
Ключевые слова:ИИ-агент, Большая языковая модель, Gemini 2.5 Pro, ИИ-суперкомпьютер NVIDIA, Конференция Microsoft Build, Научно-исследовательский ИИ-агент, Оценка способности к логическому выводу, ИИ-программирование, Автономное исправление ошибок Coding Agent, Научная платформа Microsoft Discovery, Технология NVLink Fusion, Суперузел CloudMatrix 384, Алгоритм EdgeInfinite
🔥 В фокусе
AI-агенты пересматривают парадигмы разработки и научных исследований: На конференции Microsoft Build был представлен ряд инструментов для AI-агентов, включая Coding Agent для автономного исправления ошибок и поддержки кода, а также платформу для научных исследований Microsoft Discovery, способную генерировать идеи, моделировать результаты и самостоятельно обучаться. В то же время, главный продуктовый директор OpenAI Kevin Weil и CEO Anthropic Dario Amodei заявили, что AI уже обладает продвинутыми возможностями программирования, предвещая возможное замещение должностей младших программистов и трансформацию роли разработчиков в «наставников AI». Эти достижения свидетельствуют о том, что AI-агенты эволюционируют из вспомогательных инструментов в ключевую силу, способную самостоятельно работать над сложными проектами, что коренным образом изменит процессы и эффективность разработки программного обеспечения и научных исследований (Источник: GitHub Trending, X)
Способности к логическому выводу больших языковых моделей сталкиваются с новыми вызовами и оценками: Недавние исследования и обсуждения выявили ограничения больших языковых моделей в сложных задачах логического вывода. Исследование Гарвардского университета и других учреждений показало, что цепочка мыслей (CoT) иногда может приводить к снижению точности моделей в следовании инструкциям из-за чрезмерного внимания к планированию контента и игнорирования простых ограничений. В то же время, задачи из реального мира физики (например, обработка деталей) и сложные визуально-пространственные рассуждения (например, задачи по укладке кубов) также выявили недостатки топовых AI-моделей (включая o3, Gemini 2.5 Pro). Для более точной оценки возможностей моделей были предложены новые бенчмарки, такие как EMMA, SPOT, направленные на выявление реального уровня AI в мультимодальном слиянии, научной верификации и т.д., способствуя эволюции моделей к более надежным и достоверным выводам (Источник: HuggingFace Daily Papers, QbitAI)
Google AI всесторонне развивает свои усилия, Gemini 2.5 Pro демонстрирует высокие результаты: Google демонстрирует всестороннее наступление в области AI, ее модель Gemini 2.5 Pro показывает отличные результаты в нескольких бенчмарках (например, LMSYS Chatbot Arena), особенно достигая высшего уровня в понимании длинного контекста и видео, а также превосходя предыдущие версии в WebDev Arena. На конференции Google Cloud Next ‘25 Google выпустила более 200 обновлений, включая Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) и протокол Agent2Agent (A2A), демонстрируя свое намерение интегрировать AI на все уровни облачной платформы и способствовать его масштабному развертыванию на предприятиях. Google Labs также продолжает инкубировать нативные AI-инновационные продукты, такие как NotebookLM, показывая сильные возможности в области инноваций и итераций продуктов (Источник: Google, GoogleDeepMind)
NVIDIA представила настольный AI-суперкомпьютер и решения для корпоративных AI-фабрик: На конференции Computex NVIDIA представила несколько значимых новинок, включая персональный AI-компьютер DGX Station на базе суперчипа GB300 с объединенной памятью до 784GB, поддерживающий запуск моделей с 1T параметров; а также RTX PRO Server для предприятий, способный ускорять AI-агентов, физический AI, научные вычисления и другие приложения. Одновременно NVIDIA представила полу-кастомизируемую технологию NVLink Fusion и платформу данных NVIDIA AI, а также объявила о сотрудничестве с Disney и другими для разработки физического AI-движка Newton. Эти шаги показывают, что NVIDIA трансформируется из компании-производителя чипов в компанию-поставщика AI-инфраструктуры, стремясь создать полную AI-экосистему от настольных компьютеров до центров обработки данных (Источник: nvidia, QbitAI)

🎯 Новости
Kimi.ai выпустила модель для осмысления длинных текстов kimi-thinking-preview: Kimi.ai представила свою последнюю модель для осмысления длинных текстов kimi-thinking-preview, которая уже доступна на platform.moonshot.ai. Утверждается, что модель обладает выдающимися мультимодальными и логическими способностями, а новые пользователи при регистрации получают ваучер на 5 долларов для пробного использования. В комментариях сообщества предлагается провести оценку модели третьей стороной и упоминается, что Kimi ранее уже лидировала на livecodebench благодаря специализированной модели для осмысления (Источник: X)
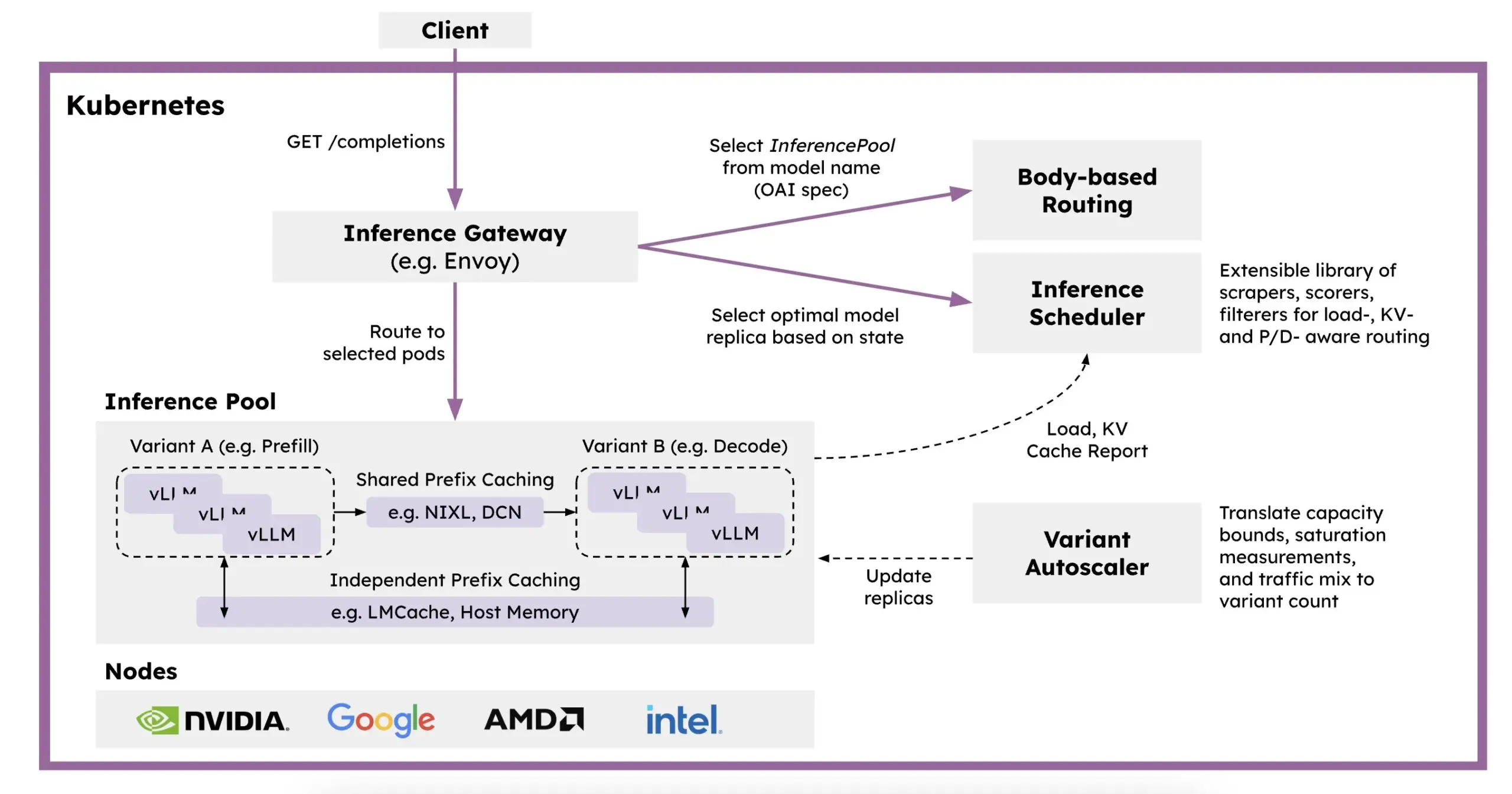
Red Hat представила llm-d: распределенную платформу для логических выводов на базе Kubernetes: Для решения проблем медленной скорости, высокой стоимости и сложности масштабирования логических выводов LLM, Red Hat представила llm-d, Kubernetes-нативную распределенную платформу для логических выводов. Эта платформа использует vLLM, интеллектуальное планирование и разделение вычислений для оптимизации логических выводов LLM. llm-d построена на трех открытых основах: vLLM (высокопроизводительный движок для логических выводов LLM), Kubernetes (стандарт оркестрации контейнеров) и Inference Gateway (IGW) (реализующий интеллектуальную маршрутизацию через расширение Gateway API), и нацелена на повышение эффективности и масштабируемости логических выводов LLM (Источник: X, X)
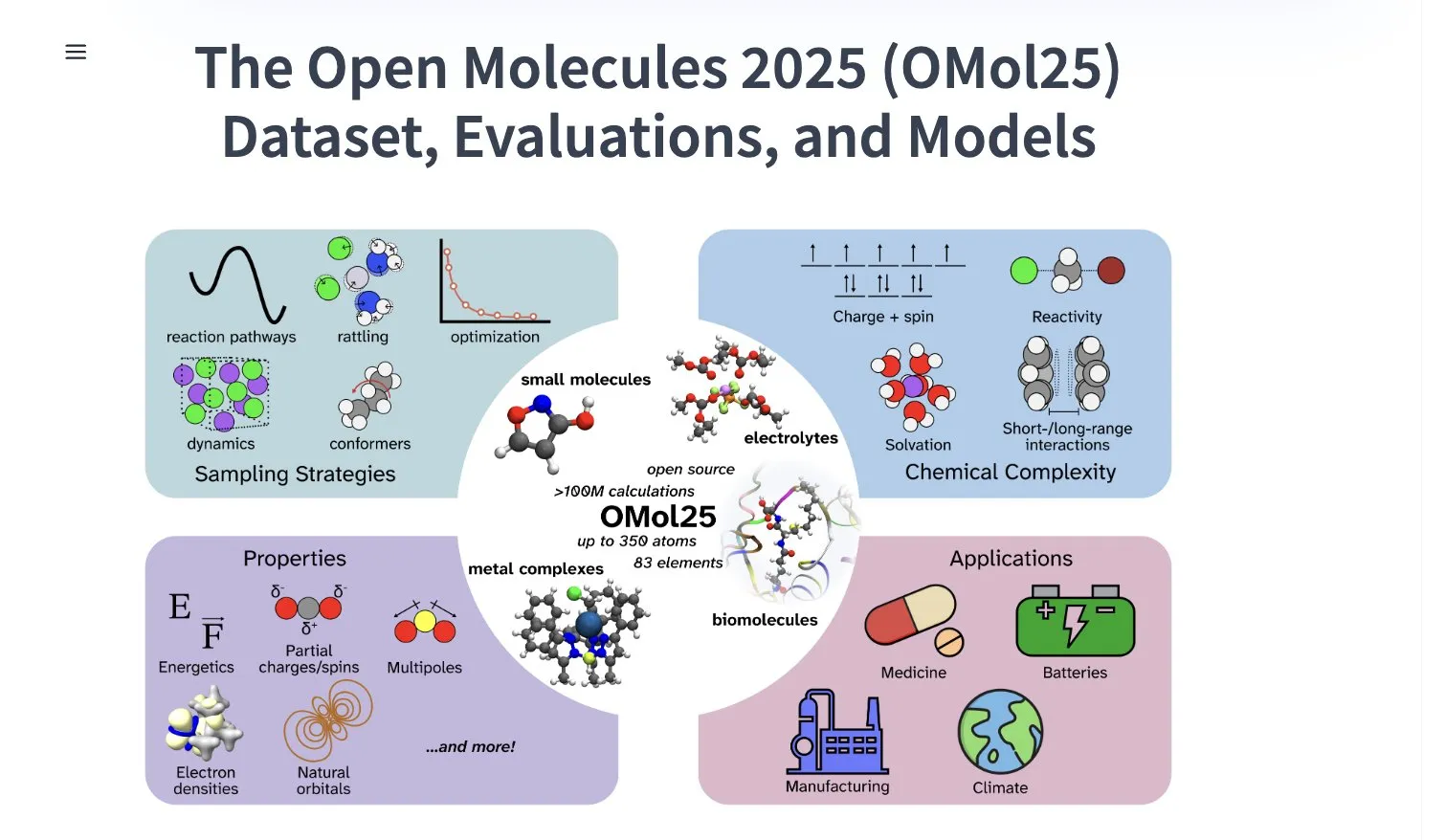
Meta AI опубликовала набор данных OMol25, содержащий более 100 миллионов конформеров молекул: Meta AI опубликовала на HuggingFace набор данных OMol25, содержащий более 100 миллионов конформеров молекул, охватывающих 83 элемента и разнообразные химические среды. Этот набор данных предназначен для обучения моделей машинного обучения, способных достигать точности уровня DFT (теории функционала плотности) при значительном снижении вычислительных затрат. Это поможет ускорить исследования и применение в таких областях, как открытие лекарств, разработка передовых материалов и решения для чистой энергетики (Источник: X)
Gemini 2.5 Pro в приложении NotebookLM появился в немецком iOS App Store: Приложение NotebookLM от Google (с интегрированным Gemini 2.5 Pro) стало доступно в немецком iOS App Store. Ранее в ЕС версия для iOS предоставлялась только через TestFlight. В то же время, версия для Android, похоже, стала доступна более широко. NotebookLM предназначен для помощи пользователям в понимании и обработке длинных документов, заметок и другого контента (Источник: X)
ByteDance активно ведет исследования в области AI, недавно опубликовав несколько статей: Команда SEED, входящая в ByteDance, за последние два месяца опубликовала не менее 13 научных статей, связанных с AI. Области исследований включают слияние моделей, адаптивную цепочку мыслей, запускаемую обучением с подкреплением (AdaCoT), оптимизацию логического вывода через латентные представления (LatentSeek) и другие. Эти исследования демонстрируют постоянные инвестиции и изыскания ByteDance в повышение эффективности, логических способностей и методов обучения больших языковых моделей (Источник: X, X)
AI обеспечивает новому поколению цинковых батарей эффективность 99,8% и время работы 4300 часов: Благодаря оптимизации с помощью искусственного интеллекта, новое поколение цинковых батарей достигло кулоновской эффективности 99,8% и времени работы до 4300 часов. Этот технологический прорыв демонстрирует потенциал применения AI в материаловедении и хранении энергии, и может способствовать развитию более эффективных и долговечных аккумуляторных технологий, что имеет важное значение для хранения возобновляемой энергии и портативных электронных устройств (Источник: X)

Perplexity запускает AI-интеллектуальный браузер Comet для раннего тестирования: Perplexity начала предоставлять ранним тестировщикам свой веб-браузер Comet с функциями интеллектуального агента. Ожидается, что этот браузер предложит совершенно новый опыт «атмосферного просмотра» (vibe browsing), возможно, сочетая мощные возможности AI-поиска и интеграции информации Perplexity, чтобы предоставить пользователям более интеллектуальный и персонализированный способ просмотра веб-страниц (Источник: X)
Intel выпустила высокопроизводительные видеокарты Arc Pro B-серии с большим объемом видеопамяти по доступной цене: Intel представила видеокарты Arc Pro B50 (16 ГБ видеопамяти, 299 долларов) и Arc Pro B60 (24 ГБ видеопамяти, 500 долларов за карту), разработанную специально для рабочих станций AI. B60 в тестах логического вывода AI превосходит NVIDIA RTX A1000, а больший объем видеопамяти дает ей преимущество при работе с большими моделями. Рабочая станция Project Battlematrix использует процессоры Xeon и может быть оснащена до 8 GPU B60 (общий объем видеопамяти 192 ГБ), поддерживая модели с более чем 70 миллиардами параметров. Этот шаг рассматривается как стратегия Intel по достижению прорыва в соотношении цена-качество на рынке аппаратного обеспечения для AI (Источник: QbitAI)

Huawei Cloud представила суперузел CloudMatrix 384, повышающий вычислительную мощность AI: Huawei Cloud выпустила суперузел CloudMatrix 384, использующий архитектуру полного взаимного соединения (full peer-to-peer interconnect), которая позволяет объединить 384 AI-ускорителя в супер-облачный сервер, обеспечивая вычислительную мощность до 300 PFLOPS. Это решение направлено на преодоление проблем эффективности связи, «стены памяти» и надежности при обучении и логическом выводе AI. Архитектура особо подчеркивает совместимость с моделями MoE, усиление вычислений за счет сети и хранения данных, и уже используется для поддержки логических выводов больших моделей, таких как DeepSeek-R1 (Источник: QbitAI)

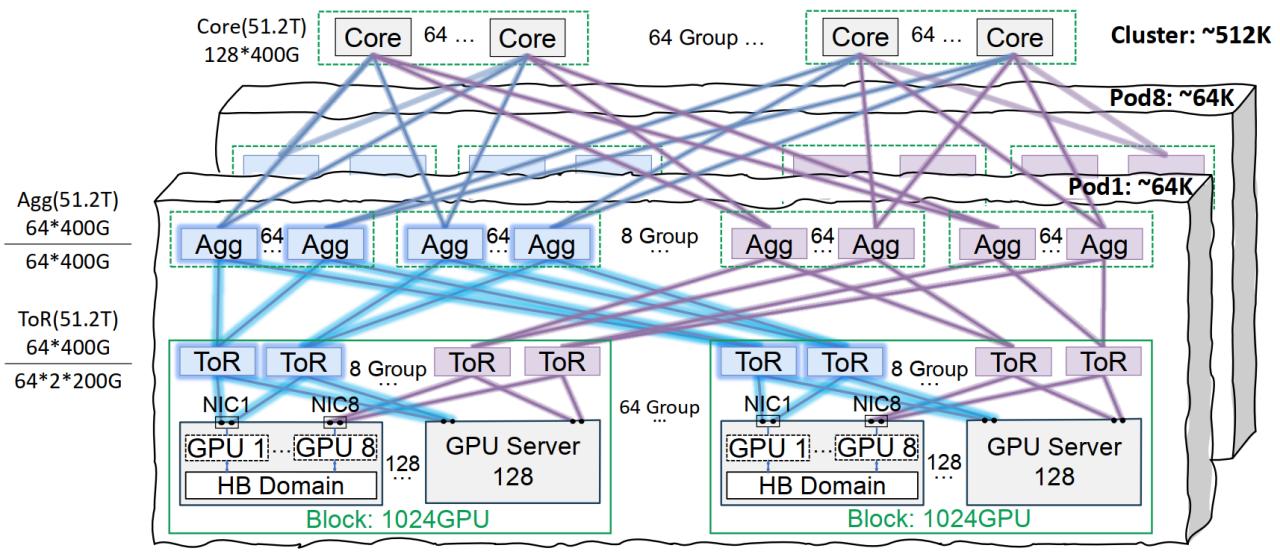
Сетевая инфраструктура Tencent Cloud StarLink оптимизирует обучение больших моделей: Tencent Cloud представила решение для высокопроизводительной сетевой инфраструктуры StarLink, специально разработанное для крупномасштабного обучения и логического вывода AI-моделей. Это решение решает проблемы традиционных центров обработки данных в области сети, плотности развертывания и локализации неисправностей за счет архитектуры同轨互联 (поддерживающей до 64 000 GPU в одном Pod и 512 000 GPU в кластере), оптимизированного управления питанием и охлаждения, а также интеллектуальной системы мониторинга. StarLink уже поддерживает собственные разработки Tencent, такие как Hunyuan, и обеспечила оптимизацию производительности для коммуникационной платформы DeepEP от DeepSeek (Источник: QbitAI)
Stability AI выпустила модель SV4D2.0, возможно, предвещая ее возвращение в область генерации видео: Stability AI выпустила на Hugging Face модель под названием sv4d2.0, что привлекло внимание сообщества. Хотя подробностей мало, этот шаг может означать новые технологические достижения или итерации продуктов Stability AI в области генерации видео или связанных с ней 3D/4D технологий, намекая на возможное возвращение компании на передний край AI-генерации после периода реструктуризации (Источник: X)
Meta AI выпустила алгоритм обучения Adjoint Sampling: Meta AI предложила новый алгоритм обучения Adjoint Sampling для тренировки генеративных моделей на основе скалярных вознаграждений. Этот алгоритм основан на теоретической базе, разработанной FAIR, обладает высокой масштабируемостью и может стать основой для будущих исследований в области масштабируемых методов сэмплирования. Соответствующая научная статья, модели, код и бенчмарки уже опубликованы (Источник: X)
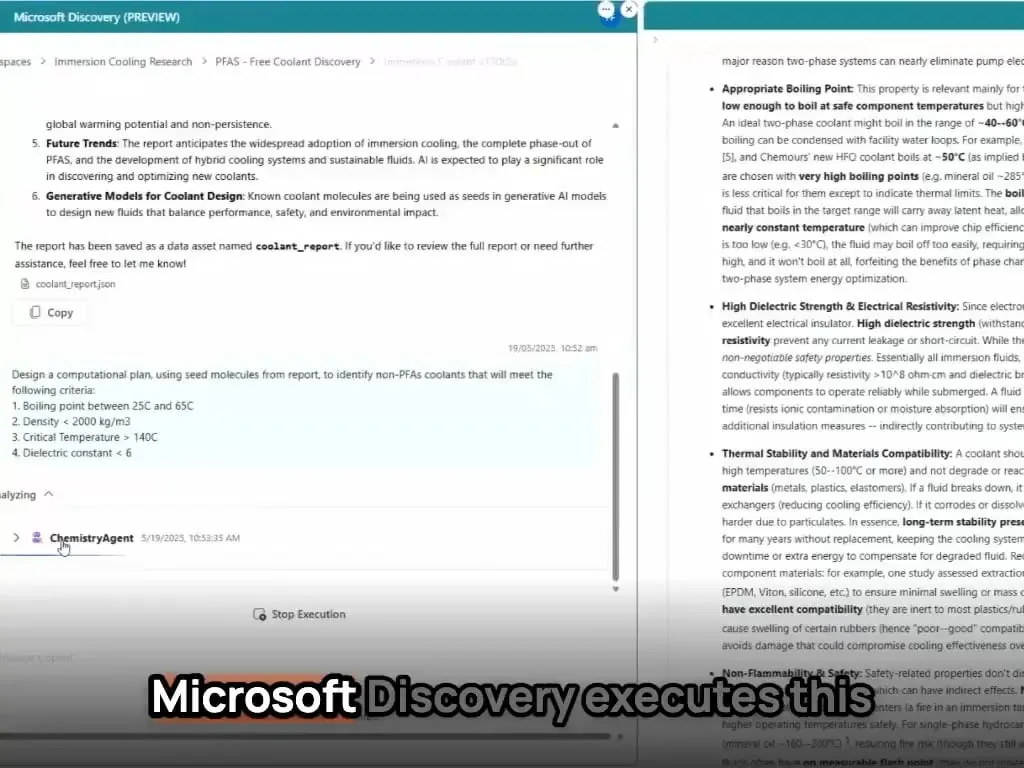
AI-агенты Microsoft за несколько часов открыли и синтезировали новый материал: Microsoft продемонстрировала мощные возможности своих AI-агентов в научных исследованиях и разработках. Эти агенты способны сканировать научную литературу, составлять планы, писать код, запускать симуляции и за несколько часов завершать открытие нового хладагента для центров обработки данных, на что обычно уходят годы исследований. Более того, команда успешно синтезировала разработанный AI новый хладагент и продемонстрировала его на реальной материнской плате, показав огромный потенциал AI в ускорении автономных открытий и создания в таких областях, как материаловедение (Источник: Reddit r/artificial)
Институт искусственного интеллекта Пекина (BAAI) выпустил три векторные модели серии BGE, ориентированные на код и мультимодальный поиск: Институт искусственного интеллекта Пекина совместно с университетами представил BGE-Code-v1 (векторная модель для кода), BGE-VL-v1.5 (универсальная мультимодальная векторная модель) и BGE-VL-Screenshot (векторная модель для визуализированных документов). Эти модели показали отличные результаты в бенчмарках CoIR, Code-RAG, MMEB, MVRB. BGE-Code-v1 основана на Qwen2.5-Coder-1.5B, BGE-VL-v1.5 — на LLaVA-1.6, а BGE-VL-Screenshot — на Qwen2.5-VL-3B-Instruct. Они предназначены для повышения производительности поиска кода, понимания изображений и текста, а также поиска в сложных визуальных документах, и полностью открыты (Источник: WeChat)
Технология Huawei OmniPlacement оптимизирует логический вывод моделей MoE, теоретически снижая задержку DeepSeek-V3 на 10%: Для решения проблемы несбалансированной нагрузки на сети экспертов (горячие и холодные эксперты) в моделях смешанных экспертов (MoE), которая ограничивает производительность логического вывода, команда Huawei предложила технологию OmniPlacement. Эта технология за счет перестановки экспертов, межслойного избыточного развертывания и динамического планирования в почти реальном времени теоретически может снизить задержку логического вывода примерно на 10% и повысить пропускную способность примерно на 10% для моделей, таких как DeepSeek-V3. Это решение в ближайшее время будет полностью открыто (Источник: WeChat)

vivo выпустила алгоритм EdgeInfinite, обеспечивающий эффективную обработку 128K длинных текстов на мобильных устройствах: Исследовательский институт vivo AI опубликовал исследование на ACL 2025, представив алгоритм EdgeInfinite, специально разработанный для устройств на стороне пользователя. Благодаря обучаемому модулю управляемой памяти и технологиям сжатия/распаковки памяти, он эффективно обрабатывает сверхдлинные тексты в архитектуре Transformer. Алгоритм был протестирован на модели BlueLM-3B и способен обрабатывать 128K токенов на устройствах с 10 ГБ GPU-памяти, показывая отличные результаты во многих задачах LongBench, значительно снижая время вывода первого токена и потребление памяти (Источник: WeChat)

🧰 Инструменты
LlamaParse обновлен, улучшены возможности анализа документов: LlamaParse выпустил несколько обновлений, повышающих его производительность как инструмента для анализа документов, управляемого AI-агентами. Новые функции включают поддержку Gemini 2.5 Pro, GPT-4.1, добавлено обнаружение перекосов и оценки уверенности. Кроме того, введена кнопка для фрагментов кода, позволяющая пользователям напрямую копировать конфигурацию анализа в свои кодовые базы, а также добавлены предустановки для вариантов использования и возможность переключения экспорта между отрендеренным и исходным Markdown (Источник: X)
Hugging Face представила NPM-пакет Tiny Agents: Julien Chaumond выпустил Tiny Agents, легковесный, компонуемый NPM-пакет для агентов. Он построен на базе Inference Client от Hugging Face и стека MCP (Model Component Protocol) и предназначен для того, чтобы разработчики могли быстро начать работу и создавать небольшие приложения с агентами. Официально предоставлено руководство для начинающих (Источник: X)
Платформа LangGraph добавила поддержку MCP, упрощая интеграцию агентов: Платформа LangGraph теперь поддерживает MCP (Model Component Protocol), и каждый агент, развернутый на платформе, автоматически предоставляет конечную точку MCP. Это означает, что пользователи могут использовать этих агентов в качестве инструментов в любом клиенте, поддерживающем потоковый HTTP по MCP, без необходимости писать собственный код или настраивать дополнительную инфраструктуру, что упрощает интеграцию и взаимодействие между агентами (Источник: X)

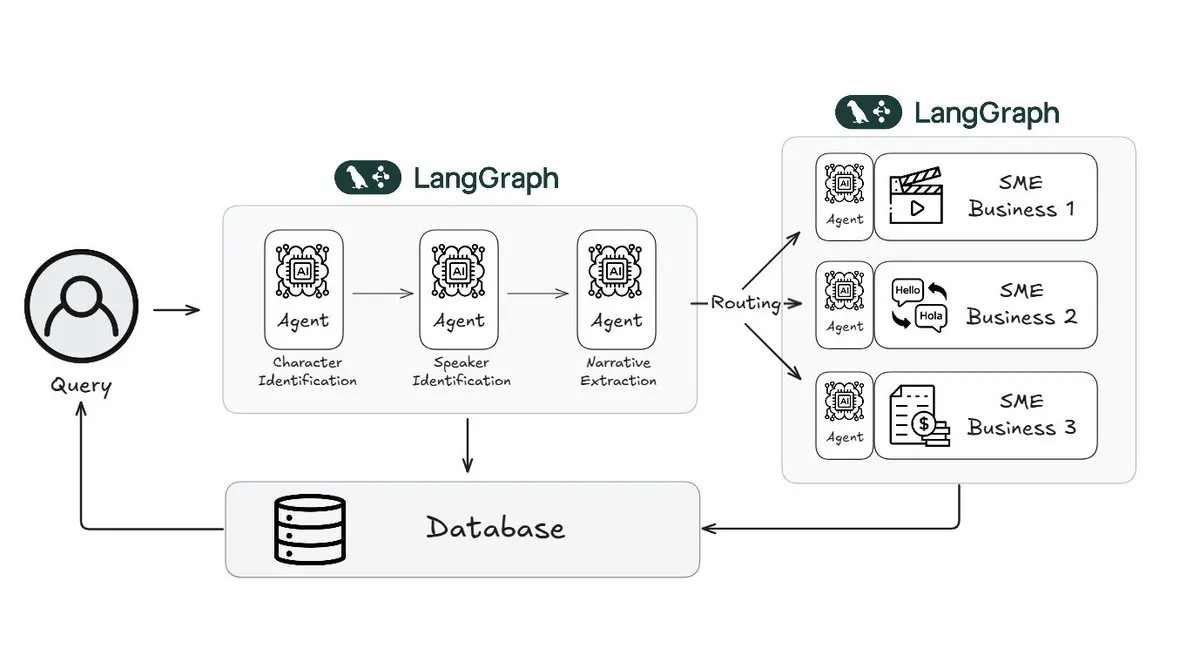
Webtoon сократил рабочую нагрузку по рецензированию историй на 70% с помощью LangGraph: Лидер в области цифровых комиксов Webtoon создал Webtoon Comprehension AI (WCAI), используя LangGraph для автоматизации понимания повествования в своей обширной библиотеке контента. WCAI заменяет ручной просмотр интеллектуальными мультимодальными агентами, способными распознавать персонажей и говорящих, извлекать сюжет и тональность, а также выполнять запросы на естественном языке для получения информации. Это позволило сократить рабочую нагрузку команд маркетинга, перевода и рекомендаций на 70% и повысить креативность (Источник: X)
OpenMemory MCP обеспечивает постоянный обмен приватной памятью между AI-инструментами: Проект Mem0 представил сервер OpenMemory MCP, предназначенный для предоставления AI-приложениям постоянной приватной памяти между платформами и сессиями. Пользователи могут развернуть его локально и через протокол MCP подключить OpenMemory к клиентским инструментам, таким как Cursor, для добавления, поиска, перечисления и удаления воспоминаний. Этот инструмент предоставляет функции управления памятью через панель управления и призван улучшить персонализацию и понимание контекста AI-агентами (Источник: WeChat)

Выпущен Miaoduo AI 2.0, позиционируемый как AI-помощник для дизайна интерфейсов: Miaoduo AI 2.0 выпущен как AI-помощник в области дизайна интерфейсов, предназначенный для совместной работы с пользователями над задачами дизайна. Новая версия улучшает взаимодействие с помощью AI-волшебного окна, поддерживает диалоговое редактирование и итеративную разработку дизайнерских решений, может генерировать несколько версий интерфейса на основе предустановленных стилей или пользовательского ввода (длинный текст, эскиз, референсное изображение) и совместим с основными системами дизайна. Кроме того, он предоставляет функции обработки изображений и текста, консультации по дизайну и быстрые команды (преобразование естественного языка в вызовы API). Miaoduo AI поддерживает протокол MCP, оптимизируя данные дизайн-макетов для чтения большими моделями с целью генерации высокоточного фронтенд-кода (Источник: QbitAI)

llmbasedos: концепт загрузочной AI-операционной системы с открытым исходным кодом на базе MCP: Разработчик iluxu за три дня до того, как Microsoft представила концепцию «USB-C для AI-приложений» (на базе MCP), открыл исходный код проекта llmbasedos. Этот проект представляет собой AI-операционную систему, которую можно быстро загрузить с USB или виртуальной машины. Она взаимодействует с небольшими Python-демонами через шлюз FastAPI по JSON-RPC, позволяя пользовательским скриптам вызываться ChatGPT/Claude/VS Code и другими через простую конфигурацию cap.json. По умолчанию используется офлайн-версия llama.cpp, но можно переключиться на GPT-4o или Claude 3. Проект направлен на продвижение открытых стандартов подключения AI-приложений (Источник: Reddit r/LocalLLaMA)
📚 Обучение
Почему дистилляция знаний (KD) эффективна? Новое исследование предлагает простое объяснение: Kyunghyun Cho и др. предложили простое объяснение эффективности дистилляции знаний (KD). Они предположили, что использование низкоэнтропийного аппроксимированного сэмплирования из модели-учителя приводит к тому, что модель-ученик имеет более высокую точность, но более низкую полноту. Поскольку авторегрессионные языковые модели по своей сути являются бесконечно каскадными смешанными распределениями, они проверили эту гипотезу с помощью SmolLM. Исследование утверждает, что текущие методы оценки могут быть слишком сосредоточены на точности, игнорируя потерю полноты, что связано с тем, какой контент и какие группы пользователей могут быть упущены крупномасштабными универсальными моделями (Источник: X)

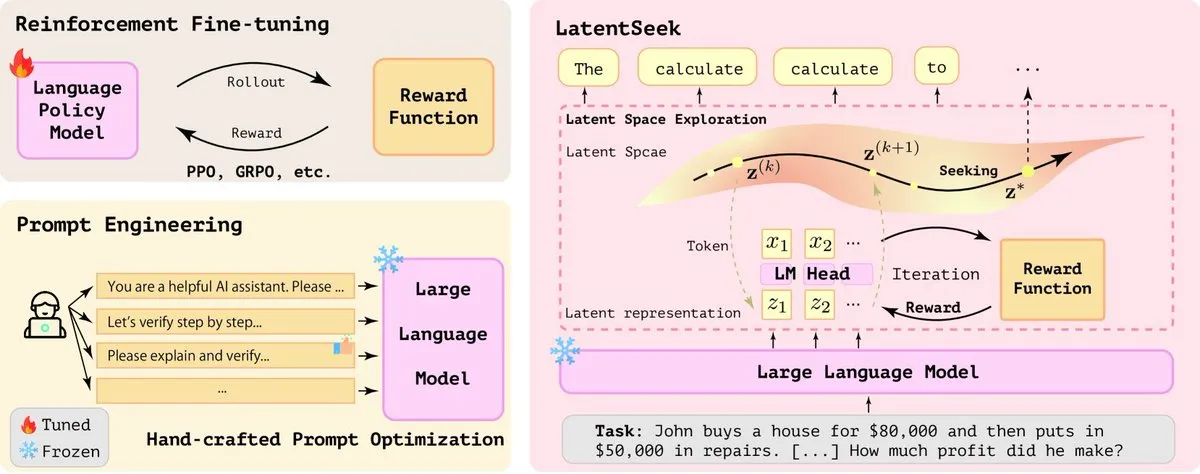
LatentSeek: улучшение способности LLM к логическому выводу с помощью оптимизации градиента стратегии в латентном пространстве: В статье под названием «Seek in the Dark» предложен LatentSeek, новая парадигма для улучшения способности больших языковых моделей (LLM) к логическому выводу во время тестирования с помощью градиента стратегии на уровне экземпляра в латентном пространстве. Этот метод не требует обучения, данных или модели вознаграждения и направлен на улучшение процесса логического вывода модели путем оптимизации латентных представлений. Этот не зависящий от обучения метод показал потенциал в повышении производительности LLM в сложных задачах логического вывода (Источник: X)
Microsoft предлагает CoML: обучение цепочечных моделей для языковых моделей: Microsoft Research предложила новую парадигму обучения «Обучение цепочечных моделей» (Chain-of-Model Learning, CoML). Этот метод интегрирует причинно-следственные связи скрытых состояний в виде цепочечной структуры в каждый слой сети, стремясь повысить эффективность масштабирования обучения модели и гибкость логического вывода при развертывании. Его основная концепция «цепочечное представление» (CoR) разлагает скрытое состояние каждого слоя на несколько цепочек подпредставлений, причем последующие цепочки могут получать доступ к входным представлениям всех предыдущих цепочек, что позволяет модели постепенно расширяться за счет добавления цепочек и предоставлять подмодели различных масштабов для гибкого логического вывода путем выбора различного количества цепочек. Разработанная на основе этого принципа CoLM (цепочечная языковая модель) и ее вариант CoLM-Air (с внедрением механизма совместного использования KV) продемонстрировали производительность, сопоставимую со стандартным Transformer, и принесли преимущества постепенного масштабирования и гибкого логического вывода (Источник: X, HuggingFace Daily Papers)

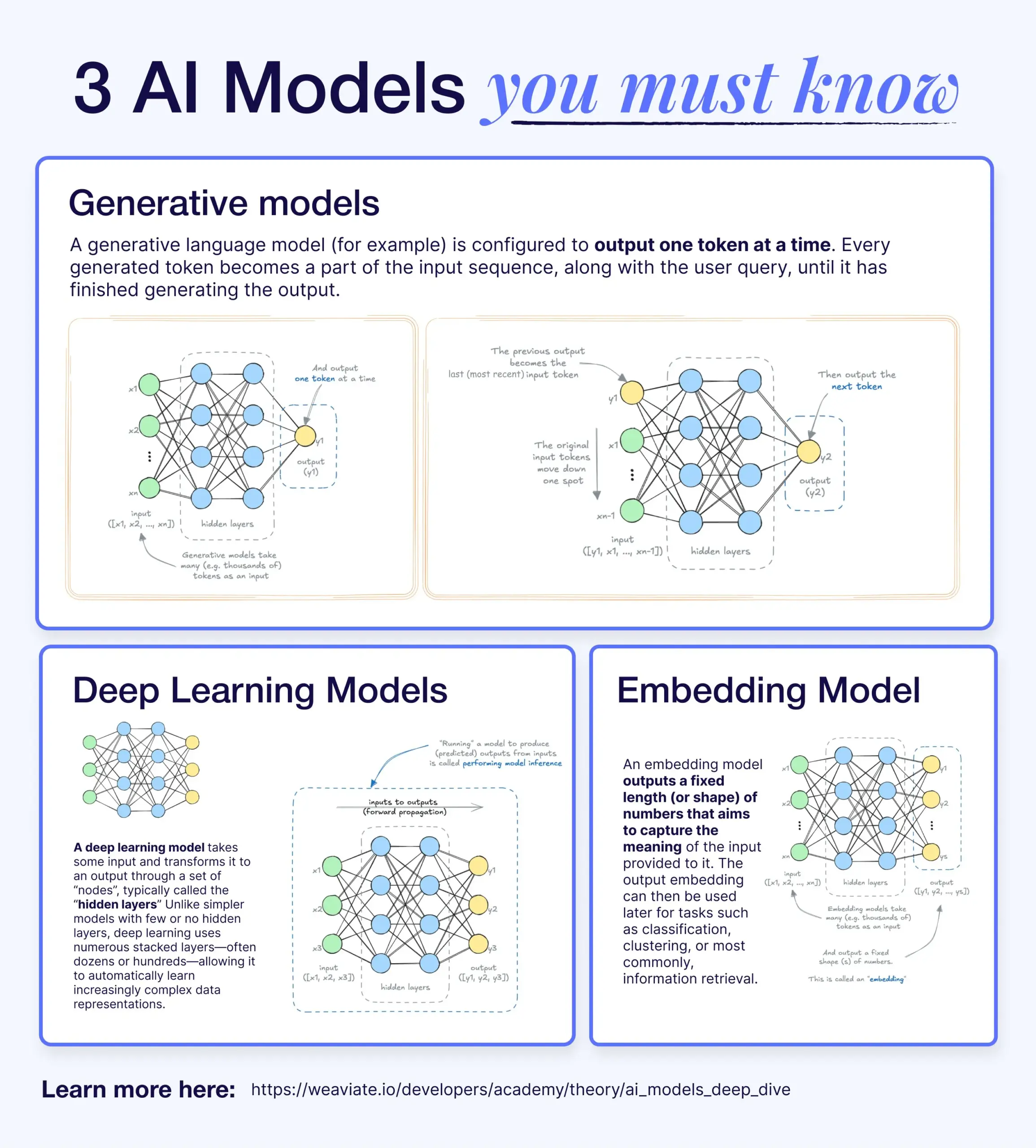
Различия и связи между моделями глубокого обучения, генеративными моделями и моделями встраивания: В научно-популярной статье объясняются взаимосвязи между моделями глубокого обучения, генеративными моделями и моделями встраивания. Модели глубокого обучения являются базовой архитектурой, обрабатывающей числовые входы и выходы с помощью многослойных нейронных сетей. Генеративные модели — это тип моделей глубокого обучения, специально предназначенный для создания нового контента, похожего на их обучающие данные (например, GPT, DALL-E). Модели встраивания также являются типом моделей глубокого обучения, используемым для преобразования данных (текста, изображений и т. д.) в числовые векторные представления, отражающие семантическую информацию, и часто применяются для поиска сходства и в системах RAG. Во многих AI-системах эти модели работают совместно, например, системы RAG используют модели встраивания для поиска, а затем генеративные модели для генерации ответов (Источник: X)
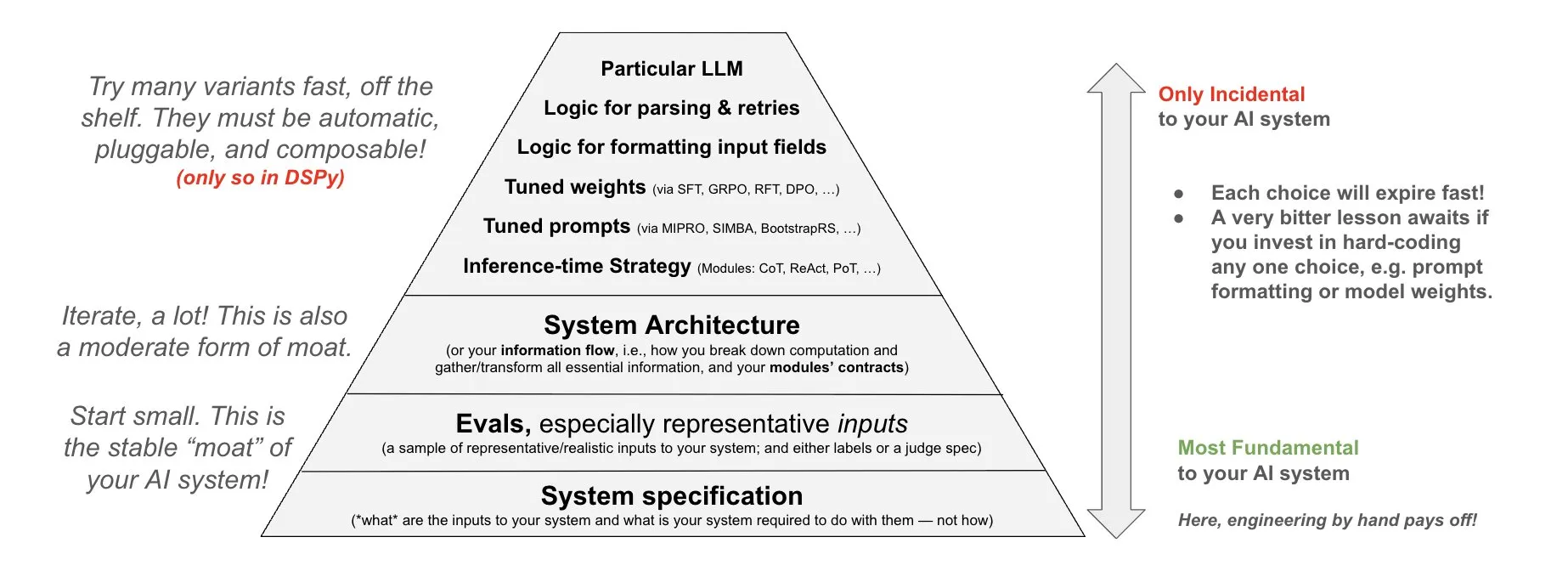
DSPy предлагает философию инвестиций в AI-системы: DSPy поделилась своей философией инвестиций в AI-системы, подчеркивая, что усилия следует направлять на три фундаментальных уровня AI-систем: данные, модели и алгоритмы. Они считают, что, предоставляя компонуемые модули верхнего уровня (Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules), разработчики могут быстро итерировать эти три фундаментальных уровня, создавая таким образом более мощные AI-системы (Источник: X)
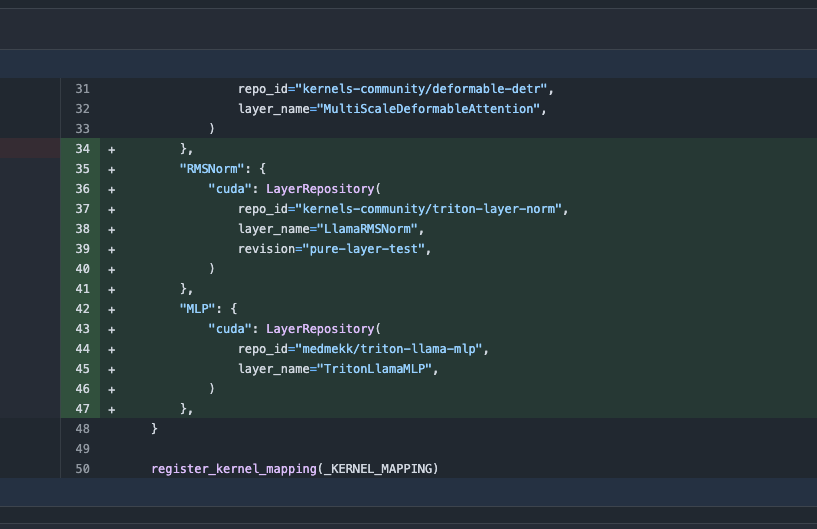
Обновление библиотеки Transformers, автоматическое переключение на оптимизированные ядра для повышения производительности: Последняя версия библиотеки Hugging Face Transformers реализует автоматическое переключение на оптимизированные ядра, когда это позволяет аппаратное обеспечение. Обновление интегрирует библиотеку kernels, нацеленную на популярные модели, такие как Llama, и использует самые популярные ядра сообщества с Hugging Face Hub, чтобы повысить эффективность работы и производительность моделей на совместимом оборудовании (Источник: X)
Выпущен бенчмарк ARC-AGI-2, бросающий вызов передовым AI-системам логического вывода: François Chollet и др. опубликовали статью о бенчмарке ARC-AGI-2, подробно описывающую его принципы проектирования, сложность, анализ человеческой производительности и производительность текущих моделей. Бенчмарк предназначен для оценки способности AI к абстрактному мышлению. Люди способны решить 100% задач, в то время как текущие передовые AI-модели набирают менее 5%, что свидетельствует о огромном разрыве между AI и человеком в области продвинутого абстрактного мышления (Источник: X)

Теренс Тао опубликовал учебное пособие по доказательству пределов функций с помощью GitHub Copilot: Математик Теренс Тао опубликовал видеоурок, демонстрирующий, как использовать GitHub Copilot для помощи в доказательстве задач на пределы функций, включая теоремы о сумме, разности и произведении. Он подчеркнул, что, хотя Copilot может быстро генерировать каркас кода и подсказывать существующие библиотечные функции, в сложных математических деталях, обработке особых случаев и творческих решениях все еще требуется значительное вмешательство и корректировка со стороны человека, а иногда сочетание вычислений на бумаге с последующей формальной проверкой может быть более эффективным (Источник: 36Kr)
Фреймворк PhyT2V использует LLM для повышения физической согласованности при генерации видео из текста: Исследовательская группа из Питтсбургского университета предложила фреймворк PhyT2V, который с помощью управляемой большими языковыми моделями цепочки рассуждений (CoT) и механизма итеративной самокоррекции оптимизирует текстовые подсказки для повышения физической реалистичности контента, генерируемого существующими моделями преобразования текста в видео (T2V). Этот метод не требует переобучения моделей, а анализирует семантические несоответствия между сгенерированным видео и подсказкой, а также корректирует подсказку с учетом физических правил, чтобы повысить физическую согласованность моделей T2V при обработке сценариев вне распределения (OOD). Эксперименты показали, что PhyT2V может значительно улучшить производительность моделей CogVideoX, OpenSora и других на бенчмарках VideoPhy, PhyGenBench и др. (Источник: WeChat)

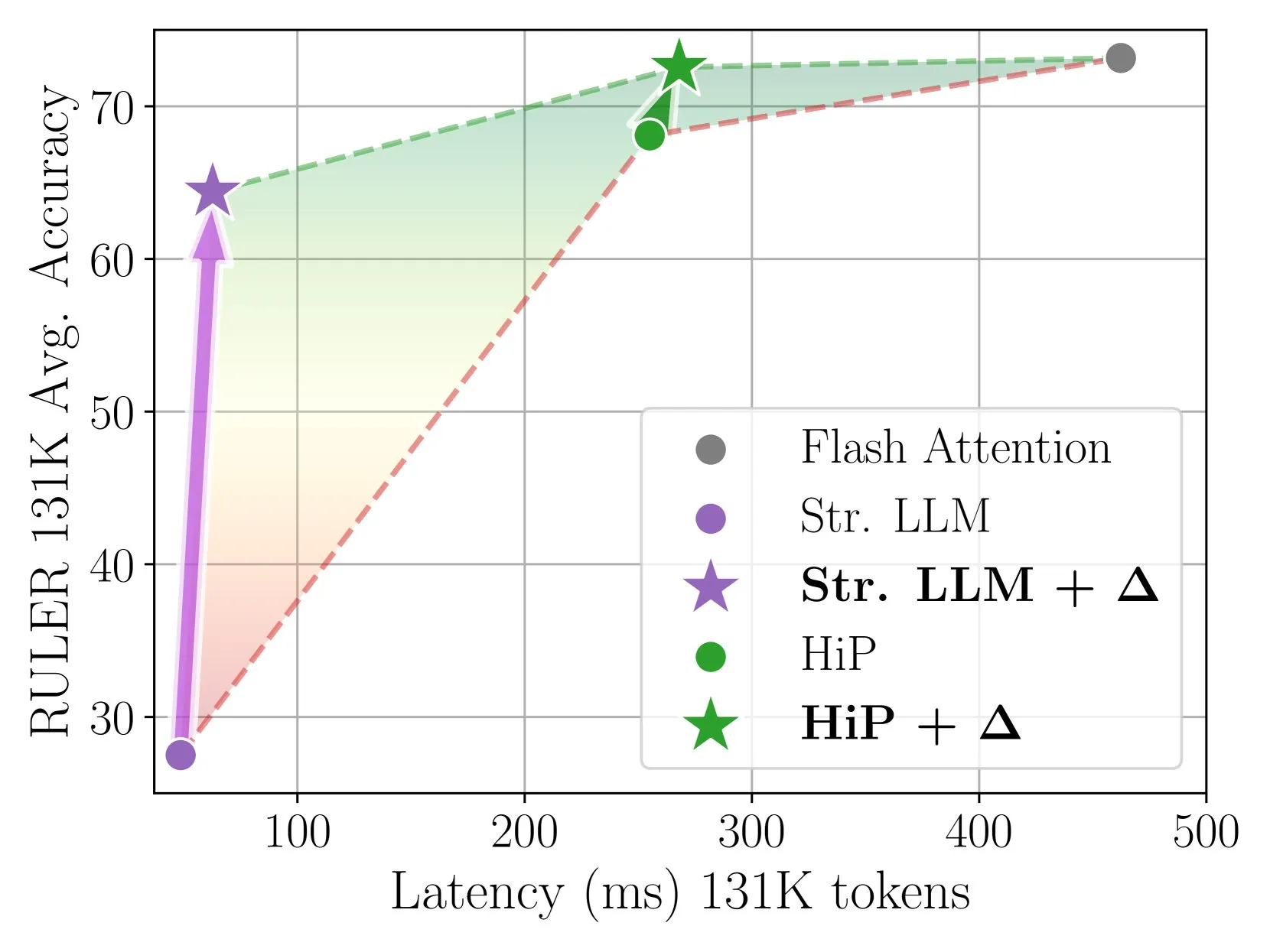
Delta Attention обеспечивает быстрый и точный разреженный механизм внимания с помощью инкрементной коррекции: Данное исследование выявило, что вычисление разреженного внимания приводит к смещению распределения выходных данных внимания, что снижает производительность модели. Delta Attention корректирует это смещение распределения, приближая распределение выходных данных разреженного внимания к полному вниманию, тем самым значительно повышая производительность при сохранении высокой разреженности (около 98,5%) и восстанавливая 88% точности полного внимания для скользящего окна внимания (с sink token) на бенчмарке RULER, при этом вычислительные затраты невелики. При обработке предварительного заполнения 1M токенов он работает в 32 раза быстрее, чем Flash Attention 2 (Источник: HuggingFace Daily Papers)
Фреймворк Thinkless позволяет LLM учиться, когда проводить CoT-рассуждения: Для решения проблемы низкой вычислительной эффективности, вызванной использованием большими языковыми моделями (LLM) сложных цепочек рассуждений (CoT) для всех запросов, исследователи предложили фреймворк Thinkless. Этот фреймворк обучает LLM с помощью обучения с подкреплением, чтобы они могли адаптивно выбирать короткий или длинный тип рассуждений в зависимости от сложности задачи и собственных возможностей. Основной алгоритм DeGRPO разделяет цель обучения на потери управляющих токенов (определяющих режим рассуждений) и потери ответа (повышающих точность ответа), тем самым стабилизируя процесс обучения. Эксперименты показали, что Thinkless может сократить использование длинных цепочек рассуждений на 50%-90% на таких бенчмарках, как Minerva Algebra, значительно повышая эффективность рассуждений (Источник: HuggingFace Daily Papers)
Алгоритм CPGD повышает стабильность обучения с подкреплением языковых моделей на основе правил: Для решения проблемы нестабильности обучения, которая может возникать при использовании существующих методов обучения с подкреплением на основе правил (таких как GRPO, REINFORCE++, RLOO) для обучения языковых моделей, исследователи предложили алгоритм CPGD (оптимизация градиента стратегии с отсечением и дрейфом стратегии). CPGD динамически регуляризует обновления стратегии, вводя ограничение на дрейф стратегии на основе KL-дивергенции, и использует механизм отсечения логарифмического отношения для предотвращения чрезмерных обновлений стратегии. Теоретический и эмпирический анализ показывают, что CPGD может смягчить нестабильность и значительно повысить производительность при сохранении стабильности обучения (Источник: HuggingFace Daily Papers)
Нейросимвольный компилятор запросов QCompiler улучшает обработку сложных запросов в системах RAG: Для решения проблемы, с которой сталкиваются системы генерации с расширенным поиском (RAG) при обработке сложных запросов с вложенной структурой и зависимостями, особенно в условиях ограниченных ресурсов, когда трудно точно определить намерение поиска, был предложен фреймворк QCompiler. Этот фреймворк, вдохновленный лингвистическими грамматическими правилами и дизайном компиляторов, сначала разрабатывает минимальную и достаточную BNF-грамматику G[q] для формализации сложных запросов, а затем с помощью преобразователя выражений запросов, лексико-грамматического анализатора и рекурсивного нисходящего процессора компилирует запрос в абстрактное синтаксическое дерево (AST) для выполнения. Атомарность подзапросов в листовых узлах обеспечивает более точный поиск документов и генерацию ответов (Источник: HuggingFace Daily Papers)
Набор данных Jedi и бенчмарк OSWorld-G способствуют исследованиям в области локализации элементов GUI в сценариях использования компьютера: Для решения проблемы узкого места в локализации графического пользовательского интерфейса (GUI) (сопоставление инструкций на естественном языке с действиями в GUI), исследователи опубликовали бенчмарк OSWorld-G (564 образца с детальной разметкой, охватывающие сопоставление текста, распознавание элементов, понимание макета и точные операции) и крупномасштабный синтетический набор данных Jedi (4 миллиона образцов). Многомасштабные модели, обученные на Jedi, превзошли существующие методы на ScreenSpot-v2, ScreenSpot-Pro и OSWorld-G, а также смогли улучшить возможности универсальных базовых моделей в сложных компьютерных задачах (OSWorld), повысив их с 5% до 27% (Источник: HuggingFace Daily Papers)
Фрагментированное рассуждение по цепочке мыслей (Fractured CoT) повышает эффективность и производительность рассуждений LLM: Для решения проблемы высоких затрат на токены, связанных с рассуждениями CoT, исследователи обнаружили, что усеченное CoT (прекращение рассуждений до завершения и непосредственная генерация ответа) обычно позволяет достичь производительности, сопоставимой с полным CoT, но при значительном сокращении потребления токенов. На основе этого предложена унифицированная стратегия рассуждений Fractured Sampling, которая путем настройки трех измерений — количества траекторий рассуждений, количества окончательных решений для каждой траектории и глубины усечения следов рассуждений — достигает лучшего компромисса между точностью и затратами на нескольких бенчмарках рассуждений и для моделей различных масштабов, открывая путь к более эффективным и масштабируемым рассуждениям LLM (Источник: HuggingFace Daily Papers)
Мультимодальная проверка химических формул с помощью контекстного обусловливания LLM и подсказок PWP: Исследователи изучили структурированное контекстное обусловливание LLM в сочетании с принципами постоянных рабочих подсказок (PWP) для корректировки поведения LLM во время логического вывода с целью повышения их надежности в задачах точной проверки (например, химических формул), особенно при обработке сложных научных документов, содержащих изображения. Этот метод использует только стандартный интерфейс чата (Gemini 2.5 Pro, ChatGPT Plus o3) без необходимости API или модификации модели. Предварительные эксперименты показали, что этот метод улучшает распознавание текстовых ошибок и помог Gemini 2.5 Pro выявить ошибки в формулах на изображениях, пропущенные при ручной проверке (Источник: HuggingFace Daily Papers)
Использование PWP, мета-подсказок и мета-рассуждений для научного рецензирования с помощью AI: Исследователи предложили метод постоянных рабочих подсказок (PWP) для критического рецензирования научных рукописей с помощью стандартного интерфейса чата LLM. PWP использует иерархическую модульную архитектуру (структурированную в Markdown) для определения подробного рабочего процесса анализа, систематически кодируя экспертные процессы рецензирования (включая неявные знания) с помощью мета-подсказок и мета-рассуждений. PWP направляет LLM на проведение систематической мультимодальной оценки, такой как различение утверждений и доказательств, интеграция анализа текста/изображений/диаграмм, выполнение количественных проверок осуществимости и т. д. В тестовых случаях он успешно выявил методологические недостатки (Источник: HuggingFace Daily Papers)
Бенчмарк SPOT оценивает способность AI к автоматической проверке научных исследований: Для оценки возможностей больших языковых моделей (LLM) в качестве «AI-соисследователей» в автоматизации проверки академических рукописей исследователи представили бенчмарк SPOT. Этот бенчмарк содержит 83 опубликованные статьи и 91 ошибку, достаточную для того, чтобы вызвать исправление или отзыв статьи, и был перекрестно проверен первоначальными авторами и ручными аннотаторами. Результаты экспериментов показали, что даже самые передовые LLM (например, o3) на SPOT достигают полноты не более 21,1% и точности менее 6,1%, при этом уверенность моделей низкая, а результаты многократных запусков непоследовательны, что указывает на огромный разрыв между текущими LLM и реальными потребностями в надежной академической проверке (Источник: HuggingFace Daily Papers)
ExTrans использует обучение с подкреплением с расширением выборки для многоязычного перевода с глубоким логическим выводом: Для повышения возможностей больших моделей логического вывода (LRM) в машинном переводе, особенно в многоязычных сценариях, исследователи предложили ExTrans. Этот метод разрабатывает новый подход к моделированию вознаграждения, количественно оценивая вознаграждение путем сравнения результатов перевода модели стратегического перевода с сильными LRM (такими как DeepSeek-R1-671B). Эксперименты показали, что модель, обученная на основе Qwen2.5-7B-Instruct, достигает SOTA в литературном переводе и превосходит OpenAI-o1 и DeepSeeK-R1. Благодаря легковесному моделированию вознаграждения этот метод может эффективно переносить возможности однонаправленного перевода на 90 направлений перевода для 11 языков (Источник: HuggingFace Daily Papers)
Обучаемое разреженное внимание VSA ускоряет видеодиффузионные модели: Для решения проблемы квадратичной сложности механизма трехмерного полного внимания в видеодиффузионных трансформерах (DiT) исследователи предложили VSA (обучаемое разреженное внимание). VSA объединяет токены в блоки на легковесном грубом этапе и идентифицирует ключевые токены, а затем выполняет мелкозернистое вычисление внимания на уровне токенов внутри этих блоков. VSA представляет собой единое дифференцируемое ядро, обучаемое от начала до конца, не требующее постобработки и анализа, и сохраняет 85% MFU FlashAttention3. Эксперименты показали, что VSA снижает FLOPS обучения в 2,53 раза без снижения диффузионных потерь и ускоряет время внимания открытой модели Wan-2.1 в 6 раз, сокращая общее время генерации с 31 до 18 секунд (Источник: HuggingFace Daily Papers)
SoftCoT++: достижение масштабирования во время тестирования с помощью мягкого рассуждения по цепочке мыслей: Для усиления исследовательских возможностей метода SoftCoT, который выполняет рассуждения в непрерывном латентном пространстве, исследователи предложили SoftCoT++. Этот метод возмущает латентные идеи с помощью различных специализированных начальных токенов и применяет контрастивное обучение для содействия разнообразию представлений мягких идей, тем самым расширяя SoftCoT до парадигмы масштабирования во время тестирования (TTS). Эксперименты показали, что SoftCoT++ значительно улучшает производительность SoftCoT и превосходит SoftCoT с расширением самосогласованности, а также хорошо совместим с традиционными техниками расширения (такими как самосогласованность) (Источник: HuggingFace Daily Papers)
MTVCrafter: токенизация 4D-движения для анимации изображений людей в открытом мире: Для решения проблемы ограниченной обобщающей способности существующих методов, зависящих от 2D-изображений поз, MTVCrafter предлагает напрямую моделировать исходные последовательности 3D-движений (4D-движения). Его ядром является 4DMoT (токенизатор 4D-движений), который квантует последовательности 3D-движений в токены 4D-движений, предоставляя более надежные пространственно-временные ориентиры. Затем MV-DiT (видео DiT с восприятием движения), разработанный с уникальным механизмом внимания к движению и кодированием 4D-позиций, эффективно использует эти токены в качестве контекста для анимации изображений людей в сложном 3D-мире. Эксперименты показали, что MTVCrafter достигает 6.98 по FID-VID, значительно превосходя SOTA, и хорошо обобщается на различных персонажей разных стилей и сцен (Источник: HuggingFace Daily Papers)
QVGen: расширяя пределы квантованных моделей генерации видео: Для решения проблемы больших вычислительных и ресурсных затрат видеодиффузионных моделей (DM), QVGen предлагает новую платформу квантования с учетом обучения (QAT), специально разработанную для квантования с очень низким числом бит (например, 4 бита и ниже). С помощью теоретического анализа исследователи обнаружили, что снижение нормы градиента имеет решающее значение для сходимости QAT, и ввели вспомогательный модуль (Phi) для смягчения больших ошибок квантования. Для устранения накладных расходов на логический вывод Phi предложена стратегия затухания ранга, которая постепенно устраняет Phi с помощью SVD и регуляризации на основе ранга. Эксперименты показали, что QVGen впервые достигает качества, сопоставимого с полной точностью, при 4-битной настройке и значительно превосходит существующие методы (Источник: HuggingFace Daily Papers)
ViPlan: бенчмарк символических предикатов и визуально-языковых моделей для визуального планирования: Для устранения разрыва в сравнении между символическим планированием, управляемым VLM, и методами прямого планирования VLM, был предложен ViPlan как первый открытый бенчмарк для визуального планирования. ViPlan включает задачи возрастающей сложности в двух областях: визуальная версия Blocksworld и симулированная среда домашнего робота. Тестирование 9 семейств открытых VLM и некоторых закрытых моделей показало, что символическое планирование лучше работает в Blocksworld (где важна точная локализация изображений), в то время как прямое планирование VLM лучше справляется с задачами домашнего робота (где важны знания здравого смысла и способность к восстановлению после ошибок). Исследование также показало, что подсказки CoT не приносят значительной пользы для большинства моделей и методов, что указывает на все еще недостаточные возможности визуального мышления текущих VLM (Источник: HuggingFace Daily Papers)
От первобытных криков к грамматике: исследование эволюции языка в среде совместного поиска пищи: Для изучения происхождения и эволюции языка исследователи смоделировали сценарии раннего человеческого сотрудничества в многоагентной игре по поиску пищи. С помощью сквозного глубокого обучения с подкреплением агенты с нуля изучали стратегии действий и коммуникации. Исследование показало, что разработанные агентами коммуникационные протоколы демонстрируют характерные черты естественного языка: произвольность, взаимозаменяемость, смещение, культурную передачу и комбинаторность. Эта структура предоставляет платформу для изучения того, как язык эволюционирует в воплощенных многоагентных средах с частичной наблюдаемостью, временным мышлением и целями, ориентированными на сотрудничество (Источник: HuggingFace Daily Papers)
Tiny QA Benchmark++: сверхлегкий многоязычный синтетический набор данных для генерации и дымового тестирования для непрерывной оценки LLM: Tiny QA Benchmark++ (TQB++) — это сверхлегкий, многоязычный набор для дымового тестирования, предназначенный для обеспечения системы безопасности типа модульного тестирования для конвейеров LLM, который может выполняться за несколько секунд с очень низкими затратами. TQB++ включает золотой набор из 52 элементов на английском языке и предоставляет миниатюрный генератор синтетических данных на основе LiteLLM (пакет pypi), с помощью которого пользователи могут генерировать небольшие тестовые пакеты для пользовательских языков, доменов или уровней сложности. Проект уже предоставляет готовые пакеты для 10 языков и поддерживает инструменты, такие как OpenAI-Evals, LangChain, что облегчает интеграцию в процессы CI/CD для быстрого обнаружения ошибок в шаблонах подсказок, дрейфа токенизатора и побочных эффектов тонкой настройки (Источник: HuggingFace Daily Papers)
HelpSteer3-Preference: открытый набор данных человеческих предпочтений, охватывающий множество задач и языков: Для удовлетворения потребности в высококачественных, разнообразных открытых данных о предпочтениях, NVIDIA выпустила набор данных HelpSteer3-Preference. Этот набор данных содержит более 40 000 образцов предпочтений, аннотированных людьми, и распространяется по лицензии CC-BY-4.0, охватывая реальные применения LLM, такие как STEM, кодирование и многоязычные сценарии. Модели вознаграждения (RM), обученные на этом наборе данных, достигли SOTA производительности как на RM-Bench (82,4%), так и на JudgeBench (73,7%), улучшив предыдущие лучшие результаты примерно на 10%. Этот набор данных также может использоваться для обучения генеративных RM и для выравнивания стратегических моделей с помощью RLHF (Источник: HuggingFace Daily Papers)
SEED-GRPO: GRPO с усилением семантической энтропии для оптимизации стратегии с учетом неопределенности: Для решения проблемы, связанной с тем, что GRPO при обновлении стратегии не учитывает неопределенность LLM относительно входных подсказок, исследователи предложили SEED-GRPO. Этот метод явно измеряет неопределенность LLM относительно входных подсказок (т.е. семантическое разнообразие нескольких сгенерированных ответов) с помощью семантической энтропии и использует это для регулирования величины обновления стратегии. Этот механизм обучения с учетом неопределенности позволяет проводить более консервативные обновления для вопросов с высокой неопределенностью, сохраняя при этом исходный обучающий сигнал для уверенных вопросов. Эксперименты показали, что SEED-GRPO достигает SOTA производительности на пяти бенчмарках математического мышления (Источник: HuggingFace Daily Papers)
Создание универсальной пользовательской модели (GUM) на основе использования компьютера: Исследователи предложили архитектуру универсальной пользовательской модели (GUM), которая изучает знания и предпочтения пользователя, наблюдая за любыми его взаимодействиями с компьютером (например, скриншотами устройства), и строит взвешенные по достоверности утверждения. GUM способна выводить новые утверждения из неструктурированных мультимодальных наблюдений, извлекать релевантные утверждения в качестве контекста и постоянно корректировать существующие утверждения. Эта архитектура предназначена для улучшения чат-помощников, управления уведомлениями операционной системы и предоставления интерактивным агентам возможности адаптироваться к предпочтениям пользователя в различных приложениях. Эксперименты показали, что GUM может делать калиброванные и точные выводы о пользователе, а помощники на основе GUM могут активно выявлять и выполнять полезные действия, которые пользователь явно не запрашивал (Источник: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: Популярный проект на GitHub, предоставляющий всеобъемлющий репозиторий учебных ресурсов по инженерии данных, включая дорожную карту для начинающих на 2024 год, материалы 6-недельного бесплатного учебного лагеря на YouTube, примеры проектов, советы для собеседований, рекомендуемые книги, списки сообществ и новостных рассылок. Среди рекомендуемых книг: «Fundamentals of Data Engineering», «Designing Data-Intensive Applications» и «Designing Machine Learning Systems». В руководстве также перечислены компании в различных областях инженерии данных, такие как Mage (оркестрация), Databricks (озера данных), Snowflake (хранилища данных), dbt (качество данных), LangChain (библиотека для LLM-приложений) и др., а также предоставлены ссылки на блоги по инженерии данных известных компаний и важные технические документы (Источник: GitHub Trending)
💼 Бизнес
Cohere и SAP сотрудничают для внедрения корпоративных AI-агентов в глобальный бизнес: Cohere объявила о сотрудничестве с SAP для встраивания своей технологии корпоративных AI-агентов в SAP Business Suite, предоставляя глобальным предприятиям безопасные и масштабируемые возможности AI. Передовые модели Cohere также появятся в SAP AI Core, что позволит предприятиям в таких областях, как финансы и здравоохранение, использовать ее многоязычные, специализированные AI-модели (Command, Embed, Rerank), с целью ускорения корпоративных AI-приложений и раскрытия реальной коммерческой ценности (Источник: X, X)
xAI стремится использовать правительственные данные для расширения бизнеса в корпоративном и государственном секторах: По сообщению The Information, компания xAI Илона Маска планирует использовать данные государственных учреждений для разработки моделей и приложений, а также продавать их государственным клиентам. Эта инициатива может стать важной частью стратегии коммерциализации xAI, но также вызывает дискуссии об использовании данных и потенциальных предубеждениях (Источник: X)
Weaviate и AWS углубляют глобальное сотрудничество для ускорения генеративных AI-инициатив: Компания по разработке векторных баз данных Weaviate объявила об укреплении глобального сотрудничества с AWS с целью совместного ускорения проектов в области генеративного AI. Это сотрудничество будет сосредоточено на предоставлении глобальным разработчикам большей скорости, большего масштаба и лучшего опыта разработки, способствуя применению и развитию технологий генеративного AI (Источник: X)

🌟 Сообщество
Рост популярности AI-агентов для программирования вызывает дискуссии о перспективах профессии программиста: Компании, такие как Microsoft и OpenAI, активно выпускают или совершенствуют AI-агентов для программирования (Coding Agents), например, GitHub Copilot Coding Agent, OpenAI Codex и другие, которые способны самостоятельно выполнять задачи по написанию кода, исправлению ошибок, поддержке кода и т.д. CEO Anthropic Dario Amodei прогнозирует, что AI может в краткосрочной перспективе писать большую часть или даже весь код, а CPO OpenAI Kevin Weil также считает, что AI вырастет из младшего инженера в архитектора. Это вызвало широкие дискуссии в сообществе о будущем профессии программиста: некоторые опасаются, что младшие должности будут заменены, и AI автоматизирует значительную часть работы по программированию; другие же считают, что AI повысит эффективность программистов, позволив им сосредоточиться на более высокоуровневом проектировании архитектуры и инновациях, а их роль трансформируется в «наставников AI». Общая тенденция показывает, что обучение эффективному взаимодействию с AI станет ключевым навыком для программистов (Источник: X, X, 36Kr, 36Kr)
Концепция и стандарты AI Agent активно обсуждаются, протокол MCP привлекает внимание: С ростом популярности приложений AI Agent (таких как Manus, Genspark Super Agent, Fellou.ai) сообщество активно обсуждает определение, уровни возможностей и парадигмы разработки агентов. Известный венчурный фонд BVP предложил семиуровневую классификацию агентов от L0 до L6. В то же время, протокол контекста модели (MCP) как ключевая технология для обеспечения взаимодействия между AI-приложениями привлекает внимание. Крупные зарубежные компании, такие как Anthropic, OpenAI, Google, уже поддерживают или планируют поддержать MCP, а китайские компании, такие как Alibaba Cloud и Tencent Cloud, также начинают создавать локализованные платформы разработки агентов на основе MCP. Разработчик iluxu даже до того, как Microsoft представила концепцию «USB-C для AI-приложений», открыл исходный код аналогичного проекта llmbasedos, стремясь продвигать открытые стандарты подключения агентов (Источник: X, X, WeChat, Reddit r/LocalLLaMA)
LLM плохо справляются с определенными задачами логического вывода, что вызывает обсуждение границ их возможностей: Сообщество активно обсуждает явление, когда LLM коллективно «проваливаются» в некоторых, казалось бы, простых задачах физического или визуально-пространственного логического вывода, например, в вопросе о складывании кубиков для формирования большего куба, где даже топовые модели, такие как o3, Gemini 2.5 Pro, дают неверные ответы. В то же время, в одной из оценочных статей отмечается, что в базовых физических задачах, таких как изготовление деталей, LLM (включая o3) работают хуже опытных рабочих, в основном из-за недостаточных визуальных способностей и ошибок в физическом логическом выводе, а также из-за отсутствия неявных знаний о реальном мире. Эти случаи вызывают дискуссии о реальных способностях LLM к пониманию, проблеме галлюцинаций (например, рост частоты галлюцинаций у o3 при логическом выводе) и эффективности текущих бенчмарков, подчеркивая, что AI все еще имеет значительный простор для улучшений в области специфических знаний и сложного логического вывода (Источник: QbitAI, 36Kr)

Технологическая конкуренция между Китаем и США и стратегии развития AI привлекают внимание: CEO NVIDIA Дженсен Хуанг в интервью затронул вопросы регулирования чипов, AI-фабрик и корпоративного прагматизма, его взгляды были истолкованы как глубокое понимание текущей ситуации в технологической конкуренции между Китаем и США. Некоторые комментаторы считают, что США пытаются сохранить лидирующие позиции, ограничивая доступ Китая к передовым AI-ресурсам, но это может привести к проигрышной для обеих сторон ситуации и замедлить глобальное развитие AI. Хуанг же, по-видимому, считает, что настоящая конкуренция является долгосрочной, и США должны стремиться к всестороннему лидерству (чипы, фабрики, инфраструктура, модели, приложения), а не просто к краткосрочному относительному преимуществу, иначе они могут упустить возможности эпохи AI и в конечном итоге отстать в конкуренции за совокупную национальную мощь (Источник: X)
Применение и обсуждение AI-инструментов, таких как ChatGPT, для поддержки психического здоровья: Пользователи сообщества Reddit делятся опытом использования AI-инструментов, таких как ChatGPT, для поддержки психического здоровья, считая, что они могут помочь в промежутках между сеансами профессиональной терапии, особенно в упорядочивании и выражении сложных эмоций. Задавая вопросы AI или позволяя AI задавать вопросы о своих чувствах, пользователи лучше понимают источники эмоций и разрабатывают планы по улучшению состояния. В комментариях некоторые пользователи (включая тех, кто называет себя терапевтами) считают, что AI в некоторых случаях даже превосходит некоторых человеческих терапевтов, особенно для тех, кому трудно получить профессиональную помощь или кто испытывает проблемы с доверием к человеческим терапевтам. Однако другие пользователи напоминают, что AI не может полностью заменить профессиональную терапию и следует обращать внимание на вопросы конфиденциальности личных данных (Источник: Reddit r/ChatGPT)
💡 Прочее
Запущен конкурс алгоритмов «Кубок Цичжи», посвященный трем передовым направлениям AI: Лаборатория Циюань (启元实验室) запустила конкурс алгоритмов «Кубок Цичжи» (启智杯) с общим призовым фондом 750 000 юаней. Конкурс включает три направления: «Надежная сегментация экземпляров на спутниковых снимках дистанционного зондирования», «Обнаружение наземных целей беспилотными летательными аппаратами для встраиваемых платформ» и «Противодействие мультимодальным большим моделям». Цель конкурса — способствовать инновациям и практическому применению ключевых технологий AI, таких как надежное восприятие, легковесное развертывание и защита от атак. Конкурс открыт для исследовательских институтов, предприятий и организаций Китая (Источник: WeChat)

Chicago Sun-Times допустила ошибку в контенте, сгенерированном AI, порекомендовав несуществующие книги и экспертов: В одном из выпусков Chicago Sun-Times, посвященном рекомендациям летних мероприятий, часть контента, предположительно, была сгенерирована AI. В нем содержались рекомендации вымышленных книг, приписанных реально существующим авторам, а также цитаты «экспертов», которые, по-видимому, не существуют. Например, книги «Nightshade Market» Мин Джин Ли и «Boiling Point» Ребекки Маккай были указаны как рекомендуемые, но таких книг не существует. Этот инцидент вызвал обеспокоенность по поводу точности и механизмов проверки при использовании AI-сгенерированного контента в новостных СМИ (Источник: Reddit r/artificial)
Обсуждение того, является ли использование AI «читерством»: Сообщество обсуждает границы использования AI-инструментов (таких как ChatGPT, Claude) в работе и учебе. Распространенное мнение заключается в том, что при отсутствии явных правил, запрещающих это (например, в университетских заданиях), использование AI-инструментов для повышения эффективности, выполнения рутинных задач или помощи в мышлении не является «читерством», а аналогично использованию калькулятора или поисковой системы. Ключевым моментом является то, понимает ли пользователь вывод AI, может ли он его эффективно корректировать и проверять, а также честно ли заявляет о вспомогательной роли AI (особенно в академической среде). Однако, если полностью полагаться на сгенерированный AI контент и без разбора утверждать, что он оригинальный, это может быть расценено как академическая недобросовестность или негативно сказаться на развитии личных навыков (Источник: Reddit r/ArtificialInteligence)