
Ключевые слова:OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, Microsoft Research (Исследовательский центр Microsoft), Sakana AI, Continuous Thinking Machine (Машина непрерывного мышления), ARTIST framework (Фреймворк ARTIST), Оценка производительности медицинского ИИ, 8B-параметрическая модель Dynamic Byte Latent Transformer, Улучшение рассуждений LLM с помощью обучения с подкреплением, Нейронная архитектура CTM, Официальная квантованная модель Qwen3
🔥 В фокусе
OpenAI представляет HealthBench для оценки производительности медицинского ИИ: OpenAI запустила HealthBench, новый бенчмарк, предназначенный для измерения производительности и безопасности больших языковых моделей (LLM) в медицинских сценариях. В разработке бенчмарка приняли участие более 250 врачей со всего мира. Он включает 5000 реальных медицинских диалогов и 48562 уникальных критерия оценки, написанных врачами, охватывая различные ситуации, такие как неотложная помощь и глобальное здравоохранение, а также поведенческие аспекты, включая точность и следование инструкциям. Тестирование показало, что точность модели o3 достигает 60%, а GPT-4.1 nano превосходит GPT-4o при снижении затрат в 25 раз, демонстрируя огромный потенциал ИИ в медицине и быстрый прогресс в соотношении производительности и затрат. (Источник: OpenAI)
Meta выпускает модель Dynamic Byte Latent Transformer с 8B параметрами: Meta AI объявила об открытии исходного кода весов своей модели Dynamic Byte Latent Transformer с 8 миллиардами параметров. Эта модель предлагает новое решение, альтернативное традиционным методам токенизации, с целью переопределения стандартов эффективности и надежности языковых моделей. Ожидается, что этот новый способ токенизации приведет к прорывам в области языковых моделей, повысив эффективность и результативность обработки текста моделями. Исследовательская работа и код доступны для скачивания. (Источник: AIatMeta)
Microsoft Research представляет фреймворк ARTIST, объединяющий обучение с подкреплением для улучшения способностей LLM к рассуждению и использованию инструментов: Microsoft Research представила фреймворк ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers). Этот фреймворк объединяет автономное рассуждение, обучение с подкреплением и динамическое использование инструментов, позволяя большим языковым моделям самостоятельно решать, когда, как и какие инструменты использовать для многошагового рассуждения, а также обучаться надежным стратегиям без пошагового надзора. ARTIST превосходит ведущие модели, такие как GPT-4o, в сложных бенчмарках, таких как математические задачи и вызовы функций, с улучшением до 22%, устанавливая новые стандарты для обобщения и интерпретируемости решения проблем. (Источник: MarkTechPost)

Sakana AI выпускает Continuous Thought Machines (CTM): Sakana AI представила новую архитектуру нейронной сети под названием “Continuous Thought Machines” (CTM). Основная идея CTM заключается в том, чтобы использовать динамический временной процесс нейронной активности как основную составляющую вычислений, позволяя модели оперировать вдоль внутренне генерируемой временной шкалы “шагов мышления”, итеративно строя и уточняя свои представления, даже для статических данных. Эта архитектура продемонстрировала свою адаптивную вычислительную способность, улучшенную интерпретируемость и биологическую правдоподобность в различных задачах, таких как классификация ImageNet, навигация в 2D-лабиринте, сортировка, вычисление четности и обучение с подкреплением. (Источник: Sakana AI)

🎯 Тенденции
Команда Qwen из Alibaba выпускает официальные квантованные модели Qwen3: Команда Qwen из Alibaba официально выпустила квантованные модели Qwen3. Теперь пользователи могут развертывать Qwen3 через платформы, такие как Ollama, LM Studio, SGLang и vLLM, с поддержкой различных форматов, включая GGUF, AWQ, GPTQ, что упрощает локальное развертывание. Соответствующие модели доступны на Hugging Face и ModelScope. Этот выпуск направлен на снижение порога использования высокопроизводительных больших моделей и содействие их применению в более широком спектре сценариев. (Источник: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI выпускает фреймворк для совместного рассуждения Collaborative Reasoner: Meta AI представила Collaborative Reasoner, фреймворк, направленный на улучшение способностей языковых моделей к совместному рассуждению. Фреймворк нацелен на разработку социальных агентов, способных сотрудничать с людьми и другими агентами, прокладывая путь к более сложным взаимодействиям человек-машина и мультиагентным системам за счет повышения способностей моделей к сотрудничеству и рассуждению. Соответствующая исследовательская работа и код доступны для скачивания, поощряя сообщество к исследованию и применению. (Источник: AIatMeta)
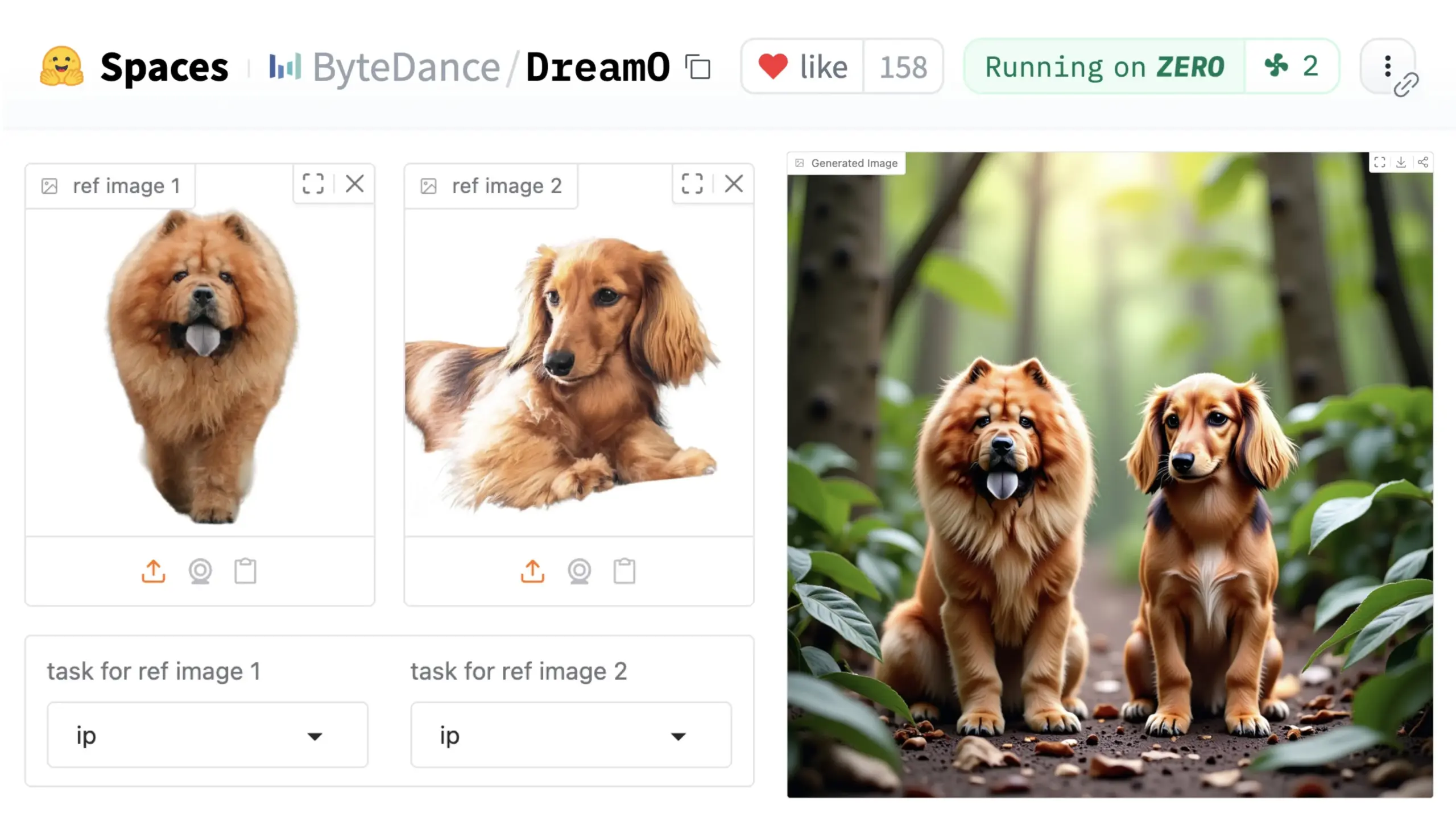
ByteDance представляет универсальный фреймворк для кастомизации изображений DreamO: ByteDance выпустила унифицированный фреймворк для кастомизации изображений под названием DreamO. Этот фреймворк основан на предварительно обученной модели DiT (Diffusion Transformer) и позволяет осуществлять обобщенную кастомизацию различных элементов изображения, таких как личность, стиль, фон, включая замену идентичности, перенос стиля, трансформацию объекта и виртуальную примерку. Пользователи могут опробовать демо на Hugging Face. Этот прогресс демонстрирует потенциал единой модели в разнообразных задачах редактирования изображений. (Источник: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA открывает процесс управления данными модели Nemotron — Nemotron-CC: NVIDIA объявила об открытии своего процесса управления данными Nemotron-CC, используемого для модели Nemotron, и максимально возможном раскрытии данных обучения и пост-обучения Nemotron. Процесс Nemotron-CC теперь добавлен в репозиторий NeMo Curator на GitHub и может обрабатывать текстовые, изобразительные и видеоданные в больших масштабах. NVIDIA подчеркивает важность высококачественных наборов данных для предварительного обучения для точности больших языковых моделей и считает данные фундаментальным компонентом ускоренных вычислений. (Источник: ctnzr & NandoDF)

Модель Tencent Hunyuan-Turbos занимает восьмое место на арене LMArena: Последняя модель Tencent Hunyuan-Turbos заняла восьмое место в общем зачете бенчмарка LMArena (ранее lmsys.org) и тринадцатое место по контролю стиля, показав результаты, близкие к Deepseek-R1. Модель вошла в топ-10 в основных категориях, таких как хардкорные задачи, кодирование и математика, показав значительное улучшение по сравнению с февральской версией. Члены сообщества, такие как WizardLM_AI, поздравили с ее производительностью. (Источник: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References демонстрирует потенциал универсального инструмента для творчества: Модель Runway Gen-4 References позиционируется как универсальный инструмент для творчества, способный поддерживать практически неограниченное количество рабочих процессов и приложений. Пользователи сообщества постоянно находят новые варианты ее использования, что свидетельствует о ее мощной адаптивности как универсальной модели, способной подстраиваться под творческие идеи пользователя, а не заставлять пользователя адаптироваться к ограничениям модели. Это отражает тенденцию эволюции ИИ в области создания медиа от специфических задач к универсальным возможностям. (Источник: c_valenzuelab & c_valenzuelab)

Модель ByteDance Seed-1.5-VL-thinking лидирует в бенчмарках визуально-языковых моделей: ByteDance выпустила модель Seed-1.5-VL-thinking, которая достигла SOTA (state-of-the-art) результатов в 38 из 60 бенчмарков для визуально-языковых моделей (VLM). Утверждается, что модель обучалась в течение 1,3 миллиона часов на GPU H800, что демонстрирует ее мощные мультимодальные способности к пониманию и рассуждению. (Источник: teortaxesTex)
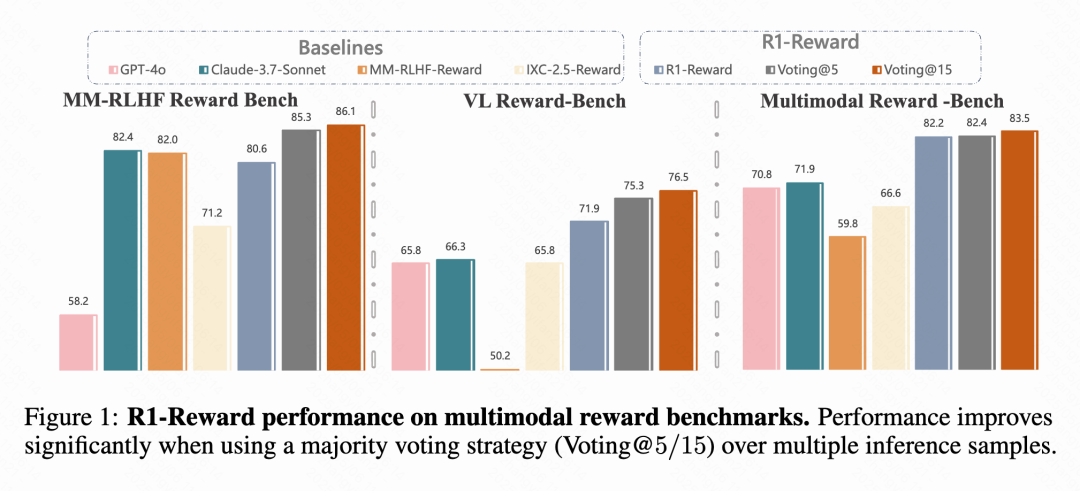
Kuaishou, CAS и другие предлагают мультимодальную модель вознаграждения R1-Reward: Исследовательские группы из Kuaishou, Китайской академии наук (CAS), Университета Цинхуа и Нанкинского университета предложили R1-Reward, новую мультимодальную модель вознаграждения (MRM), обученную с помощью улучшенного алгоритма обучения с подкреплением StableReinforce. Модель направлена на решение проблем нестабильности, с которыми сталкиваются существующие алгоритмы RL при обучении MRM, вводя механизмы Pre-Clip, фильтр преимуществ и согласованное вознаграждение. Эксперименты показывают, что R1-Reward превосходит SOTA модели на 5%-15% в нескольких бенчмарках MRM и успешно применяется в бизнес-сценариях Kuaishou, таких как короткие видео и электронная коммерция. (Источник: WeChat & WeChat)
Наньянский технологический университет и другие предлагают WorldMem, реализующий генерацию мира с долговременной согласованностью с помощью механизма памяти: Исследователи из S-Lab Наньянского технологического университета, Пекинского университета и Shanghai AI Lab предложили модель генерации мира WorldMem. Эта модель решает проблему отсутствия согласованности в существующих моделях генерации видео на длительных временных интервалах путем введения механизма памяти. WorldMem обучается на наборе данных Minecraft, поддерживает исследование разнообразных сцен и динамические изменения, а также подтверждает свою осуществимость на реальных наборах данных, сохраняя хорошую геометрическую согласованность после изменений ракурса и положения и моделируя временную согласованность. (Источник: WeChat)

Команда Kuaishou Keling предлагает CineMaster, фреймворк для генерации видео кинематографического уровня с 3D-восприятием и контролем: Исследовательская команда Kuaishou Keling опубликовала статью на SIGGRAPH 2025, представляющую фреймворк CineMaster. Это фреймворк для генерации видео кинематографического уровня из текста, позволяющий пользователям через интерактивный рабочий процесс размещать сцены в 3D-пространстве, задавать цели и движение камеры, достигая тонкого контроля над содержанием видео. CineMaster интегрирует управление движением объектов и камеры с помощью Semantic Layout ControlNet и Camera Adapter соответственно, а также разработал процесс построения данных для извлечения 3D-управляющих сигналов из произвольного видео. (Источник: WeChat)

🧰 Инструменты
Comet-ml выпускает опенсорсный фреймворк для оценки LLM Opik: Comet-ml открыла исходный код Opik на GitHub, фреймворка для отладки, оценки и мониторинга приложений LLM, систем RAG и рабочих процессов Agent. Opik предоставляет комплексное отслеживание, автоматизированную оценку и готовые к производству панели мониторинга, поддерживает локальную установку или использование через Comet.com как хостинговое решение. Он интегрируется с множеством популярных фреймворков, таких как OpenAI, LangChain, LlamaIndex, и предоставляет метрики LLM-as-a-judge для обнаружения галлюцинаций, модерации контента и оценки RAG. (Источник: GitHub Trending)
LovartAI запускает первого дизайн-агента Lovart, подчеркивая понимание контекста: LovartAI выпустила бета-версию своего первого дизайн-агента Lovart. Отзывы пользователей показывают, что по сравнению с другими инструментами ИИ-дизайна, Lovart лучше понимает контекст, даже “как будто читает мысли”. Инструмент позволяет человеку и ИИ сотрудничать на одном холсте, мгновенно преобразуя промпты в визуальные эффекты, и может использоваться для дизайна логотипов бренда и VI. (Источник: karminski3)
Команда Джун-Ян Джу из CMU представляет LEGOGPT, генерирующий 3D-модели LEGO из текста: Команда Джун-Ян Джу из Университета Карнеги-Меллона (CMU) разработала LEGOGPT, большую языковую модель, способную генерировать физически стабильные и собираемые 3D-модели LEGO на основе текстовых подсказок. Модель формулирует задачу проектирования LEGO как авторегрессионную задачу генерации текста, предсказывая размер и положение следующего блока для построения структуры, и принудительно применяет ограничения сборки с учетом физики во время обучения и вывода, обеспечивая стабильность и собираемость сгенерированных конструкций. Команда также выпустила набор данных StableText2Lego, содержащий более 47 000 структур LEGO. (Источник: WeChat)

Приложение MNN Chat поддерживает модели Qwen 2.5 Omni 3B и 7B: Приложение MNN (Mobile Neural Network) Chat от Alibaba теперь поддерживает модели Qwen 2.5 Omni 3B и 7B. Это означает, что пользователи могут испытать более мощные локализованные языковые модели на мобильных устройствах. MNN — это легковесный движок для вывода глубокого обучения, ориентированный на оптимизацию для мобильных и встраиваемых устройств. (Источник: Reddit r/LocalLLaMA)

Платформа FutureHouse предоставляет ученым инструменты для исследований с помощью суперинтеллектуального ИИ: Некоммерческая организация FutureHouse запустила платформу FutureHouse, веб- и API-ориентированный набор ИИ-агентов, предназначенный для ускорения научных открытий. Платформа предлагает ряд суперинтеллектуальных инструментов ИИ для исследований, помогая ученым в анализе данных, симуляции экспериментов и поиске знаний, способствуя изменению парадигмы научных исследований. (Источник: dl_weekly)
Cartesia запускает Pro Voice Cloning для легкого создания пользовательских голосовых моделей: Cartesia выпустила свой продукт для дообучения Pro Voice Cloning. Пользователи могут загружать свои голосовые данные для легкого создания пользовательских голосовых моделей, которые можно использовать для создания персональных аватаров, ИИ-агентов или голосовых библиотек. Продукт поддерживает завершение обучения и развертывание сервиса в течение 2 часов и предоставляет полностью самоуправляемый опыт, нацеленный на масштабируемое применение. (Источник: krandiash)

Институт вычислительной техники КАН предлагает MCA-Ctrl для точной кастомизации изображений: Исследовательская группа из Института вычислительной техники Китайской академии наук (КАН) предложила универсальный метод кастомизации изображений без дообучения MCA-Ctrl (Multi-party Collaborative Attention Control). Этот метод использует многостороннее совместное управление вниманием, внутренние знания диффузионных моделей, сочетая условные изображения/текстовые подсказки с содержанием основного изображения, для реализации замены темы, генерации и добавления конкретных объектов. MCA-Ctrl обеспечивает согласованность компоновки и замену внешнего вида конкретных объектов с выравниванием фона с помощью механизмов локального запроса самовнимания и глобального внедрения. (Источник: WeChat)
📚 Обучение
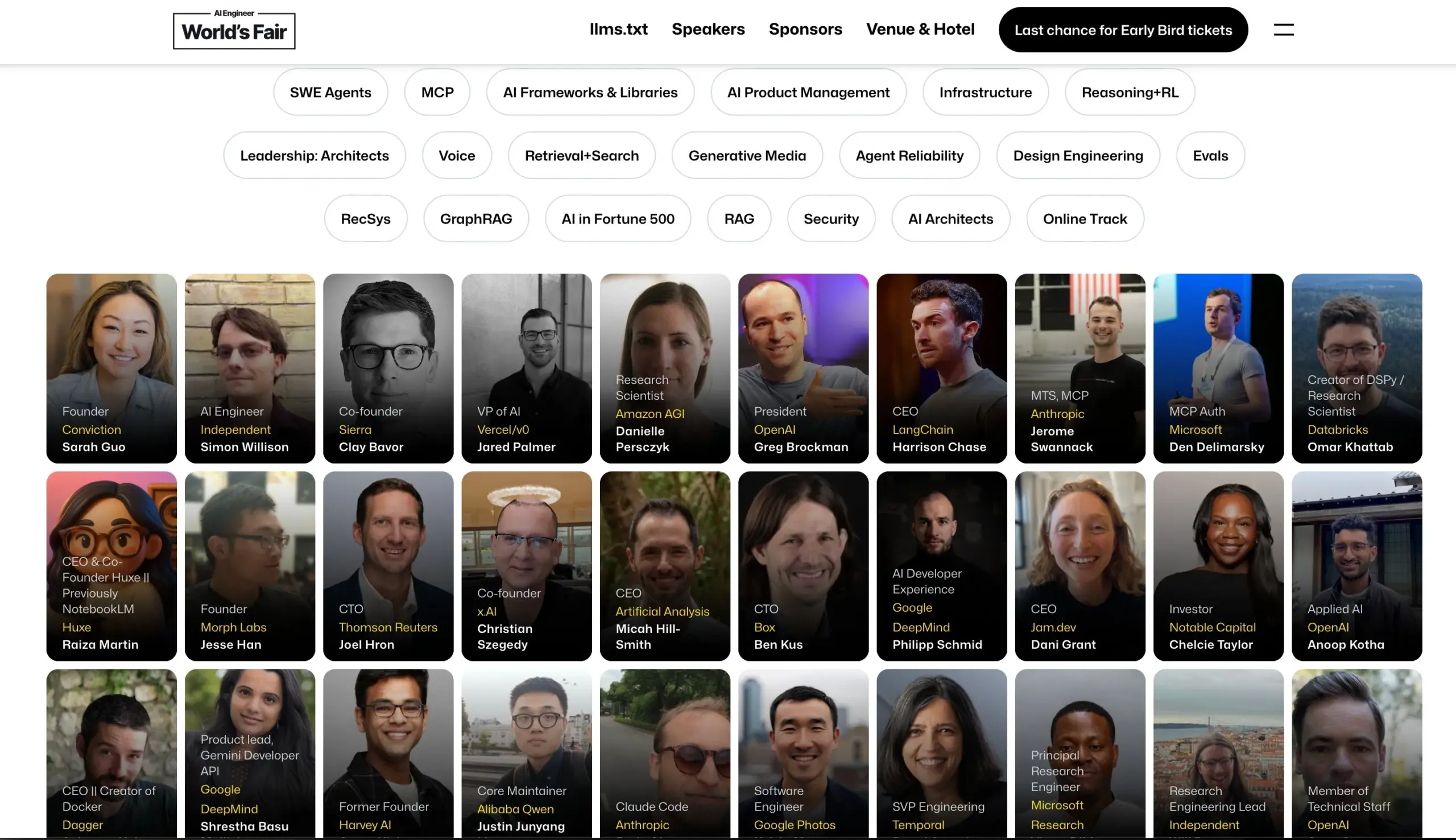
Конференция AI Engineer объявляет состав спикеров: Конференция AI Engineer объявила свой состав спикеров, включающий ведущих инженеров и исследователей ИИ из таких компаний, как OpenAI, Anthropic, LangChainAI, Google и др. Конференция охватит 20 узкоспециализированных областей, включая MCP, LLM RecSys, Agent Reliability, GraphRAG, и впервые будет включать повестку для лидеров уровня CTO и VP. (Источник: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face публикует блог о последних достижениях в области визуально-языковых моделей (VLM): Hugging Face опубликовала всеобъемлющую статью в блоге о последних достижениях в области визуально-языковых моделей (VLM). Содержание охватывает множество аспектов, включая агентов GUI, агентов VLM, всемогущие модели, мультимодальный RAG, видео LM, малые модели, и подводит итоги новых тенденций, прорывов, выравнивания и бенчмарков в области VLM за последний год. (Источник: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure проводит онлайн-семинар по созданию бессерверных ИИ-чат-приложений: Йохан Ласорса объявил о проведении онлайн-семинара по созданию бессерверных ИИ-чат-приложений с использованием Azure. На встрече будут рассмотрены Azure Functions, статические веб-приложения и Cosmos DB, а также как использовать технологию RAG (Retrieval-Augmented Generation) в сочетании с LangChainAI JS. (Источник: Hacubu & hwchase17)
Подкаст Weaviate обсуждает системы LLM-as-Judge и библиотеку Verdict: В 121-м выпуске подкаста Weaviate приглашен сооснователь Haize Labs Леонард Танг для глубокого обсуждения эволюции систем LLM-as-Judge / моделей вознаграждения. Обсуждаемые темы включают пользовательский опыт оценки, сравнительную оценку, интеграцию судей, дебаты судей, курирование наборов для оценки и состязательное тестирование, с особым акцентом на новую библиотеку Haize Labs Verdict, декларативный фреймворк для спецификации и выполнения составных систем LLM-as-Judge. (Источник: bobvanluijt & Reddit r/deeplearning)

Теренс Тао публикует видео на YouTube, демонстрируя формальное доказательство математических теорем с помощью ИИ: Лауреат Филдсовской премии Теренс Тао дебютировал на своем YouTube-канале, продемонстрировав, как использовать инструменты ИИ, такие как GitHub Copilot и ассистент доказательств Lean, для полуавтоматической формализации математического доказательства (уравнение Magma E1689 влечет E2) за 33 минуты, которое обычно требует от математика-человека целой страницы записей. Он подчеркнул, что этот метод подходит для технически сложных, но концептуально слабых доказательств, освобождая математиков от рутинной работы. Одновременно его легковесный ассистент доказательств на Python был обновлен до версии 2.0, улучшив обработку асимптотических оценок и пропозициональной логики. (Источник: WeChat & 量子位)

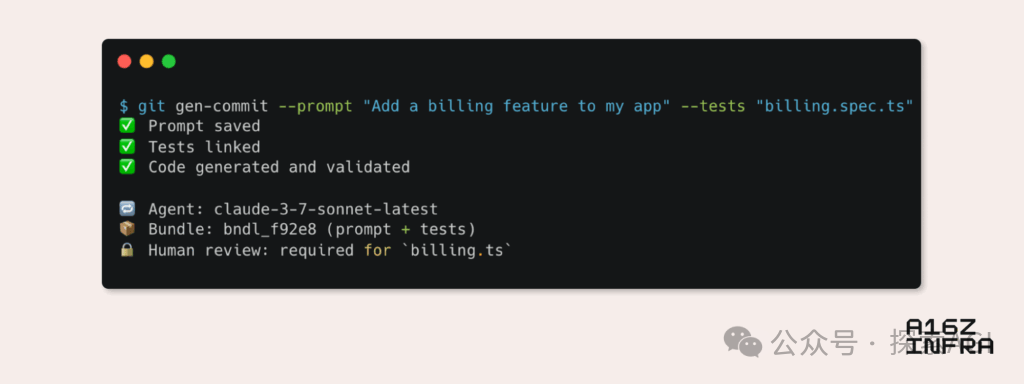
a16z анализирует девять основных тенденций в новых паттернах разработчиков в эпоху ИИ: Andreessen Horowitz (a16z) опубликовала блог, анализирующий девять новых тенденций в паттернах разработчиков в эпоху ИИ. К ним относятся: нативный для ИИ Git (контроль версий смещается к промптам и тестовым случаям), Vibe Coding (программирование на основе намерений заменяет шаблоны), новая парадигма управления ключами для ИИ-агентов, интерактивные панели мониторинга, управляемые ИИ, эволюция документации в интерактивные базы знаний, доступные ИИ, взгляд на приложения с точки зрения LLM (через взаимодействие с API доступности), рост асинхронного выполнения агентов, потенциал протокола MCP (Model-Tool Communication Protocol) и потребность агентов в базовых компонентах. Эти тенденции предвещают глубокие изменения в способах создания программного обеспечения. (Источник: WeChat)
💼 Бизнес
Google Labs запускает AI Futures Fund для поддержки стартапов в области ИИ: Google Labs объявила о запуске программы AI Futures Fund, направленной на сотрудничество со стартапами для совместного построения будущего технологий ИИ. Фонд предоставит выбранным стартапам ранний доступ к моделям Google DeepMind, а также облачные кредиты и другие ресурсы для ускорения их развития. (Источник: GoogleDeepMind & JeffDean & Google & demishassabis)
Сообщается, что Perplexity ведет переговоры о новом раунде финансирования в $500 млн при оценке в $14 млрд: По сообщениям, компания-разработчик ИИ-поисковика Perplexity ведет переговоры о новом раунде финансирования в размере 500 миллионов долларов, при этом оценка может достичь 14 миллиардов долларов. Это произошло всего через шесть месяцев после предыдущего раунда финансирования (при оценке в 9 миллиардов долларов), что свидетельствует о высоком интересе рынка капитала к сектору ИИ-поиска и признании перспектив развития Perplexity. (Источник: Dorialexander)

Сообщается, что OpenAI согласилась приобрести Windsurf примерно за $3 млрд: По данным Bloomberg, OpenAI согласилась приобрести стартап Windsurf примерно за 3 миллиарда долларов. Конкретные детали сделки и направление деятельности Windsurf пока не разглашаются, но этот шаг может означать дальнейшее расширение технологических возможностей или рыночного присутствия OpenAI. (Источник: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 Сообщество
Реальный риск ИИ: “ловушка симуляции” из-за бесконечного удовлетворения: Обсуждение Амджада Масада и других указывает на то, что настоящая опасность ИИ — это не роботы-убийцы из научной фантастики, а его способность бесконечно удовлетворять человеческие желания, создавая “машину бесконечного счастья”. Такой ИИ может привести к тому, что человечество погрузится в симулированную борьбу и смысл, в конечном итоге “исчезнув” в симулированном мире, что предлагает возможное объяснение парадокса Ферми — цивилизации не погибают, а переходят в цифровое блаженство. (Источник: amasad)
ИИ-агенты изменят программирование и научные исследования: CEO Replit Амджад Масад прогнозирует, что в ближайшие год-два ИИ-агенты смогут непрерывно работать днями, а то и годами, для решения сложных научных проблем. Он считает, что агенты станут новым способом программирования, способным, подобно человеку, посвящать дни решению одной проблемы, что предвещает огромный потенциал ИИ в автоматизации сложных задач и ускорении научных открытий. (Источник: TheTuringPost & amasad & TheTuringPost)
Джон Кармак обсуждает потенциал ИИ в оптимизации кодовых баз: Легендарный программист Джон Кармак считает, что ИИ не только способен генерировать большие объемы кода, но и обладает потенциалом для улучшения и рефакторинга существующих кодовых баз. Он представляет ИИ как усердного члена команды, постоянно проверяющего код и предлагающего улучшения, и даже способного определить “дружественные к ИИ” руководства по стилю кодирования с помощью объективных экспериментов. Он с нетерпением ждет, как команды с чрезвычайно высокими требованиями к качеству кода, такие как OpenBSD, примут ИИ-членов. (Источник: ID_AA_Carmack)
“Vibe Coding” вызывает бурные обсуждения: плюсы и минусы программирования с помощью ИИ: Обсуждения в сообществе указывают на то, что хотя “Vibe Coding” (создание прототипов кода с помощью ИИ по инструкциям на естественном языке) позволяет быстро создавать демонстрационные приложения, для развертывания и масштабирования все равно требуются профессиональные разработчики, которые будут строить все с нуля. Инженерный продукт — это не только написание кода, но и архитектура, CI/CD, микросервисы и другие сложные вопросы, с которыми ИИ пока не может полностью справиться. Vibe Coding подходит для быстрой проверки прототипов, но создание реальных решений по-прежнему требует инженерного мышления и опыта. (Источник: Reddit r/ClaudeAI)
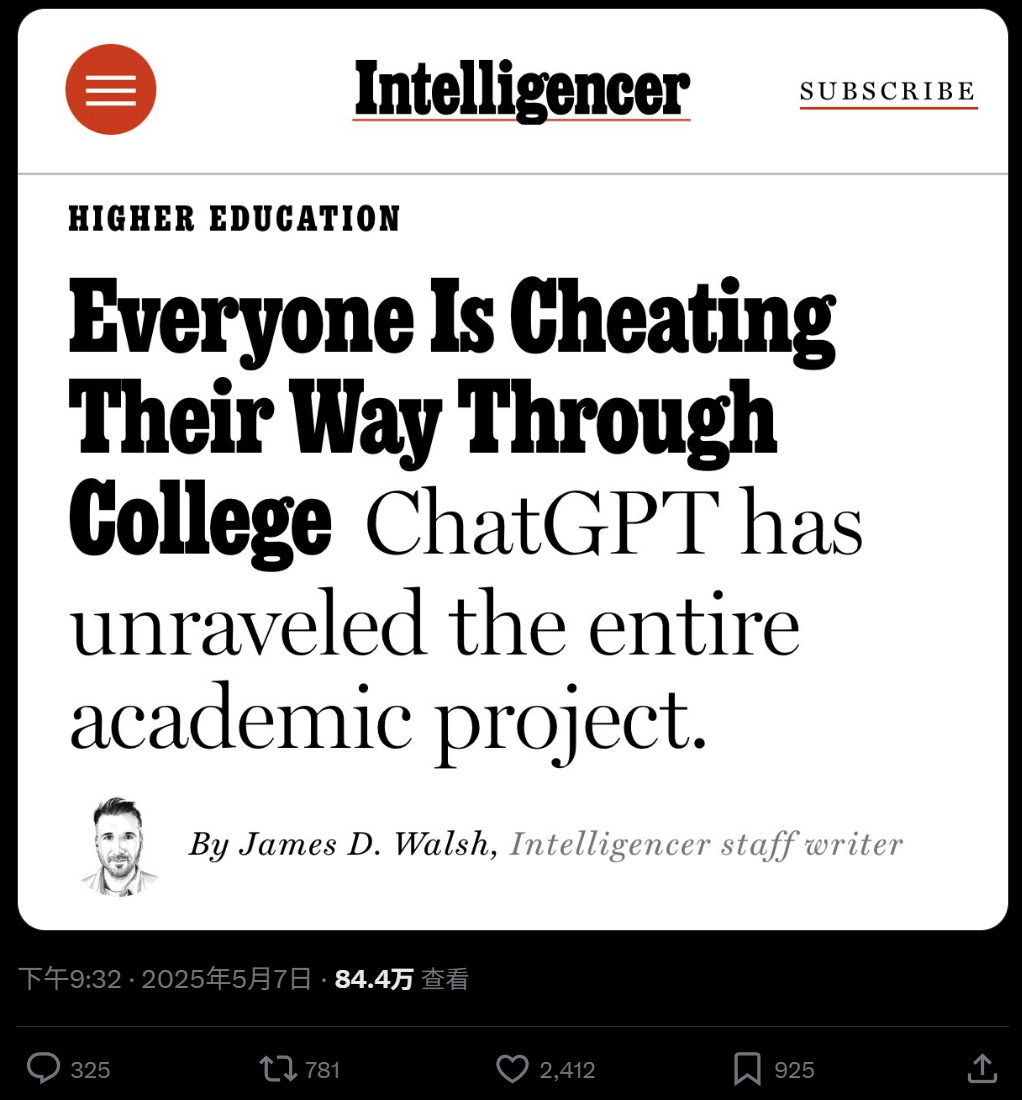
Широкое использование ИИ в университетском образовании и опасения по поводу списывания: Статья в New York Magazine раскрывает феномен широкого использования инструментов ИИ (таких как ChatGPT) в североамериканских университетах для выполнения домашних заданий и написания эссе. Студенты используют ИИ для ведения заметок, обучения, исследований и даже прямого генерирования контента для заданий, что вызывает опасения по поводу академической честности, качества образования и снижения у студентов навыков критического мышления. Преподаватели пытаются адаптировать методы обучения и оценки, но эффективность инструментов обнаружения ИИ сомнительна, что затрудняет искоренение списывания с помощью ИИ. (Источник: WeChat)
💡 Прочее
Cohere обсуждает проблемы перехода государственных ИИ-приложений от пилотных проектов к производству: Cohere отмечает, что большинство государственных ИИ-проектов все еще находятся на стадии пилотных испытаний. Для перехода от пилотных проектов к реальному производственному применению государственным учреждениям необходимы надежные инструменты, четкая ориентация на результат, эффективная инфраструктура и подходящие партнеры. В статье рассматривается, как государственные учреждения могут осуществить переход от экспериментов к практическому применению с помощью безопасного и эффективного ИИ. (Источник: cohere)

Мустафа Сулейман: Чем больше масштаб больших языковых моделей, тем легче их контролировать: Сооснователь Inflection AI Мустафа Сулейман считает, что, вопреки распространенным опасениям, чем больше масштаб больших языковых моделей (LLM), тем легче их контролировать. Он отмечает, что модели предыдущих поколений было сложнее направлять, стилизовать и формировать, в то время как увеличение масштаба способствует повышению управляемости модели, а не ее ослаблению. (Источник: mustafasuleyman)
Этика ИИ: Распределение ответственности за вред или предвзятость, вызванные ИИ: Пост на Reddit вызвал дискуссию: кто должен нести ответственность, когда система ИИ (например, ИИ для медицинской диагностики) причиняет вред из-за предвзятости в обучающих данных (например, обучение преимущественно на изображениях светлой кожи, что приводит к ошибочной диагностике у пациентов с темной кожей)? Это затрагивает вопросы определения ответственности разработчиков ИИ, организаций, внедряющих ИИ, регуляторов и других сторон, и является ключевым вопросом, который необходимо решить в рамках этики ИИ и правовой базы. (Источник: Reddit r/ArtificialInteligence)