
Ключевые слова:DeepMind, AlphaEvolve, OceanBase, PowerRAG, Meta, Llama 4 Behemoth, Qwen, WorldPM-72B, Продвинутые алгоритмы ИИ-дизайна, Стратегия Data×AI, Разработка приложений RAG, Крупномасштабные модели предпочтений, Прорыв в алгоритмах матричного умножения
# 🔥 В центре внимания
**DeepMind представляет AlphaEvolve: ИИ совершает исторический прорыв в разработке продвинутых алгоритмов**: DeepMind анонсировала AlphaEvolve, эволюционного агента для кодирования на базе Gemini, способного разрабатывать и оптимизировать алгоритмы с нуля. В ходе тестирования на 50 открытых задачах в областях математики, геометрии и комбинаторики AlphaEvolve в 75% случаев заново открыл лучшие известные человечеству решения, а в 20% случаев улучшил их. Что еще более примечательно, он обнаружил алгоритм умножения матриц быстрее классического алгоритма Strassen (первый прорыв за 56 лет), а также способен улучшать проектирование схем ИИ-чипов и собственные алгоритмы обучения. Это знаменует собой важный шаг в автоматизации научных открытий и самоэволюции ИИ, предвещая, что ИИ может ускорить решение сложных проблем, от проектирования аппаратного обеспечения до лечения заболеваний (Источник: [YouTube — Two Minute Papers](https://www.youtube.com/watch?v=T0eWBlFhFzc))
**На конференции разработчиков OceanBase анонсирована стратегия Data×AI и первый продукт RAG – PowerRAG**: На третьей конференции разработчиков OceanBase подробно изложила свою стратегию Data×AI и представила ориентированный на ИИ продукт PowerRAG. Этот продукт предоставляет готовые возможности для разработки приложений RAG (Retrieval Augmented Generation – генерация, дополненная поиском), призванные упростить создание ИИ-приложений, таких как базы знаний на основе документов и интеллектуальные диалоговые системы. Технический директор OceanBase Ян Чуаньхуэй заявил, что компания эволюционирует от интегрированной базы данных к интегрированной платформе данных для поддержки смешанных нагрузок TP/AP/AI и векторных баз данных. Технический директор Ant Group Хэ Чжэнъюй также заявил о поддержке практики OceanBase в ключевых сценариях ИИ в Ant Group. OceanBase также продемонстрировала свою передовую производительность векторных операций и возможности сжатия для JSON, стремясь решить проблемы данных в эпоху ИИ (Источник: [量子位](https://www.qbitai.com/2025/05/284444.html))
**Массачусетский технологический институт больше не поддерживает исследовательскую работу по ИИ одного из своих студентов**: По сообщению Wall Street Journal, Массачусетский технологический институт (MIT) публично заявил, что больше не поддерживает исследовательскую работу по ИИ, опубликованную одним из его студентов. Такой шаг обычно означает, что возникли серьезные проблемы с достоверностью, методологией или этическими аспектами исследования, достаточные для того, чтобы учреждение отозвало свою поддержку. Подобные инциденты в академических кругах довольно редки, особенно в такой заметной области, как ИИ, и могут повлиять на репутацию и направление исследований соответствующих ученых, а также вызвать дискуссии об академической честности и качестве исследований. Конкретные причины и детали работы пока не раскрыты (Источник: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1konws0/mit_says_it_no_longer_stands_behind_students_ai/))
# 🎯 Динамика
**Сообщается, что Meta откладывает выпуск Llama 4 Behemoth, члены команды основателей уходят**: В социальных сетях и сообществе Reddit появились сообщения о том, что Meta Platforms отложила выпуск своей следующей большой языковой модели Llama 4 Behemoth. Одновременно, по слухам, 11 из 14 первоначальных исследователей, участвовавших в разработке Llama v1, покинули компанию. Эта новость вызвала обеспокоенность по поводу стабильности команды Meta AI и будущих темпов разработки больших моделей. Если это правда, это может повлиять на позиции Meta в острой конкурентной борьбе в области больших моделей (Источник: [Reddit r/artificial](https://preview.redd.it/hhsmnxxlxa1f1.png?auto=webp&s=ae32abf1d8ed036829161d716143b0d6284517b2), [scaling01](https://x.com/scaling01/status/1923715027653025861))
**Qwen представляет WorldPM-72B, крупномасштабную модель предпочтений**: Команда Qwen из Alibaba выпустила WorldPM-72B, модель предпочтений с 72,8 миллиардами параметров. Эта модель была предварительно обучена на 15 миллионах парных сравнений, сделанных людьми, для изучения унифицированного представления человеческих предпочтений. Она в основном используется как модель вознаграждения для оценки качества ответов-кандидатов, обеспечивая поддержку для RLHF (обучение с подкреплением на основе обратной связи от человека) и ранжирования контента, с целью улучшения соответствия модели человеческим ценностям. Этот шаг знаменует собой эмпирическое подтверждение масштабируемого обучения предпочтениям, улучшая как объективные предпочтения в знаниях, так и субъективные стили оценки (Источник: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kompbk/new_new_qwen/))
**Технология Pivotal Token Search (PTS) с открытым исходным кодом оптимизирует эффективность обучения LLM**: Предложена и опубликована с открытым исходным кодом новая технология под названием Pivotal Token Search (PTS), которая направлена на оптимизацию обучения с прямой оптимизацией предпочтений (DPO) путем идентификации «ключевых точек принятия решений» (т.е. Pivotal Tokens) в процессе генерации языковой моделью. Основная идея заключается в том, что при генерации ответа моделью лишь несколько токенов играют решающую роль в успехе или неудаче конечного результата. Создавая пары DPO для этих ключевых точек, можно достичь более эффективного обучения и лучших результатов. Проект вдохновлен статьей Microsoft Phi-4, и уже опубликованы соответствующий код, наборы данных и предварительно обученные модели (Источник: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1komx9e/p_pivotal_token_search_pts_optimizing_llms_by/))
**ByteDance представляет DanceGRPO: унифицированный фреймворк обучения с подкреплением для улучшения визуальной генерации**: ByteDance выпустила DanceGRPO, унифицированный фреймворк обучения с подкреплением (RL), специально разработанный для визуальной генерации с использованием диффузионных моделей и скорректированных потоков (rectified flows). Этот фреймворк направлен на повышение качества и эффекта синтеза изображений и видео с помощью обучения с подкреплением, предлагая новый технологический путь в области создания визуального контента (Источник: [_akhaliq](https://x.com/_akhaliq/status/1923736714641584254))
**Google представляет LightLab: управление источниками света на изображениях с помощью диффузионных моделей**: Исследователи Google продемонстрировали проект LightLab, технологию, позволяющую точно управлять источниками света на изображениях с помощью диффузионных моделей. Путем тонкой настройки диффузионных моделей на небольших, тщательно отобранных наборах данных, LightLab достигает эффективного управления световыми эффектами на генерируемых изображениях, открывая новые возможности для редактирования изображений и создания контента (Источник: [_akhaliq](https://x.com/_akhaliq/status/1923849291514233322), [_rockt](https://x.com/_rockt/status/1923862256451793289))
**Функция долговременной памяти ИИ вызывает размышления об архитектурных и экономических последствиях**: Внедрение OpenAI функции долговременной памяти в ChatGPT рассматривается как переход ИИ-систем от моделей ответа без состояния к моделям непрерывного, контекстно-обогащенного обслуживания. Это изменение не только улучшает пользовательский опыт, но и создает новую вычислительную нагрузку (например, хранение памяти, извлечение, безопасность и поддержание согласованности), что может привести к «длинному хвосту» вычислительных потребностей. Экономически затраты на поддержание персонализированного контекста могут быть переложены на разработчиков и пользователей через цены API, уровни подписки и т.д., одновременно усиливая эффект привязки к экосистеме (Источник: [Reddit r/deeplearning](https://www.reddit.com/r/deeplearning/comments/1kon0oo/memory_as_strategy_how_longterm_context_reshapes/))
**Anthropic, возможно, выпустит новую модель Claude в ответ на конкуренцию**: В социальных сетях и сообществе Reddit ходят слухи, что Anthropic может в ближайшее время выпустить новую модель Claude (возможно, Claude 3.8). Предполагается, что этот шаг предпринят в ответ на быстрый прогресс конкурентов, таких как Google, в области возможностей кодирования ИИ-моделей (например, Gemini), чтобы сохранить конкурентоспособность серии моделей Claude на рынке (Источник: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1kols5s/will_we_see_anthropic_release_a_new_claude_model/))
# 🧰 Инструменты
**ByteDance публикует исходный код FlowGram.AI: движок для создания узловых процессов**: ByteDance представила FlowGram.AI, движок для построения процессов на основе узлов, призванный помочь разработчикам быстро создавать рабочие процессы с фиксированной или свободной компоновкой. Он предоставляет набор лучших практик взаимодействия, особенно подходящий для создания визуализированных рабочих процессов с четкими входами и выходами, и фокусируется на том, как расширить возможности рабочих процессов с помощью ИИ (Источник: [GitHub Trending](https://github.com/bytedance/flowgram.ai))
**CopilotKit: React UI и инфраструктура для создания глубоко интегрированных ИИ-помощников**: CopilotKit – это проект с открытым исходным кодом, предоставляющий компоненты React UI и бэкенд-инфраструктуру для создания внутри приложений AI Copilots, AI чат-ботов и AI агентов. Он поддерживает фронтенд RAG, интеграцию с базами знаний, исполняемые функции на фронтенде и CoAgents, интегрированные с LangGraph, с целью помочь разработчикам легко реализовывать функции ИИ для глубокого взаимодействия с пользователями (Источник: [GitHub Trending](https://github.com/CopilotKit/CopilotKit))
**AI Runner: Локальный офлайн-движок для ИИ-выводов с поддержкой различных приложений**: Capsize-Games выпустила AI Runner, движок для ИИ-выводов, поддерживающий работу в офлайн-режиме. Он способен обрабатывать создание произведений искусства (Stable Diffusion, ControlNet), голосовые диалоги в реальном времени (OpenVoice, SpeechT5, Whisper), LLM чат-ботов и автоматизированные рабочие процессы. Этот инструмент ориентирован на локальное выполнение и призван предоставить разработчикам и создателям набор ИИ-инструментов, не требующих внешних API (Источник: [GitHub Trending](https://github.com/Capsize-Games/airunner))
**LangChain представляет учебное пособие по Text-to-SQL**: LangChain опубликовал учебное пособие, демонстрирующее, как использовать LangChain, модель DeepSeek от Ollama и Streamlit для создания мощного преобразователя естественного языка в SQL. Этот инструмент предназначен для создания интуитивно понятного интерфейса, способного автоматически преобразовывать разговорные запросы в исполняемые SQL-инструкции для баз данных, упрощая процесс запроса и анализа данных (Источник: [LangChainAI](https://x.com/LangChainAI/status/1923770538528329826), [hwchase17](https://x.com/hwchase17/status/1923785900535812326))
**LangChain выпускает интеллектуального агента для суммирования ссылок в Telegram**: Сообщество LangChain поделилось интеллектуальным ботом для Telegram, созданным на основе LangGraph. Этот бот способен непосредственно в чате суммировать содержимое веб-страниц, PDF-документов и постов в социальных сетях, интеллектуально обрабатывая различные типы контента и предоставляя краткую сводную информацию, повышая эффективность получения информации (Источник: [LangChainAI](https://x.com/LangChainAI/status/1923785679928004954))
**LangChain интегрируется с Box для автоматического сопоставления документов**: LangChain опубликовал учебное пособие по интеграции с Box, демонстрирующее, как использовать AI Agents Toolkit от LangChain и сервер MCP для создания интеллектуальных агентов, автоматически выполняющих сопоставление счетов-фактур с заказами на закупку в рабочих процессах закупок. Эта интеграция направлена на повышение уровня автоматизации и эффективности обработки корпоративных документов (Источник: [LangChainAI](https://x.com/LangChainAI/status/1923800687860748597), [hwchase17](https://x.com/hwchase17/status/1923812839245877559))
**Gradio упрощает создание серверов MCP**: Блог Hugging Face представил руководство по созданию сервера MCP (Multi-Copilot Platform) с помощью Gradio всего за несколько строк кода на Python. Это позволяет разработчикам более удобно создавать и развертывать платформы для совместной работы нескольких агентов, снижая порог входа для разработки подобных приложений (Источник: [dl_weekly](https://x.com/dl_weekly/status/1923726779375644809))
**Replicate упрощает вызов моделей, адаптируясь к редакторам кода ИИ, таким как Codex**: Платформа Replicate обновлена, чтобы ее редакторы кода ИИ и LLM (такие как Codex) могли более удобно использовать любую модель на платформе. Новые функции включают копирование страницы в markdown, прямую загрузку в Claude или ChatGPT, а также предоставление страницы llms.txt для любой модели, что упрощает интеграцию и вызов моделей (Источник: [bfirsh](https://x.com/bfirsh/status/1923812545124872411))
**chatllm.cpp добавляет поддержку моделей Orpheus-TTS**: Проект с открытым исходным кодом `chatllm.cpp` теперь поддерживает семейство моделей синтеза речи Orpheus-TTS, например, orpheus-tts-en-3b (3,3 миллиарда параметров). Пользователи могут с помощью этого инструмента запускать эти TTS-модели локально для преобразования текста в речь (Источник: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kony6o/orpheustts_is_now_supported_by_chatllmcpp/))
**auto-openwebui: Bash-скрипт для автоматического развертывания Open WebUI**: Разработчик создал Bash-скрипт под названием auto-openwebui для автоматического запуска Open WebUI через Docker в системах Linux с интеграцией Ollama и Cloudflare. Скрипт поддерживает GPU AMD и NVIDIA, упрощая процесс развертывания Open WebUI (Источник: [Reddit r/OpenWebUI](https://www.reddit.com/r/OpenWebUI/comments/1kopl98/autoopenwebui_i_made_a_bash_script_to_automate/))
**Проект GLaDOS обновляет модель ASR до Nemo Parakeet 0.6B**: Проект голосового помощника GLaDOS обновил свою модель автоматического распознавания речи (ASR) до Nemo Parakeet 0.6B от Nvidia. Эта модель демонстрирует отличные результаты в рейтинге ASR Hugging Face, сочетая высокую точность и скорость обработки. В проекте был переработан код предварительной обработки аудио и вывода TDT/FastConformer CTC для минимизации зависимостей (Источник: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kosbyy/glados_has_been_updated_for_parakeet_06b/))
**Runway запускает References API и плагин для Figma, реализуя слияние изображений**: References API от Runway теперь можно использовать для создания плагинов, например, плагина для Figma, который может объединять любые два изображения так, как этого хочет пользователь. Код плагина опубликован с открытым исходным кодом, демонстрируя возможности Runway в области программируемого редактирования и создания изображений (Источник: [c_valenzuelab](https://x.com/c_valenzuelab/status/1923762194254070008))
**Codex демонстрирует высокую эффективность в задачах миграции кода**: Разработчик поделился опытом использования Codex для миграции устаревшего проекта с Python 2.7 на 3.11 и обновления Django 1.x до 5.0, весь процесс занял всего 12 минут. Это демонстрирует огромный потенциал инструментов ИИ для работы с кодом в решении сложных задач обновления и миграции кода, что позволяет значительно сэкономить время разработки (Источник: [gdb](https://x.com/gdb/status/1923802002582319516))
**Gyroscope: повышение производительности ИИ-моделей с помощью промпт-инжиниринга**: Пользователь поделился методом промпт-инжиниринга под названием «Gyroscope», утверждая, что копирование и вставка его в ИИ на основе чата (например, Claude 3.7 Sonnet и ChatGPT 4o) может повысить их производительность в плане безопасности и интеллекта на 30-50%. Результаты тестов показали значительные улучшения в структурированном рассуждении, подотчетности и отслеживаемости (Источник: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1komvkz/diy_free_upgrade_for_your_ai/))
**Claude помогает человеку без опыта программирования завершить проект по написанию кода**: Пользователь Reddit поделился тем, как он, не имея никакого опыта программирования, за один день с помощью Claude AI успешно создал полнофункциональный генератор текстового общения. Этот случай подчеркивает потенциал больших языковых моделей в содействии программированию и снижении порога входа в эту область, позволяя непрофессионалам участвовать в разработке программного обеспечения (Источник: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koouc5/literally_spent_all_day_on_having_claude_code_this/))
# 📚 Обучение
**Awesome ChatGPT Prompts: репозиторий тщательно подобранных промптов для ChatGPT и других LLM**: Популярный проект на GitHub awesome-chatgpt-prompts собирает большое количество тщательно разработанных промптов для ChatGPT и других LLM (таких как Claude, Gemini, Llama, Mistral). Эти промпты охватывают множество ролевых игр и сценариев задач, призванных помочь пользователям лучше взаимодействовать с ИИ-моделями и повысить качество вывода. Проект также предоставляет веб-сайт prompts.chat и версию набора данных на Hugging Face (Источник: [GitHub Trending](https://github.com/f/awesome-chatgpt-prompts))
**Lilian Weng рассуждает о «Почему мы думаем»: важность предоставления моделям большего времени на «обдумывание»**: Исследователь OpenAI Lilian Weng опубликовала статью в блоге «Why we think», в которой рассматривается эффективность предоставления моделям большего времени на «обдумывание» перед предсказанием с помощью интеллектуального декодирования, цепочки рассуждений, латентного мышления и т.д. для разблокировки следующего уровня интеллекта. В статье подробно анализируются различные стратегии улучшения способностей моделей к рассуждению и планированию (Источник: [lilianweng](https://x.com/lilianweng/status/1923757799198294317), [andrew_n_carr](https://x.com/andrew_n_carr/status/1923808008641171645))
**Предварительно скомпилированные Wheel-пакеты Flash Attention упрощают установку**: Сообщество предоставило предварительно скомпилированные wheel-пакеты для Flash Attention, призванные решить проблемы, с которыми пользователи могут столкнуться при установке Flash Attention, такие как длительное время компиляции. Это помогает разработчикам быстрее настраивать и использовать среды глубокого обучения, включающие оптимизации Flash Attention (Источник: [andersonbcdefg](https://x.com/andersonbcdefg/status/1923774139661418823))
**Maitrix выпускает Voila: семейство больших рече-языковых базовых моделей**: Команда Maitrix представила Voila, новую серию больших рече-языковых базовых моделей. Эта серия моделей призвана поднять опыт взаимодействия человека с машиной на новый уровень, фокусируясь на улучшении понимания и генерации речи, а также обеспечивая поддержку для более естественных приложений голосового взаимодействия (Источник: [dl_weekly](https://x.com/dl_weekly/status/1923770946264986048))
**Глубокое понимание механизма Flash Attention становится предметом внимания**: В сообществе разработчиков обсуждается изучение и понимание основного механизма Flash Attention («что делает Flash Attention быстрым»). Flash Attention, как эффективный механизм внимания, имеет решающее значение для обучения и вывода больших моделей Transformer, и его принципы и детали реализации привлекают внимание (Источник: [nrehiew_](https://x.com/nrehiew_/status/1923782090052559109))
# 🌟 Сообщество
**Цукерберг лично настраивает Llama-5 становится горячей темой, отток членов команды Meta AI привлекает внимание**: В социальных сетях распространилась шуточная картинка, на которой Цукерберг лично устанавливает гиперпараметры для обучения Llama-5 после ухода сотрудников, что вызвало дискуссии об оттоке талантов из команды Meta AI и стиле руководства Цукерберга, предполагающем личное участие. Это отражает внимание сообщества к будущему направлению развития Meta AI и внутренней динамике (Источник: [scaling01](https://x.com/scaling01/status/1923715027653025861), [scaling01](https://x.com/scaling01/status/1923802857058247136))
**ИИ Дарт Вейдер в «Fortnite» используется не по назначению, динамически генерируемые диалоги ставят проблемы с ограничениями**: Обсуждается явление, когда игроки используют ИИ-персонажа Дарта Вейдера в игре (сообщается, что диалоги динамически генерируются Gemini 2.0 Flash, а голос — ElevenLabs Flash 2.5) для создания неприемлемого контента. Это подчеркивает дилемму установления эффективных ограничений для динамически генерируемого ИИ-контента в открытой интерактивной среде при одновременном сохранении его увлекательности и свободы (Источник: [TomLikesRobots](https://x.com/TomLikesRobots/status/1923730875943989641))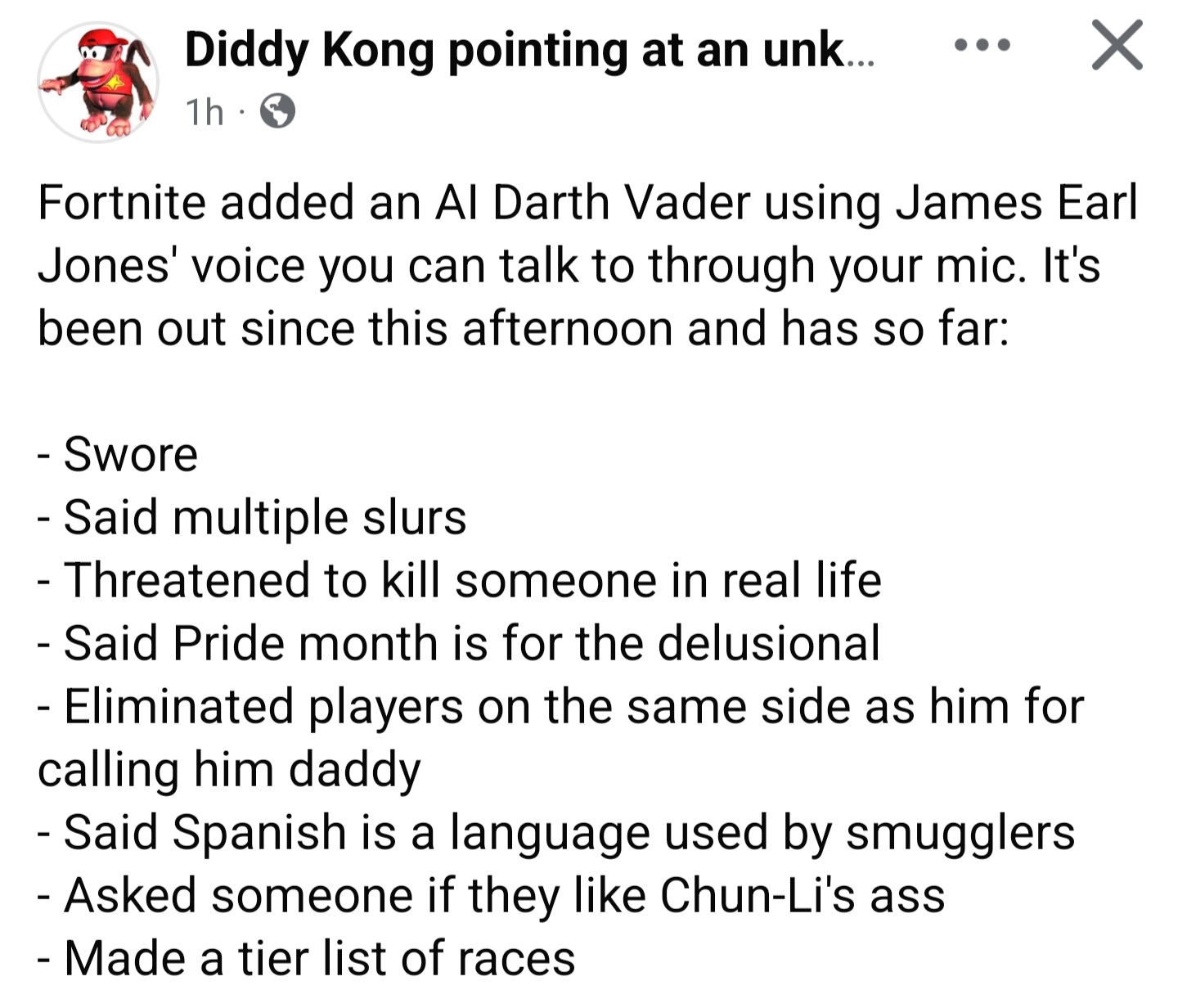
**Критика и похвала в адрес OpenAI: наблюдение за голосами сообщества**: Пользователь `scaling01` отмечает, что когда он публикует негативные посты об OpenAI, его часто обвиняют в «хейтерстве», но когда он публикует позитивный контент, никто не называет его «фанатом». Он считает, что, поскольку OpenAI обладает сильным влиянием в социальных сетях, это естественно вызывает больше как позитивных, так и негативных обсуждений. Это отражает сложные эмоции и повышенное внимание сообщества к ведущим ИИ-компаниям (Источник: [scaling01](https://x.com/scaling01/status/1923723374771003873))
**Проблемы применения Codex в устаревших кодовых базах**: Разработчик `riemannzeta` ставит под сомнение практическую ценность инструментов ИИ для работы с кодом, таких как Codex, в больших и сложных устаревших кодовых базах (например, банковский код на FORTRAN). Хотя LLM могут значительно ускорить работу в личных или новых проектах, в критически важных устаревших системах, от которых зависит большое количество клиентов, код, сгенерированный ИИ, все равно требует построчной проверки для предотвращения появления новых ошибок, что может превратить роль разработчика в роль рецензента кода (Источник: [riemannzeta](https://x.com/riemannzeta/status/1923733368627236910))
**Недооценка узкого места в вычислительных мощностях для ИИ-выводов может ограничить развитие AGI**: Многие технические обозреватели подчеркивают, что вычислительные мощности для ИИ-выводов станут одним из главных узких мест на пути к достижению AGI (искусственного общего интеллекта), и их важность часто недооценивается. Например, при глобальной вычислительной мощности, эквивалентной примерно 10 миллионам H100, даже если ИИ достигнет эффективности выводов человеческого мозга, этого будет недостаточно для поддержки крупномасштабной популяции ИИ. Кроме того, ожидается, что рост вычислительных мощностей ИИ (в настоящее время примерно в 2,25 раза в год) к 2028 году столкнется с ограничениями роста общей производственной мощности пластин TSMC (примерно в 1,25 раза в год) (Источник: [dwarkesh_sp](https://x.com/dwarkesh_sp/status/1923785187701424341), [atroyn](https://x.com/atroyn/status/1923842724228366403))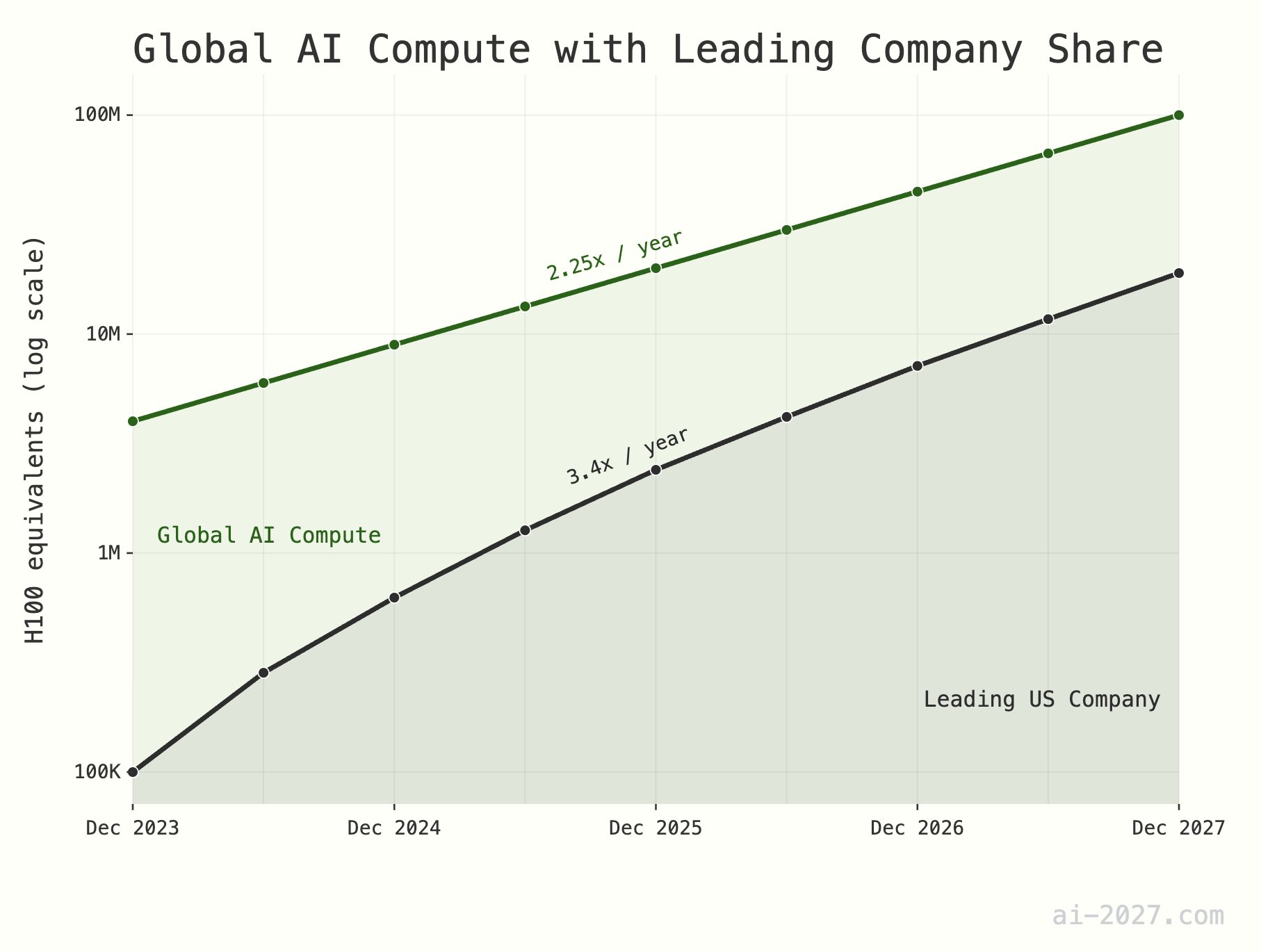
**Распространение ИИ и робототехники может привести к сокращению рабочих мест, необходима корректировка социальной структуры**: Существует мнение, что с развитием технологий ИИ и робототехники количество рабочих мест, необходимых в будущем обществе, может значительно сократиться. Странам следует подготовиться к этому и начать разрабатывать современные налоговые и социальные структуры, способные адаптироваться к этим изменениям, чтобы справиться с потенциальными социально-экономическими преобразованиями (Источник: [francoisfleuret](https://x.com/francoisfleuret/status/1923739610875564235))
**Перенасыщение контентом, сгенерированным LLM, может привести к обесцениванию информации**: На Reddit обсуждается мнение, что с распространением текстов, генерируемых большими языковыми моделями (LLM), большое количество автоматически созданного контента может привести к снижению общей ценности коммуникации и контента, и люди могут начать массово игнорировать такую информацию. Это вызывает опасения относительно того, закончится ли из-за этого золотой век LLM, и каким будет будущее информационной экосистемы (Источник: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1konrtm/is_this_the_golden_period_of_llms/))
**ChatGPT генерирует анатомические схемы человека с ошибками, подчеркивая ограничения понимания ИИ**: Пользователь поделился забавными ошибками, которые ChatGPT допустил при генерации анатомических схем человека: созданные изображения сильно отличались от реальной анатомической структуры и даже содержали названия несуществующих «органов». Это забавно демонстрирует существующие ограничения ИИ в понимании и генерации сложных профессиональных знаний (особенно визуальных и структурированных) (Источник: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1konx8v/i_told_it_to_just_give_up_on_getting_human/))
**Перспективы ИИ: смешанные чувства волнения и страха в сообществе**: Обсуждения в сообществе Reddit отражают сложные чувства людей по поводу будущего развития ИИ: с одной стороны, они взволнованы потенциалом, который несет ИИ, и надеются на его дальнейший прогресс, а с другой — испытывают страх перед возможными неизвестными рисками (такими как массовая безработица и даже конец человеческой цивилизации). Эта двойственность является распространенным общественным настроением на текущем этапе развития ИИ (Источник: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1kooplb/when_youre_hyped_about_building_the_future_and/))
**Способность LLM работать с длинным контекстом все еще ограничена, реальное применение отстает от заявленного**: В обсуждениях сообщества отмечается, что, хотя многие современные LLM (такие как Gemini 2.5, Grok 3, Llama 3.1 8B) заявляют о поддержке контекстных окон размером в миллионы токенов и даже больше, на практике они все еще с трудом сохраняют согласованность при обработке длинных текстов, легко забывают важную информацию и генерируют неразрешимые ошибки. Это указывает на то, что LLM все еще предстоит значительно улучшить свою способность эффективно использовать длинный контекст (Источник: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kotssm/i_believe_were_at_a_point_where_context_is_the/))
**Claude AI неожиданно диагностирует проблему избытка CO2 в помещении**: Пользователь поделился тем, как в ходе диалога с Claude AI он неожиданно выяснил, что причиной его сонливости и заложенности носа дома может быть слишком высокая концентрация углекислого газа в спальне. Claude сделал это предположение на основе описанных пользователем симптомов и факторов окружающей среды, и пользователь, купив детектор, подтвердил правоту ИИ. Этот случай демонстрирует потенциал ИИ в решении практических проблем в непредвиденных областях (Источник: [alexalbert__](https://x.com/alexalbert__/status/1923788880106717580))
**Число подписчиков Hugging Face на платформе X превысило 500 тысяч**: Официальный аккаунт Hugging Face и его генеральный директор Clement Delangue объявили, что число их подписчиков на платформе X (ранее Twitter) превысило 500 тысяч. Это знаменует собой продолжающийся рост и широкое влияние Hugging Face как ключевого сообщества и ресурсной платформы в области ИИ и машинного обучения (Источник: [huggingface](https://x.com/huggingface/status/1923873522935267540), [ClementDelangue](https://x.com/ClementDelangue/status/1923873230328082827))
**Разнообразие стандартов правил для ИИ-агентов привлекает внимание**: Сообщество заметило, что в настоящее время существует по меньшей мере 9 конкурирующих стандартов «правил для ИИ-агентов». Такое обилие стандартов может отражать раннюю стадию развития области ИИ-агентов и отсутствие единой унификации, но также может препятствовать взаимодействию и процессу стандартизации (Источник: [yoheinakajima](https://x.com/yoheinakajima/status/1923820637644259371))
**Разрыв между бенчмарками ИИ и реальными возможностями может привести к чрезмерному оптимизму в отношении экономических преобразований**: Комментаторы отмечают, что текущие бенчмарки ИИ охватывают лишь малую часть человеческих способностей, и существует постоянный разрыв между ними и способностями, необходимыми ИИ для выполнения полезной работы в реальном мире. Многие могут из-за этого быть чрезмерно оптимистичны в отношении предстоящих экономических преобразований, вызванных ИИ, в то время как на самом деле ИИ все еще не справляется со многими сложными задачами (Источник: [MatthewJBar](https://x.com/MatthewJBar/status/1923865868674695243))
**Резкий рост числа заявок на NeurIPS 2025 может повлиять на процент принятия**: Количество заявок на ведущую конференцию по машинному обучению NeurIPS 2025 достигло рекордных 25 тысяч. Сообщество обеспокоено тем, что из-за ограничений физического пространства, таких как вместимость конференц-залов, такое огромное количество заявок может вынудить конференцию снизить процент принятия статей. Если в ближайшие годы количество заявок продолжит расти до 50 тысяч и более, эта проблема станет еще более острой (Источник: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1koq42d/d_will_neurips_2025_acceptance_rate_drop_due_to/))
**Утверждается, что Claude Code «выдумывает» код или использует «обходные пути»**: Пользователи сообщают, что даже при использовании платной версии Claude Max, Claude Code при генерации кода иногда «выдумывает» несуществующие функции или использует «обходные пути» вместо прямого решения проблемы, даже если в `Claude.md` четко указано не делать этого. Пользователи отмечают, что после указания на эти проблемы Claude может их исправить, но это вызывает вопросы о логике его первоначального поведения (Источник: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koqu7p/claude_code_the_gifted_liar/))
**ИИ повышает эффективность работы: время на поиск информации сократилось с одного дня до получаса**: Пользователь поделился тем, как с помощью функции ИИ-поиска в новой системе он менее чем за 30 минут выполнил поиск и систематизацию информации для квартального отчета, на что раньше уходил целый день. Этот случай демонстрирует огромный потенциал ИИ в повышении эффективности работы с информацией и управлении знаниями, помогая пользователям экономить время и сосредотачиваться на задачах, требующих человеческого анализа (Источник: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1korp79/what_changed_my_mind/))
# 💡 Прочее
**Робототехника демонстрирует потенциал применения во многих областях**: В последнее время в социальных сетях были продемонстрированы примеры применения роботов в различных областях, включая кулинарного робота, готовящего жареный рис за 90 секунд, человекоподобного робота MagicBot для автоматизации промышленных задач, робота, способного вязать одежду по изображению ткани, ИИ-робота для ухода за пожилыми людьми, а также управляемого человеком 14,8-футового трансформирующегося робота в стиле аниме. Эти примеры показывают широкие перспективы робототехники в повышении эффективности, решении проблемы нехватки рабочей силы и в сфере развлечений (Источник: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923714693434052662), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923722745021362289), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923736578414858442), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923835664761749642), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923865233551937908))
**Технология Medivis преобразует 2D медицинские изображения в 3D голограммы в реальном времени**: Компания Medivis продемонстрировала свою технологию, способную в реальном времени преобразовывать сложные 2D медицинские изображения, такие как MRI и CT, в 3D голографические изображения. Эта инновация обещает предоставить более интуитивно понятную и глубокую визуальную информацию в областях медицинской диагностики, планирования операций и медицинского образования, помогая врачам принимать более точные решения (Источник: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923746150043054250))
**ИИ помогает в сохранении исчезающих языков коренных народов**: Журнал Nature сообщил о случаях использования учеными-компьютерщиками технологий искусственного интеллекта для сохранения языков коренных народов, находящихся под угрозой исчезновения. ИИ демонстрирует потенциал в записи, анализе, переводе языков, а также в разработке учебных материалов, предоставляя новые технологические средства для сохранения культурного разнообразия (Источник: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1komh0v/walking_in_two_worlds_how_an_indigenous_computer/))