
Ключевые слова:Безопасность ИИ, Этика искусственного интеллекта, ИИ агенты, 3D генерация, Модели кода, Оценка рисков ИИ, Gemini 2.5 Pro понимание видео, AssetGen 2.0 3D генерация, Seed-Coder модель кода, AgentOps управление агентами
🔥 В центре внимания
Риски безопасности AI вызывают обеспокоенность, эксперты призывают использовать опыт ядерной безопасности для оценки рисков: Международное сообщество все больше обеспокоено потенциальными рисками искусственного интеллекта. Некоторые эксперты (например, Max Tegmark) призывают компании, занимающиеся AI, перед выпуском опасных систем AI проводить строгую оценку вероятности выхода AI из-под контроля (константа Compton), подобно методам расчета безопасности, использованным Робертом Оппенгеймером при первом ядерном испытании. Этот шаг направлен на формирование отраслевого консенсуса, содействие созданию глобального механизма безопасности AI и предотвращение катастрофических последствий, которые может принести сверхинтеллект. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

Новый Папа Франциск (под псевдонимом Leo XIV) уделяет большое внимание социальным изменениям, вызванным AI: Новоизбранный Папа Франциск (предположительно Leo XIV) определил искусственный интеллект как одну из главных проблем, стоящих перед человечеством. Он выбрал имя «Leo» отчасти из-за новых социальных проблем и промышленной революции, вызванных AI, что перекликается с реакцией Папы Льва XIII на первую промышленную революцию. Папа подчеркивает, что AI бросает вызов «человеческому достоинству, справедливости и труду», и планирует в будущем опубликовать важные документы по этике AI, демонстрируя глубокую озабоченность религиозного лидера этическими и социальными последствиями технологий AI. (Источник: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google опубликовал 76-страничную белую книгу по AI-агентам, разъясняющую AgentOps и будущие приложения: Google выпустил 76-страничную белую книгу по AI-агентам, в которой подробно описывается создание, оценка и применение агентов. В белой книге подчеркивается важность эксплуатации агентов (AgentOps) как ответвления эксплуатации генеративного AI. AgentOps фокусируется на управлении инструментами, настройке основных подсказок, функциях памяти и декомпозиции задач, необходимых для эффективной работы агентов. В белой книге также рассматривается архитектура сотрудничества нескольких агентов, в которой разные агенты играют роли планирования, извлечения, выполнения и оценки, совместно выполняя сложные задачи, и прогнозируются перспективы применения агентов на предприятиях для помощи сотрудникам и автоматизации фоновых задач, таких как корпоративная версия NotebookLM и Agentspace. (Источник: WeChat)

Meta представляет AssetGen 2.0: генерация высококачественных 3D-материалов из текста/изображений: Meta выпустила свою последнюю базовую AI-модель для 3D, AssetGen 2.0, которая способна создавать высококачественные 3D-ресурсы на основе текстовых и графических подсказок. AssetGen 2.0 включает две подмодели: одна для генерации 3D-сетки, использующая одноэтапную 3D-диффузионную модель для повышения детализации и точности; другая модель TextureGen для генерации текстур, в которой представлены методы улучшения согласованности вида, восстановления текстур и более высокого разрешения текстур. Эта технология в настоящее время используется внутри Meta для создания 3D-миров и планируется к внедрению для создателей Horizon позже в этом году. (Источник: Reddit r/artificial)

🎯 Новости
ByteDance Seed открывает исходный код 8B-модели Seed-Coder, используя новую парадигму управления данными с помощью моделей: Команда Seed из ByteDance впервые открыла исходный код своей 8-миллиардной кодовой модели Seed-Coder, включающей версии Base, Instruct и Reasoning. Модель показала отличные результаты в нескольких бенчмарках генерации кода, особенно превзойдя такие модели, как Qwen3, на HumanEval и MBPP. Основным нововведением Seed-Coder является предложение «модельно-центричного» подхода к обработке данных, использующего сам LLM для генерации и отбора высококачественных обучающих данных кода, включая код на уровне файлов, код на уровне репозиториев, данные коммитов и связанные с кодом веб-данные, с общим объемом обучающих данных в 6T токенов. Этот шаг направлен на снижение участия человека и повышение возможностей кодовых моделей. (Источник: WeChat)
Gemini 2.5 Pro достигает прорыва в понимании видео, реализуя нативную интеграцию аудиовизуальных данных и кода: Последние модели Google Gemini 2.5 Pro и Flash достигли значительного прогресса в способности понимать видео. Gemini 2.5 Pro достигла уровня SOTA в нескольких ключевых бенчмарках понимания видео, даже превзойдя GPT 4.1. Серия моделей Gemini 2.5 впервые реализовала нативную бесшовную интеграцию аудиовизуальной информации с другими форматами данных, такими как код, позволяя напрямую преобразовывать видео в интерактивные приложения (например, обучающие приложения), генерировать анимацию p5.js на основе видео, а также точно извлекать и описывать видеофрагменты, демонстрируя мощные возможности временного рассуждения. Эти функции уже доступны в Google AI Studio, Gemini API и Vertex AI. (Источник: WeChat)

ModelScope представляет унифицированную модель изображений Nexus-Gen с открытым исходным кодом, нацеленную на возможности обработки изображений GPT-4o: Команда ModelScope представила Nexus-Gen, унифицированную мультимодальную модель, способную одновременно обрабатывать понимание, генерацию и редактирование изображений, стремясь сравняться с возможностями обработки изображений GPT-4o. Модель использует технологический маршрут token → transformer → diffusion → pixels, объединяя возможности текстового моделирования MLLM с возможностями рендеринга изображений модели Diffusion. Для решения проблемы накопления ошибок при авторегрессионном прогнозировании непрерывных эмбеддингов изображений команда предложила стратегию предварительного заполнения авторегрессии. Nexus-Gen обучена примерно на 25 миллионах пар изображений и текстов, включая недавно открытый сообществом ModelScope набор данных для редактирования ImagePulse. (Источник: WeChat)

Выпущена версия Cursor 0.50, упрощающая ценообразование и улучшающая множество функций редактирования кода: Редактор кода AI Cursor выпустил версию 0.50 со значительными обновлениями. Модель ценообразования упрощена до модели на основе запросов, режим Max поддерживает все ведущие модели AI и использует ценообразование на основе токенов. Улучшения функций включают: новая модель Tab поддерживает межфайловые предложения и рефакторинг кода; фоновый агент (предварительная версия) поддерживает параллельное выполнение нескольких агентов и выполнение задач в удаленной среде; контекст кодовой базы позволяет добавлять целые кодовые базы через @folders; оптимизирован пользовательский интерфейс встроенного редактирования, добавлены функции редактирования всего файла и отправки агенту; редактирование длинных файлов вводит инструмент поиска и замены; поддержка многокорневых рабочих пространств для обработки нескольких кодовых баз; улучшены функции чата, поддерживается экспорт в Markdown и копирование. (Источник: op7418)
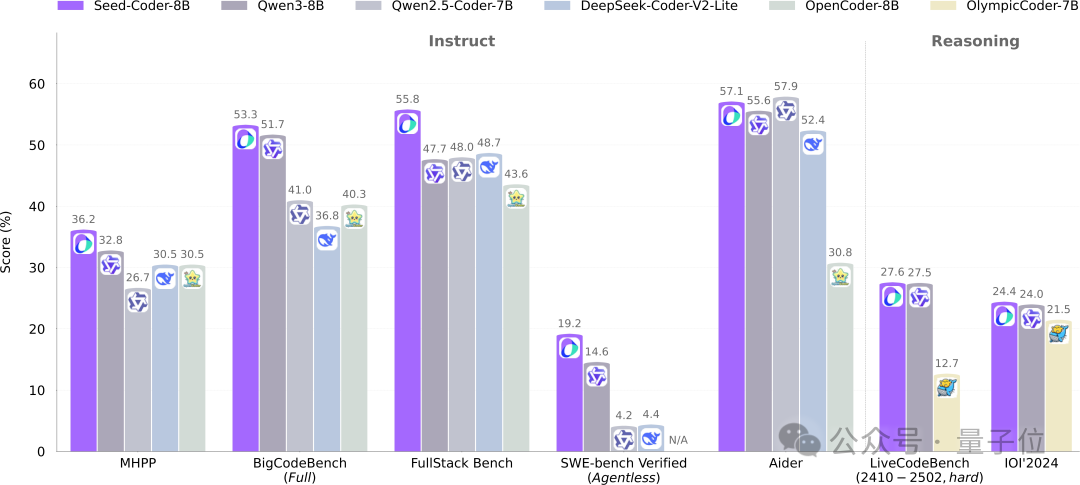
llama.cpp добавляет поддержку визуально-языковых моделей (VLM), позволяя создавать полные конвейеры Vision RAG: Проект с открытым исходным кодом llama.cpp объявил о поддержке визуально-языковых моделей (VLM), теперь пользователи могут использовать визуальные функции через сервер llama.cpp и веб-интерфейс. Это обновление означает, что на llama.cpp можно загружать одну и ту же базовую модель с поддержкой нескольких LoRA, а также модели эмбеддингов, что позволяет создавать полные конвейеры генерации с расширенным визуальным поиском (Vision RAG). Этот шаг еще больше расширяет возможности llama.cpp по локальному запуску больших языковых моделей, позволяя им обрабатывать мультимодальные задачи. (Источник: mervenoyann, mervenoyann)
Tencent выпускает HunyuanCustom: архитектуру для кастомизированной генерации видео на основе HunyuanVideo: Tencent опубликовала на Hugging Face HunyuanCustom, мультимодальную архитектуру, специально разработанную для кастомизированной генерации видео. Эта работа основана на HunyuanVideo и делает особый акцент на сохранении согласованности объекта при генерации видео, одновременно поддерживая ввод различных условий, таких как изображения, аудио, видео и текст, предоставляя пользователям более гибкие и персонализированные возможности для создания видео. (Источник: _akhaliq)
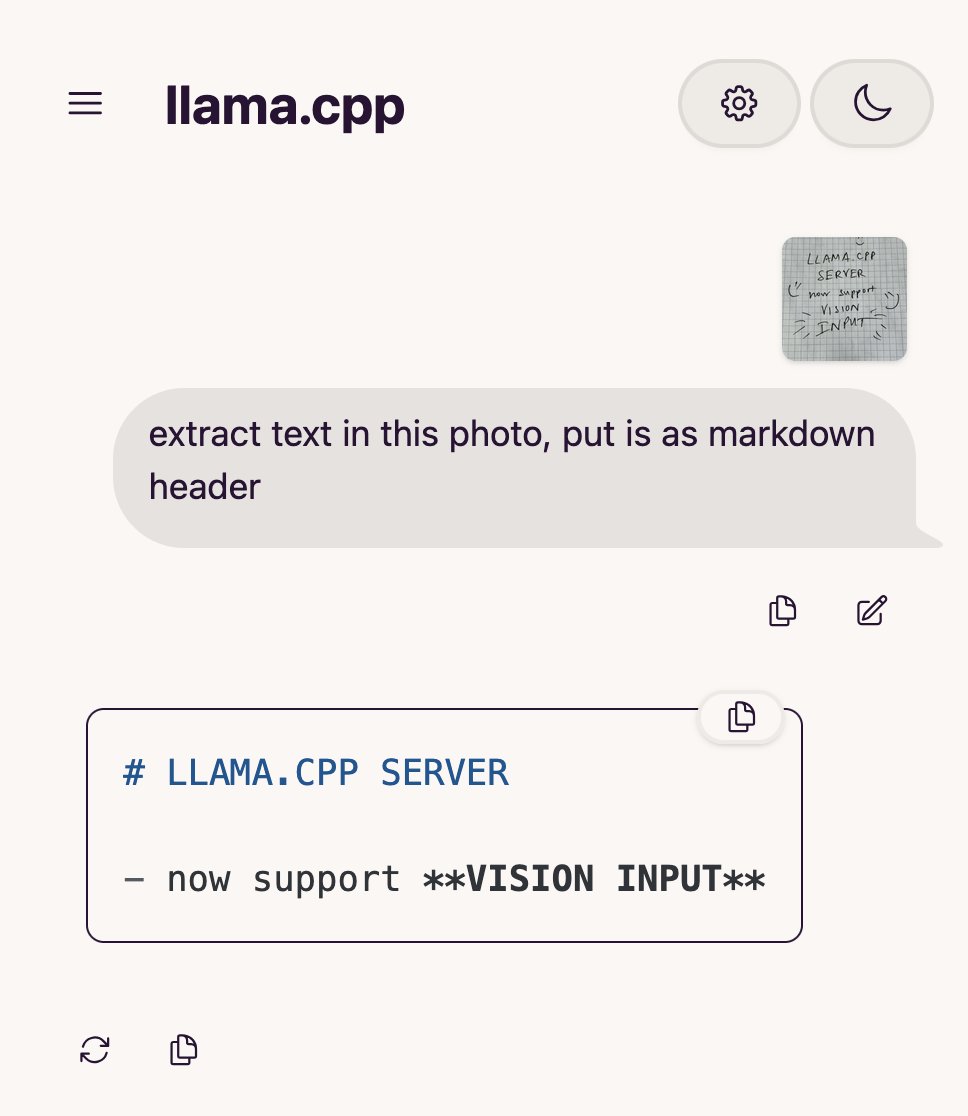
Qwen Chat добавляет режим «Веб-разработка», генерируя веб-приложения React одной фразой: Alibaba Qwen Chat запустил режим «Веб-разработка» (Web Dev), позволяющий пользователям генерировать веб-приложения, включающие HTML, CSS и JavaScript, всего одной фразой-командой. В основе используются фреймворк React и Tailwind CSS. Эта функция позволяет быстро создавать личные веб-сайты, копировать существующие веб-интерфейсы (например, Twitter, GitHub) или создавать определенные формы и анимации по описанию. Пользователи могут выбирать различные модели Qwen и комбинировать их с режимом «глубокого мышления» для повышения качества веб-страниц. Эта функция призвана упростить процесс фронтенд-разработки и быстро создавать прототипы приложений. (Источник: WeChat)
Unitree Robotics отвечает на уязвимость безопасности робота-собаки Go1, подчеркивая обновление последующих продуктов: Unitree Robotics отреагировала на слухи об уязвимости «бэкдора» в серии роботов-собак Go1, производство которой было прекращено около двух лет назад, признав проблему уязвимостью безопасности. Злоумышленники могли использовать ключ управления стороннего облачного туннельного сервиса для изменения данных пользовательских устройств, получения доступа к изображениям с камер и системным правам. Unitree Robotics заявила, что последующие серии роботов используют более безопасные обновленные версии, не подверженные этой уязвимости. Этот инцидент вызвал обеспокоенность по поводу безопасности цепочки поставок интеллектуальных роботов и конфиденциальности данных, особенно на фоне первого года коммерциализации гуманоидных роботов, когда отрасль сталкивается с множеством проблем, включая технологические прорывы, контроль затрат и поиск путей коммерциализации. (Источник: 36氪)

Claude Code теперь поддерживает ссылки на другие файлы .MD, оптимизируя организацию инструкций: Claude Code от Anthropic обновил свои функции: версия 0.2.107 позволяет файлам CLAUDE.md импортировать другие файлы Markdown. Пользователи могут добавлять [u/path/to/file].md в основной файл CLAUDE.md для загрузки дополнительного содержимого файла при запуске. Это улучшение позволяет пользователям лучше организовывать и управлять инструкциями для Claude, повышая надежность и модульность конфигурации инструкций в крупных проектах и решая проблемы путаницы, которые ранее могли возникать из-за разрозненных файлов. (Источник: Reddit r/ClaudeAI)

Бюро авторского права США занимает более жесткую позицию в отношении предварительного обучения AI, ослабляя защиту «добросовестного использования»: В последнем отчете Бюро авторского права США заняло более жесткую позицию по вопросу использования материалов, защищенных авторским правом, на этапе предварительного обучения моделей AI. В отчете отмечается, что, поскольку лаборатории AI теперь заявляют, что их модели могут конкурировать с правообладателями (например, генерируя контент, схожий с оригинальными произведениями), это ослабляет их аргументы в пользу «добросовестного использования» (fair use) в судебных процессах по нарушению авторских прав. Это изменение может оказать существенное влияние на источники обучающих данных для моделей AI и их соответствие требованиям. (Источник: Dorialexander)

Nvidia выпускает профессиональную видеокарту RTX Pro 5000 с 48 ГБ памяти GDDR7: Nvidia представила новый профессиональный настольный GPU RTX Pro 5000 на базе архитектуры Blackwell. Видеокарта оснащена 48 ГБ памяти GDDR7 с пропускной способностью до 1344 ГБ/с и энергопотреблением 300 Вт. Хотя официально она называется «недорогой» 48-гигабайтной видеокартой Blackwell, ожидается, что ее цена все же будет высокой (в комментариях упоминается уровень 4000 долларов США), и она в основном ориентирована на пользователей профессиональных рабочих станций, обеспечивая мощную вычислительную поддержку для таких задач, как обучение моделей AI и рендеринг крупных 3D-сцен. (Источник: Reddit r/LocalLLaMA)

🧰 Инструменты
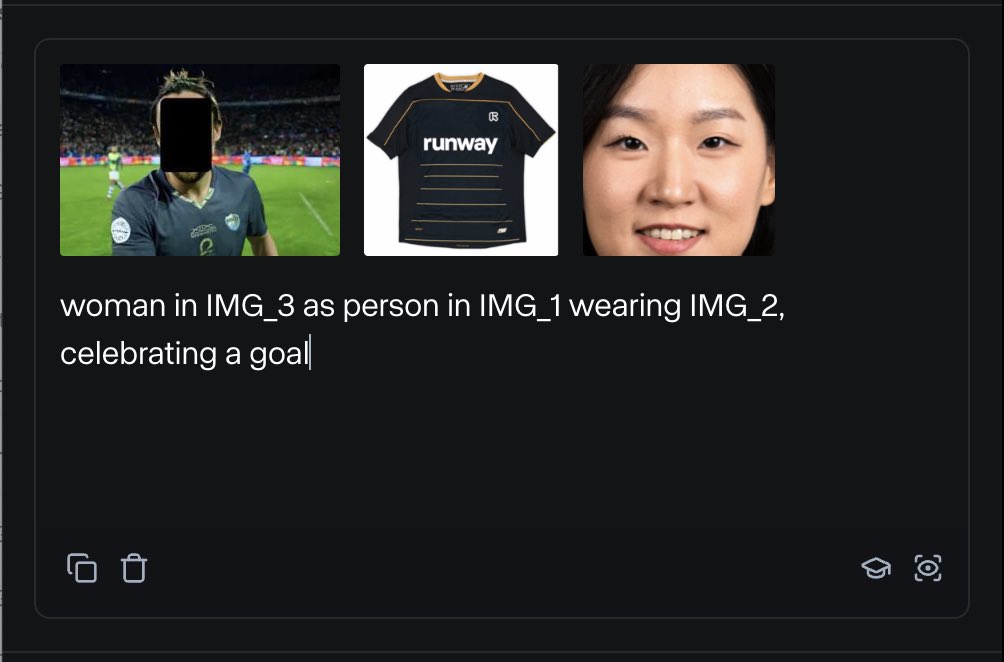
RunwayML запускает функцию References, позволяющую смешивать различные референсные материалы для генерации контента: Новая функция “References” от RunwayML позволяет пользователям смешивать различные референсные материалы (например, изображения, стили) в качестве «ингредиентов» и генерировать новый визуальный контент на основе любой комбинации этих «ингредиентов». Эта функция рассматривается как почти что машина для творчества в реальном времени, способная помочь пользователям быстро реализовывать различные творческие идеи, значительно расширяя гибкость и возможности AI в создании визуального контента. (Источник: c_valenzuelab)
Chat2DB: AI-клиент для работы с базами данных на естественном языке: Chat2DB — это клиент для баз данных на базе AI, который позволяет пользователям взаимодействовать с базами данных на естественном языке. Например, пользователь может спросить: «Какой клиент потратил больше всего в этом месяце?», и Chat2DB сможет понять вопрос с помощью AI, автоматически сгенерировать соответствующий SQL-запрос на основе структуры таблиц базы данных, выполнить запрос и вернуть результат. Это значительно снижает технический барьер для работы с базами данных, позволяя нетехническим специалистам легко выполнять запросы и анализ данных. Проект открыт на GitHub. (Источник: karminski3)
Модель Qwen 3 8B демонстрирует отличные способности к кодированию, способна генерировать HTML-клавиатуру: Модель Qwen 3 8B (квантованная версия Q6_K), несмотря на небольшой размер параметров, демонстрирует отличные результаты в генерации кода. Пользователь с помощью двух коротких подсказок успешно заставил модель сгенерировать код для интерактивной HTML-клавиатуры. Это показывает потенциал миниатюрных моделей для достижения высокой практической ценности в конкретных задачах, особенно привлекательный для сценариев локального развертывания с ограниченными ресурсами. (Источник: Reddit r/LocalLLaMA)
Ollama Chat: инструмент для локального чата с LLM с интерфейсом в стиле Claude: Ollama Chat — это веб-интерфейс для чата с локальными большими языковыми моделями, чей стиль пользовательского интерфейса и опыт взаимодействия заимствованы у Claude от Anthropic. Инструмент поддерживает загрузку текстовых файлов, историю диалогов и настройку системных подсказок, стремясь предоставить простое в использовании и эстетически приятное решение для локального взаимодействия с LLM. Проект открыт на GitHub, что позволяет пользователям самостоятельно развертывать и использовать его. (Источник: Reddit r/LocalLLaMA)
Советы по созданию подсказок для AI для генерации персонализированных открыток (на день рождения/День матери): Пользователь поделился советами по созданию подсказок для AI для генерации персонализированных открыток (например, на день рождения, День матери). Ключевым моментом является четкое указание темы открытки (например, День матери, день рождения), стиля (например, женский стиль, детский стиль), получателя (например, мама, Сэнди, Джимми), возраста (например, 30 лет, 6 лет) и конкретного содержания поздравления или теплого, милого тона. Комбинируя эти элементы, можно направить AI на создание дизайна открытки, соответствующего потребностям. (Источник: dotey)

📚 Обучение
Google опубликовал белую книгу по промпт-инжинирингу, обучающую пользователей эффективно задавать вопросы: Google опубликовал белую книгу по промпт-инжинирингу (доступна через Kaggle), цель которой — научить пользователей более эффективно задавать вопросы моделям AI. Учебное пособие написано ясно и подробно описывает, как четко определять требования к выводу, ограничивать диапазон вывода и использовать переменные, помогая пользователям повысить эффективность и результативность взаимодействия с большими языковыми моделями для получения более точных и полезных ответов. (Источник: karminski3)

Команда HKUST(GZ) предложила MultiGO: иерархическое гауссово моделирование для генерации 3D-текстурированных людей из одного изображения: Команда из Гонконгского университета науки и технологий (Гуанчжоу) представила инновационный фреймворк под названием MultiGO, который реконструирует 3D-модели людей с текстурами из одного изображения с помощью иерархического гауссова моделирования. Метод разлагает человеческое тело на различные уровни точности, такие как скелет, суставы, морщины, и уточняет их поэтапно. Основная технология использует гауссовы сплэттинг-точки в качестве 3D-примитивов и включает модули для улучшения скелета, суставов и оптимизации морщин. Результаты исследования были отобраны для CVPR 2025 и предлагают новый подход к реконструкции 3D-людей из одного изображения; код скоро будет открыт. (Источник: WeChat)

Университеты Цинхуа, Фудань и HKUST совместно выпустили RM-BENCH: первый бенчмарк для оценки моделей вознаграждения: В ответ на существующие проблемы в оценке моделей вознаграждения больших языковых моделей, такие как «форма важнее содержания» и стилевые предубеждения, исследовательские группы из Университета Цинхуа, Университета Фудань и Гонконгского университета науки и технологий совместно выпустили RM-BENCH, первый систематический бенчмарк для оценки моделей вознаграждения. Бенчмарк охватывает четыре основные области: чат, код, математику и безопасность. Оценивая чувствительность модели к незначительным различиям в содержании и ее устойчивость к стилевым отклонениям, он направлен на установление более надежного нового стандарта «судьи контента». Исследование показало, что существующие модели вознаграждения плохо справляются с задачами в области математики и кода и повсеместно демонстрируют стилевые предубеждения. Эта работа была принята на ICLR 2025 Oral. (Источник: WeChat)

Тяньцзиньский университет и Tencent открыли исходный код решения COME: 5 строк кода повышают устойчивость TTA и решают проблему коллапса модели: Тяньцзиньский университет в сотрудничестве с Tencent предложили метод COME (Conservatively Minimizing Entropy), направленный на решение проблемы чрезмерной уверенности и коллапса модели, вызванных минимизацией энтропии (EM) в процессе адаптации во время тестирования (TTA). COME вводит явное моделирование неопределенности прогнозов с помощью субъективной логики и использует адаптивное ограничение логитов (замораживание нормы логитов) для косвенного контроля неопределенности, тем самым достигая консервативной минимизации энтропии. Этот метод не требует изменения архитектуры модели, для его встраивания в существующие методы TTA требуется лишь небольшое количество кода. Он значительно повышает устойчивость и точность модели на таких наборах данных, как ImageNet-C, при этом вычислительные затраты минимальны. Статья принята на ICLR 2025, код открыт. (Источник: WeChat)
Huawei и Институт информационных технологий предложили DEER: механизм «динамического раннего выхода» из цепочки рассуждений для повышения эффективности и точности вывода LLM: Huawei совместно с Институтом информационных технологий Китайской академии наук предложили механизм DEER (Dynamic Early Exit in Reasoning), направленный на решение проблемы чрезмерного обдумывания, которая может возникнуть у больших языковых моделей при длинных цепочках рассуждений (Long CoT). DEER отслеживает точки перехода в рассуждениях, индуцирует пробные ответы и оценивает их достоверность, динамически определяя, следует ли досрочно прекратить обдумывание и сгенерировать вывод. Эксперименты показали, что на LLM для рассуждений, таких как серия DeepSeek, DEER без дополнительного обучения в среднем сокращает длину генерируемой цепочки рассуждений на 31%-43%, одновременно повышая точность на 1.7%-5.7%. (Источник: WeChat)

Китайская академия наук и др. предложили R1-Reward: обучение мультимодальных моделей вознаграждения с помощью стабильного обучения с подкреплением: Исследовательские группы из Китайской академии наук, Университета Цинхуа, Kuaishou и Нанкинского университета предложили R1-Reward, метод обучения мультимодальных моделей вознаграждения (MRM) с помощью стабильного алгоритма обучения с подкреплением StableReinforce, направленный на повышение их способности к длительным рассуждениям. StableReinforce улучшает существующие алгоритмы RL, такие как PPO, которые могут столкнуться с проблемами нестабильности при обучении MRM, за счет стратегии Pre-Clip, фильтра преимуществ и нового механизма согласованного вознаграждения (введение модели-арбитра для проверки согласованности анализа и ответа) для стабилизации процесса обучения. Эксперименты показали, что R1-Reward превосходит по производительности модели SOTA на нескольких бенчмарках MRM, а производительность может быть дополнительно улучшена за счет многократного сэмплирования и голосования во время вывода. (Источник: WeChat)
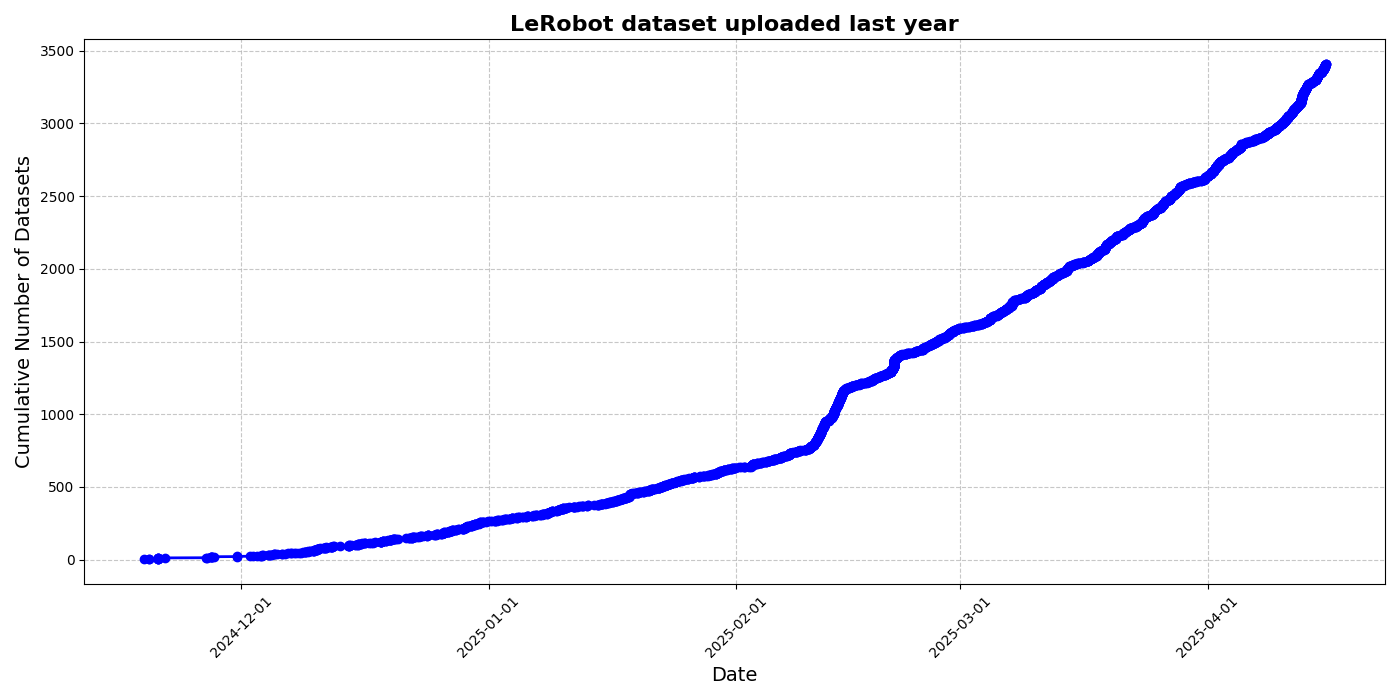
HuggingFace запускает инициативу по созданию набора данных сообщества LeRobot, способствуя «моменту ImageNet» для робототехники: HuggingFace инициировал проект набора данных сообщества LeRobot, целью которого является создание «ImageNet» для области робототехники, способствуя развитию универсальных робототехнических технологий за счет вклада сообщества. В статье подчеркивается важность разнообразия данных для способности роботов к обобщению и отмечается, что существующие наборы данных для роботов в основном происходят из ограниченных академических сред. LeRobot упрощает сбор данных, процесс загрузки и снижает затраты на оборудование, поощряя пользователей делиться данными от различных роботов (таких как So100, манипулятор Koch) при выполнении разнообразных задач (таких как игра в шахматы, управление ящиками). В то же время в статье предлагаются стандарты качества данных и список лучших практик для решения проблем, таких как несогласованность аннотирования данных и нечеткое сопоставление признаков, способствуя созданию высококачественных и разнообразных наборов данных для робототехники. (Источник: HuggingFace Blog, LoubnaBenAllal1)
В блоге HuggingFace обобщены 11 алгоритмов выравнивания и оптимизации LLM: TheTuringPost поделился статьей на HuggingFace, в которой обобщены 11 алгоритмов для выравнивания и оптимизации больших языковых моделей (LLM). Эти алгоритмы включают PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) и SPIN (Self-Play Fine-Tuning) и другие. Статья предоставляет ссылки на эти алгоритмы и дополнительную информацию, предлагая исследователям и разработчикам обзор методов оптимизации LLM. (Источник: TheTuringPost)
Калифорнийский университет в Беркли делится материалами курса CS280 по компьютерному зрению для аспирантов: Профессора Angjoo Kanazawa и Jitendra Malik из Калифорнийского университета в Беркли поделились всеми лекционными материалами своего аспирантского курса по компьютерному зрению CS280, который они преподавали в этом семестре. Они считают, что этот набор материалов, сочетающий классическое и современное компьютерное зрение, оказался эффективным, и сделали его общедоступным для ознакомления. (Источник: NandoDF)
GVM-RAFT: динамическая структура сэмплирования для оптимизации логических выводов в цепочке мыслей: Новая статья представляет фреймворк GVM-RAFT, который оптимизирует логические выводы в цепочке мыслей (chain-of-thought), динамически настраивая стратегию сэмплирования для каждой подсказки с целью минимизации дисперсии градиента. Утверждается, что этот метод обеспечивает ускорение в 2-4 раза при решении задач математического вывода и повышает точность. (Источник: _akhaliq)
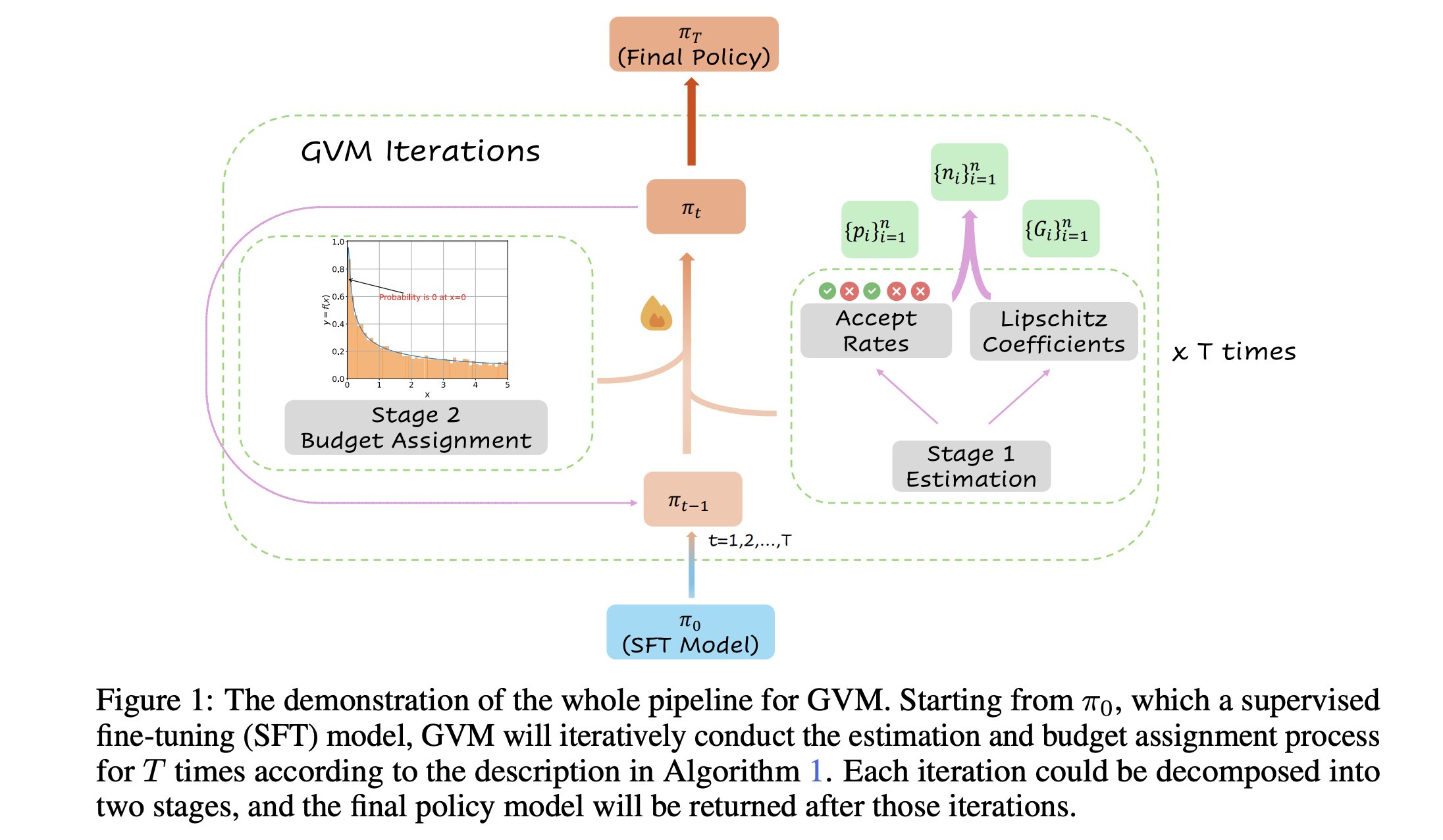
Новый фреймворк R&B улучшает производительность языковых моделей за счет динамического балансирования обучающих данных: Новое исследование под названием R&B предлагает новый фреймворк, который улучшает производительность языковых моделей за счет динамического балансирования их обучающих данных, добавляя всего 0,01% дополнительных вычислительных затрат. Этот метод направлен на оптимизацию эффективности использования данных для улучшения производительности модели при небольших затратах. (Источник: _akhaliq)
Статья рассматривает новую перспективу безопасности AI: представление социального и технологического прогресса как штопки лоскутного одеяла: Новая статья, опубликованная на arXiv под названием «Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt», предлагает новый взгляд на безопасность AI, утверждая, что ядро безопасности AI должно быть сосредоточено на предотвращении эскалации разногласий в конфликты. Статья сравнивает социальный и технологический прогресс со штопкой постоянно растущего, меняющегося, полного заплат и разноцветного лоскутного одеяла, подчеркивая важность поддержания стабильности и сотрудничества в сложных системах. (Источник: jachiam0)
Статья рассматривает адаптивные вычисления в авторегрессионных языковых моделях: Обсуждается интерес к адаптивным вычислениям в глубоком обучении и перечисляются соответствующие технологические разработки: PonderNet (DeepMind, 2021) как ранний инструмент для интеграции нейронных сетей и циклов; диффузионные модели, выполняющие вычисления путем многократных прямых проходов; и недавние языковые модели для рассуждений, достигающие аналогичного эффекта путем генерации произвольного количества токенов. Это отражает тенденцию к гибкости и динамичности в распределении и использовании вычислительных ресурсов моделями. (Источник: jxmnop)
Статья исследует, как «плохие данные» могут порождать «хорошие модели»: Статья Гарвардского университета 2025 года «When Bad Data Leads to Good Models» (arXiv:2505.04741) исследует, как в некоторых случаях данные, кажущиеся некачественными (например, данные предварительного обучения, содержащие контент с 4chan), могут, наоборот, способствовать выравниванию модели и сокрытию ее «уровня силы» (power level), что приводит к ее лучшей производительности. Это вызвало дискуссию о качестве данных, выравнивании моделей и подлинности поведения моделей. (Источник: teortaxesTex)

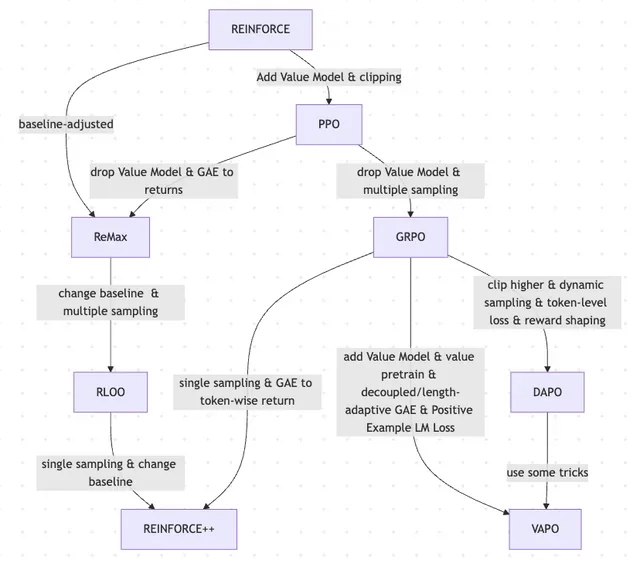
Статья рассматривает эволюцию RLHF и его вариантов, от REINFORCE до VAPO: Исследовательская статья обобщает эволюцию методов обучения с подкреплением (RL), используемых для тонкой настройки больших языковых моделей (LLM). Статья прослеживает эволюцию от классических алгоритмов PPO и REINFORCE до недавних методов, таких как GRPO, ReMax, RLOO, DAPO и VAPO, анализируя отказ от моделей ценности, изменения в стратегиях выборки, корректировку базовых линий, а также применение таких техник, как формирование вознаграждения и потери на уровне токенов. Исследование направлено на четкое представление исследовательской картины RLHF и его вариантов в области выравнивания LLM. (Источник: Reddit r/MachineLearning)
Статья «Absolute Zero»: AI проводит усиленное самообучающееся рассуждение без данных от человека: Белая книга под названием «Absolute Zero: Reinforced Self-Play Reasoning with Zero Data» (arXiv:2505.03335) исследует новые методы обучения логического AI. Исследователи обучали модели логического AI без использования наборов данных, помеченных человеком; модель могла самостоятельно генерировать задачи на рассуждение, решать проблемы и проверять решения путем выполнения кода. Это вызвало дискуссию о том, может ли AI в полностью лишенной априорных знаний (таких как математика, физика, язык) среде с нуля изобретать символические представления, определять логические структуры, развивать числовые системы и строить причинно-следственные модели, а также о потенциале и рисках такого «инородного интеллекта». (Источник: Reddit r/ArtificialInteligence, Reddit r/artificial)
Лаборатория интеллектуального взаимодействия человека и машины Фуданьского университета набирает магистрантов и аспирантов на 2026 год: Лаборатория интеллектуального взаимодействия человека и машины факультета компьютерных наук и технологий Фуданьского университета набирает магистрантов и аспирантов для летней школы/рекомендательного зачисления на 2026 год. Лабораторию возглавляет профессор Шан Ли, направления исследований включают носимый AGI (умные очки MemX в сочетании с LLM), воплощенный интеллект с открытым исходным кодом, сжатие моделей (от больших к малым) и системы машинного обучения (например, оптимизация компиляции ML, AI-процессоры). Лаборатория стремится исследовать человеко-ориентированный интеллект, объединяя большие модели с новыми парадигмами взаимодействия человека и машины в интеллектуальных носимых устройствах и системах воплощенного интеллекта. (Источник: WeChat)

💼 Бизнес
Обзор 10 AI-стартапов с оценкой более 1 миллиарда долларов и штатом менее 50 человек: Business Insider составил список 10 AI-стартапов с оценкой более 1 миллиарда долларов, но штатом менее 50 сотрудников. Среди них Safe Superintelligence (оценка 320 миллиардов долларов, 20 сотрудников), OG Labs (оценка 20 миллиардов долларов, 40 сотрудников), Magic (оценка 15,8 миллиарда долларов, 20 сотрудников), Sakana AI (оценка 15 миллиардов долларов, 28 сотрудников) и другие. Эти компании демонстрируют потенциал AI-сферы для достижения высоких оценок малыми командами, отражая высокую ценность технологий и инноваций на капиталовом рынке. (Источник: hardmaru)
Fourier Intelligence углубляет присутствие в сфере реабилитации и ухода, сотрудничая с Шанхайским международным медицинским центром для создания базы реабилитации на основе воплощенного интеллекта: Единорог в области воплощенного интеллекта Fourier Intelligence на своем первом саммите по экосистеме воплощенного интеллекта объявил о сотрудничестве с Шанхайским международным медицинским центром для совместного продвижения применения роботов с воплощенным интеллектом в сценариях медицинской реабилитации, включая разработку стандартов, совместное создание решений и научные исследования, а также создание первой в стране демонстрационной базы реабилитации на основе воплощенного интеллекта. Основатель Fourier Intelligence Гу Цзе представил основную стратегию на ближайшие десять лет: «опираться на реабилитацию и уход, сосредоточиться на взаимодействии, служить людям», подчеркнув, что медицинская реабилитация является их основой. С момента своего основания в 2015 году компания постепенно расширила свою деятельность от реабилитационных роботов до универсальных гуманоидных роботов серий GR-1 и GRx, поставив в общей сложности сотни единиц. (Источник: 36氪)
Сообщается, что Meta нанимает бывших чиновников Пентагона, возможно, для усиления позиций в военной сфере: По данным Forbes, компания Meta нанимает бывших чиновников Пентагона, что может означать, что компания планирует усилить свою деятельность в области военных технологий или оборонных разработок. Этот шаг вызвал обсуждение и обеспокоенность по поводу участия крупных технологических компаний в военных разработках. (Источник: Reddit r/artificial)

🌟 Сообщество
Предложение Andrej Karpathy о недостающей важной парадигме обучения LLM «обучение системным подсказкам» вызвало бурное обсуждение: Andrej Karpathy считает, что в текущем обучении LLM отсутствует важная парадигма, которую он называет «обучение системным подсказкам». Он отмечает, что предварительное обучение предназначено для знаний, а тонкая настройка (контролируемое/усиленное обучение) — для привычного поведения, и оба включают изменение параметров, но большое количество человеческого взаимодействия и обратной связи, похоже, не используется в полной мере. Он сравнивает это с предоставлением главному герою «Memento» блокнота для хранения глобальных знаний и стратегий решения проблем. Эта точка зрения вызвала широкое обсуждение; некоторые считают, что это близко к идеям DSPy или затрагивает проблемы памяти/оптимизации, непрерывного обучения, и обсуждают, как реализовать подобный механизм в Langgraph. (Источник: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Требование AI-компаний к соискателям не использовать AI для написания заявлений о приеме на работу вызвало бурное обсуждение: Требование AI-компаний, таких как Anthropic, к соискателям не использовать инструменты AI при написании заявлений о приеме на работу (например, резюме) вызвало обсуждение в сообществе. Некоторые рекрутеры заявили, что получают много «текстового мусора» в резюме, сгенерированных AI, и даже опытные специалисты могут из-за этого упустить главное. Однако некоторые соискатели считают, что AI помогает им лучше оптимизировать резюме под требования вакансии, выделить навыки и повысить читабельность. Обсуждение также коснулось явления переполнения платформ, таких как LinkedIn, контентом, сгенерированным AI, и вопроса о том, следует ли использовать другие способы оценки соискателей, например, видео. (Источник: Reddit r/artificial, Reddit r/ArtificialInteligence)

«Распознаваемость» контента, сгенерированного AI, вызывает дискуссии, пользователи считают его легко заметным: В сообществе отмечают, что контент, сгенерированный AI (особенно ChatGPT), легко распознать не только по специфическим знакам препинания (например, длинным тире) или конструкциям предложений (например, «Это не x; это y.»), но и по характерному «ритму» и «пресности». Как только следы AI распознаны, контент кажется нереальным, лишенным индивидуальности. Некоторые пользователи сообщают, что сталкивались с подобными случаями в электронных письмах, постах в социальных сетях и даже в видеоиграх, считая, что прямое использование AI для генерации всего контента приводит к скучному и неискреннему результату, и рекомендуют пользователям использовать AI как инструмент для редактирования и персонализации. (Источник: Reddit r/ChatGPT)
Развитие AI демонстрирует цикл «медовый месяц – откат», отражая предпочтение человеком подлинности: Существует мнение, что появление новых генеративных моделей AI (текст, изображения, музыка и т.д.) часто сопровождается «медовым месяцем», когда люди поражаются их возможностям. Но вскоре, когда люди начинают распознавать «шаблоны» или «следы» генерации AI, возникает откат, и похвала сменяется сомнением, вплоть до утверждений, что у них «нет души». Это явление быстрого обучения распознаванию произведений AI и предпочтения несовершенных человеческих творений может означать, что AI скорее является вспомогательным инструментом, а не полной заменой человеческих творцов, поскольку люди ценят историю, стоящую за произведением, авторский замысел и подлинность. (Источник: Reddit r/ArtificialInteligence)
Внутренняя генерация кода AI в Anthropic превышает 70%, вызывая ассоциации с самоитерацией AI: Mike Krieger из Anthropic сообщил, что более 70% pull requests внутри компании теперь генерируются AI. Эти данные вызвали обсуждение в сообществе, некоторые провели аналогии со сценариями саморедактирования и самосовершенствования машин, подобными сюжетам из научной фантастики. В то же время, некоторые выразили сомнения в достоверности этих данных и их конкретном значении (например, сложности этих PR). (Источник: Reddit r/ClaudeAI)

Генеральный директор Nvidia Дженсен Хуанг подчеркивает необходимость всеобщего внедрения AI-агентов, AI изменит роль разработчиков: Генеральный директор Nvidia Дженсен Хуанг заявил, что компания обеспечит всех сотрудников AI-помощниками, AI-агенты будут встроены в повседневную разработку, оптимизируя код, выявляя уязвимости и ускоряя прототипирование. Он считает, что в будущем каждый будет управлять несколькими AI-помощниками, а производительность будет расти экспоненциально. Генеральный директор Meta Марк Цукерберг, генеральный директор Microsoft Сатья Наделла и другие придерживаются схожих взглядов, считая, что AI будет выполнять большую часть работы по написанию кода, а роль разработчиков сместится к «управлению AI» и «определению требований». Эта тенденция предвещает кардинальные изменения в цикле разработки программного обеспечения, а инструменты AI-программирования, такие как GitHub Copilot, Cursor и другие, станут повсеместными. (Источник: WeChat)

Обсуждение: Возможно ли исследователю ML читать 1000-2000 статей в год?: В сообществе обсуждается, что ведущие исследователи в области машинного обучения могут читать около 2000 статей в год. На это есть комментарии, что само по себе количество прочитанных статей является лишь косвенным показателем, по-настояшему важно умение отфильтровывать сигналы из большого объема информации, извлекать полезную информацию и правильно ее применять. Способность следить за основными моментами и тенденциями в области и при необходимости углубляться в конкретный контент — это ключевой навык этого века. (Источник: torchcompiled)
Обсуждение: Покупка GPU против аренды GPU для обучения/тонкой настройки моделей: Практики машинного обучения сталкиваются с выбором между покупкой или арендой ресурсов GPU. Опытные пользователи советуют применять гибридную стратегию: иметь локально одну потребительскую GPU средней производительности для небольших экспериментов, а для крупномасштабных задач обучения арендовать облачные GPU. Выбор зависит от сложности модели, объема данных и бюджета. Облачные GPU имеют преимущества в организации ML Ops, но при той же цене распространенные облачные GPU, такие как T4, могут уступать по производительности высококлассным потребительским картам (например, 3090/4090), однако облако может предоставить топовые GPU с большим объемом видеопамяти, такие как A100/H100. (Источник: Reddit r/MachineLearning)
💡 Прочее
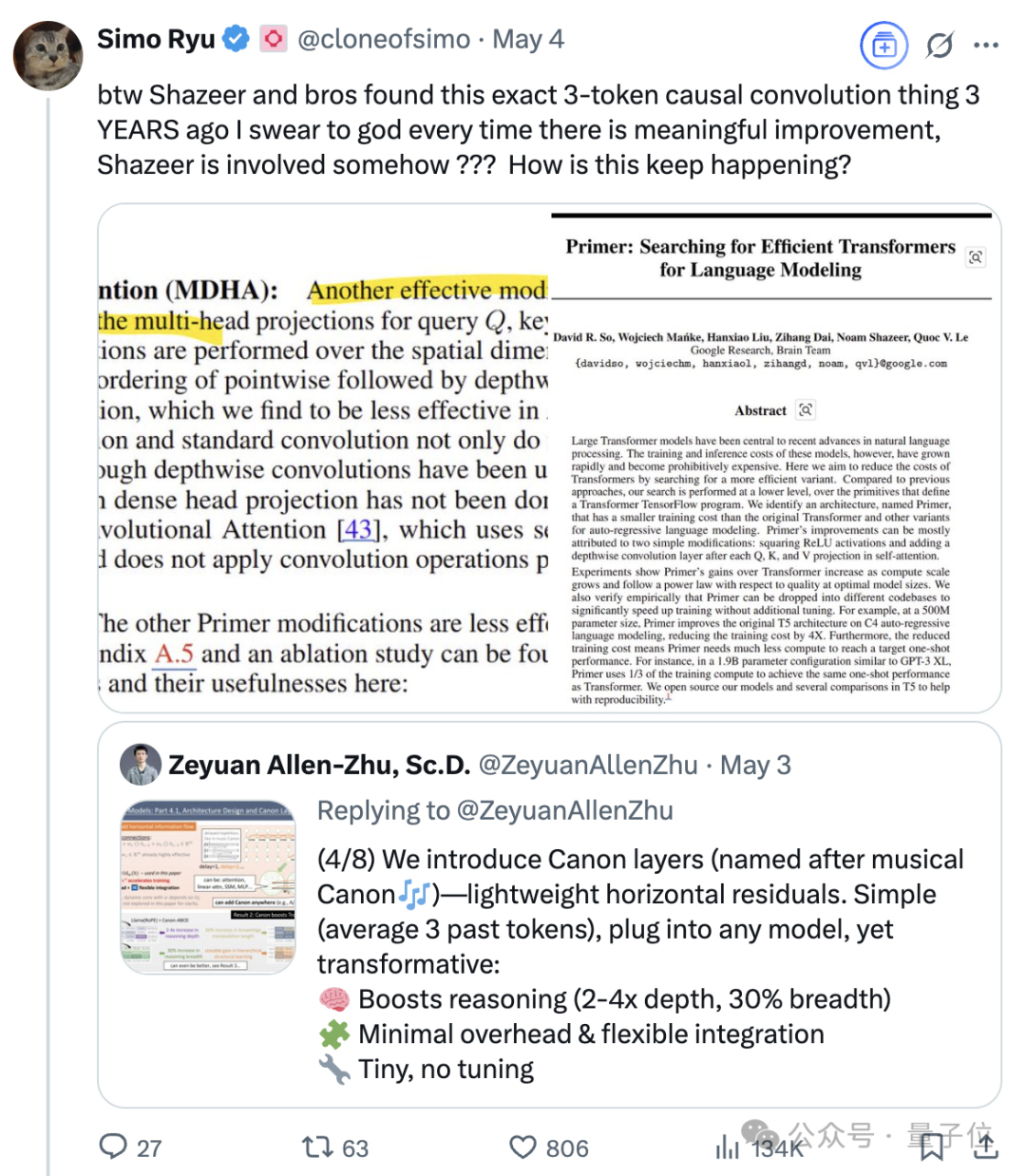
Продолжающееся влияние Noam Shazeer, одного из восьми авторов Transformer: Noam Shazeer, один из восьми авторов статьи о архитектуре Transformer «Attention Is All You Need», считается внесшим наибольший вклад. Его влияние простирается далеко за пределы этого, включая ранние исследования по внедрению разреженных смесей экспертов с гейтированием (MoE) в языковые модели, оптимизатор Adafactor, многозапросное внимание (MQA) и гейтированные линейные слои (GLU) в Transformer. Эти работы заложили основу для современных основных архитектур больших языковых моделей, что делает Shazeer ключевой фигурой, продолжающей определять технологические парадигмы в области AI. Он покинул Google, чтобы основать Character.AI, а затем вернулся в Google после приобретения компании, став соруководителем проекта Gemini. (Источник: WeChat)
Технологические гиганты сталкиваются с «кризисом среднего возраста», вызванным AI: В статье анализируется, что «великолепная семерка» технологических компаний, включая Google, Apple, Meta, Tesla, сталкивается с разрушительными вызовами, вызванными искусственным интеллектом, и переживает «кризис среднего возраста». Поисковый бизнес Google находится под угрозой из-за модели прямых ответов AI, Apple медленно продвигается в инновациях AI, Meta пытается интегрировать AI в социальные сети, но Llama 4 не оправдала ожиданий, а Tesla сталкивается с падением продаж и курса акций. Эти бывшие лидеры отрасли, подобно примерам из «Дилеммы инноватора», должны справиться с冲击 от новых рынков и моделей, принесенных AI, иначе они могут стать «Nokia» эпохи AI. (Источник: WeChat)

AI от Google превосходит врачей-людей в симуляции медицинских диалогов: Исследование показало, что система AI, обученная для проведения медицинских опросов, в диалогах с симулированными пациентами и составлении списка возможных диагнозов на основе истории болезни показала результаты, сопоставимые или даже превосходящие результаты врачей-людей. Исследователи считают, что такая система AI потенциально может помочь в обеспечении доступности и демократизации медицинских услуг. (Источник: Reddit r/ArtificialInteligence)
