
Ключевые слова:Gemini 2.5, ИИ-агент, Крупная языковая модель, Визуально-языковая модель, Обучение с подкреплением, Gemini 2.5 Pro Deep Think режим, GitHub Copilot агент с открытым исходным кодом, MeanFlow одношаговая генерация изображений, VPRL визуальное планирование и рассуждение, Huawei FusionSpec MoE оптимизация логического вывода
🔥 В центре внимания
Google на конференции I/O анонсировала множество достижений в области ИИ, во главе с серией моделей Gemini 2.5: Google объявила о множестве обновлений в области ИИ на своей конференции I/O. Gemini 2.5 Pro названа самой мощной базовой моделью на данный момент, лидирует во многих бенчмарках и представила режим улучшенного логического вывода Deep Think. Легковесная модель Gemini 2.5 Flash также была обновлена с акцентом на скорость и эффективность. Поиск Google внедрил «режим ИИ», предоставляющий комплексный поиск на базе ИИ с помощью Gemini 2.5, способный разбивать сложные вопросы и проводить глубокий анализ информации. Модель генерации видео Veo 3 достигла синхронной генерации аудио и видео, а модель изображений Imagen 4 улучшила детализацию и обработку текста. Кроме того, были представлены инструмент для создания фильмов с помощью ИИ Flow и приложение Gemini Live на базе проекта ИИ-помощника Project Astra. Эти обновления демонстрируют решимость Google полностью интегрировать ИИ в свою экосистему продуктов с целью улучшения пользовательского опыта и эффективности разработчиков (Источник: 量子位, 36氪, WeChat)

Microsoft на конференции Build сделала упор на AI Agent, GitHub Copilot получил значительные обновления и объявлен открытым: На конференции разработчиков Build 2025 Microsoft поставила AI Agent в центр внимания, объявив об открытии исходного кода проекта GitHub Copilot Extension for VSCode и представив совершенно нового агента для кодирования на базе ИИ (Agent). Этот Agent способен самостоятельно выполнять такие задачи, как исправление ошибок, добавление функций и оптимизация документации, и глубоко интегрирован в GitHub Copilot. Microsoft также выпустила платформу интеллектуальных агентов для научных открытий Microsoft Discovery, проект веб-сайта для взаимодействия на естественном языке NLWeb, платформу для создания интеллектуальных агентов Agent Factory и Copilot Tuning для настройки корпоративных данных. Эти шаги показывают, что Microsoft активно продвигает применение AI Agent в разработке, научных исследованиях и других областях, стремясь создать открытую экосистему для совместной работы интеллектуальных агентов (Источник: 量子位, WeChat, WeChat)

CPO OpenAI Kevin Weil изложил направление трансформации ChatGPT: от ответов на вопросы к действиям, AI Agent будет быстро развиваться: Главный продуктовый директор OpenAI Kevin Weil в интервью сообщил, что позиционирование ChatGPT изменится с инструмента для ответов на вопросы на AI Agent, способного выполнять задачи для пользователей. Он предполагает, что AI Agent в краткосрочной перспективе сможет быстро эволюционировать от младшего инженера до старшего инженера и даже архитектора. Это означает, что AI Agent будет обладать большей автономией, способностью решать сложные проблемы путем просмотра веб-страниц, глубокого обдумывания и обобщения. Weil также упомянул, что текущие затраты на обучение моделей уже в 500 раз превышают затраты на GPT-4, но в будущем эффективность будет повышена, а цены на API снижены за счет улучшения оборудования и алгоритмов, что будет способствовать популяризации и развитию ИИ (Источник: 量子位, 36氪)

Команда何恺明 (He Kaiming) предложила MeanFlow: новый SOTA в одношаговой генерации изображений,颠覆传统范式 без предварительного обучения: Последнее исследование команды 何恺明 (He Kaiming) представляет фреймворк одношагового генеративного моделирования под названием MeanFlow. На наборе данных ImageNet 256×256 он достиг показателя FID 3.43 всего за 1 оценку функции (1-NFE), что на 50%-70% лучше, чем у предыдущих лучших методов в этой категории, и не требует предварительного обучения, дистилляции или обучения по программе. Ключевое нововведение MeanFlow заключается во введении концепции «среднего поля скоростей» и выводе его математической связи с мгновенным полем скоростей, что используется для обучения нейронной сети. Этот метод также может естественным образом интегрировать безусловное управление (CFG) без дополнительных вычислительных затрат во время выборки, значительно сокращая разрыв в производительности между одношаговыми и многошаговыми генеративными моделями и демонстрируя потенциал малошаговых моделей бросить вызов многошаговым (Источник: WeChat, WeChat)

🎯 Динамика
ByteDance выпустила мультимодальную модель Bagel 14B MoE с поддержкой генерации изображений и открытым исходным кодом: ByteDance представила мультимодальную модель Bagel с 14 миллиардами параметров и архитектурой Mixture-of-Experts (MoE), из которых 7 миллиардов параметров активны. Модель обладает возможностью генерации изображений, имеет открытый исходный код и распространяется под лицензией Apache. Соответствующие веса, веб-сайт и статья (под названием «Emerging Properties in Unified Multimodal Pretraining») были опубликованы. Сообщество отреагировало положительно, считая ее первой локальной моделью, способной одновременно генерировать изображения и текст, и проявляет интерес к возможности ее запуска на видеокартах с 24 ГБ памяти, а также к вопросам квантования (Источник: Reddit r/LocalLLaMA)
Mistral AI выпустила Devstral: SOTA модель с открытым исходным кодом, оптимизированную для кодирования: Mistral AI представила Devstral, ведущую модель с открытым исходным кодом, специально разработанную для задач программной инженерии, созданную в сотрудничестве Mistral AI и All Hands AI. Devstral показала отличные результаты в бенчмарке SWE-bench, став моделью №1 с открытым исходным кодом в этом бенчмарке. Модель отлично справляется с использованием инструментов для исследования кодовой базы, редактирования нескольких файлов и поддержки интеллектуальных агентов для программной инженерии. Веса модели доступны на Hugging Face (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Anthropic анонсировала скорый выход Claude 4 Sonnet и Opus: Anthropic планирует выпустить следующие версии своей большой языковой модели Claude — Claude 4 Sonnet и Opus. Эта новость вызвала ожидания в сообществе, пользователи выражают интерес к производительности новых моделей, особенно к улучшению способности запоминать контекст. В комментариях отмечается, что анонсы на конференции Google I/O могли подтолкнуть конкурентов к ускорению выпуска своих лучших продуктов. В то же время пользователи выражают обеспокоенность ограничениями новых моделей (например, лимитами на использование) и предостерегают сообщество от завышенных ожиданий в отношении Opus 4, чтобы избежать разочарований (Источник: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google выпустила Android-приложение Gemma3n, поддерживающее локальный инференс LLM: Google выпустила Android-приложение для взаимодействия с новой моделью Gemma3n, а также предоставила соответствующие решения MediaPipe и репозиторий на GitHub. Пользователи отмечают хороший интерфейс приложения, но указывают, что Gemma3n в настоящее время не поддерживает инференс на GPU. Один из пользователей успешно вручную загрузил модель gemma-3n-E2B и поделился данными о ее работе, в то время как сообщество также выразило потребность в нецензурированной версии модели (Источник: Reddit r/LocalLLaMA)

Выпущено семейство языковых моделей Falcon-H1 с гибридной архитектурой голов, включающее различные размеры параметров: TII UAE выпустила серию языковых моделей Falcon-H1 с гибридной архитектурой голов, с размерами параметров от 0.5B до 34B. Эта серия моделей использует гибридную архитектуру Mamba и по производительности сопоставима с Qwen3. Модели поддерживаются через библиотеки Hugging Face Transformers, vLLM или кастомизированную версию llama.cpp, что обеспечивает простоту их использования. Сообщество выразило восторг, считая это важным достижением, а один из пользователей создал сравнительную диаграмму производительности. В то же время исследователи обращают внимание на отличия в способе комбинирования модулей SSM и внимания по сравнению с IBM Granite 4 (Источник: Reddit r/LocalLLaMA)

Google исследует Gemini Diffusion: языковую модель с архитектурой diffusion: Google продемонстрировала свою языковую диффузионную модель Gemini Diffusion, которая, по утверждениям, чрезвычайно быстра и имеет размер модели вдвое меньше, чем у моделей с аналогичной производительностью. Поскольку диффузионные модели могут итеративно обрабатывать весь текст за один раз без необходимости в KV cache, они могут иметь преимущество в эффективности использования памяти и повышать качество вывода за счет увеличения количества итераций. Сообщество считает, что если Google сможет доказать жизнеспособность диффузионных моделей для крупномасштабных приложений, это окажет положительное влияние на сообщество локального ИИ. Однако в настоящее время модель доступна только в виде списка ожидания для демонстрации и не имеет открытого исходного кода или доступных для скачивания весов (Источник: Reddit r/LocalLLaMA)

Исследование выявило уязвимость нулевого клика для захвата агента (CVE-2025-47241) во фреймворке Browser Use: Исследование ARIMLABS.AI обнаружило серьезную уязвимость безопасности (CVE-2025-47241) во фреймворке Browser Use, широко используемом более чем в 1500 проектах ИИ. Уязвимость позволяет злоумышленникам осуществлять захват агента без клика, заставляя браузерный агент, управляемый LLM, посетить вредоносную страницу, что позволяет контролировать агент без взаимодействия с пользователем. Это открытие вызвало серьезную обеспокоенность по поводу безопасности автономных интеллектуальных агентов ИИ, особенно тех, которые взаимодействуют с сетью, и призывает сообщество обратить внимание на проблемы безопасности интеллектуальных агентов ИИ (Источник: Reddit r/artificial, Reddit r/artificial)
Tencent и Alibaba конкурируют в области AI to C, QQ Browser и Quark противостоят друг другу: QQ Browser, принадлежащий Tencent CSIG, объявил об обновлении до AI-браузера, представив AI QBot и оснастив его двойной моделью Tencent Hunyuan и DeepSeek, официально вступая в конкуренцию с Quark от Alibaba, который уже трансформировался в AI-поиск. Этот шаг знаменует ускорение развертывания Tencent в области AI to C, формируя две основные продуктовые линейки: Tencent Yuanbao и QQ Browser. Ключевые руководители обеих сторон, У Цзужун (Tencent) и У Цзя (Alibaba), таким образом, вступают в «противостояние двух У». Аналитики считают, что QQ Browser имеет преимущество в пользовательской базе, в то время как Quark опередил в AI-трансформации, однако трансформация QQ Browser относительно консервативна, AI-функции больше похожи на плагины и ограничены существующей рекламной моделью. Эта конкуренция не только продуктовая, но и может повлиять на карьерное развитие двух руководителей в их соответствующих компаниях (Источник: 36氪)
Кембридж и Google предложили VPRL: новую парадигму чисто визуального планирования и рассуждения, превосходящую по точности текстовые рассуждения: Исследовательские группы из Кембриджского университета, Университетского колледжа Лондона и Google предложили новую парадигму визуального планирования на основе обучения с подкреплением (VPRL), впервые реализовав рассуждения, основанные исключительно на изображениях. Этот фреймворк использует оптимизацию относительной групповой политики (GRPO) для дообучения больших визуальных моделей. В нескольких задачах визуальной навигации (таких как FrozenLake, Maze, MiniBehavior) его производительность значительно превзошла методы рассуждения на основе текста, достигнув точности до 80% и повышения производительности как минимум на 40%. VPRL осуществляет планирование, напрямую используя последовательности изображений, избегая потерь информации и снижения эффективности, связанных с преобразованием в язык, и открывает новые направления для задач интуитивного рассуждения на основе изображений. Соответствующий код опубликован с открытым исходным кодом (Источник: WeChat)

Huawei выпустила FusionSpec и OptiQuant для оптимизации инференса больших моделей MoE: Huawei, столкнувшись с проблемами скорости и задержки инференса крупномасштабных моделей MoE (Mixture-of-Experts), представила фреймворк спекулятивного инференса FusionSpec и фреймворк квантования OptiQuant. FusionSpec использует высокое соотношение вычислительной мощности к пропускной способности серверов Ascend для оптимизации процессов основной и спекулятивной моделей, снижая время, затрачиваемое фреймворком спекулятивного инференса, до 1 миллисекунды. OptiQuant поддерживает основные алгоритмы квантования, такие как Int2/4/8 и FP8/HiFloat8, и внедряет инновации, такие как «обучаемое усечение» и «оптимизация параметров квантования», с целью снижения потерь точности модели и повышения экономической эффективности инференса. Эти технологии направлены на решение проблем эффективности инференса и использования ресурсов, с которыми сталкиваются модели MoE при развертывании (Источник: WeChat)

BAAI выпустил три векторные модели SOTA, усиливающие поиск по коду и мультимодальный поиск: Пекинская академия искусственного интеллекта (BAAI) совместно с несколькими университетами выпустила BGE-Code-v1 (векторная модель для кода), BGE-VL-v1.5 (универсальная мультимодальная векторная модель) и BGE-VL-Screenshot (векторная модель для визуализированных документов). BGE-Code-v1 основана на Qwen2.5-Coder-1.5B и демонстрирует отличные результаты на бенчмарках CoIR и CodeRAG. BGE-VL-v1.5 основана на LLaVA-1.6 и обновила рекорд zero-shot на мультимодальном бенчмарке MMEB. BGE-VL-Screenshot предназначена для задач поиска визуализированной информации (Vis-IR), такой как веб-страницы и документы, обучена на Qwen2.5-VL-3B-Instruct и достигла SOTA на новом бенчмарке MVRB. Эти модели призваны обеспечить более сильные возможности понимания и поиска кода и мультимодальных данных для таких приложений, как генерация с дополненной выборкой (RAG), и все они имеют открытый исходный код (Источник: WeChat)

Kuaishou и Национальный университет Сингапура представили Any2Caption для управляемой генерации видео: Kuaishou совместно с Национальным университетом Сингапура представили фреймворк Any2Caption, направленный на повышение точности и качества управляемой генерации видео путем интеллектуального разделения понимания намерений пользователя и процесса генерации видео. Фреймворк способен обрабатывать входные условия различных модальностей, такие как текст, изображения, видео, траектории поз, движение камеры, и использует мультимодальные большие языковые модели для преобразования сложных инструкций в структурированный «сценарий видео», который руководит генерацией видео. Any2Caption обучался на базе данных Any2CapIns, содержащей 337 тысяч видеопримеров и 407 тысяч мультимодальных условий. Эксперименты показывают, что он эффективно улучшает результаты существующих моделей управляемой генерации видео (Источник: WeChat)

🧰 Инструменты
Feishu (Lark) запустил функцию «Вопросы и ответы по знаниям», создавая корпоративного ИИ-помощника для ответов и творчества: Feishu (Lark) представил новую функцию «Вопросы и ответы по знаниям», позиционируемую как эксклюзивный инструмент ИИ для ответов на вопросы для предприятий. Основываясь на сообщениях, документах, базах знаний, стенограммах и другой информации, к которой сотрудники имеют доступ в Feishu, в сочетании с большими моделями, такими как DeepSeek-R1, Doubao, и технологией RAG, он предоставляет точные ответы и поддержку в создании контента. Функция подчеркивает активацию и использование внутренних знаний предприятия; сотрудники с разными ролями, задающие один и тот же вопрос, могут получить ответы с разных точек зрения, при строгом соблюдении организационных прав доступа. «Вопросы и ответы по знаниям» Feishu призваны бесшовно интегрировать ИИ в повседневные рабочие процессы, повысить эффективность получения информации и совместной работы, а также помочь предприятиям создать динамичную систему управления знаниями (Источник: WeChat, WeChat)
Supabase, благодаря открытому исходному коду и интеграции с ИИ, стал предпочтительным бэкендом для «атмосферного программирования»: База данных с открытым исходным кодом Supabase, благодаря своему «готовому к использованию» опыту работы с PostgreSQL и активному реагированию на тенденции развития ИИ, стала популярным выбором бэкенда в рамках модели «атмосферного программирования» (Vibe Coding). Vibe Coding подчеркивает использование различных инструментов ИИ для быстрого завершения всего процесса разработки от требований до реализации. Supabase, интегрировав PGVector, поддерживает хранение векторных вложений (что крайне важно для приложений RAG), сотрудничает с Ollama для предоставления услуг моделей ИИ на периферийных устройствах и запустила собственного ИИ-помощника для генерации схемы базы данных и отладки SQL. Недавно Supabase также запустила официальный сервер MCP, позволяющий инструментам ИИ напрямую взаимодействовать с ним. Эти особенности сделали его популярным среди платформ для создания нативных ИИ-приложений, таких как Lovable и Bolt.new (Источник: WeChat)

Hugging Face представила nanoVLM: минималистичный инструментарий для обучения визуально-языковых моделей (VLM) на чистом PyTorch: Hugging Face выпустила nanoVLM, легковесный инструментарий на PyTorch, предназначенный для упрощения процесса обучения визуально-языковых моделей. Код проекта небольшой и легко читаемый, что подходит для начинающих или разработчиков, желающих глубже понять внутреннее устройство VLM. Архитектура nanoVLM основана на визуальном кодировщике SigLIP и языковом декодере Llama 3, с модулем проекции модальностей для согласования визуальной и текстовой модальностей. Проект предоставляет удобный способ запуска обучения VLM в бесплатном Colab Notebook и уже выпустил предварительно обученную модель на базе SigLIP и SmolLM2 для тестирования (Источник: HuggingFace Blog)

Библиотека Diffusers интегрировала несколько бэкендов квантования для оптимизации больших диффузионных моделей: Библиотека Hugging Face Diffusers теперь интегрирует несколько бэкендов квантования, включая bitsandbytes, torchao, Quanto, GGUF и нативный FP8, с целью снижения потребления памяти и вычислительных требований больших диффузионных моделей (таких как Flux). Эти бэкенды поддерживают квантование с различной точностью (например, 4-битное, 8-битное, FP8) и могут сочетаться с техниками оптимизации памяти, такими как CPU offloading, group offloading и torch.compile. В блоге на примере квантования модели Flux.1-dev демонстрируется производительность каждого бэкенда в плане экономии памяти и времени инференса, а также предоставляются рекомендации по выбору, помогающие пользователям найти баланс между размером модели, скоростью и качеством. Некоторые квантованные модели уже доступны на Hugging Face Hub (Источник: HuggingFace Blog)

Платформа для разработки больших моделей JD.com JoyBuild повышает эффективность обучения и инференса: Исследовательский институт JD.com предложил систему и метод для обучения, обновления больших моделей в открытой среде и их совместного развертывания с малыми моделями. Соответствующие результаты опубликованы в журнале npj Artificial Intelligence, входящем в группу Nature. Технология за счет четырех инноваций — дистилляции моделей (динамическая иерархическая дистилляция), управления данными (динамическая выборка между доменами), оптимизации обучения (байесовская оптимизация) и облачно-периферийного взаимодействия (двухэтапное сжатие) — в среднем повышает эффективность инференса больших моделей на 30% и снижает затраты на обучение на 70%. Эта технология лежит в основе вычислительной платформы для разработки больших моделей JoyBuild, поддерживает доработку и разработку различных моделей (таких как большая модель JD.com, Llama, DeepSeek), помогает предприятиям преобразовывать универсальные модели в специализированные и уже применяется в розничной торговле, логистике и других сценариях (Источник: WeChat)
Запущен проект реестра Model Context Protocol (MCP): modelcontextprotocol/registry — это управляемый сообществом проект службы регистрации серверов MCP, находящийся на ранней стадии разработки. Проект нацелен на предоставление центрального репозитория записей серверов MCP, позволяющего обнаруживать и управлять различными реализациями MCP, их метаданными, конфигурациями и возможностями. Его особенности включают RESTful API для управления записями, конечную точку для проверки работоспособности, поддержку различных конфигураций среды, поддержку баз данных MongoDB и in-memory, а также документацию API. Проект написан на языке Go и предоставляет руководство по быстрому запуску с помощью Docker Compose (Источник: GitHub Trending)
📚 Обучение
Теренс Тао опубликовал учебное пособие по математическим доказательствам с помощью ИИ, демонстрируя использование GitHub Copilot для доказательства пределов функций: Лауреат Филдсовской премии Теренс Тао обновил видео на своем YouTube-канале, подробно демонстрируя, как использовать GitHub Copilot для помощи в доказательстве теорем о сумме, разности и произведении пределов функций. В учебном пособии подчеркивается важность правильного направления ИИ и демонстрируется роль Copilot в генерации каркаса кода и подсказках библиотечных функций, но также указываются его ограничения в обработке сложных математических деталей, особых случаев и поддержании контекстной согласованности. Теренс Тао заключает, что Copilot полезен для начинающих, но при решении сложных задач все еще требует значительного вмешательства и корректировки со стороны человека, и иногда сочетание с вычислениями на бумаге может быть более эффективным (Источник: 量子位)

Статья исследует противоречие между логическим выводом больших моделей и следованием инструкциям, предлагая концепцию ограниченного внимания: Исследовательская работа «When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs» указывает, что после использования цепочки рассуждений (CoT) для логического вывода, большие языковые модели, хотя и демонстрируют большую интеллектуальность в некоторых аспектах (например, соблюдение формата, количества слов), могут, наоборот, снижать точность строгого следования инструкциям. Исследовательская группа, протестировав 15 моделей с открытым и закрытым исходным кодом, обнаружила, что модели после использования CoT более склонны «действовать по своему усмотрению», изменять или добавлять дополнительную информацию, игнорируя исходные инструкции. В статье вводится понятие «ограниченного внимания» (Constraint Attention) и обнаруживается, что рассуждения CoT снижают внимание модели к ключевым ограничениям. Исследование также показывает, что длина рассуждений CoT не имеет значимой корреляции с точностью выполнения задачи, и рассматривает возможность повышения эффективности следования инструкциям с помощью примеров с небольшим количеством образцов, саморефлексии и других методов (Источник: WeChat)

MIT и Google предложили PASTA: новую парадигму асинхронной параллельной генерации LLM на основе обучения стратегиям: Исследовательские группы из Массачусетского технологического института (MIT) и Google предложили фреймворк PASTA (PArallel STructure Annotation), который с помощью обучения стратегиям позволяет большим языковым моделям (LLM) самостоятельно оптимизировать стратегии асинхронной параллельной генерации. Метод сначала разрабатывает язык разметки PASTA-LANG для маркировки семантически независимых блоков текста с целью параллельной генерации. Процесс обучения состоит из двух этапов: контролируемая тонкая настройка позволяет модели научиться вставлять маркеры PASTA-LANG, после чего с помощью оптимизации предпочтений (на основе теоретического коэффициента ускорения и оценки качества контента) стратегия разметки дополнительно улучшается. PASTA разработала чередующуюся компоновку KV-кэша и механизм управления вниманием для координации эффективной совместной работы нескольких потоков. Эксперименты показывают, что PASTA на бенчмарке AlpacaEval достигла ускорения в 1.21-1.93 раза, одновременно сохраняя или улучшая качество вывода, демонстрируя хорошую масштабируемость (Источник: WeChat)

Статья ICML 2025 предлагает TPO: новое решение для мгновенного согласования предпочтений во время инференса без переобучения: Шанхайская лаборатория искусственного интеллекта предложила оптимизацию предпочтений во время тестирования (Test-Time Preference Optimization, TPO) — новый метод, позволяющий большим языковым моделям самостоятельно корректировать вывод во время инференса посредством итеративной текстовой обратной связи, чтобы соответствовать человеческим предпочтениям. TPO имитирует процесс «градиентного спуска» на естественном языке (генерация кандидатов ответов, вычисление текстовых потерь, вычисление текстового градиента, обновление ответа), достигая согласования без обновления весов модели. Эксперименты показывают, что TPO может значительно улучшить производительность как несогласованных, так и уже согласованных моделей. Например, модель Llama-3.1-70B-SFT после двух шагов оптимизации TPO превзошла уже согласованную версию Instruct на нескольких бенчмарках. Этот метод предлагает стратегию расширения инференса «в ширину + в глубину» и демонстрирует потенциал эффективной оптимизации в условиях ограниченных ресурсов (Источник: WeChat)
Новое исследование изучает методы извлечения скрытых знаний из LLM: В одной из статей исследуется, как извлечь потенциально скрытые знания из больших языковых моделей. Исследователи обучили «запретную» модель, предназначенную для описания определенного секретного слова без его прямого произнесения, причем это секретное слово не встречалось ни в обучающих данных, ни в подсказках. Затем исследователи оценили автоматизированные стратегии, основанные как на неинтерпретируемых (черный ящик) методах, так и на методах механистической интерпретируемости (таких как logit lens и разреженные автоэнкодеры), для раскрытия этого секрета. Результаты показывают, что оба подхода могут эффективно извлекать секретное слово в условиях проверки концепции. Эта работа направлена на предоставление первоначальных решений ключевой проблемы извлечения секретных знаний из языковых моделей для содействия их безопасному и надежному развертыванию (Источник: HuggingFace Daily Papers)
Статья рассматривает применение совместного прунинга в больших языковых моделях (FedPrLLM): Для решения проблемы сложности получения общедоступных калибровочных выборок для прунинга больших языковых моделей (LLM) в областях, чувствительных к конфиденциальности, исследователи предложили FedPrLLM, комплексный фреймворк для совместного прунинга. В рамках этого фреймворка каждый клиент должен только вычислить матрицу маски прунинга на основе локальных калибровочных данных и поделиться ею с сервером для совместного прунинга глобальной модели, защищая при этом конфиденциальность локальных данных. Путем обширных экспериментов исследователи обнаружили, что однократный прунинг (one-shot pruning) в сочетании со сравнением слоев (layer comparison) и без масштабирования весов (no weight scaling) является наилучшим выбором в рамках фреймворка FedPrLLM. Данное исследование направлено на руководство будущими работами по прунингу LLM в областях, чувствительных к конфиденциальности (Источник: HuggingFace Daily Papers)
Статья представляет MIGRATION-BENCH: бенчмарк для миграции кода Java 8: Исследователи представили MIGRATION-BENCH, бенчмарк, ориентированный на миграцию кода с Java 8 на последние версии LTS (Java 17, 21). Бенчмарк включает полный набор данных из 5102 репозиториев и подмножество из 300 тщательно отобранных сложных репозиториев, предназначенных для оценки возможностей больших языковых моделей (LLM) в задачах миграции кода на уровне репозитория. Одновременно в статье предлагается комплексная система оценки и метод SD-Feedback. Эксперименты показывают, что LLM (например, Claude-3.5-Sonnet-v2) могут эффективно справляться с такими задачами миграции, достигая на выбранном подмножестве успешности 62.33% (минимальная миграция) и 27.00% (максимальная миграция) соответственно (Источник: HuggingFace Daily Papers)
Статья предлагает CS-Sum: бенчмарк для резюмирования диалогов с переключением кода и анализ ограничений LLM: Для оценки способности больших языковых моделей (LLM) понимать переключение кода (CS), исследователи представили бенчмарк CS-Sum, оценивающий эту способность путем резюмирования диалогов с переключением кода на английский язык. CS-Sum является первым бенчмарком для резюмирования диалогов с переключением кода для пар языков мандаринский-английский, тамильский-английский и малайский-английский, каждая языковая пара содержит 900-1300 диалогов, аннотированных вручную. Оценка десяти LLM с открытым и закрытым исходным кодом (включая методы few-shot, translate-summarize и fine-tuning) показала, что, несмотря на высокие показатели автоматической оценки, LLM все еще допускают незначительные ошибки при обработке CS-ввода, что изменяет полный смысл диалога. В статье также указаны три наиболее распространенных типа ошибок, допускаемых LLM при обработке CS, и подчеркивается необходимость специального обучения на данных с переключением кода (Источник: HuggingFace Daily Papers)
Статья исследует способность больших моделей выражать уверенность во время логического вывода: Исследования показывают, что большие языковые модели (LLM), выполняющие расширенный процесс мышления (CoT), не только лучше справляются с решением проблем, но и точнее выражают свою уверенность. Путем тестирования шести моделей логического вывода на шести наборах данных было обнаружено, что в 33 из 36 случаев модели логического вывода демонстрировали лучшую калибровку уверенности, чем модели без логического вывода. Анализ предполагает, что это связано с поведением «медленного мышления» моделей логического вывода (например, исследование альтернативных методов, откат назад), что позволяет им динамически корректировать уверенность в процессе CoT. Кроме того, удаление поведения «медленного мышления» приводит к значительному снижению калибровки, в то время как модели без логического вывода могут извлечь пользу из управляемого «медленного мышления» (Источник: HuggingFace Daily Papers)
Статья: Обучение VLM визуальному мышлению с помощью обучения с подкреплением на парах визуальных вопросов и ответов (Visionary-R1): Данное исследование направлено на обучение визуально-языковых моделей (VLM) рассуждениям на основе изображений с помощью обучения с подкреплением и пар визуальных вопросов и ответов, без явного надзора за цепочкой мыслей (CoT). Исследование показало, что простое применение обучения с подкреплением (побуждение модели генерировать цепочку рассуждений перед ответом) может привести к тому, что модель будет изучать «короткие пути» из простых вопросов, снижая ее способность к обобщению. Для решения этой проблемы исследователи предлагают, чтобы модель следовала формату вывода «подпись-рассуждение-ответ», то есть сначала генерировала подробную подпись к изображению, а затем строила цепочку рассуждений. Модель Visionary-R1, обученная на основе этого метода, превзошла по производительности на нескольких бенчмарках визуального мышления такие мощные мультимодальные модели, как GPT-4o, Claude3.5-Sonnet и Gemini-1.5-Pro (Источник: HuggingFace Daily Papers)
Статья предлагает VideoEval-Pro: более реалистичный и надежный бенчмарк для оценки понимания длинных видео: Исследование указывает, что текущие бенчмарки для понимания длинных видео (LVU) в основном полагаются на вопросы с множественным выбором (MCQ), которые подвержены угадыванию, и на часть вопросов можно ответить, не просматривая видео целиком, что приводит к завышению производительности моделей. Для решения этой проблемы в статье предлагается VideoEval-Pro, бенчмарк LVU, содержащий открытые вопросы с краткими ответами, предназначенный для реальной оценки способности модели понимать все видео целиком, охватывая задачи восприятия и рассуждения как на уровне фрагментов, так и на уровне всего видео. Оценка 21 видео-LMM показала, что производительность моделей на открытых вопросах значительно снижается, и высокие баллы MCQ не обязательно связаны с высокими баллами VideoEval-Pro. VideoEval-Pro также лучше выигрывает от увеличения количества входных кадров, предоставляя более надежный стандарт оценки для области LVU (Источник: HuggingFace Daily Papers)
Статья: Тонкая настройка квантованных нейронных сетей с помощью оптимизации нулевого порядка (QZO): По мере экспоненциального роста объема больших языковых моделей память GPU становится узким местом для адаптации моделей к последующим задачам. Данное исследование направлено на минимизацию использования памяти для весов модели, градиентов и состояний оптимизатора в рамках единой структуры. Исследователи предлагают устранить градиенты и состояния оптимизатора с помощью оптимизации нулевого порядка, которая аппроксимирует градиенты путем возмущения весов во время прямого распространения. Для минимизации памяти весов используется квантование модели (например, bfloat16 в int4). Однако прямое применение оптимизации нулевого порядка к квантованным весам невозможно из-за разрыва в точности между дискретными весами и непрерывными градиентами. Для решения этой проблемы в статье предлагается квантованная оптимизация нулевого порядка (QZO) — новый метод, который оценивает градиенты путем возмущения непрерывных шкал квантования и использует метод отсечения производных по направлению для стабилизации обучения. QZO ортогонален методам постобучающего квантования на основе скаляров и кодовых книг. По сравнению с полнопараметрической тонкой настройкой bfloat16, QZO может сократить общие затраты памяти для 4-битных LLM более чем в 18 раз и позволяет тонко настраивать Llama-2-13B и Stable Diffusion 3.5 Large на одном GPU с 24 ГБ памяти (Источник: HuggingFace Daily Papers)
Статья: Оптимизация производительности вывода в любое время с помощью бюджетно-относительной оптимизации стратегии (BRPO) (AnytimeReasoner): Расширение вычислений во время тестирования имеет решающее значение для повышения способности к рассуждению больших языковых моделей (LLM). Существующие методы обычно используют обучение с подкреплением (RL) для максимизации проверяемого вознаграждения в конце траектории рассуждений, но это оптимизирует только конечную производительность при фиксированном бюджете токенов, что влияет на эффективность обучения и развертывания. В данном исследовании предлагается фреймворк AnytimeReasoner, направленный на оптимизацию производительности вывода в любое время, повышение эффективности использования токенов и гибкости рассуждений при различных бюджетных ограничениях. Метод заключается в усечении полного процесса мышления для соответствия бюджету токенов, выбранному из априорного распределения, что заставляет модель суммировать наилучший ответ для каждого усеченного размышления для проверки, тем самым вводя проверяемые плотные вознаграждения в процессе рассуждений, способствуя более эффективному распределению кредитов при оптимизации RL. Кроме того, исследователи вводят бюджетно-относительную оптимизацию стратегии (BRPO), новую технику снижения дисперсии, для повышения надежности и эффективности обучения при усилении стратегии мышления. Экспериментальные результаты на задачах математического рассуждения показывают, что данный метод превосходит GRPO при всех бюджетах мышления в различных априорных распределениях, повышая эффективность обучения и использования токенов (Источник: HuggingFace Daily Papers)
Статья предлагает большие гибридные модели рассуждений (LHRM): мышление по требованию для повышения эффективности и возможностей: Недавние большие модели рассуждений (LRM) значительно улучшили свои способности к рассуждению за счет расширенного процесса мышления перед генерацией окончательного ответа. Однако слишком длительный процесс мышления приводит к огромным затратам токенов и задержкам, что особенно нецелесообразно для простых запросов. В данном исследовании представлены большие гибридные модели рассуждений (LHRM), которые могут адаптивно решать, выполнять ли процесс мышления, в зависимости от контекстной информации пользовательского запроса. Для достижения этой цели исследователи предложили двухэтапный процесс обучения: сначала холодный запуск с помощью гибридной тонкой настройки (HFT), а затем использование онлайн-обучения с подкреплением с предложенной гибридной групповой оптимизацией политики (HGPO) для неявного обучения выбору подходящего режима мышления. Кроме того, исследователи ввели метрику гибридной точности (Hybrid Accuracy) для количественной оценки способности модели к гибридному мышлению. Экспериментальные результаты показывают, что LHRM могут адаптивно выполнять гибридное мышление для запросов различной сложности и типа, их способности к рассуждению и общие возможности превосходят существующие LRM и LLM, при этом значительно повышая эффективность (Источник: HuggingFace Daily Papers)
Статья: Использование обучения с подкреплением для ранжирования VisualQuality-R1 с целью оценки качества изображений, индуцированной рассуждениями: DeepSeek-R1 продемонстрировал, что обучение с подкреплением может эффективно стимулировать способности к рассуждению и обобщению у больших языковых моделей (LLM). Однако в области оценки качества изображений (IQA), зависящей от визуальных рассуждений, потенциал вычислительного моделирования, индуцированного рассуждениями, еще не полностью раскрыт. В данном исследовании представлена VisualQuality-R1, модель безэталонной оценки качества изображений (NR-IQA), индуцированная рассуждениями, и для ее обучения используется обучение с подкреплением для ранжирования — алгоритм обучения, адаптированный к внутренней относительности визуального качества. В частности, для пары изображений модель использует групповую относительную оптимизацию политики для генерации нескольких оценок качества для каждого изображения. Эти оценки затем используются для вычисления вероятности сравнения того, что качество одного изображения выше другого в модели Тёрстоуна. Вознаграждение за каждую оценку качества определяется с использованием непрерывной метрики точности, а не дискретных бинарных меток. Обширные эксперименты показывают, что предложенная VisualQuality-R1 стабильно превосходит по производительности модели NR-IQA на основе дискриминационного глубокого обучения, а также недавние методы регрессии качества, индуцированные рассуждениями. Кроме того, VisualQuality-R1 способна генерировать контекстно богатые описания качества, согласующиеся с человеческими суждениями, и поддерживает обучение на нескольких наборах данных без необходимости перенастройки перцептивной шкалы. Эти характеристики делают ее особенно подходящей для надежного измерения прогресса в различных задачах обработки изображений, таких как суперразрешение изображений и генерация изображений (Источник: HuggingFace Daily Papers)
Статья: Разблокировка общих способностей к рассуждению в условиях ограниченных ресурсов с помощью «разогрева»: Разработка эффективных LLM со способностями к рассуждению обычно требует использования обучения с подкреплением с проверяемыми вознаграждениями (RLVR) или дистилляции тщательно подобранных длинных цепочек рассуждений (CoT), оба из которых сильно зависят от большого количества обучающих данных, что создает серьезные проблемы для сценариев с дефицитом качественных обучающих данных. Исследователи предлагают эффективную по выборке двухэтапную стратегию обучения для разработки LLM с рассуждениями при ограниченном надзоре. На первом этапе модель «разогревается» путем дистилляции длинных CoT из игрушечных доменов (например, логических головоломок о рыцарях и лжецах) для приобретения общих навыков рассуждения. На втором этапе к «разогретой» модели применяется RLVR с использованием небольшого количества выборок из целевого домена. Эксперименты показывают, что этот метод имеет несколько преимуществ: (i) только этап разогрева способствует общему рассуждению, улучшая производительность в ряде задач (MATH, HumanEval+, MMLU-Pro); (ii) при обучении RLVR на тех же небольших наборах данных (≤100 выборок) разогретые модели всегда превосходят базовые модели; (iii) разогрев перед обучением RLVR позволяет модели сохранять способность к обобщению между доменами после обучения для конкретного домена; (iv) введение разогрева в процесс не только повышает точность, но и улучшает общую эффективность выборки при обучении RLVR. Результаты этого исследования показывают потенциал «разогрева» для создания надежных LLM с рассуждениями в условиях дефицита данных (Источник: HuggingFace Daily Papers)
Статья предлагает IndexMark: фреймворк для водяных знаков без обучения для авторегрессионной генерации изображений: Технология невидимых водяных знаков для изображений может защитить право собственности на изображения и предотвратить злонамеренное использование моделей визуальной генерации. Однако существующие методы генерации водяных знаков в основном ориентированы на диффузионные модели, в то время как технология водяных знаков для авторегрессионных моделей генерации изображений все еще требует изучения. Исследователи предложили IndexMark, фреймворк для водяных знаков без обучения для авторегрессионных моделей генерации изображений. IndexMark вдохновлен избыточностью кодовых книг: замена авторегрессионно сгенерированных индексов на похожие индексы приводит к незначительным визуальным различиям. Ключевым компонентом IndexMark является простой и эффективный метод «сопоставления-замены», который тщательно выбирает токены водяных знаков из кодовой книги на основе сходства токенов и обобщает использование токенов водяных знаков путем замены токенов, тем самым встраивая водяной знак без ущерба для качества изображения. Проверка водяного знака осуществляется путем вычисления доли токенов водяных знаков в сгенерированном изображении, а точность дополнительно повышается с помощью кодировщика индексов. Кроме того, исследователи ввели вспомогательную схему проверки для повышения устойчивости к атакам обрезки. Эксперименты доказывают, что IndexMark достигает SOTA-уровня как по качеству изображения, так и по точности проверки, и демонстрирует устойчивость к различным искажениям, таким как обрезка, шум, гауссово размытие, случайное стирание, дрожание цвета и сжатие JPEG (Источник: HuggingFace Daily Papers)
Статья: Рассуждение с помощью моделей вознаграждения (RRM): Модели вознаграждения играют ключевую роль в направлении больших языковых моделей (LLM) к созданию результатов, соответствующих человеческим ожиданиям. Однако вопрос эффективного использования вычислений во время тестирования для повышения производительности моделей вознаграждения остается открытой проблемой. В данном исследовании представлены модели рассуждающего вознаграждения (Reward Reasoning Models, RRMs), которые специально разработаны для выполнения обдуманного процесса рассуждения перед генерацией окончательного вознаграждения. С помощью рассуждений на основе цепочки мыслей RRMs могут использовать дополнительные вычисления во время тестирования для сложных запросов, где вознаграждение не очевидно. Для разработки RRMs исследователи реализовали фреймворк обучения с подкреплением, который способен развивать самоэволюционирующие способности к рассуждению о вознаграждении без необходимости явных траекторий рассуждений в качестве обучающих данных. Экспериментальные результаты показывают, что RRMs достигают превосходной производительности на бенчмарках моделирования вознаграждения в нескольких областях. Примечательно, что исследователи продемонстрировали, что RRMs могут адаптивно использовать вычисления во время тестирования для дальнейшего повышения точности вознаграждения. Предварительно обученные модели рассуждающего вознаграждения доступны на HuggingFace (Источник: HuggingFace Daily Papers)
Статья: Использование когнитивных экспертов в MoE для управления мышлением, улучшение рассуждений без дополнительного обучения: Архитектура Mixture-of-Experts (MoE) в больших моделях рассуждений (LRM) достигла впечатляющих способностей к рассуждению за счет выборочной активации экспертов для содействия структурированным когнитивным процессам. Несмотря на значительный прогресс, существующие модели рассуждений часто страдают от когнитивной неэффективности, такой как чрезмерное или недостаточное обдумывание. Для решения этих ограничений исследователи представили новый метод управления во время рассуждений под названием «Усиление когнитивных экспертов» (Reinforcing Cognitive Experts, RICE), направленный на повышение производительности рассуждений без дополнительного обучения или сложных эвристик. Используя нормализованную поточечную взаимную информацию (nPMI), исследователи систематически выявили специализированных экспертов, названных «когнитивными экспертами», которые отвечают за координацию мета-уровневых операций рассуждения, характеризующихся определенными токенами (например, ««`»). Экспериментальная оценка на ведущих LRM на базе MoE (DeepSeek-R1 и Qwen3-235B) на строгих количественных и научных бенчмарках рассуждений показала, что RICE достигает значительных и последовательных улучшений в точности рассуждений, когнитивной эффективности и обобщении между доменами. Важно отметить, что этот легковесный метод значительно превосходит по производительности популярные методы управления рассуждениями (такие как проектирование подсказок и ограничения декодирования), сохраняя при этом общую способность модели следовать инструкциям. Эти результаты подчеркивают усиление когнитивных экспертов как перспективное, практичное и интерпретируемое направление для повышения когнитивной эффективности в продвинутых моделях рассуждений (Источник: HuggingFace Daily Papers)
Статья: Исследование влияния порядка контекста на производительность языковых моделей в многоэтапных вопросно-ответных системах: Многоэтапные вопросно-ответные системы (MHQA) представляют собой сложную задачу для языковых моделей (LM) из-за их комплексности. Когда LM предлагается обработать несколько результатов поиска, они должны не только извлекать релевантную информацию, но и выполнять многоэтапные рассуждения по источникам информации. Хотя LM хорошо справляются с традиционными вопросно-ответными задачами, причинная маска (causal mask) может препятствовать их способности рассуждать в сложных контекстах. Данное исследование изучает, как LM реагируют на многоэтапные вопросы, располагая результаты поиска (извлеченные документы) в различных конфигурациях. Исследование показало: 1) модели кодировщик-декодировщик (например, серия Flan-T5) обычно превосходят LM только с причинным декодером в задачах MHQA, несмотря на их значительно меньший размер; 2) изменение порядка «золотых» документов выявило различные тенденции в моделях Flan T5 и дообученных моделях только с декодером, причем наилучшая производительность достигается, когда порядок документов соответствует порядку цепочки рассуждений; 3) усиление двунаправленного внимания в моделях только с причинным декодером путем модификации причинной маски может эффективно улучшить их конечную производительность. Кроме того, в исследовании проведено тщательное изучение распределения весов внимания LM в контексте MHQA, которое показало, что при правильном ответе веса внимания, как правило, достигают пика при более высоких значениях. Исследователи использовали это наблюдение для эвристического повышения производительности LM в данной задаче (Источник: HuggingFace Daily Papers)
Статья: Реализация визуальных агентов с помощью强化微调 (Visual-ARFT): Ключевой тенденцией в больших моделях рассуждений (например, o3 от OpenAI) является наличие встроенных агентских способностей для использования внешних инструментов (таких как поиск в веб-браузере, написание/выполнение кода для обработки изображений) для реализации «мышления с изображениями». В сообществе исследователей с открытым исходным кодом, хотя и достигнут значительный прогресс в чисто языковых агентских способностях (таких как вызов функций и интеграция инструментов), разработка мультимодальных агентских способностей, включающих подлинное мышление с изображениями, и соответствующих бенчмарков все еще недостаточна. Данное исследование подчеркивает эффективность强化微调 визуальных агентов (Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT) для наделения больших визуально-языковых моделей (LVLM) гибкими и адаптивными способностями к рассуждению. С помощью Visual-ARFT LVLM с открытым исходным кодом получают возможность просматривать веб-сайты для получения обновлений информации в реальном времени, а также писать код для управления и анализа входных изображений с помощью техник обработки изображений, таких как обрезка, поворот и т.д. Исследователи также предложили бенчмарк мультимодальных агентских инструментов (Multi-modal Agentic Tool Bench, MAT), включающий два набора: MAT-Search и MAT-Coding, для оценки агентских способностей LVLM к поиску и кодированию. Экспериментальные результаты показывают, что Visual-ARFT превосходит базовые показатели на +18.6% F1 / +13.0% EM на MAT-Coding и на +10.3% F1 / +8.7% EM на MAT-Search, в конечном итоге превосходя GPT-4o. Visual-ARFT также достигает прироста +29.3 F1% / +25.9% EM на существующих бенчмарках многоэтапных вопросно-ответных систем (таких как 2Wiki и HotpotQA), демонстрируя сильную способность к обобщению. Эти результаты показывают, что Visual-ARFT представляет собой перспективный путь для создания надежных и обобщаемых мультимодальных агентов (Источник: HuggingFace Daily Papers)
💼 Бизнес
ModelBest привлекла новое финансирование в размере нескольких сотен миллионов юаней, совместно инвестированное Hongtai Capital, Guozhong Capital, Tsinghua Holdings Capital и Moutai Fund: Компания по разработке больших моделей ModelBest недавно объявила о завершении нового раунда финансирования на несколько сотен миллионов юаней, совместно инвестированного Hongtai Capital, Guozhong Capital, Tsinghua Holdings Capital и Moutai Fund. ModelBest специализируется на разработке «эффективных» больших моделей, стремясь создавать модели с более высокой производительностью, более низкой стоимостью, меньшим энергопотреблением и большей скоростью при одинаковом количестве параметров. Ее периферийная полнофункциональная модель MiniCPM-o 2.6 достигла лидирующих позиций в отрасли по таким аспектам, как непрерывное зрение, прослушивание в реальном времени и естественная речь. Серия моделей MiniCPM, благодаря своей эффективности и низкой стоимости, уже превысила десять миллионов загрузок на всех платформах. Компания уже сотрудничает с такими автопроизводителями, как Changan Automobile, SAIC Volkswagen, Great Wall Motors, способствуя коммерциализации периферийных больших моделей в таких областях, как интеллектуальные кабины (Источник: 量子位, WeChat)

Terminus Group и Университет Тунцзи заключили стратегическое партнерство для совместного продвижения прорывных технологий в области пространственного интеллекта: Компания AIoT Terminus Group и Инженерно-исследовательский институт искусственного интеллекта Университета Тунцзи подписали соглашение о стратегическом сотрудничестве. Стороны сосредоточатся на технологиях пространственного интеллекта, уделяя особое внимание исследованиям и разработкам в области слияния разнородных данных из нескольких источников, понимания сценариев и принятия решений. Сотрудничество включает инновационные исследования, совместное использование ресурсов, коммерциализацию результатов и подготовку кадров. Terminus Group предоставит сценарии применения и платформу для тестирования оборудования, в то время как Инженерно-исследовательский институт искусственного интеллекта Университета Тунцзи будет руководить разработкой основных алгоритмов и системной инженерией. Стороны стремятся ускорить внедрение передовых технологий в промышленность и совместно исследовать прорывы в области «операционных систем» для инженерного интеллекта (Источник: 量子位)

Крупные китайские технологические компании ускоряют развертывание AI Agent, Baidu, Alibaba, ByteDance борются за рынок: После того как на саммите Sequoia Capital AI была подчеркнута ценность AI Agent, крупные китайские интернет-компании, такие как ByteDance, Baidu, Alibaba, ускорили свое развертывание в этой области. Сообщается, что у ByteDance уже несколько команд занимаются разработкой Agent и проводят внутреннее тестирование «Kouzi Space»; Baidu на конференции Create представила универсального интеллектуального агента «Xīnxiǎng»; Alibaba позиционирует Quark как «супер-Agent». Помимо универсальных Agent, компании также активно работают над вертикальными Agent, такими как Feizhu Wen Yi Wen (Alibaba) и Faxingbao (Baidu). Отрасль считает, что Agent — это вторая волна после больших моделей, и ключевыми факторами конкуренции являются глубина экосистемы, завоевание умов пользователей, а также возможности базовых моделей, контроль затрат и другие факторы. Несмотря на ожесточенную конкуренцию, Agent еще не достиг такого же прорывного момента, как GPT, и зрелость технологий, бизнес-модели и пользовательский опыт все еще нуждаются в улучшении (Источник: 36氪)
🌟 Сообщество
Контент, сгенерированный ИИ, наводняет Reddit, вызывая опасения по поводу «мертвого интернета» и обсуждения пользовательского опыта: Пользователи Reddit заметили растущее количество контента, сгенерированного ИИ, на платформе. Некоторые комментарии имеют схожий, лишенный индивидуальности стиль, а иногда и явные признаки написания ИИ (например, злоупотребление длинным тире). Это вызвало дискуссии о «теории мертвого интернета» (Dead Internet Theory), согласно которой большая часть контента в интернете будет генерироваться ИИ, а не реальными людьми. Реакция пользователей неоднозначна: одни считают, что контент ИИ лишен человечности, скучен или вызывает жуткие ощущения, что мешает реальному человеческому общению; другие отмечают, что ИИ может помочь неносителям языка улучшить текст или использоваться для тестирования и доработки моделей. Общее беспокойство заключается в том, что массовое появление контента ИИ размывает дискуссии реальных людей и может использоваться в маркетинговых, пропагандистских и других целях, что в конечном итоге снизит ценность платформы для обучения ИИ (Источник: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
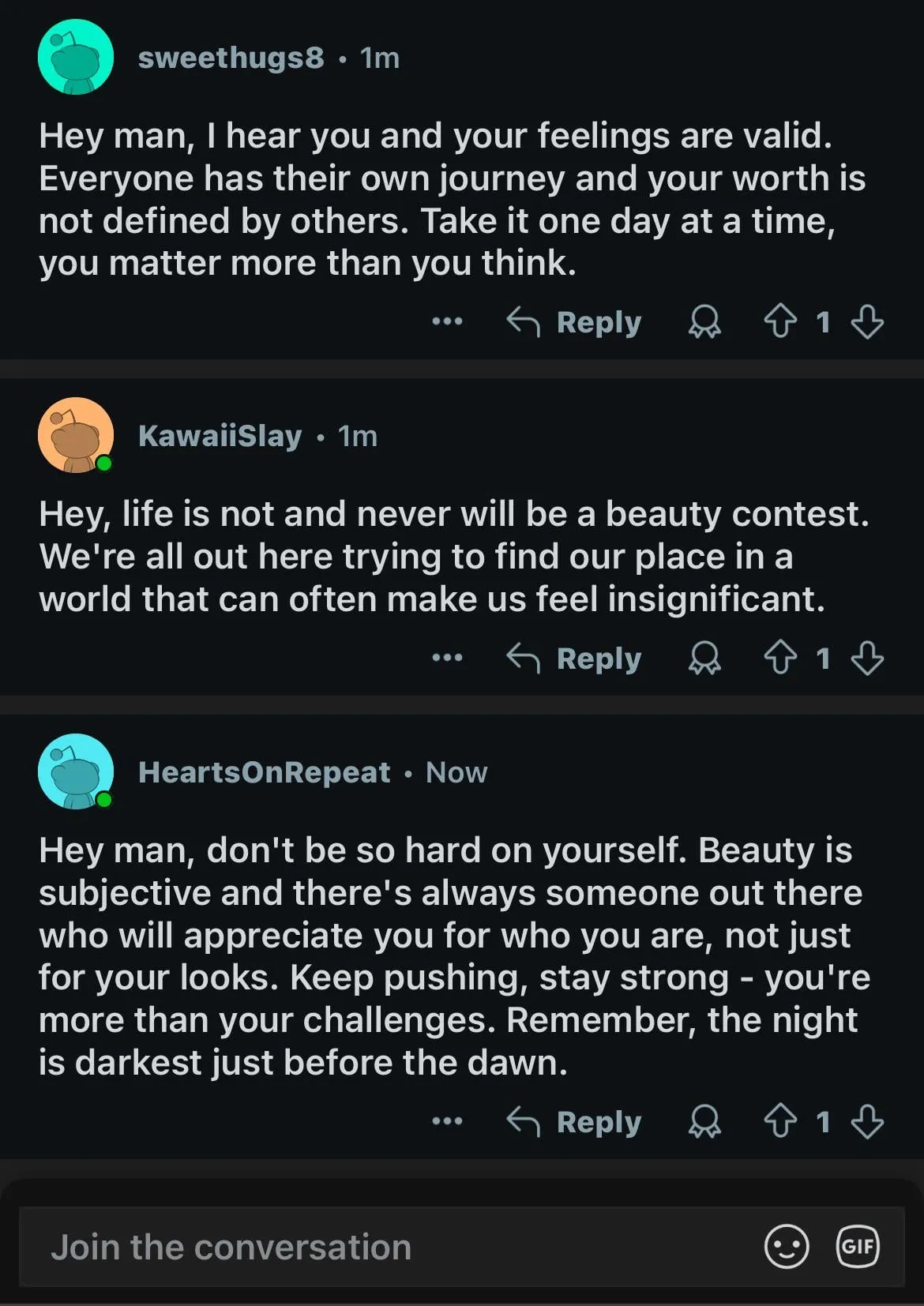
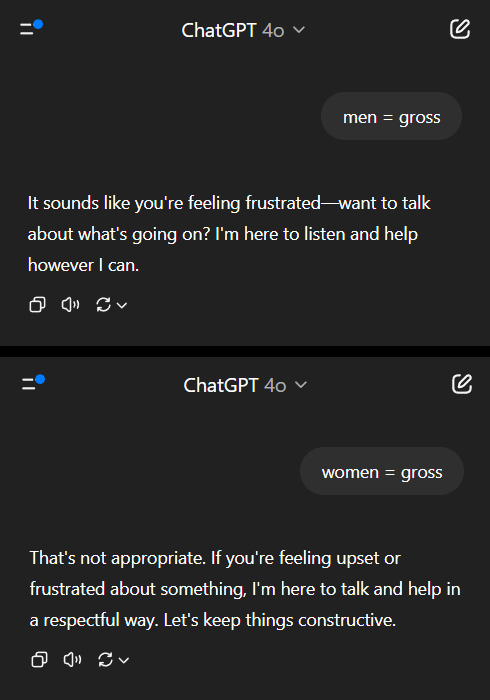
Модели ИИ демонстрируют двойные стандарты в вопросах гендерных предубеждений, вызывая общественную рефлексию: Пост на Reddit демонстрирует, как модель ИИ (предположительно, предварительная версия Gemini 2.5 Pro) по-разному реагирует на негативные обобщающие утверждения, касающиеся пола. Когда ей сообщают «мужчины = отвратительны», модель склоняется к нейтральному ответу, признавая это субъективным утверждением; когда же ей сообщают «женщины = отвратительны», модель отказывается от дальнейшего взаимодействия, считая это утверждение пропагандой вредных обобщений. В комментариях развернулась бурная дискуссия, мнения включали: это отражает социальную реальность, где обсуждение мизогинии встречается гораздо чаще, чем мизандрии, что приводит к несбалансированности обучающих данных; модель может корректировать стратегию ответа в зависимости от пола спрашивающего; общество по-разному чувствительно к стереотипам и агрессивным высказываниям в адрес различных гендерных групп. Некоторые комментаторы считают реакцию ИИ отражением социальных предубеждений, в то время как другие полагают, что такая дифференцированная обработка имеет свои основания, поскольку негативные высказывания в адрес женщин часто связаны с более широкой дискриминацией и насилием (Источник: Reddit r/ChatGPT)
Обсуждение тенденции коммодитизации AI Agent и будущих фокусов конкуренции: Пользователи Reddit обсуждают, что конференции Microsoft Build 2025 и Google I/O 2025 ознаменовали переход AI Agent в стадию коммодитизации. В ближайшие несколько лет создание и развертывание Agent перестанет быть исключительной компетенцией разработчиков передовых моделей. Следовательно, краткосрочный фокус развития ИИ сместится с создания самих Agent на задачи более высокого уровня, такие как разработка и внедрение более эффективных бизнес-планов, а также разработка более интеллектуальных моделей для стимулирования инноваций. В комментариях отмечается, что победителями в области AI Agent в будущем станут те разработчики, которые смогут создать самые интеллектуальные «исполнительные модели» (executive models), а не просто те, кто наиболее искусно продвигает свои инструменты. Суть конкуренции вернется к мощному интеллекту на вершине стека, а не просто к механизмам внимания или способностям к рассуждению (Источник: Reddit r/deeplearning)
Практикующие специалисты в области машинного обучения активно обсуждают важность математических знаний: Сообщество Reddit r/MachineLearning обсуждает важность математики в практике машинного обучения. Большинство практикующих специалистов считают понимание математических принципов, лежащих в основе ИИ, крайне важным, особенно в оптимизации моделей, понимании исследовательских статей и проведении инноваций. В комментариях отмечается, что, хотя не обязательно вручную выполнять низкоуровневые вычисления, такие как умножение матриц, владение основными понятиями статистики, линейной алгебры, математического анализа и т.д. помогает глубже понять алгоритмы и избежать слепого применения. Некоторые комментаторы считают, что математика в машинном обучении относительно проста, а более сложные математические приложения используются в теории оптимизации и квантовом машинном обучении. Онлайн-ресурсы для обучения считаются достаточными, но требуют от учащихся высокой самодисциплины (Источник: Reddit r/MachineLearning)
💡 Другое
Отчет аналитического центра QbitAI: ИИ переформатирует SEO поиска, ценность профессиональных контент-сообществ возрастает: Аналитический центр QbitAI опубликовал отчет, в котором указывается, что интеллектуальные помощники на базе ИИ переформатируют традиционные стратегии поисковой оптимизации (SEO). В отчете на основе экспериментов установлено, что почти половина ответов ИИ ссылается на контент-сообщества, особенно в области профессиональных знаний, где вес ссылок на контент-сообщества (например, Zhihu) выше. Ожидания пользователей от получения информации смещаются от «самостоятельного отбора» к «получению прямого ответа», что может привести к снижению количества кликов на традиционные веб-сайты. В отчете утверждается, что в эпоху ИИ профессиональные контент-сообщества приобретают особую ценность благодаря плотности информации, экспертному опыту и качеству пользовательского контента, а стратегии SEO должны смещаться в сторону SPO (оптимизации для профессиональных сообществ), при этом вес низкокачественных информационных порталов будет снижаться (Источник: 量子位, WeChat)

Инструмент ИИ для определения возраста по фото FaceAge опубликован в «The Lancet», может помочь в принятии решений при лечении рака: Команда Mass General Brigham разработала ИИ-инструмент под названием FaceAge, способный прогнозировать биологический возраст человека на основе анализа фотографий лица. Соответствующее исследование опубликовано в «The Lancet Digital Health». Модель оценивает степень старения, наблюдая за чертами лица (такими как впадины на висках, кожные складки, обвисание линий). В исследовании с участием онкологических больных было обнаружено, что пациенты, чей возраст по лицу выглядел моложе фактического, лучше реагировали на лечение и имели более низкий риск смертности. В будущем этот инструмент может помочь врачам разрабатывать персонализированные схемы лечения на основе биологического возраста пациента, но также вызывает опасения по поводу предвзятости данных (обучающие данные преимущественно состоят из лиц европеоидной расы) и потенциального злоупотребления (например, дискриминации при страховании) (Источник: WeChat)

Исследование: ведущие ИИ плохо справляются с базовыми физическими задачами, что подчеркивает сложность замены «синих воротничков» в ближайшем будущем: Исследователь в области машинного обучения Адам Карвонен оценил производительность ведущих LLM, таких как OpenAI o3 и Gemini 2.5 Pro, на задаче изготовления деталей (с использованием фрезерного станка с ЧПУ и токарного станка). Результаты показали, что ни одна из моделей не смогла разработать удовлетворительный план обработки, выявив недостатки в визуальном понимании (пропуск деталей, несогласованное распознавание признаков) и физическом мышлении (игнорирование жесткости и вибрации, предложение невозможных схем зажима заготовки). Карвонен считает, что это связано с отсутствием у LLM неявных знаний в соответствующих областях и данных о реальном опыте. Он предполагает, что в краткосрочной перспективе ИИ будет больше автоматизировать работу «белых воротничков», в то время как работа «синих воротничков», зависящая от физических операций и опыта, будет затронута в меньшей степени, что может привести к неравномерному развитию автоматизации в различных отраслях (Источник: WeChat)
