
Ключевые слова:ИИ-программирующий агент, Codex, AlphaEvolve, Парадигма ИИ-рассуждений, Модель MoE, ИИ-чип, ИИ-образование, ИИ-минисериал, Модель OpenAI Codex-1, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Технология Qwen ParScale, Система NVIDIA GB300
🔥 В центре внимания
OpenAI выпустила облачного AI-агента для программирования Codex, работающего на новой модели codex-1: OpenAI представила облачного AI-агента для программирования Codex, основанного на codex-1 — специальной версии o3, оптимизированной для программной инженерии. Codex может безопасно и параллельно обрабатывать несколько задач в облачной песочнице, интегрируется с GitHub для прямого вызова репозиториев кода, позволяя быстро создавать модули, отвечать на вопросы по кодовой базе, исправлять уязвимости, отправлять PR и автоматически проводить тестирование и проверку. Задачи, на которые раньше уходили дни или часы, Codex может выполнить за 30 минут. Этот инструмент уже доступен пользователям ChatGPT Pro, Enterprise и Team и призван стать «10x инженером» для разработчиков, перестраивая процесс разработки программного обеспечения. (Источник: 36氪)
Google DeepMind представила AlphaEvolve, автономная эволюция ИИ достигает прорывов в математике и алгоритмах: AI-система AlphaEvolve от Google DeepMind, благодаря самоэволюции и обучению больших языковых моделей, достигла прорывов в нескольких математических и научных областях. Она улучшила алгоритм умножения матриц 4×4 (впервые за 56 лет), оптимизировала задачу упаковки шестиугольников (впервые за 16 лет) и продвинулась в «задаче о целующихся числах». AlphaEvolve способна автономно оптимизировать алгоритмы и даже нашла способ ускорить обучение модели Gemini, что уже применяется для оптимизации внутренней вычислительной инфраструктуры Google, сэкономив 0,7% вычислительных ресурсов. Это знаменует, что ИИ не только решает проблемы, но и открывает новые знания, обещая революционизировать научно-исследовательскую парадигму и реализовать научное творчество с помощью ИИ. (Источник: 36氪)
Выступление Альтмана на саммите Sequoia AI: ИИ войдет в реальный мир в течение трех лет, изменив жизнь и работу: CEO OpenAI Сэм Альтман на саммите Sequoia AI предсказал, что в 2025 году AI-агенты станут практическими (особенно в области кодирования), в 2026 году ИИ будет способствовать крупным научным открытиям, а в 2027 году роботы войдут в физический мир для создания ценности. Он рассказал об пути OpenAI от ранних исследований до создания ChatGPT и предположил, что будущие AI-продукты будут представлять собой услугу «основной AI-подписки», способную вместить весь жизненный опыт человека и стать интеллектуальным интерфейсом по умолчанию. OpenAI сосредоточится на основных моделях и сценариях применения, сохраняя организационную эффективность «маленькой команды с большой ответственностью». (Источник: 36氪)
Выступление NVIDIA на Computex: персональные AI-компьютеры запущены в производство, представлена система следующего поколения GB300, планируется строительство AI-суперкомпьютера на Тайване: CEO NVIDIA Дженсен Хуанг на Computex 2025 объявил, что персональный AI-компьютер DGX Spark полностью запущен в производство и поступит в продажу в течение нескольких недель; AI-система следующего поколения GB300 (оснащенная 72 GPU Blackwell Ultra и 36 CPU Grace) будет выпущена в третьем квартале. NVIDIA совместно с TSMC и Foxconn построит AI-суперкомпьютерный центр на Тайване. Одновременно были представлены рабочие станции серии Blackwell RTX Pro 6000 и Grace Blackwell Ultra Superchip, а в июле планируется открыть исходный код физического движка Newton для обучения роботов. Дженсен Хуанг подчеркнул, что ИИ будет повсюду, подтвердив его революционное влияние. (Источник: 36氪)

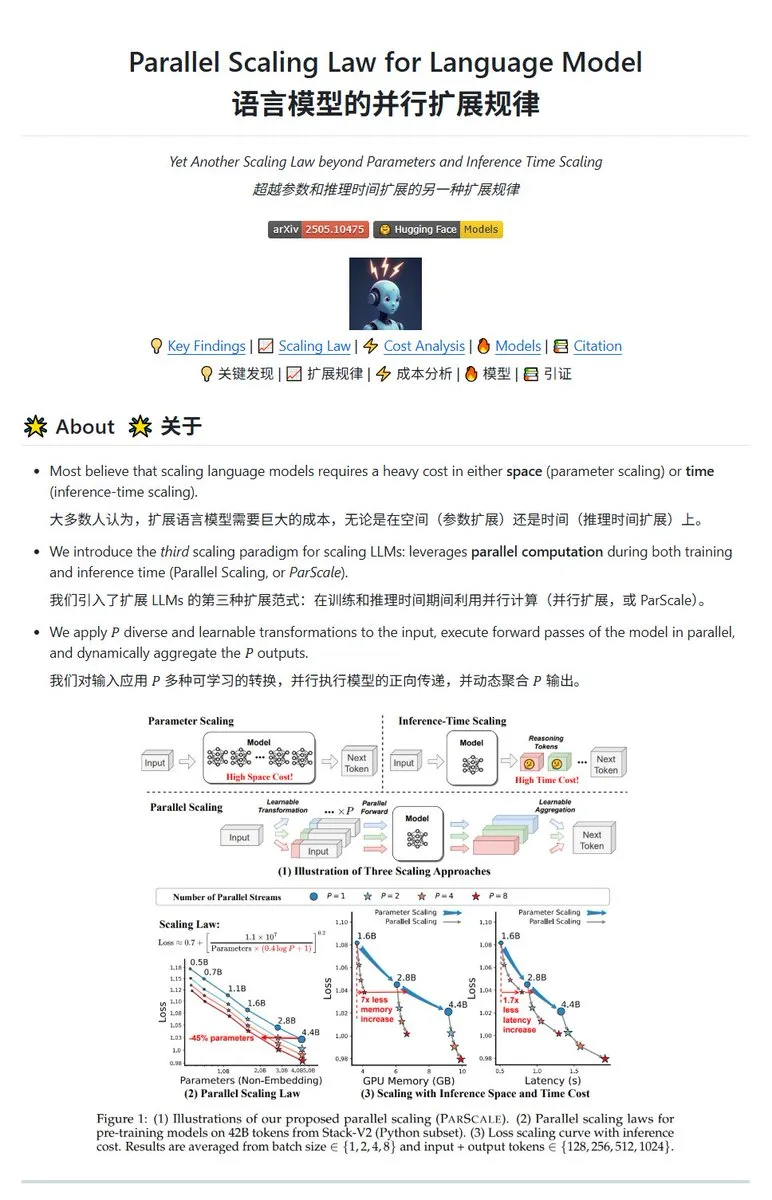
Qwen представила технологию параллельного масштабирования ParScale, позволяющую малым моделям достигать эффективности больших: Команда Qwen представила технологию ParScale, которая повышает возможности модели за счет параллельного логического вывода. Этот метод использует n параллельных потоков для вывода, каждый из которых обрабатывает входные данные с помощью обучаемого дифференцированного преобразования, а результаты объединяются с помощью механизма динамической агрегации. Исследования показывают, что P параллельных потоков эквивалентны увеличению количества параметров модели в O(log P) раз, например, модель 30B с 8 параллельными потоками может достичь эффективности модели 42.5B. Эта технология обещает повысить производительность модели без значительного увеличения занимаемой видеопамяти или уменьшить размер существующих моделей за счет увеличения параллелизма, но, возможно, ценой увеличения вычислительных потребностей и снижения скорости вывода. (Источник: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Динамика
Отчет Poe: OpenAI и Google лидируют в гонке ИИ, Anthropic демонстрирует спад: Последний отчет об использовании Poe (январь-май 2025 г.) показывает резкие изменения на рынке ИИ. В области генерации текста лидирует GPT-4o (35,8%), Gemini 2.5 Pro занимает первое место по возможностям логического вывода (31,5%). В генерации изображений доминируют Imagen3, GPT-Image-1 и серия Flux. В области генерации видео неожиданно вырвался вперед Kling-2.0-Master, доля Runway значительно снизилась. Среди агентов наилучшие результаты показал o3. В отчете отмечается, что возможности логического вывода стали ключевым полем битвы, рыночная доля Claude от Anthropic снизилась, а доля пользователей DeepSeek R1 также упала с пиковых значений. Предприятиям необходимо обращать внимание на точность и надежность моделей при выполнении сложных задач и гибко подходить к выбору AI-моделей. (Источник: 36氪)

Выпуск флагманской AI-модели Meta Behemoth (Llama 4) отложен, что может вызвать корректировку AI-стратегии: По сообщениям, выпуск 2-триллионнопараметрической большой модели Behemoth (Llama 4) от Meta, первоначально запланированный на апрель, отложен до осени или более позднего срока из-за того, что производительность не оправдала ожиданий. Эта модель, предварительно обученная на 30Т мультимодальных токенов на 32K GPU, призвана конкурировать с OpenAI, Google и другими. Трудности в разработке вызвали внутреннее разочарование в работе команды Llama 4 и могут привести к корректировке команды AI-продуктов. В то же время, из 14 человек первоначальной команды Llama 1 уже ушли 11. Руководство Meta опровергло слухи об «увольнении 80% команды», подчеркнув, что ушедшие в основном из команды, работавшей над статьей о Llama 1. Это событие усилило опасения общественности относительно того, не столкнулась ли Meta с трудностями в гонке ИИ. (Источник: 36氪)

ByteDance и Google DeepMind опубликовали новое исследование моделей MoE, сосредоточившись на эффективности и применении в производственных системах: В статье ByteDance «MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production» представлена производственная система, специально разработанная для эффективного обучения крупномасштабных моделей MoE. Благодаря совмещению коммуникации и вычислений на уровне операторов, система достигла в 1,88 раза большей эффективности по сравнению с Megatron-LM и уже развернута в ее дата-центрах для обучения продуктовых моделей (таких как Internal-352B, 32 эксперта, top-3). Google DeepMind представила AlphaEvolve, которая благодаря самоэволюции ИИ и обучению LLM достигла прорывов в математике и алгоритмах, например, улучшив умножение матриц 4×4 и задачу упаковки шестиугольников, демонстрируя потенциал ИИ в научных открытиях. (Источник: teortaxesTex, 36氪)

OpenAI обсуждает парадигму логического вывода ИИ, подчеркивая ее ключевую роль в повышении производительности: Исследователь OpenAI Ноам Браун отметил, что развитие ИИ перешло от парадигмы предварительного обучения (предсказание следующего слова на основе огромных объемов данных) к парадигме логического вывода. Предварительное обучение дорогостоящее, в то время как парадигма логического вывода повышает качество ответов за счет увеличения времени «мышления» модели (объема вычислений для вывода), даже если затраты на обучение остаются неизменными. Например, модели серии o на математических олимпиадах (AIME) и научных задачах докторского уровня (GPQA) благодаря более длительному времени вывода достигли значительно более высокой точности, чем GPT-4o. Главный экономист OpenAI Ронни Чаттерджи обсудил, как ИИ меняет корпоративный ландшафт, считая ключевым то, как компании интегрируют ИИ для усиления или замены человеческих ролей, и как технологии ИИ встраиваются в цепочку создания стоимости. (Источник: 36氪)

CEO Google Пичаи ответил на «теорию смерти Google», подчеркнув эволюцию поиска на базе ИИ и преимущества инфраструктуры: CEO Google Сундар Пичаи в эксклюзивном интервью ответил на опасения по поводу «замены поиска Google искусственным интеллектом», заявив, что Google с помощью таких функций, как «AI Overview» и «AI Mode», превращает поиск из реактивного запроса в предиктивного, персонализированного интеллектуального помощника. Он подчеркнул, что долгосрочные инвестиции Google в инфраструктуру ИИ (собственные TPU, крупномасштабные дата-центры) и эффективность моделей являются ключевыми преимуществами, позволяющими предоставлять передовые модели по выгодной цене. Пичаи считает ИИ «технологической платформой для всех сценариев», которая изменит поиск, YouTube, Cloud и другие основные бизнесы, а также породит новые формы. Он также упомянул, что конкурентоспособность китайского ИИ (например, DeepSeek) нельзя недооценивать, и отметил, что электроэнергия станет ключевым узким местом в развитии ИИ. (Источник: 36氪)

Обзор стартапов, применяющих ИИ в образовании: В статье представлен обзор 13 образовательных AI-стартапов, на которые стоит обратить внимание в 2025 году. Они меняют преподавание с помощью персонализированных учебных траекторий, интеллектуальных систем репетиторства, автоматической оценки и создания иммерсивного контента. Например, Merlyn — это голосовой AI-ассистент, снижающий административную нагрузку на учителей; Brisk Teaching — расширение для Chrome, упрощающее учебные задачи; Edexia — AI-платформа для оценки, обучающаяся стилю учителя; Storytailor сочетает библиотерапию с AI для создания персонализированных историй; Brainly предоставляет помощь с домашними заданиями, усиленную ИИ. Эти компании демонстрируют широкий потенциал применения ИИ в образовании, от повышения эффективности до реализации персонализированного обучения и образовательного равенства. (Источник: 36氪)
AI-короткометражки сталкиваются с техническими и коммерческими проблемами, производственный эффект не соответствует ожиданиям: Хотя инструменты ИИ обещают снизить затраты на производство короткометражек и сократить сроки, практики обнаружили, что AI-короткометражки сталкиваются со значительными техническими трудностями в обеспечении согласованности объектов, синхронизации губ и естественности языка кинокамеры, что приводит к тому, что многие работы больше похожи на «PPT-короткометражки». ИИ с трудом понимает сюрреалистические идеи, что ограничивает возможности для фэнтези и научной фантастики. В настоящее время технология ИИ больше подходит для создания коротких роликов, а не полноценных короткометражек, и коммерческие перспективы неясны. Крупные кинокомпании, такие как Bona Film Group и Huace Group, благодаря своим ресурсам имеют больше шансов на прорыв, в то время как большинство мелких создателей сталкиваются с высокими затратами на пробы и ошибки, а также с быстрой сменой технологий, что приводит к быстрому устареванию работ. (Источник: 36氪)
MSI представила AI PC с интегрированным суперчипом NVIDIA GB10, включающим 6144 ядер CUDA и 128 ГБ памяти LPDDR5X: MSI продемонстрировала свой EdgeExpert MS-C931 S, AI PC, оснащенный суперчипом NVIDIA GB10. Подтверждено, что чип имеет 6144 ядра CUDA и 128 ГБ памяти LPDDR5X. Это еще один производитель после ASUS, Dell и Lenovo, выпустивший персональный AI-компьютер на базе архитектуры NVIDIA DGX Spark. Появление таких продуктов знаменует постепенное распространение высокопроизводительных вычислительных мощностей ИИ на персональные и периферийные устройства, однако некоторые комментаторы отмечают, что их цена может затруднить конкуренцию с такими продуктами, как Mac Mini. (Источник: Reddit r/LocalLLaMA)
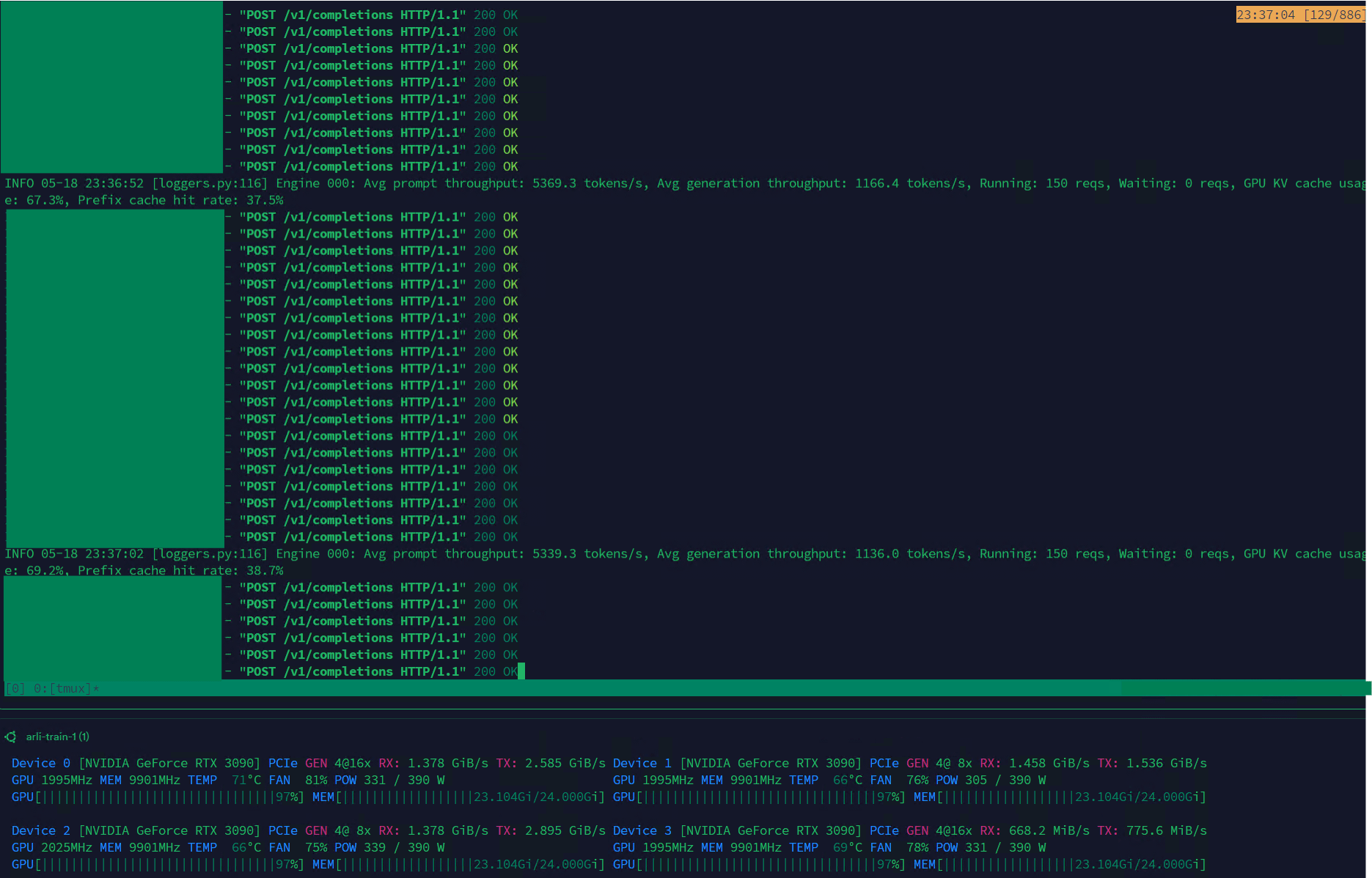
Qwen3-30B достигает высокой пропускной способности на VLLM, подходит для управления наборами данных: Модель Qwen3-30B-A3B на фреймворке VLLM и видеокартах RTX 3090s демонстрирует превосходную скорость вывода (5K т/с предварительное заполнение, 1K т/с генерация), что делает ее очень подходящей для таких задач, как фильтрация и управление наборами данных. Несмотря на возможное небольшое ухудшение по сравнению с QwQ, ее преимущество в скорости делает ее более практичной для обработки данных. Основная существующая проблема — чрезвычайно медленная скорость обучения, но в библиотеке Hugging Face Transformers уже есть PR, пытающийся решить эту проблему, и в будущем ожидается выпуск улучшенных наборов данных модели RpR на базе Qwen3-30B. (Источник: Reddit r/LocalLLaMA)
Bilibili открыла исходный код модели генерации анимационных видео Index-AniSora, поддерживающей различные стили аниме: Bilibili представила модель с открытым исходным кодом Index-AniSora, специально разработанную для генерации видео в стиле аниме, основанную на ее технологической структуре AniSora (принятой на IJCAI25). Эта модель может преобразовывать комиксы в анимацию одним щелчком мыши, поддерживая различные стили, такие как сериалы, китайская анимация, адаптации манги, VTuber и т. д. Система AniSora, создав набор данных из десятков миллионов высококачественных пар текст-видео, разработала единую структуру диффузионной генерации и ввела механизм пространственно-временного маскирования для точного контроля мимики и движений персонажей. Одновременно Bilibili разработала эталон для оценки анимационных видео и автоматизированную систему оценки, оптимизированную на основе VLM. Открытый исходный код будет включать AniSoraV1.0 (на базе CogVideoX-5B), AniSoraV2.0 (на базе Wan2.1-14B, с поддержкой обучения на Huawei 910B), а также инструменты для создания соответствующих наборов данных и оценки. (Источник: WeChat)

ByteDance выпустила визуально-языковую модель Seed1.5-VL, демонстрирующую превосходные результаты в мультимодальных задачах: ByteDance представила визуально-языковую модель Seed1.5-VL, состоящую из визуального кодировщика с 532 млн параметров и LLM типа «смесь экспертов» (MoE) с 20 млрд активных параметров. Эта модель достигла производительности SOTA в 38 из 60 общедоступных бенчмарков и превзошла ведущие системы, такие как OpenAI CUA и Claude 3.7, в задачах, ориентированных на агентов, таких как управление GUI и игровой процесс, демонстрируя мощные возможности мультимодального понимания и логического вывода. (Источник: WeChat)
Nous Research представила Psyche Network, реализующую распределенное предварительное обучение LLM с 40 млрд параметров: Nous Research выпустила Psyche Network, децентрализованную сеть для обучения, основанную на архитектуре DeepSeek V3 MLA, которая в первом же тесте провела предварительное обучение большой языковой модели с 40 млрд параметров. Сеть использует оптимизатор DisTrO и пользовательский сетевой стек peer-to-peer, объединяя распределенные по всему миру вычислительные мощности GPU, позволяя отдельным лицам и небольшим группам проводить обучение на одном H/DGX и запускать на GPU 3090. Этот шаг направлен на то, чтобы сломать монополию технологических гигантов на вычислительные мощности и сделать обучение крупномасштабных моделей более доступным. (Источник: 量子位)

🧰 Инструменты
Sim Studio: конструктор рабочих процессов для AI-агентов с открытым исходным кодом: Sim Studio — это легковесная платформа с открытым исходным кодом для создания рабочих процессов AI-агентов, предоставляющая интуитивно понятный интерфейс, с помощью которого пользователи могут быстро создавать и развертывать LLM-приложения, подключающие различные инструменты. Поддерживается облачная хостинговая версия и самостоятельный хостинг (рекомендуется среда Docker, поддержка локальных моделей, таких как Ollama). Технологический стек включает Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow и Turborepo. (Источник: GitHub Trending)

Cherry Studio: полнофункциональное десктопное LLM-приложение с открытым исходным кодом привлекает внимание: Cherry Studio — это десктопное LLM-приложение с открытым исходным кодом, объединяющее RAG, веб-поиск, доступ к локальным моделям (через Ollama, LM Studio) и облачным моделям (таким как Gemini, ChatGPT) и другие функции. Пользователи отмечают, что его поддержка и управление MCP (Multi-Control Protocol) превосходят Open WebUI и LibreChat, а также простоту установки и настройки. Приложение также поддерживает прямое подключение к базе знаний Obsidian. Хотя некоторые пользователи выражают обеспокоенность по поводу его происхождения, его всеобъемлющий набор функций делает его привлекательным выбором. (Источник: Reddit r/LocalLLaMA)

MLX-LM-LoRA: добавление LoRA к моделям MLX и поддержка различных методов обучения: Проект с открытым исходным кодом mlx-lm-lora позволяет пользователям интегрировать модули LoRA (Low-Rank Adaptation) в модели фреймворка Apple MLX. Проект не только поддерживает добавление LoRA, но и включает различные методы обучения для выравнивания, такие как ORPO, DPO, CPO, GRPO, что позволяет пользователям тонко настраивать модели в соответствии со своими потребностями, генерировать настраиваемые модули LoRA и применять их к предпочитаемым моделям MLX. (Источник: karminski3)
DeepDrone: открытый проект дрона, управляемого ИИ на базе Qwen: Разработчик создал проект дрона, управляемого ИИ, под названием DeepDrone на базе большой модели Qwen и выложил его в открытый доступ на HuggingFace и GitHub. Проект демонстрирует потенциал применения больших языковых моделей для автономного управления дронами, вызывая дискуссии об ИИ в автоматизации и потенциальных военных применениях. (Источник: karminski3)
Qwen Web Dev: создание и развертывание веб-сайта по одному запросу: Команда Alibaba Qwen объявила об усовершенствовании своего инструмента Qwen Web Dev, который позволяет пользователям генерировать веб-сайт всего лишь с помощью одного запроса (prompt) и развертывать его одним щелчком мыши. Инструмент призван снизить порог вхождения в веб-разработку, позволяя пользователям более удобно превращать идеи в реально доступные веб-сайты и делиться ими с миром. (Источник: Alibaba_Qwen, huybery)
SuperGo.AI: инструмент с единым интерфейсом, объединяющий восемь моделей LLM: Энтузиаст ИИ разработал инструмент под названием SuperGo.AI, который в одном интерфейсе объединяет восемь LLM с разными ролями (например, AI Super Brain, AI Imagination, AI Ethics, AI Universe и т.д.). Эти AI-роли могут воспринимать друг друга и взаимодействовать, а пользователи могут выбирать режимы «Creative», «Scientific» и «Mixed» для получения смешанных ответов. Инструмент предназначен для предоставления нового опыта совместной работы нескольких ИИ и в настоящее время не имеет платного доступа. (Источник: Reddit r/artificial)
Kokoro-JS: реализация неограниченного локального преобразования текста в речь (TTS): Kokoro-JS — это инструмент для преобразования текста в речь, работающий на 100% локально и на 100% с открытым исходным кодом, который реализуется путем загрузки AI-модели размером около 300 МБ в браузере. Вводимый пользователем текст не отправляется ни на какие серверы, что гарантирует конфиденциальность и доступность в автономном режиме. Инструмент предназначен для предоставления неограниченных функций TTS. (Источник: Reddit r/LocalLLaMA)
📚 Обучение
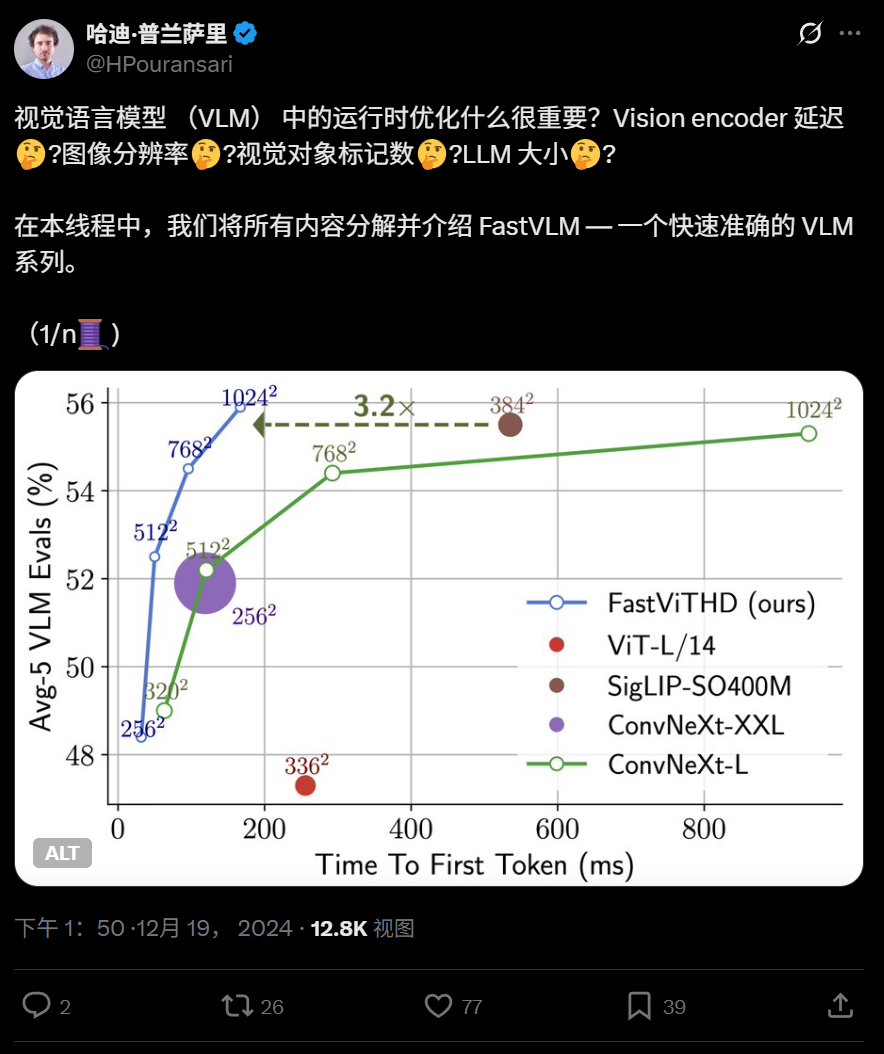
Apple открыла исходный код эффективной визуально-языковой модели FastVLM, оптимизированной для работы на конечных устройствах: Apple открыла исходный код FastVLM, визуально-языковой модели, специально разработанной для эффективной работы на устройствах, таких как iPhone. FastVLM представляет новый гибридный визуальный кодировщик FastViTHD, сочетающий сверточные слои с модулями Transformer, и использует многомасштабное объединение и методы понижающей дискретизации, что значительно сокращает количество визуальных токенов, необходимых для обработки изображений (в 16 раз меньше, чем у традиционного ViT), и ускоряет вывод первого токена в 85 раз. Модель совместима с основными LLM и уже предоставляет демонстрационное приложение для iOS/macOS на базе фреймворка MLX, подходящее для периферийных устройств и задач обработки изображений и текста в реальном времени. (Источник: WeChat)
Харбинский технологический институт и Пенсильванский университет предложили PointKAN, улучшающий анализ 3D-облаков точек на основе KAN: Исследовательские группы Харбинского технологического института (Шэньчжэнь) и Пенсильванского университета представили PointKAN, новую архитектуру для 3D-восприятия, основанную на сетях Колмогорова-Арнольда (KANs). PointKAN заменяет фиксированные функции активации в традиционных MLP на обучаемые функции активации, повышая способность к изучению сложных геометрических признаков. Она включает модуль геометрического аффинного преобразования и модуль параллельного извлечения локальных признаков. Команда также предложила версию PointKAN-elite, использующую структуру Efficient-KANs, которая применяет рациональные функции в качестве базисных функций и группирует общие параметры, что значительно снижает количество параметров и вычислительную сложность, демонстрируя при этом производительность SOTA в задачах классификации, частичной сегментации и обучения на малых выборках. (Источник: 量子位)

Питтсбургский университет предложил фреймворк PhyT2V для повышения физической реалистичности видео, генерируемых ИИ: Лаборатория интеллектуальных систем Питтсбургского университета разработала фреймворк PhyT2V, направленный на повышение физической согласованности контента, генерируемого моделями преобразования текста в видео (T2V). Этот метод не требует переобучения моделей или крупномасштабных внешних данных, а использует управляемое большими языковыми моделями (LLM) цепочечное рассуждение (CoT) и итеративный механизм самокоррекции для многоэтапного анализа и оптимизации текстовых подсказок на предмет соблюдения физических правил. PhyT2V способен выявлять физические правила, семантические несоответствия и генерировать исправленные подсказки, тем самым улучшая обобщающую способность основных моделей T2V (таких как CogVideoX, OpenSora) в реалистичных физических сценариях (твердые тела, жидкости, гравитация и т. д.), особенно в сценариях вне распределения, с повышением показателей физического здравого смысла (PC) и семантического соответствия (SA) до 2,3 раз. (Источник: WeChat)
Последние исследования LLM: мультимодальность, выравнивание во время тестирования, агенты, оптимизация RAG и др.: Еженедельные достижения в исследованиях LLM включают: 1. Вашингтонский университет предложил QALIGN, метод выравнивания во время тестирования, не требующий модификации модели или доступа к логитам, который достигает лучшего выравнивания при генерации текста с помощью MCMC. 2. UCLA предварительно обучила Clinical ModernBERT, расширив контекстную длину кодировщика в биомедицинской области до 8192 токенов. 3. Skoltech предложил легковесный, независимый от LLM метод адаптивного поиска RAG, основанный на внешней информации (популярность сущностей, тип вопроса). 4. PSU определила проблему автоматического определения причин сбоев в многоагентных системах LLM и разработала набор данных и методы оценки. 5. Фуданьский университет предложил многомерную структуру ограничений и автоматизированный процесс генерации инструкций для улучшения способности LLM следовать инструкциям. 6. a-m-team открыла исходный код AM-Thinking-v1 (32B), чьи возможности математического кодирования сопоставимы с DeepSeek-R1-671B. 7. Xiaomi выпустила MiMo-7B, которая благодаря оптимизации предварительного обучения и последующего обучения демонстрирует превосходные результаты в задачах логического вывода. 8. MiniMax представила авторегрессионную модель TTS MiniMax-Speech, поддерживающую клонирование тембра голоса для 32 языков без предварительного обучения. 9. ByteDance создала визуально-языковую модель Seed1.5-VL, демонстрирующую выдающиеся результаты в мультимодальных задачах и задачах, ориентированных на агентов. 10. Первая в мире языковая модель с 32 млрд параметров INTELLECT-2 реализовала распределенное обучение с подкреплением, предложив фреймворк PRIME-RL. (Источник: WeChat)
Семинары AAAI 2025 посвящены нейронному выводу, математическим открытиям и ускорению науки и инженерии с помощью ИИ: Семинары AAAI 2025 были посвящены применению ИИ в научных областях. В частности, на семинаре «Нейронный вывод и математические открытия» было подчеркнуто, что нейронные сети типа «черный ящик» могут использоваться для выдвижения математических гипотез и генерации новых геометрических фигур, но также было отмечено, что они не могут достичь символического логического вывода, и была предложена междисциплинарная методология. Другой семинар «ИИ для ускорения науки и инженерии» (четвертый по счету, посвященный ИИ в биологических науках) сосредоточился на таких темах, как базовые модели для разработки терапевтических средств, генеративные модели для открытия лекарств, разработка антител в замкнутом цикле в лаборатории, глубокое обучение в геномике и причинно-следственный вывод в биологических приложениях, а также обсуждались проблемы и возможности генеративных моделей в биологических науках. (Источник: aihub.org)

Google и Anthropic разошлись во мнениях по поводу исследований интерпретируемости ИИ, механистическая интерпретируемость сталкивается с проблемами: Характер «черного ящика» ИИ ограничивает его применение во многих ключевых областях. Google DeepMind недавно объявила о снижении приоритета исследований «механистической интерпретируемости», считая, что обратная инженерия внутренних механизмов ИИ с помощью таких методов, как разреженные автоэнкодеры (SAE), сталкивается с многочисленными проблемами, такими как отсутствие объективного эталона, неполное покрытие концепций, искажение признаков и т. д., а существующие технологии SAE не смогли выявить необходимые «концепции» в ключевых задачах. В то же время CEO Anthropic Дарио Амодеи выступает за усиление исследований в этой области и выражает оптимизм по поводу достижения «МРТ для ИИ» в ближайшие 5-10 лет. Этот спор подчеркивает глубинные проблемы понимания и контроля поведения ИИ. (Источник: 36氪)

Пекинский университет/StepStar/Lightelligence предложили InfiniteHBD: архитектуру нового поколения для доменов высокой пропускной способности GPU, снижающую затраты и повышающую эффективность: В ответ на ограничения существующих архитектур доменов высокой пропускной способности (HBD) в масштабируемости, стоимости и отказоустойчивости, команды Пекинского университета, StepStar и Lightelligence предложили архитектуру InfiniteHBD. Эта архитектура центрирована вокруг оптического коммутационного модуля (OCSTrx) и, благодаря встраиванию недорогой возможности оптической коммутации (OCS) в оптоэлектронные преобразовательные модули, реализует динамически реконфигурируемую топологию K-Hop Ring масштаба дата-центра и изоляцию сбоев на уровне узлов. Стоимость единицы InfiniteHBD составляет всего 31% от NVL-72, коэффициент потерь GPU близок к нулю, а MFU (использование FLOPs моделью) по сравнению с NVIDIA DGX увеличено до 3,37 раз, что предоставляет более оптимальное решение для крупномасштабного обучения больших моделей. Статья принята на SIGCOMM 2025. (Источник: WeChat)

OceanBase выпустила PowerRAG, полностью охватывая ИИ и создавая интегрированную платформу данных Data×AI: На конференции разработчиков OceanBase представила прикладной продукт для ИИ PowerRAG, предназначенный для предоставления готовых к использованию возможностей разработки RAG, объединяя данные, платформы, интерфейсы и прикладной уровень. Технический директор Ян Чуаньхуэй подробно изложил AI-стратегию OceanBase: создание возможностей Data×AI, эволюция от интегрированной базы данных к интегрированной платформе данных. OceanBase усилит векторные возможности, улучшит гибридный поиск, реализует динамическое обновление хранилища корпоративных знаний, углубит интеграцию с последующим обучением и тонкой настройкой моделей, а также уже адаптирована для основных платформ агентов, таких как Dify, FastGPT, и протокола MCP. Ее векторная производительность показала лидирующие результаты в тесте VectorDBBench, а благодаря алгоритму квантования BQ значительно снижены требования к памяти. (Источник: WeChat)

💼 Бизнес
Фонды, связанные с Shanghai Guotou, инвестируют в компании по производству AI-чипов CorePhotonics, Enflame Technology, Biren Technology и др.: Shanghai State-owned Capital Operation Co., Ltd. (Shanghai Guotou) недавно подписала инвестиционные соглашения с тремя полупроводниковыми компаниями: CorePhotonics, Enflame Technology и Biren Technology. Ранее ее материнский фонд AI уже возглавил пред-IPO раунд финансирования Biren Technology. Shanghai Guotou заявила, что будет активно инвестировать в такие направления, как базовые модели, вычислительные чипы, воплощенный интеллект и т.д. CorePhotonics специализируется на полупроводниковых IP, особенно на технологии Chiplet; ее основатель Цзэн Кэцян ранее был вице-президентом Synopsys China. Enflame Technology и Biren Technology являются компаниями-разработчиками GPU-чипов. Этот шаг демонстрирует фокус Shanghai Guotou на верхних эшелонах цепочки поставок ИИ, особенно в области вычислительных чипов. (Источник: 36氪)
Sakana AI и банк Mitsubishi UFJ заключили всеобъемлющее партнерство для разработки специализированного банковского ИИ: Японский AI-стартап Sakana AI объявил о подписании многолетнего партнерского соглашения с банком Mitsubishi UFJ (MUFG). Sakana AI разработает для MUFG AI-агентов, специально предназначенных для банковских операций, с целью продвижения трансформации банковского дела и практического применения ИИ. Одновременно соучредитель и главный операционный директор Sakana AI Рэн Ито станет консультантом MUFG, помогая банку в реализации его AI-стратегии. Это сотрудничество знаменует важный шаг Sakana AI в применении передовых AI-технологий для решения конкретных задач японского финансового сектора. (Источник: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

Сооснователь 01.AI Гу Сюэмэй ушла для создания собственного стартапа, бизнес-фокус компании смещается на B2B: Гу Сюэмэй, сооснователь 01.AI, отвечавшая за предварительное обучение моделей и C2C-продукты, ушла несколько месяцев назад и в настоящее время готовится к запуску собственного стартапа. 01.AI подтвердила этот факт и поблагодарила ее за вклад. С 2025 года бизнес-фокус 01.AI сместился с AI ToC-приложений и API моделей на B2B-сценарии, такие как цифровые люди, кастомизация и развертывание моделей. Ее C2C-продукты, такие как китайская версия офисного инструмента «Wan Zhi», прекратили работу из-за недостаточного количества пользователей, а коммерциализация зарубежного продукта для ролевых игр Mona также оказалась неудачной. Ранее сооснователь Дай Цзунхун также ушел для создания собственного стартапа. (Источник: 36氪)

🌟 Сообщество
Детектирование AIGC в научных работах вызывает споры, точность подвергается сомнению, выпуск студентов под угрозой: В этом году многие вузы ввели проверку на AIGC как часть процесса рецензирования выпускных работ, чтобы предотвратить злоупотребление студентами ИИ при написании. Однако эта мера вызвала широкие споры. Студенты сообщают, что написанный ими контент часто ошибочно определяется как сгенерированный ИИ, а после редактирования с помощью ИИ подозрительность наоборот возрастает. Даже тесты показывают, что «Предисловие к павильону Тэнван» имеет подозрительность генерации ИИ до 99,2%. Сами инструменты обнаружения AIGC также работают на ИИ, их принцип заключается в анализе языковых особенностей текста и сравнении с паттернами письма ИИ, но их точность вызывает сомнения, ранний инструмент OpenAI имел точность всего 26%. Эта неопределенность не только создает проблемы и дополнительные расходы для студентов (результаты разных сайтов для проверки различаются, услуги по снижению уникальности платные), но и вызывает размышления о сущности инструментов ИИ: ИИ имитирует человеческое письмо, а затем ИИ используется для проверки, похож ли человеческий текст на ИИ, что само по себе содержит логический парадокс. (Источник: 36氪)

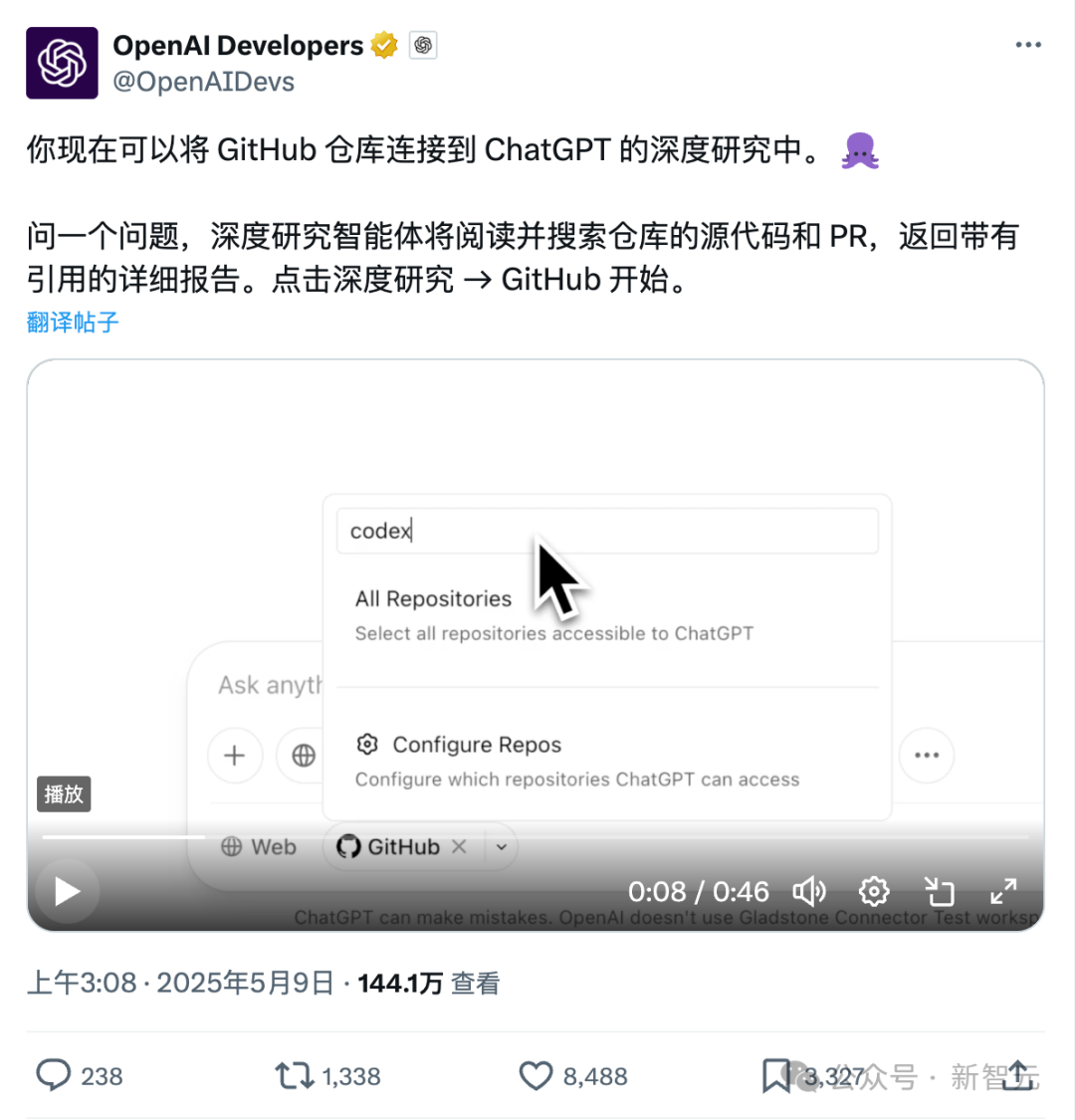
Новая функция ChatGPT для прямого подключения к Github: глубокое исследование репозиториев кода и профессиональной документации: Недавно запущенная функция Deep Research в ChatGPT добавила возможность прямого подключения к репозиториям Github, позволяя пользователям авторизовать ChatGPT для доступа к их публичным или частным репозиториям для глубокого анализа кода, обобщения архитектуры функций, идентификации технологического стека, оценки качества кода и анализа применимости проекта. Эта функция не ограничивается кодом; пользователи могут загружать PDF, Word и другие типы документов в репозитории Github, используя ChatGPT для глубокого исследования материалов в определенной области, что эквивалентно реализации комбинации RAG+MCP с ограниченной областью действия. Функция в настоящее время доступна пользователям Plus и, благодаря ограничению области исследования, обещает повысить профессионализм и точность исследовательских отчетов, а также уменьшить количество «галлюцинаций». (Источник: 36氪)
Конкуренция на рынке AI Agent обостряется, Manus полностью открывает регистрацию, крупные компании, такие как ByteDance и Baidu, выходят на рынок: Manus, известный как «всемогущий агент», 12 мая объявил о полной открытой регистрации, пользователи могут получить доступ без ожидания. В то же время на рынке ходят слухи, что Manus проводит новый раунд финансирования с оценкой в 1,5 миллиарда долларов. С момента своего запуска в марте Manus вызвал бум проектов типа Agent, но также столкнулся с падением трафика и появлением конкурентов. ByteDance запустила Coze Space, Baidu — «Miaoda» и «Xinxiang», а дизайнерский агент Lovart также начал тестирование. Рынок агентов переходит от ранней проверки концепции к всесторонней конкуренции в области функциональности продуктов, бизнес-моделей и роста пользователей. (Источник: 36氪)
AI-ассистенты кодирования меняют рабочий процесс разработчиков, повышая производительность, но требуют осторожности из-за риска чрезмерной зависимости: Пользователь Reddit поделился тем, как AI-ассистенты кодирования значительно изменили его опыт программирования, особенно при работе с крупными устаревшими проектами и понимании сложного кода. AI-инструменты могут построчно объяснять код, предлагать решения, выделять потенциальные проблемы, обобщать файлы, находить фрагменты и генерировать комментарии, как будто имеешь круглосуточного эксперта-наставника. В комментариях отмечается, что ИИ может выполнять рутинное кодирование, повышать эффективность, предлагать новые подходы, добавлять комментарии и даже помогать разработчикам выполнять задачи, выходящие за рамки их возможностей, сокращая дни работы до нескольких часов. Однако это также вызывает размышления об эволюции навыков разработчиков и зависимости от AI-инструментов. (Источник: Reddit r/artificial)
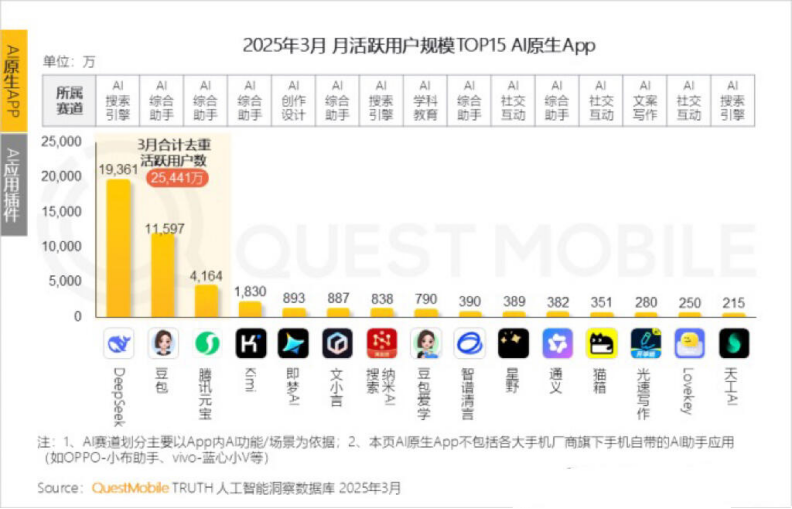
Ежемесячная активная аудитория Kimi снижается, Moonshot AI ищет прорывы в нишевых областях и социальную трансформацию: Ежемесячная активная аудитория Kimi Chat от Moonshot AI, по данным QuestMobile, снизилась с 36 миллионов в октябре прошлого года до 18,2 миллиона в марте этого года, опустившись на четвертое место. Для повышения удержания пользователей Kimi переходит от универсальной большой модели к освоению нишевых областей, например, сотрудничает с Caixin Media для улучшения качества поиска финансового контента, развивает AI-поиск в медицинской сфере и внедряет видеоконтент с Bilibili. Одновременно Kimi запускает челленджи на Xiaohongshu, пытаясь через социальные платформы охватить больше C2C-пользователей. Ее пользовательский интерфейс также меняется в сторону мультимодальности, сходства с Doubao и ориентации на сообщество. Столкнувшись с конкурентами, такими как DeepSeek, и выходом крупных компаний на рынок AI-приложений, технологическое лидерство Kimi подвергается удару, коммерческое давление растет, и компания активно ищет новые точки роста. (Источник: 36氪)
Обсуждение того, должен ли ИИ называть себя от первого лица: Пользователь Reddit инициировал обсуждение, считая, что использование ChatGPT и другими LLM местоимений «я» или «ты» для обращения к себе и пользователям может быть неуместным, поскольку по своей сути они являются «вещами», а не «людьми». Предлагается использовать третье лицо, например, «ChatGPT поможет вам…», чтобы избежать создания у пользователей впечатления, что это персонифицированное существо, что может привести к потенциальным опасностям или этическим проблемам. В комментариях некоторые считают, что третье лицо, наоборот, подразумевает самосознание, другие же находят третье лицо глупым и неприятным. Это обсуждение отражает размышления пользователей о позиционировании идентичности ИИ и способах взаимодействия человека и машины. (Источник: Reddit r/ArtificialInteligence)
💡 Прочее
MIT экстренно отозвал широко обсуждаемую AI-статью, указав на сомнения в достоверности данных и исследования: Массачусетский технологический институт (MIT) отозвал статью «Искусственный интеллект, научные открытия и инновации в продуктах», написанную докторантом экономического факультета Айданом Тонер-Роджерсом. Статья ранее привлекла большое внимание благодаря утверждению, что AI-инструменты могут значительно повысить инновационную эффективность ведущих ученых, но могут усугубить «разрыв между богатыми и бедными» в науке и снизить уровень счастья обычных исследователей, и получила одобрение нобелевских лауреатов и других известных профессоров. MIT заявил, что после получения сообщения о нарушении исследовательской этики и проведения внутреннего расследования, институт утратил доверие к источнику, надежности, достоверности данных и подлинности исследования, и потребовал от arXiv и «Quarterly Journal of Economics» удалить статью. Автор покинул MIT, а связанные с ним профессора также выступили с заявлениями, отрицающими свою причастность. Сообщается, что во время расследования автор приобрел поддельный домен, чтобы выдавать себя за представителя крупной компании по электронной почте, был разоблачен и привлечен к ответственности. (Источник: 36氪)

Изображения, сгенерированные ИИ, используются для интернет-мошенничества, вызывая настороженность пользователей: Пользователь Reddit поделился примерами использования изображений людей, сгенерированных ИИ, для продвижения товаров в социальных сетях, таких как Facebook. На этих изображениях люди и сцены часто содержат нелогичные детали (например, модель странным образом входит и выходит из ящика, на заднем плане появляются нерелевантные персонажи), но согласованность образов персонажей довольно высока. Комментаторы отметили, что такой контент, сгенерированный ИИ, уже используется для мошенничества, и призвали пользователей быть бдительными. Блогеры, такие как Pleasant Green, также создавали видео, разоблачающие подобные схемы. (Источник: Reddit r/ChatGPT)
Обсуждение имитации стиля и извлечения промптов из изображений, сгенерированных ИИ: Пользователи обсуждали, как заставить AI-модели (например, DALL-E 3) имитировать определенный художественный стиль (например, стиль Pixar в сочетании со стилем Designer Toy для портрета Сальвадора Дали) при создании портретов персонажей, и поделились подробными промптами, подчеркнув особенности персонажа, фон, освещение и тени, а также ключевые концепции (например, тень как ментальная проекция). Кроме того, другие пользователи предоставили шаблон промпта для извлечения параметров стиля из изображения и вывода их в формате JSON, с целью помочь пользователям реконструировать стиль изображения, хотя точное воспроизведение все еще затруднительно. (Источник: dotey, dotey)
