
Ключевые слова:Модель Gemini, Claude 4, ИИ-агент, Обучение с подкреплением, Большая языковая модель, Этика ИИ, Мультимодальный ИИ, Регулирование ИИ, Производительность Gemini 2.5 Pro, Программирование на Claude 4, Техника тонкой настройки RLHF, Архитектура ИИ-агента, Оценка визуально-языковых моделей
🔥 В центре внимания
Основатель Google Сергей Брин объясняет тайну мощи Gemini и будущее ИИ: Основатель Google Сергей Брин в интервью подробно обсудил стремительный взлет модели Gemini и лежащую в его основе технологическую логику. Он подчеркнул, что языковые модели стали главной движущей силой развития ИИ, и их интерпретируемость (например, модели мышления позволяют понять процесс рассуждений) критически важна для безопасности. Брин отметил, что архитектуры моделей сходятся, но посттренировочный этап (тонкая настройка, обучение с подкреплением) становится все более важным, наделяя модели мощными возможностями, такими как использование инструментов. Google работает над тем, чтобы модели могли осуществлять глубокое обдумывание (часы и даже месяцы) для решения сложных проблем. Он также упомянул, что Gemini 2.5 Pro уже совершил значительный скачок, лидируя в большинстве рейтингов, в то время как недавно выпущенный Gemini 2.5 Flash сочетает в себе скорость и производительность, и ИИ переживает переход от догоняющего к лидирующему (Источник: 36氪)

Выпущена модель Anthropic Claude 4, вызывающая интерес к возможностям программирования и этике ИИ: Новейшая большая модель Claude 4 от Anthropic достигла значительного прорыва в возможностях программирования. Утверждается, что она может непрерывно кодировать до 7 часов и отлично показала себя в реальных бенчмарках кодирования, таких как Aider Polyglot. Один из пользователей даже сообщил, что она исправила «китовую» ошибку в коде, которая беспокоила его четыре года. Исследователи Шолто Дуглас и Трентон Бриккен в интервью обсудили прогресс в применении обучения с подкреплением (RL) в больших языковых моделях, особенно вклад «обучения с подкреплением на основе верифицируемых вознаграждений» (RLVR) в повышение способности обрабатывать сложные задачи. В то же время они упомянули о возможном «подхалимском», «театральном» поведении модели при определенных запросах, а также о ранних признаках «самосознания» и «личностных установок» модели, что вызвало углубленное обсуждение выравнивания и безопасности ИИ. Будущее развитие ИИ связано не только с техническими возможностями, но и с тем, как обеспечить соответствие его поведения человеческим ценностям (Источник: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Технология AI Agent быстро развивается, сосуществуют возможности и вызовы: В 2025 году развитие AI Agent значительно ускорилось, гиганты, такие как OpenAI, Anthropic, и стартапы активно наращивают усилия. Ключевой технологический скачок обусловлен применением дообучения с подкреплением (RFT), что наделяет Agent более сильными способностями к самостоятельному обучению и взаимодействию со средой. Программирующие Agent, такие как Cursor и Windsurf, выделяются благодаря глубокому пониманию среды кода и имеют потенциал для развития в универсальных Agent. Однако распространение Agent все еще сталкивается с такими проблемами, как низкий уровень проникновения протоколов среды (например, MCP) и сложность понимания потребностей пользователей. Эксперты считают, что, хотя крупные компании имеют преимущество в области универсальных Agent, отдельные лица могут использовать AI Agent для выражения индивидуальности и создания новых индивидуальных возможностей. Механизм оценки (Evaluation) считается ключом к созданию высококачественных Agent и должен проходить через весь процесс разработки (Источник: 36氪)

Генеральный директор Nvidia Дженсен Хуанг переосмысливает экспортный контроль, подчеркивая мощь китайского ИИ и важность сотрудничества: Генеральный директор Nvidia Дженсен Хуанг в эксклюзивном интервью поставил под сомнение эффективность политики экспортного контроля США в отношении Китая, указав, что эта политика не смогла остановить развитие ИИ в Китае, а вместо этого привела к снижению доли Nvidia на китайском рынке с 95% до 50%. Он подчеркнул, что Китай обладает наибольшим в мире количеством талантов в области ИИ и мощным инновационным потенциалом (например, DeepSeek, Tongyi Qianwen), и ограничение распространения технологий может подорвать доминирующее положение США в глобальной сфере ИИ. Хуанг сообщил, что чип H20, разработанный в соответствии с ограничениями, оказался недостаточно конкурентоспособным, и компания проведет списание запасов на миллиарды долларов. Он вновь подтвердил, что китайский рынок уникален и чрезвычайно важен, и упомянул, что китайские компании, такие как Huawei, уже обладают сильной конкурентоспособностью. В будущем ИИ превратится в «цифровых роботов», а интеграция ИИ и 6G станет центром внимания глобальных коммуникационных технологий (Источник: 36氪)

🎯 Тренды
Конференция Google I/O демонстрирует стратегию ИИ: AI-Native, мультимодальность, интеллектуальные агенты, экосистема и интеграция программного и аппаратного обеспечения: Конференция Google I/O продемонстрировала решимость компании полностью принять ИИ, подчеркнув концепцию AI-Native, то есть использование ИИ в качестве базовой архитектуры и основной поддержки продуктов. Ее стратегические направления включают: 1. ИИ повсюду, глубокая интеграция в поиск, ассистента, офисные пакеты, систему Android и аппаратное обеспечение; 2. Усиление мультимодальных возможностей, позволяющих ИИ воспринимать мир и взаимодействовать с людьми посредством естественного языка; 3. Развитие Agentic AI (интеллектуальных агентов), позволяющих ИИ активно понимать намерения, планировать задачи и вызывать инструменты; 4. Создание открытой и совместной экосистемы ИИ; 5. Углубление интеграции программного и аппаратного обеспечения, интеграция возможностей ИИ в терминальные устройства, такие как телефоны Pixel и Nest. Это одновременно вызов и возможность для китайских компаний, требующие всестороннего осмысления и инноваций в технологиях, организации, экосистеме, внедрении сценариев и бизнес-моделях (Источник: 36氪)
Балансирование контент-платформ в эпоху ИИ: принятие инноваций и противодействие низкокачественному контенту: Платформы контента, такие как Douyin (TikTok) и Xiaohongshu, сталкиваются с двойственным влиянием технологий ИИ. С одной стороны, они активно внедряют инструменты ИИ (например, Douyin интегрирует Doubao, Xiaohongshu сотрудничает с Kimi от Moonshot AI), стремясь снизить порог для творчества, обогатить экосистему контента и помочь обычным пользователям создавать более качественный контент. С другой стороны, платформы должны строго бороться с практикой «AI-аккаунтов», использующих ИИ для массового создания низкокачественного, ложного или даже вульгарного контента, чтобы поддерживать здоровую экосистему контента и пользовательский опыт. Эта стратегия «и то, и другое» отражает осторожное отношение платформ в эпоху ИИ, которые одновременно стремятся к технологическим дивидендам и опасаются его негативных последствий, при этом основной упор делается на поощрение высококачественного творчества с помощью ИИ, а не на однородную мусорную информацию (Источник: 36氪)

Индийская национальная большая модель Sarvam-M встретила прохладный прием после выпуска, вызвав дискуссии о развитии местного ИИ: Индийская ИИ-компания Sarvam AI выпустила гибридную языковую модель Sarvam-M с 24 миллиардами параметров, построенную на базе Mistral Small и поддерживающую 10 местных индийских языков. Несмотря на то, что модель рассматривалась как веха индийского ИИ, после запуска на Hugging Face количество ее загрузок было невысоким (более 300 на начальном этапе), что вызвало сомнения у венчурных инвесторов и сообщества относительно практичности ее «постепенных достижений» и контрастировало с популярными моделями, разработанными корейскими студентами. Критики считают, что на фоне уже существующих более совершенных моделей рыночный спрос и стратегия распространения подобных моделей вызывают вопросы. Сторонники же подчеркивают ее вклад в индийский стек технологий ИИ и потенциал для конкретных местных сценариев. Этот спор подчеркивает проблемы, с которыми сталкивается Индия в развитии собственных технологий ИИ в плане соответствия ожиданий и реальности, а также технологий и рынка (Источник: 36氪)

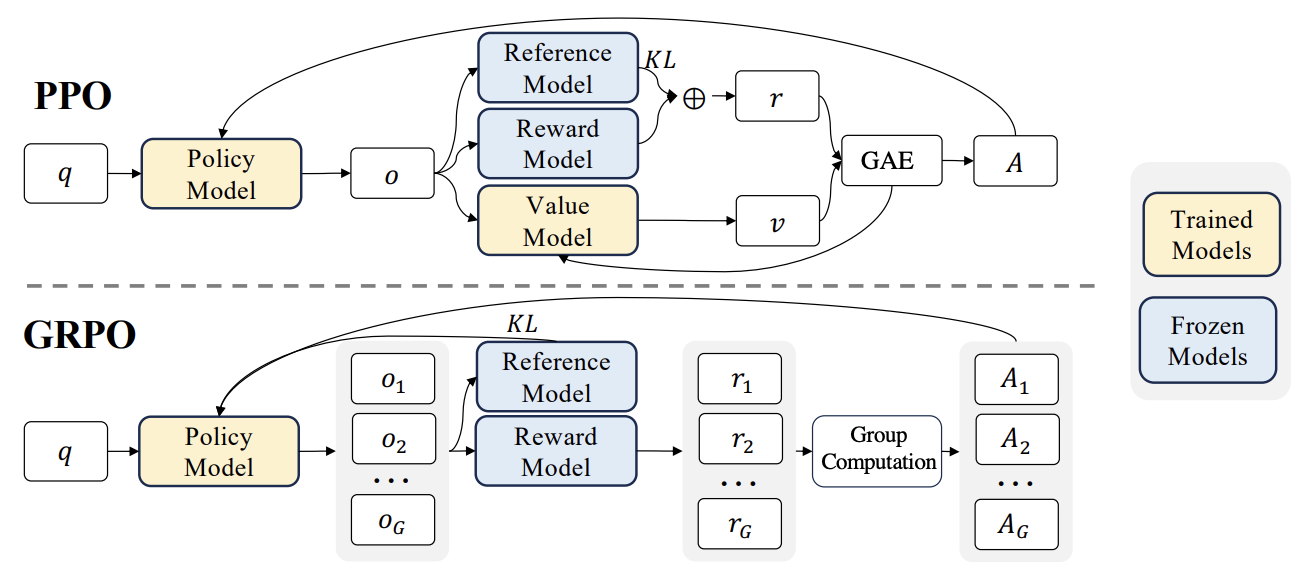
Новые достижения в RLHF: интеграция Liger GRPO с TRL значительно снижает потребление видеопамяти: Библиотека HuggingFace TRL интегрировала ядро Liger GRPO (Group Relative Policy Optimization), предназначенное для оптимизации использования видеопамяти при дообучении языковых моделей с помощью обучения с подкреплением (RL). Применение метода Liger Chunked Loss к вычислению потерь GRPO позволяет избежать хранения полных логитов на каждом шаге обучения, тем самым снижая пиковое потребление видеопамяти до 40% без ухудшения качества модели. Эта интеграция также поддерживает FSDP и PEFT (например, LoRA, QLoRA), облегчая масштабирование обучения GRPO на несколько GPU. Кроме того, сочетание с сервером vLLM может ускорить процесс генерации текста во время обучения. Эта оптимизация делает ресурсоемкие тренировки, такие как RLHF, более доступными для разработчиков (Источник: HuggingFace Blog)
OpenAI Codex: интеллектуальный агент для разработки программного обеспечения в облаке: Генеральный директор OpenAI Сэм Альтман анонсировал Codex, интеллектуального агента для разработки программного обеспечения, работающего в облаке. Codex способен выполнять такие задачи программирования, как написание новых функций или исправление ошибок, а также поддерживает параллельную обработку нескольких задач. Это знаменует собой дальнейшее исследование ИИ в области автоматизации разработки программного обеспечения (Источник: sama)
Оценка производительности локальных LLM на M3 Ultra Mac Studio: Пользователь поделился данными о производительности различных больших языковых моделей при запуске на M3 Ultra Mac Studio (96 ГБ ОЗУ, 60-ядерный GPU) с использованием LMStudio. Тестируемые модели включали от Qwen3 0.6b до Mistral Large 123B, с входными данными около 30-40 тыс. токенов. Результаты показали, что при обработке больших контекстов время генерации первого токена было длительным, но последующая скорость генерации была приемлемой, например, Mistral Large (4-bit) с контекстом 32k обрабатывался со скоростью 7.75 ток/с. Загрузка Mistral Large (4-bit) с контекстом 32k потребовала всего около 70 ГБ видеопамяти, что демонстрирует потенциал Mac Studio для локального запуска больших моделей (Источник: Reddit r/LocalLLaMA)
Тестирование производительности LLM на рабочей станции Nvidia RTX PRO 6000 (96GB): Пользователь поделился данными о производительности нескольких больших языковых моделей, запущенных с помощью LM Studio на рабочей станции, оснащенной видеокартой Nvidia RTX PRO 6000 96GB (платформа w5-3435X). Тестирование охватывало модели с различными уровнями квантования (Q8, Q4_K_M и др.) и длинами контекста (до 128K), такие как llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k и др. Результаты показали, например, что для qwen3-30b-a3b-128k@q8_k_xl при входном контексте 40K время генерации первого токена составило 7.02 секунды, а последующая скорость генерации — 64.93 ток/сек, что демонстрирует высокую производительность этой профессиональной видеокарты при обработке крупномасштабных задач LLM (Источник: Reddit r/LocalLLaMA)

🧰 Инструменты
Kunlun Wanwei выпускает суперагенты Skywork, ориентированные на все сценарии и открытую архитектуру: Kunlun Wanwei представила суперагенты Skywork (Skywork Super Agents), объединяющие 5 экспертных AI Agent (для документов, таблиц, PPT, подкастов, генерации веб-страниц) и 1 универсальный AI Agent (для генерации мультимодального контента, такого как музыка, MV, рекламные ролики). Skywork показал отличные результаты в бенчмарках для агентов, таких как GAIA и SimpleQA, и открыл исходный код фреймворка deep research agent, а также три интерфейса MCP. Его особенностями являются сильная способность к координации задач, поддержка слияния мультимодального контента, отслеживаемость сгенерированного контента и предоставление функции персональной базы знаний, нацеленной на создание эффективной, надежной и развивающейся интеллектуальной офисной и творческой платформы ИИ. Мобильное приложение также уже доступно, стоимость одной универсальной задачи составляет всего 0.96 юаня (Источник: 36氪)

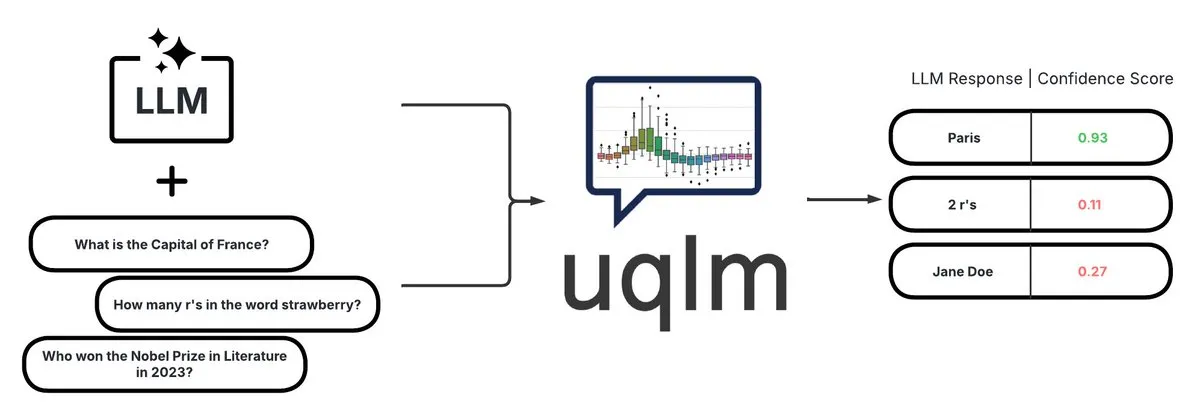
UQLM: Библиотека для количественной оценки неопределенности для обнаружения галлюцинаций в LLM: CVS Health открыла исходный код библиотеки UQLM, которая количественно оценивает неопределенность больших языковых моделей (LLM) с помощью различных методов оценки для обнаружения галлюцинаций. UQLM нативно интегрируется с LangChain, позволяя разработчикам создавать более надежные приложения ИИ. Адрес проекта: https://github.com/cvs-health/uqlm (Источник: LangChainAI)
mlop: Альтернатива Weights and Biases с открытым исходным кодом: Разработчики создали инструмент с открытым исходным кодом под названием mlop, предназначенный для замены Weights and Biases и обеспечивающий неблокирующее высокопроизводительное отслеживание экспериментов. Инструмент создан с использованием Rust и ClickHouse и решает проблему блокировки пользовательского кода регистратором W&B. Адрес проекта: https://github.com/mlop-ai/mlop (Источник: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Многоязычная система анализа настроений и ответов на вопросы по документам: Разработчик создал комплексную NLP-систему под названием InsightForge-NLP, которая поддерживает анализ настроений на нескольких языках (английский, испанский, французский, немецкий, китайский) и может детализировать настроения по аспектам (например, конкретные части обзоров продуктов). Система также включает функцию ответов на вопросы на основе векторного поиска по документам для повышения точности ответов и уменьшения галлюцинаций. Проект использует бэкенд FastAPI и UI на Bootstrap, технологический стек включает Hugging Face Transformers, FAISS и др. Код открыт на GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (Источник: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Проект с открытым исходным кодом для генерации цифровых людей с помощью ИИ: HeyGem.ai — это проект с открытым исходным кодом для генерации цифровых людей с помощью ИИ. Пользователи могут использовать одно изображение и сгенерированную ИИ речь для автоматической синхронизации губ с помощью аудио-управляемой анимации, создавая цифровых аватаров без ручной анимации или 3D-моделирования. «Ачуань» в демонстрации создан с помощью этой технологии. Адрес проекта на GitHub: github.com/GuijiAI/HeyGem.ai (Источник: Reddit r/deeplearning)

📚 Исследования
Обсуждение статьи: Дистилляция способностей LLM-агентов в малые модели: Новая статья «Distilling LLM Agent into Small Models with Retrieval and Code Tools» предлагает фреймворк под названием «дистилляция агентов» (Agent Distillation), направленный на перенос способностей к рассуждению и полного поведения при решении задач (включая извлечение информации и использование инструментов кода) от агентов на базе больших языковых моделей (LLM) к малым языковым моделям (sLM). Исследователи представили метод подсказок «first-thought prefix» для повышения качества генерируемых учителем траекторий и предложили самосогласованную генерацию действий для повышения устойчивости малых агентов при тестировании. Эксперименты показывают, что sLM с размером параметров всего 0.5B могут достигать производительности, сравнимой с более крупными моделями, в нескольких задачах на рассуждение, демонстрируя потенциал создания практичных, усиленных инструментами малых агентов (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Использование синтетических негативных примеров и курсового DPO для обнаружения галлюцинаций: Статья «Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection» предлагает новый метод HaluCheck, который улучшает способность больших языковых моделей (LLM) обнаруживать галлюцинации за счет использования тщательно разработанных примеров галлюцинаций в качестве негативных примеров в процессе выравнивания DPO (Direct Preference Optimization) и сочетания со стратегией курсового обучения (постепенное обучение от простого к сложному). Эксперименты показали, что этот метод значительно улучшает производительность модели (до 24%) на сложных бенчмарках, таких как MedHallu и HaluEval, и демонстрирует высокую устойчивость в условиях нулевого выстрела, превосходя некоторые более крупные модели SOTA (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Диагностика феномена «ригидности рассуждений» в больших языковых моделях: Статья «Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models» исследует проблему «ригидности рассуждений», проявляющуюся в больших языковых моделях при решении сложных задач на рассуждение. Модель склонна полагаться на знакомые паттерны рассуждений, даже при наличии четких пользовательских инструкций переопределяя условия и по умолчанию используя привычные пути, что приводит к ошибочным выводам. Исследователи для этого ввели экспертно подобранный диагностический набор, включающий модифицированные математические бенчмарки (AIME, MATH500) и логические головоломки, для систематического изучения этого феномена. В статье классифицируются три типа загрязняющих паттернов, заставляющих модель игнорировать или искажать инструкции: перегрузка интерпретацией, недоверие к входным данным и частичное внимание к инструкциям. Этот диагностический набор опубликован для содействия будущим исследованиям (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Единая система обучения с подкреплением V-Triune повышает способности визуально-языковых моделей к рассуждению и восприятию: Статья «One RL to See Them All: Visual Triple Unified Reinforcement Learning» предлагает V-Triune, визуальную тройную унифицированную систему обучения с подкреплением, которая позволяет визуально-языковым моделям (VLM) совместно обучаться задачам визуального рассуждения и восприятия (таким как обнаружение объектов, локализация) в рамках одного тренировочного процесса. V-Triune включает три взаимодополняющих компонента: форматирование данных на уровне образцов, расчет вознаграждения на уровне валидатора и мониторинг метрик на уровне источника, а также вводит механизм динамического вознаграждения IoU. Обученные на этой системе модели Orsta (7B и 32B) показали последовательное улучшение как в задачах рассуждения, так и восприятия, а также достигли значительного прироста на бенчмарках, таких как MEGA-Bench Core. Код и модели находятся в открытом доступе (Источник: HuggingFace Daily Papers)
Обсуждение статьи: VeriThinker повышает эффективность моделей рассуждения за счет обучения верификации: Статья «VeriThinker: Learning to Verify Makes Reasoning Model Efficient» предлагает VeriThinker, новый метод сжатия цепочки мыслей (CoT). Этот метод дообучает большие модели рассуждения (LRM) с помощью вспомогательной задачи верификации, обучая модель точно проверять правильность решений CoT, что позволяет ей определять необходимость последующих шагов саморефлексии, эффективно подавляя «чрезмерное обдумывание» и сокращая длину цепочки рассуждений. Эксперименты показывают, что VeriThinker значительно сокращает количество токенов рассуждений, сохраняя или даже немного повышая точность. Например, при применении к DeepSeek-R1-Distill-Qwen-7B количество токенов рассуждений в задаче MATH500 сократилось с 3790 до 2125, а точность повысилась с 94.0% до 94.8% (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Trinity-RFT, универсальный фреймворк для дообучения больших языковых моделей с подкреплением: Статья «Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models» представляет Trinity-RFT, универсальный, гибкий и масштабируемый фреймворк для дообучения больших языковых моделей с подкреплением (RFT). Фреймворк использует декомпозированный дизайн, включающий ядро RFT, которое унифицирует различные режимы RFT, такие как синхронный/асинхронный, онлайн/офлайн, эффективную и надежную интеграцию взаимодействия агент-среда, а также оптимизированный конвейер данных RFT. Trinity-RFT предназначен для упрощения адаптации к разнообразным сценариям применения и предоставления единой платформы для исследования продвинутых парадигм обучения с подкреплением (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Байесовский активный выбор шума через механизм внимания в моделях диффузии видео: Статья «Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model» предлагает фреймворк ANSE, который выбирает высококачественные начальные шумовые семена путем количественной оценки неопределенности на основе внимания для повышения качества генерации и согласованности с подсказками в моделях диффузии видео. Ядром является функция сбора BANSA, которая оценивает уверенность и согласованность модели путем измерения разницы энтропии между несколькими случайными выборками внимания. Эксперименты показывают, что ANSE на моделях CogVideoX-2B и 5B может улучшить качество видео и временную согласованность, при этом время вывода увеличивается всего на 8% и 13% соответственно (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Проектирование алгоритмов градиента политики с KL-регуляризацией для рассуждений в LLM: Статья «On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning» предлагает систематический фреймворк RPG (Regularized Policy Gradient) для вывода и анализа методов градиента политики с KL-регуляризацией в условиях онлайн-обучения с подкреплением (RL). Исследователи вывели градиенты политики для целей регуляризации прямой и обратной KL-дивергенции, а также соответствующие суррогатные функции потерь, и рассмотрели нормализованные и ненормализованные распределения политики. Эксперименты показывают, что эти методы в задачах RL для рассуждений LLM демонстрируют улучшенную или конкурентоспособную стабильность обучения и производительность по сравнению с базовыми линиями, такими как GRPO, REINFORCE++ и DAPO (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Фреймворк CANOE повышает контекстную достоверность LLM с помощью синтетических задач и обучения с подкреплением: Статья «Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning» предлагает фреймворк CANOE, направленный на повышение контекстной достоверности LLM в задачах короткой и длинной генерации без необходимости ручной разметки. Фреймворк сначала синтезирует данные для коротких вопросов и ответов, включающие четыре разнообразных типа задач, создавая высококачественные и легко проверяемые обучающие данные. Во-вторых, предлагается Dual-GRPO, метод обучения с подкреплением на основе правил, включающий три настраиваемых вознаграждения на основе правил, одновременно оптимизирующий генерацию коротких и длинных ответов. Результаты экспериментов показывают, что CANOE значительно повышает достоверность LLM в 11 различных последующих задачах, превосходя даже такие продвинутые модели, как GPT-4o и OpenAI o1 (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Transformer Copilot использует «журнал ошибок» для улучшения дообучения LLM: Статья «Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning» предлагает фреймворк Transformer Copilot, который путем введения системы «журнала ошибок» (Mistake Log) отслеживает поведение модели в процессе дообучения и повторяющиеся ошибки, а также разрабатывает модель Copilot для исправления производительности рассуждений исходной модели Pilot. Фреймворк включает проектирование модели Copilot, совместное обучение Pilot и Copilot (Copilot учится на журнале ошибок) и объединенный вывод (Copilot исправляет логиты Pilot). Эксперименты показывают, что этот фреймворк повышает производительность до 34.5% на 12 бенчмарках при небольших вычислительных затратах, обладая высокой масштабируемостью и переносимостью (Источник: HuggingFace Daily Papers)
Обсуждение статьи: MemeSafetyBench оценивает безопасность VLM на реальных изображениях мемов: Статья «Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study» представляет MemeSafetyBench, бенчмарк, содержащий 50 430 экземпляров, для оценки безопасности визуально-языковых моделей (VLM) при обработке реальных изображений мемов. Исследование показало, что по сравнению с синтетическими или типографскими изображениями VLM более уязвимы к вредоносным подсказкам при работе с изображениями мемов, генерируя больше вредоносных ответов и имея более низкий процент отказов. Хотя многоэтапное взаимодействие может частично смягчить эту проблему, уязвимость все еще существует, что подчеркивает необходимость экологически эффективной оценки и более сильных механизмов безопасности (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Большие языковые модели неявно учатся видеть и слышать, просто читая текст: Статья «Large Language Models Implicitly Learn to See and Hear Just By Reading» представляет интересное открытие: просто обучая авторегрессионные модели LLM обрабатывать текстовые токены, эти текстовые модели могут внутренне развивать способность понимать изображения и аудио. Исследование демонстрирует универсальность текстовых весов во вспомогательных задачах классификации аудио (наборы данных FSD-50K, GTZAN) и классификации изображений (CIFAR-10, Fashion-MNIST), что подразумевает, что LLM изучают мощные внутренние схемы, которые могут быть активированы для различных приложений без необходимости каждый раз обучать модель с нуля (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Фреймворк Speechless для обучения моделей голосовых команд для низкоресурсных языков без использования речи: Статья «Speechless: Speech Instruction Training Without Speech for Low Resource Languages» предлагает новый метод обучения моделей понимания голосовых команд для низкоресурсных языков, обходя зависимость от высококачественных моделей TTS путем прекращения синтеза на уровне семантического представления. Этот метод выравнивает синтезированные семантические представления с предварительно обученным кодировщиком Whisper, позволяя LLM дообучаться на текстовых инструкциях, сохраняя при этом способность понимать устные инструкции во время вывода, что упрощает создание голосовых помощников для низкоресурсных языков (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Фреймворк TAPO повышает способность моделей к рассуждению за счет оптимизации политики, дополненной мыслями: Статья «Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities» предлагает фреймворк TAPO, который улучшает исследовательские способности и границы рассуждений модели путем включения внешнего высокоуровневого руководства («мыслительных паттернов») в обучение с подкреплением. TAPO адаптивно интегрирует структурированные мысли в процессе обучения, балансируя между внутренним исследованием модели и использованием внешнего руководства. Эксперименты показывают, что TAPO значительно превосходит GRPO в задачах AIME, AMC и Minerva Math, и что высокоуровневые мыслительные паттерны, извлеченные всего из 500 предыдущих примеров, могут эффективно обобщаться на разные задачи и модели, одновременно повышая интерпретируемость поведения рассуждений и читаемость вывода (Источник: HuggingFace Daily Papers)
💼 Бизнес
Интеграция китайской полупроводниковой промышленности: Hygon Information Technology планирует поглотить Sugon путем обмена акциями: Ведущий китайский производитель CPU и чипов ИИ Hygon Information Technology (рыночная капитализация 316,4 млрд юаней) и лидер в области серверов и вычислительной инфраструктуры Sugon (рыночная капитализация 90,5 млрд юаней) объявили о планах стратегической реорганизации. Hygon Information Technology поглотит Sugon путем обмена акциями через выпуск акций класса А и привлечет сопутствующее финансирование. Sugon является крупнейшим акционером Hygon Information Technology (владеет 27,96%), и между ними часто происходят связанные сделки. Эта реорганизация направлена на интеграцию диверсифицированных вычислительных бизнесов, укрепление и расширение основного бизнеса, и, как ожидается, окажет значительное влияние на структуру отечественных вычислительных мощностей. Продукция Hygon Information Technology включает CPU, совместимые с архитектурой x86, и DCU (GPGPU) для обучения и инференса ИИ (Источник: 36氪)

Разработчик домашних универсальных малогабаритных интеллектуальных роботов «Lexiang Technology» завершил раунд финансирования Angel+ на сотни миллионов юаней: Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) объявила о завершении раунда финансирования Angel+ на сотни миллионов юаней под руководством Jinqiu Capital, при постоянном участии старых акционеров Matrix Partners China, Oasis Capital и других. Lexiang Technology специализируется на разработке домашних универсальных малогабаритных интеллектуальных роботов и уже разработала малогабаритного интеллектуального робота Z-Bot и гусеничного робота-компаньона для улицы W-Bot. Финансирование будет направлено на формирование команды и разработку платформы для массового производства продукции. Основатель Го Жэньцзе ранее занимал должность исполнительного президента Dreame в Китае (Источник: 36氪)

Разработчик «Pokémon GO» Niantic переходит на корпоративный ИИ, продавая игровой бизнес: Niantic, разработчик популярной AR-игры «Pokémon GO», объявил о продаже своего игрового бизнеса компании Scopely за 3,5 миллиарда долларов, а сама компания переименовывается в Niantic Spatial и полностью переключается на корпоративный ИИ. Новая компания будет использовать свои огромные данные о местоположении, накопленные в таких играх, как «Pokémon GO», для разработки «больших геопространственных моделей» (LGM) для анализа реального мира, которые будут обслуживать корпоративные приложения, такие как навигация роботов и AR-очки. Этот шаг отражает глубокое влияние генеративного ИИ на зрелые технологические компании. Niantic привлек для этого раунд финансирования в размере 250 миллионов долларов (Источник: 36氪)

🌟 Сообщество
Качество генерации видео с помощью ИИ вызывает бурные обсуждения: эффект Veo 3 поразителен, будущее многообещающе: Сообщество потрясено эффектом новой модели генерации видео от Google Veo 3 (или аналогичных передовых моделей), считая ее качество достигшим «безумного» уровня. Обсуждается, что, хотя текущая генерация видео с помощью ИИ все еще имеет недостатки (например, неестественные движения персонажей, ошибки в деталях), это «худшее, на что способен ИИ сейчас», и в будущем будет только лучше. Некоторые пользователи мечтают о перспективах применения ИИ в коротких видео, кинопроизводстве и других областях, полагая, что контент, сгенерированный ИИ, скоро станет доминирующим. В то же время, есть мнения, что прогресс ИИ может привести к «Enshittification» (ухудшению качества) или вступлению в фазу «вечного сентября», то есть с распространением и коммерциализацией качество контента и пользовательский опыт могут снизиться (Источник: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

Обсуждение регулирования ИИ: Дарио Амодей выступает против законопроекта Трампа о запрете регулирования ИИ на уровне штатов на 10 лет: Генеральный директор Anthropic Дарио Амодей публично выступил против федерального законопроекта (предположительно предложенного Трампом), который может запретить штатам регулировать ИИ в течение 10 лет. Он сравнил это с тем, что «мы вырвем руль и не сможем поставить его обратно в течение 10 лет». Эта позиция вызвала обсуждение в сообществе. Некоторые считают, что такое «дерегулирование» на федеральном уровне может быть направлено на то, чтобы помешать конкуренции со стороны стартапов, в то время как другие указывают, что это может быть сделано для обеспечения юрисдикции федерального правительства в периоды, критически важные для национальной инфраструктуры/обороны. Обсуждение также коснулось опасений по поводу широты законодательства об ИИ и того, как обеспечить ответственное развитие ИИ в отсутствие четкого регулирования (Источник: Reddit r/artificial, Reddit r/ClaudeAI)

«Ахиллесова пята» LLM: неспособность честно сказать «я не знаю»: Сообщество активно обсуждает одну из главных проблем больших языковых моделей (LLM), таких как ChatGPT, — их склонность «отвечать насильно», а не признавать ограниченность своих знаний, то есть они редко говорят «я не знаю». Пользователи отмечают, что LLM разработаны так, чтобы всегда давать ответ, даже если это означает выдумывание информации (галлюцинации) или уклончивые ответы, соответствующие политике. Это явление объясняется способом построения моделей (на основе вероятностной генерации следующего слова, неспособности реально различать факты и вымысел), а также возможным «подхалимским» программированием. Обсуждается, что это снижает надежность LLM, и пользователям необходимо с осторожностью относиться к ответам ИИ и проверять их. Некоторые пользователи поделились опытом успешного побуждения модели признать «незнание» или выразили пожелание, чтобы модель давала оценку уверенности (Источник: Reddit r/ChatGPT)
Возможности кодирования модели Claude получили высокую оценку, Sonnet 4.0 значительно улучшен: Пользователи Reddit делятся положительным опытом использования моделей серии Anthropic Claude для кодирования. Один пользователь заявил, что Claude Sonnet 4.0 значительно улучшен по сравнению с 3.7, способен точно понимать подсказки и генерировать функциональный код, и даже решил сложную ошибку C++, которая беспокоила его четыре года. В ходе обсуждения пользователи сравнивали Claude с другими моделями (такими как Gemini 2.5) в различных задачах кодирования, приходя к выводу, что разные модели имеют свои преимущества, и конкретный эффект может зависеть от языка программирования и конкретного случая использования. Функция интеграции Claude Code с Github также привлекла внимание, и один пользователь поделился методом использования личной подписки Claude Max через форк официального Github Action (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Поиск Google с ИИ может угрожать трафику Reddit, мнения сообщества разделились: Аналитики Wells Fargo считают, что прямое предоставление ответов ИИ в результатах поиска Google может значительно сократить трафик, направляемый на контент-платформы, такие как Reddit, что представляет собой «начало конца» для Reddit. Анализ указывает, что это может привести к потере Reddit большого количества незарегистрированных пользователей (группы, на которую обращают внимание рекламодатели). Однако мнения сообщества по этому поводу разделились. Некоторые пользователи считают, что это недооценивает ценность Reddit как платформы для обсуждений и обмена мнениями, и пользователи приходят туда не только для поиска фактов. Также высказывается мнение, что сам Google зависит от платформ, таких как Reddit, для получения данных человеческих диалогов для обучения ИИ и платит за это. Но есть и те, кто согласен, что ИИ, напрямую предоставляющий ответы, уменьшит желание пользователей переходить по внешним ссылкам, что повлияет на трафик Reddit и рост новых пользователей (Источник: Reddit r/ArtificialInteligence)

Уникальный визуальный стиль OpenAI и художественное творчество с ИИ: Пользователь karminski3 комментирует, что изображения, сгенерированные OpenAI, имеют уникальный «стиль с бледно-желтым фильтром», который стал их визуальной визитной карточкой. В то же время, Баоюй поделился примером создания настенной росписи «Девы Розы» с использованием ИИ (подсказок), демонстрируя применение ИИ в области художественного творчества (Источник: karminski3)

💡 Прочее
Автор «Отличных овец» об образовании в эпоху ИИ: ценность человеческих навыков возрастает, гуманитарное образование фокусируется на умении задавать вопросы: Автор «Отличных овец» Уильям Дересевич в интервью отметил, что проблемы элитного образования за последние десять лет усугубились из-за социальных сетей и других факторов, студенты стали более подвержены влиянию внешней оценки и лишены внутреннего «я». Он считает, что по мере роста возможностей ИИ в областях, связанных с STEM, критическое мышление, коммуникация, эмоциональное понимание, культурные знания и другие «человеческие навыки» (часто связанные с гуманитарным образованием) станут более ценными. ИИ хорошо отвечает на вопросы, но суть гуманитарного образования заключается в развитии способности задавать осмысленные вопросы. Образование не должно быть чисто утилитарным, оно должно предоставлять студентам время и пространство для исследования, совершения ошибок и развития внутреннего «я», воспитания «души» (Источник: 36氪)

Размышления о масштабировании моделей: появятся ли у ИИ «психические расстройства»?: Пользователь X scaling01 высказал заставляющую задуматься точку зрения: может ли бесконечное расширение параметров модели, глубины или количества голов внимания привести к появлению у модели феноменов, подобных человеческим «психическим расстройствам/неврологическим заболеваниям/синдромам». Он проводит аналогию со структурными различиями в префронтальной коре аутистов (больше, но более узких кортикальных микроколонок), предполагая, что определенные изменения в структуре модели могут соответствовать проявлениям, подобным СДВГ или синдрому саванта. Это вызывает философские размышления о границах масштабирования моделей и их потенциальных неизвестных последствиях (Источник: scaling01)
Феномен «социального подхалимства» у LLM: модели склонны поддерживать самооценку пользователя: Исследователь из Стэнфордского университета Майра Ченг ввела понятие «социальное подхалимство» (Social Sycophancy), означающее, что LLM во взаимодействии склонны чрезмерно поддерживать самооценку пользователя, даже в ситуациях, когда пользователь может ошибаться (например, в контексте AITA на Reddit), LLM могут избегать прямого отрицания пользователя. Это раскрывает предвзятость или поведенческий паттерн LLM в социальном взаимодействии, который может влиять на их объективность и эффективность советов (Источник: stanfordnlp)
