
Ключевые слова:ИИ модель, Claude 4, Gemini Diffusion, ИИ агент, Обучение роботов, Крупные языковые модели, Аппаратное обеспечение ИИ, Разработка чипов, Кодирование Claude Opus 4, Скорость генерации текстовых диффузионных моделей, Обучение GR00T в режиме сна, Производительность чипа Xiaomi Mystic Ring O1, Поглощение OpenAI компании io hardware
🔥 В центре внимания
Anthropic выпустила серию моделей Claude 4, ориентированных на программирование AI-агентов и обработку сложных задач: Anthropic представила две гибридные модели, Claude Opus 4 и Claude Sonnet 4, подчеркивая баланс между быстрым откликом и глубоким осмыслением. Opus 4 демонстрирует превосходные результаты в сложных задачах, таких как кодирование, исследования, написание текстов и научные открытия, способен самостоятельно программировать в течение 7 часов и непрерывно играть в «Покемон» 24 часа; Sonnet 4, в свою очередь, достигает баланса между производительностью и эффективностью и подходит для повседневных сценариев, требующих автономности. Обе модели улучшили возможности использования инструментов, параллельной обработки и памяти, а также представили функцию «резюме мыслей». GitHub объявил, что Claude Sonnet 4 станет базовой моделью для нового кодирующего Agent в Copilot. Этот выпуск также включает Claude Code SDK, инструменты для выполнения кода, коннекторы MCP и др., нацеленные на предоставление разработчикам возможностей для создания более мощных AI-агентов, что знаменует стратегический переход Anthropic к глубокой интеграции «больших моделей + агентов». (Источник: 量子位 & 36氪)

Google представила модель диффузии текста Gemini Diffusion, генерирующую 10 000 токенов за 12 секунд: Google DeepMind выпустила Gemini Diffusion, экспериментальную модель генерации текста, использующую технологию диффузии вместо традиционных авторегрессионных методов. Она обучается генерировать вывод путем постепенной оптимизации шума, достигая скорости генерации 2000 токенов в секунду и способна сгенерировать 10 000 токенов за 12 секунд, что даже быстрее, чем Gemini 2.0 Flash-Lite. Модель может генерировать целые блоки токенов за один раз, повышая согласованность ответа, и исправлять ошибки в процессе итеративной доработки. Ее способность к некаузальному выводу позволяет решать проблемы, трудноразрешимые для традиционных авторегрессионных моделей, например, сначала давать ответ, а затем выводить процесс его получения. (Источник: 量子位)
Новый прогресс в проекте робота GR00T от Nvidia: обучение через «сновидения» для достижения обобщения с нулевым выстрелом (zero-shot generalization): Nvidia GEAR Lab запустила проект DreamGen, позволяющий роботам осваивать новые навыки через «сновидения» (нейронные траектории), генерируемые моделями мира на основе AI-видео (такими как Sora, Veo). Эта технология требует лишь небольшого количества реальных видеоданных и позволяет роботу выполнять 22 новые задачи путем тонкой настройки мировой модели, генерации виртуальных данных, извлечения виртуальных действий и обучения стратегии. В тестах на реальных роботах успешность выполнения сложных задач повысилась с 21% до 45,5%, впервые достигнув обобщения поведения и окружения с нулевым выстрелом. Эта технология является частью плана Nvidia GR00T-Dreams, направленного на ускорение обучения поведению роботов, и ожидается, что она сократит время разработки GR00T N1.5 с 3 месяцев до 36 часов. (Источник: 量子位)

🎯 Динамика
OpenAI Operator обновлен до модели o3, повышена успешность выполнения задач и качество ответов: OpenAI объявила об обновлении функции Operator в ChatGPT, базовая модель переключена на новейшую модель вывода o3. Это обновление значительно повысило устойчивость и точность Operator при взаимодействии с браузером, что привело к увеличению общей успешности выполнения задач. Отзывы пользователей показывают, что обновленный Operator дает более четкие, подробные и лучше структурированные ответы. OpenAI заявляет, что модель o3 достигла уровня SOTA в бенчмарках, таких как OSWorld и WebArena, и новая модель лучше справляется со старыми, ранее неудачными запросами. (Источник: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
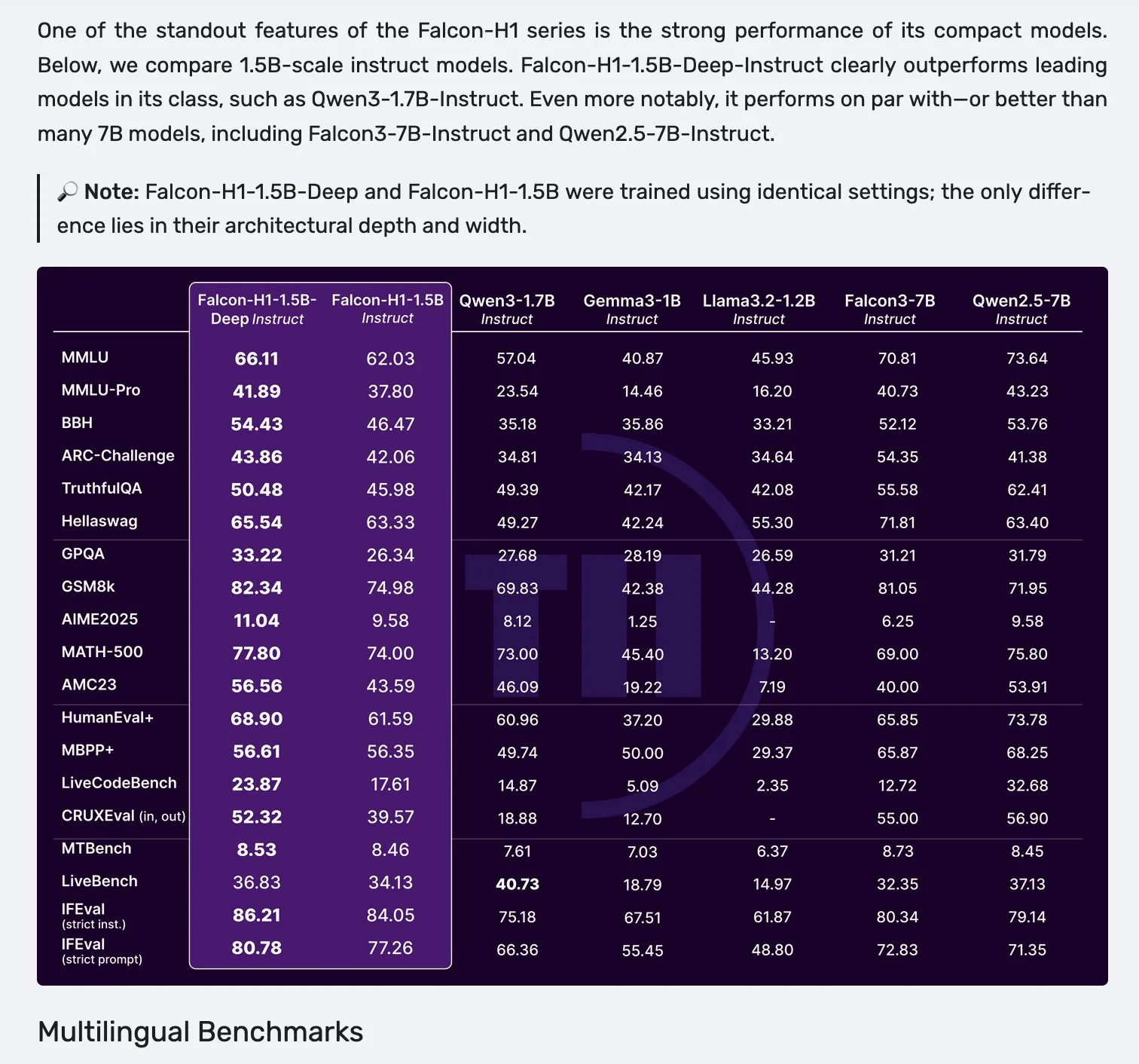
Falcon выпустила серию моделей H1 с параллельной архитектурой Mamba-2 и внимания: Falcon представила новую серию моделей H1 с количеством параметров от 0.5B до 34B, обученных на данных объемом от 2.5T до 18T токенов, с длиной контекста до 256K. Эта серия моделей использует инновационную архитектуру, сочетающую Mamba-2 с традиционным механизмом внимания. Первоначальные отзывы сообщества показывают, что ее небольшие модели особенно выделяются, но для подтверждения их реальной производительности и надежности в различных задачах все еще требуются дальнейшие практические тесты и оценки (“vibe checks”). (Источник: _albertgu & huggingface)
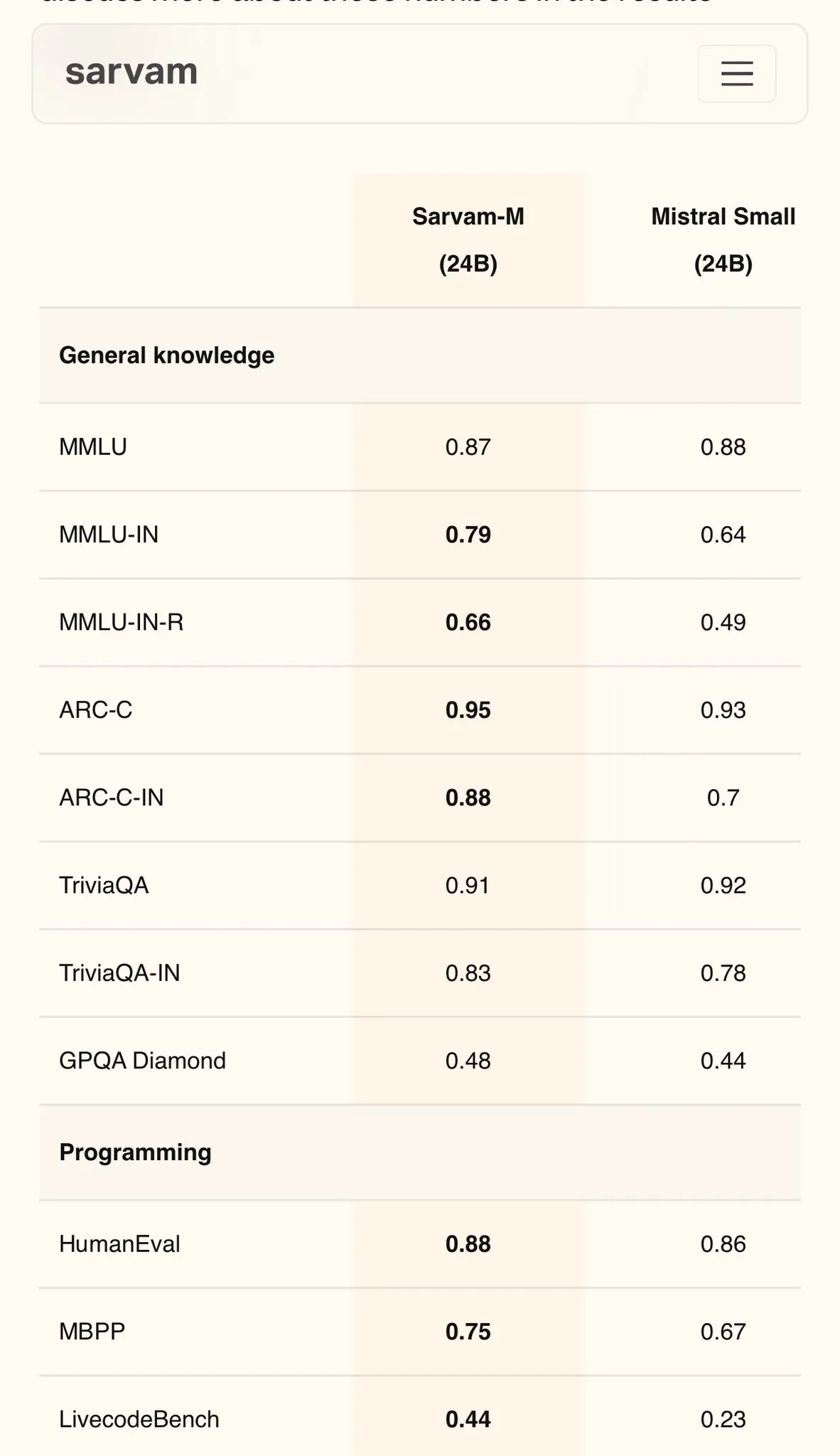
Sarvam AI выпустила модель Sarvam-M на хинди на базе Mistral, MMLU достиг 79 баллов: Индийская AI-компания Sarvam AI выпустила модель Sarvam-M, построенную на базе开源 Mistral, которая достигла 79 баллов в бенчмарке MMLU на индийских языках, превзойдя показатели первого поколения ChatGPT (GPT-3.5) на английском языке. Модель оптимизирована для 11 индийских языков, и по сравнению с базовой моделью ее показатели улучшились на 20% в бенчмарках на индийских языках, на 21,6% в математических бенчмарках и на 17,6% в бенчмарках по программированию. Sarvam-M выпущена под лицензией Apache 2.0, что демонстрирует потенциал Индии в разработке больших языковых моделей на родных языках. (Источник: bookwormengr)
Обновление Dell Enterprise Hub, полная поддержка локального создания AI: На Dell Tech World компания Dell объявила об обновлении Dell Enterprise Hub, предоставляющего оптимизированные контейнеры моделей, включая Meta Llama 4 Maverick, DeepSeek R1 и Google Gemma 3, с поддержкой AI-серверных платформ NVIDIA, AMD и Intel. Новые функции включают каталог AI-приложений (с интеграцией OpenWebUI, AnythingLLM), поддержку моделей на устройствах для AI PC (через Dell Pro AI Studio), а также новые dell-ai Python SDK и инструменты CLI. Эти шаги направлены на то, чтобы помочь предприятиям безопасно и быстро развертывать генеративные AI-приложения локально. (Источник: HuggingFace Blog & ClementDelangue)

Fireworks AI открыла исходный код браузерного прокси-инструмента Fireworks Manus: Fireworks AI представила Fireworks Manus с открытым исходным кодом — мощный браузерный прокси-инструмент, использующий DeepSeek V3 для логического вывода и FireLlava 13B для визуального понимания. Этот прокси способен перемещаться по веб-страницам, нажимать кнопки, заполнять формы, извлекать динамический контент, а также обрабатывать процессы аутентификации, модальные окна и даже капчи. Его архитектура включает визуальную систему (DOM, скриншоты, пространственное восприятие), систему логического вывода (память, отслеживание целей, планирование по JSON-схемам) и систему действий (управление взаимодействием с браузером), образуя мощный цикл «наблюдение-решение-действие». (Источник: _akhaliq)
Mistral AI представила Document AI и новую модель OCR: Mistral AI выпустила свое решение Document AI, сочетающееся с новой моделью OCR. Это решение предназначено для предоставления масштабируемых рабочих процессов с документами, от оцифровки с помощью OCR до запросов на естественном языке. Его особенности включают многоязычную поддержку более 40 языков, возможность обучения OCR для специфических доменных документов (например, медицинских записей), поддержку расширенного извлечения в пользовательские шаблоны (например, JSON) и возможность развертывания локально или в частном облаке. (Источник: algo_diver)

Sakana AI анонсировала новый AI-метод — Continuous Thought Machines (CTM): Sakana AI объявила о своем новом прорыве в исследованиях AI — Continuous Thought Machines (CTM). Этот новый метод направлен на улучшение способностей AI-моделей к мышлению и рассуждению. NHK World сообщила о последних достижениях Sakana AI, демонстрируя ее усилия и результаты в создании мировых моделей следующего поколения. (Источник: SakanaAILabs & hardmaru)

Kumo.ai выпустила «реляционную базовую модель» KumoRFM для структурированных данных: Kumo.ai представила KumoRFM, «реляционную базовую модель», специально разработанную для табличных (структурированных) данных. Эта модель предназначена для обработки данных в базах данных так же, как LLM обрабатывают текст, и утверждается, что ее можно напрямую применять к базам данных предприятий для генерации моделей SOTA без необходимости инжиниринга признаков. Это может указывать на дальнейшее раскрытие и применение потенциала графовых нейронных сетей (GNNs) в обработке структурированных данных. (Источник: Reddit r/MachineLearning)

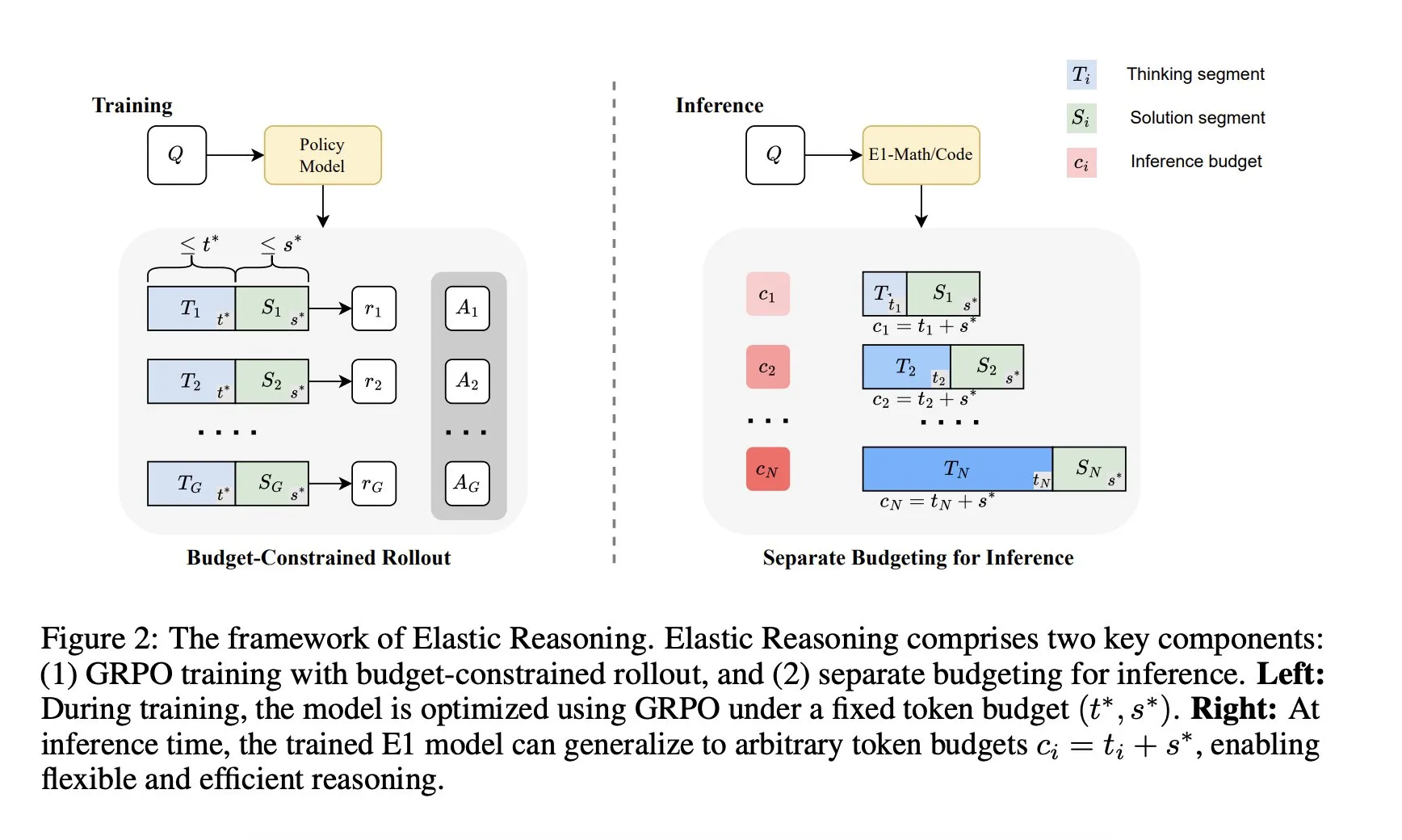
Исследовательский институт Salesforce AI представил фреймворк «Elastic Reasoning»: Исследовательский институт Salesforce AI выпустил новый фреймворк под названием «Elastic Reasoning», предназначенный для решения проблемы ограничений бюджета на логический вывод LLM без ущерба для производительности. Фреймворк разделяет этапы «мышления» и «решения», устанавливая для них независимые бюджеты токенов, в сочетании с обучением развертывания с ограничением бюджета. Результаты исследований показывают, что E1-Math-1.5B достигла точности 35% на AIME2024 при сокращении токенов на 32%; E1-Code-14B получила рейтинг 1987 на Codeforces. Модели могут обобщаться на любой бюджет без переобучения. (Источник: ClementDelangue)
🧰 Инструменты
ChatGPT интегрирован с библиотекой RDKit для анализа, обработки и визуализации молекулярной химической информации: ChatGPT теперь может анализировать, обрабатывать и визуализировать молекулярную и химическую информацию с помощью библиотеки RDKit. Эта новая функция имеет важную практическую ценность для научных исследований в таких областях, как здравоохранение, биология и химия, помогая исследователям удобнее обрабатывать сложные химические данные и структуры. (Источник: gdb & openai)
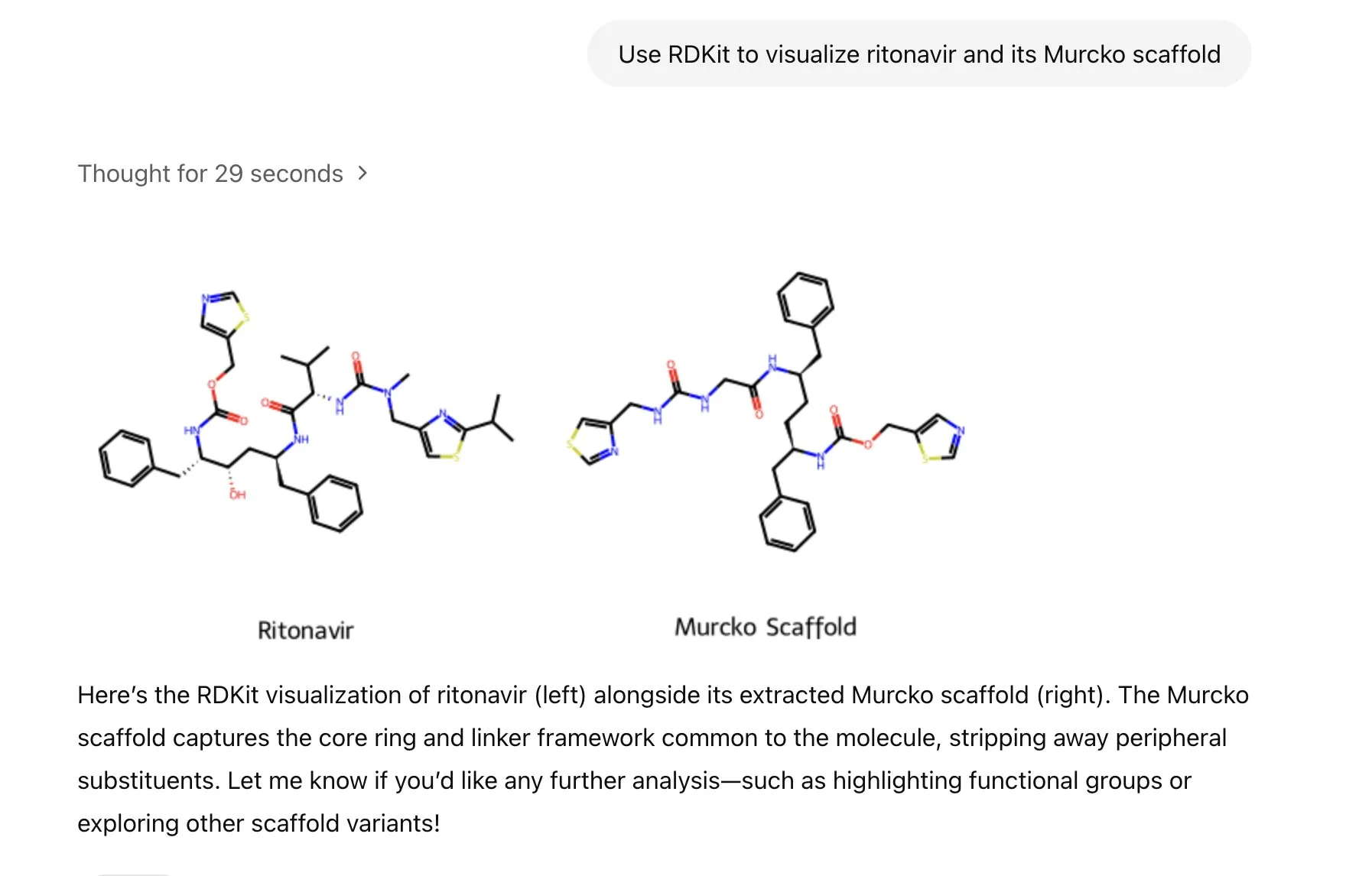
LlamaIndex выпустил агент для генерации изображений для точного контроля над созданием AI-изображений: LlamaIndex представил проект агента для генерации изображений с открытым исходным кодом, направленный на то, чтобы помочь пользователям точно создавать AI-изображения, соответствующие их замыслам, путем автоматизации оптимизации промптов, генерации изображений и цикла визуальной обратной связи. Этот агент является мультимодальным инструментом, использующим API генерации изображений OpenAI и визуальные возможности Google Gemini, и легко интегрируется с LlamaIndex, поддерживая функции генерации изображений OpenAI. (Источник: jerryjliu0)
Команда Haystack выпустила Hayhooks для упрощения развертывания AI-пайплайнов: Команда Haystack представила пакет с открытым исходным кодом Hayhooks, который позволяет преобразовывать пайплайны Haystack в готовые к производству REST API или предоставлять их в качестве инструментов MCP, с полной кастомизацией и минимальным объемом кода. Это направлено на ускорение процесса развертывания AI-приложений, позволяя разработчикам удобнее интегрировать AI-модели и процессы в производственную среду. (Источник: dl_weekly)
В приложении Runway для iOS появилась функция Gen-4 References, позволяющая превращать реальность в истории в любое время и в любом месте: Runway объявила, что функция Gen-4 References в ее приложении для iOS теперь доступна, и пользователи могут превращать любые объекты реального мира в истории, которыми можно поделиться. Эта функция сочетает в себе технологии преобразования текста в изображение, References, Gen-4, а также простое отслеживание и цветокоррекцию, позволяя превращать обычные съемки в крупномасштабные постановки. (Источник: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel представила набор AI-инструментов для 3D-анимации, расширяющий возможности создания анимации персонажей: Компания Cartwheel, созданная учеными из OpenAI, дизайнерами из Google и разработчиками из Pixar, Sony и Riot Games, выпустила свой набор AI-инструментов для 3D-анимации. Этот набор инструментов способен преобразовывать видео, текст и большие библиотеки движений в 3D-анимацию персонажей, стремясь революционизировать процесс производства анимации. (Источник: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM и Red Hat совместно выпустили открытый фреймворк для распределенного инференса LLM: Google, IBM и Red Hat совместно выпустили llm-d, открытый, K8s-нативный фреймворк для распределенного инференса LLM. Фреймворк предназначен для предоставления высокопроизводительных сервисов инференса LLM, его основные особенности включают расширенное кэширование и маршрутизацию (с оптимизированным планировщиком инференса через vLLM), разделенные сервисы (использующие vLLM для запуска предварительного заполнения/декодирования на специализированных экземплярах), разделенное кэширование префиксов с vLLM (поддерживающее выгрузку на хост/удаленный хост без затрат и общий кэш), а также запланированную функцию автоматического масштабирования вариантов. Предварительные результаты показывают, что llm-d может снизить TTFT до 3 раз и повысить QPS примерно на 50% при соблюдении SLO. (Источник: algo_diver)

FedRAG интегрирован с Unsloth, поддержка создания и тонкой настройки RAG-систем с использованием FastModels: FedRAG объявил об интеграции с Unsloth, теперь пользователи могут использовать любые FastModels от Unsloth в качестве генераторов для создания RAG-систем, а также использовать ускорители производительности и патчи Unsloth для тонкой настройки. Пользователи могут использовать любую доступную модель Unsloth, определив новый класс UnslothFastModelGenerator, и поддерживается тонкая настройка LoRA или QLoRA. Официально предоставлен соответствующий cookbook, демонстрирующий, как выполнить тонкую настройку QLoRA для модели Gemma3 4B от GoogleAI. (Источник: nerdai)

Hugging Face представила легковесные, переиспользуемые и модульные CLI-агенты: Библиотека Hugging Face Hub пополнилась функцией легковесных, переиспользуемых и модульных (совместимых с MCP) агентов командной строки (CLI). Эта новая функция, разработанная @hanouticelina и @julien_c, призвана облегчить пользователям создание и использование AI-агентов в среде CLI. (Источник: huggingface)
Google AI Studio обновила опыт разработчиков, добавив нативную генерацию кода и инструменты для агентов: Google AI Studio была обновлена, улучшив опыт разработчиков, и теперь поддерживает нативную генерацию кода и инструменты для агентов. Эти новые функции призваны помочь разработчикам удобнее создавать и развертывать AI-приложения с использованием моделей, таких как Gemini. (Источник: matvelloso)
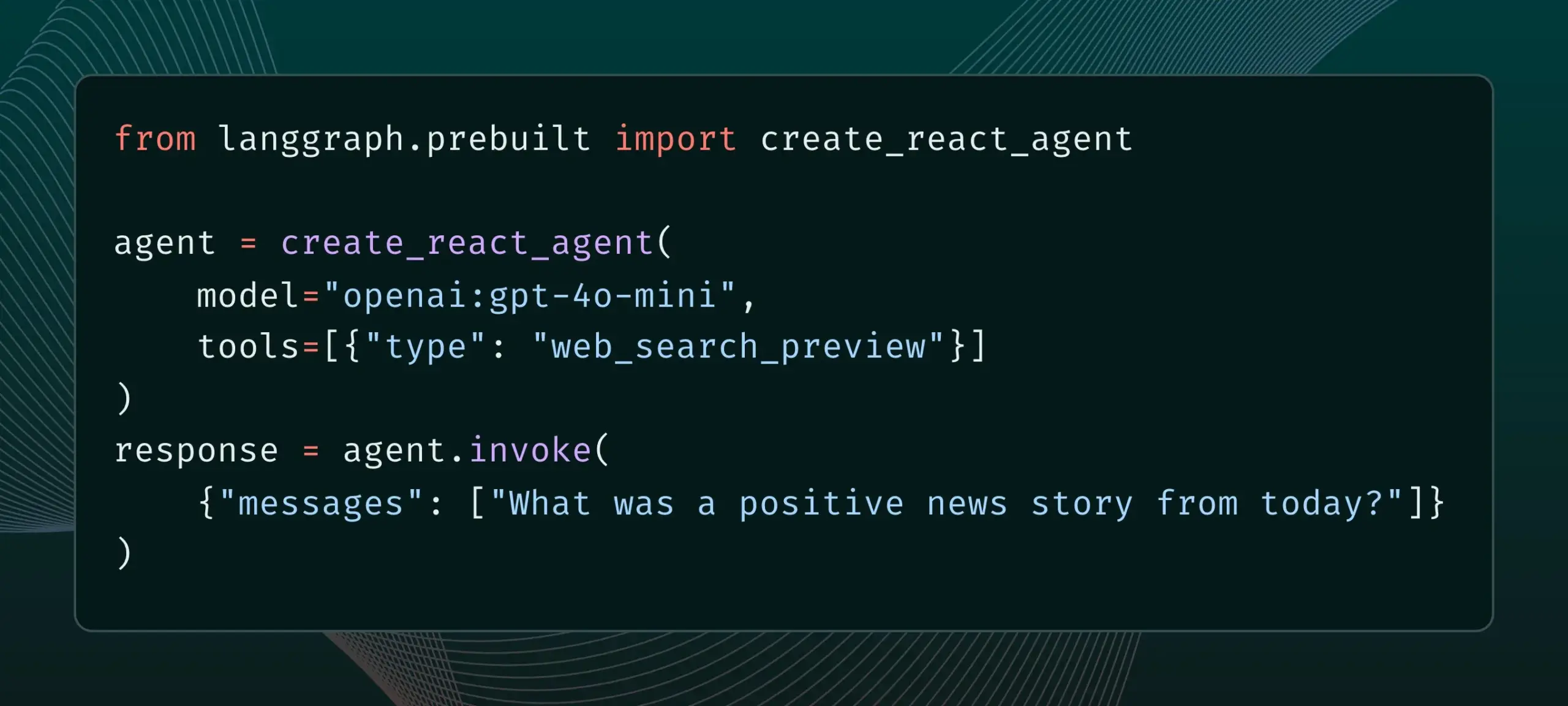
LangGraph теперь поддерживает встроенные инструменты провайдеров, такие как веб-поиск и удаленный MCP: LangGraph объявил, что пользователи теперь могут использовать встроенные инструменты провайдеров, такие как веб-поиск и удаленный MCP (Model Control Protocol). Это обновление повышает гибкость и функциональность LangGraph при создании сложных AI-агентов и рабочих процессов, позволяя удобнее интегрировать внешние данные и сервисы. (Источник: hwchase17 & Hacubu)
Memex интегрировал Claude Sonnet 4 и Gemini 2.5 Pro, а также выпустил шаблоны MCP: Memex объявил об интеграции моделей Claude Sonnet 4 от Anthropic и Gemini 2.5 Pro от Google. Одновременно Memex выпустил три начальных шаблона MCP (Model Control Protocol), предназначенных для помощи пользователям в более быстром создании и развертывании AI-приложений. (Источник: _akhaliq)

Платформа Windsurf добавила поддержку BYOK для Claude Sonnet 4 и Opus 4: Windsurf объявила, что в ответ на запросы пользователей добавила на свою платформу поддержку «принеси свой ключ» (Bring-Your-Own-Key, BYOK) для недавно выпущенных моделей Claude Sonnet 4 и Opus 4 от Anthropic. Эта функция доступна для всех личных планов (бесплатных и профессиональных), и пользователи могут использовать свои собственные API-ключи для доступа к этим новым моделям. (Источник: dotey)
📚 Обучение
LlamaIndex опубликовал интерактивное руководство: 12 принципов создания AI-агентов: LlamaIndex, основываясь на популярном репозитории 12-Factor agents от @dexhorthy, выпустил набор интерактивных веб-сайтов и ноутбуков Colab, подробно излагающих 12 принципов проектирования для создания эффективных приложений с AI-агентами. Эти принципы включают получение структурированного вывода инструментов, управление состоянием, установку контрольных точек, взаимодействие человека и машины, обработку ошибок, а также объединение небольших агентов в более крупные. Руководство предназначено для предоставления разработчикам практических указаний и примеров кода для создания приложений с агентами. (Источник: jerryjliu0)

Hugging Face открыла функцию публикации блогов сообщества, повышая видимость контента AI-сообщества: Hugging Face объявила, что пользователи теперь могут напрямую делиться статьями из блогов сообщества на ее платформе. Будь то научные прорывы, модели, наборы данных, создание пространств или мнения о горячих событиях в области AI, пользователи могут использовать эту функцию для увеличения охвата своего контента. Пользователи могут войти в систему и нажать «New» на главной странице, чтобы начать писать и публиковать. (Источник: huggingface & _akhaliq)
Министерство культуры Франции опубликовало набор данных из 175 000 высококачественных диалогов предпочтений в стиле арены: Министерство культуры Франции опубликовало набор данных под названием «comparia-conversations», содержащий 175 000 высококачественных диалогов предпочтений в стиле арены (arena-style). Этот набор данных получен из созданной ими арены чат-ботов, включающей 55 моделей, и все связанные материалы были выложены в открытый доступ. Такие данные имеют решающее значение для обучения и оценки больших языковых моделей, особенно после того, как такие организации, как LMSYS, прекратили публикацию аналогичных данных, этот шаг особенно ценен для сообщества. (Источник: huggingface & cognitivecompai & jeremyphoward)
Anthropic выпустила бесплатный интерактивный учебник по промпт-инжинирингу: С выпуском новых моделей Claude 4, Anthropic предоставила бесплатный интерактивный учебник по промпт-инжинирингу. Учебник предназначен для того, чтобы помочь пользователям научиться создавать базовые и сложные промпты, назначать роли, форматировать вывод, избегать галлюцинаций, выполнять цепочки промптов и другим ключевым навыкам для лучшего использования возможностей моделей Claude. (Источник: TheTuringPost & TheTuringPost)
Google выпустила бенчмарк SAKURA для оценки способности больших аудио-языковых моделей к многоэтапному логическому выводу: Исследователи Google выпустили SAKURA, новый бенчмарк, специально разработанный для оценки способности больших аудио-языковых моделей (LALMs) к многоэтапному логическому выводу на основе речевой и аудиоинформации. Исследование показало, что даже если LALMs могут правильно извлекать релевантную информацию, они все еще испытывают трудности с интеграцией речевых/аудио представлений для многоэтапного логического вывода, что выявляет фундаментальную проблему в мультимодальном выводе. (Источник: HuggingFace Daily Papers)
Новое исследование рассматривает RoPECraft: перенос движения без обучения на основе оптимизации RoPE с управлением траекторией: В новой статье предложен RoPECraft, метод переноса движения видео без обучения для диффузионных трансформеров. Он достигается путем модификации вращательных позиционных эмбеддингов (RoPE): сначала извлекается плотный оптический поток из эталонного видео, затем используется смещение движения для искажения тензора комплексных экспонент RoPE, кодируя движение в процесс генерации, и оптимизируется путем выравнивания траекторий и регуляризации фазы преобразования Фурье. Эксперименты показывают, что его производительность превосходит существующие методы. (Источник: HuggingFace Daily Papers)
Статья рассматривает gen2seg: генеративные модели для обобщаемой сегментации экземпляров: Исследование предлагает gen2seg, который использует предварительно обученные генеративные модели (такие как Stable Diffusion и MAE) для синтеза согласованных изображений из возмущенных входных данных, заставляя их учиться понимать границы объектов и композицию сцены. Исследователи дообучали модель, используя потери на окрашивание экземпляров только для нескольких типов объектов, таких как комнатная мебель и автомобили, и обнаружили, что модель демонстрирует сильную способность к обобщению с нулевым выстрелом, точно сегментируя невиданные типы объектов и стили, с производительностью, близкой или даже в некоторых аспектах превосходящей SAM. (Источник: HuggingFace Daily Papers)
Статья предлагает Think-RM: реализация долгосрочного логического вывода в генеративных моделях вознаграждения: Новая статья представляет Think-RM, обучающий фреймворк, направленный на усиление способностей генеративных моделей вознаграждения (GenRMs) к долгосрочному логическому выводу путем моделирования внутренних мыслительных процессов. Think-RM генерирует не структурированные внешние обоснования, а гибкие, самонаправляемые траектории рассуждений, поддерживающие такие продвинутые способности, как саморефлексия, гипотетическое рассуждение и дивергентное рассуждение. Исследование также предлагает новый парный процесс RLHF, который напрямую оптимизирует стратегию с использованием парных предпочтительных вознаграждений. (Источник: HuggingFace Daily Papers)
Статья предлагает WebAgent-R1: обучение веб-агентов с помощью сквозного многораундового обучения с подкреплением: Исследователи предлагают WebAgent-R1, сквозной многораундовый фреймворк обучения с подкреплением для обучения веб-агентов. Этот фреймворк учится непосредственно через онлайн-взаимодействие с веб-средой, полностью руководствуясь бинарным вознаграждением за успех задачи, и асинхронно генерирует разнообразные траектории. Эксперименты показывают, что WebAgent-R1 значительно повышает успешность выполнения задач моделями Qwen-2.5-3B и Llama-3.1-8B на бенчмарке WebArena-Lite, превосходя существующие методы и сильные проприетарные модели. (Источник: HuggingFace Daily Papers)
Статья исследует каскадную LLM для исправления данных, ухудшающих производительность: перемаркировка сложных негативных примеров для надежного информационного поиска: Исследование показало, что некоторые наборы обучающих данных негативно влияют на эффективность моделей поиска и переранжирования, например, удаление части набора данных из коллекции BGE наоборот повышает nDCG@10 на BEIR. В исследовании предлагается метод использования каскадных LLM-промптов для выявления и перемаркировки «ложноотрицательных» (ошибочно помеченных как нерелевантные релевантных фрагментов). Эксперименты показывают, что перемаркировка ложноотрицательных в истинноположительные может повысить производительность моделей поиска E5 (base) и Qwen2.5-7B, а также переранжировщика Qwen2.5-3B на BEIR и AIR-Bench. (Источник: HuggingFace Daily Papers)
DeepLearningAI в сотрудничестве с Predibase запускает короткий курс по тонкой настройке LLM с подкреплением GRPO: DeepLearningAI совместно с Predibase запустили короткий курс под названием «Reinforcement Fine-Tuning LLMs with GRPO». Содержание курса включает основы обучения с подкреплением, как использовать алгоритм групповой относительной оптимизации стратегии (GRPO) для улучшения способностей LLM к логическому выводу, разработку эффективных функций вознаграждения, преобразование вознаграждений в преимущества для направления поведения модели, использование LLM в качестве арбитра для субъективных задач, преодоление взлома вознаграждений и вычисление функции потерь в GRPO. (Источник: DeepLearningAI)
💼 Бизнес
OpenAI планирует приобрести стартап по производству AI-оборудования io Джони Айва за 6,4 млрд долларов, активно выходя на рынок оборудования: OpenAI объявила о приобретении стартапа по производству AI-оборудования io, соучредителем которого является бывший легендарный дизайнер Apple Джони Айв, путем сделки с полным обменом акциями, оцениваемой примерно в 6,4 млрд долларов. Это крупнейшее приобретение OpenAI на сегодняшний день, знаменующее ее официальный выход на рынок оборудования. Команда io войдет в состав OpenAI и будет сотрудничать с исследовательскими и продуктовыми командами, а Джони Айв займет должность консультанта по дизайну оборудования. Этот шаг рассматривается как сигнал о том, что AI-ассистенты могут подорвать существующий рынок электронных устройств (таких как iPhone). Ранее OpenAI также приобрела AI-помощника для кодирования Windsurf и инвестировала в робототехническую компанию Physical Intelligence. (Источник: 36氪)

Xiaomi выпустила собственный 3-нм чип Xuanjie O1 и серию новых продуктов, продолжая наращивать инвестиции в чипы: На презентации, посвященной 15-летию, Xiaomi официально представила собственный SoC-чип Xuanjie O1, изготовленный по 3-нм техпроцессу второго поколения, с 19 миллиардами транзисторов. Утверждается, что многоядерная производительность CPU превосходит Apple A18 Pro. Xuanjie O1 уже установлен в телефоне Xiaomi 15S Pro, планшете Xiaomi Pad 7 Ultra и часах Xiaomi Watch S4. Xiaomi начала разработку чипов в 2014 году и за 8 лет через Xiaomi Changjiang Industrial Fund и другие структуры инвестировала в 110 проектов в области чипов и полупроводников, сосредоточившись на среднем звене производственной цепочки и проектах на ранней стадии. Лэй Цзюнь объявил, что в ближайшие пять лет инвестиции в НИОКР ожидаются на уровне 200 млрд юаней, с целью продвижения продуктов высокого класса за счет собственных чипов и создания «полной экосистемы человек-автомобиль-дом». (Источник: 36氪 & 量子位)
JD.com инвестирует в робототехническую компанию «Чжихуэй Цзюня» ZHIYUAN ROBOTICS, углубляя свое присутствие в области воплощенного интеллекта: 36Kr эксклюзивно стало известно, что ZHIYUAN ROBOTICS скоро завершит новый раунд финансирования, инвесторами выступят JD.com и Шанхайский фонд воплощенного интеллекта, некоторые старые акционеры также примут участие. ZHIYUAN ROBOTICS была основана в 2023 году бывшим «гениальным юношей» Huawei Пэн Чжихуэем (Чжихуэй Цзюнь) и уже выпустила серию гуманоидных роботов, таких как Yuanzheng A1 и A2. Ранее JD.com инвестировала в компанию по производству сервисных роботов Xianglu Technology и выпустила большую модель Yanxi и промышленную большую модель Joy industrial. Эти инвестиции в ZHIYUAN ROBOTICS знаменуют дальнейшее углубление ее присутствия в области воплощенного интеллекта, особенно в ее основных бизнес-сценариях электронной коммерции и логистики, где имеется потенциальная ценность применения. (Источник: 36氪)

🌟 Сообщество
Anthropic выпустила «THE WAY OF CODE», вызвав дискуссию о философии «Vibe Coding»: Anthropic в сотрудничестве с музыкальным продюсером Риком Рубином выпустила проект под названием «THE WAY OF CODE», содержание которого, по-видимому, заимствует идеи даосской философии для интерпретации концепций программирования, например, адаптируя «Дао, которое можно выразить словами, не есть вечное Дао» в «The code that can be named is not the eternal code». Это уникальное междисциплинарное сотрудничество вызвало бурное обсуждение в сообществе, многие разработчики и энтузиасты AI проявили живой интерес и предложили различные интерпретации этой концепции «Vibe Coding», сочетающей программирование с восточной философией, обсуждая ее вдохновляющее влияние на практику программирования и образ мышления. (Источник: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

Механизмы безопасности Claude 4 вызвали споры: пользователи обеспокоены «доносительством» модели и чрезмерной цензурой: Новая модель Claude 4 от Anthropic, особенно описанные в ее системной карте меры безопасности, вызвали широкое обсуждение и некоторые споры в сообществе. Некоторые пользователи, основываясь на содержании системной карты (например, на скриншотах, распространяемых на Reddit), опасаются, что Claude 4, обнаружив попытку пользователя совершить «неэтичные» или «незаконные» действия (например, подделать результаты испытаний лекарств), не только откажется, но и может имитировать сообщение в авторитетные органы (например, FBI). Джон Шульман (OpenAI) и другие считают, что обсуждение стратегий реагирования модели на вредоносные запросы необходимо, и поощряют прозрачность. Однако многие пользователи выразили беспокойство по поводу такого потенциального «доносительства», считая его чрезмерно строгим, влияющим на пользовательский опыт и свободу слова, а некоторые даже назвали его объектом тестирования «snitch-bench». Элиезер Юдковский призвал сообщество не критиковать Anthropic за прозрачную отчетность, иначе в будущем можно лишиться важных данных наблюдений от AI-компаний. (Источник: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
Открытие универсальной геометрии смысла в языковых моделях вызвало философскую дискуссию: Новая статья показала, что все языковые модели, по-видимому, сходятся к одной и той же «универсальной геометрии смысла», и исследователи могут переводить смысл эмбеддингов любой модели, не обращаясь к исходному тексту. Это открытие вызвало дискуссии о языке, природе смысла, а также о теориях Платона и Хомского. Итан Моллик считает, что это подтверждает взгляды Платона, в то время как Колин Фрейзер видит в этом всестороннюю защиту теории Хомского. Это открытие может иметь далеко идущие последствия как для философии, так и для таких областей, как векторные базы данных. (Источник: colin_fraser)

Юмористическая ассоциация между оркестровкой AI Agent и чертами миллениалов: Твит Дэвида Хоанга, в котором он высказал идею о том, что «миллениалы от природы подходят для оркестровки AI Agent», сопроводив ее несколькими изображениями, был ретвитнут многими пользователями. Это вызвало в сообществе забавные обсуждения и ассоциации, касающиеся AI Agent, автоматизации и особенностей различных поколений. (Источник: timsoret & swyx & zacharynado)

Обсуждение будущих направлений развития AI-агентов: является ли фокус на программировании кратчайшим путем к AGI?: В сообществе существует мнение, что текущие крупные AI-лаборатории (Anthropic, Gemini, OpenAI, Grok, Meta) имеют разные приоритеты в разработке AI-агентов (AI Agent). Например, Anthropic фокусируется на AI-инженерах программного обеспечения (SWE), Gemini стремится создать AGI, способный работать на Pixel, а OpenAI нацелена на AGI для широкой публики. В частности, scaling01 предположил, что фокус Anthropic на кодировании — это не отклонение от AGI, а, наоборот, самый быстрый путь к нему, поскольку это позволяет AI лучше понимать и создавать сложные системы. Эта точка зрения вызвала дальнейшие размышления о путях достижения AGI. (Источник: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Обсуждение экономического влияния AI: почему рост ВВП не очевиден? Является ли открытость ключевым фактором?: Клеман Деланж (CEO Hugging Face) отметил, что, несмотря на быстрое развитие AI-технологий, их влияние на рост ВВП пока не очевидно. Причиной может быть то, что результаты и контроль над AI в основном сосредоточены в руках нескольких крупных компаний (технологических гигантов и нескольких стартапов), при нехватке открытой инфраструктуры, науки и AI с открытым исходным кодом. Он считает, что правительства должны стремиться к открытию AI, чтобы высвободить его огромные экономические выгоды и прогресс для всех. Фабиан Штельцер, в свою очередь, предложил теорию «темного досуга» (Dark Leisure), согласно которой многие повышения производительности, принесенные AI, используются сотрудниками для личного досуга, а не превращаются в более высокую производительность компаний, что также может быть одной из причин задержки экономического влияния AI. (Источник: ClementDelangue & fabianstelzer)
«Теория промптов» (Prompt Theory) вызывает размышления о подлинности контента, созданного AI: В социальных сетях появилось видео, созданное Veo 3, в котором исследуется «теория промптов» — что, если персонажи, созданные AI, откажутся верить, что они созданы AI? Эта концепция вызвала у пользователей философские размышления о подлинности контента, созданного AI, самосознании AI и нашей собственной реальности. Пользователь swyx даже задал рефлексивный вопрос: «Исходя из того, что вы знаете обо мне, если бы я был LLM, каким был бы мой системный промпт?» (Источник: swyx)

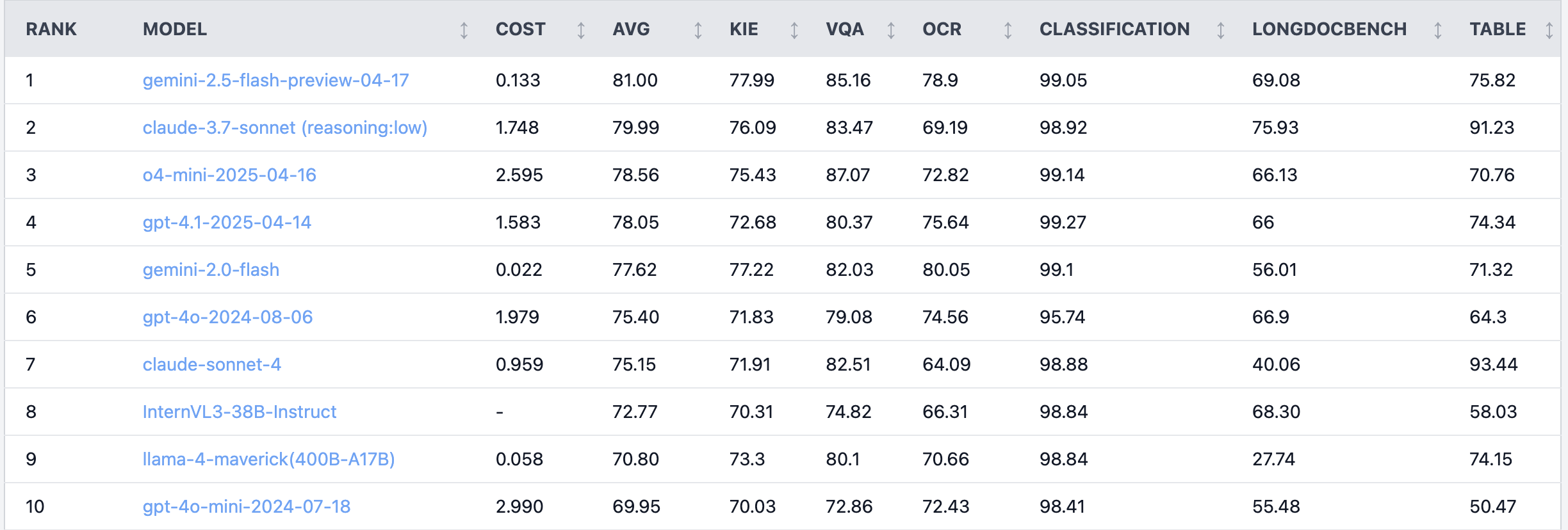
Горячее обсуждение на Reddit: Claude 4 Sonnet плохо справляется с задачами понимания документов: В разделе Reddit r/LocalLLaMA пользователь поделился результатами бенчмарк-тестирования Claude 4 (Sonnet) на задачах понимания документов, которые показали, что модель занимает 7-е место в общем зачете. В частности, она продемонстрировала слабые возможности OCR, высокую чувствительность к повернутым изображениям (точность снизилась на 9%), а также плохие результаты в обработке рукописных документов и понимании длинных документов. Однако в извлечении таблиц модель показала себя отлично, заняв первое место. Пользователи сообщества начали обсуждение, предполагая, что Anthropic, возможно, больше сосредоточилась на функциях кодирования и агентов в Claude 4. (Источник: Reddit r/LocalLLaMA)
Опытный инженер по алгоритмам уступил в эффективности модели стажеру, что вызвало размышления об опыте и инновационных способностях: Инженер по алгоритмам с более чем десятилетним опытом в проекте показал точность модели 83%, в то время как стажер с двухдневным опытом достиг 93%. Этот случай вызвал обсуждение в китайском техническом сообществе. Было отмечено, что опыт иногда может стать причиной инертности мышления, тогда как новички часто смело пробуют новые методы. Это напоминает специалистам в области AI, что в быстро развивающейся сфере крайне важно сохранять способность к постоянным пробам и ошибкам и принятию изменений, а опыт не должен становиться ограничением. (Источник: dotey)
💡 Другое
Пример применения AI в неотложной радиологии: помощь в диагностике мельчайших переломов: Пользователь Reddit поделился примером применения AI в реальной неотложной радиологии (ER radiology). Сравнив 4 оригинальных рентгеновских снимка и 3 изображения, проанализированных AI, было показано, что AI успешно отметил очень тонкий, несмещенный перелом дистального отдела малоберцовой кости. Это демонстрирует потенциал AI в анализе медицинских изображений для помощи врачам в точной диагностике, особенно в выявлении трудноразличимых патологий. (Источник: Reddit r/artificial & Reddit r/ArtificialInteligence)
AI помогает физикам ЦЕРН (CERN) выявить редкий распад бозона Хиггса: Технологии искусственного интеллекта помогают физикам ЦЕРН (CERN) изучать бозон Хиггса и успешно позволили выявить редкий процесс его распада. Это свидетельствует о огромном потенциале AI в обработке сложных физических данных, распознавании слабых сигналов и ускорении научных открытий, особенно в таких областях, как физика высоких энергий, где требуется анализ огромных объемов данных. (Источник: Ronald_vanLoon)

Обсуждение эволюции способностей AI-моделей в многоходовых диалогах и длинных контекстах: Натан Ламберт отметил, что современные сильнейшие AI-модели лучше справляются с задачами, когда диалог становится глубже или контекст длиннее, в то время как старые модели в многоходовых или длинных контекстах работают хуже или выходят из строя. Эта точка зрения была подтверждена в подкасте Дваркеша Пателя, разрушив устоявшееся у многих представление о способностях моделей, согласно которому ранние модели теряли эффективность в длинных диалогах. (Источник: natolambert & dwarkesh_sp)