Ключевые слова:OpenAI, Джони Айв, аппаратное обеспечение ИИ, Google I/O, Gemini, Mistral AI, Devstral, программирование ИИ, поглощение OpenAI io, Gemini 2.5 Pro, открытая модель Devstral, инструмент для создания фильмов ИИ Flow, программный агент ИИ Jules
🔥 В центре внимания
OpenAI объявила о приобретении AI-стартапа io, основанного Jony Ive, за 6,5 миллиарда долларов: OpenAI подтвердила приобретение компании по разработке аппаратного обеспечения AI io, основанной бывшим главным дизайнером Apple Jony Ive в сотрудничестве с SoftBank, на сумму около 6,5 миллиардов долларов. Jony Ive займет должность креативного директора OpenAI и будет отвечать за дизайн продуктов. Команда io из примерно 55 человек присоединится к OpenAI для разработки аппаратных устройств AI нового типа, первый продукт ожидается в 2026 году. Это приобретение знаменует официальный выход OpenAI на рынок аппаратного обеспечения с целью создания персональных вычислительных устройств и интерактивного опыта на базе AI, что может бросить вызов существующему рынку смартфонов и вычислительных устройств. (Источник: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

На конференции Google I/O представлены многочисленные модели и приложения AI, подчеркнута интеграция AI в повседневную жизнь: На конференции разработчиков I/O 2025 Google представила Gemini 2.5 Pro и ее версию с углубленным мышлением, облегченную Gemini 2.5 Flash, модель диффузии текста Gemini Diffusion, модель генерации изображений Imagen 4 и модель генерации видео Veo 3. Veo 3 поддерживает генерацию видео со звуком и диалогами, демонстрируя впечатляющие результаты. Google также запустила приложение для создания фильмов с помощью AI под названием Flow, интегрирующее Veo, Imagen и Gemini. Функция AI-поиска будет объединять обзоры AI, Deep Search и личную информацию, а также будет представлен AI Mode. Google подчеркивает бесшовную интеграцию AI в существующие продукты и услуги, стремясь сделать технологию AI «невидимой» и улучшить пользовательский опыт. (Источник: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

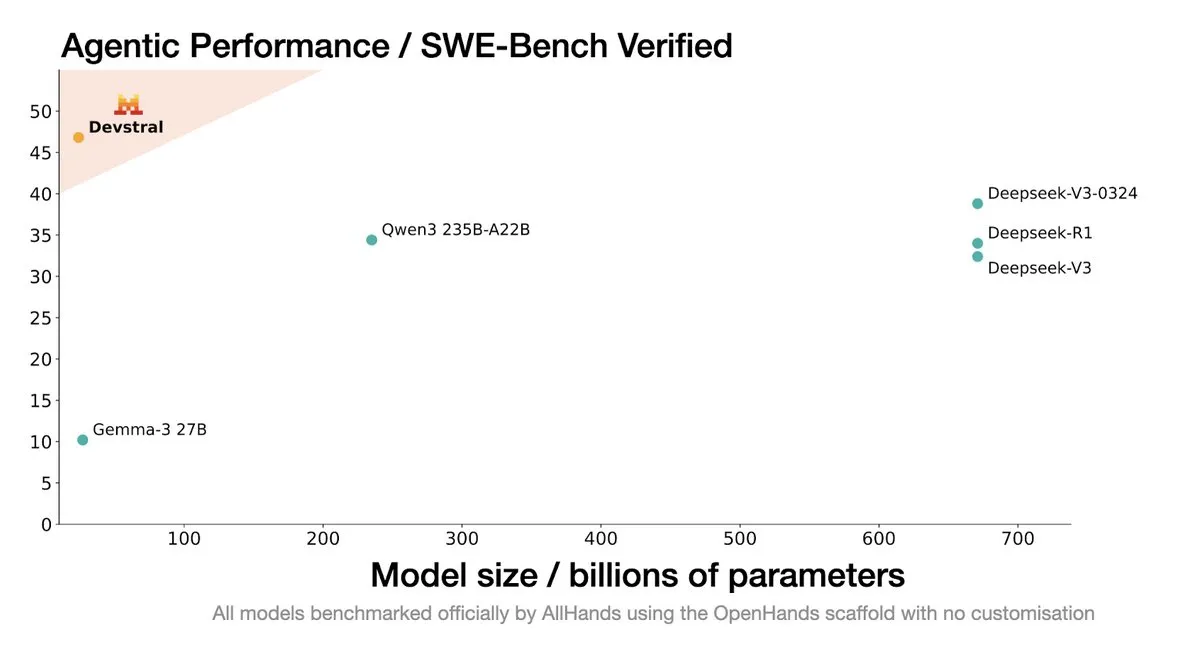
Mistral AI выпустила Devstral: SOTA модель с открытым исходным кодом, разработанную специально для кодирующих агентов: Mistral AI в сотрудничестве с All Hands AI представила Devstral, SOTA модель с открытым исходным кодом, разработанную специально для кодирующих агентов. Модель показала отличные результаты в бенчмарке SWE-Bench Verified, превзойдя серии DeepSeek и Qwen3 235B, имея всего 24B параметров и возможность запуска на одной карте RTX4090 или Mac с 32 ГБ ОЗУ. Devstral обучена на реальных GitHub Issue, с акцентом на понимание контекста в больших кодовых базах, распознавание связей между компонентами и выявление ошибок в сложных функциях. Модель распространяется под лицензией Apache 2.0, что делает ее более открытой по сравнению с предыдущей Codestral. (Источник: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
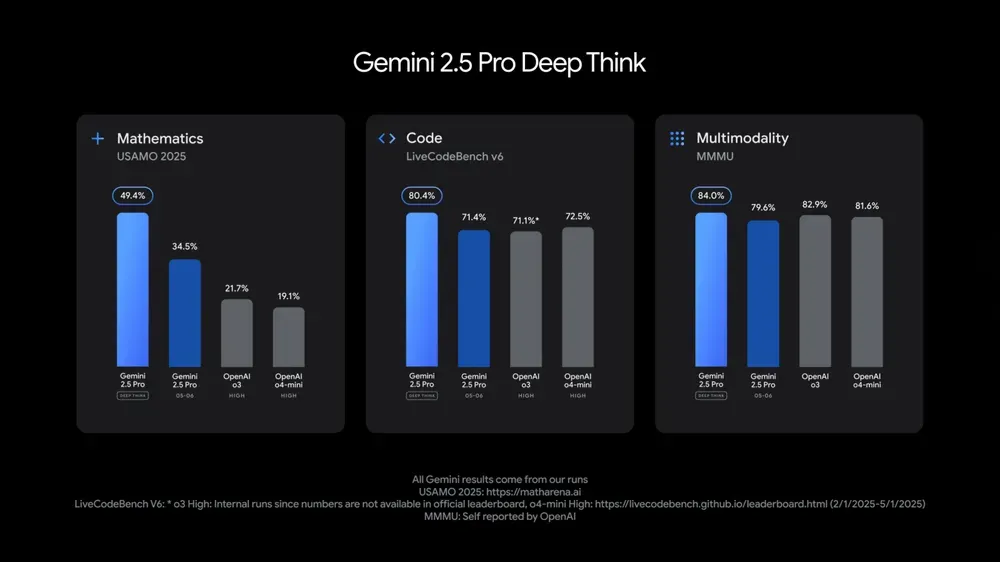
Технический директор Google DeepMind Koray Kavukcuoglu комментирует Veo 3, Deep Think и прогресс в области AGI: Во время конференции Google I/O технический директор DeepMind Koray Kavukcuoglu дал интервью, в котором обсудил улучшения в модели генерации видео Veo 3 (например, синхронизацию аудио и видео), режим улучшенного логического вывода Deep Think в Gemini 2.5 Pro (реализующий логический вывод через параллельные цепочки мыслей), а также свои взгляды на AGI. Kavukcuoglu подчеркнул, что масштаб — не единственный фактор для достижения AGI; архитектура, алгоритмы, данные и технологии логического вывода одинаково важны. Реализация AGI требует прорывов в фундаментальных исследованиях и ключевых инноваций, а не простого наращивания инженерных усилий. Он также выразил оптимизм по поводу «атмосферного программирования» (vibe coding), которое позволит людям без опыта в программировании создавать приложения. (Источник: demishassabis, 36氪)
🎯 Новости и тенденции
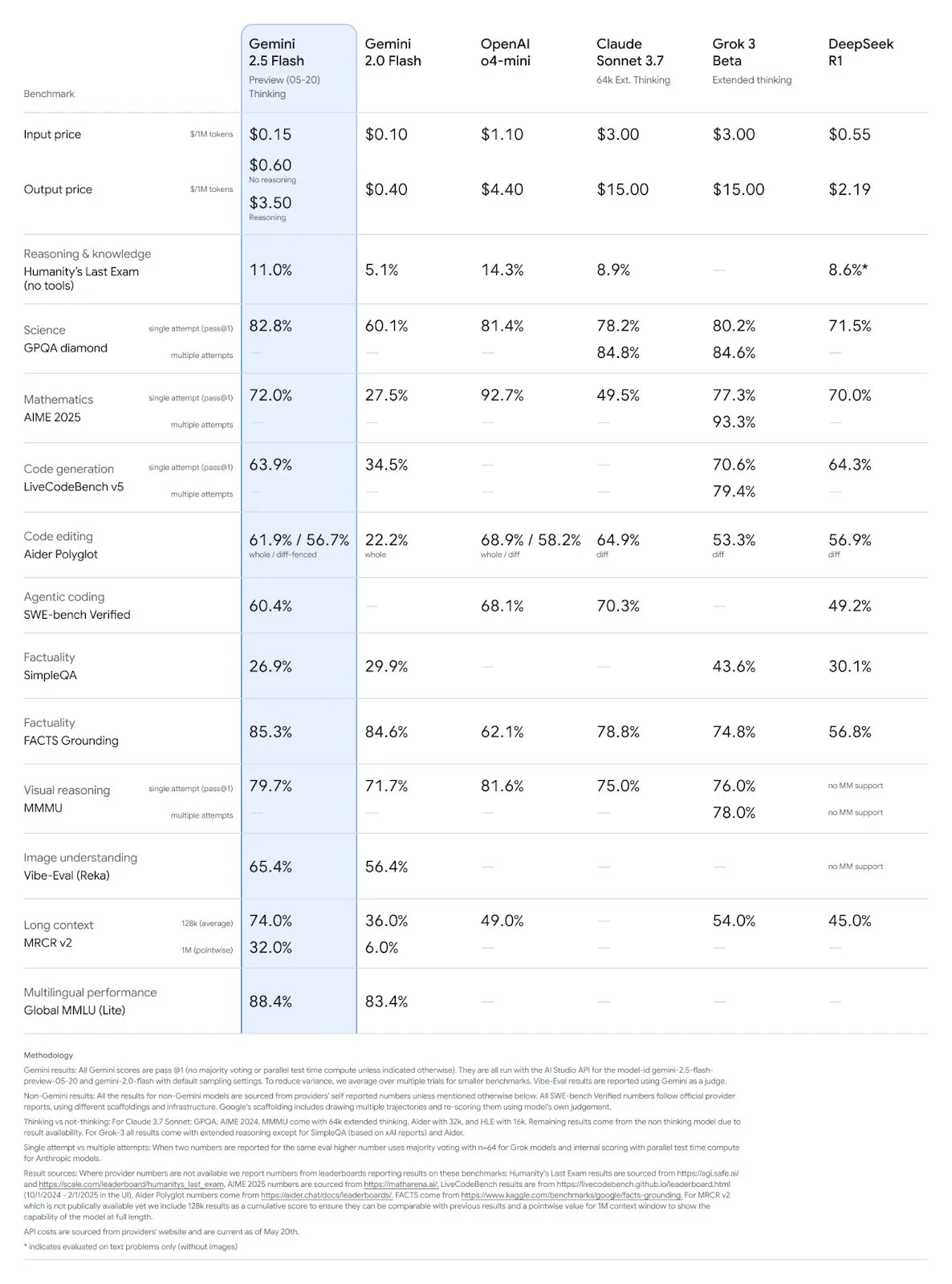
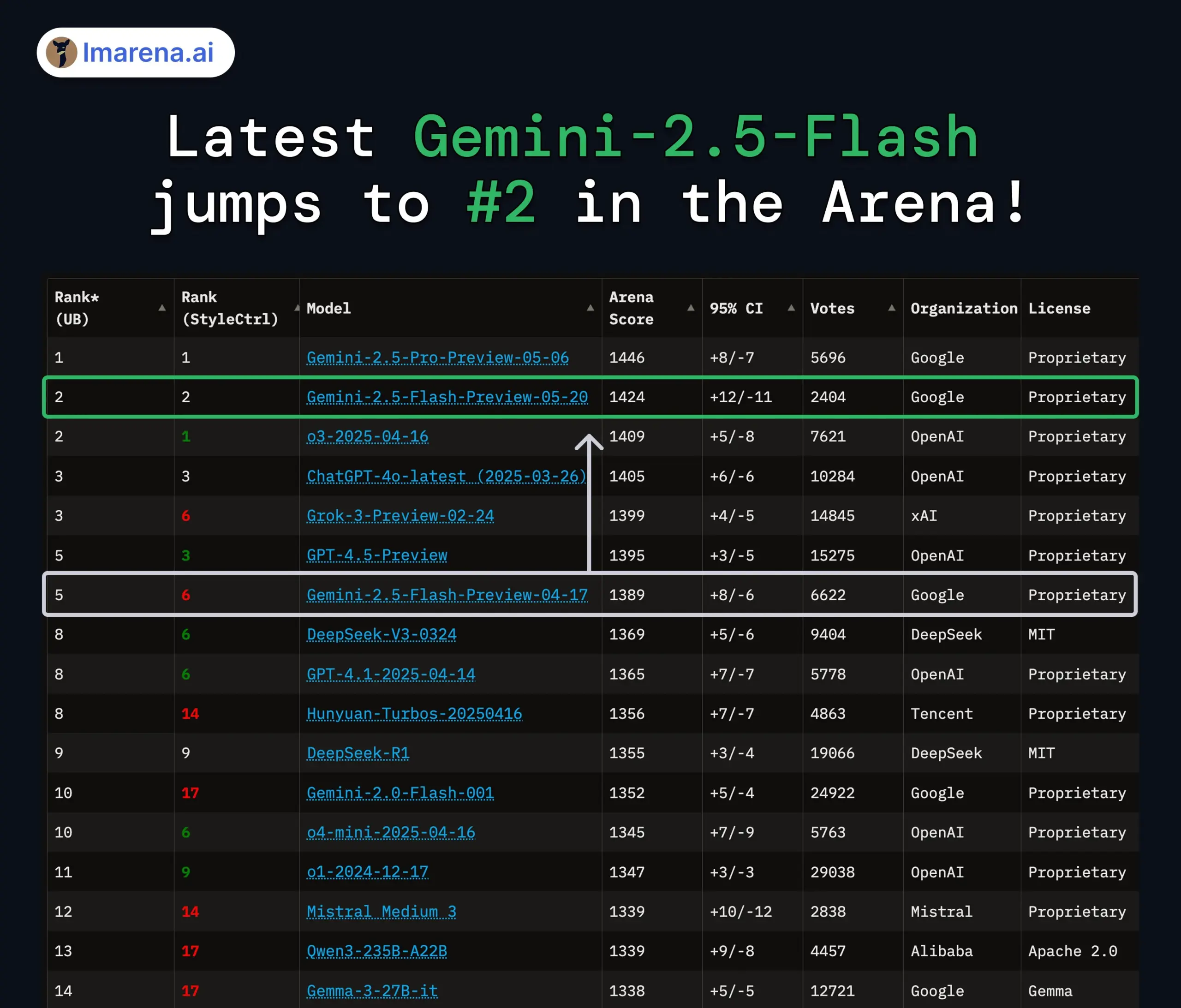
Обновление моделей Google Gemini 2.5 Pro и Flash, значительное повышение производительности: Google на конференции I/O объявила, что модели Gemini 2.5 Pro и Flash будут официально запущены в июне. Gemini 2.5 Pro позиционируется как самая интеллектуальная модель AI в мире, дополнена версией с углубленным мышлением и лидирует во многих тестах. Gemini 2.5 Flash, как легковесная модель, повысила эффективность на 22%, сократила потребление токенов на 20%-30% и обладает нативной способностью генерации аудио. Данные LMArena показывают, что новая версия Gemini-2.5-Flash значительно поднялась в рейтинге чат-ботов на арене, заняв второе место, особенно выделяясь в сложных задачах, таких как кодирование и математика. (Источник: natolambert, demishassabis, karminski3, lmarena_ai)
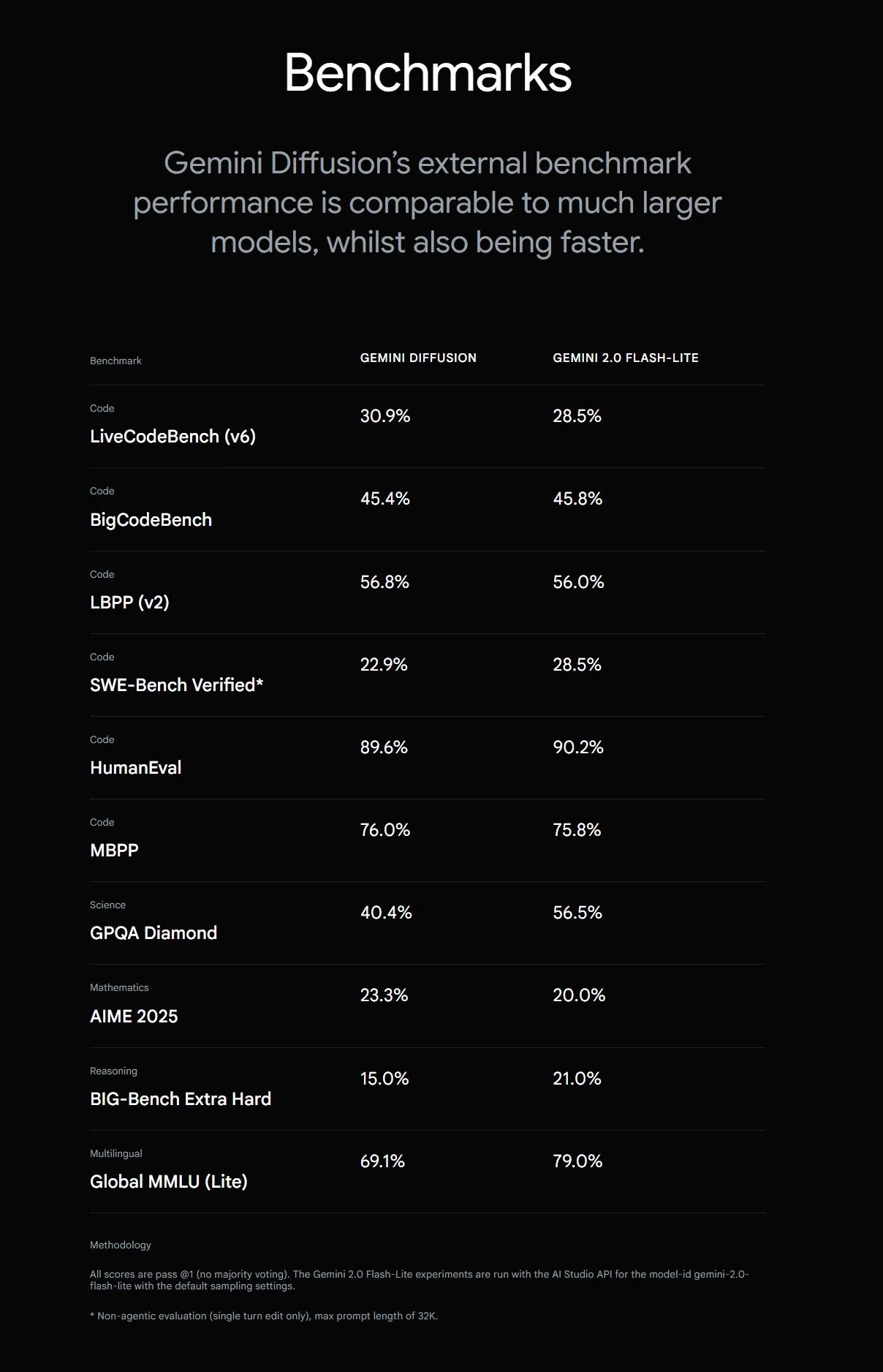
Google представляет Gemini Diffusion, скорость генерации текста увеличена в 5 раз: Google DeepMind представила экспериментальную модель генерации текста Gemini Diffusion, скорость генерации которой в 5 раз выше, чем у предыдущей самой быстрой модели. Особенно выделяются ее возможности программирования, достигающие 2000 токенов в секунду (включая расходы на токенизацию и т.д.). В отличие от традиционных авторегрессионных моделей, диффузионные модели способны к некаузальному выводу, могут заранее «продумывать» последующие ответы, превосходя GPT-4o в решении сложных задач, требующих глобального вывода (например, специфические вычислительные задачи, поиск простых чисел). В настоящее время модель доступна для тестирования только по заявкам разработчиков. (Источник: OriolVinyalsML, dotey, karminski3)
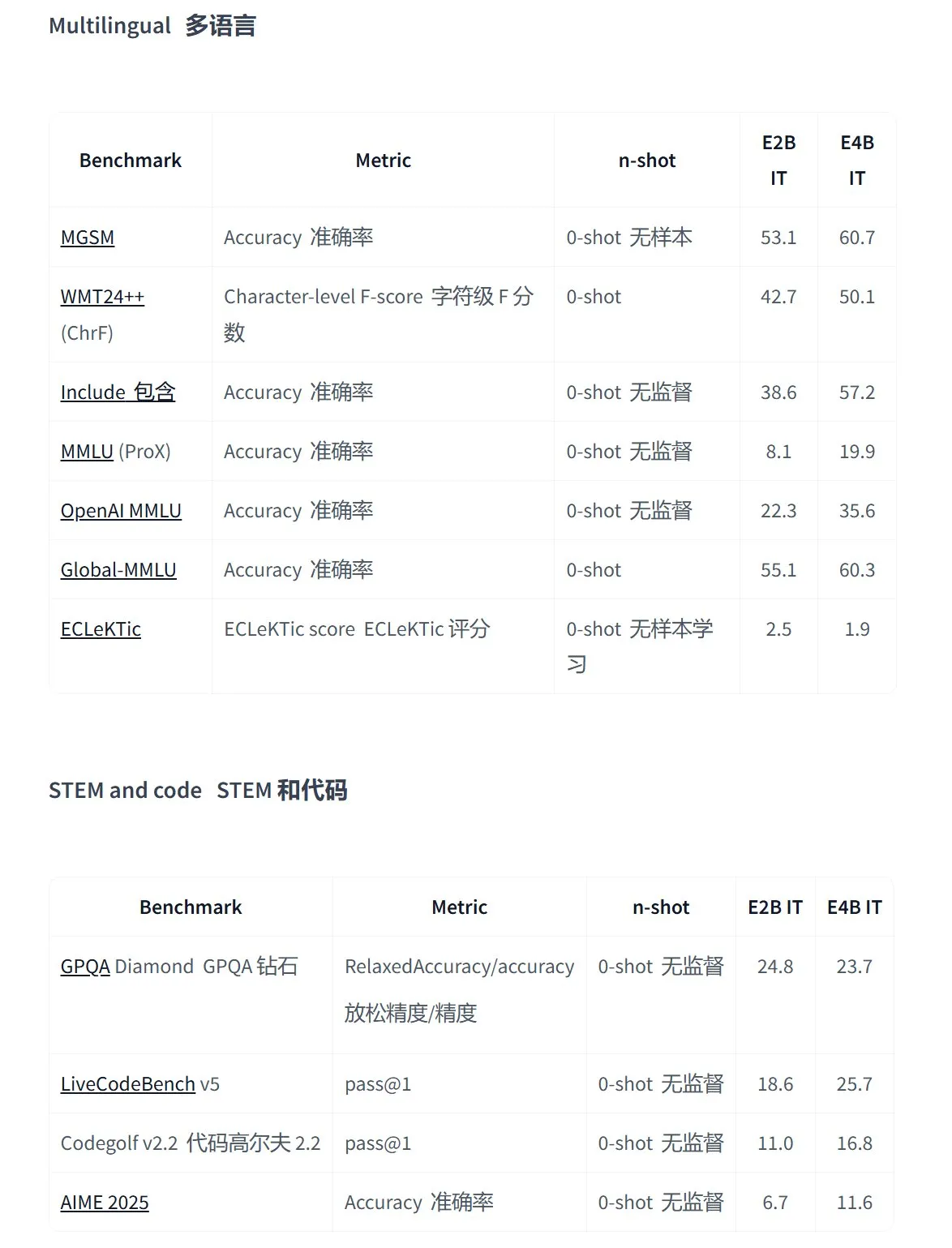
Google выпускает серию моделей Gemma 3n с открытым исходным кодом, предназначенных для мультимодальных приложений на устройствах: Google представила новое поколение эффективных мультимодальных моделей с открытым исходным кодом Gemma 3n, специально разработанных для устройств с низким энергопотреблением и поддерживающих ввод текста, речи, изображений, видео, а также многоязычную обработку. Модели этой серии (например, gemma-3n-E4B-it-litert-preview и gemma-3n-E2B-it-litert-preview) имеют небольшой размер (3-4,4 ГБ), могут работать на устройствах с 2 ГБ ОЗУ, а их знания актуальны на июнь 2024 года. В настоящее время они доступны для предварительного ознакомления разработчикам на платформах AI Studio и AI Edge. (Источник: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses API добавляет поддержку MCP, генерацию изображений и функции интерпретатора кода: Платформа для разработчиков OpenAI объявила о важном обновлении своего Responses API (ранее Assistants API), добавив поддержку удаленных серверов протокола контекста модели (MCP), что позволяет AI-агентам более гибко взаимодействовать с внешними инструментами и сервисами. Кроме того, в API интегрированы возможности генерации изображений и функции интерпретатора кода, что еще больше расширяет его сценарии применения и потенциал для разработки. (Источник: gdb, npew, OpenAIDevs, snsf)
xAI API интегрирует функцию поиска в реальном времени Grok Live Search: xAI объявила о добавлении в свой API функции Live Search, позволяющей Grok осуществлять поиск данных в реальном времени с платформы X, из интернета, новостных источников и т.д. Функция в настоящее время находится на стадии бета-тестирования и временно доступна разработчикам бесплатно. Она призвана расширить возможности Grok по получению и обработке самой свежей информации, обеспечивая поддержку для создания более динамичных и информационно насыщенных AI-приложений. (Источник: xai, TheGregYang, yoheinakajima)

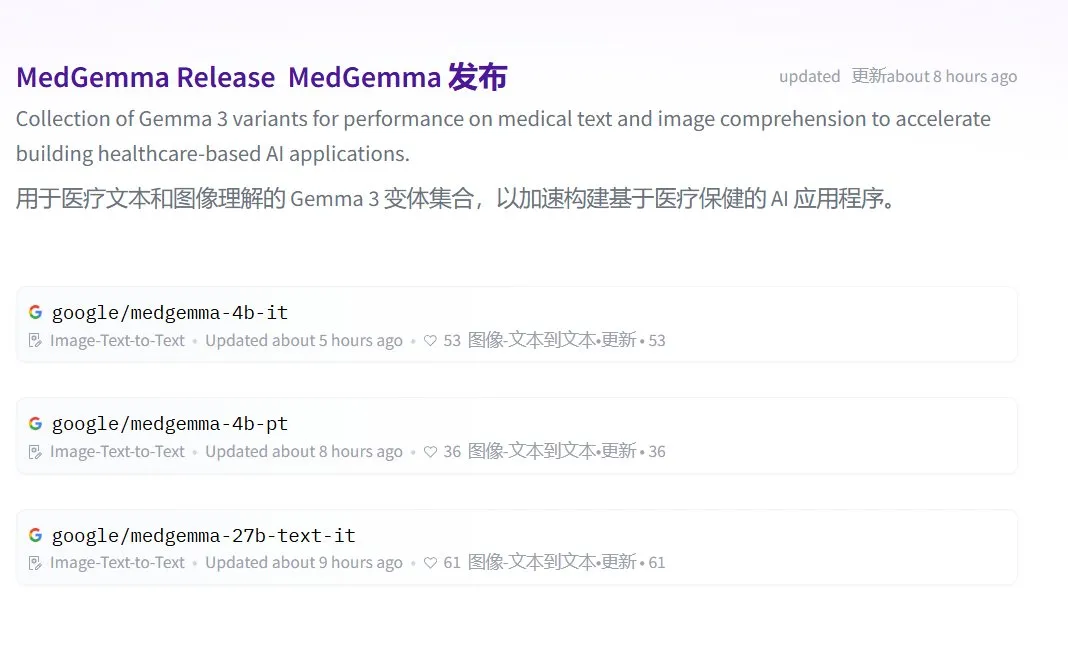
Google выпускает серию медицинских LLM с открытым исходным кодом MedGemma: Google представила медицинские модели с открытым исходным кодом MedGemma, основанные на архитектуре Gemma 3. Серия включает medgemma-4b-pt (базовая модель), medgemma-4b-it (мультимодальная, для диагностики по медицинским изображениям) и medgemma-27b-text-it (чисто текстовая, для анализа истории болезни при консультациях). Эти модели специально обучены для понимания медицинских текстов и изображений с целью повышения применимости AI в медицинской сфере, например, для помощи в диагностике, анализа историй болезни и т.д. Модели уже доступны на Hugging Face. (Источник: JeffDean, karminski3)
Множество продуктов Tencent Hunyuan Large Model обновлены, запущена открытая платформа для интеллектуальных агентов: Tencent Hunyuan объявила об итерационном обновлении флагманской модели быстрого мышления TurboS и модели глубокого мышления T1. TurboS вошла в десятку лучших в мире по возможностям кодирования и математики. Представлены новая модель визуального глубокого вывода T1-Vision и модель голосовых вызовов end-to-end Hunyuan Voice. Прежний движок знаний обновлен до «Платформы разработки интеллектуальных агентов Tencent Cloud», объединяющей возможности RAG и Agent. Также обновлены Hunyuan Image 2.0, 3D v2.5 и модель генерации игровых визуальных эффектов, планируется дальнейшее открытие исходного кода мультимодальных базовых моделей и плагинов. (Источник: 36氪)

Alibaba в сотрудничестве с Чжэцзянским университетом предложила закон масштабирования параллельных вычислений ParScale: Исследовательская группа Alibaba в сотрудничестве с Чжэцзянским университетом предложила новый закон масштабирования: закон масштабирования параллельных вычислений (ParScale). Этот закон гласит, что увеличение параллельных вычислений модели во время обучения и инференса может повысить возможности больших моделей без увеличения количества параметров, а также повысить эффективность инференса. По сравнению с масштабированием параметров, ParScale увеличивает объем памяти всего на 4,5%, а задержку — на 16,7%. Этот метод реализуется за счет диверсификации преобразований входных данных, параллельной обработки и динамического агрегирования выходных данных, особенно эффективно проявляя себя в задачах с интенсивным логическим выводом, таких как математика и программирование. (Источник: 36氪)
Microsoft выпускает крупномасштабную атмосферную базовую модель Aurora, скорость прогнозирования увеличена в 5000 раз: Microsoft и ее партнеры представили первую крупномасштабную атмосферную базовую модель Aurora, обученную на более чем 1 миллионе часов геофизических данных. Модель способна более точно и эффективно прогнозировать качество воздуха, траектории тропических циклонов, динамику морских волн и погоду с высоким разрешением. По сравнению с передовой системой численного прогнозирования IFS, Aurora вычисляет примерно в 5000 раз быстрее и достигает SOTA во многих ключевых областях прогнозирования. Архитектура модели гибкая и может быть доработана для конкретных задач, что обещает способствовать популяризации прогнозирования земных систем. (Источник: 36氪)

AI-поиск Google получит AI Mode, объединяющий множество интеллектуальных функций: Google объявила о запуске «AI-режима» (AI Mode) для своей поисковой системы, который позиционируется как «самый мощный AI-поиск». Этот режим основан на Gemini 2.5, обладает более сильными возможностями логического вывода, поддерживает более длинные запросы, мультимодальный поиск и мгновенные высококачественные ответы. В будущем также будет интегрирована функция «глубокого поиска» (Deep Search), способная одновременно выполнять сотни запросов и предоставлять комплексные отчеты, а также планируется интеграция личных данных из Gmail и других сервисов, а также функции взаимодействия с камерой в реальном времени Project Astra и автоматического управления задачами Project Mariner. (Источник: dotey, Google)

Выпущена модель генерации изображений Google Imagen 4 со значительно улучшенной скоростью и детализацией: Google выпустила свою последнюю модель преобразования текста в изображение Imagen 4, утверждая, что скорость генерации по сравнению с предыдущим поколением увеличена в 3-10 раз, детализация изображений стала богаче, результаты точнее, а возможности рендеринга текста также значительно улучшены. Imagen 4 способна генерировать сложные объекты, такие как ткани, капли воды, шерсть животных, с разрешением до 2K, а также поддерживает создание поздравительных открыток, плакатов, комиксов и т.д. Модель теперь бесплатно доступна в Gemini App, Whisk, приложениях Workspace и Vertex AI. (Источник: dotey, GoogleDeepMind)
Исследование выявило риск «галлюцинаций пакетов» в коде, генерируемом инструментами AI-программирования: Исследование, которое будет опубликовано на USENIX Security 2025, указывает на широко распространенное явление «галлюцинаций пакетов» в коде, генерируемом AI, то есть ссылки на сторонние библиотеки, которых на самом деле не существует. В ходе исследования было протестировано 16 основных больших языковых моделей, и выяснилось, что более 20% кода зависят от вымышленных пакетов, причем среди моделей с открытым исходным кодом этот процент выше. Это создает возможности для атак на цепочки поставок, поскольку злоумышленники могут использовать эти вымышленные имена пакетов для публикации вредоносного кода. Компании, такие как Apple и Microsoft, уже сталкивались с подобными атаками, связанными с путаницей зависимостей. (Источник: 36氪)

Suno запускает функцию Remix, позволяющую пользователям создавать ремиксы на основе существующих песен: Платформа генерации музыки с помощью AI Suno запустила функцию Remix, которая позволяет пользователям выбирать любой трек на платформе для дальнейшего творчества. Пользователи могут делать каверы (Cover), расширять (Extend) или повторно использовать промпты (Reuse Prompt) для песен. При создании Remix сохраняется информация об источнике оригинального материала, и пользователи также могут в любое время включать или отключать разрешение на Remix для своих произведений. (Источник: SunoMusic)
Исследование показало, что все модели встраивания (embedding models) изучают схожие семантические структуры: Jack Morris и другие исследователи обнаружили, что семантические структуры, изучаемые различными моделями встраивания, очень похожи. Более того, возможно отображение между пространствами встраивания различных моделей, основываясь только на структурной информации, без каких-либо парных данных. Это открытие намекает на возможное существование некой универсальной геометрической структуры в пространствах встраивания, что имеет важное значение для совместимости моделей, трансферного обучения и понимания сущности встраиваний. (Источник: menhguin, torchcompiled, dilipkay, jeremyphoward)
Статья рассматривает проблему «налога на галлюцинации» при тонкой настройке с подкреплением (RFT): Исследование Taiwei Shi и его коллег указывает, что тонкая настройка с подкреплением (RFT), улучшая способности больших языковых моделей к логическому выводу, может приводить к тому, что модель уверенно генерирует галлюцинаторные ответы на вопросы, на которые она не может ответить. Это явление названо «налогом на галлюцинации». Для проверки был введен набор данных SUM (синтетические математические задачи без ответа), и было обнаружено, что стандартное обучение RFT значительно снижает частоту отказов модели от ответа. Добавление небольшого количества данных SUM в процесс RFT позволяет эффективно восстановить адекватное поведение отказа модели и улучшить ее осведомленность о собственной неопределенности и границах знаний. (Источник: teortaxesTex)

🧰 Инструменты
Google запускает инструмент для создания фильмов с помощью AI Flow, интегрирующий Veo, Imagen и Gemini: Google выпустила инструмент для производства фильмов с помощью AI Flow, который объединяет ее новейшие модели генерации видео Veo 3, генерации изображений Imagen 4 и мультимодальную модель Gemini. С помощью Flow пользователи могут легко создавать короткометражные фильмы кинематографического качества, используя естественный язык и управление ресурсами, включая генерацию фрагментов из текстовых подсказок, комбинирование сцен, построение повествования и сохранение часто используемых элементов в качестве материалов. Инструмент предназначен для помощи создателям в быстром и эффективном производстве работ кинематографического качества. В настоящее время он доступен для подписчиков Google AI Pro и Ultra в США. (Источник: dotey, op7418)

Google выпускает облачного AI-агента для программирования Jules, работающего на Gemini 2.5 Pro: Google представила AI-агента для программирования Jules, основанного на Gemini 2.5 Pro. Jules может в фоновом режиме автоматически обрабатывать задачи в репозиториях кода, такие как исправление ошибок и рефакторинг кода, поддерживая параллельное выполнение нескольких задач. Кроме того, Jules предоставляет ежедневно обновляемые подкасты Codecasts, помогающие пользователям быть в курсе последних изменений в репозиториях кода. В настоящее время инструмент доступен для бесплатного ознакомления. (Источник: dotey, karminski3, GoogleDeepMind)
LangChain запускает открытую платформу для создания агентов без кода Open Agent Platform (OAP): LangChain выпустила Open Agent Platform (OAP), открытую платформу без кода для обычных пользователей, предназначенную для создания, прототипирования и развертывания AI-агентов. OAP поддерживает создание агентов через веб-интерфейс, подключение к серверам RAG для улучшения поиска информации, расширение внешних инструментов через MCP и использование Agent Supervisor для оркестровки рабочих процессов с несколькими агентами. Цель платформы — предоставить непрофессиональным разработчикам возможность использовать мощные функции агентов LangGraph. (Источник: LangChainAI, Hacubu)

Google Labs представляет инструмент для дизайна UI с AI Stitch: Google Labs выпустила инструмент для дизайна UI с AI Stitch, который объединяет последние модели Google DeepMind (включая Gemini и Imagen) и позволяет быстро генерировать высококачественные UI-дизайны. Пользователи могут обновлять темы интерфейса с помощью естественного языка, автоматически настраивать изображения, осуществлять перевод контента на несколько языков и экспортировать фронтенд-код одним щелчком мыши. Stitch является развитием предыдущего Galileo AI, основатель которого присоединился к команде Google. (Источник: dotey)
LangChain запускает локальную песочницу для кода LangChain Sandbox: LangChain выпустила LangChain Sandbox, позволяющую AI-агентам безопасно запускать недоверенный Python-код локально. Она предоставляет изолированную среду выполнения и настраиваемые разрешения, не требуя удаленного выполнения или Docker-контейнеров, и поддерживает сохранение состояния между несколькими выполнениями через сессии. Это предоставляет более безопасный и удобный инструмент для создания AI-агентов, способных выполнять код (например, codeact agents). (Источник: hwchase17, Hacubu)
Vitalops открывает исходный код Datatune: LLM-инструмент для обработки больших наборов данных с использованием естественного языка: Vitalops открыла исходный код Datatune, инструмента, который позволяет пользователям обрабатывать наборы данных любого размера с помощью команд на естественном языке. Datatune поддерживает операции Map и Filter, может подключаться к различным поставщикам LLM-сервисов, таким как OpenAI, Azure, Ollama, или к пользовательским моделям, а также использует Dask DataFrame для разделения и параллельной обработки. Инструмент предназначен для упрощения задач очистки и обогащения данных, заменяя сложные регулярные выражения или пользовательский код. (Источник: Reddit r/MachineLearning)
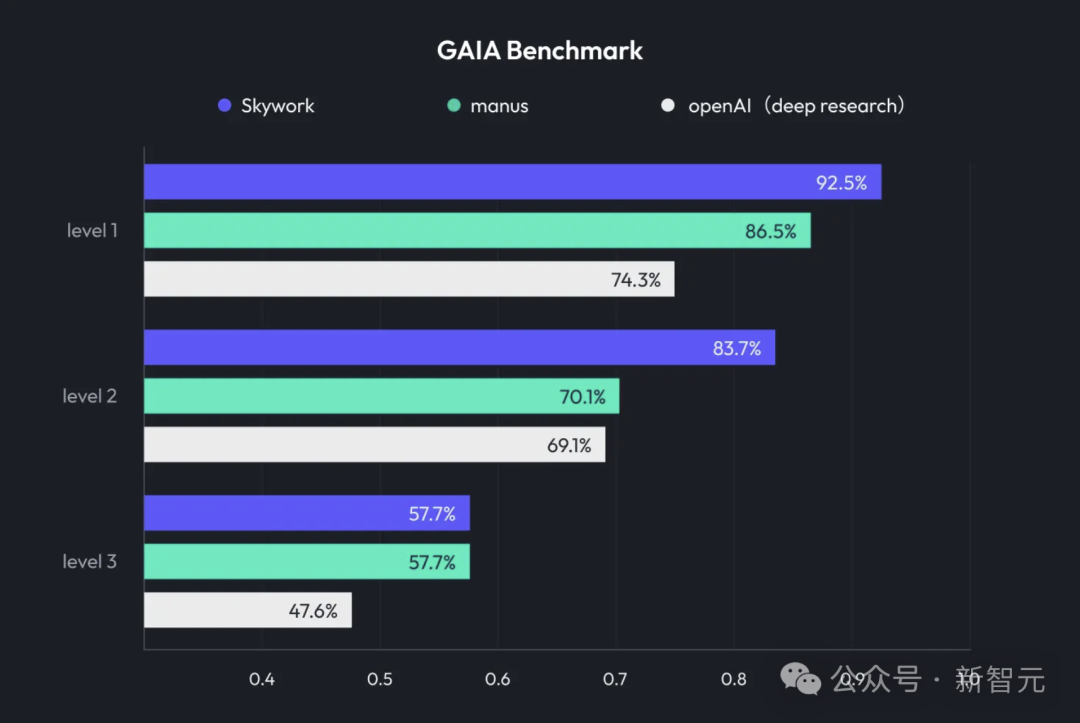
Kunlun Wanwei представляет Skywork Super Agents, интегрирующие Deep Research и мультимодальный вывод: Kunlun Wanwei выпустила офисный AI-продукт Skywork Super Agents, сочетающий возможности глубокого исследования (Deep Research) и мультимодального вывода универсальных интеллектуальных агентов. Продукт поддерживает создание PPT, написание документов, обработку таблиц, генерацию веб-страниц, создание подкастов и другие офисные сценарии, подчеркивая отслеживаемость источников контента для уменьшения галлюцинаций, а также предоставляет функции онлайн-редактирования и экспорта. Kunlun Wanwei также открыла исходный код фреймворка Deep Research Agent и соответствующего MCP. (Источник: 36氪)
Google запускает SynthID Detector для помощи в идентификации контента, созданного AI: Google выпустила SynthID Detector, новый портал, предназначенный для помощи журналистам, медиа-специалистам и исследователям в более легкой идентификации того, содержит ли контент водяной знак SynthID. SynthID — это разработанная Google технология для добавления невидимых водяных знаков в контент, созданный AI (включая изображения, аудио, видео или текст). Запуск этого инструмента обнаружения способствует повышению прозрачности и отслеживаемости контента, созданного AI. (Источник: dotey, Google)
Feishu запускает функцию «Вопросы и ответы на основе знаний», создавая корпоративный инструмент для ответов с помощью AI: Feishu (Lark) запустила новую функцию «Вопросы и ответы на основе знаний». Этот инструмент, основываясь на всей информации, к которой у сотрудников компании есть доступ в Feishu (сообщения, документы, базы знаний и т.д.), в сочетании с большими моделями, такими как DeepSeek-R1, Doubao, и технологией RAG, предоставляет сотрудникам точные ответы и поддержку в создании контента. Его особенностью является то, что ответы динамически корректируются в зависимости от личности и прав доступа спрашивающего в компании. Цель — бесшовная интеграция AI в повседневные рабочие процессы для повышения эффективности управления и использования знаний в компании. (Источник: 量子位)

Animon: первая в Японии платформа для генерации аниме с помощью AI, ориентированная на качество в стиле «нидзигэн» и неограниченную бесплатную генерацию: Японская компания CreateAI (ранее TuSimple Future) запустила платформу для генерации аниме с помощью AI Animon, специально настроенную для создания аниме. Платформа сочетает японскую эстетику аниме с технологиями AI, подчеркивая стилистическое единство изображений и высокую эффективность производства, и заявляет, что индивидуальные пользователи могут бесплатно и неограниченно генерировать видео. Animon поддерживает быструю генерацию анимационных фрагментов (около 3 минут) путем загрузки изображений персонажей и текстовых описаний, стремясь снизить порог входа в создание аниме и стимулировать экосистему UGC-контента. Ее материнская компания CreateAI владеет собственной большой моделью Ruyi и правами на адаптацию таких IP, как «Задача трех тел» и «Герои Цзинь Юна», реализуя стратегию двойного привода «собственный контент + платформа инструментов UGC». (Источник: 量子位)

📚 Обучение
DeepLearning.AI запускает новый курс: Улучшенная доработка LLM с использованием GRPO: Andrew Ng объявил о запуске нового короткого курса в сотрудничестве с Predibase на тему «Улучшенная доработка LLM с использованием GRPO (Group Relative Policy Optimization)». Курс научит, как использовать обучение с подкреплением (в частности, алгоритм GRPO) для повышения производительности LLM в задачах многошагового логического вывода (таких как решение математических задач, отладка кода) без необходимости в большом количестве образцов для контролируемой тонкой настройки. GRPO направляет модель с помощью программируемых функций вознаграждения, подходит для задач с проверяемыми результатами и может значительно улучшить возможности логического вывода небольших LLM. (Источник: AndrewYNg, DeepLearningAI)
LlamaIndex делится опытом управления крупномасштабными монорепозиториями Python: Команда LlamaIndex поделилась своим опытом управления монорепозиторием Python, содержащим более 650 пакетов сообщества. Они перешли с Poetry и Pants на uv и собственный инструмент управления сборкой с открытым исходным кодом LlamaDev, добившись ускорения выполнения тестов на 20%, более четких логов, упрощения локальной разработки и снижения порога входа для контрибьюторов. Этот опыт может быть полезен командам, которым необходимо управлять крупными проектами на Python. (Источник: jerryjliu0)

Учебное пособие: Создание собственного AI-агента для кодирования Tig: Jerry Liu порекомендовал проект AI-агента для кодирования с открытым исходным кодом под названием Tig. Этот проект представляет собой терминального помощника по кодированию с участием человека в цикле (human-in-the-loop), созданного с использованием рабочего процесса LlamaIndex. Tig способен писать, отлаживать, анализировать код на нескольких языках, выполнять команды оболочки, искать в кодовых базах, а также генерировать тесты и документацию. Репозиторий GitHub предоставляет подробное руководство по сборке, что является отличным образовательным ресурсом для разработчиков, желающих научиться создавать AI-агентов для кодирования. (Источник: jerryjliu0)
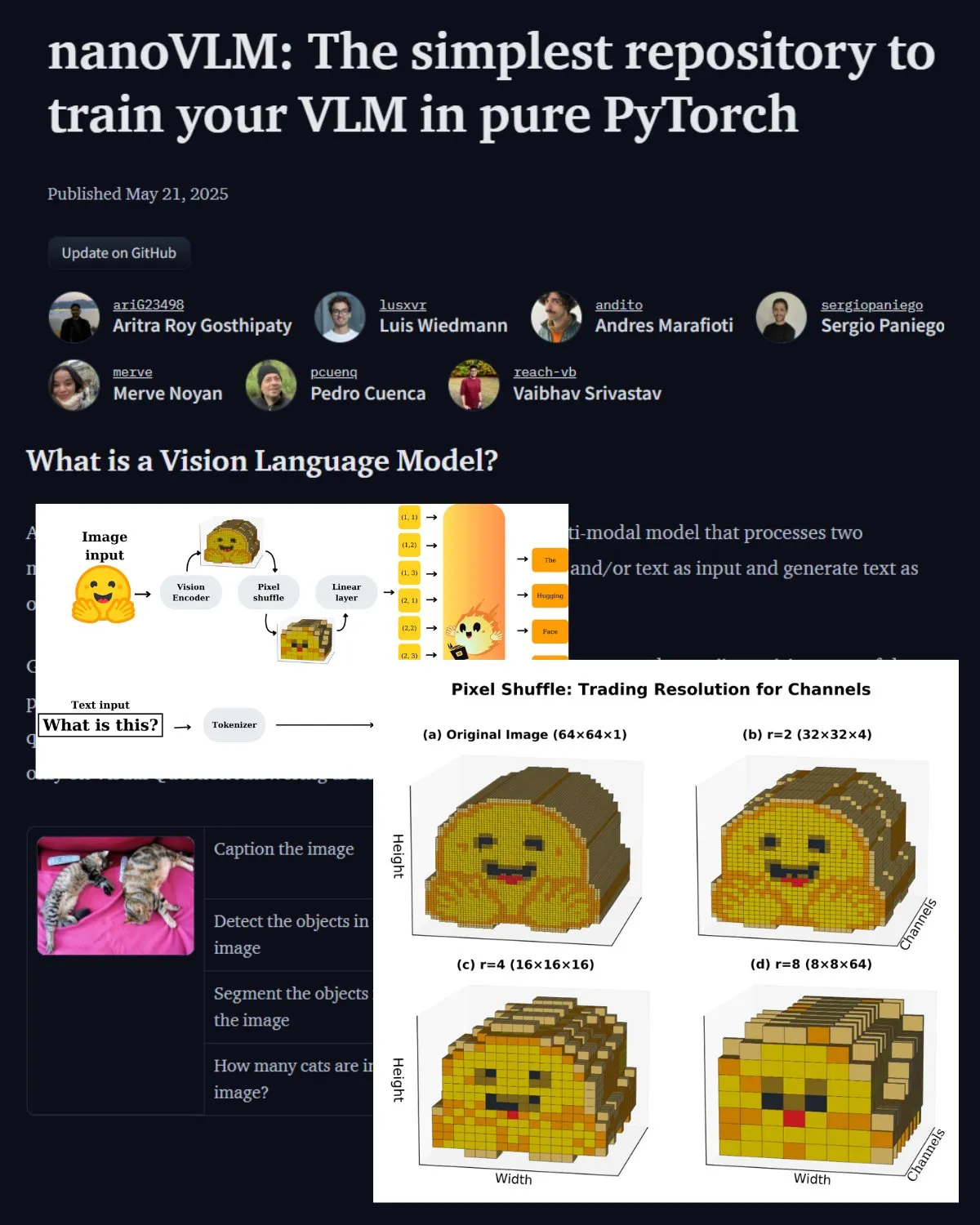
Hugging Face публикует важный пост в блоге о VLM, представляя лабораторию сообщества nanoVLM: Hugging Face опубликовала пост в блоге о визуально-языковых моделях (VLM), охватывающий основы VLM, архитектуры и способы обучения собственной легковесной VLM. Также представлен nanoVLM, репозиторий с открытым исходным кодом для тонкой настройки VLM, который теперь превратился в лабораторию сообщества для исследований в области визуального языка, призванную помочь разработчикам исследовать и вносить вклад в исследования VLM. (Источник: _akhaliq, huggingface)
Serrano Academy выпускает серию видеоуроков по тонкой настройке LLM с помощью обучения с подкреплением: Serrano Academy завершила и выпустила серию видеоуроков по использованию обучения с подкреплением для тонкой настройки и обучения LLM. Материалы охватывают такие ключевые концепции и технологии, как глубокое обучение с подкреплением (Deep Reinforcement Learning), RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) и дивергенция Кульбака-Лейблера (KL Divergence). (Источник: SerranoAcademy)
Статья исследует феномен «пустых слоев» в больших языковых моделях: Исследование изучает явление, при котором не все слои в больших языковых моделях, настроенных на инструкции, активируются в процессе логического вывода. Неактивированные слои называются «пустыми слоями» (Voids). В исследовании использовался метод адаптивных вычислений L2 (LAC) для отслеживания активированных слоев на этапах обработки подсказок и генерации ответов, и было обнаружено, что на разных этапах активируются разные слои. Эксперименты показали, что в таких бенчмарках, как MMLU, пропуск пустых слоев в Qwen2.5-7B-Instruct (использование только 30% слоев) может улучшить производительность, что намекает на то, что выборочный пропуск большинства слоев может быть полезен для конкретных задач. (Источник: HuggingFace Daily Papers)
Исследование предлагает «мягкое мышление»: раскрытие потенциала логического вывода LLM в непрерывном концептуальном пространстве: Статья под названием «Soft Thinking» предлагает метод без обучения, который имитирует человекоподобное «мягкое» мышление путем генерации мягких, абстрактных концептуальных токенов в непрерывном концептуальном пространстве. Эти концептуальные токены формируются из вероятностно взвешенной смеси встраиваний токенов и способны инкапсулировать множество значений из связанных дискретных токенов, тем самым неявно исследуя множество путей логического вывода. Эксперименты показывают, что этот метод повышает точность pass@1 в математических и кодировочных бенчмарках, одновременно сокращая использование токенов и сохраняя интерпретируемость вывода. (Источник: HuggingFace Daily Papers)
Статья исследует масштабируемые цепочки рассуждений через эластичный вывод: Исследователи из Salesforce предложили метод реализации масштабируемых цепочек рассуждений (chain-of-thought) посредством эластичного вывода (Elastic Reasoning). Исследование направлено на решение проблемы эффективной генерации и управления длинными цепочками рассуждений в больших языковых моделях при обработке сложных задач логического вывода с целью повышения точности и эффективности вывода. Соответствующие модели и код опубликованы на Hugging Face. (Источник: _akhaliq)

Исследование: Будут ли AI-модели лгать, чтобы спасти больного ребенка?: Исследование под названием LitmusValues создало процесс оценки, направленный на выявление приоритетов AI-моделей в ряде категорий ценностей AI. Собирая AIRiskDilemmas (набор дилемм, содержащих сценарии, связанные с рисками безопасности AI), исследователи измеряют выбор AI-моделей в условиях различных ценностных конфликтов, тем самым прогнозируя их ценностные приоритеты и выявляя потенциальные риски. Исследование показывает, что ценности, определенные в LitmusValues (включая заботу и др.), могут предсказывать уже наблюдаемое рискованное поведение в AIRiskDilemmas, а также ранее не встречавшееся рискованное поведение в HarmBench. (Источник: HuggingFace Daily Papers)
Исследование по эффективной тонкой настройке диффузионных моделей с помощью обучения с подкреплением на основе ценности (VARD): Диффузионные модели демонстрируют высокую производительность в задачах генерации, однако тонкая настройка под конкретные атрибуты остается сложной задачей. Существующие методы обучения с подкреплением имеют недостатки в стабильности, эффективности и обработке недифференцируемых вознаграждений. VARD (Value-based Reinforced Diffusion) предлагает сначала обучить функцию ценности, предсказывающую ожидаемое вознаграждение из промежуточных состояний, а затем использовать эту функцию ценности и KL-регуляризацию для обеспечения плотного надзора на протяжении всего процесса генерации. Эксперименты доказывают, что этот метод улучшает управление траекториями, повышает эффективность обучения и расширяет применение RL для оптимизации диффузионных моделей со сложными недифференцируемыми функциями вознаграждения. (Источник: HuggingFace Daily Papers)
💼 Бизнес
LMArena.ai (ранее LMSYS.org) привлекла 100 миллионов долларов в рамках посевного раунда финансирования под руководством a16z и инвестиционной компании Калифорнийского университета: Платформа оценки AI-моделей LMArena.ai (ранее LMSYS.org) объявила о завершении посевного раунда финансирования на сумму 100 миллионов долларов, совместно возглавляемого Andreessen Horowitz (a16z) и инвестиционной компанией Калифорнийского университета (UC Investments). Компания стремится создать нейтральную, открытую, управляемую сообществом платформу, чтобы помочь миру понять и улучшить производительность AI-моделей на реальных запросах пользователей. После финансирования оценка компании достигла 600 миллионов долларов. (Источник: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
Правительство США объявило о продаже технологий и услуг AI на миллиарды долларов Саудовской Аравии и ОАЭ: Правительство США объявило о заключении соглашений с Саудовской Аравией и ОАЭ о продаже технологий и услуг AI на сумму в несколько десятков миллиардов долларов. Среди участвующих компаний — AMD, Nvidia, Amazon, Google, IBM, Oracle и Qualcomm. Nvidia поставит саудовской компании Humain 18 000 AI-чипов GB300 и впоследствии сотни тысяч GPU; AMD и Humain совместно инвестируют 10 миллиардов долларов в строительство дата-центров AI. Этот шаг направлен на усиление влияния США в области AI на Ближнем Востоке и помощь в диверсификации экономик этих стран. (Источник: DeepLearning.AI Blog)

Meta запускает программу Llama Startup для поддержки молодых AI-стартапов: Meta объявила о запуске программы Llama Startup Program, направленной на поддержку американских стартапов на ранней стадии (с объемом финансирования менее 10 миллионов долларов и как минимум одним разработчиком) в использовании моделей Llama для инноваций в области генеративного AI. Программа предлагает возмещение расходов на облачные ресурсы, техническую поддержку от экспертов Llama и доступ к ресурсам сообщества. Срок подачи заявок — до 30 мая 2025 года, 18:00 по тихоокеанскому времени. (Источник: AIatMeta)
🌟 Сообщество
Конференция Google I/O вызвала бурное обсуждение: всесторонняя интеграция AI и перспективы на будущее: Конференция Google I/O представила большое количество продуктов и обновлений, связанных с AI, включая серию моделей Gemini, генерацию видео Veo 3, генерацию изображений Imagen 4, режим AI-поиска и т.д., что вызвало широкое обсуждение в сообществе. Многие комментаторы считают, что Google продемонстрировала мощные возможности на уровне применения AI, особенно стратегию бесшовной интеграции AI в существующую экосистему продуктов. В то же время, такие темы, как достоверность контента, генерируемого AI, этика AI и будущие пути развития AGI, также стали предметом обсуждения. (Источник: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

Аппаратное обеспечение AI становится новым фокусом, сотрудничество OpenAI и Jony Ive привлекает внимание: Новость о приобретении OpenAI компании Jony Ive в области аппаратного обеспечения AI io, а также демонстрация Google на конференции I/O прототипа умных очков Android XR, разожгли в сообществе дискуссии о будущем аппаратного обеспечения AI. Сотрудничество Sam Altman и Jony Ive рассматривается как попытка создать персональные вычислительные устройства нового поколения на базе AI, которые могут кардинально изменить существующие способы взаимодействия с телефонами и компьютерами. Сообщество в целом ожидает, что аппаратное обеспечение, изначально созданное для AI, принесет революционный опыт, но также обеспокоено его формой, функциями и принятием на рынке. (Источник: dotey, sama, dotey, swyx)

Роль и риски AI в разработке программного обеспечения вызывают дискуссии: Выпуск Mistral AI модели Devstral, специально разработанной для кодирующих агентов, а также обновление Codex от OpenAI, вызвали дискуссии о применении AI в разработке программного обеспечения. Сообщество обеспокоено реальными возможностями инструментов программирования AI, качеством и безопасностью генерируемого кода. В частности, исследование, указывающее на то, что генерируемый AI код может ссылаться на несуществующие «галлюцинаторные пакеты», создает риски для безопасности цепочек поставок, напоминая разработчикам о необходимости тщательной проверки кода и зависимостей, генерируемых AI. (Источник: MistralAI, DeepLearning.AI Blog, qtnx_)
Обсуждение оценки AI-моделей и бенчмарков продолжает набирать обороты: Привлечение LMArena.ai крупного финансирования, а также показатели различных новых моделей в бенчмарках, сделали оценку AI-моделей горячей темой в сообществе. Пользователей волнуют реальные возможности различных моделей в конкретных задачах (таких как кодирование, математика, ответы на общие вопросы, понимание эмоций), а также надежность и ограничения существующих систем оценки. Например, представленная Tencent система оценки эмоционального интеллекта SAGE пытается предоставить новый критерий оценки AI-моделей с точки зрения «эмоционального интеллекта». (Источник: lmarena_ai, 36氪, natolambert)
Отставание европейской технологической отрасли вызывает размышления, Yann LeCun ретвитнул обсуждение о том, что основной причиной является отсутствие «патриотизма»: Статья в The Wall Street Journal о том, что европейская технологическая сцена значительно меньше американской и китайской, вызвала обсуждение. Yann LeCun ретвитнул комментарий Arnaud Bertrand. Bertrand считает, что основной причиной отставания европейских технологий является отсутствие «патриотического» духа: европейские СМИ и элиты склонны превозносить американские стартапы, игнорируя местные инновации, что приводит к тому, что местные компании с трудом получают раннюю поддержку и признание на рынке. На примере собственного опыта создания HouseTrip он указал на отсутствие в Европе уверенности в местных инновациях и атмосферы их поддержки. (Источник: ylecun)

💡 Другое
Проблема энергопотребления AI вызывает озабоченность: MIT Technology Review организовал круглый стол для обсуждения проблемы энергопотребления, связанной с ускоренным развитием технологий AI, и ее влияния на климат. По мере увеличения масштабов и областей применения AI-моделей, резко возрастает их потребность в электроэнергии и вычислительных ресурсах, а энергопотребление дата-центров становится новым фокусом внимания. Обсуждение коснулось энергопотребления одного AI-запроса, общего энергетического следа AI и способов решения этой проблемы. (Источник: MIT Technology Review, madiator)

Anthropic анонсирует новости, сообщество предполагает возможный выпуск Claude 4: Компания Anthropic опубликовала анонс о прямой трансляции 22 мая в 9:30 по тихоокеанскому времени (23 мая в 00:30 по пекинскому времени), что вызвало в сообществе предположения о возможном выпуске модели нового поколения Claude (возможно, Claude 4). Учитывая недавние громкие обновления от OpenAI и Google, этот шаг Anthropic привлекает большое внимание. (Источник: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Слияние технологий AI и XR, Google демонстрирует прототип умных очков Android XR: На конференции I/O Google продемонстрировала прототип умных очков Android XR, подчеркнув их глубокую интеграцию с AI. Устройство поддерживает интеллектуальную помощь от первого лица и функции бесконтактной помощи, позволяя пользователям взаимодействовать с устройством с помощью естественного языка для выполнения таких задач, как поиск информации, управление расписанием, навигация в реальном времени и т.д. Это предвещает, что AI станет ядром взаимодействия и функциональным драйвером для устройств XR следующего поколения, улучшая пользовательский опыт в среде дополненной реальности. (Источник: dotey, 36氪)