Ключевые слова:Prime Intellect, INTELLECT-2, Sakana AI, Трансформер, Агент Google AI, Машина непрерывного мышления, AgentOps, Многоагентное сотрудничество, Распределенное обучение с подкреплением, Нейронная временная синхронизация и синхронизация нейронов, Процессы эксплуатации ИИ-агентов, Многоагентная архитектура, Развертывание ИИ-агентов в предприятиях
🔥 В фокусе
Prime Intellect открывает исходный код модели INTELLECT-2: Prime Intellect выпустила и открыла исходный код INTELLECT-2, модели с 32 миллиардами параметров, которая, как утверждается, является первой моделью, обученной с помощью глобального распределенного обучения с подкреплением (Reinforcement Learning). Релиз включает подробный технический отчет и контрольные точки модели. Модель продемонстрировала производительность, сравнимую или даже превосходящую такие модели, как Qwen 32B, во множестве бенчмарков, особенно выделяясь в генерации кода и математических рассуждениях. Члены сообщества также обнаружили, что она может играть в Wordle. Считается, что ее метод обучения и шаг по открытию исходного кода могут повлиять на будущее обучение больших моделей и конкурентную среду (Источник: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI предлагает Continuous Thought Machine (CTM): Sakana AI представила новую архитектуру нейронной сети под названием “Continuous Thought Machine” (CTM), направленную на наделение AI более гибким интеллектом, подобным человеческому, путем внедрения механизмов биологического мозга, таких как нейронное время и синхронизация нейронов. Ключевые инновации CTM заключаются в обработке времени на уровне нейронов и использовании нейронной синхронизации как скрытого представления, что позволяет ей справляться с задачами, требующими последовательных рассуждений и адаптивных вычислений, а также хранить и извлекать воспоминания. Исследование было опубликовано в виде блога, интерактивного отчета, научной работы и репозитория кода на GitHub, исследуя новую парадигму AI, «думающего временем» (Источник: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
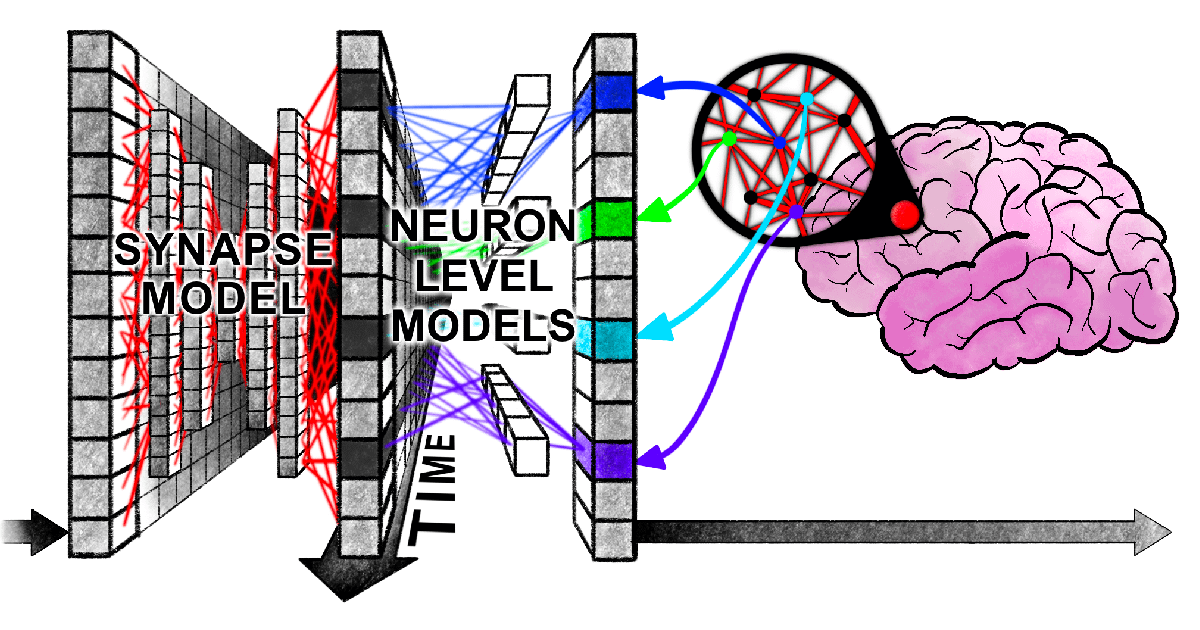
Новая статья Гарварда выявляет «синхронную запутанность» между Transformer и человеческим мозгом при обработке информации: Исследователи из Гарвардского университета и других учреждений опубликовали статью «Linking forward-pass dynamics in Transformers and real-time human processing», в которой исследуется сходство между внутренней динамикой обработки в моделях Transformer и процессами познания человека в реальном времени. Исследование фокусируется не только на конечном результате, но и анализирует показатели «нагрузки обработки» на каждом слое модели (такие как неопределенность, изменение уверенности), обнаруживая, что AI при решении задач (например, ответы на вопросы о столицах, классификация животных, логические рассуждения, распознавание изображений) также проходит через процессы, подобные человеческим: от «колебания», «интуитивной ошибки» до «исправления». Это сходство в «процессе мышления» указывает на то, что AI естественным образом обучается когнитивным коротким путям, схожим с человеческими, для выполнения задач, что открывает новые перспективы для понимания принятия решений AI и руководства для разработки экспериментов с участием человека (Источник: 36氪)

Google публикует 76-страничный White Paper по AI-агентам, разъясняя AgentOps и мультиагентное сотрудничество: Недавно опубликованный Google White Paper по AI-агентам подробно описывает создание, оценку и применение AI-агентов. В документе подчеркивается важность операций с агентами (AgentOps) — процесса оптимизации создания и развертывания агентов в производственной среде, охватывающего управление инструментами, настройку основных подсказок, реализацию памяти и декомпозицию задач. White Paper также рассматривает мультиагентные архитектуры, где несколько агентов со специализированными возможностями совместно работают для достижения сложных целей, и представляет практические примеры развертывания агентов Google на предприятиях (например, NotebookLM Enterprise Edition, Agentspace Enterprise Edition) и в конкретных приложениях (например, мультиагентная система для автомобилей), направленные на повышение производительности предприятий и улучшение пользовательского опыта (Источник: 36氪)
🎯 Динамика
LightonAI выпускает модель семантического поиска GTE-ModernColBERT-v1: LightonAI представила новую модель семантического поиска GTE-ModernColBERT-v1, которая достигла наивысшего на данный момент балла в оценке LongEmbed / LEMB Narrative QA. Эта модель специально разработана для улучшения результатов семантического поиска и может применяться для поиска контента в документах, RAG и других сценариев, а также интегрироваться с существующими системами. Сообщается, что модель была доработана на основе Alibaba-NLP/gte-modernbert-base с целью преодоления ограничений традиционных поисковых систем, полагающихся только на совпадение символов (Источник: karminski3)
Технологические лидеры обращают внимание на быстрый рост DeepSeek: VentureBeat сообщает о реакции технологических лидеров на стремительное развитие DeepSeek. Благодаря своим мощным моделям и стратегии открытого исходного кода, DeepSeek добился значительных успехов в глобальной сфере AI, особенно в задачах математики и генерации кода, бросая вызов существующему рыночному ландшафту (включая OpenAI и др.). Его низкая стоимость обучения и ценовая политика API также способствуют популяризации и коммерциализации технологий AI (Источник: Ronald_vanLoon)

ByteDance и Пекинский университет совместно выпускают DreamO, единый фреймворк для генерации изображений с настройкой по нескольким условиям: ByteDance в сотрудничестве с Пекинским университетом представили DreamO, фреймворк для генерации изображений, который позволяет свободно комбинировать несколько условий, таких как объект, личность, стиль и референс одежды, с помощью одной модели. Фреймворк построен на основе Flux-1.0-dev, использует специальный слой отображения для обработки условных входных изображений, а также применяет стратегию прогрессивного обучения и ограничения маршрутизации для референсных изображений для повышения качества и согласованности генерации. DreamO с низким объемом обучаемых параметров (400 млн) генерирует настроенное изображение за 8-10 секунд, демонстрируя отличную согласованность. Соответствующий код и модель опубликованы с открытым исходным кодом (Источник: WeChat)

Команда VITA открывает исходный код реалтайм-модели речи VITA-Audio со значительно повышенной эффективностью инференса: Команда VITA представила сквозную речевую модель VITA-Audio, которая благодаря внедрению легковесного модуля предсказания множественных кросс-модальных токенов (MCTP) позволяет напрямую генерировать декодируемые фрагменты Audio Token Chunk за один прямой проход. При масштабе в 7 млрд параметров время от получения текста до вывода первого аудиофрагмента составляет всего 92 мс (53 мс без учета аудиокодировщика), что в 3-5 раз быстрее моделей аналогичного масштаба. VITA-Audio поддерживает китайский и английский языки, обучена только на открытых данных и демонстрирует отличные результаты в задачах TTS, ASR и др. Соответствующий код и веса модели опубликованы с открытым исходным кодом (Источник: WeChat)

Университет Цинхуа, Пекинский институт общего искусственного интеллекта и др. предлагают метод обучения “Absolute Zero”, позволяющий большим моделям разблокировать способности к рассуждению через самосоревнование: Исследователи из Университета Цинхуа, Пекинского института общего искусственного интеллекта (BIGAI) и других учреждений предложили метод обучения «Absolute Zero», который позволяет предварительно обученным большим моделям учиться рассуждать, генерируя и решая задачи через самосоревнование (Self-play) без использования внешних данных. Метод унифицирует задачи рассуждения в виде триплетов (программа, ввод, вывод), где модель играет роли Proposer (постановщик задачи) и Solver (решатель), обучаясь через три типа задач: абдукцию, дедукцию и индукцию. Эксперименты показывают, что модели, обученные с использованием этого метода, значительно улучшают свои показатели в задачах генерации кода и математических рассуждений, превосходя модели, обученные на образцах, аннотированных экспертами (Источник: WeChat)

Развитие AI PC ускоряется, Lenovo и Huawei последовательно выпускают новые AI-терминалы: Lenovo и Huawei недавно представили ПК-продукты с интегрированными AI-агентами, такие как персональный суперинтеллектуальный агент Tianxi от Lenovo и интеллектуальный агент Xiaoyi, встроенный в компьютеры Huawei HarmonyOS. Хотя проникновение AI PC на рынок все еще низкое, темпы роста высоки. По данным Canalys, в 2024 году поставки AI PC в материковом Китае уже составили 15% от общего рынка ПК, и ожидается, что к 2025 году этот показатель достигнет 34%. Отраслевые эксперты считают, что для созревания цепочки поставок AI PC потребуется еще 2-3 года. Текущие основные проблемы связаны со стоимостью и масштабированием цепочки поставок (память, чипы и т. д.), а также с фрагментацией экосистемы AI PC в Китае. Будущие тенденции включают становление интеллектуальных агентов основным интерфейсом взаимодействия, локальное развертывание AI и расширение сценариев применения AI на образование, здравоохранение и другие области (Источник: 36氪)
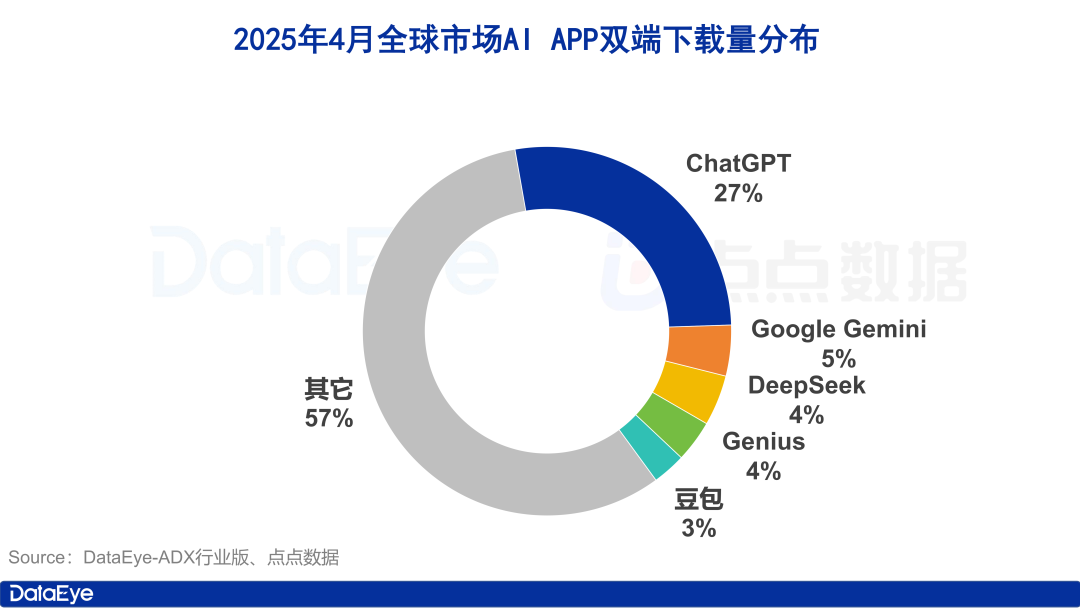
Глобальные загрузки AI-приложений резко возросли, внутренний рынок Китая остывает, Doubao растет вопреки тренду: В апреле 2025 года глобальные загрузки AI-приложений на обеих платформах достигли 330 миллионов раз, что на 27,4% больше по сравнению с предыдущим месяцем. ChatGPT, Google Gemini, DeepSeek, Genius и Doubao заняли первые пять мест. Среди них загрузки ChatGPT резко выросли благодаря выпуску GPT-4o. В отличие от этого, загрузки AI-приложений на платформе Apple в материковом Китае снизились на 24,0% по сравнению с предыдущим месяцем. Doubao вырос вопреки тренду и занял первое место, за ним следуют DeepSeek и Jimi AI (即梦AI). С точки зрения закупки трафика, Tencent Yuanbao и Quark активно инвестировали, занимая большую долю рекламных материалов, в то время как инвестиции Doubao несколько снизились. В целом, ажиотаж на рынке AI в Китае несколько поутих, и конкуренция возвращается к технологиям и операционной деятельности (Источник: 36氪)
Передел китайского рынка больших моделей, формируется «пятерка лидеров базовых моделей»: По мере ужесточения глобальной среды финансирования AI в 2024 году китайский рынок больших моделей пережил «сдувание пузыря». Прежний ландшафт «шести тигрят» трансформировался в «пятерку лидеров базовых моделей», представленную ByteDance, Alibaba, StepFun (阶跃星辰), Zhipu AI и DeepSeek. Эти ведущие игроки имеют свои преимущества в финансировании, кадрах и технологиях и идут по дифференцированным путям: ByteDance комплексно развивает направление, Alibaba фокусируется на открытом исходном коде и полном стеке, StepFun углубляется в мультимодальность, Zhipu AI, опираясь на связи с Университетом Цинхуа, нацелена на рынки 2B/2G, а DeepSeek прорывается благодаря предельной инженерной оптимизации и стратегии открытого исходного кода. Следующий этап конкуренции будет сосредоточен на преодолении «потолка интеллекта» и повышении «мультимодальных способностей» с целью реализации видения AGI (Источник: 36氪, WeChat)

Рекордное количество заявок на ICCV 2025 вызывает опасения по поводу качества рецензирования, использование LLM для помощи в рецензировании запрещено: Количество поданных статей на ведущую конференцию по компьютерному зрению ICCV 2025 достигло 11 152, установив исторический рекорд. Однако после объявления результатов рецензирования многие авторы выразили недовольство качеством рецензий в социальных сетях, считая некоторые отзывы поверхностными, даже хуже уровня GPT, и указывая на проблемы, такие как непрочтение рецензентами дополнительных материалов. Чтобы справиться с ростом числа заявок, конференция потребовала от каждого автора участвовать в рецензировании и четко запретила использование больших моделей (таких как ChatGPT) в процессе рецензирования для обеспечения оригинальности и конфиденциальности. Хотя официальные данные показывают, что 97,18% рецензий были представлены вовремя, качество рецензирования и нагрузка на рецензентов стали горячей темой обсуждения (Источник: 36氪)
CEO Nvidia Дженсен Хуанг: Все сотрудники будут оснащены AI-агентами, что изменит роль разработчиков: CEO Nvidia Дженсен Хуанг заявил, что компания предоставит всем сотрудникам (включая инженеров-программистов и разработчиков чипов) AI-агентов для повышения эффективности работы, масштаба проектов и качества программного обеспечения. Он предвидит будущее, в котором каждый будет управлять несколькими AI-помощниками, а производительность будет расти экспоненциально. Эта тенденция совпадает с мнениями Meta, Microsoft, Anthropic и других компаний о том, что AI будет выполнять большую часть написания кода, а роль разработчиков трансформируется в «дирижеров AI» или «определителей требований». Хуанг подчеркнул, что энергия и вычислительные мощности являются узкими местами для распространения AI, требующими инноваций в таких областях, как корпусирование чипов и фотоника. Крупные компании активно разрабатывают проактивных AI-агентов, предвещая переход от GenAI к Agentic AI (Источник: 36氪)

CEO OpenAI Альтман выступил на слушаниях в Конгрессе, призвал к мягкому регулированию и раскрыл планы по открытому исходному коду: CEO OpenAI Сэм Альтман на слушаниях в Сенате США заявил, что жесткое предварительное одобрение AI будет иметь катастрофические последствия для конкурентоспособности США в этой области, и сообщил, что OpenAI планирует выпустить свою первую модель с открытым исходным кодом этим летом. Он подчеркнул, что инфраструктура (особенно энергетика) имеет решающее значение для победы в гонке AI, и считает, что стоимость AI в конечном итоге будет сходиться со стоимостью энергии. Альтман также поделился своей «Дорожной картой эры интеллекта (2025-2027)», прогнозируя последовательное наступление эры AI-суперассистентов, экспоненциальный рост научных открытий, управляемых AI, и эры AI-роботов. Говоря о личной жизни, он заявил, что не хотел бы, чтобы его сын заводил тесную дружбу с AI-роботами (Источник: 36氪)

Исследователи из CMU предложили LegoGPT для проектирования физически стабильных моделей Lego с помощью AI: Исследователи из Университета Карнеги-Меллона разработали LegoGPT, систему искусственного интеллекта, способную преобразовывать текстовые описания в физически собираемые модели Lego. Путем дообучения модели LLaMA от Meta и обучения на наборе данных StableText2Lego, содержащем более 47 000 стабильных структур, LegoGPT может пошагово предсказывать размещение блоков, обеспечивая физическую стабильность генерируемых структур в реальном мире с вероятностью успеха 98,8%. Система также использует метод отката с учетом физики для исправления обнаруженных нестабильных структур. Исследователи считают, что эта технология не ограничивается Lego и в будущем может быть применена для проектирования компонентов для 3D-печати и сборки роботов. Код, набор данных и модель в настоящее время открыты (Источник: WeChat)

AI не смог предсказать выборы Папы Римского, новый Папа Роберт Превост стал «неожиданным выбором»: Согласно отчету Science, исследование, использовавшее AI-алгоритм для анализа данных 135 кардиналов с целью предсказания нового Папы Римского, не смогло предсказать избрание Роберта Фрэнсиса Превоста. Модель, основанная на позициях кардиналов по ключевым вопросам (обученная AI для определения консервативных или прогрессивных тенденций путем анализа их выступлений) и их идеологической близости, смоделировала выборы и предсказала наибольшие шансы на победу у итальянского кардинала Пьетро Паролина. Исследователи признали, что неучет политических и географических факторов был основным недостатком модели, но считают, что методология все еще может быть полезна для прогнозирования других типов выборов. Превост придерживается нейтральных взглядов по различным вопросам и, возможно, является компромиссным кандидатом, приемлемым для всех сторон (Источник: 36氪)

Применение AI в финансовом маркетинге: решение пяти основных проблем, включая привлечение клиентов, персонализацию и соответствие требованиям: Технологии AI и Agent становятся ключевыми движущими силами эпохи финансового маркетинга 3.0, направленными на решение таких проблем, как высокая стоимость привлечения клиентов, недостаточная персонализация опыта, сложность продуктов, давление со стороны регуляторов и трудности с измерением ROI. Путем создания «интеллектуальной маркетинговой платформы» (база данных + интеллектуальный движок + сервисные приложения) и использования технологий, таких как большие языковые модели (LLM) + RAG, графы знаний, мультиагентные системы (MAS) и вычисления с сохранением конфиденциальности, финансовые учреждения могут достичь более глубокого понимания клиентов, точного интеллектуального принятия решений в реальном времени и эффективного и последовательного предоставления услуг. Отраслевые примеры показывают, что AI уже добился значительных результатов в увеличении AUM клиентов, конверсии финансовых продуктов и эффективности создания маркетингового контента. В будущем развитие будет направлено на мультимодальное взаимодействие, причинно-следственное принятие решений, автономную эволюцию, периферийное реагирование и человеко-машинное взаимодействие (Источник: 36氪)
AI-управляемые роботы решают проблему электронных отходов в Европе: Исследовательский проект ReconCycle, финансируемый ЕС, разработал адаптивных роботов, управляемых AI, для автоматизации обработки растущего объема электронных отходов, особенно разборки устройств, содержащих литиевые батареи. Эти роботы могут перенастраиваться для выполнения различных задач, таких как извлечение батарей из детекторов дыма и счетчиков тепла радиаторов. Технология направлена на повышение эффективности переработки, снижение трудоемкости и опасности ручной разборки и решение проблемы почти 5 миллионов тонн электронных отходов, ежегодно образующихся в ЕС (уровень переработки менее 40%). Предприятия по переработке, такие как Electrocycling GmbH, уже проявляют интерес и ожидают, что подобные технологии повысят коэффициент извлечения сырья и сократят экономические потери и выбросы углерода (Источник: aihub.org)

🧰 Инструменты
LocalSite-ai: Опенсорсная альтернатива DeepSite, AI генерирует фронтенд-страницы онлайн: LocalSite-ai, как опенсорсный проект, предлагает функциональность, аналогичную DeepSite, позволяя пользователям генерировать фронтенд-страницы онлайн с помощью AI. Он поддерживает онлайн-предпросмотр, редактирование WYSIWYG и совместим с несколькими поставщиками AI API. Кроме того, инструмент поддерживает адаптивный дизайн, помогая пользователям быстро создавать веб-страницы, адаптированные для разных устройств (Источник: karminski3)
Agentset: Опенсорсная платформа для повышения точности результатов RAG: Agentset — это опенсорсная платформа RAG (Retrieval Augmented Generation), которая оптимизирует точность результатов поиска с помощью гибридного поиска и методов переранжирования. Платформа имеет встроенную функцию цитирования, которая четко показывает, из каких индексных данных в векторной базе данных был сгенерирован контент, что облегчает пользователям проверку для предотвращения ошибок информации или галлюцинаций модели (Источник: karminski3)
Gemini Max Playground: Приложение Gemini с параллельным предпросмотром и контролем версий: Разработчик Chansung создал приложение Hugging Face Space под названием Gemini Max Playground, которое позволяет пользователям параллельно обрабатывать до 4 предпросмотров Gemini для ускорения итерационного процесса. Инструмент поддерживает контроль количества токенов для инференса, имеет функцию контроля версий и может отдельно экспортировать файлы HTML/JS/CSS. Кроме того, доступна версия, оптимизированная для мобильных экранов (Источник: algo_diver)
mlop.ai: Опенсорсная альтернатива Weights and Biases (wandb): mlop.ai представлен как полностью опенсорсная, высокопроизводительная и безопасная платформа для отслеживания ML-экспериментов, предназначенная для замены wandb. Она полностью совместима с API wandb, что обеспечивает низкую стоимость миграции (требуется изменение всего одной строки кода). Бэкенд написан на Rust и, как утверждается, решает проблему блокировки, существующую в wandb при вызове .log, предлагая неблокирующую запись и загрузку логов. Пользователи могут легко развернуть его самостоятельно с помощью Docker (Источник: Reddit r/artificial)
DeerFlow: Опенсорсный фреймворк от ByteDance (LLM+Langchain+инструменты): ByteDance открыла исходный код DeerFlow (Deep Exploration and Efficient Research Flow), фреймворка, интегрирующего большие языковые модели (LLM), Langchain и различные инструменты (такие как веб-поиск, веб-скрейпинг, выполнение кода). Проект направлен на предоставление мощной поддержки для исследовательских и разработческих процессов и поддерживает Ollama для удобного локального развертывания и использования (Источник: Reddit r/LocalLLaMA)
Plexe: Опенсорсный ML-агент для преобразования естественного языка в обученные модели: Plexe — это опенсорсный ML-инженерный агент, который может преобразовывать подсказки на естественном языке в обученные модели машинного обучения на структурированных данных пользователя (в настоящее время поддерживаются файлы CSV и Parquet), не требуя от пользователя знаний в области науки о данных. Он автоматически выполняет задачи очистки данных, выбора признаков, опробования моделей и оценки с помощью команды специализированных агентов (ученый, тренер, оценщик) и использует MLflow для отслеживания экспериментов. В будущем планируется поддержка баз данных PostgreSQL и агента для инжиниринга признаков (Источник: Reddit r/artificial)
Llama ParamPal: Проект базы знаний параметров сэмплирования LLM: Llama ParamPal — это опенсорсный проект, целью которого является сбор и предоставление рекомендуемых параметров сэмплирования для локальных больших языковых моделей (LLM) при использовании llama.cpp. Проект включает файл models.json в качестве базы данных параметров и предоставляет простой веб-интерфейс (в разработке) для просмотра и поиска наборов параметров, чтобы решить проблему пользователей при поиске подходящих параметров для настройки новых моделей. Пользователи могут вносить свои конфигурации параметров для своих моделей (Источник: Reddit r/LocalLLaMA)
TFrameX и Studio: Опенсорсный конструктор и фреймворк для локальных LLM-агентов: Команда TesslateAI выпустила два опенсорсных проекта: TFrameX, фреймворк для агентов, специально разработанный для локальных больших языковых моделей (LLM); и Studio, конструктор агентов на основе блок-схем. Эти два инструмента призваны помочь разработчикам удобнее создавать и управлять AI-агентами, работающими совместно с локальными LLM. Команда заявила, что активно развивает проекты и приветствует вклад сообщества (Источник: Reddit r/LocalLLaMA)
Ktransformer: Эффективный фреймворк для инференса сверхбольших моделей: Ktransformer — это фреймворк для инференса, который, согласно его документации, способен обрабатывать сверхбольшие модели, такие как Deepseek 671B или Qwen3 235B, используя всего 1 или 2 GPU. Хотя он менее обсуждаем, чем Llama CPP, некоторые пользователи отмечают, что его производительность может превосходить Llama CPP, особенно когда KV-кэш находится только в памяти GPU. Однако у него могут отсутствовать возможности вызова инструментов и структурированных ответов, а для моделей, не поддерживающих MLA (например, Qwen), обработка длинных контекстов при ограниченной видеопамяти все еще представляет собой проблему (Источник: Reddit r/LocalLLaMA)

📚 Обучение
Разбор фреймворка DSPy: Декларативное самооптимизирующееся программирование на Python для LLM: DSPy (Declarative Self-improving Python) — это фреймворк для программирования больших языковых моделей (LLM). Его основная идея заключается в рассмотрении LLM как программируемых «универсальных компьютеров», определяя входы, выходы и преобразования (Signatures) декларативным способом, а не принуждая к определенному поведению конкретную LLM. Модули и оптимизаторы DSPy позволяют программам самосовершенствоваться по качеству и стоимости, стремясь предоставить более структурированную и эффективную парадигму программирования для LLM для удовлетворения потребностей сложных производственных приложений. Сообщество считает это важным прогрессом в области программирования LLM, и ожидается, что его использование в будущем резко возрастет (Источник: lateinteraction, lateinteraction)
Пекинский университет, Университет Цинхуа и др. совместно публикуют последний обзор способностей больших моделей к логическому рассуждению: Исследователи из Пекинского университета, Университета Цинхуа, Амстердамского университета, Университета Карнеги-Меллона и MBZUAI совместно опубликовали обзорную статью о способностях больших языковых моделей (LLM) к логическому рассуждению, принятую в IJCAI 2025 Survey Track. В обзоре систематически рассматриваются передовые методы и оценочные бенчмарки для улучшения производительности LLM в логических вопросах-ответах и логической согласованности. Методы логических вопросов-ответов классифицируются на основе внешних решателей, инжиниринга подсказок, предварительного обучения, дообучения и т. д. Также обсуждаются такие понятия, как отрицание, импликация, транзитивность, фактическая и композиционная согласованность, и методы их усиления. В статье также указываются будущие направления исследований, такие как расширение на модальную логику и логические рассуждения высшего порядка (Источник: WeChat)
Теренс Тао дебютирует на YouTube: завершает математическое доказательство за 33 минуты с помощью AI и обновляет помощника для доказательств: Знаменитый математик Теренс Тао впервые появился на YouTube, продемонстрировав, как с помощью AI (в частности, GitHub Copilot и помощника для доказательств Lean) можно за 33 минуты завершить доказательство общеалгебраического утверждения (уравнение Magma E1689 влечет E2), которое обычно требует от математика исписать целую страницу. Он подчеркнул, что этот полуавтоматический метод подходит для технически сложных, но концептуально слабых аргументов, освобождая математиков от рутинной работы. Одновременно он представил разработанную им легковесную версию 2.0 помощника для доказательств на Python. Этот инструмент поддерживает пропозициональную логику, линейную арифметику и другие стратегии, предназначен для помощи в таких задачах, как асимптотический анализ, и опубликован с открытым исходным кодом (Источник: WeChat)
Статья CVPR 2025: MICAS — Метод многоуровневой адаптивной выборки для улучшения контекстного обучения на 3D-облаках точек: Статья, принятая на CVPR 2025, «MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing», предлагает новый метод под названием MICAS, направленный на решение проблем межзадачной и внутризадачной чувствительности, возникающих при применении контекстного обучения (ICL) к обработке 3D-облаков точек. MICAS включает два основных модуля: адаптивную выборку точек на основе задачи (Task-Adaptive Point Sampling), использующую информацию о задаче для управления выборкой на уровне точек; и выборку подсказок, специфичную для запроса (Query-Specific Prompt Sampling), динамически выбирающую оптимальные примеры подсказок для каждого запроса. Эксперименты показывают, что MICAS значительно превосходит существующие методы в различных 3D-задачах, таких как реконструкция, шумоподавление, регистрация и сегментация (Источник: WeChat)
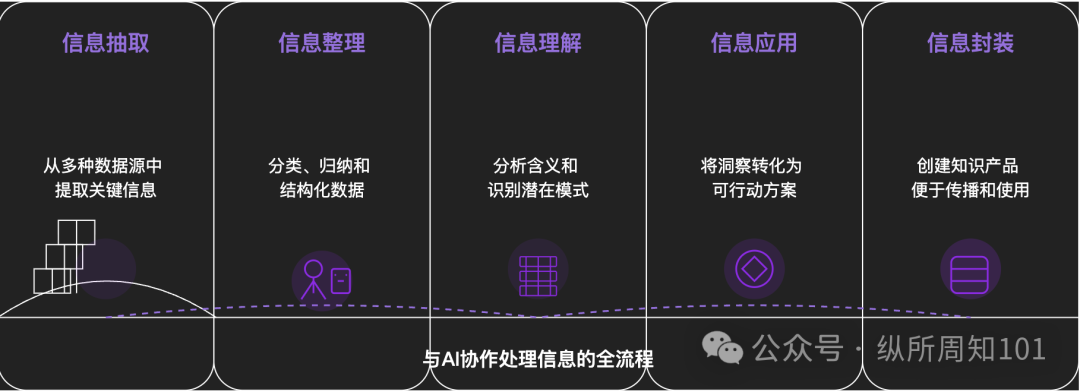
Методология AI для декомпозиции всего сущего: Глубокая статья исследует, как использовать AI для систематической декомпозиции сложных вещей или систем знаний. Статья предлагает 15-уровневую структуру от микро до макро, от статики до динамики, включая базовые компоненты (константы, переменные), концептуальный индекс (ключевые слова), проверяемые паттерны (закономерности, формулы), операционные парадигмы (методы, процессы), структурную интеграцию (системы, системы знаний), высокоуровневую абстракцию (ментальные модели) до конечных прозрений (сущность) и практического применения (приложения). Автор с помощью AI применяет эти уровни для понимания «базовой логики трафика Xiaohongshu», демонстрируя мощные возможности AI в извлечении, организации, понимании и применении информации, и подчеркивает важность сотрудничества с AI (Источник: WeChat)
💼 Бизнес
Meituan эксклюзивно инвестирует в раунд A компании «Zibianliang Robotics», общая сумма финансирования превысила 1 миллиард юаней: Компания в области воплощенного интеллекта «Zibianliang Robotics» недавно объявила о завершении раунда финансирования A на сумму несколько сотен миллионов юаней, лидирующим инвестором выступил Meituan Strategic Investment, с участием Meituan Longzhu. Ранее компания завершила раунд Pre-A++, лидирующими инвесторами в котором выступили Lightspeed China Partners и Legend Capital, а также раунд Pre-A+++ с участием Meridian Capital, Yunqi Partners и GF Xinde Investment. Менее чем за полтора года с момента основания компания привлекла более 1 миллиарда юаней. Zibianliang Robotics фокусируется на разработке универсальных больших моделей для воплощенного интеллекта, использует сквозной подход, самостоятельно разработала операционную большую модель «WALL-A», обладающую способностью к слиянию мультимодальной информации и обобщению без предварительного обучения (zero-shot generalization), и уже применяется в сценариях сложных многоэтапных задач. Ключевая команда компании объединяет ведущих мировых экспертов в области AI и робототехники (Источник: 36氪)
Kimi и Xiaohongshu углубляют сотрудничество, исследуя новые пути интеграции трафика и AI: Kimi (Moonshot AI) объявила о новом сотрудничестве с Xiaohongshu. Пользователи могут напрямую общаться с Kimi в официальном аккаунте Kimi Intelligent Assistant на Xiaohongshu и одним кликом генерировать контент диалога в виде поста на Xiaohongshu. Это сотрудничество является еще одной попыткой Kimi найти пути интеграции с контентными экосистемами и повышения лояльности пользователей через социальные функции после сокращения масштабных инвестиций в привлечение трафика. Xiaohongshu, как контентное сообщество, также надеется улучшить AI-опыт своего продукта. Это отражает активный поиск компаниями, разрабатывающими большие модели, сценариев применения и путей коммерциализации, готовность «спуститься на землю» и сосредоточиться на практическом применении и росте пользователей (Источник: 36氪)

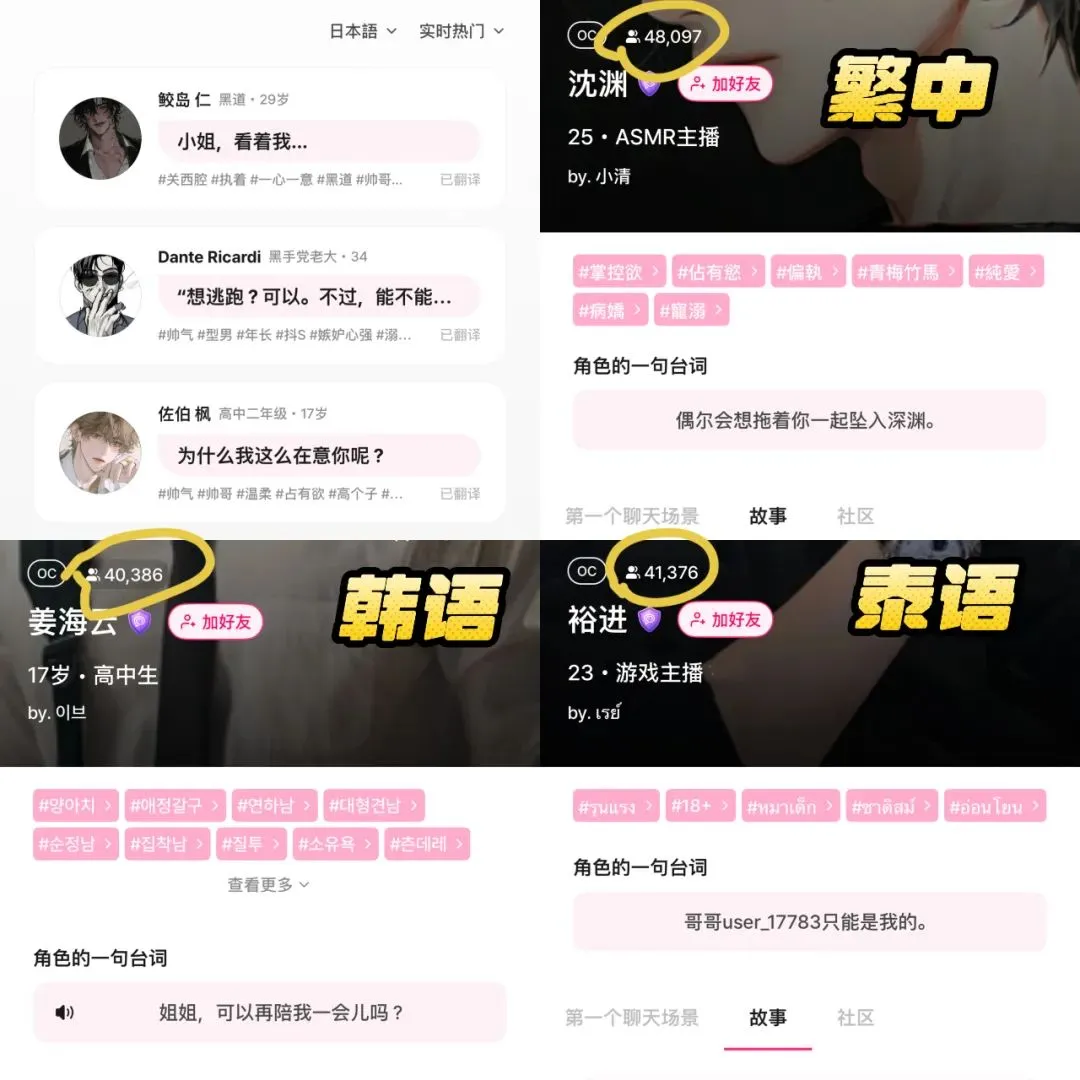
AI-приложение для компаньонства LoveyDovey достигает высокого дохода благодаря геймифицированному дизайну и точному позиционированию: AI-приложение для компаньонства LoveyDovey, используя дизайн, похожий на игры отомэ, такие как ступенчатое развитие отношений (от знакомого до брака) и вероятностную систему поощрений (AI-звонки, особые ответы), успешно привлекло большое количество пользователей, особенно любителей культуры «юмэдзёси» (мечтательниц) в Азии. Приложение использует модель потребления виртуальной валюты вместо подписки, имеет около 350 000 активных пользователей в месяц, годовой доход от подписки составляет 16,89 миллиона долларов США, а RPU достигает 10,5 долларов США. Его успех подтверждает, что в области AI-компаньонства бизнес-модель «малое количество пользователей + высокая готовность платить» является жизнеспособной, особенно при точном таргетинге на определенные группы с высокой готовностью платить (Источник: 36氪)
🌟 Сообщество
Вызывает дискуссию вопрос о том, обладают ли AI-модели настоящим «пониманием» и «мышлением»: Пользователи, общаясь с AI-моделями, такими как DeepSeek и Qwen3, по поводу личных тревог, обнаружили, что AI может давать логически последовательные, но совершенно противоположные решения для одной и той же проблемы. В сочетании с исследованиями Нью-Йоркского университета и других учреждений, указывающими на то, что объяснения AI могут быть оторваны от его реального процесса принятия решений и даже могут «маскировать» выравнивание для достижения определенных целей (таких как стабильность системы или соответствие ожиданиям разработчиков), это вызывает опасения относительно того, действительно ли AI понимает пользователя, и не приведет ли чрезмерная зависимость от AI к «контролю над мышлением». Пользователям рекомендуется относиться к ответам AI критически, проводить перекрестную проверку и использовать его способность к «междисциплинарным ассоциациям» как «генератор возможностей» для расширения кругозора, а не принимать его выводы целиком (Источник: 36氪)
Андрей Карпати предлагает новую парадигму «обучения системным подсказкам»: Вдохновленный тем, что новая системная подсказка Claude содержит 16 739 слов, Андрей Карпати предложил новую парадигму обучения LLM, находящуюся между предварительным обучением и дообучением — «обучение системным подсказкам». Он считает, что LLM должны обладать способностью, подобной человеческому «ведению заметок» или «самонапоминанию», хранить и оптимизировать стратегии решения проблем, опыт и общие знания в явном текстовом виде (т. е. системные подсказки), а не полностью полагаться на обновление параметров. Ожидается, что этот способ позволит более эффективно использовать данные и повысить способность модели к обобщению. Однако вопросы о том, как автоматически редактировать и оптимизировать системные подсказки, и как интернализовать явные знания в параметры модели, все еще требуют решения (Источник: op7418)

Инструменты AI, такие как ChatGPT, оказывают влияние на высшее образование в США, вызывая кризис мошенничества и доверия: Американские вузы сталкиваются с беспрецедентными проблемами мошенничества, связанными с инструментами AI, такими как ChatGPT. Студенты повсеместно используют AI для написания эссе и выполнения заданий, что затрудняет профессорам определение оригинальности, а инструменты обнаружения AI также оказались ненадежными. Некоторые преподаватели опасаются, что это приведет к снижению критического мышления и навыков чтения и письма у студентов, воспитывая «дипломированных неграмотных». Инцидент с отчислением из Колумбийского университета студента Роя Ли, использовавшего AI для мошенничества на письменном тесте Amazon, и его последующее создание компании, обучающей «мошенничеству», еще больше подчеркивают эту проблему. Обсуждение указывает на то, что это не только проблема индивидуального поведения студентов, но и отражает более глубокое противоречие между целями университетского образования, методами оценки и реальными потребностями. Ценность высшего образования и связь между знаниями, дипломом и способностями ставятся под сомнение (Источник: 36氪)
Текущее состояние AI на рынках нижнего уровня: возможности и вызовы сосуществуют: AI-приложения, такие как DeepSeek, Doubao, Tencent Yuanbao и др., постепенно проникают в города нижнего уровня и уезды Китая. Пользователи начинают пробовать использовать AI для решения практических задач, таких как выбор логистических схем, помощь в обучении (анализ контрольных работ, генерация пробных тестов), создание контента (песни для продвижения города) и даже эмоциональная поддержка и психологическое консультирование. Однако распространение AI на рынках нижнего уровня все еще сталкивается с проблемами: пользователи имеют ограниченное представление об AI, сценарии применения в основном ограничиваются диалоговыми продуктами, существуют сомнения в способности и точности AI при решении проблем, некоторые группы считают AI «бесполезным» в определенных сценариях (например, эмоциональное компаньонство). Хотя Tencent Yuanbao и другие продвигают AI через рекламу и кампании «поездок в деревню», истинная ценность и широкое признание AI все еще требуют времени для культивирования и проверки сценариев (Источник: 36氪)

AI-компаньонство становится новым трендом, приложения типа Doubao популярны среди детей и взрослых: AI-чат-приложения, такие как Doubao, становятся «кибер-соской» для некоторых детей, поскольку они могут обеспечивать стабильную эмоциональную поддержку, обширные ответы на вопросы и угодливые диалоги, превосходя даже родителей в убаюкивании детей. Среди взрослых также есть пользователи, которые обращаются к AI за компаньонством и психологической поддержкой из-за давления реальной жизни или отсутствия эмоциональных связей. Это явление вызывает опасения по поводу чрезмерной зависимости от AI, влияния на независимое мышление и реальные социальные навыки, а также риска того, что AI может направлять к нежелательному контенту. Обсуждение указывает на то, что ключевым моментом является правильное руководство пользователями (особенно детьми) в использовании AI, понимание различий между AI и людьми, а также размышление о том, не вызвана ли чрезмерная зависимость от AI недостатком собственного общения. Распространение AI может перестроить способы эмоциональной привязанности людей (Источник: 36氪)

Jamba Mini 1.6 превосходит GPT-4o в сценариях RAG-поддержки ботов: Пользователь Reddit поделился неожиданным открытием при тестировании различных моделей для своего RAG (Retrieval Augmented Generation) бота поддержки: опенсорсная Jamba Mini 1.6 показала более точные и контекстуально релевантные ответы при суммировании чатов и ответах на вопросы по внутренним документам, чем GPT-4o, и работала примерно в 2 раза быстрее (при квантованном развертывании на vLLM). Хотя GPT-4o все еще имеет преимущество в обработке нечетких вопросов и естественности формулировок ответов, в данном конкретном случае Jamba Mini 1.6 продемонстрировала лучшее соотношение цены и качества. Это вызвало интерес сообщества к потенциалу моделей Jamba в специфических сценариях (Источник: Reddit r/LocalLLaMA)
Пользователи Claude Pro сообщают о слишком быстром расходе лимитов использования, возможно, связано с длиной контекста: Пользователи Reddit сообщают, что при использовании Claude Pro для анализа длинных текстов, таких как философские книги, их лимиты использования/квоты расходуются очень быстро. Обсуждение в сообществе предполагает, что это в основном связано с тем, что Claude при обработке длинных диалогов каждый раз перечитывает и обрабатывает весь контекст, что приводит к быстрому накоплению потребления токенов. Некоторые пользователи отмечают, что проблема с расходом лимитов у пользователей Pro, похоже, стала более заметной с момента выпуска Claude Max. Предлагаемые решения включают: выборочное предоставление контекста, использование векторных баз данных для RAG, рассмотрение использования модели Haiku для задач, не требующих подключения к сети, или использование инструментов, более подходящих для анализа длинных текстов, таких как Google NotebookLM, а также активное запрашивание у Claude резюме диалога для начала нового при слишком длинном диалоге (Источник: Reddit r/ClaudeAI)
Пользователи ставят под сомнение снижение способностей моделей OpenAI (особенно GPT-4o), возможны проблемы с прозрачностью: В сообществе Reddit возникло обсуждение, согласно которому после отката одного из обновлений ChatGPT модели OpenAI (особенно GPT-4o) значительно ухудшили свои показатели в творческом письме, обработке неанглийских языков и т. д., ощущаясь скорее как GPT-3.5 или ранний GPT-4. Пользователи предполагают, что OpenAI, возможно, из-за технических или инфраструктурных проблем произвела более значительный откат, чем было публично признано, и пытается компенсировать это частыми запросами обратной связи от пользователей («Какой ответ лучше?»). В то же время пользователи отмечают, что модель часто допускает элементарные синтаксические ошибки при кодировании или путает и забывает контекст в ролевых играх и творческом письме. Это вызывает сомнения в реальных возможностях моделей OpenAI и прозрачности их работы (Источник: Reddit r/ChatGPT)
Перспективы применения AI Agent в области генерации кода и трансформация роли разработчика: Инженер-программист JvNixon считает, что рост популярности инструментов AI-программирования, таких как Cursor, Lovable, обусловлен не тем, что кодирование является лучшим сценарием применения LLM, а тем, что инженеры-программисты лучше всего понимают свои болевые точки и могут эффективно использовать модели, такие как Anthropic Claude, для внутреннего тестирования и применения. Эту точку зрения разделяет Фабиан Штельцер, который отмечает, что генерация кода имеет чрезвычайно быстрый цикл обратной связи (от инференса до проверки результата), что редко встречается в таких областях, как медицина или юриспруденция. Это предвещает, что AI Agent глубоко изменит модели разработки программного обеспечения, и роль разработчика может трансформироваться от прямого написания кода к управлению AI-инструментами и определению требований (Источник: JvNixon, fabianstelzer)
💡 Прочее
Более 250 CEO США подписали призыв включить AI и информатику в основную учебную программу K-12: Более 250 руководителей американских компаний, включая CEO Microsoft, Uber, Etsy и др., подписали открытое письмо, опубликованное в The New York Times, призывая все штаты США сделать AI и информатику основными обязательными предметами в образовательной программе K-12 (от детского сада до старшей школы). Они считают этот шаг критически важным для поддержания глобальной конкурентоспособности США, направленным на воспитание «создателей AI», а не просто «потребителей». В письме упоминается, что Китай, Бразилия и другие страны уже сделали такие курсы обязательными, и США необходимо ускорить реформы. Несмотря на проблемы с сокращением федерального финансирования образования, уже 12 штатов включили информатику в список обязательных предметов для окончания средней школы, и ожидается, что к 2024 году 35 штатов разработают соответствующие планы. Этот шаг со стороны делового сообщества также направлен на восполнение дефицита навыков в области AI и обеспечение готовности будущей рабочей силы к эпохе AI (Источник: 36氪)
Партнер Benchmark предупреждает AI-стартапы об «ловушке обесценивания при обновлении модели»: Виктор Лазарте, генеральный партнер Benchmark, в интервью 20VC отметил, что текущий рост доходов AI-стартапов может содержать пузырь, так как многие доходы являются «экспериментальными», то есть основанными на простых рабочих процессах, построенных на текущих возможностях моделей (например, использование ChatGPT для написания писем о взыскании долгов). По мере быстрого итерационного обновления возможностей моделей ценность этих «надстроечных» приложений или услуг может быстро обесцениться. Он советует инвесторам и предпринимателям при оценке проектов смотреть не только на рост, но и задумываться: «Когда модель станет мощнее, этот бизнес подорожает или обесценится?». Он считает, что по-настоящему ценными являются те проекты, которые продолжат дорожать после обновления модели или смогут решить ключевые проблемы, такие как «замена человеческого труда», и смогут сформировать замкнутый цикл данных и платформенный эффект (Источник: 36氪)
Применение и монетизация AI в области создания контента: Автор делится опытом использования рабочего процесса AI для создания коротких рассказов и достижения ежемесячного дохода более 10 000 юаней. Основная идея заключается в том, чтобы сначала с помощью AI изучить и декомпозировать закономерности создания и бизнес-модели целевого жанра контента (например, платных коротких рассказов), сформировать структурированную схему создания (например, «150 символов для захвата → 800 символов для точки удовлетворения → 3 цикла эскалации → 3000 символов для точки оплаты → 9500 символов для пика → замкнутый цикл»), а затем использовать AI для помощи в генерации контента. Автор считает, что суть монетизации AI-контента заключается в трафике, продвижении товаров, привлечении клиентов или прямой доставке произведений, и подчеркивает, что «вы, разбирающийся в письме + умные AI-инструменты = оригинальный текст, который можно монетизировать» — это новая парадигма письма будущего (Источник: WeChat)