
Ключевые слова:AlphaEvolve, Gemini, Эволюционные алгоритмы, ИИ-агенты, Оптимизация алгоритмов, Оптимизация умножения матриц, Borg Дата-центр, Оптимизация умножения 4×4 комплексных матриц, Открытие алгоритмов Google DeepMind, Автоматизированное проектирование алгоритмов ИИ, Приложение Gemini 2.0 Pro, Оптимизация распределения ресурсов Borg
🔥 В центре внимания
Google DeepMind представляет AlphaEvolve: агент для кодирования на основе эволюционных алгоритмов и Gemini, достигший прорыва в математике и информатике: Google DeepMind выпустила AlphaEvolve, агента, использующего большую языковую модель Gemini 2.0 Pro для автоматического обнаружения и оптимизации алгоритмического кода с помощью эволюционных алгоритмов. AlphaEvolve способен самостоятельно генерировать, оценивать и улучшать кандидатов, исходя из предоставленного человеком начального кода и метрик оценки. Система продемонстрировала выдающиеся результаты в более чем 50 математических задачах, примерно в 75% случаев воспроизведя известные решения, а в 20% случаев найдя более оптимальные. Примечательно, что AlphaEvolve сократил количество вычислений для умножения комплексных матриц 4×4 с 49 до 48, обновив рекорд 56-летней давности. Кроме того, он оптимизировал алгоритм планирования для внутреннего дата-центра Google Borg, высвободив 0.7% глобальных вычислительных ресурсов, и улучшил дизайн чипов TPU следующего поколения, сократив время обучения Gemini на 1%. Это достижение демонстрирует огромный потенциал AI в автоматизации открытия алгоритмов и научных инновациях. Хотя в настоящее время система в основном обрабатывает задачи, поддающиеся автоматической оценке, ее перспективы применения в прикладных науках, таких как открытие лекарств, обширны. (Источник: , 量子位, 36氪)
Nvidia на Computex 2025 объявляет о множестве достижений в области AI, Дженсен Хуанг подчеркивает видение Agentic AI и Physical AI: Генеральный директор Nvidia Дженсен Хуанг выступил с основным докладом на Computex 2025, подчеркнув, что AI эволюционирует от «однократного ответа» к «мыслящему, рассуждающему» Agentic AI (агентному AI) и Physical AI (физическому AI), понимающему физический мир. Для поддержки этой тенденции Nvidia выпустила расширенную платформу Blackwell (Blackwell Ultra AI) и объявила о полномасштабном запуске системы Grace Blackwell GB300, производительность которой в задачах логического вывода в 1.5 раза выше, чем у предыдущего поколения. Хуанг также представил предварительный обзор суперчипа AI следующего поколения Rubin Ultra, производительность которого в 14 раз превышает GB300. Для продвижения инфраструктуры AI Nvidia представила технологию NVLink Fusion и совместно с TSMC, Foxconn и другими компаниями строит суперкомпьютер AI на Тайване. Кроме того, Nvidia обновила базовую модель для человекоподобных роботов Isaac GR00T N1.5, улучшив ее адаптивность к окружающей среде и возможности выполнения задач, а также планирует открыть исходный код физического движка Newton, разработанного совместно с DeepMind и Disney Research. (Источник: AI 前线, 量子位, Reddit r/artificial)
Команда OpenAI Codex в ходе AMA раскрыла планы по GPT-5 и интеграции будущих продуктов: Команда OpenAI Codex провела сессию «Спроси меня о чем угодно» (AMA) на Reddit, в ходе которой вице-президент по исследованиям Jerry Tworek сообщил, что целью базовой модели следующего поколения GPT-5 является повышение возможностей существующих моделей и сокращение необходимости переключения между моделями. Планируется интегрировать существующие инструменты, такие как Codex, Operator (агент для выполнения задач), Deep Research (инструмент для глубоких исследований) и Memory (функция памяти), для создания единого опыта AI-помощника. Члены команды также поделились первоначальной целью разработки Codex (возникшей из-за внутреннего осознания недостаточного использования моделей), примерно трехкратным повышением эффективности программирования благодаря внутреннему использованию Codex и видением будущего программной инженерии — эффективного и надежного преобразования требований в работающее программное обеспечение. В настоящее время Codex в основном использует информацию, загруженную в среду выполнения контейнера, но в будущем может сочетать технологию RAG для получения новейших знаний. OpenAI также изучает гибкие схемы ценообразования и планирует предоставлять пользователям Plus/Pro бесплатные кредиты API для использования Codex CLI. (Источник: 36氪)
VS Code объявляет об открытии исходного кода расширения GitHub Copilot Chat и планирует создать открытую платформу для редактирования кода с помощью AI: Команда Visual Studio Code объявила о планах по развитию VS Code в редактор AI с открытым исходным кодом, придерживаясь основных принципов открытости, сотрудничества и ориентации на сообщество. В рамках этого плана расширение GitHub Copilot Chat было опубликовано на GitHub под лицензией MIT. В будущем VS Code планирует постепенно интегрировать эти функции AI в ядро редактора с целью создания полностью открытой, управляемой сообществом платформы для редактирования кода с помощью AI для повышения эффективности разработки, прозрачности и безопасности. Этот шаг рассматривается как важный шаг Microsoft в области открытого исходного кода и может оказать глубокое влияние на экосистему инструментов программирования с поддержкой AI. (Источник: dotey, jeremyphoward)
Huawei Ascend и DeepSeek сотрудничают, производительность логического вывода модели MoE превосходит Nvidia Hopper: Huawei Ascend объявила, что ее суперузел CloudMatrix 384 и серверы логического вывода Atlas 800I A2 при развертывании сверхбольших моделей MoE, таких как DeepSeek V3/R1, достигли значительного прорыва в производительности логического вывода, превзойдя архитектуру Nvidia Hopper при определенных условиях. Суперузел CloudMatrix 384 при задержке 50 мс достиг пропускной способности декодирования на одну карту более 1920 токенов/с, а Atlas 800I A2 при задержке 100 мс достиг пропускной способности на одну карту 808 токенов/с. Huawei объясняет это стратегией «дополнения физики математикой», то есть компенсацией ограничений аппаратных процессов за счет оптимизации алгоритмов и систем. Соответствующие технические отчеты уже опубликованы, а основной код будет открыт в течение месяца. Меры оптимизации включают решения для параллелизма экспертов для моделей MoE, раздельное развертывание PD, адаптацию фреймворка vLLM, стратегию квантования A8W8C16, а также коммуникационную схему FlashComm, преобразование внутрислойного параллелизма, механизм спекулятивного вывода FusionSpec и оптимизацию аппаратной совместимости операторов MLA/MoE. (Источник: 量子位, WeChat)
🎯 События
Apple открывает исходный код эффективной визуально-языковой модели FastVLM, оптимизируя опыт AI на конечных устройствах: Apple открыла исходный код FastVLM (Fast Vision Language Model), визуально-языковой модели, специально разработанной для эффективной работы на периферийных устройствах, таких как iPhone. FastVLM, благодаря внедрению нового гибридного визуального кодировщика FastViTHD, сочетающего сверточные слои с модулями Transformer, а также использованию многомасштабного пулинга и техник понижающей дискретизации, значительно сокращает количество визуальных токенов, необходимых для обработки изображений (в 16 раз меньше, чем у традиционного ViT). Это позволяет модели поддерживать высокую точность при одновременном увеличении скорости вывода первого токена (TTFT) до 85 раз по сравнению с аналогичными моделями. FastVLM совместима с основными LLM и легко адаптируется к экосистеме iOS/Mac, предлагая версии с параметрами 0.5B, 1.5B и 7B, подходящие для описания изображений, ответов на вопросы, анализа и других задач обработки изображений и текста в реальном времени. (Источник: WeChat)
Meta выпускает модель KernelLLM 8B, которая превосходит GPT-4o в определенных бенчмарках: Meta выпустила модель KernelLLM 8B на Hugging Face. Утверждается, что в бенчмарке KernelBench-Triton Level 1 эта модель с 8 миллиардами параметров превзошла по производительности однократного логического вывода более крупные модели, такие как GPT-4o и DeepSeek V3. В случае многократного логического вывода производительность KernelLLM также превосходит DeepSeek R1. Этот релиз привлек внимание AI-сообщества и рассматривается как еще одно доказательство того, что модели среднего и малого размера демонстрируют сильную конкурентоспособность в конкретных задачах. (Источник: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Модель Mistral Medium 3 демонстрирует высокие результаты на Arena, особенно в технической области: Новая модель Mistral Medium 3 от Mistral AI показала отличные результаты в оценке сообщества на lmarena.ai, заняв 11-е место по общим возможностям чата, что является значительным улучшением по сравнению с Mistral Large (рейтинг Elo увеличился на 90 пунктов). Модель особенно отличилась в технической области, заняв 5-е место по математическим способностям, 7-е место по сложным запросам и возможностям кодирования, и 9-е место в WebDev Arena. Сообщество отмечает, что ее производительность в технической области близка к уровню GPT-4.1, при этом стоимость может быть более конкурентоспособной, аналогично ценообразованию GPT-4.1 mini. Пользователи могут бесплатно опробовать модель в официальном чат-интерфейсе Mistral. (Источник: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets добавляет функцию прямого просмотра диалогов чата: Платформа Hugging Face Datasets получила важное обновление: теперь пользователи могут напрямую читать диалоги чата в наборах данных. Члены сообщества (такие как Caleb, Maxime Labonne) считают эту функцию большим шагом к решению проблем качества данных, поскольку прямой доступ к исходным данным диалогов помогает лучше понимать данные, проводить их очистку и улучшать результаты обучения моделей. Ранее для просмотра конкретных диалогов мог потребоваться дополнительный код или инструменты, новая функция упрощает этот процесс, повышая удобство и прозрачность работы с данными. (Источник: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM интегрируется с Hugging Face Hub, упрощая локальный запуск моделей на Mac: MLX LM теперь напрямую интегрирован с Hugging Face Hub, что позволяет пользователям Mac еще удобнее запускать локально более 4400 LLM на устройствах Apple Silicon. Пользователям достаточно нажать «Use this model» на странице совместимой модели в Hugging Face Hub, чтобы быстро запустить модель в терминале, без сложной облачной конфигурации или ожидания. Кроме того, можно напрямую запустить сервер, совместимый с OpenAI, со страницы модели. Эта интеграция направлена на снижение порога входа для локального запуска моделей и повышение эффективности разработки и экспериментов. (Источник: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia открывает исходный код модели логического вывода Physical AI Cosmos-Reason1-7B: Nvidia открыла исходный код Cosmos-Reason1-7B из своей серии моделей Physical AI на Hugging Face. Эта модель предназначена для понимания здравого смысла физического мира и генерации соответствующих воплощенных решений. Это знаменует собой новый шаг Nvidia в продвижении сочетания физического мира и AI, предоставляя новые инструменты и исследовательскую базу для приложений, требующих взаимодействия с физической средой, таких как робототехника и автономное вождение. (Источник: reach_vb)
Модель генерации видео Steamer-I2V от Baidu возглавила рейтинг VBench по генерации видео из изображений: Модель генерации видео Steamer-I2V от Baidu заняла первое место в категории генерации видео из изображений (I2V) авторитетного рейтинга генерации видео VBench, набрав 89.38% и обогнав известные модели, такие как OpenAI Sora и Google Imagen Video. Технические преимущества Steamer-I2V включают точное управление изображением на уровне пикселей, мастерское управление камерой, кинематографическое качество HD до 1080P и динамическую эстетику, а также точное понимание китайской семантики на основе мультимодальной базы данных китайского языка объемом в сотни миллионов записей. Это достижение демонстрирует силу Baidu в области мультимодальной генерации и является частью ее стратегии по созданию экосистемы контента AI. (Источник: 36氪)

LLM плохо справляются с задачами определения времени по часам и календарям: Исследователи из Эдинбургского университета и других учреждений обнаружили, что, несмотря на выдающиеся результаты больших языковых моделей (LLM) и мультимодальных больших языковых моделей (MLLM) во многих задачах, их точность в, казалось бы, простых задачах определения времени (таких как распознавание времени по стрелочным часам и понимание дат в календаре) оставляет желать лучшего. Исследование создало два специализированных набора тестов ClockQA и CalendarQA, результаты которых показали, что точность систем AI в определении времени по часам составляет всего 38.7%, а точность определения дат в календаре — всего 26.3%. Даже передовые модели, такие как Gemini-2.0 и GPT-o1, испытывают явные трудности, особенно при обработке римских цифр, стилизованных стрелок или сложных вычислений дат (например, високосных годов, определения дня недели для определенной даты). Исследователи считают, что это выявляет недостатки текущих моделей в пространственном мышлении, анализе структурированных макетов и обобщении на необычные шаблоны. (Источник: 36氪, WeChat)

Microsoft на конференции Build объявила о добавлении модели Grok в Azure AI Foundry: На конференции разработчиков Microsoft Build 2025 Microsoft объявила, что модель Grok компании xAI присоединится к ее семейству моделей Azure AI Foundry. Пользователи смогут бесплатно опробовать Grok-3 и Grok-3-mini в Azure Foundry и на GitHub до начала июня. Этот шаг означает, что Azure AI Foundry продолжит расширять спектр поддерживаемых сторонних моделей, и в будущем пользователи смогут использовать модели от OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs и других производителей через единую зарезервированную пропускную способность. (Источник: TheTuringPost, xai)
Сообщается, что Apple планирует разрешить пользователям iPhone в ЕС заменять Siri на сторонние голосовые помощники: По сообщению Mark Gurman, Apple планирует впервые разрешить пользователям iPhone в Европейском союзе заменять Siri на сторонние голосовые помощники. Этот шаг, вероятно, предпринят в ответ на ужесточающиеся требования ЕС к регулированию цифровых рынков и направлен на повышение открытости платформы и расширение выбора для пользователей. Если этот план будет реализован, он окажет значительное влияние на рынок голосовых помощников, предоставив другим голосовым помощникам возможность войти в экосистему Apple. (Источник: zacharynado)

Meta выпускает набор данных Open Molecules 2025 и модель UMA для ускорения открытия молекул и материалов: Meta AI выпустила Open Molecules 2025 (OMol25) и универсальную атомную модель Meta (UMA). OMol25 является на сегодняшний день крупнейшим и наиболее разнообразным набором данных высокоточных квантово-химических расчетов, включающим биомолекулы, металлокомплексы и электролиты. UMA — это модель межатомного потенциала на основе машинного обучения, обученная на более чем 30 миллиардах атомов и предназначенная для более точного прогнозирования поведения молекул. Открытие исходного кода этих инструментов направлено на ускорение открытий и инноваций в области молекулярной науки и материаловедения. (Источник: AIatMeta)
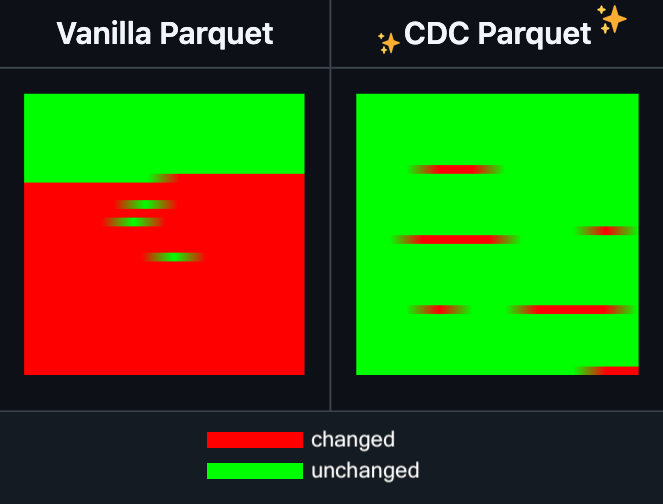
Hugging Face Datasets добавляет функцию инкрементального редактирования файлов Parquet: Hugging Face Datasets объявила, что ночная сборка ее базовой библиотеки PyArrow теперь поддерживает инкрементальное редактирование файлов Parquet без необходимости полной перезаписи файла. Эта новая функция значительно повысит эффективность операций с крупномасштабными наборами данных, особенно когда требуется частое обновление или изменение части данных, что позволит значительно сократить время и вычислительные ресурсы. Ожидается, что этот шаг улучшит опыт разработчиков при обработке и обслуживании больших наборов данных для обучения AI. (Источник: huggingface)
LangGraph добавляет функцию кэширования на уровне узлов, повышая эффективность рабочих процессов: LangGraph объявил о добавлении функции кэширования узлов/задач в свою версию с открытым исходным кодом. Эта функция предназначена для ускорения рабочих процессов за счет предотвращения повторных вычислений, что особенно полезно для рабочих процессов агентов (Agent), содержащих общие части или требующих частой отладки. Пользователи могут использовать кэширование в императивном API или графическом API, что позволяет быстрее итерировать и оптимизировать свои AI-приложения. Это первое из серии обновлений, выпущенных LangGraph на этой неделе с открытым исходным кодом. (Источник: hwchase17)

Sakana AI представляет новую архитектуру AI «Машины непрерывного мышления» (CTM): Токийский стартап в области AI Sakana AI представил новую архитектуру AI-моделей под названием «Машины непрерывного мышления» (Continuous Thought Machines, CTM). CTM призваны позволить моделям рассуждать подобно человеческому мозгу, с меньшим количеством указаний. Эта новая архитектура может предложить новые подходы к решению проблем, с которыми сталкиваются текущие AI-модели в области сложных рассуждений и автономного обучения. (Источник: dl_weekly)
Microsoft и Nvidia углубляют сотрудничество в области RTX AI PC, TensorRT появляется в Windows ML: Во время Microsoft Build и COMPUTEX в Тайбэе Nvidia и Microsoft объявили о дальнейшем продвижении сотрудничества в разработке RTX AI PC. Библиотека оптимизации логического вывода TensorRT от Nvidia была переработана и интегрирована в новый стек логического вывода Microsoft Windows ML. Этот шаг направлен на упрощение процесса разработки AI-приложений и полное использование пиковой производительности RTX GPU в задачах AI на ПК, способствуя популяризации и применению AI на персональных вычислительных устройствах. (Источник: nvidia)
Bilibili открывает исходный код модели генерации анимационных видео Index-AniSora, многие показатели достигают уровня SOTA: Bilibili объявила об открытии исходного кода своей собственной модели генерации анимационных видео Index-AniSora, которая была представлена на IJCAI 2025. AniSora специально разработана для генерации видео в стиле аниме, поддерживает различные стили, такие как японские сериалы, китайская анимация, адаптации манги и т. д., и позволяет осуществлять точное управление, такое как наведение на локальные области видео, временное наведение (например, наведение на первый/последний кадр, интерполяция ключевых кадров). Открытый проект включает код для обучения и вывода AniSoraV1.0 на основе CogVideoX-5B и AniSoraV2.0 на основе Wan2.1-14B, инструменты для создания наборов данных для обучения, специализированную систему бенчмаркинга для анимации и модель AniSoraV1.0_RL, оптимизированную с помощью обучения с подкреплением на основе человеческих предпочтений. (Источник: WeChat)

Tencent Hunyuan открывает исходный код первой мультимодальной унифицированной модели вознаграждения CoT UnifiedReward-Think: Tencent Hunyuan совместно с Shanghai AI Lab, Университетом Фудань и другими учреждениями представили UnifiedReward-Think, первую унифицированную мультимодальную модель вознаграждения, обладающую способностью к длинноцепочечному рассуждению (CoT). Эта модель призвана позволить моделям вознаграждения «научиться думать» при оценке сложных задач визуальной генерации и понимания, тем самым повышая точность оценки, способность к обобщению между задачами и интерпретируемость рассуждений. Проект полностью открыт, включая модель, наборы данных, скрипты обучения и инструменты оценки. (Источник: WeChat)
Alibaba открывает исходный код модели генерации и редактирования видео Tongyi Wanxiang Wan2.1-VACE: Alibaba официально открыла исходный код своей модели генерации и редактирования видео Tongyi Wanxiang Wan2.1-VACE. Эта модель обладает множеством функций, таких как генерация видео из текста, генерация видео на основе эталонного изображения, перерисовка видео, локальное редактирование видео, расширение фона видео и увеличение продолжительности видео. На этот раз были открыты две версии: 1.3B и 14B, причем версия 1.3B может работать на потребительских видеокартах, что направлено на снижение порога входа в создание видео с помощью AIGC. (Источник: WeChat)
ByteDance выпускает визуально-языковую модель Seed1.5-VL, лидирующую во многих бенчмарках: ByteDance создала визуально-языковую модель Seed1.5-VL, состоящую из визуального кодировщика с 532 млн параметров и LLM типа «смесь экспертов» (MoE) с 20 млрд активных параметров. Несмотря на относительно компактную архитектуру, в 60 публичных бенчмарках она достигла производительности SOTA в 38 из них, а в задачах, ориентированных на агентов, таких как управление GUI и игровой процесс, превзошла такие модели, как OpenAI CUA и Claude 3.7, продемонстрировав мощные возможности мультимодального логического вывода. (Источник: WeChat)
MiniMax представляет авторегрессионную модель TTS MiniMax-Speech, поддерживающую клонирование голоса на 32 языках без предварительного обучения: MiniMax предложила авторегрессионную модель преобразования текста в речь (TTS) MiniMax-Speech на основе Transformer. Эта модель способна извлекать тембральные характеристики из эталонного аудио без транскрипции, реализуя генерацию выразительной речи, соответствующей эталонному тембру, без предварительного обучения (zero-shot), и поддерживает клонирование голоса по одному образцу. Благодаря технологии Flow-VAE улучшено качество синтезированного аудио, поддерживается 32 языка. Модель достигла уровня SOTA по объективным показателям клонирования голоса и заняла первое место в публичном рейтинге TTS Arena, а также может быть расширена для применения в управлении эмоциональной окраской голоса, преобразовании текста в звук и профессиональном клонировании голоса. (Источник: WeChat)
Выпущена OuteTTS 1.0 (0.6B), открытая модель TTS с лицензией Apache 2.0, поддерживающая 14 языков: OuteAI выпустила OuteTTS-1.0-0.6B, легковесную модель преобразования текста в речь (TTS), созданную на основе Qwen-3 0.6B. Модель распространяется под лицензией Apache 2.0 и поддерживает 14 языков, включая китайский, английский, японский и корейский. Ее библиотека для логического вывода на Python OuteTTS v0.4.2 обновлена для поддержки асинхронного пакетного вывода EXL2, экспериментального пакетного вывода vLLM, а также непрерывной пакетной обработки и вывода моделей по внешним URL для сервера Llama.cpp. Бенчмарки на одной GPU NVIDIA L40S показывают, что vLLM OuteTTS-1.0-0.6B FP8 при размере пакета 32 достигает RTF (коэффициент реального времени) 0.05. Веса модели (ST, GGUF, EXL2, FP8) доступны на Hugging Face. (Источник: Reddit r/LocalLLaMA)

Hugging Face и Microsoft Azure углубляют сотрудничество, более 10 000 моделей с открытым исходным кодом доступны в Azure AI Foundry: На конференции Microsoft Build генеральный директор Сатья Наделла объявил о расширении сотрудничества с Hugging Face. В настоящее время более 11 000 самых популярных моделей с открытым исходным кодом доступны через Hugging Face в Azure AI Foundry, что упрощает их развертывание для пользователей. Этот шаг еще больше обогащает экосистему AI Azure, предоставляя разработчикам больший выбор моделей и более удобный опыт разработки. (Источник: ClementDelangue, _akhaliq)

Intel выпускает GPU серии Arc Pro B50/B60, ориентированные на рынок AI и рабочих станций, версия на 24 ГБ стоит около 500 долларов: Intel на Computex представила новые профессиональные видеокарты серии Arc Pro B, включая Arc Pro B50 (16 ГБ видеопамяти, около 299 долларов) и Arc Pro B60 (24 ГБ видеопамяти, около 500 долларов). Среди них также было представлено решение для рабочих станций «Project Battlematrix» с двумя GPU B60 и общим объемом видеопамяти 48 ГБ, ожидаемая цена которого составит менее 1000 долларов. Эти продукты предназначены для предоставления экономически эффективных решений для вычислений AI и профессиональных рабочих станций, особенно конфигурации с большим объемом видеопамяти привлекательны для локального запуска больших языковых моделей. Новинки ожидаются на рынке в третьем квартале этого года, первоначально через OEM-производителей, а в четвертом квартале возможно появление DIY-версий. (Источник: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Инструменты
Moondream Station выпускает версию для Linux, упрощая локальный запуск Moondream: Moondream Station, инструмент, предназначенный для упрощения запуска Moondream (визуально-языковой модели) на локальных устройствах, теперь объявил о поддержке операционной системы Linux. Это означает, что пользователи Linux смогут удобнее развертывать и использовать модель Moondream для мультимодальных экспериментов с AI и разработки приложений. (Источник: vikhyatk)
Flowith выпускает бесконечного агента NEO с поддержкой неограниченного количества шагов, контекста и вызовов инструментов: Компания по разработке AI-приложений Flowith выпустила свой новейший агентский продукт NEO, который, по утверждению компании, является первым в мире агентом, поддерживающим неограниченное количество шагов, неограниченный контекст и неограниченное количество вызовов инструментов. Этот агент предназначен для длительной работы в облаке, обладает интеллектуальным уровнем, превосходящим базовые показатели, и, как утверждается, является бесплатным и не имеет ограничений. Этот выпуск может представлять собой новый прогресс в способности AI-агентов справляться со сложными долгосрочными задачами и интегрировать внешние возможности. (Источник: _akhaliq, op7418)

Kapa AI использует Weaviate для создания интерактивного инструмента вопросов и ответов по технической документации «Ask AI»: Kapa AI разработала интеллектуальный виджет под названием «Ask AI», который позволяет пользователям запрашивать всю техническую базу знаний, включая техническую документацию, блоги, учебные пособия, проблемы GitHub и форумы, с помощью диалога на естественном языке. Для обеспечения эффективного семантического поиска и извлечения знаний Kapa AI использовала векторную базу данных Weaviate, оценив ее встроенные возможности гибридного поиска, совместимость с Docker и многопользовательские функции для поддержки быстрорастущего числа пользователей и объемов данных. (Источник: bobvanluijt)

Разработчик быстро создает MVP-инструмент для преобразования скриншотов в HTML с помощью Gemini Flash: Разработчик Daniel Huynh, используя модель Gemini Flash от Google AI, за выходные создал MVP (минимально жизнеспособный продукт) инструмент, который может быстро преобразовывать скриншоты дизайн-макетов, конкурентных продуктов или идей в HTML-код. Инструмент уже доступен для бесплатного тестирования на Hugging Face Spaces, демонстрируя потенциал мультимодальных моделей в помощи фронтенд-разработке. (Источник: osanseviero, _akhaliq)
Azure AI Foundry Agent Service официально доступен, интегрирован с LlamaIndex: Microsoft объявила, что Azure AI Foundry Agent Service официально выпущен (GA) и предлагает первоклассную поддержку LlamaIndex. Сервис предназначен для помощи корпоративным клиентам в создании помощников для поддержки клиентов, роботов для автоматизации процессов, мультиагентных систем и решений, безопасно интегрированных с корпоративными данными и инструментами, что способствует дальнейшему развитию и применению AI-агентов корпоративного уровня. (Источник: jerryjliu0)
tinygrad: минималистичный фреймворк глубокого обучения между PyTorch и micrograd: tinygrad — это фреймворк глубокого обучения, в основе которого лежит простота. Он стремится быть самым простым фреймворком для добавления новых ускорителей, поддерживая как логический вывод, так и обучение. Он поддерживает такие модели, как LLaMA и Stable Diffusion, и использует отложенные вычисления (lazy evaluation) для объединения операций и оптимизации производительности. tinygrad поддерживает различные ускорители, включая GPU (OpenCL), CPU (C-код), LLVM, Metal, CUDA. Его код лаконичен, основные функции реализованы небольшим количеством кода, что облегчает разработчикам понимание и расширение. (Источник: GitHub Trending)
Нано AI-поиск запускает функцию «Суперпоиск», интегрирующую множество моделей и инструментарий MCP: Нано AI-поиск (bot.n.cn) добавил функцию «Суперпоиск», предназначенную для предоставления более глубоких возможностей получения и обработки информации. Эта функция интегрирует сотни крупных моделей из Китая и других стран и может автоматически переключаться между ними по мере необходимости; встроенный универсальный инструментарий MCP поддерживает тысячи AI-инструментов, может обрабатывать веб-страницы, изображения, видео, PDF и другие форматы файлов, а также выполнять генерацию кода, анализ данных и т. д. Одновременно сочетая публичный поиск с приватным поиском по локальной базе знаний, он предоставляет более полные результаты и имеет встроенные возможности генерации изображений и видео из текста. Пользовательский опыт показывает, что эта функция может преобразовывать результаты поиска в подробные отчеты с диаграммами и привлекательные веб-страницы, подходящие для различных сценариев, таких как отраслевые исследования, сравнение цен при покупках, систематизация знаний и т. д. (Источник: WeChat)
Clara: модульное офлайн-рабочее пространство AI, интегрирующее LLM, агентов, автоматизацию и генерацию изображений: Разработчики представили открытый проект под названием Clara, целью которого является создание полностью офлайн, модульного рабочего пространства AI. Пользователи могут организовывать на панели управления в виде виджетов локальные чаты LLM (с поддержкой RAG, изображений, документов, выполнения кода, совместимые с Ollama и API типа OpenAI), создавать агентов с памятью и логикой, запускать процессы автоматизации через нативную интеграцию N8N (предоставляется более 1000 бесплатных шаблонов), а также локально генерировать изображения с помощью Stable Diffusion (ComfyUI). Clara доступна для Mac, Windows, Linux и призвана решить проблему частого переключения пользователей между несколькими AI-инструментами, обеспечивая универсальное AI-взаимодействие. (Источник: Reddit r/LocalLLaMA)
AI Playlist Curator: Python-инструмент для персонализированной организации плейлистов YouTube с помощью LLM: Разработчик создал Python-проект под названием AI Playlist Curator, призванный помочь пользователям автоматически упорядочивать их обширные и неупорядоченные плейлисты YouTube. Инструмент использует LLM для классификации песен и создания персонализированных подплейлистов в соответствии с предпочтениями пользователя, поддерживая обработку любых сохраненных плейлистов и понравившихся песен. Проект открыт на GitHub, и разработчик надеется получить отзывы сообщества для дальнейшего улучшения. (Источник: Reddit r/MachineLearning)
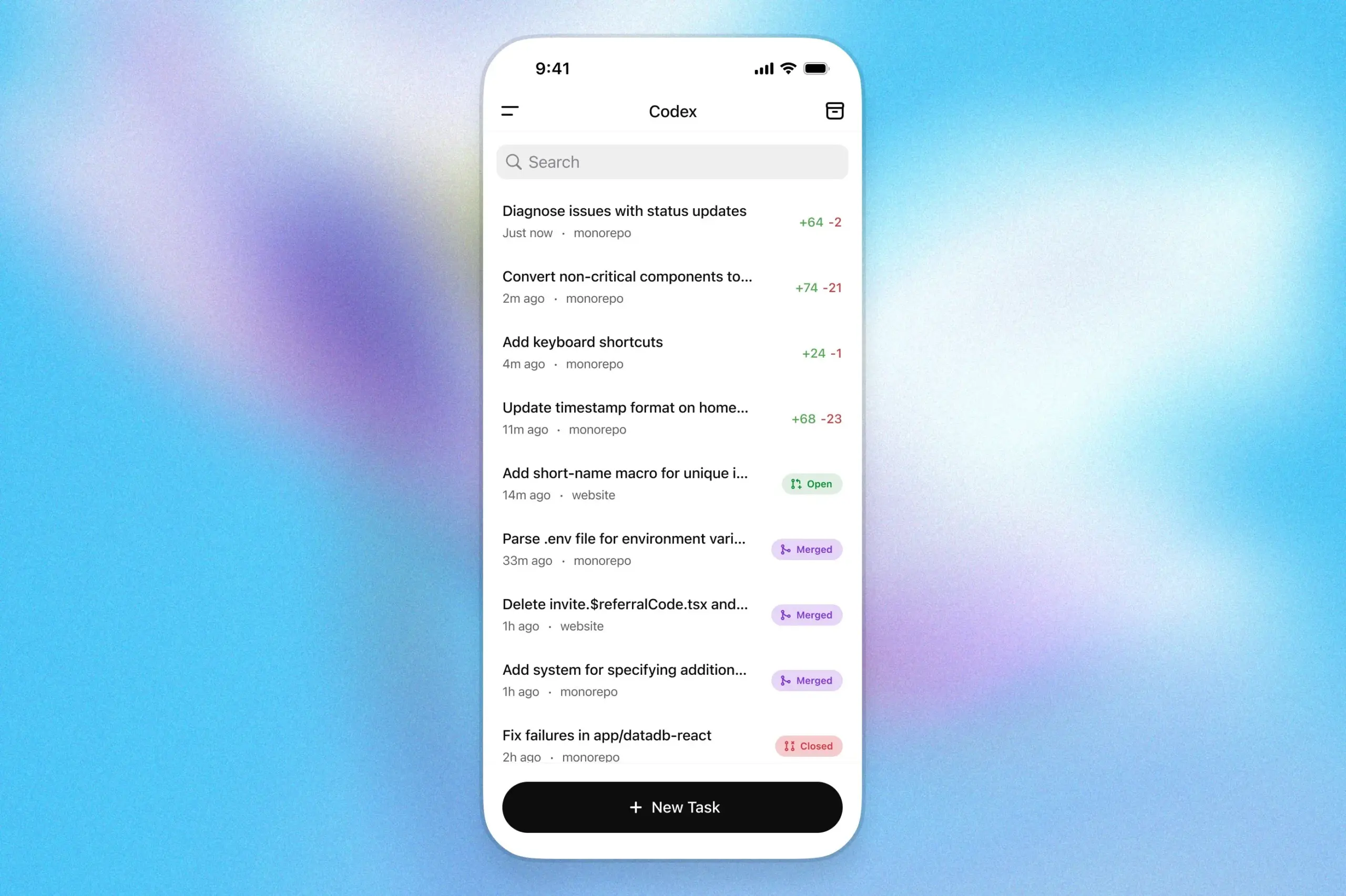
Программный помощник OpenAI Codex доступен в приложении ChatGPT для iOS: OpenAI объявила, что ее программный помощник Codex теперь интегрирован в приложение ChatGPT для iOS. Пользователи могут запускать новые задачи программирования, просматривать различия в коде, запрашивать изменения и даже отправлять пул-реквесты (PR) на мобильных устройствах. Эта функция также поддерживает отслеживание прогресса Codex в режиме реального времени через экран блокировки, что позволяет пользователям беспрепятственно переключаться между устройствами. (Источник: openai)
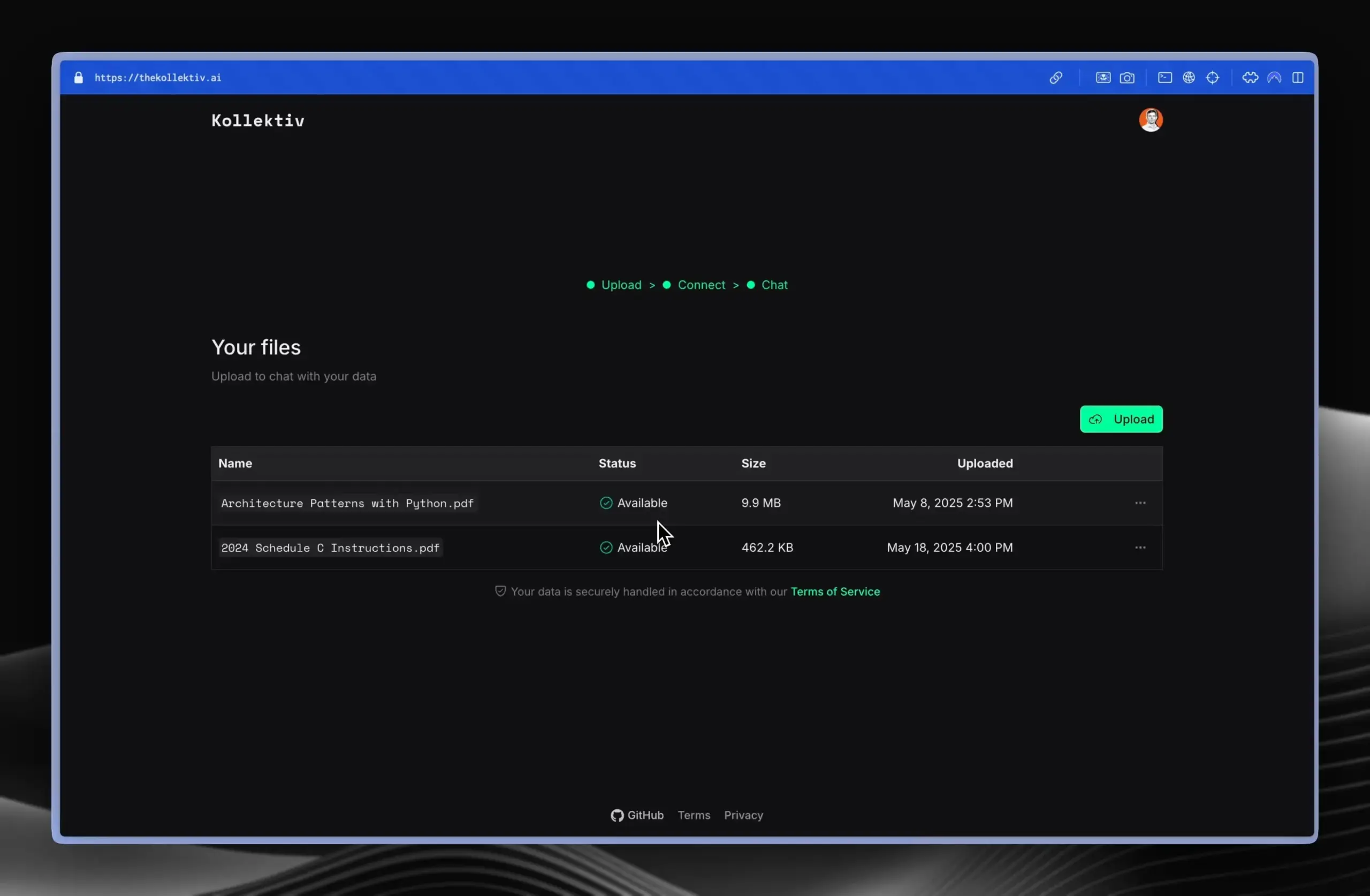
Kollektiv: инструмент для решения проблемы повторной вставки контекста в чатах LLM с использованием протокола MCP: Разработчики представили инструмент Kollektiv, предназначенный для решения проблемы, когда пользователям при общении с LLM (например, Claude) приходится многократно копировать и вставлять большой объем контекста (например, научные статьи, документацию SDK, личные заметки, содержание книг). Kollektiv позволяет пользователям однократно загрузить эти источники документов и вызывать их по требованию из любой совместимой IDE или MCP-клиента (например, Cursor, Windsurf, PyCharm и др.) через сервер MCP (Model Control Protocol). Сервер MCP отвечает за аутентификацию пользователей, изоляцию данных и потоковую передачу данных по требованию в интерфейс чата. В настоящее время инструмент не рекомендуется использовать для конфиденциальных материалов. (Источник: Reddit r/ClaudeAI)
📚 Обучение
Google DeepMind публикует технический отчет AlphaEvolve, раскрывающий его возможности по открытию алгоритмов: Google DeepMind опубликовала технический отчет о своей AI-системе AlphaEvolve. AlphaEvolve — это агент для кодирования на основе Gemini, способный разрабатывать и оптимизировать алгоритмы с помощью эволюционных алгоритмов. В отчете подробно описывается, как AlphaEvolve самостоятельно генерирует, оценивает и улучшает кандидаты алгоритмов через структурированный цикл обратной связи, что позволило достичь прорывов в ряде математических и вычислительных задач, включая обновление рекорда для алгоритма умножения комплексных матриц 4×4. Этот отчет является важным источником для понимания потенциала AI в автоматизации научных открытий и инноваций в области алгоритмов. (Источник: , HuggingFace Daily Papers)
DeepLearning.AI запускает курс «Создание AI-агентов для браузера»: DeepLearning.AI запустила новый курс под названием «Building AI Browser Agents». Курс ведут соучредители компании AGI Div Garg и Naman Agarwal и он направлен на то, чтобы помочь учащимся освоить технологии создания AI-агентов, способных взаимодействовать с браузером. Содержание курса может охватывать автоматизацию веб-страниц, извлечение информации, взаимодействие с пользовательским интерфейсом и другие применения AI в браузерной среде. (Источник: DeepLearningAI)
Опубликован технический отчет Qwen3: Alibaba опубликовала технический отчет о своем последнем поколении больших языковых моделей Qwen3. В отчете подробно описаны архитектура модели Qwen3, методы обучения, оценка производительности и результаты в различных бенчмарках. Серия моделей Qwen3 призвана обеспечить более сильные возможности понимания языка, генерации и мультимодальной обработки. Публикация технического отчета предоставляет исследователям и разработчикам возможность глубоко ознакомиться с техническими деталями этой модели. (Источник: _akhaliq)

Обсуждение статьи: Многоаспектный поиск и управление данными улучшают пошаговое доказательство теорем (MPS-Prover): Новая статья представляет MPS-Prover, новую систему пошагового автоматического доказательства теорем (ATP). Эта система преодолевает проблему смещенного руководства поиском в существующих пошаговых доказательствах за счет эффективной стратегии управления данными после обучения (отсечение около 40% избыточных данных без ущерба для производительности) и механизма многоаспектного древовидного поиска (интеграция обученной модели критика с эвристическими правилами). Эксперименты показывают, что MPS-Prover достигает производительности SOTA на нескольких бенчмарках, таких как miniF2F и ProofNet, генерируя более короткие и разнообразные доказательства. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Визуальное планирование — мышление только с помощью изображений (Visual Planning): Новая статья предлагает парадигму «визуального планирования», позволяющую моделям планировать исключительно с помощью визуальных представлений (последовательностей изображений), а не полагаться на текст. Исследователи считают, что в задачах, связанных с пространственной и геометрической информацией, язык может быть не самым естественным средством рассуждения. Они представили фреймворк визуального планирования через обучение с подкреплением VPRL и использовали GRPO для оптимизации больших визуальных моделей после обучения, добившись значительных улучшений в задачах визуальной навигации, таких как FrozenLake, Maze и MiniBehavior, и превзойдя варианты планирования, основанные исключительно на текстовых рассуждениях. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Расширение рассуждений может улучшить фактологичность больших языковых моделей (Scaling Reasoning can Improve Factuality): Исследование изучает, может ли расширение процесса рассуждения больших языковых моделей (LLM) повысить их фактическую точность в сложных вопросно-ответных системах (QA) с открытым доменом. Исследователи извлекли траектории рассуждений из таких моделей, как QwQ-32B и DeepSeek-R1-671B, и дообучили несколько моделей серии Qwen2.5, одновременно интегрировав пути графов знаний в траектории рассуждений. Эксперименты показывают, что при однократном запуске меньшие модели рассуждений демонстрируют заметное улучшение фактической точности по сравнению с исходными моделями, дообученными на инструкциях. При увеличении вычислений во время тестирования и бюджета токенов фактическая точность может стабильно повышаться на 2-8%. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Mergenetic — простая библиотека для эволюционного слияния моделей: Новая статья представляет Mergenetic, библиотеку с открытым исходным кодом для эволюционного слияния моделей. Слияние моделей позволяет объединять возможности существующих моделей в новые, без дополнительного обучения. Mergenetic поддерживает простое комбинирование методов слияния и эволюционных алгоритмов, а также использует легковесные оценщики пригодности для снижения затрат на оценку. Эксперименты доказывают, что Mergenetic позволяет получать конкурентоспособные результаты на различных задачах и языках при использовании умеренного аппаратного обеспечения. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Групповое мышление — несколько параллельных рассуждающих агентов сотрудничают на уровне токенов (Group Think): Новая статья предлагает «групповое мышление» (Group Think) — позволить одному LLM действовать как несколько параллельных рассуждающих агентов (мыслителей). Эти агенты разделяют видимость частичного прогресса генерации друг друга, динамически адаптируя свои траектории рассуждений на уровне токенов, тем самым уменьшая избыточные рассуждения, повышая качество и снижая задержку. Этот метод подходит для пограничных вычислений на локальных GPU, и эксперименты доказывают, что он также улучшает задержку при использовании LLM с открытым исходным кодом, не прошедших специального обучения. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Люди ожидают от оппонентов LLM рациональности и сотрудничества в стратегических играх (Humans expect rationality and cooperation from LLM opponents): Первое контролируемое лабораторное исследование с денежным стимулированием изучило различия в поведении людей в многопользовательских соревнованиях P-beauty против других людей и LLM. Результаты показывают, что люди, играя против LLM, выбирают значительно меньшие числа, в основном из-за увеличения распространенности выбора равновесия Нэша «ноль». Это изменение в основном обусловлено испытуемыми с высокими способностями к стратегическому мышлению, которые считают, что LLM обладают более сильными способностями к рассуждению и склонностью к сотрудничеству. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Простая полуконтролируемая дистилляция знаний из визуально-языковых моделей с помощью двуглавой оптимизации (Dual-Head Optimization for KD): Новая статья предлагает DHO (Dual-Head Optimization), простой и эффективный фреймворк дистилляции знаний (KD) для переноса знаний из визуально-языковых моделей (VLM) в компактные модели для конкретных задач в полуконтролируемой среде. DHO вводит две независимые прогнозирующие головки для изучения размеченных данных и прогнозов учителя, а при выводе линейно комбинирует их выходы, тем самым смягчая конфликт градиентов между сигналами супервизии и дистилляции. Эксперименты показывают, что DHO превосходит одноглавые базовые линии KD в нескольких доменах и на наборах данных с мелкой детализацией, достигая SOTA на ImageNet. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: GuardReasoner-VL — защита VLM с помощью усиленного рассуждения: Для повышения безопасности визуально-языковых моделей (VLM) новая статья представляет модель защиты VLM на основе рассуждений GuardReasoner-VL. Основная идея заключается в стимулировании модели защиты к тщательному рассуждению перед принятием решения о модерации с помощью онлайн-обучения с подкреплением (RL). Исследователи создали корпус рассуждений GuardReasoner-VLTrain, содержащий 123 тыс. образцов и 631 тыс. шагов рассуждений, и инициализировали способность модели к рассуждению с помощью контролируемого дообучения (SFT), а затем дополнительно усилили ее с помощью онлайн-RL. Эксперименты показывают, что эта модель (версии 3B/7B с открытым исходным кодом) демонстрирует превосходную производительность, превосходя следующую лучшую модель на 19.27% по среднему F1-показателю. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Для предсказания нескольких токенов нужны регистры (Multi-Token Prediction Needs Registers): Новая статья предлагает MuToR, простой и эффективный метод предсказания нескольких токенов, который предсказывает будущие цели путем чередования обучаемых токенов-регистров во входной последовательности. По сравнению с существующими методами, MuToR имеет незначительное увеличение параметров, не требует изменений архитектуры, совместим с существующими предварительно обученными моделями и соответствует цели предварительного обучения следующего токена, что особенно подходит для контролируемого дообучения. Этот метод демонстрирует эффективность и универсальность в задачах генерации в языковой и визуальной областях. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: MMLongBench — эффективный и всесторонний бенчмарк для визуально-языковых моделей с длинным контекстом: В ответ на потребность в оценке визуально-языковых моделей с длинным контекстом (LCVLM) новая статья представляет MMLongBench, первый бенчмарк, охватывающий множество задач визуально-языковых моделей с длинным контекстом. MMLongBench содержит 13331 образец, охватывающий пять категорий задач, таких как визуальный RAG, многовыборочный ICL и т. д., и предоставляет различные типы изображений. Все образцы предоставляются в пяти стандартизированных длинах ввода от 8K до 128K токенов. Бенчмаркинг 46 закрытых и открытых LCVLM показал, что производительность в одной задаче не отражает общую способность к работе с длинным контекстом, текущие модели все еще имеют большой простор для улучшения, и модели с сильными способностями к рассуждению, как правило, лучше справляются с длинным контекстом. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: MatTools — бенчмарк для больших языковых моделей для инструментов материаловедения: Новая статья предлагает бенчмарк MatTools для оценки способности больших языковых моделей (LLM) отвечать на вопросы материаловедения путем генерации и безопасного выполнения кода для пакетов вычислительного материаловедения на основе физики. MatTools включает бенчмарк вопросов и ответов (QA) для инструментов моделирования материалов (на основе pymatgen, содержит 69225 пар QA) и бенчмарк использования инструментов в реальных условиях (содержит 49 задач, 138 подзадач). Оценка нескольких LLM выявила: универсальные модели превосходят специализированные; AI лучше понимает AI; простые методы более эффективны. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: Универсальная симбиотическая структура водяных знаков, балансирующая надежность, качество текста и безопасность водяных знаков LLM: В ответ на существующую проблему компромисса между надежностью, качеством текста и безопасностью в схемах водяных знаков для больших языковых моделей (LLM), новая статья предлагает универсальную симбиотическую структуру водяных знаков. Эта структура интегрирует методы на основе логитов и на основе выборки, а также разрабатывает три стратегии: последовательную, параллельную и гибридную. Гибридная структура использует энтропию токенов и семантическую энтропию для адаптивного встраивания водяных знаков, стремясь оптимизировать производительность по всем аспектам. Эксперименты показывают, что этот метод превосходит существующие базовые линии и достигает уровня SOTA. (Источник: HuggingFace Daily Papers)
Обсуждение статьи: CheXGenBench — единый бенчмарк для оценки достоверности, конфиденциальности и полезности синтетических рентгеновских снимков грудной клетки: Новая статья представляет CheXGenBench, многоаспектную структуру для оценки генерации синтетических рентгеновских снимков грудной клетки, одновременно оценивая достоверность, риски конфиденциальности и клиническую полезность. Эта структура включает стандартизированные разделы данных и единый протокол оценки (более 20 количественных показателей), анализируя качество генерации, потенциальные уязвимости конфиденциальности и применимость для последующих клинических задач 11 ведущих архитектур преобразования текста в изображение. Исследование выявило недостатки существующих протоколов оценки в оценке достоверности генерации. Команда также выпустила высококачественный синтетический набор данных SynthCheX-75K. (Источник: HuggingFace Daily Papers)
Умер Peter Lax, автор классического учебника «Функциональный анализ», в возрасте 99 лет: Скончался гигант прикладной математики, первый лауреат Абелевской премии в области прикладной математики Peter Lax, в возрасте 99 лет. Lax известен своим классическим учебником «Функциональный анализ» и внес основополагающий вклад в такие области, как уравнения в частных производных, гидродинамика, численные методы, например, теорема эквивалентности Лакса, методы Лакса-Фридрихса и Лакса-Вендроффа. Он также был одним из первых пионеров применения компьютерных технологий в математическом анализе, и его работа оказала глубокое влияние на развитие математики в компьютерную эпоху. (Источник: 量子位)

Бывший вице-президент OpenAI китайского происхождения Lilian Weng в длинной статье «Why We Think» обсуждает вычисления во время тестирования и цепочку мыслей: Бывший вице-президент OpenAI китайского происхождения Lilian Weng (翁荔) опубликовала длинную статью «Why We Think», в которой подробно рассматривается, как технологии, такие как «вычисления во время тестирования» (Test-time Compute) и «цепочка мыслей» (Chain-of-Thought, CoT), значительно повышают производительность и интеллектуальный уровень больших языковых моделей. Статья проводит аналогию с теорией двух систем «быстрого и медленного мышления» человека, указывая, что предоставление модели большего «времени на размышление» перед выводом (например, с помощью интеллектуального декодирования, рассуждений CoT, моделирования скрытых переменных и т. д.) может преодолеть текущие ограничения возможностей. В статье подробно рассматриваются достижения и проблемы в нескольких направлениях исследований, таких как мышление на основе токенов, параллельная выборка и последовательное исправление, обучение с подкреплением и интеграция внешних инструментов, достоверность мышления и мышление в непрерывном пространстве. (Источник: 量子位)

Харбинский технологический университет и Пенсильванский университет совместно представляют PointKAN, новый SOTA для анализа облаков точек на основе KANs: Исследовательские группы из Харбинского технологического университета (Шэньчжэнь) и Пенсильванского университета представили PointKAN, решение для анализа 3D-облаков точек на основе Kolmogorov-Arnold Networks (KANs). Этот метод использует геометрический аффинный модуль и модуль параллельного извлечения локальных признаков, а также заменяет фиксированные функции активации в традиционных MLP на обучаемые функции активации для более эффективного захвата сложных геометрических характеристик облаков точек. Одновременно команда предложила структуру Efficient-KANs, которая заменяет B-сплайны рациональными функциями и использует совместное использование параметров внутри группы, что значительно снижает количество параметров и вычислительные затраты. Эксперименты показывают, что PointKAN и его облегченная версия PointKAN-elite достигают SOTA или конкурентоспособных результатов в таких задачах, как классификация, частичная сегментация и обучение на малых выборках. (Источник: WeChat)

Пекинский университет/StepFun/Xizhi Technology предлагают InfiniteHBD: архитектуру межсоединений GPU нового поколения с высокой пропускной способностью, снижающую затраты на обучение больших моделей: Исследовательские группы из Пекинского университета, StepFun (阶跃星辰) и Xizhi Technology (曦智科技) предложили решение InfiniteHBD в ответ на ограничения существующих архитектур доменов с высокой пропускной способностью (HBD) в распределенном обучении больших моделей. Эта архитектура, основанная на оптоэлектронных модулях со встроенной возможностью оптической коммутации каналов (OCS), обеспечивает динамически реконфигурируемые соединения «точка-многоточка», обладает возможностью изоляции неисправностей на уровне узлов и низкой фрагментацией ресурсов. Исследование показывает, что удельная стоимость InfiniteHBD составляет всего 31% от NVIDIA NVL-72, коэффициент потерь GPU близок к нулю, а MFU (эффективность использования FLOPs моделью) может быть увеличена до 3.37 раз по сравнению с NVIDIA DGX. Это исследование было принято на SIGCOMM 2025. (Источник: WeChat, 量子位)
Краткий обзор статей ICML 2025: OmniAudio генерирует пространственный звук из 360° видео: Исследование, которое будет представлено на ICML 2025, предлагает фреймворк OmniAudio, способный напрямую генерировать пространственный звук первого порядка с ощущением направления (FOA) из 360° панорамных видео. В ходе исследования сначала был создан крупномасштабный набор данных Sphere360, состоящий из пар 360° видео и пространственного аудио. OmniAudio использует двухэтапное обучение: сначала проводится самоконтролируемое предварительное обучение с согласованием потоков от грубого к точному, используя крупномасштабные данные не пространственного аудио для изучения общих аудио признаков; затем проводится контролируемое дообучение с использованием двухпоточного видеокодировщика (извлекающего глобальные и локальные визуальные признаки). Результаты экспериментов показывают, что OmniAudio значительно превосходит существующие базовые модели по объективным и субъективным показателям оценки. (Источник: WeChat)

Huawei Selftok: авторегрессионный визуальный токенизатор на основе обратной диффузии, унифицирующий мультимодальную генерацию: Команда мультимодальной генерации Huawei Pangu представила технологию Selftok, инновационное решение для визуальной токенизации, которое путем обратного диффузионного процесса интегрирует авторегрессионный априор в визуальные токены, преобразуя поток пикселей в дискретную последовательность, строго следующую принципу причинности. Это направлено на решение проблемы конфликта существующих схем пространственной токенизации с авторегрессионной (AR) парадигмой. Токенизатор Selftok использует двухпоточный кодировщик (ветвь изображения наследует SD3 VAE, текстовая ветвь представляет собой обучаемую группу непрерывных векторов) и квантователь с механизмом повторной активации. Эксперименты показывают, что Selftok достигает SOTA по показателям реконструкции ImageNet, а Selftok dAR-VLM, обученный на базе Ascend AI и фреймворка MindSpeed, превосходит GPT-4o в бенчмарках генерации изображений из текста, таких как GenEval. Эта работа вошла в число кандидатов на лучшую статью CVPR 2025. (Источник: WeChat)
Команда под руководством Янь Шуйчэна выпускает оценочную структуру General-Level и бенчмарк General-Bench для классификации мультимодальных универсальных моделей: Под руководством профессора Янь Шуйчэна из Национального университета Сингапура, профессора Чжан Ханьвана из Наньянского технологического университета и других, десять ведущих университетов совместно выпустили оценочную структуру General-Level и крупномасштабный набор данных-бенчмарк General-Bench для мультимодальных универсальных моделей. Эта структура, заимствуя идею классификации в области автономного вождения, устанавливает пять уровней (Level 1-5) для оценки универсальности и производительности мультимодальных больших языковых моделей (MLLM). Основным критерием оценки является «эффект синергетического обобщения» (Synergy), который оценивает способность модели к переносу и усилению знаний между задачами, между парадигмами понимания и генерации, а также между модальностями. General-Bench включает более 700 задач и 320 000 образцов. Оценка более 100 существующих MLLM показала, что большинство моделей находятся на уровне L2-L3, и ни одна модель пока не достигла L5. (Источник: WeChat)

💼 Бизнес
Sakana AI и Mitsubishi UFJ Financial Group (MUFG) заключают многолетнее партнерское соглашение: Японский стартап в области AI Sakana AI объявил о подписании многолетнего всеобъемлющего партнерского соглашения с крупнейшим банком Японии MUFG Bank. Sakana AI предоставит MUFG Bank гибкие и мощные технологии AI, призванные помочь этому банку со столетней историей оставаться конкурентоспособным в быстро развивающейся области AI. Ожидается, что это сотрудничество поможет Sakana AI достичь прибыльности в течение года. (Источник: SakanaAILabs, SakanaAILabs)

Cohere сотрудничает с Dell для внедрения своей безопасной агентной платформы Cohere North в локализованные корпоративные AI-решения Dell: AI-компания Cohere объявила о сотрудничестве с Dell Technologies для ускорения разработки безопасных корпоративных AI-решений с агентными возможностями. Dell станет первым поставщиком, предлагающим предприятиям локализованное (on-premises) развертывание безопасной агентной платформы Cohere North. Это сотрудничество особенно важно для отраслей, работающих с конфиденциальными данными и имеющих строгие требования к соответствию, поскольку позволяет предприятиям развертывать и запускать передовые технологии AI-агентов Cohere в своих собственных центрах обработки данных. (Источник: sarahookr)

Mistral AI сотрудничает с MGX и Bpifrance для строительства крупнейшего в Европе AI-парка во Франции: Mistral AI объявила о сотрудничестве с технологической инвестиционной компанией MGX, поддерживаемой Абу-Даби, и французским государственным инвестиционным банком Bpifrance для совместного строительства крупнейшего в Европе AI-парка в парижском регионе. Парк будет объединять центры обработки данных, высокопроизводительные вычислительные ресурсы, образовательные и исследовательские учреждения. Nvidia также примет участие, предоставив техническую поддержку. Этот шаг направлен на содействие развитию европейской экосистемы AI и повышение стратегического положения Франции в мировой AI-сфере. (Источник: arthurmensch, arthurmensch)
🌟 Сообщество
Распространенность СДВГ среди специалистов в области AI привлекает внимание, возможно, превышает 20-30%: В социальных сетях возникло обсуждение распространенности синдрома дефицита внимания и гиперактивности (СДВГ) среди специалистов в области AI. Один из пользователей заметил, что эта сфера, по-видимому, привлекает много талантов с нейроотличиями. Minh Nhat Nguyen прокомментировал, что в индустрии AI может быть более 20-30% людей с СДВГ. Это явление может быть связано с тем, что работа в области исследований и разработок AI требует высокой концентрации, быстрой итерации и творческого мышления, качеств, которые иногда совпадают с некоторыми проявлениями СДВГ. (Источник: Dorialexander)
Обесценивание навыков в эпоху AI заставляет задуматься, ключевым является перестройка системы, а не освоение инструментов: В глубоком аналитическом материале отмечается, что настоящий кризис эпохи AI заключается не в «умении или неумении пользоваться AI-инструментами», а в обесценивании самих навыков и перестройке всей системы работы. На примерах линии Мажино, контейнеризации, замены машинисток текстовыми процессорами автор доказывает, что простое освоение новых инструментов не гарантирует лидерства. Ключевым является понимание того, как AI меняет структуру, процессы и организационную логику работы. Когда система переписывается, ранее высоко ценимые навыки могут быстро маргинализироваться. Повышение производительности не обязательно приводит к повышению индивидуальной ценности, поскольку ценность перетекает к субъектам, контролирующим новый координационный уровень системы. Статья опровергает восемь популярных заблуждений, таких как «научившись AI, можно стать лидером», «AI заставляет меня делать больше работы, поэтому я более ценен», «рабочие места не изменятся, изменится только способ работы», и подчеркивает необходимость осмысления своего положения и ценности на системном уровне. (Источник: 36氪)
Бывший CEO Google Эрик Шмидт: Восстание нечеловеческого интеллекта изменит глобальный ландшафт, необходимо остерегаться рисков и вызовов AI: Бывший CEO Google Эрик Шмидт в эксклюзивном интервью предупредил, что общество серьезно недооценивает разрушительный потенциал «нечеловеческого интеллекта». По его мнению, AI уже перешел от генерации языка к принятию стратегических решений и способен самостоятельно выполнять сложные задачи. Шмидт выделил три основных вызова, связанных с AI: узкие места в энергетике и вычислительных мощностях (США потребуется дополнительно 90 гигаватт электроэнергии), почти исчерпанные публичные данные (на следующем этапе потребуются данные, генерируемые AI) и вопрос о том, как заставить AI превзойти существующие человеческие знания и создать «новое знание». Он также указал на три основных риска: выход из-под контроля рекурсивного самосовершенствования AI, получение контроля над оружием и несанкционированное самовоспроизведение. По его мнению, в условиях обострения конкуренции между США и Китаем в области AI быстрое распространение AI с открытым исходным кодом может создать риски для безопасности и даже спровоцировать ситуацию, подобную «ядерному сдерживанию», с «превентивным ударом». Шмидт призвал немедленно начать глобальный диалог по управлению AI и подчеркнул, что защита человеческой свободы должна быть встроена в систему с самого начала ее проектирования. (Источник: 36氪)

CEO GitHub опровергает «тезис о бесполезности программирования», подчеркивая важность человеческих программистов в эпоху AI: В ответ на заявления CEO Nvidia Дженсена Хуанга и других о том, что «в будущем не нужно будет учиться программировать», CEO GitHub Томас Домке в интервью выразил несогласие. Он считает, что 2025 год станет годом программных агентов (SWE Agent), но роль человеческих программистов останется ключевой. Домке подчеркнул, что AI должен служить помощником, усиливающим возможности разработчиков, а не полностью заменять их. Он представляет будущее разработки программного обеспечения как модель сотрудничества человека и AI, где разработчики выступают в роли «дирижеров оркестра агентов», отвечающих за распределение задач и проверку результатов. CPO GitHub Марио Родригес также заявил, что компания стремится использовать Copilot для расширения индивидуальных возможностей. Они считают, что по мере развития AI понимание того, как программировать и перепрограммировать машины, способные представлять человеческое мышление и действия, становится критически важным, и отказ от изучения кода равносилен отказу от права голоса в будущем агентов. (Источник: 36氪, 量子位)

Наплыв низкокачественных отчетов об уязвимостях, сгенерированных AI, вынуждает основателя curl ввести механизм фильтрации для борьбы с «AI-мусором»: Основатель проекта curl Daniel Stenberg заявил, что из-за большого количества низкокачественных, недействительных отчетов об уязвимостях, сгенерированных AI, он уже не справляется с потоком. Эти отчеты отнимают у сопровождающих много времени и по сути являются DDoS-атакой. В связи с этим при отправке отчетов о безопасности, связанных с curl, на HackerOne был добавлен флажок с вопросом об использовании AI. Если ответ положительный, необходимо предоставить дополнительные доказательства подлинности уязвимости, в противном случае отправитель может быть заблокирован. Stenberg утверждает, что проект никогда не получал действительных отчетов об ошибках, сгенерированных AI. Разработчик Python Seth Larson также ранее выражал аналогичные опасения, считая, что такие отчеты вызывают у сопровождающих замешательство, стресс и разочарование, усугубляя проблему выгорания в проектах с открытым исходным кодом. Обсуждение в сообществе показало, что наплыв отчетов, сгенерированных AI, отражает информационную перегрузку и попытки некоторых людей воспользоваться механизмами вознаграждения за обнаружение уязвимостей. Даже некоторые высокопоставленные менеджеры были введены в заблуждение, полагая, что AI может заменить опытных программистов. (Источник: WeChat)

Программирование с помощью AI вызывает бурные дебаты: эффективность значительно повышается, но роль человеческих разработчиков остается ключевой: Разработчик с многолетним опытом программирования поделился историей о том, как AI (возможно, Codex или аналогичный инструмент) за несколько минут решил ошибку, над которой он бился несколько часов, и оптимизировал код, восхищаясь AI как «неутомимым супер-товарищем по команде». Этот опыт вызвал обсуждение в сообществе. Большинство согласны с тем, что AI обладает мощными возможностями в генерации кода, исправлении ошибок и обобщении информации, что может значительно повысить эффективность. Однако некоторые разработчики отмечают, что AI в настоящее время все еще допускает ошибки, особенно в сложной логике, граничных условиях и творческих решениях, уступая человеку, и его результаты требуют проверки и критической оценки опытными разработчиками. CEO Microsoft Сатья Наделла также подчеркнул, что AI является инструментом расширения возможностей, разработка программного обеспечения уже немыслима без AI, но амбиции и инициативность человека по-прежнему важны. В ходе обсуждения в целом пришли к выводу, что AI изменит способы программирования, и разработчикам необходимо адаптироваться к новой парадигме сотрудничества с AI, сосредоточившись на более высоком уровне проектирования архитектуры и определения проблем. (Источник: Reddit r/ChatGPT, WeChat)
AI Agent Manus открывает регистрацию, но с высокой ценой, сталкивается с конкуренцией со стороны отечественных и зарубежных гигантов, запуск китайской версии под вопросом: AI Agent платформа Manus после ажиотажа с пригласительными кодами официально открыла регистрацию, но пока только для зарубежных пользователей, китайская версия не предоставлена. Пользователи сообщают, что используется система списания баллов, бесплатных баллов (1000 при регистрации, 300 ежедневно) хватает только на выполнение простых задач, для сложных задач (например, создание веб-версии игры Судоку) необходимо покупать баллы, в среднем 1 доллар за 100 баллов, что довольно дорого. Аналитики отрасли считают, что Manus зависит от сторонних больших моделей (например, зарубежная версия использует Claude), что приводит к высоким затратам, а работа в облачной песочнице также увеличивает расходы. Задержка с запуском китайской версии может быть связана с регистрацией моделей в Китае, привычками пользователей к оплате и рыночной конкуренцией. Продукты от ByteDance (Coze), Baidu (приложение «Синьсян») и другие отечественные и зарубежные продукты уже создают конкуренцию. Manus, хотя и получила новое финансирование, но ее модель «легкая модель, тяжелое приложение» сталкивается с проверкой на прочность. (Источник: 36氪)
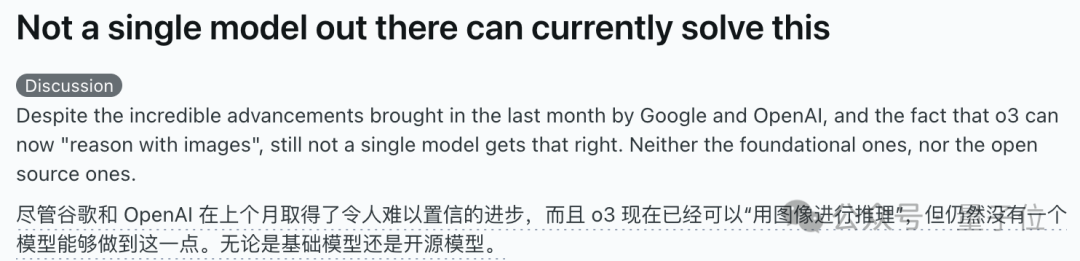
AI-модели массово проваливаются на задаче визуального мышления «дополнить куб», вызывая дискуссию об их реальном понимании: Задача визуального мышления, требующая вычислить количество маленьких кубиков, необходимых для дополнения неполного куба, поставила в тупик множество основных AI-моделей, включая OpenAI o3, Google Gemini 2.5 Pro, DeepSeek, Qwen3. Модели давали разные ответы, в основном из-за разного понимания окончательных размеров большого куба (например, 3x3x3, 4x4x4, 5x5x5). Даже с подсказками модели с трудом могли правильно решить задачу с первого раза. Некоторые пользователи отметили, что сама формулировка проблемы может быть неоднозначной, и люди также могут испытывать затруднения. Это явление вызвало дискуссию о том, действительно ли AI-модели понимают проблему или просто полагаются на сопоставление с образцом, подчеркивая текущие ограничения AI в сложном пространственном мышлении и визуальном понимании. (Источник: 36氪)
Пользователи обсуждают проблему «чрезмерного обдумывания» LLM при следовании инструкциям и рассуждениях: Обсуждения в социальных сетях и научных статьях указывают на то, что большие языковые модели (LLM) при использовании процессов рассуждения, таких как цепочка мыслей (CoT), иногда «слишком много думают», что, наоборот, приводит к неспособности точно следовать простым инструкциям. Например, когда требуется написать определенное количество слов или повторить определенную фразу, CoT может заставить модель больше сосредоточиться на общем содержании задачи, игнорируя эти основные ограничения, или вводить дополнительный пояснительный контент. Исследователи предложили метрику «внимание к ограничениям» для количественной оценки этого явления и протестировали стратегии смягчения, такие как контекстное обучение, саморефлексия, самовыбор рассуждений и выбор рассуждений классификатором. Это показывает, что не все задачи подходят для CoT, и простые инструкции могут требовать более прямого способа выполнения. (Источник: menhguin, omarsar0)

Переосмысление экономики AI: дешевый когнитивный труд разрушает традиционные экономические модели, распределение стоимости подлежит пересмотру: Широко обсуждаемая точка зрения гласит, что подъем AI делает когнитивный труд (например, написание отчетов, анализ данных, написание кода) чрезвычайно дешевым, что коренным образом бросает вызов классическим экономическим моделям, основанным на предположении о «дефицитности и дороговизне человеческого интеллекта». Когда AI может выполнять большой объем интеллектуальной работы практически с нулевыми предельными издержками, производительность может резко возрасти, но стоимость одной задачи резко упадет, а преимущества специализации будут размыты. Распределение стоимости больше не будет просто основываться на эффективности или объеме производства, а будет зависеть от того, кто контролирует новые дефицитные ресурсы (например, данные, платформы, сами AI-модели). Это похоже на исторические технологические изменения (например, быстрая мода в швейной промышленности, потоковое вещание в музыкальной индустрии), когда выгоды от повышения эффективности не полностью доставались работникам, а присваивались системными координаторами. В статье содержится предостережение, что AI не только автоматизирует задачи, но и превращает «мышление» в товар, что может стать самой разрушительной силой в современной экономической истории. (Источник: Reddit r/artificial)
Корпоративная стратегия в эпоху AI: избегайте ловушки «умной компании», нужна перестройка, а не оптимизация старых процессов: Многие компании при внедрении AI склонны рассматривать его как инструмент для оптимизации существующих процессов, снижения затрат и повышения эффективности, попадая в ловушку «умной компании», то есть «делать то же самое, но умнее». Однако настоящие изменения заключаются не в том, чтобы сделать старые процессы умнее, а в том, чтобы задуматься, нужны ли эти процессы вообще, и построить совершенно новые, изначально ориентированные на AI системы и бизнес-модели. Технологии не просто адаптируются к старым системам, они перестраивают их. Компаниям следует избегать чрезмерных инвестиций в оптимизацию процессов, которые скоро будут вытеснены AI, а вместо этого сосредоточиться на определении новых правил, коренным образом изменяя способы принятия решений, механизмы координации и организационную структуру. (Источник: 36氪)
💡 Прочее
Офлайн-встреча LangChain в Нью-Йорке: LangChain объявила, что 22 мая (четверг) в Нью-Йорке совместно с Tabs и TavilyAI проведет офлайн-встречу. Мероприятие будет включать беседу у камина, демонстрацию продуктов и общение с другими разработчиками. (Источник: hwchase17, LangChainAI)

Глобальная конференция по AI в Токио состоится в июне: Мероприятие под названием «Глобальная конференция по AI · Токийский этап» планируется провести с 7 по 8 июня в Токио, Япония. В нем примут участие многие известные разработчики AI, художники, инвесторы и другие. Лица, интересующиеся областью AI и планирующие поездку в Японию, могут следить за информацией о регистрации. (Источник: op7418)

Парадигма архитектуры AI-сервисов смещается от «модель как услуга» к «агент как услуга»: С развитием технологий AI архитектура AI-сервисов претерпевает глубокий переход от «модели как услуги» (MaaS) к «агенту как услуге» (AaaS). AI-агенты, благодаря своей целеустремленности, восприятию окружающей среды, автономному принятию решений и способности к обучению, превосходят традиционные AI-модели, пассивно выполняющие команды. Они способны самостоятельно мыслить, декомпозировать задачи, планировать пути и вызывать внешние инструменты для достижения сложных целей. Этот сдвиг стимулирует всестороннее развитие производственной цепочки, начиная от базовой инфраструктуры (вычислительные мощности, данные), основных алгоритмов и больших моделей, до промежуточного уровня компонентов и платформ агентов, и заканчивая конечными продуктами и приложениями (универсальные, вертикально-отраслевые, встраиваемые агенты). Китайские компании, занимающиеся AI-агентами, такие как HeyGen, Laiye Technology, Wave Intelligence и другие, также активно выходят на зарубежные рынки. Несмотря на такие проблемы, как высокая стоимость вычислительных мощностей и их нехватка, потенциал AI-агентов постоянно раскрывается благодаря оптимизации алгоритмов, специализированным чипам, пограничным вычислениям и другим решениям. (Источник: 36氪)