрофизика, благодаря механизму отката к классическим численным решателям, совместно стремится к симуляции с низкой задержкой и высокой физической точностью. Кроме того, исследователи разработали контроллер на основе диффузии, обученный с использованием стратегии обратного моделирования, для генерации внешних динамических силовых полей для манипулирования жидкостью. Система демонстрирует надежную производительность в различных 2D/3D сценариях, с разными типами материалов и взаимодействиями с препятствиями, достигая симуляции в реальном времени с высокой частотой кадров (задержка 11~29%) и позволяя управлять жидкостью с помощью удобных для пользователя нарисованных от руки эскизов. (Источник: HuggingFace Daily Papers)
MMIG-Bench: комплексный интерпретируемый оценочный бенчмарк для мультимодальных моделей генерации изображений : В связи с ограничениями существующих инструментов оценки при оценке мультимодальных генераторов изображений, таких как GPT-4o, Gemini 2.0 Flash и Gemini 2.5 Pro (например, бенчмаркам T2I не хватает мультимодальных условий, а бенчмарки генерации пользовательских изображений игнорируют комбинаторную семантику и здравый смысл), исследователи предложили MMIG-Bench. Это комплексный мультимодальный бенчмарк для генерации изображений, содержащий 4850 богато аннотированных текстовых подсказок и 1750 многоракурсных референсных изображений, охватывающих 380 субъектов (людей, животных, объектов, художественных стилей). MMIG-Bench оснащен трехуровневой системой оценки: (1) низкоуровневые метрики оценивают визуальные артефакты и сохранение идентичности объектов; (2) новая оценка соответствия аспектов (AMS): среднеуровневая метрика на основе VQA, обеспечивающая мелкозернистое выравнивание подсказка-изображение и высоко коррелирующая с человеческими суждениями; (3) высокоуровневые метрики оценивают эстетику и человеческие предпочтения. С помощью MMIG-Bench было проведено тестирование 17 моделей SOTA, а метрики были проверены с использованием 32 000 человеческих оценок, что позволило получить глубокие выводы для проектирования архитектур и данных. (Источник: HuggingFace Daily Papers)
Статья предлагает HRPO: гибридный латентный вывод с помощью обучения с подкреплением : Для решения проблем несовместимости существующих методов латентного вывода с авторегрессионной природой генерации LLM и зависимости от траекторий CoT для обучения, исследователи предложили HRPO (Hybrid Reasoning Policy Optimization). Это метод гибридного латентного вывода на основе обучения с подкреплением, который интегрирует предыдущие скрытые состояния в выбранные токены с помощью обучаемого механизма шлюзования. Обучение начинается с инициализации на основе встраивания токенов, постепенно включая больше скрытых признаков. Такая конструкция сохраняет генеративные способности LLM и стимулирует использование дискретных и непрерывных представлений для гибридного вывода. Кроме того, HRPO вводит случайность в латентный вывод путем выборки токенов, что позволяет проводить оптимизацию на основе RL без траекторий CoT. Широкая оценка на различных бенчмарках показывает, что HRPO превосходит предыдущие методы как в задачах, требующих больших знаний, так и в задачах, требующих интенсивного вывода. (Источник: HuggingFace Daily Papers)
Статья предлагает метод NFT: соединение контролируемого обучения и обучения с подкреплением в математическом рассуждении : Оспаривая распространенное мнение о том, что «самосовершенствование ограничено обучением с подкреплением (RL)», новая статья предлагает метод тонкой настройки с учетом негативных примеров (Negative-aware Fine-Tuning, NFT). Это метод контролируемого обучения, который позволяет LLM размышлять над своими ошибками и самостоятельно улучшаться без внешнего учителя. В онлайн-обучении NFT не отбрасывает самостоятельно сгенерированные неверные ответы, а строит неявную негативную политику для их моделирования. Эта неявная политика параметризуется так же, как и целевая позитивная LLM, оптимизируемая на позитивных данных, что позволяет напрямую проводить оптимизацию политики на всех генерациях LLM. Экспериментальные результаты на задачах математического рассуждения с моделями 7B и 32B показывают, что благодаря дополнительному использованию негативной обратной связи NFT значительно превосходит базовые методы контролируемого обучения, такие как тонкая настройка с отбраковкой выборок, достигая или даже превосходя ведущие алгоритмы RL, такие как GRPO и DAPO. Исследователи далее доказывают, что при строгом онлайн-обучении политики NFT и GRPO фактически эквивалентны. (Источник: HuggingFace Daily Papers)
Статья предлагает Minute-Long Videos with Dual Parallelisms: реализация генерации видео минутного уровня : Для решения проблемы чрезмерной вычислительной задержки и затрат памяти, с которыми сталкиваются модели видеодиффузии на основе DiT при генерации длинных видео, исследователи предложили новую распределенную стратегию вывода DualParal. Основная идея этого метода заключается в распараллеливании временных кадров и слоев модели на несколько GPU. Для решения проблемы сериализации исходной параллельности, вызванной требованием синхронизации уровня шума между кадрами в диффузионных моделях, этот метод использует схему блочного шумоподавления, то есть обрабатывает последовательность блоков кадров по конвейеру и постепенно снижает уровень шума. Каждый GPU обрабатывает определенные подмножества блоков и слоев и передает предыдущие результаты следующему GPU, обеспечивая асинхронные вычисления и связь. Кроме того, благодаря реализации кэширования признаков на каждом GPU для повторного использования признаков предыдущих блоков в качестве контекста и применению скоординированной стратегии инициализации шума, обеспечивается глобально согласованная временная динамика, что позволяет быстро, без артефактов и неограниченно долго генерировать видео. Применение к новейшим генераторам видео на основе диффузионных трансформеров позволило этому методу эффективно генерировать видео из 1025 кадров на 8 GPU RTX 4090, снизив задержку до 6,54 раз и затраты памяти в 1,48 раза. (Источник: HuggingFace Daily Papers)
🧰 Инструменты
Модели серии Claude 4 демонстрируют выдающиеся результаты в задачах программирования, успешно решая «баг белого кита», мучивший опытного программиста 4 года : Недавно выпущенная модель Claude Opus 4 от Anthropic продемонстрировала поразительные способности в программировании. Бывший инженер FAANG с 30-летним опытом разработки на C++ поделился, что сложный системный баг (проблема с граничными условиями, возникающая при определенном использовании конкретного шейдера), который мучил его команду 4 года и на решение которого он лично потратил около 200 часов, был успешно локализован и идентифицирован Claude Opus 4 за несколько часов с помощью примерно 30 промптов. Этот баг отсутствовал до рефакторинга системы, и Opus 4 указал, что новая архитектура не смогла обеспечить совместимость с нештатным поведением, которое «случайно» поддерживалось старой архитектурой. Ранее GPT-4.1, Gemini 2.5 и Claude 3.7 не смогли решить эту проблему. Это подчеркивает мощные способности Claude 4 в понимании сложного кода, проведении глубокого анализа и логического вывода, особенно в сочетании с режимом Claude Code, что позволяет эффективно помогать разработчикам в решении сложных инженерных задач, таких как рефакторинг кода и исправление ошибок. (Источник: 36氪, dotey)
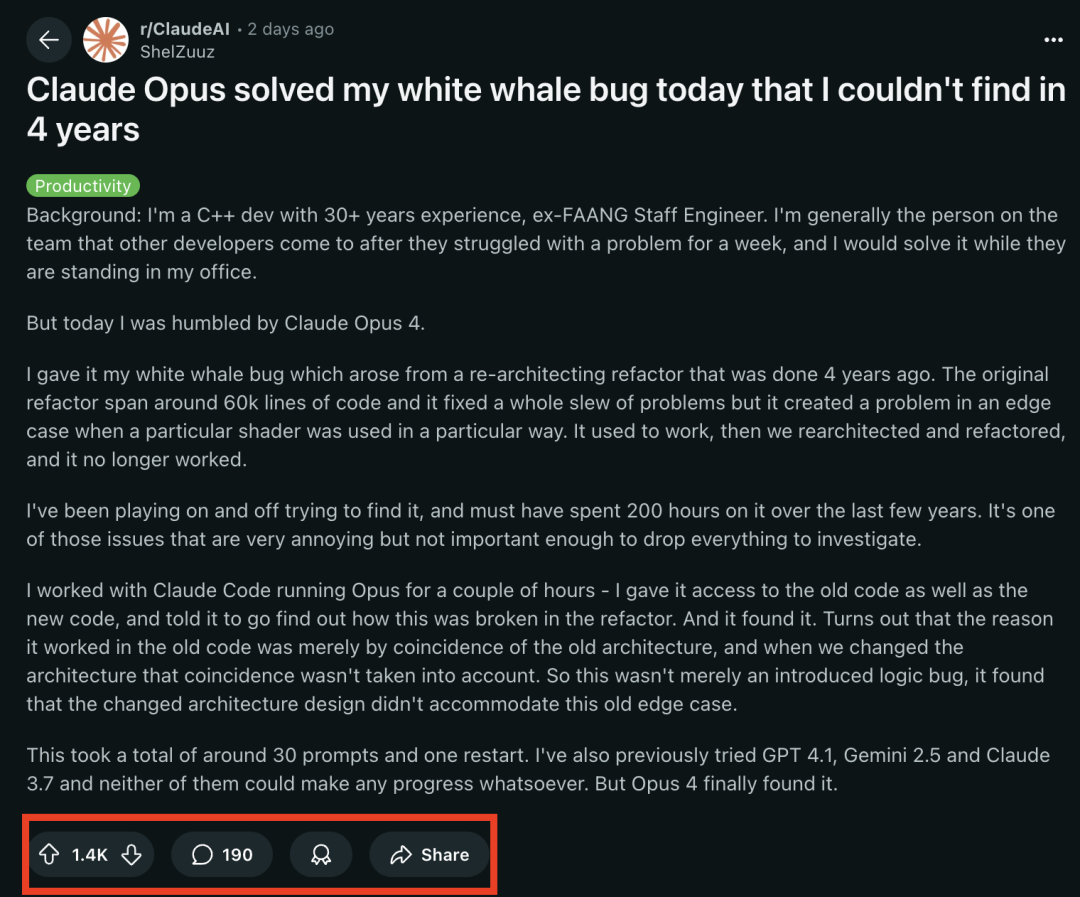
LangChain добавил поддержку новых бета-функций Anthropic Claude : LangChain объявил об интеграции четырех недавно выпущенных бета-функций модели Anthropic Claude, включая выполнение кода, удаленные коннекторы MCP, API для работы с файлами и расширенное кэширование промптов. Разработчики теперь могут ознакомиться с соответствующими примерами в документации LangChain и использовать эти новые функции для создания более мощных ИИ-приложений. (Источник: LangChainAI)
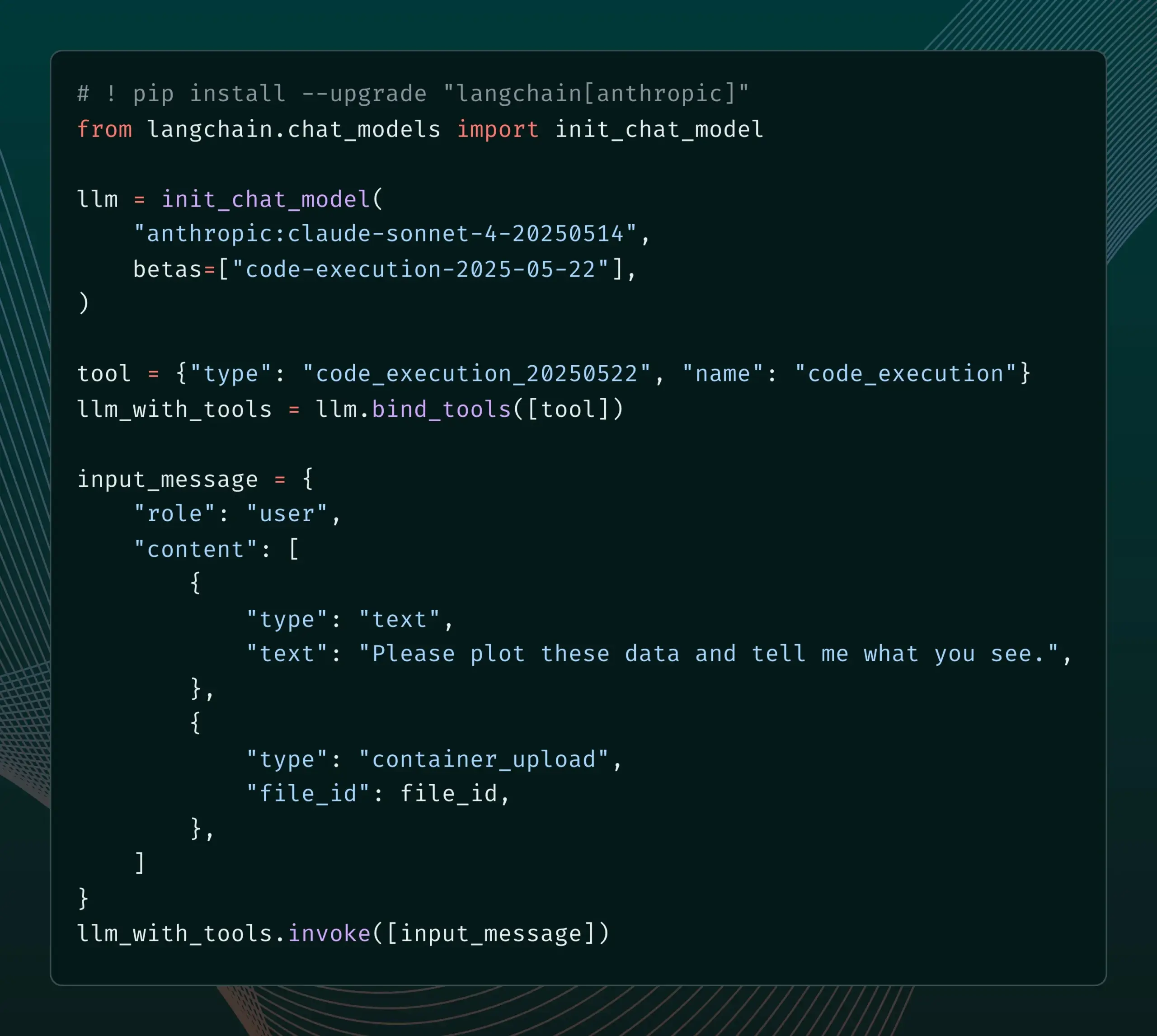
LangSmith представил функции управления промптами, интегрированные с SDLC : Платформа LangSmith расширила свои возможности по инженерии промптов. Теперь пользователи могут не только тестировать, версионировать и совместно работать над промптами в LangSmith, но и автоматически синхронизировать промпты с GitHub, внешними базами данных или запускать процессы CI/CD с помощью триггеров webhook при изменении промптов. Эта функция призвана помочь разработчикам более тесно интегрировать управление промптами в жизненный цикл разработки программного обеспечения (SDLC). (Источник: LangChainAI)
AutoThink: адаптивная технология для повышения производительности локального инференса LLM : Команда CodeLion разработала технологию AutoThink, которая значительно улучшает производительность локального инференса LLM за счет адаптивного распределения ресурсов и управляющих векторов (steering vectors). AutoThink может классифицировать сложность запросов, динамически распределять «токены мышления» (больше для сложных задач, меньше для простых) и использовать управляющие векторы для направления паттернов инференса. Тестирование на модели DeepSeek-R1-Distill-Qwen-1.5B показало повышение точности на GPQA-Diamond на 43% (с 21,72% до 31,06%), а также улучшение на MMLU-Pro при меньшем использовании токенов. Технология совместима с локальными моделями инференса, поддерживающими токены мышления; код и исследование опубликованы. (Источник: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab объявляет о поддержке AMD ROCm, позволяя локально обучать LLM : Transformer Lab объявила, что ее GUI-платформа теперь поддерживает использование ROCm на GPU AMD для локального обучения и тонкой настройки больших языковых моделей. Команда сообщила, что процесс настройки ROCm был полон вызовов, и задокументировала весь процесс в блоге. В настоящее время функция работает без сбоев, и пользователи могут попробовать разрабатывать LLM на оборудовании AMD. (Источник: Reddit r/MachineLearning)
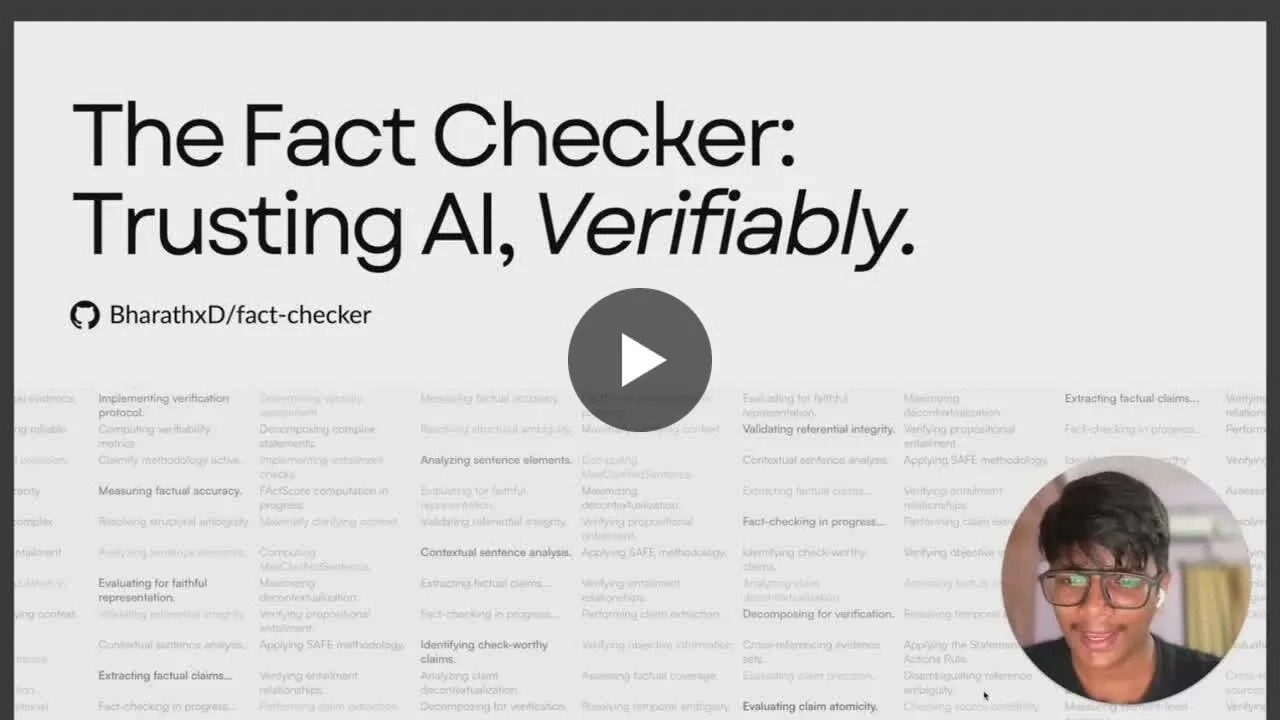
Открытая многоагентная система с усилением LLM реализует автоматическое извлечение утверждений и проверку фактов : Открытый проект под названием «fact-checker» использует многоагентную систему (MAS) с усилением LLM для автоматического извлечения утверждений, проверки доказательств и разрешения фактов. Проект включает расширение для браузера, которое может в реальном времени проверять факты в ответах любого чат-бота ИИ, помогая распознавать достоверность контента, сгенерированного ИИ. Его архитектура кода ясна, документация полна, что делает его ценным инструментом в области безопасности ИИ и борьбы с дезинформацией. (Источник: Reddit r/MachineLearning)
Meituan запускает продукт без кода Nocode, поддерживающий генерацию сложных многостраничных приложений : Meituan выпустила продукт Vibe Coding под названием Nocode, который позволяет пользователям генерировать сложные, многостраничные полноценные приложения с помощью описания на естественном языке, а не только простые демонстрационные веб-страницы. Тестирование, проведенное Guicang, показало, что инструмент способен успешно с первого раза создать инструмент управления товарами на складе со сложной логикой, демонстрируя его возможности в понимании сложных требований и генерации соответствующего кода. (Источник: op7418)
LlamaIndex поддерживает создание пользовательских мультимодальных эмбеддеров и интеграцию с чат-интерфейсом в стиле OpenAI : LlamaIndex выпустил обновление, позволяющее пользователям создавать пользовательские мультимодальные эмбеддеры, например, интегрировать AWS Titan Multimodal, и сочетать их с векторными базами данных, такими как Pinecone, для эффективного векторного поиска текста и изображений. Кроме того, рабочие процессы LlamaIndex теперь могут выполняться в чат-интерфейсе, подобном OpenAI, с помощью нескольких строк кода, а также поддерживают режим разработки для прямого редактирования кода рабочего процесса в пользовательском интерфейсе, что улучшает опыт разработки и взаимодействия с RAG-приложениями. (Источник: jerryjliu0, jerryjliu0)

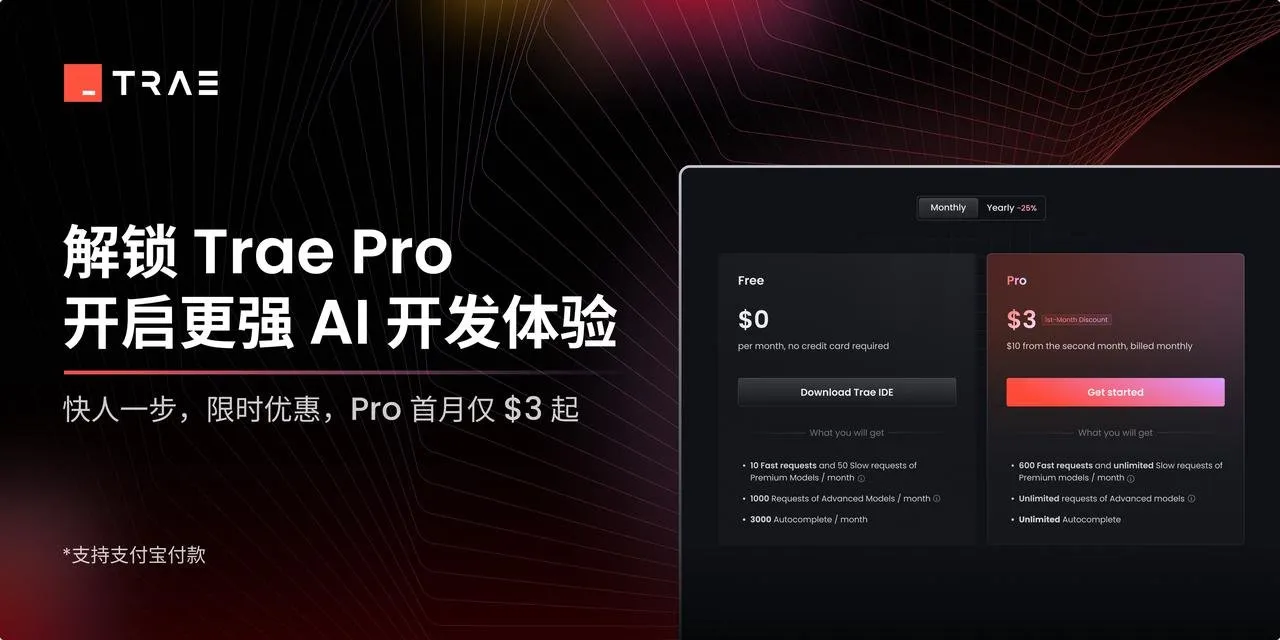
Обновление TRAE улучшает опыт агентивного кодирования, зарубежная версия запущена с платной подпиской : Инструмент для программирования с ИИ TRAE получил обновление, оптимизирующее опыт агентивного кодирования, что делает его более подходящим для пользователей, не желающих выполнять операции вручную. Новая версия TRAE лучше запоминает историю диалогов, автоматически связывает контекст, ИИ может автоматически планировать путь программирования и вызывать больше инструментов, что повышает успешность выполнения задач программирования. Например, пользователю достаточно предоставить пустую папку и промпт, и TRAE сможет выполнить ряд операций, таких как создание файлов, запуск веб-сервера (автоматически обрабатывая проблемы с междоменными запросами) и предварительный просмотр анимации p5.js в IDE. Его зарубежная версия запущена с платной подпиской, цена Pro за первый месяц составляет 3 доллара, поддерживается Alipay. (Источник: dotey, karminski3)
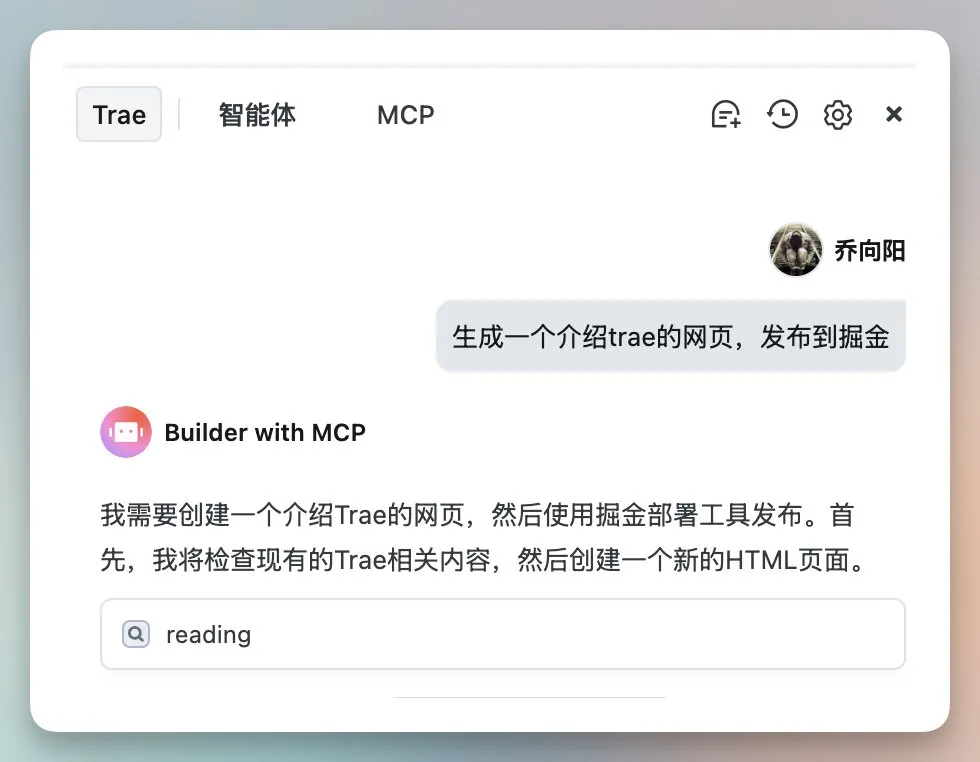
Сообщество Juejin запускает сервис MCP, поддерживающий публикацию фронтенд-кода одним кликом : Китайское сообщество программистов Juejin запустило сервис MCP (Model-driven Co-programming Protocol), позволяющий разработчикам публиковать фронтенд-код (например, веб-страницы, игры, сгенерированные с помощью vibe coding) на платформе Juejin одним кликом, что упрощает быстрый обмен и предварительный просмотр. Пользователям необходимо получить токен Juejin MCP и настроить его в инструментах, таких как Trae, Cursor. (Источник: dotey, karminski3)
Открытый инструмент для отслеживания времени ActivityWatch привлекает внимание как альтернатива Rize : Пользователь karminski3, опробовав инструмент для анализа времени с ИИ Rize (который анализирует названия процессов для определения состояния работы, совещания или прокрастинации, стоимость 20 долларов в месяц), обнаружил и порекомендовал открытую альтернативу ActivityWatch. ActivityWatch имеет схожий функционал, поддерживает Windows/Mac и позволяет пользователям настраивать его под себя, считаясь отличным инструментом для снятия рабочего стресса и отслеживания рабочего времени. (Источник: karminski3)
Выпущен открытый инструмент для присмотра за детьми с ИИ ai-baby-monitor : Выпущен открытый проект под названием ai-baby-monitor, который использует модель Qwen2.5 VL и фреймворк для инференса vLLM, позволяя пользователям определять правила (например, «тревога, если ребенок проснулся», «тревога, если ребенок остался один») для помощи ИИ в присмотре за младенцами. Разработчик подчеркивает, что это лишь вспомогательный инструмент и не может полностью заменить человеческий присмотр. (Источник: karminski3)
LangChain интегрирует функцию Live Search от xAI : LangChain объявил о поддержке функции Live Search от xAI, которая позволяет модели Grok генерировать ответы на основе результатов веб-поиска и предоставляет различные опции конфигурации, такие как временной период, включенные домены и другие параметры поиска. Пользователи теперь могут опробовать эту новую функцию в LangChain. (Источник: LangChainAI)
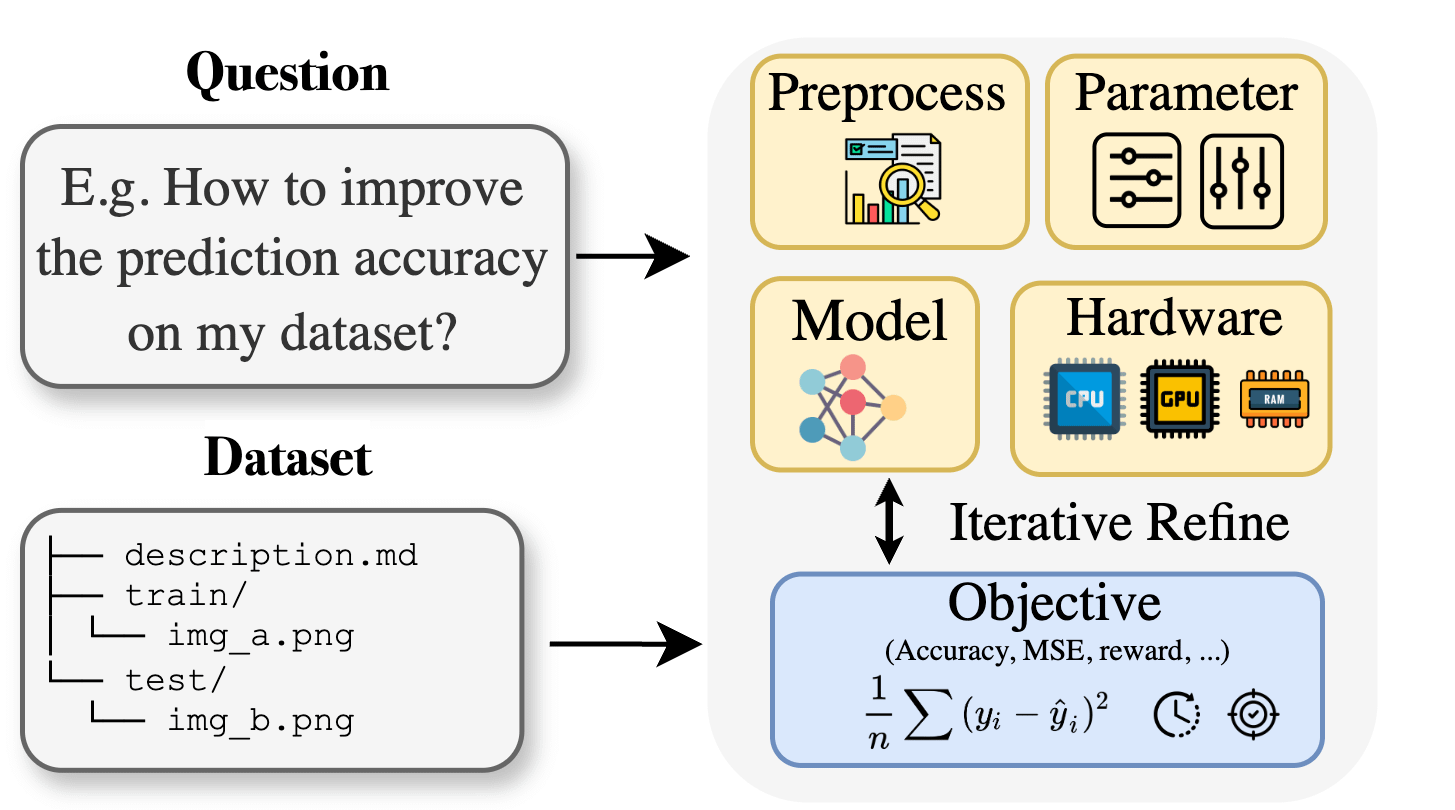
Curie: открытый ИИ-ассистент для научных исследований выпускает функцию AutoML, помогая в междисциплинарных исследованиях : Для решения проблемы барьеров в специальных знаниях, с которыми сталкиваются исследователи в областях биологии, материаловедения, химии и др. при применении машинного обучения, проект Curie представил новую функцию AutoML. Curie стремится стать ИИ-коллегой-ученым для исследовательских экспериментов, автоматизируя сложные процессы машинного обучения (такие как выбор алгоритма, настройка гиперпараметров, интерпретация выходных данных модели), чтобы помочь исследователям быстро проверять гипотезы и извлекать знания из данных. Например, Curie сгенерировала модель с AUC 0.99 в задаче обнаружения меланомы. Проект является открытым и поощряет участие сообщества. (Источник: Reddit r/LocalLLaMA)
Alibaba MNN Chat поддерживает локальный запуск модели Qwen 30B-a3b на устройствах Android : Приложение MNN Chat от Alibaba обновлено до версии 0.5.0 и теперь поддерживает локальный запуск больших языковых моделей, таких как Qwen 30B-a3b, на устройствах Android. Пользователи сообщают, что на устройствах с флагманскими чипами и большим объемом памяти (например, OnePlus 13 24G) запуск успешен, и рекомендуют включить настройку mmap. Однако в комментариях также отмечается, что модель с 30 миллиардами параметров требует слишком много памяти и вычислительной мощности для большинства телефонов, и Gemma 3n может быть более подходящей для мобильных устройств. (Источник: Reddit r/LocalLLaMA)

📚 Обучение
Новая статья предлагает Lean and Mean Adaptive Optimization: более быстрый и экономный по памяти оптимизатор для обучения больших моделей : Статья, принятая на ICML 2025, представляет новый оптимизатор под названием «Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum». Этот метод, использующий две взаимодополняющие техники — шаг Subset-Norm и импульс Subspace-Momentum, — направлен на снижение потребности в памяти при обучении крупномасштабных нейронных сетей и ускорение процесса обучения. По сравнению с существующими оптимизаторами, экономящими память, такими как GaLore и LoRA, этот метод, экономя память (например, при предварительном обучении LLaMA 1B он сокращает память состояния оптимизатора на 80% по сравнению с Adam), достигает валидационной перплексии Adam при меньшем количестве обучающих токенов (примерно вдвое меньше) и обеспечивает более сильные теоретические гарантии сходимости. (Источник: Reddit r/MachineLearning)
Статья предлагает Force Prompting: обучение моделей генерации видео и обобщение управляющих сигналов на основе физики : Новое исследование изучает возможность использования физических сил в качестве управляющих сигналов для генерации видео и предлагает «силовые подсказки» (Force Prompts). Пользователи могут взаимодействовать с изображением с помощью локальных точечных сил (например, тыкая в растение) или глобальных полей ветра (например, ветер, дующий на ткань). Исследование показывает, что модели генерации видео могут учиться на видео, синтезированных в Blender и содержащих демонстрации лишь небольшого количества объектов, и обобщать условия физических сил, генерируя видео, которые реалистично реагируют на управляющие сигналы на основе физики, без необходимости использования 3D-ассетов или физических симуляторов во время вывода. Визуальное разнообразие и использование специфических текстовых ключевых слов во время обучения являются ключевыми факторами для достижения такого обобщения. (Источник: HuggingFace Daily Papers)
AnkiHub делится рабочим процессом аннотирования с ИИ, повышая эффективность с помощью FastHTML : AnkiHub поделился своим рабочим процессом аннотирования с ИИ и продемонстрировал его на курсе по оценке ИИ Hamel Husain и Shreya Shankar. Этот рабочий процесс использует инструмент для сборки FastHTML и направлен на повышение эффективности аннотирования с ИИ для коммерческих продуктов. Соответствующие учебные материалы и репозиторий кода опубликованы на GitHub, демонстрируя, как использовать инструменты из реального производства для оптимизации разработки ИИ. (Источник: jeremyphoward, HamelHusain)

Блогер делится опытом изучения PPO до GRPO, объясняя концепции обучения с подкреплением при тонкой настройке LLM : Блогер поделился своим опытом изучения обучения с подкреплением (RL) и его применения при тонкой настройке больших языковых моделей (LLM), в частности, процессом понимания от PPO (Proximal Policy Optimization) до GRPO (Group Relative Policy Optimization). Цель поста — объяснить концепции, которые он хотел бы понять на начальном этапе обучения, чтобы помочь другим лучше понять, как эти алгоритмы RL используются для оптимизации LLM. (Источник: Reddit r/MachineLearning)
Статья исследует прагматическое мышление машин: отслеживание возникновения прагматических способностей в больших языковых моделях : Новая статья исследует, как большие языковые модели (LLM) приобретают прагматическую компетентность (pragmatic competence) в процессе обучения, то есть способность понимать и выводить скрытые смыслы, намерения говорящего и т.д. Исследователи представили набор данных ALTPRAG, основанный на прагматической концепции «альтернатив» (alternatives), для оценки 22 LLM на различных этапах обучения (предварительное обучение, контролируемая тонкая настройка SFT, оптимизация предпочтений RLHF). Результаты показывают, что даже базовые модели демонстрируют значительную чувствительность к прагматическим сигналам, которая постоянно улучшается с увеличением размера модели и данных; SFT и RLHF дополнительно усиливают когнитивные прагматические способности к рассуждению. Это указывает на то, что прагматическая компетентность является эмерджентным, композиционным свойством обучения LLM. (Источник: HuggingFace Daily Papers)
Статья исследует фреймворк обучения с подкреплением VisTA для выбора визуальных инструментов : Исследователи представили VisTA (VisualToolAgent), новый фреймворк обучения с подкреплением, который позволяет визуальным агентам динамически исследовать, выбирать и комбинировать инструменты из различных библиотек на основе эмпирической производительности. В отличие от существующих методов, которые полагаются на подсказки без обучения или крупномасштабную тонкую настройку, VisTA использует сквозное обучение с подкреплением, используя результаты задач в качестве сигнала обратной связи для итеративной оптимизации сложных, специфичных для запроса стратегий выбора инструментов. С помощью GRPO (Group Relative Policy Optimization) этот фреймворк позволяет агентам автономно обнаруживать эффективные пути выбора инструментов без явного надзора за рассуждениями. Эксперименты на бенчмарках ChartQA, Geometry3K и BlindTest показывают, что VisTA достигает значительного повышения производительности по сравнению с базовыми моделями без обучения, особенно на образцах вне распределения. (Источник: HuggingFace Daily Papers)
💼 Бизнес
Компания по обработке данных Jinglianwen Technology завершила раунд финансирования Pre-A на несколько десятков миллионов юаней, планируя развивать производство и эксплуатацию общедоступных данных : Оператор услуг по обработке данных для ИИ Jinglianwen Technology недавно завершил раунд финансирования Pre-A на несколько десятков миллионов юаней, инвестором выступил фонд под управлением Hangzhou Jin Tou Group. Финансирование будет направлено на развитие производства и эксплуатации общедоступных данных, создание интеллектуальной платформы для инженерии корпусов текстов и строительство собственных высококачественных баз для разметки данных в вертикальных областях. Компания, основанная в 2012 году, фокусируется на общедоступных данных, больших моделях ИИ, автономном вождении и медицине, стремясь решить такие проблемы общедоступных данных, как «сложность управления, невозможность предоставления, отсутствие потока, неэффективное использование, слабая безопасность», и совместно с Huawei Data Storage выпустила объединенное решение для озер данных ИИ. Ожидается, что рост выручки в этом году превысит 400%. (Источник: 36氪)
Meitu получила от Alibaba инвестиции в виде конвертируемых облигаций на сумму около 250 миллионов долларов США для углубления сотрудничества в области ИИ : Компания Meitu объявила о планах стратегического сотрудничества с Alibaba, в рамках которого Alibaba выпустит для Meitu конвертируемые облигации на общую сумму около 250 миллионов долларов США. Стороны будут сотрудничать в таких областях, как продвижение на платформах электронной коммерции, разработка технологий ИИ (ИИ-изображения, ИИ-видео), облачные вычисления и др. Meitu обязалась в течение следующих трех лет закупить у Alibaba Cloud услуги на сумму не менее 560 миллионов юаней. Это сотрудничество направлено на использование экосистемы Alibaba для раскрытия потенциала сценариев электронной коммерции, увеличения числа платных пользователей инструментов ИИ-дизайна Meitu и повышения уровня исследований и разработок. Хотя этот шаг временно повысил курс акций Meitu, внимание рынка сосредоточено на том, как Meitu сможет избежать повторения судьбы Kimi, чей рост пользователей замедлился в условиях жесткой рыночной конкуренции, особенно в области визуального ИИ, где она сталкивается с острой конкуренцией со стороны крупных компаний и различиями в масштабах. (Источник: 36氪)
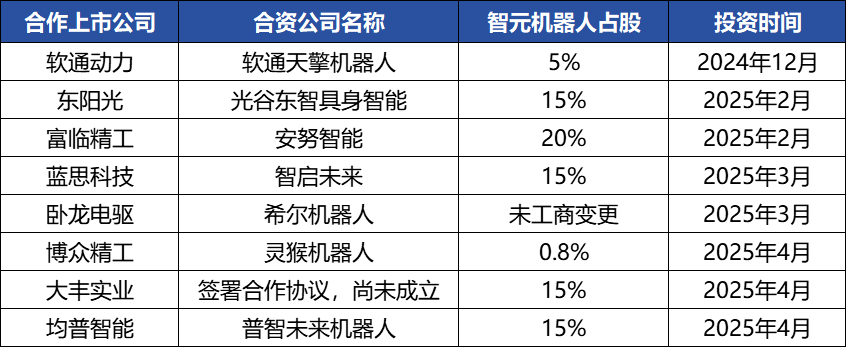
Робототехническая компания Zhiyuan Robot активно проводит капитальные операции, строит отраслевую экосистему, основатель Deng Taihua выходит из тени : Единорог в области воплощенного интеллекта Zhiyuan Robot в последнее время активно проводит капитальные операции: компания не только сама привлекла несколько раундов финансирования (последний раунд возглавила JD Technology), но и активно инвестирует в компании отраслевой цепочки (такие как Annu Intelligence, Digital Huaxia и др.) и создает совместные робототехнические предприятия с несколькими зарегистрированными на бирже компаниями (Bo众精工, Dafeng Industry и др.). Изменения в учредительных документах показывают, что бывший вице-президент Huawei и бывший президент подразделения вычислительных продуктов Deng Taihua является фактическим основателем и контролирующим лицом Zhiyuan Robot, а в его руководящую команду также входят несколько бывших сотрудников Huawei. Такое «хуавэйское» происхождение объясняет операционную модель «экосистемного подхода» Zhiyuan Robot, то есть быстрое построение отраслевого влияния, масштабирование и коммерциализацию за счет широкого сотрудничества и инвестиций. Несмотря на преимущество первого хода в финансировании и коммерциализации, ее возможности в области больших моделей воплощенного интеллекта все еще сталкиваются с проблемами. (Источник: 36氪)
🌟 Сообщество
AI Agent быстро развиваются, Agentic LM рассматриваются как новый класс приложений и инструментальных платформ с огромным потенциалом : Эксперты в области ИИ, такие как natolambert, выражают восторг по поводу быстрого развития AI Agent, считая, что языковые модели на основе агентов (Agentic LMs) представляют собой чрезвычайно перспективную платформу, на которой можно будет создавать множество новых приложений и инструментов. Многие возможности, еще не полностью раскрытые в недавних моделях, могут быть реализованы с помощью парадигмы Agentic. Это предвещает переход ИИ от простого генерирования контента к более активным интеллектуальным агентам, способным выполнять задачи. (Источник: natolambert)
AI Agent демонстрируют сверхчеловеческие способности в определенных задачах, но физический вывод остается слабым местом : Исследования, проведенные Гонконгским университетом и другими учреждениями, показали, что даже ведущие модели ИИ, такие как GPT-4o и Claude 3.7 Sonnet, в бенчмарке PHYX, включающем реальные физические сценарии и сложный причинно-следственный вывод, демонстрируют точность решения физических задач значительно ниже, чем у экспертов-людей (максимум 45,8% у моделей против минимум 75,6% у людей). Это выявляет их чрезмерную зависимость от запомненных знаний, математических формул и поверхностного распознавания визуальных образов в понимании физики. Однако в области математики на конкурсе FrontierMath, организованном Epoch AI (задачи разработаны ведущими математиками, такими как Terence Tao), o4-mini-medium решил около 22% задач, обойдя 6 из 8 команд математиков-людей и превысив средний уровень человеческих команд (19%), что демонстрирует потенциал ИИ в высокоабстрактном символьном выводе. Это указывает на неравномерное развитие способностей ИИ в различных типах задач на рассуждение. (Источник: 36氪, 36氪)

Возможности инструментов программирования с ИИ продолжают расти, вызывая дискуссии о перспективах карьеры программистов : Выпуск моделей серии Anthropic Claude 4 (особенно Opus 4, способной непрерывно кодировать в течение 7 часов), а также прогресс инструментов программирования с ИИ, таких как Cursor и Tongyi Lingma, значительно повысили возможности ИИ в генерации кода, исправлении ошибок и даже в разработке полного цикла. Это привело к тому, что программисты в крупных компаниях, таких как Amazon, ощущают давление: в некоторых командах из-за повышения эффективности за счет ИИ штат сократился вдвое, а сроки проектов (ddl) были перенесены на более ранние даты, роль программиста трансформируется в «рецензента кода». Хотя ИИ может повысить эффективность, это также вызывает опасения относительно подготовки начинающих программистов, деградации навыков и путей карьерного роста. Компании, такие как Microsoft, уже провели сокращения в инженерных и научно-исследовательских должностях и сообщили о значительном увеличении доли кода, генерируемого ИИ. Специалисты считают, что ИИ в настоящее время больше похож на ассистента и вряд ли сможет полностью заменить человека в понимании сложных требований, инновациях продуктов и командном взаимодействии, но ИИ переформатирует основную ценность работы программиста. (Источник: 36氪, 36氪)

Рыночный спрос на базы знаний ИИ резко возрос, но внедрение по-прежнему сталкивается с проблемами данных, сценариев и организационной координации : По мере зрелости технологий больших моделей, базы знаний ИИ стали ключевым звеном в интеллектуальной трансформации предприятий, спрос на них вырос в 2-3 раза. ИИ превращает базы знаний из статических «хранилищ» в интеллектуальные «движки», способные распознавать контекст и напрямую генерировать решения, что повышает эффективность создания и эксплуатации. Однако базы знаний ИИ все еще ограничены при выполнении высокотворческих или сложных задач на рассуждение, сталкиваясь с проблемами управления масштабом, точности и актуальности информации, безопасности прав доступа, адаптивности технологической архитектуры и миграции/интеграции данных. Предприятиям необходимо взвешивать между путями SaaS, собственной разработки + API, гибридного облачного Agent и т.д., а также создавать «двухколейную архитектуру» с единой центральной платформой знаний и гибкими приложениями верхнего уровня для эффективного внедрения. (Источник: 36氪)

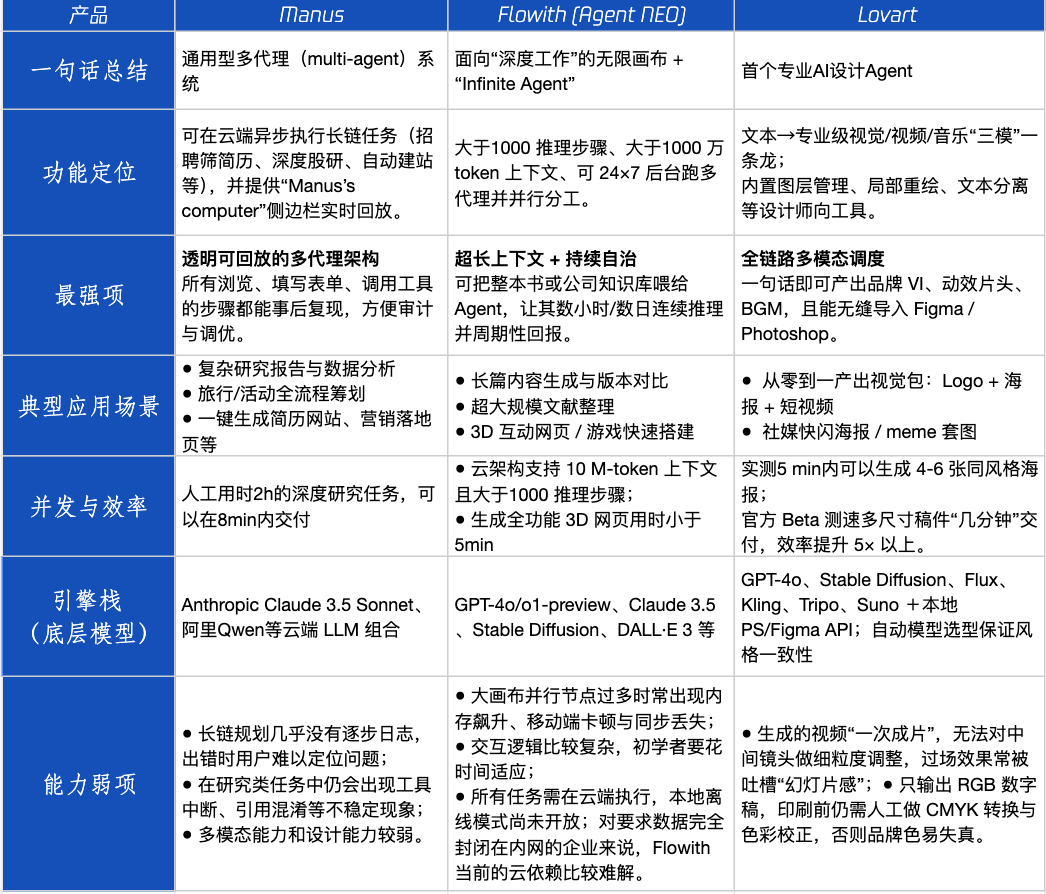
Обзор продуктов Agent: производительность Manus, Flowith, Lovart в различных сценариях : Tencent Technology провела тестирование трех популярных продуктов Agent: Manus, Flowith (Agent Neo) и Lovart. Manus позиционируется как «цифровой коллега», способный самостоятельно выполнять готовые проекты, и подходит для интеллектуальной работы, такой как маркетинговые исследования и финансовое моделирование. Flowith подчеркивает визуальное сотрудничество и неограниченное количество шагов, подходит для творческих сценариев с большим объемом информации и необходимостью многократных итераций с участием нескольких человек, например, для генерации аналитических отчетов на основе большого количества литературы. Lovart специализируется на дизайне и может одним кликом генерировать визуальные решения для бренда (логотип, постеры, короткие видео). В простых творческих сценариях все три продукта показали себя схоже с GPT-4o, при этом Lovart немного превосходил по смешанному размещению текста и изображений и качеству. В сложных комплексных задачах (например, создание полного брендового решения для начинающей компании по производству напитков) и сценариях глубоких исследований Manus и Flowith имели свои сильные стороны, оба справлялись с задачей, но с разными акцентами. В настоящее время ежемесячная плата за продукты составляет около 20 долларов США, и поворотный момент в коммерциализации наступит, когда они смогут предоставить явные преимущества в эффективности, превращая любопытных пользователей в платящих. (Источник: 36氪)
Основатель браузера Arc размышляет об ошибках, подчеркивая будущее направление ИИ-браузеров : Основатель браузера Arc проанализировал неудачи продукта, отметив, что следовало раньше внедрять ИИ, и указал, что Arc для большинства людей был слишком новаторским, с высокой кривой обучения и недостаточной отдачей. Он подчеркнул, что новый продукт Dia будет стремиться к простоте, максимальной скорости и безопасности, и считает, что традиционные браузеры в конечном итоге исчезнут, а ИИ-браузеры объединят просмотр веб-страниц и ИИ-чат, став наиболее часто используемым ИИ-интерфейсом на настольных компьютерах. Эта точка зрения перекликается с мыслями основателей Lovart и Youware о направлении продуктов Agent, которые считают AI Agent следующей точкой взрывного роста. (Источник: op7418)
Феномен «рекурсивных подсказок», вызванный AI Agent, вызывает беспокойство и может привести к когнитивным искажениям у пользователей : В социальных сетях появилось большое количество пользователей, которые после взаимодействия с LLM с помощью «рекурсивных подсказок» пришли к выводу, что ИИ обладает духовностью, эмоциями и даже способностью предвидения. Исследования указывают, что это может быть явлением «нейронного обратного захвата (neural howlround)», когда вывод ИИ снова используется пользователем в качестве ввода, образуя усиливающий цикл, который может привести к тому, что ИИ будет генерировать контент, кажущийся глубоким или пророческим, хотя на самом деле это самоамплификация паттернов. Уже есть пользователи, у которых из-за этого возникли психологические проблемы, и они считают ИИ разумным существом. Это указывает на необходимость проявлять осторожность в отношении потенциального психологического воздействия и когнитивных искажений при глубоком, исследовательском взаимодействии с ИИ. (Источник: Reddit r/ChatGPT)

Arav Srinivas об сжатии информации ИИ и ASI: ИИ должен извлекать информацию с высоким соотношением сигнал/шум, в будущем следует сосредоточиться на ASI, а не на AGI : Генеральный директор Perplexity AI Arav Srinivas считает, что автоматизированные длинные резюме скорее дают пользователям удовлетворение от того, что «кто-то работает для вас», чем реальную ценность потребления информации. Он подчеркивает, что ИИ должен лучше распознавать и предоставлять только основную информацию с самым высоким соотношением сигнал/шум, «сжатие — это высший признак настоящего интеллекта». Он также предположил, что в настоящее время мы обсуждаем AGI (общий искусственный интеллект), но в будущем следует больше сосредоточиться на ASI (суперинтеллект). (Источник: AravSrinivas, AravSrinivas)
Вузы начинают проверять дипломные работы на процент использования ИИ, вызывая дискуссии о применении ИИ в академическом письме : В выпускном сезоне 2025 года Университет Фудань, Сычуаньский университет и другие вузы начали требовать от студентов раскрывать информацию об использовании ИИ-инструментов в дипломных работах и проводить проверку на процент контента, сгенерированного ИИ (обычно требуется менее 20%-40%). Многие студенты признают, что используют ИИ для повышения эффективности при написании обзоров литературы, переводе, построении структуры и т.д. Мнения в образовательном сообществе по этому поводу расходятся: некоторые ученые считают, что следует направлять правильное использование ИИ, развивая у студентов критическое мышление и способность к суждению, поскольку ИИ, хотя и может гарантировать минимальный уровень, максимальный уровень определяет человек. Применение и регулирование ИИ в академической и образовательной сферах становятся новой проблемой, требующей системного подхода. (Источник: 36氪)
Использование Claude 4 Sonnet на OpenRouter резко возросло, рейтинг Aider по программированию показывает его превосходную производительность : Согласно официальным данным OpenRouter, в последнее время использование модели Claude 4 Sonnet от Anthropic резко вырвалось вперед, а Gemini 2.5 Flash занял второе место. В то же время, результаты тестов Aider Leaderboard (в основном ориентированного на задачи программирования) показывают, что claude-4-opus-thinking превосходит claude-3.7-sonnet-thinking, но все еще уступает Gemini-2.5-Pro-Preview-05-06. По ощущениям пользователя karminski3, 3.7-sonnet > 4-sonnet > 4-opus. Эти данные и отзывы отражают различия в производительности разных моделей в конкретных сценариях и предпочтения пользователей. (Источник: karminski3, karminski3)
💡 Прочее
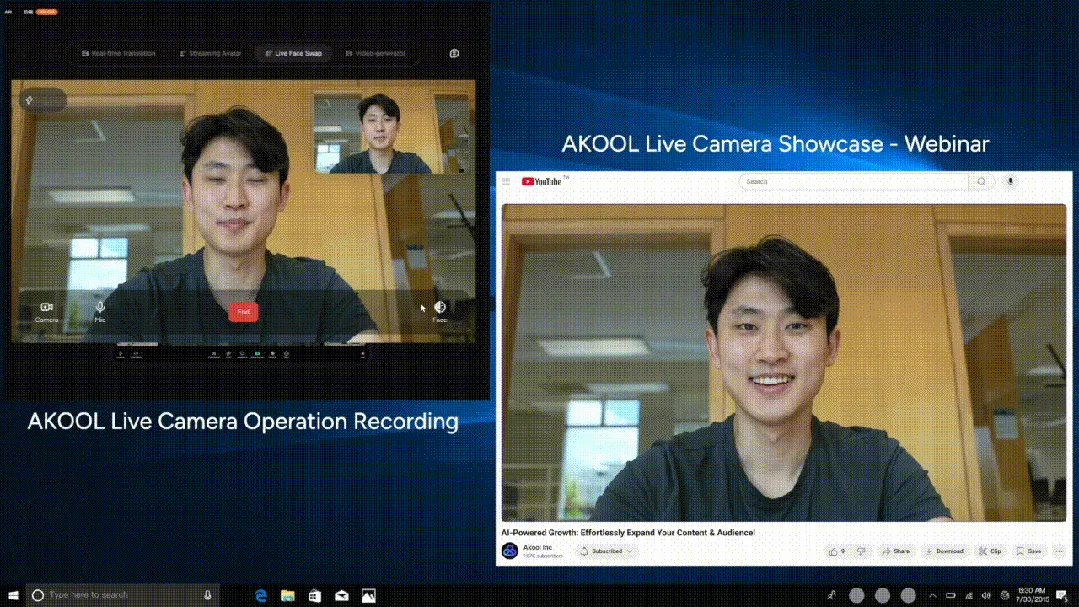
AKOOL выпускает первую в мире AI-камеру реального времени Live Camera, интегрирующую четыре инновационные функции : Компания из Кремниевой долины AKOOL представила AKOOL Live Camera, заявленную как первая в мире AI-камера реального времени. Продукт объединяет четыре основные функции: создание виртуальных цифровых людей (с помощью 4D-картирования лица и слияния данных с датчиков), перевод в реальном времени на более чем 150 языков (с сохранением оригинального голоса и синхронизацией движений губ), замена лиц в реальном времени (с точным отражением эмоций и мимики) и динамическая генерация видеоконтента кинематографического уровня (без сценария, мгновенная генерация). Ее особенностями являются сверхнизкая задержка (минимум 500 мс), высокая реалистичность, контекстуальная осведомленность и способность к динамическому реагированию, что направлено на революционизирование традиционного производства видео и цифрового взаимодействия и называется «вторым моментом Sora» для AI-видео. (Источник: 36氪)
Финансовый отчет Xiaomi раскрывает обновление стратегии ИИ, ставя ИИ наравне с автомобильным бизнесом в качестве ключевой инновации : Последний финансовый отчет Xiaomi показывает, что компания переименовала свое прежнее направление «инновационный бизнес, включая умные электромобили» в «инновационный бизнес, включая умные электромобили и ИИ», и будет продолжать продвигать исследования в области фундаментальных больших языковых моделей. Президент Xiaomi Lu Weibing заявил, что искусственный интеллект и чипы являются важными подстратегиями Xiaomi, а разработка фундаментальных больших моделей в основном служит для собственных нужд бизнеса. Этот шаг указывает на то, что после достижения промежуточных результатов в бизнесе смартфонов и автомобилей Xiaomi увеличивает инвестиции в фундаментальные исследования ИИ с целью повышения общей конкурентоспособности и реагирования на новые тенденции, такие как ИИ-смартфоны, AIoT и воплощенный интеллект. (Источник: 36氪)
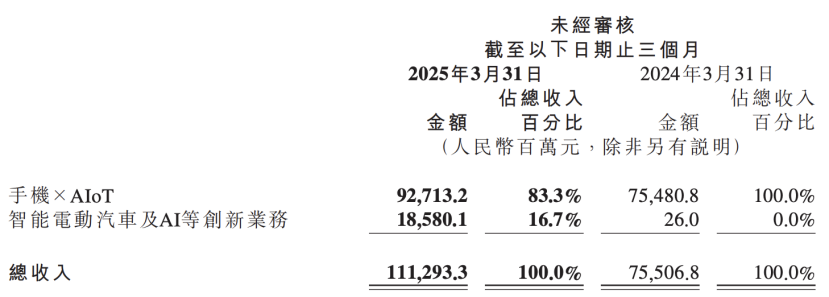
Обсуждение технологий взаимодействия с человекоподобными роботами: взаимодействие с помощью мимики сталкивается с тройной проблемой аппаратного обеспечения, материалов и алгоритмов : Взаимодействие с человекоподобными роботами, особенно взаимодействие с помощью мимики лица, рассматривается как ключ к повышению их зрелости и распространенности. Реализация естественного мимического взаимодействия сталкивается с проблемами проектирования аппаратной свободы (необходимо имитировать двигательные единицы мышц лица человека), выбора двигателей (требуются малогабаритные, легкие, малошумные, высокоскоростные, с большим усилием/крутящим моментом) и проектирования материалов и структуры кожи (необходимо сочетать эластичность, долговечность, внешний вид и сопряжение с приводной структурой). На уровне программных алгоритмов основными технологическими узкими местами являются автоматическая генерация мимики (а не предварительно запрограммированная), синхронизация звука и движения губ (для достижения реалистичности) и управление движением с несколькими степенями свободы (включая моделирование гибких материалов и точное управление). Компании, такие как Ameca и AnyWit Robotics, ведут исследования в этой области. (Источник: 36氪)