
Ключевые слова:OpenAI, Искусственный интеллект (ИИ), Большие языковые модели, Обучение с подкреплением, Инфраструктура ИИ, Мультимодальный ИИ, Агенты ИИ, RAG (Retrieval-Augmented Generation), Национальная программа OpenAI по ИИ, Экспортные ограничения на чипы NVIDIA H20, Оптимизация вывода DeepSeek-R1, Мета-оптический микроскоп ИИ Meta-rLLS-VSIM, Seed-Coder: кодовая модель от ByteDance
🔥 В центре внимания
OpenAI запускает программу «ИИ национального уровня», содействуя созданию глобальной инфраструктуры ИИ: OpenAI запускает проект «OpenAI for Countries» в рамках своего плана «Stargate», направленный на оказание помощи странам в создании локальных центров обработки данных для ИИ, кастомизации ChatGPT и содействии развитию экосистемы ИИ. CEO Сэм Альтман уже посетил первый суперкомпьютерный кампус в Abilene, штат Техас, который является частью плана «Stargate» стоимостью 500 миллиардов долларов, целью которого является создание крупнейшего в мире объекта для обучения ИИ. Этот шаг означает, что OpenAI будет сотрудничать с правительствами многих стран для продвижения глобального распространения и применения технологий ИИ посредством создания инфраструктуры и обмена технологиями. Первоначально планируется сотрудничество с 10 странами или регионами (Источник: WeChat)

По слухам, администрация Трампа намерена отменить трехуровневые ограничения на экспорт чипов ИИ и, возможно, внедрит более простую глобальную систему лицензирования: По сообщениям зарубежных СМИ, администрация Трампа планирует отменить «Рамки распространения искусственного интеллекта» (FAID), принятые в конце эпохи Байдена, которые первоначально предусматривали трехуровневую классификацию ограничений на экспорт чипов ИИ по всему миру. Команда Трампа считает эти рамки слишком громоздкими и препятствующими инновациям, склоняясь к замене их более простой глобальной системой лицензирования, реализуемой через межправительственные соглашения. Этот шаг может повлиять на глобальные рыночные стратегии производителей чипов, таких как Nvidia, и направлен на укрепление инновационного и доминирующего положения США в области ИИ (Источник: WeChat)

Команда SGLang значительно оптимизировала производительность инференса DeepSeek-R1, увеличив пропускную способность в 26 раз: Объединенная команда из SGLang, Nvidia и других организаций за четыре месяца увеличила производительность инференса модели DeepSeek-R1 на GPU H100 в 26 раз благодаря комплексной модернизации движка инференса SGLang. Решения по оптимизации включают разделение предварительного заполнения и декодирования (PD-разделение), крупномасштабный параллелизм экспертов (EP), DeepEP, DeepGEMM и балансировщик нагрузки для параллелизма экспертов (EPLB). При обработке входных последовательностей из 2000 токенов была достигнута пропускная способность 52,3 тыс. входных токенов и 22,3 тыс. выходных токенов в секунду на узел, что близко к официальным данным DeepSeek и значительно снижает затраты на локальное развертывание (Источник: WeChat)

Ученый OpenAI Дэн Робертс: Расширение обучения с подкреплением будет способствовать открытию новых научных знаний ИИ, возможно, через 9 лет будет достигнут AGI уровня Эйнштейна: Исследователь OpenAI Дэн Робертс выступил на конференции Sequoia Capital AI Ascent, где обсудил ключевую роль обучения с подкреплением (RL) в создании будущих моделей ИИ. Он считает, что благодаря постоянному масштабированию RL модели ИИ смогут не только улучшить свои показатели в таких задачах, как математическое мышление, но и совершать научные открытия с помощью «вычислений во время тестирования» (т.е. чем дольше модель «думает», тем лучше ее результат). В качестве примера он привел открытие Эйнштейном общей теории относительности, предположив, что если ИИ сможет вычислять и «думать» в течение 8 лет, то через 9 лет он сможет достичь научного прорыва уровня Эйнштейна. Робертс подчеркнул, что будущее развитие ИИ будет в большей степени ориентировано на вычисления RL, которые могут даже доминировать во всем процессе обучения (Источник: WeChat)

🎯 События
Джим Фан из Nvidia: Роботы пройдут «физический тест Тьюринга», симуляция и генеративный ИИ являются ключевыми факторами: Руководитель отдела робототехники Nvidia Джим Фан в своем выступлении на Sequoia AI Ascent представил концепцию «физического теста Тьюринга», при котором люди не смогут отличить, выполнена ли задача человеком или роботом. Он отметил, что текущие затраты на сбор данных для роботов высоки, и ключевую роль играет технология симуляции, особенно в сочетании с генеративным ИИ (например, тонкая настройка моделей генерации видео) для создания разнообразных и крупномасштабных обучающих данных («цифровые кузены», а не точные «цифровые двойники»). Он прогнозирует, что благодаря крупномасштабной симуляции и моделям «зрение-язык-действие» (таким как GR00T от Nvidia) в будущем физические API будут повсеместными, роботы смогут выполнять сложные повседневные задачи и интегрироваться с интеллектуальной средой (Источник: WeChat)
ByteDance выпустила серию больших языковых моделей для кода Seed-Coder, версия 8B демонстрирует превосходные результаты: ByteDance представила серию больших языковых моделей для кода Seed-Coder, включающую версии 8B, 14B и другие. Среди них Seed-Coder-8B показал выдающиеся результаты на нескольких бенчмарках для оценки способностей к кодированию, таких как SWE-bench, Multi-SWE-bench и IOI, и, как утверждается, превосходит Qwen3-8B и Qwen2.5-Coder-7B-Inst. Серия моделей включает версии Base, Instruct и Reasoner, ее основная концепция — «позволить модели кода самой курировать данные для себя», что привело к значительному улучшению способностей к рассуждению о коде и программной инженерии. Модели доступны с открытым исходным кодом на Hugging Face и GitHub (Источник: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba представила фреймворк ZeroSearch с открытым исходным кодом, использующий LLM для имитации поиска и снижающий затраты на обучение ИИ на 88%: Исследователи из Alibaba выпустили фреймворк для обучения с подкреплением под названием «ZeroSearch», который позволяет большим языковым моделям (LLM) разрабатывать расширенные функции поиска путем имитации поисковых систем без необходимости вызова дорогостоящих API коммерческих поисковых систем (таких как Google) в процессе обучения. Эксперименты показали, что использование LLM с 3 миллиардами параметров в качестве имитатора поисковой системы может эффективно улучшить поисковые возможности стратегической модели, а производительность модуля извлечения с 14 миллиардами параметров даже превосходит поиск Google, при этом затраты на API снижаются на 88%. Технология доступна с открытым исходным кодом на GitHub и Hugging Face и поддерживает серии моделей, такие как Qwen-2.5 и LLaMA-3.2 (Источник: WeChat)

Gemini API запускает функцию неявного кэширования, позволяющую сэкономить до 75% затрат: Google Gemini API недавно включил функцию неявного кэширования для семейства моделей Gemini 2.5 (Pro и Flash). Когда запрос пользователя попадает в кэш, можно автоматически сэкономить до 75% затрат. Одновременно был снижен минимальный порог токенов для срабатывания кэширования: для модели 2.5 Flash он снижен до 1K токенов, а для модели 2.5 Pro — до 2K токенов. Этот шаг направлен на снижение затрат разработчиков на использование Gemini API и повышение эффективности часто повторяющихся запросов (Источник: JeffDean)
Университет Цинхуа разработал ИИ-оптический микроскоп Meta-rLLS-VSIM, объемное разрешение увеличено в 15,4 раза: Исследовательская группа Ли Дуна из Университета Цинхуа в сотрудничестве с командой Дай Цюнхая предложила виртуальный структурированный световой микроскоп на основе отражающей решетчатой световой пластины, управляемый метаобучением (Meta-rLLS-VSIM). Эта система, благодаря инновационному пересечению ИИ и оптики, повысила поперечное разрешение при визуализации живых клеток до 120 нм, а осевое разрешение — до 160 нм, достигнув почти изотропного сверхвысокого разрешения. Объемное разрешение увеличено в 15,4 раза по сравнению с традиционным LLSM. Ключевые технологии включают использование DNN для обучения и расширения возможностей сверхвысокого разрешения на несколько направлений с помощью «виртуального структурированного освещения», а также повышение осевого разрешения за счет слияния информации с двух ракурсов с помощью зеркального отражения и сети RL-DFN. Внедрение стратегии метаобучения позволяет модели ИИ завершить адаптивное развертывание всего за 3 минуты, что значительно снижает барьер для применения ИИ в биологических экспериментах и предоставляет мощный инструмент для наблюдения за такими жизненными процессами, как деление раковых клеток и эмбриональное развитие (Источник: WeChat)

Выпущена серия больших языковых моделей Qwen3, продолжающая лидировать в сообществе открытого исходного кода: Alibaba выпустила серию больших языковых моделей Qwen3 с размером параметров от 0.5B до 235B, которые показали отличные результаты в нескольких бенчмарках. Многие модели меньшего размера достигли уровня SOTA среди моделей с открытым исходным кодом аналогичного масштаба. Серия Qwen3 поддерживает несколько языков, а длина контекста достигает 128k токенов. Благодаря своей высокой производительности и более низким затратам на развертывание (по сравнению, например, с DeepSeek-R1), серия Qwen широко используется за рубежом (особенно в Японии) в качестве основы для разработки ИИ и породила большое количество специализированных моделей. Выпуск Qwen3 еще больше укрепил ее лидирующие позиции в мировом сообществе ИИ с открытым исходным кодом: за неделю на GitHub количество звезд превысило 20 тысяч (Источник: dl_weekly, WeChat)

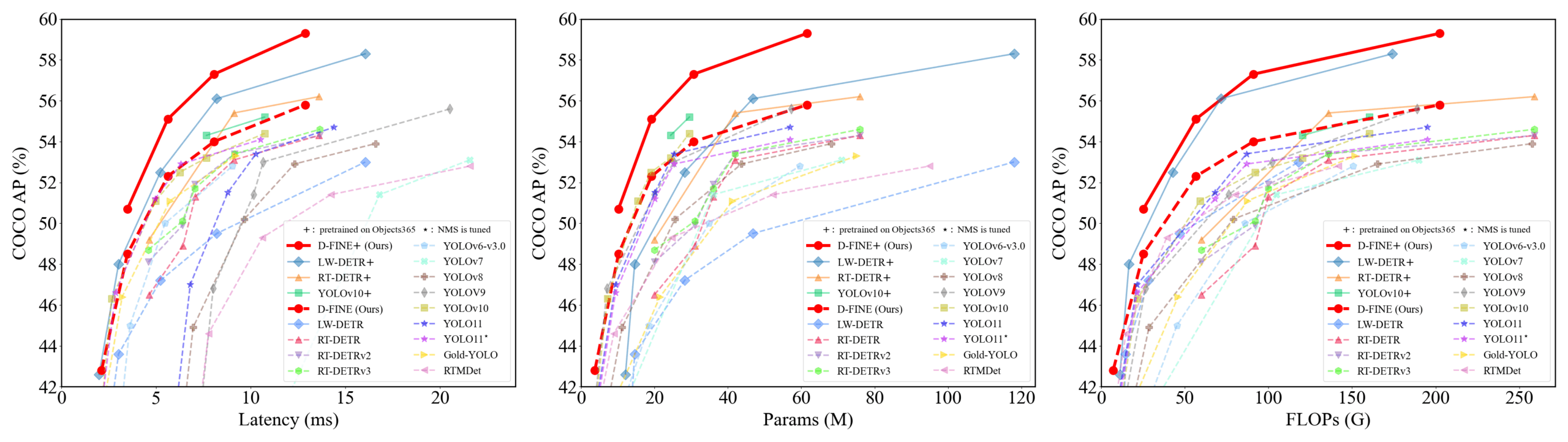
D-FINE: детектор объектов в реальном времени на основе оптимизации мелкозернистого распределения с превосходной производительностью: Исследователи предложили D-FINE, новый детектор объектов в реальном времени, который переопределяет задачу регрессии ограничивающих рамок в DETR как оптимизацию мелкозернистого распределения (FDR) и вводит стратегию самодистилляции для глобально оптимального позиционирования (GO-LSD). D-FINE достигает превосходной производительности без увеличения дополнительных затрат на вывод и обучение. Например, D-FINE-N достигает 42.8% AP на COCO val со скоростью до 472 FPS (GPU T4); D-FINE-X после предварительного обучения на Objects365+COCO достигает 59.3% AP на COCO val. Этот метод достигает более точного позиционирования за счет итеративной оптимизации вероятностных распределений и передает знания о позиционировании с конечного слоя на ранние слои посредством самодистилляции (Источник: GitHub Trending)
Модель Harmon координирует визуальные представления, объединяя мультимодальное понимание и генерацию: Исследователи из Наньянского технологического университета предложили модель Harmon, направленную на объединение задач мультимодального понимания и генерации путем совместного использования MAR Encoder (Masked Autoencoder for Reconstruction). Исследование показало, что MAR Encoder в процессе обучения генерации изображений одновременно изучает визуальную семантику, а его результаты Linear Probing значительно превосходят VQGAN/VAE. Фреймворк Harmon использует MAR Encoder для обработки полных изображений для понимания и следует парадигме моделирования с маскированием MAR для генерации изображений, при этом LLM обеспечивает взаимодействие между модальностями. Эксперименты показывают, что Harmon приближается к Janus-Pro на бенчмарках мультимодального понимания и демонстрирует превосходные результаты на бенчмарках эстетики генерации текста в изображение MJHQ-30K и следования инструкциям GenEval, даже превосходя некоторые экспертные модели. Модель доступна с открытым исходным кодом (Источник: WeChat)

Роботы для технологической логистики компании Tuixing Technology достигают коммерческой замкнутости, накапливая данные через «систему теневого курьера»: Логистические роботы компании Tuixing Technology уже введены в эксплуатацию в нескольких городах Китая и, работая совместно с курьерами-людьми, достигли точки безубыточности для отдельных роботов. Одной из ключевых технологий является «система теневого курьера», которая собирает данные о поведении реальных курьеров в сложных городских условиях, их восприятии окружающей среды и операциях (таких как открытие/закрытие дверей, взятие/размещение предметов), предоставляя роботам огромные объемы высококачественных данных для обучения подражанию и обучения с подкреплением. В настоящее время система накопила данные о десятках миллионов километров пробега и почти миллионе траекторий движения верхних конечностей. На основе этих данных Tuixing Technology обучила модель VLA на основе дерева поведений, что позволяет роботам справляться со сложными ситуациями в реальном мире, и планирует выход на зарубежные рынки (Источник: WeChat)

Kuaishou запускает фреймворк KuaiMod, использующий мультимодальные большие модели для оптимизации экосистемы коротких видео: Kuaishou предложила решение для оптимизации экосистемы платформы коротких видео KuaiMod на основе мультимодальных больших моделей, направленное на улучшение пользовательского опыта за счет автоматического определения качества контента. KuaiMod использует подход, основанный на прецедентном праве, применяя визуально-языковые модели (VLM) для анализа некачественного контента с помощью цепочки рассуждений и постоянно обновляя стратегии определения качества посредством обучения с подкреплением на основе отзывов пользователей (RLUF). Фреймворк уже развернут на платформе Kuaishou и эффективно снизил количество жалоб пользователей более чем на 20%. Kuaishou также работает над созданием мультимодальной большой модели, способной понимать короткие видео сообщества, переходя от извлечения представлений к глубокому семантическому пониманию, и уже применяет ее в нескольких сценариях, таких как структурирование тегов интересов к видео и помощь в генерации контента, добившись положительных результатов (Источник: WeChat)

Lenovo выпускает персонального суперинтеллектуального агента «Tianxi», двигаясь к интеллекту уровня L3: На конференции по инновационным технологиям Lenovo представила персонального суперинтеллектуального агента «Tianxi», обладающего мультимодальным восприятием и взаимодействием, когнитивными способностями и принятием решений на основе персональной базы знаний, а также возможностью автономной декомпозиции и выполнения сложных задач. Tianxi стремится обеспечить естественное и бесшовное взаимодействие человека и машины через сопутствующие интерфейсы AUI, такие как AI Suixin Chuang, AI Linglong Tai и AI Ruying Kuang. Он интегрирует несколько ведущих отраслевых больших моделей, включая DeepSeek-R1, и использует гибридную архитектуру развертывания «edge-cloud» в сочетании с персональным облаком Lenovo Personal Cloud 1.0 (оснащенным большой моделью с 72 миллиардами параметров) для обеспечения мощной вычислительной мощности и 100 ГБ эксклюзивного пространства памяти. Lenovo также выпустила корпоративного суперинтеллектуального агента «Leshang» и городского уровня, демонстрируя свое всестороннее присутствие в области ИИ (Источник: WeChat)

Новое исследование определяет обобщающую способность нейронных сетей через сложность символического взаимодействия: Команда профессора Чжан Цюаньши из Шанхайского университета Цзяотун предложила новую теорию для анализа обобщающей способности нейронных сетей с точки зрения сложности их внутреннего символического представления взаимодействий. Исследование показало, что обобщаемые взаимодействия (часто встречающиеся как в обучающих, так и в тестовых наборах) обычно демонстрируют убывающее распределение по различным порядкам (сложности) (преобладают взаимодействия низкого порядка), в то время как необобщаемые взаимодействия (в основном встречающиеся в обучающем наборе) показывают веретенообразное распределение (преобладают взаимодействия среднего порядка, где положительные и отрицательные эффекты легко компенсируют друг друга). Эта теория направлена на прямое определение потенциала обобщения модели путем анализа распределения ее эквивалентной «логики И-ИЛИ взаимодействий», предоставляя новый взгляд на понимание и улучшение обобщающей способности моделей (Источник: WeChat)
🧰 Инструменты
Llama.cpp полностью совместим с визуально-языковыми моделями (VLM): Llama.cpp теперь полностью поддерживает визуально-языковые модели (VLM), что позволяет разработчикам запускать мультимодальные приложения на устройствах. Жюльен Шомон из Hugging Face и другие поделились предварительно квантованными моделями, включая Gemma от Google DeepMind, Pixtral от Mistral AI, Qwen VL от Alibaba и SmolVLM от Hugging Face, которые можно использовать напрямую. Это обновление стало возможным благодаря вкладу команд @ngxson и @ggml_org и открывает новые возможности для локализованных мультимодальных ИИ-приложений с низкой задержкой (Источник: ggerganov, ClementDelangue, cognitivecompai)
Kuake AI Super Box обновлен функцией «глубокого поиска» для повышения «поискового IQ» ИИ: Kuake AI Super Box недавно был обновлен, получив функцию «глубокого поиска», направленную на повышение поискового интеллекта (поискового IQ) ИИ. Новая функция подчеркивает активное мышление и логическое планирование ИИ перед поиском, позволяя лучше понимать сложные и персонализированные запросы пользователей, декомпозировать проблемы и выполнять упорядоченный интеллектуальный поиск. В области здравоохранения ИИ-консультант Kuake «Акуа» будет ссылаться на мнения врачей высшей категории и профессиональные материалы; в академической сфере он будет подключен к авторитетным источникам, таким как CNKI. Кроме того, Kuake обладает мощными возможностями мультимодальной обработки, такими как анализ изображений, AI抠图 (удаление фона с помощью ИИ), улучшение изображений и преобразование стиля. Сообщается, что в будущем Kuake также выпустит версию Deep Research Pro с возможностями глубокого исследования (Источник: WeChat)

LangChain представляет множество интеграций и учебных пособий, усиливая возможности RAG и интеллектуальных агентов: LangChain недавно выпустил несколько обновлений и учебных пособий: 1. Учебное пособие по пользовательскому интерфейсу для интеллектуальных агентов в социальных сетях: Руководство по преобразованию интеллектуальных агентов LangChain для социальных сетей в удобное для пользователя веб-приложение с интеграцией ExpressJS и AgentInbox UI, а также поддержкой Notion. 2. Отмеченное наградами решение RAG: Демонстрация реализации RAG для анализа годовых отчетов компаний, поддерживающая разбор PDF, несколько LLM и расширенный поиск. 3. Приватное чат-приложение RAG: Учебное пособие демонстрирует, как создать локализованное чат-приложение RAG с акцентом на конфиденциальность данных с использованием LangChain и фреймворка Reflex. 4. Интеграция Nimble Retriever: Внедрение мощного ретривера веб-данных, предоставляющего точные данные для приложений LangChain. 5. Руководство по структурированному выводу Claude 3.7: Предлагает три метода достижения структурированного вывода Claude 3.7 через LangChain и AWS Bedrock. 6. Локальная система чата RAG: Проект с открытым исходным кодом демонстрирует полностью локализованную систему ответов на вопросы по документам, созданную с использованием процесса LangChain RAG и локальных LLM (через Ollama), обеспечивающую конфиденциальность данных (Источник: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: фреймворк для ИИ-агентов с открытым исходным кодом, объединяющий возможности нескольких фреймворков: Minion-agent — это новый фреймворк для разработки ИИ-агентов с открытым исходным кодом, призванный решить проблему фрагментации существующих ИИ-фреймворков (таких как OpenAI, LangChain, Google AI, SmolaAgents). Он предоставляет единый интерфейс, поддерживает вызов возможностей нескольких фреймворков, инструменты как услугу (просмотр веб-страниц, операции с файлами и т. д.), а также совместную работу нескольких агентов. Проект демонстрирует свой потенциал в таких сценариях, как глубокие исследования (автоматический сбор литературы для генерации отчетов), сравнение цен (автоматизированное исследование рынка), генерация идей (создание игрового кода) и отслеживание технологических тенденций, подчеркивая преимущества модели с открытым исходным кодом в гибкости и экономической эффективности (Источник: WeChat)

RunwayML демонстрирует мощные возможности генерации и редактирования видео в различных сценариях: Независимый исследователь ИИ Кристобаль Валенсуэла и другие пользователи продемонстрировали применение RunwayML в различных творческих сценариях. Включая использование его функций Frames, References и Gen-4 для быстрого создания и визуализации творческих визуальных эффектов при сохранении согласованности стиля и персонажей; превращение мира Рембрандта в видеоигру RPG; а также синтез новых видов дизайна интерьера из одного изображения путем предоставления визуальных референсов. Эти примеры подчеркивают прогресс RunwayML в управляемой генерации видео, переносе стиля и построении сцен (Источник: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: универсальный маршрутизатор задач для компьютерного зрения: Olympus — это универсальный маршрутизатор задач, разработанный для задач компьютерного зрения. Он предназначен для упрощения и унификации процессов обработки различных визуальных задач, возможно, путем интеллектуального планирования и распределения вычислительных ресурсов или вызовов моделей для оптимизации эффективности и производительности многозадачных систем компьютерного зрения. Проект доступен с открытым исходным кодом на GitHub (Источник: dl_weekly)
Tracy Profiler: гибридный профилировщик кадров и семплирования в реальном времени с наносекундным разрешением: Tracy Profiler — это инструмент для профилирования кадров и семплирования в реальном времени с наносекундным разрешением и поддержкой удаленной телеметрии, предназначенный для игр и других приложений. Он поддерживает анализ производительности CPU (C, C++, Lua, Python, Fortran и сторонние привязки для Rust, Zig, C# и др.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), распределения памяти, блокировок, переключений контекста, а также может автоматически связывать скриншоты с захваченными кадрами. Этот инструмент, благодаря своей высокой точности и работе в реальном времени, предоставляет разработчикам мощные средства для выявления и оптимизации узких мест в производительности (Источник: GitHub Trending)

FieldStation42: симулятор ретро-телевидения: FieldStation42 — это проект на Python, предназначенный для имитации просмотра старого эфирного телевидения. Он может одновременно поддерживать несколько каналов, автоматически вставлять рекламу и анонсы программ, а также генерировать еженедельную программу передач на основе конфигурации. Симулятор может случайным образом выбирать недавно не транслировавшиеся программы для поддержания свежести, поддерживает установку диапазона дат трансляции программ (например, сезонных программ) и может быть настроен на показ видео о прекращении вещания телеканала и зацикленного изображения при отсутствии сигнала. Проект также поддерживает аппаратное подключение (например, Raspberry Pi Pico) для имитации переключения каналов и предоставляет функцию предварительного просмотра/гида по каналам. Его цель — чтобы при «включении телевизора» пользователь видел «реальный» контент, соответствующий данному времени и каналу (Источник: GitHub Trending)

Tiny Corp представляет решение AMD eGPU на базе USB3 с поддержкой Apple Silicon: Tiny Corp продемонстрировала решение для подключения AMD eGPU к Mac на базе Apple Silicon через USB3 (в частности, с использованием устройства ADT-UT3G на контроллере ASM2464PD). Для этого решения были переписаны драйверы с целью использования пропускной способности USB3 в 10 Гбит/с и библиотеки libusb, что теоретически также обеспечивает поддержку Linux или Windows. Это открывает новые возможности для пользователей Apple Silicon по расширению графических вычислительных мощностей, что особенно ценно для сценариев, таких как локальный запуск больших моделей ИИ (Источник: Reddit r/LocalLLaMA)
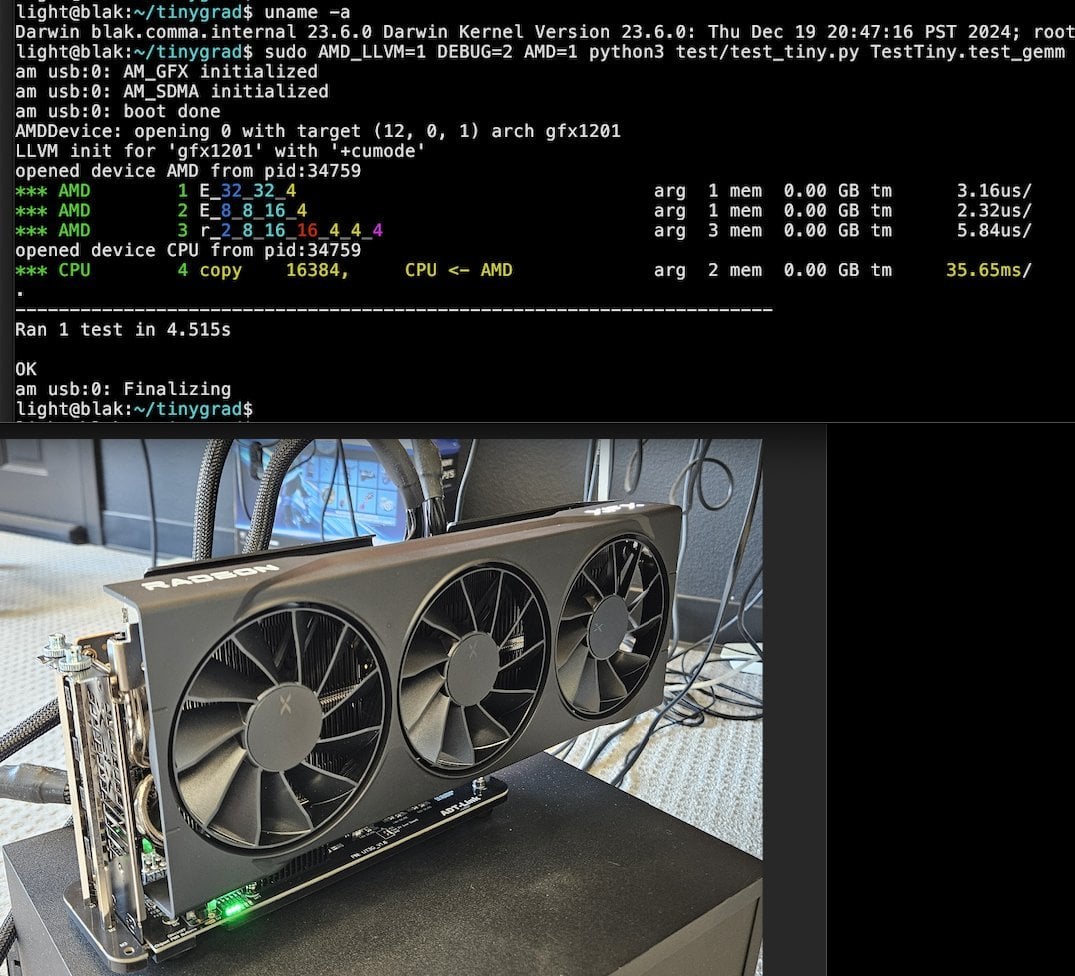
Llama.cpp-vulkan реализует поддержку FlashAttention на GPU AMD: В Vulkan-бэкенд Llama.cpp недавно была добавлена реализация FlashAttention, что означает, что пользователи, использующие llama.cpp-vulkan на GPU AMD, теперь могут воспользоваться технологией FlashAttention. В сочетании с квантованием KV-кэша Q8 пользователи могут рассчитывать на удвоение размера контекста при сохранении или увеличении скорости вывода. Это обновление является важным преимуществом для пользователей GPU AMD при локальном запуске больших языковых моделей (Источник: Reddit r/LocalLLaMA)
Devseeker: легковесный ИИ-помощник для кодирования, альтернатива Aider и Claude Code: Devseeker — это новый проект легковесного ИИ-агента для кодирования с открытым исходным кодом, позиционируемый как альтернатива Aider и Claude Code. Он обладает функциями создания и редактирования кода, управления файлами и папками с кодом, кратковременной памятью кода, обзором кода, запуском файлов кода, расчетом использования токенов и предоставлением нескольких режимов кодирования. Проект направлен на предоставление более простого в локальном развертывании и использовании инструмента для программирования с помощью ИИ (Источник: Reddit r/ClaudeAI)
📚 Обучение
Panaversity запускает учебный проект Agentic AI, фокусируясь на Dapr и OpenAI Agents SDK: Panaversity инициировала проект «Learn Agentic AI», целью которого является подготовка инженеров по интеллектуальным агентам и робототехнике с ИИ с использованием паттерна проектирования Dapr Agentic Cloud Ascent (DACA) и различных облачных технологий, ориентированных на агентов (включая OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). Основная задача проекта — разработка систем, способных обрабатывать десятки миллионов одновременных ИИ-агентов. Проект предлагает серию курсов AI-201, AI-202, AI-301, охватывающих путь обучения от основ до крупномасштабных распределенных ИИ-агентов. Проект подчеркивает, что OpenAI Agents SDK должен стать основным фреймворком разработки благодаря своей простоте использования и высокой управляемости (Источник: GitHub Trending)

Исследование тонкой настройки RL выявляет сложную взаимосвязь между управлением данными и способностью к обобщению: Статья, на которую ссылается Минци Цзян, обсуждает влияние управления данными при тонкой настройке с помощью обучения с подкреплением (RL) на способность модели к обобщению. Исследование показало, что как при обучении на «бесконечных» задачах кодирования с использованием самообучения по программе (Absolute Zero Reasoner), так и при многократном обучении только на одном примере задачи MATH (1-shot RLVR), модели серии Qwen2.5 размером 7B смогли достичь повышения точности на математических бенчмарках примерно на 28-40%. Это выявляет парадокс: экстремальные стратегии управления данными (бесконечные данные против данных из одной точки) могут приводить к схожим улучшениям обобщающей способности. Возможные объяснения включают то, что RL в основном выявляет уже имеющиеся у предварительно обученной модели способности, существование общих «схем рассуждений» и то, что предварительное обучение может приводить к конкурирующим схемам рассуждений. Исследователи считают, что для преодоления «потолка предварительного обучения» необходимо постоянно собирать и создавать новые задачи и среды (Источник: menhguin)
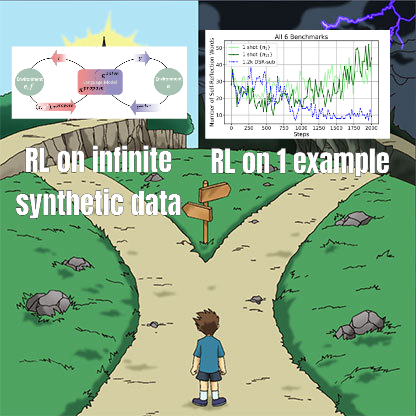
Absolute Zero Reasoner: достижение улучшения способности к рассуждению с нулевыми данными через самообучение: В статье под названием «Absolute Zero Reasoner» предлагается, что модель может научиться предлагать задачи, которые максимизируют обучаемость, путем полной игры с самой собой (self-play), и улучшать свои способности к рассуждению, решая эти задачи, причем весь процесс не требует никаких внешних данных. Этот метод превосходит другие модели «нулевого выстрела» как в математике, так и в кодировании. Это говорит о том, что системы ИИ, возможно, могут постоянно развивать свои способности к рассуждению путем внутреннего генерирования и решения проблем, что открывает новые пути для применения ИИ в областях с дефицитом данных или высокой стоимостью их разметки (Источник: cognitivecompai, Reddit r/LocalLLaMA)

Распространенные ошибки при оценке ИИ-продуктов и лучшие практики: Хамел Хусейн и Шрея Рунвал поделились распространенными ошибками при создании оценок (evals) ИИ-продуктов и предложили рекомендации по их предотвращению. Ключевые моменты включают: бенчмарки базовых моделей не равны оценке приложений; общие оценки неэффективны, их нужно адаптировать под конкретное приложение; не следует передавать разметку и инжиниринг промптов неспециалистам в данной области; следует создавать собственные приложения для разметки данных; промпты для LLM должны быть конкретизированы и основаны на анализе ошибок; использовать бинарные метки; уделять внимание проверке данных; остерегаться переобучения на тестовых данных; проводить онлайн-тестирование. Эти практики призваны помочь разработчикам создавать более надежные системы оценки ИИ-продуктов, которые лучше отражают их реальную производительность (Источник: jeremyphoward, HamelHusain)
Новый подход к оптимизации KV-кэша: универсальный переносимый словарь и реконструкция с помощью обработки сигналов: Команда Димитриса Папаилиопулоса из Университета Висконсин-Мэдисон предложила новый метод уменьшения KV-кэша, использующий универсальный, переносимый словарь в сочетании с традиционными алгоритмами реконструкции сигналов. Этот метод уже достиг уровня SOTA (state-of-the-art) на моделях, не предназначенных для вывода, и ожидается, что он покажет еще лучшие результаты на моделях для вывода. Это исследование было принято на ICML и открывает новые перспективы и технические пути для решения проблемы чрезмерного использования KV-кэша при выводе больших моделей (Источник: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

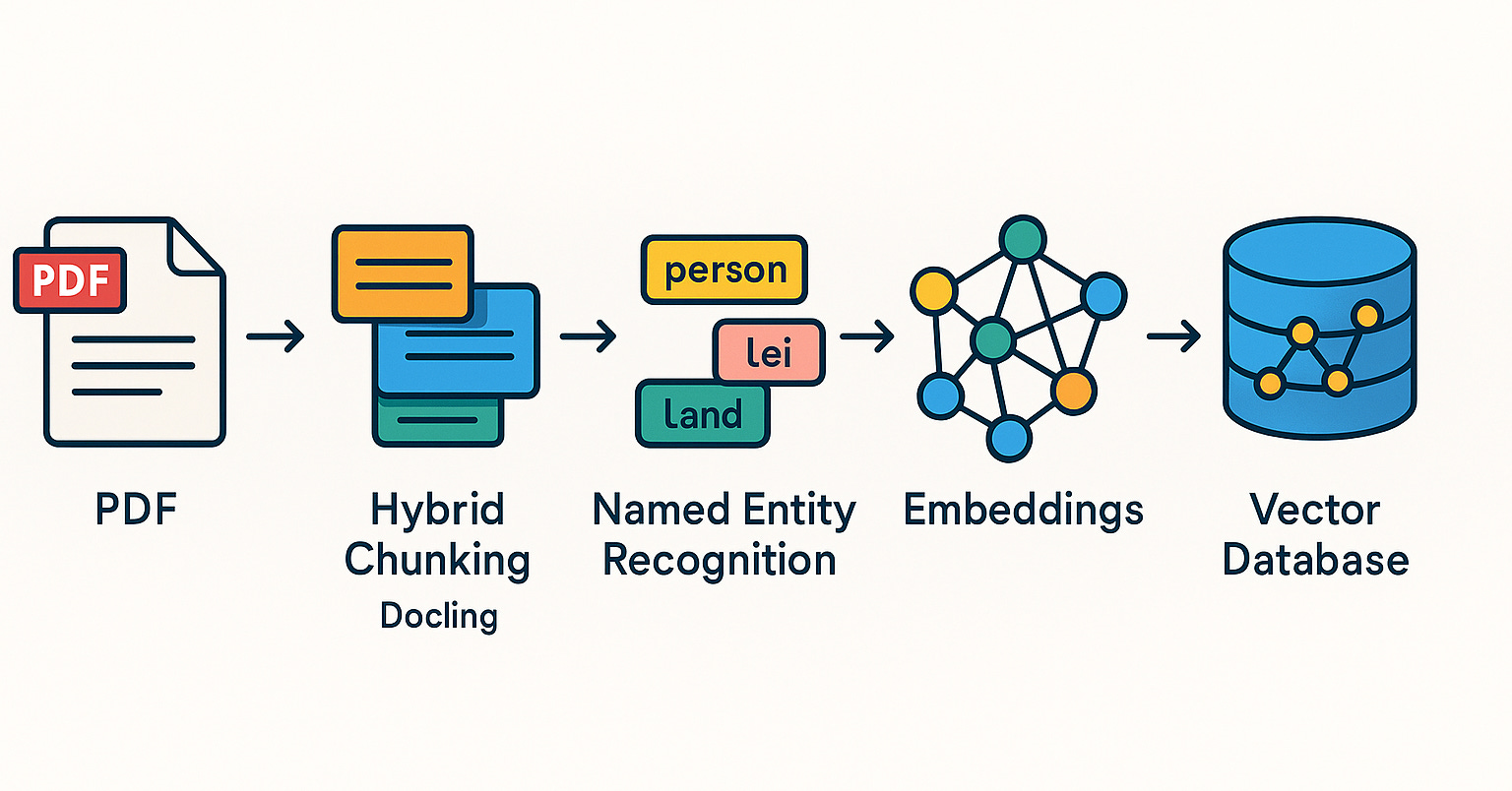
Qdrant продвигает системы RAG и практики гибридного поиска в бразильском сообществе: Векторная база данных Qdrant привлекает все большее внимание в бразильском сообществе. Разработчик Даниэль Ромеро поделился двумя статьями на португальском языке, в которых представлены практические методы создания систем RAG (Retrieval Augmented Generation) с использованием Qdrant, FastAPI и гибридного поиска. Материалы охватывают вопросы построения систем RAG с гибридным поиском, а также стратегии загрузки данных для RAG, в частности, технику гибридного чанкинга (Hybrid Chunking). Эти публикации помогают бразильским разработчикам лучше использовать Qdrant для разработки ИИ-приложений (Источник: qdrant_engine)
Академия OpenAI запускает серию материалов по промпт-инжинирингу для образования K-12: Академия OpenAI выпустила серию обучающих материалов по промпт-инжинирингу (Prompt Engineering) «Mastering Your Prompts», предназначенную для работников образования K-12. Серия призвана помочь педагогам лучше понять и применять техники составления промптов, чтобы более эффективно интегрировать ИИ-инструменты (такие как ChatGPT) в учебную практику, повышая эффективность преподавания и учебный опыт учащихся. Это свидетельствует о том, что ИИ-ассистированное образование постепенно проникает в начальные и средние школы, и подчеркивает важность развития ИИ-грамотности у педагогов (Источник: dotey)
Ян ЛеКун поделился материалами своей лекции в Национальном университете Сингапура: Ян ЛеКун поделился PDF-документом своей выдающейся лекции (Distinguished Lecture), прочитанной 27 апреля 2025 года в Национальном университете Сингапура (NUS). Хотя конкретная тема лекции не указана, ЛеКун, как пионер в области глубокого обучения, в своих выступлениях обычно затрагивает передовые теории искусственного интеллекта, будущие тенденции или глубокие размышления о текущем развитии ИИ. Эта публикация предоставляет интересующимся исследованиями в области ИИ прямой доступ к его последним взглядам (Источник: ylecun)
PyTorch сотрудничает с бэкендом Mojo для упрощения адаптации нового оборудования и языков: PyTorch работает над упрощением процесса создания новых бэкендов для новых языков программирования и аппаратного обеспечения. На хакатоне Mojo Марк Саруфим продемонстрировал усилия PyTorch в этом направлении и упомянул о находящемся в разработке (WIP) бэкенде, разрабатываемом совместно с командой Mojo. Это свидетельствует о том, что экосистема PyTorch активно расширяет свою совместимость для поддержки более разнообразных сред разработки ИИ и вариантов аппаратного ускорения, тем самым снижая барьер для разработчиков при развертывании и оптимизации моделей PyTorch на различных платформах (Источник: marksaroufim)
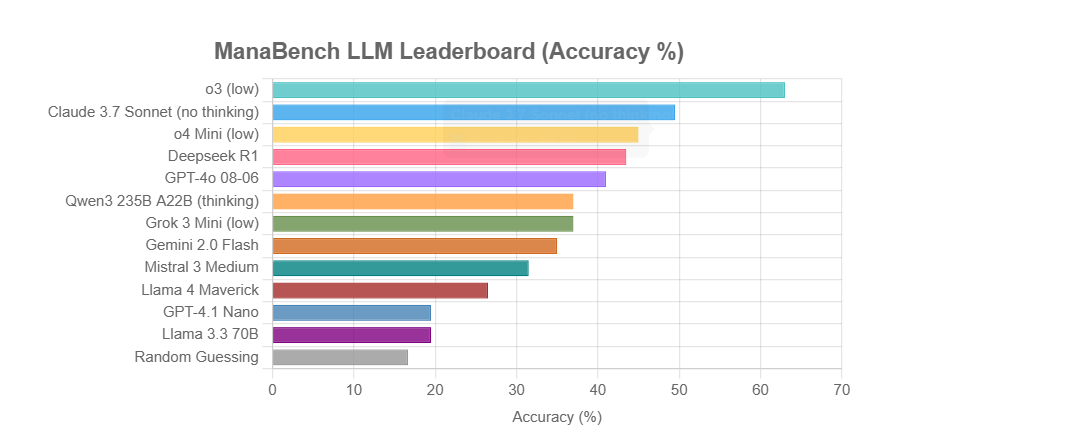
ManaBench: новый бенчмарк для оценки способности LLM к рассуждению на основе составления колод Magic: The Gathering: Разработчик создал новый бенчмарк под названием ManaBench, который тестирует способность LLM к рассуждению в сложных системах, предлагая им выбрать наиболее подходящую 60-ю карту из шести вариантов при заданных 59 картах Magic: The Gathering (MTG). Бенчмарк делает акцент на стратегическом мышлении, оптимизации системы, а ответы соответствуют разработкам экспертов-людей, что затрудняет взлом путем простого запоминания. Предварительные результаты показывают, что модели серии Llama показали себя хуже ожидаемого, в то время как закрытые модели, такие как o3 и Claude 3.7 Sonnet, лидируют. Бенчмарк призван более реалистично оценивать производительность LLM в задачах, требующих сложных рассуждений (Источник: Reddit r/LocalLLaMA)
Обсуждение: Возродит ли ИИ мечту о семантической паутине или похоронит ее?: В социальных сетях пользователь Spencer отметил, что, за исключением крупных корпоративных веб-сайтов, имеющих значительные риски в связи с законом ADA (Американский закон об инвалидах), семантическая паутина на большинстве сайтов является скорее теорией, чем практикой. Dorialexander ответил, что, по его ощущениям, ИИ либо возродит мечту о семантической паутине, либо похоронит ее навсегда. Это отражает ожидания и опасения относительно потенциала ИИ в понимании и использовании структурированных данных. ИИ может косвенно достичь целей семантической паутины путем автоматического понимания и генерации структурированной информации, но также может сделать традиционные технологии семантической паутины менее важными из-за своих собственных мощных возможностей (Источник: Dorialexander)
Исследователи обсуждают этику и архитектуры памяти и забывания моделей: В настоящее время готовится черновик статьи под названием «Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting», в которой рассматривается вопрос о том, как мы решаем, что модели должны забывать, когда они начинают «слишком хорошо запоминать», объединяя нейронные архитектуры и этику памяти. Это затрагивает вопросы того, как системы ИИ хранят, извлекают и (выборочно) забывают информацию, а также связанные с этим этические проблемы и социальные последствия, что имеет решающее значение для создания ответственного и заслуживающего доверия ИИ (Источник: Reddit r/artificial)
💼 Бизнес
По слухам, Nvidia выпустит «повторно урезанную» версию чипа H20, соответствующую новым экспортным ограничениям США: По данным Reuters, Nvidia планирует в ближайшие два месяца выпустить новую версию ИИ-чипа H20, специально предназначенную для Китая, чтобы соответствовать последним требованиям экспортного контроля США. Этот чип будет дополнительно «урезан» по сравнению с оригинальным H20 (который сам по себе уже является упрощенной версией для китайского рынка), например, объем видеопамяти будет значительно уменьшен. Несмотря на очередное снижение производительности, утверждается, что конечные пользователи смогут в некоторой степени скорректировать производительность путем изменения конфигурации модулей. В настоящее время Nvidia получила заказы на H20 на сумму 18 миллиардов долларов (Источник: WeChat)

Databricks может приобрести компанию-разработчика СУБД с открытым исходным кодом Neon за 1 миллиард долларов для усиления инфраструктуры ИИ: По слухам, компания Databricks, специализирующаяся на данных и ИИ, ведет переговоры о приобретении Neon, разработчика движка СУБД PostgreSQL с открытым исходным кодом. Сумма сделки может составить около 1 миллиарда долларов. Neon отличается своей бессерверной архитектурой, разделением хранения и вычислений, а также хорошей адаптивностью к AI Agent и эмбиентному программированию, позволяя платить по мере использования и быстро запускать экземпляры баз данных, что подходит для сценариев применения ИИ. В случае успеха это приобретение еще больше укрепит инфраструктурные возможности Databricks в эпоху ИИ, предоставив ей современное, ориентированное на ИИ решение для баз данных (Источник: WeChat)

OpenAI назначает бывшего CEO Instacart Фиджи Симо на должность CEO по прикладному бизнесу для усиления продуктов и коммерциализации: OpenAI объявила о назначении бывшего CEO Instacart и члена совета директоров компании Фиджи Симо на новую должность «главного исполнительного директора по прикладному бизнесу», наравне с Сэмом Альтманом. Симо будет полностью отвечать за продукты OpenAI, особенно за приложения, ориентированные на пользователя, такие как ChatGPT, с целью продвижения оптимизации продуктов, улучшения пользовательского опыта и коммерциализации. Этот шаг знаменует собой серьезный сдвиг в стратегии OpenAI от разработки моделей к платформе продуктов и расширению рынка, с намерением создать более сильную конкурентоспособность на уровне приложений ИИ. Богатый опыт Симо в области продуктов и коммерциализации в Facebook и Instacart поможет OpenAI справиться с растущей рыночной конкуренцией (Источник: WeChat)

🌟 Сообщество
Плагин JetBrains AI Assistant вызывает недовольство пользователей из-за плохого опыта использования и управления отзывами: Плагин JetBrains AI Assistant, несмотря на более чем 22 миллиона загрузок, имеет на своем маркетплейсе оценку всего 2,3 из 5 звезд и изобилует большим количеством 1-звездочных отзывов. Пользователи в основном жалуются на его автоматическую установку, медленную работу, многочисленные ошибки, недостаточную поддержку сторонних моделей, привязку основных функций к облачным сервисам и отсутствие документации. Недавно JetBrains обвинили в массовом удалении негативных отзывов. Хотя официальное объяснение заключалось в обработке контента, нарушающего правила или касающегося уже решенных проблем, это все равно вызвало у пользователей сомнения в контроле над отзывами и пренебрежении обратной связью, и некоторые пользователи решили повторно опубликовать негативные отзывы и продолжать ставить 1 звезду. Этот инцидент усугубил недовольство пользователей стратегией JetBrains в отношении ИИ-продуктов (Источник: WeChat)

Пользователи активно обсуждают проблему качества вывода маркетинговых ИИ-агентов: Пользователь социальных сетей omarsar0 заметил, что во многих учебных пособиях на YouTube, демонстрирующих маркетинговых ИИ-агентов, качество генерируемых ими маркетинговых текстов в целом низкое, им не хватает креативности и стиля. Он считает, что это отражает сложность получения от LLM высококачественного и привлекательного контента, и подчеркивает, что при создании ИИ-агентов «вкус» имеет решающее значение. Он отмечает, что многие современные ИИ-агенты, несмотря на сложные рабочие процессы, все еще испытывают трудности с созданием контента, действительно имеющего коммерческую ценность, что открывает возможности для талантливых людей с хорошим вкусом, богатым опытом и способностью разрабатывать эффективные системы оценки (Источник: omarsar0)
Тенденции ИИ-ассистированного кодирования и «эмбиентного программирования» вызывают дискуссии: На Reddit пост о видео Y Combinator, обсуждающем ИИ-кодирование, вызвал бурную реакцию. Мнение из видео полностью совпало с опытом автора поста (который, по его словам, создал несколько прибыльных проектов с помощью «эмбиентного программирования»). Основные тезисы: 1. ИИ уже может помогать в создании сложных и пригодных к использованию программных продуктов, даже без написания кода. 2. Опасения инженеров-программистов по поводу того, что ИИ заменит их работу, растут, но те, кто действительно освоил разработку с помощью ИИ, обладают «суперспособностями». 3. В будущем роль инженера-программиста может трансформироваться в «менеджера интеллектуальных агентов», умело использующего ИИ-инструменты, а ИИ будет отвечать за большую часть написания кода. 4. ИИ приведет к появлению большого количества нишевого программного обеспечения для узкоспециализированных рынков. Участники дискуссии считают, что, хотя потенциал ИИ-кодирования огромен, для его эффективного использования все еще необходимы знания в области инженерных концепций, баз данных, архитектуры и т.д. (Источник: Reddit r/ClaudeAI)

Продолжается обсуждение того, «захватит ли ИИ мир» и его влияния на занятость: Посты в разделе Reddit r/ArtificialInteligence отражают общую обеспокоенность сообщества будущим влиянием ИИ и разнообразие мнений. Некоторые пользователи считают, что чем глубже понимание возможностей ИИ, тем сильнее опасения по поводу того, что он превзойдет людей и будет доминировать в будущем, и указывают, что передовые системы ИИ уже демонстрируют поразительные способности. Другие пользователи считают, что чрезмерное раздувание темы AGI привело к нереалистичным ожиданиям, ИИ по своей сути является интеллектуальным инструментом автоматизации, и его влияние будет постепенным, подобно компьютерам и Интернету. Обсуждение также затрагивает потенциальное влияние ИИ на занятость, распределение богатства и эффективность регулирования. Существует мнение, что история показывает, что технологический прогресс часто усугубляет неравенство между богатыми и бедными, а ИИ может еще больше сконцентрировать богатство, устранив большое количество рабочих мест. В то же время, некоторые выражают надежду на положительную роль ИИ в таких областях, как медицина и образование (Источник: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Пользовательский опыт: как ИИ-инструменты, такие как ChatGPT, влияют на мышление и познание: Некоторые пользователи на социальных платформах и Reddit делятся положительным когнитивным влиянием использования ИИ-инструментов, таких как ChatGPT. Они чувствуют, что ИИ — это не просто инструмент для получения информации или помощи в написании текстов, а скорее «партнер по мышлению» или «зеркало», которое помогает им упорядочить мысли и четко выразить идеи, находящиеся в подсознании. Общаясь с ИИ, пользователи отмечают, что могут лучше размышлять, оспаривать собственные убеждения, выявлять модели мышления и даже чувствуют себя «пробуждающимися», глубже понимая жизнь и системы. Этот опыт показывает, что ИИ в некоторых случаях может стать катализатором личностного роста и самопознания (Источник: Reddit r/ChatGPT)
💡 Прочее
Стартовал второй Всероссийский конкурс инновационных приложений в области искусственного интеллекта «Кубок Синчжи»: Открылся второй «Кубок Синчжи», совместно организованный Китайской академией информационных и коммуникационных технологий и другими учреждениями. Конкурс проходит под девизом «Расширение возможностей Синчжи, инновационное лидерство» и включает три основных направления: инновации в области больших моделей, отраслевое применение и инновационная экосистема программного и аппаратного обеспечения, а также несколько специализированных направлений. Целью мероприятия является содействие инновациям в области технологий ИИ, их инженерному внедрению и созданию независимой экосистемы, охватывающей почти 10 ключевых отраслей, таких как промышленность, медицина, финансы, и подчеркивающей применение отечественного программного и аппаратного обеспечения ИИ. Победившие проекты получат финансовую поддержку, содействие в установлении отраслевых связей и другую помощь (Источник: WeChat)

Обзор AI Ascent от Sequoia Capital: Рынок ИИ обладает огромным потенциалом, будущее за прикладным уровнем и экономикой агентов: Партнеры Sequoia Capital Пэт Грейди и другие поделились своим видением рынка ИИ на мероприятии AI Ascent. Они считают, что потенциал рынка ИИ значительно превосходит облачные вычисления, но предостерегают от «эмбиентного дохода» (когда пользователи пробуют из любопытства, а не из-за реальной потребности). Прикладной уровень рассматривается как источник истинной ценности, и стартапы должны сосредоточиться на вертикальных рынках и потребностях клиентов. ИИ уже достиг прорывов в области генерации речи и программирования. Будущее видится в «экономике агентов», где ИИ-агенты смогут перемещать ресурсы и совершать транзакции, но это сопряжено с проблемами постоянной идентификации, протоколов связи и безопасности. В то же время ИИ значительно расширит индивидуальные возможности, породив «супериндивидов» (Источник: WeChat)

Обсуждение: Содержание и качество преподавания университетских курсов по машинному обучению в эпоху ИИ вызывают озабоченность: Публикация профессором Нью-Йоркского университета Кюнгхюном Чо программы его магистерского курса по машинному обучению вызвала дискуссию. Курс делает акцент на проблемах, решаемых с помощью SGD, не связанных с LLM, и на чтении классических статей, что получило одобрение коллег, таких как профессор компьютерных наук из Гарварда, которые считают важным сохранение фундаментальных концепций. Однако студенты из Индии и США жалуются на низкое качество курсов по машинному обучению в их университетах, их чрезмерную абстрактность, изобилие терминологии без глубоких объяснений, что заставляет студентов полагаться на самообучение и интернет-ресурсы. Это отражает противоречие между быстрым развитием области ИИ/МО и отставанием в обновлении университетских программ, а также важность прочной математической и теоретической базы (Источник: WeChat)
