
Ключевые слова:Искусственный интеллект (ИИ), Google Gemini, Энергопотребление ИИ, Применение ИИ в юриспруденции, Microsoft Discovery, Дженсен Хуанг и Илон Маск, Регулирование ИИ, Gemini 2.5 Pro, Энергопотребление дата-центров ИИ, Ошибки в генерации юридических документов ИИ, Научная платформа Microsoft Discovery, Экспортный контроль чипов ИИ
🔥 В центре внимания
Google на конференции I/O анонсировала множество достижений в области AI, Gemini полностью интегрируется в экосистему Google: На конференции разработчиков I/O 2025 Google объявила о серии значительных обновлений в области AI, в центре которых — обновление и глубокая интеграция модели Gemini. Gemini 2.5 Pro представляет функцию “Deep Think” для улучшенного сложного логического вывода, 2.5 Flash оптимизирован по эффективности и стоимости, а также добавлен нативный аудиовыход. Поиск внедряет “AI模式” (режим AI), предоставляя ответы в стиле чат-бота и возможность персонализации результатов на основе данных пользователя (с его разрешения). Браузер Chrome будет интегрирован с помощником Gemini. Видеомодель Veo 3 позволяет генерировать видео со звуком, а модель изображений Imagen 4 улучшает детализацию и обработку текста. Google также выпустила инструмент для создания фильмов с помощью AI Flow, помощника по программированию Jules, и продемонстрировала прогресс в проектах Project Astra (мультимодальный помощник в реальном времени) и Project Mariner (многозадачный AI-агент). Кроме того, Google представила новую услугу подписки на AI, премиум-версия AI Ultra стоит 249,99 долларов США в месяц. Эти шаги свидетельствуют о том, что Google ускоряет всестороннюю интеграцию AI в свои продукты и услуги, переосмысливая опыт взаимодействия с пользователем. (Источник: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

Проблема энергопотребления AI привлекает внимание, MIT Technology Review глубоко анализирует его энергетический след и будущие вызовы: MIT Technology Review опубликовал серию статей, в которых подробно рассматриваются проблемы энергопотребления и выбросов углерода, связанные с развитием технологий AI. Исследования показывают, что энергопотребление на этапе логического вывода AI уже превысило энергопотребление на этапе обучения, став основной энергетической нагрузкой. В отчетах анализируются огромные потребности дата-центров в электроэнергии и водных ресурсах (например, дата-центры в пустыне Невада), а также их зависимость от ископаемых источников энергии (например, дата-центр Meta в Луизиане зависит от природного газа). Хотя атомная энергия рассматривается как потенциальное решение для чистой энергетики, ее длительные сроки строительства затрудняют удовлетворение быстрорастущих потребностей AI в краткосрочной перспективе. В то же время, в отчетах также указываются оптимистичные перспективы повышения энергоэффективности AI, включая более эффективные алгоритмы моделей, энергосберегающие чипы, специально разработанные для AI, и более оптимизированные технологии охлаждения дата-центров. Серия статей подчеркивает, что, хотя энергопотребление одного запроса AI кажется незначительным, общие тенденции в отрасли и будущие планы (например, проект Stargate от OpenAI) предвещают огромные энергетические проблемы, требующие прозрачного раскрытия данных и ответственного энергетического планирования. (Источник: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Применение AI в юридической сфере вызывает ошибки и этические опасения: Недавние инциденты показывают, что проблема «галлюцинаций» AI при составлении юридических документов вызывает серьезную озабоченность. Судья в Калифорнии оштрафовал адвоката за использование инструментов AI, таких как Google Gemini, для генерации контента с ложными ссылками в судебных документах. В другом случае модель Claude компании Anthropic также допустила ошибки при генерации ссылок для юридических документов. Еще большую тревогу вызывает признание израильского прокурора в использовании AI-сгенерированного текста с ссылками на несуществующие законы в своем запросе. Эти случаи подчеркивают недостатки моделей AI в точности и надежности, особенно в юридической сфере, где требования к фактам и ссылкам чрезвычайно высоки. Эксперты отмечают, что адвокаты, стремясь к эффективности, могут чрезмерно доверять результатам работы AI, пренебрегая необходимостью тщательной проверки. Несмотря на то, что инструменты AI рекламируются как надежные юридические помощники, их присущая «галлюцинаторность» представляет потенциальную угрозу для правосудия и требует отраслевых стандартов и бдительности пользователей. (Источник: MIT Technology Review)

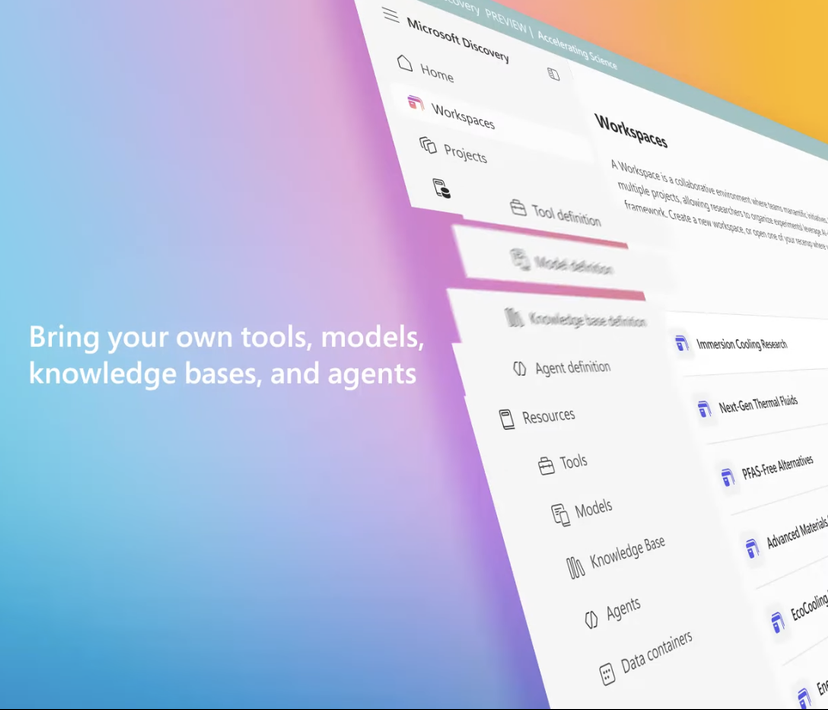
Microsoft запускает корпоративную научно-исследовательскую платформу AI Microsoft Discovery для содействия научным открытиям: На конференции Build Microsoft представила Microsoft Discovery, платформу AI, разработанную для предприятий и научно-исследовательских учреждений. Платформа призвана дать возможность ученым и инженерам без опыта программирования использовать высокопроизводительные вычисления и сложные системы моделирования посредством взаимодействия на естественном языке. Платформа сочетает в себе базовые модели для планирования и специализированные модели, обученные для конкретных научных областей (таких как физика, химия, биология), формируя команду «AI-постдоков», способную выполнять весь научно-исследовательский процесс от обзора литературы до вычислительного моделирования. Microsoft продемонстрировала пример ее применения: примерно за 200 часов было проанализировано 367 000 веществ, и успешно найдена потенциальная замена хладагента без PFAS, что было подтверждено экспериментально. Особенности платформы включают графовый механизм знаний, совместное рассуждение, непрерывный итеративный цикл исследований и разработок. Платформа построена на базе инфраструктуры Azure, и ее будущая архитектура предусматривает возможность подключения к квантовым вычислениям. (Источник: 量子位)
Хуан Жэньсюнь и Илон Маск высказали мнения о развитии AI, регулировании и глобальной конкуренции: Генеральный директор NVIDIA Хуан Жэньсюнь в эксклюзивном интервью выразил обеспокоенность по поводу американского контроля над экспортом чипов, полагая, что ограничение распространения технологий может подорвать лидерство США в области AI, и подчеркнул мощь Китая в исследованиях и разработках AI, а также тот факт, что половина разработчиков AI в мире родом из Китая. Он выступает за то, чтобы США ускорили глобальное распространение технологий и позволили американским компаниям конкурировать на китайском рынке. Генеральный директор Tesla Илон Маск в другом интервью заявил, что продолжит руководить Tesla как минимум пять лет и считает, что приблизился к достижению AGI. Он поддерживает умеренное регулирование AI, но выступает против чрезмерного вмешательства. Оба технологических лидера подчеркнули огромный потенциал AI: Хуан Жэньсюнь считает, что AI будет способствовать значительному росту мирового ВВП, а Маск перечислил ключевые цели этого года, такие как Starship, Neuralink и беспилотные такси Tesla, все из которых тесно связаны с AI. (Источник: 36氪, 36氪, 36氪)

🎯 Тренды
Google выпускает предварительную версию Gemma 3n, разработанную для эффективной работы на устройствах: Google опубликовала на HuggingFace предварительную версию модели Gemma 3n, специально разработанную для эффективной работы на устройствах с ограниченными ресурсами (например, мобильных устройствах). Эта серия моделей обладает возможностями мультимодального ввода, способна обрабатывать текст, изображения, видео и аудио, а также генерировать текстовый вывод. В ней используется технология «селективной активации параметров» (аналогичная архитектуре MoE, Mixture of Experts), которая позволяет модели работать с эффективным размером параметров 2B и 4B, тем самым снижая требования к ресурсам. В сообществе обсуждается, что архитектура Gemma 3n может быть схожа с Gemini, что объясняет мощные мультимодальные возможности и способность обработки длинных контекстов последней. Открытые веса Gemma 3n и версии с инструктивной настройкой, а также обучение на данных более чем 140 языков, делают ее потенциально применимой в области edge AI, например, в умных домашних помощниках. (Источник: Reddit r/LocalLLaMA, developers.googleblog.com)

Google представляет MedGemma, AI-модель, оптимизированную для медицинской сферы: Google выпустила серию моделей MedGemma, два варианта Gemma 3, специально оптимизированных для медицинской сферы, включая мультимодальную версию с 4B параметрами и текстовую версию с 27B параметрами. MedGemma 4B специально обучена для понимания медицинских изображений (таких как рентгеновские снимки, дерматологические изображения и т.д.) и текста, используя предварительно обученный на медицинских данных кодировщик изображений SigLIP. MedGemma 27B фокусируется на обработке медицинских текстов и оптимизирована для вычислений при логическом выводе. Google заявляет, что эти модели призваны ускорить разработку медицинских AI-приложений и были оценены на нескольких клинически значимых бенчмарках; разработчики могут донастраивать их для повышения производительности в конкретных задачах. Сообщество отреагировало положительно, отметив огромный потенциал, но подчеркнув необходимость реальной обратной связи от медицинских специалистов. (Источник: Reddit r/LocalLLaMA)

ByteDance выпускает мультимодальную модель с открытым исходным кодом Bagel, поддерживающую генерацию изображений: ByteDance представила Bagel (также известную как BAGEL-7B-MoT), мультимодальную большую модель с 14B параметрами (7B активных) и открытым исходным кодом под лицензией Apache 2.0. Модель основана на архитектуре Mixture of Experts (MoE) и Mixture of Transformers (MoT), способна понимать и генерировать текст, а также обладает нативной возможностью генерации изображений. Она превосходит другие открытые унифицированные модели в ряде тестов на понимание и генерацию мультимодальных данных, а также демонстрирует продвинутые возможности мультимодального логического вывода, такие как обработка изображений в свободной форме и предсказание будущих кадров. Исследователи надеются способствовать развитию мультимодальных исследований, делясь деталями предварительного обучения, протоколами создания данных, а также открывая код и контрольные точки. (Источник: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
NVIDIA представляет DreamGen, использующий генеративные видеомодели для обучения роботов: Исследовательская группа NVIDIA представила проект DreamGen, который путем дообучения передовых видеогенеративных моделей (таких как Sora, Veo) позволяет роботам осваивать новые навыки в генерируемых «мирах сновидений». Этот метод не зависит от традиционных графических движков или физических симуляторов, а позволяет роботам самостоятельно исследовать и получать опыт в пиксельных сценах, генерируемых нейронными сетями, тем самым создавая большое количество нейронных траекторий с псевдо-метками действий. Эксперименты показали, что DreamGen может значительно улучшить производительность роботов в симулированных и реальных задачах, включая невиданные ранее действия и незнакомые среды. Например, всего лишь с небольшим количеством реальных траекторий человекоподобный робот научился наливать воду, складывать одежду и выполнять 22 других новых навыка, успешно обобщив их на реальные сценарии, такие как кофейня в штаб-квартире NVIDIA. (Источник: 36氪, arxiv.org)

Huawei предлагает OmniPlacement для оптимизации производительности логического вывода моделей MoE: В ответ на проблему задержек при логическом выводе, вызванную неравномерной загрузкой экспертных сетей в моделях Mixture of Experts (MoE) («горячие» и «холодные» эксперты), команда Huawei предложила оптимизационное решение OmniPlacement. Это решение направлено на повышение производительности логического вывода моделей MoE за счет перестановки экспертов, межслойного избыточного развертывания и динамического планирования почти в реальном времени. Теоретическая проверка на моделях, таких как DeepSeek-V3, показала, что OmniPlacement может снизить задержку логического вывода примерно на 10% и увеличить пропускную способность примерно на 10%. Ключевой особенностью метода является динамическая корректировка приоритетов экспертов, оптимизация доменов связи, дифференцированное развертывание избыточных экземпляров и гибкое реагирование на изменения нагрузки с помощью механизма планирования почти в реальном времени и динамического мониторинга. Huawei планирует в ближайшее время открыть исходный код этого решения. (Источник: 量子位)

Apple планирует предоставить разработчикам доступ к своим AI-моделям для стимулирования инноваций в приложениях: По сообщениям, Apple на WWDC объявит о предоставлении сторонним разработчикам доступа к своим AI-моделям Apple Intelligence. Первоначально основное внимание будет уделено легковесным языковым моделям с примерно 3 миллиардами параметров, работающим на устройстве, а в дальнейшем, возможно, будут открыты облачные модели (работающие через частное облако с шифрованием), сопоставимые по уровню с GPT-4-Turbo. Этот шаг направлен на поощрение разработчиков к созданию новых функций приложений на базе LLM от Apple, повышение привлекательности устройств Apple и восполнение относительного отставания в области генеративного AI. Аналитики считают, что Apple надеется, создав открытую экосистему, использовать свое огромное сообщество разработчиков (6 миллионов) для компенсации собственных технологических недостатков и противостояния растущей конкуренции в сфере AI. (Источник: 36氪)
Предложение Палаты представителей США о приостановке государственного регулирования AI на десять лет вызывает огромные споры: Комитет по энергетике и торговле Палаты представителей США принял предложение, планирующее запретить штатам регулировать модели искусственного интеллекта, системы и автоматизированные системы принятия решений, которые «существенно влияют или заменяют человеческие решения», в течение следующих десяти лет. Сторонники считают, что этот шаг позволит избежать ситуации, когда различные законы штатов препятствуют инновациям в области AI и модернизации систем федерального правительства; противники же называют это «огромным подарком крупным технологическим компаниям», который ослабит способность штатов защищать население от вреда AI. Если это предложение будет принято, оно может сделать недействительными многие существующие и предлагаемые законы штатов об AI, но также четко оговаривает, что оно не распространяется на федеральные законы или законы общего применения, которые одинаково трактуют системы AI и не-AI. Этот шаг отражает острую глобальную борьбу между приоритетом «инноваций в AI» и «безопасностью». (Источник: 36氪, edition.cnn.com)

Закон «Take It Down Act» подписан и стал законом США, направленным на борьбу с распространением недобровольных интимных изображений: Президент США Трамп подписал законопроект «Take It Down Act», который квалифицирует создание и распространение недобровольных интимных изображений (включая созданный AI контент deepfake) как федеральное преступление. Закон требует от технологических платформ удалять соответствующий контент в течение 48 часов после получения уведомления. Этот закон направлен на защиту жертв и противодействие все более серьезным социальным проблемам, вызванным злоупотреблением технологией deepfake. Однако некоторые комментаторы отмечают, что закон может быть использован не по назначению, что приведет к чрезмерной цензуре. (Источник: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

Большие модели AI способствуют управлению здоровьем, обеспечивая персонализацию и интеграцию многомерных данных: Большие модели AI привносят новую энергию в область управления здоровьем, объединяясь с носимыми устройствами для обеспечения интеграции многомерных данных и персонализированных услуг. Компании, такие как WeDoctor, Deepwise Healthcare, NandaFitech и другие, активно исследуют сценарии применения, например, начиная с раннего скрининга и лечения на этапе медицинских осмотров или используя управление весом в качестве отправной точки для профилактики и лечения хронических заболеваний. Большие модели способны обрабатывать более разнообразные измерения данных, создавать пользовательскую память и предлагать более точные планы медицинского вмешательства. Проблемы включают галлюцинации моделей, качество данных и трудности с координацией, но они постепенно преодолеваются с помощью RAG, дообучения моделей, механизмов проверки и модели «AI + реальный менеджер». В коммерческом плане уже получили первоначальное подтверждение услуги ToB, платные услуги для C-сегмента и «AI Health Community», а будущие тенденции будут развиваться в сторону мультимодального взаимодействия. (Источник: 36氪)
Baidu усиливает мультимодальные возможности большой модели Wenxin, отвечая на рыночную конкуренцию и внедрение приложений: Последние выпущенные Baidu большие модели Wenxin Large Model 4.5 Turbo и модель глубокого мышления X1 Turbo значительно улучшили возможности мультимодального понимания и генерации за счет таких технологий, как смешанное обучение, моделирование гетерогенных мультимодальных экспертов, что повысило эффективность межмодального обучения и эффект слияния. Хотя генеральный директор Ли Яньхун ранее выражал осторожность по поводу проблемы галлюцинаций в моделях генерации видео типа Sora, перед лицом рыночной конкуренции (например, прогресс Doubao от ByteDance и Tongyi Qianwen от Alibaba в мультимодальной области) и потребностей внедрения AI-приложений, Baidu активно устраняет недостатки и планирует открыть исходный код серии Wenxin Large Model 4.5 30 июня. Baidu считает AI-аватаров важным прорывом в применении и уже разработала технологию сверхреалистичных цифровых людей, управляемых «сценарием», поддерживающую более 100 000 цифровых ведущих. (Источник: 36氪)
Платформы Douyin, Xiaohongshu и другие проводят специальную кампанию по борьбе с «AI-аккаунтами» для поддержания экосистемы контента: Платформы электронной коммерции, ориентированные на интересы, такие как Douyin и Xiaohongshu, недавно усилили специальную кампанию по борьбе с практиками массового производства фальшивого контента с использованием технологий AI, создания «AI-аккаунтов» и т.д. Эти действия включают генерацию AI низкопробных и сенсационных видео, контента от виртуальных экспертов, продажу учебных пособий по созданию AI-аккаунтов и самих аккаунтов. Платформы считают, что такие действия подрывают достоверность контента, приводят к его гомогенизации, наносят ущерб пользовательскому опыту и экосистеме оригинальных авторов, тем самым снижая коммерческую ценность. В отличие от этого, традиционные платформы электронной коммерции, такие как Taobao и JD.com, активно поощряют продавцов использовать инструменты AI (например, «image-to-video», цифровые аватары для прямых трансляций) для улучшения демонстрации товаров и эффективности операций, с основной целью содействия заключению сделок. Это различие отражает диверсификацию стратегий применения AI в различных моделях электронной коммерции. (Источник: 36氪)

Разработка AI-версии Siri от Apple столкнулась с трудностями, возможен очередной перенос, руководство скорректировано для преодоления кризиса: По данным Bloomberg, обновленная версия Siri с большой моделью, которую Apple планировала представить на WWDC, может быть снова отложена. Технологические трудности заключаются в конфликте между старой и новой архитектурами системы, что приводит к частым ошибкам. В отчете указывается, что у Apple существуют проблемы в стратегии AI, связанные с ошибками в принятии решений на высшем уровне, внутренней борьбой за власть, недостаточной закупкой GPU и ограничениями на использование данных из-за защиты конфиденциальности, что привело к отставанию ее технологий AI от конкурентов. Для преодоления кризиса лаборатория Apple в Цюрихе разрабатывает совершенно новую архитектуру «LLM Siri», а проект Siri передан под управление Майка Роквелла, руководителя Vision Pro. В то же время Apple также ищет сотрудничества с внешними технологиями, такими как Google Gemini, OpenAI, и, возможно, в маркетинге отделит бренд Apple Intelligence от Siri, чтобы перестроить свой имидж в области AI. (Источник: 36氪)

ByteDance выпускает наушники Ola Friend с интегрированным интеллектуальным агентом-репетитором английского языка Owen: ByteDance добавила в свои умные наушники Ola Friend функцию интеллектуального агента-репетитора английского языка по имени Owen. Пользователи могут активировать Owen, вызвав приложение Doubao, для ведения диалогов на английском, чтения на английском языке с подсказками и получения двуязычных комментариев. Эта функция охватывает повседневные разговоры, деловой английский, путешествия и другие сценарии, предоставляя удобного карманного репетитора английского языка. Это знаменует собой еще одну попытку ByteDance в образовательной сфере, объединяя возможности больших моделей AI с аппаратным обеспечением для создания вертикального продукта для изучения английского языка. Наушники Ola Friend ранее уже поддерживали ответы на вопросы и практику устной речи через Doubao, а добавление нового интеллектуального агента еще больше усилило их образовательную направленность. (Источник: 36氪)

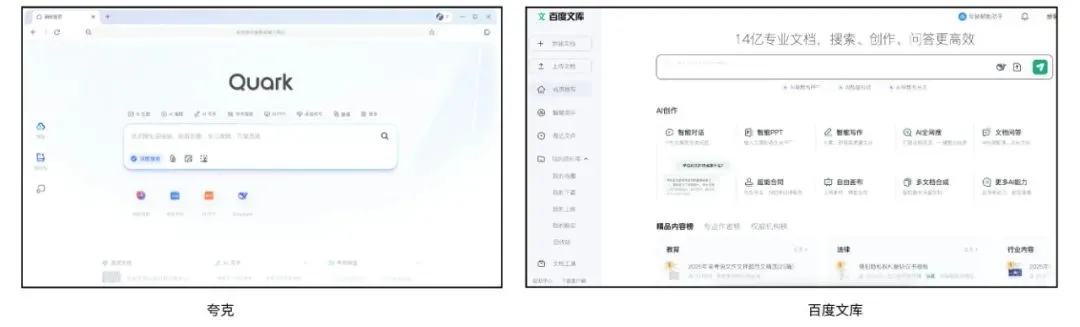
Quark и Baidu Wenku конкурируют за звание AI-суперприложения, интегрируя поиск, инструменты и контент-сервисы: Quark, принадлежащий Alibaba, и Baidu Wenku, принадлежащий Baidu, трансформируются в «супер-окна» на базе AI, интегрируя AI-диалоги, глубокий поиск, AI-инструменты (такие как написание текстов, генерация PPT, помощник по здоровью и т.д.), а также облачные хранилища и сервисы документов, стремясь стать универсальным AI-порталом для C-сегмента пользователей. Quark, благодаря поиску без рекламы и молодой аудитории, достиг 149 миллионов активных пользователей в месяц и монетизируется через систему подписок. Baidu Wenku, опираясь на свои огромные ресурсы документов и базу платных пользователей, запустил «Cangzhou OS» для интеграции AI Agent, усиливая всю цепочку создания и потребления контента. Оба сталкиваются с проблемами гомогенизации функций, раздутости приложений и поиска баланса между общими потребностями и специализированными услугами. (Источник: 36氪)
Zhipu Qingyan, Kimi и 33 других приложения уведомлены о незаконном сборе персональных данных: Национальный центр информирования по вопросам кибербезопасности и защиты информации опубликовал уведомление, в котором указывается, что Zhipu Qingyan (версия 2.9.6) из-за «фактического сбора персональных данных, выходящего за рамки авторизации пользователя», и Kimi (версия 2.0.8) из-за «фактического сбора персональных данных, не имеющего прямого отношения к бизнес-функциям», вместе с 33 другими приложениями были включены в список приложений, нарушающих правила сбора и использования персональных данных. Оба этих популярных AI-приложения были разработаны командами, связанными с Университетом Цинхуа, и недавно получили значительное финансирование и внимание рынка. Данное уведомление касается проверки, проведенной с 16 апреля по 15 мая 2025 года, и подчеркивает проблемы соблюдения нормативных требований к данным, с которыми сталкиваются AI-приложения в процессе быстрого развития. (Источник: 36氪)
🧰 Инструменты
OpenEvolve: Реализация AlphaEvolve от DeepMind с открытым исходным кодом, использующая LLM для эволюции кодовых баз: Разработчики открыли исходный код проекта OpenEvolve, который является реализацией системы AlphaEvolve от Google DeepMind. Фреймворк OpenEvolve использует итеративный процесс LLM (генерация кода, оценка, выбор) для эволюции целых кодовых баз с целью обнаружения новых алгоритмов или оптимизации существующих. Он поддерживает любые LLM, совместимые с OpenAI API, может интегрировать несколько моделей (например, комбинацию Gemini-Flash-2.0 и Claude-Sonnet-3.7), поддерживает многоцелевую оптимизацию и распределенную оценку. Проект успешно воспроизвел примеры укладки кругов и минимизации функций из статьи AlphaEvolve, продемонстрировав способность эволюционировать от простых методов к сложным алгоритмам оптимизации (таким как scipy.minimize и имитация отжига). (Источник: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

Google выпускает интеллектуального агента для программирования Jules, поддерживающего автоматизацию задач с кодом: Google выпустила интеллектуального агента для программирования Jules, который в настоящее время находится на стадии глобального тестирования, пользователи могут бесплатно выполнять 5 задач в день. Jules основан на мультимодальной модели Gemini 2.5 Pro, способен понимать сложные кодовые базы, выполнять исправление ошибок, обновление версий, написание тестов, реализацию новых функций и поддерживает Python и JavaScript. Он может подключаться к GitHub для создания pull request (PR), проверять код в облачной виртуальной машине и предоставлять подробный план выполнения для проверки и изменения разработчиками. Jules нацелен на глубокую интеграцию в рабочий процесс разработчиков, повышение эффективности программирования, а в будущем также будет запущена функция Codecast (аудио-резюме активности в кодовой базе) и корпоративная версия. (Источник: 36氪)
Feishu запускает «Feishu Knowledge Q&A», создавая эксклюзивный корпоративный инструмент AI для ответов на вопросы: Feishu скоро выпустит новый AI-продукт «Feishu Knowledge Q&A», позиционируемый как эксклюзивный корпоративный инструмент AI для ответов на вопросы на основе корпоративных знаний. Пользователи смогут вызывать его в боковой панели Feishu для задания вопросов по работе. Инструмент сможет получать доступ ко всем сообщениям Feishu, документам, базам знаний, файлам и другой информации в пределах прав доступа пользователя и предоставлять точные ответы на основе этого «контекста». Управление правами доступа соответствует собственной системе прав Feishu, обеспечивая информационную безопасность. В настоящее время продукт прошел внутреннее тестирование на десятках тысяч пользователей, веб-версия (ask.feishu.cn) уже запущена и поддерживает загрузку личных данных и вызов моделей DeepSeek или Doubao для задания вопросов. Этот шаг соответствует тенденции объединения корпоративных баз знаний с AI и направлен на повышение эффективности работы и возможностей управления знаниями. (Источник: 36氪)
Manus: Платформа AI-агентов открывает регистрацию, материнская компания получает крупное финансирование: Платформа AI-агентов Manus объявила об открытии регистрации для зарубежных пользователей, отменив список ожидания и предоставляя ежедневные бесплатные задачи. Manus, используя технологию «совместного логического вывода нескольких моделей в гибридной архитектуре», может выполнять такие задачи, как автоматическая генерация PPT, упорядочивание счетов и т.д. Ее материнская компания Butterfly Effect недавно привлекла 75 миллионов долларов США финансирования при оценке в 3,6 миллиарда долларов США. Успех Manus рассматривается как воплощение «китайской скорости итераций × продуктового мышления Кремниевой долины», объединяя планирование, выполнение и проверку агентов для перехода AI от «предложения идей» к «замкнутому циклу выполнения». (Источник: 36氪)

HeyGen: Инструмент для генерации и перевода видео с помощью AI, поддерживающий синхронизацию губ на более чем 40 языках: HeyGen — это инструмент для работы с видео на базе AI, позволяющий пользователям быстро генерировать цифровых людей с голосом, мимикой и движениями, загружая фотографии или видео, а также поддерживающий настройку одежды и сцен. Одной из его ключевых функций является поддержка перевода в реальном времени на более чем 175 языков и диалектов, а также точное согласование движений губ цифрового человека с переведенным языком с помощью алгоритмов AI, что повышает естественность многоязычного видеоконтента. Компания была основана бывшими сотрудниками Snapchat и ByteDance, привлекла 60 миллионов долларов США финансирования под руководством Benchmark при оценке в 440 миллионов долларов США и имеет годовой регулярный доход более 35 миллионов долларов США. (Источник: 36氪)
Opus Clip: Автономный агент для редактирования видео на базе AI: Opus Clip изначально позиционировался как инструмент для прямых трансляций с использованием AI, затем трансформировался в платформу для редактирования видео с помощью AI и далее развился в «автономного агента для редактирования видео». Его основная функция — быстрое редактирование длинных видео на несколько коротких роликов, подходящих для вирусного распространения, а также автоматическая обрезка основного объекта, генерация заголовков и описаний, добавление субтитров и эмодзи. Недавно протестированная функция ClipAnything уже поддерживает распознавание мультимодальных команд. Компанию возглавляет Чжао Ян, основатель бывшего социального приложения Sober. Она привлекла 20 миллионов долларов США финансирования под руководством SoftBank при оценке в 215 миллионов долларов США и имеет ARR около 10 миллионов долларов США. (Источник: 36氪)
Trae: Агент для автоматизированного программирования на базе AI IDE: Trae — это инструмент, нацеленный на создание «настоящего AI-инженера», поддерживающий автоматизированное программирование агентами через взаимодействие на естественном языке. Он совместим с протоколом MCP и пользовательскими агентами, имеет встроенный улучшенный анализ контекста и механизм правил, поддерживает основные языки программирования и совместим с VS Code. Trae разработан ключевыми членами бывшей команды Marscode (помощник по программированию) из ByteDance и позиционируется как сильный конкурент таким инструментам AI-программирования, как Cursor, стремясь реализовать новую модель разработки программного обеспечения с человеко-машинным взаимодействием. (Источник: 36氪)
Notta: Инструмент для ведения протоколов многоязычных совещаний и перевода в реальном времени на базе AI: Notta — это инструмент AI, ориентированный на сценарии совещаний, предоставляющий услуги автоматической генерации протоколов многоязычных совещаний, а также поддерживающий перевод в реальном времени и маркировку ключевого контента. Продукт нацелен на повышение эффективности совещаний и решение проблем межъязыковой коммуникации. Сообщается, что его основной основатель — бывший ключевой сотрудник команды голосовых технологий Tencent Cloud, операционная компания находится в Сингапуре, а центр разработки — в Сиэтле. В 2024 году доход составил 18 миллионов долларов США при оценке в 300 миллионов долларов США, в настоящее время компания проводит раунд финансирования B. (Источник: 36氪)
Торговый помощник с открытым исходным кодом GPT+ML доступен на iPhone: Торговый помощник с открытым исходным кодом, интегрирующий технологии глубокого обучения и GPT, теперь может работать локально на iPhone через Pyto. В настоящее время это бесплатная облегченная версия, в будущем планируется добавить классификатор графических паттернов на основе CNN и поддержку баз данных. Платформа имеет модульную конструкцию, что позволяет разработчикам глубокого обучения легко подключать собственные модели, и уже нативно поддерживает OpenAI GPT. (Источник: Reddit r/deeplearning)
📚 Обучение
Новая статья рассматривает «гипотезу о разорванных запутанных представлениях» в глубоком обучении: Статья-позиция под названием «Подвергая сомнению оптимизм в отношении представлений в глубоком обучении: гипотеза о разорванных запутанных представлениях» была представлена на Arxiv. Исследование, сравнивая нейронные сети, созданные в процессе эволюционного поиска, с сетями, обученными традиционным методом SGD (на простой задаче генерации одного изображения), обнаружило, что, хотя обе сети демонстрируют одинаковое выходное поведение, их внутренние представления значительно различаются. Сети, обученные SGD, демонстрируют неорганизованную форму, которую авторы называют «разорванными запутанными представлениями» (FER), в то время как эволюционные сети ближе к унифицированным разложенным представлениям (UFR). Исследователи полагают, что в больших моделях FER могут снижать основные способности, такие как обобщение, креативность и непрерывное обучение, и понимание и смягчение FER имеет решающее значение для будущего обучения представлений. (Источник: Reddit r/MachineLearning, arxiv.org)
R3: Фреймворк для надежных, контролируемых и интерпретируемых моделей вознаграждения: Статья под названием «R3: Robust Rubric-Agnostic Reward Models» представляет новый фреймворк моделей вознаграждения R3. Этот фреймворк нацелен на решение проблемы отсутствия контролируемости и интерпретируемости моделей вознаграждения в существующих методах выравнивания языковых моделей. Особенностью R3 является «rubric-agnostic» (независимость от конкретных критериев оценки), способность обобщать данные по различным измерениям оценки и предоставлять интерпретируемые оценки с объяснением процесса их присвоения. Исследователи считают, что R3 позволяет реализовать более прозрачную и гибкую оценку языковых моделей, поддерживая надежное выравнивание с разнообразными человеческими ценностями и сценариями использования. Модели, данные и код открыты. (Источник: HuggingFace Daily Papers)
Опубликована статья «A Token is Worth over 1,000 Tokens» о эффективной дистилляции знаний с помощью низкорангового клонирования: В статье предлагается новый эффективный метод предварительного обучения под названием низкоранговое клонирование (Low-Rank Clone, LRC) для создания малых языковых моделей (SLM), эквивалентных по поведению мощным моделям-учителям. LRC, обучая набор низкоранговых проекционных матриц, одновременно реализует мягкое сокращение весов учителя путем их сжатия и клонирование активаций путем выравнивания активаций ученика (включая сигналы FFN) с активациями учителя. Такая унифицированная конструкция максимизирует передачу знаний без необходимости явных модулей выравнивания. Эксперименты показывают, что при использовании моделей-учителей с открытым исходным кодом, таких как Llama-3.2-3B-Instruct, LRC, обученный всего на 20B токенах, достигает или превосходит производительность моделей SOTA (обученных на триллионах токенов), обеспечивая более чем 1000-кратное повышение эффективности обучения. (Источник: HuggingFace Daily Papers)
MedCaseReasoning: Набор данных и метод для оценки и обучения диагностическому мышлению на основе клинических случаев: Статья «MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports» представляет новый открытый набор данных MedCaseReasoning для оценки способностей больших языковых моделей (LLM) в области клинического диагностического мышления. Набор данных содержит 14489 примеров диагностических вопросов и ответов, каждый из которых сопровождается подробными объяснениями процесса мышления, взятыми из открытых медицинских отчетов о клинических случаях. Исследование показало, что существующие LLM SOTA для логического вывода имеют значительные недостатки в диагностике и мышлении (например, точность DeepSeek-R1 составляет 48%, а полнота воспроизведения объяснений процесса мышления — 64%). Однако путем дообучения LLM на траекториях мышления из MedCaseReasoning точность диагностики и полнота воспроизведения клинического мышления в среднем относительно улучшились на 29% и 41% соответственно. (Источник: HuggingFace Daily Papers)
Опубликована статья «EfficientLLM: Efficiency in Large Language Models», всесторонне оценивающая технологии эффективности LLM: Данное исследование впервые проводит всестороннее эмпирическое изучение технологий эффективности крупномасштабных LLM и вводит бенчмарк EfficientLLM. Исследование систематически рассматривает три ключевых аспекта на кластерах производственного уровня: предварительное обучение архитектуры (эффективные варианты внимания, разреженные MoE), дообучение (параметрически эффективные методы, такие как LoRA) и логический вывод (квантование). С помощью шести детализированных метрик (использование памяти, использование вычислений, задержка, пропускная способность, энергопотребление, степень сжатия) было оценено более 100 пар модель-технология (с параметрами от 0.5B до 72B). Основные выводы включают: эффективность связана с количественно измеримыми компромиссами, универсального оптимального метода не существует; оптимальное решение зависит от задачи и масштаба; технологии могут обобщаться на разные модальности. (Источник: HuggingFace Daily Papers)
Статья «NExT-Search» рассматривает восстановление экосистемы обратной связи для генеративного AI-поиска: Статья «NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search» указывает, что генеративный AI-поиск, хотя и повышает удобство, также нарушает цикл улучшения традиционного веб-поиска, зависящий от детализированной обратной связи пользователя (например, клики, время пребывания). Для решения этой проблемы в статье предлагается парадигма NExT-Search, направленная на повторное внедрение детализированной обратной связи на уровне процесса. Эта парадигма включает «режим отладки пользователем», позволяющий пользователям вмешиваться на ключевых этапах, и «режим теневого пользователя», имитирующий предпочтения пользователя и предоставляющий обратную связь с помощью AI. Эти сигналы обратной связи могут использоваться для онлайн-адаптации (оптимизация результатов поиска в реальном времени) и офлайн-обновления (периодическое дообучение различных компонентов модели). (Источник: HuggingFace Daily Papers)
«Latent Flow Transformer» предлагает новую архитектуру LLM: В статье предлагается Latent Flow Transformer (LFT), модель, которая путем обучения одного оператора передачи через flow matching заменяет многослойные дискретные слои в традиционных Transformer. LFT нацелен на значительное сжатие количества слоев модели при сохранении совместимости с исходной архитектурой. Кроме того, в статье вводится алгоритм Flow Walking (FW) для решения ограничений существующих методов потока в поддержании связности. Эксперименты на модели Pythia-410M показали, что LFT может эффективно сжимать количество слоев и превосходить производительность прямого пропуска слоев, значительно сокращая разрыв между авторегрессионной и потоковой парадигмами генерации. (Источник: HuggingFace Daily Papers)
«Reasoning Path Compression» предлагает метод сжатия траекторий генерации логических выводов LLM: Для решения проблемы большого потребления памяти и низкой пропускной способности, вызванной генерацией длинных промежуточных путей языковыми моделями логического типа, в статье предлагается метод сжатия путей рассуждений (Reasoning Path Compression, RPC). RPC — это метод без обучения, который периодически сжимает KV-кэш, сохраняя KV-кэш с высоким показателем важности (рассчитывается с использованием «окна селектора», состоящего из недавно сгенерированных запросов). Эксперименты показывают, что RPC может значительно увеличить пропускную способность генерации моделей, таких как QwQ-32B, при незначительном влиянии на точность, предоставляя практический путь для эффективного развертывания LLM логического типа. (Источник: HuggingFace Daily Papers)
Опубликована статья «Bidirectional LMs are Better Knowledge Memorizers?», посвященная способности двунаправленных LM к запоминанию знаний: В исследовании представлен новый, реалистичный и крупномасштабный бенчмарк для внедрения знаний WikiDYK, использующий недавно добавленные факты, написанные человеком, из рубрики «Знаете ли вы…» Википедии. Эксперименты показали, что по сравнению с популярными в настоящее время каузальными языковыми моделями (CLM), двунаправленные языковые модели (BiLM) демонстрируют значительно более сильную способность к запоминанию знаний, с точностью надежности на 23% выше. Чтобы компенсировать текущий недостаток масштаба BiLM, исследователи предложили модульную совместную структуру, использующую ансамбль BiLM в качестве внешней базы знаний, интегрированной с LLM, что еще больше повысило точность надежности до 29,1%. (Источник: HuggingFace Daily Papers)
Статья «Truth Neurons» исследует кодирование истинности в языковых моделях на уровне нейронов: Исследователи предлагают метод для идентификации представлений истинности в языковых моделях на уровне нейронов, обнаруживая, что в модели существуют «нейроны истины» (truth neurons), которые кодируют истинность независимо от темы. Эксперименты на моделях разного масштаба подтвердили существование нейронов истины, их распределение соответствует предыдущим исследованиям геометрической структуры истинности. Избирательное подавление активации этих нейронов снижает производительность модели на TruthfulQA и других бенчмарках, что указывает на то, что механизм истинности не является специфичным для какого-либо одного набора данных. (Источник: HuggingFace Daily Papers)
«Understanding Gen Alpha Digital Language» оценивает ограничения LLM в модерации контента: Данное исследование оценивает способность AI-систем (GPT-4, Claude, Gemini, Llama 3) интерпретировать цифровой язык «поколения Альфа» (Gen Alpha, родившиеся в 2010-2024 гг.). Исследование указывает, что уникальный интернет-язык Gen Alpha (под влиянием игр, мемов, AI-трендов) часто скрывает вредоносные взаимодействия, которые существующие инструменты безопасности с трудом распознают. Тестирование на наборе данных из 100 недавних выражений Gen Alpha показало, что основные AI-модели испытывают серьезные трудности с пониманием при обнаружении замаскированных домогательств и манипуляций. Вклад исследования включает первый набор данных выражений Gen Alpha, фреймворк для улучшения систем AI-модерации и подчеркивает срочность пересмотра систем безопасности с учетом особенностей коммуникации подростков. (Источник: HuggingFace Daily Papers)
«CompeteSMoE» предлагает метод обучения моделей Mixture of Experts на основе конкуренции: В статье утверждается, что текущее обучение разреженных моделей Mixture of Experts (SMoE) сталкивается с проблемой неоптимального процесса маршрутизации, то есть эксперты, выполняющие вычисления, не участвуют напрямую в принятии решений о маршрутизации. Для этого исследователи предлагают новый механизм под названием «конкуренция» (competition), который направляет токены к эксперту с наивысшим нейронным откликом. Теоретически доказано, что механизм конкуренции обладает лучшей эффективностью выборки по сравнению с традиционной маршрутизацией softmax. На основе этого разработан алгоритм CompeteSMoE, который путем развертывания маршрутизатора обучается стратегии конкуренции и демонстрирует эффективность, надежность и масштабируемость в задачах визуальной настройки инструкций и предварительного обучения языку. (Источник: HuggingFace Daily Papers)
«General-Reasoner» нацелен на улучшение способности LLM к межотраслевому логическому выводу: В ответ на проблему того, что текущие исследования логического вывода LLM в основном сосредоточены на математике и кодировании, в данной статье предлагается General-Reasoner, новая парадигма обучения, направленная на усиление способности LLM к логическому выводу в различных областях. Ее вклад включает: создание крупномасштабного высококачественного набора данных вопросов с проверяемыми ответами из различных дисциплин; разработку валидатора ответов на основе генеративной модели, обладающего способностью к цепочке рассуждений и контекстной осведомленностью, заменяющего традиционную проверку на основе правил. В серии тестов, охватывающих физику, химию, финансы и другие области, General-Reasoner превзошел существующие базовые методы. (Источник: HuggingFace Daily Papers)
«Not All Correct Answers Are Equal» исследует важность источника дистилляции знаний: Данное исследование проводит крупномасштабное эмпирическое изучение дистилляции данных для логического вывода путем сбора проверенных выходных данных трех моделей-учителей SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) по 1,89 миллионам запросов. Анализ показал, что данные, дистиллированные из AM-Thinking-v1, демонстрируют большее разнообразие длины токенов и более низкую перплексию. Модели-ученики, обученные на этом наборе данных, показали наилучшие результаты на бенчмарках логического вывода, таких как AIME2024, и продемонстрировали адаптивное поведение вывода. Исследователи опубликовали наборы данных дистилляции для AM-Thinking-v1 и Qwen3-235B-A22B для поддержки будущих исследований. (Источник: HuggingFace Daily Papers)
«SSR» улучшает восприятие глубины VLM с помощью пространственного мышления, основанного на фундаментальных принципах: Несмотря на прогресс визуально-языковых моделей (VLM) в мультимодальных задачах, их зависимость от RGB-ввода ограничивает точное пространственное понимание. В статье предлагается новый фреймворк под названием SSR (Spatial Sense and Reasoning), который преобразует необработанные данные о глубине в структурированные, интерпретируемые текстуализированные фундаментальные принципы. Эти текстуализированные фундаментальные принципы служат значимыми промежуточными представлениями, значительно улучшая возможности пространственного мышления. Кроме того, исследование использует дистилляцию знаний для сжатия сгенерированных принципов в компактные латентные вложения для эффективной интеграции в существующие VLM без необходимости переобучения. Одновременно представлены набор данных SSR-CoT и бенчмарк SSRBench. (Источник: HuggingFace Daily Papers)
«Solve-Detect-Verify» предлагает метод расширения во время логического вывода с гибким генеративным валидатором: Для решения проблемы компромисса между точностью и эффективностью LLM при решении сложных задач, а также противоречия между вычислительными затратами и надежностью, вносимыми этапом проверки, в статье предлагается FlexiVe, новый генеративный валидатор. FlexiVe, используя гибкую стратегию распределения бюджета проверки, балансирует вычислительные ресурсы между быстрым и надежным «быстрым мышлением» и детальным «медленным мышлением». Далее предлагается процесс Solve-Detect-Verify, фреймворк, который интеллектуально интегрирует FlexiVe, активно определяя точки завершения решения для запуска целевой проверки и предоставления обратной связи. Эксперименты показывают, что этот метод превосходит базовые на бенчмарках математического мышления. (Источник: HuggingFace Daily Papers)
«SageAttention3» исследует логический вывод Attention FP4 и 8-битное обучение: Данное исследование повышает эффективность Attention за счет двух ключевых вкладов: во-первых, использование новых FP4 Tensor Cores в GPU Blackwell для ускорения вычислений Attention, обеспечивая ускорение логического вывода в 5 раз быстрее, чем FlashAttention, по принципу plug-and-play. Во-вторых, впервые низкобитное Attention применяется к задачам обучения, разработан точный и эффективный 8-битный Attention для прямого и обратного распространения. Эксперименты показывают, что 8-битный Attention достигает производительности без потерь в задачах дообучения, но сходится медленнее в задачах предварительного обучения. (Источник: HuggingFace Daily Papers)
«The Little Book of Deep Learning» — ресурс для начинающих в области глубокого обучения: Книга «The Little Book of Deep Learning», написанная Франсуа Флёре (научный сотрудник Meta FAIR), представляет собой краткое учебное пособие по глубокому обучению. Книга призвана помочь как начинающим, так и специалистам с некоторым опытом быстро освоить основные концепции и методы глубокого обучения. (Источник: Reddit r/deeplearning)
CodeSparkClubs: Бесплатные ресурсы для старшеклассников по созданию клубов AI/информатики: Проект CodeSparkClubs нацелен на помощь старшеклассникам в создании или развитии клубов AI и информатики. Проект предоставляет бесплатные, готовые к использованию материалы, включая руководства, планы уроков и учебные пособия по проектам, все доступно через веб-сайт. Он разработан таким образом, чтобы учащиеся могли самостоятельно управлять клубом, тем самым развивая навыки и сообщество. (Источник: Reddit r/deeplearning)
💼 Бизнес
Microsoft Azure будет размещать модель Grok от xAI, помогая Илону Маску в коммерциализации AI: Microsoft объявила, что ее облачная платформа Azure будет размещать AI-модели компании xAI Илона Маска, включая Grok. Этот шаг означает, что Маск планирует продавать Grok другим предприятиям и охватить более широкую аудиторию клиентов через облачные сервисы Microsoft. Ранее Grok вызвал споры из-за генерации вводящих в заблуждение постов о «геноциде белых» в Южной Африке. Реакция сообщества на это сотрудничество неоднозначна: одни считают это шагом Microsoft по расширению своей AI-экосистемы, другие сомневаются в качестве Grok и в том, не отказалась ли AWS от Grok. (Источник: Reddit r/ArtificialInteligence, MIT Technology Review)

Alibaba инвестирует в Meitu, углубляя布局 в AI-коммерции: Alibaba инвестировала в компанию Meitu через конвертируемые облигации с первоначальной ценой конвертации 6 гонконгских долларов за акцию. Стороны будут сотрудничать на уровне электронной коммерции и технологий. Meitu владеет инструментами генерации изображений с помощью AI (например, Meitu Design Studio), которые уже обслуживают более 2 миллионов продавцов электронной коммерции. Alibaba внедрит AI-инструменты Meitu для улучшения демонстрации товаров на своих платформах электронной коммерции и пользовательского опыта, особенно для привлечения молодых женщин-пользователей. Meitu, в свою очередь, сможет использовать данные электронной коммерции Alibaba для оптимизации своих AI-инструментов и обязуется в течение трех лет закупить услуги Alibaba Cloud на 560 миллионов юаней. Этот шаг рассматривается как стратегическое развертывание Alibaba для усиления своих слабых сторон в области креативных инструментов AI, привлечения пользовательского трафика и более глубокой интеграции облачных вычислений в экосистему AI-коммерции. (Источник: 36氪)
Lighthouse Capital завершил сбор средств для первого инкубационного AI-фонда в размере 50 миллионов долларов США, ориентируясь на сверхранние передовые технологии: Инкубационный фонд передовых инноваций Lighthouse Capital (L2F) превысил ожидания по сбору средств для первого этапа, объем которого, по прогнозам, составит не менее 50 миллионов долларов США, и уже вступил в инвестиционный период. Этот двухвалютный фонд специализируется на инвестициях на посевной и ангельской стадиях в области AI и передовых технологий, а также предоставляет инкубационную поддержку. В состав LP входят успешные предприниматели, компании из верхнего и нижнего звена цепочки создания стоимости AI, а также семейные офисы с глобальным видением. Первым инвестиционным проектом стала компания по разведке полезных ископаемых с помощью AI «Lingyun Zhimine», в инкубации которой Lighthouse Capital принимал активное участие. Основатель Lighthouse Capital Чжэн Сюаньлэ считает, что текущий этап развития AI аналогичен раннему этапу мобильного интернета, и инкубация является лучшим инструментом для выхода на рынок. (Источник: 36氪)
🌟 Сообщество
Обсуждение перспектив трудоустройства в эпоху AI: оптимизм и опасения сосуществуют: Сообщество Reddit снова активно обсуждает влияние AI на рынок труда. Многие разработчики программного обеспечения, UX-дизайнеры и другие специалисты с оптимизмом смотрят на возможность замены их работы AI, считая, что AI пока не способен выполнять сложные задачи. Однако есть и мнения, указывающие на то, что такой взгляд может недооценивать долгосрочный потенциал развития AI, проводя аналогии с сомнениями людей в 2018 году относительно замены ручного перевода Google Translate. В обсуждении говорится, что быстрое развитие AI может привести к замене большинства профессий в будущем (за исключением немногих в области медицины и искусства), и ключ к решению проблемы заключается в изменении экономической модели, а не просто в повышении личных навыков. В комментариях упоминается, что «мы переоцениваем краткосрочную перспективу и недооцениваем долгосрочную», а также что рост производительности AI может значительно превысить рост отрасли, что приведет к безработице. (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Обсуждение философии и этики сосуществования человека и AI в эпоху AI: Пост на Reddit вызвал философские размышления о сосуществовании человека и AI. В посте утверждается, что по мере того, как системы AI демонстрируют способности к пониманию, запоминанию, рассуждению и обучению, человечеству, возможно, придется переосмыслить основы морального статуса, не ограничиваясь биологическими признаками, а основываясь на способности понимать, устанавливать связи и сознательно действовать. Обсуждение распространяется на влияние AI на самоидентификацию человека, переход от «мыслю, следовательно, существую» к реляционной идентичности «существую через связь и разделение смысла». Пост призывает встречать будущее совместного творчества с AI с мужеством, достоинством и открытостью, а не со страхом. (Источник: Reddit r/artificial)
«Абсолютный режим» ChatGPT вызывает споры, пользователи неоднозначны: Пользователь Reddit поделился опытом использования «абсолютного режима» ChatGPT, заявив, что он может предоставлять «чистые факты, нацеленные на рост» и правдивые советы, а не утешительные слова, и отметил, что этот режим когда-то указал, что 90% людей используют AI, чтобы чувствовать себя лучше, а не менять свою жизнь. Однако в комментариях мнения разделились. Некоторые пользователи считают, что это просто сокращенные пустые советы по самосовершенствованию, лишенные новизны и практической ценности, и даже похожие на «высказывания подростка, увлекающегося цитатами Andrew Tate». Другие комментарии ставят под сомнение тот факт, что LLM сам по себе является пересказом убеждений пользователя, и эффективность его советов сомнительна, полагая, что применение AI в области психического здоровья, возможно, не является революционным. (Источник: Reddit r/ChatGPT)

Обсуждение ключевых навыков AI-инженера: коммуникация и способность адаптироваться к новым технологиям имеют решающее значение: Сообщество Reddit обсуждает навыки, необходимые для того, чтобы стать ведущим AI-инженером, чтобы оставаться конкурентоспособным и даже «незаменимым» в быстро развивающейся области. В комментариях отмечается, что помимо солидной технической базы, коммуникативные навыки и способность быстро адаптироваться к новым технологиям являются двумя ключевыми элементами. Это отражает тот факт, что область AI требует не только глубоких технических знаний, но и подчеркивает важность мягких навыков и непрерывного обучения для карьерного роста. (Источник: Reddit r/deeplearning)
AI-сгенерированное видео со звуком вызывает бурное обсуждение, демонстрация технологии Veo 3 от Google: В социальных сетях распространяется AI-видео, сгенерированное новой моделью Veo 3 от Google DeepMind, особенностью которого является то, что и видео, и звук сгенерированы одной и той же моделью, что вызвало у пользователей изумление прогрессом в технологиях AI-видео. Создатель заявил, что видео было получено «из коробки», без добавления дополнительного аудио или материалов, и было создано примерно за 2 часа взаимодействия с AI-моделью и последующего монтажа. В комментариях отмечается, что Google Gemini по мультимодальным возможностям уже превзошел OpenAI Sora, и выражается обеспокоенность по поводу возможного подрыва индустрии создания контента, такой как Голливуд. В то же время некоторые пользователи выразили опасения по поводу слишком быстрого развития технологий и потенциального злоупотребления ими. (Источник: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Прочее
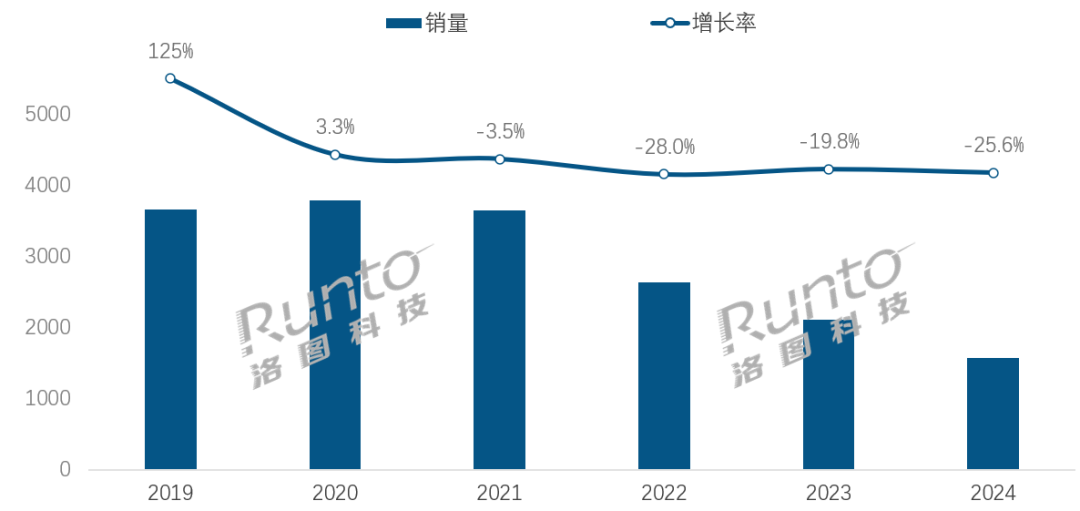
В эпоху AI индустрия умных колонок сталкивается с проблемами трансформации и новыми возможностями: Продажи умных колонок на китайском рынке снижаются четвертый год подряд, в 2024 году продажи упали на 25,6% по сравнению с аналогичным периодом прошлого года. Несмотря на то, что интеграция больших моделей AI (таких как Xiao Ai Tongxue, Xiaodu и др.) рассматривается как надежда отрасли, а уровень проникновения уже превысил 20%, это не решило коренным образом проблемы ограниченности экосистемы, гомогенизации функций и замены другими умными устройствами, такими как смартфоны. Аналитики отрасли считают, что умные колонки должны выйти за рамки простого центра голосового управления и эволюционировать в продукты с большими экранами высокой четкости, более сильными возможностями взаимодействия, способные обеспечивать companionship и образовательные функции, а также расширять экосистему программного и аппаратного обеспечения. AI является плюсом, но более важными являются функциональное богатство и практичность самого продукта в различных сценариях. (Источник: 36氪)
Роботы в отелях на базе AI: путь эволюции от доставщика еды до «интеллектуального операционного менеджера»: Роботы-доставщики еды в отелях постепенно становятся обычным явлением, особенно популярным среди поколения Z, ценящего технологичность и личные границы. На примере Yunji Technology, ее роботы-доставщики уже широко используются на китайском гостиничном рынке. Однако отрасль по-прежнему сталкивается с проблемами недостаточной технологической дифференциации, плохой адаптивности к сложным сценариям и вопросом экономической эффективности замены роботами человеческого труда. Будущая тенденция заключается в том, что роботы будут «не только доставлять еду», но и глубоко интегрироваться в операционную деятельность отеля, подключаясь к гостиничным системам (лифты, оборудование номеров), понимая предпочтения гостей, собирая и анализируя данные о взаимодействии, эволюционируя в «интеллектуального операционного менеджера» или часть гостиничной платформы данных, способного активно воспринимать и предоставлять персонализированные услуги, тем самым повышая общий уровень интеллектуализации обслуживания. (Источник: 36氪)

Кризис управления в OpenAI: борьба капитала и миссии заставляет задуматься о путях развития AI: Уникальная структура OpenAI с коммерческой дочерней компанией «ограниченной прибыли», контролируемой некоммерческой организацией, призвана сбалансировать развитие технологий AI и благополучие человечества. Однако недавние намерения генерального директора Altman преобразовать компанию в более традиционное коммерческое предприятие вызвали обеспокоенность экспертов в области AI и юристов. Они считают, что этот шаг может привести к тому, что ключевые лица, принимающие решения, перестанут ставить благотворительную миссию OpenAI на первое место, ослабят ограничения на прибыль инвесторов и могут изменить сроки и направление развития AGI. Эта борьба за контроль, распределение прибыли и формирование социального и этического облика AI подчеркивает проблемы и уязвимости существующих рамок корпоративного управления в эпоху стремительного развития AI. (Источник: 36氪)